
Genetic Algorithm for the Optimization of a Building Power Consumption Prediction Model



Abstract
1. Introduction
2. Related Works
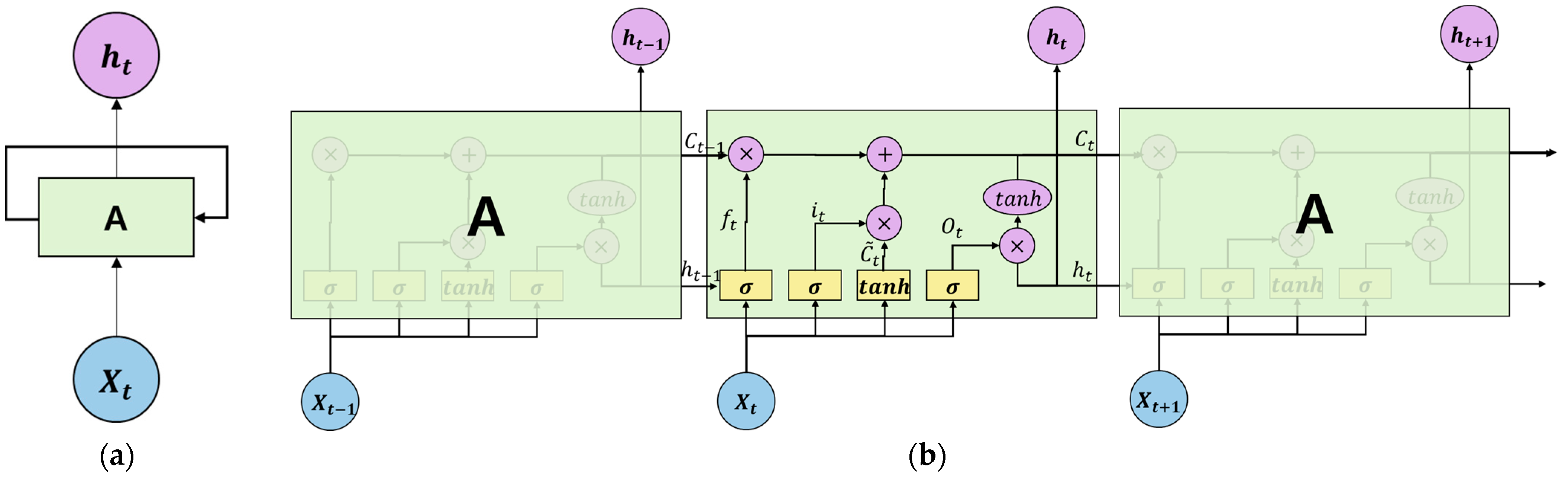
2.1. Deep Learning Model
2.2. Hyper-Parameters of Deep Learning
2.3. Neural Architecture Search
2.4. Genetic Algorithm
2.5. Genetic-Algorithm-Based Optimal Model
3. Deep Learning Network and Hyper-Parameter Optimization
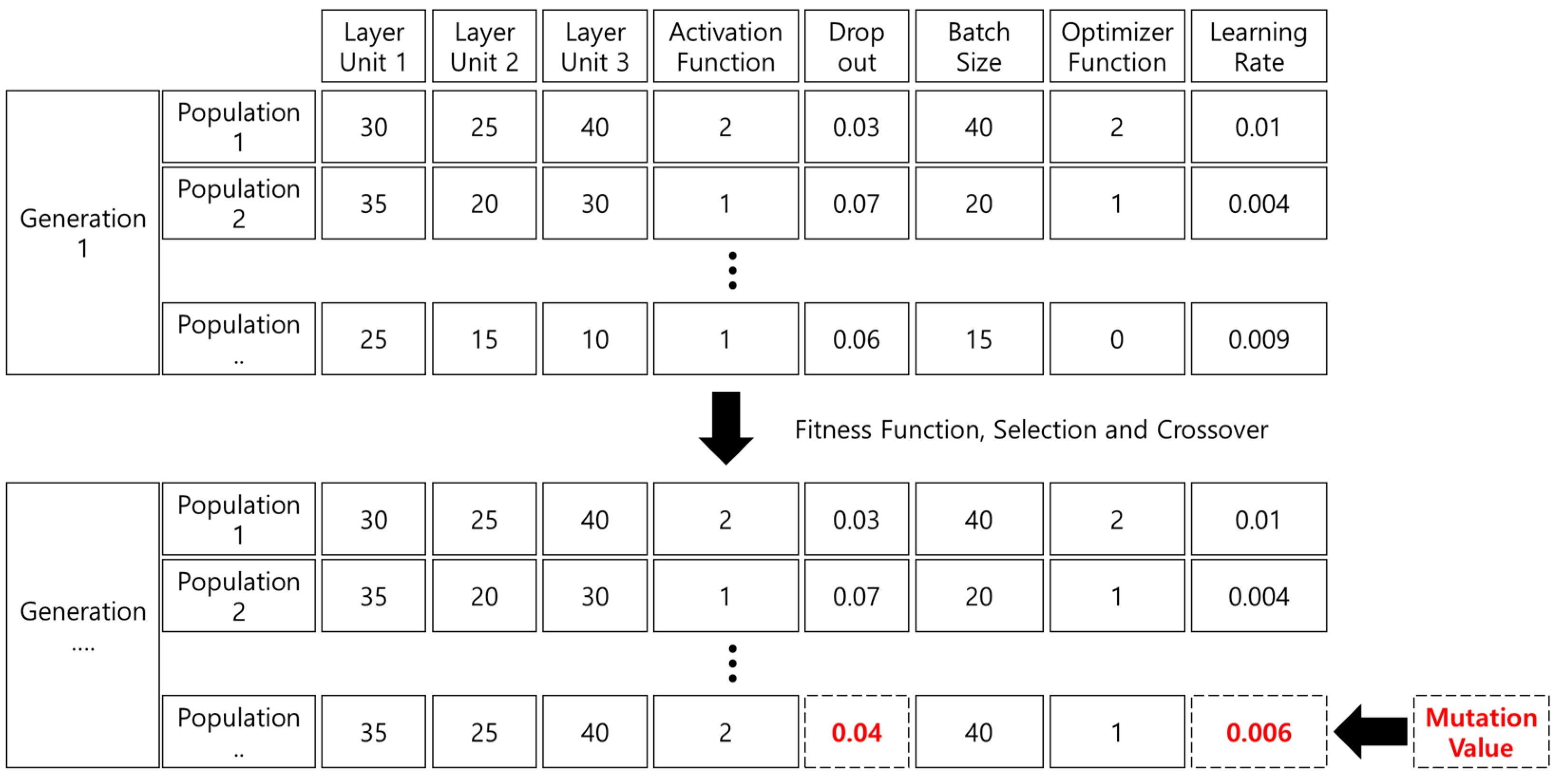
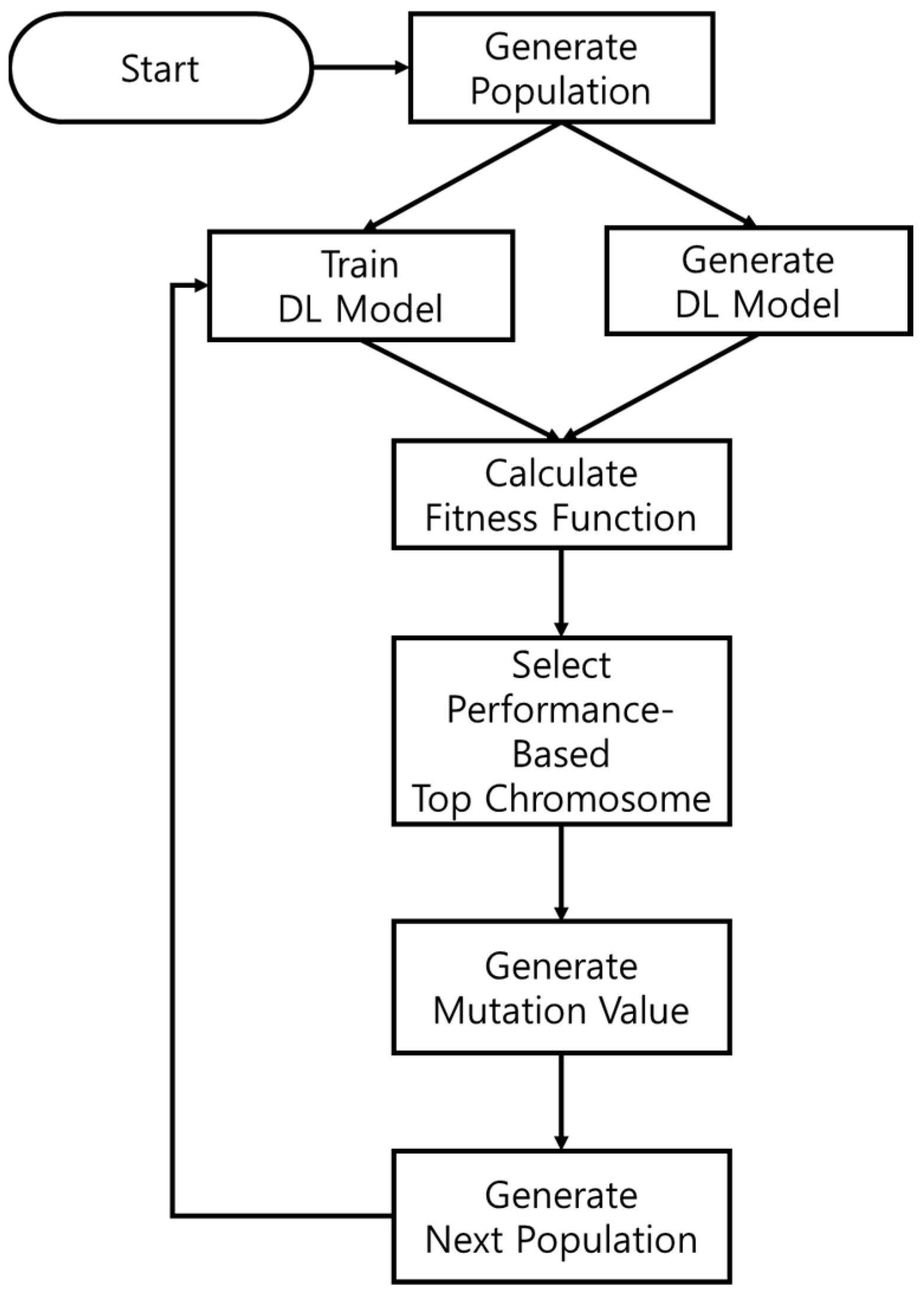
3.1. Genetic Algorithm for the Deep Learning Model
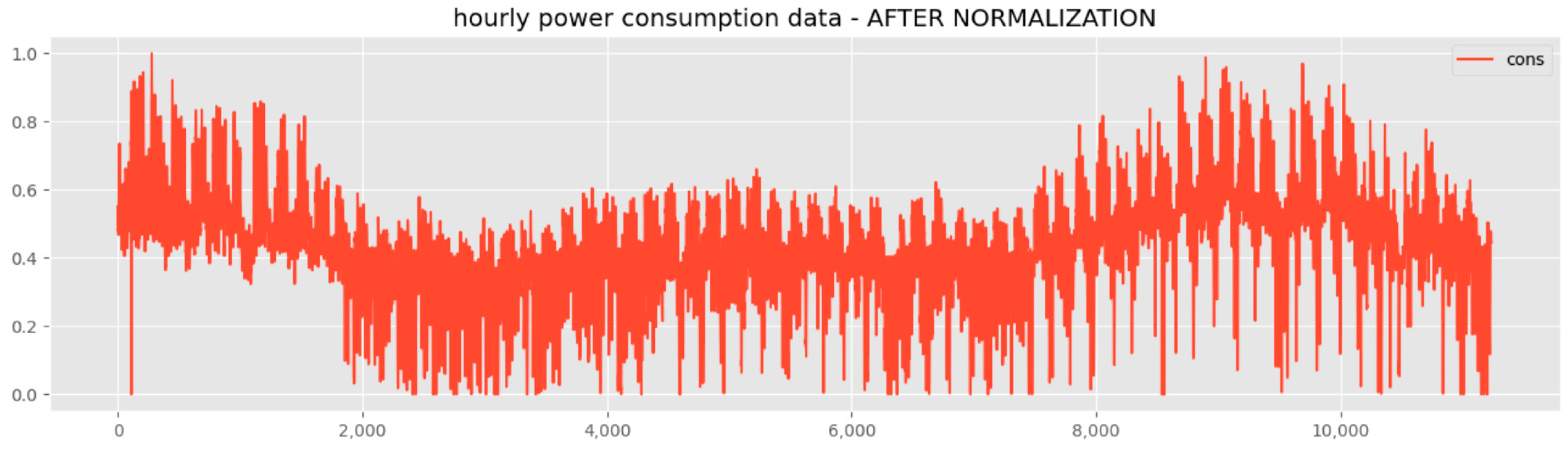
3.2. Dataset
4. Results and Discussion
4.1. Experimental Setting
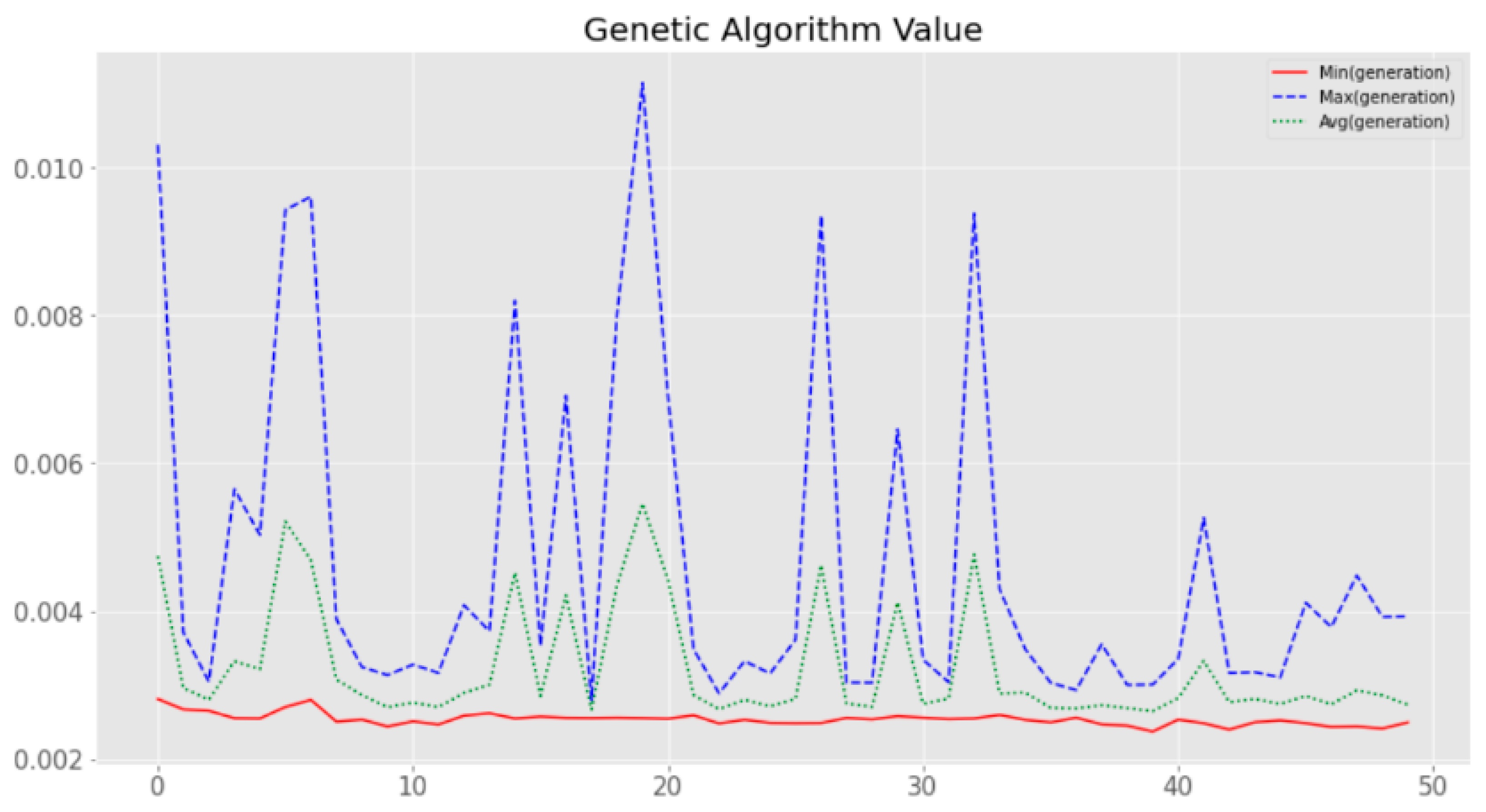
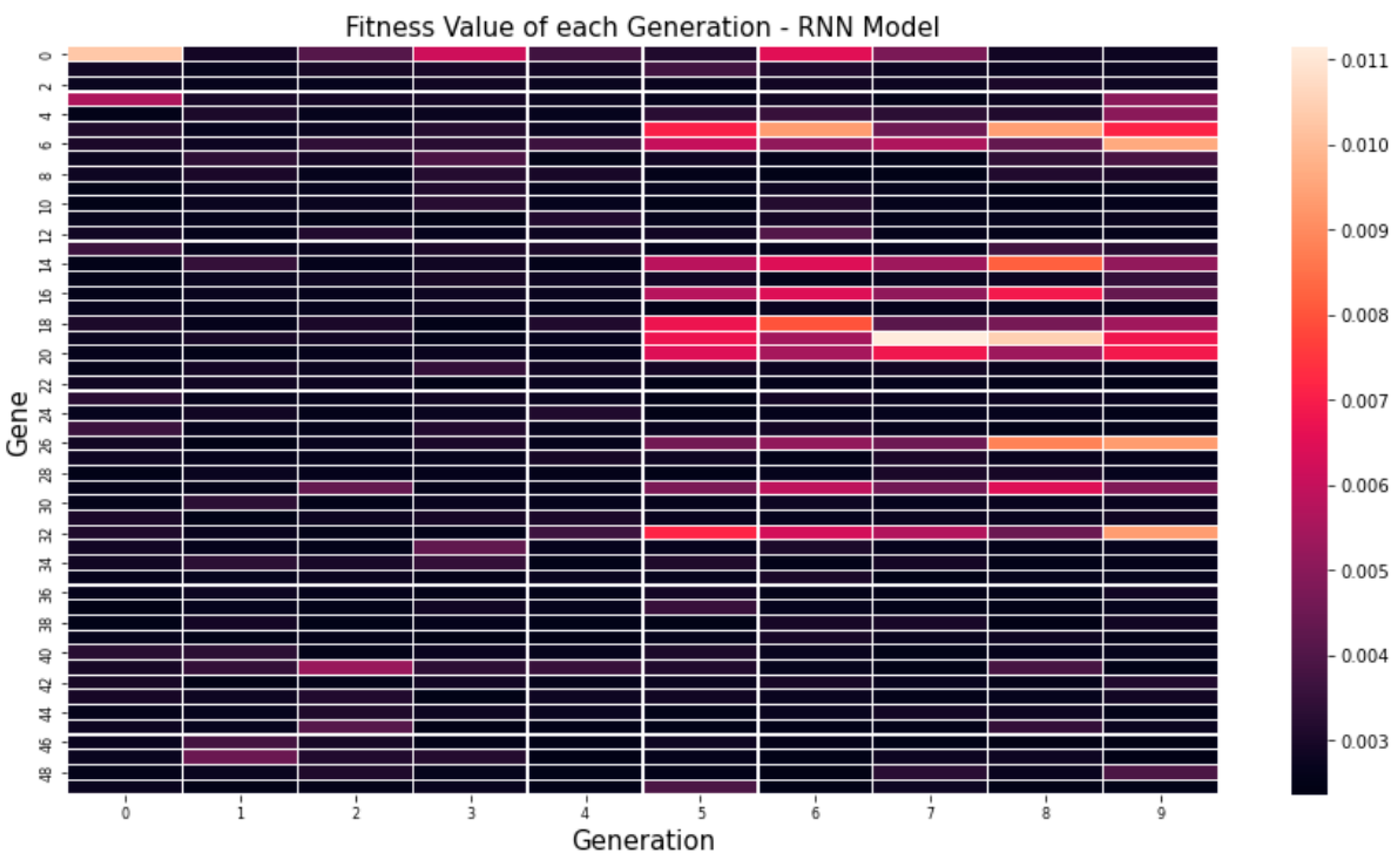
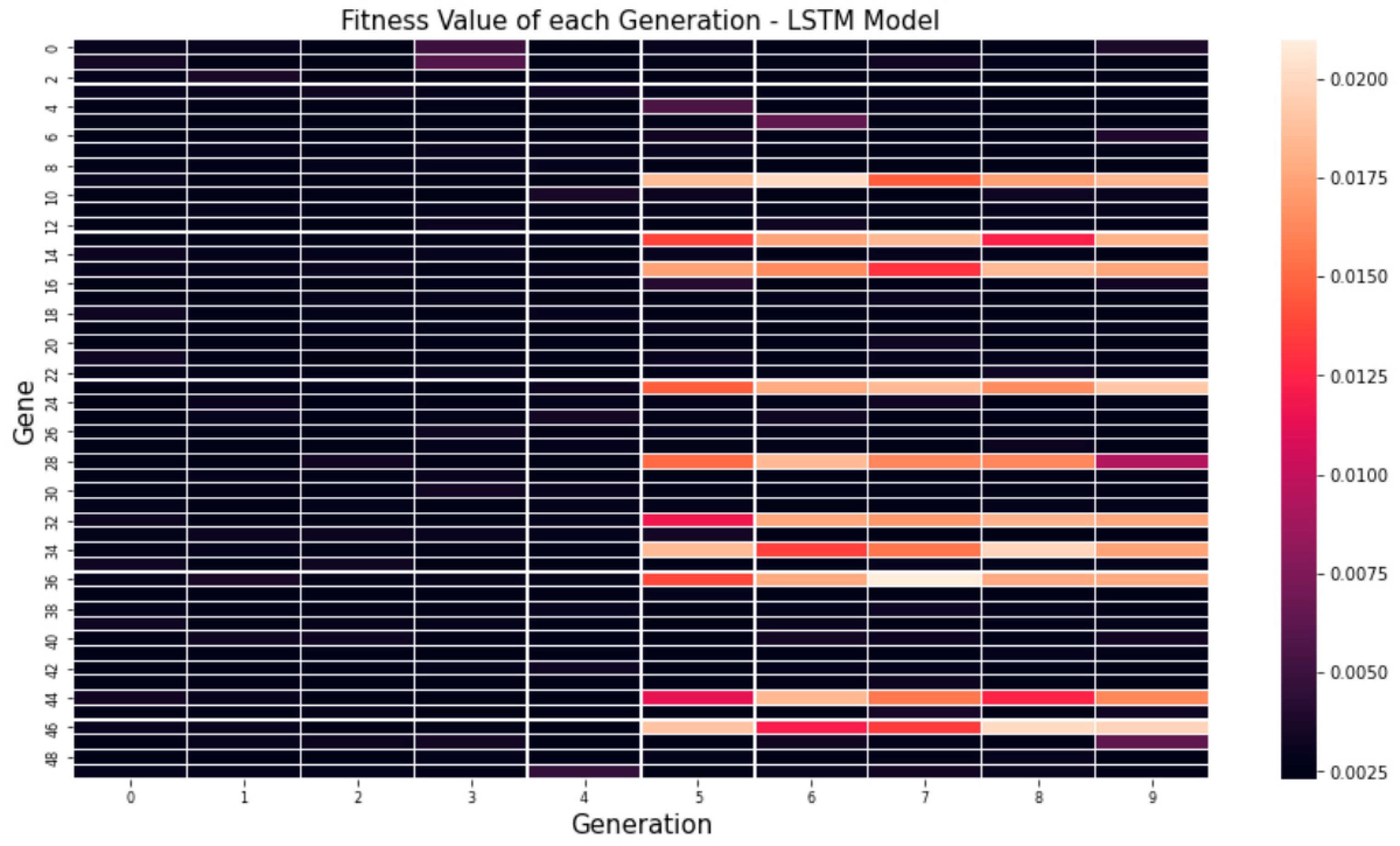
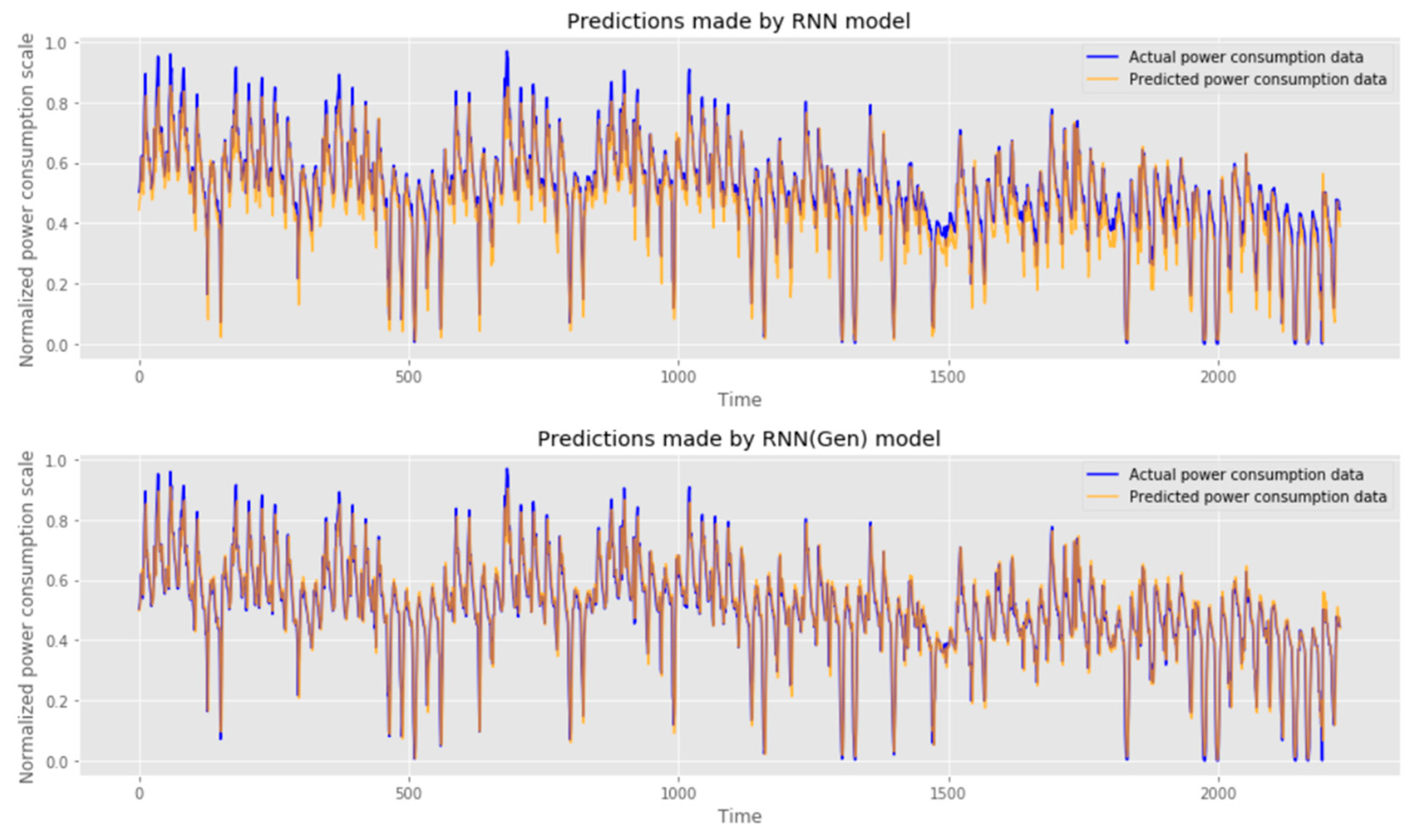
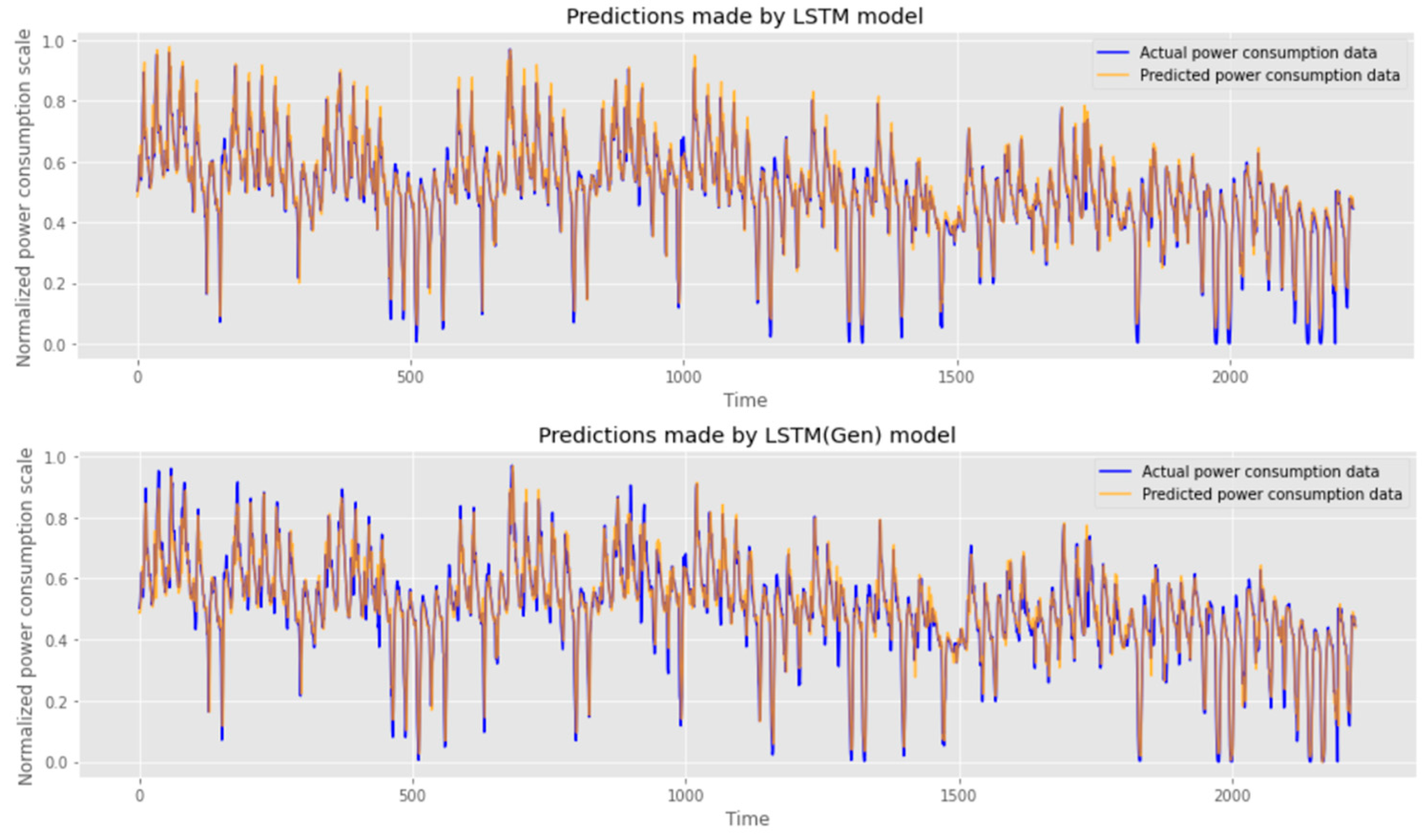
4.2. Result
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hilty, L.M.; Coroama, V.; de Eicker, M.O.; Ruddy, T.F.; Müller, E. The Role of ICT in Energy Consumption and Energy Efficiency; Empa Swiss Federal Laboratories for Materials Testing and Research: St. Gallen, Switzerland, 2009. [Google Scholar]
- Lange, S.; Pohl, J.; Santarius, T. Digitalization and energy consumption. Does ICT reduce energy demand? Ecol. Econ. 2020, 176, 106760. [Google Scholar] [CrossRef]
- Tuballa, M.L.; Abundo, M.L. A review of the development of Smart Grid technologies. Renew. Sustain. Energy Rev. 2016, 59, 710–725. [Google Scholar] [CrossRef]
- Deb, C.; Zhang, F.; Yang, J.; Lee, S.E.; Shah, K.W. A review on time series forecasting techniques for building energy consumption. Renew. Sustain. Energy Rev. 2017, 74, 902–924. [Google Scholar] [CrossRef]
- Ozturk, S.; Ozturk, F. Forecasting Energy Consumption of Turkey by Arima Model. J. Asian Sci. Res. 2018, 8, 52–60. [Google Scholar] [CrossRef]
- Mocanu, E.; Nguyen, P.H.; Gibescu, M.; Kling, W.L. Deep learning for estimating building energy consumption. Sustain. Energy Grids Netw. 2016, 6, 91–99. [Google Scholar] [CrossRef]
- Yu, T.; Zhu, H. Hyper-parameter optimization: A review of algorithms and applications. arXiv 2020, arXiv:2003.05689. [Google Scholar]
- Young, S.R.; Rose, D.C.; Karnowski, T.P.; Lim, S.-H.; Patton, R.M. Optimizing deep learning hyper-parameters through an evolutionary algorithm. In Proceedings of the Workshop on Machine Learning in High-Performance Computing Environments, Austin, TX, USA, 15–20 November 2015. [Google Scholar]
- Whitley, D. A genetic algorithm tutorial. Stat. Comput. 1994, 4, 65–85. [Google Scholar] [CrossRef]
- Hamdia, K.M.; Zhuang, X.; Rabczuk, T. An efficient optimization approach for designing machine learning models based on genetic algorithm. Neural Comput. Appl. 2021, 33, 1923–1933. [Google Scholar] [CrossRef]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.-L.; Chen, S.-C.; Iyengar, S.S. A Survey on Deep Learning: Algorithms, Techniques, and Applications. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.S.; Asari, V.K. A State-of-the-Art Survey on Deep Learning Theory and Architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef]
- Petneházi, G. Recurrent neural networks for time series forecasting. arXiv 2019, arXiv:1901.00069. [Google Scholar]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Recurrent Neural Networks for Time Series Forecasting: Current status and future directions. arXiv 2019, arXiv:1909.00590. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural. Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Sadeghi, A.; Wang, G.; Giannakis, G.B. Deep Reinforcement Learning for Adaptive Caching in Hierarchical Content Delivery Networks. IEEE Trans. Cogn. Commun. Netw. 2019, 5, 1024–1033. [Google Scholar] [CrossRef]
- Dubey, A.K.; Jain, V. Comparative Study of Convolution Neural Network’s ReLu and Leaky-ReLu Activation Functions. In Applications of Computing, Automation and Wireless Systems in Electrical Engineering; Springer: Singapore, 2019; pp. 873–880. [Google Scholar]
- Halgamuge, M.N.; Daminda, E.; Nirmalathas, A. Best optimizer selection for predicting bushfire occurrences using deep learning. Nat. Hazards 2020, 103, 845–860. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Vani, S.; Madhusudhana Rao, T.V. An Experimental Approach towards the Performance Assessment of Various Optimizers on Convolutional Neural Network. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019. [Google Scholar]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural Architecture Search: A Survey. arXiv 2018, arXiv:1808.05377. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Wu, J.; Chen, X.-Y.; Zhang, H.; Xiong, L.-D.; Lei, H.; Deng, S.-H. Hyperparameter optimization for machine learning models based on Bayesian optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar]
- Xiao, X.; Yan, M.; Basodi, S.; Ji, C.; Pan, Y. Efficient Hyperparameter Optimization in Deep Learning Using a Variable Length Genetic Algorithm. arXiv 2020, arXiv:cs.NE/2006.12703. [Google Scholar]
- Folino, G.; Forestiero, A.; Spezzano, G. A Jxta Based Asynchronous Peer-to-Peer Implementation of Genetic Programming. J. Softw. 2006, 1, 12–23. [Google Scholar] [CrossRef]
- Forestiero, A.; Papuzzo, G. Agents-Based Algorithm for a Distributed Information System in Internet of Things. IEEE Internet Things J. 2021, 8, 16548–16558. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gene | Min | Max | ||
|---|---|---|---|---|
| Layer 1 Unit | 20 | 50 | ||
| Layer 2 Unit | 20 | 50 | ||
| Layer 3 Unit | 20 | 50 | ||
| Activation Function | tan h | Leaky ReLU | ELU | |
| Optimizer | SGD | ADAM | ADAMAX | |
| Dropout | 0.01 | 0.2 | ||
| Batch size | 20 | 50 | ||
| Learning Rate | 0.001 | 0.015 | ||
| Gene | Min | Max | ||
|---|---|---|---|---|
| Layer 1 Unit | 20 | 50 | ||
| Layer 2 Unit | 20 | 50 | ||
| Layer 3 Unit | 20 | 50 | ||
| Optimizer | SGD | ADAM | ADAMAX | |
| Dropout | 0.01 | 0.2 | ||
| Batch size | 20 | 50 | ||
| Learning Rate | 0.001 | 0.015 | ||
| Gene | Min | Max |
|---|---|---|
| Layer 1 Unit | −10 | 10 |
| Layer 2 Unit | −10 | 10 |
| Layer 3 Unit | −10 | 10 |
| Activation Function | Random | |
| Optimizer | Random | |
| Dropout | −0.1 | 0.1 |
| Batch Size | 100 | 200 |
| Learning Rate | −0.1 | 0.1 |
| Training Dataset | Test Dataset | ||
|---|---|---|---|
| Input | Target | Input | Target |
| (8985, 20, 1) | (8985, 1) | (2227, 20, 1) | (2227, 1) |
| Gene | RNN | Random-Search-Based RNN | Genetic-Based RNN Model | LSTM | Genetic-Based LSTM Model |
|---|---|---|---|---|---|
| Layer 1 Unit | 40 | 44 | 42 | 40 | 50 |
| Layer 2 Unit | 40 | 47 | 59 | 40 | 20 |
| Layer 3 Unit | 40 | 35 | 29 | 40 | 31 |
| Activation Function | tan h | Leaky RELU | ELU | - | - |
| Optimizer | ADAM | ADAM | ADAM | ADAM | ADAM |
| Dropout | 0.15 | 0.08 | 0.02 | 0.15 | 0.04 |
| Batch Size | 10 | 28 | 40 | 10 | 20 |
| Learning Rate | 0.01 | 0.002 | 0.008 | 0.01 | 0.004 |
| Random-Search-Based Method | Proposed Method | |
|---|---|---|
| Generation 1 | 668 | 704 |
| Generation 2 | 666 | 683 |
| Generation 3 | 662 | 612 |
| Generation 4 | 665 | 602 |
| Generation 5 | 664 | 598 |
| Average running time | 665 | 639.8 |
| Performance Function | RNN | Random-Search-Based RNN | Genetic-Based RNN Model | LSTM | Genetic-Based LSTM Model |
|---|---|---|---|---|---|
| MSE | 0.00421 | 0.00314 | 0.00298 | 0.00261 | 0.00239 |
| MAE | 0.04884 | 0.03955 | 0.03874 | 0.0348 | 0.033 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oh, S.; Yoon, J.; Choi, Y.; Jung, Y.-A.; Kim, J. Genetic Algorithm for the Optimization of a Building Power Consumption Prediction Model. Electronics 2022, 11, 3591. https://doi.org/10.3390/electronics11213591
Oh S, Yoon J, Choi Y, Jung Y-A, Kim J. Genetic Algorithm for the Optimization of a Building Power Consumption Prediction Model. Electronics. 2022; 11(21):3591. https://doi.org/10.3390/electronics11213591
Chicago/Turabian StyleOh, Seungmin, Junchul Yoon, Yoona Choi, Young-Ae Jung, and Jinsul Kim. 2022. "Genetic Algorithm for the Optimization of a Building Power Consumption Prediction Model" Electronics 11, no. 21: 3591. https://doi.org/10.3390/electronics11213591
APA StyleOh, S., Yoon, J., Choi, Y., Jung, Y.-A., & Kim, J. (2022). Genetic Algorithm for the Optimization of a Building Power Consumption Prediction Model. Electronics, 11(21), 3591. https://doi.org/10.3390/electronics11213591