
Wireless Powered Mobile Edge Computing Systems: Simultaneous Time Allocation and Offloading Policies

 , , ,
, , ,  ,
,  and
and 
Abstract
1. Introduction
Novelty and Contribution
- For the first time in MEC, we use a deep learning approach for both optimal offloading policy and optimal time fraction for harvesting in partial offloading schemes and propose a deep learning-based algorithm which gives minimum cost, in terms of delay and energy consumption, for computational offloading in MEC.
- Our approach is scalable in terms of time resolution, number of components per task, and distance between HAP and MD. The proposed algorithm generates training datasets for different desired values of time resolution, number of components per task, and distance between HAP and MD.
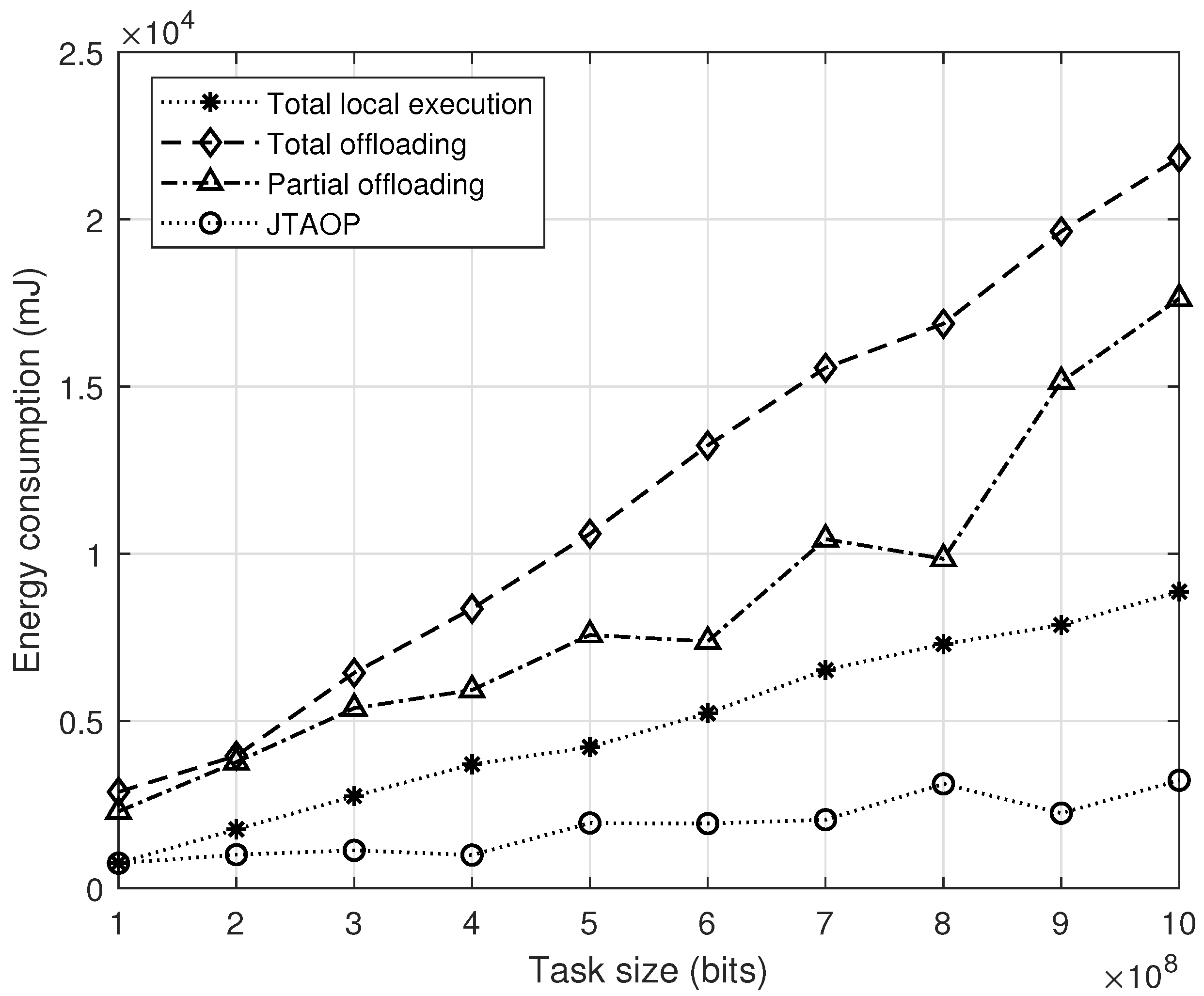
- The proposed algorithm, when compared with three benchmark cases—namely, total local computation, total offloading, and partial offloading—demonstrates better performance in terms of minimum cost, delay, and energy consumption.
2. Related Work
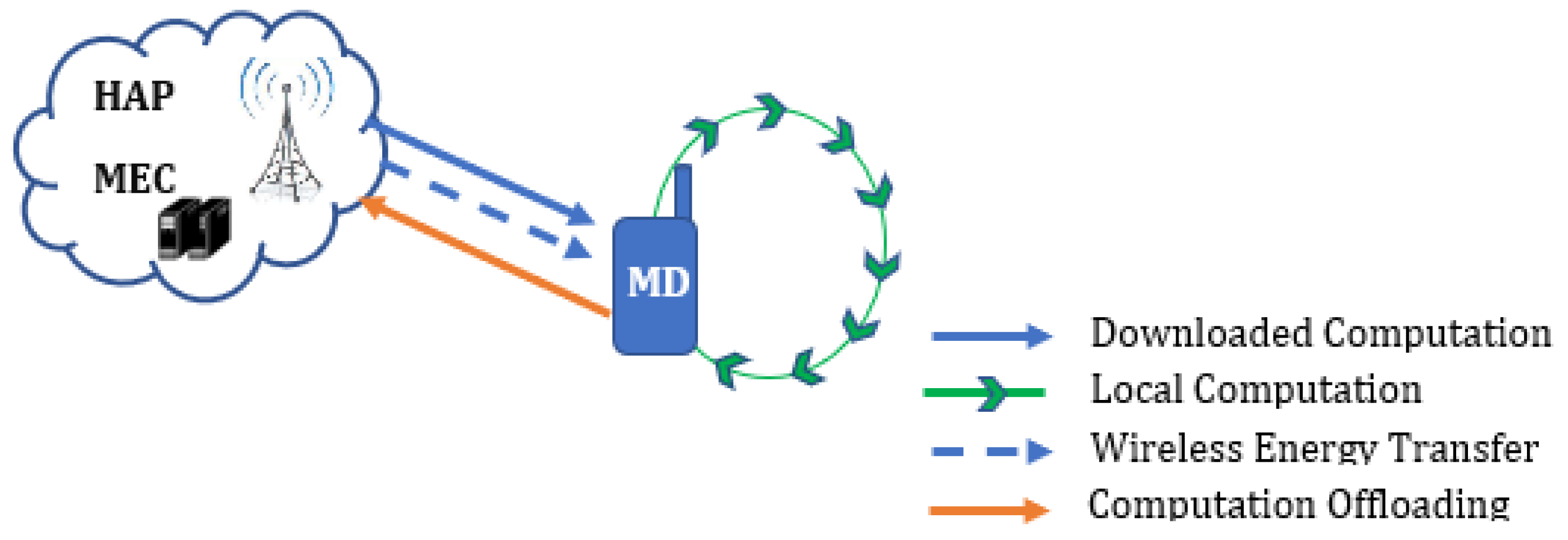
3. System Model and Problem Formulation
3.1. Local Execution Model
3.2. Remote Execution Model
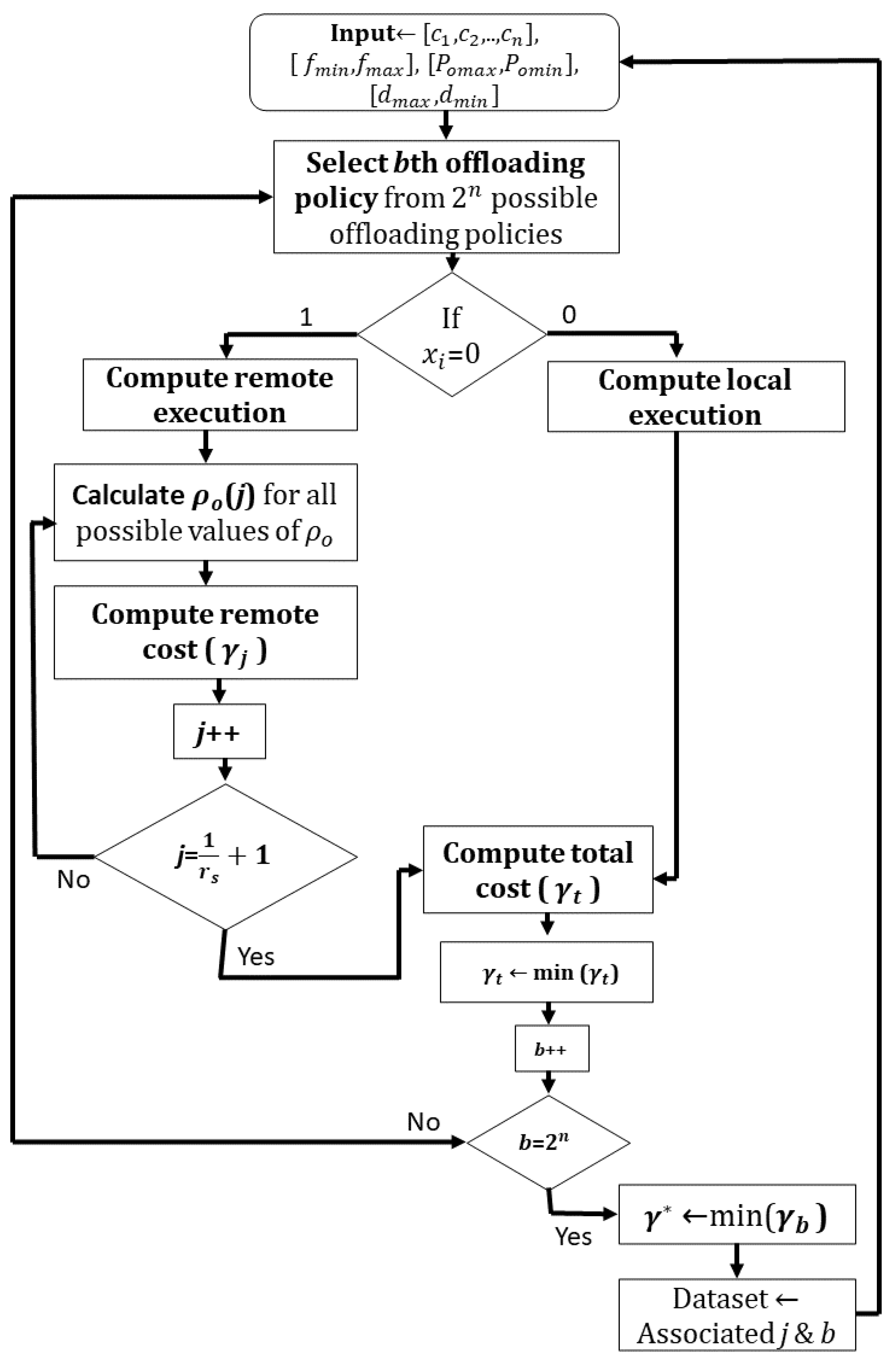
3.3. The Proposed Algorithm
| Algorithm 1: Joint Time Allocation and Offload Policy |
 |
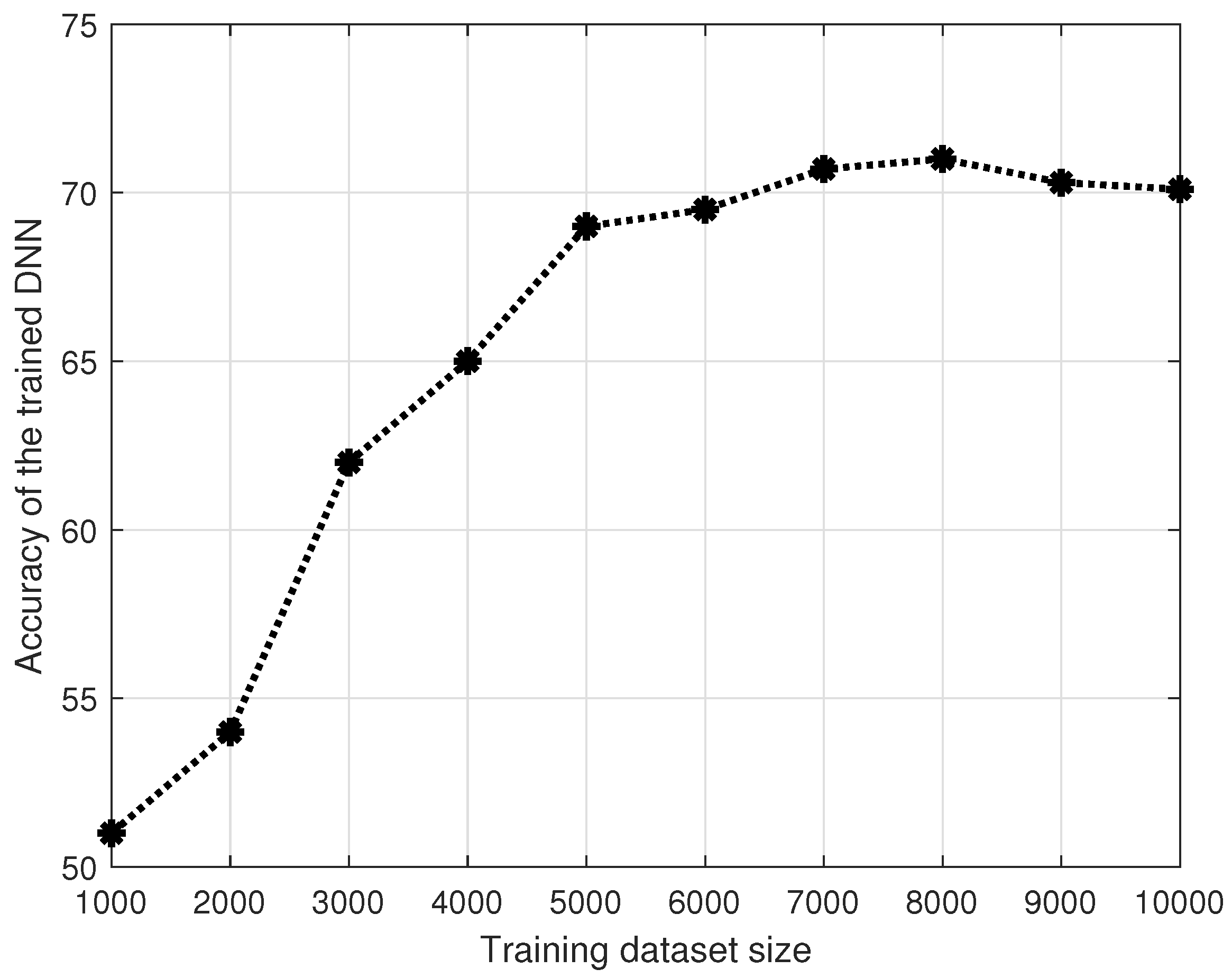
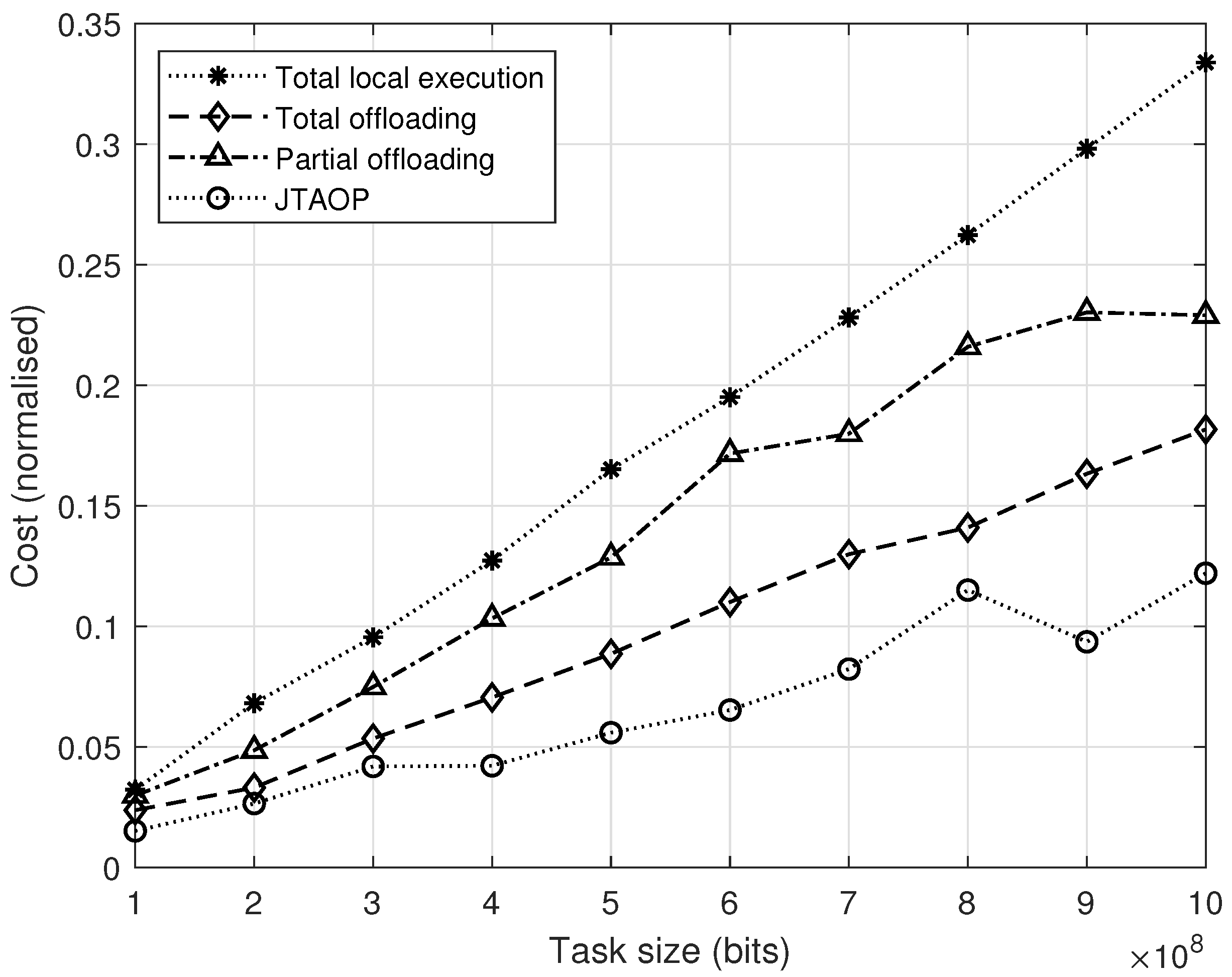
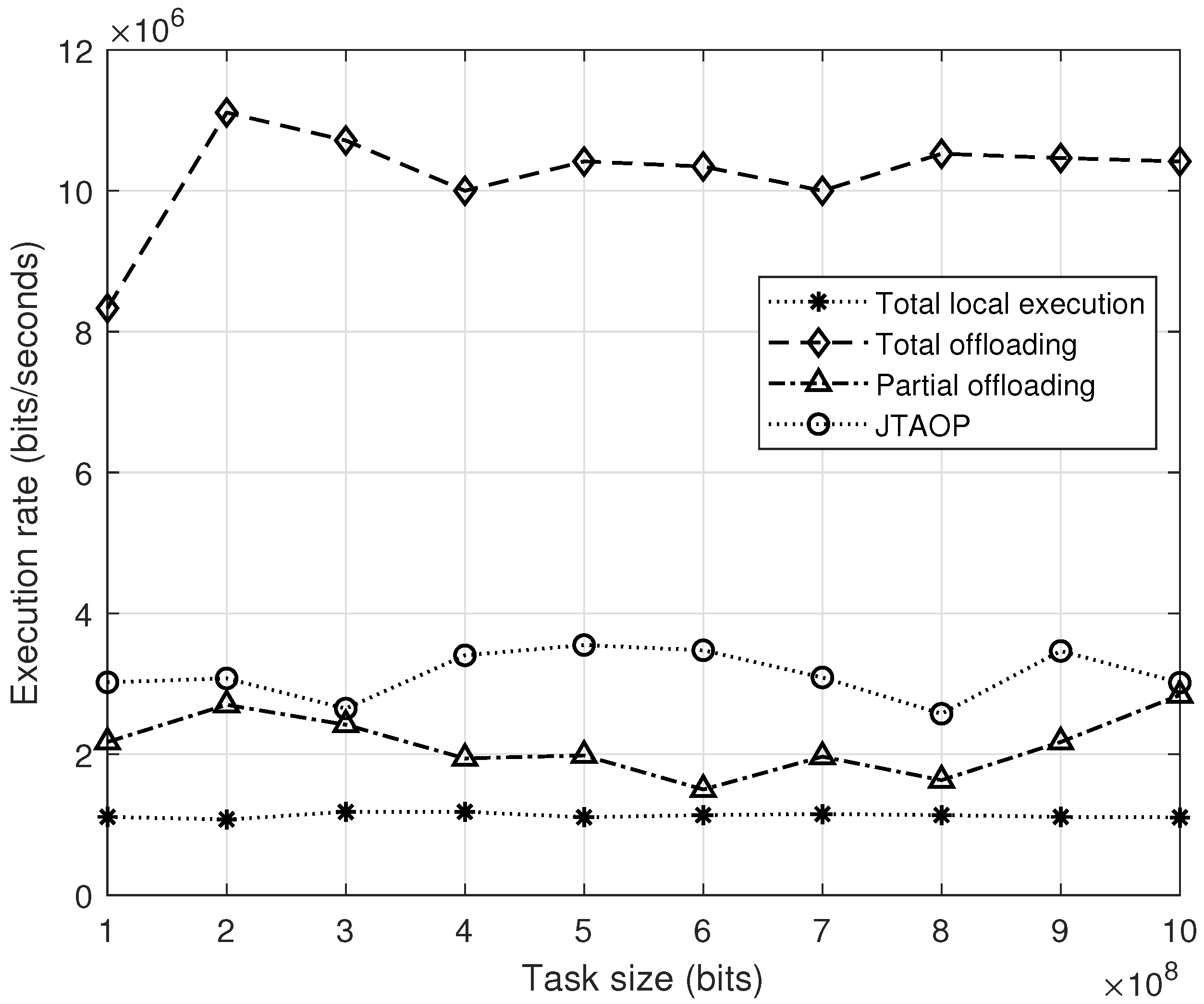
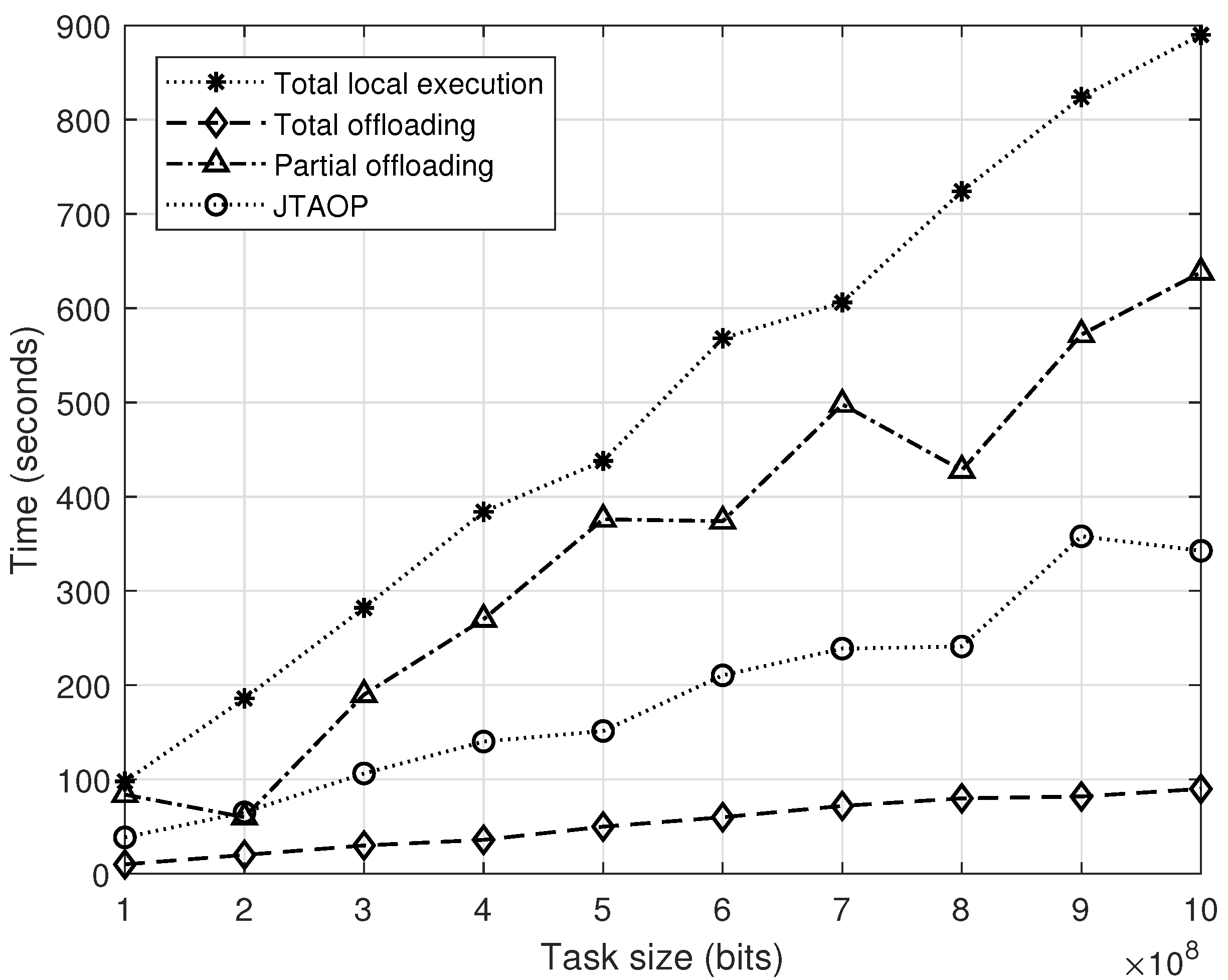
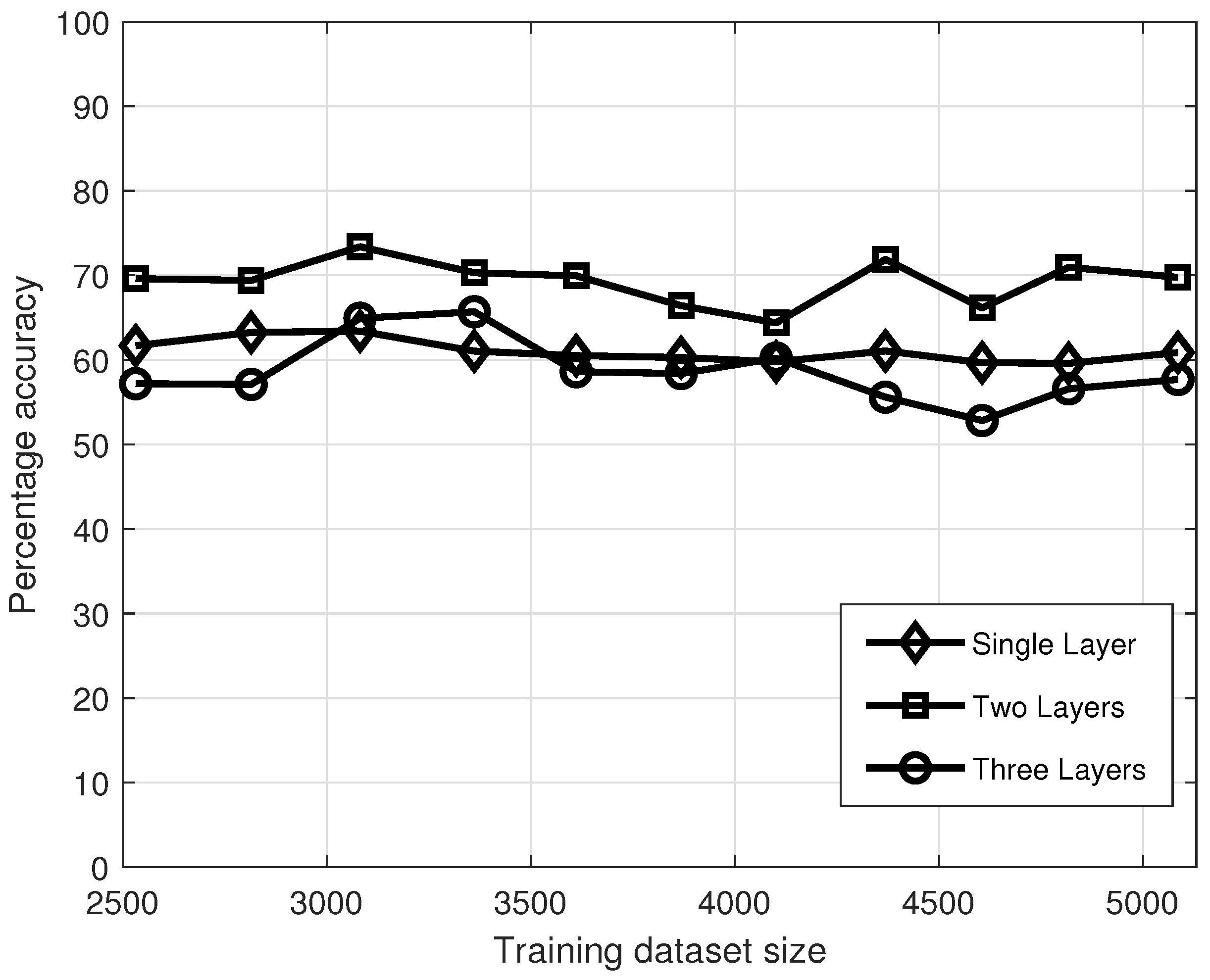
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ratasuk, R.; Prasad, A.; Li, Z.; Ghosh, A.; Uusitalo, M. Recent advancements in M2M communications in 4G networks and evolution towards 5G. In Proceedings of the 18th International Conference on Intelligence in Next Generation Networks, Paris, France, 17–19 February 2015; pp. 52–57. [Google Scholar]
- Ren, J.; Yu, G.; He, Y.; Li, G.Y. Collaborative cloud and edge computing for latency minimization. IEEE Trans. Veh. Technol. 2019, 68, 5031–5044. [Google Scholar] [CrossRef]
- Ali, Z.; Jiao, L.; Baker, T.; Abbas, G.; Abbas, Z.H.; Khaf, S. A deep learning approach for energy efficient computational offloading in mobile edge computing. IEEE Access 2019, 7, 149623–149633. [Google Scholar] [CrossRef]
- Wu, H.; Tian, H.; Nie, G.; Zhao, P. Wireless powered mobile edge computing for industrial internet of things systems. IEEE Access 2020, 8, 101539–101549. [Google Scholar] [CrossRef]
- Li, C.; Song, M.; Zhang, L.; Chen, W.; Luo, Y. Offloading optimization and time allocation for multiuser wireless energy transfer based mobile edge computing system. Mob. Netw. Appl. 2020. [Google Scholar] [CrossRef]
- Yu, S.; Chen, X.; Yang, L.; Wu, D.; Bennis, M.; Zhang, J. Intelligent edge: Leveraging deep imitation learning for mobile edge computation offloading. IEEE Wirel. Commun. 2020, 27, 92–99. [Google Scholar] [CrossRef]
- Zhou, F.; Wu, Y.; Hu, R.Q.; Qian, Y. Computation rate maximization in UAV-Enabled wireless-powered mobile-edge computing systems. IEEE J. Sel. Areas Commun. 2018, 36, 1927–1941. [Google Scholar] [CrossRef]
- Wang, F.; Xu, J.; Wang, X.; Cui, S. Joint offloading and computing optimization in wireless powered mobile-edge computing systems. IEEE J. Sel. Areas Commun. 2018, 17, 1784–1797. [Google Scholar] [CrossRef]
- Bi, S.; Zhang, Y.J. Computation rate maximization for wireless powered mobile-edge computing with binary computation offloading. IEEE Trans. Wirel. Commun. 2018, 17, 4177–4190. [Google Scholar] [CrossRef]
- Li, C.; Chen, W.; Tang, H.; Xin, Y.; Luo, Y. Stochastic computation resource allocation for mobile edge computing powered by wireless energy transfer. Ad Hoc Netw. 2019, 93, 101897. [Google Scholar] [CrossRef]
- Wu, D.; Wang, F.; Cao, X.; Xu, J. Wireless powered user cooperative computation in mobile edge computing systems. In Proceedings of the 2018 IEEE Globecom Workshops (GC Wkshps), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–7. [Google Scholar]
- Mao, S.; Leng, S.; Yang, K.; Huang, X.; Zhao, Q. Fair energy-efficient scheduling in wireless powered full-duplex mobile-edge computing systems. In Proceedings of the IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- Mao, S.; Leng, S.; Maharjan, S.; Zhang, Y. Energy efficiency and delay tradeoff for wireless powered mobile-edge computing systems with multi-access schemes. IEEE Trans. Wirel. Commun. 2020, 19, 1855–1867. [Google Scholar] [CrossRef]
- Bi, S.; Ho, C.K.; Rui, Z. Wireless powered communication: Opportunities and challenges. IEEE Commun. Mag. 2014, 53, 117–125. [Google Scholar]
- Yang, M.; Wen, Y.; Cai, J.; Foh, C.H. Energy minimization via dynamic voltage scaling for real-time video encoding on mobile devices. In Proceedings of the IEEE International Conference on Communications, (ICC’12), Ottawa, ON, Canada, 10–15 June 2012; pp. 2026–2031. [Google Scholar]
- Koech, K. Softmax Activation Function-How It Actually Works. Available online: https://towardsdatascience.com/softmax-activation-function-how-it-actually-works-d292d335bd78 (accessed on 1 January 2021).
- Huang, L.; Bi, S.; Zhang, Y.J.A. Deep reinforcement learning for online computation offloading in wireless powered mobile-edge computing networks. IEEE Trans. Mob. Comput. 2020, 19, 2581–2593. [Google Scholar] [CrossRef]
- Liu, B.; Xu, H.; Zhou, X. Resource allocation in wireless-powered mobile edge computing systems for internet of things applications. Electronics 2019, 8, 206. [Google Scholar] [CrossRef]
- Wang, F.; Xu, J.; Cui, S. Optimal energy allocation and task offloading Policy for wireless powered mobile edge computing systems. IEEE Trans. Wirel. Commun. 2020, 19, 2443–2459. [Google Scholar] [CrossRef]
- Wu, Q.; Chen, W.; Ng, D.W.K.; Li, J.; Schober, R. User-centric energy efficiency maximization for wireless powered communications. IEEE Trans. Wirel. Commun. 2016, 15, 6898–6912. [Google Scholar] [CrossRef]
- Mao, S.; Wu, J.; Liu, L.; Lan, D.; Taherkordi, A. Energy-efficient cooperative communication and computation for wireless powered mobile-edge computing. IEEE Syst. J. 2020, 6, 1–12. [Google Scholar] [CrossRef]
- Back to Basics: The Shannon-Hartley Theorem-Ingenu. Available online: https://www.ingenu.com/2016/07/back-to-basics-the-shannon-hartley-theorem/ (accessed on 10 December 2020).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Offloading Policy | 1st Component | 2nd Component | 3rd Component |
|---|---|---|---|
| Policy-1 | 0 | 0 | 0 |
| Policy-2 | 0 | 0 | 1 |
| Policy-3 | 0 | 1 | 0 |
| Policy-4 | 0 | 1 | 1 |
| Policy-5 | 1 | 0 | 0 |
| Policy-6 | 1 | 0 | 1 |
| Policy-7 | 1 | 1 | 0 |
| Policy-8 | 1 | 1 | 1 |
| Time Allocation Policy | (Harvesting Time Percent) | (Offloading Time Percent) |
|---|---|---|
| 1 | 0 | 1 |
| 2 | 0.1 | 0.9 |
| 3 | 0.2 | 0.8 |
| 4 | 0.3 | 0.7 |
| 5 | 0.4 | 0.6 |
| 6 | 0.5 | 0.5 |
| 7 | 0.6 | 0.4 |
| 8 | 0.7 | 0.3 |
| 9 | 0.8 | 0.2 |
| 10 | 0.9 | 0.1 |
| 11 | 1 | 0 |
| Notation | Meaning |
|---|---|
| B | Bandwidth |
| Battery of MD | |
| ith component of a task in current time slot | |
| ith component of a task in next time slot | |
| d | Distance between MD and HAP |
| Reference distance | |
| Total energy consumption of MD | |
| Energy consumption by MD for ith component | |
| Harvested energy by the MD for ith component | |
| Maximum energy consumption by MD | |
| Offloading energy consumption in remote model | |
| Frequency of MD for ith component | |
| CPU frequency at MES | |
| Path loss | |
| Channel power gain of ith component | |
| Downlink channel gain of ith component | |
| L | Number of CPU cycles to process 1 bit of data |
| Noise spectral density | |
| Transmit power of ith component of MD | |
| Transmit power of MEC | |
| Transmit power of HAP | |
| R | Execution rate |
| Maximum data rate on the down-link channel of ith Component | |
| Maximum data rate on the up-link channel of ith Component | |
| Total time delay for the whole task | |
| Time delay of ith component in remote model | |
| Down-link delay time | |
| Processing time at MEC | |
| Time delay of ith component in local execution model | |
| Maximum time delay of MD | |
| Total time delay of ith component | |
| Up-link delay time from MD to MEC | |
| Weighing constants | |
| Variable indicating the offloading policy for ith component | |
| Scaling factors | |
| Cost of offloading policy | |
| Energy harvesting constant | |
| Time policy for harvesting energy from HAP | |
| Time policy for offloading task to MES | |
| Effective switching capacitance | |
| Path loss exponent |
| Parameters | Values |
|---|---|
| B | MHz |
| d | [3–200] m |
| 1 m | |
| [0.1–1] GHz | |
| dB | |
| L | 737.5 cycles/bit |
| dBm/Hz | |
| ≥2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Irshad, A.; Abbas, Z.H.; Ali, Z.; Abbas, G.; Baker, T.; Al-Jumeily, D. Wireless Powered Mobile Edge Computing Systems: Simultaneous Time Allocation and Offloading Policies. Electronics 2021, 10, 965. https://doi.org/10.3390/electronics10080965
Irshad A, Abbas ZH, Ali Z, Abbas G, Baker T, Al-Jumeily D. Wireless Powered Mobile Edge Computing Systems: Simultaneous Time Allocation and Offloading Policies. Electronics. 2021; 10(8):965. https://doi.org/10.3390/electronics10080965
Chicago/Turabian StyleIrshad, Amna, Ziaul Haq Abbas, Zaiwar Ali, Ghulam Abbas, Thar Baker, and Dhiya Al-Jumeily. 2021. "Wireless Powered Mobile Edge Computing Systems: Simultaneous Time Allocation and Offloading Policies" Electronics 10, no. 8: 965. https://doi.org/10.3390/electronics10080965
APA StyleIrshad, A., Abbas, Z. H., Ali, Z., Abbas, G., Baker, T., & Al-Jumeily, D. (2021). Wireless Powered Mobile Edge Computing Systems: Simultaneous Time Allocation and Offloading Policies. Electronics, 10(8), 965. https://doi.org/10.3390/electronics10080965