
Jamming and Anti-Jamming Strategies of Mobile Vehicles


Abstract
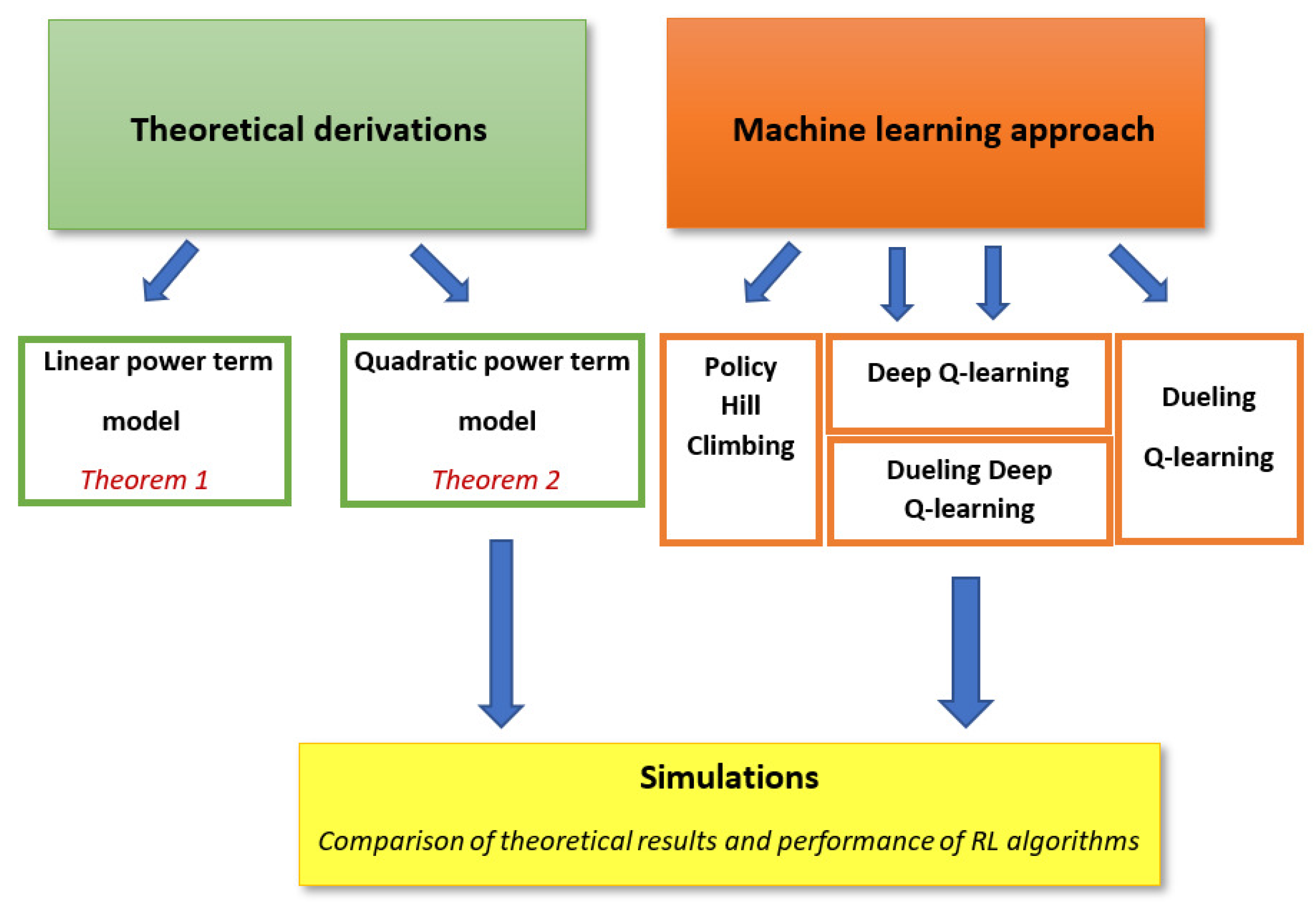
:1. Introduction
2. Game Description
3. Nash Equilibrium in the Case of the Linear Cost Function
4. Nash Equilibrium in the Case of the Quadratic Cost Function
5. Machine Learning Solution
| Algorithm 1 Anti-jamming game algorithm |
| 1: while (Game is not terminated) do |
| 2: Recalculate jammer power distribution |
| 3: Recalculate state of the system using intelligent Driver model |
| 4: Choose new vehicle transmission channel according to pseudo-random sequence |
| 5: Retrieve and discretize from memory obtained from the previous iteration |
| 6: Calculate using exponential decay rule (23) |
| 7: |
| 8: Calculate and discretize after action |
| 9: Add to memory |
| 10: Retrain algorithm |
| 11: Save current state of the system |
| 12: end while |
6. Simulations
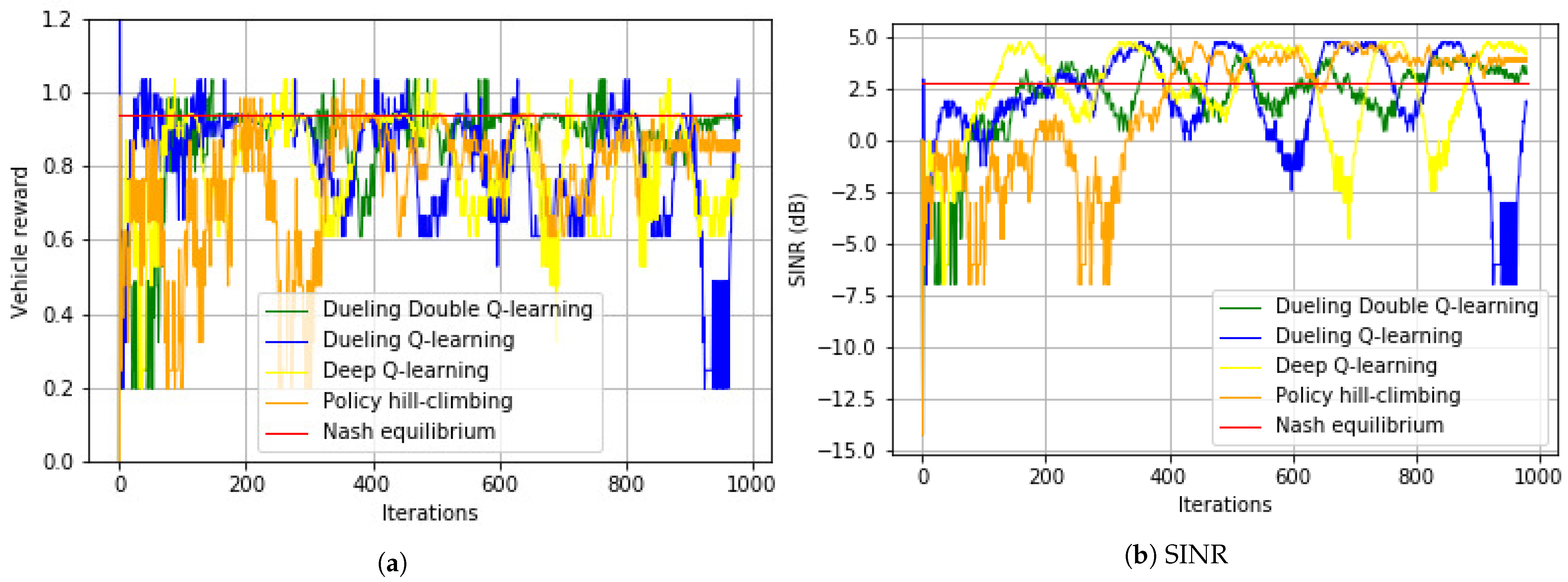
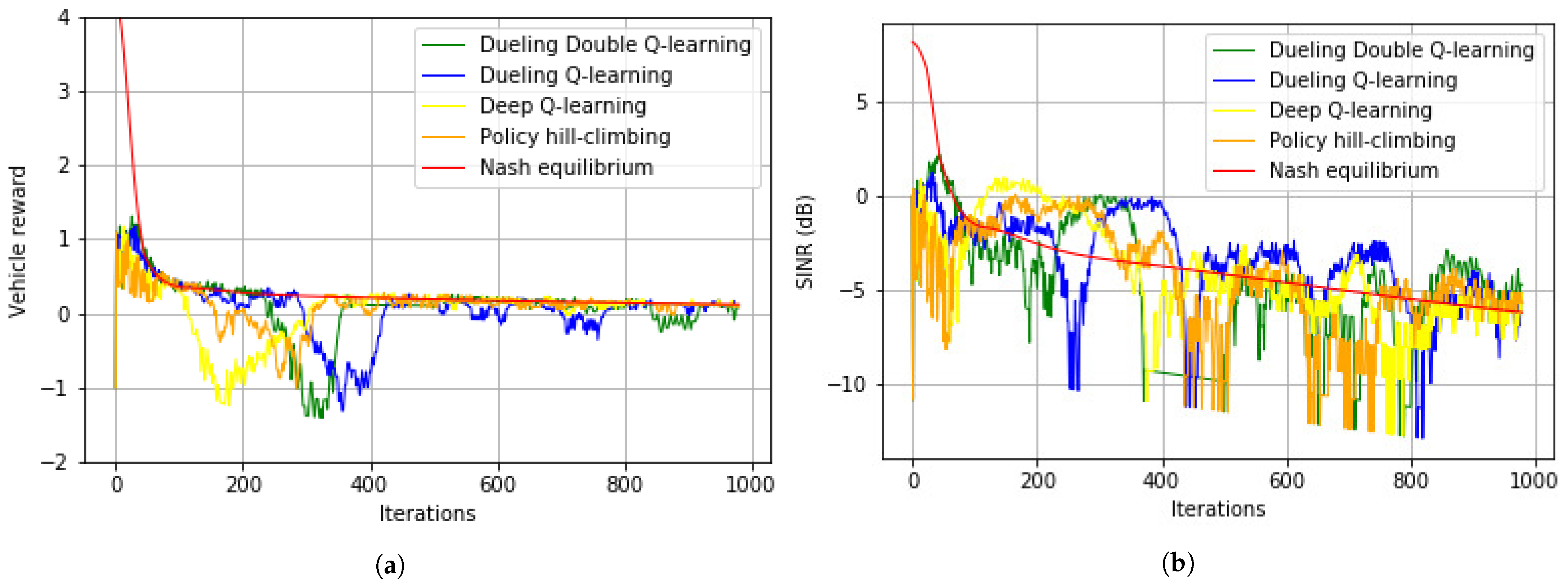
6.1. Single-Channel Game with Quadratic Power Function
6.2. Multi-Channel Game with Quadratic Power Function
7. Summary
Author Contributions
Funding
Conflicts of Interest
Appendix A. Proof of Theorem 1
Appendix B. Proof of Theorem 2
References
- Myerson, R.B. Game Theory; Harvard University Press: Cambridge, MA, USA, 2013. [Google Scholar]
- Alpaydin, E. Introduction to Machine Learning; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning; MIT Press Cambridge: Cambridge, MA, USA, 1998. [Google Scholar]
- Fan, Y.; Xiao, X.; Feng, W. An Anti-Jamming Game in VANET Platoon with Reinforcement Learning. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), Taichung, Taiwan, 19–21 May 2018; pp. 1–2. [Google Scholar]
- Lu, X.; Xu, D.; Xiao, L.; Wang, L.; Zhuang, W. Anti-jamming communication game for UAV-aided VANETs. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- Xiao, L.; Lu, X.; Xu, D.; Tang, Y.; Wang, L.; Zhuang, W. UAV relay in VANETs against smart jamming with reinforcement learning. IEEE Trans. Veh. Technol. 2018, 67, 4087–4097. [Google Scholar] [CrossRef]
- Aumann, R.; Brandenburger, A. Epistemic conditions for Nash equilibrium. Econom. J. Econom. Soc. 1995, 1161–1180. [Google Scholar] [CrossRef]
- Aref, M.A.; Jayaweera, S.K. A novel cognitive anti-jamming stochastic game. In Proceedings of the 2017 Cognitive Communications for Aerospace Applications Workshop (CCAA), Cleveland, OH, USA, 27–28 June 2017; pp. 1–4. [Google Scholar]
- Yao, F.; Jia, L. A Collaborative Multi-agent Reinforcement Learning Anti-jamming Algorithm in Wireless Networks. IEEE Wirel. Commun. Lett. 2019, 8, 1024–1027. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Xu, Y.; Xu, Y.; Yang, Y.; Luo, Y.; Wu, Q.; Liu, X. A Multi-Leader One-Follower Stackelberg Game Approach for Cooperative Anti-Jamming: No Pains, No Gains. IEEE Commun. Lett. 2018, 22, 1680–1683. [Google Scholar] [CrossRef]
- Han, C.; Liu, A.; Wang, H.; Huo, L.; Liang, X. Dynamic Anti-Jamming Coalition for Satellite-Enabled Army IoT: A Distributed Game Approach. IEEE Internet Things J. 2020, 7, 10932–10944. [Google Scholar] [CrossRef]
- Han, C.; Huo, L.; Tong, X.; Wang, H.; Liu, X. Spatial Anti-Jamming Scheme for Internet of Satellites Based on the Deep Reinforcement Learning and Stackelberg Game. IEEE Trans. Veh. Technol. 2020, 69, 5331–5342. [Google Scholar] [CrossRef]
- Treiber, M.; Hennecke, A.; Helbing, D. Congested traffic states in empirical observations and microscopic simulations. Phys. Rev. E 2000, 62, 1805. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xiao, L.; Jiang, D.; Xu, D.; Zhu, H.; Zhang, Y.; Poor, H.V. Two-dimensional antijamming mobile communication based on reinforcement learning. IEEE Trans. Veh. Technol. 2018, 67, 9499–9512. [Google Scholar] [CrossRef] [Green Version]
- Bowling, M.; Veloso, M. Rational and Convergent Learning in Stochastic Games. In Proceedings of the 17th International Joint Conference on Artificial Intelligence-Volume 2 (IJCAI’01), Seattle, WA, USA, 4–10 August 2001; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 2001; pp. 1021–1026. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari With Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Van Hasselt, H.; Lanctot, M.; De Freitas, N. Dueling network architectures for deep reinforcement learning. arXiv 2015, arXiv:1511.06581. [Google Scholar]
- Treiber, M.; Kesting, A. Traffic flow dynamics. In Traffic Flow Dynamics: Data, Models and Simulation; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Desired speed | 54 km/h |
| Time gap T | 1.0 s |
| Minimum gap | 2 m |
| Acceleration exponent | 4 |
| Acceleration a | 1.0 m/s |
| Comfortable deceleration b | 1.5 m/s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dubosarskii, G.; Primak, S. Jamming and Anti-Jamming Strategies of Mobile Vehicles. Electronics 2021, 10, 2772. https://doi.org/10.3390/electronics10222772
Dubosarskii G, Primak S. Jamming and Anti-Jamming Strategies of Mobile Vehicles. Electronics. 2021; 10(22):2772. https://doi.org/10.3390/electronics10222772
Chicago/Turabian StyleDubosarskii, Gleb, and Serguei Primak. 2021. "Jamming and Anti-Jamming Strategies of Mobile Vehicles" Electronics 10, no. 22: 2772. https://doi.org/10.3390/electronics10222772
APA StyleDubosarskii, G., & Primak, S. (2021). Jamming and Anti-Jamming Strategies of Mobile Vehicles. Electronics, 10(22), 2772. https://doi.org/10.3390/electronics10222772