1. Introduction
The complexity and dynamics of current electronic systems induce a high level of performance uncertainty during field application. Many of these complex systems consist of multiple components/subsystems, and the complexity induces multiple failure/deterioration mechanisms under multiple physical loadings, eventually increasing the performance uncertainties among the individuals [
1,
2]. An LED module is a good example of a complex system. It exhibits a variety of physics because it converts electrical energy to light and heat; it comprises multiple components, including the LED chip, wires, die-bonding material, and substrate. Considering the manufacturing uncertainties and different thermal degradation rates, the light output of the LED module might deviate from the statistical averages [
3,
4]. These biases increase in-service inconsistency and system maintenance costs.
Dragičević et al. [
5] reviewed the recent reliability research regarding power electronics, identifying a paradigm shift toward the design-for-reliability (DfR) approach, and finding that the reliability performance of power devices is always investigated under different thermal loadings, because high temperature plays an important role in many relevant degradation mechanisms. Fan et al. [
6] investigated the long-term reliability of LED packages, using thermal loading as one of the degradation factors. Yazdan et al. [
7] studied the degradation of polymer materials, and correlated its impact to the light/color output of LED modules. Moreover, Lu et al. [
8] further studied the color shift of LED modules. Sun et al. [
9] studied the driver electronics in LED systems.
To facilitate the DfR concept, researchers have developed modeling techniques to predict the average reliability responses from a given set of design and loading parameters for complex electronic systems [
10,
11]. Conventionally, the physics-of-failure concept is always applied. By analyzing the failure/degradation mechanisms in detail, corresponding physical-driven models have been developed for decades [
12]. Due to the interactions between multiple failure/degradation mechanisms, AI-based reliability modeling methods have also been developed [
4]. Zhao et al. [
13] indicated that neural network methods are viable for power electronics because the significant development of computing hardware unleashes the potential of neural network methods in dealing with complex tasks, and the structure of neural networks is flexible enough for performance improvement.
Chou et al. [
14] and Hsiao et al. [
15] proposed deep machine learning modeling methods to replace the expert-driven finite element model. Yuan et al. [
16] applied the long short-term memory (LSTM) method for the solder joint risk assessment of wafer-level chip-scale packaging (WLCSP) with limited datasets. Panigrahy et al. [
17] overviewed the efficiencies and accuracies of the finite element method based on AI-assisted design-on-simulation methods, including artificial neural networks, recurrent neural networks, support-vector regression, kernel ridge regression, k-nearest neighbors, and random forests. Fan et al. [
18] applied neural network architecture to model the spectral power distribution (SPD) of a light source. Yuan et al. [
4] improved this method using a gated network with a two-step learning algorithm to build the empirical relationships between the design parameters, the thermal aging loading, and the SPD of LED products.
The maintenance costs of electronic systems grow as their complexity increases. Due to the uncertainties of the system, the maintenance cost is more than the material and operational costs, but the resource planning, storage, and management should also be included [
19]. The accurate prediction of an in-service electronic system contributes to cost reduction of the system’s maintenance cost. Jin et al. [
20] applied a stochastic model to predict the failures of an in-service electric system by considering the latent failures. Grenyer et al. [
21] reviewed the recent scientific approaches to the uncertainty engineering problem, and identified two major research gaps: the lack of frameworks to aggregate the multivariate uncertainty, and limited approaches to forecasting individual and aggregate uncertainty for complex engineering systems—especially for the in-service phase. Moreover, Grenyer et al. believe that deep learning techniques might contribute to the uncertainty forecast methods.
Li et al. [
22] developed a structure-adjustable online learning neural network for gradually available data, such as in-service data, by applying an adjustable hidden layer to overcome the stability–plasticity dilemma of the online learning. Hu and Du [
23] developed a time-dependent surrogate model with inner and outer loops. Moreover, Hu and Mahadevan [
24] reported that the crossing points did not need to be highly accurate to predict the reliability during their study using the single-loop Kriging surrogate modeling method. Lieu et al. [
25] developed an adaptive surrogate model based on a deep neural network by introducing a threshold to switch from a global prediction to a local one.
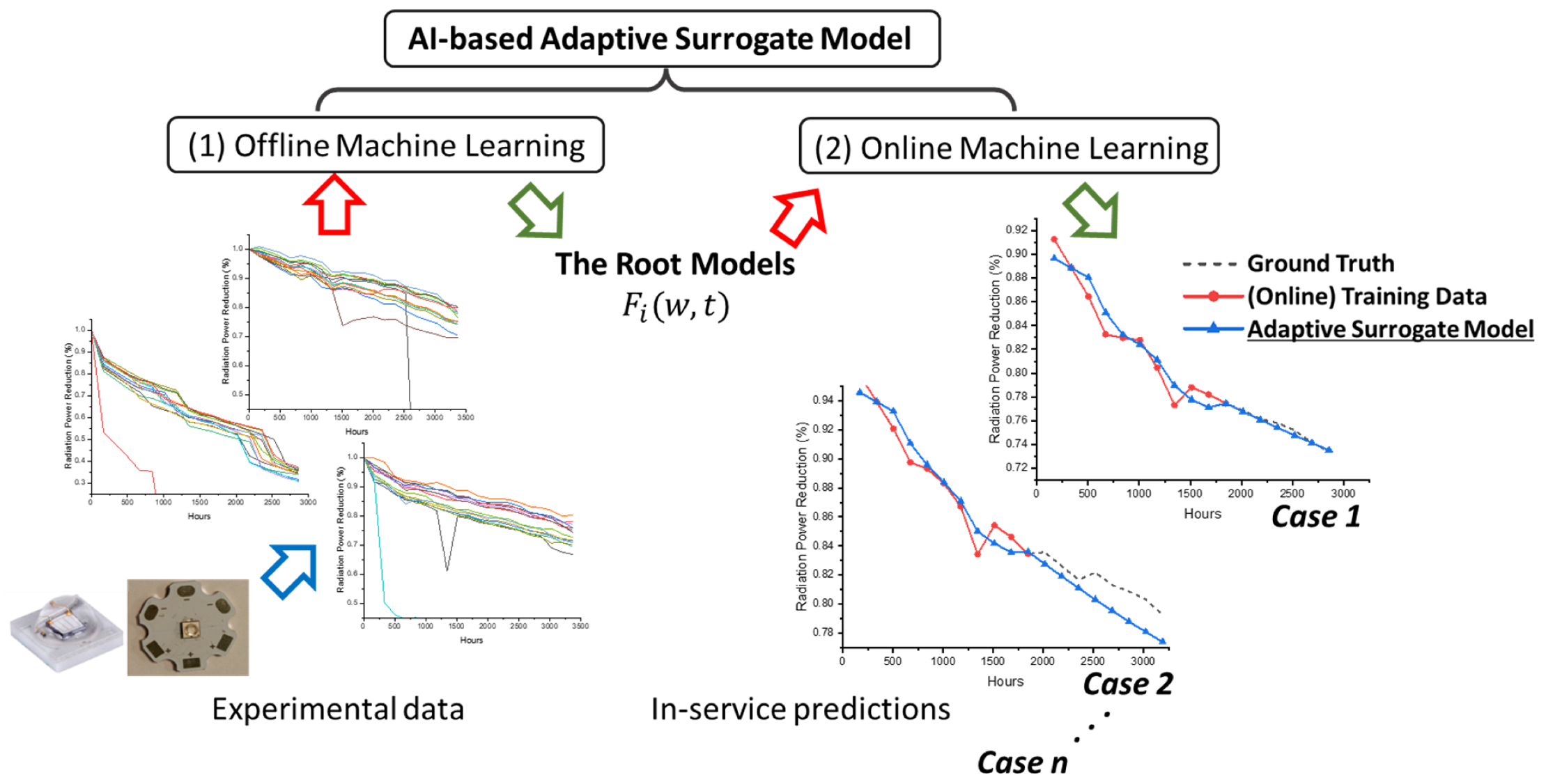
In this research, an AI-based adaptive surrogate modeling method that is able to represent and predict the individual product performance characteristics is established. As indicated in
Figure 1, the hybrid machine learning method comprises offline learning and online learning parts. The experimental information is (partially) provided to the offline machine learning procedure in order to train the root models. Consequently, the same root models are input into the online machine learning to obtain the ASM against different training data. In this research, three sets of direct measurements of the UVLED module were applied to verify this algorithm. With careful definitions of error estimation, the function of offline learning, the predictive capability of the online learning procedure, and the ASM control scheme were analyzed.
This paper is organized as follows: The fundamental scientific issues, field application requirements, and literature review are presented in the first section, “Introduction”. The following section, “Methods”, presents hybrid offline/online machine learning methods for adaptive surrogate models, along with the mathematical definition of the error estimations. The section “UVLED Measurement” describes the test object and the characteristics of the data. The section “Offline/Online Machine Learning” describes the implementation and results of hybrid machine learning. The following section, “Discussion”, discusses the offline/online learning parameters and online learning control scheme to stabilize the learning against the measurement noise. The Conclusions of this paper are presented in the final section.
2. Methods
For an in-service electronic system, the response at time is written as . To emphasize the “future” response of such an in-service electronic system, we defined , where is the current measurement time.
The
can be expressed as a linear combination of several evolved root models, as follows:
where
and
are the weightings and evolved root models that are obtained at time
, respectively. In this study,
represents a neural network, while
and
represent the parameters obtained at time
and the inputs at time
, respectively. This linear combination of evolved root models (Equation (1)) is defined as the adaptive surrogate model (ASM). It should be noted that the root model in this research is defined as a neural network model due to its numerical flexibility and information abstracting ability.
The hybrid machine learning consists of two steps, as illustrated in
Figure 1. The first offline learning contributes to the
, and the collection of
(
corresponds to the root models. By learning the measurement points at
, the weightings
and the evolved root models
are achieved by the subsequent online learning procedure. It should be noted that one set of the root models can, in principle, be the start of several online learning procedures, as illustrated in
Figure 1.
2.1. The Offline Machine Learning
The main purpose of the offline machine learning is to obtain stable and reliable root models. The experimental measurements are categorized into groups to form the training datasets for the offline machine learning, as , where and are the input and output vectors, respectively. The backpropagation-based approaches with optimizers are taken to obtain the optimized weightings against the inputs and time, and form the -th root models .
To reduce the instability of the weightings of the neural-network-based approach, the combination of a genetic algorithm (GA) and the principal component analysis (PCA) framework, as described by Yuan et al. [
26], was implemented. Moreover, the progressing GA optimizer and exponential kernel function for PCA can be expressed as follows:
where
and
are the genes obtained by different GA procedures, and the parameter
is set to 1.
2.2. The Online Machine Learning
The goal of the online machine learning is to obtain the stable weighting
and the evolved root models
. The in-service response
can then be expressed by the linear combination using Equation (1). Since the information obtained at time
is prescribed by the root models, the stability–plasticity dilemma mentioned by Li et al. [
22] can be reduced without complicating the neural network structure.
The online training set at the time is defined as , where is the measured response vector, , and . In this research, balancing between using a large to avoid measurement instability and a small to increase the online machine learning speed, was set to 3.
The ASM weightings— in Equation (1)—are defined as the ratio of the inverse of the online training errors (against ). In each online machine learning step, in the parameters of the neural network , is updated by the machine learning process against . Learning whether will remain at is an option for the online machine learning procedure.
To stabilize the online machine learning, the weighing change ratio is defined as follows:
where
and
are the neural network weighting vectors before and after the online machine learning, respectively, while
and
are the components of the neural network weighting vectors, and
is the component count of the vectors.
2.3. The Definitions of the Predictive Capability
Given a prediction accuracy tolerance
(
), and considering an in-service system at time
, the system response before
is recorded by the hybrid machine learning algorithm into the ASM, but the information after
is unknown. The predictive capability (PC) at
is defined in two ways: First, from the practical point of view, the PC is defined by
, and is an estimation based on the information obtained before
. Define
as the error estimation of the ASM at time
, as
. Define the set
as a collection of
, which satisfies
for
, but
if
. Define the function
as a component counter of a set, and
is defined as follows:
where
is the data measurement period.
On the other hand, to fine-tune the parameters for the hybrid machine learning procedure, one may apply known in-service historical responses. We define the prediction capability as PC from the oracle’s point of view (
). The term “oracle” comes from Greek mythology, and refers to someone able to communicate directly with the gods and give a response or message from the gods to someone else. In the actual application, the prediction at time
(
) can be achieved at time
by the ASM model, but not the prediction accuracy. This is because the actual system reaction at time
is not available. However, in this parameter-tuning stage, the
response can be known by using the historical responses. Therefore, the term “oracle” is applied to obtain a clear distinction between
and
. Define the actual response as
and
as the error estimation of the ASM at time
, which becomes
The
can be defined as follows:
From the application point of view, should be smaller than and as close to as possible, so as to ensure that the prediction is accurate and conservative. It depends on the characteristics of and the online machine learning settings to stabilize the neural network training against and the selection of . The selection of is recommended to refer to the learning performance of the root models against .
3. UVLED Measurement
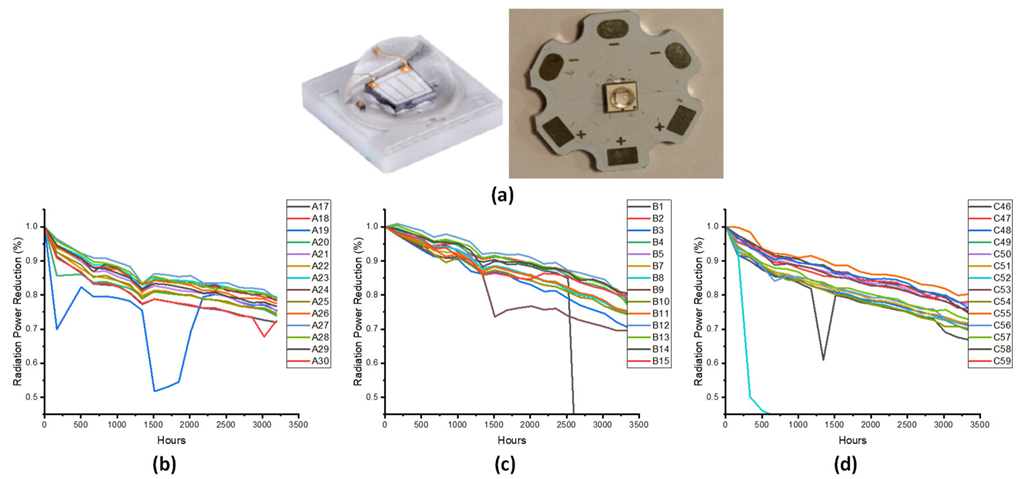
The UVLED packages (left panel of
Figure 2a) were first mounted onto the metal-core printed circuit board (right panel of
Figure 2a). The peak emission wavelength of the test samples ranged from 365 nm to 375 nm, with a rated driving current of 350 mA. Both the constant-stress acceleration degradation and step-stress acceleration degradation tests were implemented by Liang et al. [
27]. Three experiments, with the input currents within the UVLED design range, were selected for this investigation, and are noted as sets A, B, and C.
Table 1 lists the loading conditions of each test set. There were 14 samples in each set and the reliability measurement results, in terms of the radiation power reduction (in %) over time, are plotted in
Figure 2b–d.
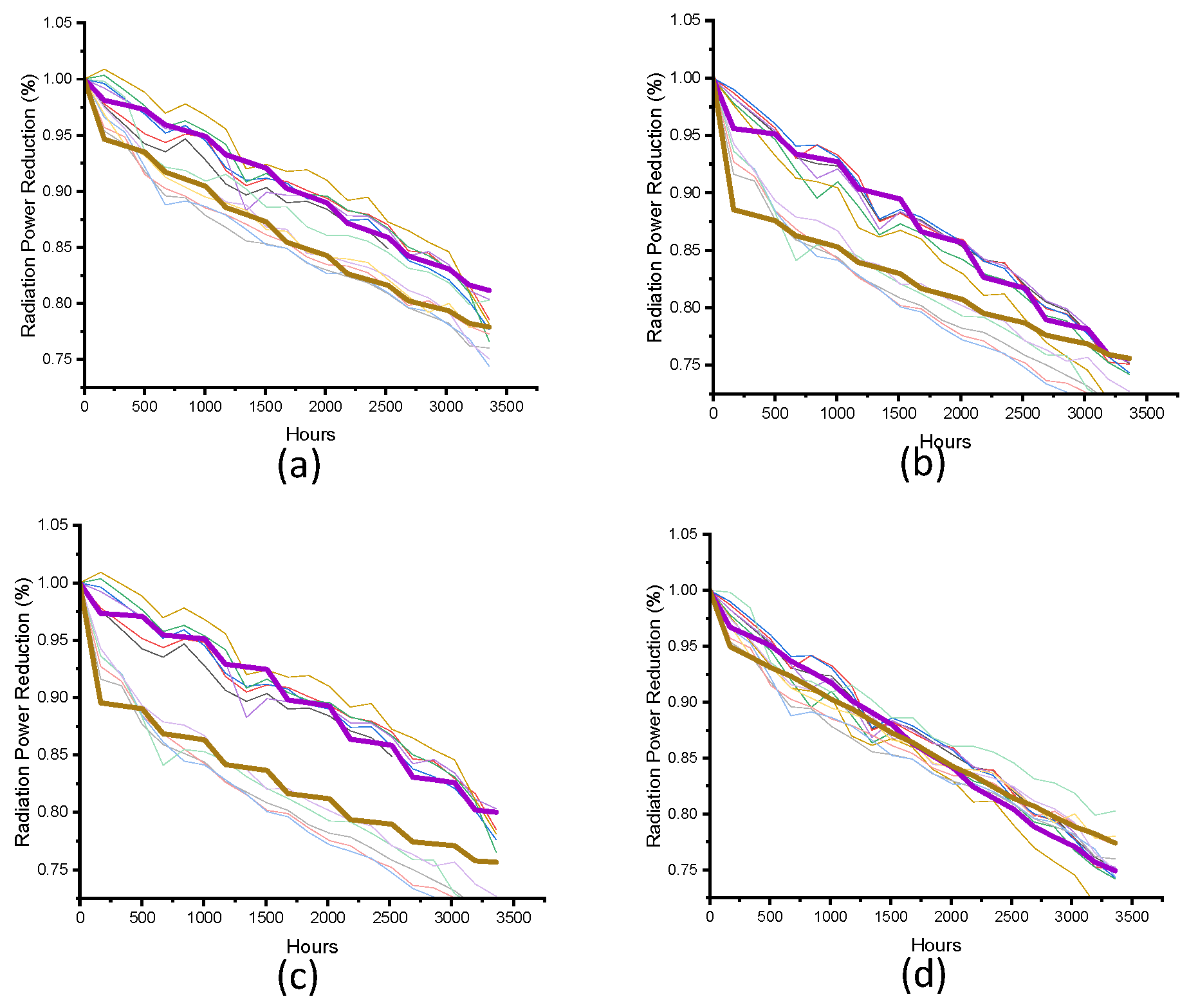
Analyzing the measurement data from
Figure 2b–d, we can first eliminate the statistical outliers, such as A19 of
Figure 2b, B1 and B9 of
Figure 2b, and C46 and C52 of
Figure 2c. The deviation of sets A, B, and C is plotted against time in
Figure 3a–c, respectively. Deviation existed regardless of the constant-stress (set A) or the step-stress tests (sets B and C). The average deviation (i.e., the difference between the maximum and the minimum) over time was 0.0806, 0.0611, and 0.0860 for sets A, B, and C. Since the degradation tests were carried out within a controlled oven and power supplier, and the light output of the UVLED was measured using a calibrated integrated sphere [
27], these deviations indicate that the in-service response of the UVLED system is influenced by the interaction of multiple causes of degradation.
6. Conclusions
In this research, an AI-based hybrid machine learning method, including offline and online machine learning, was developed to obtain an adaptive surrogate model (ASM) for the performance prediction of an in-service complex electronic system. The offline machine learning aims to obtain the root models (i.e., neural network models) based on known experience. Since the root models’ quality impacts the later online learning performance, a genetic algorithm is recommended to obtain a stable root model. The ASM is available through the online learning algorithm against the available measurements, via a liner combination based on Equation (1).
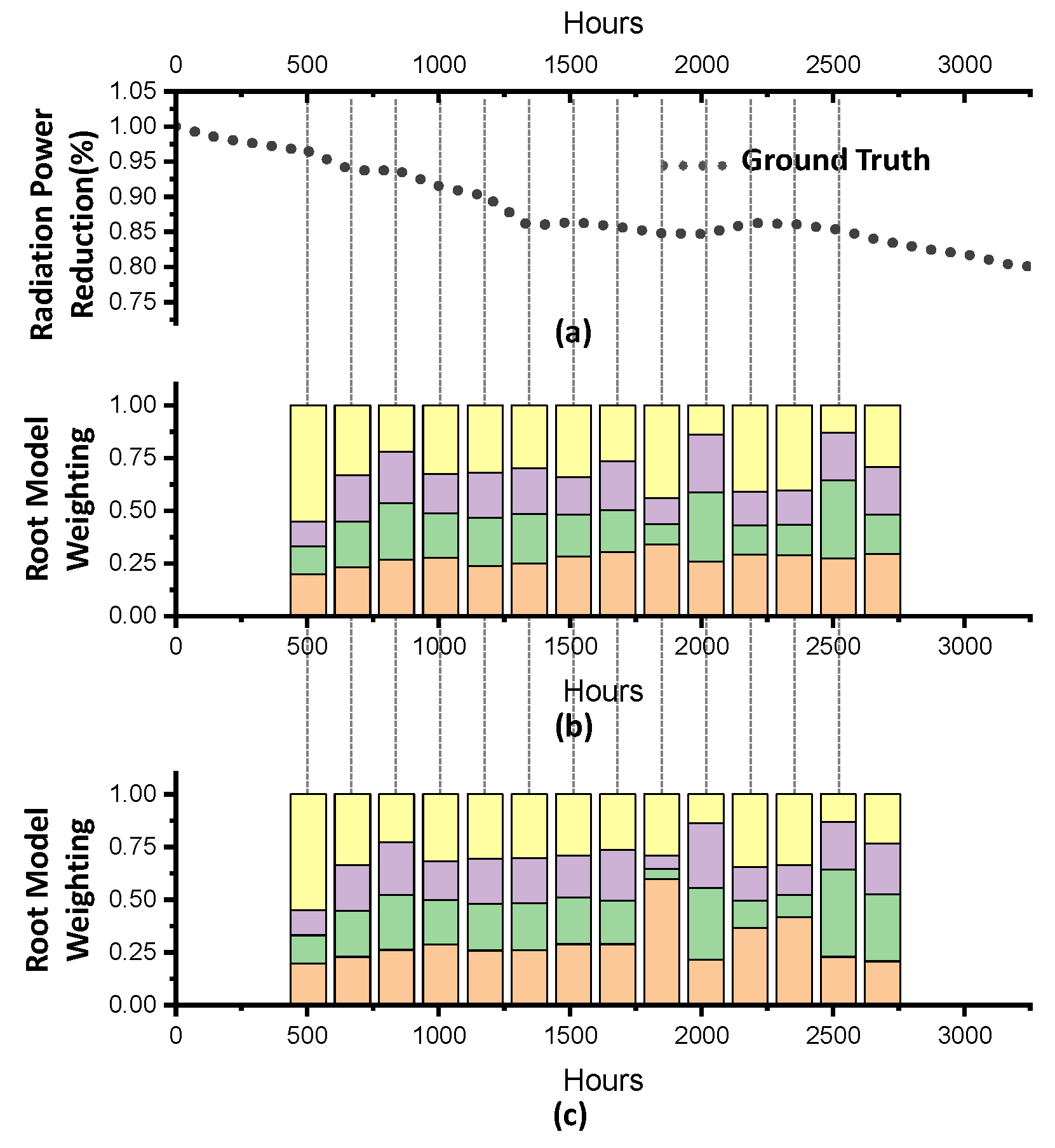
Three sets of UVLED module performance measurements were used for the validation of the hybrid machine learning, with three input parameters, including the case temperature, input current, and time, as well as the output of the radiation power reduction (in %). Via the offline learning, including the genetic algorithm and principle component analysis processes, four root models were obtained, with an error norm of 0.0179, and these four root models were applied for all of the online machine learning.
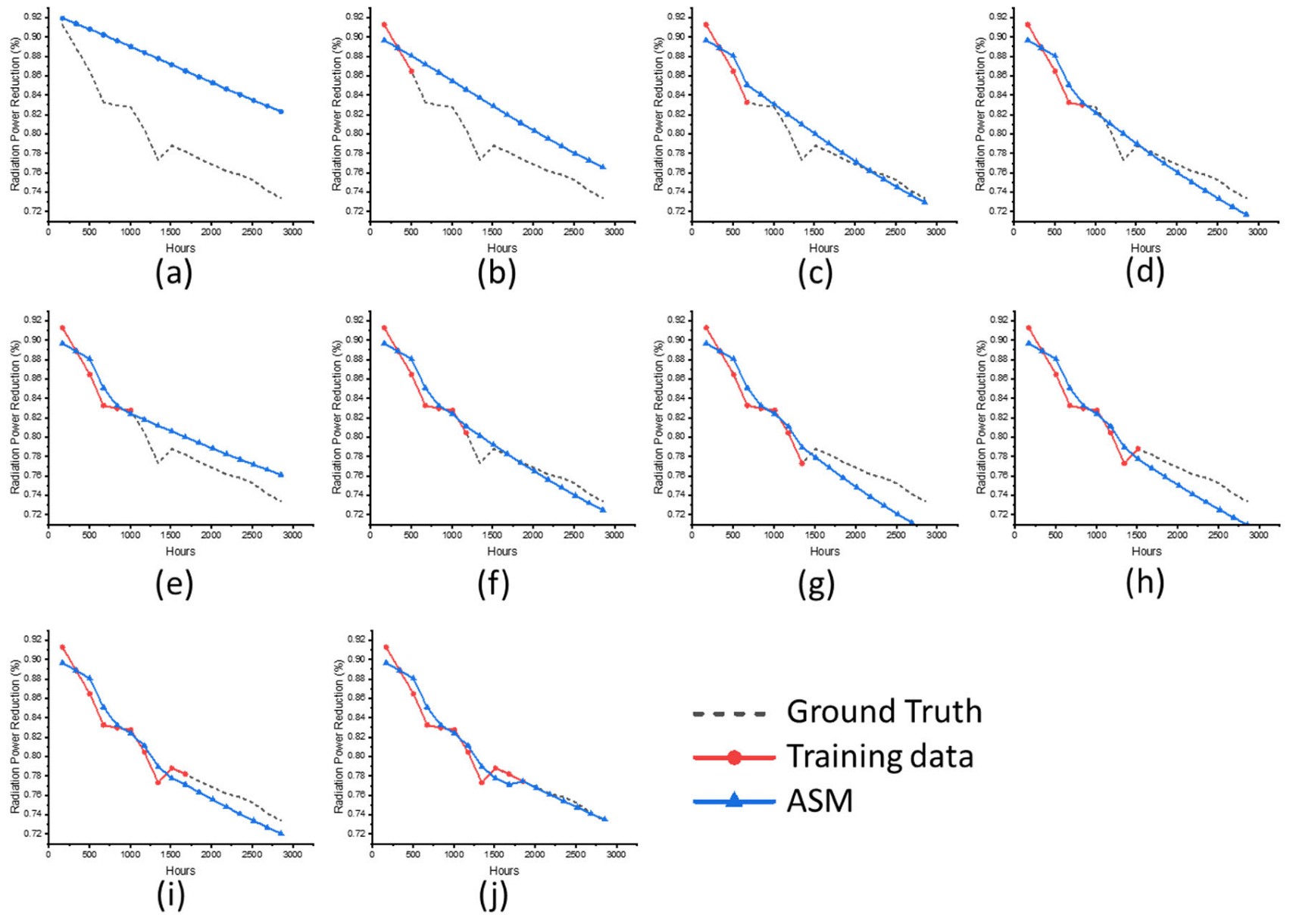
During the online machine learning, three data points are provided to the backpropagation to generate the ASM at each measurement point. The results show that when the measurement data exhibit significant discontinuity, the error of the ASM increases. These errors can be decreased after a few more online learning iterations.
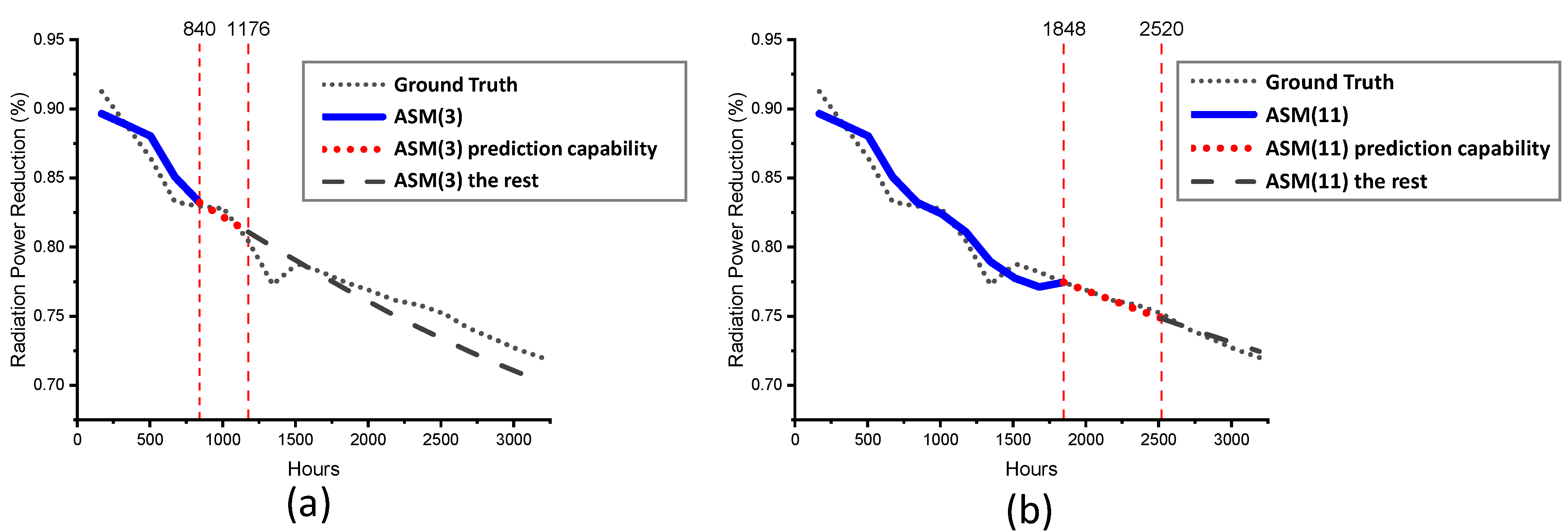
Considering the unavailability of future measurement at the present time, the predictive capabilities from the practical point of view are defined by Equation (4). By defining the error criterion of 0.02, the average difference between the actual capability and the prediction is approximately ( = 168 h), and the definition of the practical predictive capabilities is believed to be reasonable and conservative.
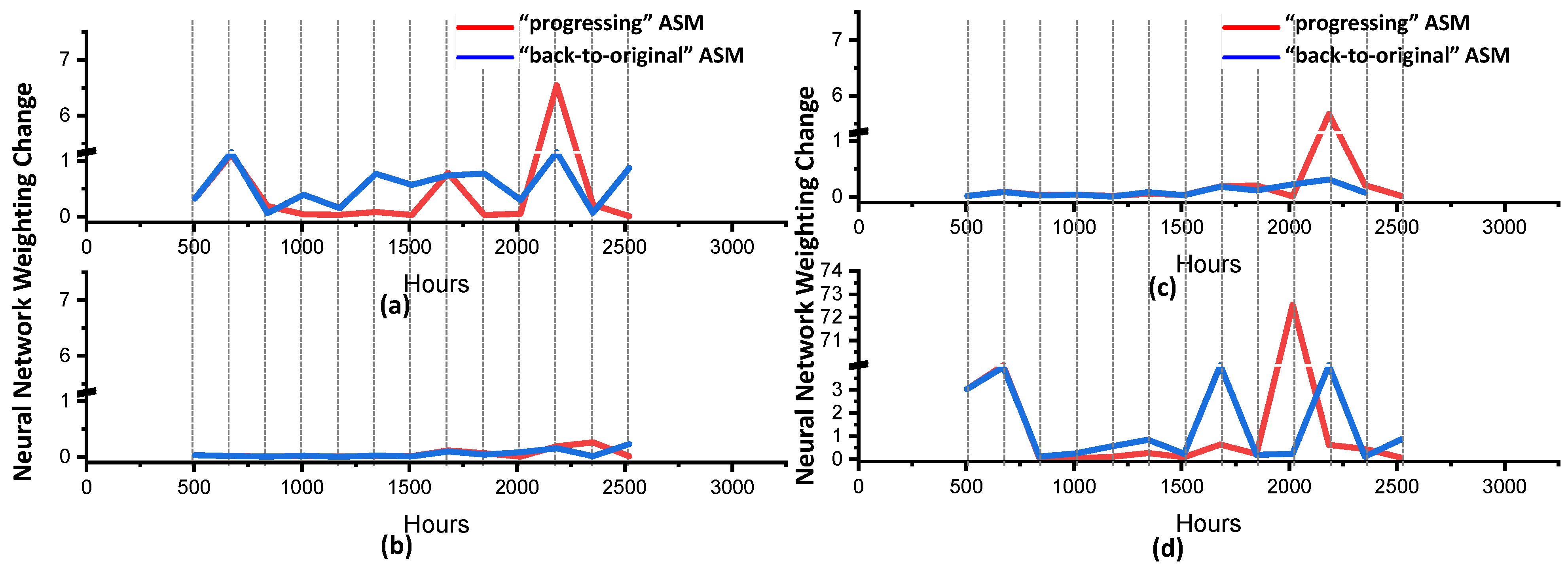
The contribution of the four root models was studied, and their equal importance was detected. To stabilize the online learning, the “back-to-original” and “progressing” approaches were investigated for their stability and sensitivity. The ASMs from both approaches performed with high similarity. However, the weighting change of the evolved root model was stable, and was very sensitive to the changes in the incoming data in the progressing approach. The quality of the root model influences the online learning performance, and more advanced genetic algorithms should be implemented, such as non-dominated sorting genetic algorithms (NSGAs).
In this research, the same four root models were applied to all online learning optimizations. When the loading condition ranges were within the root models, the ASM approached the real response after approximately 9–10 learning iterations (approximately 1500–1800 h), with the real prediction capability of more than ( = 168 h), considering an average response deviation of 0.0760 and a given accuracy requirement of 0.02.
In engineering terms, in this research, the success of the ASM was not intrinsic [
28], but was a combination of many factors, including full coverage of the potential degradation mechanisms through a priori knowledge, flexible and robust root models that obtained via offline learning, and sufficient online learning against reliable real-time measurement. Using the known data, one should fine-tune these offline/online training parameters and validate the accuracy of the ASM to improve its applicability.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}