
Muon–Electron Pulse Shape Discrimination for Water Cherenkov Detectors Based on FPGA/SoC

 , ,
, ,  ,
,  , ,
, ,
Abstract
1. Introduction
- a SoC FPGA implementation of two methods for pulse shape analysis for cosmic rays detection with high overall accuracy and low execution times;
- a pulse shape discriminator through a neural network inference, getting a fast and accurate model, using compression techniques and reconfigurable hardware for computation acceleration;
- the use of the novel hls4ml package in the context of cosmic rays detection to map the inference stage into the FPGA;
- the use of a correlation method using FIR filters and the design of a decision logic for online pulse discrimination;
- a comparison of these methods in two different SoC FPGA platforms measuring resources utilization, power consumption and execution times.
2. Related Works
2.1. Neural Networks
2.2. FIR Filters
3. Methodology
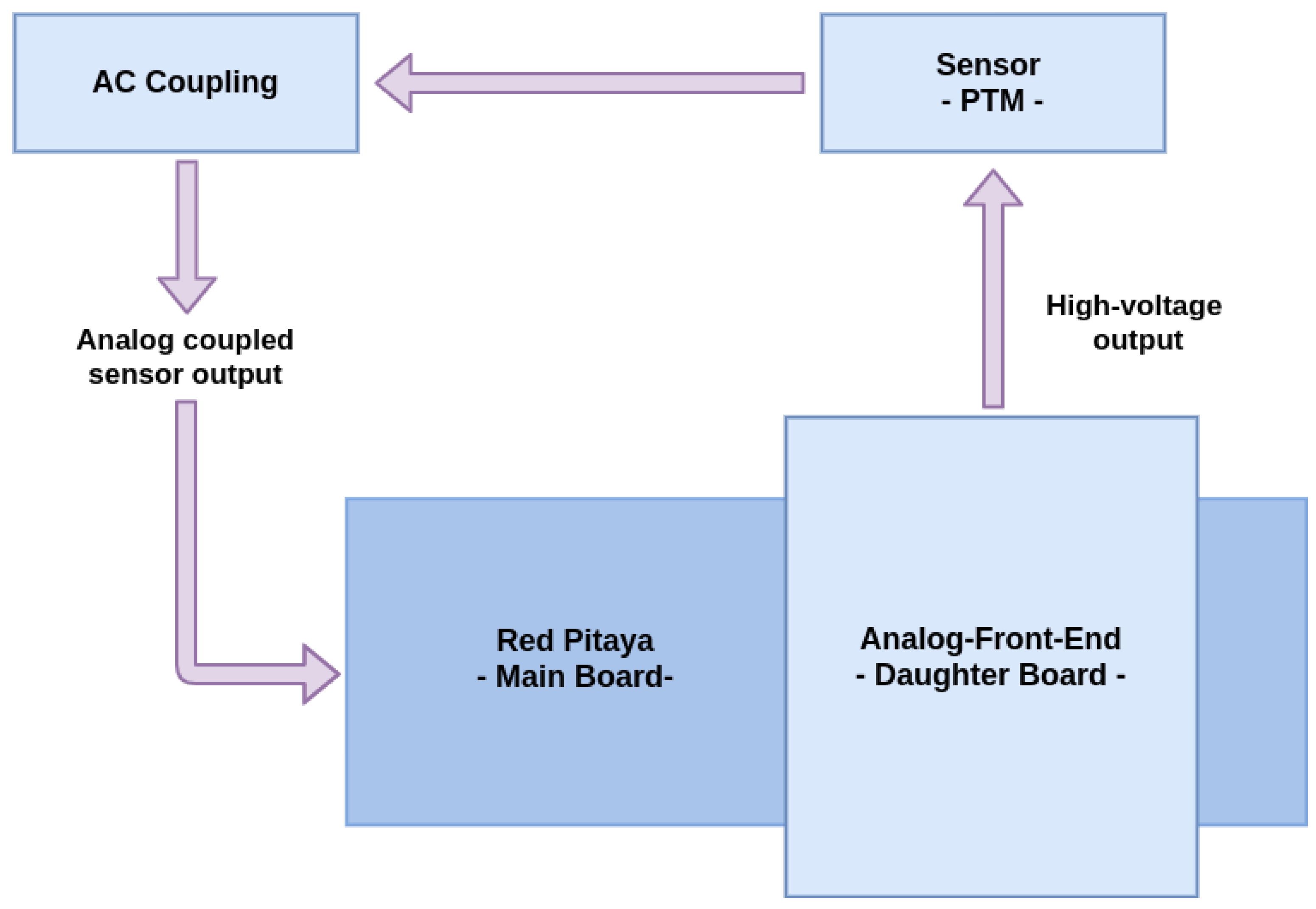
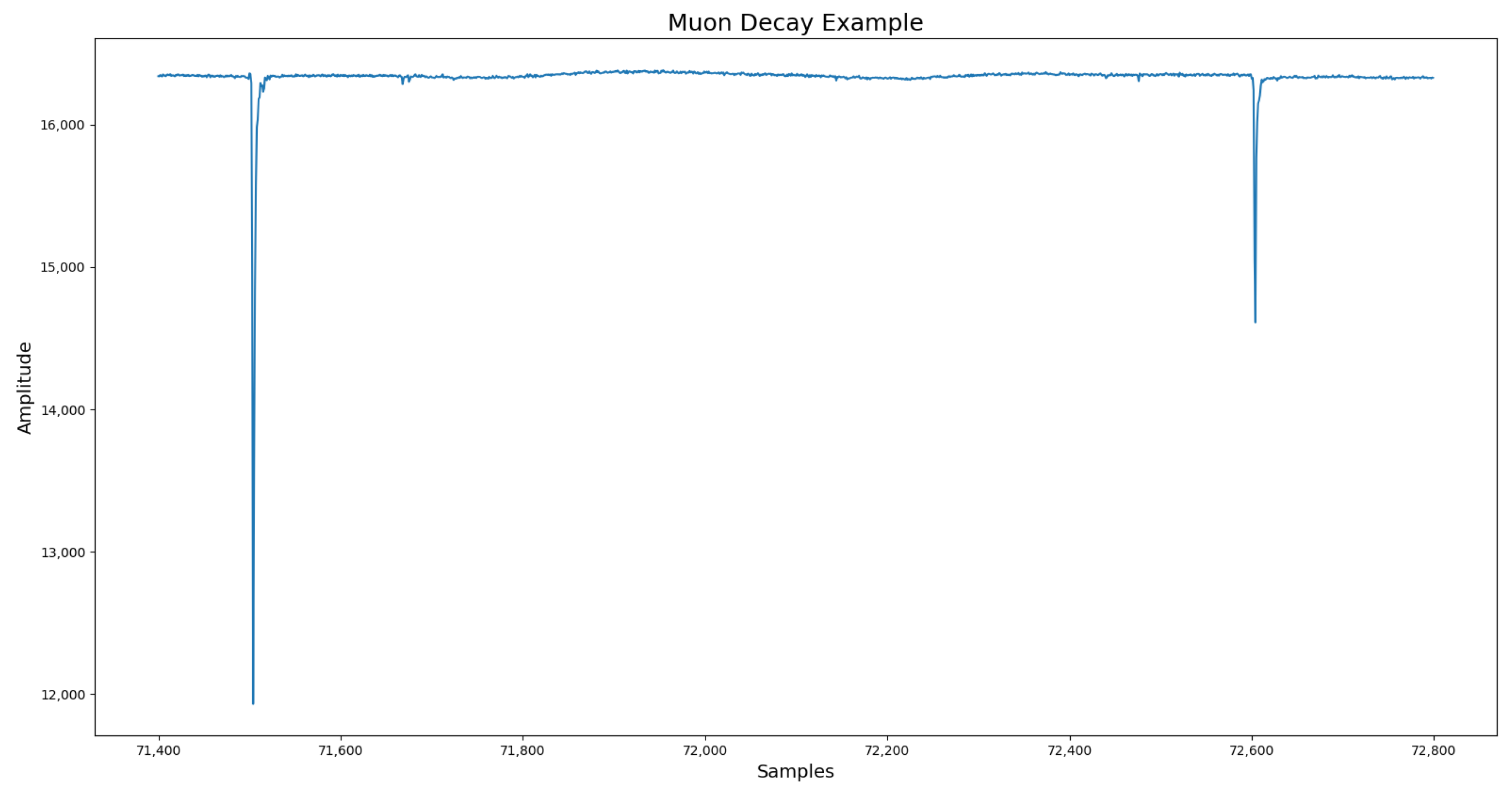
3.1. Data Acquisition
3.1.1. Analog Front-End
3.1.2. Slow Control
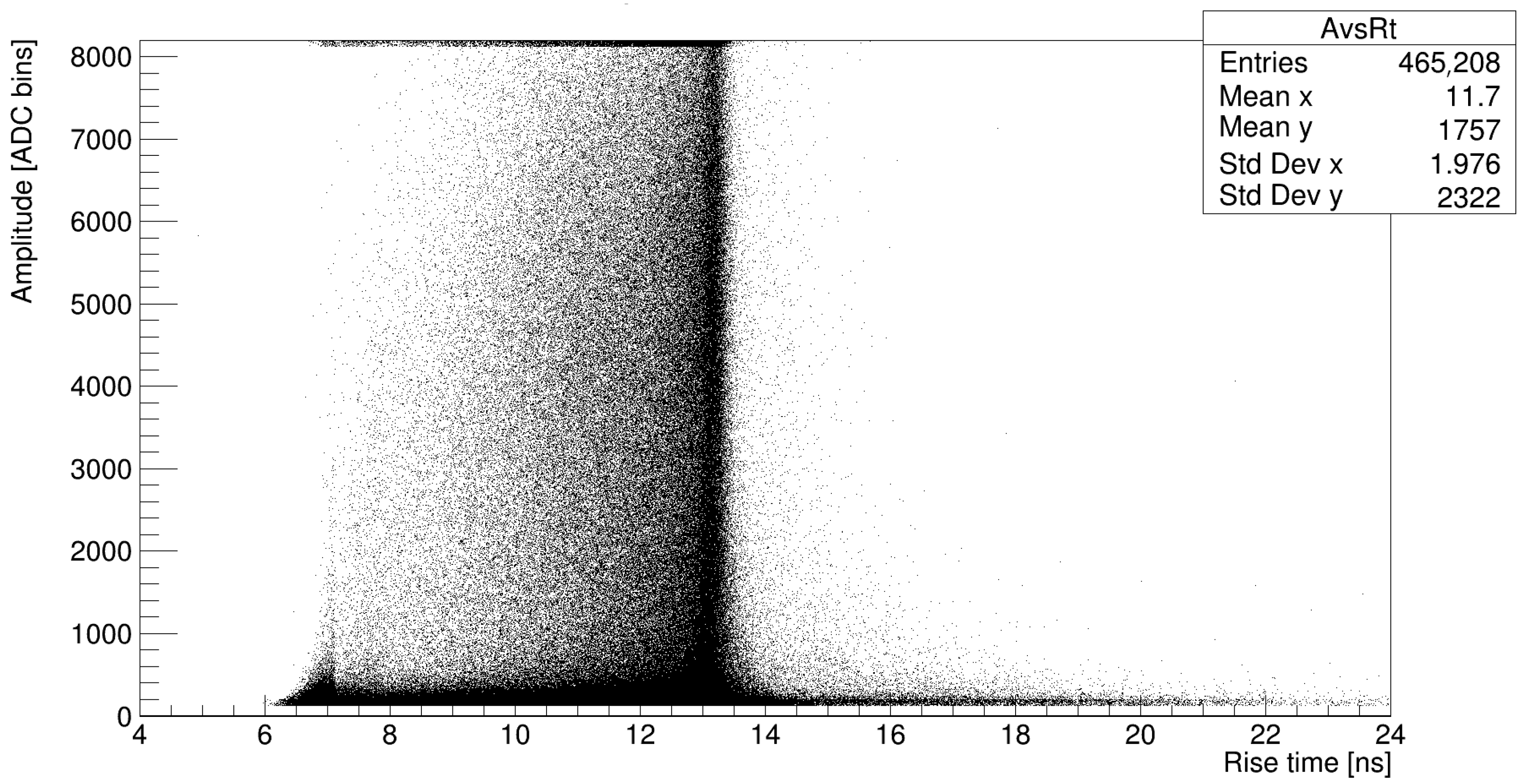
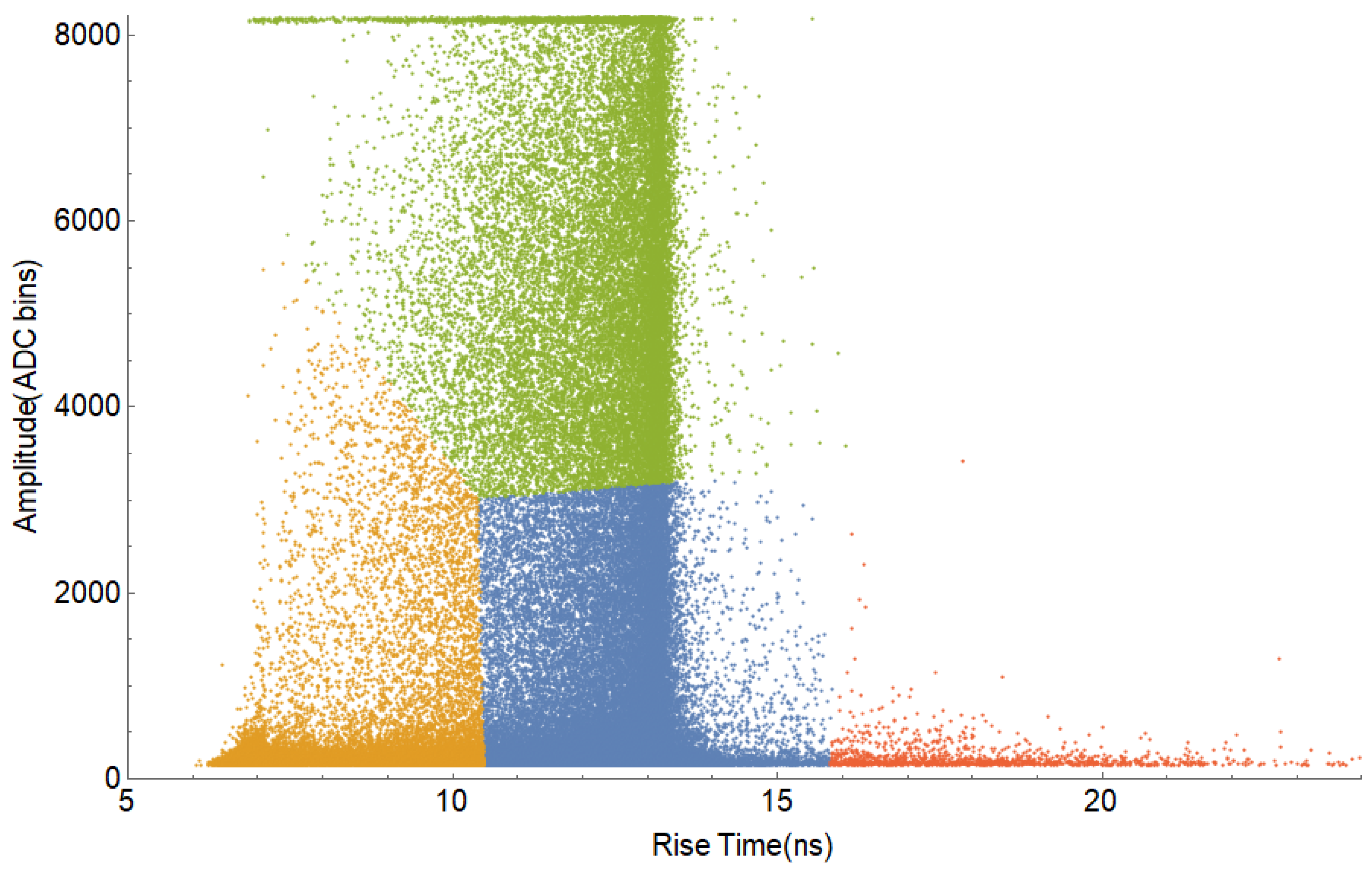
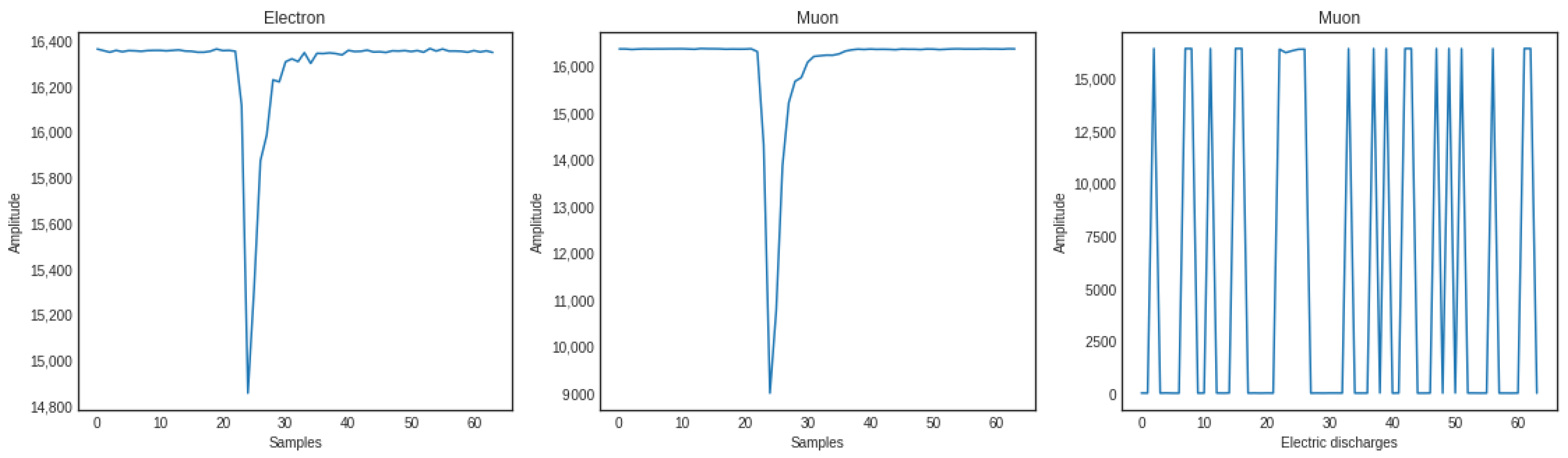
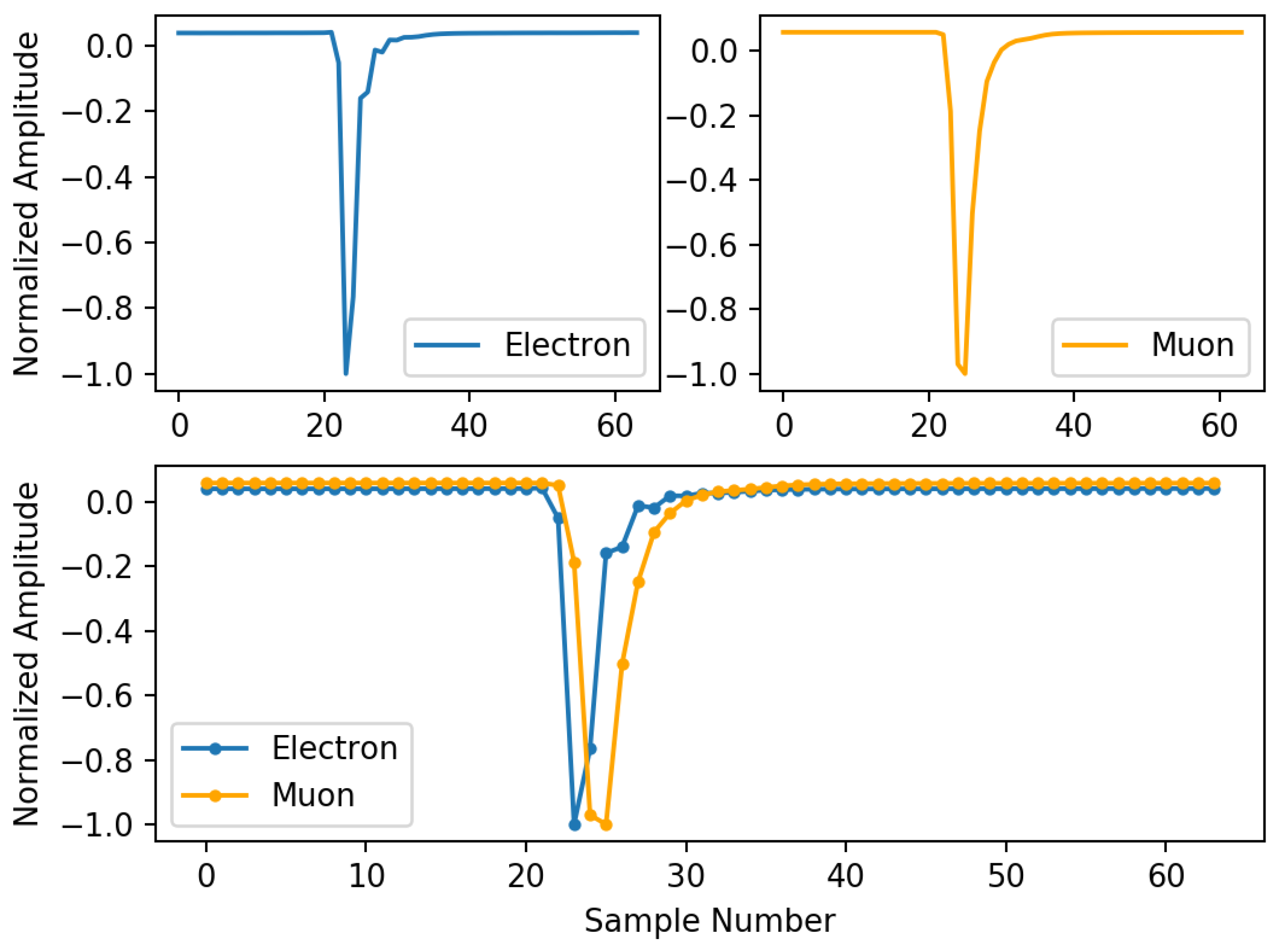
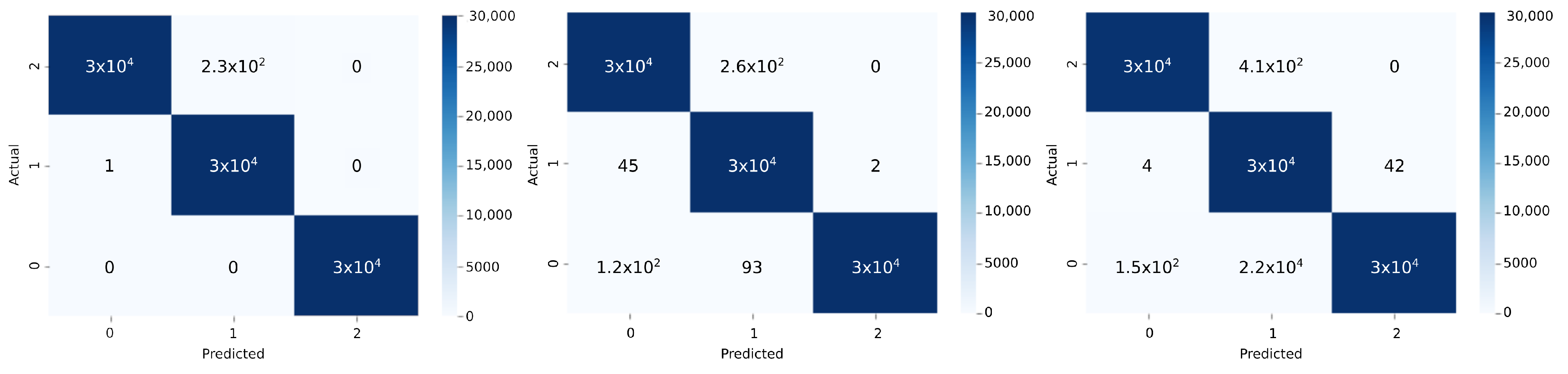
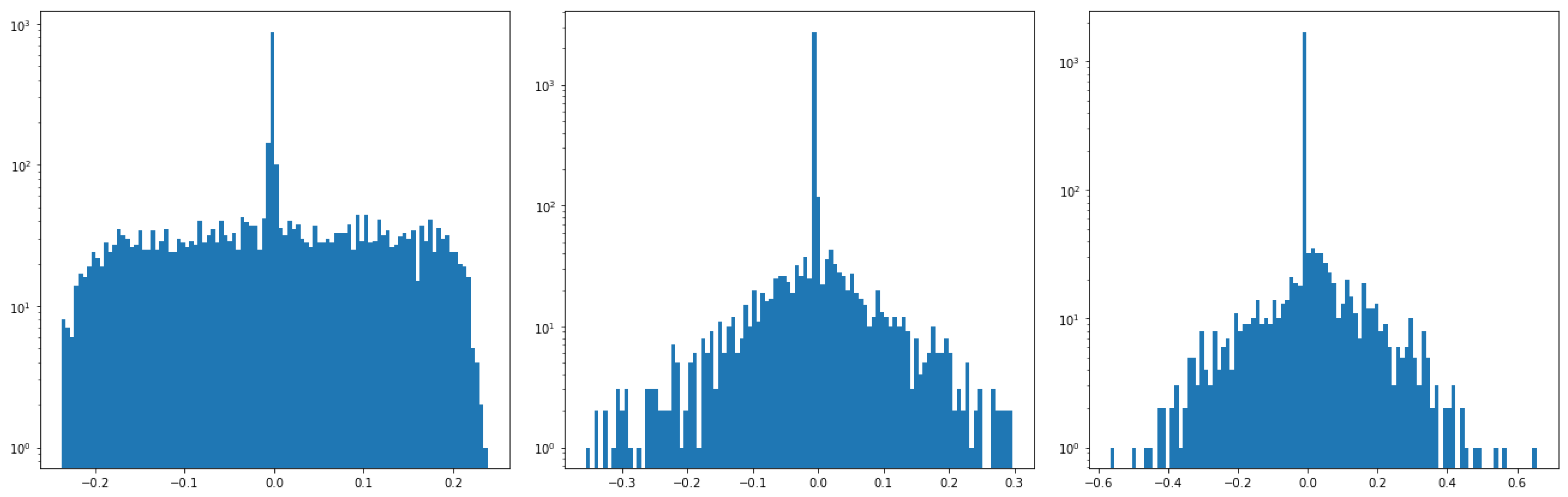
3.2. Data Set Analysis and Pulse Discrimination Criteria
- Electron: amplitude below 3000—Rise time: between 6 and 9 ns.
- Muon: amplitude from 3000 to 8000—Rise time: between 11 and 15 ns.
- Electrical Discharge: amplitude greater than 8000 or data that do not fall in the previous categories.
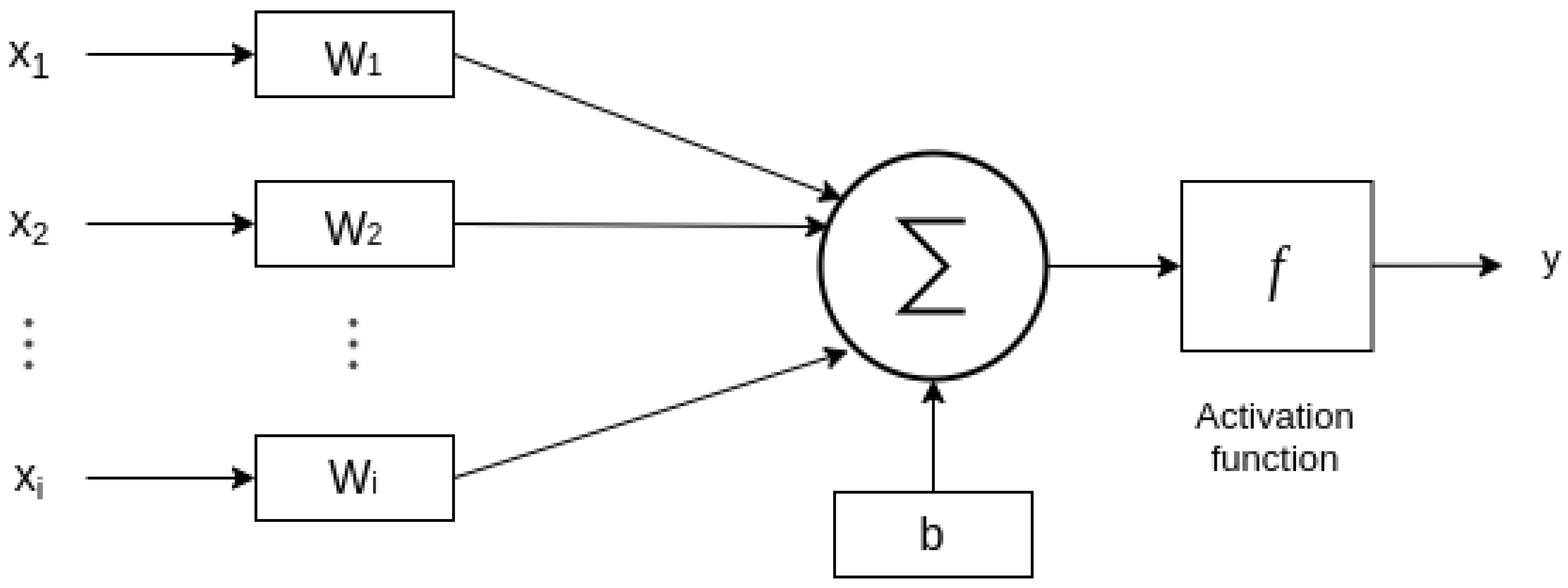
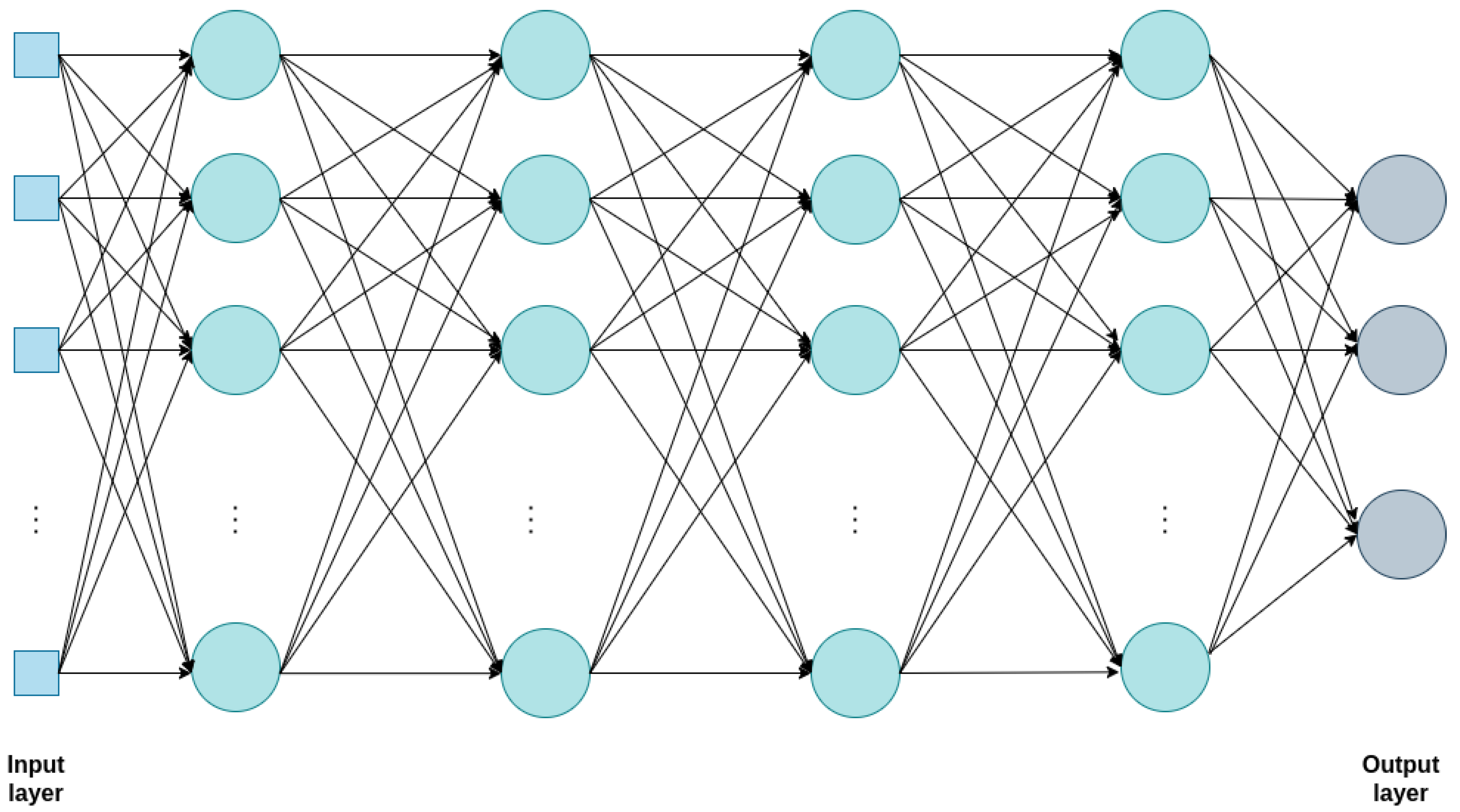
3.3. Neural Network Approach Based on Multilayer Perceptron
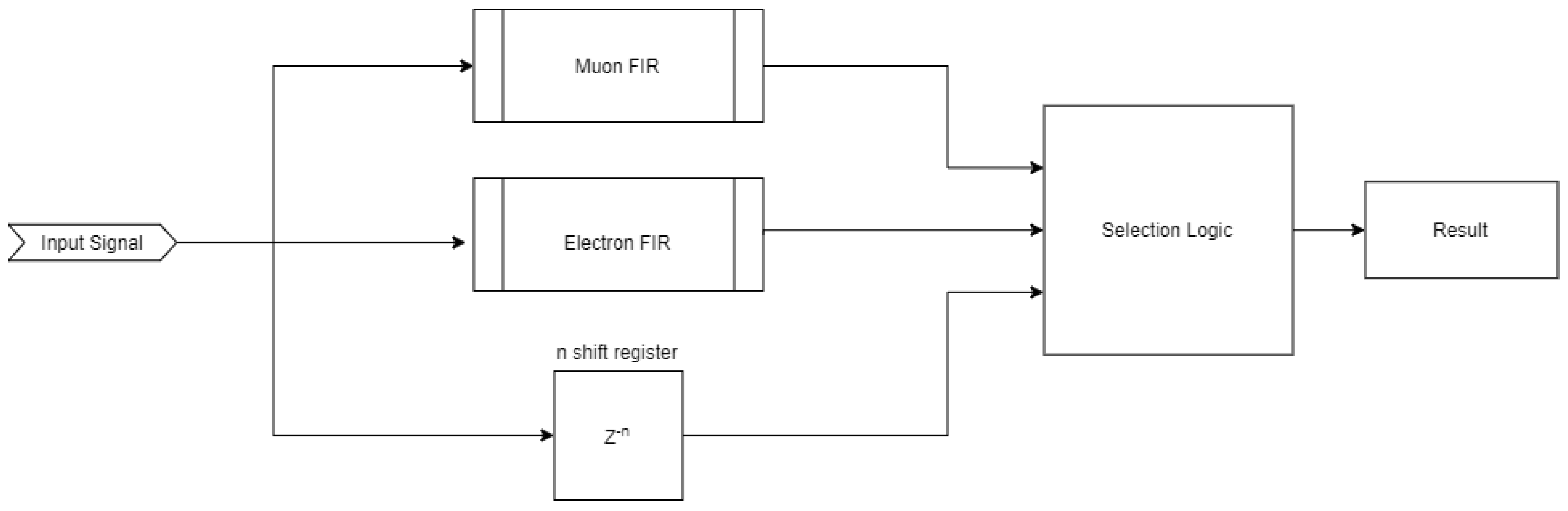
3.4. FIR Correlation Approach
- If and are greater than a base reference value () pass to the next criteria. This will discard uncorrelated signals like electrical discharges.
- If , the signal is an electron, else if , the signal is a muon.
- In the case of , the amplitude of the peak will be used to take the decision. If , the result is a muon.
- If the signal is in saturation , the selection logic will classify it as an electrical discharge.
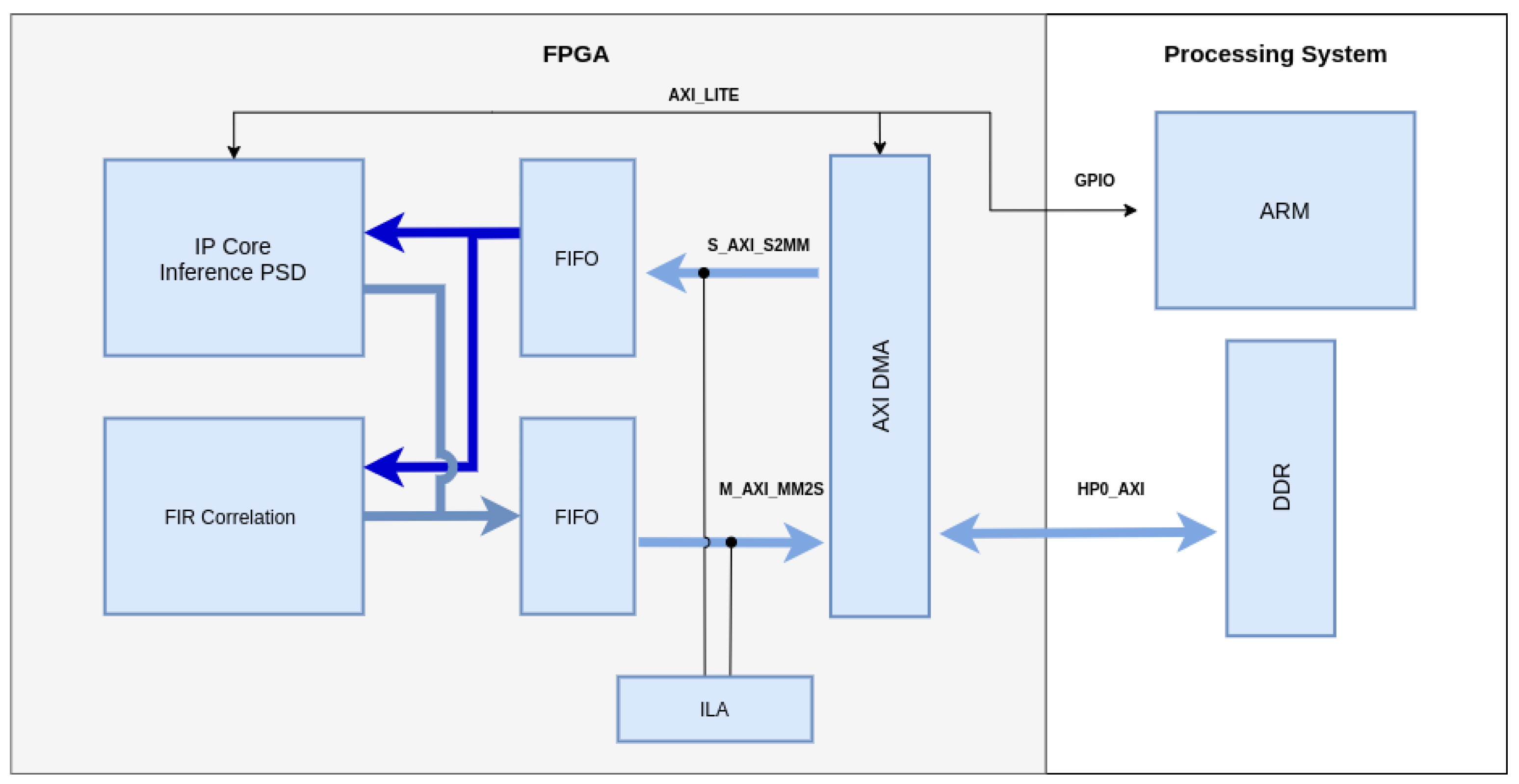
4. Implementation
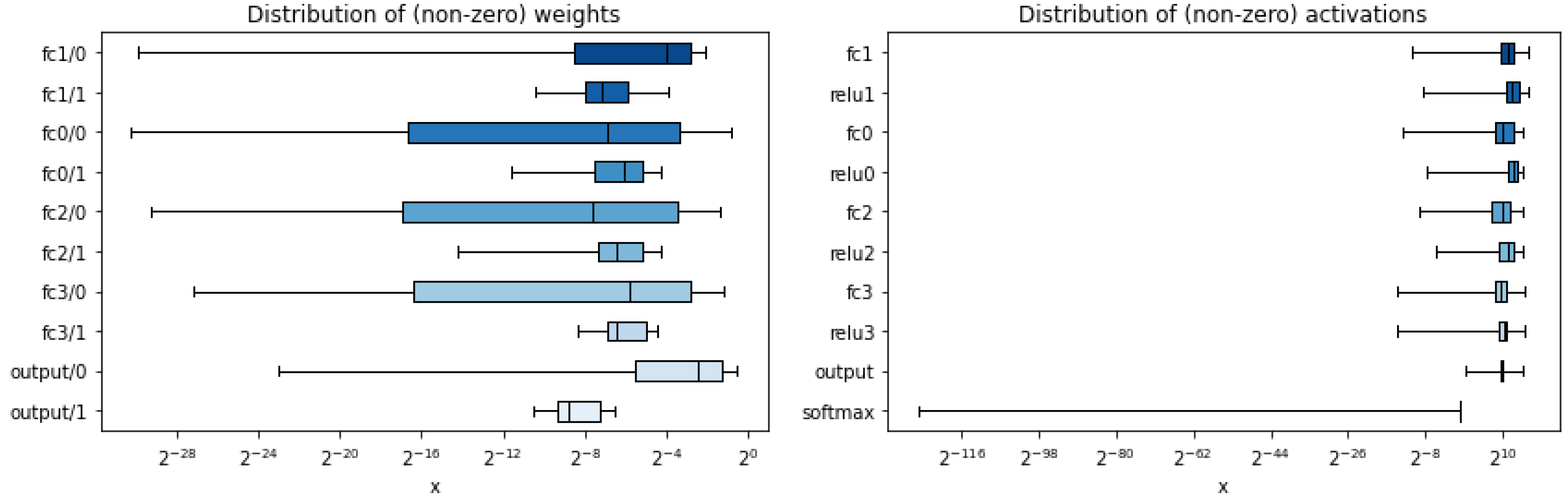
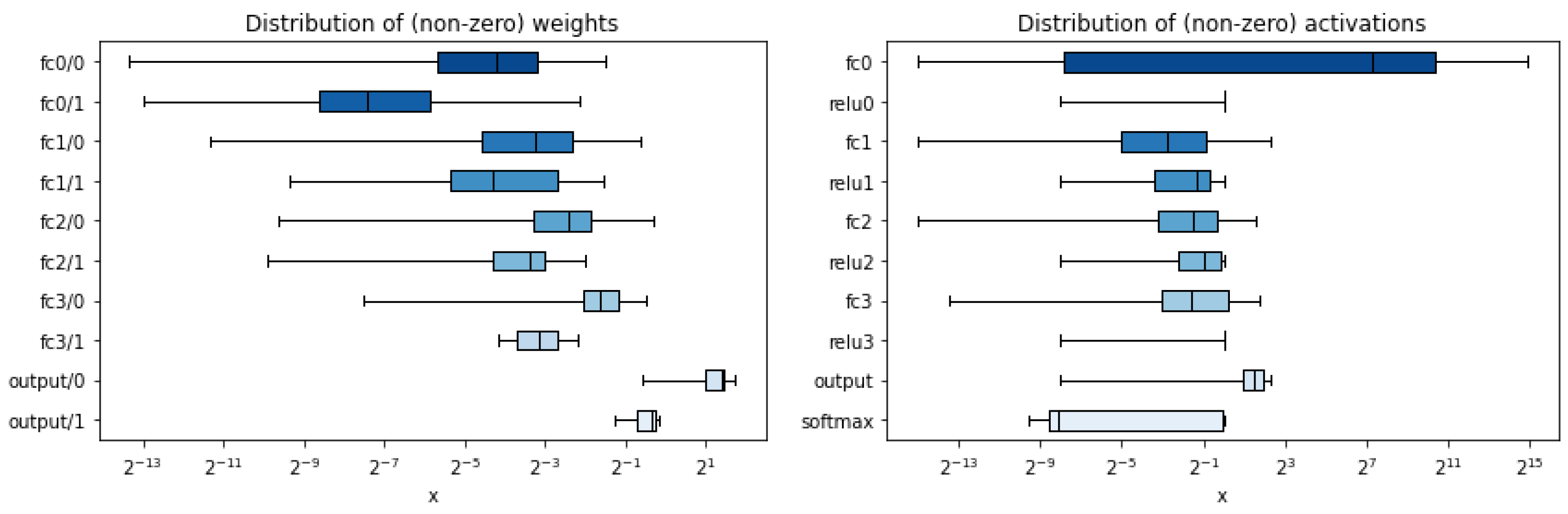
4.1. Neural Network Implementation
- Training 1: for the base network to verify the performance with L1 regularization for kernels and bias in each layer with a value of 0.0001.
- Training 2: for the quantized network with L2 regularization for kernels and bias in each layer with a value of 0.0001 was used. In this implementation, a better accuracy was obtained compared with L1 normalization when training the quantized network. The quantization was performed with 16 bits in the input and first dense layer, 9 bits for weights and bias for the rest of the layers and 18 bits for the last layer with Softmax activation function.
- Training 3: for pruning the network.
- ap_fixed<17,1> for weights and bias for the first fully connected layer;
- ap_fixed<9,1> for weights and bias for the rest fully connected layers;
- ap_fixed<9,1,AP_RND,AP_SAT> for all activation layers based on the ReLU;
- ap_fixed<19,9> for weights and ap_fixed<9,1> for bias corresponding to the output layer;
- ap_fixed<23,15> for the model.
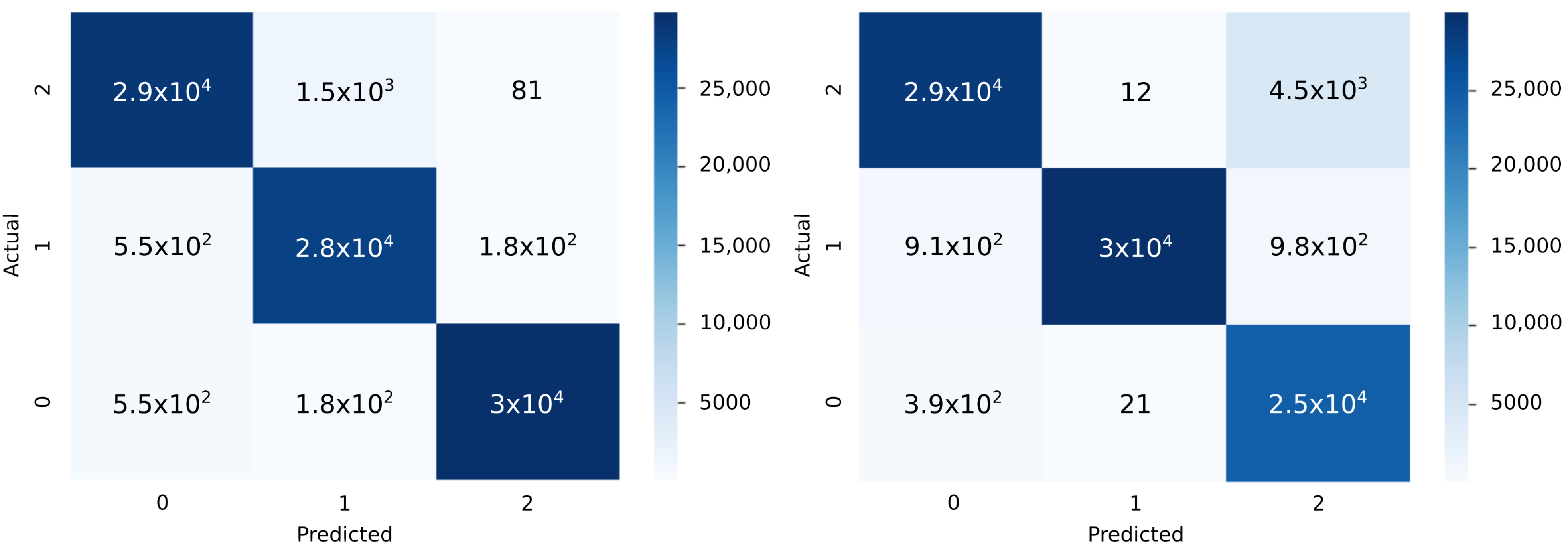
Neural Network Results
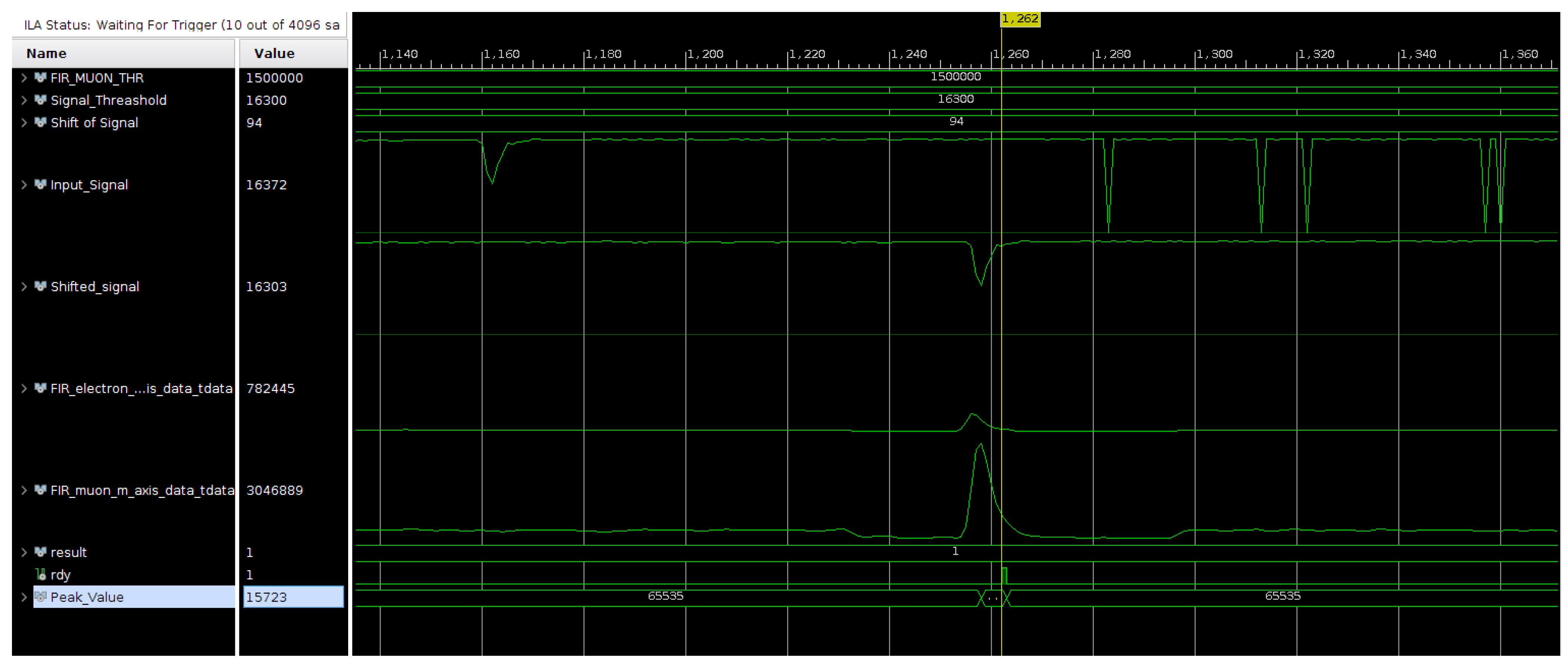
4.2. FIR Implementation
5. Analysis of Results
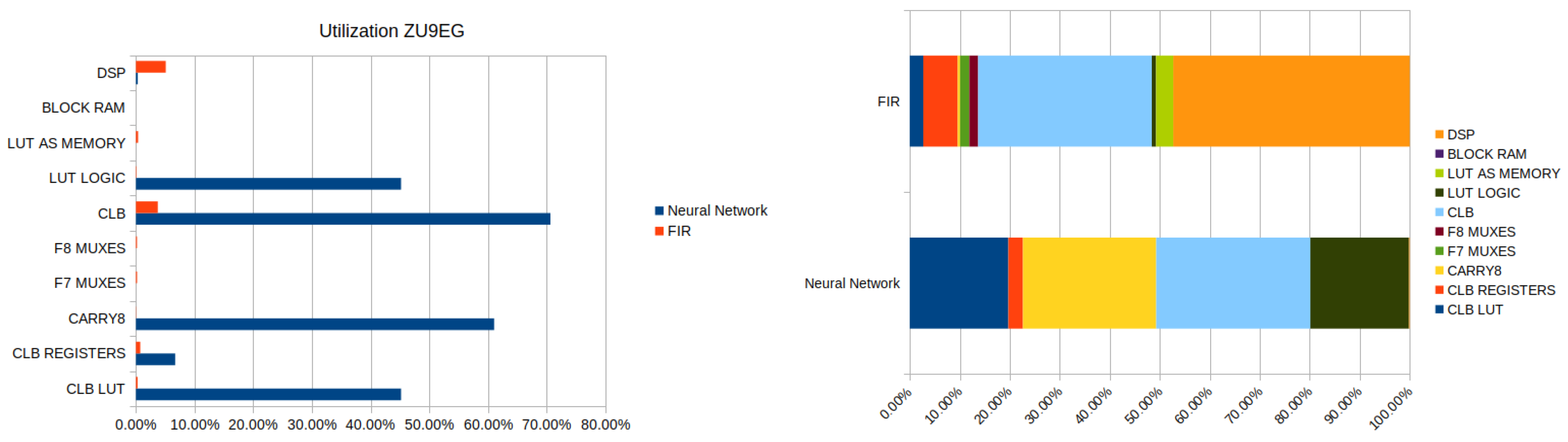
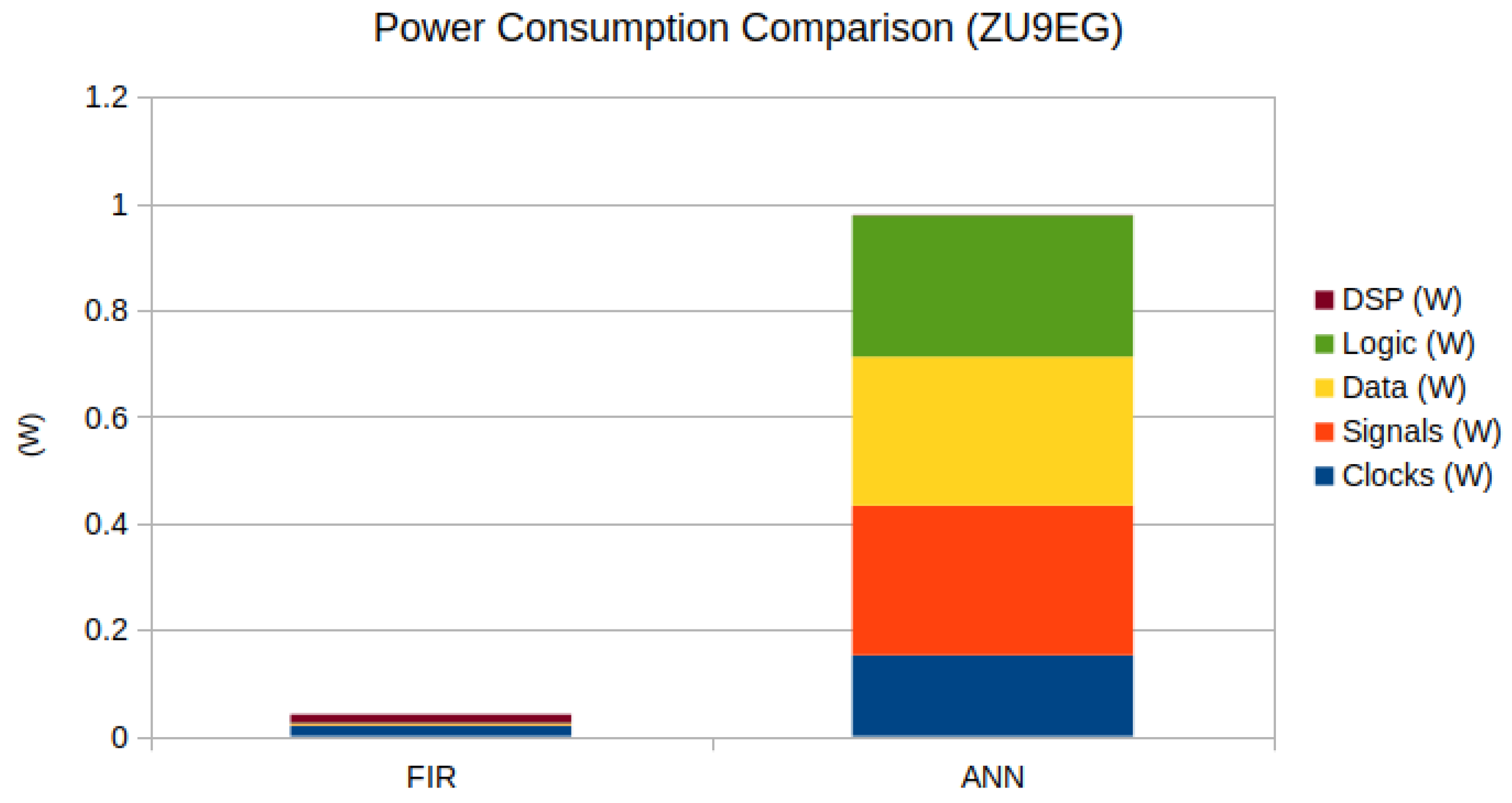
Resources Utilization and Power Consumption
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADC | Analog-to-Digital Converter |
| AFE | Analog Front End |
| ANN | Artificial Neural Network |
| BRAM | Block Random Access Memory |
| CCN | Convolutional Neural Network |
| CLB | Configurable Logic Block |
| CRs | Cosmic Rays |
| DAQ | Data Acquisition System |
| DCNN | Deconvolutional Neural Network |
| DMA | Direct Memory Access |
| DSP | Digital Signal Processing |
| EAS | Extensive Air Showers |
| FIR | Finite Impulse Response |
| FPGA | Field Programmable Gate Array |
| GRB | Gamma Ray Burst |
| HLS4ML | High-Level Synthesis for Machine Learning |
| HLS | High-Level Synthesis |
| ILA | Integrated Logic Analyzer |
| LUT | Lookup table |
| MLP | Multilayer Perceptron |
| NPV | Negative Predicted Value |
| PMT | Photomultiplier tube |
| PSD | Pulse Shape Discrimination |
| PPV | Positive Predicted Value |
| ReLU | Rectified Linear Unit |
| SoC | System on Chip |
| TNR | True Negative Rate |
| TPR | True Positive Rate |
| WCD | Water Cherenkov Detectors |
References
- Pierre Auger Collaboration. The Pierre Auger Cosmic Ray Observatory. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2015, 798, 172–213. [Google Scholar] [CrossRef]
- DeYoung, T. The HAWC observatory. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2012, 692, 72–76. [Google Scholar] [CrossRef]
- Castellina, A. AugerPrime: The Pierre Auger Observatory Upgrade. EPJ Web Conf. 2019, 210, 06002. [Google Scholar] [CrossRef]
- Allard, D.; Allekotte, I.; Alvarez, C.; Asorey, H.; Barros, H.; Bertou, X.; Burgoa, O.; Berisso, M.G.; Martínez, O.; Loza, P.M.; et al. Use of water-Cherenkov detectors to detect gamma ray bursts at the Large Aperture GRB Observatory (LAGO). Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2008, 595, 70–72. [Google Scholar] [CrossRef]
- STEMLab. Red Pitaya 0.97 Documentation-Red Pitaya Developers Guide. 2017. Available online: https://redpitaya.readthedocs.io/en/latest/ (accessed on 30 December 2020).
- Arnaldi, L.H.; Cazar, D.; Audelo, M.; Sidelnik, I. Preliminary results of the design and development of the data acquisition and processing system for the LAGO Collaboration. PoS 2019, ICRC2019, 175. [Google Scholar] [CrossRef]
- Garcia Ordóñez, L.G.; Morales Argueta, I.R.; Crespo, M.L.; Carrato, S.; Cicuttin, A.; Perez, H.; Barrientos, D.; Levorato, S.; Valinoti, B.; Florian, W.; et al. DAQ platform based on SoC-FPGA for high resolution time stamping in cosmic ray detection. PoS 2019, ICRC2019, 266. [Google Scholar] [CrossRef]
- De Rújula, A. An introduction to Cosmic Rays and Gamma-Ray Bursts, and to their simple understanding. arXiv 2007, arXiv:0711.0970. [Google Scholar]
- Aab, A.; Abreu, P.; Aglietta, M.; Al Samarai, I.; Albuquerque, I.; Allekotte, I.; Almela, A.; Castillo, J.A.; Alvarez-Muñiz, J.; Anastasi, G.A.; et al. Observation of a large-scale anisotropy in the arrival directions of cosmic rays above 8 × 1018 eV. Science 2017, 357, 1266–1270. [Google Scholar]
- Anchordoqui, L.A. Ultra-high-energy cosmic rays. Phys. Rep. 2019, 801, 1–93. [Google Scholar] [CrossRef]
- Piron, F. Gamma-ray bursts at high and very high energies. Comptes Rendus Phys. 2016, 17, 617–631. [Google Scholar] [CrossRef]
- Liu, G.; Aspinall, M.; Ma, X.; Joyce, M. An investigation of the digital discrimination of neutrons and γ rays with organic scintillation detectors using an artificial neural network. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2009, 607, 620–628. [Google Scholar] [CrossRef]
- Chandhran, P.; Holbert, K.E.; Johnson, E.B.; Whitney, C.; Vogel, S.M. Neutron and gamma ray discrimination for CLYC using normalized cross correlation analysis. In Proceedings of the 2014 IEEE Nuclear Science Symposium and Medical Imaging Conference (NSS/MIC), Seattle, WA, USA, 8–15 November 2014; pp. 1–8. [Google Scholar] [CrossRef]
- Fu, C.; Fulvio, A.D.; Clarke, S.; Wentzloff, D.; Pozzi, S.; Kim, H. Artificial neural network algorithms for pulse shape discrimination and recovery of piled-up pulses in organic scintillators. Ann. Nucl. Energy 2018, 120, 410–421. [Google Scholar] [CrossRef]
- D’Mellow, B.; Aspinall, M.; Mackin, R.; Joyce, M.; Peyton, A. Digital discrimination of neutrons and γ-rays in liquid scintillators using pulse gradient analysis. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2007, 578, 191–197. [Google Scholar] [CrossRef]
- Ammerlaan, C.; Rumphorst, R.; Koerts, L. Particle identification by pulse shape discrimination in the p-i-n type semiconductor detector. Nucl. Instrum. Methods 1963, 22, 189–200. [Google Scholar] [CrossRef]
- Winyard, R.; Lutkin, J.; McBeth, G. Pulse shape discrimination in inorganic and organic scintillators. I. Nucl. Instrum. Methods 1971, 95, 141–153. [Google Scholar] [CrossRef]
- Bartle, C. A study of (n,p) and (n,α) reactions in NaI(Tl) using a pulse-shape-discrimination method. Nucl. Instrum. Methods 1975, 124, 547–550. [Google Scholar] [CrossRef]
- Salazar, H.; Villasenor, L. Separation of cosmic-ray components in a single water Cherenkov detector. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2005, 553, 295–298. [Google Scholar] [CrossRef]
- Salazar, H.; Villasenor, L. Ground detectors for the study of cosmic ray showers. J. Phys. Conf. Ser. 2008, 116, 012008. [Google Scholar] [CrossRef]
- Schoorlemmer, H.; Hinton, J.; López-Coto, R. Characteristics of extensive air showers around the energy threshold for ground-particle-based γ-ray observatories. Eur. Phys. J. C 2019, 79, 427. [Google Scholar] [CrossRef]
- Zhu, J.; Gong, G.; Xue, T.; Cao, Z.; Wei, L.; Li, J. Preliminary Design of Integrated Digitizer Base for Photomultiplier Tube. IEEE Trans. Nucl. Sci. 2019, 66, 1130–1137. [Google Scholar] [CrossRef]
- Mace, E.; Ward, J.; Aalseth, C. Use of neural networks to analyze pulse shape data in low-background detectors. J. Radioanal. Nucl. Chem. 2018, 318, 117–124. [Google Scholar] [CrossRef]
- Griffiths, J.; Kleinegesse, S.; Saunders, D.; Taylor, R.; Vacheret, A. Pulse Shape Discrimination and Exploration of Scintillation Signals Using Convolutional Neural Networks. Mach. Learn. Sci. Technol. 2020, 1, 045022. [Google Scholar] [CrossRef]
- Holl, P.; Hauertmann, L.; Majorovits, B.; Schulz, O.; Schuster, M.; Zsigmond, A.J. Deep learning based pulse shape discrimination for germanium detectors. Eur. Phys. J. C 2019, 79. [Google Scholar] [CrossRef]
- Droz, D.; Tykhonov, A.; Wu, X. Neural Networks for Electron Identification with DAMPE. In Proceedings of the 36th International Cosmic Ray Conference—PoS(ICRC2019), Madison, WI, USA, 24 July–1 August 2019; Volume 358, p. 064. [Google Scholar] [CrossRef]
- Villasenor, L.; Jeronimo, Y.; Salazar, H. Use of Neural Networks to Measure the Muon Contents of EAS Signals in a Water Cherenkov Detector. In Proceedings of the International Cosmic Ray Conference, Tsukuba, Japan, 31 July–7 August 2003. [Google Scholar]
- Kohonen, T. Self-Organization and Associative Memory, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 1989. [Google Scholar]
- Guo, K.; Zeng, S.; Yu, J.; Wang, Y.; Yang, H. A Survey of FPGA-Based Neural Network Accelerator. arXiv 2018, arXiv:1712.08934. [Google Scholar]
- Wei, X.; Liang, Y.; Cong, J. Overcoming Data Transfer Bottlenecks in FPGA-based DNN Accelerators via Layer Conscious Memory Management. In Proceedings of the 56th Annual Design Automation Conference 2019, DAC 2019, Las Vegas, NV, USA, 2–6 June 2019; p. 125. [Google Scholar]
- Zhang, X.; Das, S.; Neopane, O.; Kreutz-Delgado, K. A Design Methodology for Efficient Implementation of Deconvolutional Neural Networks on an FPGA. arXiv 2017, arXiv:1705.02583. [Google Scholar]
- Kim, J.H.; Grady, B.; Lian, R.; Brothers, J.; Anderson, J.H. FPGA-based CNN inference accelerator synthesized from multi-threaded C software. In Proceedings of the 2017 30th IEEE International System-on-Chip Conference (SOCC), Munich, Germany, 5–8 September 2017. [Google Scholar] [CrossRef]
- Meloni, P.; Capotondi, A.; Deriu, G.; Brian, M.; Conti, F.; Rossi, D.; Raffo, L.; Benini, L. NEURAghe: Exploiting CPU-FPGA Synergies for Efficient and Flexible CNN Inference Acceleration on Zynq SoCs. ACM Trans. Reconfig. Technol. Syst. 2018, 11, 18:1–18:24. [Google Scholar] [CrossRef]
- Duarte, J.; Han, S.; Harris, P.; Jindariani, S.; Kreinar, E.; Kreis, B.; Ngadiuba, J.; Pierini, M.; Rivera, R.; Tran, N.; et al. Fast inference of deep neural networks in FPGAs for particle physics. J. Instrum. 2018, 13, P07027. [Google Scholar] [CrossRef]
- Nottbeck, N.; Schmitt, D.C.; Büscher, P.D.V. Implementation of high-performance, sub-microsecond deep neural networks on FPGAs for trigger applications. J. Instrum. 2019, 14, P09014. [Google Scholar] [CrossRef]
- Xilinx. FIR Compiler v7.2. LogiCORE IP Product Guide PG149. Xilinx, 2020. Available online: https://www.xilinx.com/support/documentation/ip_documentation/fir_compiler/v7_1/pg149-fir-compiler.pdf (accessed on 30 December 2020).
- Park, S.Y.; Meher, P.K. Efficient FPGA and ASIC Realizations of a DA-Based Reconfigurable FIR Digital Filter. IEEE Trans. Circuits Syst. II Express Briefs 2014, 61, 511–515. [Google Scholar] [CrossRef]
- Malacari, M.; Farmer, J.; Fujii, T.; Albury, J.; Bellido, J.; Chytka, L.; Hamal, P.; Horvath, P.; Hrabovský, M.; Mandat, D.; et al. The first full-scale prototypes of the fluorescence detector array of single-pixel telescopes. Astropart. Phys. 2020, 119, 102430. [Google Scholar] [CrossRef]
- Balmer, M.J.; Gamage, K.A.; Taylor, G.C. Comparative analysis of pulse shape discrimination methods in a 6Li loaded plastic scintillator. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2015, 788, 146–153. [Google Scholar] [CrossRef]
- Szadkowski, Z.; Fraenkel, E.D.; van den Berg, A.M. FPGA/NIOS implementation of an adaptive FIR filter using linear prediction to reduce narrow band RFI for radio detection of cosmic rays. In Proceedings of the 2012 18th IEEE-NPSS Real Time Conference, Berkeley, CA, USA, 9–15 June 2012; pp. 1–8. [Google Scholar] [CrossRef]
- Socha, P.; Miškovský, V.; Kubátová, H.; Novotný, M. Optimization of Pearson correlation coefficient calculation for DPA and comparison of different approaches. In Proceedings of the 2017 IEEE 20th International Symposium on Design and Diagnostics of Electronic Circuits Systems (DDECS), Dresden, Germany, 19–21 April 2017; pp. 184–189. [Google Scholar] [CrossRef]
- Lusher, J.; Ji, J.; Orr, J. High-Performance Correlation and Mapping Engine for rapid generating brain connectivity networks from big fMRI data. J. Comput. Sci. 2018, 26, 157–164. [Google Scholar] [CrossRef]
- Photonis. Photomultiplier Tubes Catalogue. 2007. Available online: https://hallcweb.jlab.org/DocDB/0008/000809/001/PhotonisCatalog.pdf (accessed on 30 December 2020).
- Cotzomi, J.; Moreno, E.; Murrieta, T.; Palma, B.; Perez, E.; Salazar, H.; Villasenor, L. The water Cherenkov detector array for studies of cosmic rays at the University of Puebla. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2005, 553, 290–294. [Google Scholar] [CrossRef]
- Abeysekara, A.; Aguilar, J.; Aguilar, S.; Alfaro, R.; Almaraz, E.; Álvarez, C.; Álvarez-Romero, J.d.D.; Álvarez, M.; Arceo, R.; Arteaga-Velázquez, J.; et al. On the sensitivity of the HAWC observatory to gamma-ray bursts. Astropart. Phys. 2012, 35, 641–650. [Google Scholar] [CrossRef]
- Galindo, A.; Moreno, E.; Carrasco, E.; Torres, I.; Carramiñana, A.; Bonilla, M.; Salazar, H.; Conde, R.; Alvarez, W.; Alvarez, C.; et al. Calibration of a large water-Cherenkov detector at the Sierra Negra site of LAGO. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2017, 861, 28–37. [Google Scholar] [CrossRef]
- XP Power. C Series, DC-HVDC Converter. 2020. Available online: https://www.xppower.com/portals/0/pdfs/SF_C_Series.pdf (accessed on 30 December 2020).
- Texas Instruments. TLV5616C, TLV5616I 2.7-V to 5.5-V Low Power 12-bit Digital-to-Analog Converters with Power Down. 1997. Available online: https://www.ti.com/lit/ds/symlink/tlv5616.pdf?ts=1610973116569&ref_url=https%253A%252F%252Fwww.google.com%252F (accessed on 30 December 2020).
- Genolini, B.; Raux, L.; de La Taille, C.; Pouthas, J.; Tocut, V. A large dynamic range integrated front-end for photomultiplier tubes. Nucl. Instrum. Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2006, 567, 209–213. [Google Scholar] [CrossRef][Green Version]
- Xiao, Y.; Xiang, S.; Zhao, Z.; Qian, Z. Design of high reliability nuclear logging probe. Procedia Eng. 2010, 7, 223–228. [Google Scholar] [CrossRef][Green Version]
- Arnaldi, L.H.; Cazar, D.; Audelo, M.; Sidelnik, I. The new data acquisition system of the LAGO Collaboration based on the Redpitaya board. In Proceedings of the 2020 Argentine Conference on Electronics (CAE), Buenos Aires, Argentina, 27–28 February 2020; pp. 87–92. [Google Scholar] [CrossRef]
- Knoll, G.F. Radiation Detection and Measurement; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
- Chapman, K. Digitally removing a DC offset: DSP without mathematics. Xilinx White Pap. 2008, 279, 134. [Google Scholar]
- Widmann, A.; Schröger, E.; Maess, B. Digital filter design for electrophysiological data–a practical approach. J. Neurosci. Methods 2015, 250, 34–46. [Google Scholar] [CrossRef]
- Sánchez, L.P.; Izraelevitch, F. Muon lifetime measurement in Chiapas and the Escaramujo project. J. Phys. 2017. [Google Scholar] [CrossRef]
- Group, P.D.; Zyla, P.A.; Barnett, R.M.; Beringer, J.; Dahl, O.; Dwyer, D.A.; Groom, D.E.; Lin, C.J.; Lugovsky, K.S.; Pianori, E.; et al. Review of Particle Physics. Prog. Theor. Exp. Phys. 2020, 2020. [Google Scholar] [CrossRef]
- Valle, A.; García, L.; Pérez, H. Medición de la Vida Media del Muón. Rev. De La Esc. De Física 2019, 5, 11–15. [Google Scholar] [CrossRef]
- Wang, S.C. Artificial Neural Network. In Interdisciplinary Computing in Java Programming; Springer: Boston, MA, USA, 2003; pp. 81–100. [Google Scholar] [CrossRef]
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 30 December 2020).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 30 December 2020).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Cheng, Y.; Wang, D.; Zhou, P.; Zhang, T. A Survey of Model Compression and Acceleration for Deep Neural Networks. arXiv 2017, arXiv:1710.09282. [Google Scholar]
- Coelho, C.N., Jr.; Kuusela, A.; Li, S.; Zhuang, H.; Aarrestad, T.; Loncar, V.; Ngadiuba, J.; Pierini, M.; Pol, A.A.; Summers, S. Automatic deep heterogeneous quantization of Deep Neural Networks for ultra low-area, low-latency inference on the edge at particle colliders. arXiv 2020, arXiv:2006.10159. [Google Scholar]
- Coelho, J.; Kuusela, A.; Zhuang, H.; Aarrestad, T.; Loncar, V.; Ngadiuba, J.; Pierini, M.; Summers, S. Ultra Low-latency, Low-area Inference Accelerators using Heterogeneous Deep Quantization with QKeras and hls4ml. arXiv 2020, arXiv:2006.10159. [Google Scholar]
- Guglielmo, G.D.; Duarte, J.M.; Harris, P.C.; Hoang, D.; Jindariani, S.; Kreinar, E.; Liu, M.; Loncar, V.; Ngadiuba, J.; Pedro, K.; et al. Compressing deep neural networks on FPGAs to binary and ternary precision with HLS4ML. arXiv 2020, arXiv:2003.06308. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Implementation | Accuracy |
|---|---|
| Base network | 99.67% |
| Quantized network with L1 norm | 99.02% |
| Quantized network with L2 norm | 99.24% |
| Pruned network | 98.83% |
| Solution | Directives | Estimated Clock [ns] | Clock Cycles | Inference Clock Cycles | Interval | BRAM | DSP | FF | LUT |
|---|---|---|---|---|---|---|---|---|---|
| ZU9EG | |||||||||
| 1 | No | 4.653 | 36,917 | 36,848 | 36,917 | 23 | 2 | 2407 | 5732 |
| 2 | Yes + Softmax | 4.653 | 18,526 | 18,457 | 18,526 | 2 | 1245 | 26,192 | 180,066 |
| 3 | Yes + NS + RF: 1 | 4.251 | 84 | 19 | 64 | 0 | 1235 | 27221 | 167,158 |
| 4 | Yes + NS + RF: 8 | 4.993 | 115 | 50 | 64 | 0 | 155 | 38,571 | 141,443 |
| XC7Z020 | |||||||||
| 5 | No | 6.508 | 91,777 | 91,707 | 91,777 | 23 | 2 | 4313 | 6952 |
| 6 | Yes + Softmax | 6.508 | 40,063 | 39,993 | 40,063 | 2 | 1245 | 188,626 | 171,599 |
| 7 | Yes + NS + RF: 1 | 4.350 | 121 | 55 | 64 | 0 | 1235 | 189,059 | 159,351 |
| 8 | Yes + NS + RF: 8 | 5.561 | 143 | 77 | 64 | 0 | 155 | 76,286 | 118,936 |
| ZU9EG | XC7Z020 | ZU9EG | XC7Z020 | ZU9EG | XC7Z020 | ZU9EG | XC7Z020 | |
|---|---|---|---|---|---|---|---|---|
| Description | BRAM | DSP | FF | LUT | ||||
| Shift Register | 0 | 0 | 0 | 0 | 576 | 688 | 1088 | 1088 |
| FIR electron | 0 | 0 | 64 | 64 | 2538 | 2838 | 58 | 188 |
| FIR muon | 0 | 0 | 64 | 64 | 2514 | 2818 | 58 | 188 |
| Selection Logic | 0 | 0 | 0 | 0 | 146 | 5778 | 378 | 12,508 |
| Total | 0 | 0 | 128 | 128 | 5767 | 12,122 | 1582 | 13,972 |
| Sensitivity (TPR) | Specificity (TNR) | PPV | NPV | |||||
|---|---|---|---|---|---|---|---|---|
| NN | FIR | NN | FIR | NN | FIR | NN | FIR | |
| Electron | 94.83% | 86.54% | 98.15% | 97.73% | 96.35% | 95.71% | 97.36% | 92.54% |
| Muon | 97.46% | 94.07% | 97.26% | 99.94% | 94.34% | 99.89% | 98.79% | 96.89% |
| Electric Discharges | 97.62% | 98.38% | 99.56% | 91.62% | 99.14% | 82.02% | 98.78% | 99.32% |
| Overall Accuracy | 96.62% | 92.50% | ||||||
| Kappa Coef. | 0.949 | 0.887 | ||||||
| Method | Execution Time [s] |
|---|---|
| ANN-CPU | 44,000 |
| ANN-FPGA | 0.848 |
| FIR-FPGA | 0.752 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garcia, L.G.; Molina, R.S.; Crespo, M.L.; Carrato, S.; Ramponi, G.; Cicuttin, A.; Morales, I.R.; Perez, H. Muon–Electron Pulse Shape Discrimination for Water Cherenkov Detectors Based on FPGA/SoC. Electronics 2021, 10, 224. https://doi.org/10.3390/electronics10030224
Garcia LG, Molina RS, Crespo ML, Carrato S, Ramponi G, Cicuttin A, Morales IR, Perez H. Muon–Electron Pulse Shape Discrimination for Water Cherenkov Detectors Based on FPGA/SoC. Electronics. 2021; 10(3):224. https://doi.org/10.3390/electronics10030224
Chicago/Turabian StyleGarcia, Luis Guillermo, Romina Soledad Molina, Maria Liz Crespo, Sergio Carrato, Giovanni Ramponi, Andres Cicuttin, Ivan Rene Morales, and Hector Perez. 2021. "Muon–Electron Pulse Shape Discrimination for Water Cherenkov Detectors Based on FPGA/SoC" Electronics 10, no. 3: 224. https://doi.org/10.3390/electronics10030224
APA StyleGarcia, L. G., Molina, R. S., Crespo, M. L., Carrato, S., Ramponi, G., Cicuttin, A., Morales, I. R., & Perez, H. (2021). Muon–Electron Pulse Shape Discrimination for Water Cherenkov Detectors Based on FPGA/SoC. Electronics, 10(3), 224. https://doi.org/10.3390/electronics10030224