
Posting Recommendations in Healthcare Q&A Forums


Abstract
1. Introduction
2. Related Work
3. Posting Recommender Systems (RSs)
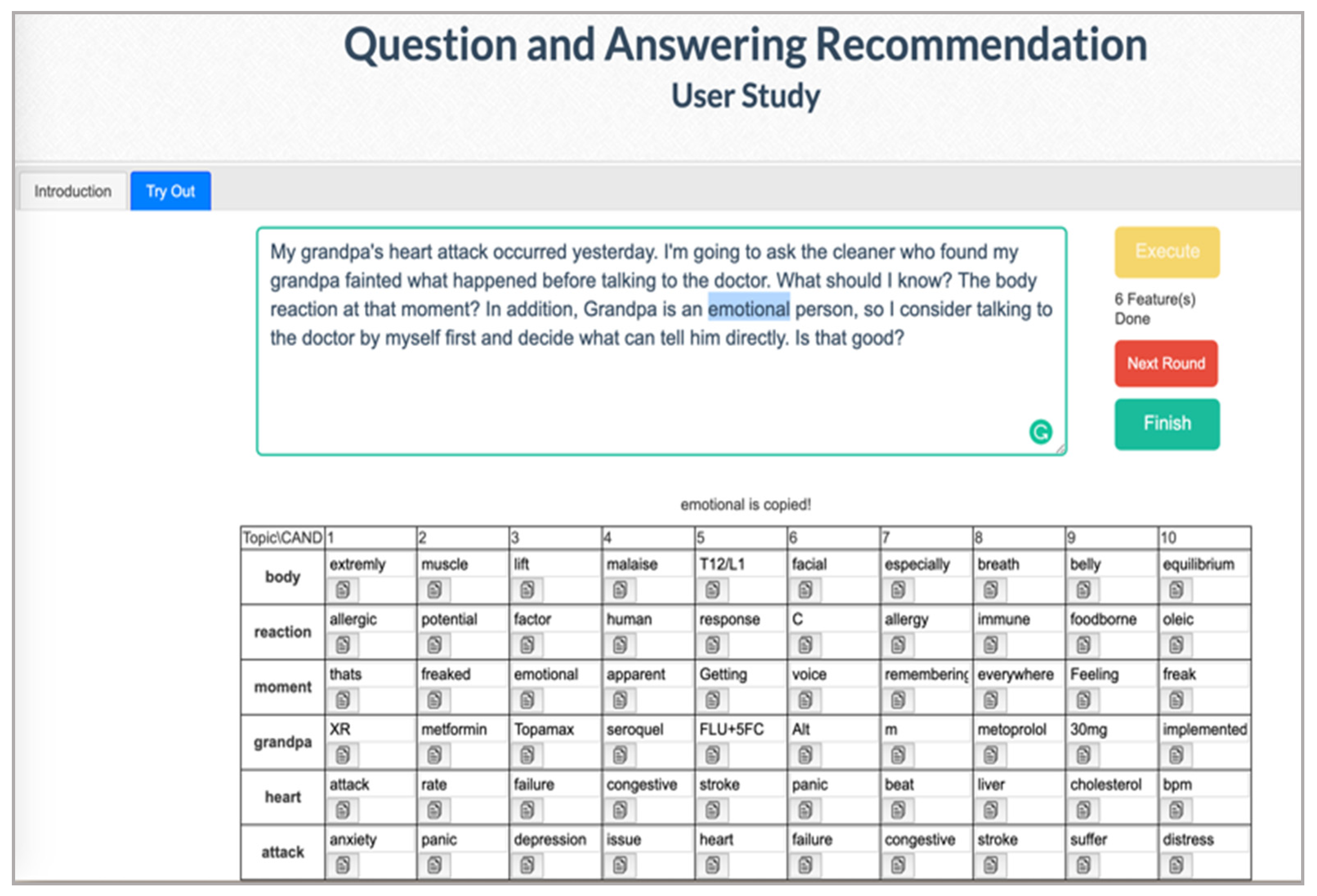
3.1. Interface Design
3.2. Recommendation Models
4. Research Design
4.1. Dataset
4.2. Tasks and Experimental Materials
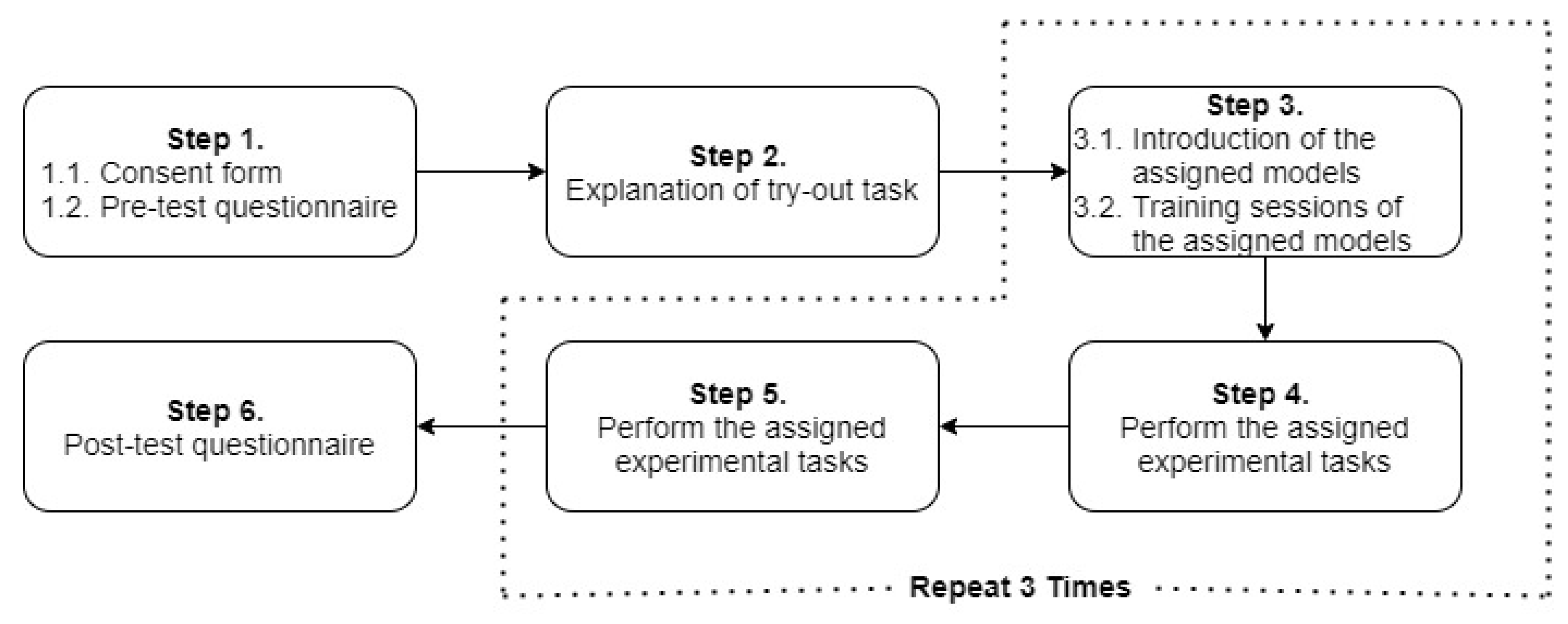
4.3. Participants and Procedure
- (1)
- After signing the consent form, the participants took the pre-test questionnaire on their background and past experience using Q&A forums.
- (2)
- A training task was then provided to ensure that participants fully understood the experimental systems and task requirements. An example of an expected post was given to encourage the participant to compose complete questions. Participants were allowed to ask any questions during this step.
- (3)
- A brief description of the assigned model was also provided. The participant was given sufficient time to become familiar with the system.
- (4)
- A description of the general context of the assigned task was provided to the participant, after which the participant began her posting.
- (5)
- Another description of the complex context of the task was given to the participant. Then, the participant began her posting. Please note that as each participant completed all three tasks with the three models, she completed (3)–(5) three times.
- (6)
- A post-questionnaire was issued to the participant to evaluate each user’s experience with each model, including her perception of the system process, system speed, and the extent to which they would prefer using our RSs.
4.4. Analysis Method
5. Analysis of Results
5.1. Log Analysis
5.2. Opinion Analysis
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Supportive Paragraphs for Participants






References
- Tanis, M. Health-related on-line forums: What’s the big attraction? Health J. Commun. 2008, 13, 698–714. [Google Scholar] [CrossRef]
- Zeng, Q.; Kogan, S.; Ash, N.; Greenes, R.A.; Boxwala, A.A. Characteristics of consumer terminology for health information retrieval. Methods Inf. Med. 2002, 41, 289–298. [Google Scholar]
- Riahi, F.; Zolaktaf, Z.; Shafiei, M.; Milios, E. Finding expert users in community question answering. In Proceedings of the 21st International Conference Companion on World Wide Web—WWW ’12 Companion, Lyon, France, 16–20 April 2012; pp. 791–798. [Google Scholar]
- Li, B.; King, I. Routing questions to appropriate answerers in community question answering services. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management—CIKM ’2010, Toronto, ON, Canada, 26–30 October 2010; Volume 10, pp. 1585–1588. [Google Scholar]
- Neshati, M.; Fallahnejad, Z.; Beigy, H. On dynamicity of expert finding in community question answering. Inf. Process. Manag. 2017, 53, 1026–1042. [Google Scholar] [CrossRef]
- Agichtein, E.; Castillo, C.; Donato, D.; Gionis, A.; Mishne, G. Finding high-quality content in social media. In Proceedings of the International Conference on Web Search and Web Data Mining—WSDM ’08, Seattle, WA, USA, 8–12 February 2008; p. 183. [Google Scholar]
- Li, B.; Jin, T.; Lyu, M.R.; King, I.; Mak, B. Analyzing and predicting question quality in community question answering services. In Proceedings of the 21st International Conference Companion on World Wide Web—WWW ’12 Companion, Lyon, France, 16–20 April 2012; pp. 775–782. [Google Scholar]
- Baltadzhieva. Question quality in community question answering forums: A survey. ACM Sigkdd Explor. Newsl. 2015, 17, 8–13. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; Volume 2, pp. 3111–3119. [Google Scholar]
- Jacobs, W.; Amuta, A.O.; Jeon, K.C. Health information seeking in the digital age: An analysis of health information seeking behavior among US adults. Cogent Soc. Sci. 2017, 3, 1302785. [Google Scholar] [CrossRef]
- Haux, R. Health information systems—Past, present, future. Int. Med. J. Inform. 2006, 75, 268–281. [Google Scholar] [CrossRef]
- Isern, D.; Moreno, A. A systematic literature review of agents applied in healthcare. J. Med. Syst. 2016, 40, 43. [Google Scholar] [CrossRef]
- Frost, J.H.; Massagli, M.P. Social uses of personal health information within PatientsLikeMe, an online patient community: What can happen when patients have access to one another’s data. Med. J. Internet Res. 2008, 10, e15. [Google Scholar] [CrossRef]
- Bakker, P.; Sádaba, C. The impact of the internet on users. In The Internet and the Mass Media; SAGE: London, UK, 2008; pp. 86–101. [Google Scholar]
- Budalakoti, S.; Deangelis, D.; Barber, K.S. Expertise modeling and recommendation in online question and answer forums. In Proceedings of the 12th IEEE International Conference on Computational Science and Engineering CSE 2009, Vancouver, BC, Canada, 29–31 August 2009; Volume 4, pp. 481–488. [Google Scholar]
- Yang, L.; Amatriain, X. Recommending the world’s knowledge: Application of recommender systems at Quora. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; p. 389. [Google Scholar]
- Xia, X.; Lo, D.; Wang, X.; Zhou, B. Tag recommendation in software information sites. In Proceedings of the 2013 10th Working Conference on Mining Software Repositories, San Francisco, CA USA, 18–19 May 2013; pp. 287–296. [Google Scholar]
- Pedro, J.S.; Karatzoglou, A. Question recommendation for collaborative question answering systems with RankSLDA. In Proceedings of the 8th ACM Conference on Recommender Systems 2014, Foster City, CA, USA, 6–10 October 2014; pp. 193–200. [Google Scholar]
- Wang, S.; Lo, D.; Vasilescu, B.; Serebrenik, A. EnTagRec++: An enhanced tag recommendation system for software information sites. Empir. Softw. Eng. 2018, 23, 800–832. [Google Scholar] [CrossRef]
- Singh, P.; Simperl, E. Using semantics to search answers for unanswered questions in Q&A forums. In Proceedings of the 25th International Conference Companion on World Wide Web, Montréal, QC, Canada, 11–15 May 2016; pp. 699–706. [Google Scholar]
- Cray, A.T.; Dorfman, E.; Ripple, A.; Ide, N.C.; Jha, M.; Katz, D.G.; Loane, R.F.; Tse, T. Usability issues in developing a Web-based consumer health site. In Proceedings of the AMIA Symposium, Los Angeles, CA, USA, 4–8 November 2000; pp. 556–560. [Google Scholar]
- Cho, D.J.H.; Sondhi, P.; Zhai, C.; Schatz, B. Resolving healthcare forum posts via similar thread retrieval. In Proceedings of the 5th ACM Conference on Bioinformatics, Computational Biology, and Health Informatics, Newport Beach, CA, USA, 20–23 September 2014; pp. 33–42. [Google Scholar]
- Bochet, A.; Guisolan, S.C.; Munday, M.F.; Noury, O.M.; Polla, R.; Zhao, N.; Soulié, P.; Cosson, P. Cyberchondria. Rev. Med. Suisse 2014, 10, 4. [Google Scholar]
- Spink, A.; Yang, Y.; Jansen, J.; Nykanen, P.; Lorence, D.P.; Ozmutlu, S.; Ozmutlu, H.C. A study of medical and health queries to web search engines. Health Inform. Libr. J. 2004, 21, 44–51. [Google Scholar] [CrossRef]
- Zhang, Y. Contextualizing consumer health information searching: An analysis of questions in a social Q&A community. In Proceedings of the 1st ACM International Health Informatics Symposium 2010, Arlington, VA, USA, 11–12 November 2010; pp. 210–219. [Google Scholar]
- Boratto, L.; Carta, S.; Fenu, G.; Saia, R. Semantics-aware content-based recommender systems: Design and architecture guidelines. Neurocomputing 2017, 254, 79–85. [Google Scholar] [CrossRef]
- Ren, H.; Feng, W. Concert: A concept-centric web news recommendation system. In Proceedings of the International Conference on Web-Age Information Management, Beidaihe, China, 14–16 June 2013; pp. 796–798. [Google Scholar]
- Hong, M.-D.; Oh, K.-J.; Ga, M.-H.; Jo, G.-S. Content-based recommendation based on social network for personalized news services. Intell. J. Inf. Syst. 2013, 19, 57–71. [Google Scholar]
- Ortega, F.; Hernando, A.; Bobadilla, J.; Kang, J.H. Recommending items to group of users using matrix factorization based collaborative filtering. Inf. Sci. 2016, 345, 313–324. [Google Scholar] [CrossRef]
- Rao, J.; Jia, A.; Feng, Y.; Zhao, D. Personalized news recommendation using ontologies harvested from the web. In Proceedings of the International Conference on Web-Age Information Management, Beidaihe, China, 14–16 June 2013; pp. 781–787. [Google Scholar]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Fellbaum. WordNet. In The Encyclopedia of Applied Linguistics; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- Van Damme, C.; Hepp, M.; Siorpaes, K. FolksOntology: An integrated approach for turning folksonomies into ontologies. Bridg. Gap Semant. Web Web 2007, 2, 57–70. [Google Scholar]
- Mikolov, T.; Yih, W.; Zweig, G. Linguistic regularities in continuous space word representations. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 746–751. [Google Scholar]
- Esmeli, R.; Bader-El-Den, M.; Abdullahi, H. Using Word2Vec recommendation for improved purchase prediction. In Proceedings of the IEEE World Congress on Computational Intelligence (WCCI) 2020, Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Sapatinas, T. The elements of statistical learning. Stat. J. R. Soc. Ser. A 2004, 167, 192. [Google Scholar] [CrossRef]
- Aigner, M.; Ziegler, G.M. Completing Latin squares. In Proofs from THE BOOK; Springer: Berlin/Heidelberg, Germany, 2001; pp. 161–166. [Google Scholar]
- Liang, K.Y.; Zeger, S.L. Longitudinal data analysis using generalized linear models. Biometrika 1986, 73, 13–22. [Google Scholar] [CrossRef]
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Viera, J.; Garrett, J.M. Understanding interobserver agreement: The kappa statistic. Fam. Med. 2005, 37, 360–363. [Google Scholar]
- Schwartzberg, J.G.; Cowett, A.; VanGeest, J.; Wolf, M.S. Communication techniques for patients with low health literacy: A survey of physicians, nurses, and pharmacists. Am. Health J. Behav. 2007, 1, 96–104. [Google Scholar] [CrossRef]
- Zeng, Q.; Cimino, J.J. Providing multiple views to meet physician information needs. In Proceedings of the Hawaii International Conference on System Sciences, Maui, HI, USA, 7 January 2000; p. 111. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Post Length | Med-Related Word Count | Existence of Descriptions | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | S.E. | Min. | Max. | Mean | S.E. | Min. | Max. | True | False | TTL. | |
| A | 59.87 | 26.937 | 18 | 154 | 3.87 | 1.602 | 0 | 9 | 35 | 19 | 54 |
| B | 62.81 | 34.575 | 19 | 189 | 4.56 | 2.661 | 0 | 12 | 33 | 21 | 54 |
| C | 60.93 | 33.389 | 15 | 149 | 3.89 | 2.724 | 0 | 16 | 35 | 19 | 54 |
| Factor | Word Embedding | Semantic | Baseline | |
|---|---|---|---|---|
| Expert 1 (pharmacist) | Willingness | 3.59 0.09 | 3.52 0.09 | 3.57 0.06 |
| Completeness | 3.93 0.07 | 3.98 0.08 | 3.94 0.09 | |
| Clarity | 4.22 0.08 | 4.17 0.08 | 4.15 0.00 | |
| Expert 2 (physician) | Willingness | 3.83 0.09 | 3.70 0.08 | 3.96 0.09 |
| Completeness | 2.98 0.11 | 2.85 0.12 | 2.93 0.07 | |
| Clarity | 3.20 0.10 | 3.19 0.13 | 3.20 0.14 |
| Factor | Word Count | Med-Related Word Count | |
|---|---|---|---|
| Expert 1 (pharmacist) | Willingness | Nonsignificant | Nonsignificant |
| Completeness | r = 0.136, p = 0.084 | Nonsignificant | |
| Clarity | r = 0.145, p = 0.066 | Nonsignificant | |
| Expert 2 (physician) | Willingness | Nonsignificant | Nonsignificant |
| Completeness | r = 0.468, p < 0.001 | r = 0.266, p = 0.001 | |
| Clarity | r = 0.192, p = 0.014 | r = 0.248, p = 0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y.-L.; Chien, S.-Y.; Chen, Y.-J. Posting Recommendations in Healthcare Q&A Forums. Electronics 2021, 10, 278. https://doi.org/10.3390/electronics10030278
Lin Y-L, Chien S-Y, Chen Y-J. Posting Recommendations in Healthcare Q&A Forums. Electronics. 2021; 10(3):278. https://doi.org/10.3390/electronics10030278
Chicago/Turabian StyleLin, Yi-Ling, Shih-Yi Chien, and Yi-Ju Chen. 2021. "Posting Recommendations in Healthcare Q&A Forums" Electronics 10, no. 3: 278. https://doi.org/10.3390/electronics10030278
APA StyleLin, Y.-L., Chien, S.-Y., & Chen, Y.-J. (2021). Posting Recommendations in Healthcare Q&A Forums. Electronics, 10(3), 278. https://doi.org/10.3390/electronics10030278