
A Deep Learning Model for Network Intrusion Detection with Imbalanced Data



Abstract
:
1. Introduction
- (1)
- A DLNID model combining attention mechanism and Bi-LSTM is proposed. This DLNID model can classify network traffic data accurately;
- (2)
- To address the issue of imbalanced network data, ADASYN is used for data augmentation of the minority class of samples eventually making the distribution of the number of each sample type relatively symmetrical, allowing the model to learn adequately;
- (3)
- An improved stacked autoencoder is proposed and used for data dimensionality reduction with the objective of enhancing information fusion.
2. Technology
2.1. ADASYN
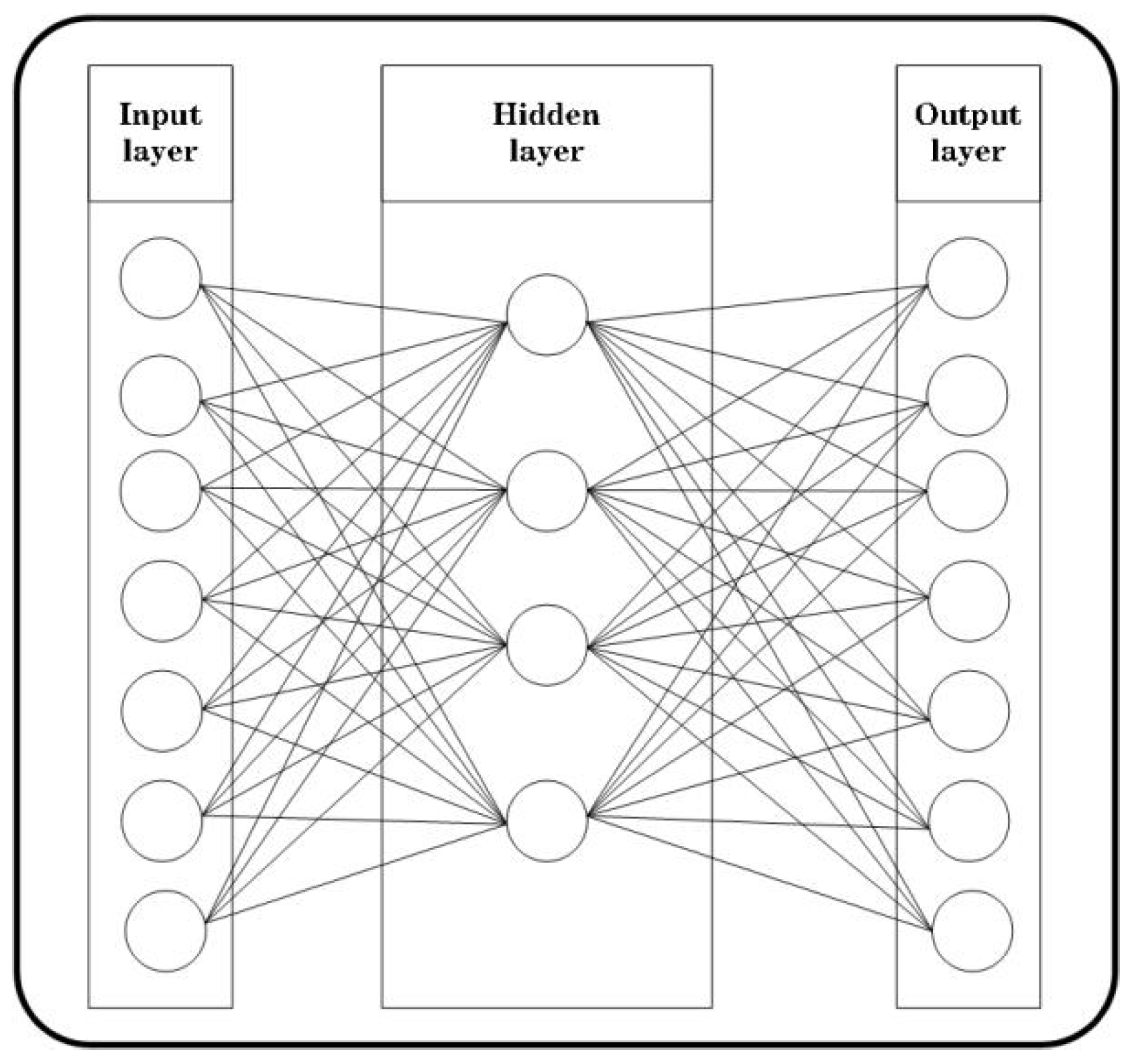
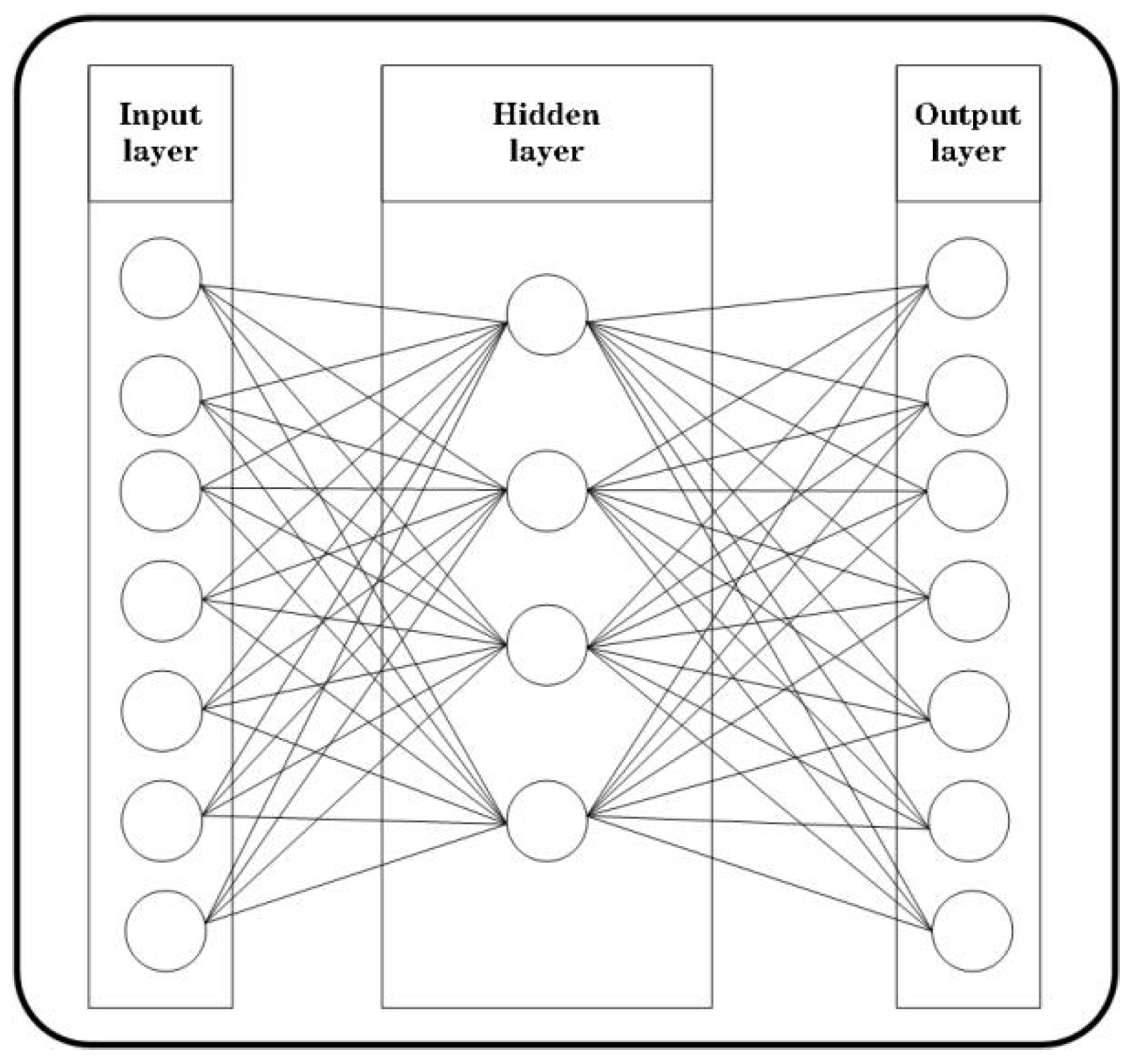
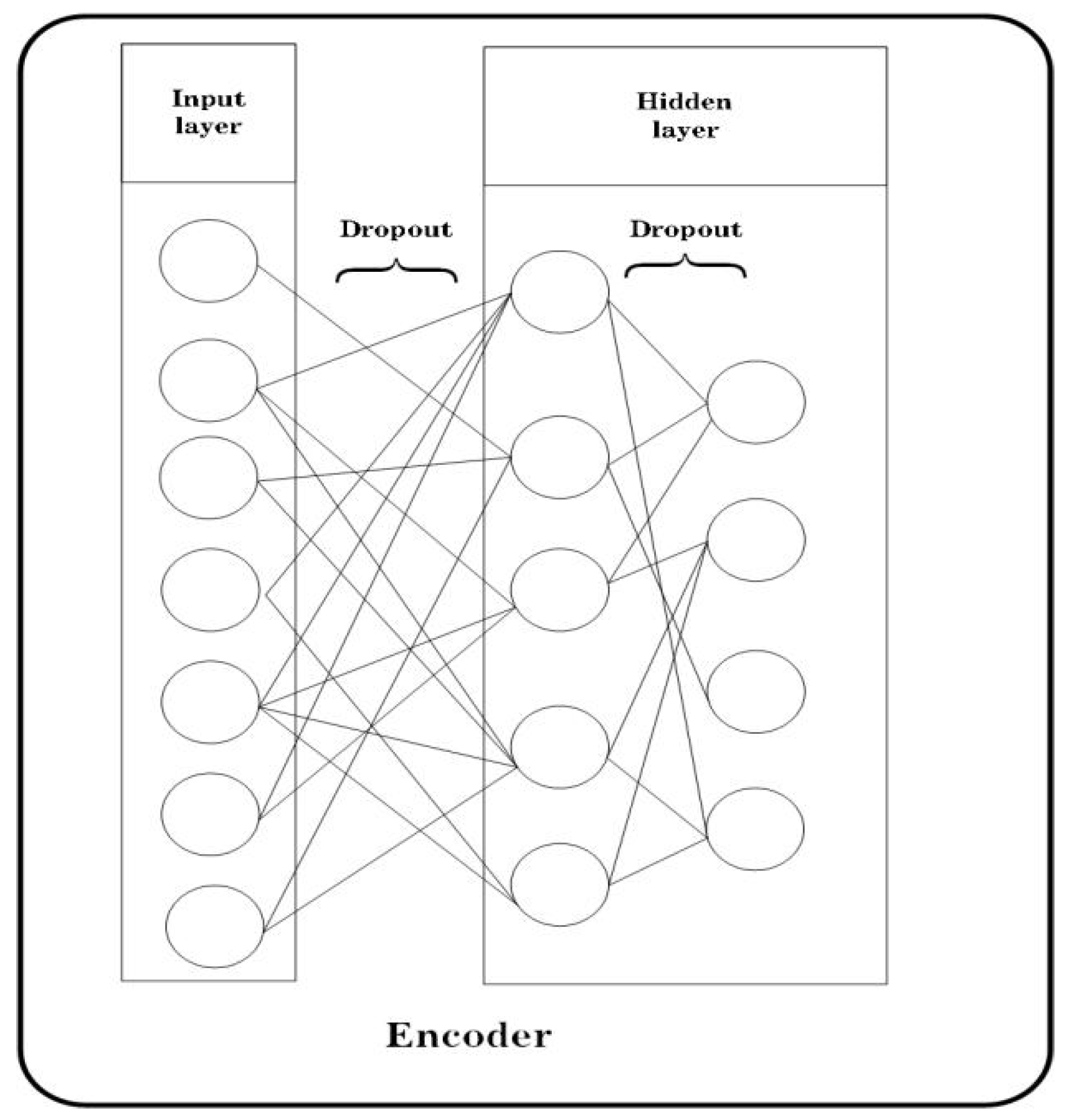
2.2. Autoencoder
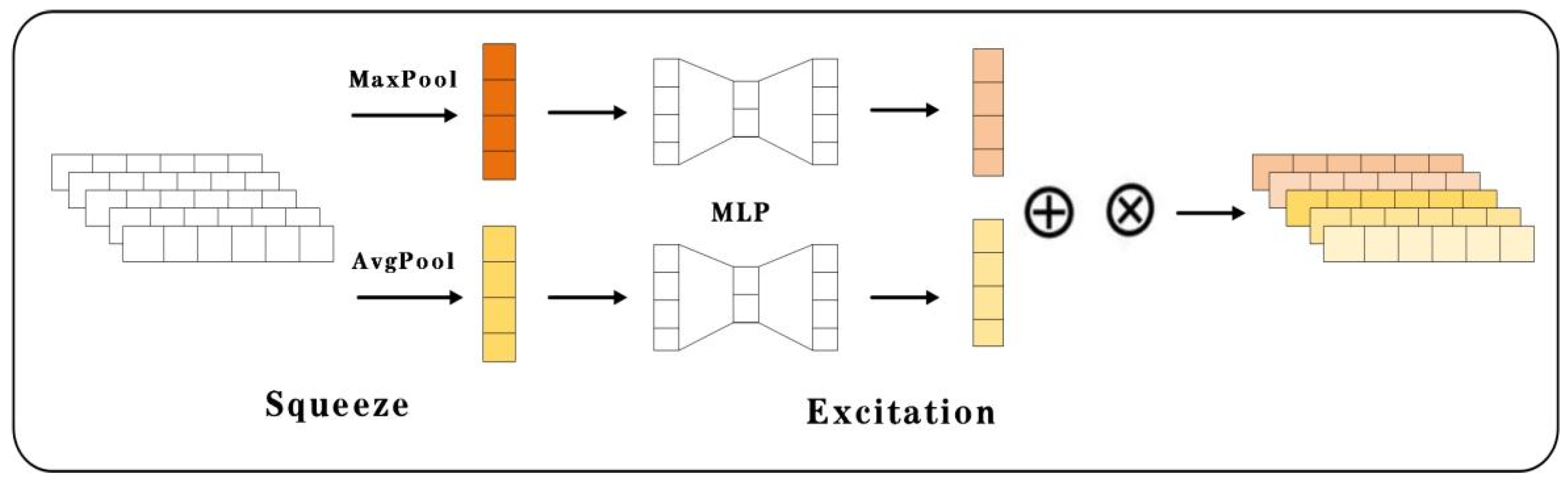
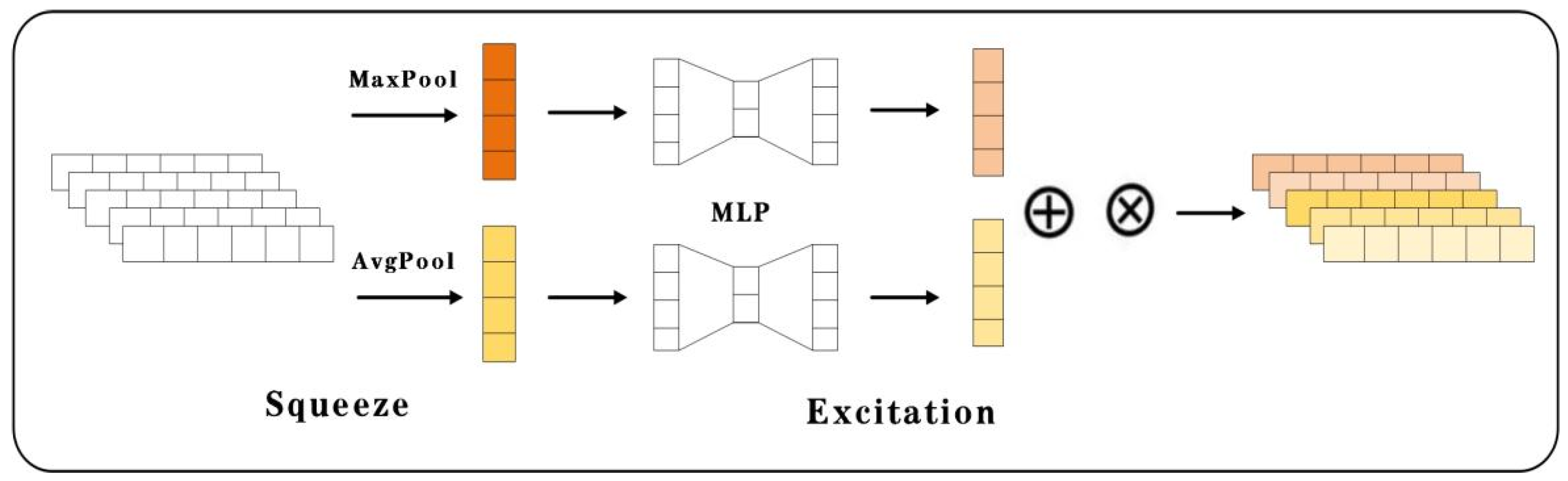
2.3. Channel Attention
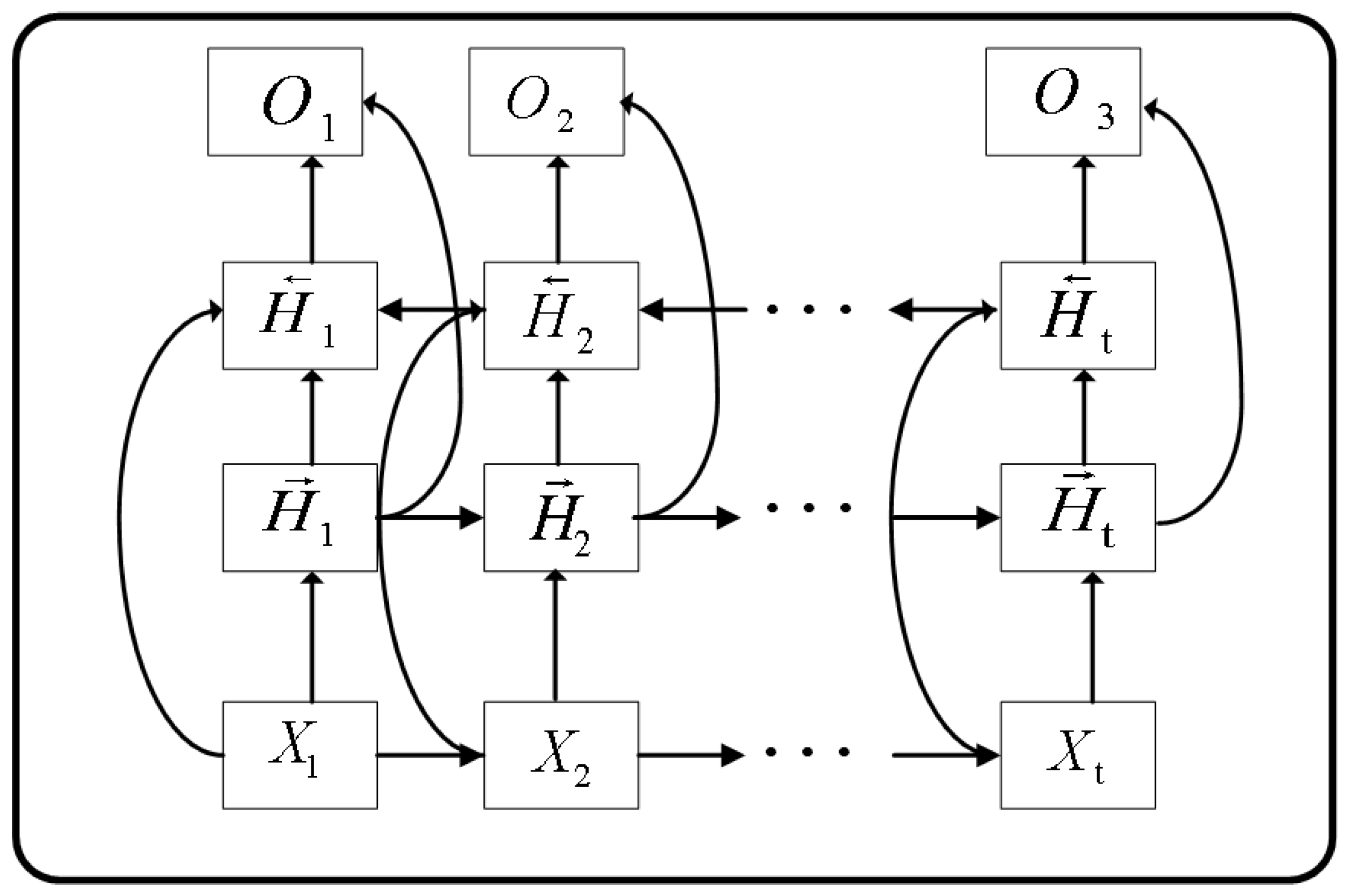
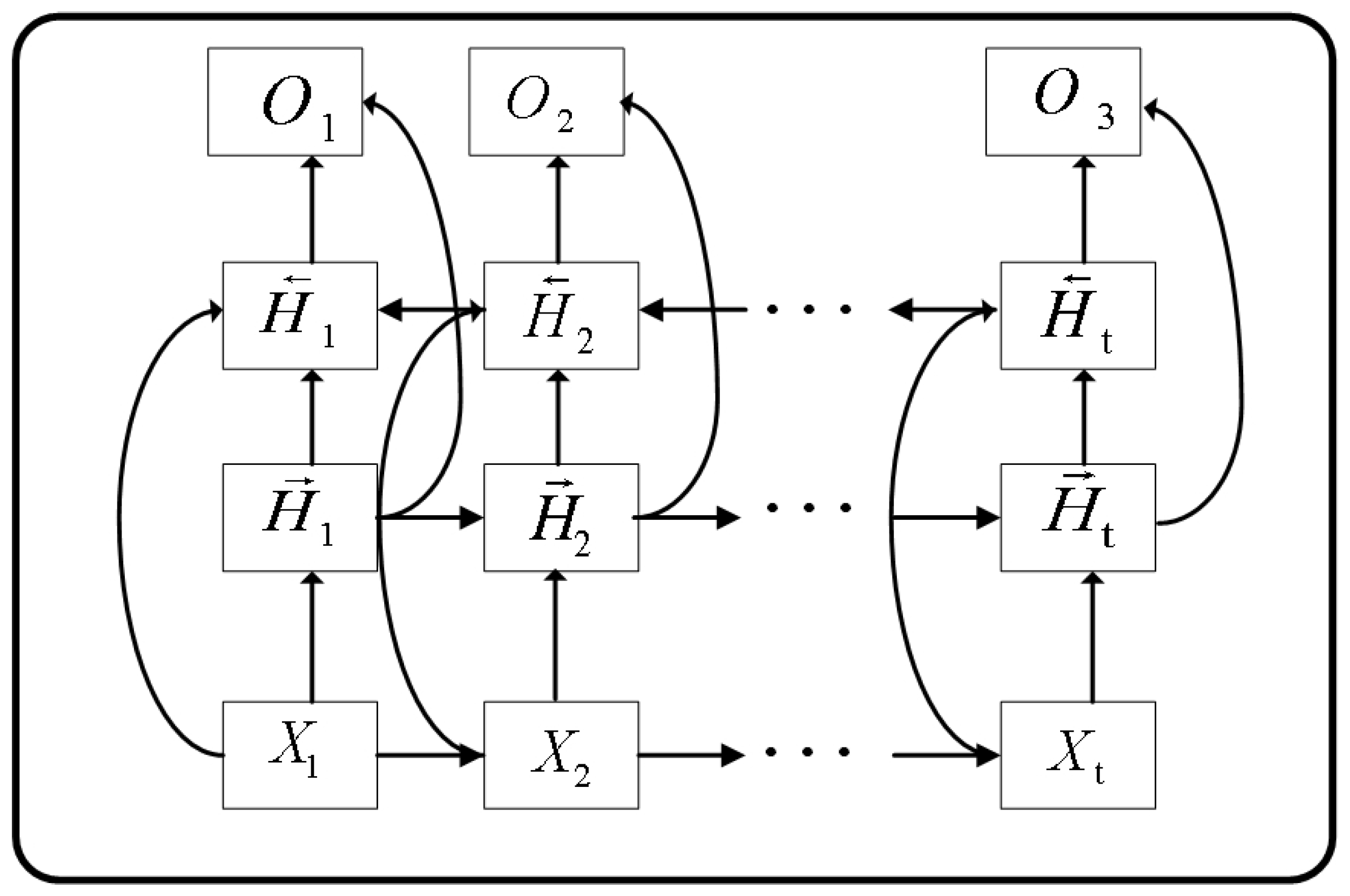
2.4. Bidirectional LSTM
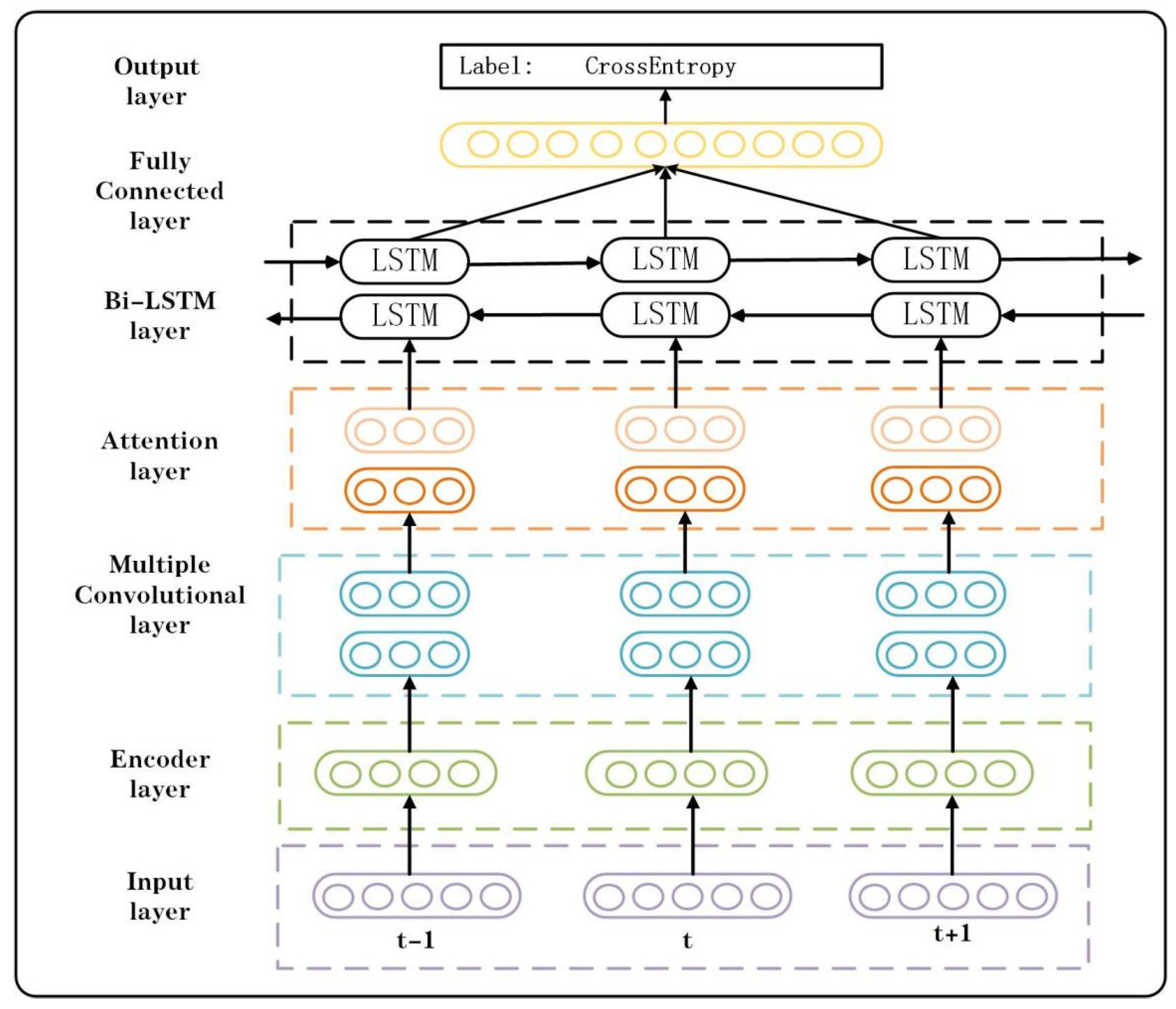
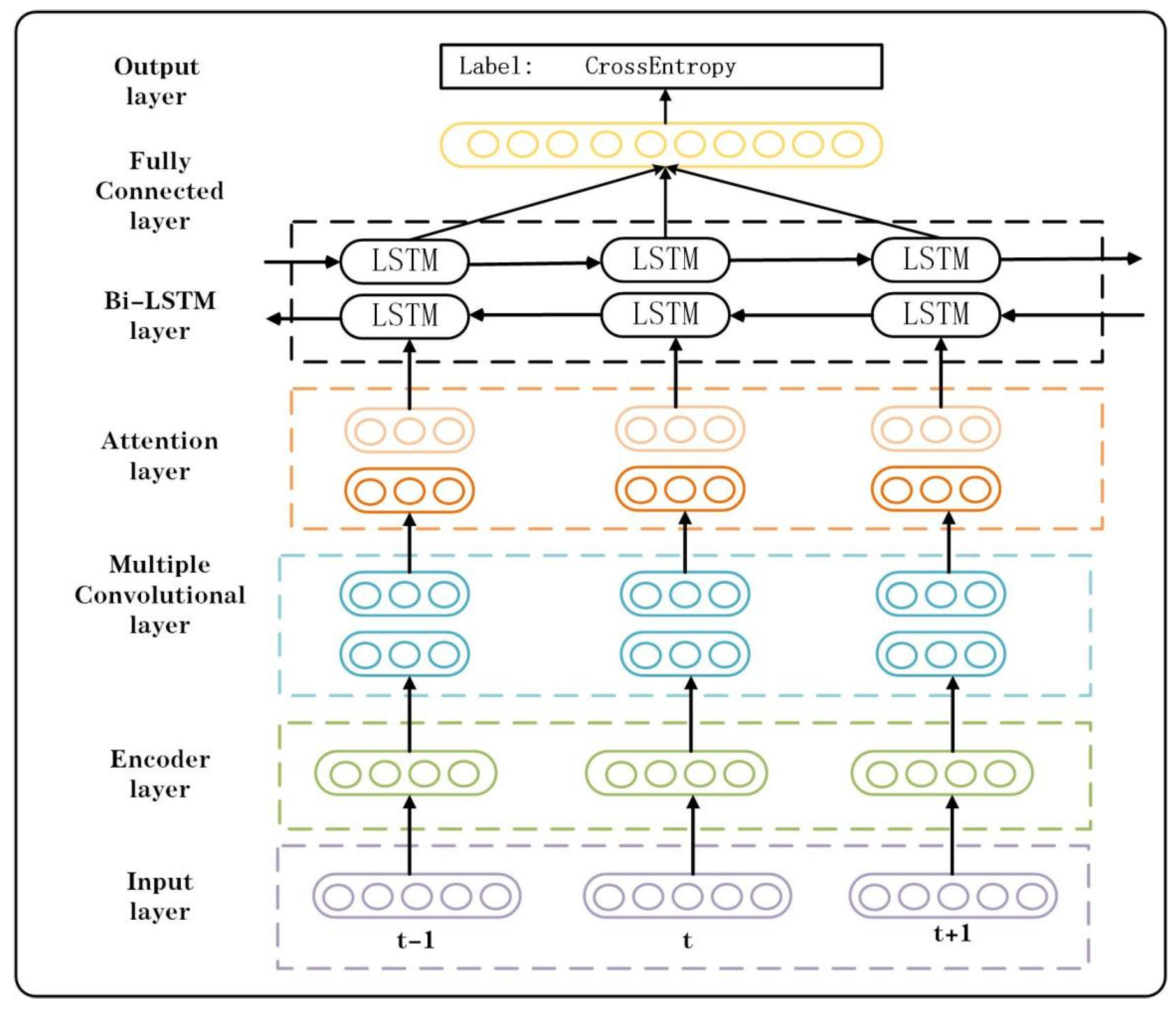
2.5. Network Architecture
| Algorithm 1: DLNID Training |
| Input: NSL-KDD dataset Output: Accuracy, Precision, Recall, F1 score 1 For data in the training set or test set; do 2 One-hot encoding; 3 If training set, 4 ADASYN data augmentation; 5 Normalization; 6 End. 7 For data in the training set or test set; do 8 Use encoder for data dimensionality reduction; 9 Perform multilayer convolution operations; 10 Use CDAM to redistribute channel weights; 11 Use Bi-LSTM to learn sequence information; 12 Flatten the dimension; 13 Send to the Fully connected layer and classify; 14 End. 15 Test model on NSL-KDDTest+; 16 Obtain loss and update DLNID by Adam; 17 Return accuracy, precision, recall, F1 score. |
3. Datasets
3.1. Data Analysis
3.2. Data Preprocessing
3.2.1. One-Hot Encoding
3.2.2. Data Augmentation
3.2.3. Normalization
4. Results
4.1. Experimental Settings
4.2. Performance Metrics
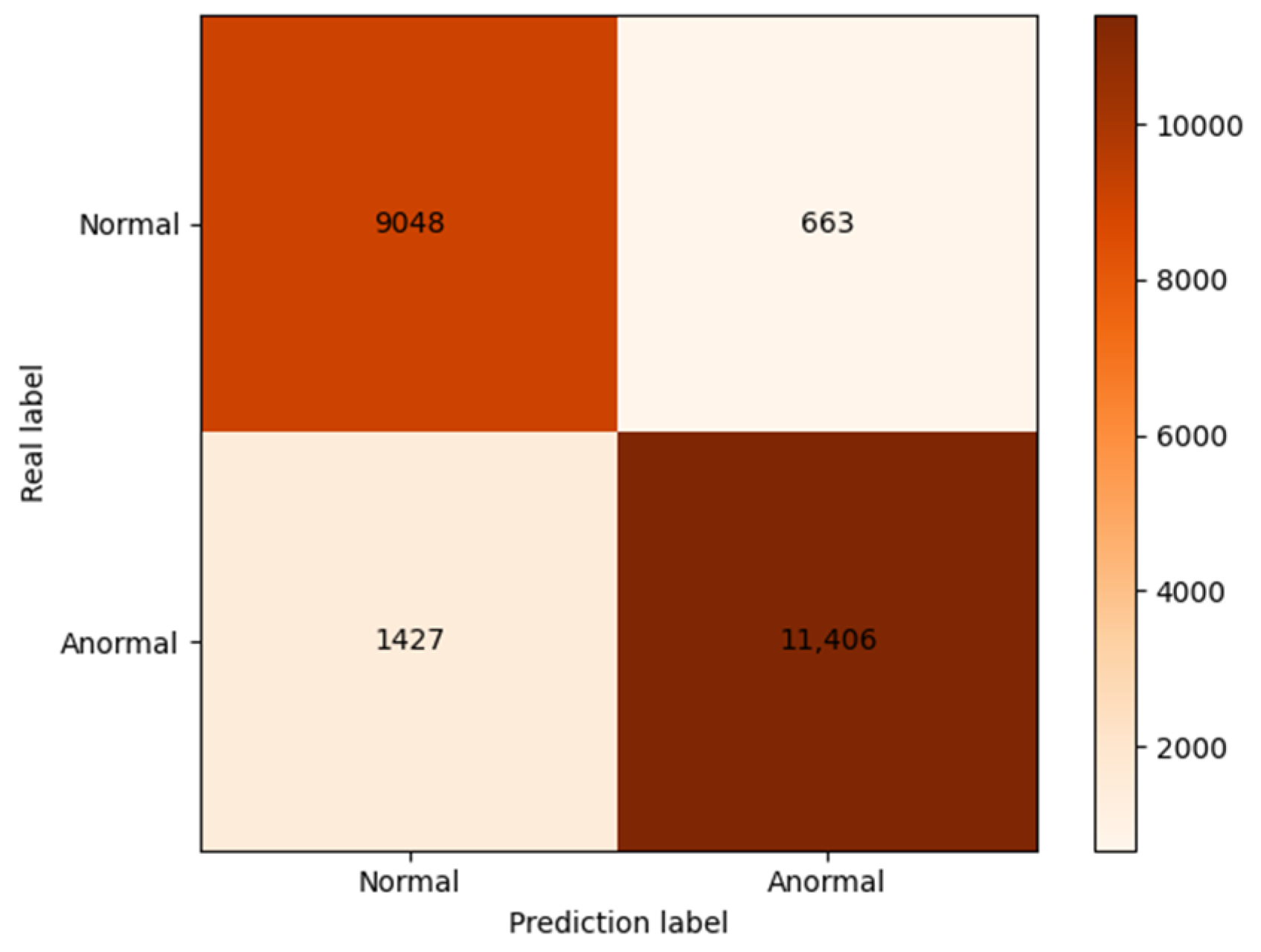
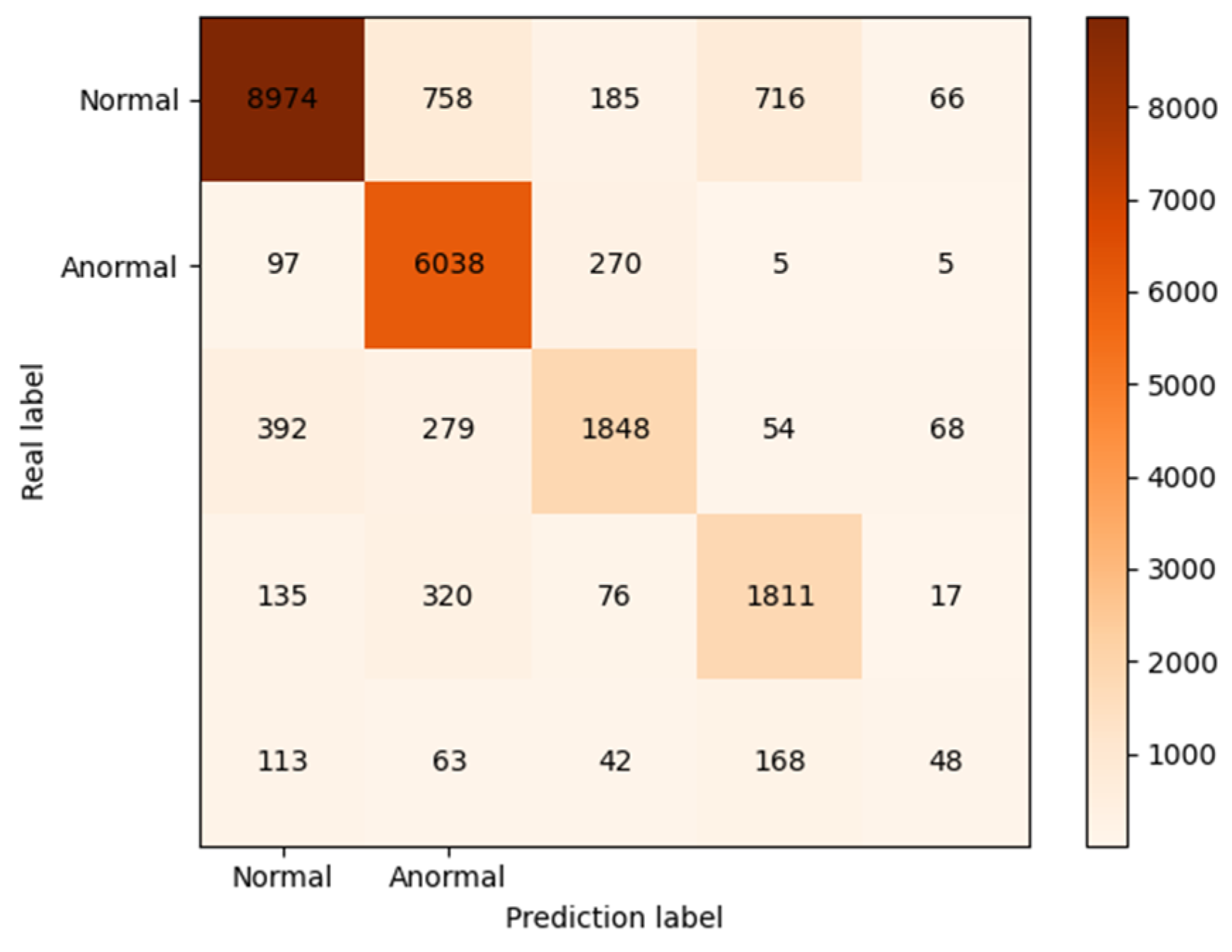
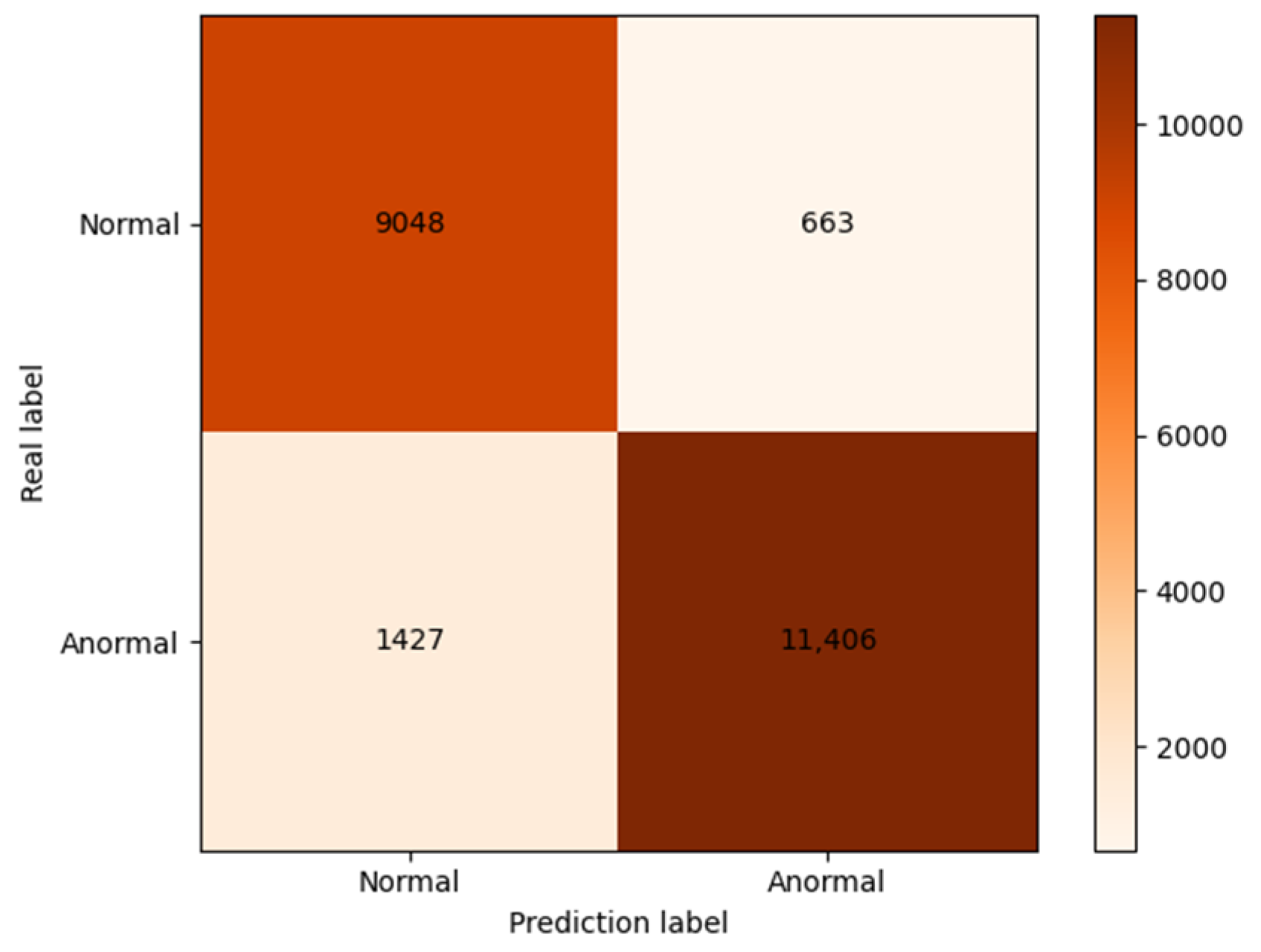
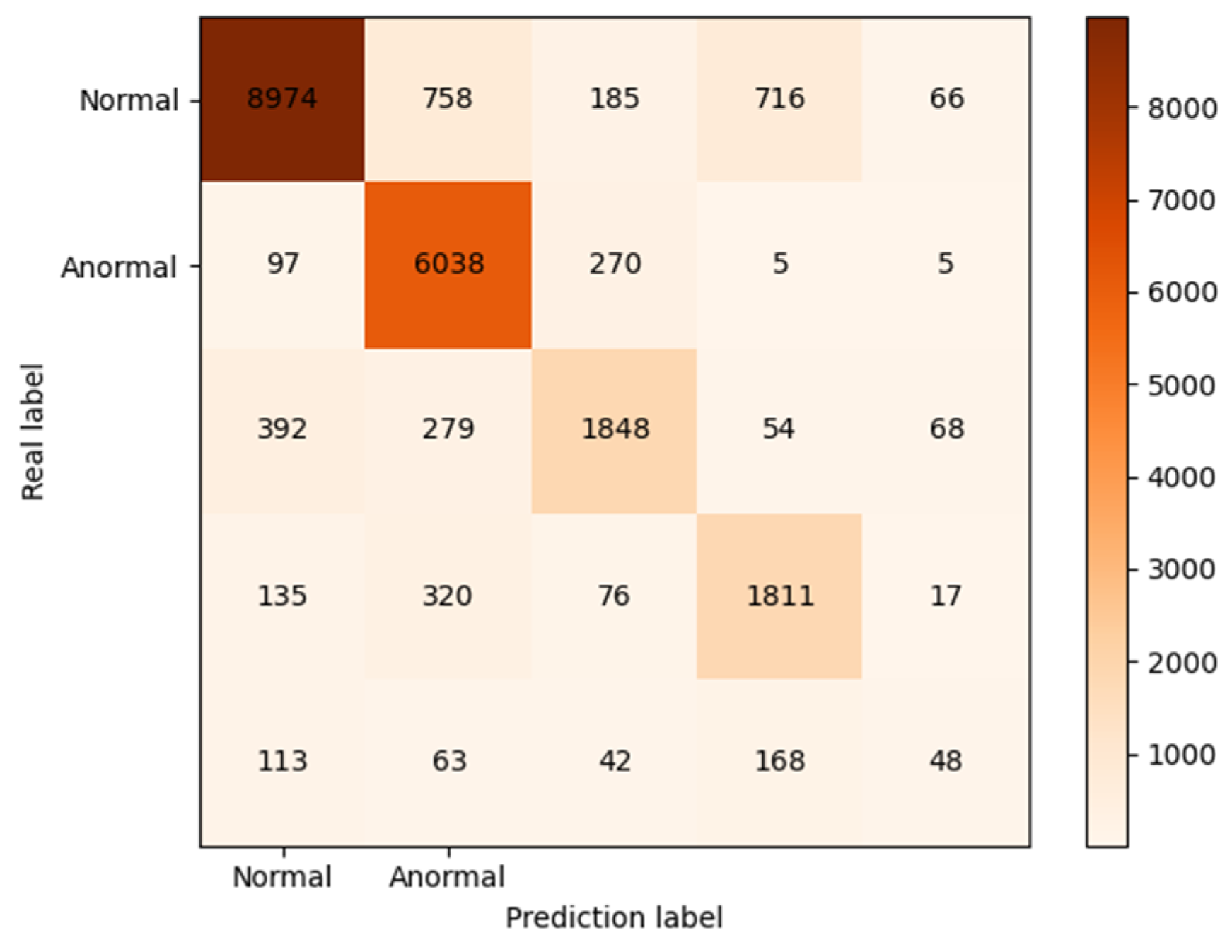
4.3. Result Analysis
4.3.1. Comparison of Data Enhancement Methods
4.3.2. Dimensionality Reduction Comparison
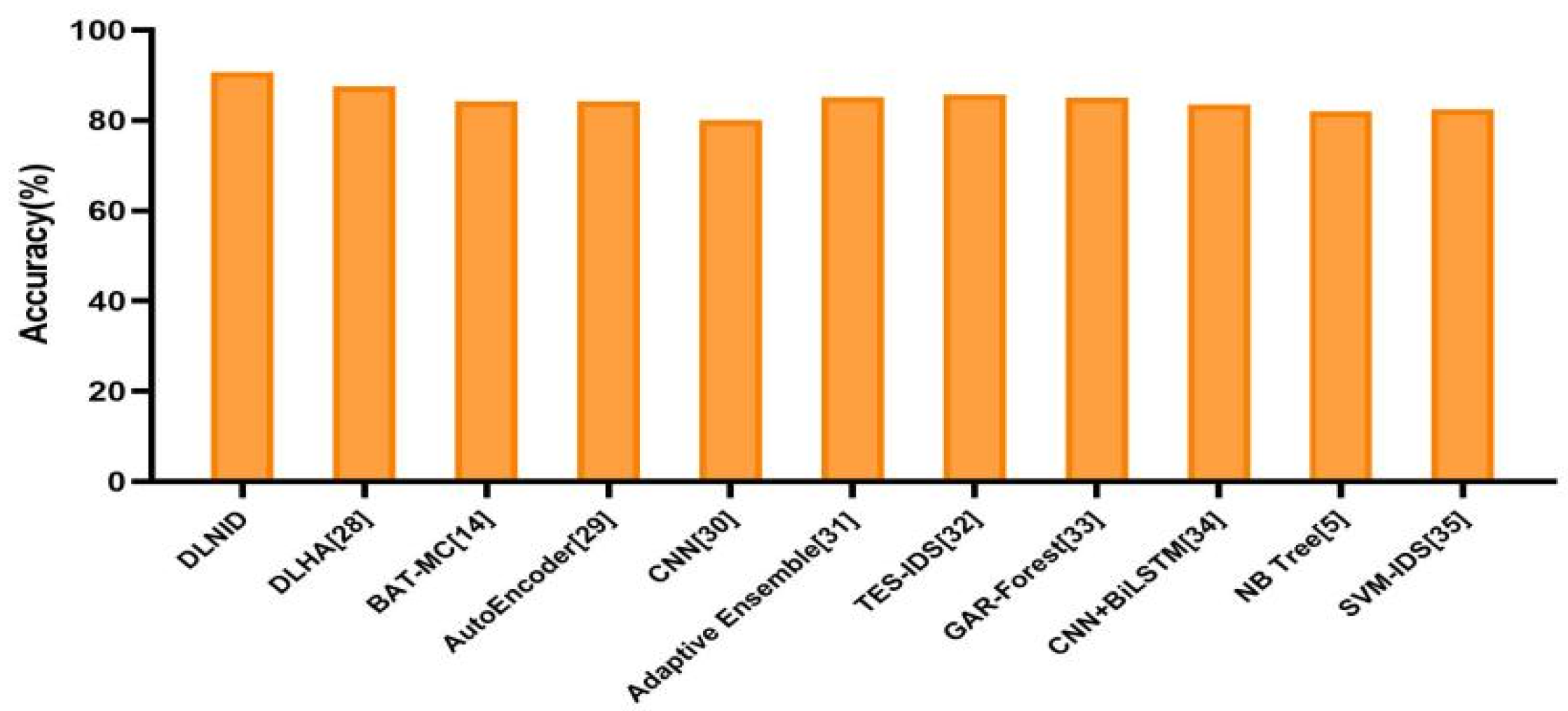
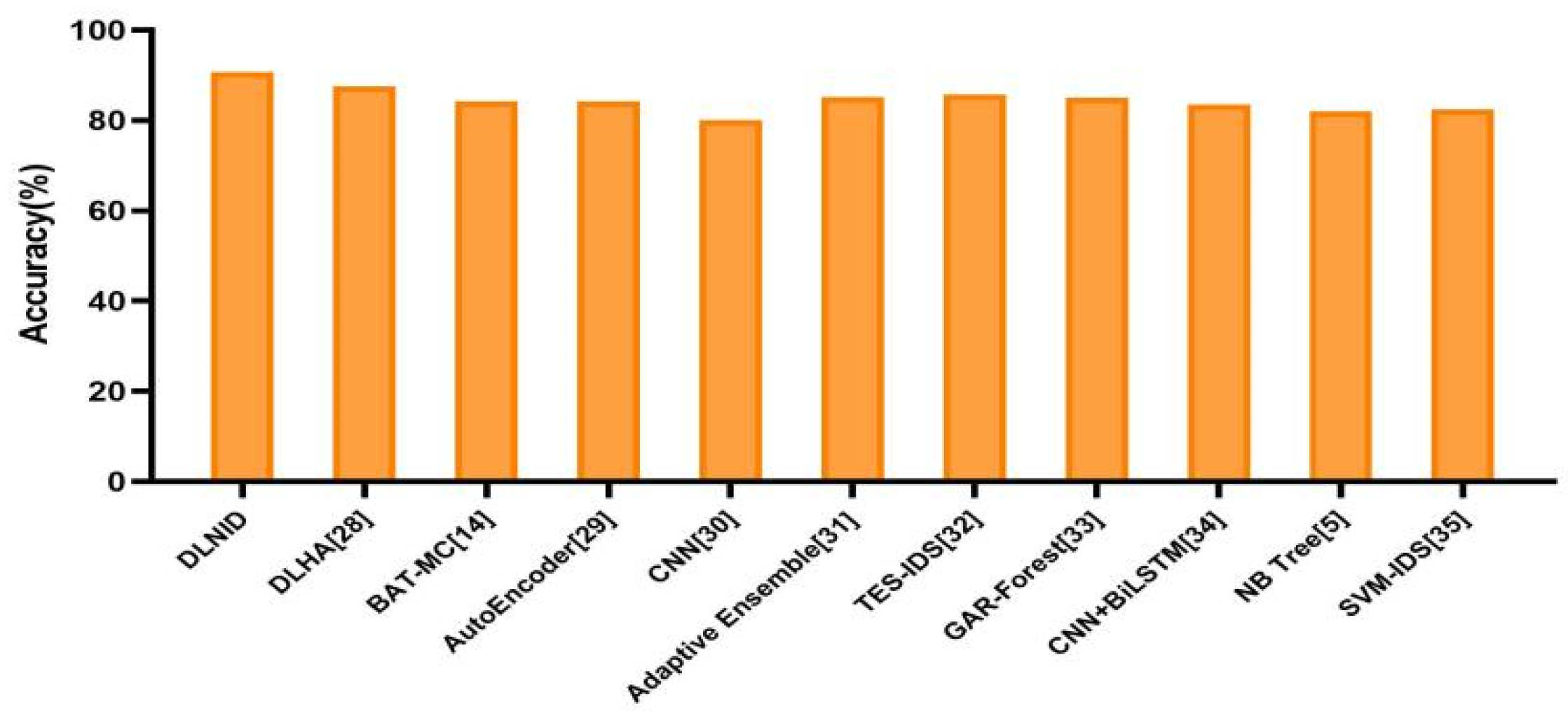
4.3.3. Model Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Patel, A.; Qassim, Q.; Wills, C. A survey of intrusion detection and prevention systems. Inf. Manag. Comput. Secur. 2010, 18, 277–290. [Google Scholar] [CrossRef]
- Khraisat, A.; Gondal, I.; Vamplew, P.; Kamruzzaman, J. Survey of intrusion detection systems: Techniques, datasets and challenges. Cybersecurity 2019, 2, 20. [Google Scholar] [CrossRef]
- Yuan, L.; Chen, H.; Mai, J.; Chuah, C.N.; Su, Z.; Mohapatra, P. Fireman: A toolkit for firewall modeling and analysis. In Proceedings of the 2006 IEEE Symposium on Security and Privacy (S&P’06), Berkeley/Oakland, CA, USA, 21–24 May 2006; IEEE: Manhattan, NY, USA, 2006; pp. 15–213. [Google Scholar]
- Musa, U.S.; Chhabra, M.; Ali, A.; Kaur, M. Intrusion detection system using machine learning techniques: A review. In Proceedings of the 2020 International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 10–12 September 2020; IEEE: Manhattan, NY, USA, 2020; pp. 149–155. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; IEEE: Manhattan, NY, USA, 2009; pp. 1–6. [Google Scholar]
- Amor, N.B.; Benferhat, S.; Elouedi, Z. Naive bayes vs. decision trees in intrusion detection systems. In Proceedings of the Proceedings of the 2004 ACM Symposium on Applied Computing, Nicosia, Cyprus, 14–17 March 2004; Association for Computing Machinery: New York, NY, USA, 2004; pp. 420–424. [Google Scholar]
- Tao, P.; Sun, Z.; Sun, Z. An improved intrusion detection algorithm based on GA and SVM. IEEE Access 2018, 6, 13624–13631. [Google Scholar] [CrossRef]
- Jiadong, R.; Xinqian, L.; Qian, W.; Haitao, H.; Xiaolin, Z. A multi-level intrusion detection method based on KNN outlier detection and random forests. J. Comput. Res. Dev. 2019, 56, 566. [Google Scholar]
- Shapoorifard, H.; Shamsinejad, P. Intrusion detection using a novel hybrid method incorporating an improved KNN. Int. J. Comput. Appl. 2017, 173, 5–9. [Google Scholar] [CrossRef]
- Kim, G.; Lee, S.; Kim, S. A novel hybrid intrusion detection method integrating anomaly detection with misuse detection. Expert Syst. Appl. 2014, 41, 1690–1700. [Google Scholar] [CrossRef]
- Zhao, G.; Zhang, C.; Zheng, L. Intrusion detection using deep belief network and probabilistic neural network. In Proceedings of the 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Guangzhou, China, 21–24 July 2017; IEEE: Manhattan, NY, USA, 2017; Volume 1, pp. 639–642. [Google Scholar]
- Wang, W.; Zhu, M.; Zeng, X.; Ye, X.; Sheng, Y. Malware traffic classification using convolutional neural network for representation learning. In Proceedings of the 2017 International Conference on Information Networking (ICOIN), Da Nang, Vietnam, 11–13 January 2017; IEEE: Manhattan, NY, USA, 2017; pp. 712–717. [Google Scholar]
- Torres, P.; Catania, C.; Garcia, S.; Garino, C.G. An analysis of recurrent neural networks for botnet detection behavior. In Proceedings of the 2016 IEEE Biennial Congress of Argentina (ARGENCON), Buenos Aires, Argentina, 15–17 June 2016; IEEE: Manhattan, NY, USA, 2016; pp. 1–6. [Google Scholar]
- Su, T.; Sun, H.; Zhu, J.; Wang, S.; Li, Y. BAT: Deep learning methods on network intrusion detection using NSL-KDD dataset. IEEE Access 2020, 8, 29575–29585. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008. [Google Scholar]
- Meng, Q.; Catchpoole, D.; Skillicom, D.; Kennedy, P.J. Relational autoencoder for feature extraction. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; IEEE: Manhattan, NY, USA, 2017; pp. 364–371. [Google Scholar]
- Roweis, S. EM algorithms for PCA and SPCA. Adv. Neural Inf. Processing Syst. 1998, 10, 626–632. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Jie, H.; Li, S.; Gang, S. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gui, Z.; Sun, Y.; Yang, L.; Peng, D.; Li, F.; Wu, H.; Guo, C.; Guo, W.; Gong, J. LSI-LSTM: An attention-aware LSTM for real-time driving destination prediction by considering location semantics and location importance of trajectory points. Neurocomputing 2021, 440, 72–88. [Google Scholar] [CrossRef]
- Lin, T.; Horne, B.G.; Tino, P.; Giles, C.L. Learning long-term dependencies in NARX recurrent neural networks. IEEE Trans. Neural Netw. 1996, 7, 1329–1338. [Google Scholar] [PubMed] [Green Version]
- Hochreiter, S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef] [Green Version]
- Engen, V.; Vincent, J.; Phalp, K. Exploring discrepancies in findings obtained with the KDD Cup 99 data set. Intell. Data Anal. 2011, 15, 251–276. [Google Scholar] [CrossRef]
- Bisong, E. Introduction to scikit-learn. In Building Machine Learning and Deep Learning Models on Google Cloud Platform; Apress: Berkeley, CA, USA, 2019; pp. 215–229. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Wisanwanichthan, T.; Thammawichai, M. A double-layered hybrid approach for network intrusion detection system using combined naive bayes and SVM. IEEE Access 2021, 9, 138432–138450. [Google Scholar] [CrossRef]
- Ieracitano, C.; Adeel, A.; Morabito, F.C.; Hussain, A. A novel statistical analysis and autoencoder driven intelligent intrusion detection approach. Neurocomputing 2020, 387, 51–62. [Google Scholar] [CrossRef]
- Ding, Y.; Zhai, Y. Intrusion detection system for NSL-KDD dataset using convolutional neural networks. In Proceedings of the 2018 2nd International Conference on Computer Science and Artificial Intelligence, Shenzhen, China, 8–10 December 2018; pp. 81–85. [Google Scholar]
- Gao, X.; Shan, C.; Hu, C.; Niu, Z.; Liu, Z. An adaptive ensemble machine learning model for intrusion detection. IEEE Access 2019, 7, 82512–82521. [Google Scholar] [CrossRef]
- Tama, B.A.; Comuzzi, M.; Rhee, K. TSE-IDS: A two-stage classifier ensemble for intelligent anomaly-based intrusion detection system. IEEE Access 2019, 7, 94497–94507. [Google Scholar] [CrossRef]
- Kanakarajan, N.K.; Muniasamy, K. Improving the accuracy of intrusion detection using GAR-forest with feature selection. In Proceedings of the 4th International Conference on Frontiers in Intelligent Computing: Theory and Applications (FICTA) 2015, Durgapur, India, 16–18 November 2015; Springer: New Delhi, India, 2016; pp. 539–547. [Google Scholar]
- Jiang, K.; Wang, W.; Wang, A.; Wu, H. Network intrusion detection combined hybrid sampling with deep hierarchical network. IEEE Access 2020, 8, 32464–32476. [Google Scholar] [CrossRef]
- Pervez, M.S.; Farid, D.M. Feature selection and intrusion classifi-cation in NSL-KDD Cup 99 dataset employing SVMs. In Proceedings of the 8th International Conference on Software, Knowledge, Information Management and Applications (SKIMA 2014), Dhaka, Bangladesh, 18–20 December 2014; pp. 1–6. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author(s) | Year | Algorithm | Main Contribution | Field |
|---|---|---|---|---|
| Amor et al. [6] | 2004 | Naive Bayes | Proposed the use of naive Bayes for the identification of anomalous networks. | Machine Learning |
| Kim et al. [10] | 2014 | C4.5 decision tree and SVM | Proposed a novel intrusion detection method that first decomposes the network data into smaller subsets by C4.5 decision tree algorithm and then creates multiple SVM models for the subsets. | Machine Learning |
| Shapoorifard et al. [9] | 2017 | K-MEANS and KNN | Proposed a classifier combining K-MEANS clustering and KNN classifier to improve the accuracy of detection. | Machine Learning |
| Tao et al. [7] | 2018 | SVM and genetic algorithm | Proposed genetic algorithm to optimize the selection, parameters, and weights of SVM features. | Machine Learning |
| Jiadong et al. [8] | 2019 | Random forest | Proposed a multilevel random forest model to detect abnormal network behavior. | Machine Learning |
| Torres et al. [13] | 2016 | RNN | Proposed the use of RNN model to Botnet anomaly detection. | Deep Learning |
| Wang et al. [12] | 2017 | CNN | Proposed to use CNN to detect the network traffic data. Processed into the form of pictures. | Deep Learning |
| Zhao et al. [11] | 2017 | DBN and PNN | Proposed a model structure based on DBN and PNN to reduce the dimensionality of the data using DBN and then classify the data using PNN. | Deep Learning |
| Su et al. [14] | 2020 | CNN and LSTM | Proposed a model based on CNN and LSTM to detect each attack type. | Deep Learning |
| Type | Parameter |
|---|---|
| Encoder | - |
| Conv1d | 5 × 5 |
| BatchNorma1d | - |
| Maxpool1d | 3 × 3 |
| Conv1d | 1 × 1 |
| ChannelAttention | - |
| Bidirectional LSTM | - |
| Dropout | 0.3 |
| Fully connected (LeakyRelu) | 32 |
| Dropout | 0.2 |
| Fully connected () | 16 |
| Loss function | CrossEntropy |
| Optimizer | Adam |
| Learning rate | 0.0005 |
| Type | Rec (%) | FPR (%) |
|---|---|---|
| Normal | 92.14 | 13.44 |
| Dos | 80.96 | 2.47 |
| Probe | 76.33 | 3.94 |
| R2L | 65.76 | 2.77 |
| U2R | 24.00 | 1.73 |
| Type | ACC (%) | Pre (%) | Rec (%) | F1 (%) |
|---|---|---|---|---|
| Not processed | 80.01 | 70.71 | 91.63 | 79.82 |
| SMOTE [27] | 88.64 | 85.32 | 88.83 | 87.04 |
| ADASYN | 90.73 | 86.38 | 93.17 | 89.65 |
| Type | ACC (%) | Pre (%) | Rec (%) | F1 (%) |
|---|---|---|---|---|
| PCA | 85.29 | 83.45 | 82.14 | 82.79 |
| Autoencoder | 86.09 | 85.08 | 82.12 | 83.57 |
| Improved stacked autoencoder | 90.73 | 86.38 | 93.17 | 89.65 |
| Type | ACC (%) | Pre (%) | Rec (%) | F1 (%) |
|---|---|---|---|---|
| DLNID | 90.73 | 86.38 | 93.17 | 89.65 |
| DLHA [28] | 87.55 | 88.16 | 90.14 | 89.19 |
| BAT-MC [14] | 84.25 | - | - | - |
| Autoencoder [29] | 84.24 | 87.00 | 80.37 | 81.98 |
| CNN [30] | 80.13 | - | - | - |
| Adaptive Ensemble [31] | 85.20 | 86.50 | 86.50 | 85.20 |
| TES-IDS [32] | 85.79 | 88.00 | 86.80 | 87.39 |
| GAR-Forest [33] | 85.06 | 87.50 | 85.10 | 85.10 |
| CNN+BiLSTM [34] | 83.58 | 85.82 | 84.49 | 85.14 |
| NB Tree [5] | 82.02 | - | - | - |
| SVM-IDS [35] | 82.37 | - | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Y.; Du, Y.; Cao, Z.; Li, Q.; Xiang, W. A Deep Learning Model for Network Intrusion Detection with Imbalanced Data. Electronics 2022, 11, 898. https://doi.org/10.3390/electronics11060898
Fu Y, Du Y, Cao Z, Li Q, Xiang W. A Deep Learning Model for Network Intrusion Detection with Imbalanced Data. Electronics. 2022; 11(6):898. https://doi.org/10.3390/electronics11060898
Chicago/Turabian StyleFu, Yanfang, Yishuai Du, Zijian Cao, Qiang Li, and Wei Xiang. 2022. "A Deep Learning Model for Network Intrusion Detection with Imbalanced Data" Electronics 11, no. 6: 898. https://doi.org/10.3390/electronics11060898
APA StyleFu, Y., Du, Y., Cao, Z., Li, Q., & Xiang, W. (2022). A Deep Learning Model for Network Intrusion Detection with Imbalanced Data. Electronics, 11(6), 898. https://doi.org/10.3390/electronics11060898