
Prediction of Highway Blocking Loss Based on Ensemble Learning Fusion Model


Abstract
:1. Introduction
- (1)
- For the missing data in the data set, the missing values are filled in using the same blocking location and similar blocking loss characteristics between adjacent points. For other short character sets with obvious characteristics such as letters, numbers and Chinese characters, one-hot encoding is conducted to overcome the inherent data loss in the blocking event, data set errors and confusion of time logic.
- (2)
- A prediction model of highway blocking loss based on the ensemble learning fusion model is proposed. Using three performance evaluation criteria, the ensemble learning method we designed is compared with three meta-model algorithms, XGBoost, RF regression and SVR, on a data set, and the performance of each model under different learning rates is compared.
- (3)
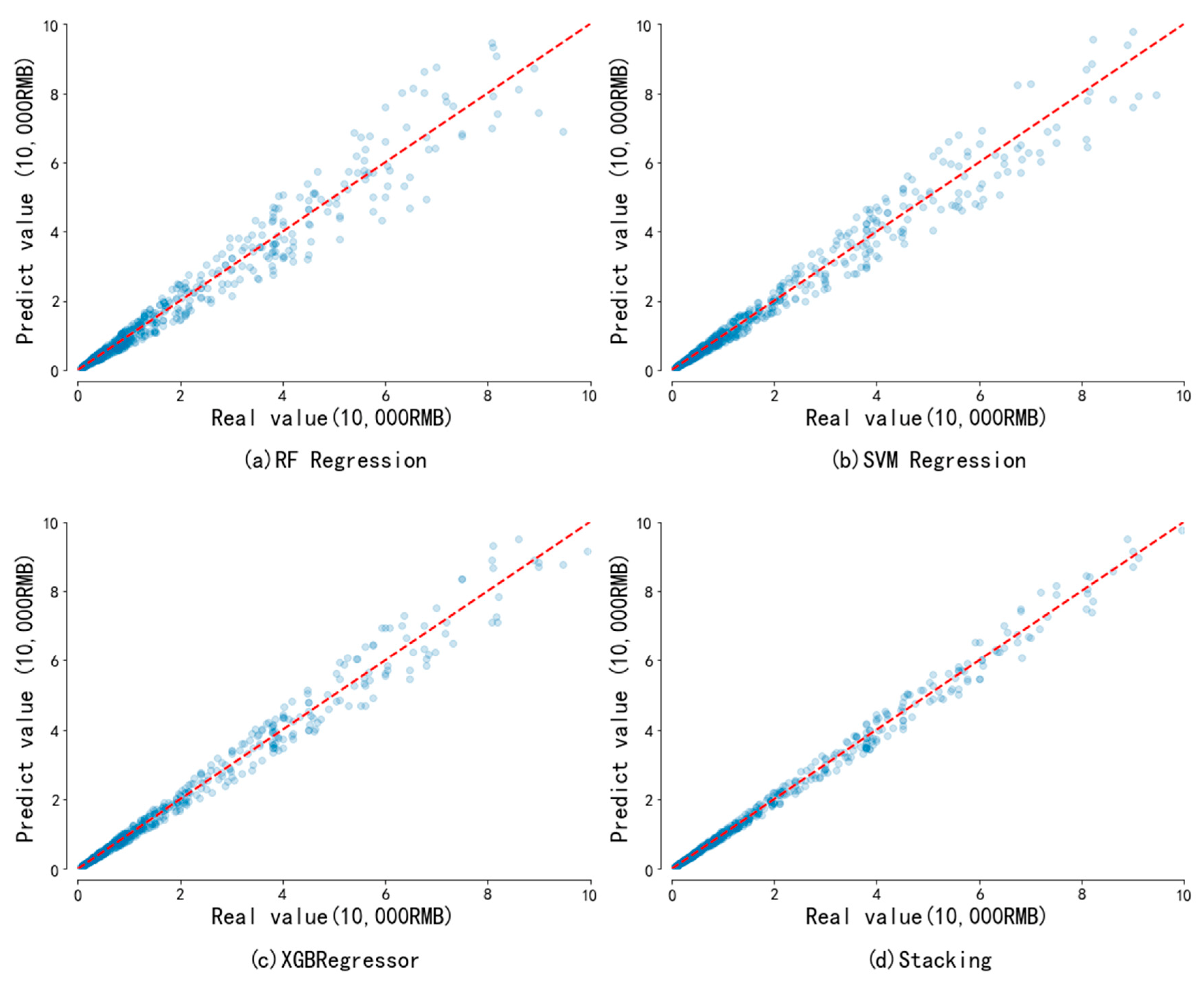
- The test set is used to verify the prediction results of the model. The results show that compared with the three meta-models, RF regression, SVR and XGBoost, the R2 value predicted by the stacking fusion model reaches 0.91. The stacking fusion model proposed in this paper has high prediction accuracy, which provides an intelligent prediction method for the loss prediction of highway blocking events.
2. Related Works
2.1. XGBoost
2.2. RF Regression
2.3. SVR
2.4. Prediction Model of Highway Blocking Loss Based on Ensemble Learning
3. Data Preprocessing
3.1. Data Description
3.2. Data Cleaning
3.3. Data Processing
- (1)
- Route numbers, such as G213, S304 and “Yuanmeng xian”, have obvious characteristics of letters, numbers and Chinese characters. They are short character sets and unstructured languages with noise. After unifying the data format, they are processed by one-hot encoding. It transforms the language used by human communication into machine language that can be understood by machines.
- (2)
- The characteristics of starting point stake number and ending point stake number have great relevance to the prediction of the loss amount in this paper. Firstly, the stake number can be used as information to determine the exact location of the event, that is, somewhere on the road. In addition, the road mileage affected by an accident can be calculated by combining the starting point and ending point.
- (3)
- For the interruption time and recovery time, the day of month method is used for timestamp, which will generate a series of hour numbers. The corresponding hour information data (integer from 0 to 23) can be subtracted to obtain the blocking time.
- (4)
- The text description information of emergency repair measures in the data is very different, but after sorting, it can be divided into three categories: manual processing, mechanical and man-machine cooperation. Therefore, the method of assigning weight is adopted for processing. After assigning weight, it is input with numerical characteristics.
- (5)
- The place and quantity of landslides caused by the event can be input using the one-hot coding and number of cubic meters, respectively.
- (6)
- Blocking reason is used to specifically describe the causes of highway blocking events. This feature requires manual classification of data into snow disasters, debris flow, landslides, collapses, rolling stones and other types of disasters. The loss amount (10,000 RMB/1459 USD) is used as the predicted value. All the data samples are preprocessed to obtain the training set.
4. Results and Analysis
4.1. Evaluating Indicators
4.2. Model Training
4.3. Experimental Result
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Y.; Ma, Z.; Pan, Z.; Liu, N.; You, X. Prophet model and Gaussian process regression based on user traffic prediction in wireless networks. Sci. China Inf. Sci. 2020, 63, 207–214. [Google Scholar] [CrossRef]
- Hofleitner, A.; Herring, R.; Abbeel, P.; Bayen, A. Learning the Dynamics of Arterial Traffic From Probe Data Using a Dynamic Bayesian Network. Ieee Trans. Intell. Transp. Syst. 2012, 13, 1679–1693. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, L. Vehicle actuation based short-term traffic flow prediction model for signalized intersections. J. Cent. South Univ. 2012, 19, 287–298. [Google Scholar] [CrossRef]
- Lin, P.; Xia, Y.; Zhou, C. Freeway travel time prediction based on spatial temporal characteristics of road networks. J. South China Univ. Technol. Nat. Sci. Ed. 2021, 49, 1–11. [Google Scholar]
- Zhao, S.; Zhang, B. Traffic flow prediction of urban road network based on LSTM-RF model. J. Meas. Sci. Instrum. 2020, 11, 135–142. [Google Scholar]
- Tian, Y.; Zhang, K.; Li, J.; Lin, X.; Yang, B. LSTM-based Traffic Flow Prediction with Missing Data. Neurocomputing 2018, 318, 297–305. [Google Scholar] [CrossRef]
- Li, Y.; Ren, C.; Zhao, H.; Chen, G. Investigating long-term vehicle speed prediction based on GA-BP algorithms and the road-traffic environment. Sci. China Inf. Sci. 2020, 63, 121–123. [Google Scholar] [CrossRef]
- Nantes, A.; Ngoduy, D.; Bhaskar, A.; Miska, M.; Chung, E. Real-time traffic state estimation in urban corridors from heterogeneous data. Transp. Res. Part C Emerg. Technol. 2016, 66, 99–118. [Google Scholar] [CrossRef]
- Nanthawichit, C.; Nakatsuji, T.; Suzuki, H. Application of Probe-Vehicle Data for Real-Time Traffic-State Estimation and Short-Term Travel-Time Prediction on a Freeway. Transp. Res. Rec. J. Transp. Res. Board 2003, 1855, 49–59. [Google Scholar] [CrossRef]
- Zhang, L.; Alharbe, N.R.; Luo, G.; Yao, Z.; Li, Y. A Hybrid Forecasting Framework Based on Support Vector Regression with a Modified Genetic Algorithm and a Random Forest for Traffic Flow Prediction. Tsinghua Sci. Technol. 2018, 23, 479–492. [Google Scholar] [CrossRef]
- Li, Y.; Liu, G.; Cheng, Y.; Wu, J.; Xiong, Y.; Ma, R.; Wang, Y. Application of Artificial Intelligence Technology in Traffic Flow Forecast. J. Phys. Conf. Ser. 2021, 1852, 022076. [Google Scholar] [CrossRef]
- Xi, H.; Dai, X.; Qi, Y. Improved k-nearest neighbor algorithm for short-term traffic flow forecasting. J. Transp. Eng. 2014, 14, 87–94. [Google Scholar]
- Allström, A.; Ekström, J.; Gundlegård, D.; Ringdahl, R.; Rydergren, C.; Bayen, A.M.; Patire, A.D. Hybrid Approach for Short-Term Traffic State and Travel Time Prediction on Highways. Transp. Res. Rec. J. Transp. Res. Board 2016, 2554, 60–68. [Google Scholar] [CrossRef] [Green Version]
- Xin-yue, X.U.; Yu-hang, W.U.; Ying-nan, Z.H.A.N.G.; Xue-qin, W.A.N.G.; Jun, L.I.U. Short-term passenger flow forecasting method of rail transit under station closure considering spatio-temporal modification. J. Transp. Eng. 2021, 21, 251–264. [Google Scholar]
- Fusco, G.; Colombaroni, C.; Comelli, L.; Isaenko, N. Short-term traffic predictions on large urban traffic networks: Applications of network-based machine learning models and dynamic traffic assignment models. In Proceedings of the 2015 International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS), Budapest, Hungary, 3–5 June 2015. [Google Scholar]
- Seng, D.; Lv, F.; Liang, Z.; Shi, X.; Fang, Q. Forecasting traffic flows in irregular regions with multi-graph convolutional network and gated recurrent unit. Front. Inf. Technol. Electron. Eng. 2021, 22, 1179–1193. [Google Scholar] [CrossRef]
- Hashemi, H.; Abdelghany, K.F. Real-time traffic network state estimation and prediction with decision support capabilities: Application to integrated corridor management. Transp. Res. Part C 2016, 73, 128–146. [Google Scholar] [CrossRef]
- Pu, L.Y.U.; Qiang, B.A.I.; Lin, C.H.E.N. A model predicting the severity of accidents on mountainous expressways based on inverted residuals and attention mechanisms. Chin. J. Highw. 2021, 34, 205–213. [Google Scholar]
- Kampffmeyer, M.; Salberg, A.B.; Jenssen, R. Semantic Segmentation of Small Objects and Modeling of Uncertainty in Urban Remote Sensing Images Using Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Zhao, H.; Li, X.; Cheng, H.; Zhang, J.; Wang, Q.; Zhu, H. Deep Learning-Based Prediction of Traffic Accidents Risk for Internet of Vehicles. China Commun. 2022, 19, 214–224. [Google Scholar] [CrossRef]
- Jiang, W.; Zhang, L. Geospatial Data to Images: A Deep-Learning Framework for Traffic Forecasting. Tsinghua Sci. Technol. 2019, 24, 52–64. [Google Scholar] [CrossRef]
- Luo, H.; Cai, J.; Zhang, K.; Xie, R.; Zheng, L. A multi-task deep learning model for short-term taxi demand forecasting considering spatiotemporal dependences. J. Traffic Transp. Eng. Engl. Ed. 2021, 8, 83–94. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. Int. Conf. Mach. Learn. 2015, 37, 448–456. [Google Scholar]
- Yang, W.; Zhang, Z.; Wushouer, S.; Wen, J.; Fu, Y.; Wang, L.; Wang, T. GBRT traffic accident prediction model based on time series relationship. J. Univ. Electron. Sci. Technol. 2020, 49, 615–621. [Google Scholar]
- Wang, S.; Li, R.; Guo, M. Application of nonparametric regression in predicting traffic incident duration. Transport 2015, 33, 22–31. [Google Scholar] [CrossRef]
- Oh, S.; Byon, Y.J.; Yeo, H. Improvement of Search Strategy With K-Nearest Neighbors Approach for Traffic State Prediction. Ieee Trans. Intell. Transp. Syst. 2016, 17, 1146–1156. [Google Scholar] [CrossRef]
- Li, Y.; Chen, M.; Lu, X.; Zhao, W. Research on optimized GA-SVM vehicle speed prediction model based on driver-vehicle-road-traffic system. Sci. China Technol. Sci. 2018, 61, 782–790. [Google Scholar] [CrossRef]
- Li, R.; Huang, Y.; Wang, J. Long-term Traffic Volume Prediction Based on K-means Gaussian Interval Type-2 Fuzzy Sets. IEEE/CAA J. Autom. Sin. 2019, 6, 1344–1351. [Google Scholar] [CrossRef]
- Nabian, M.A.; Meidani, H. Deep Learning for Accelerated Seismic Reliability Analysis of Transportation Networks. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 443–458. [Google Scholar] [CrossRef] [Green Version]
- Singh, S.; Hoiem, D.; Forsyth, D. Swapout: Learning an ensemble of deep architectures. Adv. Neural Inf. Process. Syst. 2016, 29, 28–36. [Google Scholar]
- Dietterich, T.G. Ensemble Methods in Machine Learning. proc international workshgp on multiple classifier systems. In International Workshop on Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. Comput. Sci. 2014. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Z.; Vu, H.L.; Lyu, C. A spatio-temporal ensemble method for largescale traffic state prediction. Comput. Aided Civ. Inf. 2020, 35, 26–44. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Z.; Lyu, C.; Ye, J. Attention-Based Deep Ensemble Net for Large-Scale Online Taxi-Hailing Demand Prediction. Ieee Trans. Intell. Transp. Syst. 2020, 21, 4798–4807. [Google Scholar] [CrossRef]
- Guzman, E.; EL-haliby, M.; Bruegge, B. Ensemble Methods for App Review Classification: An Approach for Software Evolution (N). In Proceedings of the IEEE/ACM International Conference on Automated Software Engineering, Lincoln, NE, USA, 9–13 November 2015. [Google Scholar]
- Li, G.; Guo, M.; Luo, Y. Traffic congestion identification of air route network segment based on ensemble learning algorithms. Transp. Syst. Eng. Inf. 2020, 20, 166–173. [Google Scholar]
- Hu, J.; He, C.; Zhu, X.-l.; Yang, G.-y. Prediction remaining useful life of electric vehicle battery based on real vehicle data. Transp. Syst. Eng. Inf. 2022, 22, 292–300. [Google Scholar]
- Thomas, P.; Neves, M.; Solt, I.; Tikk, D.; Leser, U. Relation extraction for drug-drug interactions using ensemble learning. Training 2011, 4, 402–425. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Route Number | Starting Point Stake | Ending Point Stake | Blocking Reason | Blocking Time | Recovery Time | Emergency Repair Measures | Number of Collapse Sites | Number of Landslides | Loss Amount |
|---|---|---|---|---|---|---|---|---|---|
| S101 | K183 + 580 | K183 + 640 | Slope collapse | 24 June 2014 10:00 | 24 June 2014 16:00 | 1 | 1 | 40.0 | 0.16 |
| S237 | K139 + 287 | K139 + 307 | Debris flow | 6 April 2016 4:30 | 6 April 2016 9:30 | 3 | 1 | 400 | 0.32 |
| G213 | K148 + 758 | K158 + 758 | Snowstorm | 8 February 2018 15:40 | 9 February 2018 20:10 | 3 | 1 | 83,965 | 83.97 |
| Features | Missing Values | Percent of Total Values (%) |
|---|---|---|
| Stop station | 104 | 3.3 |
| Blocking reason | 34 | 1.1 |
| State and city | 28 | 0.9 |
| County (township) | 27 | 0.9 |
| Parameter | Explanation | Distribution |
|---|---|---|
| N-estimators | Number of trees | [50, 1050] |
| Ref-lambda | Λ | [0, 10] |
| Min-split-loss | Γ | [0, 1] |
| Subsample | Subsample ratio | [0.3, 1] |
| Learning-rate | Step size shrinkage | [0.02, 0.1] |
| Learning Rate | RMSE | ||||
|---|---|---|---|---|---|
| XGBoost | RF | SVR | Directly Weighted Models | Stacking | |
| 0.02 | 0.2935 | 0.4745 | 0.3753 | 0.3811 | 0.2796 |
| 0.03 | 0.2865 | 0.4119 | 0.3589 | 0.3524 | 0.2681 |
| 0.04 | 0.2784 | 0.4555 | 0.3124 | 0.3488 | 0.1809 |
| 0.05 | 0.2571 | 0.4762 | 0.2931 | 0.3421 | 0.1707 |
| 0.06 | 0.2822 | 0.4718 | 0.2705 | 0.3415 | 0.2136 |
| 0.07 | 0.3391 | 0.4821 | 0.2979 | 0.3730 | 0.2479 |
| 0.08 | 0.3522 | 0.4936 | 0.3794 | 0.4084 | 0.2874 |
| 0.09 | 0.3345 | 0.5148 | 0.4211 | 0.4235 | 0.3115 |
| 0.10 | 0.4665 | 0.5682 | 0.4778 | 0.5042 | 0.3452 |
| Learning Rate | MAE | ||||
|---|---|---|---|---|---|
| XGBoost | RF | SVR | Directly Weighted Models | Stacking | |
| 0.02 | 0.0507 | 0.0749 | 0.0555 | 0.0604 | 0.0355 |
| 0.03 | 0.0513 | 0.0736 | 0.0544 | 0.0598 | 0.0443 |
| 0.04 | 0.0494 | 0.0791 | 0.0551 | 0.0612 | 0.0471 |
| 0.05 | 0.0491 | 0.0911 | 0.0577 | 0.0660 | 0.0341 |
| 0.06 | 0.0521 | 0.0846 | 0.0541 | 0.0636 | 0.0361 |
| 0.07 | 0.0617 | 0.0877 | 0.0602 | 0.0699 | 0.0576 |
| 0.08 | 0.0551 | 0.0879 | 0.0671 | 0.0700 | 0.0554 |
| 0.09 | 0.0573 | 0.0882 | 0.0814 | 0.0756 | 0.0617 |
| 0.10 | 0.0773 | 0.0976 | 0.0942 | 0.0897 | 0.0665 |
| Method | RMSE | MAE | R2 |
|---|---|---|---|
| XGBoost | 0.2571 | 0.0491 | 0.86 |
| RF | 0.4119 | 0.0736 | 0.77 |
| SVR | 0.2705 | 0.0541 | 0.82 |
| Directly weights models | 0.3415 | 0.0598 | 0.82 |
| Stacking | 0.1707 | 0.0341 | 0.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, H.; Zhang, J.; Zhang, J.; Li, Y. Prediction of Highway Blocking Loss Based on Ensemble Learning Fusion Model. Electronics 2022, 11, 2792. https://doi.org/10.3390/electronics11172792
Guo H, Zhang J, Zhang J, Li Y. Prediction of Highway Blocking Loss Based on Ensemble Learning Fusion Model. Electronics. 2022; 11(17):2792. https://doi.org/10.3390/electronics11172792
Chicago/Turabian StyleGuo, Honglie, Jiahong Zhang, Jing Zhang, and Yingna Li. 2022. "Prediction of Highway Blocking Loss Based on Ensemble Learning Fusion Model" Electronics 11, no. 17: 2792. https://doi.org/10.3390/electronics11172792
APA StyleGuo, H., Zhang, J., Zhang, J., & Li, Y. (2022). Prediction of Highway Blocking Loss Based on Ensemble Learning Fusion Model. Electronics, 11(17), 2792. https://doi.org/10.3390/electronics11172792