1. Introduction
Vehicle Re-identification (Re-ID), a challenging task in computer vision, aims at identifying a vehicle of query by matching vehicle pictures captured from non-overlapping surveillance cameras. Indeed, it plays a crucial role in a broad range of surveillance applications, including the analysis of vehicle trajectory [
1], handling traffic jams [
2], and multi-camera tracking [
3].
Currently, Re-ID is becoming increasingly attractive to researchers, enterprises, and the government, but it still remains unsolved due to two main reasons. First, diversified and complicated circumstances pose challenges, and illuminations and resolutions can vary widely in disjoint cameras. Second, vehicles of the same type and color also cause considerable difficulties in identifying the target vehicle. In consequence, the distinctions among vehicles are subtle, thus increasing the difficulty of distinguishing identities.
To capture the discriminative cues in feature learning, many part-based methods are proposed to aggregate part features and then formulate a combined representation for each vehicle image. Among them, Parsing-guided Cross-part Reasoning Network (PCRNet) [
4], a strong part feature learning baseline, adopts a partition strategy to acquire the semantic segmentation-divided part features. Despite some remarkable achievements, these methods tend to treat all parts equally in the final representation and place too little emphasis on the salient part. Furthermore, they are ignorant of the importance of cross-camera consistency, thus being vulnerable to occlusions and background clutter.
Notably, considerable efforts [
5,
6,
7,
8,
9,
10,
11,
12,
13] have been devoted to investigating attention mechanisms in Re-ID, which can effectively focus on vehicle-related features and meanwhile reduce background clutter. The most popular solution is to adopt a parallel arrangement for spatial and channel attention modules, taking advantage of exploiting two kinds of attention information. However, existing soft attention modules tend to extract different kinds of attention information independently, neglecting their crucial complementary effects. In addition, the authors of [
7] exploit simple and homogeneous-scale spatial attention, thus only employing coarse-grained attention information. To sum up, there is still much room for improvement in the existing attention Re-ID models.
To fill the research gap, in this paper, we propose a novel Attentive Part-based Alignment Network (APANet) to tackle the above problems concurrently. It seamlessly integrates part-based alignment mechanisms and attention modules throughout the entire network. The features extracted from APANet are more robust, diverse, and discriminative, which is of great significance for correct matching. In addition, in APANet, the intra-class and inter-class distances are optimized simultaneously for better classification. In brief, APANet gains a benefit toward higher accuracy.
Our contributions can be mainly summarized as follows:
(1) With the purpose of enhancing the discrimination capacity of part feature representations, we adopt two part-level alignment mechanisms encompassing Part-level Orthogonality Loss (POL) and Part-level Attention Alignment Loss (PAAL). To begin with, a novel POL is formulated to learn diverse part-uncorrelated features via an orthogonal regulation among parts. We argue that the diversity of part features can fully realize the potential of final feature representations, thereby bringing a considerable performance boost. Furthermore, an effective PAAL is designed to perform attention alignment in a part-level manner, which facilitates modeling while exploiting camera-invariant features.
(2) In order to learn more discriminative features, a new Multi-receptive-field Attention (MA) module is proposed to exploit heterogeneous-scale pyramid attention information with multi-receptive-field streams. Notably, we intend to reduce the size of the module parameter as well as computational cost by adopting an efficient pyramid structure, therefore making up for the deficiency of multi-receptive-field streams. Additionally, the MA module cascades channel and spatial attention parts in series, bringing the complementary benefits of two kinds of attention information. In addition, the MA module adopts a unique embedded structure which places attention modules and residual blocks in parallel.
(3) To optimize the extracted features during the training stage, an improved TriHard loss and a Inter-group Feature Centroid Loss (IFCL) function are formulated to simultaneously optimize the intra-group and inter-group distances, respectively. For the former, an extra loss item is added to place more constraints on intra-class distances. As to the latter, inter-group distances among groups are calculated and optimized in a centroid-based fashion.
(4) To confirm the effectiveness of APANet, we conduct extensive experiments on two large vehicle Re-ID datasets. One is a large-scale benchmark dataset for vehicle Re-ID in the real-world urban surveillance scenario, named VeRi-776 [
3,
14,
15] which is shown in
Figure 1. Another dataset is called VERI-Wild [
16] which is to promote the research of vehicle Re-ID in the wild. According to the experiment results, APANet achieves rank-1 accuracy of 96.4% on VeRi-776 and 89.2% on VERI-Wild (Small), surpassing multiple existing state-of-the-art Re-ID models.
The rest of this paper is organized as follows.
Section 2 introduces related work with respect to vehicle Re-ID.
Section 3 describes the details of our proposed approach.
Section 4 presents the experiments and addresses some qualitative analysis.
Section 5 offers the concluding remarks.
3. Proposed Approach
Attention mechanisms are widely utilized in vehicle Re-ID networks but often miss the attention alignment across views. Our work is meticulously proposed to learn part features that are robust, diverse, and discriminative. It can not only adopt part-level alignment mechanisms which allocate more attention towards the most discriminative part and realize cross-view attention consistency, but also learn discriminative features by exploiting multi-receptive-field attention information in an efficient pyramid structure. In addition, the MA module concatenates channel and spatial parts in series, thereby exploiting complementary benefits of two kinds of attention information. In this section, we firstly give a brief introduction to Attentive Part-based Alignment (APANet) in
Section 3.1. The formulations of Part-level Orthogonality Loss (POL) and Part-level Attention Alignment Loss (PAAL) are elaborated in
Section 3.2 and
Section 3.3, respectively. The construction of the Multi-receptive-field Attention (MA) module and its attention mechanism are presented in
Section 3.4. Finally, the classification module with multiple loss functions is introduced in
Section 3.5.
3.1. Attentive Part-Based Alignment (APANet) and Network Structure
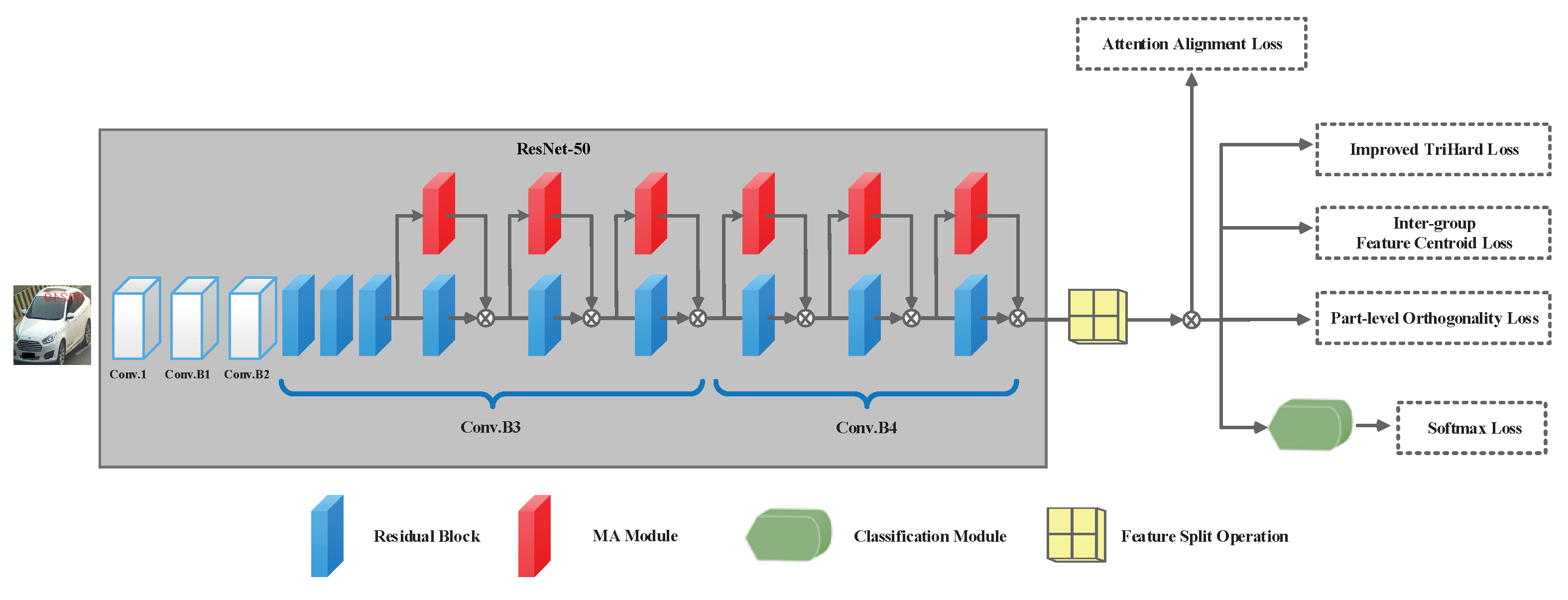
We firstly describe the backbone network of APANet, which is clearly illustrated in
Figure 2. ResNet-50 is a 50-layer deep residual neural network proposed by He et al. [
29]. Without loss of generality, all convolutional layers in ResNet-50 [
29] are utilized as the backbone network. For a clearer illustration, we divide these convolutional layers into five parts, which are Conv.1 (i.e., the 1st layer), Conv.B1, Conv.B2, Conv.B3, and Conv.B4. In detail, there are 3, 4, 6, 3 residual blocks in the last four parts, respectively, and three convolutional layers are stacked for feature extraction in each residual block.
In the following, we intend to elaborate the design idea of the APANet framework. As aforementioned, APANet aims to obtain discriminative and robust presentations and enhance the discrimination of part features. Consequently, three requirements need to be satisfied in the network design.
To begin with, our proposed network should adopt a part-level alignment mechanism which is capable of enhancing the discrimination of part features and realizing attention alignment. The part features are generated through feature split operation. The number of part features
is determined by the experiment detailed in
Section 4.6.2. Correspondingly, we propose two effective loss functions, namely, Part-level Orthogonality Loss (POL) and Part-level Attention Alignment Loss (PAAL), to enhance the representations of part features. The former aims to enforce diversity among parts via orthogonality regulations whilst the latter focuses on achieving the cross-view consistency of part-level attention. Secondly, APANet is expected to adopt powerful attention modules which are crucial components in extracting part-based discriminative features. Finally, both the intra-class and inter-class distance of part features are expected to be meticulously optimized. In particular, we firstly add an extra constraint on intra-distance to improve triplet loss. Then, we propose a Inter-group Feature Centroid Loss (IFCL) to reduce inter-group distance. More details are elaborated in the following subsections.
3.2. Part-Level Orthogonality Loss (POL)
In particular, we propose a novel Part-level Orthogonality Loss (POL) to promote discrimination of part features. Sun et al. [
30] drew the conclusion that correlations among feature embeddings would significantly degrade the final matching performance. Intuitively, the attention mechanism tends to learn discriminative features in a more compact subspace, therefore bringing higher feature correlations. To this end, POL maximizes part-level diversity via an orthogonality regulation loss item, advocating lower correlations among part features. Specifically, we intend to regard cosine similarity as an orthogonality metric so as to reduce feature correlations, which is beneficial to correct matching. Given two arbitrary vectors
, we give the definition of cosine similarity as:
where
is L2-norm and
S stands for cosine similarity.
When it comes to the implementation details of cosine similarity, a simple yet effective linear function is meticulously introduced to provide a non-negative similarity value. Then, for each targeted image
j with
part features, it can be obtained that
where
N denotes the number of images in a training batch and
stands for the
a-th part feature for the targeted vehicle image
j and
S stands for cosine similarity.
3.3. Part-Level Attention Alignment Loss (PAAL)
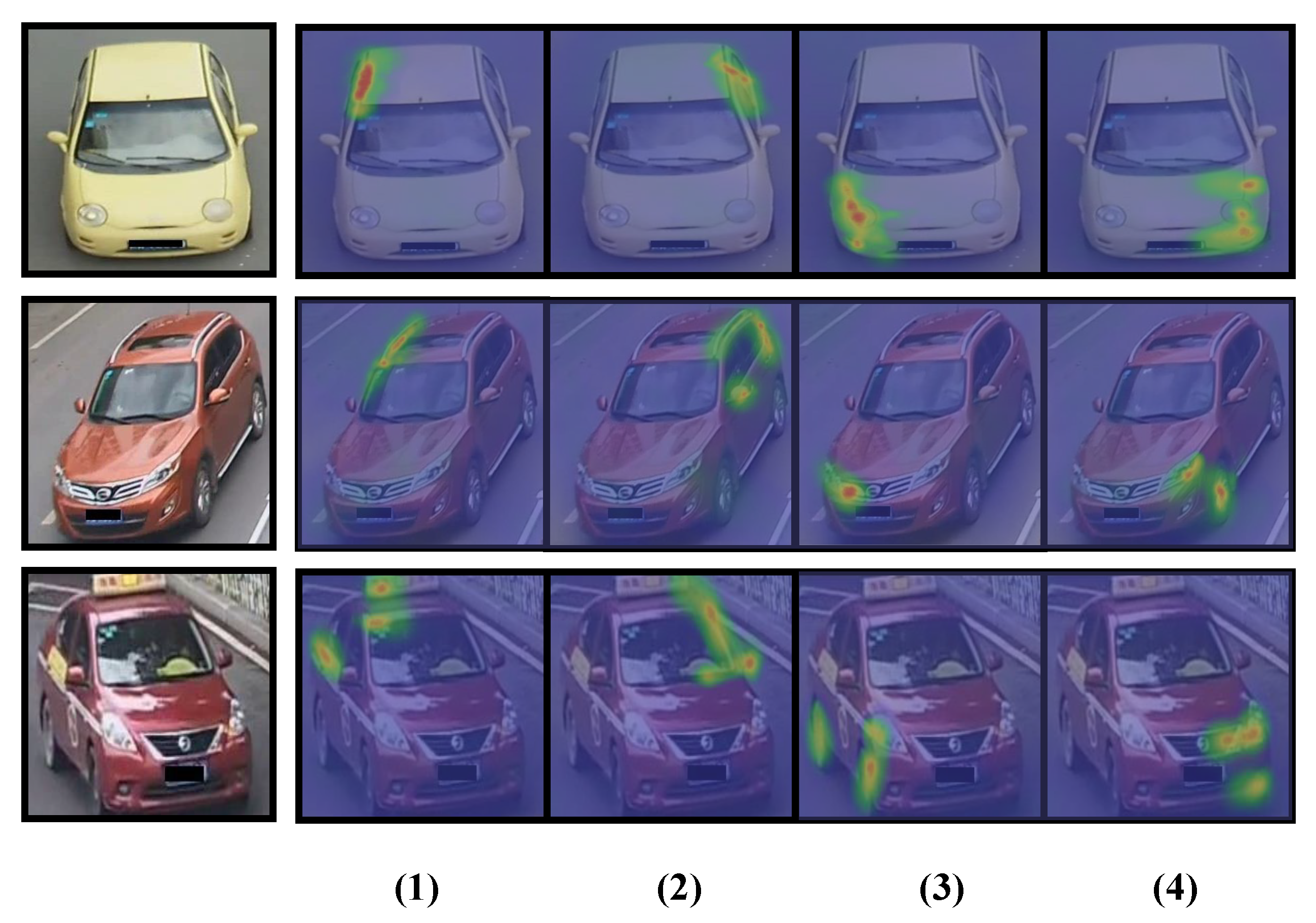
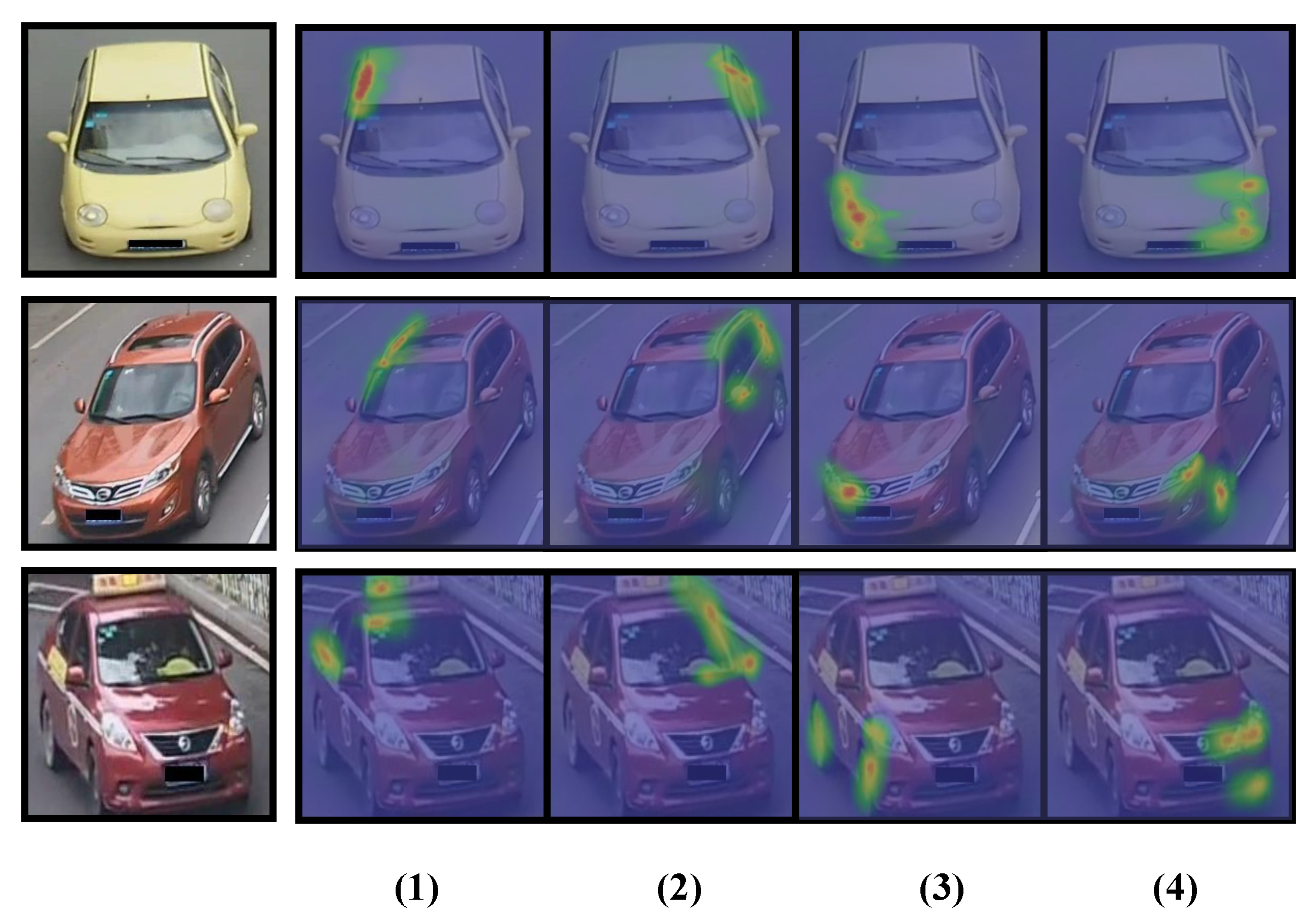
As aforementioned, the MA module is responsible for eliminating background clusters by employing comprehensive attention information. However, we argue that attention alignment, often neglected in designing attention modules, is significant for learning view-invariant and robust features.
Motivated by this idea, Part-level Attention Alignment Loss (PAAL) is meticulously proposed to reduce the adverse impact of cross-view variations and realize cross-camera consistency. Our intuition is that the shared regions of same-vehicle images across various cameras are crucial for correct matching and should be supervised during end-to-end training. Here, cosine distance
is utilized to express the vector dissimilarity between two non-zero vectors, and is considered as the metric of attention consistency.
We obtained a part-attention feature
, where
denotes the output channel of features. Thereafter, the cross-channel global average pooling is introduced and defined as:
where
represents the flattened part-level attention map. This specific cross-channel pooling is reasonable since all channels share the identical part-level spatial attention map.
To cope with the potential misalignment issue among vehicles, we further improve PAA by introducing a soft threshold parameter T (experimentally set to be 0.2 in our implementation) to eliminate the background clutter. A part-level spatial attention map can be more precisely cropped so as to select salient foreground parts and reduce background clutter. Afterwards, all attention vectors are resized to have the same dimensions via interpolation operations.
Furthermore, based on cosine distance, PAAL is designed to supervise attention consistency in a part-level fashion. Formally, for every targeted vehicle
and its randomly sampled
K images, PAAL can be written as:
where
denotes the number of combinations of
K images taking 2 images at a time.
P is the number of vehicle identities in a batch, and each vehicle has
K images.
By virtue of PAAL, the part-level attention maps can be vertically aligned among various images of the same targeted vehicle i, which facilitates APANet to learn more view-invariant features.
3.4. Multi-Receptive-Field Attention (MA)
There have been numerous tentative efforts [
31,
32,
33,
34] in exploiting this spatial attention map by virtue of convolution. However, most of them employ homogeneous-scale spatial attention, and therefore are confined to mining coarse and simple spatial information.
With the purpose of improving the attention mechanism, we propose a Multi-receptive-field Attention (MA) module which manages to extract pyramid attention maps with multi-receptive-field streams, thereby enhancing the feature representation. Compared with existing attention modules, the main advantage of the MA module is employing more comprehensive attention information in an efficient pyramid structure which only involves relatively small parameters and requires a low extra computational cost. To the best of our knowledge, current existing methods mainly adopt a multi-scale mechanism in learning features and it is unusual in Re-ID to apply a multi-scale mechanism in designing attention modules.
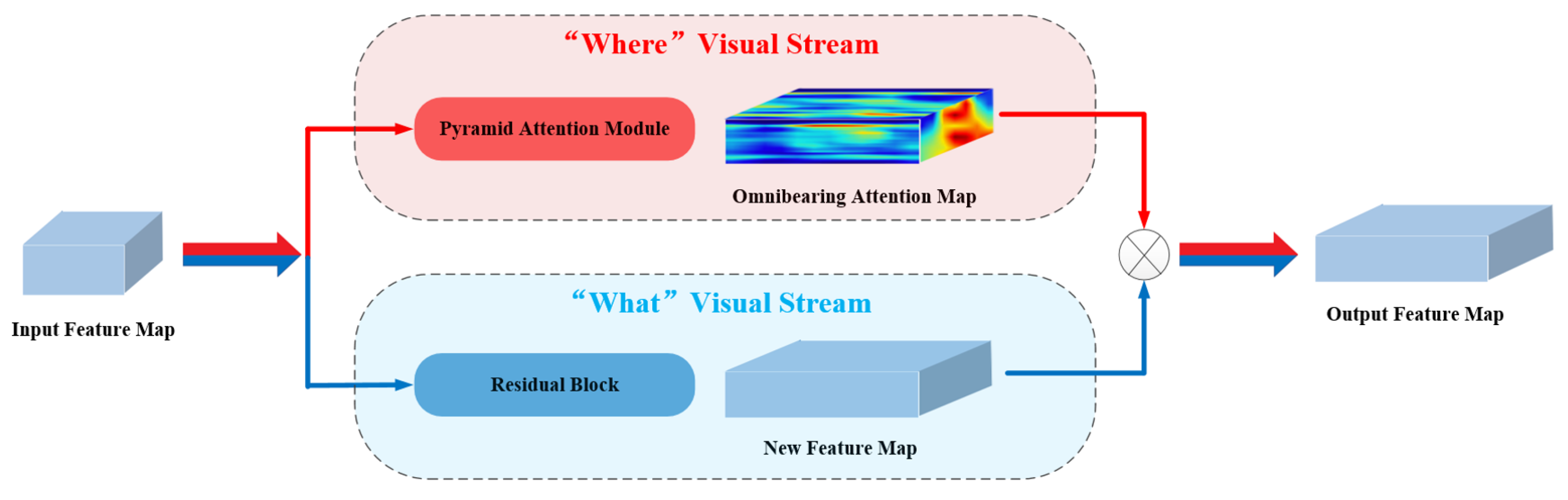
3.4.1. Embedded Structure
To begin with, we propose a unique embedded structure in pursuit of the best attention effect. Inspired by the two-stream hypothesis theory of the human visual system [
35], we aim to construct a “what” visual stream (i.e., residual module) and a “where” visual stream (i.e., attention module) in two independent branches. Specifically, as presented in
Figure 3, MA modules are in a parallel concatenation with residual blocks, whilst conventional Re-ID attention networks place them in series.
Formally, we define the input to an MA module as a three-dimension tensor
where
,
H, and
W stand for the number of input channels, height, and width. The corresponding output feature strengthened by the MA module can be written as:
where
is the output feature map, the final omnibearing attention map obtained from the MA module is denoted by
, ⊗ denotes the Hadamard product, and the function
represents the specific parallel residual block in ResNet-50.
Remarks. Our proposed MA module is conceptually similar to the Convolutional Block Attention Module (CBAM) [
32] since both of them employ the spatial and channel attention information. However, there are significant distinctions between them which can summarized as: (1) Concatenation arrangement. MA modules are placed in parallel with residual blocks retrieved from ResNet-50. On the contrary, the CBAM tends to concatenate them in series. Motivated by the two-stream hypothesis theory of the vehicle visual system, our intuition is to transmit the attention information continuously. Otherwise, the transmission channel of attention flow tends to be blocked by residual block. (2) Improvement of attention mechanism. We further improve the attention mechanism in an efficient and cost-effective pyramid structure. With exploiting heterogeneous-scale spatial attention, the MA module can explicitly guide the model to learn more discriminative features.
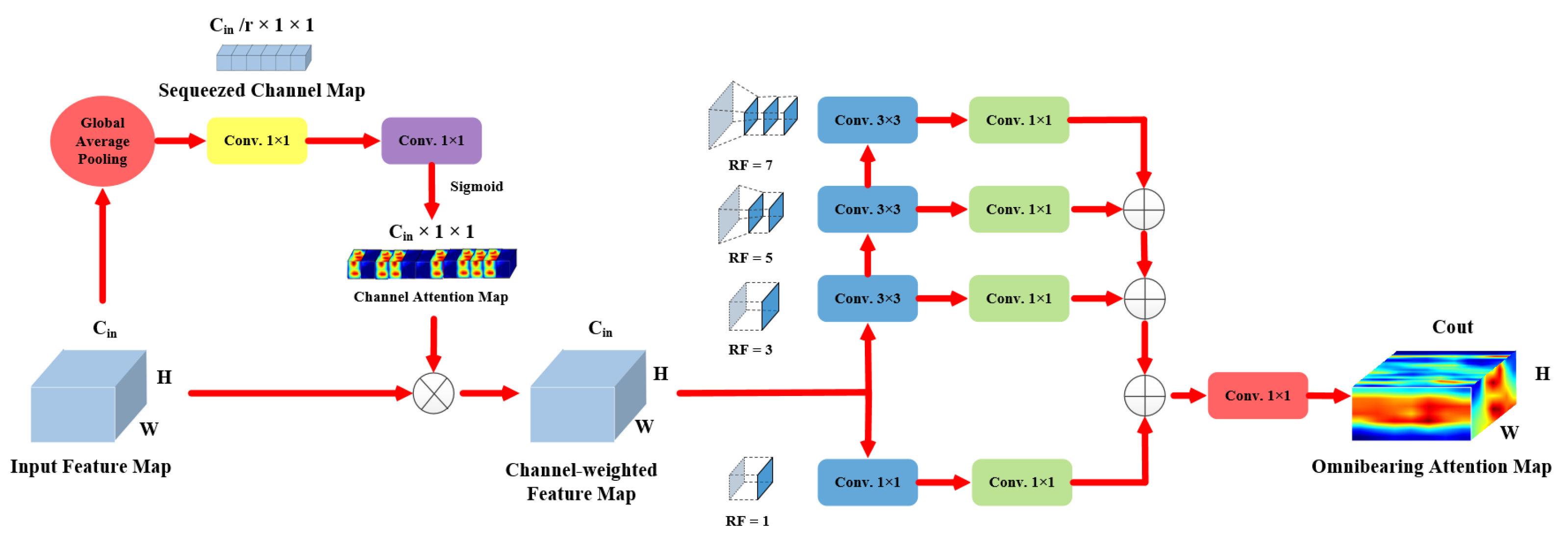
Once the embedded structure is proposed, we then elaborate the detailed scheme of our proposed MA module. As shown in
Figure 4, the MA module cascades channel and spatial attention in series. The serial concatenation employs the benefits of channel and spatial attention information, and more importantly, provides a crucial complementary effect, since spatial pyramid attention maps are extracted from the previous channel-weighted feature.
3.4.2. Channel Attention
Inspired by Squeeze and Excitation networks (SE block) [
36], we firstly apply channel attention to exploit intrinsic interaction among channels, laying a solid foundation for later pyramid spatial attention. The channel-weighted feature,
, strengthened by channel attention can be written as:
where
is the input feature.
(
parameters) and
(
parameters) represent the parameter matrix of
convolutional layers in sequence. Here,
r (experimentally set to be 8 in our implementation) denotes the channel reduction rate.
is the sigmoid function which normalizes the channel attention map within
.
3.4.3. Spatial Attention
As for the spatial attention part, multi-receptive-field streams are proposed to mine multi-scale spatial attention information. More specifically, there are four branches with receptive fields of
,
,
, and
in the spatial attention part. Following the successful practices of Simonyan et al. [
37], who argue that the stack of two
convolution layers has an equivalent receptive field of a
convolution layer, we employ this strategy in our pyramid spatial attention to reduce computation overheads as well as parameter size, e.g., a
convolution filter is replaced by a stack of three convolution layers in series. In this way, the MA module is efficient and cost-effective with the pyramid structure introduced.
To provide a more intuitive insight into its advantage of light weight, we intend to compare the pyramid structure with a parallel structure. Assume that there are also four multi-receptive-field branches in a parallel structure. The space complexity (number of parameters) of the parallel structure is calculated as follows:
The
denotes the input channel number and r is the channel reduction rate which has an impact on model inference time. The space complexity of the pyramid structure is calculated as follows:
Compared with the parallel structure, the pyramid structure obtains a noticeable reduction in parameters of . Obviously, the MA module applied with the pyramid structure has lower complexity, being computationally lightweight.
In the following, the scheme of the MA module is illustrated in more detail. Firstly, in the branch of receptive field size, the channel-weighted feature map of is convoluted by a convolutional layer which reduces the number of channels from to (the value of r is experimentally assigned as 8 for optimal results). Note that the channel number, height, and width of the input channel-weighted feature are denoted by , H, and W, respectively. In terms of the other three streams, three convolutional layers with kernel size of are utilized to construct the streams of the receptive fields. More specifically, the detailed parameters of three convolutional layers can be denoted as , , and . Note that the four items in the brackets are filter number, filter size, stride, and padding, respectively.
Afterward, in every stream, a convolutional layer of is introduced for the expansion in channel dimension. In this way, the channel size of the attention map can be matched with that of the output feature from the specific parallel residual block. Moreover, four multi-receptive-field streams are incorporated to retain more attention information. Furthermore, another convolutional layer of is adopted in the main stream so as to achieve a better integration among attention information of different spatial scales. At the end, the extracted attention map is normalized in the range of with a sigmoid function.
Remark 1. Res2Net is a new multi-scale backbone architecture proposed by Gao et al. [38] There are significant distinctions between the spatial part and Res2Net [38] module which can be summarized as the following three aspects: (1) Design purpose: the MA module is aims to exploit multi-scale attention information whereas the Res2Net module utilizes the strategy of multi-scale to learn omni-scale features. More generally, the former is equivalent to the extraction of a comprehensive spatial attention map with multi-receptive-field streams whilst the latter can be interpreted as fine-grained feature extraction or learning multi-scale representations. (2) Concatenation arrangement: MA modules are placed in parallel with residual blocks retrieved from ResNet-50. In contrast, the Res2Net module is an alternative architecture for residual blocks with learning of stronger multi-scale features. In each revised residual block, the original convolution layer is replaced with smaller groups of convolutional filters. (3) Specific design: The MA module exploits heterogeneous-scale spatial attention in an efficient and cost-effective pyramid structure. The Res2Net module intends to split the feature maps into several feature map subsets which are further processed in a multi-scale fashion with four branches. Additionally, in the MA module, channel reduction is introduced in every receptive field branch to reduce module parameters and computational overheads. 3.5. Classification Module
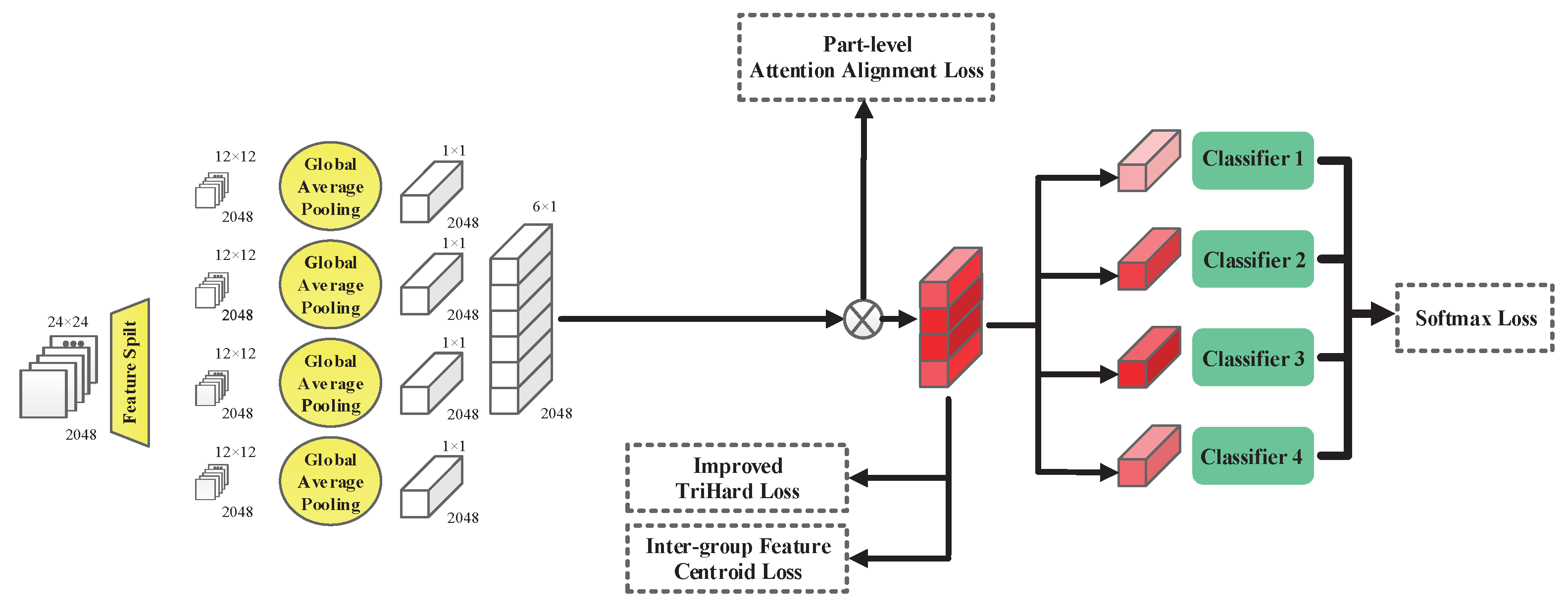
In every mini-batch of the training stage,
P classes (vehicle identities) and
K images of each identity are randomly sampled. Given a set of images
encompassing
images in a training batch, we obtain
part feature maps for each image
. As shown in
Figure 5, each part feature map will be further fed into a classifier which is implemented with a Fully Connected (FC) layer and a sequential softmax layer. Each identity classifier predicts the identity of the input image and is supervised by softmax loss:
where
denotes the number of vehicle labels in each training batch,
z is the index of extracted features in
part-based branches, and
represents the prediction result of the
j-th input image
in the
z-th part branch.
Moreover, we utilize the improved Triplet Loss with Hard Mining (TriHard) which places extra constraints on intra-class distance. In particular, an extra constraint is designed to further improve the effect of TriHard loss. Formally, for a specific feature anchor
belonging to vehicle
i, the positive point
is expected to be pulled closer compared with the arbitrary negative point
of the
j identity. In particular, in every training batch, the hardest positive and negative samples will be selected for supervision. The improved TriHard loss can be defined as:
where
m is margin (experimentally set to be
in our implementation),
stand for all the anchor images of batch.
represents the function of
and
denotes the Euclidean distance.
Furthermore, we propose a straightforward Inter-group Feature Centroid Loss (IFCL) function to further maximize the inter-group distance in a centroid-based fashion. We firstly calculate the centroid of the output feature maps,
, within group
i as:
where
K means the total number of images in group
i, and
denotes the feature map of the
t-th image in group
i,
Then, for
P groups in a training batch, the IFCL function can be written as:
With the combination of the aforementioned supervised losses, the final objective function in APANet can be given as:
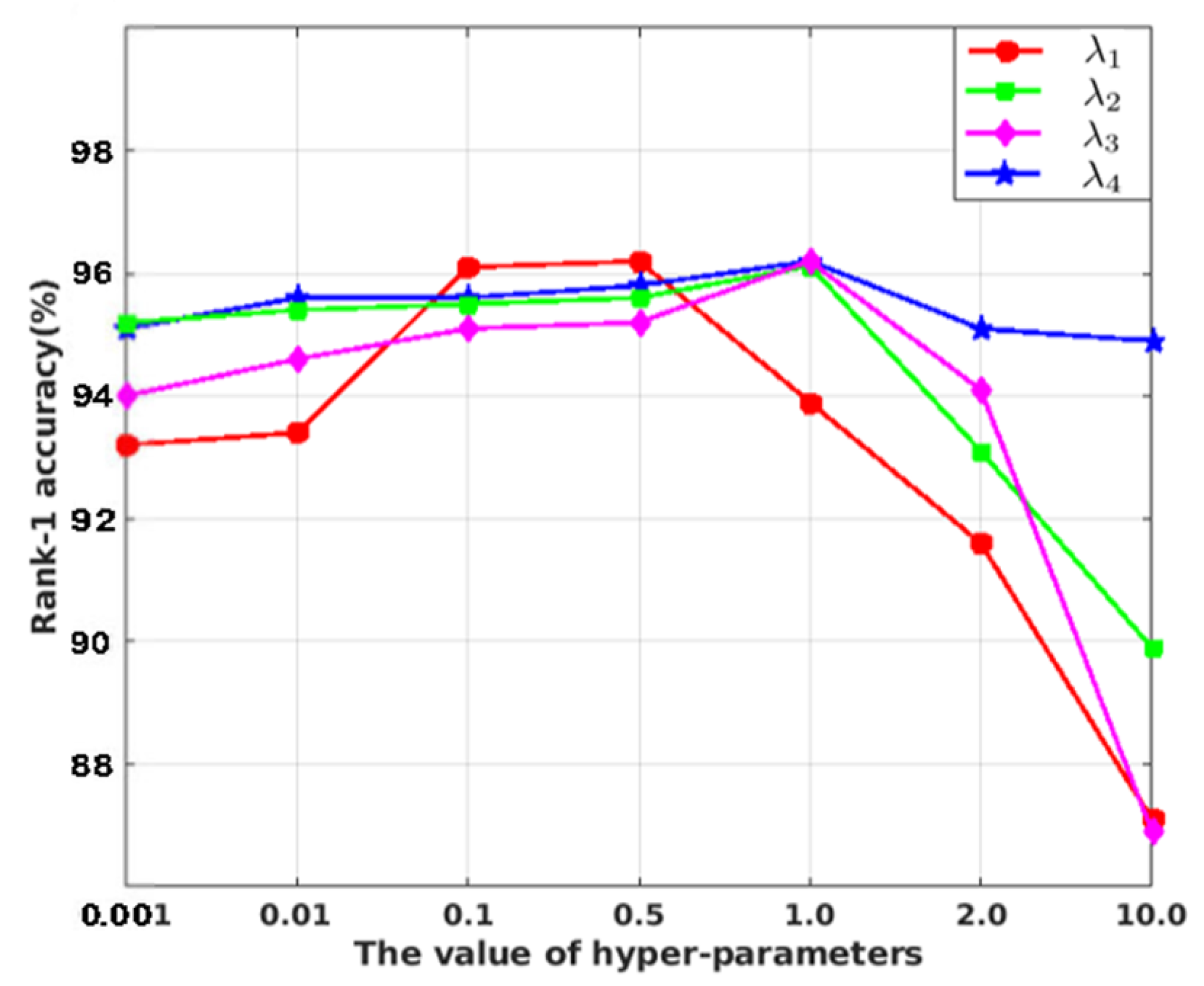
where
are hyper-parameters for different loss items. When hyper-parameters are all set to the optimal value, the final objective function is capable of learning discriminative and robust features.
Altogether, these five loss items are mutually integrated with one another. Softmax loss concentrates on the classification of vehicles and POL aims to learn diverse part-level representations by virtue of orthogonal regulations. Moreover, the PAAL loss item is beneficial to perform attention consistency in a part-level fashion. When it comes to the optimization of embedding space, the improved TriHard loss and the proposed IFCL complement each other. More specifically, the former concentrates on minimizing intra-group distance whilst the latter intends to maximize inter-group distance based on centroid features of different identities in a batch.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}