Raymarching Distance Fields with CUDA



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
Related Work and Context
- Compactness. As we noted already, raymarching is highly lightweight both in size of codebase and memory footprint. A raymarcher can be contained entirely in a fragment shader program and can be executed on a variety of hardware and platforms such as WebGL, OpenGL ES, and OpenGL.
- Performance. Raymarching is an excellent approximation for ray-tracing, making it a lightweight solution for determining geometry intersection in a rendering pipeline. Raymarching also approximates cone-tracing which makes it a lightweight solution for direct and indirect lighting computation.
- Quality. Since raymarching can ‘emulate’ a ray-tracing pipeline, it is possible to achieve the same level of photorealism as ray-tracing which has become the standard for high-fidelity offline rendering. Raymarching can take advantage of existing anti-aliasing techniques such as MSAA (multisample anti-aliasing), PPAA (post-processing antialiasing) and TAA (temporal anti-aliasing), as well as supporting interpolation based anti-aliasing similar to sub-pixel AA used by 2D font rasterizers for decades without the need of multi-sampling.
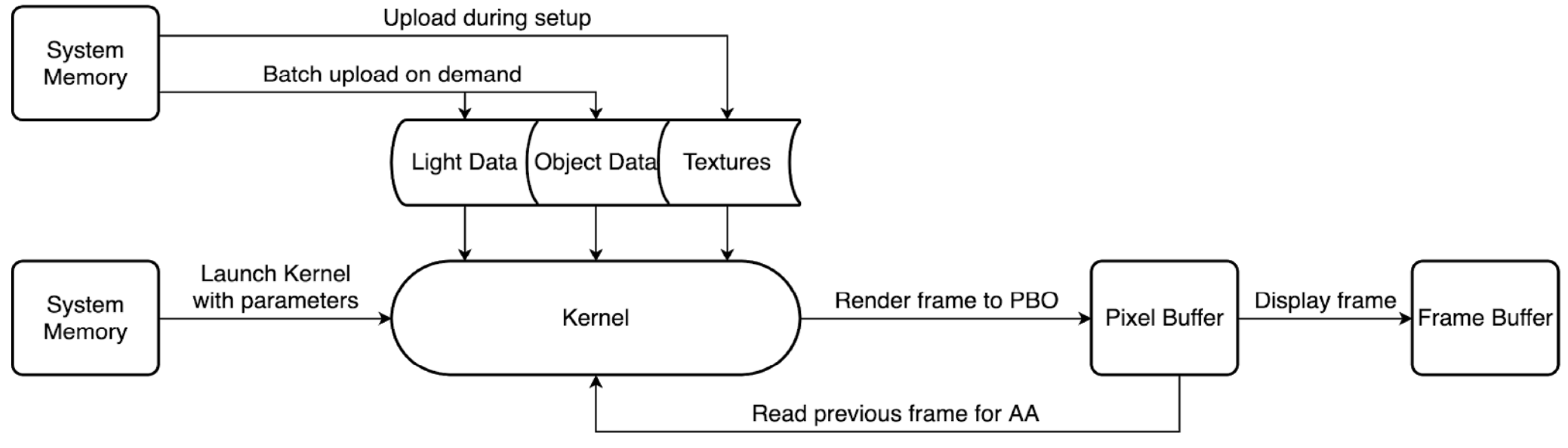
2. Proposed Framework
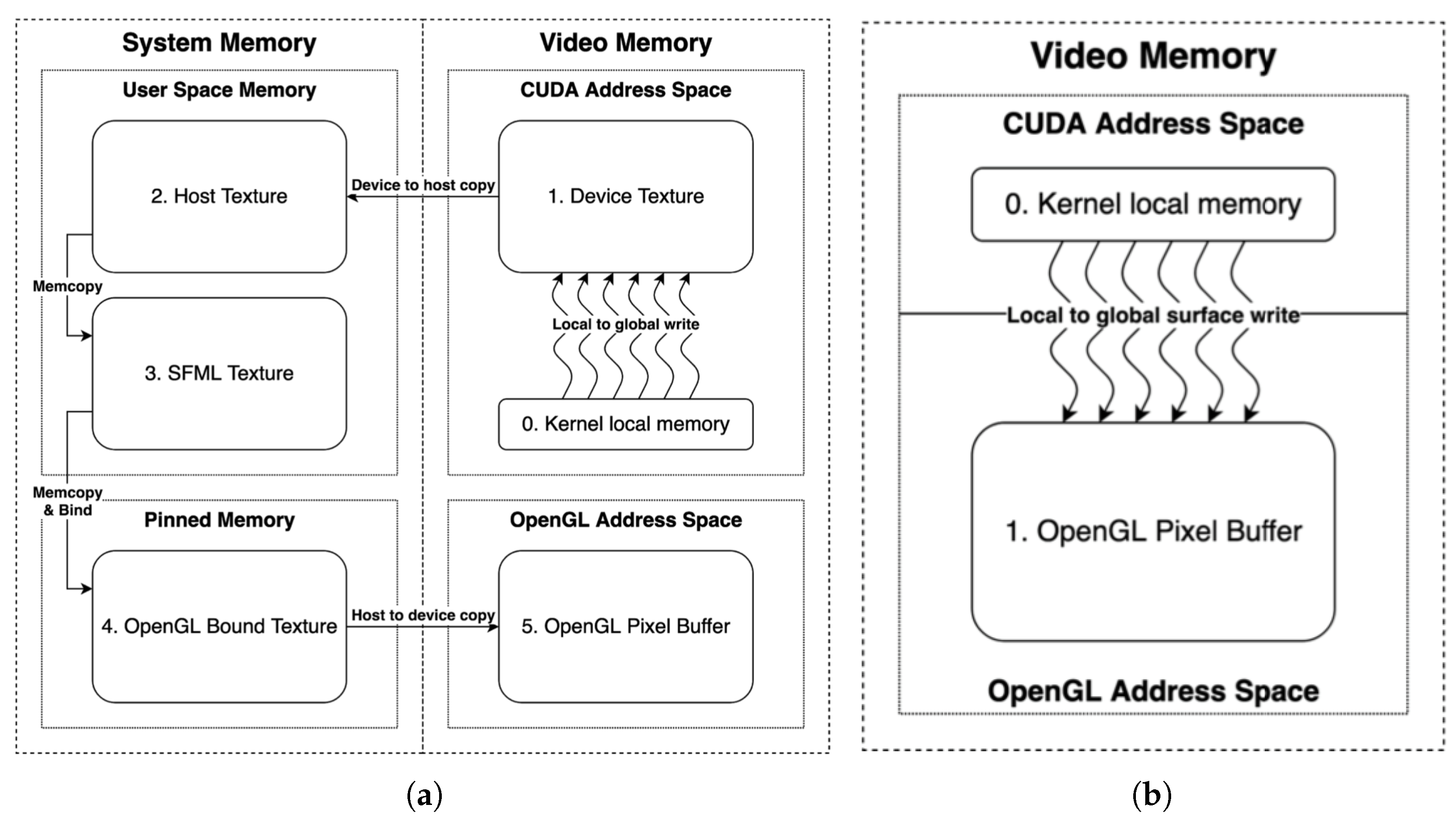
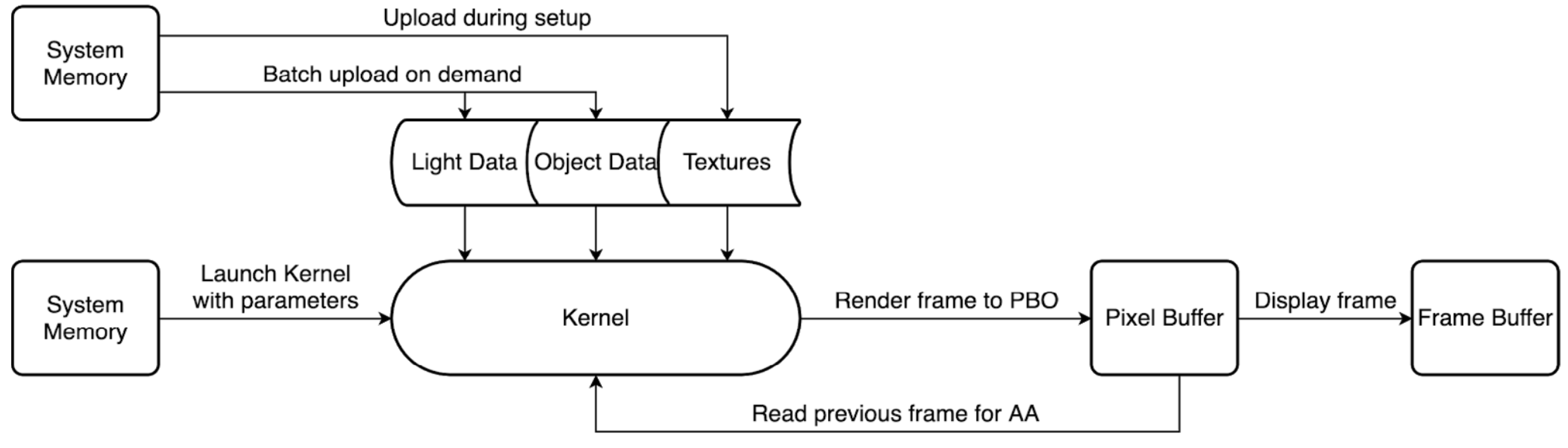
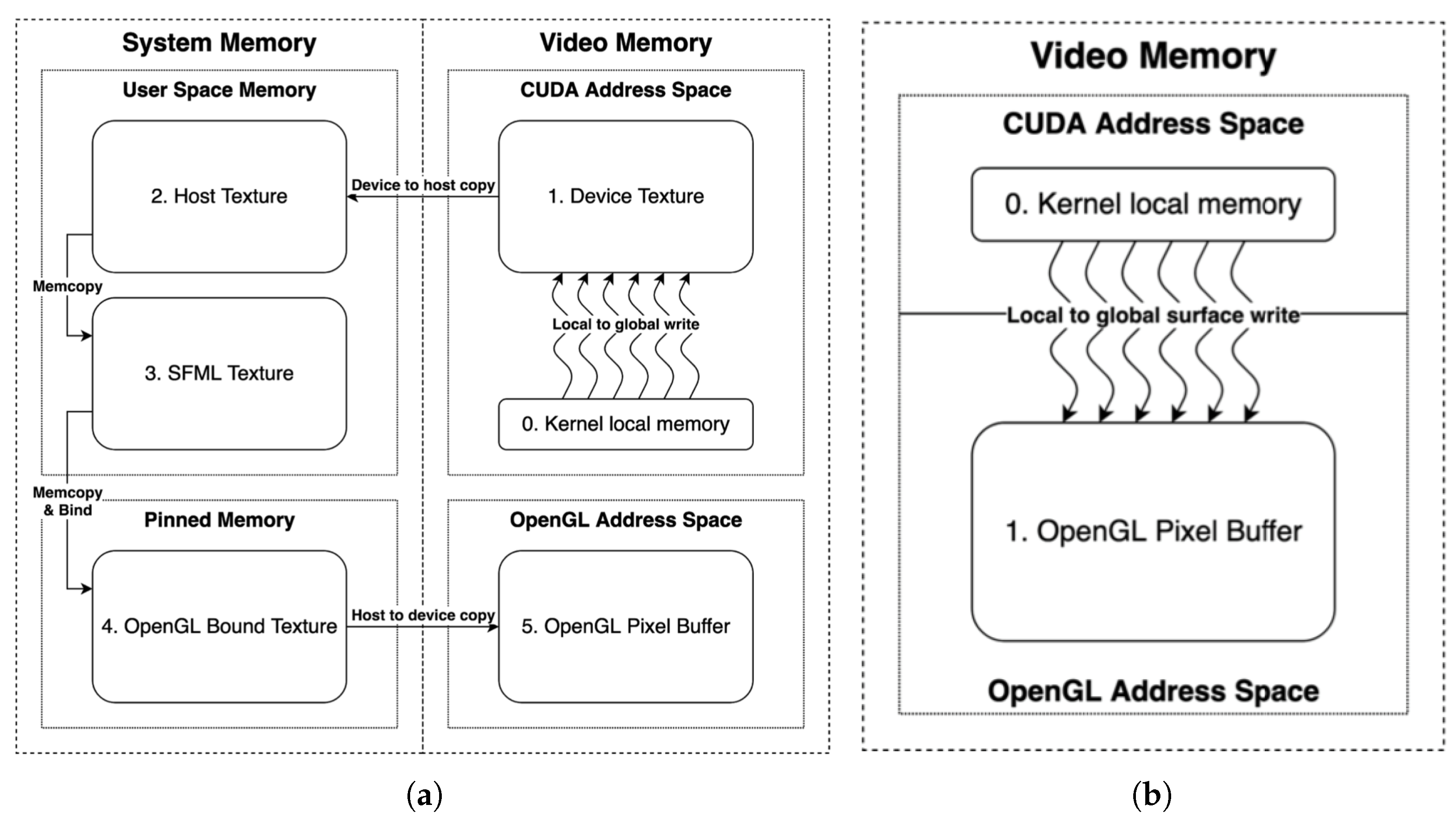
2.1. OpenGL (Open Graphics Library) and CUDA Interoperability
2.2. Texture Loading
2.3. Material Format
- albedo—the surface colour in linear, floating point RGB.
- metalness—a value in the range corresponding to how ‘metalic’ a surface is in regard to specular and diffuse shading.
- roughness—a linear value from corresponding to the smoothness of surface reflections and light scattering.
- —the base reflectivity when metalness is set to zero in linear, floating point RGB. This often corresponds to a ’specular’ term in some PBR shaders (while others do not include this at all) and is included to allow for more complex material behaviours.
- triplar—a boolean value corresponding to XZ planar mapping (false) or triplanar mapping (true) for textures.
- normalStrength—a linear floating point value which scales normal deflection from normal map textures, useful when displacing a surface at a ’less steep’ angle than the normal map is designed for.
- albedoTex—the texture descriptor of the sRGB albedo map (or −1 when not used). The texture is multiplied by the albedo value.
- normalTex—the texture descriptor for the linear detail normal map (or −1 when not used).
- roughnessTex—the texture descriptor for the linear roughness map (or −1 when not used). The texture is multiplied by the roughness value.
- metalnessTex—the texture descriptor for the linear metalness map (or −1 when not used). The texture is multiplied by the metalness value.
- heightmapTex—the texture descriptor for the linear displacement heightmap (or −1 when not used). This texture is not used for shading but is instead used by an object SDF to add real geometric displacement.
- ambietTex—the texture descriptor for the linear ambient occlusion map (or −1 when not used).
2.4. Light Format
- position—a homogeneous 3D vector for the position of a light. When the 4th component is of value 1, the light represents a point light and a value of 0 represents a directional light with the first three components corresponding to the light direction. In the material editor, this is displayed as two separate values; a 3D position vector and a boolean value.
- colour—a homogeneous 3D vector for the colour of the light. The 4th component corresponds to the inverse of the light intensity. In the material editor, this is displayed as two separate values; a linear colour RGB value and a linear intensity value.
- attenuation—a 3 component vector corresponding to constant, linear and quadratic attenuation for the light. If a light is a sky light, the attenuation values are ignored and a value of [1,0,0] is used since the light is considered to be infinitely distant.
- hardness—a linear value corresponding to the ’softness’ of shadows cast by the light. A minimum value of 3 is considered maximum softness without artefacts and a maximum value of 128 is considered to cast perfectly sharp shadows.
- radius—a linear value corresponding to the maximum distance that a light can illuminate.
- shadowRadius—a linear value corresponding to the maximum distance that a light can cast shadows.
- shadows—a boolean value to enable (true) or disable (false) shadow casting.
2.5. Ray Format
- t—a floating point value representing the distance that the ray has currently marched to.
- h—a floating point value corresponding to the closest intersection distance from the most recent ray evaluation.
- marches—an integer for the current number of march iterations.
- evaluations—an integer for the current number of SDF evaluations.
- p—a 3D vector containing the current position of the ray in space.
- materialId—an integer corresponding to the material of the closest object.
- rayType—a bitfield enum value for the ray’s current purpose which can be any combination of the following:
- –
- camera (0x00001)—used for rays cast from the camera.
- –
- shadow (0x00010)—used for rays cast from a surface towards a light to calculate light occlusion or for rays used to calculate ambient occlusion.
- –
- reflection (0x00100)—used for singular rays that are cast for sharp specular reflections. (currently not used)
- –
- transmission (0x01000)—used for rays that compute transparent transmissions (camera | transmission) or subsurface scattering (camera|shadow). (currently not used)
- –
- normal (0x10000)—used for rays which calculate surface normals.
- evaluate—a function that takes the SDF material identifier and distance sample and then returns the distance. This function increments the evaluation value and sets materialId and h if the distance is less than the previous value of h.
- isRay—a function that returns true if the ray is of the same type as the type argument.
- isOnlyRay—a function that returns true if and only if the ray is of the same type as the type argument only.
2.6. Surface Map
2.6.1. Signed Distance Function
2.6.2. Map Function
- ray—a Ray object of the current ray being marched. This is required to update materials as well as to provide different functionality for the map function based on the type of ray.
- d_materialVector—the device material vector to allow for accessing heightmap textures to displace surfaces.
- offset—used by the normal calculation algorithm and ambient occlusion algorithm to scatter the points at which to sample the distance field without affecting the ray position itself.
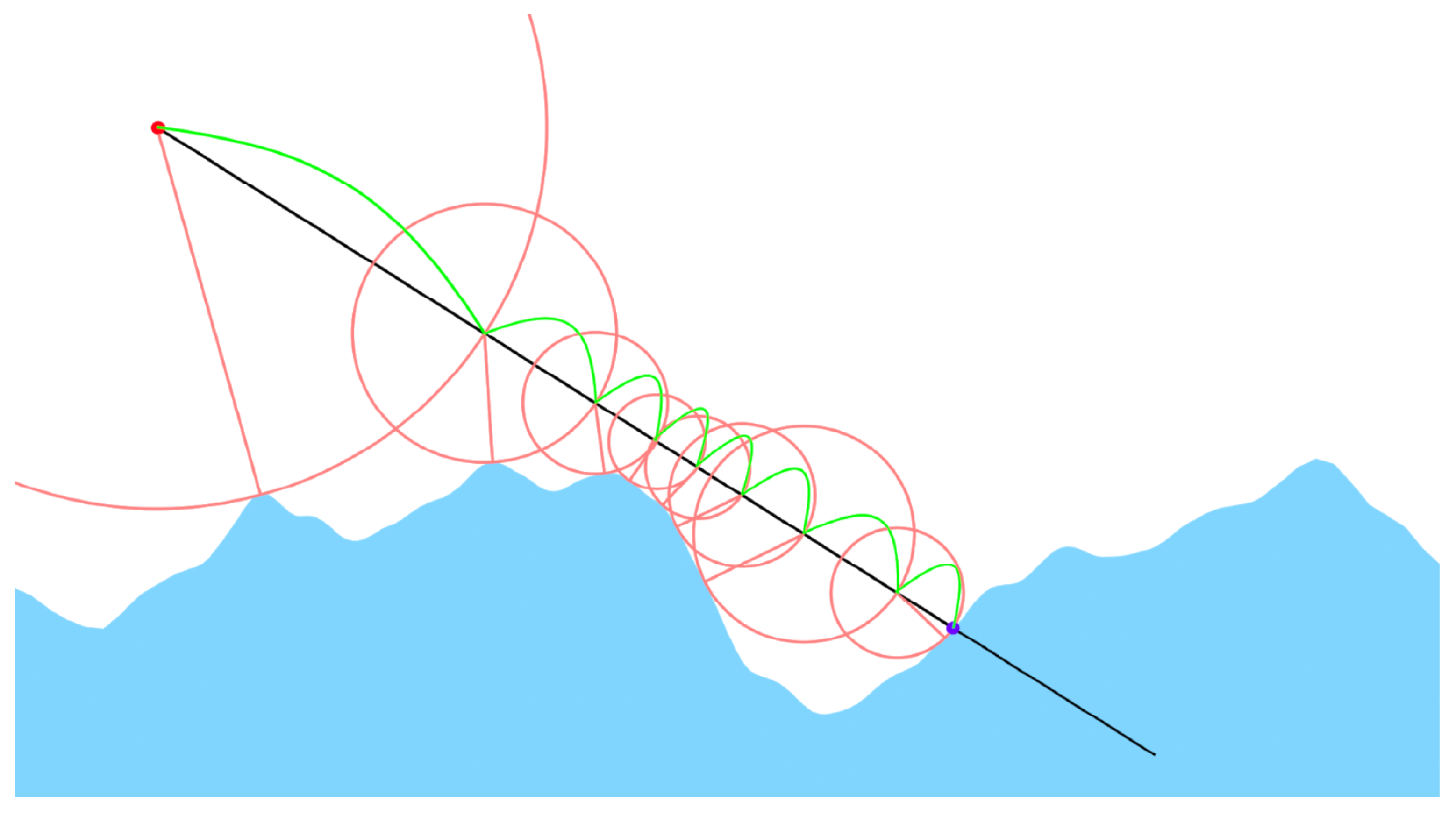
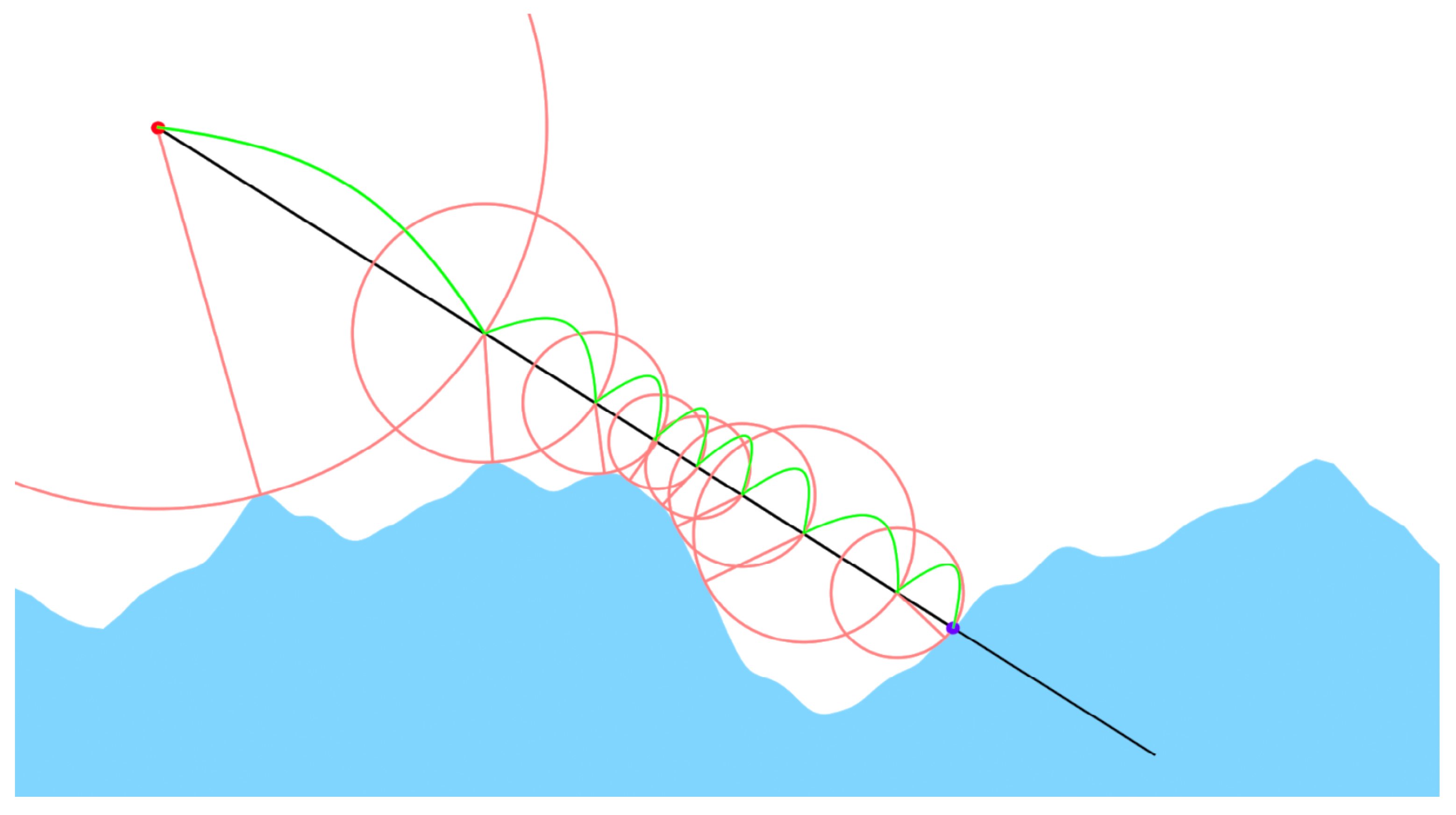
2.7. Raymarching Algorithm
- Ray Generation Program—Generate camera rays given camera position, direction and focal length.
- March Calculation—March rays towards intersections given a map function.
- Normals Calculation—Compute normals and apply detailing.
- Surface Normal—Compute the surface normals from the distance field gradient given a map.
- Detail Normals—Use surface normals and material ID to deflect normals using a texture.
- Shade Intersection Pixel—Determine pixel colour using normals, materials and lights.
- Shading & Shadows—First shading pass using the Cook–Torrance BRDF (bidirectional reflectance distribution function), emitting only shadow rays towards lights and sampling the distance field for ambient occlusion.
- Specular Environment Shading—Compute specular reflections of the ‘skybox’, emitting only one shadow ray per camera ray, randomly distributed in a specular lobe.
- Diffuse Environment Shading—Compute diffuse lighting from the ‘skybox’, emitting only one shadow ray per camera ray, randomly distributed in a hemisphere oriented from the surface normal.
- Shade Sky & Fog—Determine colour of sky from camera ray direction and light colours and linearly interpolate between the shaded surface colour and sky colour based on intersection distance for fog.
- Tone Mapping—Map the unclamped linear color space into a clamped sRGB color space to approximate HDR (high dynamic range) imagery.
- Temporal AA—Use data from the previous frame to apply anti-aliasing.
- Write Pixel—Write computed pixel colours to the Pixel Buffer.
2.7.1. Ray Generation Program
2.7.2. March Calculation
2.7.3. Normal Calculation
2.7.4. Ambient Occlusion
2.7.5. Shadow Occlusion
- Determine point p on the zero-isosurface of the distance field.
- Cast a shadow ray at point p and raymarch to light position , determining the intersection t.
- If point p is fully occluded, otherwise the point is fully lit.
2.8. Lighting Model
2.8.1. Cook–Torrance Based BRDF
- use the microfacet surface model,
- conserve energy when reflecting light, and
- use a physically based BRDF such as Cook–Torrance.
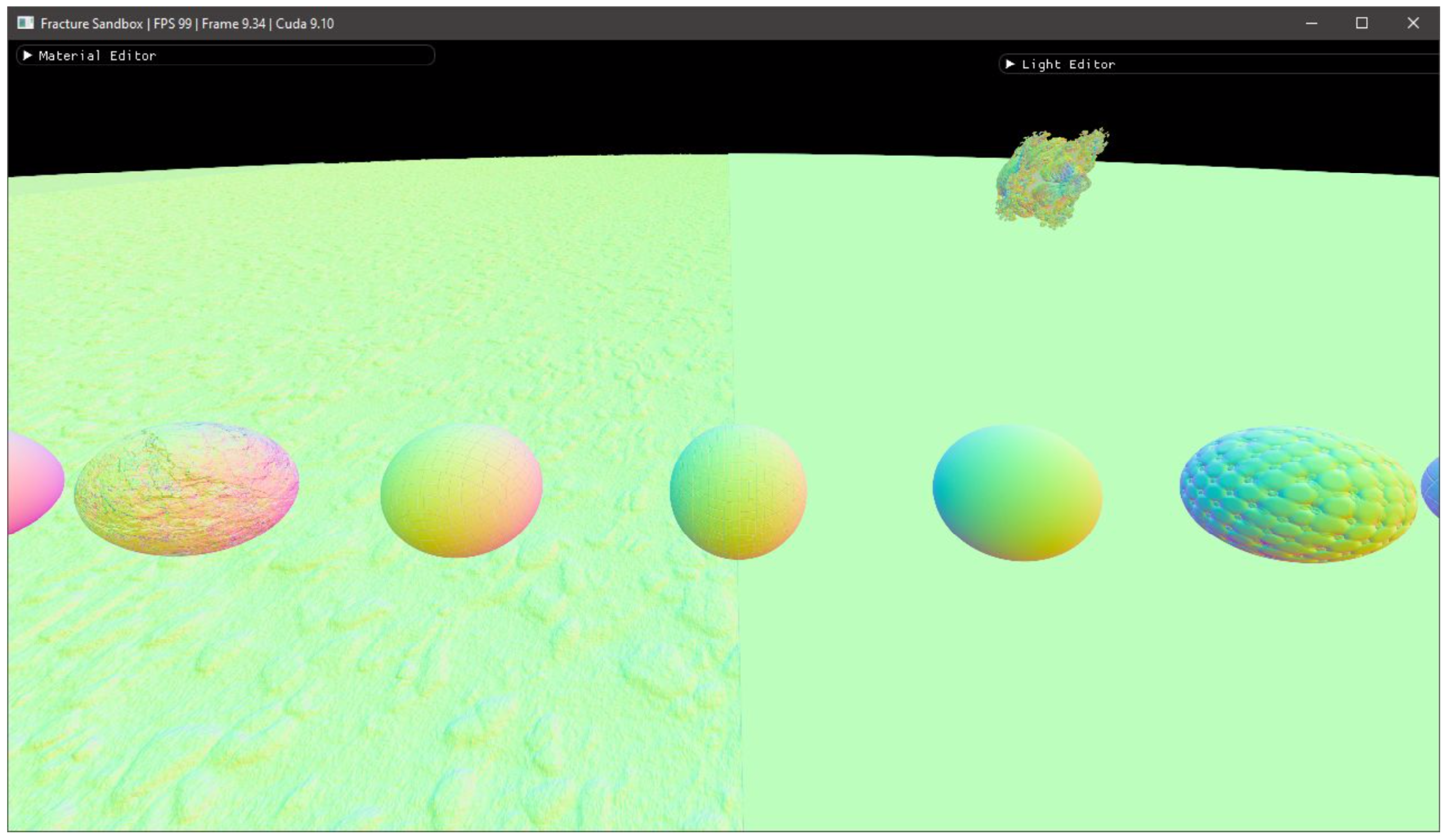
2.8.2. Texture Mapping
2.8.3. Global Illumination
2.8.4. Reflections
3. Evaluation
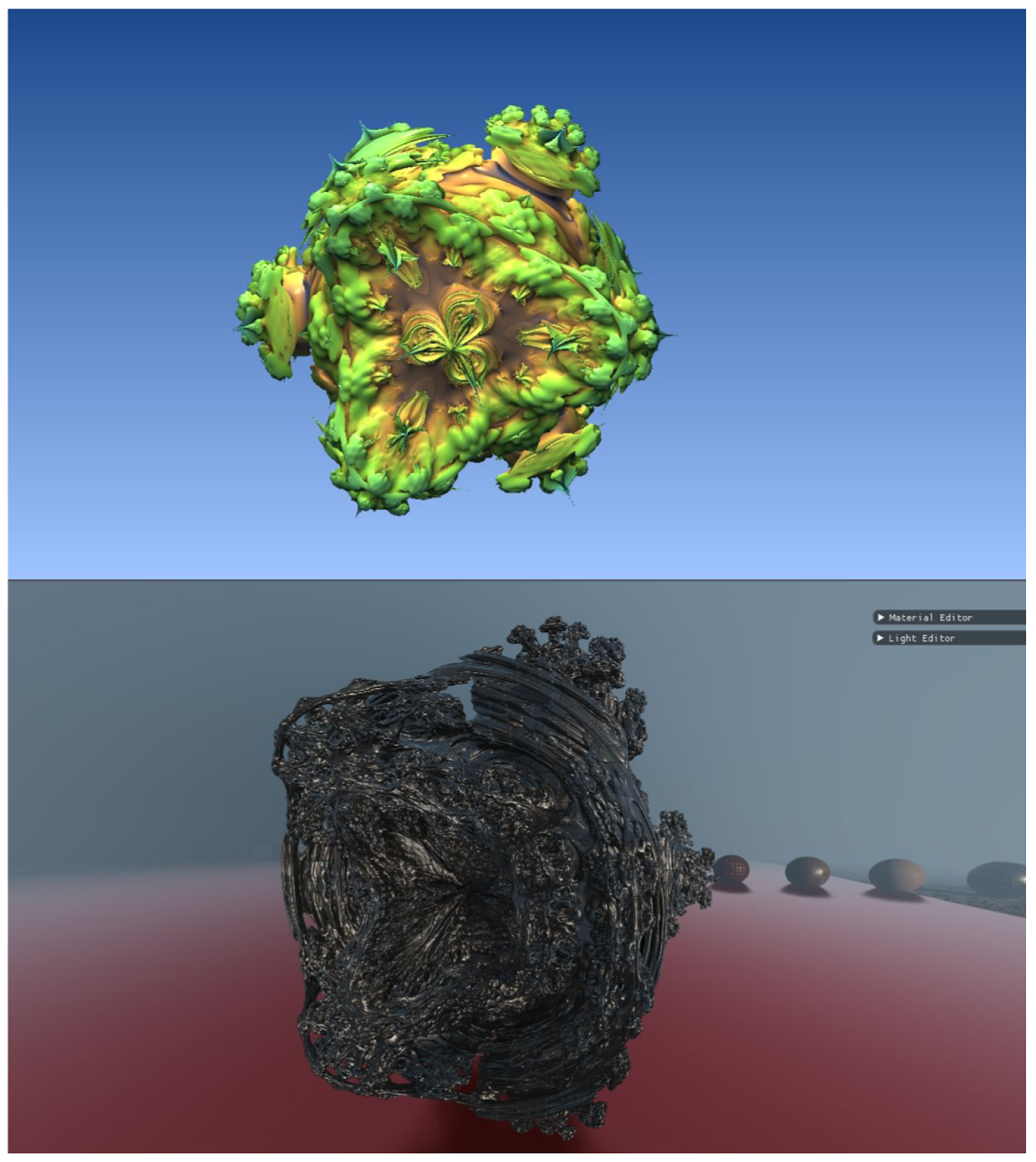
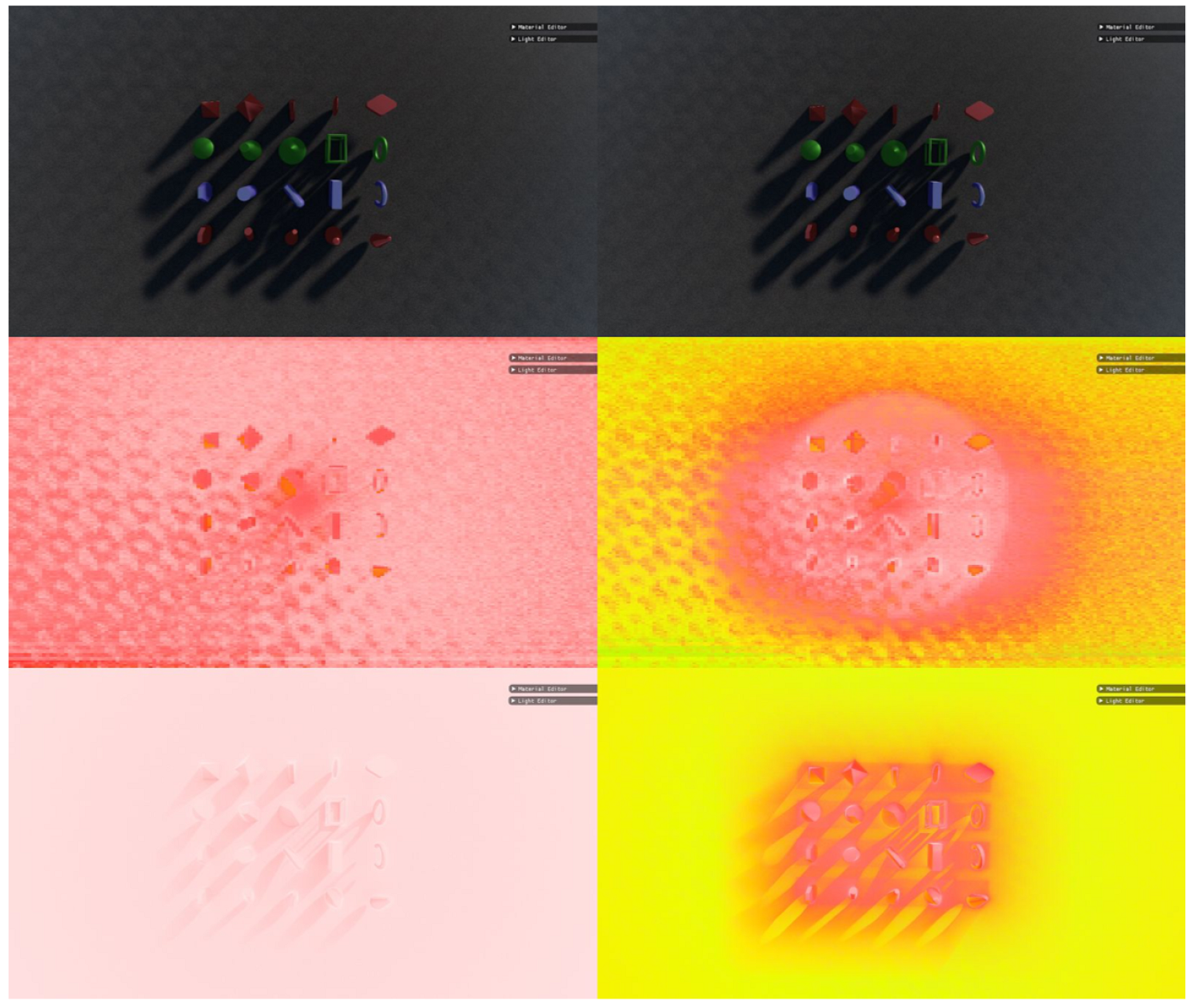
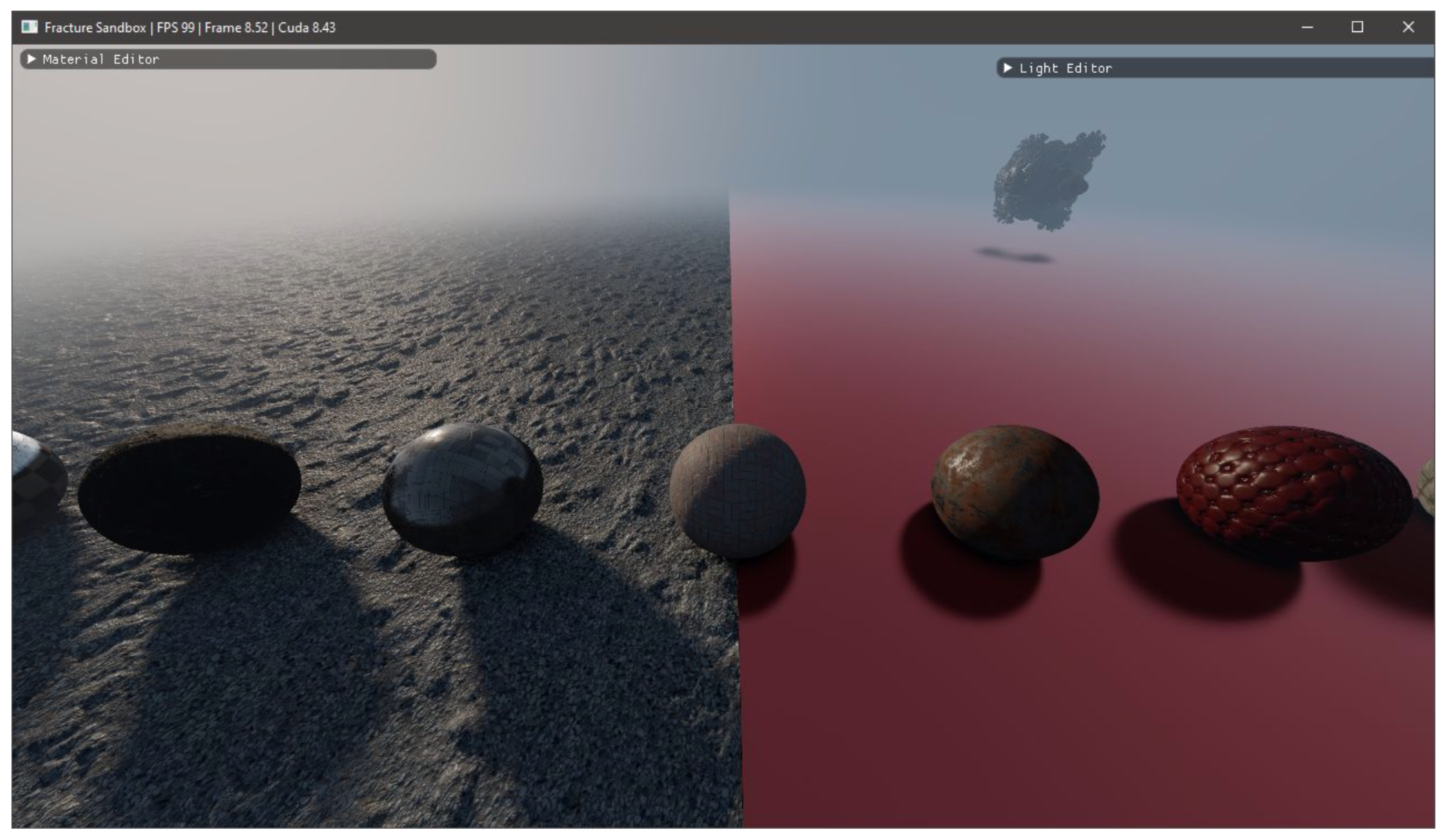
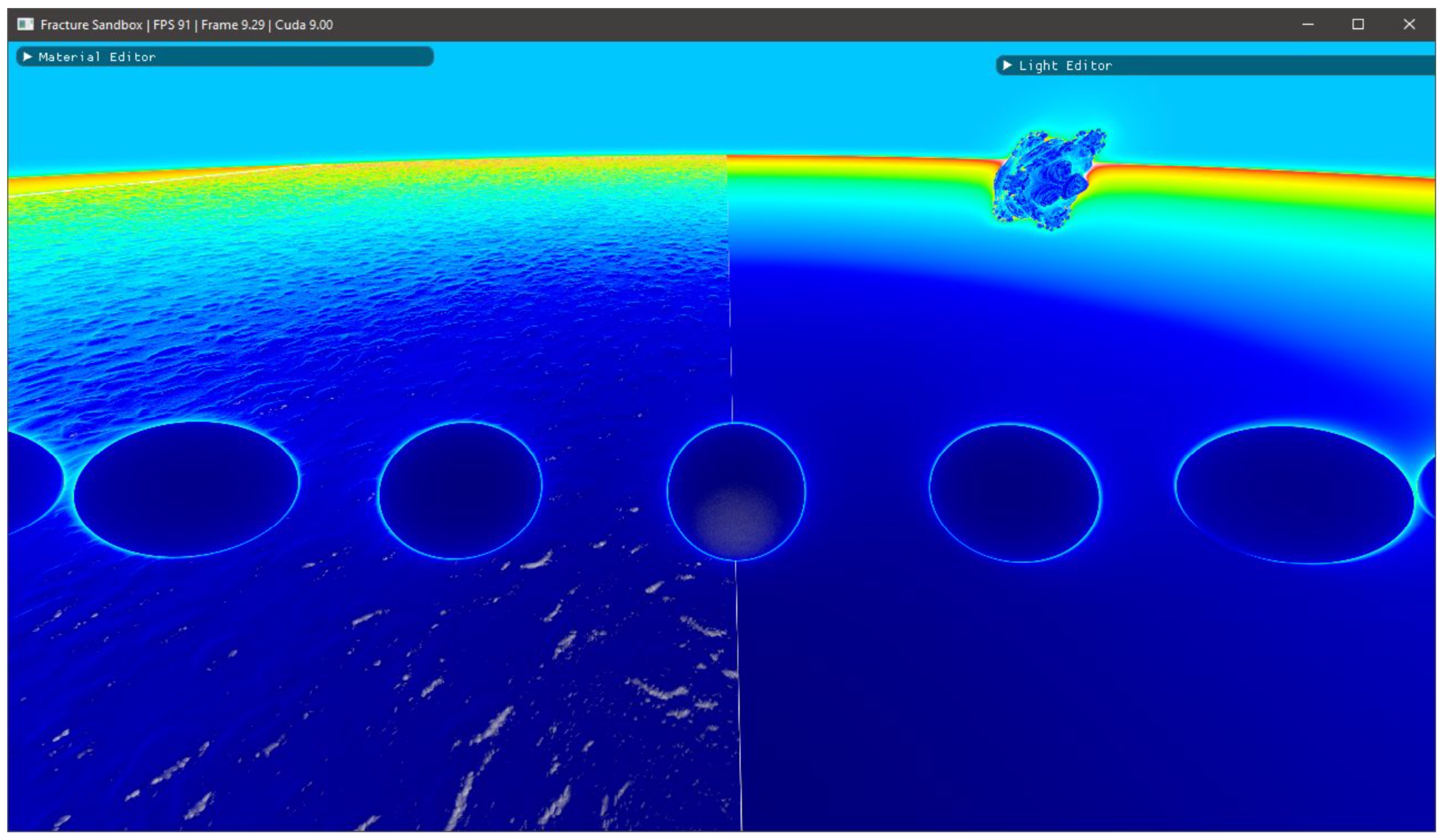
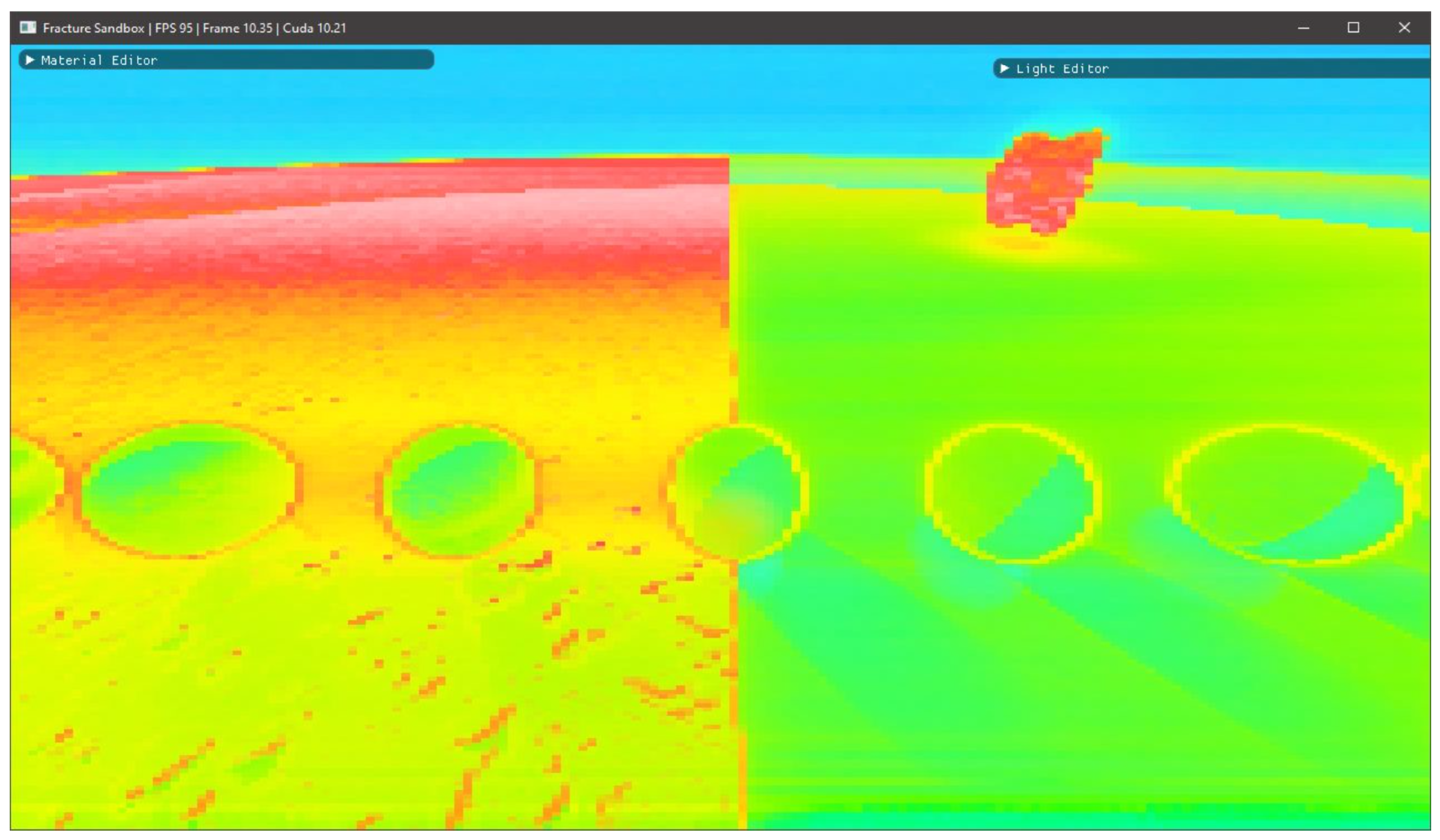
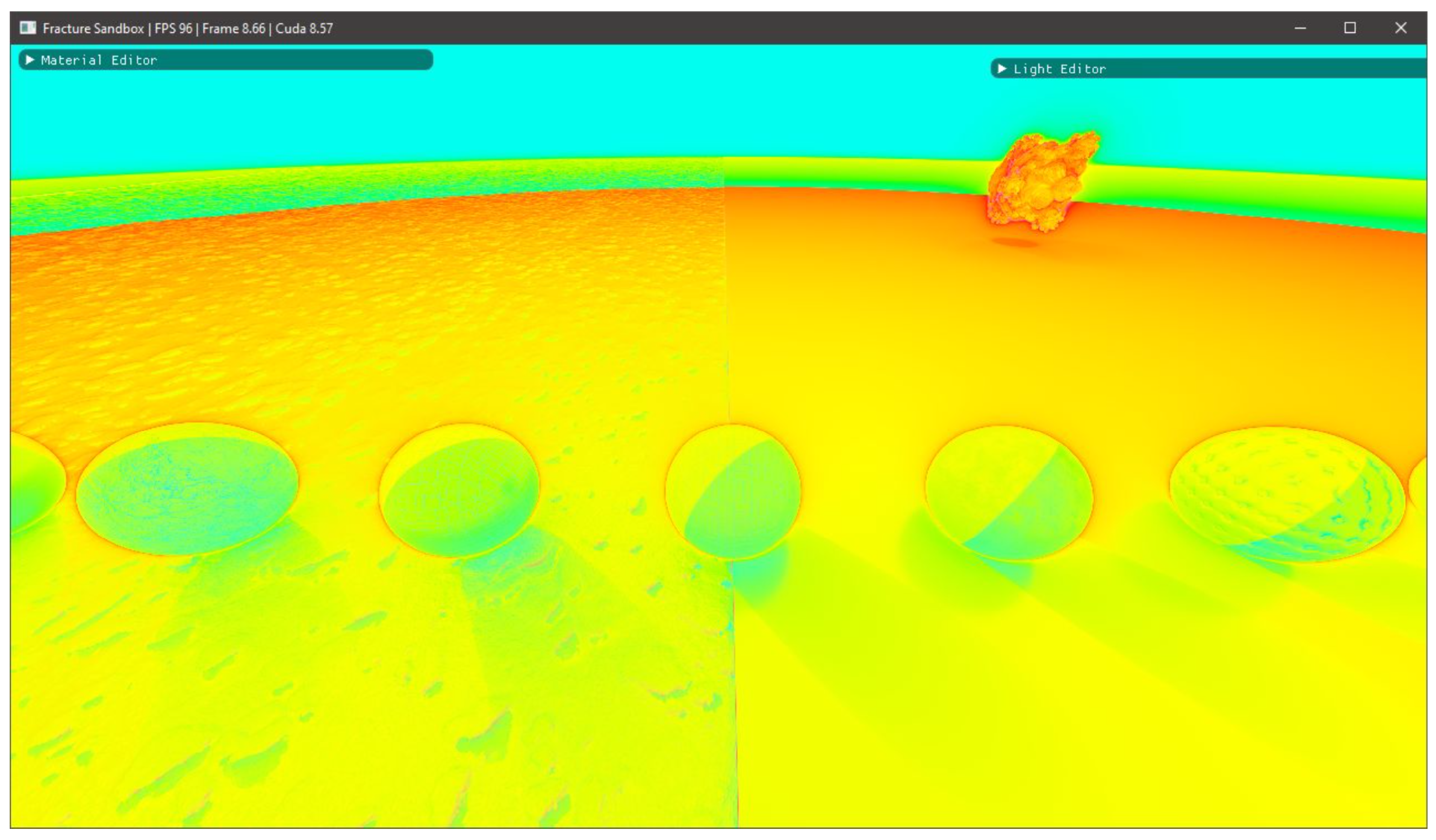
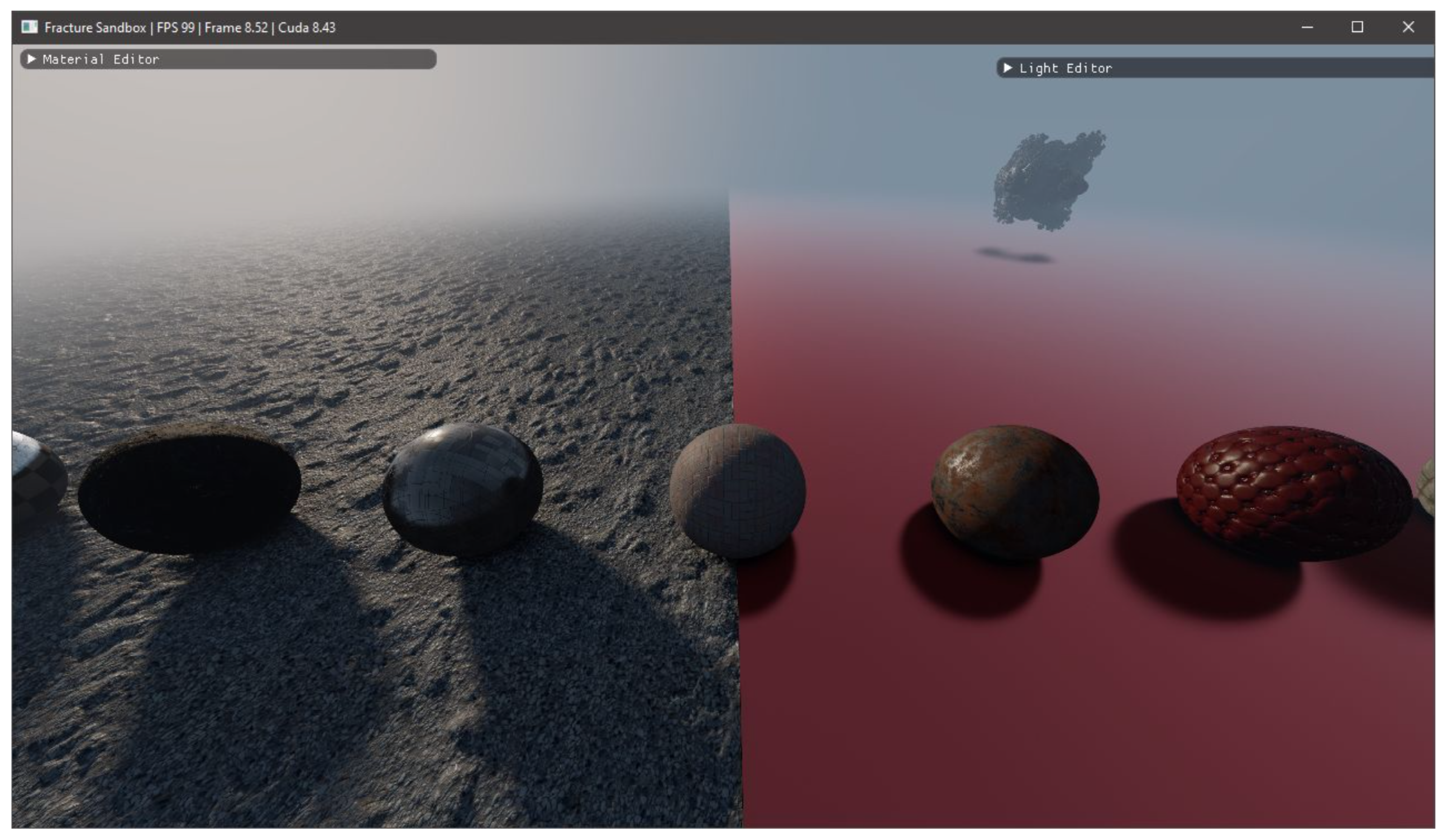
3.1. Visual Fidelity
3.1.1. Displacements
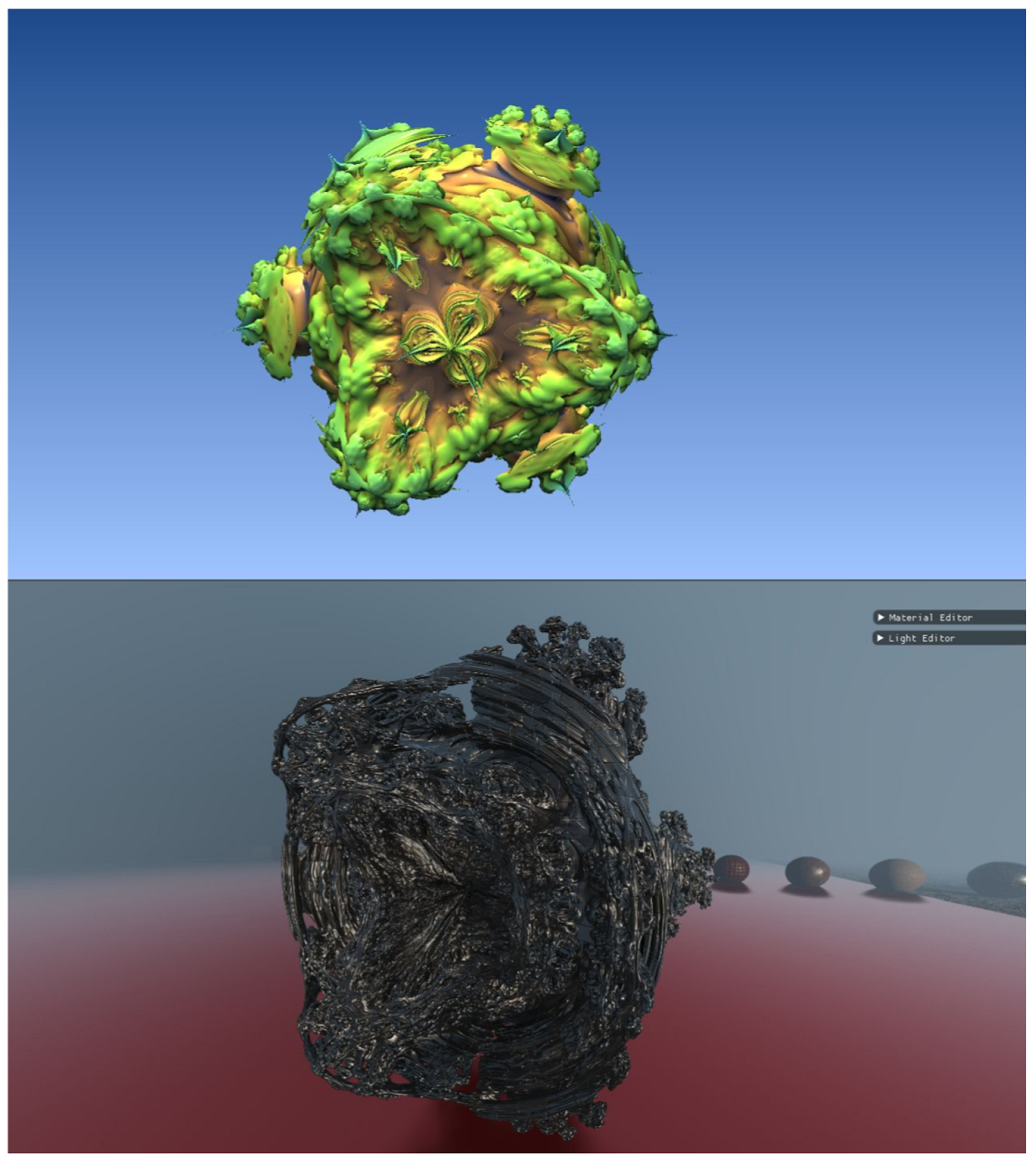
3.1.2. Fractals
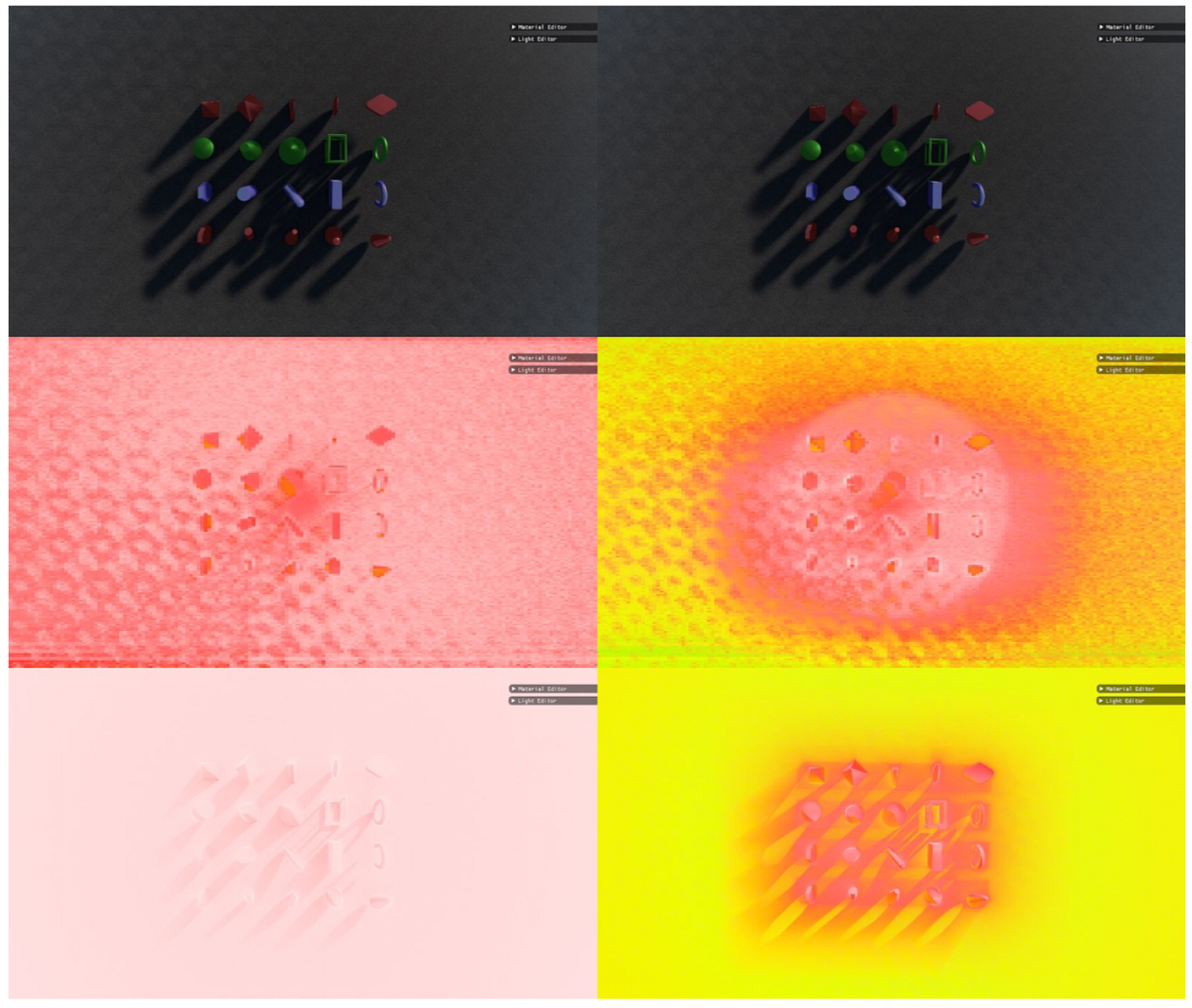
3.2. Lighting
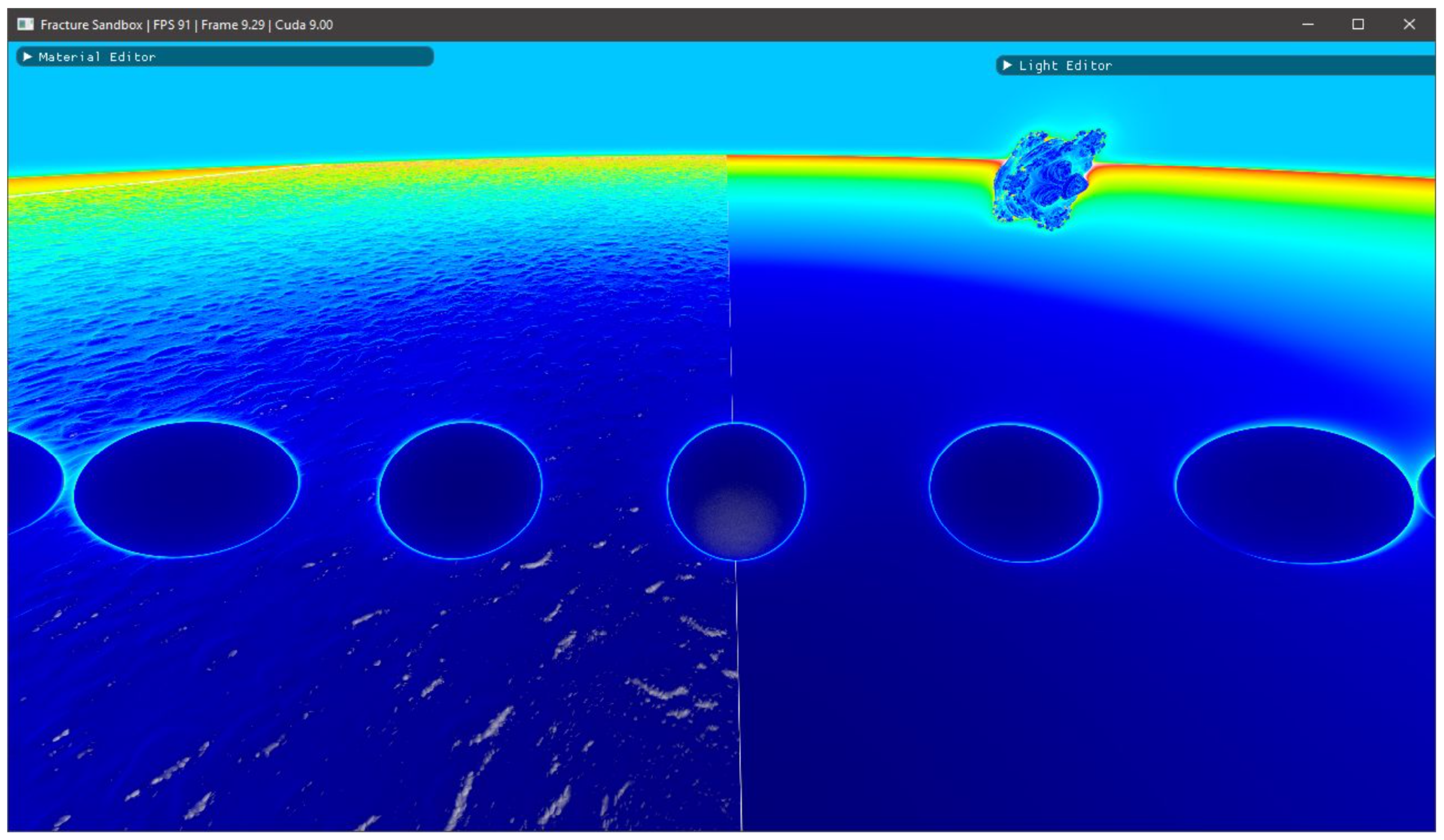
3.3. Bounding Volume Optimisation
4. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Hart, J.C.; Sandin, D.J.; Kauffman, L.H. Ray tracing deterministic 3D fractals. In Proceedings of the 16th Annual Conference on Computer Graphics and Interactive Techniques, Boston, MA, USA, 31 July–4 August 1989; pp. 289–296. [Google Scholar]
- Hart, J.C. Sphere tracing: A geometric method for the antialiased ray tracing of implicit surfaces. Vis. Comput. 1996, 12, 527–545. [Google Scholar] [CrossRef]
- Quilez, I. Rendering Worlds with Two Triangles with Ray Tracing on the GPU. 2008. Available online: https://www.iquilezles.org/www/material/nvscene2008/rwwtt.pdf (accessed on 10 June 2021).
- Quilez, I. Making a Simple Apple with Maths. 2011. Available online: https://www.youtube.com/watch?v=CHmneY8ry84/ (accessed on 10 June 2021).
- Quilez, I. Inigo Quilez: Articles. Available online: https://www.iquilezles.org/www/index.htm/ (accessed on 10 June 2021).
- Granskog, J. CUDA ray MARCHING. 2017. Available online: http://granskog.xyz/blog/2017/1/11/cuda-ray-marching/ (accessed on 10 June 2021).
- Keeter, M.J. Massively parallel rendering of complex closed-form implicit surfaces. ACM Trans. Graph. 2020, 39, 4. [Google Scholar] [CrossRef]
- Mallett, I.; Seiler, L.; Yuksel, C. Patch Textures: Hardware Support for Mesh Colors. IEEE Trans. Vis. Comput. Graph. 2020, in press. [Google Scholar] [CrossRef] [PubMed]
- Jensen, H.W.; Christensen, N.J. Photon maps in bidirectional Monte Carlo ray tracing of complex objects. Comput. Graph. 1995, 19, 215–224. [Google Scholar] [CrossRef]
- Cook, R.L.; Torrance, K.E. A reflectance model for computer graphics. ACM Trans. Graph. 1982, 1, 7–24. [Google Scholar] [CrossRef]
- Lafortune, E.P.; Willems, Y.D. Using the Modified Phong Reflectance Model for Physically Based Rendering; Report CW 197; KU Leuven: Leuven, Belgium, 1994. [Google Scholar]
- Blinn, J.F. Models of light reflection for computer synthesized pictures. In Proceedings of the 4th Annual Conference on Computer Graphics and Interactive Techniques, San Jose, CA, USA, 20–22 July 1977; pp. 192–198. [Google Scholar]
- Nicodemus, F.E. Directional reflectance and emissivity of an opaque surface. Appl. Opt. 1965, 4, 767–775. [Google Scholar] [CrossRef]
- Trowbridge, T.; Reitz, K.P. Average irregularity representation of a rough surface for ray reflection. JOSA 1975, 65, 531–536. [Google Scholar] [CrossRef]
- Walter, B.; Marschner, S.R.; Li, H.; Torrance, K.E. Microfacet Models for Refraction through Rough Surfaces. In Proceedings of the 18th Eurographics Conference on Rendering Techniques, Grenoble, France, 25–27 June 2007; pp. 195–206. [Google Scholar]
- Karis, B.; Games, E. Real Shading in Unreal Engine 4. 2013. Available online: https://www.bibsonomy.org/bibtex/203641889131c93632e2790ab7d25aa9d/ledood (accessed on 31 October 2021).
- Schlick, C. An inexpensive BRDF model for physically-based rendering. In Computer Graphics Forum; Wiley: Hoboken, NJ, USA, 1994; Volume 13, pp. 233–246. [Google Scholar]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hadji-Kyriacou, A.; Arandjelović, O. Raymarching Distance Fields with CUDA. Electronics 2021, 10, 2730. https://doi.org/10.3390/electronics10222730
Hadji-Kyriacou A, Arandjelović O. Raymarching Distance Fields with CUDA. Electronics. 2021; 10(22):2730. https://doi.org/10.3390/electronics10222730
Chicago/Turabian StyleHadji-Kyriacou, Avelina, and Ognjen Arandjelović. 2021. "Raymarching Distance Fields with CUDA" Electronics 10, no. 22: 2730. https://doi.org/10.3390/electronics10222730
APA StyleHadji-Kyriacou, A., & Arandjelović, O. (2021). Raymarching Distance Fields with CUDA. Electronics, 10(22), 2730. https://doi.org/10.3390/electronics10222730