
Unsupervised Domain Adaptive Person Re-Identification Method Based on Transformer


Abstract
1. Introduction
2. Related Work
3. Proposed Method
3.1. Pre-Training Weight
3.2. Head Branch Training
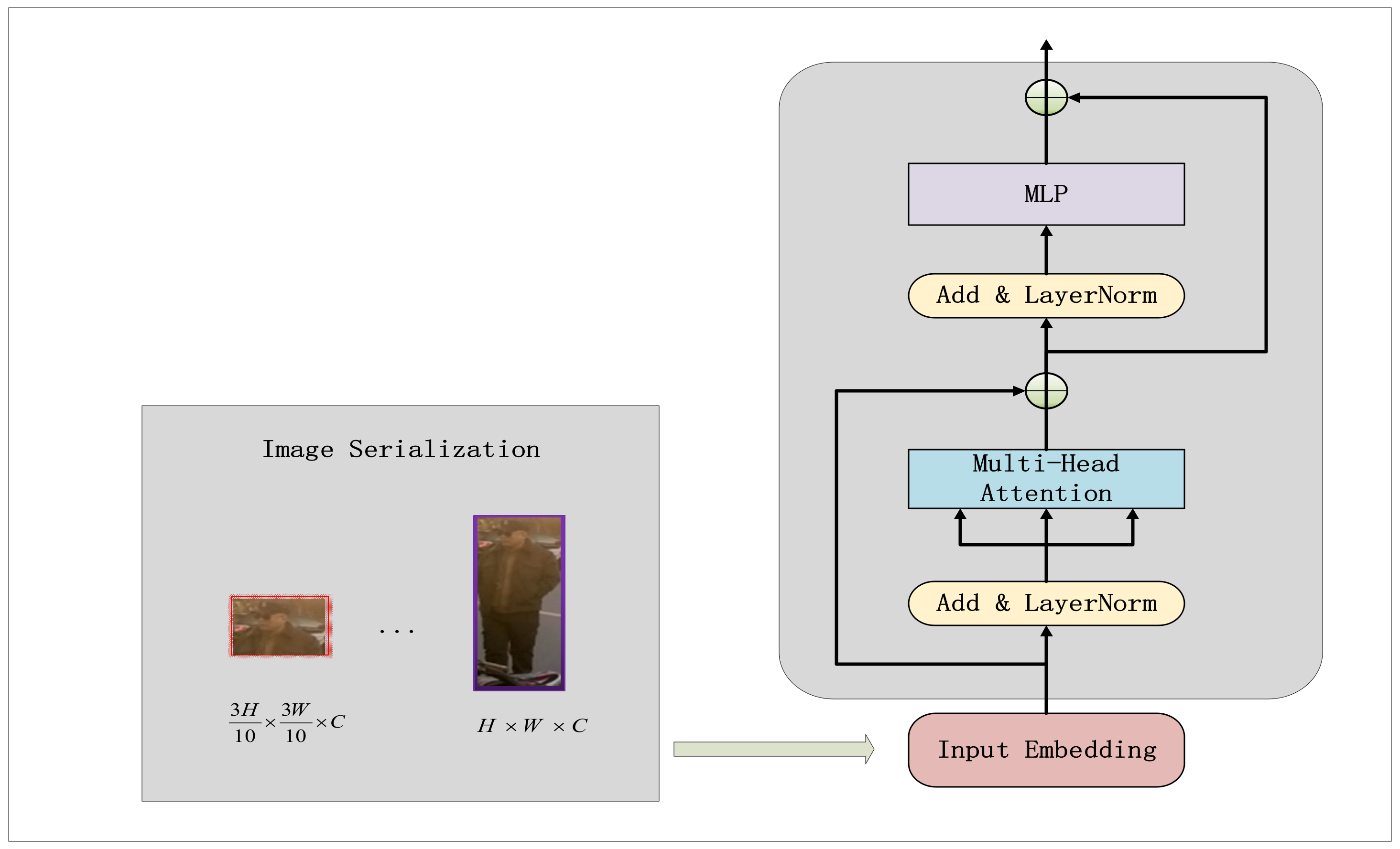
3.3. Feature Extraction Network
3.4. STC Combined Loss
4. Experiments and Results
4.1. Datasets
4.2. Evaluation Protocol
4.3. Comparision with State-of-the-Art Methods
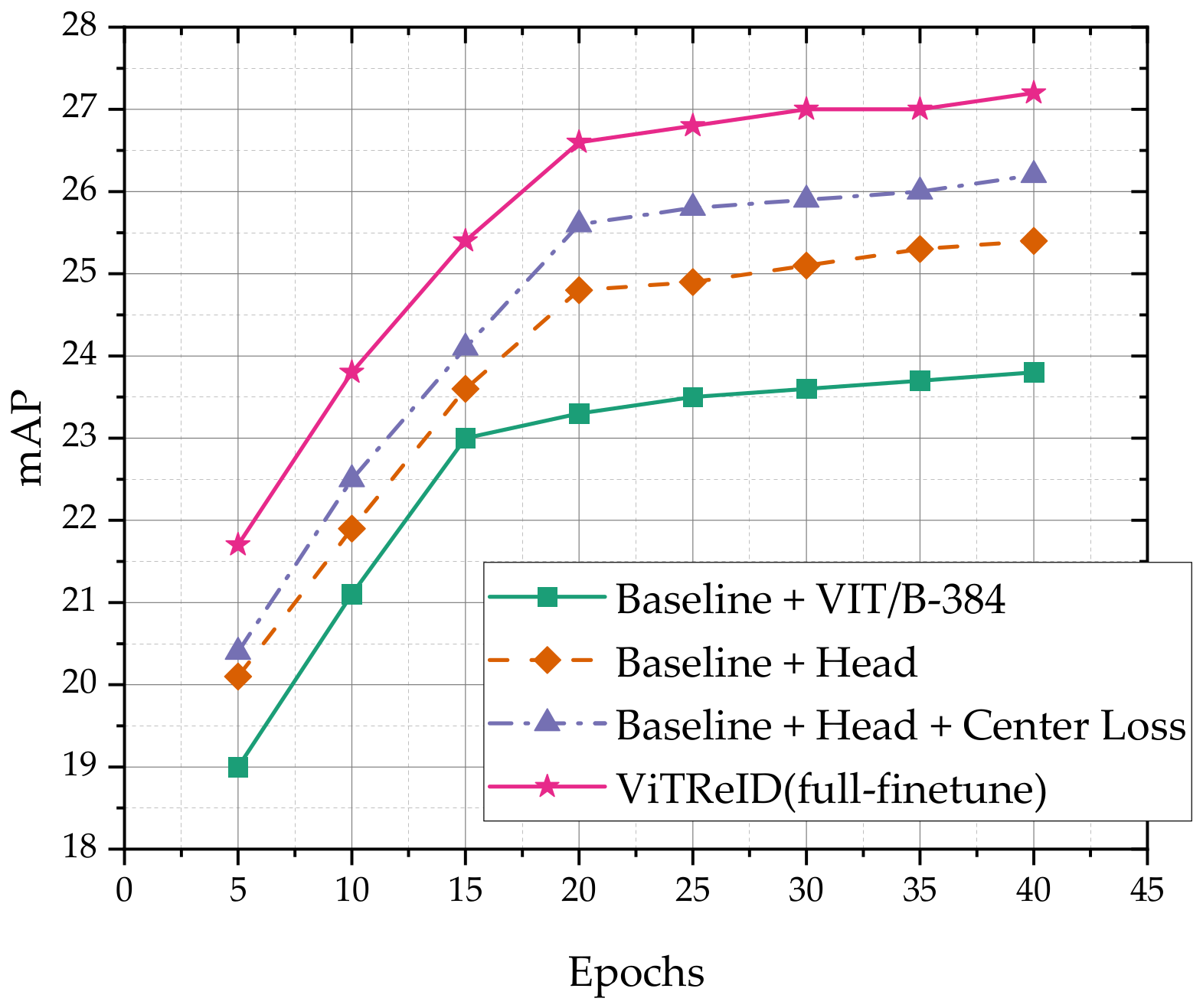
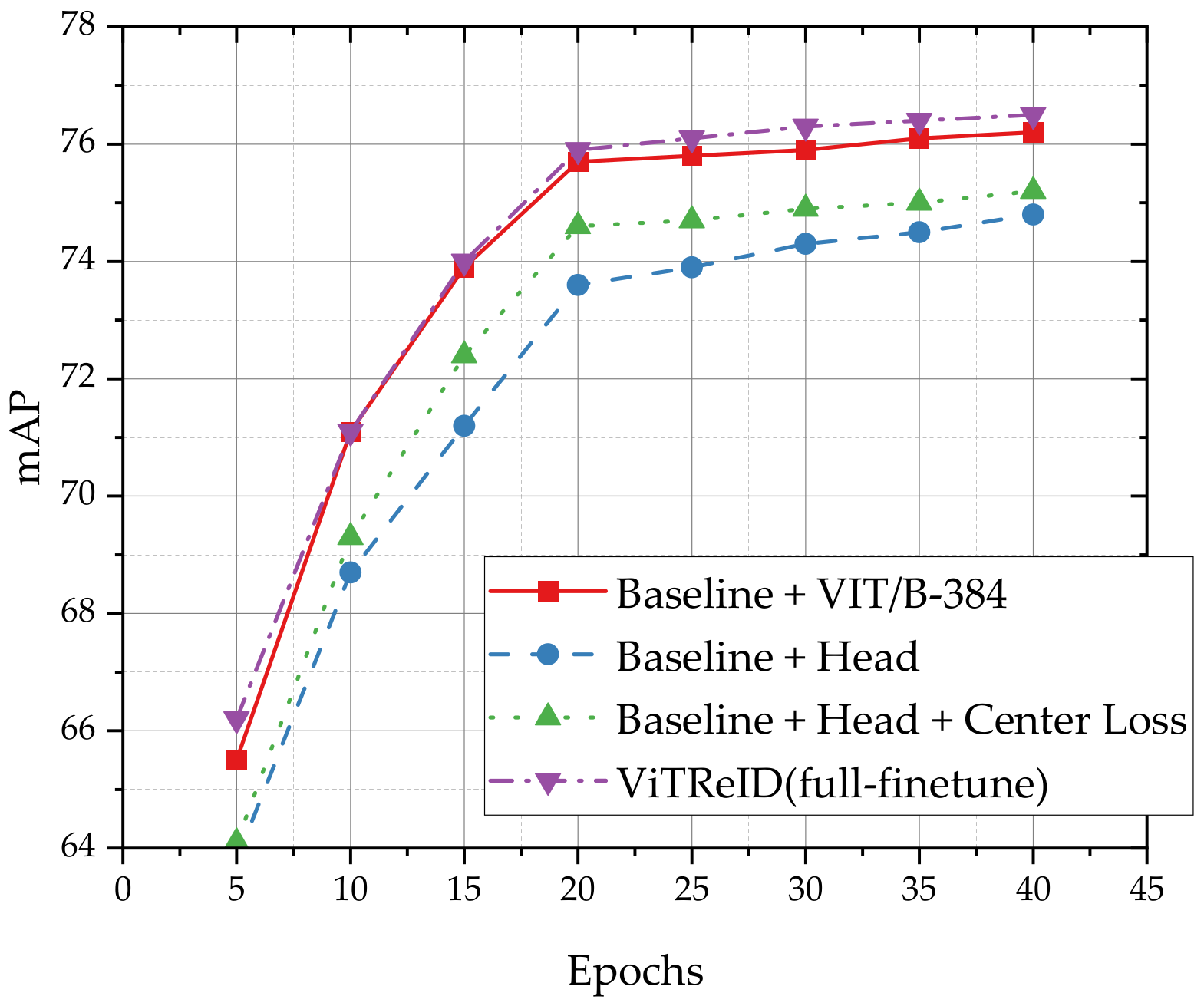
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, X.; Luo, H.; Fan, X.; Xiang, W.; Sun, Y.; Xiao, Q.; Sun, J. Alignedreid: Surpassing human-level performance in person re-identification. arXiv 2017, arXiv:1711.08184. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Fu, Y.; Wei, Y.; Wang, G.; Zhou, Y.; Shi, H.; Huang, T.S. Self-similarity grouping: A simple unsupervised cross domain adaptation approach for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6112–6121. [Google Scholar]
- Ge, Y.; Chen, D.; Li, H. Mutual mean-teaching: Pseudo label refinery for unsupervised domain adaptation on person re-identification. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26 April–1 May 2020. [Google Scholar]
- Ge, Y.; Zhu, F.; Chen, D.; Zhao, R. Self-paced contrastive learning with hybrid memory for domain adaptive object re-id. Adv. Neural Inf. Process. Syst. 2020, 33, 11309–11321. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Houlsby, N. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A Discriminative Feature Learning Approach for Deep Face Recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 499–515. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Zhang, Z.; Si, T.; Liu, S. Integration Convolutional Neural Network for Person Re-Identification in Camera Networks. IEEE Access 2018, 6, 36887–36896. [Google Scholar] [CrossRef]
- Fan, X.; Luo, H.; Zhang, X.; He, L.; Zhang, C.; Jiang, W. Scpnet: Spatial-channel parallelism network for joint holistic and partial person re-identification. In Proceedings of the Asian Conference on Computer Vision (ACCV), Perth, WA, USA, 2–6 December 2018; pp. 19–34. [Google Scholar]
- Su, C.; Li, J.; Zhang, S.; Xing, J.; Gao, W.; Tian, Q. Pose-driven deep convolutional model for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3960–3969. [Google Scholar]
- Liu, H.; Jie, Z.; Jayashree, K.; Qi, M.; Jiang, J.; Yan, S.; Feng, J. Video-based person re-identification with accumulative motion context. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 2788–2802. [Google Scholar] [CrossRef]
- Li, Y.; Zhuo, L.; Li, J.; Zhang, J.; Liang, X.; Tian, Q. Video-Based Person Re-identification by Deep Feature Guided Pooling. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1454–1461. [Google Scholar]
- Song, G.; Leng, B.; Liu, Y.; Hetang, C.; Cai, S. Region-based quality estimation network for large-scale person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018; pp. 7347–7354. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3754–3762. [Google Scholar]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person transfer gan to bridge domain gap for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 79–88. [Google Scholar]
- Deng, W.; Zheng, L.; Ye, Q.; Kang, G.; Yang, Y.; Jiao, J. Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 994–1003. [Google Scholar]
- Qian, X.; Fu, Y.; Xiang, T.; Wang, W.; Qiu, J.; Wu, Y.; Xue, X. Pose-normalized image generation for person re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 650–667. [Google Scholar]
- Song, L.; Wang, C.; Zhang, L.; Du, B.; Zhang, Q.; Huang, C.; Wang, X. Unsupervised domain adaptive re-identification: Theory and practice. Pattern Recognit. 2020, 102, 107173. [Google Scholar] [CrossRef]
- Zhang, X.; Cao, J.; Shen, C.; You, M. Self-training with progressive augmentation for unsupervised cross-domain person re-identification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8222–8231. [Google Scholar]
- Zhai, Y.; Lu, S.; Ye, Q.; Shan, X.; Chen, J.; Ji, R.; Tian, Y. Ad-cluster: Augmented discriminative clustering for domain adaptive person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 9021–9030. [Google Scholar]
- Yu, H.X.; Zheng, W.S.; Wu, A.; Guo, X.; Gong, S.; Lai, J.H. Unsupervised person re-identification by soft multilabel learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2148–2157. [Google Scholar]
- Zou, Y.; Yang, X.; Yu, Z.; Kumar, B.V.K.; Kautz, J. Joint disentangling and adaptation for cross-domain person re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 87–104. [Google Scholar]
- Mekhazni, D.; Bhuiyan, A.; Ekladious, G.; Granger, E. Unsupervised domain adaptation in the dissimilarity space for person re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 159–174. [Google Scholar]
- Zhu, X.; Morerio, P.; Murino, V. Unsupervised domain-adaptive person re-identification based on attributes. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, China, 22–25 September 2019; pp. 4110–4114. [Google Scholar]
- Chong, Y.W.; Peng, C.W.; Zhang, J.J.; Pan, S.M. Style transfer for unsupervised domain-adaptive person re-identification. Neurocomputing 2021, 422, 314–321. [Google Scholar] [CrossRef]
- Zhu, X.; Li, Y.; Sun, J. Unsupervised domain adaptive person re-identification via camera penalty learning. Multimed. Tools Appl. 2021, 80, 15215–15232. [Google Scholar] [CrossRef]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local features coupling global representations for visual recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 367–376. [Google Scholar]
- He, S.; Luo, H.; Wang, P.; Wang, F.; Li, H.; Jiang, W. Transreid: Transformer-based object re-identification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 15013–15022. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami Beach, FL, USA, 20–26 June 2009; pp. 248–255. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-identification: A Benchmark. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Bai, S.; Tang, P.; Torr, P.H.S.; Latecki, L.J. Re-Ranking via Metric Fusion for Object Retrieval and Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 740–749. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Z.; Zheng, L.; Cao, D.; Li, S. Re-ranking person re-identification with k-reciprocal encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1318–1327. [Google Scholar]
- Zhong, Z.; Zheng, L.; Luo, Z.; Li, S.; Yang, Y. Invariance matters: Exemplar memory for domain adaptive person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 598–607. [Google Scholar]
- Wang, D.; Zhang, S. Unsupervised person re-identification via multi-label classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10981–10990. [Google Scholar]
- Yang, Q.; Yu, H.X.; Wu, A.; Zheng, W.S. Patch-Based Discriminative Feature Learning for Unsupervised Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3628–3637. [Google Scholar]
- Wu, A.; Zheng, W.; Lai, J. Unsupervised Person Re-Identification by Camera-Aware Similarity Consistency Learning. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6921–6930. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Train IDs | Train Images | Test IDs | Query Images | Cameras | Total Images |
|---|---|---|---|---|---|---|
| Market1501 | 751 | 12,936 | 750 | 3368 | 6 | 32,668 |
| MSMT17 | 1041 | 32,621 | 3060 | 11,659 | 15 | 126,441 |
| PersonX | 410 | 9840 | 856 | 5136 | 6 | 45,792 |
| Methods | Market1501 → MSMT17 | Methods | MSMT17 → Market1501 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| mAP | R1 | R5 | R10 | mAP | R1 | R5 | R10 | ||
| PTGAN [18] | 2.9 | 10.2 | - | 24.4 | MAR [25] | 40.0 | 67.7 | 81.9 | - |
| ECN [39] | 8.5 | 25.3 | 36.3 | 42.1 | PAUL [41] | 40.1 | 68.5 | 82.4 | 87.4 |
| SSG [3] | 13.2 | 31.6 | - | 49.6 | CASCL [42] | 35.5 | 65.4 | 80.6 | 86.2 |
| MMCL [40] | 15.1 | 40.8 | 51.8 | 56.7 | D-MMD [27] | 50.8 | 72.8 | 88.1 | 92.3 |
| MMT [4] | 22.9 | 49.2 | 63.1 | 68.8 | DG-Net++ [26] | 64.6 | 83.1 | 91.5 | 94.3 |
| SPCL [5] | 26.8 | 53.7 | 65.0 | 69.8 | SPCL [5] | 77.5 | 89.7 | 96.1 | 97.6 |
| ViTReID | 27.2 | 54.2 | 66.5 | 71.6 | ViTReID | 76.5 | 90.9 | 96.6 | 98.2 |
| Methods | PersonX → MSMT17 | PersonX → Market1501 | ||||||
|---|---|---|---|---|---|---|---|---|
| mAP | R1 | R5 | R10 | mAP | R1 | R5 | R10 | |
| MMT-dbscan [4] | 17.7 | 39.1 | 52.6 | 58.5 | 71.0 | 86.5 | 94.8 | 97.0 |
| ViTReID | 20.8 | 46.8 | 59.1 | 64.6 | 72.5 | 87.3 | 95.8 | 97.9 |
| Methods | Market1501 → MSMT17 | MSMT17 → Market1501 | ||||||
|---|---|---|---|---|---|---|---|---|
| mAP | R1 | R5 | R10 | mAP | R1 | R5 | R10 | |
| Baseline (SSG) [3] | 13.2 | 31.6 | - | 49.6 | - | - | - | - |
| Baseline + VIT/B-384 | 23.8 | 51.6 | 63.5 | 68.8 | 76.2 | 89.3 | 96.2 | 97.7 |
| Baseline + Head | 25.4 | 49.0 | 61.4 | 67.9 | 74.8 | 89.6 | 96.0 | 97.5 |
| Baseline + Head + Center Loss | 26.2 | 49.8 | 62.8 | 68.1 | 75.2 | 90.2 | 96.3 | 97.9 |
| ViTReID (full-finetune) | 27.2 | 54.2 | 66.5 | 71.6 | 76.5 | 90.9 | 96.6 | 98.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, X.; Ding, S.; Zhou, W.; Shi, W.; Tian, H. Unsupervised Domain Adaptive Person Re-Identification Method Based on Transformer. Electronics 2022, 11, 3082. https://doi.org/10.3390/electronics11193082
Yan X, Ding S, Zhou W, Shi W, Tian H. Unsupervised Domain Adaptive Person Re-Identification Method Based on Transformer. Electronics. 2022; 11(19):3082. https://doi.org/10.3390/electronics11193082
Chicago/Turabian StyleYan, Xiai, Shengkai Ding, Wei Zhou, Weiqi Shi, and Hua Tian. 2022. "Unsupervised Domain Adaptive Person Re-Identification Method Based on Transformer" Electronics 11, no. 19: 3082. https://doi.org/10.3390/electronics11193082
APA StyleYan, X., Ding, S., Zhou, W., Shi, W., & Tian, H. (2022). Unsupervised Domain Adaptive Person Re-Identification Method Based on Transformer. Electronics, 11(19), 3082. https://doi.org/10.3390/electronics11193082