
LPAdaIN: Light Progressive Attention Adaptive Instance Normalization Model for Style Transfer


Abstract
:1. Introduction
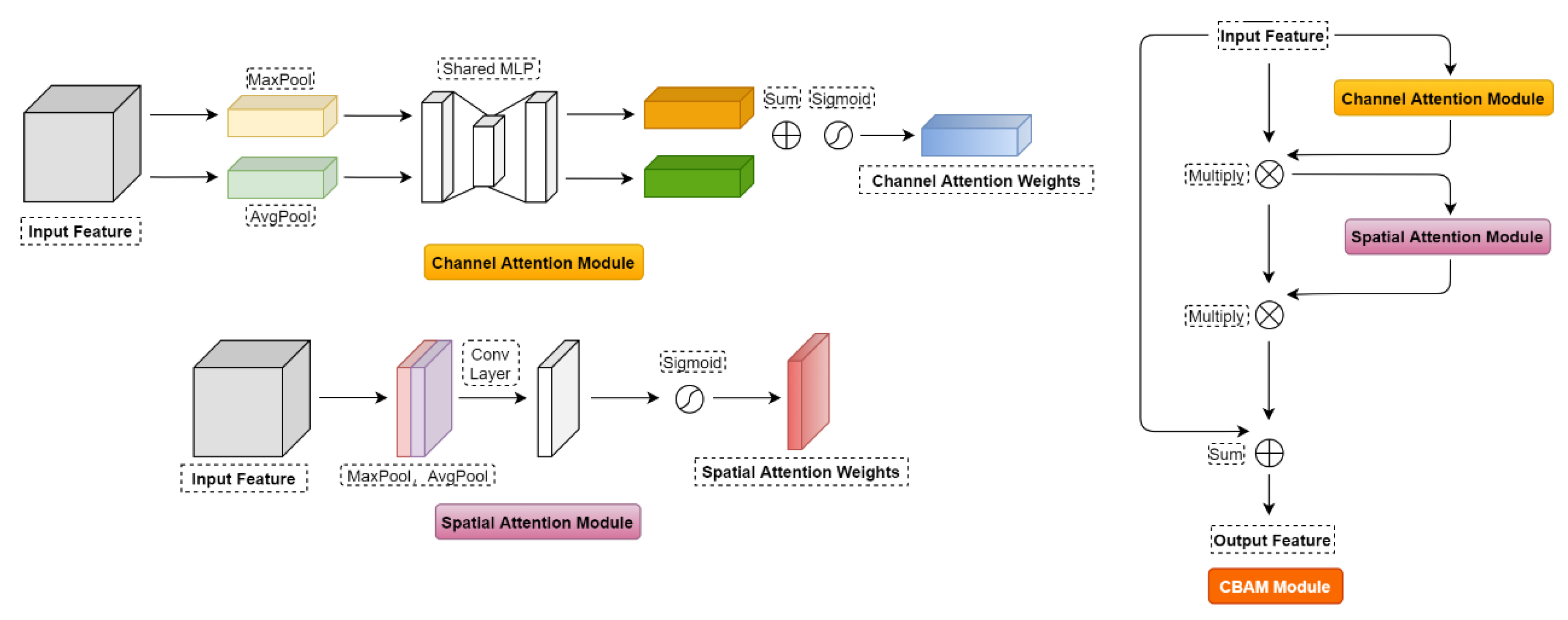
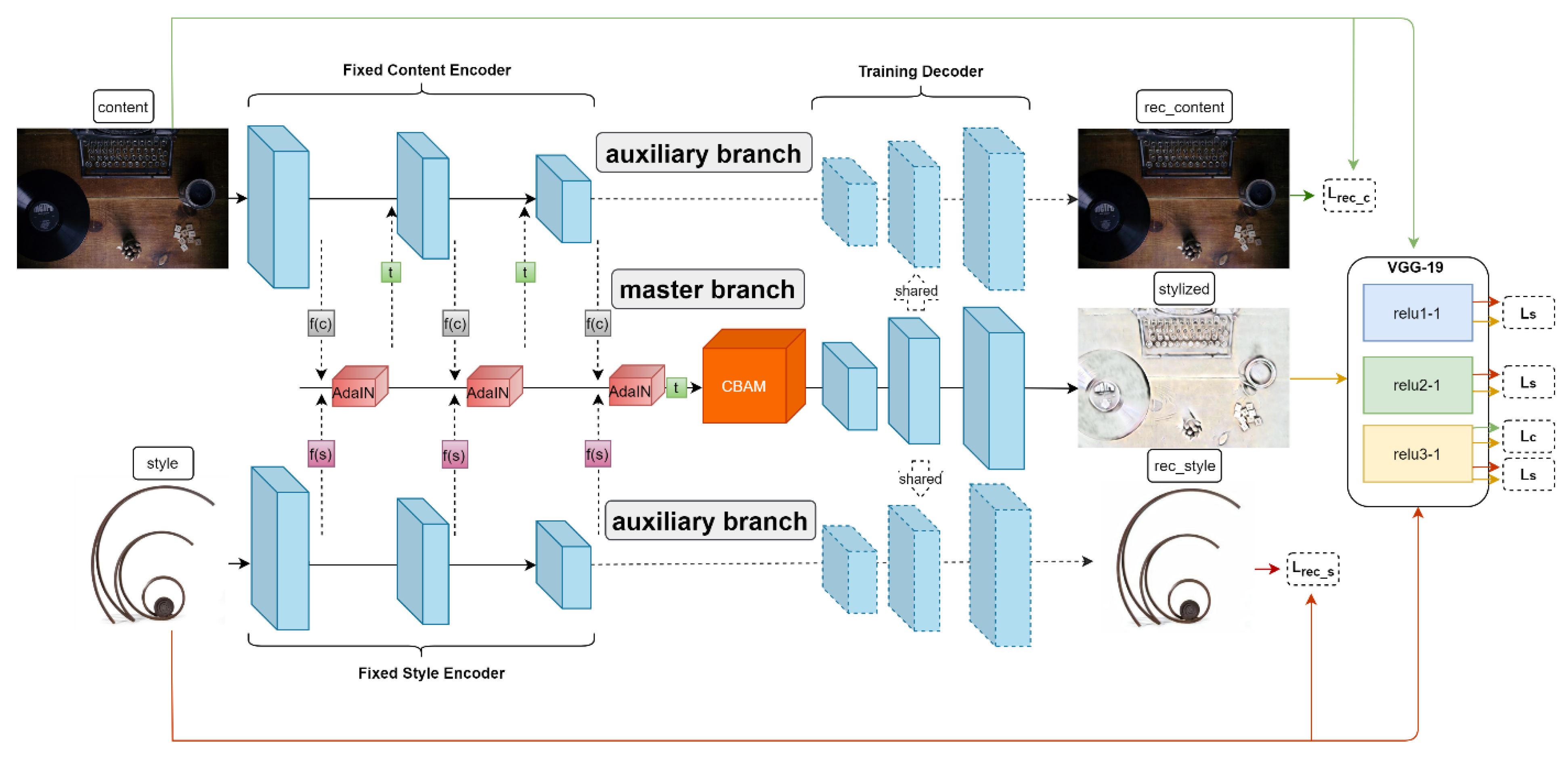
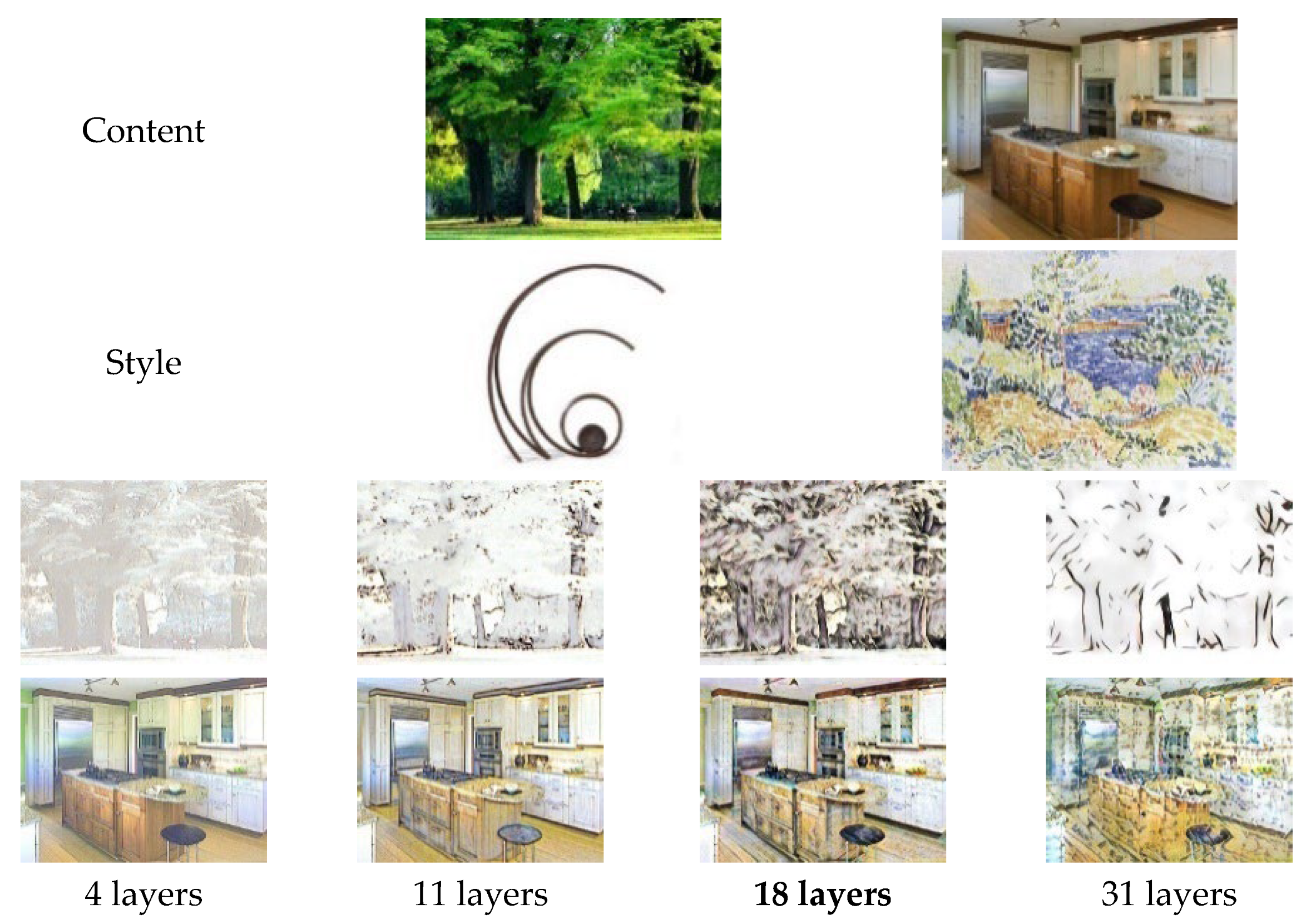
- In the construction of the model structure, first, the influence of different network depths on style transfer effects is compared, and a lightweight autoencoder with shallow network layers and an AdaIN layer is designed as a base style transfer model to improve the running speed of the model and alleviate the distortion of the stylized image structure. Second, the strategy of progressively applying the AdaIN layer is adopted in the master branch to achieve the fully fine-grained transfer of style textures. Third, a CBAM module is embedded before the decoder of the master branch to reduce the loss of important information and ensure that the main objects in the stylized image are clearly visible.
- In the optimization of the model, a new optimization objective named reconstruction loss is proposed. In auxiliary branches, the per-pixel loss on the image is computed in a supervised manner to assist the optimization of the decoder training.
- Experiments and comparisons with other models are provided to demonstrate the validity of the proposed LPAdaIN model. The LPAdaIN achieves better performance in terms of stylized image style texture refinement, the visibility of the main objects, and structure preservation.
2. Preliminary
2.1. Adaptive Instance Normalization Layer
2.2. Attention Mechanism
3. Proposed Method
3.1. Algorithm of the Proposed Method
| Algorithm 1: LPAdaIN Algorithm. |
| Step 1: Input a pair of content image Ic and style image Is Step 2: In Master Branch Step 2.1: for Ic and Is Step 2.1.1: use relu1-1 layer to extract f(c) and f(s), use AdaIN to get t Step 2.1.2: use relu2-1 layer to extract f(c) and f(s), use AdaIN to get t Step 2.1.3: use relu3-1 layer to extract f(c) and f(s), use AdaIN to get t Step 2.1.4: use CBAM to enhance important information Step 2.1.5: feed t to decoder, then get stylized image Ics Step 2.1.6: calculate content loss and style loss, then optimize decoder Step 2.2: end for Step 3: In Auxiliary Branch One Step 3.1: for Ic Step 3.1.1: use relu3-1 layer to extract f(c) Step 3.1.2: feed f(c) to decoder, then get reconstructed content image Ic_rec Step 3.1.3: calculate content reconstruction loss, then optimize decoder Step 3.2: end for Step 4: In Auxiliary Branch Two Step 4.1: for Is Step 4.1.1: use relu3-1 layer to extract f(s) Step 4.1.2: feed f(s) to decoder, then get reconstructed style image Is_rec Step 4.1.3: calculate style reconstruction loss, then optimize decoder Step 4.2: end for Step 5: Output stylized image Ics Step 6: end |
3.2. LPAdaIN Architecture
3.3. Training with Improved Loss Function
4. Experimental Results and Discussion
4.1. Implementation Details
4.2. Results Analysis
4.2.1. Qualitative Evaluations
4.2.2. Quantitative Evaluations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Piscataway, NJ, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Controlling perceptual factors in neural style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3985–3993. [Google Scholar]
- Kolkin, N.; Jason, S.; Gregory, S. Style transfer by relaxed optimal transport and self-similarity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 10051–10060. [Google Scholar]
- Xie, B.; Wang, N.; Fan, Y.W. Correlation alignment total variation model and algorithm for style transfer. J. Image Graph. 2020, 25, 0241–0254. [Google Scholar]
- Nikolai, K.; Jan, D.W.; Konrad, S. In the light of features distributions: Moment matching for neural style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 9382–9391. [Google Scholar]
- Luan, F.J.; Paris, S.; Shechtman, E.; Bala, K. Deep photo style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4990–4998. [Google Scholar]
- Kim, S.S.Y.; Kolkin, N.; Salavon, J.; Shakhnarovich, G. Deformable style transfer. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 246–261. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F.F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Dumoulin, V.; Shlens, J.; Kudlur, M. A learned representation for artistic style. arXiv 2017, arXiv:1610.07629. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Li, Y.; Fang, C.; Yang, J.; Wang, Z.; Lu, X.; Yang, M.H. Universal style transfer via features transforms. In Proceedings of the Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 386–396. [Google Scholar]
- Yao, Y.; Ren, J.Q.; Xie, X.S.; Liu, W.; Liu, Y.J.; Wang, J. Attention-aware multi-stroke style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1467–1475. [Google Scholar]
- Liu, S.H.; Lin, T.W.; He, D.L.; Li, F.; Wang, M.L.; Li, X.; Sun, Z.X.; Li, Q.; Ding, E. Adaattn: Revisit attention mechanism in arbitrary neural style transfer. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 6649–6658. [Google Scholar]
- Shen, Y.; Yang, Q.; Chen, X.P.; Fan, Y.B.; Zhang, H.G.; Wang, L. Structure refinement neural style transfer. J. Electron. Inf. Technol. 2021, 43, 2361–2369. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Peter, S.; Jakob, U.; Ashish, V. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Nichol, K. Painter by Numbers, Wikiart. Available online: https://www.kaggle.com/c/painter-by-numbers/ (accessed on 20 November 2021).
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | The Parameter Number of Each Model |
|---|---|
| CMD | 0 |
| WCT | 34239371 |
| AAMS | 147697771 |
| AdaIN | 7010959 |
| AdaAttn | 33654287 |
| LPAdaIN | 1127058 |
| Models | SSIM(0–1) |
|---|---|
| CMD | 0.521 |
| WCT | 0.286 |
| AAMS | 0.312 |
| AdaIN | 0.351 |
| AdaAttn | 0.457 |
| base | 0.480 |
| base + Progressive | 0.492 |
| base + CBAM | 0.489 |
| base + rec | 0.506 |
| LPAdaIN | 0.523 |
| Models | SSIM(0–1) | PSNR(0–100) |
|---|---|---|
| base | 0.677 | 19.2 |
| base +Progressive | 0.708 | 21.4 |
| base + CBAM | 0.690 | 20.2 |
| base +rec | 0.774 | 25.5 |
| LPAdaIN | 0.787 | 26.5 |
| Models | CMD | WCT | AAMS | AdaIN | AdaAttn | LPAdaIN | |
|---|---|---|---|---|---|---|---|
| Pixel Sizes | |||||||
| 256 × 256 | 14.548 | 0.427 | 0.793 | 0.074 | 0.063 | 0.071 | |
| 512 × 512 | 34.128 | 1.07 | 0.931 | 0.102 | 0.256 | 0.092 | |
| 1024 × 1024 | 104.158 | 3.57 | 1.185 | 0.244 | 1.2 | 0.205 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Q.; Bai, H.; Sun, J.; Cheng, C.; Li, X. LPAdaIN: Light Progressive Attention Adaptive Instance Normalization Model for Style Transfer. Electronics 2022, 11, 2929. https://doi.org/10.3390/electronics11182929
Zhu Q, Bai H, Sun J, Cheng C, Li X. LPAdaIN: Light Progressive Attention Adaptive Instance Normalization Model for Style Transfer. Electronics. 2022; 11(18):2929. https://doi.org/10.3390/electronics11182929
Chicago/Turabian StyleZhu, Qing, Huang Bai, Junmei Sun, Chen Cheng, and Xiumei Li. 2022. "LPAdaIN: Light Progressive Attention Adaptive Instance Normalization Model for Style Transfer" Electronics 11, no. 18: 2929. https://doi.org/10.3390/electronics11182929
APA StyleZhu, Q., Bai, H., Sun, J., Cheng, C., & Li, X. (2022). LPAdaIN: Light Progressive Attention Adaptive Instance Normalization Model for Style Transfer. Electronics, 11(18), 2929. https://doi.org/10.3390/electronics11182929