In this section, we describe the methodology in detail. We start by illuminating the problem that we intend to address. Next, we justify the choice of the dataset, and carry out its analysis, covering preprocessing and feature engineering. Finally, we approach the used computational techniques and describe the tests and results obtained.
3.3. Analyzing Dataset, Preprocessing, and Feature Engineering
The dataset is composed of the attributes “Review” and “Rating”.
Table 1 shows some examples of the type of records that make up the dataset. The “Rating” is between 1 and 5, where 1 is the worst and 5 is the best possible evaluation.
The dataset consisted of 20,491 records and 2 attributes, and it did not have any missing data.
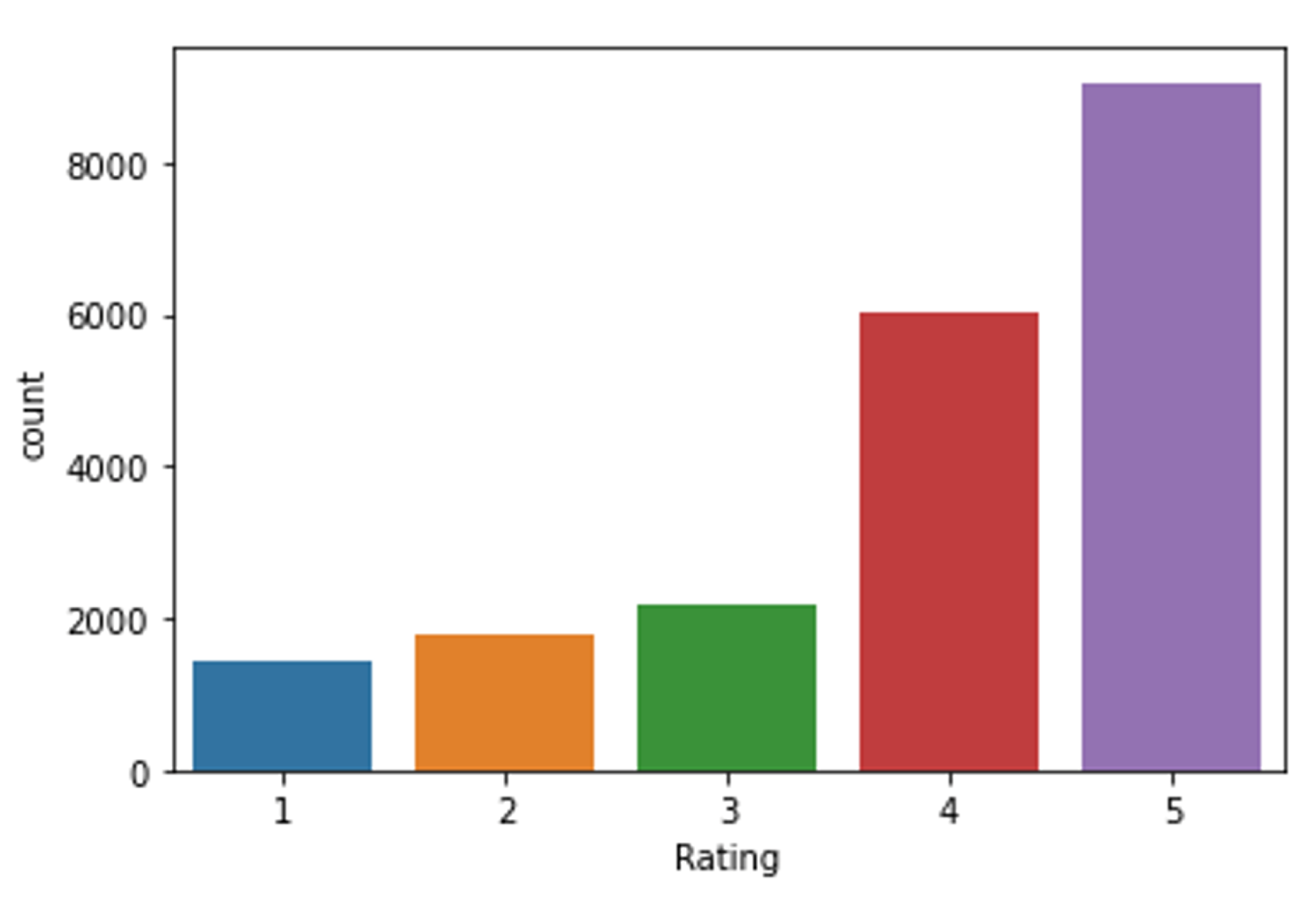
Figure 1 shows the distribution by “Rating”. As can be seen, the dataset is quite unbalanced, with many more records with a positive evaluation (Rating 5:9054; Rating 4:6039) than with a negative evaluation (Rating 2:1793; Rating 1:1421). Furthermore, the number of records with an intermediate evaluation is also much lower than the number of records with a positive evaluation (Rating 3:2184).
To study possible correlations between the “Review” and the assigned “Rating”, we created 3 new attributes: “Word_Count”, “Char_Count”, and “Average_Word_Length”. The “Word_Count” stands for the number of words used in the “Review”, the “Char_Count” stands for the number of characters used in the “Review”, and the “Average_Word_Length” stands for the average size of the words used in the “Review”. The “Average_Word_Length” did not show statistical relevance, but we found that the most negative reviews tended to be composed of more words than the most positive reviews (
Figure 2), which made us believe that the attribute “Word_Count” would be very relevant for the creation of the model.
In the next step, we analyzed which words were most used in the reviews. In addition, we analyzed which words were most used in negative reviews (Rating 1 and 2) and in positive reviews (Rating 3, 4, and 5). We found that many of the most used words were the same, both in positive and in negative reviews. In
Table 2 are presented the most used words considering all the reviews. The fact that many of the most used words are the same, in both positive and negative reviews, made us wonder if eliminating these words would be a good strategy in creating the model.
Then, we used some libraries to perform sentiment analysis. Sentiment analysis techniques allow the identification of people’s opinions, feelings, or attitudes through their comments. These techniques make it possible to determine a sentiment in a given sentence being classified as positive, negative, or neutral, using scalar values, and also through polarity (quantifying the sentiment as positive or negative through a value). These techniques are widely used in domains such as social networks, and their application is an excellent exercise to aid in interpreting and analyzing data from this particular field. Therefore, we applied 3 different libraries: Textblob, Vader, and Flair. Textblob and Vader presented similar results, while Flair did not obtain results that correlated with the “Rating”. With Textblob, we obtained 2 new attributes (Polarity and Subjectivity), and with Vader, we obtained 3 new attributes Positive_Sentiment, Negative_Sentiment, and Neutral_Sentiment.
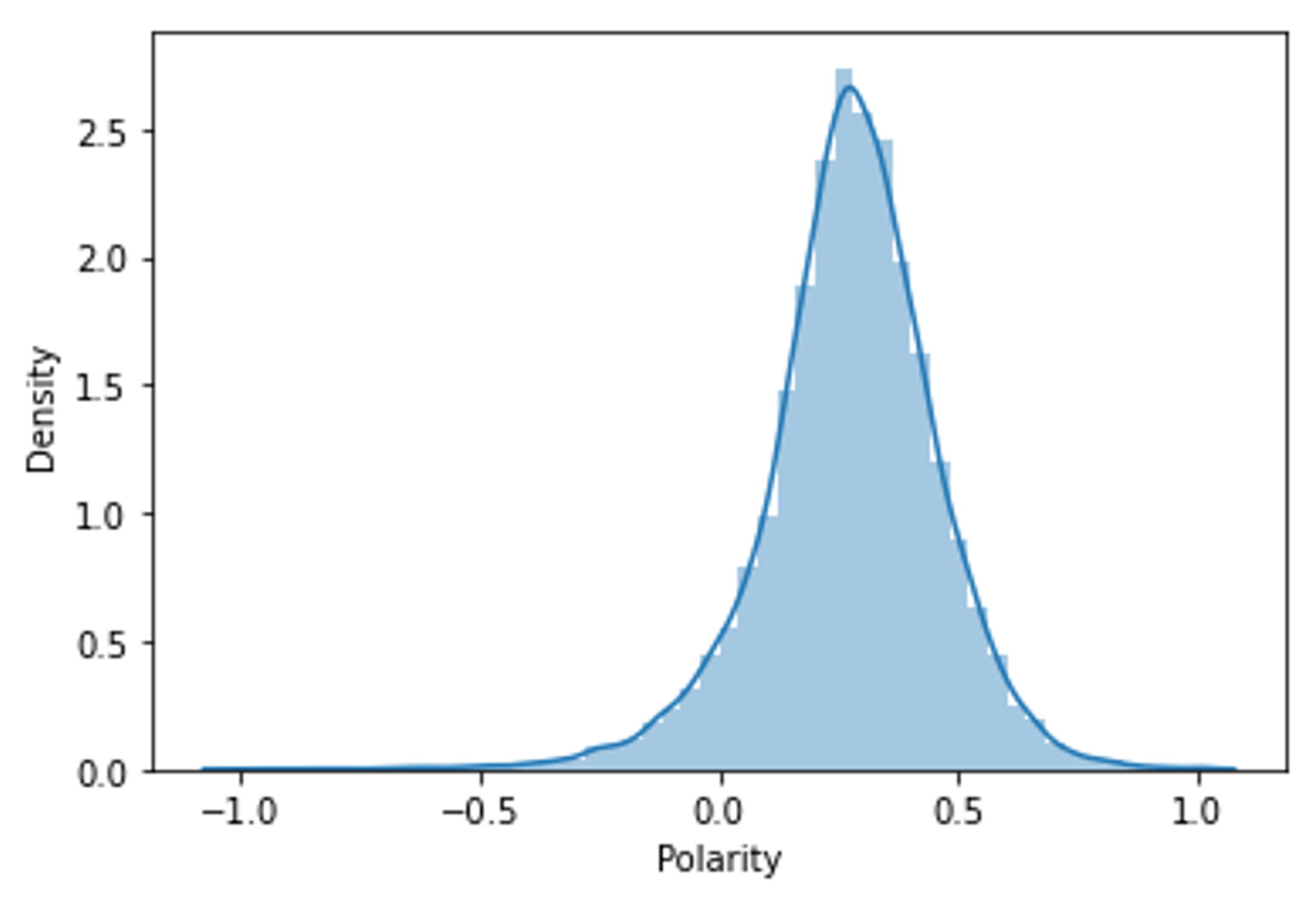
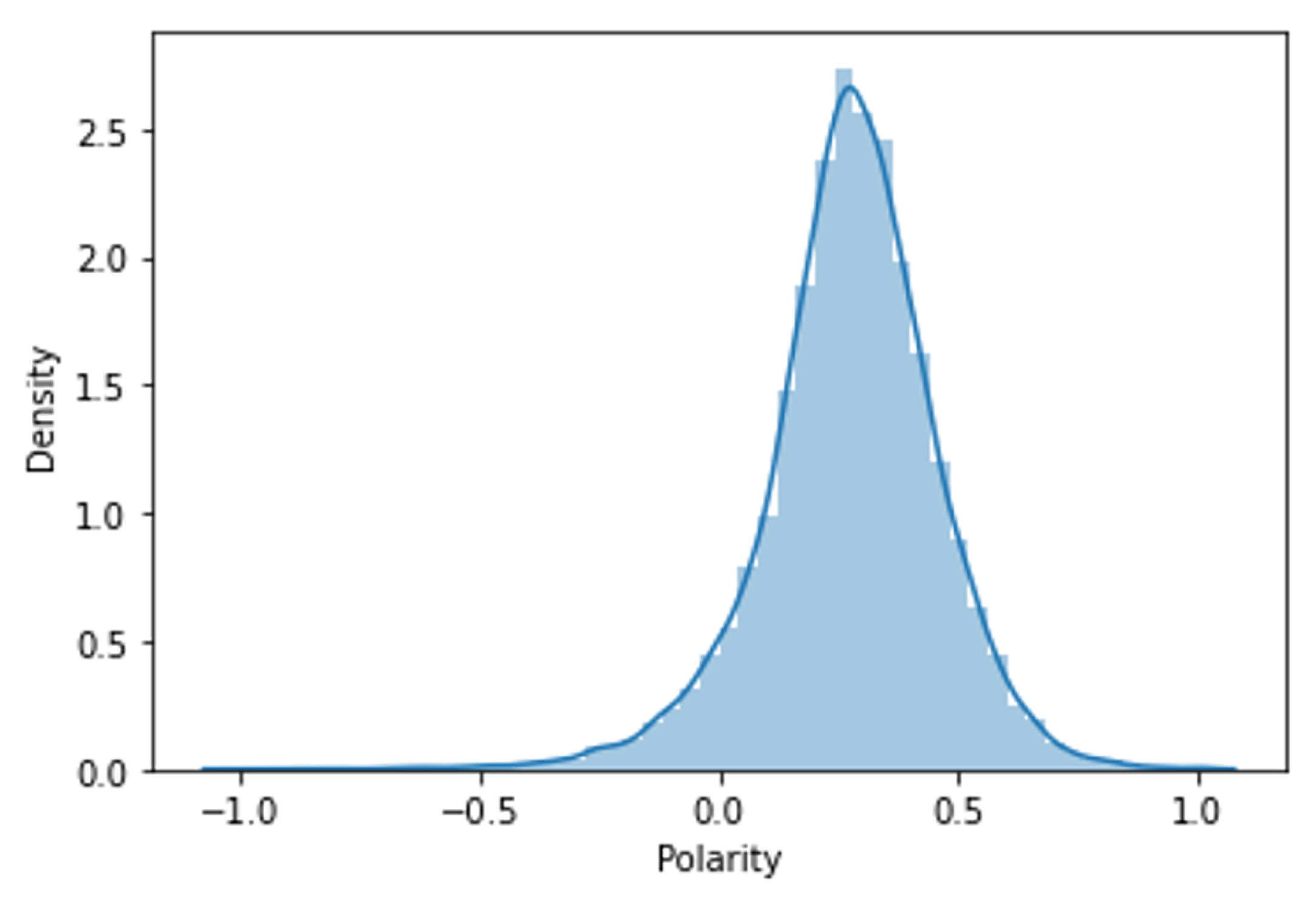
Figure 3 presents the density of the “Polarity” attribute obtained with Textblob. We found that the “Polarity” is mostly positive, which makes sense since, as we saw earlier, most reviews are also positive.
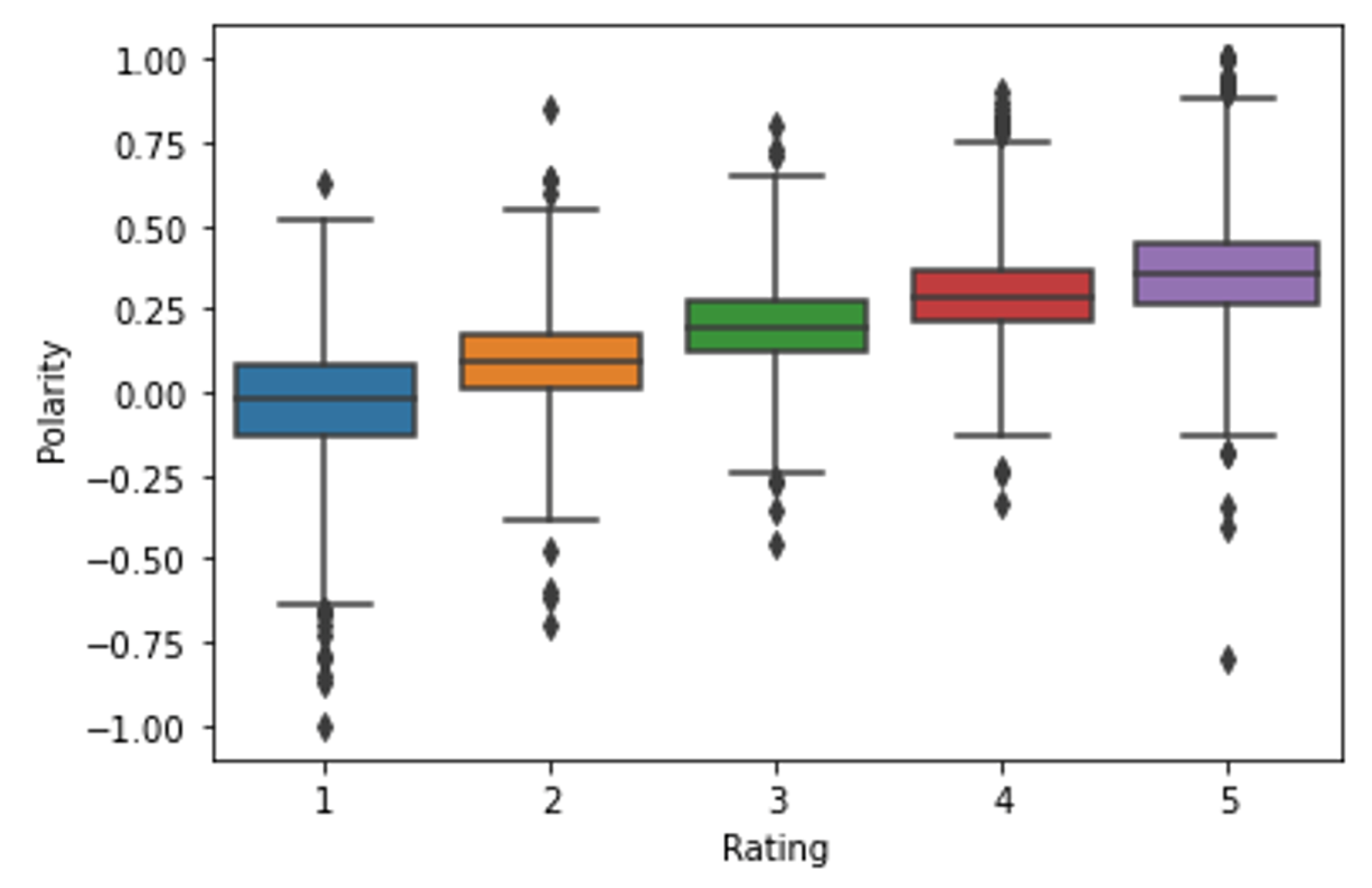
Figure 4 presents the correlation between “Polarity” and “Rating”. We can see that the polarity rises as the rating increases, which clearly demonstrates the existence of a correlation. However, we also found that the boxplots of each rating level are superimposed, which is a strong indicator of the difficulty in achieving success in creating classification models. In addition, we verified the existence of many outliers, which may not actually be accurate, as is the case for “Rating” equal to 1, in which we verified the existence of many records with polarity between −1 and −0.65.
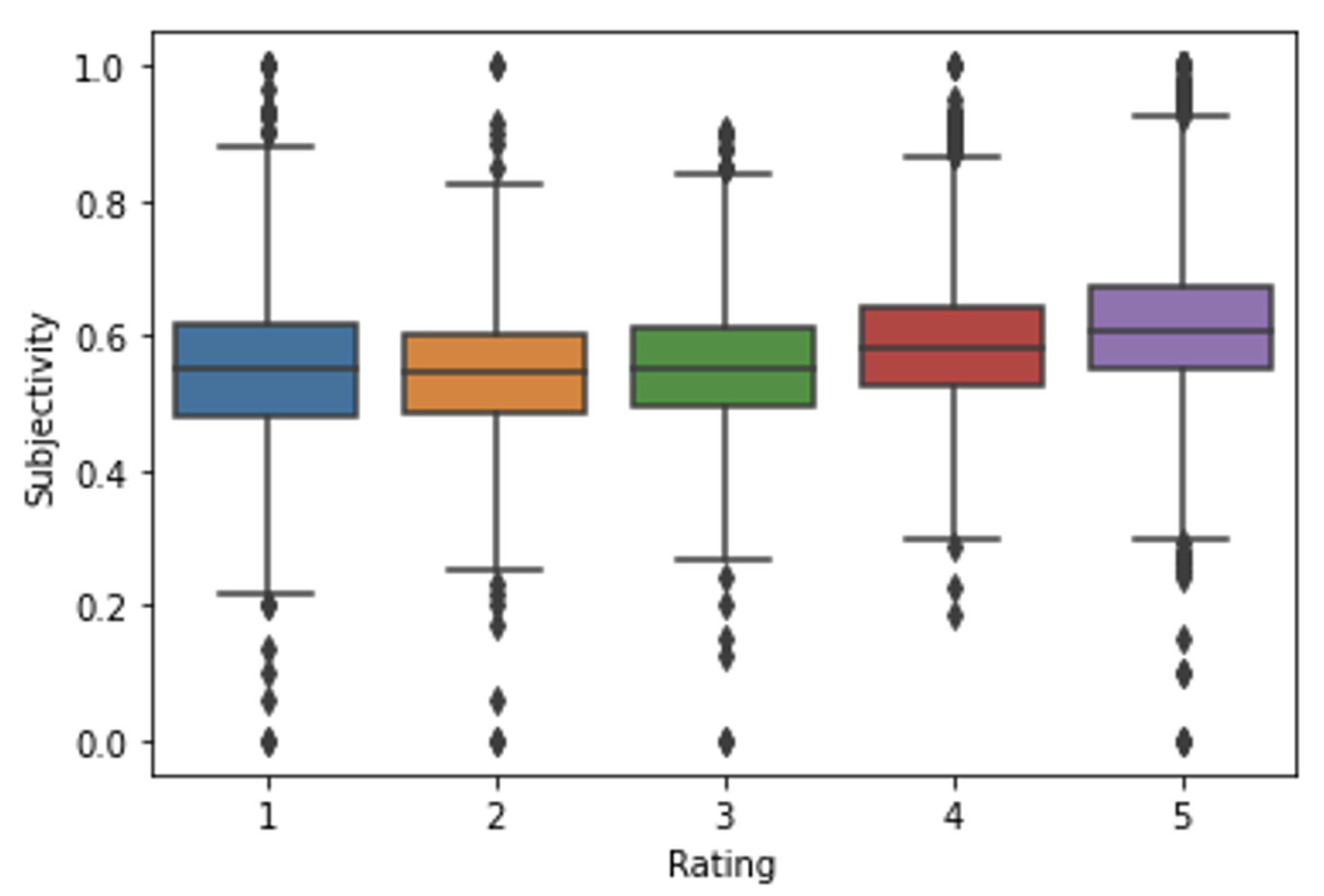
Figure 5 presents the correlation between “Subjectivity” and “Rating”. As we can see, there does not seem to exist any kind of correlation between subjectivity and rating.
To create a more simplified version of the assessment made by tourists, we generated a new attribute called “Sentiment”, with a value equal to 1 for records where the “Rating” was equal to or greater than 3 and with a value equal to 0 for records where the “Rating” was less than 3. This attribute will allow us to distinguish positive ratings from negative ratings.
We also carried out important preprocessing activities that allowed us to prepare the dataset and discover some important aspects. First, we put all the corpus in lowercase. Then, we tokenized the corpus and performed lemmatization and removed all the punctuation. In addition, we used other techniques, such as removing stopwords, stemming, and considering only the characters of the alphabet; however, these did not allow us to obtain better results. Finally, we used the MinMaxScaler to normalize the data.
3.4. Computational Techniques
Considering the objective of this work, we believed that it would be important to test the results that would be possible to obtain with different algorithms, both as classification methods and as regression methods for supervised learning. We anticipated that if algorithms as classification methods failed due to previously identified limitations, algorithms as regression methods could be an acceptable alternative in the context of the objective of this work. Due to the vast number of existing methods, we decided to choose the classic and the most widely used in the literature. Our main criterion was the diversity of the mechanics with which these methods are structured. Hence, we chose methods from different categories based on decision trees, distances, neural networks, and decision boundaries. The algorithms used were: Logistic Regression, Random Forest, Decision Tree, K-Nearest Neighbors, and Bidirectional Long/Short-Term Memory (biLSTM). The first 4 used the Scikit-learn library and the last one used the Keras library.
We also considered applying unsupervised techniques used in anomaly detection problems. These methods are present in numerous domains and research fields. These can be found in industrial machinery failure [
28,
29,
30], credit card fraud [
31,
32,
33], image processing [
34,
35], medical and public health [
36,
37,
38], network intrusion [
39,
40,
41,
42], and others [
43,
44,
45,
46,
47]. We focused on One-Class Classification (OCC) [
17] methods to understand whether we could improve the results of the best classification algorithm. To do so, we selected three unsupervised methods from the Scikit-learn library: Isolation Forest, One-Class K-Nearest Neighbor (OCKNN), and Local Outlier Factor (LOF).
3.5. Tests and Evaluation
Several experiments were carried out with the selected algorithms to tune parameters for optimization. However, as no significant differences were found, the default configuration provided by the used libraries was employed for all algorithms. For estimating the performance of the ML models, we performed cross-validation with five repetitions.
We defined six different scenarios to create models. In the first three scenarios (#1, #2 and #3), the set of most used words that did not express feelings were removed (hotel, room, staff, did, stay, rooms, stayed, location, service, breakfast, beach, food, night, day, hotel, pool, place, people, area, restaurant, bar, went, water, bathroom, bed, restaurants, trip, desk, make, floor, room, booked, nights, hotels, say, reviews, street, lobby, took, city, think, days, husband, arrived, check, and told), and in the other 3 (#4, #5 and #6), all words were kept.
For all scenarios, we used the TfidfVectorizer class from the Scikit-learn library to transform the “Review_new” feature to feature vectors, and we defined max_features equal to 5000. In addition, in scenarios #1 and #4, the features considered were: “Review_new”, “Polarity”, “Word_Count”, “Char_Count”, “Average_Word_Length”, “Positive_Vader_Sentiment”, and “Negative_Vader_Sentiment”; in scenarios #2 and #5, the features considered were “Review_new” and “Polarity”; and in scenarios #3 and #6, only the feature “Review_new” was considered. We applied each supervised learning algorithm to each scenario with both the classification and regression methods. Thus, all combinations were used for a 5-class problem (Y = “Rating”) and a 2-class problem (Y = “Sentiment”). Finally, we applied three anomaly detection methods to the output of the best classification model (2-class problem).
3.5.1. Classification and Regression Results with Supervised Methods
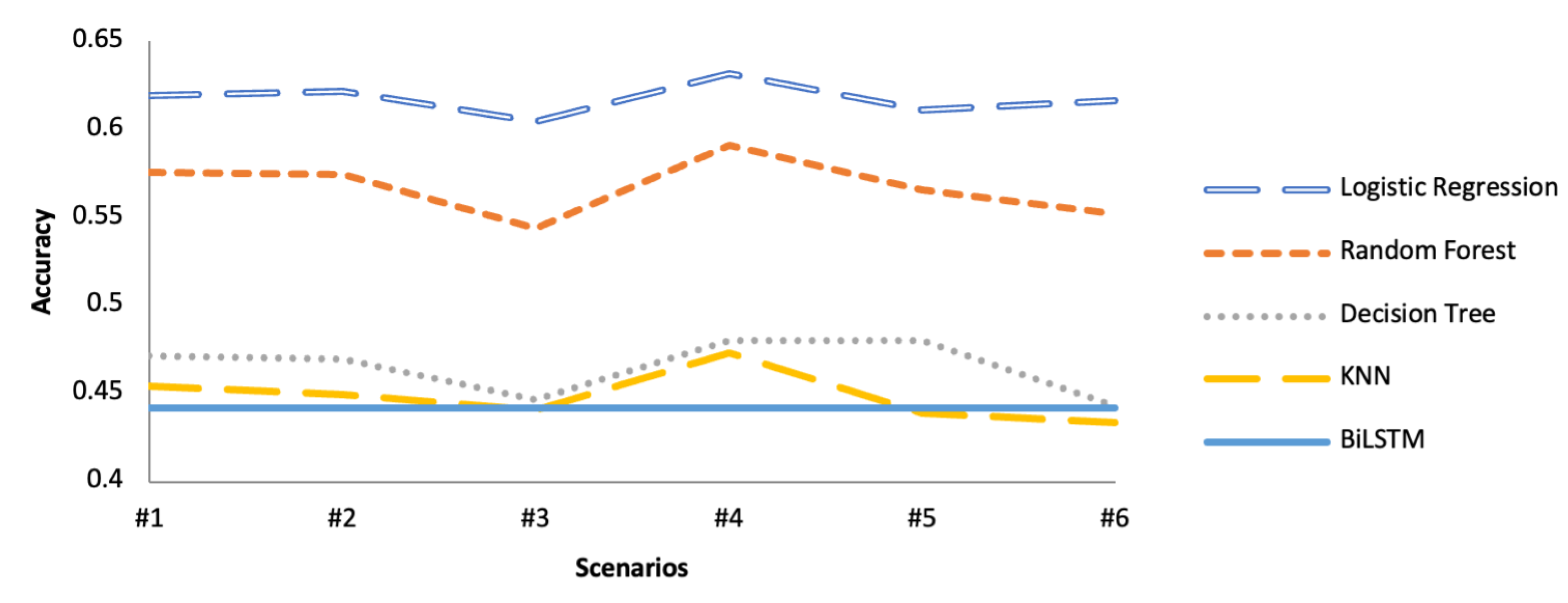
Figure 6 presents the results obtained with the five algorithms for each of the scenarios defined with the classification method for the 5-class problem (Y = “Rating”). Note that the Logistic Regression method is limited to two-class classification problems by default. However, with the Scikit-learn library, Logistic Regression can handle multi-class classification problems using the approach one-vs-rest [
48]. Analyzing
Figure 6, the Logistic Regression algorithm obtained the best results for all scenarios, with an accuracy always higher than 0.6, followed by the Random Forest algorithm. The other three algorithms obtained considerably lower results, and in the case of the BiLSTM algorithm, the results were very poor, as it classified all cases with a “Rating” of 4.
Since scenario 4 was the one that allowed us to achieve the best results, in terms of accuracy,
Table 3 presents precision and recall for each of the algorithms in scenario 4 with the classification method for the 5-class problem. We verified that the Logistic Regression and Random Forest algorithms presented interesting results. It is possible to verify that relatively high values were obtained for the extreme cases (“Rating” = 1 and “Rating” = 5), but the quality was quite low in the classification of intermediate values.
Figure 7 presents the results obtained with the 5 algorithms for each of the scenarios defined with the classification method for the 2-class problem (Y = “Sentiment”). As can be seen, the results were quite good. Once again, the Logistic Regression and Random Forest algorithms obtained the best results, with the Logistic Regression algorithm showing an accuracy very close to 0.95. The Decision Tree and K-Nearest Neighbors algorithms obtained reasonable results, mainly in scenarios where more features were considered. The BiLSTM algorithm returned the worst results.
Table 4 presents precision and recall for each of the algorithms in scenario 4 with the classification method for the 2-class problem. The results presented by the Logistic Regression algorithm are quite solid. It is verified that the recall for L 1 (Sentiment = 0) is lower than desirable, but this is probably explained by the dataset being unbalanced.
The next experiences concern the application of the algorithms to the previously presented scenarios with the regression method.
Figure 8 presents the Mean Absolute Error obtained with the 5 algorithms for each of the scenarios defined with the regression method for the 5-class problem (Y = “Rating”). We found that most algorithms obtained poor results. However, the Random Forest algorithm presented very interesting results, obtaining a Mean Absolute Error of 0.69 in scenario 4 (which is quite good considering the problem in question).
Table 5 presents the Mean Squared Error, Root Mean Square Error, and Mean Absolute Error for each of the algorithms in scenario 4 with the regression method for the 5-class problem. Once again, it is possible to verify that the Random Forest algorithm obtained very good results, unlike the other algorithms. Although the BiLSTM algorithm seems to give reasonable results, this only happens due to the fact that it always generates the same output and most reviews are positive.
Figure 9 presents the Mean Absolute Error obtained with the 5 algorithms for each of the scenarios defined with the regression method for the 2-class problem (Y = “Sentiment”). We verified that, in this case, all algorithms, with the exception of the BiLSTM algorithm, obtained very good results.
Table 6 presents the Mean Squared Error, Root Mean Square Error, and Mean Absolute Error for each of the algorithms in scenario 4 with the regression method for the 2-class problem. The Logistic Regression algorithm again presented very good results that were consistent across all experiments. In this scenario, the K-Nearest Neighbors algorithm also presented interesting results.
3.5.2. Anomaly Detection Results
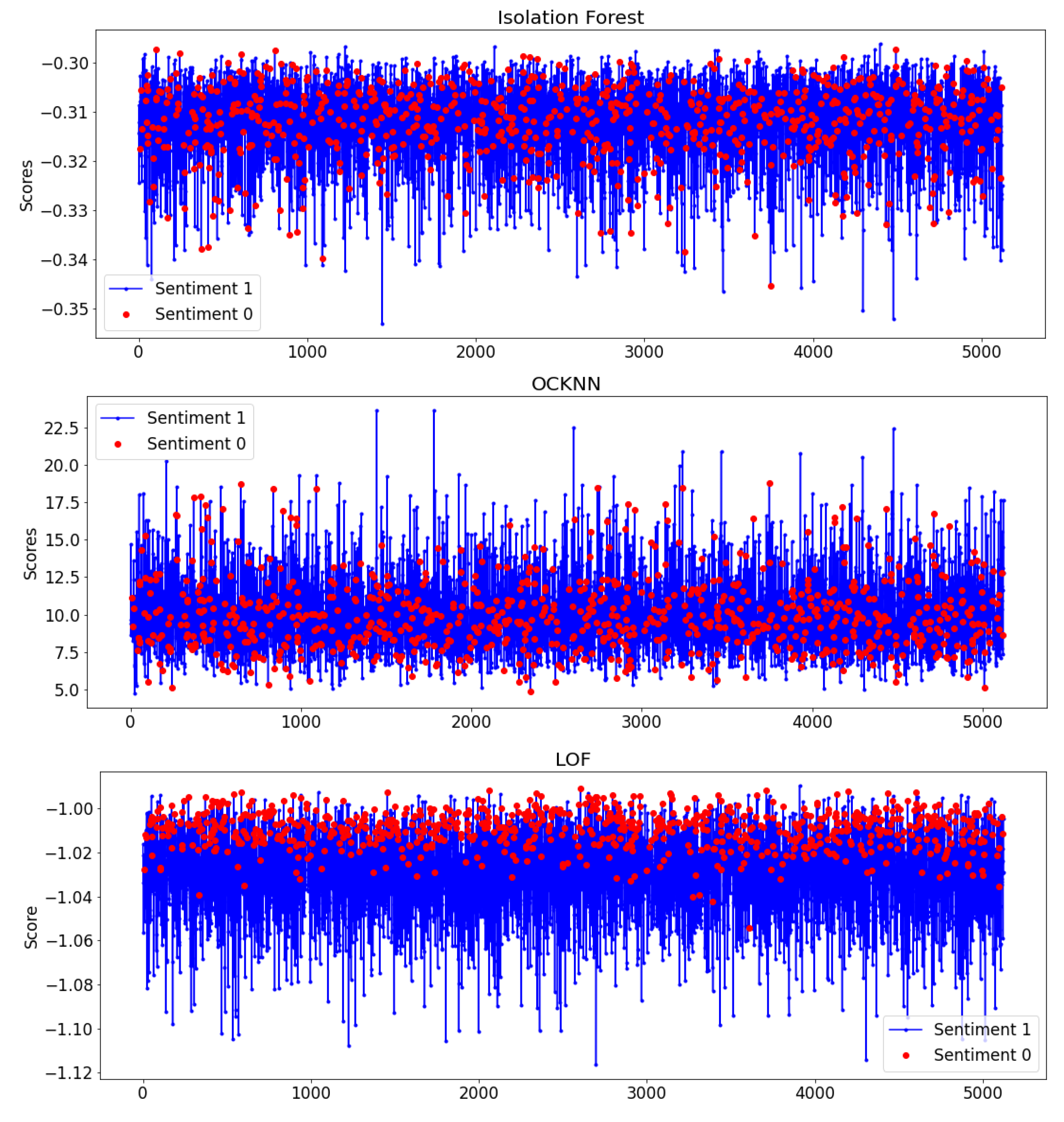
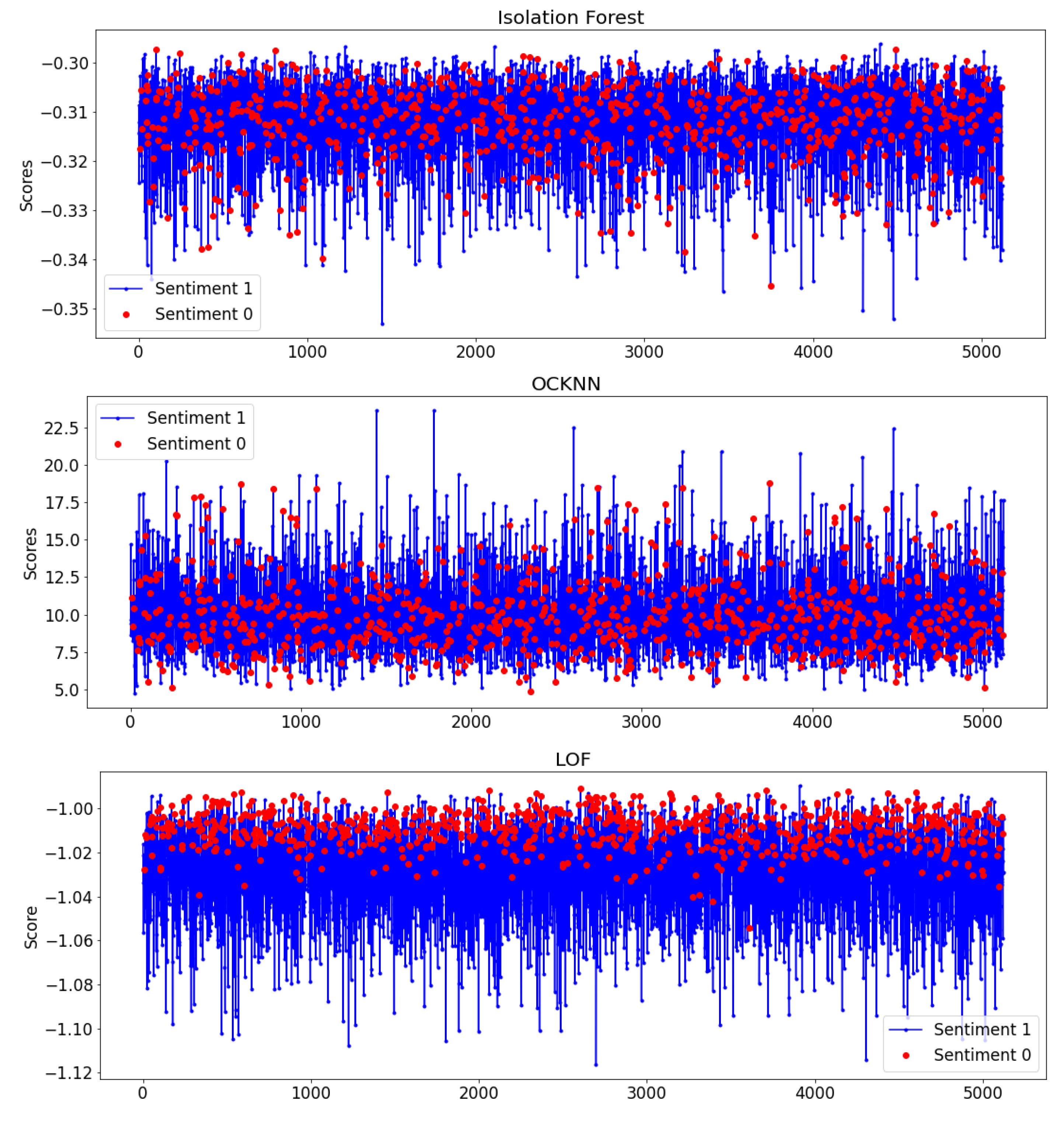
Through our next experiments, we selected OCC methods used in anomaly detection problems. We applied them to score the predicted output of the best classification algorithm—in this case, the Logistic Regression. These anomaly detectors are trained with normal data, identifying patterns that deviate from normality, which are considered anomalies. The main goal is to analyze whether these techniques can help the recommendation system that we intend to develop to correctly classify as many users as possible—that is, to detect whether they like a POI, improving the Logistic Regression performance.Therefore, as we can observe in
Figure 10, the class 0 (showed as red dots), which we have considered as the anomalous one in this scenario, is dispersed through the graph in the Isolation Forest and OCKNN methods. We can also visualize that users with negative sentiments are at the top for the LOF method, with the highest scores. However, some of them are overlapped with users with positive sentiments, which means that although improvements in reducing false positives are possible, they come with the cost of increasing false negatives. We identified LOF as the best method to apply for this purpose as it was shown to better separate the Y = “Sentiment” classes through its score compared to the other methods.
We then performed four different experiments with this technique, analyzing the precision and recall metrics, as we intended to reduce false positives (increase precision), taking the increase in false negatives (decrease recall) into account. Thus, in the first two experiments, we applied LOF to separate Y = “Sentiment” classes by training with users with positive sentiments to isolate users with negative sentiments in the first experiment, while in the second experiment, we did the same, switching the classes (training with users with negative sentiment to isolate users with positive sentiment). We repeated the process for experiments three and four, this time using Y = “Ranking” to isolate the extreme ranking values, meaning that, in experiment three, we used users who rated 5 to train in order to isolate users who rated 1 and vice versa for the fourth experiment.
To visualize the experiments, we built different graphics (
Figure 11,
Figure 12,
Figure 13 and
Figure 14). The
y-axis represents precision and recall percentage values, and in the
x-axis, the percentile thresholds from LOF are given. That is, the percentage instances with the highest score from LOF output are considered the isolated class. For example, threshold percentile 95% means that instances that have a score value greater than 95% of the highest score output are considered as the isolated class.
We can observe in all experiments that recall presents a linear increase when threshold values also increase, while precision shows a slight decrease for high threshold values. It is essential to mention that threshold percentile 100% represents the output of Logistic Regression without cuts, which is why recall is always 100%, which means the absence of false negatives since we are using the values predicted by the Logistic Regression method of only a specific class.
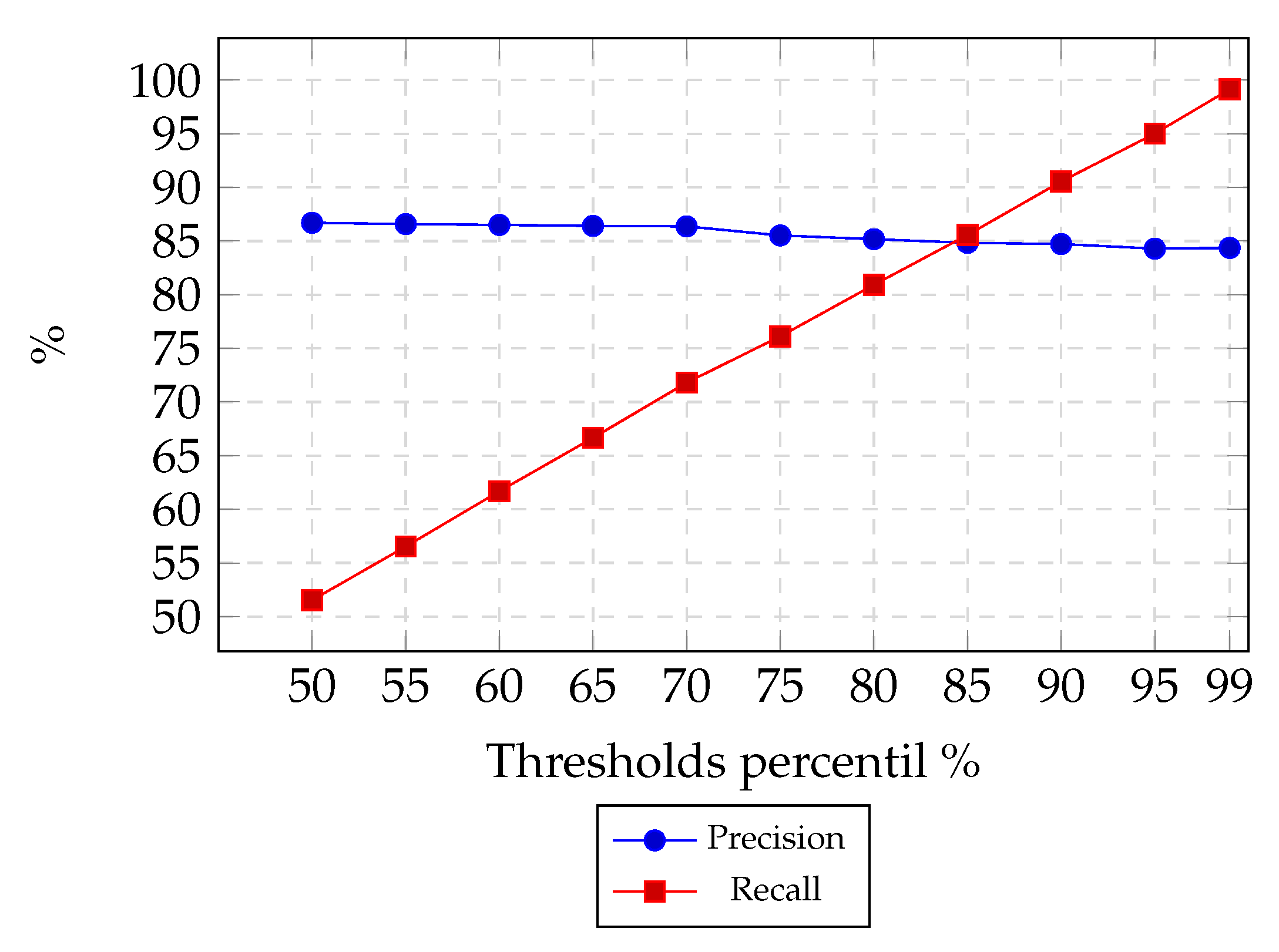
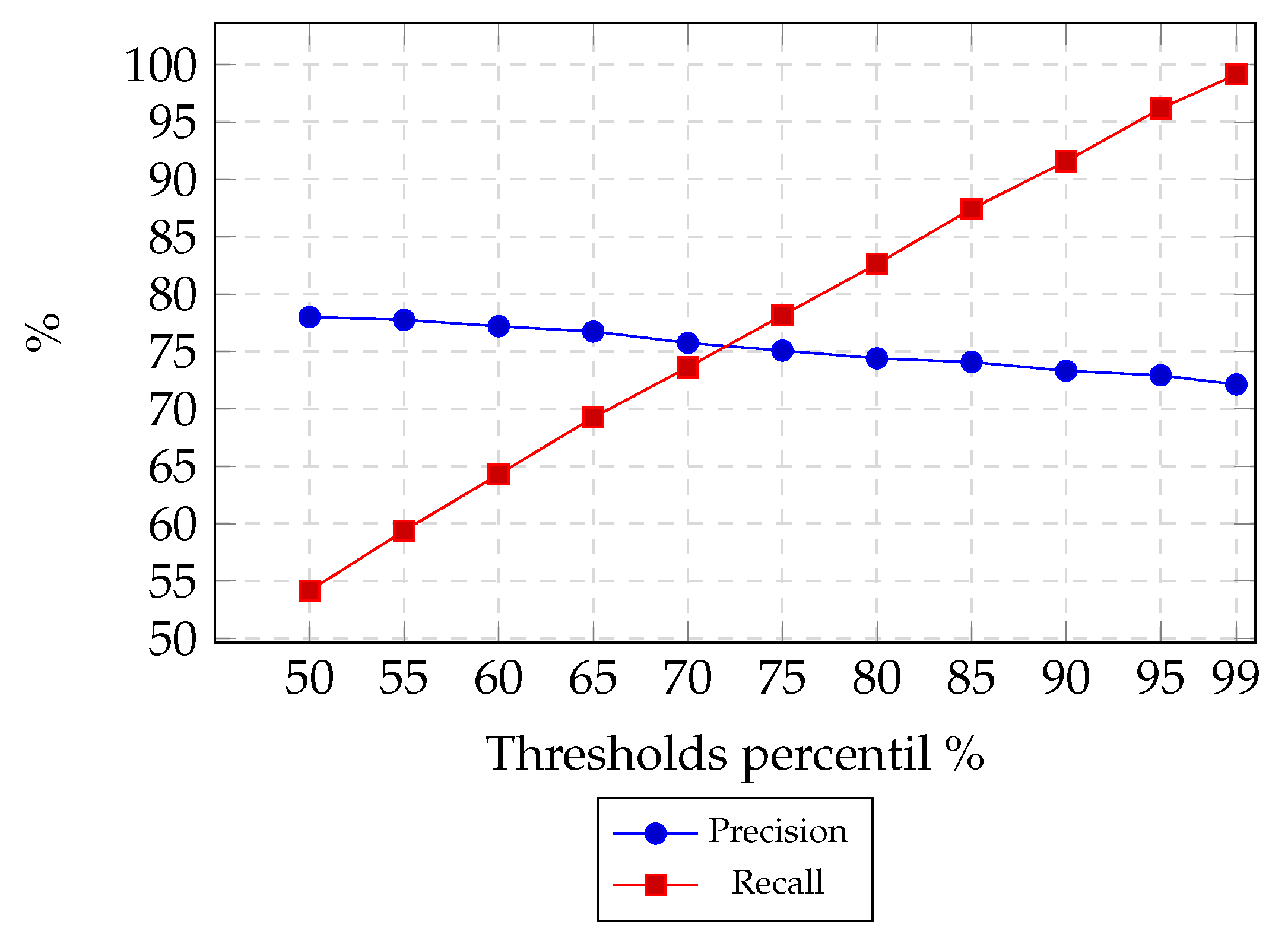
In the first experiment (
Figure 11), we aimed to discard class 0 from the Logistic Regression output, reducing the population from class 1 in order to obtain the maximum users who liked a POI. We can see that if using a threshold percentile of 50%, we obtain approximately 99% precision, but with a high cost for the recall value (52%). In this experiment, precision has a slight increase when reducing the class 1 population in 20% (threshold percentile 80%), achieving precision of 98%, while recall decreases at 82%. It obtains an acceptable recall value while precision converges to its highest value.
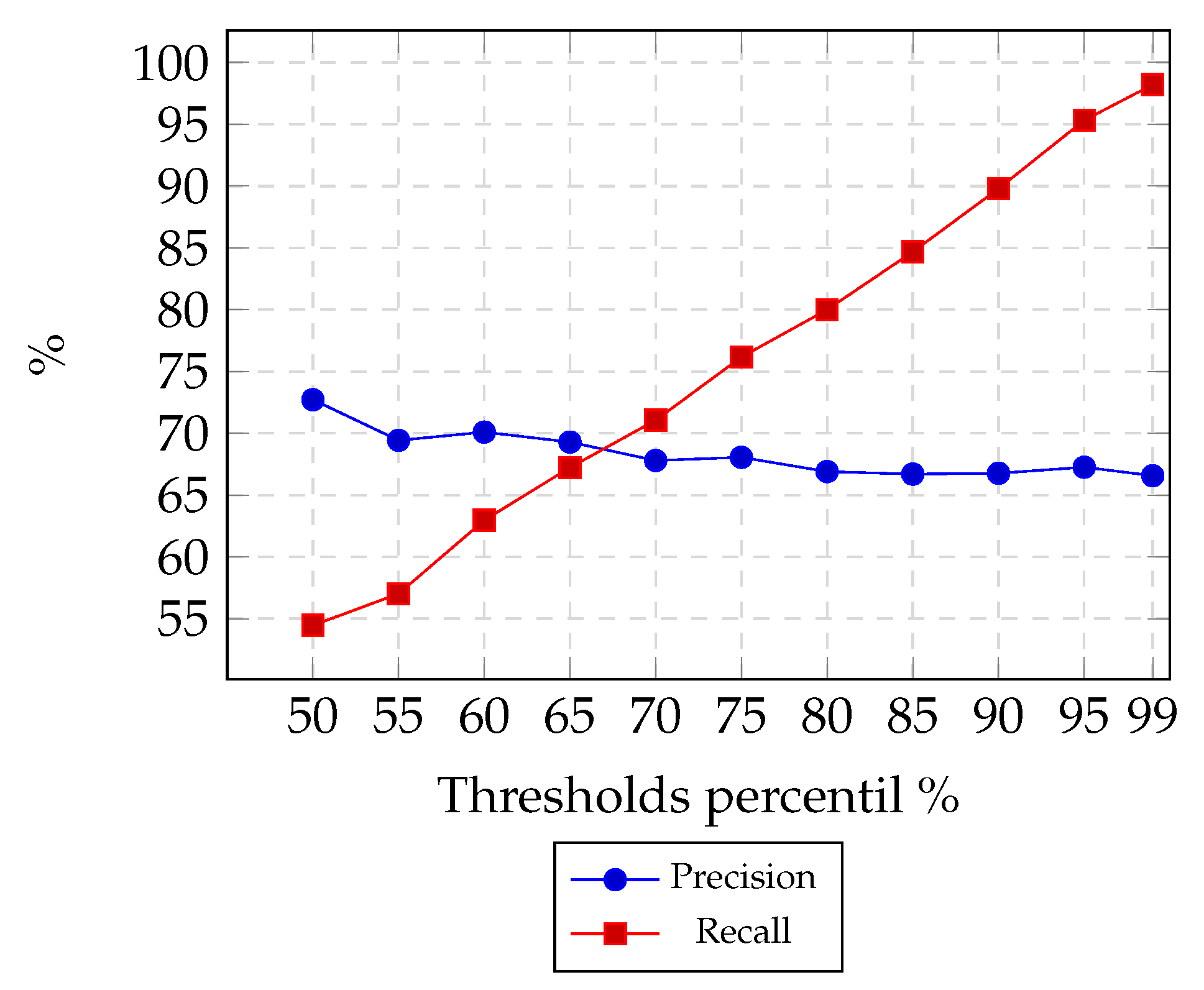
In
Figure 12, it is possible to observe the experiment in which we intended to hit the highest number of users who did not like a POI. In this scenario, LOF shows poor performance since it could not separate adequately class 1 from class 0. In order to be able to increase precision in only 2% (from 84% to 86%), recall drops from 99% to 51%.
Regarding the third experiment, shown in
Figure 13, our goal was to discard users who rated a POI as 1, while reaching the maximum number of users who rated a specific POI as 5. Regarding the third experiment, shown in
Figure 13, we wanted to discard users who rated a POI as 1 while reaching the maximum number of users who rated a specific POI as 5; it can be seen that precision can increase from 73% to 78% when reducing the population from users who rate 5 in 50%. This increase of 5% is the same, visible in the first (
Figure 11) and last experiment (
Figure 14); however, the highest precision value is much higher in the first scenario.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}