
Selective Layer Tuning and Performance Study of Pre-Trained Models Using Genetic Algorithm

 , , , ,
, , , , 
Abstract
1. Introduction
- -
- We present a search procedure with the genetic algorithm to search for selective layers of a pre-trained deep-learning model. It yielded significant speed advantages when starting with a pre-trained model rather than other search-from-scratch approaches.
- -
- We introduce HospitalAlarmSound, a dataset about alarm sounds recorded from medical appliances at the Hospital of Chonnam National University. The dataset is carefully designed for the classification task with 8 classes and 569 records in total.
2. Related Works
2.1. Fine-Tuning of Pre-Trained Models
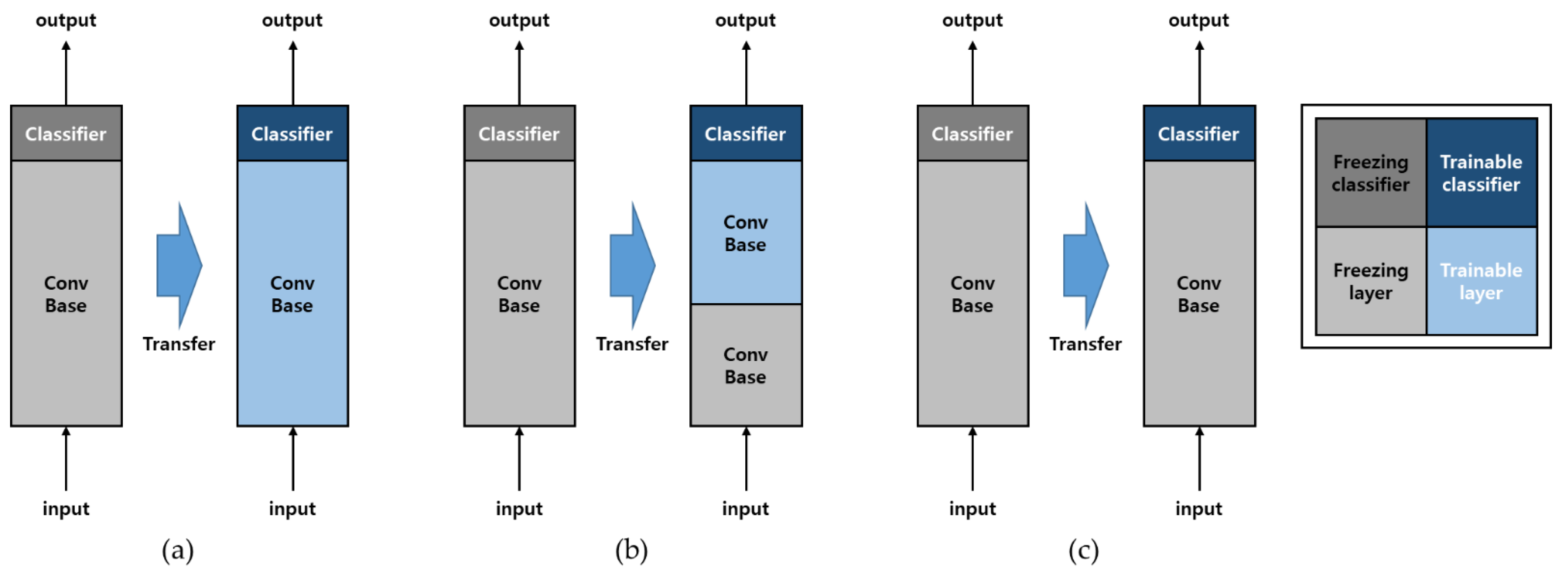
- The size of a user’s data is small, while the similarity to the pre-trained model data is high:Because the data similarity is very high, there is no need to retrain the pre-trained model or modify the classifier to fit the task (modify the dense layer and softmax layer). This is a method of using a pre-trained model as a feature extractor.
- The size of the user’s data is small, and the similarity to the pre-trained model data is low:Freeze the initial layers of the pre-trained model, retrain only the remaining layers, and modify the classifier to fit the task. The advantages of the pre-trained model can be maximized by using the low-level features of the pre-trained model as they are and changing only the high-level features to fit its data.
- The user’s data are large but less similar to the pre-trained model data:Because of the large size of the user’s data, the pre-trained model structure is imported, the classifier is modified to fit the task, and then it is trained from scratch. Because the data similarity is very low, the weights and biases of the pre-trained model adversely affect its performance.
- The user’s data are large and highly similar to the pre-trained model data:The structure, weight, and bias of the pre-trained model are used as they are, the classifier is modified to fit the task, and it is trained again with its data. In an ideal situation, the pre-trained model can be used most effectively.
2.2. Research Related to Fine-Tuning
2.3. Genetic Algorithms
2.4. Genetic Algorithm-Based Fine-Tuning Research
3. Method
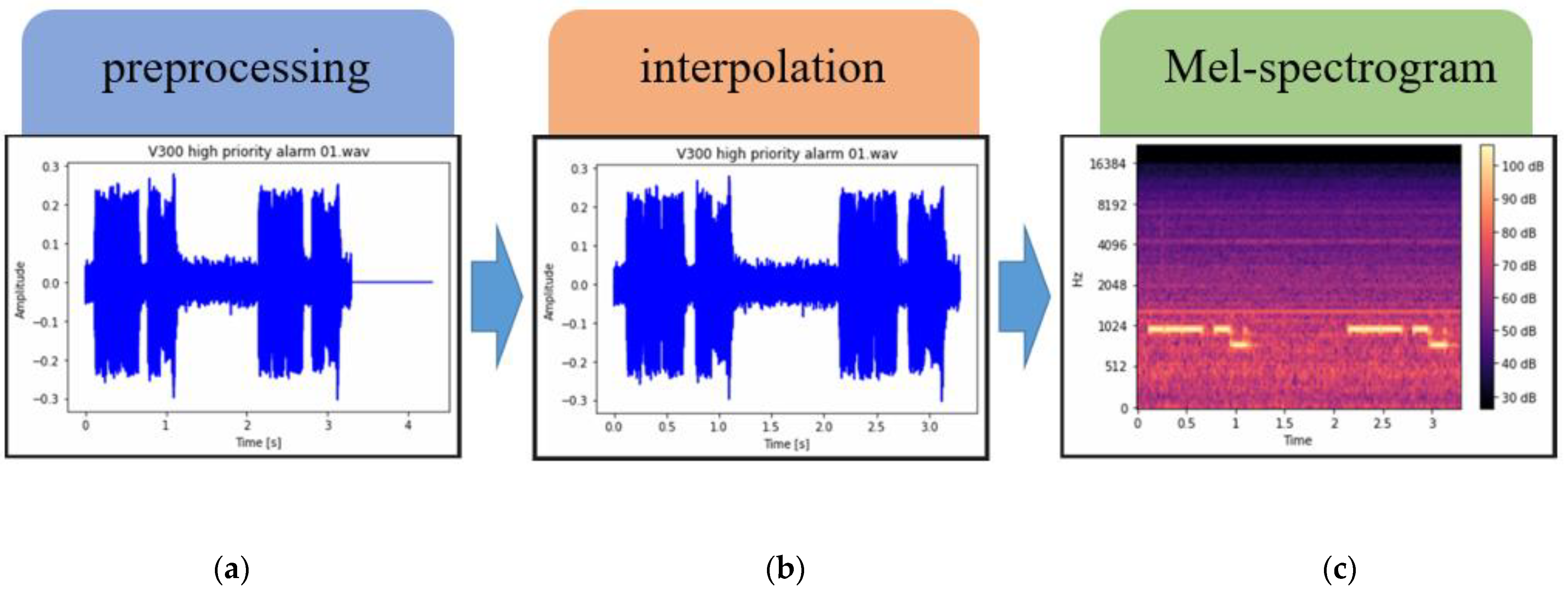
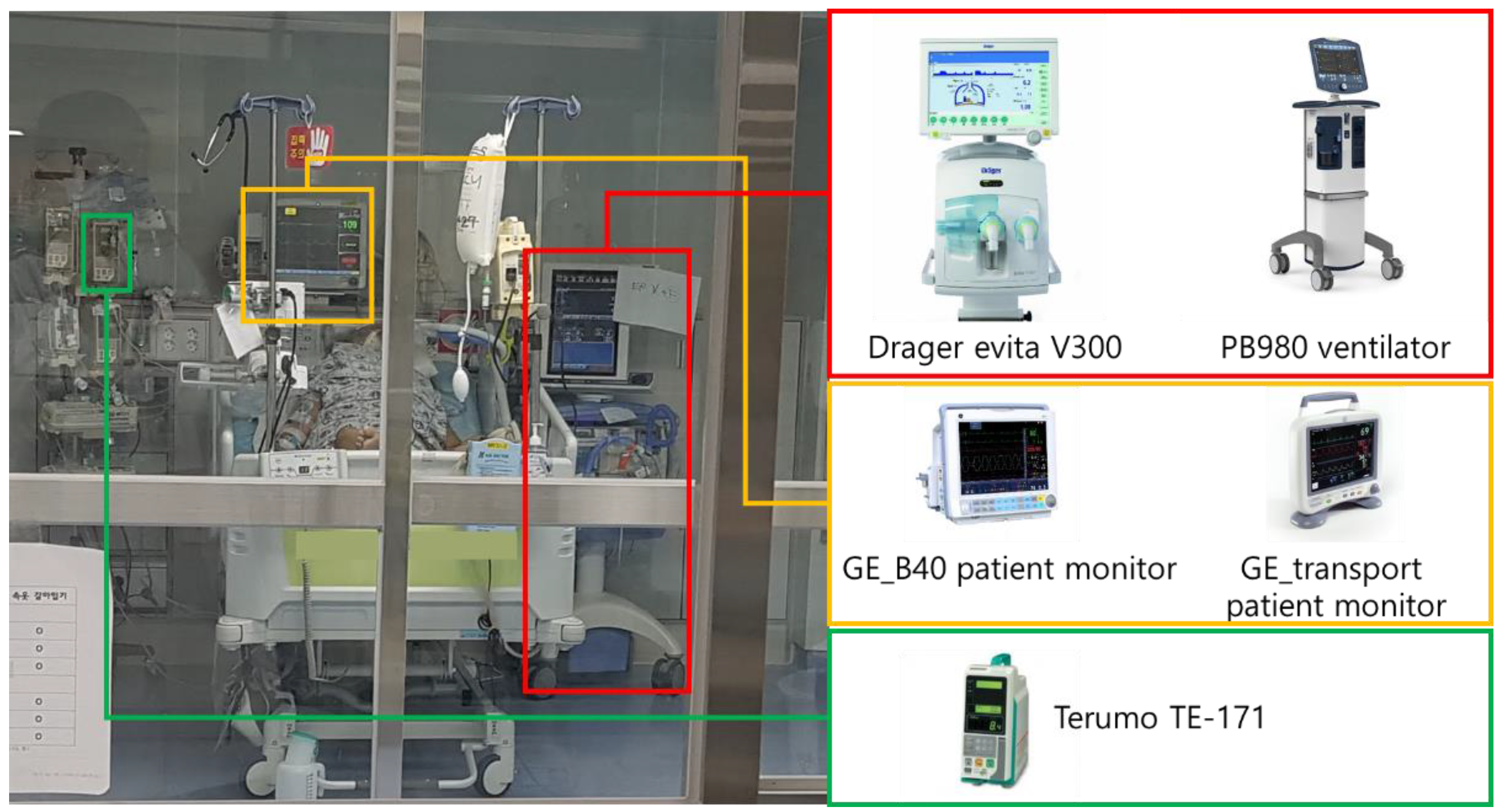
3.1. Dataset
3.2. Pre-Trained Deep-Learning Models
3.3. Selective Layer Tuning by Genetic Algorithm
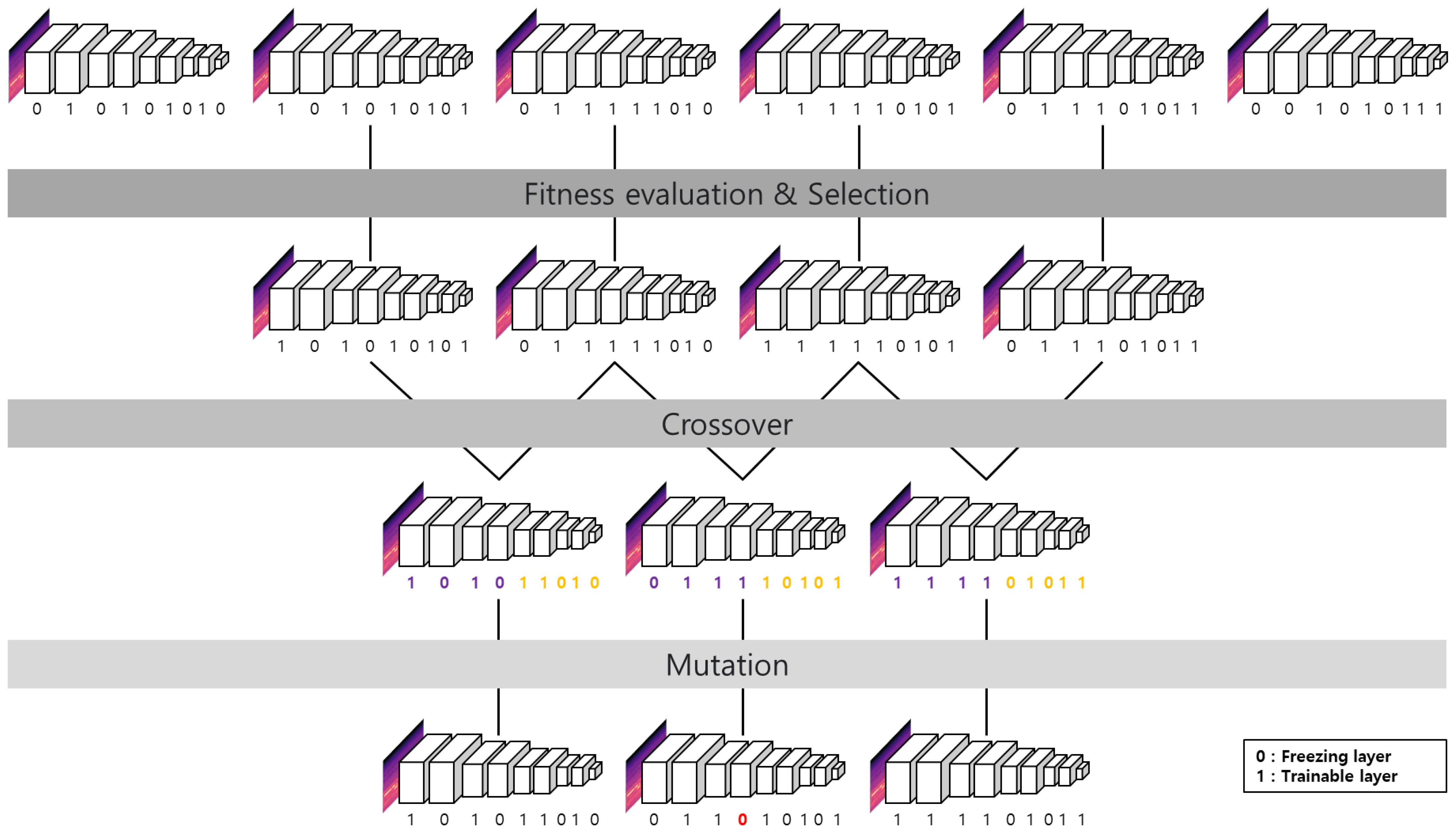
- Genome: The gene is a pre-trained model trained with the ImageNet dataset that allows all layers to be selected as a trainable layer and a freezing layer.
- Initial generation: In the first generation, the entire layer for each genome is randomly selected as the trainable layer and freezing layer.
- Fitness evaluation: Short training is performed on a given dataset based on randomly selected trainable and freezing layers, and validation accuracy is obtained for each epoch. The highest fitness score is ranked by setting a validation accuracy as a fitness indicator.
- Selection: Choose from the top dominant genomes selected through fitness evaluation.
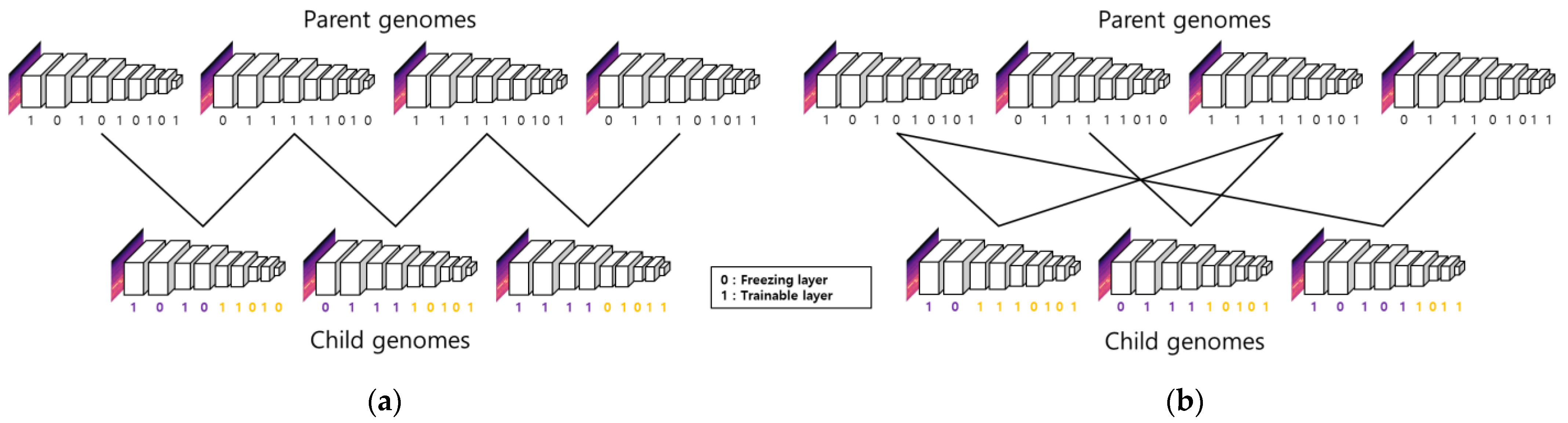
- Crossover: Select and cross over the selected dominant genomes. Two main crossover methods are used, as shown in Figure 5. The crossover of the half-mixing method according to the high fitness score is shown in Figure 5a. The selected dominant genomes are crossed over randomly to make the crossover more effective, as shown in Figure 5b.Crossover is a genetic operator that combines the genetic information of two parents to generate new offspring. This study uses regular and random crossover simultaneously to enhance the variety of the solution space through exploration, which could help avoid being corrupted early at local optima. Both regular crossover and random crossover are designed based on the one-point crossover, while the difference between them is the portion the offspring inherit from the parent generation. In the regular crossover, we generate the offspring by taking half of the genome code from two selected genomes. On the other hand, the offspring is constructed by an arbitrary crossover point in the random crossover when the random range is dependent on the size of the dominant genomes.
- Mutation: In all genomes of the current generation, a layer is randomly selected with a 4% probability and reversed.
- Next generation: Half of all genomes are selected as dominant genomes, and the dominant genomes are converted into child genomes using two crossover methods. All selected genomes undergo mutation. Finally, the total number of dominant and child genomes will be the same as the initial number of populations in the next generation.
- Iteration: Selection, crossover, mutation, and next generation are repeated until the target is achieved.
4. Experiments and Results
4.1. Experimental Environment
4.2. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jia, D.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Ashish, V.; Noam, S.; Niki, P.; Jakob, U.; Llion, J.; Aidan, G.; Łukasz, N.K.; Illia, P. Attention is All You Need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Alec, R.; Jeffrey, W.; Rewon, C.; David, L.; Dario, A.; Ilya, S. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Jacob, D.; Chang, M.-W.; Lee, K.; Kristina, T. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Wikipedia Dataset. Available online: https://dumps.wikimedia.org (accessed on 15 June 2022).
- Vo, H.; Yu, G.-H.; Dang, T.; Kim, J.-Y. Late fusion of multimodal deep neural networks for weeds classification. Comput. Electron. Agric. 2020, 175, 105506. [Google Scholar]
- Quin, T.; Karpur, A.; Norris, W.; Xia, F.; Panait, L.; Weyand, T.; Sim, J. Nutrition5k: Towards Automatic Nutritional Understanding of Generic Food. In Proceedings of the IEEE/CVF, Virtual, 19–25 June 2021. [Google Scholar]
- Dang, T.; Vo, H.; Yu, G.; Kim, J. Capsule network with shortcut routing. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2021, 104, 1043–1050. [Google Scholar] [CrossRef]
- Barret, Z.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- RahmiArda, A.; Keskin, Ş.R.; Kaya, M.; Murat, H. Classification of Trashnet Dataset Based on Deep Learning Models. In Proceedings of the IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018. [Google Scholar]
- Eva, C.; Tomislav, L.; Sonja, G. Fine-tuning convolutional neural networks for fine art classification. Expert Syst. Appl. 2018, 114, 107–118. [Google Scholar]
- Chebet, T.E.; Li, Y.; Sam, N.; Liu, Y. A comparative study of fine-tuning deep learning models for plant disease identification. Comput. Electron. Agric. 2019, 161, 272–279. [Google Scholar]
- Tao, C.; Mingfen, W.; Hexi, L. A general approach for improving deep learning-based medical relation extraction using a pre-trained model and fine-tuning. Database 2019, 2019, baz116. [Google Scholar]
- Roslidar, R.; Khairun, S.; Fitri, A.; Maimun, S.; Khairul, M. A Study of Fine-Tuning CNN Models Based on Thermal Imaging for Breast Cancer Classification. In Proceedings of the IEEE International Conference on Cybernetics and Computational Intelligence, Banda Aceh, Indonesia, 22–24 August 2019. [Google Scholar]
- Morocho, C.M.E.; Lim, W. Fine-Tuning a Pre-Trained Convolutional Neural Network Model to Trans-Late American Sign Language in Real-Time. In Proceedings of the International Conference on Computing, Networking and Communica-tions (ICNC), Honolulu, HI, USA, 18–21 February 2019. [Google Scholar]
- Tomoya, K.; Kun, Q.; Kong, Q.; Mark, D.; Björn, S.W.; Yoshiharu, Y. Audio for Audio is Better? An Investigation on Transfer Learning Models for Heart Sound Classification. In Proceedings of the 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020. [Google Scholar]
- Caisse, A.; Ernesto, J.-P.M.; Silva, C.J.A. Fine-tuning deep learning models for pedestrian detection. Bol. Ciênc. Geod. 2021, 27, e2021013. [Google Scholar] [CrossRef]
- Yanrui, J.; Chengjin, Q.; Jinlei, L.; Ke, L.; Haotian, S.; Yixiang, H.; Chengliang, L. A novel domain adaptive residual network for automatic atrial fibrillation detection. Knowl.-Based Syst. 2020, 203, 106122. [Google Scholar]
- Yanrui, J.; Chengjin, Q.; Jianfeng, T.; Chengliang, L. An accurate and adaptative cutterhead torque prediction method for shield tunnel-ing machines via adaptative residual long-short term memory network. Mech. Syst. Signal Proc. 2022, 165, 108312. [Google Scholar]
- Takahiro, S.; Shinji, W. Structure Discovery of Deep Neural Network Based on Evolutionary Algorithms. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015. [Google Scholar]
- Shancheng, J.; Kwai-Sang, C.; Long, W.; Gang, Q.; Kwok, T.L. Modified genetic algorithm-based feature selection combined with pre-trained deep neural network for demand forecasting in outpatient department. Expert Syst. Appl. 2017, 82, 216–230. [Google Scholar]
- Haiman, T.; Shu-Ching, C.; Mei-Ling, S. Genetic Algorithm Based Deep Learning Model Selection for Visual Data Classification. In Proceedings of the IEEE 20th International Conference on Information Reuse and Integration for Data Science (IRI), Los Angeles, CA, USA, 30 July–1 August 2019. [Google Scholar]
- Enes, A.; Hasan, E.; Fatih, V. Crop pest classification with a genetic algorithm-based weighted ensemble of deep convolutional neural networks. Comput. Electron. Agric. 2020, 179, 105809. [Google Scholar]
- Jesse, D.; Gabriel, I.; Roy, S.; Ali, F.; Hajishirzi, H.; Noah, S. Fine-tuning pretrained language models: Weight initializations, data orders, and early stopping. arXiv 2020, arXiv:2002.06305. [Google Scholar]
- Satsuki, N.; Shin, K.; Hajime, N. Transfer Learning Layer Selection Using Genetic Algorithm. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19 July 2020. [Google Scholar]
- Fashion-Mnist Dataset. Available online: https://github.com/zalandoresearch/fashion-mnist (accessed on 20 June 2022).
- Justin, S.; Christopher, J.; Pablo, B.J. A Dataset and Taxonomy for Urban Sound Research. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014. [Google Scholar]
- LeCun, Y.; Léon, B.; Yoshua, B.; Patrick, H. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Wei, L.; Yangqing, J.; Pierre, S.; Scott, R.; Dragomir, A.; Dumitru, E.; Vincent, V.; Andrew, R. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Xiangyu, Z.; Shaoqing, R.; Jian, S. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zoph, B.; Vijay, V.; Jonathon, S.; Quoc, L.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Howard, A.G.; Menglong, Z.; Bo, C.; Dmitry, K.; Weijun, W.; Tobias, W.; Marco, A.; Hartwig, A. Mobilenets: Efficient convolu-tional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Xinyu, Z.; Mengxiao, L.; Jian, S. Shufflenet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Tan, M.; Quoc, L. Efficientnet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Class | Number | Dataset | Class | Number | Dataset | Class | Number |
|---|---|---|---|---|---|---|---|---|
| MNIST-fashion | T-shirt/top | 7000 | Urban Sound8K | air_conditioner | 1000 | Hospital Alarm Sound | Dager evita V300 | 70 |
| Trouser | 7000 | car_horn | 429 | GE_B40-high | 72 | |||
| Pullover | 7000 | children_playing | 1000 | GE_B40-medium | 69 | |||
| Dress | 7000 | dog_bark | 1000 | GE_transport-advisory | 71 | |||
| Coat | 7000 | drilling | 1000 | GE_transport-crisis | 71 | |||
| Sandal | 7000 | engine_idling | 1000 | GE_transport-warning | 75 | |||
| Shirt | 7000 | gun_shot | 374 | PB980 | 65 | |||
| Sneaker | 7000 | jackhammer | 1000 | TE-171 | 76 | |||
| Bag | 7000 | siren | 929 | - | ||||
| Ankle boot | 7000 | street_music | 1000 | |||||
| Total | 70,000 | Total | 8732 | Total | 569 | |||
| 1: | Generate: n initial genomes |
| 2: | while Generation < Final Generation: |
| 3: | Train: n models corresponding to n genomes |
| 4: | Select: n/2 genomes based on top n/2 fitness score |
| 5: | Crossover1: n/4 child genomes based on a regular crossover |
| 6: | Crossover2: n/4 child genomes based on a random crossover |
| 7: | Mutation: n/2 genomes and n/2 child genomes |
| 8: | Align: n/2 genomes and n/2 child genomes to the next generation |
| 9: | Generation + = 1 |
| 10: | end While: |
| 11: | Return: Array of the selected layers |
| Model | Attributes | Heuristic Method | Random Method | Genetic Algorithm | ||
|---|---|---|---|---|---|---|
| EfficientNetB0 | number of trainable layers | 0 | 237 | 137 | 121 | 128 |
| test accuracy | 0.4940 | 0.8495 | 0.7895 | 0.8181 | 0.8738 | |
| number of parameters | 12,816 | 4,020,364 | 3,490,948 | 2,051,830 | 1,767,472 | |
| ResNet50 | number of trainable layers | 0 | 175 | 100 | 89 | 81 |
| test accuracy | 0.7850 | 0.9022 | 0.9032 | 0.9030 | 0.9144 | |
| number of parameters | 20,496 | 23,555,088 | 19,473,424 | 12,627,728 | 10,876,944 | |
| MobileNetV1 | number of trainable layers | 0 | 86 | 46 | 39 | 43 |
| test accuracy | 0.5033 | 0.9297 | 0.9035 | 0.9300 | 0.9319 | |
| number of parameters | 10,256 | 3,217,232 | 2,942,480 | 1,037,200 | 1,476,624 | |
| VGG16 | number of trainable layers | 0 | 19 | 9 | 11 | 6 |
| test accuracy | 0.8512 | 0.9401 | 0.9324 | 0.9348 | 0.9441 | |
| number of parameters | 5136 | 14,719,824 | 12,984,336 | 9,668,112 | 6,091,216 | |
| Model | Attributes | Heuristic Method | Random Method | Genetic Algorithm | ||
|---|---|---|---|---|---|---|
| EfficientNetB0 | number of trainable layers | 0 | 237 | 137 | 122 | 129 |
| test accuracy | 0.9599 | 0.9920 | 0.9908 | 0.9840 | 0.9931 | |
| number of parameters | 307,216 | 4,314,764 | 3,785,348 | 2,082,326 | 2,509,558 | |
| ResNet50 | number of trainable layers | 0 | 175 | 100 | 91 | 96 |
| test accuracy | 0.9851 | 0.9851 | 0.9782 | 0.9828 | 0.9920 | |
| number of parameters | 491,536 | 24,026,128 | 19,944,464 | 10,552,400 | 13,297,104 | |
| MobileNetV1 | number of trainable layers | 0 | 86 | 46 | 53 | 40 |
| test accuracy | 0.9737 | 0.9840 | 0.9828 | 0.9759 | 0.9931 | |
| number of parameters | 204,816 | 3,411,792 | 3,137,040 | 3,049,264 | 522,192 | |
| VGG16 | number of trainable layers | 0 | 19 | 9 | 8 | 5 |
| test accuracy | 0.9817 | 0.9588 | 0.9748 | 0.9794 | 0.9897 | |
| number of parameters | 102,416 | 14,817,104 | 13,081,616 | 5,119,504 | 5,008,336 | |
| Model | Attributes | Heuristic Method | Random Method | Genetic Algorithm | ||
|---|---|---|---|---|---|---|
| EfficientNetB0 | number of trainable layers | 0 | 237 | 137 | 125 | 114 |
| test accuracy | 0.9872 | 0.9952 | 0.9880 | 0.9940 | 0.9956 | |
| number of parameters | 512,016 | 4,519,564 | 3,990,148 | 2,583,768 | 2,182,418 | |
| ResNet50 | number of trainable layers | 0 | 175 | 100 | 90 | 80 |
| test accuracy | 0.9400 | 0.9736 | 0.9952 | 0.9956 | 0.9980 | |
| number of parameters | 819,216 | 24,353,808 | 20,272,144 | 9,197,456 | 4,526,544 | |
| MobileNetV1 | number of trainable layers | 0 | 86 | 46 | 41 | 46 |
| test accuracy | 0.9053 | 0.9968 | 0.9924 | 0.9936 | 0.9996 | |
| number of parameters | 368,656 | 3,575,632 | 3,300,880 | 2,351,024 | 2,864,560 | |
| VGG16 | number of trainable layers | 0 | 19 | 9 | 9 | 6 |
| test accuracy | 0.9568 | 0.9840 | 0.9824 | 0.9928 | 0.9944 | |
| number of parameters | 184,336 | 14,899,024 | 13,163,536 | 7,302,480 | 5,606,608 | |
| Method | Precision | Recall |
|---|---|---|
| Tian, H. [16] | 0.9289 | 0.9292 |
| Proposed Method (MobileNetV1) | 0.9331 | 0.9310 |
| Proposed Method (VGG16) | 0.9451 | 0.9401 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, J.-C.; Yu, G.-H.; Song, M.-G.; Vu, D.T.; Anh, L.H.; Jung, Y.-A.; Choi, Y.-A.; Um, T.-W.; Kim, J.-Y. Selective Layer Tuning and Performance Study of Pre-Trained Models Using Genetic Algorithm. Electronics 2022, 11, 2985. https://doi.org/10.3390/electronics11192985
Jeong J-C, Yu G-H, Song M-G, Vu DT, Anh LH, Jung Y-A, Choi Y-A, Um T-W, Kim J-Y. Selective Layer Tuning and Performance Study of Pre-Trained Models Using Genetic Algorithm. Electronics. 2022; 11(19):2985. https://doi.org/10.3390/electronics11192985
Chicago/Turabian StyleJeong, Jae-Cheol, Gwang-Hyun Yu, Min-Gyu Song, Dang Thanh Vu, Le Hoang Anh, Young-Ae Jung, Yoon-A Choi, Tai-Won Um, and Jin-Young Kim. 2022. "Selective Layer Tuning and Performance Study of Pre-Trained Models Using Genetic Algorithm" Electronics 11, no. 19: 2985. https://doi.org/10.3390/electronics11192985
APA StyleJeong, J.-C., Yu, G.-H., Song, M.-G., Vu, D. T., Anh, L. H., Jung, Y.-A., Choi, Y.-A., Um, T.-W., & Kim, J.-Y. (2022). Selective Layer Tuning and Performance Study of Pre-Trained Models Using Genetic Algorithm. Electronics, 11(19), 2985. https://doi.org/10.3390/electronics11192985