1. Introduction
The increasing availability of large volumes of digital text in the past decades has led to a boost in research in information extraction (IE), a branch of natural language processing (NLP) aiming to obtain structured information from unstructured text. Opinion-mining or sentiment analysis is a subdomains of IE concerned with subjective expressions, which has also thrived in recent years, not in the least due to its huge application potential in marketing and CRM [
1,
2,
3,
4]. Sentiment analysis (SA) aims to automatically identify “people’s opinions, sentiments, evaluations, appraisals, attitudes, and emotions towards entities such as products, services, organizations, individuals, issues, events, topics, and their attributes” [
5]. The value and direction of subjective opinion expressed is termed polarity and is often labeled as positive, neutral, or negative attitude. The dominant line of research in SA focuses on user-generated content such as product reviews and social media posts. The main communicative goal of these text genres is to convey a person’s opinion and subjective experience. As such, user-generated text typically conveys opinionated or evaluative content explicitly using words that directly denote subjectivity, emotion, or opinion. As a result, most sentiment analysis research is directed at the detection of subjective words and phrases. However, previous work has shown that objective-oriented texts such as news articles can also express sentiment, potentially in an indirect manner [
5,
6,
7,
8]. In the implicit case, readers must infer positive or negative impressions expressed by the author through common-sense connotations and world knowledge.
“The bad news is that AbbVie’s top-notch dividend might not be safe.”
→Explicit: Author explicitly states their negative attitude with words “bad news” and “not safe”. Positive attitude is made explicit by “top-notch”.
(b)“Boeing stock climbed on news that it would increase its production of 787 aircraft.”
→Implicit: Reader must infer a positive connotation through world knowledge.
For instance in example (a), “
bad news” and “
not be safe” are phrases that explicitly convey negative consequences for the company AbbVie and its dividend, while “
top-notch” denotes a positive evaluation. The subjective attitude stems from the inherent semantics of these word and is thus lexically explicit. Example (b) describes events such as “
stock climbing” and “
increase [in] production” from which a reader has to infer through real-world knowledge of economics and financial markets that this is positive for the target company (Boeing). In line with previous research on implicit sentiment [
6,
9], we term any span of words that expresses implicit or explicit sentiment a ‘polar span’, also called ‘sentiment expression’ or ‘opinion term’. To account for the full range of subjective information contained in text, researchers have started to analyze implicit methods of expressing sentiment [
8,
10,
11,
12,
13]. Nevertheless, the amount of work and resources in the field of implicit SA remains limited and focused on user-generated content, which is a more explicitly opinionated genre. Implicit sentiment is usually treated by coarse-grained methods, with polarity labels created at the document or sentence level, and the field is lacking in substantial gold-standard, human-annotated, token-level datasets. However, the presence of implicit sentiment in economic news [
6] combined with potential financial market applications have made it a prime target for implicit sentiment processing.
This paper presents the novel SENTiVENT resource for the processing of fine-grained implicit sentiment in English economic text. In a previous stage, the SENTiVENT corpus was annotated with schema-based event annotations [
14]. These event schemata denote an event of a certain type (e.g., product releases, revenue increases, or security value movements, deals) and relate which participating entities play a role in the event (e.g., a product, the amount of increase in stock price, and the main companies involved in a deal). We propose a method for inducing implicitly subjective sentiment–target relationships from fine-grained event schemata, alongside directly annotated expressions of sentiment and their targets. We validate the created resource in an inter-annotator agreement (IAA) study and a set of pilot experiments: coarse-grained implicit polarity classification for gold and clause-based polar expressions, and fine-grained extraction of triplet experiments of <polar span, target span, polarity> triplets. The main contributions of this work can be summarized as follows:
We construct a corpus with gold-standard annotations for economic sentiment as implicit polar expressions. The domain of implicit SA is lacking fine-grained, target-based datasets and our SENTiVENT dataset fills that gap with a substantially-sized resource containing 12,400 sentiment tuples. We use the event schemata as a basis for targeted implicit sentiment analysis, demonstrating efficient resource creation in fine-grained information extraction. Additionally, separate sentiment–target annotations are made. The quality of all annotations is demonstrated in an IAA study.
We validate implicit sentiment with coarse-grained pilot experiments by polarity classification of gold polar expressions and clauses.
In fine-grained experiments, we find a drop in performance in <polar span, target span, polarity> triplet extraction on our implicit task compared to an explicit sentiment benchmark [
15]. Error analysis highlights the need for models that exceed flat lexical inputs due to the lack of strong lexicalization of implicit polar expressions. From this, we provide corpus creation and engineering recommendations regarding implicit sentiment and our dataset.
First, in
Section 1.1, we discuss related research on implicit, fine-grained, and economic and financial SA. Next, in
Section 2.1, we describe the annotation process, definitions, and properties of the corpus, followed by the IAA study in
Section 2.2.
Section 2.3,
Section 2.4,
Section 2.5 and
Section 2.6 describe the experimental methods and data resources used in all validation experiments. Coarse-grained validation experiments are discussed in
Section 2.7, followed by the fine-grained triplet modeling approach in
Section 2.8. Performance scores are provided in
Section 3 and framed in the Discussion (
Section 4). Finally, in
Section 5, we highlight the major conclusions of our work.
1.1. Related Research
This work lies on the crossroads between economics and two recent research strands in the domain of sentiment analysis: implicit sentiment processing and fine-grained sentiment analysis (commonly referred to as aspect-based sentiment analysis (ABSA)). In each subsection, we discuss existing approaches and resources (or lack thereof) for each of these subdomains.
1.1.1. Implicit Sentiment
Explicit statements of subjective intent toward a target entity are called private states [
16,
17], and are currently the dominant topic of subjectivity analysis research. For instance, the tweet “Most bullish stocks during this dip
$GOLD” (from [
18]) contains a positive opinion about the company Barrick Gold Corp. (ticker: GOLD) expressed explicitly by the words “most bullish”. However, more factual text genres, such as news-wire text or financial reports, often contain implicit expressions of sentiment in the form of objective statements that express a generally desirable or undesirable fact [
5]. Van de Kauter et al. [
6] found that up to 60% of all sentiment to be implicit in English and Dutch business news. Implicit sentiment analysis targets opinions and attitudes that are not encoded explicitly by lexical expressions but can be inferred through common sense and connotational knowledge. For example the sentence “The computer crashed every day” (from [
9]) does not contain any explicit sentiment words, but a negative evaluation of the computer can be inferred from the factual content. Only a small body of research is aimed at implicit sentiment [
8,
10,
11,
19,
20].
Next, we briefly discuss relevant works on the manual annotation of supervised datasets centered on implicit sentiment tied to factual statements and/or events. Wilson [
21] was one of the earliest to annotate implicit sentiment in meetings defining objective polar utterances as “statements or phrases that describe positive or negative factual information about something without conveying a private state”. Toprak et al. [
9] defined and annotated implicit sentiment for polar facts: sentence descriptions of objectively verifiable facts that imply the quality of an entity or proposition. They annotated these utterances in consumer reviews (e.g., “The camera lasted for many years after warranty.” implies a positive attitude toward the camera). In the ISEAR study [
22,
23], implicit sentiment was labeled as emotions (e.g., anger, joy, etc.) belonging to descriptions of situations, and later made into the EmotiNet structured resource by Balahur et al. [
24]. Similarly, the CLIPEval dataset [
25] contains sentence descriptions of commonly pleasant and unpleasant activities and life events, and serves as a common benchmark dataset for coarse-grained event-implied sentiment. More fine-grained work can be found in Deng et al. [
26], who annotated GoodFor/BadFor (gfbf) events that positively or negatively affect entities that strictly fit into triplets of <agent, gfbg, object>. In later work, Deng and Wiebe [
27] detected implicitly expressed opinions by implicature inference over explicit sentiment expressions related to events affecting entities. In Chinese, Huang et al. [
28] annotated a corpus of hotel review snippets and clauses for positive and negative polarity. Recently, the SMP2019-ECISA (
https://www.biendata.xyz/competition/smpecisa2019/ (accessed on 7 September 2021)) shared task for Chinese implicit sentiment in social media and car product and tourism forum posts based on Liao et al. [
7] has spurred new research in implicit polarity modeling. Apart from the annotation of corpora, work on implicit sentiment also led to the creation of connotation lexicons, where words are identified that are superficially objective but have connotational value (e.g., ‘delay’ is negative), as exemplified by Feng et al. [
20] for broad-coverage and Zhang and Liu [
19] for consumer reviews.
The related work discussed here only identifies implicit sentiment at coarse-grained levels (the utterance, post, or sentence), often derived from opinionated text genres such as reviews and forum posts. Their is a clear need for a substantial fine-grained resource with token-level polar and target span annotations to enable data-driven approaches for implicit SA.
1.1.2. Fine-Grained and Target-Based Sentiment Analysis
Inherent to the definition of implicit sentiment is the inference of a positive or negative attitude change of the reader toward a target entity. Implicit sentiment processing thus contains a component of fine-grained sentiment analysis where the target is of interest. Aspect-based sentiment analysis (ABSA) identifies sentiment of target entities and their aspects [
29,
30,
31,
32,
33], and has been the dominant line of research in fine-grained opinion-mining. Given a target entity of interest, ABSA methods can identify its properties and the sentiment expressed about those properties.
In ABSA tasks as defined by the SemEval shared tasks [
31,
32,
33], aspects are pre-defined categories that express properties of a narrowly defined target domain, e.g., the screen, CPU, or battery when focusing on the laptop domain, or the service and food quality in the restaurant domain. This is a good fit for restricted-domain text genres, such as consumer product or service reviews, but does not translate well to the study of more open domains such as business news. Here, restricting targets to certain types would lead to either a proliferation of aspect categories or an omission of potential target annotations. When aspect categories are omitted and targets are processed irrespective of category, this line of research is termed targeted sentiment analysis or target-based sentiment analysis (TBSA). Traditionally, TBSA is narrowly described as target span extraction and sentiment classification (TESC) which involves (a) detecting mentions of target token spans in text (often named opinion target extraction or target/aspect span extraction (TE)) and (b) classifying polarity, a subtask named target/aspect-level/dependent/oriented sentiment (polarity) classification (SC). TE has been widely studied as a separate task in [
34,
35,
36,
37,
38,
39,
40,
41,
42], as has SC [
43,
44,
45,
46,
47,
48].
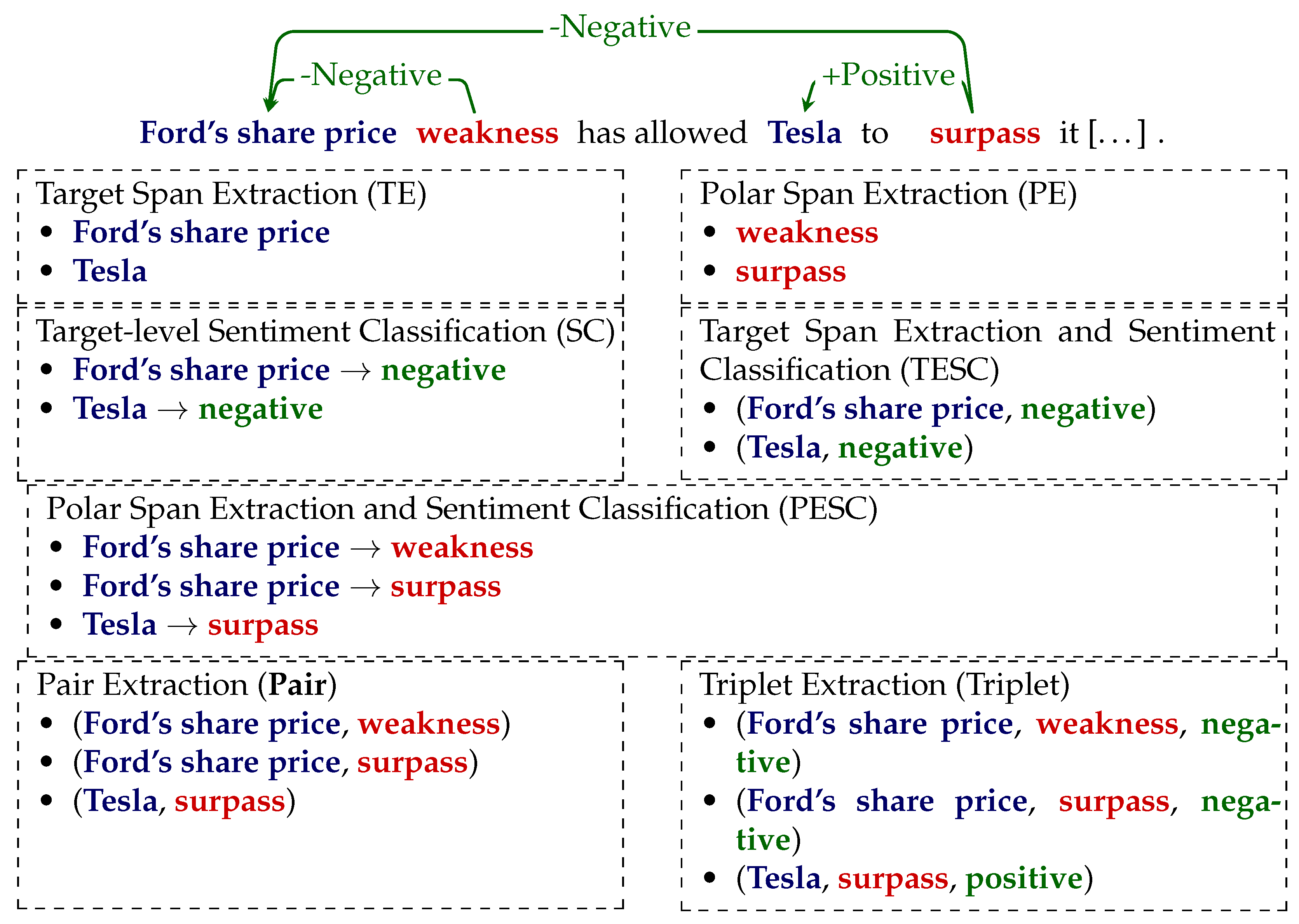
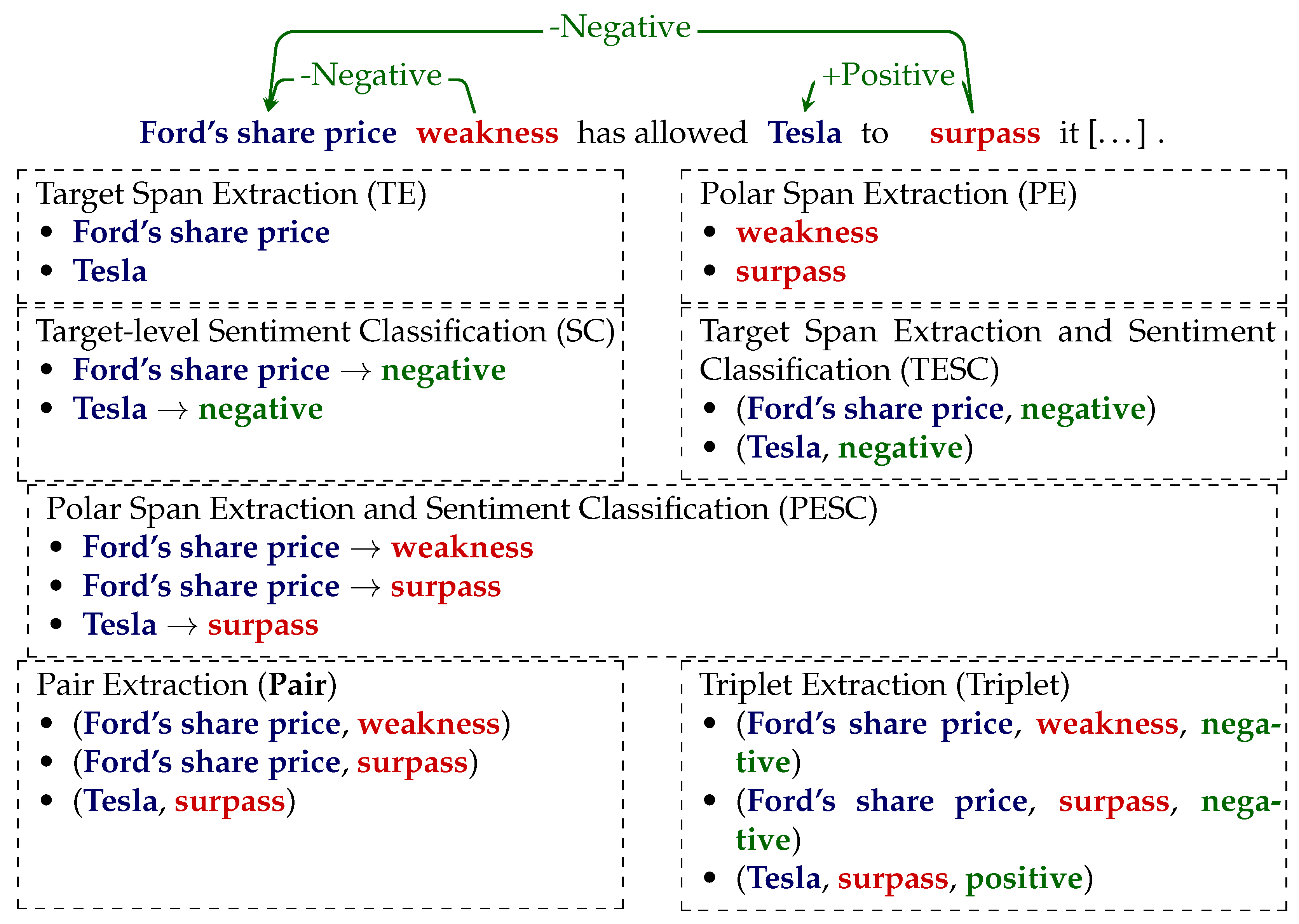
Figure 1 shows the subtasks of fine-grained TBSA that are enabled by our SENTiVENT dataset.
The vast majority of these fine-grained TBSA studies relied on the SemEval ABSA datasets, and occasionally included Mitchell et al. [
49]’s open-domain microblog resource or Dong et al. [
43]’s microblog resource. The lack of objective genres highlights the need for a manually annotated fine-grained implicit sentiment resource that is not based in opinionated text such as microblogs and reviews.
Figure 1.
Overview of fine-grained target-based sentiment analysis subtasks enabled by the SENTiVENT dataset. Overview recreated from Mao et al. [
50] but terminology adapted to implicit polar expressions.
Figure 1.
Overview of fine-grained target-based sentiment analysis subtasks enabled by the SENTiVENT dataset. Overview recreated from Mao et al. [
50] but terminology adapted to implicit polar expressions.
Since the organization of the SemEval ABSA shared tasks [
31,
32,
33] of laptop and restaurant reviews, more fine-grained annotations have been added to these datasets, such as token-level target and aspect spans and separate polarity labels for target-sentiment spans by [
15,
51], enabling the extraction of <polar span, aspect span, polarity> triplets. Currently, no ABSA or TBSA systems exist that target implicit sentiment.
Most of these studies approached SC with a given gold target span, which limits real-world applicability. Hence, more recently integrated models for both subtasks have been constructed, exploiting associations and commonalities between tasks. Unified models integrating fine-grained subtasks can take advantage of the strong coupling across subtasks: the type of target can provides clues of the sentiment expression and polarity and vice versa. Wang et al. [
52], Li et al. [
53] applied a sequence tagging approach with a unified tagging scheme to jointly model TESC and show performance competitive with pipelined approaches. He et al. [
54] took a multitask learning approach with shared representation learning. Peng et al. [
55] were the first to specify <polar span, aspect span, sentiment polarity> triplet extraction in an end-to-end model. They specified a two-stage model in which the first stage comprises sequence labeling unified aspect–sentiment span tags (aspect boundaries with sentiment polarity) and polar spans. The unified labeling approach for aspect–sentiment spans enhanced by learned polar span representations obtaied good results.
1.1.3. Financial Sentiment Analysis
Due to the direct economic incentives and value of information acquisition in financial markets, sentiment analysis has attracted a vast amount attention in the field of economics and finance. SA has been applied in various applications such as stock prediction [
56,
57,
58,
59,
60,
61], financial market analysis [
62], impression management of brands or people [
2,
63,
64,
65], macro-economic policy metrics [
66,
67], and forecasting macro-economic trends and risk [
68,
69,
70]. Many studies focused on social media text, especially financial microblog StockTwits and tweets [
18,
71,
72,
73]. More objective text types such as periodic financial reports such as 10-Ks, earnings, and sustainability reports [
74,
75,
76], as well as news-wire text [
58,
61,
77,
78], have also been studied. The lack of explicit sentiment opinions in these genres has led to the study of implicit sentiment in the economic domain. Drury and Almeida [
79] identified entity, event, and sentiment phrases in business news by manually creating a rule-based system and assigning them positive or negative polarity. (Unlike the event annotations in SENTiVENT (ours), these are not manually labeled and syntactically limited to verb phrases. The concept of events here is agentive actions by economic actors and is heavily restricted into five action categories. The sentiment words were identified by the expansion of a seed lexicon and matching; hence, they are derived from lexically explicit sentiment.) However, by combining the events and polarity with this rule-based method, they were one of the first to study implicit sentiment in economic news. Similarly, Musat and Trausan-Matu [
10] interpret implicit sentiment that emerges through the co-occurrence of economic indicators (e.g., unemployment) and future state modifiers (i.e., spans indicating the growth or decrease in the economic indicator to which they are referring).
Malo et al. [
80] annotated around 5000 sentences of English news and press releases of Helsinki Stock Exchange listed companies for polarity. The resulting Financial Phrasebank is an often-relied-on benchmark dataset for coarse-grained financial SA. Chen et al. [
81] compared writer-labeled vs. market-expert-labeled microblogs (labeling your tweet bullish/ bearish is a feature in StockTwits) in order to investigate discrepancies. Regarding fine-grained resources, Cortis et al. [
82] created the SemEval-2017 Task 5 dataset for fine-grained economic SA consisting of microblogs (2510 messages) and news headlines and statements (1647 headlines). Span annotations for the opinion words were made; targets were identified at the document level and assigned to polar spans with sentiment polarity scores. This resource thus enables target-based economic polarity classification but it lacks fine-grained target span annotations. Maia et al. [
83] presented the FiQA’18 Task 1 dataset for economic ABSA, containing a set of 529 headlines and 774 microblogs, including target annotations, sentiment scores, and aspect categories.
Many of the existing approaches to (financial) SA remain coarse-grained: they detect the mood of a certain document by taking into account all expressions of sentiment, regardless of the target. Few fine-grained financial resources exist [
82,
83] they are limited in scope and size, and/or are pre-filtered to ease annotation: FiQA’18 only includes sentence instances in which target companies are explicitly named (viz. realized as nominal phrases, e.g., ‘Berkshire Hathaway’ or ‘Tesco’); the SemEval-2017 Task 5 dataset does not contain target span annotations. All previous work has either been conducted in opinionated and/or subjective text genres such as microblogs or on news headlines instead of full article text. This work fills the need for a manually labeled implicit (and explicit) economic sentiment dataset, while enabling fine-grained SA in full news articles.
Importantly, the concept of sentiment in finance is different than in NLP: where market or investor sentiment is defined as “the expectations of market participants relative to the norm”, a bullish/bearish investor expects returns to be above/below average, whatever average may be [
84]. Additionally, sentiment definitions in economics and finance often depend on a specific application. Consumer confidence is the general consumer expectations about the future state of the economy. In behavioral finance, Long et al. [
85] showed that investors are subject to sentiment that is not strictly tied to fundamentals. Baker and Wurgler [
86] defined investor sentiment as “a belief in future cash flows and investment risks that is not justified by the facts at hand” and provided several proxies to measure sentiment such as surveys, retail investor trades, mutual fund flows, dividend premiums, trading volume, option-implied volatility, etc. Kearney and Liu [
87] proposed two general types of sentiment definition: (a) investor sentiment, which constitutes the subjective judgements and behavioral characteristics of investors; and (b) textual sentiment, which entails text-based expressions of positivity/negativity, and can also include investor sentiment and adds “the more objective reflection of conditions within the firms, institutions, and markets”. Our operationalization of investor sentiment as event-implied polar expressions fits this latter definition as we annotate the sentiment polarity of factual real-word events. We opt for the term textual investor sentiment to highlight the presumption of an imagined investor affected by the expressions of both explicit and implicit opinion in the text. This definition encompasses both implicitness and targets: it depends on the inferred attitude of an assumed reader-investor toward a target entity.
1.2. Previous Work
Our work is a continuation of the English and Dutch SentiFM business news corpus [
6,
88], which contains token-level annotations of implicit and explicit sentiments, targets, sources, source-linkers, modifiers, and cause spans. On this corpus, we experimented with coarse-grained event detection [
89]. However, SentiFM events are not directly related to sentiment, and experiments remained coarse-grained.
The SENTiVENT-Event dataset [
14,
90] of ACE/ERE-like event schemata [
91,
92] contains a typology of economic business with prototypical argument roles. We enhanced the SENTiVENT-Event dataset by (a) annotating explicit and implicit sentiment–target pairs, and (b) adding sentiment polarity labels to event triggers (i.e., the word span denoting an event). This results in a fine-grained, token-level dataset with sentiment–target annotations enabling fine-grained extraction of facts (as events) and subjectivity (as implicit sentiment) to enable target-based implicit SA.
2. Materials and Methods
We experimented with multiple sentiment analysis approaches for the detection of implicit company-dependent sentiment in economic news text. Lacking resources for this task, we applied a fine-grained annotation scheme covering polar facts and sentiment expressions.
Section 2.1 describes definitions of labeled units, dataset properties, and the annotation process with a focus on validation through an inter-annotator agreement (IAA) study. Then,
Section 2.3 specifies the experimental setup for the coarse- and fine-grained experiments, model architectures, model selection, and validation testing.
2.1. Data Collection and Annotation
In this section, we present the definitions, annotation process, and corpus properties of the English SENTiVENT financial news dataset for implicit fine-grained sentiment processing. The sentiment annotations are made in the SENTiVENT-Event English corpus of fine-grained event annotations described in previous work [
14,
90]. The dataset consists of a random crawl of full online news articles mentioning specific companies between the period of June 2016 and May 2017. The companies were randomly chosen from the S&P500 index, but sectorial diversification was ensured to avoid topical specialization. The applied definition of implicit sentiment is the following:
Textual investor sentiment: The definition of annotated subjectivity is tailored to the economic and financial domain, with the goal of enabling micro-economic information extraction and market analysis. Investor sentiment is defined as textual expressions that encode (explicitly) or affect (implicitly) investor attitude and/or opinion toward a target entity in the market. An investor is someone looking to assign capital to a company, asset, or other entity with the expectation of profit in the future. Investor sentiment can be defined as the opinions that an investor holds toward a potential investee. In financial terminology, positive economic expectations are called bullish and negative expectations, bearish. We annotate positive (bullish), neutral, and negative (bearish) polarity.
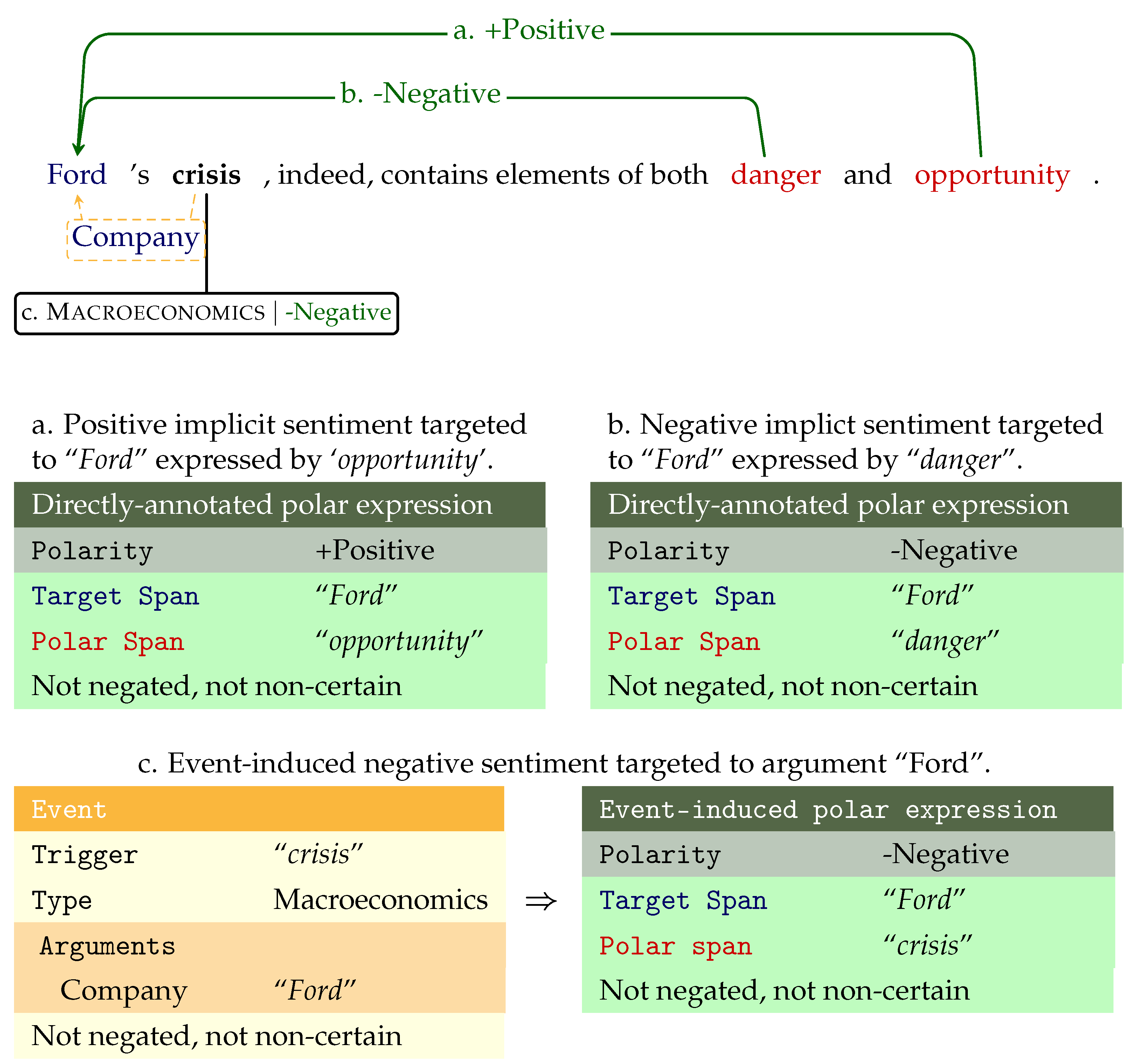
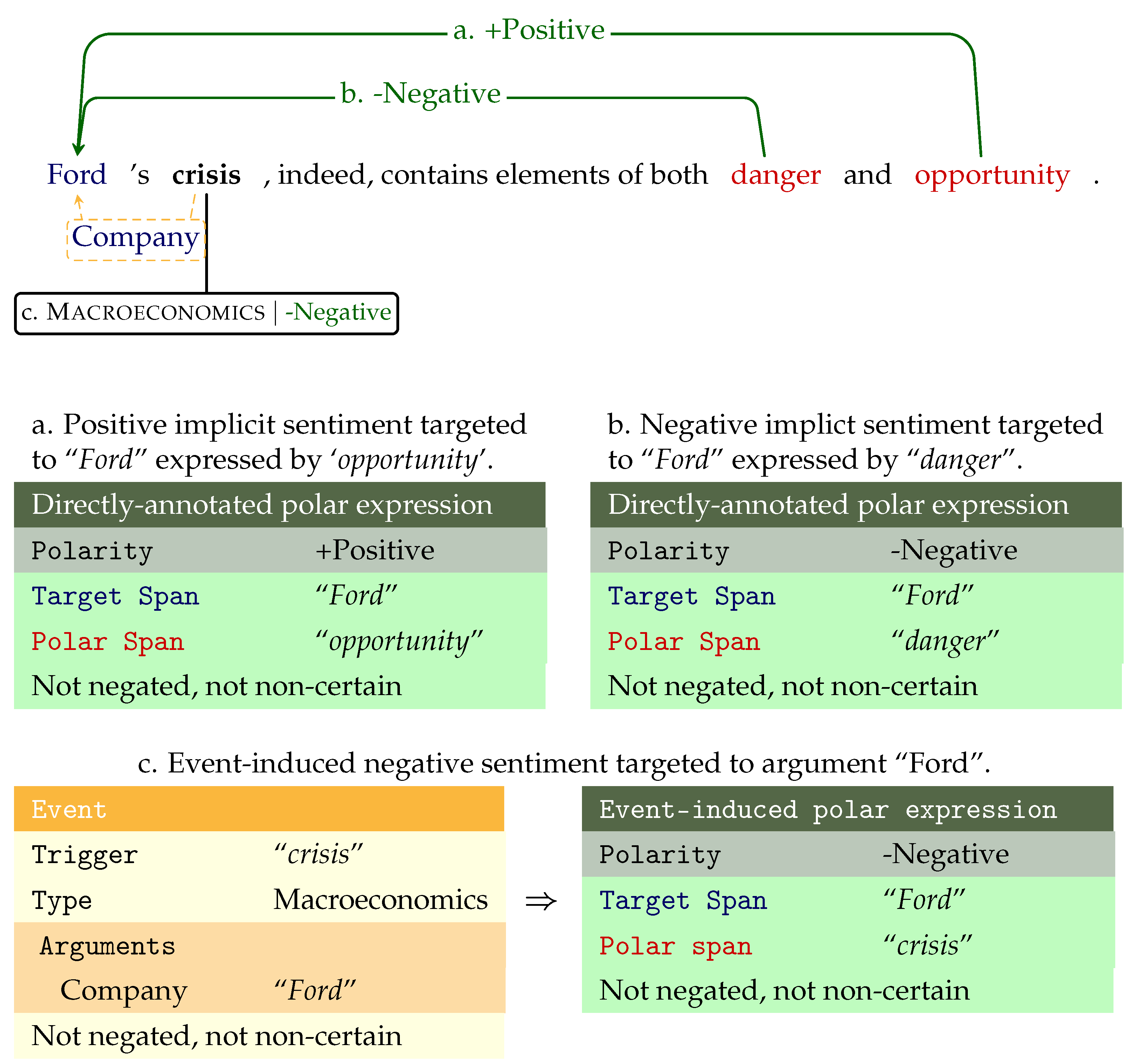
The polar expression annotations consist of the following parts exemplified in
Figure 2:
Polar span: the token span expressing the implicit or explicit investor sentiment.
Target span: the continuous token span denoting a sentiment target entity; the company, person, organization toward which the sentiment is directed.
Polarity:
- -
Positive investor expectations come from events that have a desirable effect on a business entity’s characteristics (e.g., its financial metrics, growth, and position in the market) or the larger surrounding economic situation (e.g., macro-economic factors, policy changes, and market fluctuations). Examples of positive polarity are increases in growth of sales, revenue, profit, cash flow, or other financial metrics; strategic investments; cut expenses; well-reviewed products; effective marketing efforts, growing stock price or increased price targets; upgraded ratings; optimistic analyst expectations; etc.
- -
Negative investor sentiment entails the opposite expectation that a loss will occur and the invested funds will not generate an acceptable return. Generally, negative expectations come from events that have an undesirable effect on some attribute or the surrounding situation of a business entity. Examples include inhibition of growth or decline in sales, revenue, profit, cash flow, and other financial metrics; or scandals, losses, legal issues, increased expenses, lowering stock price or price targets, downgrading of ratings, employment issues, negative analyst expectations, etc.
- -
Neutral investor sentiment is for an expression with no clear positive or negative polarity. This happens when (a) the polar expression expresses ambivalence on the part of the author, or (b) it is unclear/ambiguous how the polar expression could affect a potential investor’s attitude.
Two factuality attributes [
93]:
- -
Non-certain modality: the sentiment expression is presented as being anything other than certain (i.e., certain epistemic modality).
- -
Negation: the sentiment expression is in the scope of negation, i.e., the author indicates the sentiment/polar event is not the case.
Our sentiment annotations are of two types:
- (a)
Directly-annotated polar expressions consisting of polar spans with target span(s) and sentiment polarity annotations, as shown in
Figure 2a,b.
- (b)
Event-induced polar expressions: sentiment polarity labels added on top of the event trigger annotations to encode implicit sentiment, i.e., connotational common-sense sentiment expressed by these events, as shown in
Figure 2c.
The first type of annotations (a) is labeled everywhere in the article text where a preexisting event trigger is absent or does not adequately describe the sentiment (except when the trigger is longer or shorter than a polar span). Polar spans can be tagged with multiple or no targets and cross-sentence polar–target span relations are allowed. Positive, neutral, or negative polarity is target-dependent; occasionally, one polar span can be negative for one target and positive for another.
The preexisting event annotations of type (b) stem from the previously mentioned SENTiVENT-Event corpus. Events denote real-world occurrences drawn from a representative typology to encode prototypical event types and their argument roles. These event schemata allow for fine-grained annotation of commonly reported changes, actions, and state of affairs in company-specific news and the argument entities that take on typical roles within them. An event annotation consists of:
Trigger: the shortest span of words expressing the event.
Arguments: spans of words denoting predefined prototypical roles in the event of a certain type (48 different roles in the typology).
Type and attribute labels: the event type, subtype (18 types and 42 subtypes in the typology), and several other attributes (modality, negation, and realize).
Figure 2 contains an event schema of the Macroeconomics type as expressed by the event trigger “crisis” and it has one argument “Ford” of the role “Company”.
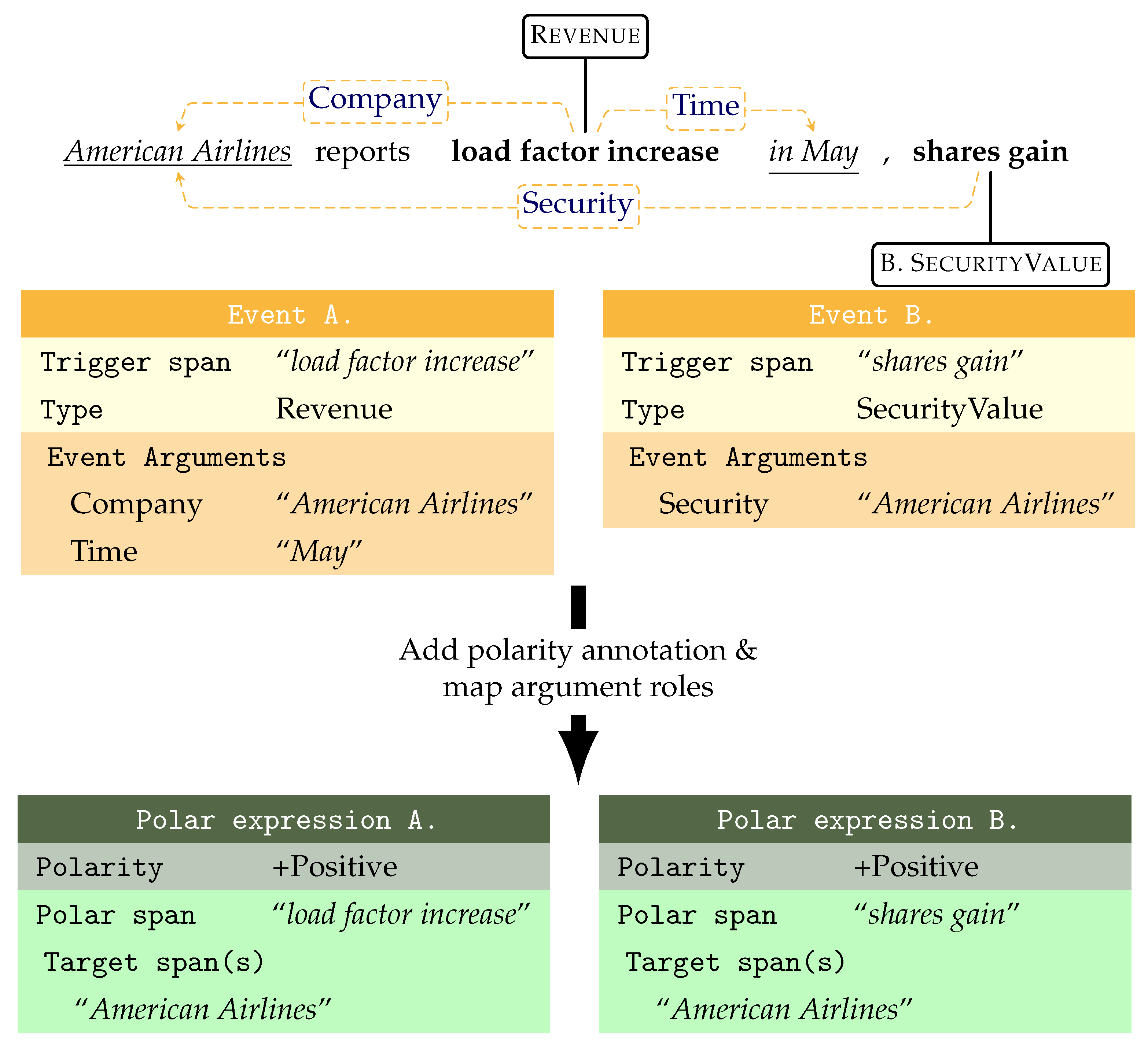
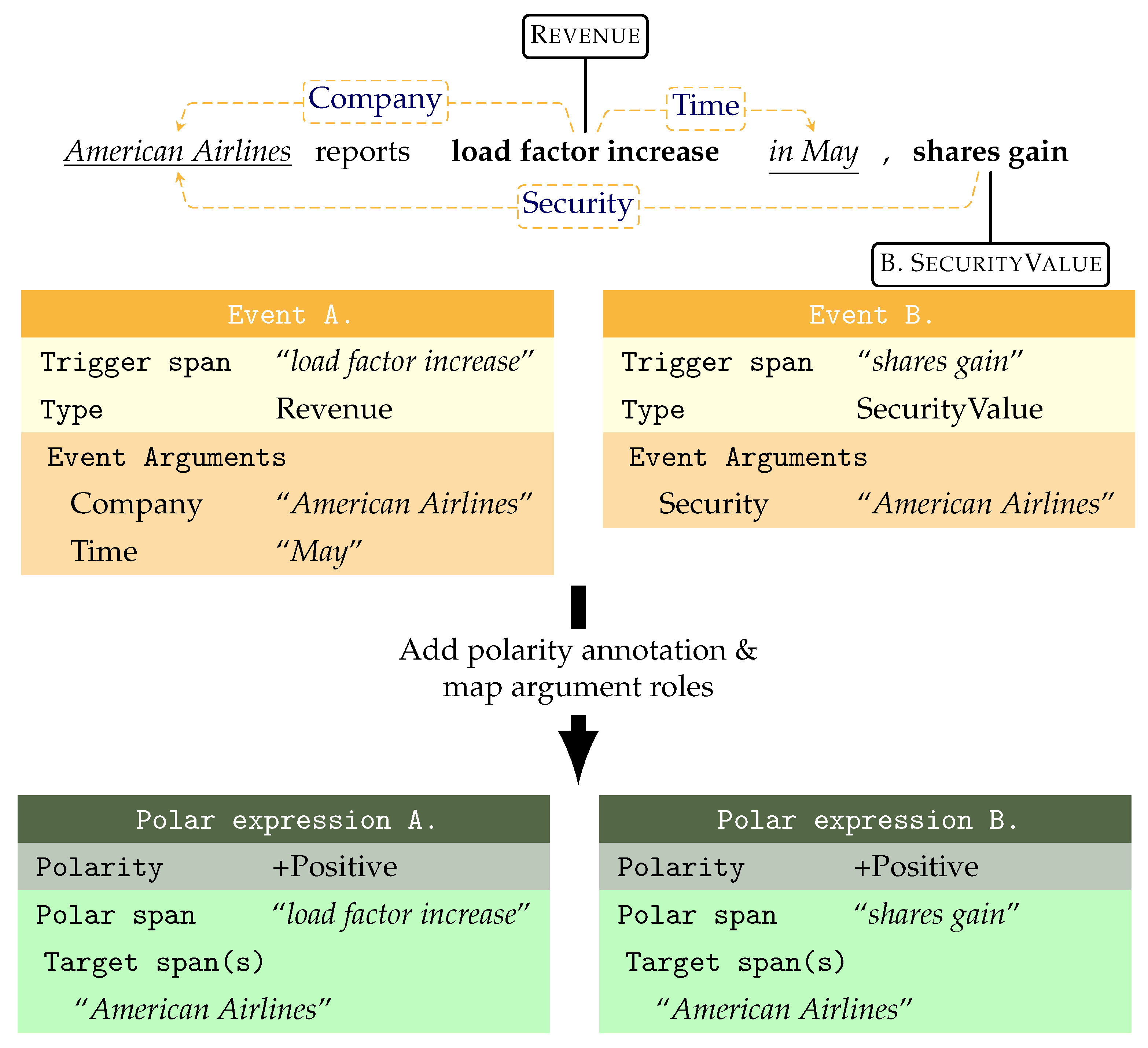
Figure 3 shows two events: one of type Revenue expressed by trigger “load factor increase” with the argument role Company pointing to “American Airlines”, and Time to “May”, and another of type SecurityValue with the trigger “shares gain” and to “American Airlines” as the Security argument.
To obtain polar expressions from event schemata, we annotated the polarity labels of the event and mapped the argument spans to targets. The event trigger span becomes the polar span expressing the sentiment. The argument-to-target is achieved by filtering argument roles in the event typology: arguments that are generally non-agentive or non-central are left out and cannot be targets. In
Figure 3, it is clear the Time argument cannot be the target of the positive effect of an increase in revenue as the time of an event is incidental. On the other hand, the Company role that experiences the event is the primary benefactor, so the positive event maps the Company role to the target. Examples of removed argument roles are those referring to amounts of capital (Dividend.YieldRatio, Expense.Amount, and Employment.Compensation), or incidental descriptors such as Time and Location, results of events (Deal.Goal,Legal_Conviction.Sentence), or non-central entities on which the event polarity cannot be reflected (Rating.Analyst). Generally, central and agentive roles that are kept as targets are filled by companies, people, or organizations (CSR/Brand.Company, Employment.Employer). This mapping takes advantage of event-level implicit polarity, reflecting and precipitating on the pre-defined argument roles. In exceptional cases, this assumption does not hold and annotators are directed to make separate directly annotated polar expressions for each target-specific polarity.
Table 1 shows the properties and annotation counts of our corpus. The corpus is larger than the currently largest fine-grained TBSA corpora from Wu et al. [
15] (8937 polar spans, 9337 target spans, and 10,390 triplets), Mitchell et al. [
49] (English: 3288 tweet-target pairs, Spanish: 6658), Dong et al. [
43] (6940 tweets, unknown number of targets). Note that the count of triplets, i.e., unique sets of <polar span, target span, polarity>, is larger than the polar span count and target count because one polar span can be related to
n multiple targets, viz. triplets are a product result of <polar span, (target span, polarity)
>).
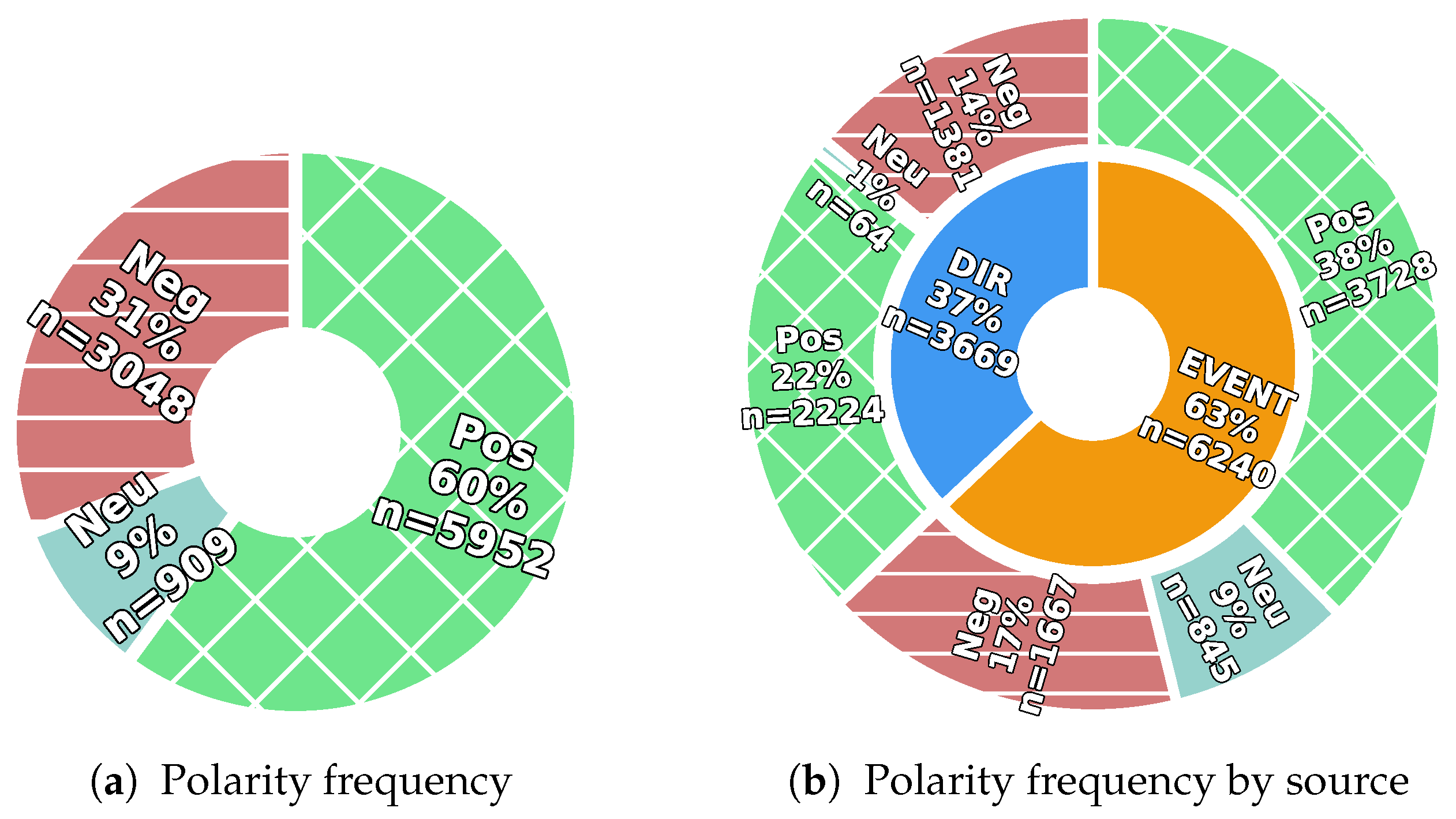
Figure 4 shows the frequency distribution of polarity labels by their annotation source. We can observe that positive/bullish sentiment is more common than negative/bearish sentiment. A larger amount of bullish sentiment was also observed by Chen et al. [
81] in their Stocktwits dataset. In our dataset, the skew is in part due the established value and stability of the selected companies, which all stem from the S&P500 index during an up-trending period. This leads to a lower likelihood of unpleasantly surprising events. The high frequency of neutral polarity in events is due to the larger likelihood of ambiguous or weak sentiment of event descriptions.
We define a standard split for reference use of the dataset (i.e., hold-in training, hold-in development evaluation, and hold-out evaluation set, cf.
Table 1). The test set corresponds to the 30 documents of the IAA study consisting of the combined and corrected annotations by three different annotators. This provides a high-quality, robust dataset for evaluation of the best model.
2.2. Inter-Annotator Agreement Study
As our task demands a large degree of interpretation (implicit sentiment requires inference by its definition, the polarity has the potential to be ambiguous), we conducted an inter-annotator agreement study to determine whether our annotation guidelines were properly defined and resulted in consistent and reproducible annotations. A subset of 30 documents discussing ten companies were included corresponding to
of the full dataset. Each document was fully annotated by three annotators. We used chance-corrected agreement measures Fleiss’ Kappa [
94]
, Krippendorf’s alpha [
95]
, and Gwet’s AC1 [
96] on aligned span annotations and used the R package irrCACC (
https://CRAN.R-project.org/package=irrCAC) (accessed on 7 September 2021) to compute these metrics. Fleiss’
[
94] generalizes Scott’s Pi to any number of annotators. Krippendorff [
95] argued for the use of
over other measures such as
because of its independence from the number of assessors and its robustness against imperfect data. AC1 was introduced by Gwet [
96] to provide a more robust measure of interrater reliability than Fleiss’
. AC1 can overcome
’s sensitivity to trait prevalence and rater’s classification probabilities (i.e., marginal probabilities) [
97]. (We did not use weighting or custom label distances when assessing disagreement, even though, for sentiment polarity, mislabeling neutral as positive or negative is much less of an error than labeling positive as negative. Discounting this type of disagreement would have provided higher scores for sentiment polarity as confusion of neutral with positive is by far most common).
In line with Lee and Sun [
98], we computed several agreement metrics by using relaxed span matching for directly annotated polar expressions using span overlap. This allowed us to determine agreement on the labels of annotation units where the exact span overlap was not of interest (cf. overlapping span matching in
Appendix A). The substantial agreement of our overlap-matched spans shows that the general area of span annotations is mostly agreed on despite the unmatched boundaries. Other work on ABSA resources performed agreement scoring at the sentence level [
33,
99] or clause level [
100], thus circumventing the issue of matching token-level annotations, but they also lost granularity.
Table 2 shows that our annotations obtained adequate agreement scores on all categories. We benchmarked these coefficients using the cumulative membership probabilities (As recommended by Gwet [
101], we set the benchmark membership probability cut-off point at 95%) within the agreement ranges as set out by Landis and Koch [
102]:
= poor agreement,
= slight agreement,
= fair agreement,
= moderate agreement,
= substantial agreement, and
= (almost) perfect agreement. For polarity, agreement obtained a Fleiss’
of 0.78, an AC1 of 0.85, and an
of 0.78 signifying substantial agreement within the 0.6–0.8 range. On negation,
is 0.74,
is 0.81, and AC1 is 0.95. For
and
, this signifies substantial agreement, while for AC1, this falls in the almost perfect agreement. On non-certainty,
is 0.60, AC1 0.82, and alpha is 0.62. For
and
, this signifies moderate agreement, while for AC1, this falls into substantial agreement. Non-certainty has lower agreement than the other categories, since annotators experienced difficulty in determining when sentiment was in the scope of modal non-certainty. While processing non-certainty is important for downstream tasks in which the factuality of sentiment and events influences decision making, it was not the focus of this work.
For pre-existing events, annotators had to assign positive, neutral, or negative sentiment polarity.
Table 3 shows the agreement analysis for polarity labels of events. Fleiss’
and Krippendorf’s
are both 0.65 and Gwet’s AC1 is 0.72. Following [
102], the agreement scores range between moderate (
and
) and substantial (AC1). The sentiment polarity annotations on existing events thus show lower agreement than on the newly annotated sentiment spans. This is readily explained by the increased difficulty in the interpretation of the polarity invoked by events. Annotators more easily recognized sentiment span annotations as they were more clearly positively or negatively polar. As also shown in
Figure 4, neutral polarity is much more common for the events than in directly annotated polar expressions (
vs.
).
Overall, we thus conclude that our annotations are adequate for use in polarity and negation tasks showing substantial agreement; ideally, the annotation guidelines for non-certainty should be revised with expanded rules for annotating this category.
2.3. Experimental Method
We present three series of experiments from coarse- to fine-grained in order to validate the created dataset and the feasibility of fine-grained implicit sentiment detection in economic news: implicit polarity classification on (1) gold polar expressions, (2) clauses, and (3) end-to-end extraction of <polar span, target span, polarity> triplets.
First, in
Section 2.7, we test multiple large-scale pre-trained language models (PLMs) in a coarse-grained classification set-up with only gold instances of polar expressions (i.e., spans containing positive, neutral, or negative sentiment polarity). The task here is to classify implicit positive, neutral, and negative polarity given the known token span of a polar expression and its targets. This is a preliminary series of experiments aimed to test the viability of implicit polarity classification: it is missing the required detection of polar expressions in a real-world setting. This simplified task allowed us to select the most viable pre-trained language model encoders for the fine-grained and increasingly difficult tasks. Subsequently, we applied coarse-grained, clause-based, implicit polarity classification, which includes a None class. Our original token-level annotations were transformed into sentential subclauses and assigned an implicit polarity label. Next, we applied coarse-grained, clause-level, implicit sentiment analysis where each sentence was split into its clauses and polarity was classified. This presents a more realistic setting since clause instances without implicit polarity are included. Clauses are also a good fit for implicit sentiment classification as they constitute fully realized semantic units that correspond well to polar expressions. Finally, in
Section 2.8, we apply end-to-end triplet extraction to test the viability of state-of-the-art approaches in explicit sentiment modeling on implicit data. This represents the most fine-grained and complete task taking full advantage of the fine granularity of our sentiment annotations.
All three series of experiments relied on the same transformer-based PLM encoders, which are discussed in
Section 2.5. For the coarse-grained experiments, we tested adding external subjectivity lexicons (both general and in-domain) as features in classification. These are discussed in more detail in
Section 2.6. For the coarse-grained experiments, we applied the same model selection approach and evaluation approach; only the evaluation approach for the fine-grained experiments differed.
Model selection: We ran hyperparameter optimization maximizing the macro-F
score using a Bayesian search with hyperband stopping [
103] for 128 runs. Optimized parameters included learning rate, batch size, and lexicon feature set. We used different hyperparameter search spaces for base- or large-size variants based on explorative experiments (cf.
Appendix D for the full search space). We also enabled early stopping within runs, evaluating inter-epoch macro-F
on the devset, selecting the best epoch of each run. This eliminated the need for including the number of epochs as a hyperparameter to optimize. The highest scoring model on devset macro-F
in the search was selected as the winner.
Model evaluation: For coarse-grained experiments, first, each winning development architecture was evaluated on the holdout test set to check for overfitting. Second, we performed a significance test on the test set predictions of each: first, we performed Cochran’s Q test across all model predictions. Cochran’s Q tests the hypothesis that there is no difference between the classification accuracy across all architectures. If this hypothesis was rejected, we performed a pairwise McNemar’s significance test to compare the best-scoring model across architectures to all others, in line with the recommendations of Dror et al. [
104]. For fine-grained experiments, we selected the best model hyperparameters by the F
-score on triplet extraction. In line with Wu et al. [
15], we re-trained and hold-out tested five times with different random seeds. The final holdout test score is the average of these five random initializations.
2.4. Pre-Processing
Prior to experimentation, we performed linguistic and annotation pre-processing. Sentence-splitting and tokenization were performed before annotation using StanfordCoreNLP [
105] to allow token-level annotations. For use with sentiment lexicons, we also applied part-of-speech tagging, stemming, and lemmatization using Spacy.
The event-to-polar mapping approach, as described in
Section 2.1, was applied to obtain a dataset of polar expressions. We removed pronominal realizations (anaphoric “it”, “that”, and “they”) of polar expressions and targets if there was no non-pronominal referent annotation present as part of the event coreference annotations. We also removed cross-sentence target relations: if a polar span was in a different sentence than its target span, we removed that relation.
2.5. Pre-Trained Models
We performed all experiments using the fine-tuning of PLM transformers BERT [
106], RoBERTa [
107], and DeBERTa [
108]. Additionally, we used domain-specific versions of BERT that were pre-trained and/or fine-tuned on economic news or other financial corpora.
BERT is an attention-based autoencoding sequence-to-sequence model using two unsupervised task objectives: The first task is word masking or masked language model (MLM), where the model guesses which word is masked in its position in the text. The second task is next sentence prediction (NSP) performed by predicting if two sentences are subsequent in the corpus, or if they are randomly sampled from the corpus.
The RoBERTa model [
107] is an improvement over BERT by dropping next sentence prediction and using only the MLM task on multiple sentences instead of single sentences. The authors argued that while NSP was intended to learn inter-sentence coherence, it actually learned topic similarity because of the random sampling of sentences in negative instances.
DeBERTa [
109] improves upon the performance of BERT and RoBERTa by using a disentangled attention mechanism and an enhanced mask decoder. The disentangled attention mechanism represents each word with a position and content vector and using disentangled attention matrices to compute attention-weights-based contents and relative positions of word pairs (more specifically, attention is computed as the sum of four attention scores of word pairs using separate matrices on contents and position such as content-to-content, content-to-position, position-to-content, and position-to-position). The enhanced mask decoder introduces absolute position in the masked-token prediction objective right before the SoftMax-decoding layer (unlike BERT, where absolute positions are added at the input layer).
We also tested two in-domain fine-tuned models that were trained on financial reports and economic news text data. Araci [
110] (henceforth FinBERT
) applied further pretraining of a general domain BERT model on the TRC2-financial corpus consisting of business news articles. Subsequently, the model was fine-tuned on the Financial Phrasebank, classifying sentence-level positive, neutral, and negative polarity in financial news. The model is a good fit for our purposes as it was further pretrained on in-domain data and fine-tuned on a task analogous to ours. Additionally, we tested Yang et al. [
111] (henceforth FinBERT
), which is a BERT model trained from scratch on corporate reports, earning call transcripts, and analyst reports. This model uses its own in-domain SentencePiece vocabulary and obtains good results when fine-tuned on the Financial Phrasebank [
80], FiQA [
83], and AnalystTone [
112] tasks.
For all transformer models, we used the available base-size with 12 layers, 768-dimensional hidden representations, 12 transformer heads, and 125 million trainable parameters. For BERT and RoBERTa, we also included the large size of 24 layers, 1024-dimensional hidden representations, 16 transformer heads, and 355 million parameters. We used model variants that maintain casing vocabulary (cased), except for FinBERT-FinVocab, for which we used the lowercasing variant (uncased) as this obtained best performance across all sentiment tasks in the original work [
111]. The references for the pretrained model weights as well as more details on the classification head can be found in Appendices
Appendix B and
Appendix C.
2.6. Subjectivity Lexicon Features
In order to leverage existing SA resources, we included several general domain and economic- and financial-domain lexicons.
Table 4 lists the lexicons used, their domain, and briefly describes their creation, categories, word-matching approach, and how we used them. We experimented with various different methods of computing and normalizing the final polarity score of a word sequence as a hyperparameter in model selection: the lexicons matched one or more words to categories, often including polarity such as positive or negative but also other categories of emotive or psycho-cognitive nature. We experimented with generating feature vectors with match counts for all categories, and combinations of methods of computing a final polarity score for the whole text sequence in the instance. Different lexicon feature-sets were generated, including direct wordlist match counts (e.g., raw, length, or match-normalized counts of negative, positive, neutral, or other specific sublists of lexicons such as Money and Anxiety in LIWC) and several methods of sequence-level polarity scoring (i.e., nominal match counts, token-length normalized, total match-normalized), were implemented and optimized in model selection. In coarse-grained experiments (
Section 2.7), we compared using no lexicons, only the domain-specific economic lexicons, and combinations of general and economic lexicons. These feature sets were grouped into three settings: polarity includes only the sequence polarity estimations;polarity + polarwordlists adds subwordlist counts for categories that denote positive, neutral, or negative polarity (if present in the lexicons); and all adds wordlist counts of non-direct polar categories. The selection of feature sets within the combination of lexicons was included as a hyperparameter in the hyperparameter optimization search as we did not consider the variations in lexicon feature sets a major architectural feature.
The lexicon match and polarity score vector was appended to the embedded representation produced by the transformer and input into the classification head. This allowed us to compare and use existing sentiment resources for implicit polarity classification.
2.7. Coarse-Grained Experiments: Implicit Polarity Classification of Gold Polar Expressions and Clauses
Our dataset contains token-level annotations that enable fine-grained implicit sentiment analysis. However, given the increased difficulty of implicit sentiment analysis vs. regular explicit tasks, we first checked the feasibility of implicit polarity classification at a more coarse-grained level in two experiments:
- (a)
Implicit polarity detection for gold polar expressions: classify implicit polarity {Pos, Neu, Neg} of known polar expressions, i.e., the known sequence of tokens denoting the implicit sentiment expression and its target(s). This does not require the detection of polar spans or target spans as they are given as input (e.g.,
Figure 5a).
- (b)
Clause-based implicit polarity detection: detect the implicit polarity {None, Pos, Neu, Neg} of sub-sentence clauses, where None indicates the absence of polarity (e.g.,
Figure 5b).
For (b), we split the corpus sentences into sub-clauses using the OpenIE 5.1 (
https://github.com/dair-iitd/OpenIE-standalone (accessed on 7 September 2021)) clause extractor [
123,
124] with a rule-based dependency-parsing fallback when OpenIE fails. When multiple polar expressions with different polarities are present in the clause, we assigned the label by majority vote, with positive and negative taking precedence over neutral in the case of a draw. OpenIE clauses are a good fit as they are a triplet representation of <subject, relation, argument(s)> where each part is a phrase. The OpenIE clause is conceptually similar to the concept of polar expressions, while providing a more fine-grained content analysis than classifying full sentences. A major difference from polar expressions and OpenIE clause triplets is that a subject–argument distinction does not exist for targets, and in OpenIE, the relational phrase is very often a verb phrase, whereas this is not the case for polar expressions, which can be any token span. However, this approach introduces the detection of relevant polar expressions as clauses, which is useful in applications for retrieving positive, neutral, and negative sub-sentence sequences that correspond to a singular description of a state of affairs involving arguments.
For both these tasks, the token spans were encoded by the transformer model with sequence classification head described in
Section 2.5 and, if applicable, the lexicon features were computed. The transformer model was fine-tuned through all layers on the implicit polarity classification task.
2.8. Fine-Grained Experiments: Implicit Triplets
Since our annotations are fine-grained at the token level, an end-to-end extraction task for <polar span, target span, polarity> is a good fit. This task has recently been enabled by a benchmark dataset released by Fan et al. [
51], which adds annotated target–opinion pairs based on SemEval ABSA challenges [
31,
32,
33]. These datasets are typical examples of explicit sentiment in reviews of restaurants and laptops. Wu et al. [
15] aligned these annotations with the corresponding sentiment polarity to obtain token-level triplet annotations. We compared the performance of a state-of-the-art model in explicit triplet extraction to our implicit dataset to test the applicability and transferability of the currently best available approach. Instead of evaluating these sub-datasets separately, we joined all instances into one large dataset (henceforth, Explicit Wu et al. [
15]) to be more comparable in size and domain-diversity to our dataset; however, the diversity in text genre and domain (i.e., consumer reviews) remained highly limited compared to SENTiVENT economic news.
Alongside the benchmark Explicit dataset, Wu et al. [
15] presented a novel grid-tagging scheme (GTS) architecture for TBSA that operationalizes triplet extraction as a unified tagging task across a grid representation. In contrast with more common pipelined approaches that suffer from error propagation, all word-pair relations are tagged and all opinion pairs simultaneously decoded.
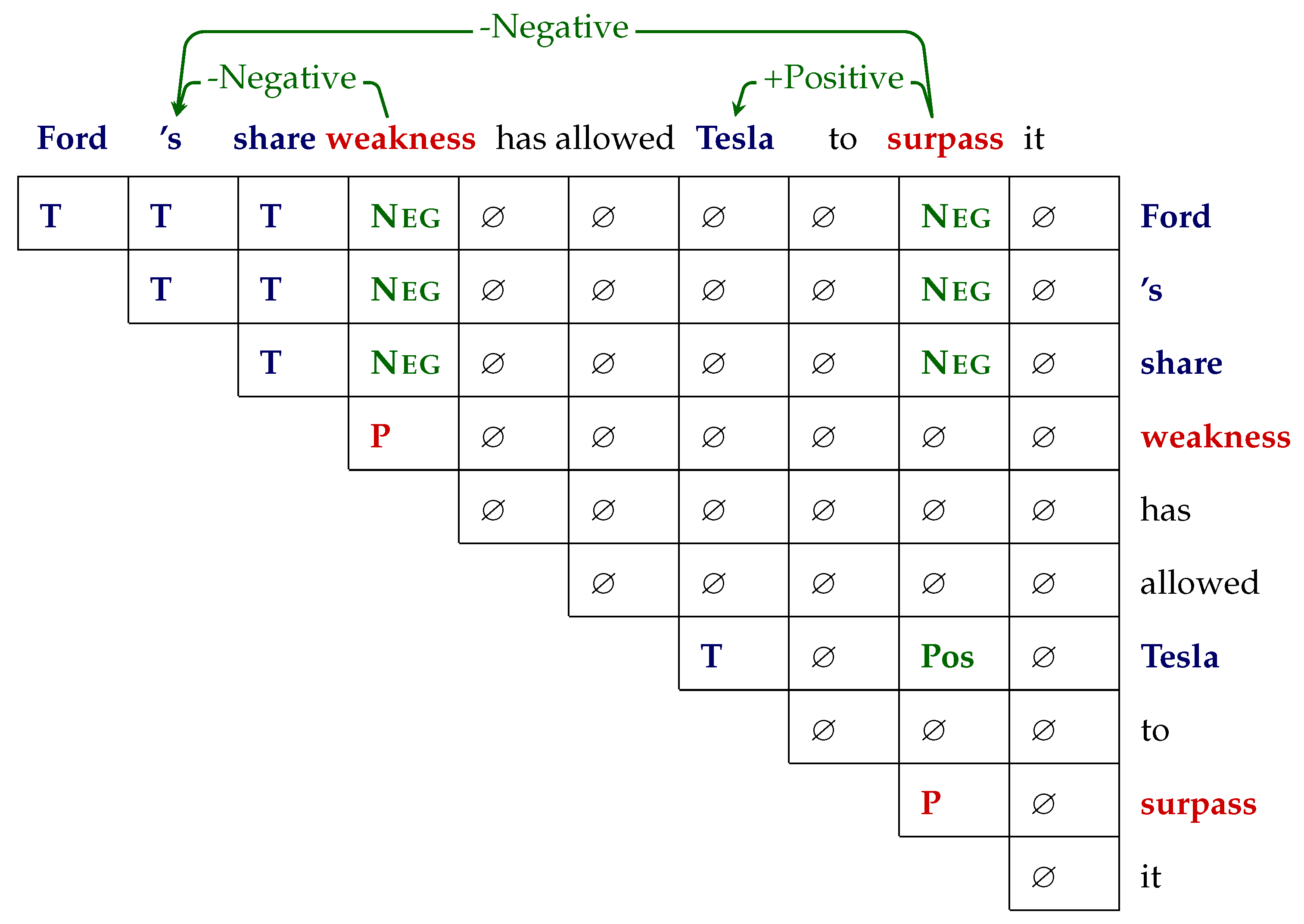
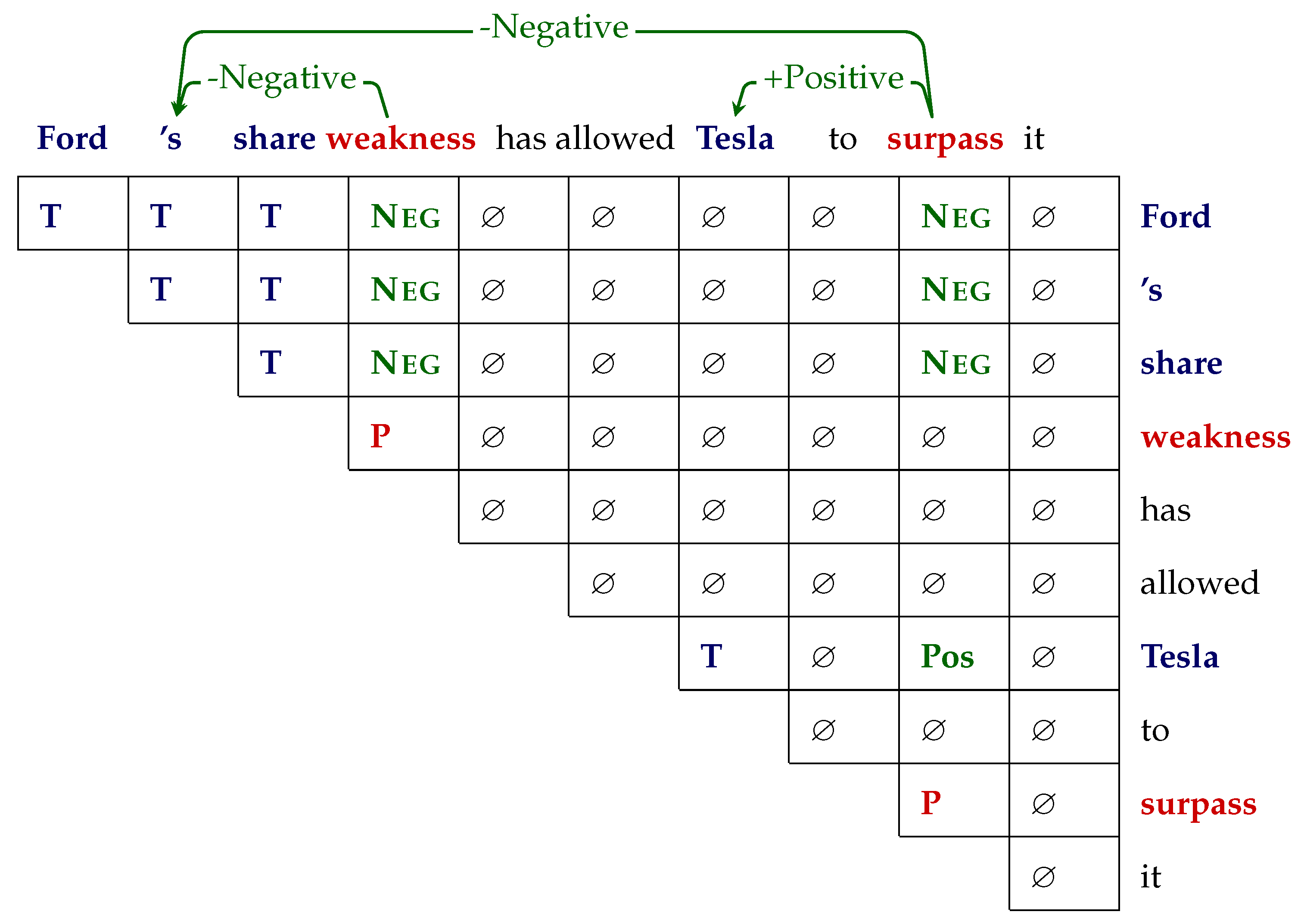
Figure 6 shows all word-pair tags in a simplified upper triangular grid for an example sentence. GTS involves two steps: (1) a unified tagging task and (2) a decoding step to robustly decode predicted word-pair tags along spans where polar spans and target/aspect spans are linked if a word pair containing a polarity tag is present.
(1) The unified grid-tagging scheme uses the tagset {T, P,
Pos,
Neu,
Neg,⌀} to denote the relation of any word pairs in a sentence.
Pos,
Neu,
Neg correspond to positive, neutral, and negative sentiment, respectively, expressed in the opinion triplet of word pair
.
Table 5 shows the meaning of the tags and
Figure 6 shows the result of tagging a sentence in the form of an upper triangular grid.
(2) The decoding stage involves relaxing constraints on the predicted tags in a sentence. Strictly matching target and polar span relations of the word-pairs would suffer from low recall due to the majority of ⌀ tags. First, the predicted tags on the main diagonal are used to recognize target and polar spans as continuous tokens. Polarity {Pos, Neu, Neg} relation tags are assigned to a word-pair if at least one of the words in a multiword span is present in the pair. If for a continuous target-opinon span pair, multiple polarity tags are predicted, the final tag is decided by majority.
The model includes an iterative prediction and inference strategy to capture interactions between mutually indicative information between spans. For instance, if a predicted word contains a target tag, it is less likely that it features in a polar span word-pair, and vice versa. We tested if iterative prediction and inference helped by optimizing the number of turns (0–3) as a hyperparameter in the optimization search. This showed us whether, for our task, polar spans and target/aspect terms are mutually indicative as they are in the explicit ABSA datasets.
The choice of the GTS model was motivated by its state-of-the-art performance in an end-to-end model and its ability to encode one-to-many target-opinion relations, which fits our annotations. The concepts of a sentiment target and aspect are not identical, as aspects are usually predefined into specific categories, which leads to less lexical diversity in the terms. However, the grid-tagging approach remains a good fit for our implicit TBSA task.
GTS allows for any word vector encoding of the input sentence containing the triplet word pairs. The results showed that BERT encoding consistently had better performance than CNN and LSTM encoders, so we limited the tested encoding architectures to pretrained transformers. Because the GTS algorithm is more computationally intensive in word-pair tagging than the previous sequence-based experiments, we only tested BERT, RoBERTa, and FinBERT
encoders, as these obtained the best results in both previous experiments. We applied the same hyperparameter search model selection and holdout test procedure as in previous experiments; however, in line with [
15], we retrained the best hyperparameterized model on the holdin (i.e., dev train + dev evaluation set) and tested on the holdout set five times, and averaged the final holdout score.
4. Discussion
Concerning the coarse-grained experiments, the scores for implicit polarity classification of gold polar expressions (76% accuracy) indicate that assigning implicit polarity is a challenging task but otherwise viable. In the clause-based experiments, acceptable performance (57% macro-F1 and 65% accuracy) was obtained, showing the feasibility of detection of clause-level implicit sentiment.
There are few similar works with which we can compare coarse-grained performance for implicit polarity classification. Compared to similar coarse-grained polarity tasks [
25,
125,
126], our coarse-grained performance is lower with less complex but similar PLM and attention-based models. This indicates increased difficulty in our dataset compared with other coarse-grained sentiment tasks. This is likely due to the more lexically open domain of our corpus: while the domain is limited to company-specific news, it encompasses a large range of topics and thus has larger lexical diversity than the studies mentioned previously. In ensuring representativeness of economic news, many different sectors and both consumer-oriented and more technical reporting were included. Additionally, unlike many other datasets, the polarity labels are also not balanced, with the neutral label being a minority class.
Regarding the fine-grained triplet experiments, the large performance gap of our dataset compared to the explicit sentiment review dataset of Wu et al. [
15] showed that the current state-of-the-art model in explicit sentiment is not sufficient for our SENTiVENT dataset. Explicit ABSA is domain-constrained to one product category (e.g., laptops) with predefined aspect categories. The large difference in performance between the explicit task and implicit economic sentiment task shows that state-of-the-art lexically based methods that have proven successful for fine-grained sentiment analysis on review data will not suffice for implicit sentiment tasks in economic newswire text. The increased difficulty of the SENTiVENT implicit sentiment dataset vs. explicit opinionated, user-generated content lies in the lexical openness of our annotations with less syntactically constrained span annotations (target and polar spans are not limited to certain types of phrases or syntactical boundaries). We see this reflected in the span extraction results, where implicit polar spans are much more difficult to identify than explicit spans or even their target spans (
Table 10). Implicit sentiment is much semantically abstracted and hence less well lexically defined than explicit sentiment.
Nearly all winning hyperparameters for the GTS model did not include the iterative prediction and inference strategy (i.e., ), whereby it captures mutually indicative information between target and polar spans in the explicit task. The lack of improvement indicates that, compared to explicit sentiment, the more lexically open targets and polar spans in our dataset contain less mutually indicative clues. This limits the applicability of unified modeling approaches to this dataset.
Regarding recommendations for further research and downstream applications (such as stock movement prediction or sentiment index aggregation) for our dataset, the inherently ambivalent neutral instances can often be omitted. This would greatly improve performance, as neutral predictions represented the largest number of confused labels and had the lowest performance of all classes. Regarding encoders, RoBERTa is the most promising, being robust across tasks, outperforming other in-domain pretrained encoders. We also observed that further in-domain pretraining and sequential multitask fine-tuning produced performance improvements over the vanilla Bert model. Although we noticed that adding lexicons did not substantially increase scores for implicit sentiment, we recommend using in-domain without general domain lexicons as it produced a small but consistent improvement across coarse-grained task. Sentiment lexicons might also be beneficial in applications where system precision is more important than recall.
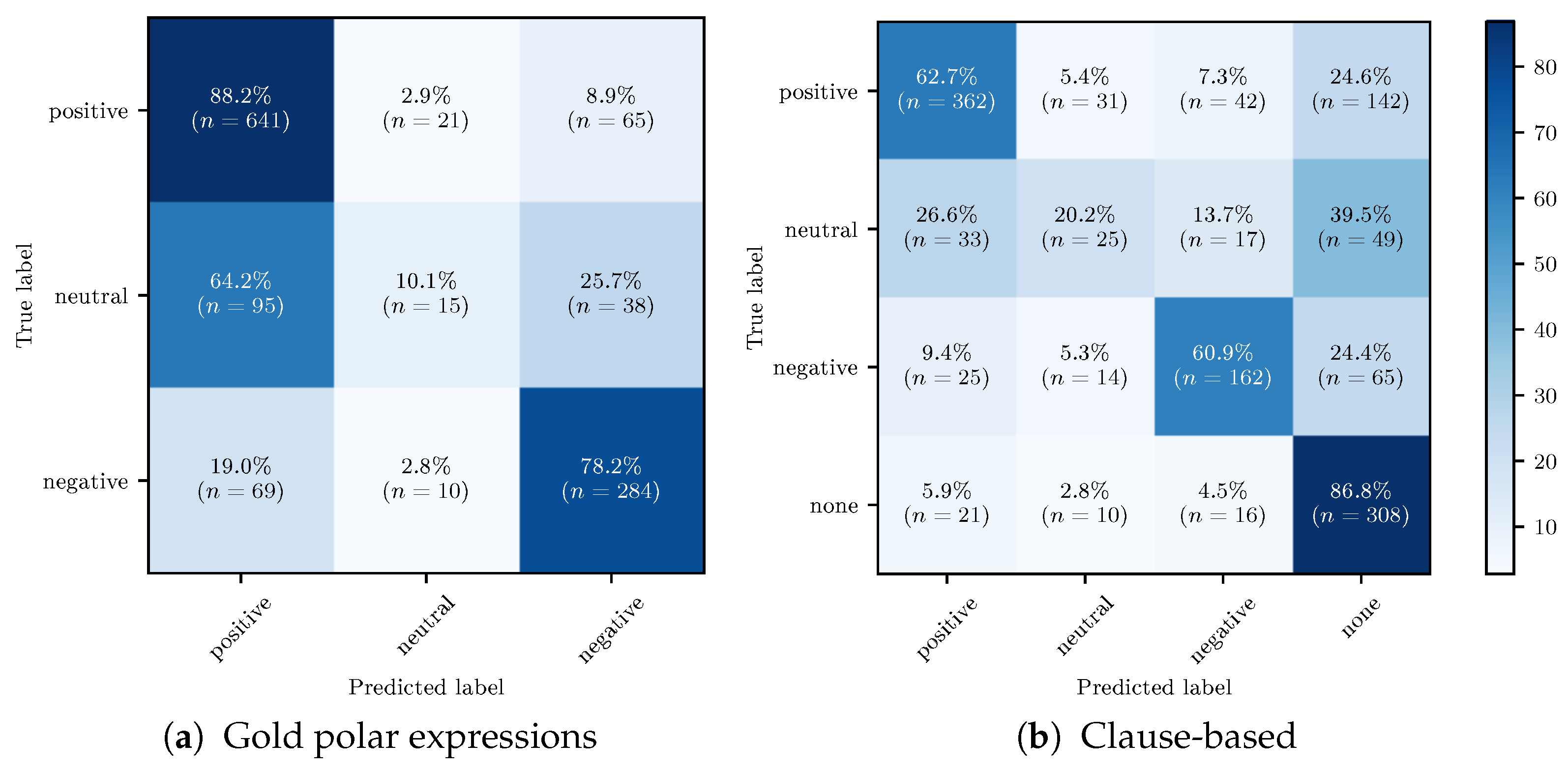
In order to gain further insight into the errors produced by the different systems, we performed a qualitative error analysis on the output of the best model for each coarse-grained task. As current fine-grained performance is too low, an error typology would provide little useful information regarding avenues of improvement. We identified and manually assigned error types to a subset (50% of gold and 41% of clause-based experiments) of classification errors on the test set. In
Table 11, we list different error categories and their frequency for both coarse-grained tasks.
“Unusual language” indicates highly idiomatic, creative language (e.g., sayings and figures of speech, e.g., Examples 1 and 2), or a high density of infrequent lexical items (usually sector-specific jargon, e.g., Example 3). This causes errors due to data scarcity.
“you hear a fair amount of Buck Rogers-sounding futurism” | True: Positive | Pred: None
“Where’s The Tylenol?” | True: negative | Pred: positive
“comes in a high-performance SRT package or a Trackhawk edition with a monstrous Hemi V-8 engine” | True: Positive | Pred: None
“Clues in global context” is another frequent error category, meaning that sentiment must be derived from contexts outside of the input string, in other clauses, or sentences throughout the document, e.g.,
“biosimilars impacting the company’s future growth” | True: Negative | Pred: Positive
→ “impacting” can be both positive and negative, that lexical ambiguity is resolved in the previous sentences where it is made clear that “biosimilars” are competitors.
“Ford CFO Bob Shanks noted that 2018 earnings were likely to be in the range of $1.45–$1.70” | True: Negative | False: Positive. Later in the article, higher expected earnings for that year are discussed and missing earnings predictions is negative; however, our coarse sample does not include this context.
This highlights the need for global context modeling as well deep contextual natural language understanding across the whole document. Example 2 also highlights the need for temporal and numerical reasoning in financial sentiment tasks: economic performance is often inferred from comparing metrics to past performance or to the general market trend. Market trends are not always mentioned in articles and often the author assumes common-ground knowledge. Modeling this would require document-external data sources and modeling of market performance and participants.
“Ignored strong lexical cue” includes instances where a strong lexical indicator of positive or negative sentiment was present. Usually there are several labeled instances containing this lexical cue in the dataset. The model failed to learn the strong sentiment association of this word.
“Amazon’s rally, the market is still underestimating the company” | True: Positive | Pred: Negative
“sees growth accelerating for the full-year” | True: Positive | Pred: None
"Preprocessing" from fine-grained annotations to coarse-grained segments sometimes introduces errors. Often, lexical clues are omitted by addition or omission of positive or negative indicators when splitting clauses, or going from discontinuous to continuous spans (e.g., Example 2). Errors are also caused by the majority voting mechanism in clause-based preprocessing, viz. when multiple polar expressions are present in a clause the, most common polarity is chosen. The majority polarity is not always the most salient (Example 1).
This error category is a weakness of our fine-to-coarse-grained transformation approach.
“Apple’s growth has been lagging the growth of the market, with IHS reporting two percent growth in a similar period” → Positive, Negative, Positive → True: Positive by majority vote | Negative (plausibly correct as the negative sentiment is most salient in this segment).
“organic sales growth projections for this year, based on management’ s comments, suggested | Negative | Positive | from original “organic sales growth projections for this year, based on management’s comments, suggested the momentum seen in the fourth quarter wouldn’t continue at the same pace”
For both tasks, “plausible prediction” is the most frequent error category. A plausible prediction occurs when the predicted label can reasonably be assigned to the instance, viz. these instances could be considered correct. This often co-occurs with all of the above error types when the input text string in isolation can plausibly be assigned the polarity. This happens frequently with neutral vs. positive or negative confusion where there is inherent ambivalence. Our annotators have global context, which can shift commonly connotationally positive and negative events toward neutral events when the context introduces ambivalence, as discussed above. Often this also co-occurs due to a preprocessing error where immediate context clues are removed, which resulted in different polarity, but now are actually correct. For the clause-based experiments, these also include plausibly spurious predictions: clauses where no gold label is present but should be.
“shift toward autonomous cars” | True: Neutral | Pred: Positive
→ Plausible due to inherent ambivalence of neutral.
“Amazon could acquire a larger entity” | True: Neutral | Pred: Positive → Plausibly positive as annotator chose neutral due to modality.
“Roughly a third of the additions last year were revisions to existing reserves” | True: None | Pred: Neutral
→ A plausible spurious prediction where a potential polar event annotation was not annotated.
“he helped fund a Steinhoff capital-raising” | True: Negative | Pred: Pos
→ From a global context, it is explained that Steinhoff was a fraudulent bank; in isolation, being funded is generally positive.
5. Conclusions
In this paper, we presented the SENTiVENT dataset with fine-grained annotations for implicit sentiment in English economic news. Our work focused on two research strands in the domain of natural language processing: implicit sentiment detection and fine-grained sentiment analysis, which both have mainly been researched in the framework of user-generated content with strongly lexicalized opinion. As many of the existing approaches to financial sentiment analysis remain coarse-grained, our work fills the need for a manually labeled implicit and explicit economic dataset, and we think that this rich resource will fuel future research on fine-grained target-based sentiment analysis of full news articles. We validated the annotation scheme with an inter-annotator agreement study, proving the high quality of the annotations.
To assess the feasibility of implicit sentiment detection in economic news, we presented three sets of experiments ranging from gold polar expression polarity classification and clause-based implicit polarity classification to end-to-end extraction of <polar span, target span, polarity> triplets. We found acceptable performance on coarse-grained experiments, demonstrating the feasibility of detecting positive, neutral, and negative implicit sentiment polarity. The fine-grained triplet task, however, remains a challenge even to current unified representation-learning methods. We showed that a state-of-the-art model for fine-grained sentiment triplet extraction, which has proven successful on a benchmark explicit sentiment dataset, is not easily portable to our implicit investor sentiment task. Error analysis showed a large lexical variety within polar expressions typical of implicit sentiment in more objective text genres such as economic news. This implies the need for methodologies that exceed flat lexical inputs to alleviate data scarcity for extracting implicitly polar spans.
Hence, in future work, we plan to experiment with multitask learning approaches [
127,
128] to take advantage of existing similar resources such as FiQA [
83], SentiFM [
88], and FinancialPhrasebank [
80]. Regarding modeling approaches, we plan to include syntax-level [
129,
130] and external sentiment resources by information fusion [
131] because lexical feature learning is currently not sufficient for implicit fine-grained triplet extraction. We will also create a financial sentiment lexicon derived from this dataset as the fine-grained annotations are a better fit for lexicon-learning [
18,
118] than most existing coarse-grained approaches.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}