
A Distributed Edge-Based Scheduling Technique with Low-Latency and High-Bandwidth for Existing Driver Profiling Algorithms




Abstract
1. Introduction
- We present a new architecture for driver-profiling with deep learning techniques in cars with embedded system.
- We achieve a greater number of responses from a driver profiling service.
- We successfully re-implement all the algorithms in an edge server environment.
- We conduct extensive experiments to confirm the advantages of our approach.
2. Related Work
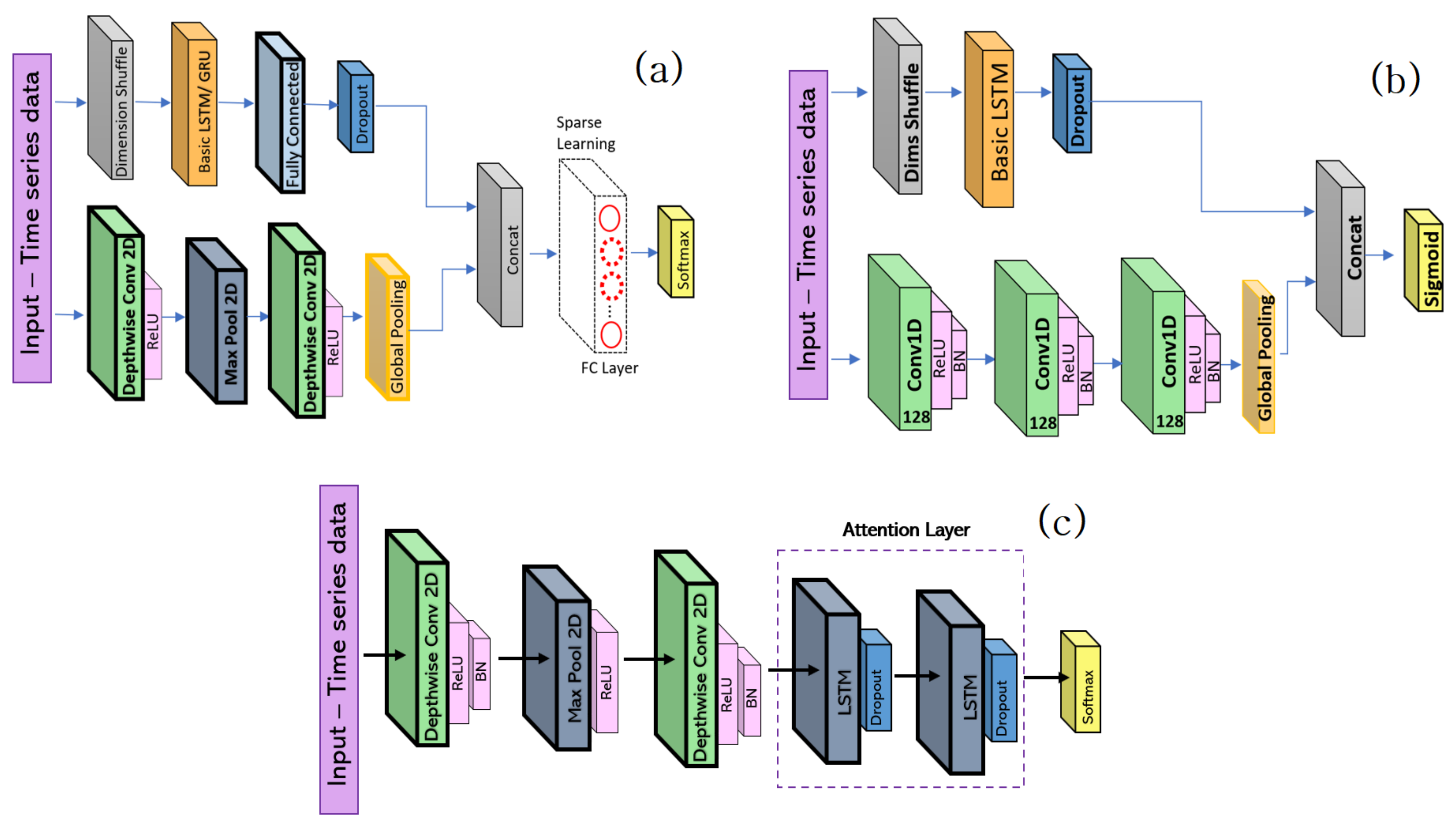
2.1. Existing Driver-Profiling Deep Learning Models
2.2. Applied Embedded Deep Learning Platforms
| Algorithm 1: The traditional EDPA [6,8,11] |
 |
3. Edge-Based Data Scheduling for FCN-LSTM Driver Profiling
| Algorithm 2: The proposed EDPA |
 |
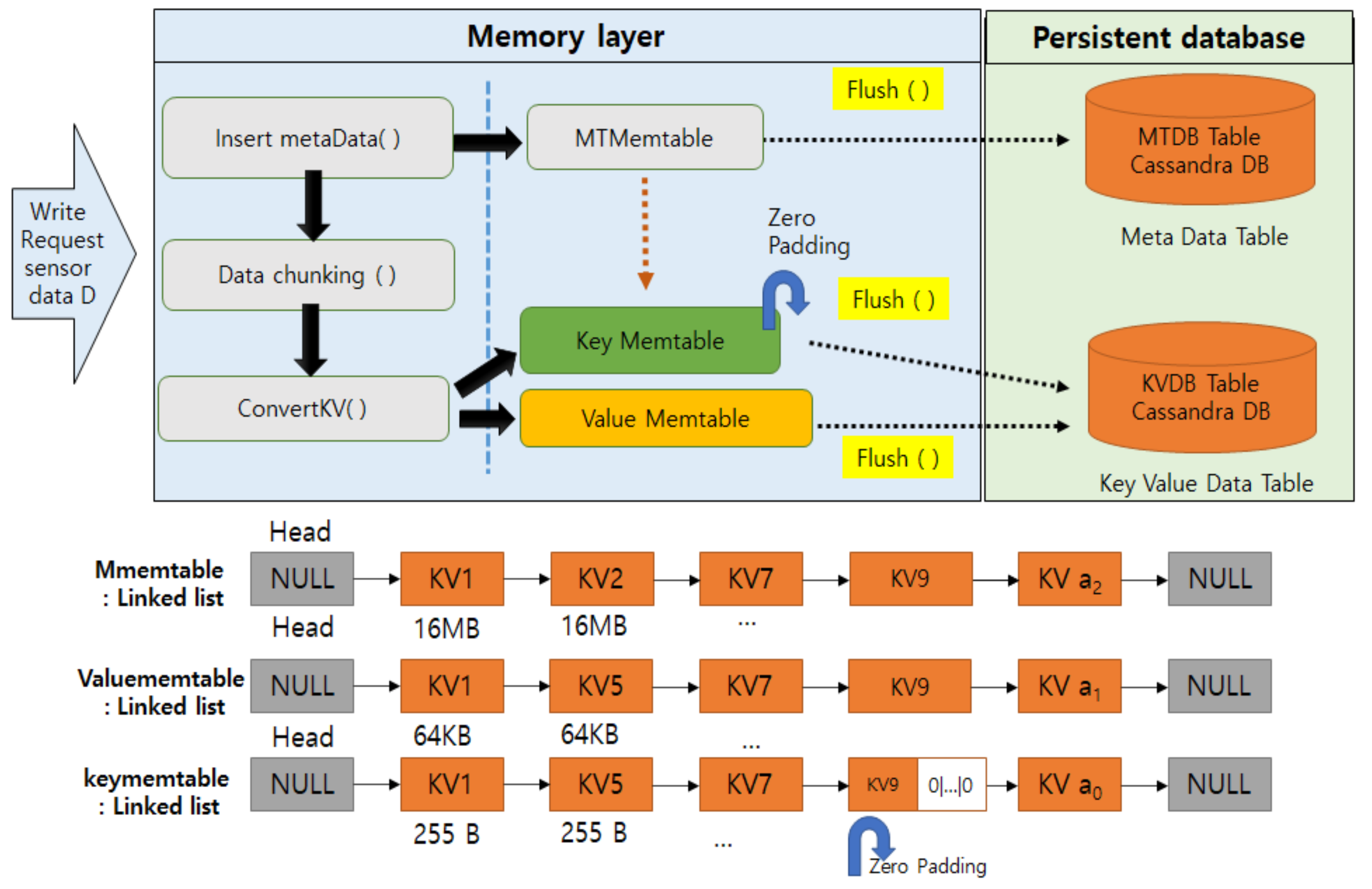
In-Memory Data Scheduler
| Algorithm 3: Data scheduling in Insert_cache function |
 |
4. Experimental Results
4.1. Data Sources
4.2. Hardware Settings
4.3. Evaluation of Driver Profiling
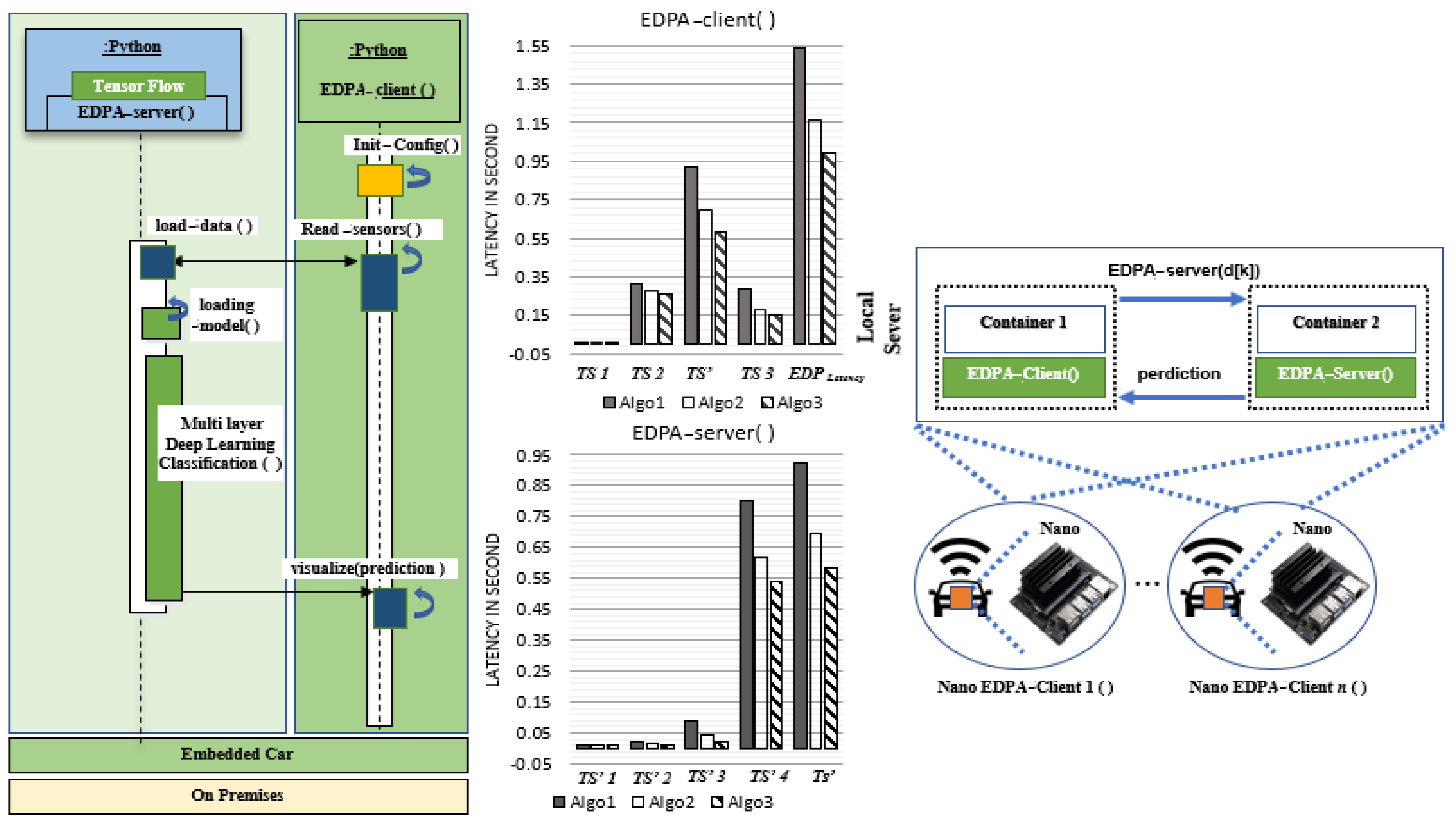
- In the traditional EDPA, EDPA-Client( ) and EDPA-Server( ) are located in different containers inside each Embedded Nano board, which clearly shows they have a 1:1 relationship. Therefore, in the traditional EDPA, Algorithm 1 does not have a loop structure in client/server, but Algorithm 2 does. In the proposed EDPA, Algorithm 2, EDPA-Server( ) uses Node.js applications which employ multiple workers in parallel which clearly show they are having 1:4 relationship. Besides, we can scale the number of Node.js applications using the load balancer. In the proposed EDPA-server function, initialization latency , memory allocation latency , and trained model loading latency are excluded from end-to-end latency , which results in improving and reducing the average of the EDPA system.
- The function driver_profiling employs the light-weight FCN-LSTM, which execute five requests per second.
- The proposed EDPA-server function connects four embedded cars via the in-memory scheduler, and at the same time uses four Node.js workers.
- The proposed EDPA-server function operates four Node.js workers in parallel.
- Each proposed EDPA-client activates a Nodejs worker using the check_server REST API.
- Each in-memory scheduler thread allocates key, value, and meta information related to each data sensor file using a linked-list structure in parallel.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kwak, B.I.; Woo, J.; Kim, H.K. Know your master: Driver profiling-based anti-theft method. In Proceedings of the 2016 14th Annual Conference on Privacy, Security and Trust (PST), Auckland, New Zealand, 12–14 December 2016; pp. 211–218. [Google Scholar]
- Zhang, X.; Zhao, X.; Rong, J. A study of individual characteristics of driving behavior based on hidden markov model. Sens. Transducers 2014, 167, 194–202. [Google Scholar]
- Miyajima, C.; Nishiwaki, Y.; Ozawa, K.; Wakita, T.; Itou, K.; Takeda, K.; Itakura, F. Driver modeling based on driving behavior and its evaluation in driver identification. Proc. IEEE 2007, 95, 427–437. [Google Scholar] [CrossRef]
- Fugiglando, U.; Massaro, E.; Santi, P.; Milardo, S.; Abida, K.; Stahlmann, R.; Netter, F.; Ratti, C. Driving behavior analysis through CAN bus data in an uncontrolled environment. IEEE Trans. Intell. Transp. Syst. 2018, 20, 737–748. [Google Scholar] [CrossRef]
- Van Ly, M.; Martin, S.; Trivedi, M.M. Driver classification and driving style recognition using inertial sensors. In Proceedings of the 2013 IEEE Intelligent Vehicles Symposium (IV), Gold Coast City, Australia, 23–26 June 2013; pp. 1040–1045. [Google Scholar]
- Zhang, J.; Wu, Z.; Li, F.; Xie, C.; Ren, T.; Chen, J.; Liu, L. A deep learning framework for driving behavior identification on in-vehicle CAN-BUS sensor data. Sensors 2019, 19, 1356. [Google Scholar] [CrossRef] [PubMed]
- Ha, S.; Choi, S. Convolutional neural networks for human activity recognition using multiple accelerometer and gyroscope sensors. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 381–388. [Google Scholar]
- El Mekki, A.; Bouhoute, A.; Berrada, I. Improving Driver Identification for the Next-Generation of In-Vehicle Software Systems. IEEE Trans. Veh. Technol. 2019, 68, 7406–7415. [Google Scholar] [CrossRef]
- Li, M.G.; Jiang, B.; Che, Z.; Shi, X.; Liu, M.; Meng, Y.; Ye, J.; Liu, Y. DBUS: Human Driving Behavior Understanding System. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Ramanishka, V.; Chen, Y.T.; Misu, T.; Saenko, K. Toward driving scene understanding: A dataset for learning driver behavior and causal reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7699–7707. [Google Scholar]
- Ullah, S.; Kim, D.-H. Lightweight Driver Behavior Identification Model with Sparse Learning on In-Vehicle CAN-BUS Sensor Data. Sensors 2020, 20, 5030. [Google Scholar] [CrossRef] [PubMed]
- Automotive Grade Linux. 2020. Available online: https://www.automotivelinux.org/ (accessed on 18 April 2020).
- Brookhuis, K.A.; De Waard, D.; Janssen, W.H. Behavioural impacts of advanced driver assistance systems—An overview. Eur. J. Transp. Infrastruct. Res. 2001, 1. [Google Scholar] [CrossRef]
- Curry, E.; Sheth, A. Next-generation smart environments: From system of systems to data ecosystems. IEEE Intell. Syst. 2018, 33, 69–76. [Google Scholar] [CrossRef]
- Mittal, S. A Survey on optimized implementation of deep learning models on the NVIDIA Jetson platform. J. Syst. Archit. 2019, 97, 428–442. [Google Scholar] [CrossRef]
- Kim, C.E.; Oghaz, M.M.; Fajtl, J.; Argyriou, V.; Remagnino, P. A comparison of embedded deep learning methods for person detection. arXiv 2018, arXiv:1812.03451. [Google Scholar]
- Tulkinbekov, K.; Pirahandeh, M.; Kim, D.-H. CLeveldb: Coalesced leveldb for small data. In Proceedings of the 2019 Eleventh International Conference on Ubiquitous and Future Networks (ICUFN), Zagreb, Croatia, 2–5 July 2019; pp. 567–569. [Google Scholar]
- Song, T.G.; Pirahandeh, M.; Ahn, C.J.; Kim, D.H. GPU-accelerated high-performance encoding and decoding of hierarchical RAID in virtual machines. J. Supercomput. 2018, 74, 5865–5888. [Google Scholar] [CrossRef]
- Pirahandeh, M.; Kim, D.-H. Energy-aware RAID scheduling methods in distributed storage applications. Clust. Comput. 2019, 22, 445–454. [Google Scholar] [CrossRef]
- Pirahandeh, M.; Kim, D.-H. EGE: A New Energy-Aware GPU Based Erasure Coding Scheduler for Cloud Storage Systems. In Proceedings of the 2018 Tenth International Conference on Ubiquitous and Future Networks (ICUFN), Prague, Czech Republic, 3–6 July 2018; pp. 619–621. [Google Scholar]
- Pirahandeh, M.; Kim, D.-H. High performance GPU-based parity computing scheduler in storage applications. Concurr. Comput. Pract. Exp. 2017, 29, e3889. [Google Scholar] [CrossRef]
- Diogo, M.; Cabral, B.; Bernardino, J. Consistency models of NoSQL databases. Future Internet 2019, 11, 43. [Google Scholar] [CrossRef]
- Gupta, A.; Tyagi, S.; Panwar, N.; Sachdeva, S.; Saxena, U. NoSQL databases: Critical analysis and comparison. In Proceedings of the 2017 International Conference on Computing and Communication Technologies for Smart Nation (IC3TSN), Gurgaon, India, 12–14 October 2017; pp. 293–299. [Google Scholar]
- Kabakus, A.T.; Kara, R. A performance evaluation of in-memory databases. J. King Saud Univ. Comput. Inf. Sci. 2017, 29, 520–525. [Google Scholar] [CrossRef]
- Kang, Y.G.; Park, K.H.; Kim, H.K. Automobile theft detection by clustering owner driver data. arXiv 2019, arXiv:1909.08929. [Google Scholar]
- Park, K.H.; Kim, H.K. This Car is Mine!: Automobile Theft Countermeasure Leveraging Driver Identification with Generative Adversarial Networks. arXiv 2019, arXiv:1911.09870. [Google Scholar]
- Castignani, G.; Derrmann, T.; Frank, R.; Engel, T. Driver behavior profiling using smartphones: A low-cost platform for driver monitoring. IEEE Intell. Transp. Syst. Mag. 2015, 7, 91–102. [Google Scholar] [CrossRef]
- Kashevnik, A.; Lashkov, I.; Gurtov, A. Methodology and Mobile Application for Driver Behavior Analysis and Accident Prevention. IEEE Trans. Intell. Transp. Syst. 2019, 21, 2427–2436. [Google Scholar] [CrossRef]
- Warren, J.; Lipkowitz, J.; Sokolov, V. Clusters of driving behavior from observational smartphone data. IEEE Intell. Transp. Syst. Mag. 2019, 11, 171–180. [Google Scholar] [CrossRef]
- Ferreira, J.; Carvalho, E.; Ferreira, B.V.; de Souza, C.; Suhara, Y.; Pentland, A.; Pessin, G. Driver behavior profiling: An investigation with different smartphone sensors and machine learning. PLoS ONE 2017, 12, e0174959. [Google Scholar] [CrossRef] [PubMed]
- Fridman, L.; Brown, D.E.; Glazer, M.; Angell, W.; Dodd, S.; Jenik, B.; Terwilliger, J.; Kindelsberger, J.; Ding, L.; Seaman, S.; et al. Mit autonomous vehicle technology study: Large-scale deep learning based analysis of driver behavior and interaction with automation. arXiv 2017, arXiv:1711.06976. [Google Scholar]
- Taamneh, S.; Tsiamyrtzis, P.; Dcosta, M.; Buddharaju, P.; Khatri, A.; Manser, M.; Ferris, T.; Wunderlich, R.; Pavlidis, I. A multimodal dataset for various forms of distracted driving. Sci. Data. 2017, 4, 170110. [Google Scholar] [CrossRef] [PubMed]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Karim, F.; Mujamdar, S.; Darabi, H.; Chen, S. LSTM fully convolutional networks for time series classification. IEEE Access 2017, 6, 1662–1669. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Representation | Applied Function |
|---|---|---|
| Initialization latency | EDPA-client( ) | |
| Read latency from sensors | EDPA-client( ) | |
| Visualization latency | EDPA-client( ) | |
| Insert data to cache | EDPA-client( ) | |
| Delay | EDPA-client( ) | |
| Initialization latency | EDPA-server( ) | |
| Memory allocation latency | EDPA-server( ) | |
| Trained model loading latency | EDPA-server( ) | |
| Driver profiling latency | EDPA-server( ) | |
| Latency when requesting a job | EDPA-server( ) | |
| Latency when updating prediction | EDPA-server( ) | |
| Total classification latency | EDPA-client( ) | |
| End-to-end latency | Embedded system |
| EDPA Reference | DA | DST | SAT | RHL | SL | EEL |
|---|---|---|---|---|---|---|
| Algorithm 1 [6] | DeepConvRNN-Attention | - | Sequential processing | Low | Low | Low |
| Algorithm 2 [8] | FCN-LSTM | - | Sequential processing | Low | Low | Low |
| Algorithm 3 [11] | light-weight FCN-LSTM | - | Sequential processing | Low | Low | Medium |
| This work | FCN-LSTM, DeepConvRNN-Attention, light-weight FCN-LSTM | Yes | Distributed-Parallel processing | High | High | High |
| Domain | Platform | Hardware Specifications | Implementation Details |
|---|---|---|---|
| Edge Server | Desktop | CPU: Intel Core.i7, RAM: 4 GB, NVME: 128 GB | An edge-Server for four clients |
| Embedded system | Jetson Nano | CPU: ARM Cortex-A57, RAM: 4 GB, HDD: 128 GB | A local server for a client * |
| Input | Algorithm | Accuracy (%) | FLOPs * | Memory | Feature Engineering | Windowing |
|---|---|---|---|---|---|---|
| 60 × 45 | Algo1 in the proposed EDPA | 97.72 | 1.524 M | 7.53 MB | Yes | Wx = 60, dx = 6 |
| 60 × 45 | Algo2 in the proposed EDPA | 95.19 | 1.521 M | 7.53 MB | Yes | Wx = 60, dx = 6 |
| 60 × 15 | Algo3 in the proposed EDPA | 95.1 | 0.46 M | 3.09 MB | No | Wx = 60, dx = 10 |
| 60 × 45 | Algo1 in the traditional EDPA [6] | 97.83 | 1.624 M | 7.88 MB | Yes | Wx = 60, dx = 6 |
| 60 × 45 | Algo2 in the traditional EDPA [8] | 95.29 | 1.623 M | 7.88 MB | Yes | Wx = 60, dx = 6 |
| 60 × 15 | Algo3 in the traditional EDPA [11] | 94.9 | 0.56 M | 3.28 MB | No | Wx = 60, dx = 10 |
| Algorithm | Req/s | Total | Average |
|---|---|---|---|
| Traditional EDPA using Algo1 DeepConvRNN_Attention [6] | 1 | 0.7910 s | 0.7910 s |
| Traditional EDPA using Algo2 FCN-LSTM [8] | 1 | 0.7510 s | 0.7510 s |
| Traditional EDPA using Algo3 light-weight FCN-LSTM [11] | 2 | 1.096 s | 0.498 s |
| Proposed EDPA using Algo3 | 7 | 0.651 s | 0.142 s |
| Proposed EDPA using Algo2 | 5 | 0.851 s | 0.182 s |
| Proposed EDPA using Algo1 | 4 | 0.951 s | 0.242 s |
| Algorithm | Total Prediction and Input Frames Data Size | Average |
|---|---|---|
| Traditional EDPA using Algo1 DeepConvRNN_Attention [6] | 10 MB | 10.09 MB/s |
| Traditional EDPA using Algo2 FCN-LSTM [8] | 10 MB | 10.51 MB/s |
| Traditional EDPA using Algo3 light-weight FCN-LSTM [11] | 5 MB | 9.12 MB/s |
| Proposed EDPA using Algo3 | 5 MB | 53.76 MB/s |
| Proposed EDPA using Algo2 | 10 MB | 58.75 MB/s |
| Proposed EDPA using Algo1 | 10 MB | 42.06 MB/s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pirahandeh, M.; Ullah, S.; Kim, D.-H. A Distributed Edge-Based Scheduling Technique with Low-Latency and High-Bandwidth for Existing Driver Profiling Algorithms. Electronics 2021, 10, 972. https://doi.org/10.3390/electronics10080972
Pirahandeh M, Ullah S, Kim D-H. A Distributed Edge-Based Scheduling Technique with Low-Latency and High-Bandwidth for Existing Driver Profiling Algorithms. Electronics. 2021; 10(8):972. https://doi.org/10.3390/electronics10080972
Chicago/Turabian StylePirahandeh, Mehdi, Shan Ullah, and Deok-Hwan Kim. 2021. "A Distributed Edge-Based Scheduling Technique with Low-Latency and High-Bandwidth for Existing Driver Profiling Algorithms" Electronics 10, no. 8: 972. https://doi.org/10.3390/electronics10080972
APA StylePirahandeh, M., Ullah, S., & Kim, D.-H. (2021). A Distributed Edge-Based Scheduling Technique with Low-Latency and High-Bandwidth for Existing Driver Profiling Algorithms. Electronics, 10(8), 972. https://doi.org/10.3390/electronics10080972