2.1. Stream-Based Lossless Data Compression
The recent type of data produced from equipment of information technology such as IoT devices mainly forms a continuous data stream such as video images and sensor data [
3]. The speed and the amount of the data stream are increasing rapidly. To support the technological aspects of the equipment, we need to reduce the amount of data itself. Therefore, we focus on lossless data compression technology that can reduce the data amount of the data stream without any quality loss. To implement compression methods for data streams, we need to address the following factors in the algorithm: (1) the algorithm does not need any buffering during compression/decompression processes. (2) it compresses/decompresses a unit of data (we call this a
symbol) in a small delay. (3) it is implementable in hardware compactly and works fast to support performance of the physical media. Due to the algorithm that supports these factors, the stream-based lossless data compression implements fast compression based on hardware and brings compactization of systems.
Lossless data compression technology has its origins in Shannon’s entropy since the 1950s. The method assigns
S bits to each symbol of an original data sequence where
S is an entropy represented by −
where it is calculated from frequent probability of each symbol
. Then, arithmetic coding [
4,
5] is the next generation of compression algorithm. It represents the target data by numeric values. It assigns each data pattern to a value in a domain where includes all symbols are presented. This mechanism improves the compression ratio, better than Shannon’s entropy. However, it needs to process all input data and must decide the domain to express all symbols appeared in the input data. The algorithm tries to find the frequent information of all symbols in the input data. The Range Coder [
6] is a similar compression algorithm to the arithmetic coding. Huffman coding [
7] is another lossless data compression. It also has the disadvantage of the buffering problem against processing data stream because it needs to create a binary tree of whole data. To overcome it, dynamic Huffman coding [
8] was proposed. It arranges a binary tree dynamically created during the compression process. However, it is too heavy calculation to process very fast data stream. Furthermore, it is too complicated to implement it on fast and small hardware. Therefore, the algorithms mentioned above are not suitable to process data stream.
In the 1970s, an algorithm based on look-up table that registers frequent symbols was proposed. A typical implementation was LZW (Lempel-Ziv-Welch) [
9,
10] instantiated on Zip, LZ4 [
11], Snappy [
12], and deflate [
13]. The algorithm compresses one or more frequent symbols by using a look-up table. The look-up table maintains the frequent symbol patterns and the compressed symbols are translated as the table indices. This kind of algorithm that uses a look-up table is called
digram coding. For example,
Figure 1 shows examples of compression/decompression processes of LZW. It compresses an ASCII character pattern “ABCABC”. In LZW, first, the table is initialized by available symbols appearing in the patterns. Typically, a table entry has a 12 bit symbol and the first 256 entries are configured to the corresponding binary bits. The compressor has a rule that a new pattern with the subsequent symbols is added to the table. While a pattern is hit in the table, the associated index is outputted. Here, to explain simply, the example initializes the table with ‘A’, ’B’ and ‘C’ first as shown in
Figure 1a. The first ‘A’ hits in the table. Then, “AB” is tried if it is hit or not in the table. However, it misses. Therefore, ‘A’ is translated to the index ‘0’ with
bits where
k is the maximum number of entries in the table. The pattern “AB” is added to the table. The ‘B’ is converted to ‘1’ as depicted in
Figure 1b. With the similar operations, “ABC” is added to the table and the compressor outputs ‘2’ as shown in
Figure 1c. After that, as illustrated in
Figure 1d, “ABC” is hit in the table and the compressor outputs ‘5’. This results “0125”. If the table index is 3 bits, the original data pattern is compressed from 48 bits to 12 bits. In the decompressor, the table is initialized as well as the compressor. During accepting the indices of compressed data, the decompressor adds new patterns to the table as well as the compressor. The compressed pattern can be decompressed to ‘A’, ‘B’, ‘C’, and “ABC”.
As we can see above, the algorithm can process data stream. However, it has a fatal drawback that the memory size for the look-up table increases infinitely as the number of symbols are compressed. This means we cannot know the required amount of memory during the compression. Because we cannot determine a fixed number of hardware resources used in the conventional digram coding such as LZW, we need to give some restrictions to the algorithm. For example, in LZW case, we can estimate the maximal size of memory for the look-up table. However, we cannot implement the algorithm on any fixed amount of memory by assigning a limited number of entries in the table. Therefore, it is typically configured to a fixed number of table entries such as 4096 used in the implementation [
14]. This is controlled in the algorithm and resets the table to process the subsequent data from the initialized table. Therefore, it is not suitable for the implementation that limits available resources such as hardware. Thus, the conventional digram coding does not satisfy the conditions of stream-based data compression because the perfect implementation needs unpredictable amount of resources.
On the other hand, we developed stream-based data compression algorithms. First, we developed a very simple one called LCA-SLT [
15] that supports the concept of LCA [
16]. It prepares a look-up table with several entries. Each entry maintains a symbol pair (
,
). When a symbol pair hits in the table, the compressor translates it to the table index
I. When a mishit happens, it outputs the original symbol pair. Each output combined with a
CMark bit that indicates if it is a compressed or an original symbol. Initially, entries are set to the pairs statistically selected from a sample data sequence. This is suitable for hardware implementation because the number of processing steps are constant. We can implement the algorithm in a small and fast hardware and also can achieve high bandwidth. Additionally, connecting the compressors, LCA-SLT can also compress a long pattern. However, due to the static table associated from the sample data sequence, when the frequency of patterns (i.e., data entropy) in a data stream changes, the compression ratio is affected significantly. To improve the compression performance, we developed LCA-DLT that includes entry exchange mechanism in the look-up table.
We added a dynamic histogram control to the look-up table of LCA-SLT and proposed LCA-DLT [
17]. When a symbol pair is received by the compressor, it is registered in an entry of the table when the compressor/decompressor does not find it in the table. We also prepared a reference counter in every table entry. The counter is reset to an initialized value at a registration of a symbol pair. We also prepared a remove pointer that rounds the table entries. The counter is decremented when the entry is pointed. Then, if the counter is zero, the entry is invalidated and recycled. At every table search operation, the reference counter is decremented at a mishit. On the other hand, at a hit, the counter is incremented. Therefore, frequent symbol pairs can be maintained due to this counter operation.
Figure 2 shows an example of the compression processes of an ASCII data pattern.
Figure 2a shows the initial registration of a symbol pair and outputs the original data. Actually, the output needs to combine a CMark bit (in this case, 0) to indicate that it is not compressed.
Figure 2b shows a hit case when an input symbol pair is matched in the table. This case needs to add a CMark bit (here, it is 1). Note that the hit case increments the reference count value. Then, it is incremented when the entry is used again. In this example, a compressed symbol becomes three bits due to four entries in the table. When a data pair is not compressed, the output becomes 17 bits. After processing the pairs,
Figure 2c shows an example when the entries in the table are invalidated. When the counter becomes zero, the entry is invalidated and reused for the subsequent input symbol pairs. The decompressor processes the same operations as the compressor does with reading the CMark bit at every output from the compressor. During the registration operation for a new entry to the table, any entry might not be invalidated. In this case, we can use the lazy compression mechanism [
1] to skip the symbol pair. As explained above, LCA-DLT compresses data stream without stalling by using a fixed number of entries. Therefore, it is easily implemented on hardware with a fixed amount of resources. In [
18], we reported an implementation with 200 MHz on an FPGA device.
The compressed data by the compressor of LCA-DLT consists of the full bits of the look-up table. This rises a compression limit that the compression ratio is affected by the number of entries in the look-up table. To overcome this performance limit, we developed a new algorithm called ASE coding [
2]. It compresses a symbol using an effect that the data entropy of data stream follows the number of occupied entries in the look-up table as used in LCA-DLT. The instantaneous compressed data is shrunk to
m bits from the number of occupied entries
k by an entropy calculation of the equation
.
Figure 3 shows an example of the compression/decompression mechanism.
Figure 3a illustrates that the compressor outputs a compressed data by shrinking the table index when the input symbol is matched in the table. The number of bits in the compressed data becomes
bits due to a CMark bit. When the decompressor receives the compressed data, it reads the CMark bit. If it is set, the compressor calculates
m, extracts
m bits from the compressed data stream and picks up the original symbol from the table. If the input symbol does not match in the table, the compressor registers the symbol to the table and outputs the original symbol with a CMark bit (in this case, 0). When the decompressor receives the CMark bit, it can know if it is compressed or not. If compressed, the subsequent
m bits are extracted by the entropy calculation and are extended to the number of bits corresponding to the table index as depicted in
Figure 3a. If not, the decompressor extracts the number of bits of an original symbol and registers it to the table. During the compression/decompression operations, the table is operated by the method shown in
Figure 3b. When the input symbol is hit in the table, the entry is moved to the top and the others are pushed to the next ones such as the LRU (Least Recently Used). When a mishit happens, the input symbol is pushed from the top entry in the table. However, while repeating the registration operations, the table always becomes full. This results in full bits of the table index as the compressed data. In this case, any original symbol is not compressed. To avoid this situation, we apply
entropy culling that invalidates the highest entry in the table after several hit operations. By performing these operations, ASE coding implements a stream-based compression mechanism by using a fixed number of entries in the table.
As explained above, ASE coding compresses the data stream without stalling the flow. It is also easily implemented on hardware due to the simple compression mechanism. The hardware resource size is deterministic because the number of entries in the look-up table is fixed. ASE coding can be implemented on hardware by a smaller resource size than LCA-DLT and also works at the same speed on FPGA devices. Thus, we implemented an effective lossless data compression targeted to data stream.
According to the discussion above, LCA-DLT and ASE coding support the conditions for the stream-based lossless data compression: (1) compression process without buffering the input data, (2) compression/decompression processes in a small delay and (3) compact hardware implementation. Thus, these compression algorithms provide a breakthrough to overcome the enormous increasing of the big data processing demands under the fast data communication situation.
2.2. Exception Handling on Lossless Data Compression
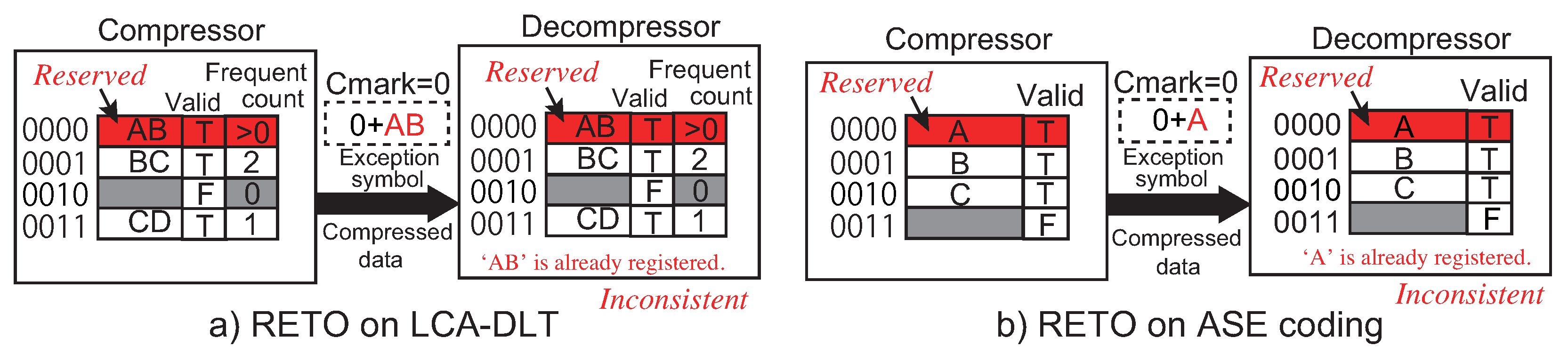
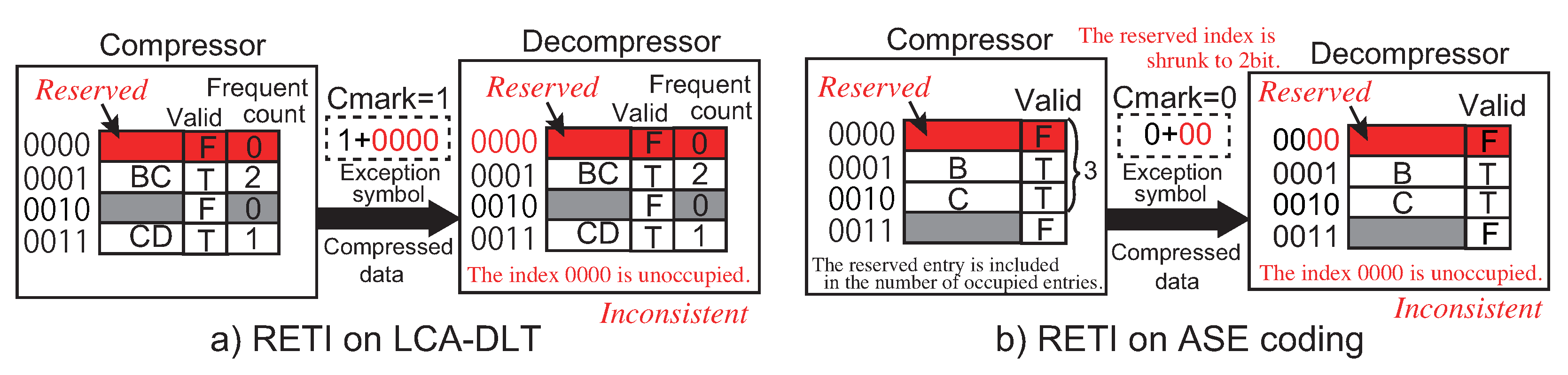
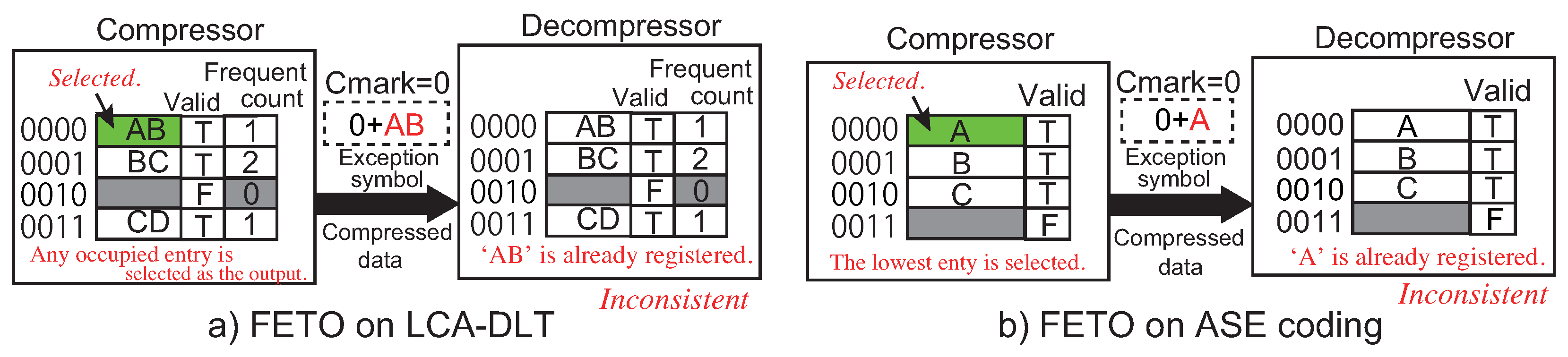
In information equipment with a stream-based data compression mechanism through the data path, the compressed data stream is continuously transferred from the producer to the consumer of the data stream. During the continuous data flow, the system needs to allow exchanging controls for the peripheral logics and/or the compression algorithm itself. The stream-based lossless data compression can control and adjust the compression performance against the target data in real time if it can send the compressed data with the control data in a single stream. For example, the digram coding will become available to reset the look-up table and also to adjust parameters for the backend system of the decompression algorithm such as sensor settings for multimedia application. When the compressor and the decompressor are implemented in hardware, the parameter adjustment must be performed in real time during the processes of a data stream. To implement this mechanism, we need to add a method to the digram coding. The method embeds an exception code that is distinguished from the normal compressed data. In the other words, the exception code is inserted in compressed data, and then, the decompressor must recognize the code seamlessly. Thus, we need to invent a mechanism to insert a control code under an exception status. In this paper, we call this control code an exception symbol.
First, the simplest method to embed exception symbols in a compressed data stream is to compress its original data stream with the exception symbols.
Figure 4a shows an example of the method. It passes a data stream to the compressor that is formatted in a rule. The exception symbols are recognized in the decompressor side after decompressed to the original data. This method has a drawback that the original data needs additional information for distinguishing data among the compressed ones and exception symbols. Furthermore, when we consider to configure the compressor and the decompressor settings via the exception symbols, it is hard to synchronize the configuration timings because the timings must be adjusted according to the delay of the compressor/decompressor.
The second method is to make packets of compressed data and exception symbols. This method needs to add a header information to each chunk.
Figure 4b illustrates an example of this method. This method needs to include a communication protocol such as that used in a packet-based network connection. This demands the compressor/decompressor to include a protocol. The compressor specifies a protocol to create a packet with chunks. Then, the decompressor extracts the chunks from the packet by following the protocol. This obviously degrades the compression performance due to the additional information combined with the compressed data stream according to the packet format. Similarly, the escape code is another well-known method that distinguishes the exception symbol and the compressed data. For example, if the code of ‘FF’ is defined as the escape code, the subsequent code is recognized as the exception symbol. Here, the compressed data that corresponds to the escape code is expressed two ’FF’s. This means that the method inevitably increases the amount of the compressed data, and thus degrades the compression performance.
The third method is to make chunks from the compressed data separated in a fixed size. The compressor outputs those chunks and inserts the exception symbol between the chunks as illustrated in
Figure 4c. This method avoids additional process in the compressor to format a packet like the second method. However, the exception symbol must be inserted after every chunk. Even if any exception does not occur, the exception symbol must be inserted by defining a void exception such as NOP (No OPeration). Although this mechanism can avoid equiping a protocol on both the compressor and the decompressor, the void exception increases the amount of compressed data. Therefore, the compression performance degrades. LZ4 [
11] uses the method to make chunks and implements a pseudo stream-based compression manner. It can use this method for the exception symbol. However, it cannot avoid degrading the compression performance.
The three methods above to insert the exception symbol to a compressed data stream are applicable to the conventional lossless data compression methods such as Shannon’s entropy and Huffman coding. However, when we consider to introduce the exception symbol to a digram coding, we must employ another method to support it by using the look-up table. For example, LZW implements the mechanism of exception symbol using the look-up table. It initially prepares entries in the table dedicated to exception symbols. At the initialization, the compressor and the decompressor prepare a look-up table respectively, setup the table with the available bit patterns for all single symbols and add two additional entries for stop and clear exceptions after the occupied entries. As a typical setting, initially 4096 entries are prepared in the table. The lower entries are initialized from 0 to 255 at first. The 257th and 258th entries are used to save the codes for the stop and the clear exceptions. The clear exception is used to reset the table. The stop exception is used to stop compression/decompression. The compressed data ‘256’ and ‘257’ are detected as the exception symbols in the decompression side. In this method, we need to prepare at least entries in the table, where k is the number of bits in an original symbol and n is the number of exception symbols. Therefore, the number of bits in a compressed data becomes larger than the original symbol because the number of bits in the table index begins with bits. In the LZW case, two entries for the exception symbols are not used for the compression processes.
However, the method stated above for managing exception symbols is not applicable to the digram coding with a fixed number of entries because the table entries are reused by the invalidation mechanism dynamically during the compression algorithm. For example, LCA-DLT and ASE coding, explained in the previous section, do not have any mechanism to reserve the entries for the exception symbols without invalidation. Even when the additional entries reserved for the exception symbols are extended in the last of the table, the number of bits in the compressed symbol increases and the compression ratio will become worse. Thus, in the aspects of control and performance, digram coding with a fixed number of table entries is not able to use the similar method employed in LZW that reserves the exception symbols in the table.
Moreover, the method used in LZW needs to register all exception symbols in the look-up table. However, such as performed in the processor architecture field, the “exception” is an event to migrate the operation mode from a normal to a supervisor mode. The processor recognizes which exception has occurred from status information that causes the event. As well as this technique, just an exception symbol for the event that migrates the compressor’s/decompressor’s mode to a supervisor mode should be prepared in the data compression algorithm. In addition, the information by which exception is caused should follow the exception symbol. However, the conventional exception methods in lossless data compression do not support this kind of diversity.
As discussed in the sections above, the stream data compression is able to compress/decompress data stream without any stalls and can be implemented on hardware compactly. However, we do not have any smart solution to support the exception symbol that causes an event to migrate the operation mode using a look-up table with a fixed number of entries. To support this, we need a novel mechanism to cause an exception event in the fixed-size look-up table. In the rest of this paper, we will propose a new mechanism to support the exception symbol that can follow the additional information for the event without degradation of data compression performance.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










