
A Novel Deep Learning Architecture with Multi-Scale Guided Learning for Image Splicing Localization



Abstract
:1. Introduction
2. Related Work
2.1. Signal Processing Methods
2.2. Deep Learning Methods
3. Proposed Methods
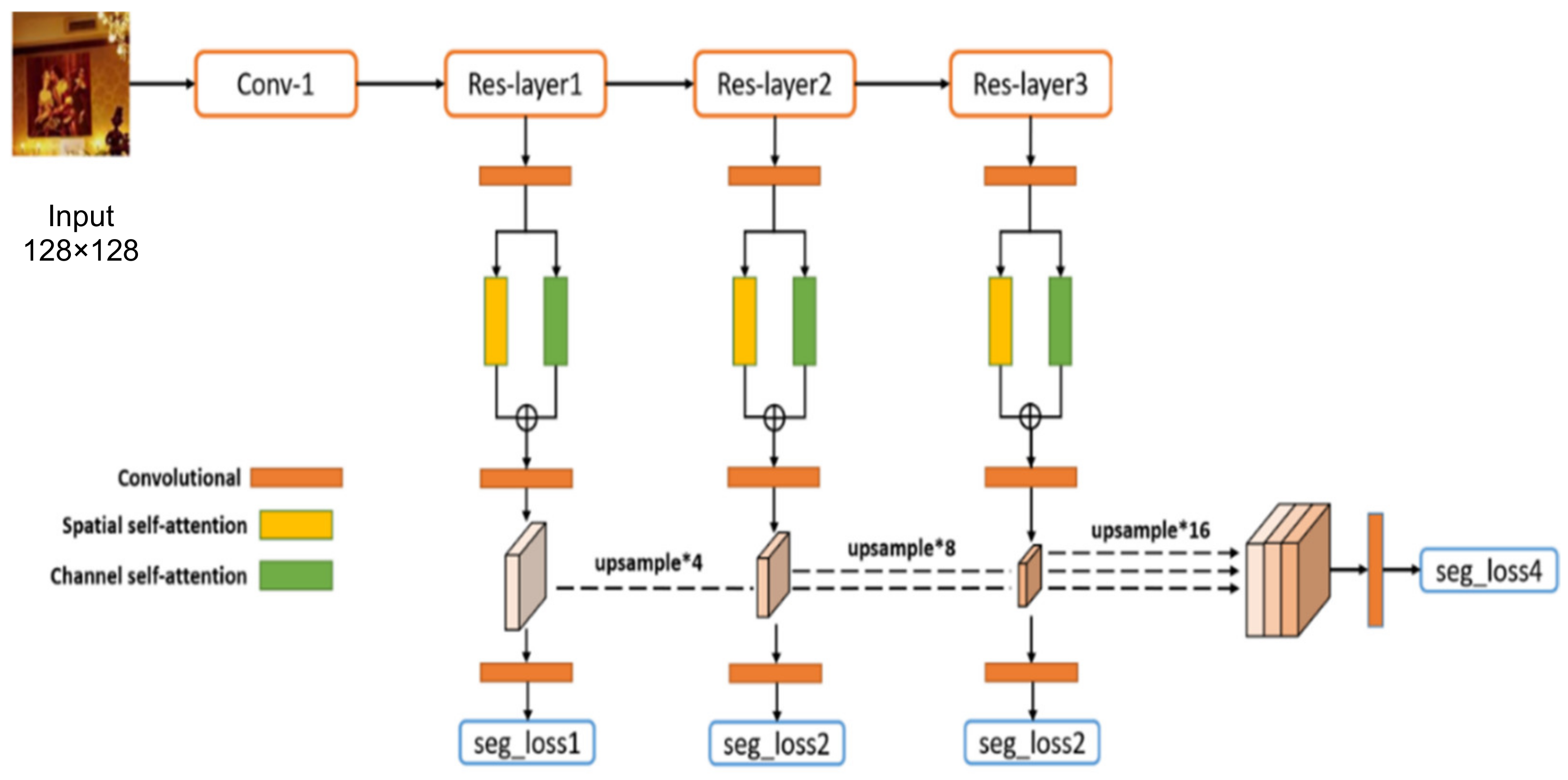
3.1. Network Architecture
3.2. Multi-Scale Guided Learning
3.3. Self-Attention Mechanisms
4. Experiments
4.1. Data Preparation
4.2. Parameters Setting
4.3. Performance Evaluation Metrics
4.4. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dirik, A.E.; Memon, N. Image tamper detection based on demosaicing artifacts. In Proceedings of the 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 1497–1500. [Google Scholar]
- Chen, M.; Fridrich, J.; Goljan, M.; Lukas, J. Determining image origin and integrity using sensor noise. IEEE Trans. Inf. Forensics Secur. 2008, 3, 74–90. [Google Scholar] [CrossRef] [Green Version]
- Cozzolino, D.; Poggi, G.; Verdoliva, L. Splicebuster: A new blind image splicing detector. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Rome, Italy, 16–19 November 2015; pp. 1–6. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 39, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bappy, J.H.; Roy-Chowdhury, A.K.; Bunk, J.; Nataraj, L.; Manjunath, B.S. Exploiting spatial structure for localizing manipulated image regions. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4970–4979. [Google Scholar]
- Salloum, R.; Ren, Y.; Kuo, C.C.J. Image splicing localization using a multi-task fully convolutional network (MFCN). J. Vis. Commun. Image Represent. 2018, 51, 201–209. [Google Scholar] [CrossRef] [Green Version]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Learning rich features for image manipulation detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 17 December 2018; pp. 1053–1061. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ferrara, P.; Bianchi, T.; De Rosa, A.; Piva, A. Image forgery localization via fine-grained analysis of CFA artifacts. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1566–1577. [Google Scholar] [CrossRef] [Green Version]
- Goljan, M.; Fridrich, J.; Filler, T. Large scale test of sensor fingerprint camera identification. In Proceedings of the SPIE, the International Society for Optics and Photonics, San Jose, CA, USA, 26–29 January 2009. [Google Scholar]
- Amerini, I.; Ballan, L.; Caldelli, R.; Bimbo, A.D.; Serra, G. A sift-based forensic method for copy–move attack detection and transformation recovery. IEEE Trans. Inf. Forensics Secur. 2011, 6, 1099–1110. [Google Scholar] [CrossRef]
- Li, W.; Yuan, Y.; Yu, N. Passive detection of doctored JPEG image via block artifact grid extraction. Signal Process. 2009, 89, 1821–1829. [Google Scholar] [CrossRef]
- Bayar, B.; Stamm, M.C. A deep learning approach to universal image manipulation detection using a new convolutional layer. In Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security, Galicia, Spain, 20–22 June 2016; pp. 5–10. [Google Scholar]
- Mayer, O.; Stamm, M.C. Forensic similarity for digital images. IEEE Trans. Inf. Forensics Secur. 2019, 15, 1331–1346. [Google Scholar] [CrossRef] [Green Version]
- Phan-Xuan, H.; Le-Tien, T.; Nguyen-Chinh, T.; Do-Tieu, T.; Nguyen-Van, Q.; Nguyen-Thanh, T. Preserving Spatial Information to Enhance Performance of Image Forgery Classification. In Proceedings of the International Conference on Advanced Technologies for Communications (ATC), Hanoi, Vietnam, 17–19 October 2019; pp. 50–55. [Google Scholar]
- Zhang, Y.; Goh, J.; Win, L.L.; Thing, V. Image Region Forgery Detection: A Deep Learning Approach. SG-CRC 2016, 2016, 1–11. [Google Scholar]
- Hammad, R. Image forgery detection using image similarity. Multimed. Tools Appl. 2020, 79, 28643–28659. [Google Scholar]
- Jindal, N. Copy move and splicing forgery detection using deep convolution neural network, and semantic segmentation. Multimed. Tools Appl. 2020, 80, 3571–3599. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Ye, S.; Sun, Q.; Chang, E.C. Detecting digital image forgeries by measuring inconsistencies of blocking artifact. In Proceedings of the IEEE International Conference on Multimedia and Expo, Beijing, China, 2–5 July 2007; pp. 12–15. [Google Scholar]
- Rozsa, A.; Zhong, Z.; Boult, T.E. Adversarial Attack on Deep Learning-Based Splice Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sets | Types | Splicing | Copy–Move | Total |
|---|---|---|---|---|
| Training Set | CASIA v2.0 | 1851 | 3272 | 5123 |
| Testing Set | CASIA v1.0 | 463 | 458 | 921 |
| Columbia | 180 | 0 | 180 | |
| DSO-1 | 100 | 0 | 100 |
| Methods | CASIA v1.0 | Columbia | DSO-1 | |||
|---|---|---|---|---|---|---|
| Score | MCC | Score | MCC | Score | MCC | |
| DCT | 0.3005 | 0.2516 | 0.5199 | 0.3256 | 0.4876 | 0.5317 |
| BLK | 0.2312 | 0.1769 | 0.5234 | 0.3278 | 0.3177 | 0.4151 |
| CNN-LSTM | 0.5011 | 0.5270 | 0.4916 | 0.5074 | 0.4223 | 0.5183 |
| MFCN | 0.5182 | 0.4935 | 0.6040 | 0.4645 | 0.4810 | 0.6128 |
| EXIF-SC | 0.6195 | 0.5817 | 0.5181 | 0.4512 | 0.5285 | 0.5028 |
| SpliceRadar | 0.5946 | 0.5397 | 0.4721 | 0.4199 | 0.4727 | 0.5429 |
| Noiseprint | 0.6003 | 0.5733 | 0.5218 | 0.4255 | 0.5085 | 0.6019 |
| Our model | 0.6457 | 0.5941 | 0.5386 | 0.4278 | 0.5187 | 0.5962 |
| Baseline | Seg_Total | Self-Attention | OHEM | Score | MCC |
|---|---|---|---|---|---|
| √ | 0.5796 | 0.5010 | |||
| √ | √ | 0.6085 | 0.5340 | ||
| √ | √ | 0.6101 | 0.5492 | ||
| √ | √ | 0.5945 | 0.5376 | ||
| √ | √ | √ | √ | 0.6457 | 0.5941 |
| Datasets | Score | ||
|---|---|---|---|
| Original (No Compression) | JPEG Quality = 90 | JPEG Quality = 70 | |
| CASIA v1.0 | 0.6457 | 0.5355 | 0.2466 |
| Columbia | 0.5386 | 0.5341 | 0.5300 |
| DSO-1 | 0.5187 | 0.5025 | 0.4712 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; You, Q.; Sun, J. A Novel Deep Learning Architecture with Multi-Scale Guided Learning for Image Splicing Localization. Electronics 2022, 11, 1607. https://doi.org/10.3390/electronics11101607
Li Z, You Q, Sun J. A Novel Deep Learning Architecture with Multi-Scale Guided Learning for Image Splicing Localization. Electronics. 2022; 11(10):1607. https://doi.org/10.3390/electronics11101607
Chicago/Turabian StyleLi, Zhongwang, Qi You, and Jun Sun. 2022. "A Novel Deep Learning Architecture with Multi-Scale Guided Learning for Image Splicing Localization" Electronics 11, no. 10: 1607. https://doi.org/10.3390/electronics11101607
APA StyleLi, Z., You, Q., & Sun, J. (2022). A Novel Deep Learning Architecture with Multi-Scale Guided Learning for Image Splicing Localization. Electronics, 11(10), 1607. https://doi.org/10.3390/electronics11101607