
A Three-Layered Multifactorial Evolutionary Algorithm with Parallelization for Large-Scale Engraving Path Planning

Abstract
:1. Introduction
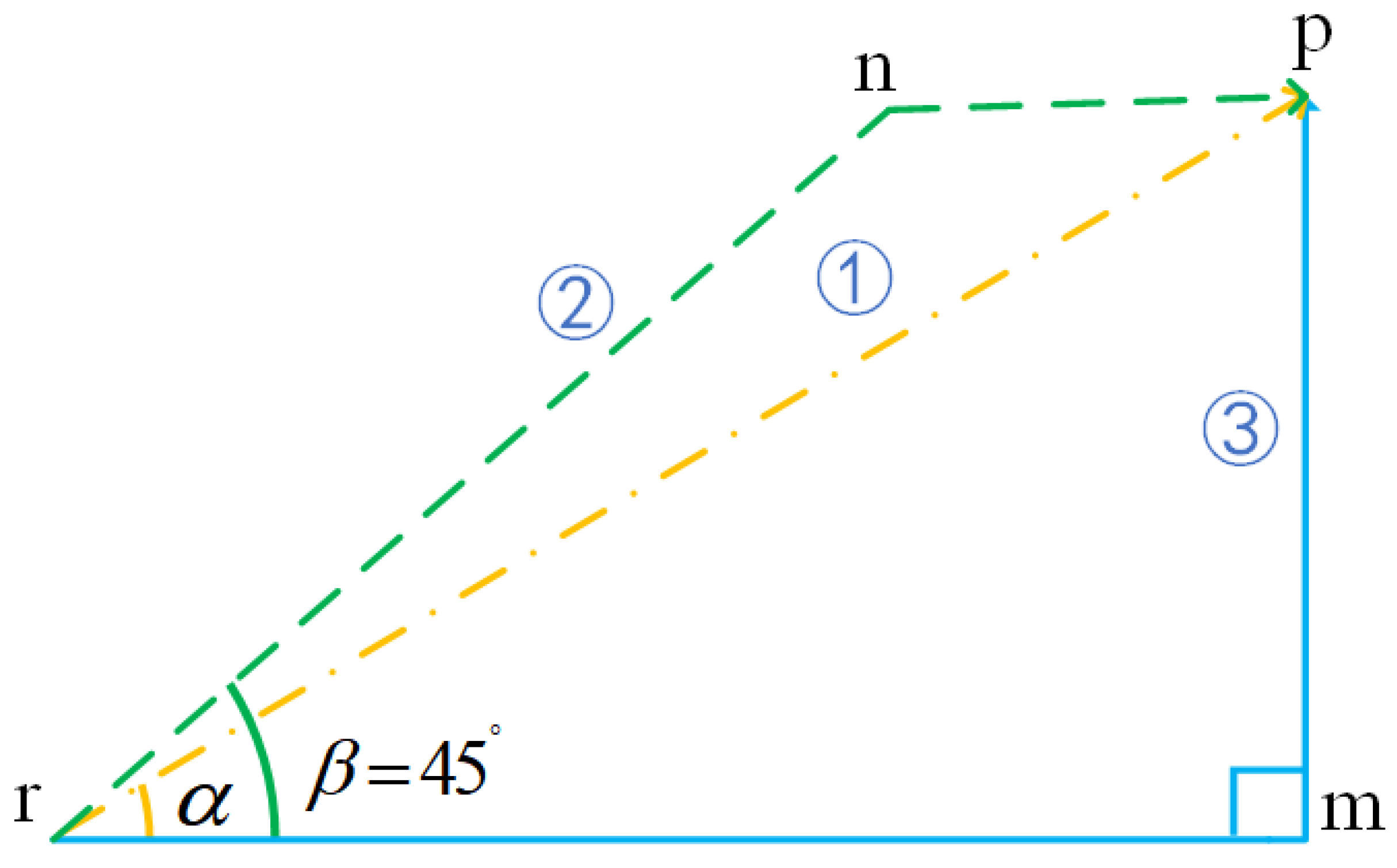
- We formulate the trajectory optimization problem in large-scale image engraving as an improved model based on the TSP. The model aims to minimize the trajectory of the image engraving and consider the infinite norm as the distance between two pixels.
- Referring to the idea of hierarchical optimization, we develop a three-layer optimization framework and combine it with EAs to solve the large-scale TSP. Concretely, we cluster the city points of large-scale TSP twice to transform them into many small-scale TSPs and use EAs to solve them; then, we reconnect the scattered small-scale city clusters of small-scale city clusters into a whole through the proposed city clusters connection strategy.
- We transfer the knowledge obtained by EAs solving small-scale TSPs to other EAs that solve small-scale TSPs so as to improve the performance of EAs. In addition, we use the CPU multi-process technology to realize the simultaneous optimization of multiple small-scale TSPs, which is found to greatly improve the optimization efficiency of the large-scale TSP.
2. Related Work
3. Proposed Model
3.1. Laser Engraving Machine Working Principle
3.2. Mathematical Model
4. Multifactorial Evolutionary Algorithm
- 1.
- Factorial Cost: If the individual in populations was evaluated on the j task , the ’s factorial cost is equal to the fitness value of on , i.e., is calculated according to the object function and . Assume there are M tasks; each individual’s factorial cost is a M-dimensional row vector and each dimension represents the fitness value of the individual in this task.
- 2.
- Factorial Rank: If the individual is evaluated on the task , ’s factorial rank is equal to the position of according to an ascending sequence of factorial cost among all the individuals that calculated factorial cost on task . If there are two or more individuals that have equal factorial cost in one task, their factorial rank will be determined randomly. Factorial rank reflects the quality of individuals in the task. If the individual’s factorial rank is smaller in the task, the performance of the individual is better in this task.
- 3.
- Scalar Fitness: The individual ’s scalar fitness is defined as the reciprocal value of the best factorial rank in the task M, i.e., . The bigger the individual’s scalar fitness, the better the individual is.
- 4.
- Skill Factor: The skill factor of the individual is the number of tasks that has the smallest factorial rank in all tasks, i.e., . If the individual ’s skill factor is equal to 1, will evaluate Task 1.
| MFEA Algorithm Framework |
| Input: Initialize a population which has N individuals as the parent population |
| Output: Solution of each task |
| 1. Evaluate all individuals in the population on per task, calculate each individual’s factorial cost, |
| factorial rank, scalar fitness, and skill factor |
| 2. While not satisfying termination conditions |
| 3. The child population is generated by executing the selection mating operation on the parent |
| population |
| 4. Execute vertical cultural propagation operation on child population to determine which |
| task will be evaluated by the child population individual |
| 5. Update the scalar fitness of the parent population and the child population |
| 6. Select N individuals which have the bigger scalar fitness in the parent population and the |
| child population to form the next generation population |
| 7. End while |
| Selection Mating |
| Input: Randomly select two individuals and in the parent population, random mating |
| probability |
| Output: Two child individuals and |
| 1. Generate a random number between |
| 2. If ( and have same skill factor) or () |
| 3. Use cross operator for and to generate two child individuals and |
| 4. Else |
| 5. Use variation operator for and to generate two child individuals and |
| 6. End |
| Vertical Cultural Propagation |
| Input: Child individual without skill factor |
| Output: Child individual that has skill factor |
| 1. If ( is generated by two parent individuals and through cross operation) |
| 2. Generate a random number between |
| 3. If () |
| 4. obtains skill factor |
| 5. Else |
| 6. obtains skill factor |
| 7. End |
| 8. Else |
| 9. If ( is generated by through variation operation) |
| 10. obtains skill factor |
| 11. Else |
| 12. obtains skill factor |
| 13. End |
| 14. End |
5. Three-Layered and Parallel Multifactorial Evolutionary Algorithm
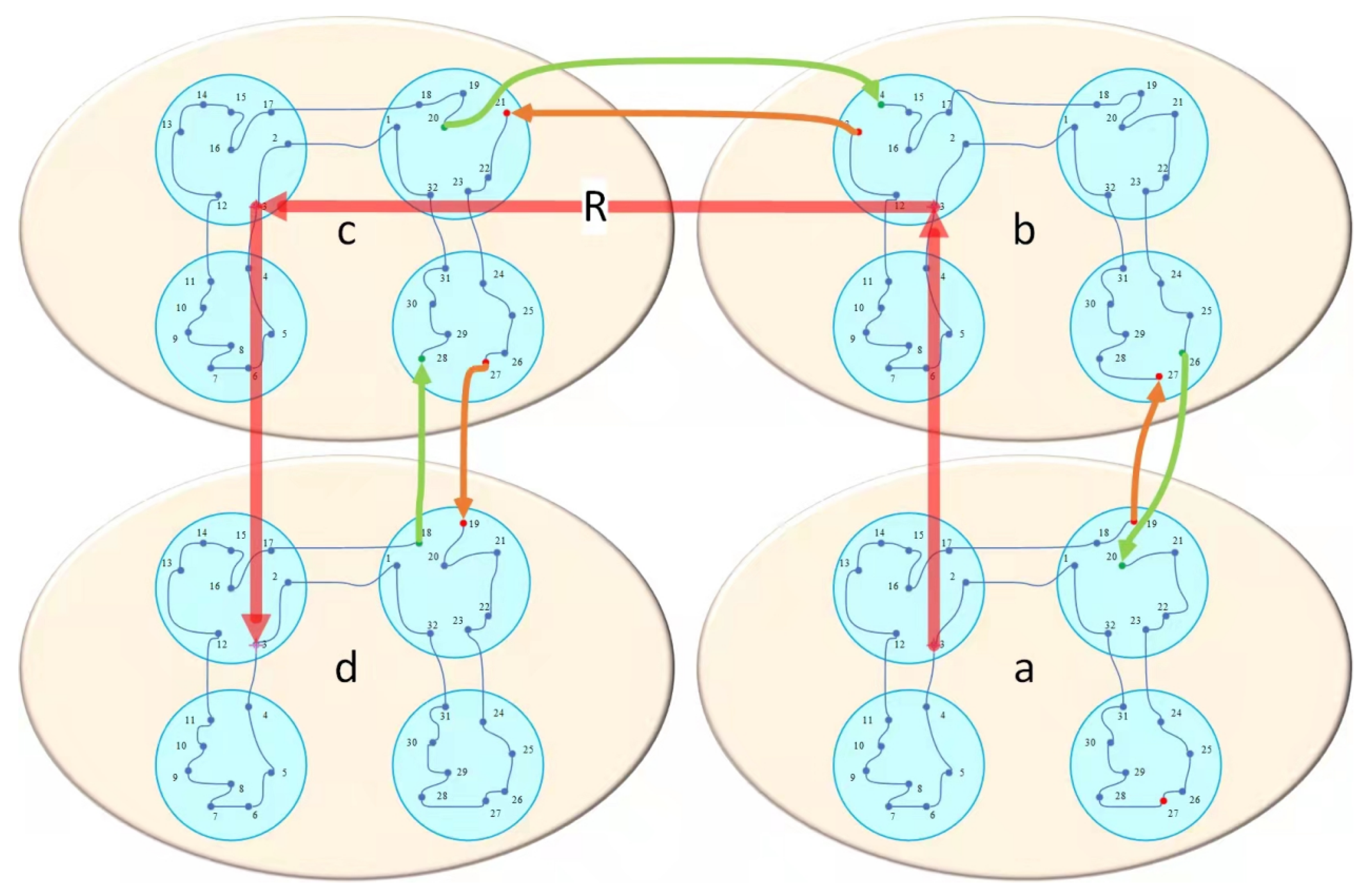
5.1. Three-Layered Evolution Optimization Framework
| Algorithm 1 Three-Layered Evolutionary Optimization Framework. |
| Input: City coordinate and city serial number , number of clusterings N (even) and iterative number of upper layer’s K-medoids, number of clusterings L (even) and iterative number of middle layer’s K-medoids, population size and maximum number of iterations of upper layer’s GA, population size and maximum number of iterations of middle layer’s GA, population size and maximum number of iterations of MFEA |
| Output: Optimal path and optimal path length |
| 1. Use K-medoids divide W citys into N medium-scale city groups, the centers of medium-scale city groups are |
| 2. Use K-medoids divide each medium-scale city groups into L small-scale city groups, the centers of small-scale city groups are |
| 3. Use GA to optimize the TSP that is composed of the centers of N medium-scale city groups to obtain optimal path R |
| 4. Use GA to optimize the TSP that is composed of the center of L small-scale city groups within each medium-scale city group to obtain N city groups’ optimal path |
| 5. Randomly divide small-scale L city groups within each medium-scale city group into city combinations to obtain a total of city combinations |
| 6. Use to optimize city combinations, respectively, to obtain city groups’ optimal path and optimal path length |
| 7. According to the best path to connect L small-scale city groups within each medium-scale city group to a whole |
| 8. According to the best path R to connect N medium-scale city groups to a whole |
5.2. Parallel Optimization of the Path in the Bottom Layer
| Algorithm 2 Parallel Path Optimization in the bottom layer. |
| 1. Create N processes from the CPU process pool, N less than , C is the number of CPU |
| cores |
| 2. N processes sequentially select tasknum city groups according to the optimal path of middle |
| layer, tasknum is the number of tasks that can be optimized by MFEA |
| 3. We use MFEA to optimize city groups that had been selected by each process |
| 4. While (The process i has completed the current optimization task and there are city groups that |
| are not selected by other processes) |
| 5. The process i select sequentially select tasknum city groups that are not selected by other |
| processes according to the optimal path |
| 6. We use MFEA to optimize city groups that had been selected by process i |
| 7. End While |
6. Simulation Experiment and Performance Analysis
6.1. Experimental Setup
6.2. Comparison and Analysis with Other Algorithms
6.3. Comparison and Analysis with the Previous Classical Methods
6.4. Experimental Results Running on a Personal Office Computer
6.5. Experimental Results Based on the Movement Route of the Engraving Machine
6.6. Experimental Results of Real Engraving Machine
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fraser, A.; Deschênes, J.M. True Traceability Enabled by In-Line Laser Marking of Lead and Zinc Ingots. In Proceedings of the PbZn 2020: 9th International Symposium on Lead and Zinc Processing, San Diego, CA, USA, 23–27 February 2020; Springer: Cham, Switzerland, 2020; pp. 767–775. [Google Scholar]
- Sundaria, R.; Nair, D.G.; Lehikoinen, A.; Arkkio, A.; Belahcen, A. Effect of laser cutting on core losses in electrical machines—Measurements and modeling. IEEE Trans. Ind. Electron. 2019, 67, 7354–7363. [Google Scholar] [CrossRef]
- Gregory, G.; Punnen, A.P. (Eds.) The Traveling Salesman Problem and Its Variations; Springer Science & Business Media: Berlin, Germany, 2006. [Google Scholar]
- Cook, W.J. In Pursuit of the Traveling Salesman: Mathematics at the Limits of Computation; Princeton University Press: Princeton, NJ, USA, 2011. [Google Scholar]
- Ruan, L.; Zhang, L.; Wu, C. A New Tour Construction Algorism and its Application in Laser Carving Path Control. J. Image Graph. 2007, 6, 1114–1118. [Google Scholar]
- Nini, L.; Zhangwei, C.; Shize, C. Optimization of laser cutting path based on local search and genetic algorithm. Comput. Eng. Appl. 2010, 46, 234–236. [Google Scholar]
- Beheshti, Z.; Shamsuddin, S.M.H. A review of population-based meta-heuristic algorithms. Int. J. Adv. Soft Comput. Appl. 2013, 5, 1–35. [Google Scholar]
- Peng, X.; Wu, Y. Large-scale cooperative co-evolution using niching-based multi-modal optimization and adaptive fast clustering. Swarm Evol. Comput. 2017, 35, 65–77. [Google Scholar] [CrossRef]
- Durmus, E.; Mohanty, M.; Taspinar, S.; Uzun, E.; Memon, N. Image carving with missing headers and missing fragments. In Proceedings of the 2017 IEEE Workshop on Information Forensics and Security (WIFS), Rennes, France, 4–7 December 2017; pp. 1–6. [Google Scholar]
- Jurek, M.; Wagnerová, R. Frequency Filtering of Source Images for LASER Engravers. In Proceedings of the 2019 20th International Carpathian Control Conference (ICCC), Krakow-Wieliczka, Poland, 26–29 May 2019; pp. 1–5. [Google Scholar]
- Yang, H.; Zhao, J.; Wu, J.; Wang, T. Research on a new laser path of laser shock process. Optik 2020, 211, 163995. [Google Scholar] [CrossRef]
- Anton, F.D.; Anton, S. Generating complex surfaces for robot milling and engraving tasks: Using images for robot task definition. In Proceedings of the 2017 21st International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 19–21 October 2017; pp. 459–464. [Google Scholar]
- Wang, D.; Yu, Q.; Zhang, Y. Research on laser marking speed optimization by using genetic algorithm. PLoS ONE 2015, 10, e0126141. [Google Scholar] [CrossRef] [PubMed]
- Hajad, M.; Tangwarodomnukun, V.; Jaturanonda, C.; Dumkum, C. Laser cutting path optimization using simulated annealing with an adaptive large neighborhood search. Int. J. Adv. Manuf. Technol. 2019, 103, 781–792. [Google Scholar] [CrossRef]
- Ding, C.; Cheng, Y.; He, M. Two-level genetic algorithm for clustered traveling salesman problem with application in large-scale TSPs. Tsinghua Sci. Technol. 2007, 12, 459–465. [Google Scholar] [CrossRef]
- Deng, W.; Xu, J.; Zhao, H. An improved ant colony optimization algorithm based on hybrid strategies for scheduling problem. IEEE Access 2019, 7, 20281–20292. [Google Scholar] [CrossRef]
- Helsgaun, K. General k-opt submoves for the Lin–Kernighan TSP heuristic. Math. Program. Comput. 2009, 1, 119–163. [Google Scholar] [CrossRef]
- Honda, K.; Nagata, Y.; Ono, I. A parallel genetic algorithm with edge assembly crossover for 100,000-city scale TSPs. In Proceedings of the 2013 IEEE Congress on Evolutionary Computation, Cancun, Mexico, 20–23 June 2013; pp. 1278–1285. [Google Scholar]
- Tan, L.Z.; Tan, Y.Y.; Yun, G.X.; Zhang, C. An improved genetic algorithm based on K-medoids clustering for solving traveling salesman problem. In Proceedings of the International conference on computer science, technology and application (CSTA2016), Changsha, China, 18–20 March 2016; pp. 334–343. [Google Scholar]
- Shahid, M.T.; Khan, M.A.; Khan, M.Z. Design and development of a computer numeric controlled 3D Printer, laser cutter and 2D plotter all in one machine. In Proceedings of the 2019 16th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 8–12 January 2019; pp. 569–575. [Google Scholar]
- Chen, J.; Wang, Y.; Xue, X.; Cheng, S.; El-Abd, M. Cooperative co-evolutionary metaheuristics for solving large-scale tsp art project. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 2706–2713. [Google Scholar]
- Gupta, A.; Ong, Y.S. Genetic transfer or population diversification? Deciphering the secret ingredients of evolutionary multitask optimization. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–7. [Google Scholar]
- Ong, Y.S.; Gupta, A. Evolutionary multitasking: A computer science view of cognitive multitasking. Cogn. Comput. 2016, 8, 125–142. [Google Scholar] [CrossRef]
- Gupta, A.; Ong, Y.S.; Feng, L. Insights on transfer optimization: Because experience is the best teacher. IEEE Trans. Emerg. Top. Comput. Intell. 2017, 2, 51–64. [Google Scholar] [CrossRef]
- Xu, Q.; Wang, N.; Wang, L.; Li, W.; Sun, Q. Multi-task optimization and multi-task evolutionary computation in the past five years: A brief review. Mathematics 2021, 9, 864. [Google Scholar] [CrossRef]
- Tan, K.C.; Feng, L.; Jiang, M. Evolutionary transfer optimization-a new frontier in evolutionary computation research. IEEE Comput. Intell. Mag. 2021, 16, 22–33. [Google Scholar] [CrossRef]
- Lei, Z. Design and Research of High Performance Multi-task Intelligent Optimization Algorithm Based on Knowledge Transfer; Chongqing University: Chongqing, China, 2019. [Google Scholar]
- Gupta, A.; Ong, Y.S.; Feng, L. Multifactorial Evolution: Toward Evolutionary Multitasking. IEEE Trans. Evol. Comput. 2016, 20, 343–357. [Google Scholar] [CrossRef]
- Anton, S.; Anton, F.D.; Constantinescu, M. Robot Engraving Services in Industry. In Service Robots; IntechOpen: London, UK, 2017. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Pop_Size | Max_Iteration | Mating | Mutation | Vertical Cultural | Number of |
|---|---|---|---|---|---|---|
| Rate | Rate | Propagation Rate | Process Pool | |||
| 3L-GA-MP | 100 | 500 | 0.7 | 0.03 | NaN | 40 |
| 2L-MFEA-MP | 100 | 500 | 0.7 | 0.03 | 0.7 | 40 |
| 3L-MFEA-MP | 100 | 500 | 0.7 | 0.03 | 0.7 | 40 |
| 3L-MFEA | 100 | 500 | 0.7 | 0.03 | 0.7 | 1 |
| Test Case | Test Algorithm | Optimal Value | Average Value | Average Time (s) |
|---|---|---|---|---|
| mona-lisa 100K | 3L-GA-MP | 6,573,858.48 | 6,580,451.45 | 1169.22 |
| 2L-MFEA-MP | 7,320,781.49 | 7,338,432.16 | 1257.24 | |
| 3L-MFEA-MP | 6,513,685.57 | 6,525,173.32 | 1030.72 | |
| vangogh 120K | 3L-GA-MP | 7,484,062.34 | 7,492,754.71 | 1433.82 |
| 2L-MFEA-MP | 10,355,545.62 | 10,368,895.74 | 1312.9 | |
| 3L-MFEA-MP | 7,423,925.39 | 7,430,062.76 | 1256.78 | |
| venus 140K | 3L-GA-MP | 7,778,041.94 | 7,786,448.81 | 1734.2 |
| 2L-MFEA-MP | 10,757,158.96 | 10,782,308.25 | 1666.52 | |
| 3L-MFEA-MP | 7,718,440.84 | 7,724,200.98 | 1518.13 | |
| earring 200K | 3L-GA-MP | 9,433,863.79 | 9,438,150.22 | 2658.72 |
| 2L-MFEA-MP | 13,419,519.17 | 13,438,280.99 | 2639.42 | |
| 3L-MFEA-MP | 9,365,519.37 | 9368743.37 | 2382.31 |
| Test Case | Test Algorithm | Optimal Value | Average Value | Average Time (s) |
|---|---|---|---|---|
| mona-lisa 100K | 3L- MFEA | 6,523,192.43 | 6,528,841.22 | 6317.92 |
| 3L-MFEA-MP | 6,513,685.57 | 6,525,173.32 | 1030.72 | |
| vangogh 120K | 3L- MFEA | 7,422,190.16 | 7,425,983.21 | 4645.26 |
| 3L-MFEA-MP | 7,423,925.39 | 7,430,062.76 | 1256.78 | |
| venus 140K | 3L- MFEA | 7,716,474.45 | 7,721,780.09 | 8933.52 |
| 3L-MFEA-MP | 7,718,440.84 | 7,724,200.98 | 1518.13 | |
| earring 200K | 3L- MFEA | 9,362,148.68 | 9,367,856.14 | 13,069.06 |
| 3L-MFEA-MP | 9,365,519.37 | 9,368,743.37 | 2382.31 |
| Test Case | Parallel GA | DM | 3L-MFEA-MP |
|---|---|---|---|
| mona-lisa 100K | 5,757,191 | 282,061,784.2 | 6,525,173.32 |
| vangogh 120K | 6,543,609 | 328,731,852.6 | 7,430,062.76 |
| venus 140K | 6,810,665 | 315,655,207.1 | 7,724,200.98 |
| earring 200K | 7,619,953 | 353,401,270.8 | 9,368,743.37 |
| Test Case | Super Computer (s) | Ordinary Computer (s) | Relative Difference (E) |
|---|---|---|---|
| mona-lisa 100K | 1030.72 | 1129.49 | 8.74% |
| vangogh 120K | 1256.78 | 1373.16 | 8.48% |
| venus 140K | 1518.13 | 1572.5 | 3.46% |
| earring 200K | 2382.31 | 2204.85 | 8.05% |
| Test Case | Average Path Length | Average Time (s) | Relative Difference |
|---|---|---|---|
| mona-lisa 100K | 5,817,834 | 821.99 | 16.60% |
| vangogh 120K | 6,633,908 | 992.831 | 16.80% |
| venus 140K | 6,880,842 | 1162 | 13.10% |
| earring 200K | 8,342,285 | 1648.42 | 13.40% |
| Test Case | 3L-MFEA-MP | DM | Relative Difference |
|---|---|---|---|
| mona-lisa 100K | 2141 | 24,904 | 1063.19% |
| vangogh 120K | 2275 | 31,116 | 1267.73% |
| venus 140K | 2447 | 29,861 | 1120.31% |
| earring 200K | 3180 | 35,931 | 715.44% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, A.; Yang, H.; Sun, L.; Sun, M. A Three-Layered Multifactorial Evolutionary Algorithm with Parallelization for Large-Scale Engraving Path Planning. Electronics 2022, 11, 1712. https://doi.org/10.3390/electronics11111712
Liang A, Yang H, Sun L, Sun M. A Three-Layered Multifactorial Evolutionary Algorithm with Parallelization for Large-Scale Engraving Path Planning. Electronics. 2022; 11(11):1712. https://doi.org/10.3390/electronics11111712
Chicago/Turabian StyleLiang, Antian, Hanshi Yang, Liming Sun, and Meng Sun. 2022. "A Three-Layered Multifactorial Evolutionary Algorithm with Parallelization for Large-Scale Engraving Path Planning" Electronics 11, no. 11: 1712. https://doi.org/10.3390/electronics11111712
APA StyleLiang, A., Yang, H., Sun, L., & Sun, M. (2022). A Three-Layered Multifactorial Evolutionary Algorithm with Parallelization for Large-Scale Engraving Path Planning. Electronics, 11(11), 1712. https://doi.org/10.3390/electronics11111712