
Autonomous Maneuver Decision Making of Dual-UAV Cooperative Air Combat Based on Deep Reinforcement Learning


Abstract
1. Introduction
2. Problem Formulation
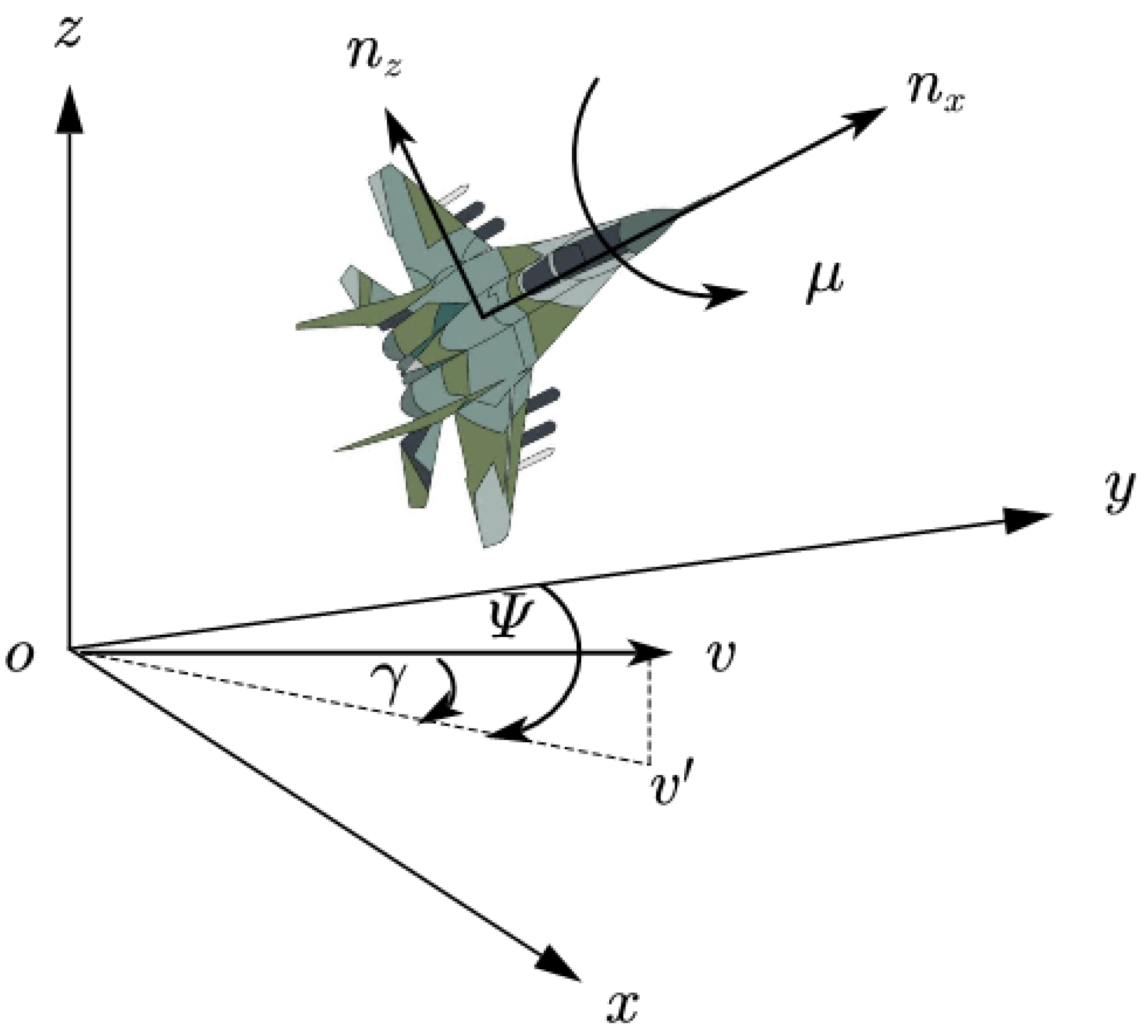
2.1. UAV Dynamic Model
2.2. Situation Assessment Model
3. Maneuver Decision Modeling by Deep Q Network
3.1. Reinforcement Learning
3.2. State Space
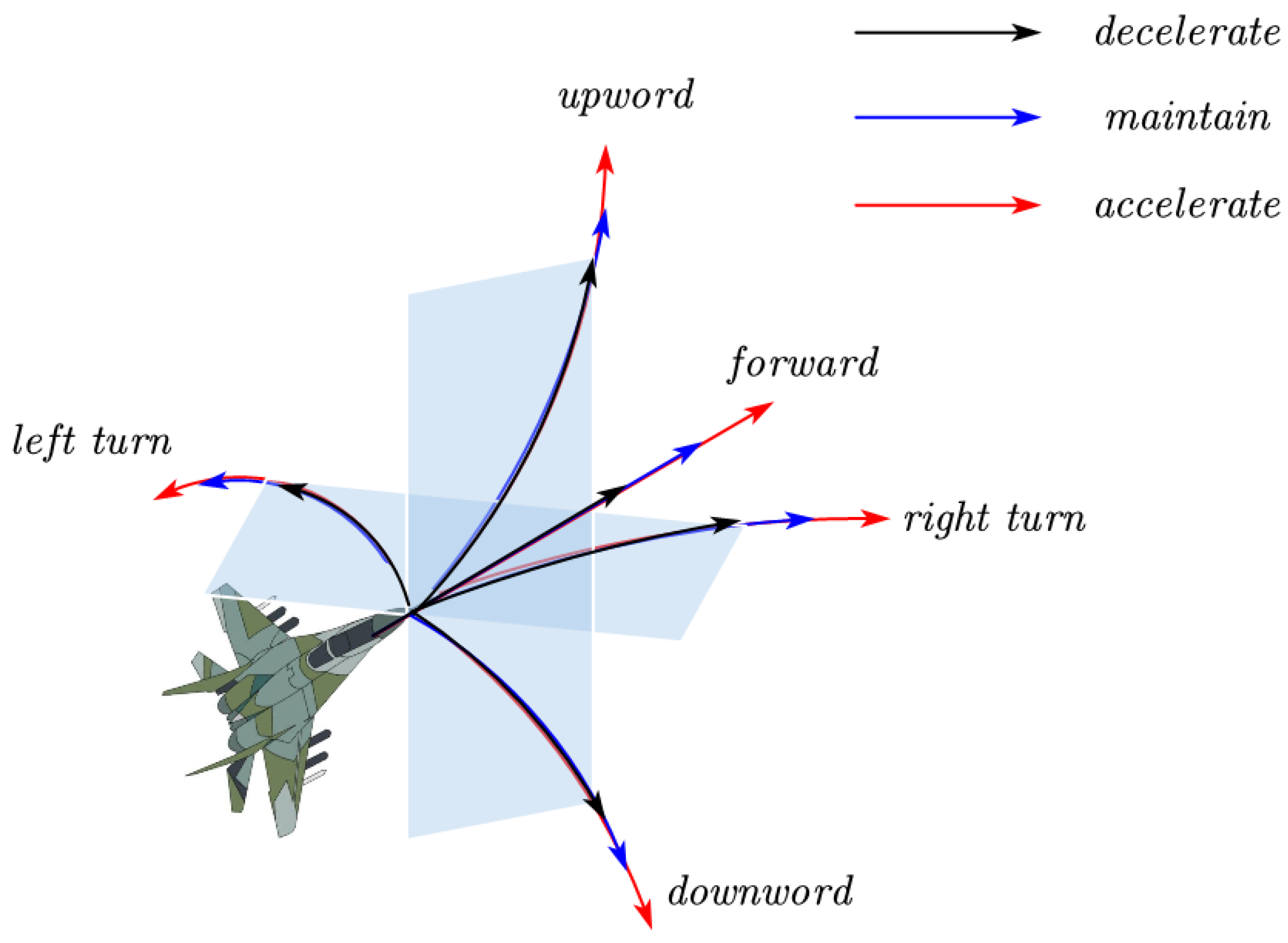
3.3. Action Space
3.4. Reward Function
3.5. Priority Sampling and Network Training
| Algorithm 1 DQN with proportional prioritization |
|
4. Olive Formation Air Combat as an Example
4.1. Task Description
4.2. Collision Avoidance and Formation Strategy
| Algorithm 2 Maneuver strategy of two UAVs olive formation in air combat |
|
5. Simulation
5.1. Simulation Setup
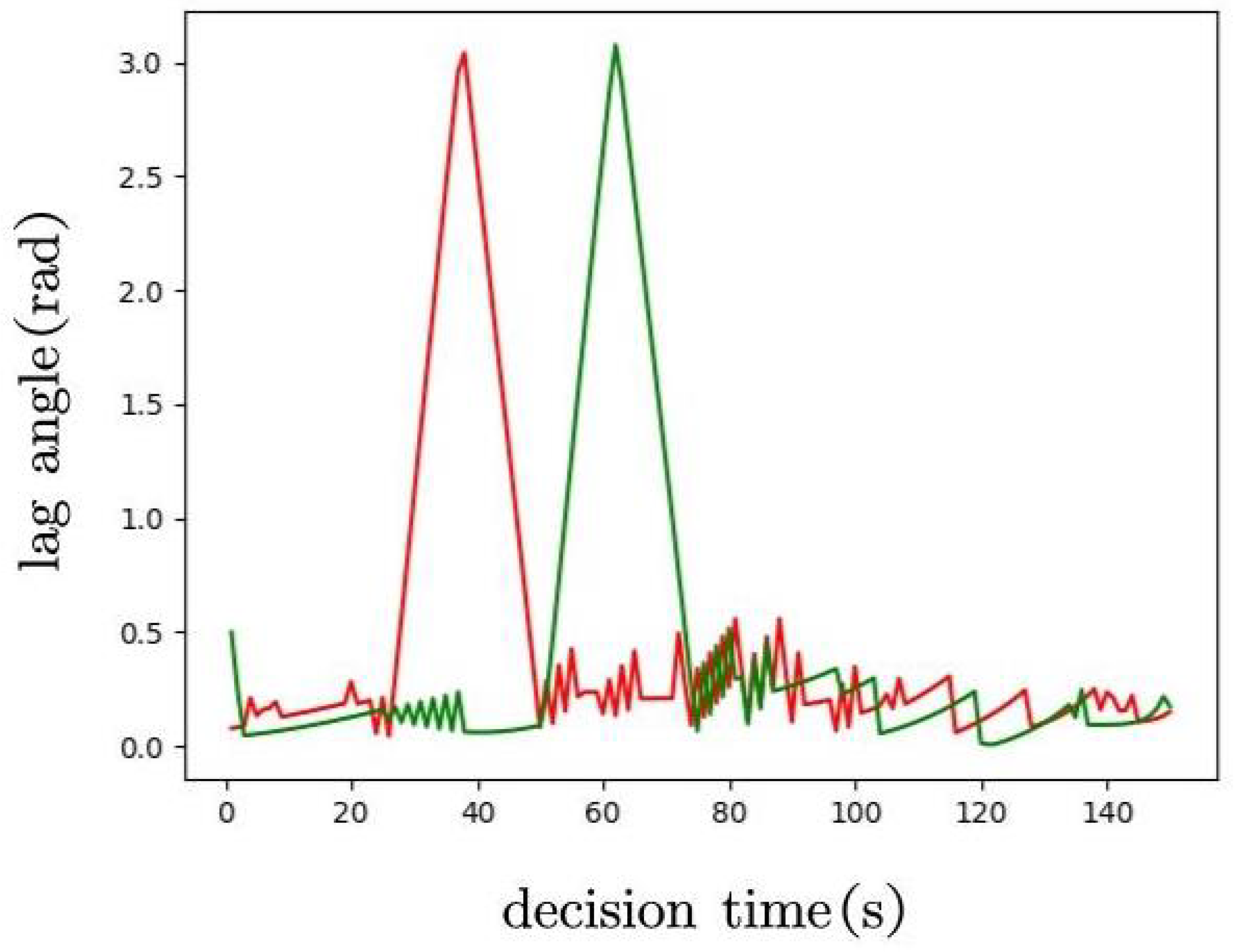
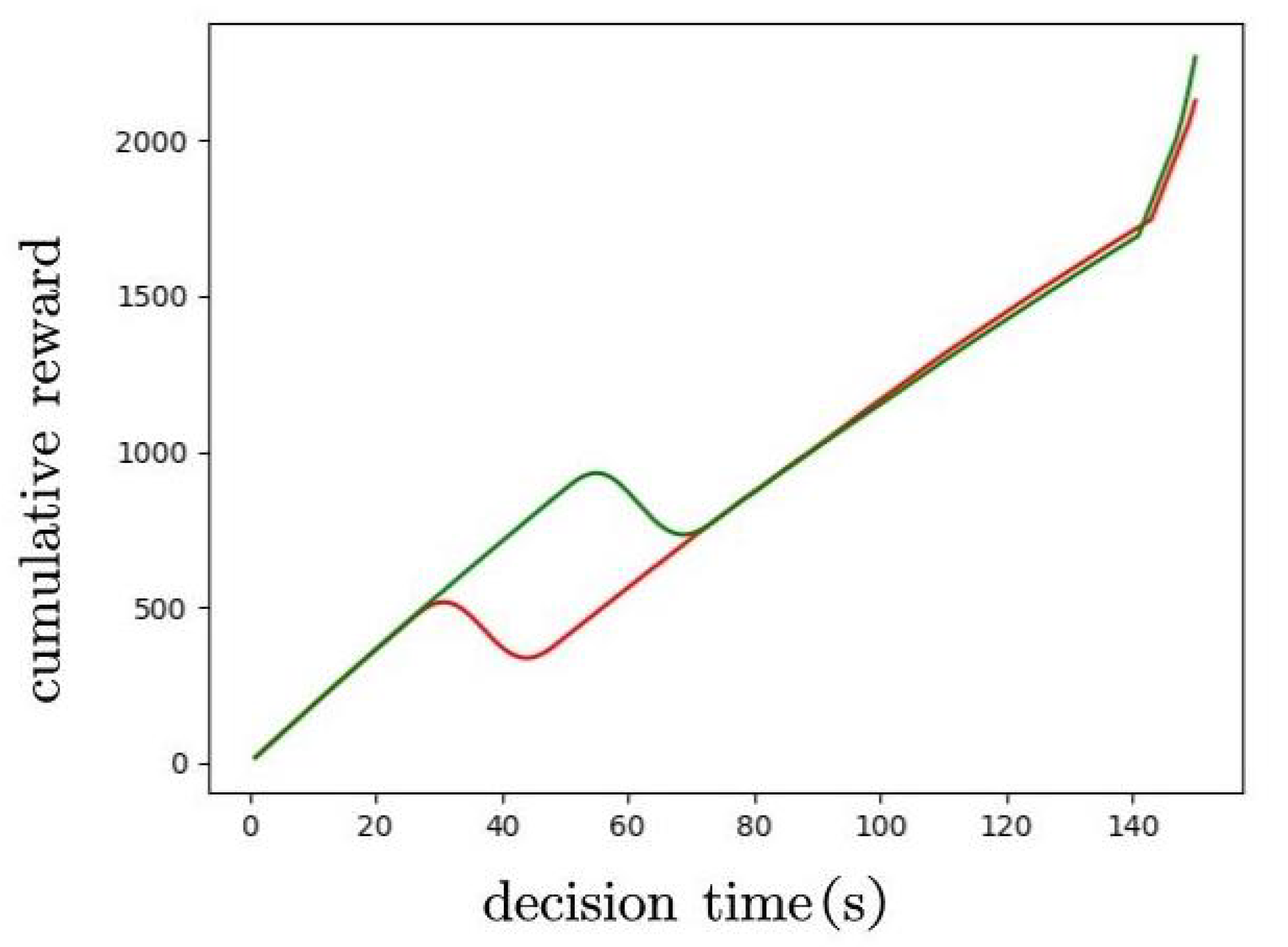
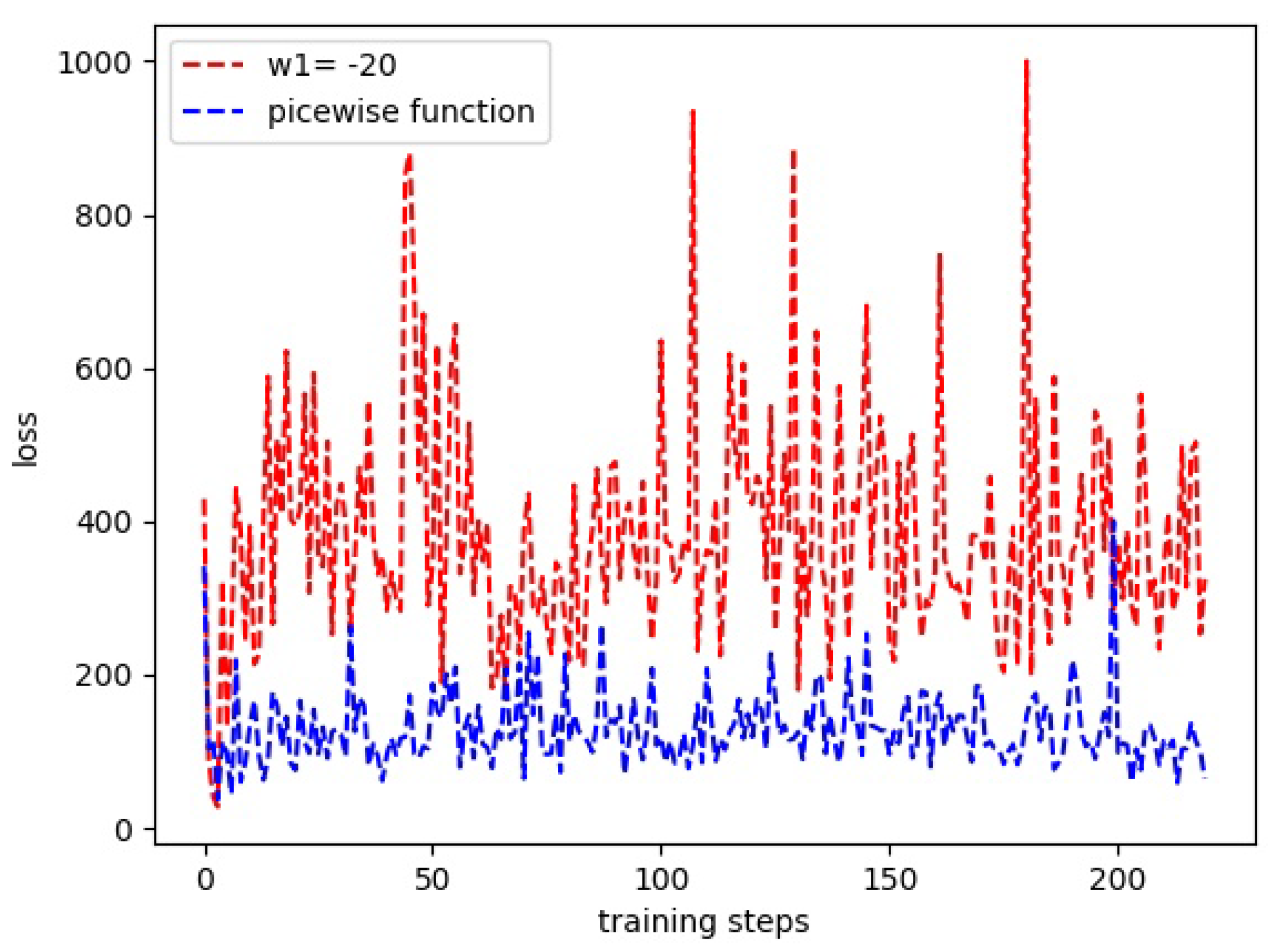
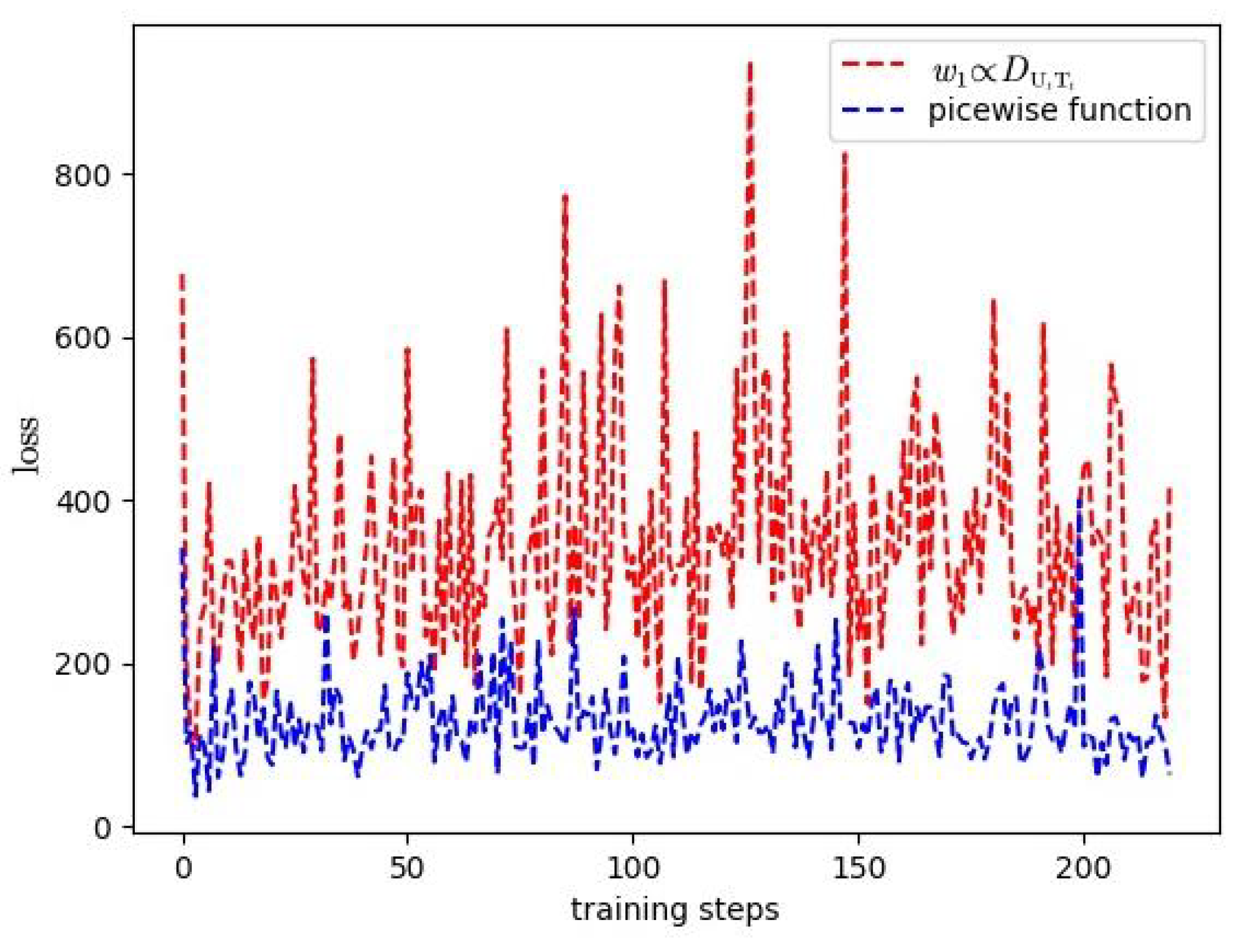
5.2. Simulation Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| DDPG | Deep Deterministic Policy Gradient |
| DQN | Deep Q Network |
| BVR | Beyond Visual Range |
| UAV | Unmanned Aerial Vehicle |
| MDP | Markov Decision Process |
| MARL | Multi-Agent Reinforcement Learning |
| IS | Important Sampling |
| TD error | Time Difference error |
| WVR | Within Visual Range |
References
- Ma, Y.; Wang, G.; Hu, X.; Luo, H.; Lei, X. Cooperative occupancy decision making of Multi-UAV in Beyond-Visual-Range air combat: A game theory approach. IEEE Access 2019, 8, 11624–11634. [Google Scholar] [CrossRef]
- Azar, A.T.; Koubaa, A.; Ali Mohamed, N.; Ibrahim, H.A.; Ibrahim, Z.F.; Kazim, M.; Ammar, A.; Benjdira, B.; Khamis, A.M.; Hameed, I.A.; et al. Drone Deep Reinforcement Learning: A Review. Electronics 2021, 10, 999. [Google Scholar] [CrossRef]
- Skorobogatov, G.; Barrado, C.; Salamí, E. Multiple UAV systems: A survey. Unmanned Syst. 2020, 8, 149–169. [Google Scholar] [CrossRef]
- Fu, L.; Xie, F.; Meng, G.; Wang, D. An UAV air-combat decision expert system based on receding horizon control. J. Beijing Univ. Aeronaut. Astronaut. 2015, 41, 1994. [Google Scholar]
- Zhang, Y.; Luo, D. Editorial of Special Issue on UAV Autonomous, Intelligent and Safe Control. Guid. Navig. Control 2021, 1, 2102001. [Google Scholar] [CrossRef]
- Austin, F.; Carbone, G.; Falco, M.; Hinz, H.; Lewis, M. Automated maneuvering decisions for air-to-air combat. AIAA J. 1987, 87, 659–669. [Google Scholar]
- Virtanen, K.; Raivio, T.; Hämäläinen, R.P. Decision Theoretical Approach to Pilot Simulation. J. Aircr. 1999, 36, 632. [Google Scholar] [CrossRef]
- Pan, Q.; Zhou, D.; Huang, J.; Lv, X.; Yang, Z.; Zhang, K.; Li, X. Maneuver decision for cooperative close-range air combat based on state predicted influence diagram. In Proceedings of the 2017 IEEE International Conference on Information and Automation (ICIA), Macau, China, 18–20 July 2017; pp. 726–731. [Google Scholar]
- An, X.; Yingxin, K.; Lei, Y.; Baowei, X.; Yue, L. Engagement maneuvering strategy of air combat based on fuzzy markov game theory. In Proceedings of the 2011 IEEE 2nd International Conference on Computing, Control and Industrial Engineering, Wuhan, China, 20–21 August 2011; Volume 2, pp. 126–129. [Google Scholar] [CrossRef]
- Chae, H.J.; Choi, H.L. Tactics games for multiple UCAVs Within-Visual-Range air combat. In Proceedings of the AIAA Information Systems-AIAA Infotech@ Aerospace, Kissimmee, FL, USA, 8–12 January 2018; p. 0645. [Google Scholar]
- Horie, K.; Conway, B.A. Optimal Fighter Pursuit-Evasion Maneuvers Found Via Two-Sided Optimization. J. Guid. Control. Dyn. 2006, 29, 105–112. [Google Scholar] [CrossRef]
- Qiuni, L.; Rennong, Y.; Chao, F.; Zongcheng, L. Approach for air-to-air confrontment based on uncertain interval information conditions. J. Syst. Eng. Electron. 2019, 30, 100–109. [Google Scholar] [CrossRef]
- Belkin, B.; Stengel, R. Systematic methods for knowledge acquisition and expert system development (for combat aircraft). IEEE Aerosp. Electron. Syst. Mag. 1991, 6, 3–11. [Google Scholar] [CrossRef]
- Schvaneveldt, R.W.; Goldsmith, T.E.; Benson, A.E.; Waag, W.L. Neural Network Models of Air Combat Maneuvering; Technical Report; New Mexico State University: Las Cruces, NM, USA, 1992. [Google Scholar]
- Huang, C.; Fei, J. UAV Path Planning Based on Particle Swarm Optimization with Global Best Path Competition. Int. J. Pattern Recognit. Artif. Intell. 2017, 32, 1859008. [Google Scholar] [CrossRef]
- Wu, A.; Yang, R.; Liang, X.; Zhang, J.; Qi, D.; Wang, N. Visual Range Maneuver Decision of Unmanned Combat Aerial Vehicle Based on Fuzzy Reasoning. Int. J. Fuzzy Syst. 2021, 1–18. [Google Scholar] [CrossRef]
- Duan, H.; Li, P.; Yu, Y. A predator-prey particle swarm optimization approach to multiple UCAV air combat modeled by dynamic game theory. IEEE/CAA J. Autom. Sin. 2015, 2, 11–18. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Gopi, S.P.; Magarini, M. Reinforcement Learning Aided UAV Base Station Location Optimization for Rate Maximization. Electronics 2021, 10, 2953. [Google Scholar] [CrossRef]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Liu, P.; Ma, Y. A deep reinforcement learning based intelligent decision method for UCAV air combat. In Proceedings of the Asian Simulation Conference, Melaka, Malaysia, 27–29 August 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 274–286. [Google Scholar]
- You, S.; Diao, M.; Gao, L. Deep reinforcement learning for target searching in cognitive electronic warfare. IEEE Access 2019, 7, 37432–37447. [Google Scholar] [CrossRef]
- Piao, H.; Sun, Z.; Meng, G.; Chen, H.; Qu, B.; Lang, K.; Sun, Y.; Yang, S.; Peng, X. Beyond-Visual-Range Air Combat Tactics Auto-Generation by Reinforcement Learning. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Weiren, K.; Deyun, Z.; Zhang, K.; Zhen, Y. Air combat autonomous maneuver decision for one-on-one within visual range engagement base on robust multi-agent reinforcement learning. In Proceedings of the 2020 IEEE 16th International Conference on Control & Automation (ICCA), Sapporo, Hokkaido, 9–11 October 2020; pp. 506–512. [Google Scholar]
- Zhang, Y.; Zu, W.; Gao, Y.; Chang, H. Research on autonomous maneuvering decision of UCAV based on deep reinforcement learning. In Proceedings of the 2018 Chinese Control and Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 230–235. [Google Scholar]
- Minglang, C.; Haiwen, D.; Zhenglei, W.; QingPeng, S. Maneuvering decision in short range air combat for unmanned combat aerial vehicles. In Proceedings of the 2018 Chinese Control and Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 1783–1788. [Google Scholar]
- Kong, W.; Zhou, D.; Yang, Z.; Zhao, Y.; Zhang, K. Uav autonomous aerial combat maneuver strategy generation with observation error based on state-adversarial deep deterministic policy gradient and inverse reinforcement learning. Electronics 2020, 9, 1121. [Google Scholar] [CrossRef]
- You, S.; Diao, M.; Gao, L. Completing Explorer Games with a Deep Reinforcement Learning Framework Based on Behavior Angle Navigation. Electronics 2019, 8, 576. [Google Scholar] [CrossRef]
- Wei, X.; Yang, L.; Cao, G.; Lu, T.; Wang, B. Recurrent MADDPG for Object Detection and Assignment in Combat Tasks. IEEE Access 2020, 8, 163334–163343. [Google Scholar] [CrossRef]
- Kong, W.; Zhou, D.; Zhang, K.; Yang, Z.; Yang, W. Multi-UCAV Air Combat in Short-Range Maneuver Strategy Generation using Reinforcement Learning and Curriculum Learning. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 14–17 December 2020; pp. 1174–1181. [Google Scholar]
- Wang, L.; Hu, J.; Xu, Z.; Zhao, C. Autonomous maneuver strategy of swarm air combat based on DDPG. Auton. Intell. Syst. 2021, 1, 1–15. [Google Scholar] [CrossRef]
- Yang, Q.; Zhang, J.; Shi, G.; Hu, J.; Wu, Y. Maneuver decision of UAV in short-range air combat based on deep reinforcement learning. IEEE Access 2019, 8, 363–378. [Google Scholar] [CrossRef]
- Hu, D.; Yang, R.; Zuo, J.; Zhang, Z.; Wu, J.; Wang, Y. Application of Deep Reinforcement Learning in Maneuver Planning of Beyond-Visual-Range Air Combat. IEEE Access 2021, 9, 32282–32297. [Google Scholar] [CrossRef]
- Lee, G.T.; Kim, C.O. Autonomous Control of Combat Unmanned Aerial Vehicles to Evade Surface-to-Air Missiles Using Deep Reinforcement Learning. IEEE Access 2020, 8, 226724–226736. [Google Scholar] [CrossRef]
- Fu, Q.; Fan, C.L.; Song, Y.; Guo, X.K. Alpha C2–An intelligent air defense commander independent of human decision-making. IEEE Access 2020, 8, 87504–87516. [Google Scholar] [CrossRef]
- Zhang, S.; Duan, H. Multiple UCAVs target assignment via bloch quantum-behaved pigeon-inspired optimization. In Proceedings of the 2015 34th Chinese Control Conference (CCC), Hangzhou, China, 28–30 July 2015; pp. 6936–6941. [Google Scholar]
- Chen, X.; Wei, X. Method of firepower allocation in multi-UCAV cooperative combat for multi-target attacking. In Proceedings of the 2012 Fifth International Symposium on Computational Intelligence and Design, Hangzhou, China, 28–29 October 2012; Volume 1, pp. 452–455. [Google Scholar]
- Wang, G.; Li, Q.; He, L.; Yang, Z. Reacher on Calculation Model for Blind Zone of an Airborne Warning Rader. Rader Sci. Technol. 2010, 8, 8. [Google Scholar]
- Vithayathil Varghese, N.; Mahmoud, Q.H. A survey of multi-task deep reinforcement learning. Electronics 2020, 9, 1363. [Google Scholar] [CrossRef]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Shaw, R.L. Fighter Combat-Tactics and Maneuvering; US Naval Institute Press: Annapolis, MD, USA, 1985. [Google Scholar]
- Breitner, M.H.; Pesch, H.J.; Grimm, W. Complex differential games of pursuit-evasion type with state constraints, part 2: Numerical computation of optimal open-loop strategies. J. Optim. Theory Appl. 1993, 78, 443–463. [Google Scholar] [CrossRef][Green Version]
- Ng, A.Y.; Harada, D.; Russell, S. Policy invariance under reward transformations: Theory and application to reward shaping. In Proceedings of the Sixteenth International Conference on Machine Learning (ICML 1999), Bled, Slovenia, 27–30 June 1999; Volume 99, pp. 278–287. [Google Scholar]
- Wiewiora, E. Potential-based shaping and Q-value initialization are equivalent. J. Artif. Intell. Res. 2003, 19, 205–208. [Google Scholar] [CrossRef]
- Brys, T.; Harutyunyan, A.; Suay, H.B.; Chernova, S.; Taylor, M.E.; Nowé, A. Reinforcement learning from demonstration through shaping. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Tan, C.Y.; Huang, S.; Tan, K.K.; Teo, R.S.H.; Liu, W.Q.; Lin, F. Collision avoidance design on unmanned aerial vehicle in 3D space. Unmanned Syst. 2018, 6, 277–295. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Mahmood, A.R.; Van Hasselt, H.; Sutton, R.S. Weighted importance sampling for off-policy learning with linear function approximation. In Proceedings of the NIPS, Montreal, Canada, 8–13 December 2014; pp. 3014–3022. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | Definition | State | Definition | State | Definition |
|---|---|---|---|---|---|
| No. | Maneuver | Control Values | ||
|---|---|---|---|---|
| forward maintain | 0 | 1 | 0 | |
| forward accelerate | 2 | 1 | 0 | |
| forward decelerate | −1 | 1 | 0 | |
| left turn maintain | 0 | 8 | ||
| left turn accelerate | 2 | 8 | ||
| left turn decelerate | −1 | 8 | ||
| right turn maintain | 0 | 8 | ||
| right turn accelerate | 2 | 8 | ||
| right turn decelerate | −1 | 8 | ||
| upward maintain | 0 | 8 | 0 | |
| upward accelerate | 2 | 8 | 0 | |
| upward decelerate | −1 | 8 | 0 | |
| downward maintain | 0 | 8 | ||
| downward accelerate | 2 | 8 | ||
| downward decelerate | −1 | 8 | ||
| Variable | Value | Variable | Value | Variable | Value |
|---|---|---|---|---|---|
| 1000 | 200 | 500 | |||
| C | 10 | 300 | b | 10 | |
| 0.9 | 45 | 20 | |||
| 0.4 | 90 | 1000 | |||
| 12,000 | 10,000 | a | 5 | ||
| 30 | 40 | 0.6 | |||
| k | 5000 | K | 300 | 20,000 | |
| 0.01 | 10,000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, J.; Wang, L.; Hu, T.; Guo, C.; Wang, Y. Autonomous Maneuver Decision Making of Dual-UAV Cooperative Air Combat Based on Deep Reinforcement Learning. Electronics 2022, 11, 467. https://doi.org/10.3390/electronics11030467
Hu J, Wang L, Hu T, Guo C, Wang Y. Autonomous Maneuver Decision Making of Dual-UAV Cooperative Air Combat Based on Deep Reinforcement Learning. Electronics. 2022; 11(3):467. https://doi.org/10.3390/electronics11030467
Chicago/Turabian StyleHu, Jinwen, Luhe Wang, Tianmi Hu, Chubing Guo, and Yanxiong Wang. 2022. "Autonomous Maneuver Decision Making of Dual-UAV Cooperative Air Combat Based on Deep Reinforcement Learning" Electronics 11, no. 3: 467. https://doi.org/10.3390/electronics11030467
APA StyleHu, J., Wang, L., Hu, T., Guo, C., & Wang, Y. (2022). Autonomous Maneuver Decision Making of Dual-UAV Cooperative Air Combat Based on Deep Reinforcement Learning. Electronics, 11(3), 467. https://doi.org/10.3390/electronics11030467