4.1. The 3P-Tree Structure
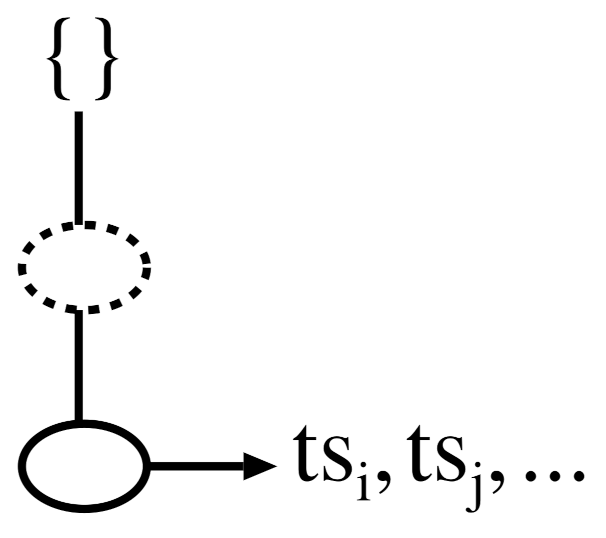
A 3P-tree consists of two components: a linear list-based data structure, named a 3P-list, and a non-linear tree-based data structure, named a prefix tree. Initially, a 3P-list is constructed by reading the complete database. It consists of two distinct components: (
i) an
item, which is denoted as i, and (
) period support, which is denoted as
and also maintains a pointer to store the link of the first node in the prefix tree that carries the item. Even though the overall representation of the items in a 3P-tree looks similar to an FP-tree, i.e., both trees arrange the items according to their support in descending order, the nodes in a 3P-tree are named ordinary nodes and tail nodes. The former is a node that is similar to that used in an FP-tree [
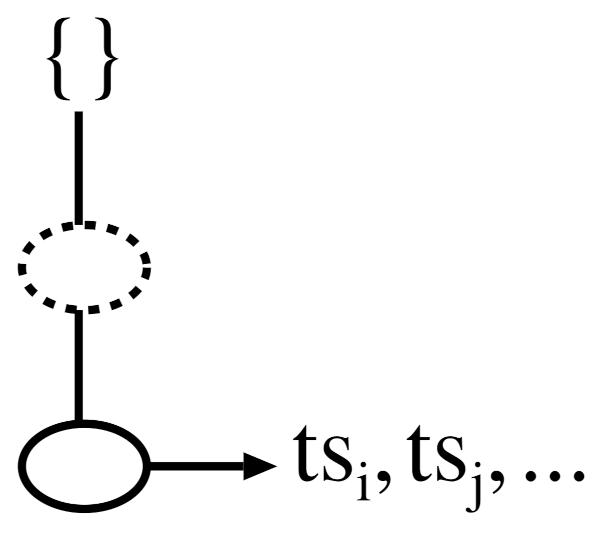
8]. In contrast, the latter represents the temporal occurrence information of the last item of any sorted transaction. The 3P-tree maintains a particular data structure, named a
-list, in the tail nodes to preserve the temporal information. Hence, the structure of a
node is
and
, where
k is the item name of the node and
is the time stamp of the transaction that contains the items from the
up to the node
k.
Figure 1 depicts the conceptual structure of a 3P-tree. Each node in a 3P-tree has parent, children, and node traversal pointers, as with an FP-tree. Please note that, unlike an FP-tree, none of the nodes in a 3P-tree preserve the support count. The items in the prefix tree are organized in descending order of support to permit a high degree of compactness.
It can be assumed that the structure of the prefix tree in a 3P-tree may not be memory-efficient since it explicitly preserves the time stamps of each transaction. However, it has been suggested that such a tree could achieve memory efficiency by only retaining transaction information in the tail nodes and omitting the support count field at each node [
17]. Furthermore, 3P-trees avoid the complicated combinatorial explosion problem of candidate generation, unlike Apriori-like algorithms [
20]. On the other hand, keeping transactional identifier information in a tree can lead to inefficient frequent pattern mining [
37] and periodic frequent pattern mining [
17].
4.2. Construction of a 3P-Tree
The construction of a 3P-tree is a two-step process. First, a 3P-list is built by reading the complete database at once and generating 1-patterns (one-length partial periodic patterns). After that, the prefix tree is built as the generated partial periodic patterns satisfy the anti-monotonic properties. The user-defined parameters
and
are then used to discard the uninteresting (or aperiodic) patterns.
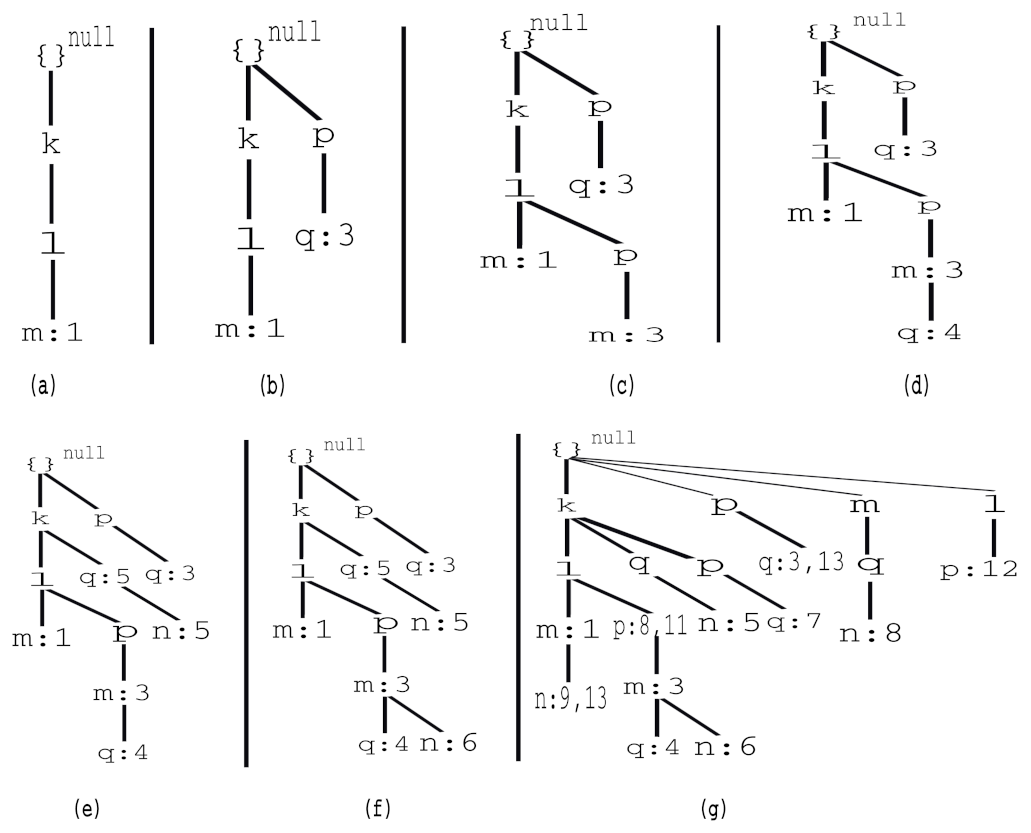
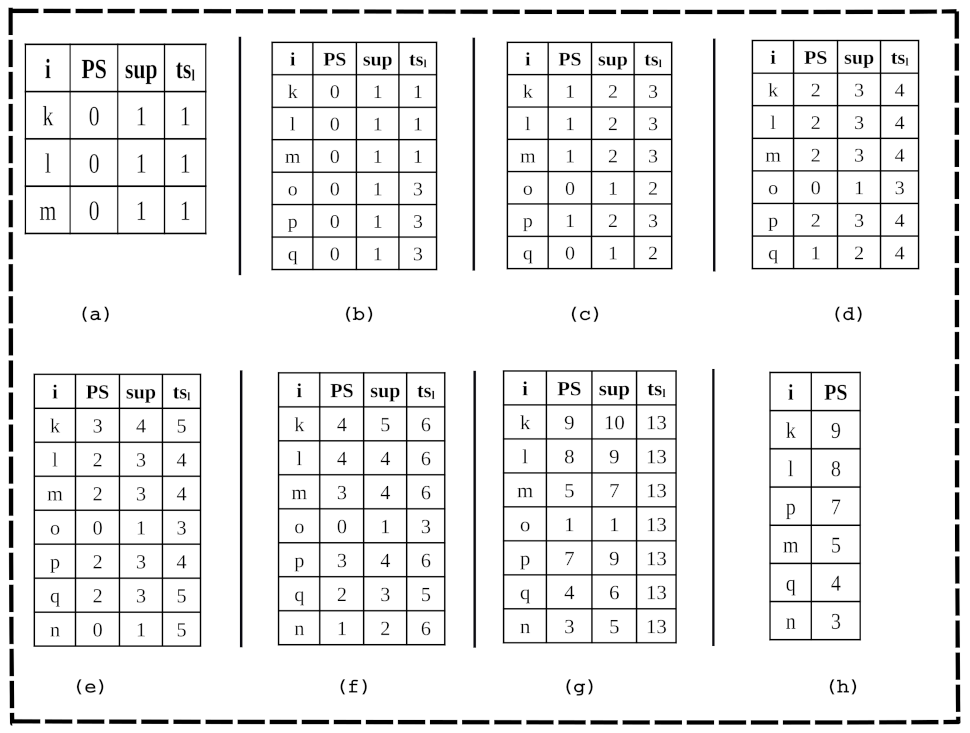
Figure 2 demonstrates how Algorithm 1 was used to create a 3P-list for
Table 2. In this study, we fixed the values of both
and
at two.
In this study, we used two temporary lists to build the complete 3P-list structure. We let
be a temporary list variable that was used to hold the
information of the items and
also be a temporary list variable that was used to hold the time of the last occurrence of an item, i.e.,
. After reading the first transaction of 1001:1:
, items
k,
l, and
m were inserted into the 3P-list and their
, and
values were set as
, and 1, respectively (lines 5 and 6 in Algorithm 1).
Figure 2a shows the 3P-list that was generated after reading the first transaction. After reading the second transaction of 1002:3:
, items
o,
p, and
q were inserted into the 3P-list and their
, and
values were set as
, and 3, respectively.
Figure 2b shows the 3P-list that was generated after reading the second transaction. After reading the third transaction of 1003:3:
, the
, and
values of the items
o,
p, and
q were kept in the 3P-list without any change. In addition, the
, and
values of existing items
k,
l,
m, and
p were updated to
, and 3, respectively (lines 8 to 10 in Algorithm 1).
Figure 2c shows the 3P-list that was generated after reading the third transaction. After reading the fourth transaction of 1004:4:
, the
, and
values of the item
o were kept in the 3P-list without any change. In addition, the
, and
values of existing items
k,
l,
m, and
p were updated to
, and 4, respectively, and for item
q, the
, and
values were updated to
, and 4, respectively.
Figure 2d shows the 3P-list that was generated after reading the fourth transaction. After reading the fifth transaction of 1005:5:
, item
n was inserted into the 3P-list by setting its
, and
values to
, and 5, respectively, and maintaining the
, and
values of the items
l,
m,
o, and
p in the 3P-list without any change. In addition, the
, and
values of existing item
k were updated to
, and 5, respectively. The
, and
values of existing item
q were also updated to
, and 5, respectively.
Figure 2e shows the 3P-list that was generated after reading the fifth transaction. After reading the sixth transaction of 1006:6:
, the
, and
values of the items
o and
p were maintained in the 3P-list without any change. In addition, the
, and
values of existing items
l,
m, and
p were updated to
, and 6, respectively. The
, and
values of existing item
k were also updated to
, and 6, respectively. The
, and
values of existing item
n were updated to
, and 6, respectively.
Figure 2f shows the 3P-list that was generated after reading the sixth transaction. A similar procedure was followed for the remaining transactions that were available in the database and generated the complete 3P-list structure. The full 3P-list, which was generated after reading the complete database, is shown in
Figure 2g. Finally, some of the aperiodic patterns that were available in the 3P-list were pruned based on the user-defined
value, i.e., item
o was pruned from the 3P-list as its
value was less than the
value. As a result, only one-length partial periodic patterns were displayed and these patterns were sorted in descending order based on their support (
) values (line 11 in Algorithm 1).
Figure 2h shows the final 3P-list, which contained a sorted list of all of the partial periodic items. We let
denote this sorted list of partial periodic items.
| Algorithm 1 Construction of 3P-list: , temporal database; I, set of items; , minimum period support; , period |
| 1: The of the last occurring transactions of all items in the 3P-list are explicitly recorded in a temporary array called for each item. Similarly, all items in the 3P-list have their explicitly recorded in another temporary array called . (To achieve memory efficiency, the 3P-tree will be built in the support descending order of items.) After finding partial periodic items (or 1-patterns), these two arrays can be ignored. |
| 2: Let denote the current transaction with identifier , representing the time stamp, and Y as a pattern, respectively; |
| 3: for each transaction do |
| 4: for each item do |
| 5: if j does not exist in 3P-list then |
| 6: Add j to the 3P-list and set , and ; |
| 7: else |
| 8: if then |
| 9: Set ; |
| 10: Set and ; |
| 11: Prune any aperiodic items from the 3P-list with a period support value of less than . Then, consider the remaining items in the 3P-list as partial periodic items, and sort them by in descending order. The symbol denotes this sorted list of items.
|
We conducted another scan of the database after discovering the partial periodic items and created the prefix tree of the 3P-tree, as shown in Algorithms 2 and 3. These are the same algorithms that are used to build an FP-tree [
8]. The primary distinction is that, unlike an FP-tree, none of the nodes in a 3P-tree keep track of the
count.
The 3P-tree in this study was constructed as follows. We created the root node of the tree and labeled it
. Then, we scanned the database once more. The items of each transaction were processed in
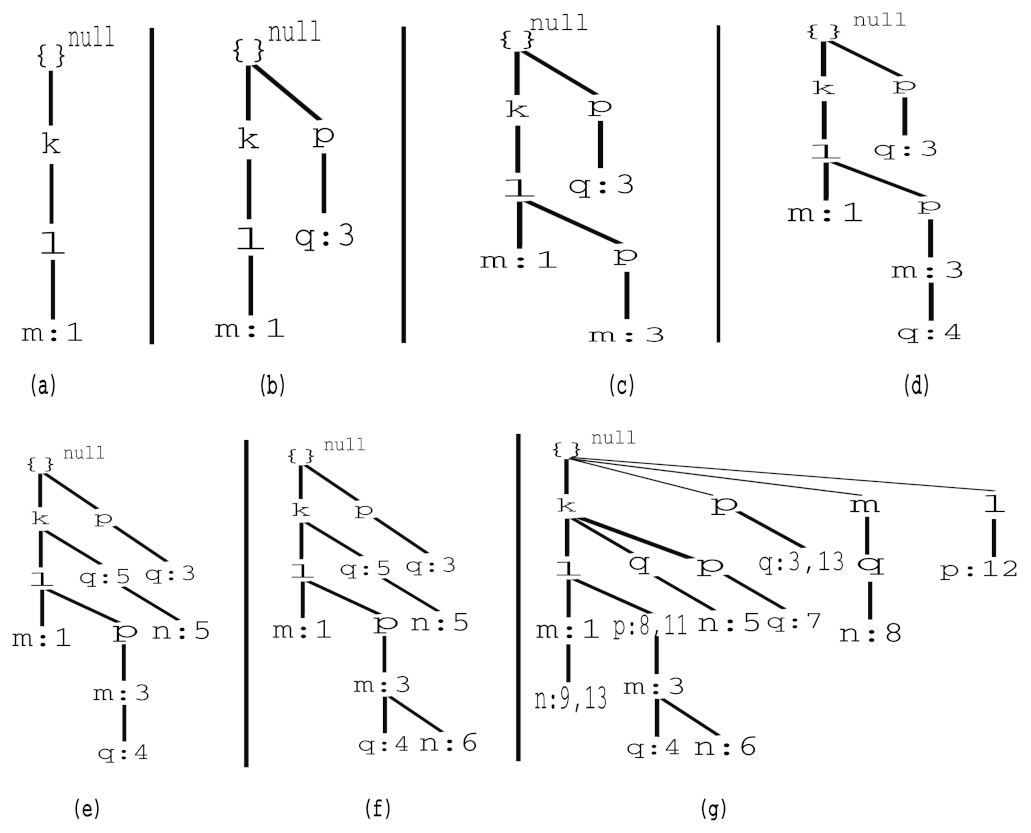
order (i.e., sorted according to descending support count). For each transaction, a branch was created so that only the tail nodes recorded the transaction time stamps. For instance, the scan of the first transaction of 1001:1:
, which contained three items (
k,
l, and
m in
order), resulted in the first branch of the tree being built with three nodes:
,
, and
, where
m is linked as a child of the root,
l is linked as a child of the node
k, and finally,
is linked as a child of the node
l.
Figure 3a shows the 3P-tree that was formed after scanning the first transaction. The second transaction of
, which had items
p and
q in
order, resulted in a branch in which
p was linked as a child of the root and
was linked as a child of the node
p.
Figure 3b shows the 3P-tree that was formed after scanning the second transaction. The third transaction of
, which had items
k,
l,
p, and
m in
order, resulted in a branch in which
p was linked as a child of the node
l and
was linked as a child of the node
p.
Figure 3c shows the 3P-tree that was formed after scanning the third transaction. The fourth transaction of
, which had items
k,
l,
p,
m, and
q in
order, resulted in a branch in which
was linked as a child of the node
. On the other hand, this branch shared the prefix
with the current path of the third transaction.
Figure 3d shows the 3P-tree that was formed after scanning the fourth transaction. The fifth transaction of
, which had items
k,
q, and
n in
order, resulted in a branch in which
n was linked as a child of the node
k and
was linked as a child of the node
q.
Figure 3e shows the 3P-tree that was formed after scanning the fifth transaction. The sixth transaction of
, which had items
k,
l,
p,
m, and
n in
order, resulted in a branch in which
was linked as a child of the node
.
Figure 3f shows the 3P-tree that was formed after scanning the sixth transaction. The remaining transactions were processed in the same way and the tree was updated accordingly.
Figure 3g shows the 3P-tree that was built after scanning the entire database. For clarity, we do not display the node traversal pointers in the trees; however, they were maintained the same way as those in an FP-tree.
| Algorithm 2 3P-tree: , 3P-list |
| 1: A root node is created for the 3P-tree and label it as “”; |
| 2: for each transaction do |
| 3: Set the corresponding transaction’s time stamp to ; |
| 4: Choose and sort the partial periodic items in t according to ’s order. Let’s say the sorted candidate item list in t is , with p being the first item and P being the rest of the list; |
| 5: Call ;
|
| Algorithm 3 Insert tree: , , T |
| 1: whileP is non-empty do |
| 2: if T has a child N such that then |
| 3: Make a new node N. Allow its parent link to point to T. Allow its node-link to be linked to nodes that have the same itemName using the node-link structure. p should be removed from P; |
| 4: Add to the leaf node;
|
The 3P-tree stored the complete information of all of the partial periodic patterns in the database. Property 2 was used to determine the correctness, as shown in Lemmas 2 and 3, where is the set of all partial periodic items in t for each transaction , i.e., , and was named as the partial periodic item projection of t.
Property 2. For each transaction in a database, a 3P-tree only keeps a complete set of partial periodic item projections once.
Lemma 2. A 3P-tree can be used to derive a complete set of all of the partial periodic item projections of all transactions in the for a set and user-defined and values.
Proof. According to Property 1, each transaction is mapped onto just one path in the tree and any path from the up to a node keeps the complete projection for exactly d transactions, where d is the total number of entries in the -list of the node. □
Lemma 3. The size of a 3P-tree (without the root node) in a for the user-specified and values is bounded by .
Proof. Each transaction t contributes at most one path of size to the 3P-tree, according to the 3P-tree construction process and Lemma 2. As a result, at best, the overall size contribution of all transactions is . The size of the 3P-tree is significantly smaller than since there are usually numerous common prefix patterns throughout the transactions. □
4.3. Mining Partial Periodic Patterns
Even though the overall representation of items in a 3P-tree is similar to that in an FP-tree, i.e., both the trees arrange the items according to their support in descending order, we could not directly utilize the FP-growth algorithm to mine the 3P-tree because FP-trees do not maintain the temporal information of the transactions. In contrast, 3P-trees maintain a particular data structure, named a -list, in each tail node to preserve the temporal information. We also designed a novel pattern-growth-based algorithm to generate partial periodic patterns in a bottom-up manner. We utilized the following property and lemma of 3P-trees as part of this algorithm.
Property 3. In a 3P-tree, a tail node keeps track of the temporal occurrence information of the patterns for all nodes in the path (from the tail node to the root), at least in its ts-list.
Lemma 4. Let be a path in a 3P-tree where node is the tail node that carries the -list of the path. When the -list is pushed up to node , then keeps the temporal occurrence information of the path for the same set of transactions in the ts-list without losing any information.
Proof. According to Property 3, keeps track of the occurrences of path in the transactions in its -list, at least. As a result, the same -list at node keeps the same transaction information for with no losses. □
In this study, the 3P-tree was mined in the following manner: (i) the mining process was initiated with each partial periodic item being named as the initial suffix pattern; () subsequently, the conditional pattern base of this pattern was built, i.e., a sub-database that consisted of the sets of prefix paths in the 3P-tree that co-occurred with the suffix patterns was created and its conditional 3P-tree was built to mine recursively; () finally, the suffix patterns with the patterns that were generated by the conditional 3P-tree were concatenated, which resulted in the generation of partial periodic patterns.
Algorithms 4 and 5 show the procedure for discovering partial periodic patterns in a 3P-tree. The working of these algorithms was as follows. Starting with the bottom-most item, i.e.,
k, we built the conditional pattern base (or prefix tree) for each partial periodic item in the 3P-list. The prefix sub-paths of node
k were accumulated in a tree structure
to construct the prefix tree for
k. Since
k was the bottom-most item in the 3P-list, every node in the 3P-tree that was labeled
k had to be a tail node. Based on Property 3, we explicitly mapped the
-list of each node of
k onto all of the items in the corresponding path in the temporary array (one for each item) while constructing
. The calculation of
period support for each item in
was made easier using this temporary array (line 2 in Algorithm 4). For example, when item
l in
had
, we built a conditional tree for it and mined it recursively to find partial periodic patterns (lines 3 to 6 in Algorithm 4 and the entire Algorithm 5). Furthermore, according to Lemma 4, the
-lists were pushed up to the respective parent nodes in the original 3P-tree as well as in
to enable the construction of the prefix tree for the next item in the 3P-list. Following that, all
k nodes in the original 3P-tree and
k entries in the 3P-list were deleted (line 7 in Algorithm 4).
| Algorithm 4 3P-growth: , |
| 1: for each in the header of Tree do |
| 2: Generate pattern . Collect all of the ts-lists into a temporary array, , and calculate by calling ; |
| 3: if then |
| 4: Construct ’s conditional pattern base then ’s conditional 3P-tree ; |
| 5: if then |
| 6: call 3P-growth(, ); |
|
7: Prune from the and push the ’s ts-list to its parent nodes;
|
| Algorithm 5 Calculate period support: , a list of time stamps that contained in the |
| 1: Set ; |
| 2: for ; ;do |
| 3: if then |
| 4: ; |
| 5: return |
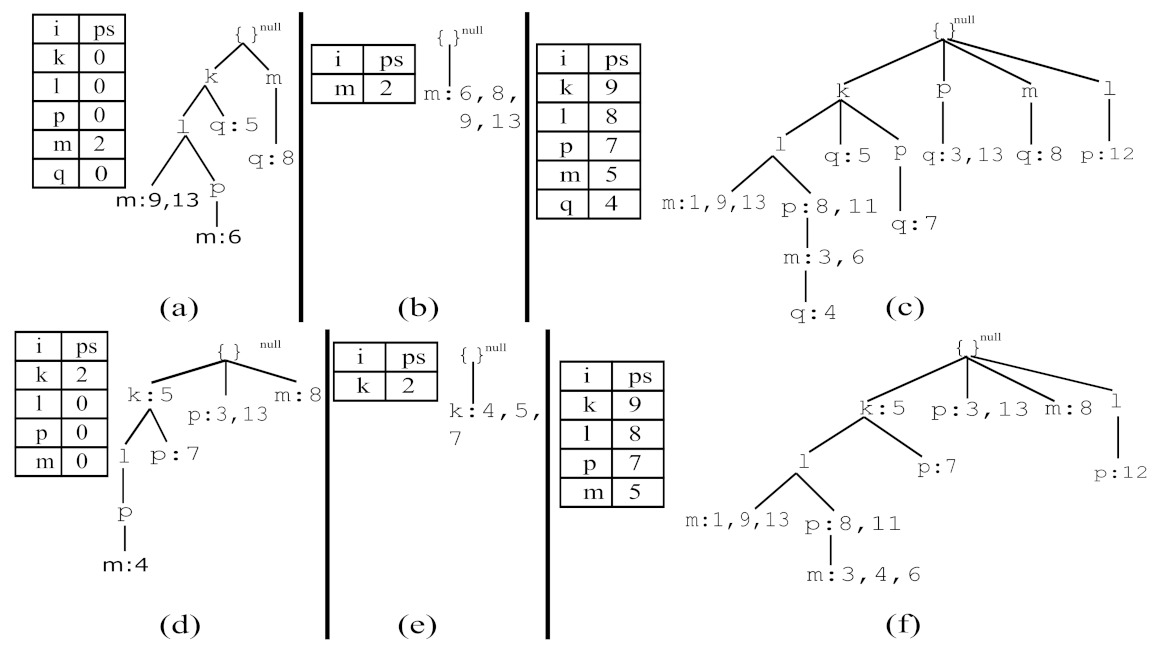
Considering item
n, which was the last item in the 3P-list, as shown in
Figure 2h, we used the 3P-tree shown in
Figure 3g to construct a prefix tree for an item
n, which was called
and is presented in
Figure 4a. It was also named as a conditional pattern base and is represented as a tuple entry in the second column of
Table 3, under the item
n. In
, there were five items:
, and
q. Only item
m fulfilled the condition
. As a result, the conditional tree
from
was built with only one item,
m, as shown in
Figure 4b. It was also named as a conditional 3P-tree and is represented as a tuple entry in the third column of
Table 3, under the item
n.
was generated using the
-list of
m in
. Algorithm 5 was used to calculate the
period support of
. Since
,
was treated as a partial periodic pattern and is represented as a tuple entry, along with its
period support, in the fourth column of
Table 3, under the item
n. Then, as illustrated in
Figure 4c,
n was pruned from the original 3P-tree and its
-lists were moved to its parent. Next, we chose the item
q, which was the next last item in the 3P-list, as shown in
Figure 2h. We used the 3P-tree shown in
Figure 4c to construct a prefix tree for an item
q, which was called
and is presented in
Figure 4d. It was also named as a conditional pattern base and is represented as a tuple entry in the second column of
Table 3, under the item
q. In
, there were four items:
, and
p. Only item
k fulfilled the condition
. As a result, the conditional tree
from
was built with only one item,
k, as shown in
Figure 4e. It was also named as a conditional 3P-tree and is represented as a tuple entry in the third column of
Table 3, under the item
q.
was generated using the
-list of
k in
. Algorithm 5 was used to calculate the
period support of
. Since
,
was treated as a partial periodic pattern and is represented as a tuple entry, along with its
period support, in the fourth column of
Table 3, under the item
q. Then, as illustrated in
Figure 4f,
q was pruned from the 3P-tree, as shown in
Figure 4c, and its
-lists were moved to its parent. A similar process was repeated until the 3P-list
. The complete mining process of the 3P-tree that is shown in
Figure 3h is represented in
Table 3.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}