
From Biological Synapses to “Intelligent” Robots

Abstract
1. Introduction
2. Biological Synapse: Adaptive Learning “from Scratch”
2.1. From Single Synapses to Brain Networks
2.2. Timing of Neural Signals
2.3. Reinforcement and Extinction
2.4. Functional Plasticity
3. Invertebrate Models of Adaptive Learning
3.1. Motor Learning and Memory
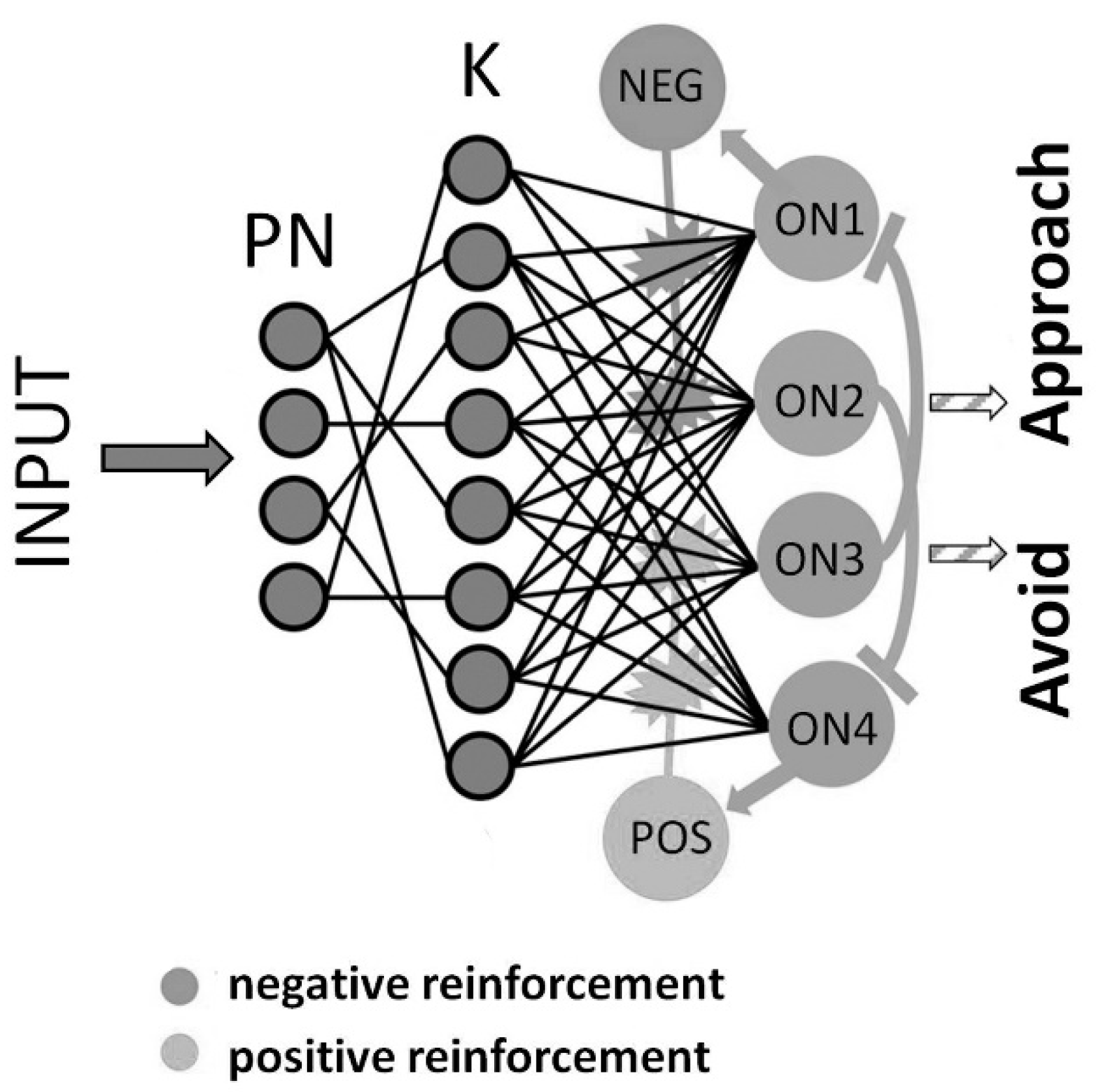
3.2. Avoidance and Approach
3.3. Adaptation to the Unexpected
4. Vertebrate Models of Learning for Cognitive Control
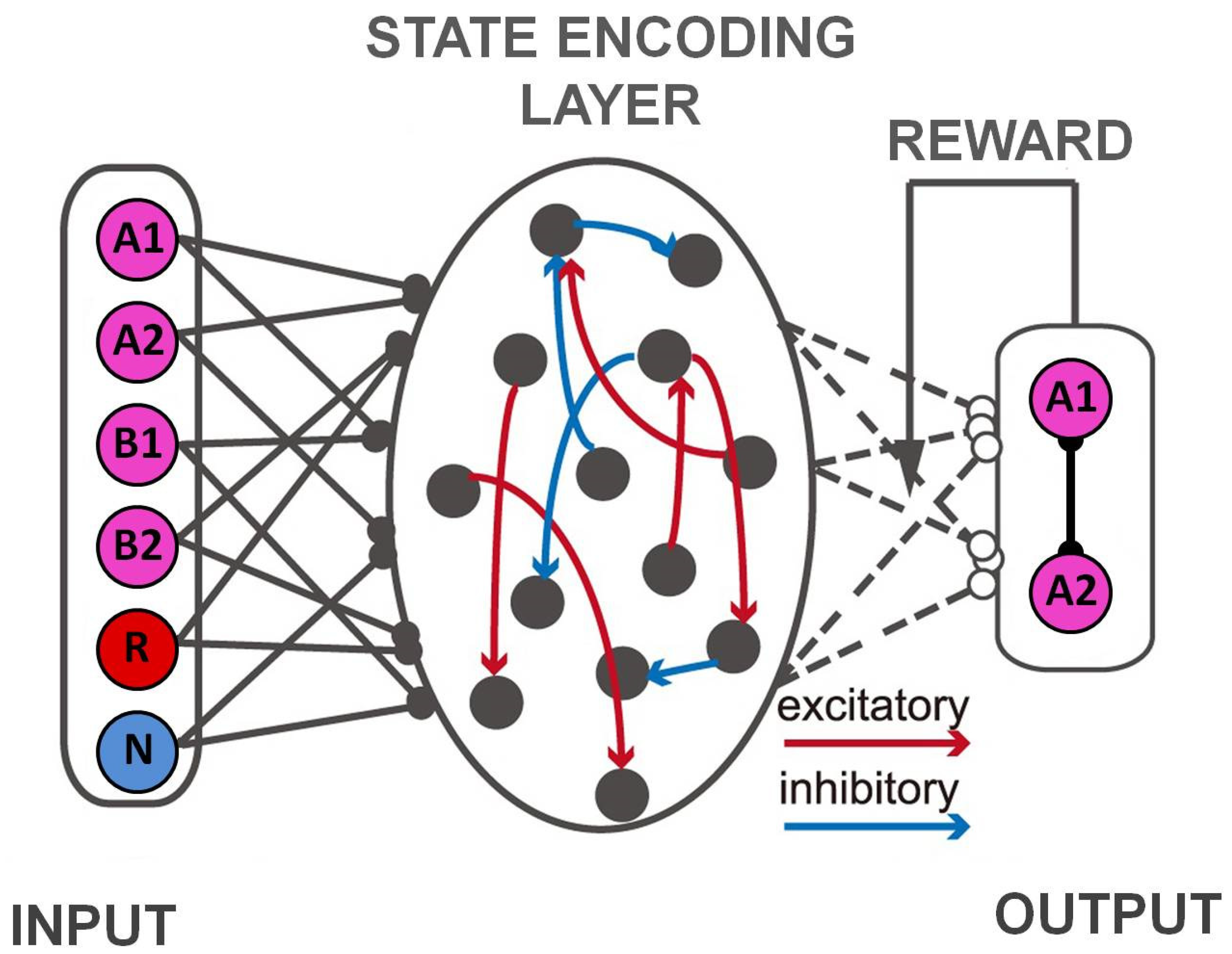
4.1. Task State Learning and Control
4.2. Memorizing Temporal Order
4.3. Self-Organization
4.4. Toward “Intelligent” Robotics
5. Current Developments in Brain-Inspired Robot Control
5.1. Repetitive or Rhythmic Behavior
5.2. Sensorimotor Integration
5.3. Movement Planning
6. Conclusions
Funding
Conflicts of Interest
References
- Hebb, D. The Organization of Behaviour; John Wiley & Sons: Hoboken, NJ, USA, 1949. [Google Scholar]
- Grossberg, S. Self-organizing neural networks for stable control of autonomous behavior in a changing world. In Mathematical Approaches to Neural Networks; Taylor, J.G., Ed.; Elsevier Science Publishers: Amsterdam, The Netherlands, 1993; pp. 139–197. [Google Scholar]
- Sepulcre, J.; Liu, H.; Talukdar, T.; Martincorena, I.; Yeo, B.T.; Buckner, R.L. The Organization of Local and Distant Functional Connectivity in the Human Brain. PLoS Comput. Biol. 2010, 6, e1000808. [Google Scholar] [CrossRef] [PubMed]
- Spillmann, L.; Dresp-Langley, B.; Tseng, C.-H. Beyond the classical receptive field: The effect of contextual stimuli. J. Vis. 2015, 15, 7. [Google Scholar] [CrossRef] [PubMed]
- Delorme, A.; Thorpe, S.J. Spikenet: An event-driven simulation package for modelling large networks of spiking neurons. Network 2003, 14, 613–627. [Google Scholar] [CrossRef] [PubMed]
- Berninger, B.; Bi, G.-Q. Synaptic modification in neural circuits: A timely action. BioEssays 2002, 24, 212–222. [Google Scholar] [CrossRef] [PubMed]
- Brette, R.; Rudolph, M.; Carnevale, T.; Hines, M.; Beeman, D.; Bower, J.M.; Diesmann, M.; Morrison, A.; Goodman, P.H.; Harris, F.C.; et al. Simulation of networks of spiking neurons: A review of tools and strategies. J. Comput. Neurosci. 2007, 23, 349–398. [Google Scholar] [CrossRef]
- Haider, B.; Schulz, D.P.; Häusser, M.; Carandini, M. Millisecond Coupling of Local Field Potentials to Synaptic Currents in the Awake Visual Cortex. Neuron 2016, 90, 35–42. [Google Scholar] [CrossRef]
- Wang, Y.; Zeng, Y.; Tang, J.; Xu, B. Biological Neuron Coding Inspired Binary Word Embeddings. Cogn. Comput. 2019, 11, 676–684. [Google Scholar] [CrossRef]
- Engel, T.A.; Chaisangmongkon, W.; Freedman, D.J.; Wang, X.-J. Choice-correlated activity fluctuations underlie learning of neuronal category representation. Nat. Commun. 2015, 6, 6454. [Google Scholar] [CrossRef]
- Muniak, M.; Ray, S.; Hsiao, S.S.; Dammann, J.F.; Bensmaia, S.J. The Neural Coding of Stimulus Intensity: Linking the Population Response of Mechanoreceptive Afferents with Psychophysical Behavior. J. Neurosci. 2007, 27, 11687–11699. [Google Scholar] [CrossRef]
- McCane, A.M.; Wegener, M.A.; Faraji, M.; Rivera-Garcia, M.T.; Wallin-Miller, K.G.; Costa, V.D.; Moghaddam, B. Adolescent Do-pamine Neurons Represent Reward Differently during Action and State Guided Learning. J. Neurosci. 2021, 41, 9419–9430. [Google Scholar] [CrossRef]
- Campese, V.D.; Brannigan, L.A.; LeDoux, J.E. Conditional Control of Instrumental Avoidance by Context Following Extinction. Front. Behav. Neurosci. 2021, 15, e730113. [Google Scholar] [CrossRef]
- Bouton, M.E.; Maren, S.; McNally, G.P. Behavioral and neurobiological mechanisms of pavlovian and instrumental extinction learning. Physiol. Rev. 2021, 101, 611–681. [Google Scholar] [CrossRef]
- Lamprecht, R.; LeDoux, J. Structural plasticity and memory. Nat. Rev. Neurosci. 2004, 5, 45. [Google Scholar] [CrossRef]
- Fischer, M.; Kaech, S.; Wagner, U.; Brinkhaus, H.; Matus, A. Glutamate receptors regulate actin-based plasticity in dendritic spines. Nat. Neurosci. 2000, 3, 887–894. [Google Scholar] [CrossRef]
- Washbourne, P.; Bennett, J.E.; McAllister, A.K. Rapid recruitment of NMDA receptor transport packets to nascent synapses. Nat. Neurosci. 2002, 5, 751–759. [Google Scholar] [CrossRef]
- Oertner, T.G.; Matus, A. Calcium regulation of actin dynamics in dendritic spines. Cell Calcium 2005, 37, 477–482. [Google Scholar] [CrossRef]
- Lüscher, C.; Xia, H.; Beattie, E.C.; Carroll, R.C.; von Zastrow, M.; Malenka, R.C.; A Nicoll, R. Role of AMPA Receptor Cycling in Synaptic Transmission and Plasticity. Neuron 1999, 24, 649–658. [Google Scholar] [CrossRef]
- Dudai, Y. Molecular bases of long-term memories: A question of persistence. Curr. Opin. Neurobiol. 2002, 12, 211–216. [Google Scholar] [CrossRef]
- Dickinson, A.; Balleine, B. Motivation control of goal-directed action. Anim. Learn. Behav. 1994, 22, 1–18. [Google Scholar] [CrossRef]
- Marder, E. Motor pattern generation. Curr. Opin. Neurobiol. 2000, 10, 691–698. [Google Scholar] [CrossRef]
- Pearson, K.G. Neural Adaptation in the Generation of Rhythmic Behavior. Annu. Rev. Physiol. 2000, 62, 723–753. [Google Scholar] [CrossRef]
- Brembs, B. Operant conditioning in invertebrates. Curr. Opin. Neurobiol. 2003, 13, 710–717. [Google Scholar] [CrossRef] [PubMed]
- Dickson, B.J. Wired for Sex: The Neurobiology of Drosophila Mating Decisions. Science 2008, 322, 904–909. [Google Scholar] [CrossRef] [PubMed]
- Brembs, B. Towards a scientific concept of free will as a biological trait: Spontaneous actions and decision-making in invertebrates. Proc. R. Soc. B Biol. Sci. 2010, 278, 930–939. [Google Scholar] [CrossRef]
- Edwards, D.H.; Issa, F.A.; Herberholz, J. The neural basis of dominance hierarchy formation in crayfish. Microsc. Res. Tech. 2003, 60, 369–376. [Google Scholar] [CrossRef] [PubMed]
- Kupfermann, I. Feeding behavior in Aplysia: A simple system for the study of motivation. Behav. Biol. 1974, 10, 1–26. [Google Scholar] [CrossRef]
- Von Philipsborn, A.C.; Liu, T.; Yu, J.Y.; Masser, C.; Bidaye, S.S.; Dickson, B.J. Neuronal control of drosophila courtship song. Neuron 2011, 69, 509–522. [Google Scholar] [CrossRef]
- Brembs, B.; Lorenzetti, F.D.; Reyes, F.D.; Baxter, D.A.; Byrne, J.H. Operant Reward Learning in Aplysia: Neuronal Correlates and Mechanisms. Science 2002, 296, 1706–1709. [Google Scholar] [CrossRef]
- Brezina, V.; Proekt, A.; Weiss, K.R. Cycle-to-cycle variability as an optimal behavioral strategy. Neurocomputing 2006, 69, 1120–1124. [Google Scholar] [CrossRef][Green Version]
- Schall, J.D. Decision making. Curr. Biol. 2005, 15, R9–R11. [Google Scholar] [CrossRef][Green Version]
- Nargeot, R. Long-Lasting Reconfiguration of Two Interacting Networks by a Cooperation of Presynaptic and Postsynaptic Plasticity. J. Neurosci. 2001, 21, 3282–3294. [Google Scholar] [CrossRef] [PubMed]
- Nargeot, R.; Baxter, D.A.; Byrne, J.H. Contingent-Dependent Enhancement of Rhythmic Motor Patterns: An In Vitro Analog of Operant Conditioning. J. Neurosci. 1997, 17, 8093–8105. [Google Scholar] [CrossRef] [PubMed]
- Kennerley, S.W.; Walton, M.E. Decision making and reward in frontal cortex: Complementary evidence from neurophysi-ological and neuropsychological studies. Behav. Neurosci. 2011, 125, 297–317. [Google Scholar] [CrossRef]
- Kristan, W.B. Neuronal Decision-Making Circuits. Curr. Biol. 2008, 18, R928–R932. [Google Scholar] [CrossRef]
- Kemenes, G. Behavioral Choice: A Novel Role for Presynaptic Inhibition of Sensory Inputs. Curr. Biol. 2009, 19, R1087–R1088. [Google Scholar] [CrossRef][Green Version]
- Gaudry, Q.; Kristan, W.B., Jr. Behavioral choice by presynaptic inhibition of tactile sensory terminals. Nat. Neurosci. 2009, 12, 1450–1457. [Google Scholar] [CrossRef]
- Balleine, B.W.; O’Doherty, J.P. Human and Rodent Homologies in Action Control: Corticostriatal Determinants of Goal-Directed and Habitual Action. Neuropsychopharmacology 2009, 35, 48–69. [Google Scholar] [CrossRef]
- Calabrese, R.L. Oscillation in motor pattern-generating networks. Curr. Opin. Neurobiol. 1995, 5, 816–823. [Google Scholar] [CrossRef]
- Soto-Treviño, C.; Thoroughman, K.A.; Marder, E.; Abbott, L.F. Activity-dependent modification of inhibitory synapses in models of rhythmic neural networks. Nat Neurosci. 2001, 4, 297–303. [Google Scholar] [CrossRef]
- Marder, E.; Bucher, D. Central pattern generators and the control of rhythmic movements. Curr. Biol. 2001, 11, R986–R996. [Google Scholar] [CrossRef]
- Marder, E.; Calabrese, R.L. Principles of rhythmic motor pattern generation. Physiol. Rev. 1996, 76, 687–717. [Google Scholar] [CrossRef]
- Harris-Warrick, R.M. General Principles of Rhythmogenesis in Central Pattern Generator Networks. Prog. Brain Res. 2010, 187, 213–222. [Google Scholar] [CrossRef]
- Reyes, M.B.; Carelli, P.V.; Sartorelli, J.C.; Pinto, R.D. A Modeling Approach on Why Simple Central Pattern Generators are Built of Irregular Neurons. PLoS ONE 2015, 10, e0120314. [Google Scholar] [CrossRef]
- Harris-Warrick, R.M. Neuromodulation and flexibility in Central Pattern Generator networks. Curr. Opin. Neurobiol. 2011, 21, 685–692. [Google Scholar] [CrossRef]
- Nusbaum, M.P.; Beenhakker, M.P. A small-systems approach to motor pattern generation. Nature 2002, 417, 343–350. [Google Scholar] [CrossRef]
- Nargeot, R.; Simmers, J. Neural mechanisms of operant conditioning and learning-induced behavioural plasticity in Ap-lysia. Cell. Mol. Life Sci. 2011, 68, 803–816. [Google Scholar] [CrossRef]
- Elliott, C.J.H.; Susswein, A.J. Comparative neuroethology of feeding control in mollusks. J. Exp. Biol. 2002, 205, 877–896. [Google Scholar] [CrossRef]
- Kemenes, G.; Benjamin, P.R. Lymnaea. Curr. Biol. 2009, 19, R9–R11. [Google Scholar] [CrossRef][Green Version]
- Kretz, R.; Shapiro, E.; Kandel, E.R. Presynaptic inhibition produced by an identified presynaptic inhibitory neuron. I. Physiological mechanisms. J. Neurophysiol. 1986, 55, 113–130. [Google Scholar] [CrossRef]
- Roberts, A.; Glanzman, D.L. Learning in Aplysia: Looking at synaptic plasticity from both sides. Trends Neurosci. 2003, 26, 662–670. [Google Scholar] [CrossRef]
- Nargeot, R.; Simmers, J. Functional organization and adaptability of a decision-making network in Aplysia. Front. Neurosci. 2012, 6, 113. [Google Scholar] [CrossRef]
- Selverston, A.I. Invertebrate central pattern generator circuits. Philos. Trans. R. Soc. B Biol. Sci. 2010, 365, 2329–2345. [Google Scholar] [CrossRef]
- Selverston, A.I.; Miller, J.P. Mechanisms underlying pattern generation in lobster stomatogastric ganglion as determined by selective inactivation of identified neurons. I. Pyloric system. J. Neurophysiol. 1980, 44, 1102–1121. [Google Scholar] [CrossRef]
- Aso, Y.; Sitaraman, D.; Ichinose, T.; Kaun, K.R.; Vogt, K.; Belliart-Guérin, G.; Plaçais, P.; Robie, A.A.; Yamagata, N.; Schnaitmann, C.; et al. Mushroom body output neurons encode valence and guide memory-based action selection in Drosophila. E-Life 2014, 3, e04580. [Google Scholar]
- Bennett, J.E.M.; Philippides, A.; Nowotny, T. Learning with reward prediction errors in a model of the Drosophila mushroom body. bioRxiv 2019. [Google Scholar] [CrossRef]
- Bouton, M.E. Context and Behavioral Processes in Extinction. Learn. Mem. 2004, 11, 485–494. [Google Scholar] [CrossRef]
- Bouton, M.E. Extinction: Behavioral Mechanisms and Their Implications. In Learning and Memory: A Comprehensive Reference, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Bouzaiane, E.; Trannoy, S.; Scheunemann, L.; Plaçais, P.-Y.; Preat, T. Two Independent Mushroom Body Output Circuits Retrieve the Six Discrete Components of Drosophila Aversive Memory. Cell Rep. 2015, 11, 1280–1292. [Google Scholar] [CrossRef]
- Chabaud, M.-A.; Preat, T.; Kaiser, L. Behavioral Characterization of Individual Olfactory Memory Retrieval in Drosophila Melanogaster. Front. Behav. Neurosci. 2010, 4, 192. [Google Scholar] [CrossRef]
- Cohn, R.; Morantte, I.; Ruta, V. Coordinated and Compartmentalized Neuromodulation Shapes Sensory Processing in Drosophila. Cell 2015, 163, 1742–1755. [Google Scholar] [CrossRef]
- Cook, R.; Fagot, J. First trial rewards promote 1-trial learning and prolonged memory in pigeon and baboon. Proc. Natl. Acad. Sci. USA 2009, 106, 9530–9533. [Google Scholar] [CrossRef]
- Delamater, A.R.; Westbrook, R.F. Psychological and neural mechanisms of experimental extinction: A selective review. Neurobiol. Learn. Mem. 2014, 108, 38–51. [Google Scholar] [CrossRef] [PubMed]
- Dudai, Y. The Neurobiology of Consolidations, Or, How Stable is the Engram? Annu. Rev. Psychol. 2004, 55, 51–86. [Google Scholar] [CrossRef] [PubMed]
- Eichler, K.; Li, F.; Litwin-Kumar, A.; Park, Y.; Andrade, I.; Schneider-Mizell, C.M.; Saumweber, T.; Huser, A.; Eschbach, C.; Gerber, B.; et al. The complete connectome of a learning and memory centre in an insect brain. Nature 2017, 548, 175–182. [Google Scholar] [CrossRef] [PubMed]
- Eisenhardt, D.; Menzel, R. Extinction learning, reconsolidation and the internal reinforcement hypothesis. Neurobiol. Learn. Mem. 2007, 87, 167–173. [Google Scholar] [CrossRef]
- Hammer, M. The neural basis of associative reward learning in honeybees. Trends Neurosci. 1997, 20, 245–252. [Google Scholar] [CrossRef]
- Eschbach, C.; Fushiki, A.; Winding, M.; Schneider-Mizell, C.M.; Shao, M.; Arruda, R.; Eichler, K.; Valdes-Aleman, J.; Ohyama, T.; Thum, A.S.; et al. Recurrent architecture for adaptive regulation of learning in the insect brain. Nat. Neurosci. 2020, 23, 544–555. [Google Scholar] [CrossRef]
- Faghihi, F.; Moustafa, A.A.; Heinrich, R.; Wörgötter, F. A computational model of conditioning inspired by Drosophila ol-factory system. Neural Netw. 2017, 87, 96–108. [Google Scholar] [CrossRef]
- Felsenberg, J.; Jacob, P.F.; Walker, T.; Barnstedt, O.; Edmondson-Stait, A.; Pleijzier, M.W.; Otto, N.; Schlegel, P.; Sharifi, N.; Perisse, E.; et al. Integration of Parallel Opposing Memories Underlies Memory Extinction. Cell 2018, 175, 709–722.e15. [Google Scholar] [CrossRef]
- Gupta, A.; Faghihi, F.; Moustafa, A.A. Computational Models of Olfaction in Fruit Flies. Comput. Models Brain Behav. 2017, 1, 199–213. [Google Scholar] [CrossRef]
- Luo, R.; Uematsu, A.; Weitemier, A.; Aquili, L.; Koivumaa, J.; McHugh, T.J.; Johansen, J.P. A dopaminergic switch for fear to safety transitions. Nat. Commun. 2018, 9, 2483. [Google Scholar] [CrossRef]
- Springer, M.; Nawrot, M.P. A Mechanistic Model for Reward Prediction and Extinction Learning in the Fruit Fly. Eneuro 2021, 8, ENEURO.0549-20.2021. [Google Scholar] [CrossRef]
- Montague, P.R.; Dayan, P.; Person, C.; Sejnowski, T.J. Bee foraging in uncertain environments using predictive hebbian learning. Nature 1995, 377, 725–728. [Google Scholar] [CrossRef] [PubMed]
- Schultz, W.; Dayan, P.; Montague, P.R. A Neural Substrate of Prediction and Reward. Science 1997, 275, 1593–1599. [Google Scholar] [CrossRef]
- Andrade, E. A semiotic framework for evolutionary and developmental biology. Biosystems 2007, 90, 389–404. [Google Scholar] [CrossRef] [PubMed]
- Haber, S.N.; Kim, K.-S.; Mailly, P.; Calzavara, R. Reward-Related Cortical Inputs Define a Large Striatal Region in Primates That Interface with Associative Cortical Connections, Providing a Substrate for Incentive-Based Learning. J. Neurosci. 2006, 26, 8368–8376. [Google Scholar] [CrossRef] [PubMed]
- Kennerley, S.W.; Behrens, T.E.J.; Wallis, J. Double dissociation of value computations in orbitofrontal and anterior cingulate neurons. Nat. Neurosci. 2011, 14, 1581–1589. [Google Scholar] [CrossRef] [PubMed]
- Daw, N.D.; Gershman, S.J.; Seymour, B.; Dayan, P.; Dolan, R.J. Model-Based Influences on Humans’ Choices and Striatal Prediction Errors. Neuron 2011, 69, 1204–1215. [Google Scholar] [CrossRef]
- Zhang, Z.; Cheng, Z.; Lin, Z.; Nie, C.; Yang, T. A neural network model for the orbitofrontal cortex and task space acquisition during reinforcement learning. PLoS Comput. Biol. 2018, 14, e1005925. [Google Scholar] [CrossRef]
- Weidel, P.; Duarte, R.; Morrison, A. Unsupervised Learning and Clustered Connectivity Enhance Reinforcement Learning in Spiking Neural Networks. Front. Comput. Neurosci. 2021, 15, 543872. [Google Scholar] [CrossRef]
- Gläscher, J.; Daw, N.; Dayan, P.; O’Doherty, J.P. States versus Rewards: Dissociable Neural Prediction Error Signals Underlying Model-Based and Model-Free Reinforcement Learning. Neuron 2010, 66, 585–595. [Google Scholar] [CrossRef]
- Wilson, R.C.; Takahashi, Y.K.; Schoenbaum, G.; Niv, Y. Orbitofrontal Cortex as a Cognitive Map of Task Space. Neuron 2014, 81, 267–279. [Google Scholar] [CrossRef] [PubMed]
- Hornak, J.; O’Doherty, J.; Bramham, J.; Rolls, E.T.; Morris, R.G.; Bullock, P.R.; Polkey, C.E. Reward-related Reversal Learning after Surgical Excisions in Orbito-frontal or Dorsolateral Prefrontal Cortex in Humans. J. Cogn. Neurosci. 2004, 16, 463–478. [Google Scholar] [CrossRef] [PubMed]
- Izquierdo, A.; Suda, R.K.; Murray, E. Bilateral Orbital Prefrontal Cortex Lesions in Rhesus Monkeys Disrupt Choices Guided by Both Reward Value and Reward Contingency. J. Neurosci. 2004, 24, 7540–7548. [Google Scholar] [CrossRef]
- Wallis, J.; Anderson, K.C.; Miller, E. Single neurons in prefrontal cortex encode abstract rules. Nature 2001, 411, 953–956. [Google Scholar] [CrossRef]
- Tsujimoto, S.; Genovesio, A.; Wise, S.P. Comparison of Strategy Signals in the Dorsolateral and Orbital Prefrontal Cortex. J. Neurosci. 2011, 31, 4583–4592. [Google Scholar] [CrossRef]
- Buonomano, D.V.; Maass, W. State-dependent computations: Spatiotemporal processing in cortical networks. Nat. Rev. Neurosci. 2009, 10, 113–125. [Google Scholar] [CrossRef]
- Laje, R.; Buonomano, D.V. Robust timing and motor patterns by taming chaos in recurrent neural networks. Nat. Neurosci. 2013, 16, 925–933. [Google Scholar] [CrossRef]
- Wunderlich, K.; Dayan, P.; Dolan, R. Mapping value based planning and extensively trained choice in the human brain. Nat. Neurosci. 2012, 15, 786–791. [Google Scholar] [CrossRef]
- Wunderlich, K.; Smittenaar, P.; Dolan, R. Dopamine Enhances Model-Based over Model-Free Choice Behavior. Neuron 2012, 75, 418–424. [Google Scholar] [CrossRef]
- Smittenaar, P.; FitzGerald, T.; Romei, V.; Wright, N.D.; Dolan, R. Disruption of Dorsolateral Prefrontal Cortex Decreases Model-Based in Favor of Model-free Control in Humans. Neuron 2013, 80, 914–919. [Google Scholar] [CrossRef]
- Dezfouli, A.; Balleine, B.W. Actions, Action Sequences and Habits: Evidence That Goal-Directed and Habitual Action Control Are Hierarchically Organized. PLoS Comput. Biol. 2013, 9, e1003364. [Google Scholar] [CrossRef]
- Buzsáki, G. Theta Oscillations in the Hippocampus. Neuron 2002, 33, 325–340. [Google Scholar] [CrossRef]
- Reifenstein, E.T.; Kempter, R.; Schreiber, S.; Stemmler, M.B.; Herz, A.V.M. Grid cells in rat entorhinal cortex encode physical space with independent firing fields and phase precession at the single-trial level. Proc. Natl. Acad. Sci. USA 2012, 109, 6301–6306. [Google Scholar] [CrossRef]
- Qasim, S.E.; Fried, I.; Jacobs, J. Phase precession in the human hippocampus and entorhinal cortex. Cell 2021, 184, 3242–3255.e10. [Google Scholar] [CrossRef]
- Korte, M.; Schmitz, D. Cellular and System Biology of Memory: Timing, Molecules, and Beyond. Physiol. Rev. 2016, 96, 647–693. [Google Scholar] [CrossRef]
- Reifenstein, E.T.; Bin Khalid, I.; Kempter, R. Author response: Synaptic learning rules for sequence learning. Elife 2021, 10, e67171. [Google Scholar] [CrossRef]
- Chance, F.S. Hippocampal Phase Precession from Dual Input Components. J. Neurosci. 2012, 32, 16693–16703. [Google Scholar] [CrossRef]
- Cheng, S. The CRISP theory of hippocampal function in episodic memory. Front. Neural Circuits 2013, 7, 88. [Google Scholar] [CrossRef][Green Version]
- Bi, G.-Q.; Poo, M.-M. Synaptic Modifications in Cultured Hippocampal Neurons: Dependence on Spike Timing, Synaptic Strength, and Postsynaptic Cell Type. J. Neurosci. 1998, 18, 10464–10472. [Google Scholar] [CrossRef]
- Bi, G.-Q.; Poo, M.-M. Synaptic Modification by Correlated Activity: Hebb’s Postulate Revisited. Annu. Rev. Neurosci. 2001, 24, 139–166. [Google Scholar] [CrossRef]
- Dudai, Y. The Restless Engram: Consolidations Never End. Annu. Rev. Neurosci. 2012, 35, 227–247. [Google Scholar] [CrossRef] [PubMed]
- Auth, J.M.; Nachstedt, T.; Tetzlaff, C. The Interplay of Synaptic Plasticity and Scaling Enables Self-Organized Formation and Allocation of Multiple Memory Representations. Front. Neural Circuits 2020, 14, 541728. [Google Scholar] [CrossRef] [PubMed]
- Dresp-Langley, B. Seven Properties of Self-Organization in the Human Brain. Big Data Cogn. Comput. 2020, 4, 10. [Google Scholar] [CrossRef]
- Kohonen, T. Self-Organizing Maps; Springer: New York, NY, USA, 2001. [Google Scholar]
- Wandeto, J.M.; Nyongesa, H.; Rémond, Y.; Dresp-Langley, B. Detection of small changes in medical and random-dot images comparing self-organizing map performance to human detection. Inform. Med. Unlocked 2017, 7, 39–45. [Google Scholar] [CrossRef]
- Wandeto, J.M.; Dresp-Langley, B. The quantization error in a Self-Organizing Map as a contrast and color specific indicator of single-pixel change in large random patterns. Neural Netw. 2019, 120, 116–128. [Google Scholar] [CrossRef]
- Dresp-Langley, B.; Wandeto, J.M. Pixel precise unsupervised detection of viral particle proliferation in cellular imaging data. Inform. Med. Unlocked 2020, 20, 100433. [Google Scholar] [CrossRef]
- Dresp-Langley, B.; Wandeto, J. Human Symmetry Uncertainty Detected by a Self-Organizing Neural Network Map. Symmetry 2021, 13, 299. [Google Scholar] [CrossRef]
- Dresp-Langley, B.; Wandeto, J.M. Unsupervised classification of cell imaging data using the quantization error in a Self Organizing Map. In Transactions on Computational Science and Computational Intelligence; Arabnia, H.R., Ferens, K., de la Fuente, D., Kozerenko, E.B., Olivas Varela, J.A., Tinetti, F.G., Eds.; Springer-Nature: Berlin/Heidelberg, Germany, 2021; pp. 201–210. [Google Scholar]
- Royakkers, L.; van Est, R. A literature review on new robotics: Automation from love to war. Int. J. Soc. Robot. 2015, 7, 549–570. [Google Scholar] [CrossRef]
- Ren, L.; Li, B.; Wei, G.; Wang, K.; Song, Z.; Wei, Y.; Ren, L.; Liu, Q. Biology and bioinspiration of soft robotics: Actuation, sensing, and system integration. iScience 2021, 24, 103075. [Google Scholar] [CrossRef]
- Ni, J.; Wu, L.; Fan, X.; Yang, S.X. Bioinspired Intelligent Algorithm and Its Applications for Mobile Robot Control: A Survey. Comput. Intell. Neurosci. 2016, 2016, 3810903. [Google Scholar] [CrossRef]
- Webster-Wood, V.A.; Gill, J.P.; Thomas, P.J.; Chiel, H.J. Control for multifunctionality: Bioinspired control based on feeding in Aplysia californica. Biol. Cybern. 2020, 114, 557–588. [Google Scholar] [CrossRef]
- Costa, R.M.; Baxter, D.A.; Byrne, J.H. Computational model of the distributed representation of operant reward memory: Combinatoric engagement of intrinsic and synaptic plasticity mechanisms. Learn. Mem. 2020, 27, 236–249. [Google Scholar] [CrossRef]
- Jing, J.; Cropper, E.C.; Hurwitz, I.; Weiss, K.R. The Construction of Movement with Behavior-Specific and Behavior-Independent Modules. J. Neurosci. 2004, 24, 6315–6325. [Google Scholar] [CrossRef]
- Jing, J.; Weiss, K.R. Neural Mechanisms of Motor Program Switching inAplysia. J. Neurosci. 2001, 21, 7349–7362. [Google Scholar] [CrossRef]
- Jing, J.; Weiss, K.R. Interneuronal Basis of the Generation of Related but Distinct Motor Programs in Aplysia: Implications for Current Neuronal Models of Vertebrate Intralimb Coordination. J. Neurosci. 2002, 22, 6228–6238. [Google Scholar] [CrossRef]
- Hunt, A.; Schmidt, M.; Fischer, M.; Quinn, R. A biologically based neural system coordinates the joints and legs of a tetrapod. Bioinspiration Biomim. 2015, 10, 55004. [Google Scholar] [CrossRef]
- Hunt, A.J.; Szczecinski, N.S.; Quinn, R.D. Development and Training of a Neural Controller for Hind Leg Walking in a Dog Robot. Front. Neurorobotics 2017, 11, 18. [Google Scholar] [CrossRef]
- Szczecinski, N.S.; Chrzanowski, D.M.; Cofer, D.W.; Terrasi, A.S.; Moore, D.R.; Martin, J.P.; Ritzmann, R.E.; Quinn, R.D. Introducing MantisBot: Hexapod robot controlled by a high-fidelity, real-time neural simulation. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 3875–3881. [Google Scholar]
- Szczecinski, N.S.; Hunt, A.J.; Quinn, R.D. A Functional Subnetwork Approach to Designing Synthetic Nervous Systems That Control Legged Robot Locomotion. Front. Neurorobotics 2017, 11, 37. [Google Scholar] [CrossRef] [PubMed]
- Szczecinski, N.S.; Quinn, R.D. Leg-local neural mechanisms for searching and learning enhance robotic locomotion. Biol. Cybern. 2017, 112, 99–112. [Google Scholar] [CrossRef]
- Capolei, M.C.; Angelidis, E.; Falotico, E.; Lund, H.H.; Tolu, S. A Biomimetic Control Method Increases the Adaptability of a Humanoid Robot Acting in a Dynamic Environment. Front. Neurorobotics 2019, 13, 70. [Google Scholar] [CrossRef]
- Nichols, E.; McDaid, L.J.; Siddique, N. Biologically Inspired SNN for Robot Control. IEEE Trans. Cybern. 2013, 43, 115–128. [Google Scholar] [CrossRef]
- Bing, Z.; Meschede, C.; Röhrbein, F.; Huang, K.; Knoll, A.C. A Survey of Robotics Control Based on Learning-Inspired Spiking Neural Networks. Front. Neurorobotics 2018, 12, 35. [Google Scholar] [CrossRef]
- Wan, C.; Chen, G.; Fu, Y.; Wang, M.; Matsuhisa, N.; Pan, S.; Pan, L.; Yang, H.; Wan, Q.; Zhu, L.; et al. An Artificial Sensory Neuron with Tactile Perceptual Learning. Adv. Mater. 2018, 30, e1801291. [Google Scholar] [CrossRef] [PubMed]
- Wan, C.; Cai, P.; Guo, X.; Wang, M.; Matsuhisa, N.; Yang, L.; Lv, Z.; Luo, Y.; Loh, X.J.; Chen, X. An artificial sensory neuron with visual-haptic fusion. Nat. Commun. 2020, 11, 4602. [Google Scholar] [CrossRef]
- Liu, S.C.; Delbruck, T. Neuromorphic sensory systems. Curr. Opin. Neurobiol. 2010, 20, 288–295. [Google Scholar] [CrossRef]
- Wan, C.; Cai, P.; Wang, M.; Qian, Y.; Huang, W.; Chen, X. Artificial Sensory Memory. Adv. Mater. 2020, 32, e1902434. [Google Scholar] [CrossRef]
- Wilson, S.; Moore, C. S1 somatotopic brain maps. Scholarpedia 2015, 10, 8574. [Google Scholar] [CrossRef]
- Braun, C.; Heinz, U.; Schweizer, R.; Wiech, K.; Birbaumer, N.; Topka, H. Dynamic organization of the somatosensory cortex induced by motor activity. Brain 2001, 124, 2259–2267. [Google Scholar] [CrossRef]
- Arber, S. Motor Circuits in Action: Specification, Connectivity, and Function. Neuron 2012, 74, 975–989. [Google Scholar] [CrossRef]
- Weiss, T.; Miltner, W.H.; Huonker, R.; Friedel, R.; Schmidt, I.; Taub, E. Rapid functional plasticity of the somatosensory cortex after finger amputation. Exp. Brain Res. 2000, 134, 199–203. [Google Scholar] [CrossRef]
- Tripodi, M.; Arber, S. Regulation of motor circuit assembly by spatial and temporal mechanisms. Curr. Opin. Neurobiol. 2012, 22, 615–623. [Google Scholar] [CrossRef]
- Dresp-Langley, B. Towards Expert-Based Speed–Precision Control in Early Simulator Training for Novice Surgeons. Information 2018, 9, 316. [Google Scholar] [CrossRef]
- Batmaz, A.U.; De Mathelin, M.; Dresp-Langley, B. Getting nowhere fast: Trade-off between speed and precision in training to execute image-guided hand-tool movements. BMC Psychol. 2016, 4, 55. [Google Scholar] [CrossRef]
- Batmaz, A.U.; De Mathelin, M.; Dresp-Langley, B. Seeing virtual while acting real: Visual display and strategy effects on the time and precision of eye-hand coordination. PLoS ONE 2017, 12, e0183789. [Google Scholar] [CrossRef]
- Batmaz, A.U.; de Mathelin, M.; Dresp-Langley, B. Effects of 2D and 3D image views on hand movement trajectories in the surgeon’s peri-personal space in a computer controlled simulator environment. Cogent Med. 2018, 5, 1426232. [Google Scholar] [CrossRef]
- Dresp-Langley, B.; Nageotte, F.; Zanne, P.; De Mathelin, M. Correlating Grip Force Signals from Multiple Sensors Highlights Prehensile Control Strategies in a Complex Task-User System. Bioengineering 2020, 7, 143. [Google Scholar] [CrossRef]
- De Mathelin, M.; Nageotte, F.; Zanne, P.; Dresp-Langley, B. Sensors for expert grip force profiling: Towards benchmarking manual control of a robotic device for surgical tool movements. Sensors 2019, 19, 4575. [Google Scholar] [CrossRef]
- Staderini, F.; Foppa, C.; Minuzzo, A.; Badii, B.; Qirici, E.; Trallori, G.; Mallardi, B.; Lami, G.; Macrì, G.; Bonanomi, A.; et al. Robotic rectal surgery: State of the art. World J. Gastrointest. Oncol. 2016, 8, 757–771. [Google Scholar] [CrossRef] [PubMed]
- Diana, M.; Marescaux, J. Robotic surgery. Br. J. Surg. 2015, 102, e15–e28. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Nageotte, F.; Zanne, P.; De Mathelin, M.; Dresp-Langley, B. Wearable Wireless Biosensors for Spatiotemporal Grip Force Profiling in Real Time. In Proceedings of the 7th International Electronic Conference on Sensors and Applications, Zürich, Switzerland, 20 November 2020; Volume 2, p. 40. [Google Scholar]
- Liu, R.; Dresp-Langley, B. Making Sense of Thousands of Sensor Data. Electronics 2021, 10, 1391. [Google Scholar] [CrossRef]
- Dresp-Langley, B.; Liu, R.; Wandeto, J.M. Surgical task expertise detected by a self-organizing neural network map. arXiv 2016, arXiv:2106.08995. [Google Scholar]
- Liu, R.; Nageotte, F.; Zanne, P.; de Mathelin, M.; Dresp-Langley, B. Deep Reinforcement Learning for the Control of Robotic Manipulation: A Focussed Mini-Review. Robotics 2021, 10, 22. [Google Scholar] [CrossRef]
- Tekülve, J.; Fois, A.; Sandamirskaya, Y.; Schöner, G. Autonomous Sequence Generation for a Neural Dynamic Robot: Scene Perception, Serial Order, and Object-Oriented Movement. Front. Neurorobotics 2019, 13. [Google Scholar] [CrossRef]
- Scott, S.H.; Cluff, T.; Lowrey, C.R.; Takei, T. Feedback control during voluntary motor actions. Curr. Opin. Neurobiol. 2015, 33, 85–94. [Google Scholar] [CrossRef]
- Marques, H.G.; Imtiaz, F.; Iida, F.; Pfeifer, R. Self-organization of reflexive behavior from spontaneous motor activity. Biol. Cybern. 2013, 107, 25–37. [Google Scholar] [CrossRef]
- Der, R.; Martius, G. Self-Organized Behavior Generation for Musculoskeletal Robots. Front. Neurorobotics 2017, 11, 8. [Google Scholar] [CrossRef]
- Martius, G.; Der, R.; Ay, N. Information Driven Self-Organization of Complex Robotic Behaviors. PLoS ONE 2013, 8, e63400. [Google Scholar] [CrossRef]
- Alnajjar, F.; Murase, K. Self-organization of spiking neural network that generates autonomous behavior in a real mobile robot. Int. J. Neural. Syst. 2006, 16, 229–239. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Functional Complexity | Agency | Species | Control Level | Implemented? | Selected References |
|---|---|---|---|---|---|
| Single NN | Rhythmic movement | I | Self-organized | Yes | [42,44,46,54] |
| Single NN | Goal-directed action | I, V | Self-organized | Yes | [30,64,68,70,71,72,80,81,82,83,91,98] |
| Single NN | Alternative choice | I, V | Self-organized | Yes | [10,26,53,62] |
| Single NN | Sequenced action | I, V | Self-organized | Yes | [46,98,99,105,128,150,152,153,154,155] |
| Multiple NNs | Sensorimotor integration | I, V | Self-organized | Yes | [53,62,114,115,128,129,131,132] |
| Multiple NNs | Cognitive planning | V | Self-organized | Partially | [2,3,98,99,150] |
| Multiple NNs | Voluntary action | V | Self-organized | No | [2,3,98,151] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dresp-Langley, B. From Biological Synapses to “Intelligent” Robots. Electronics 2022, 11, 707. https://doi.org/10.3390/electronics11050707
Dresp-Langley B. From Biological Synapses to “Intelligent” Robots. Electronics. 2022; 11(5):707. https://doi.org/10.3390/electronics11050707
Chicago/Turabian StyleDresp-Langley, Birgitta. 2022. "From Biological Synapses to “Intelligent” Robots" Electronics 11, no. 5: 707. https://doi.org/10.3390/electronics11050707
APA StyleDresp-Langley, B. (2022). From Biological Synapses to “Intelligent” Robots. Electronics, 11(5), 707. https://doi.org/10.3390/electronics11050707