


Group Class Residual ℓ1-Minimization on Random Projection Sparse Representation Classifier for Face Recognition

 ,
,  , and
, and
Abstract
:1. Introduction
2. Literature Review
3. Background of Our Algorithm
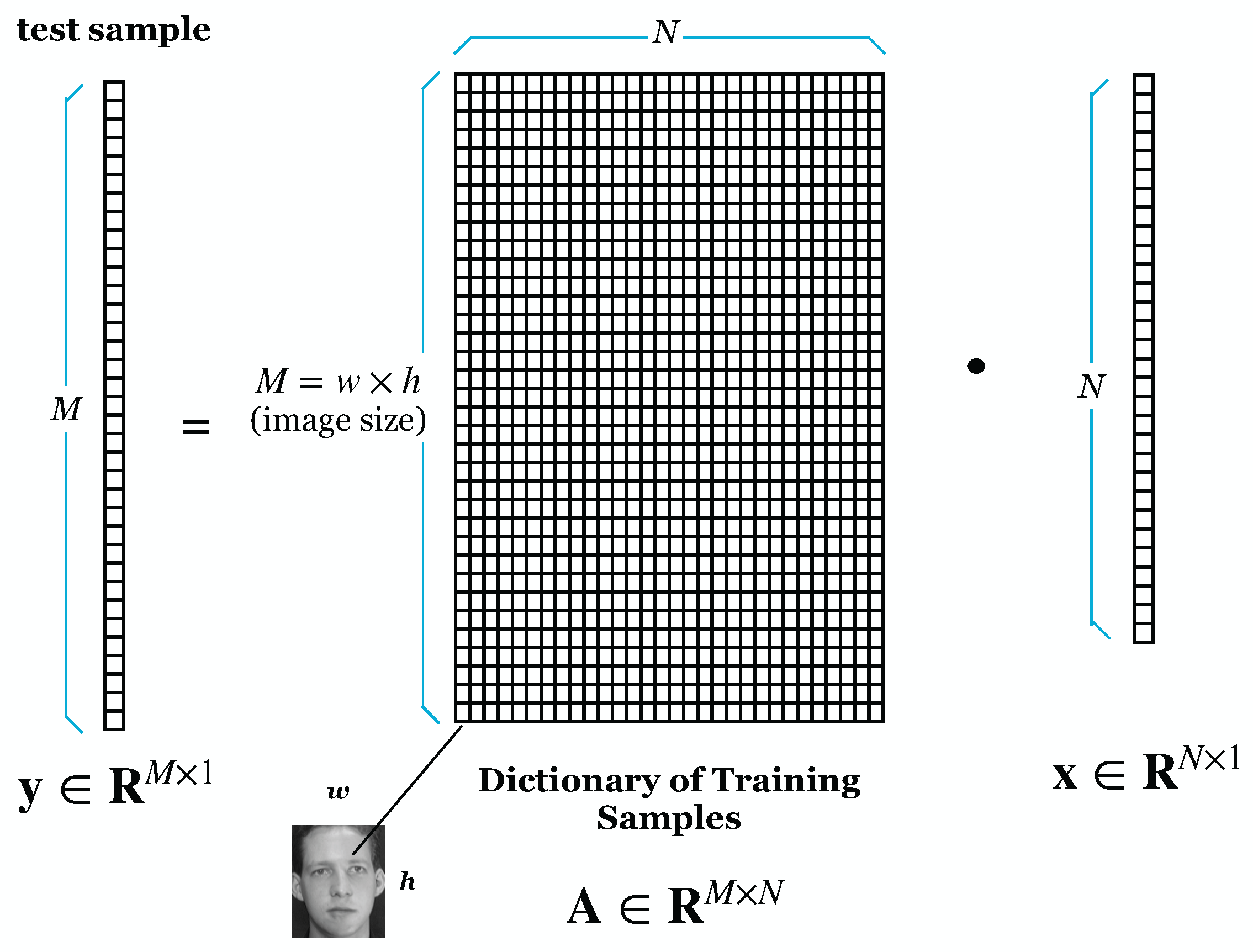
3.1. Sparse Representation-Based Classification
3.2. Coherency Principles
4. Proposed Algorithm
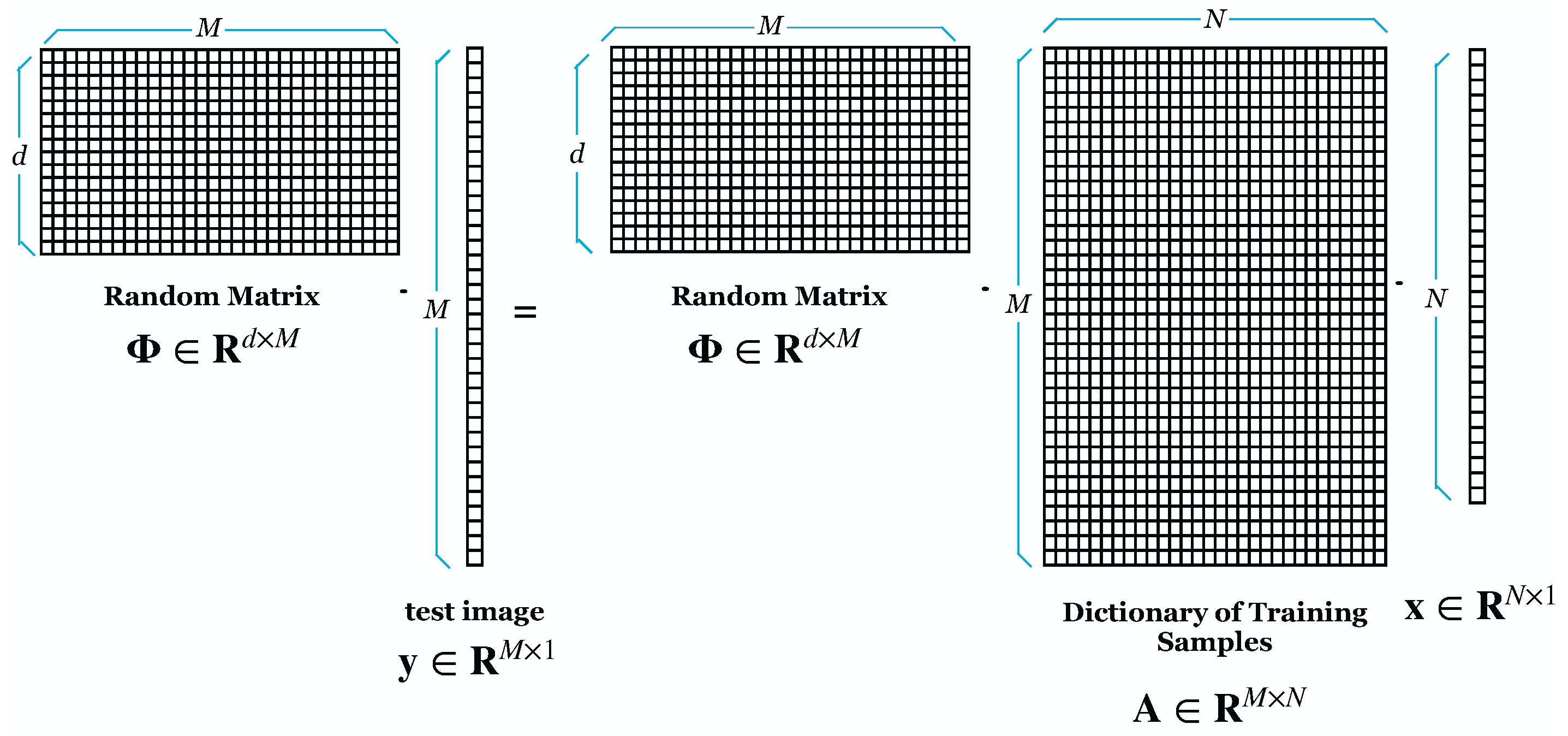
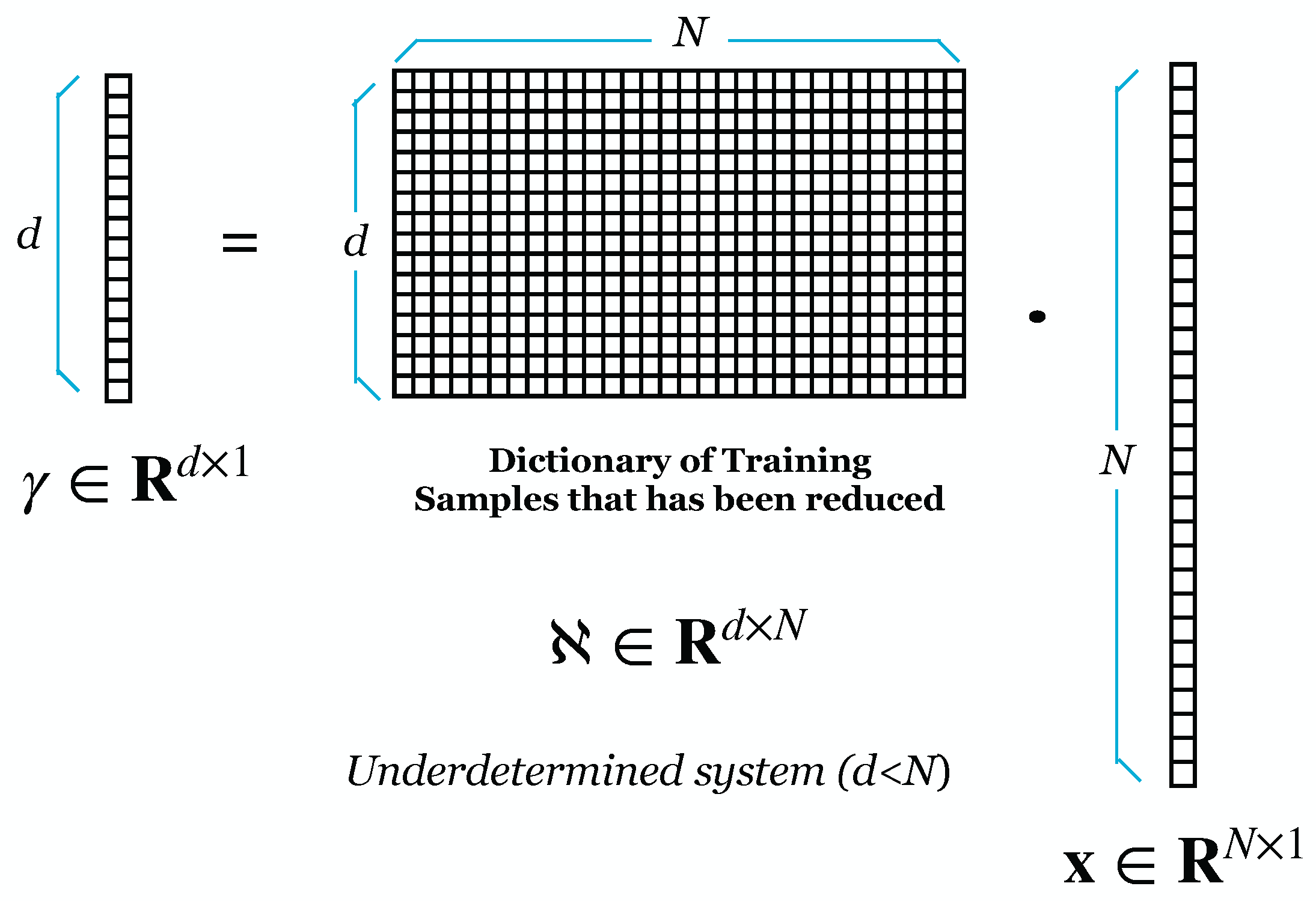
4.1. Dimensionality Reduction Using Random Projection
| Algorithm 1: Algorithm for RP-SRC |
|
Input: a matrix of training samples for c classes. a test sample (and optional error tolerance ) Output: class
(Or alternatively), solve
|
4.2. Group Class Residual-SRC
| Algorithm 2: Algorithm for GCR-RP-SRC |
|
Input: a matrix of training samples for c classes. a test sample (and optional error tolerance ) Output: class
(Or alternatively), solve
|
5. Result and Discussions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AR | Aleix Martinez and Robert Benavente |
| CS | Compressive Sensing/ Compressive Sampling |
| CNN | Convolutional Neural Network |
| DR | Dimensionality Reduction |
| DGCR | Discriminative Group Collaborative Competitive Representation-based Classification |
| E-SRC | Extended Sparse Representation based Classification |
| FR | Face Recognition |
| GT | Georgia Tech |
| GCR-SRC | Group Class Residual Sparse Representation based Classification |
| GCR-RP-SRC | Group Class Residual Random Projection Sparse Representation based Classification |
| LLP | Locality Preserving Projection |
| MFA | Marginal Fisher Analysis |
| MMC | Maximum Margin Criterion |
| NN | Nearest Neighbour |
| NS | Nearest Subspace |
| OP-SRC | Optimized Projection Sparse Representation Classification |
| PCA | Principle Component Analysis |
| RP | Random Projection |
| SDA | Semi Supervised Discriminant Analysis |
| SR | Sparse Representation |
| SRC | Sparse Representation based Classification |
| SRC-DP | Sparse Representation Classification Discriminant Projection |
| SSDR | Semi Supervised Dimensionality Reduction |
| SVM | Support Vector Machine |
References
- Shailendra, R.; Jayapalan, A.; Velayutham, S.; Baladhandapani, A.; Srivastava, A.; Kumar Gupta, S.; Kumar, M. An IOT and machine learning based intelligent system for the classification of therapeutic plants. Neural Process. Lett. 2022. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine learning: Algorithms, real-world applications and Research Directions. SN Comput. Sci. 2021, 2, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Wójcik, W.; Gromaszek, K.; Junisbekov, M. Face recognition: Issues, methods and alternative applications. In Face Recognition—Semisupervised Classification, Subspace Projection and Evaluation Methods; IntechOpen: London, UK, 2016. [Google Scholar]
- Singh, S.; Chintalacheruvu, S.C.; Garg, S.; Giri, Y.; Kumar, M. Efficient face identification and authentication tool for biometric attendance system. In Proceedings of the 2021 8th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 26–27 August 2021. [Google Scholar]
- Donoho, D. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Candes, E.; Wakin, M. An Introduction To Compressive Sampling. IEEE Signal Process. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, J.; Zhang, H.; Wang, Z.; Yang, Y.; Liu, D.; Huang, T. Sparse Coding and Its Applications in Computer Vision; World Scientific Publishing Co. Pte. Ltd.: Singapore, 2016. [Google Scholar]
- Zhang, Z.; Xu, Y.; Yang, J.; Li, X.; Zhang, D. A Survey of Sparse Representation: Algorithms and Applications. IEEE Access 2015, 3, 142–149. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.; Ganesh, A.; Sastry, S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef]
- Yang, M. Face recognition via sparse representation. Wiley Encycl. Electr. Electron. Eng. 2015, 1–12. [Google Scholar] [CrossRef]
- Lv, S.; Liang, J.; Di, L.; Yunfei, X.; Hou, Z.J. A Probabilistic Collaborative Dictionary Learning-Based Approach for Face Recognition. IET Image Process. 2020, 15, 868–884. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, W.; Chang, P.; Liu, J.; Yan, Z.; Wang, T.; Li, F. Kernel Sparse Representation-Based Classifier. IEEE Trans. Signal Process. 2012, 60, 1684–1695. [Google Scholar] [CrossRef]
- Zhang, S.; Zhao, X.; Lei, B. Robust Facial Expression Recognition via Compressive Sensing. Sensors 2012, 12, 3747–3761. [Google Scholar] [CrossRef] [Green Version]
- Xiao, H.; Hu, Z. Feature-similarity network via soft-label training for infrared facial emotional classification in human-robot interaction. Infrared Phys. Technol. 2021, 117, 103823. [Google Scholar] [CrossRef]
- Ju, J.; Zheng, H.; Li, C.; Li, X.; Liu, H.; Liu, T. AGCNNs: Attention-guided convolutional neural networks for infrared head pose estimation in assisted driving system. Infrared Phys. Technol. 2022, 123, 104146. [Google Scholar] [CrossRef]
- Lin, C.-L.; Huang, Y.-H. The application of adaptive tolerance and serialized facial feature extraction to automatic attendance systems. Electronics 2022, 11, 2278. [Google Scholar] [CrossRef]
- Alskeini, N.H.; Thanh, K.N.; Chandran, V.; Boles, W. Face recognition. In Proceedings of the 2nd International Conference on Graphics and Signal Processing—ICGSP’18, Sydney, Australia, 6–8 October 2018. [Google Scholar]
- Thushitha, V.R.; Priya, M. Comparative analysis to improve the image accuracy in face recognition system using hybrid LDA compared with PCA. In Proceedings of the 2022 International Conference on Business Analytics for Technology and Security (ICBATS), Dubai, United Arab Emirates, 16–17 February 2022. [Google Scholar]
- Chen, Z.; Zhu, Q.; Soh, Y.C.; Zhang, L. Robust Human Activity Recognition Using Smartphone Sensors via CT-PCA and Online SVM. IEEE Trans. Ind. Inform. 2017, 13, 3070–3080. [Google Scholar] [CrossRef]
- Yu, T.; Chen, J.; Yan, N.; Liu, X. A Multi-Layer Parallel LSTM Network for Human Activity Recognition with Smartphone Sensors. In Proceedings of the 2018 10th International Conference on Wireless Communications and Signal Processing (WCSP), Hangzhou, China, 18–20 October 2018; pp. 1–6. [Google Scholar]
- Wang, Y.; Wu, Q. Research on face recognition technology based on PCA and SVM. In Proceedings of the 2022 7th International Conference on Big Data Analytics (ICBDA), Guangzhou, China, 4–6 March 2022. [Google Scholar]
- Yang, A.; Zhou, Z.; Balasubramanian, A.; Sastry, S.; Ma, Y. Fast l1 Minimization Algorithms for Robust Face Recognition. IEEE Trans. Image Process. 2013, 22, 3234–3246. [Google Scholar] [CrossRef]
- Deng, W.; Hu, J.; Guo, J. Extended SRC: Undersampled Face Recognition via Intraclass Variant Dictionary. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1864–1870. [Google Scholar] [CrossRef]
- Mi, J.; Liu, J. Face Recognition Using Sparse Representation-Based Classification on K-Nearest Subspace. PLoS ONE 2013, 8, e59430. [Google Scholar]
- Wei, C.-P.; Wang, Y.-C.F. Undersampled face recognition via robust auxiliary dictionary learning. IEEE Trans. Image Process. 2015, 24, 1722–1734. [Google Scholar]
- Duan, G.L.; Li, N.; Wang, Z.; Huangfu, J. A multiple sparse representation classification approach based on weighted residuals. In Proceedings of the 2013 Ninth International Conference on Natural Computation (ICNC), Shenyang, China, 23–25 July 2013. [Google Scholar]
- Gou, J.; Wang, L.; Yi, Z.; Yuan, Y.-H.; Ou, W.; Mao, Q. Discriminative group collaborative competitive representation for visual classification. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019. [Google Scholar]
- Wei, J.-S.; Lv, J.-C.; Xie, C.-Z. A new sparse representation classifier (SRC) based on Probability judgement rule. In Proceedings of the 2016 International Conference on Information System and Artificial Intelligence (ISAI), Hong Kong, China, 24–26 June 2016. [Google Scholar]
- Krasnobayev, V.; Kuznetsov, A.; Popenko, V.; Kononchenko, A.; Kuznetsova, T. Determination of positional characteristics of numbers in the residual class system. In Proceedings of the 2020 IEEE 11th International Conference on Dependable Systems, Services and Technologies (DESSERT), Kyiv, Ukraine, 14–18 May 2020. [Google Scholar]
- Yang, J.; Chu, D.; Zhang, L.; Xu, Y.; Yang, J. Sparse representation classifier steered discriminative projection with applications to face recognition. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1023–1035. [Google Scholar] [CrossRef]
- Lu, C.-Y.; Huang, D.-S. Optimized projections for sparse representation based classification. Neurocomputing 2013, 113, 213–219. [Google Scholar] [CrossRef]
- Ben-Haim, Z.; Eldar, Y.C.; Elad, M. Coherence-based performance guarantees for estimating a sparse vector under random noise. IEEE Trans. Signal Process. 2010, 58, 5030–5043. [Google Scholar] [CrossRef]
- Qiao, L.; Chen, S.; Tan, X. Sparsity preserving projections with applications to face recognition. Pattern Recognit. 2010, 43, 331–341. [Google Scholar] [CrossRef] [Green Version]
- Lestariningati, S.I.; Suksmono, A.B.; Usman, K.; Edward, I.J. Random projection on sparse representation based classification for face recognition. In Proceedings of the 2021 13th International Conference on Information Technology and Electrical Engineering (ICITEE), Chiang Mai, Thailand, 14–15 October 2021. [Google Scholar]
- Ai, X.; Wang, Y.; Zheng, X. Sub-pattern based maximum margin criterion for face recognition. In Proceedings of the 2017 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017. [Google Scholar]
- Cai, X.-F.; Wen, G.-H.; Wei, J.; Li, J. Enhanced supervised locality preserving projections for face recognition. In Proceedings of the 2011 International Conference on Machine Learning and Cybernetics, Guilin, China, 10–13 July 2011. [Google Scholar]
- Ling, G.F.; Han, P.Y.; Yee, K.E.; Yin, O.S. Face recognition via semi-supervised discriminant local analysis. In Proceedings of the 2015 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 19–21 October 2015. [Google Scholar]
- Majumdar, A.; Ward, R.K. Robust classifiers for data reduced via random projections. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2010, 40, 1359–1371. [Google Scholar] [CrossRef]
- The ORL Database. Available online: https://cam-orl.co.uk/facedatabase.html (accessed on 24 July 2022).
- The Yale B Face Database. Available online: http://vision.ucsd.edu/~leekc/YaleDatabase/ExtYaleB.html (accessed on 24 July 2022).
- The Georgia Tech Database. Available online: http://www.anefian.com/face\protect\T1\textdollar_\protect\T1\textdollarreco.htm (accessed on 24 July 2022).
- The Aleix Martinez and Robert Benavente Database. Available online: https://www2.ece.ohio-state.edu/~aleix/ARdatabase.html (accessed on 22 August 2022).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Dimensionality Reduction | Algorithm | Recognition Rate (%) | ||
|---|---|---|---|---|---|
| = 64 | = 128 | = 256 | |||
| 1 | Downscale | SRC | 83 | 75.5 | 54.5 |
| 2 | GCR-SRC | 91.5 | 85.5 | 64.5 | |
| 3 | Random Projection | SRC | 94 | 91 | 83.5 |
| 4 | GCR-SRC | 96 | 92 | 85 | |
| Algorithm | Recognition Rate (%) with | |||
|---|---|---|---|---|
| AT&T | Yale B | Georgia Tech | AR | |
| wa SRC-Downscale [9] | 83 | 71.56 | 52.57 | 67.76 |
| GCR-SRC | 91.5 | 82.03 | 62.85 | 71.15 |
| RP-SRC [34] | 92 | 84 | 65 | 83.15 |
| GCR-RP-SRC | 96 | 6 | 69 | 86 |
| Algorithm | Processing Time (ms) with | |||
|---|---|---|---|---|
| AT&T | Yale B | Georgia Tech | AR | |
| SRC-Downscale | 7.302 | 120.018 | 43.964 | 336.074 |
| GCR-SRC | 7.561 | 125.136 | 44.254 | 356.714 |
| RP-SRC | 4.751 | 109.831 | 34.504 | 432.052 |
| GCR-RP-SRC | 4.782 | 117.094 | 39.533 | 489.365 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lestariningati, S.I.; Suksmono, A.B.; Edward, I.J.M.; Usman, K. Group Class Residual ℓ1-Minimization on Random Projection Sparse Representation Classifier for Face Recognition. Electronics 2022, 11, 2723. https://doi.org/10.3390/electronics11172723
Lestariningati SI, Suksmono AB, Edward IJM, Usman K. Group Class Residual ℓ1-Minimization on Random Projection Sparse Representation Classifier for Face Recognition. Electronics. 2022; 11(17):2723. https://doi.org/10.3390/electronics11172723
Chicago/Turabian StyleLestariningati, Susmini Indriani, Andriyan Bayu Suksmono, Ian Joseph Matheus Edward, and Koredianto Usman. 2022. "Group Class Residual ℓ1-Minimization on Random Projection Sparse Representation Classifier for Face Recognition" Electronics 11, no. 17: 2723. https://doi.org/10.3390/electronics11172723
APA StyleLestariningati, S. I., Suksmono, A. B., Edward, I. J. M., & Usman, K. (2022). Group Class Residual ℓ1-Minimization on Random Projection Sparse Representation Classifier for Face Recognition. Electronics, 11(17), 2723. https://doi.org/10.3390/electronics11172723