1. Introduction
Recommender systems are currently being applied in streaming services platforms to help consumers and the media industry with the discovery and delivery of streaming services. The personalized distribution of streaming services requires the analysis of the item listening/watching behavior by the user; however, other user and item information may also be useful. Collaborative filtering methods are widely used for recommendation in this area. They provide recommendations based on the ratings that users give to items [
1].
These techniques yield very good results; however, the difficulty in obtaining explicit feedback in the form of ratings from the users causes the sparsity problem, which occurs when the number of available ratings for the items to be recommended is small. This is the main drawback for the application of this approach in many recommender systems, and in particular in the application domain under study in this work. One way to address this problem is to derive implicit ratings from user behavior, in binary form, based on the existence or not of interaction with the system [
2], such as a purchase, or multivalued [
3], which requires the analysis of other types of behavior, such as frequency of song playback. When obtaining implicit ratings, other factors can also be taken into account. These include the evolution of user preferences over time [
4] and other temporal aspects [
5] or the position of the items in the sessions [
6]. Appreciating user preferences and behavior can assist to propose a reasonable recommendation to a specific user.
Another source of feedback from users used to infer implicit ratings is the text of their reviews about the items. Deep learning techniques are significant for sentiment analysis on social media comments, thoughts, or feedbacks [
7]. Convolutional Neural Networks (CNN), Long Short-Term Memory (LSTM), or hybrid models are widely used for achieving the highest performance on sentiment analysis tasks [
8,
9]. Kastrati et al. also applied deep learning techniques for sentiment analysis on students’ feedback [
10]. Sentiment analysis of these texts is a helpful tool for inferring user preferences and use them in recommender systems. Some examples of this can be found in the work of Dang et al. [
11], in which two hybrid deep learning models were applied to analyze sentiment in reviews. The output was used to improve and validate the recommendations of a recommender system. Kumar et al. [
12] proposed a hybrid recommender system by combining collaborative filtering and content-based filtering with the use of sentiment analysis of movie tweets to boost up the recommender system. The problem of automatically extracting opinions from online users has been a growing research topic recently [
7]. Social media data have been exploited in different ways to address some problems, especially associated with collaborative filtering approaches [
13]. In addition, Rosa et al. [
14] used a sentiment intensity metric to build a music recommender system. Users’ sentiments are extracted from sentences posted on social networks and the recommendations are made using a framework of low complexity that suggests songs based on the current user’s sentiment intensity. The research by Osman et al. [
15] addressed the data-sparsity problem of recommender systems by integrating a sentiment-based analysis. Their work was applied to the Internet Movie Dataset (IMDb) and Movie Lens datasets, but improvements in sentiment analysis have been made since the paper was published. In particular, when only sparse rating data are available, sentiment analysis can play a key role in improving the quality of recommendations. This is because recommendation algorithms mostly rely on users’ ratings to select the items to recommend. Such ratings are usually insufficient and very limited. On the other hand, sentiment-based ratings of items that can be derived from reviews or opinions given through online news services, blogs, social media, or even the recommender systems themselves are seen as being capable of providing better recommendations to users.
In addition, some recommendation approaches leverage item metadata to deal with problems mainly associated with collaborative filtering methods [
16]. Among such data, social tags have become an important input to recommender systems for streaming platforms. Many efforts have been addressed to unify tagging information to reveal behavior and extract the latent semantic relations among items [
17]. In Reference [
18], the authors proposed a method for automatic generation of social tags for music recommendation. The purpose is to avoid the cold-start problem common in such systems, when a user or an item is newly added to the system and as a result has few ratings. Instead of relying on ratings in a music recommendation method [
1,
3], social tags may be used to improve music recommender systems by calculating the similarity between music pieces by combining both tag and rating [
13,
19], in the same way that other item attributes, such as movie genres or music audio features, are used to classify items or establish item similarity [
18,
19]. In Reference [
20], musical genre classification was performed according to spectrum, rhythm, and harmony. Audio features and tags were used in Reference [
21], where a method for recommending appropriate music for videos was presented. Videos and music items were represented as a linear combination of latent factors related to their features. Low-level description of the music was also used in Reference [
22] for emotion recognition and genre classification.
Social tag embedding also was used in a collaborative filtering approach in which user similarities based on both tag embedding and ratings were combined to generate the recommendations in Reference [
13].
Sentiment-based models on reviews and tags have been exploited in recommender systems to overcome the data-sparsity problem that exists in conventional recommender systems. However, either the tags or the reviews are not available in some streaming platforms; thus, they cannot be used together. Some datasets, such as Amazon music, have ratings and reviews without social tags, while datasets from lasf.fm [
23] or MusicBrainz [
24] have tags but no reviews. To overcome this problem, we can resort to the genre attribute, which characterizes the items as tags do, and which is present in most of the datasets. This and other attributes have been commonly used in content-based methods to recommend items similar to those that the user has previously consumed or rated positively. In Reference [
25], genres that the user might prefer to watch on Movie Lens dataset were used to provide the best suggestions possible. Gunawan et al. [
26] presented a work in which genres were predicted by a model of convolutional recurrent neural networks applied for recommendation. In some works, tags were used to predict movie or music genres; thus, depending on the purpose of their use, in some recommender systems where genres are available, these could be used instead of tags. In fact, many social tag values from last.fm or MusicBrainz are really similar to the genres of artists. An example of this is the work of Hong et al. [
27], who proposed a tag-based method to calculate similarities between artists and then classify them into genres with the k-NN algorithm on the laft.fm database.
Our study raises whether integrating sentiment analysis and embedding of item attributes such as genres in recommender systems may significantly enhance the recommendation quality. In this study, we proposed to take advantage of the genre attribute and hybrid deep-learning-based sentiment analysis of reviews to improve collaborative filtering-based recommender systems in the realm of streaming services. The difference with other works in the literature lies in the fact that genre is not used in the context of content-based methods or to obtain similarity between items but to characterize users and thus provide better recommendations. Moreover, this attribute is not used raw as in most recommendation methods but is preprocessed with advanced natural-language-processing techniques. Regarding sentiment analysis, the proposed approach incorporates new specific techniques for feature extraction and hybrid deep learning methods.
The main contribution of our work to the literature lies in the proposal of new hybrid deep learning methods for sentiment analysis and their incorporation into recommender systems based on collaborative filtering, as well as the use of an item attribute, previously preprocessed with NLP techniques, to characterize the users.
The rest of this paper is organized as follows.
Section 2 provides the description of the material and methods used in this study.
Section 3 shows the results given by our proposal and their comparison with the baseline results.
Section 4 outlines the discussion, and
Section 5 offers the main conclusions.
2. Material and Methods
2.1. Collection of Data
Data gathering is the first requirement for any recommendation model. There are two categories of data that are collected: implicit or explicit. Implicit data include customer’s actions via such as order history, return history, page view, etc. Meanwhile, explicit data contain user’s actions online via the internet, including ratings, reviews of movies/songs, etc. In this study, we chose the datasets based on availability and accessibility criteria. Moreover, we took into account that they are widely accepted by the research community. The datasets used in the study to validate our proposal are described below.
Multimodal Album Reviews Dataset (MARD) [
28] contains text and metadata, which are retrieved from Amazon customer-review datasets. The music metadata of this dataset are enriched by MusicBrainz, and the audio description is updated with AcousticBrainz. In total, MARD stores 65,566 albums and 263,525 customer reviews.
Amazon Movie Reviews consists of movie reviews from Amazon [
29]. Each review also includes product and user information, ratings, and plaintext reviews. It covers a period of more than 10 years, as well, including 7,911,684 reviews with 889,176 users and 253,059 products up to October 2012.
The dataset MARD was built by combining two files, mard_metadata.json and mard_reviews.json. From the mard_reviews.json, we collected reviewID, itemID, review, and rating. Then, through itemID, we map to mard_metadata.json to get more information, including genre of the album and artist. Total data has 263,525 samples. Rating values are from 1 to 5.
The second dataset used in our study is named Amazon Movie. This dataset consists of movie reviews from the Amazon Movie Reviews dataset. Reviews include product and user information, ratings, and a plaintext review. For each product in the dataset, we crawled genre information from the Amazon system [
30] and added it to the dataset. We collected a total of 203,967 samples.
Finally, we completed two datasets with users, ratings, reviews, and genres.
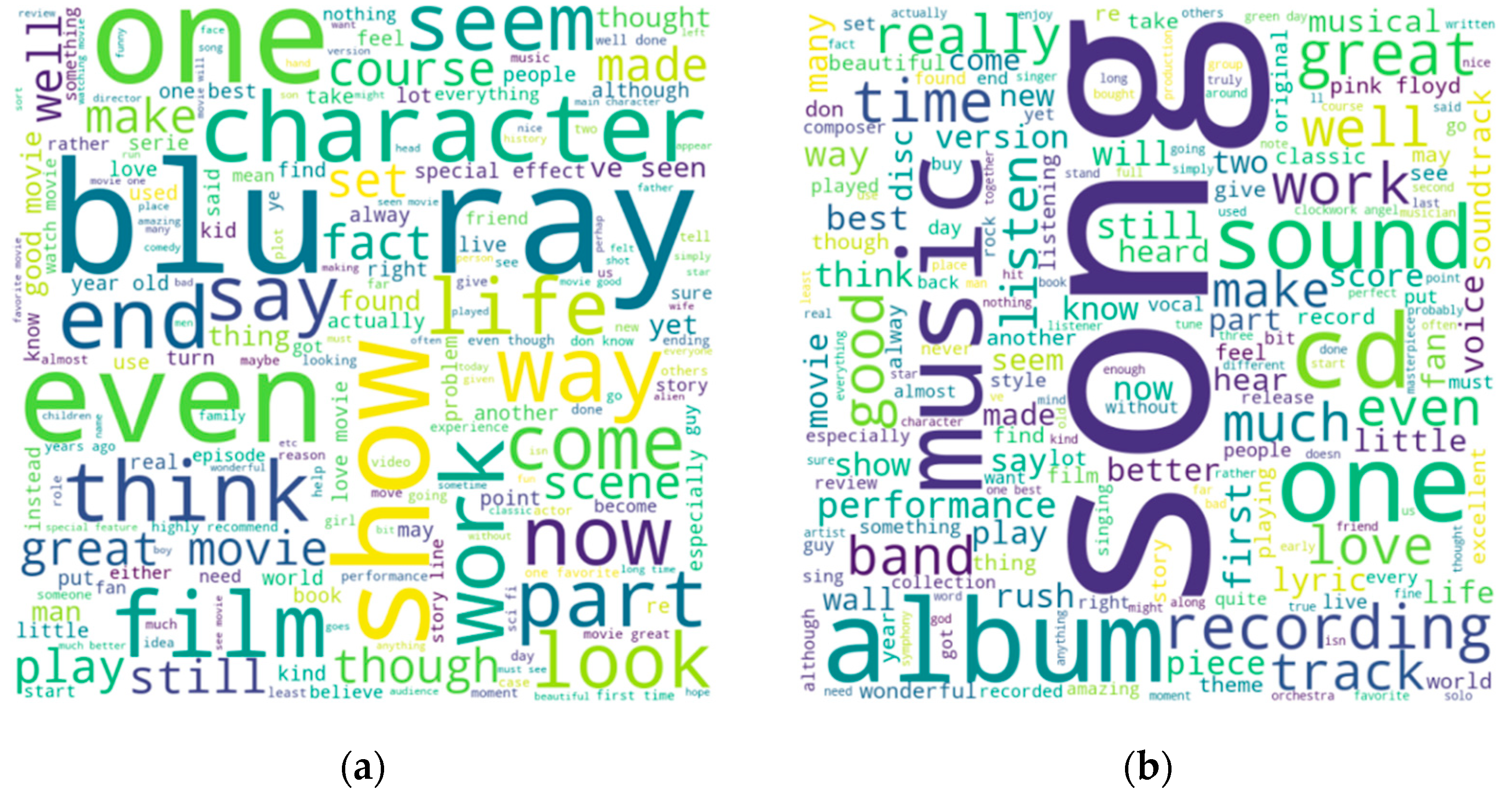
Figure 1 visualizes the word cloud of these datasets, one related to movies and the other related to music.
2.2. Proposed Recommendation Method
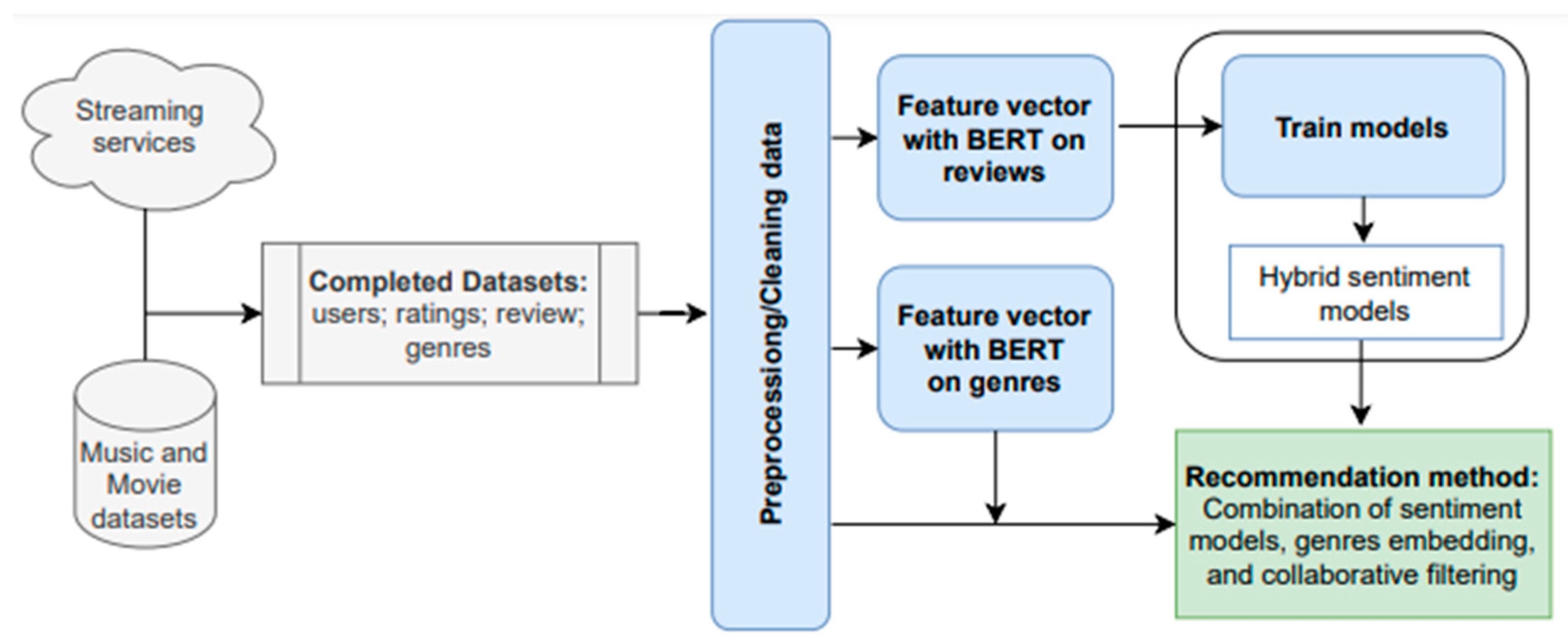
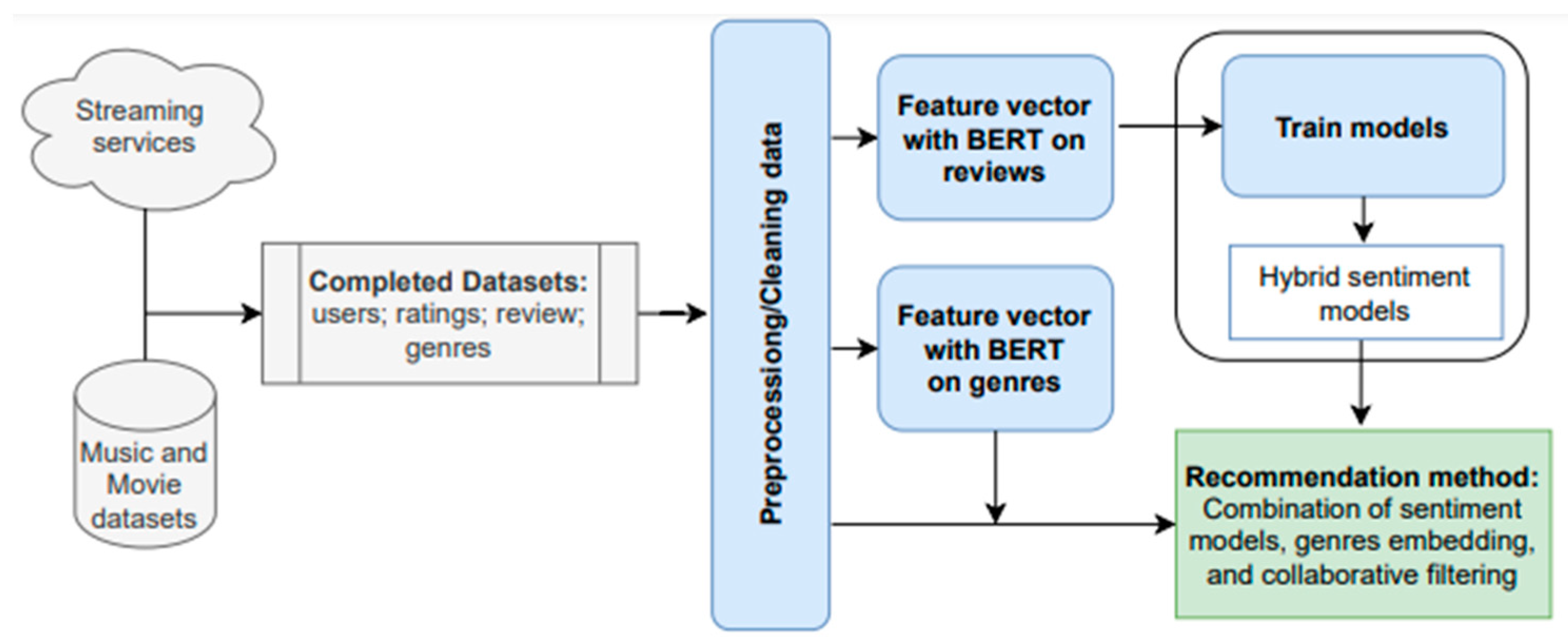
Recommender systems rely on explicit user ratings, but this is not feasible in an increasing number of domains. Moreover, when explicit ratings are available, the trust and reliability of the ratings may limit the recommender system performance. When we have a large number of reviews and the genres on these items, using the last and analyzing the sentiments in the review texts to obtain implicit feedback, in addition to traditional ratings for items, is useful and helps to improve the recommendations to users. In this study, we propose the application of advanced feature extraction techniques and hybrid deep learning methods for sentiment analysis. The advantages of BERT are exploited for both preprocessing genres and feature extraction from reviews as a preliminary step in the deep-learning-based sentiment analysis. The objective is to improve the performance and reliability of recommender systems for streaming platforms.
Figure 2 illustrates the architecture of recommender systems for streaming services based on hybrid deep learning models of sentiment analysis and item genres.
BERT is used to create feature vectors. BERT is a language model for Natural Language Processing (NLP) that was published by researchers at Google AI Language in 2018 [
31]. A pretrained BERT model was used in this study. The reviews and genre data are fed into the BERT model to generate the feature vectors. In the case of genres, the vectors are used to compute the weight of the user similarity, while feature vector obtained from reviews are the input to the hybrid deep learning models that perform the sentiment classification.
The hybrid models can increase sentiment analysis accuracy compared to a single model performance [
9]. Our proposal involves two hybrid deep learning models with variations in using CNN [
32] and LSTM [
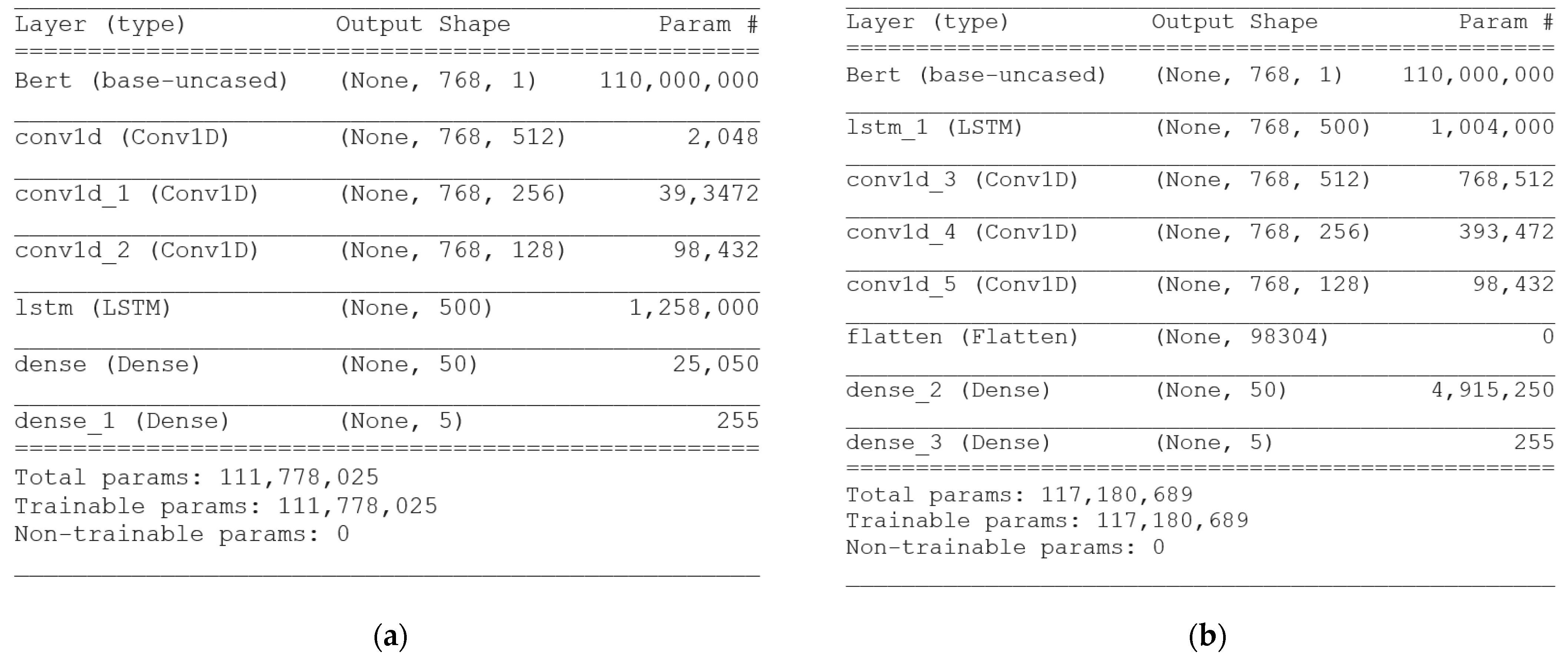
33] networks in the deep learning layers to incorporate the advantages of both and thus fill some shortcomings of individual methods. The combination helped to take advantage of CNN and LSTM: CNN can extract characteristics, and LSTM can store past information at the state nodes. The first hybrid model combines CNN and LSTM, and the second hybrid model combines LSTM and CNN. We labeled the reviews with one value of an ordinal scale of five classes (very negative, negative, neutral, positive, and very positive), analogous to the explicit ratings, to train and validate the result of sentiment analysis. The visualization of these model connections, the connection process, and the data-processing flow are indicated in
Figure 3. These models were printed from the code after we conducted and setup these models. Value “None” means that this dimension is variable. The “None” dimension in our model is always the batch size which does not need be fixed. The function embedding is the embedding layer that is initialized with random weights, and which will learn the embedding for all words in the training dataset. Then, the hybrid models combine two popular deep learning models, namely CNN and LSTM [
7], and take advantage of the two network architectures when performing sentiment analysis. Finally, the output layer has a Relu activation function.
The proposed recommendation method is a user-based collaborative filtering approach that considers explicit ratings, implicit ratings inferred from reviews’ sentiment analysis as well as user similarity derived from user ratings and item genres previously preprocessed with BERT. The objective is to achieve better predictive accuracy than widely used collaborative filtering (CF) methods, such as Singular Value Decomposition (SVD) [
34], Non-Negative Matrix Factorization (NMF) [
35], and SVD++ [
36]. The proposed method can be applied using these or other CF methods as a basis. Results from the CF recommendation method and sentiment analysis and genres are combined to predict ratings and create a list of recommendations.
The procedure requires us to compute the similarity between the active user,
, and his neighbor user,
, which would be obtained by using the cosine metric [
37], as in Equation (1). In our case, the neighbors of user
are users who have rated the same items as user
in a similar way or the score of their reviews on the same items are similar.
User similarities based on ratings given by Equation (1) are weighted by considering similarities between users in terms of the genre of the items they consume (music, movies, etc.). Therefore, the genres of all items rated by user
and
are used to determine the weight of the
. For each item of user
, we got the genres and combined them into a string,
, and converted
to a vector,
. Similarly, for each item user,
, we also got the genres, combined them into a string (
) and converted
to a vector (
). BERT is used to obtain the
and
vectors. Since gender are used to characterize the user, each input to the BERT model consists of the genders of all items rated by a given user,
. The weight of
was determined by the normalized distance between
and
. We used Euclidean distance [
38] to calculate distance between
and his neighbor
.
and the weight
are used in Equation (2) for rating prediction based on user similarity. The ratings of the k most similar users (
are used to estimate the preferences of the active user,
, about the item
that he/she has not rated.
where
is the rating that user
gives to item
respectively;
and
are the average ratings of user
and user
, respectively; and
is the similarity between the active user
and his neighbor user
;
is the weight of
.
Given a rating matrix for training, where is the number of users and is the number of items, denotes the rating of user on item .
These rating predictions are used in the sentiment-based recommendation model whose prediction is denoted by . The procedure begins with the classification of each item review in one of five possible classes by means of the hybrid deep learning models. Each class is associated with one of the sentiment scores from 1 to 5 to be consistent with rating values. Then, for each user , all items rated by user whose sentiment score matches the explicit rating are found. The next step is to find, for each item , all users who already rated item and item in the training set and their review scores also match the explicit ratings.
The two lists of data, including items and users, which are created in the previous steps, are used for predicting user rating on each item that user has not rated. That prediction denoted as is obtained by using Equation (2).
After all, the final prediction
of the rating of user
on item
in the test set is computed as follows:
where
is the rating for user
and item
predicted by Matrix Factorization methods (SVD, SVD++, and NMF), without using sentiments;
is the rating for user
and item
predicted by using the sentiment model; and
parameter used to adjust the importance of each term of the equation.
2.3. Experimental Setup
We performed experiments with two different settings without/with sentiment analysis and genres. In the former, recommendations are based on recommender system methods without sentiment, while in the second, the result of performing sentiment analysis on the reviews and using genre-based user similarity is incorporated into the recommendation process.
The configuration of related parameters, hardware devices, and the necessary library facilities was carried out before performing the experiments, such as echo = 5 and k-fold = 5. In particular, we used Google Colab Pro with GPU Tesla P100-PCIE-16GB or GPU Tesla V100-SXM2-16GB [
39], Keras [
40], Pytorch [
41], and Surprise libraries. We also used the implementation of the SVD, NMF, and SVD++ algorithms provided by the Surprise library [
42].
4. Discussion
The results shown in the previous section show that the proposal presented in this paper outperforms the baselines both in the evaluation of the top n recommendation lists and in the prediction of ratings.
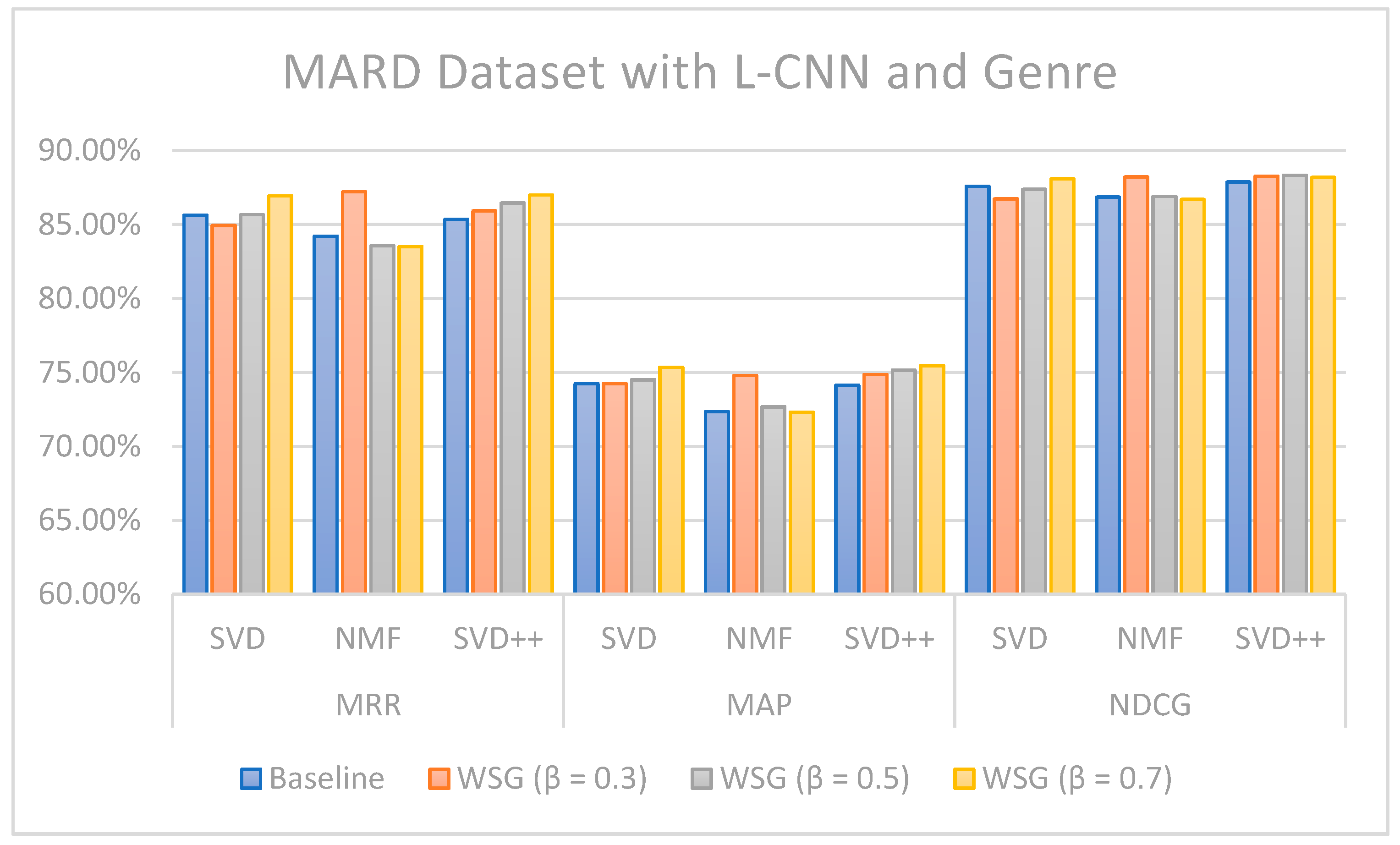
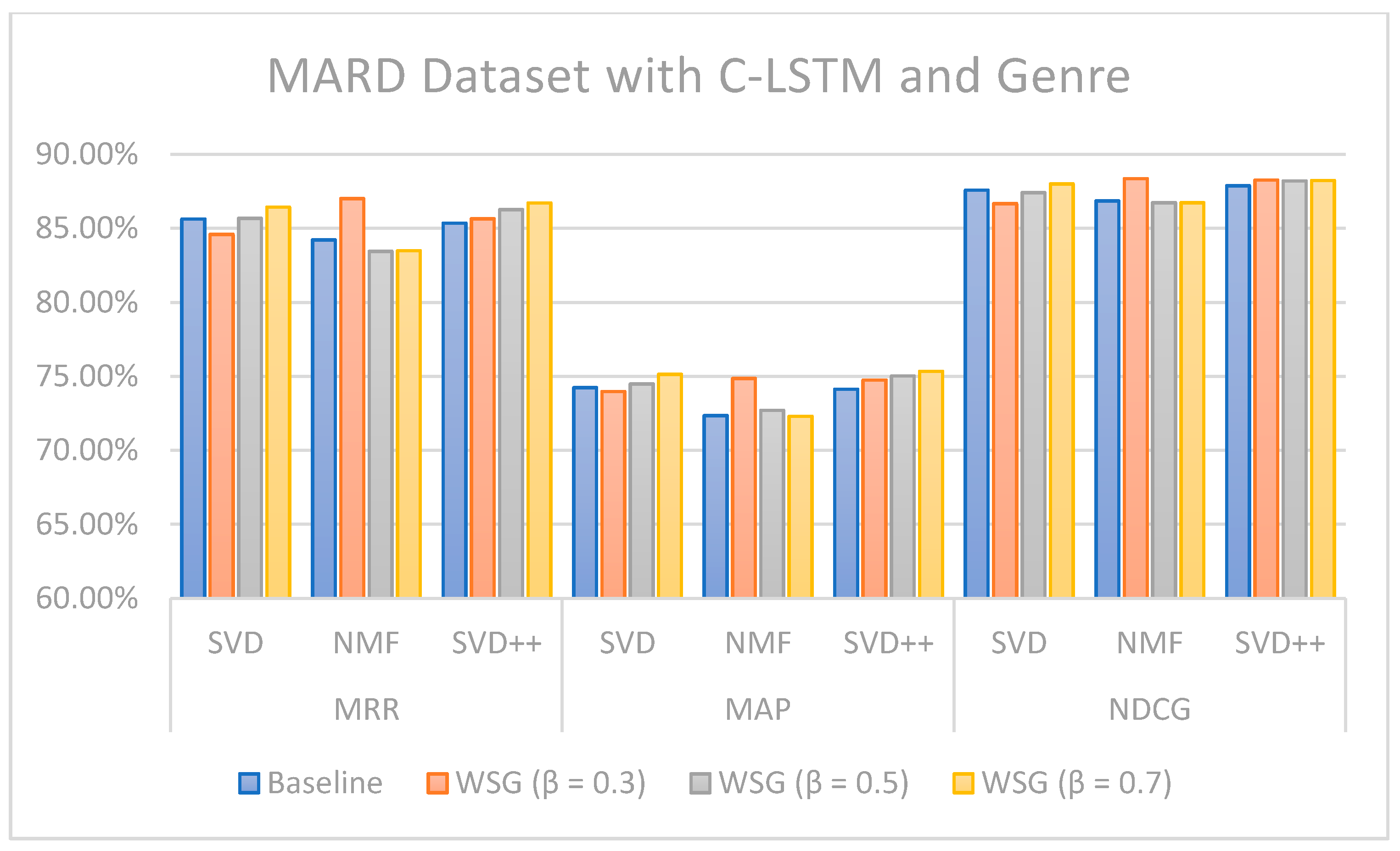
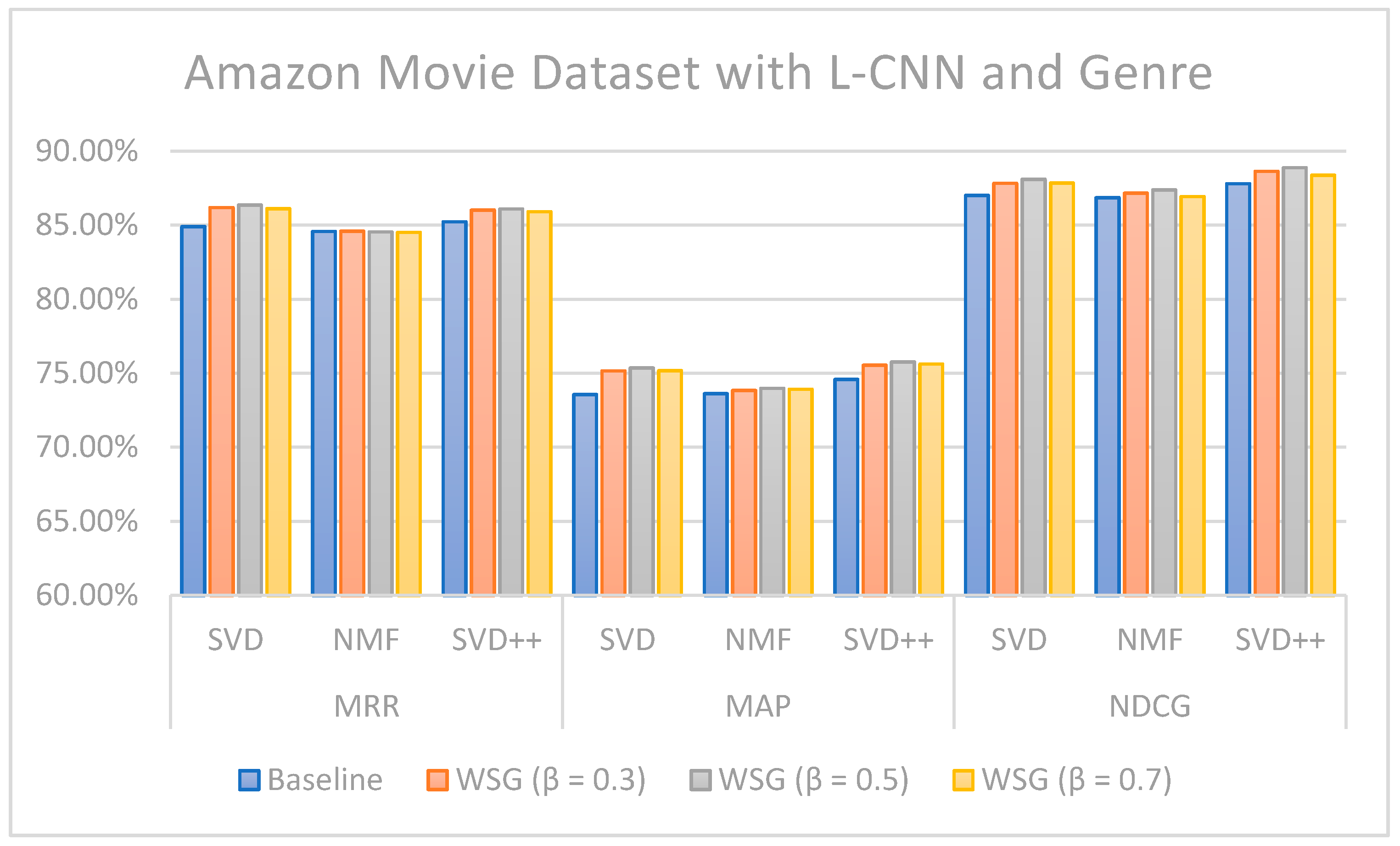
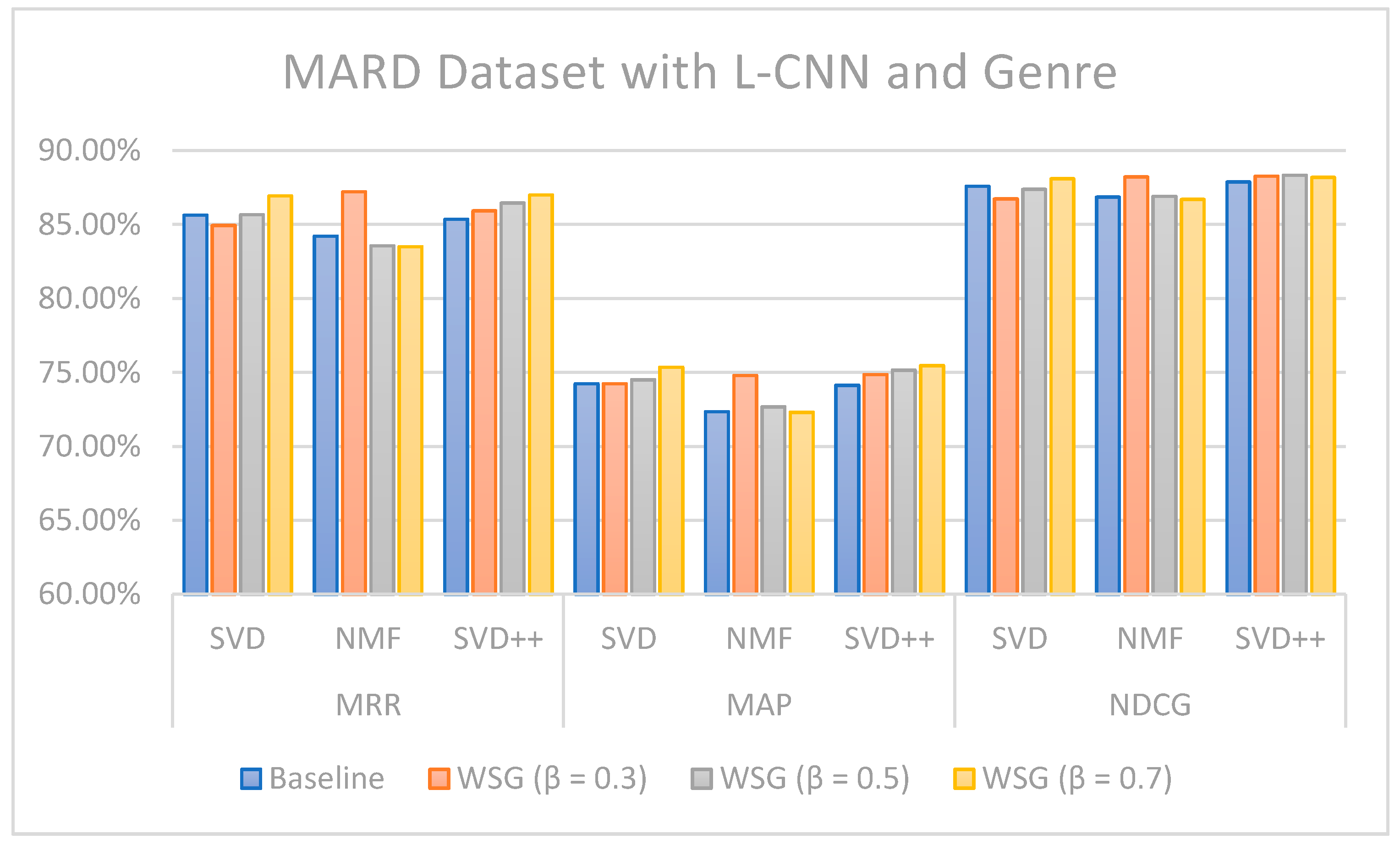
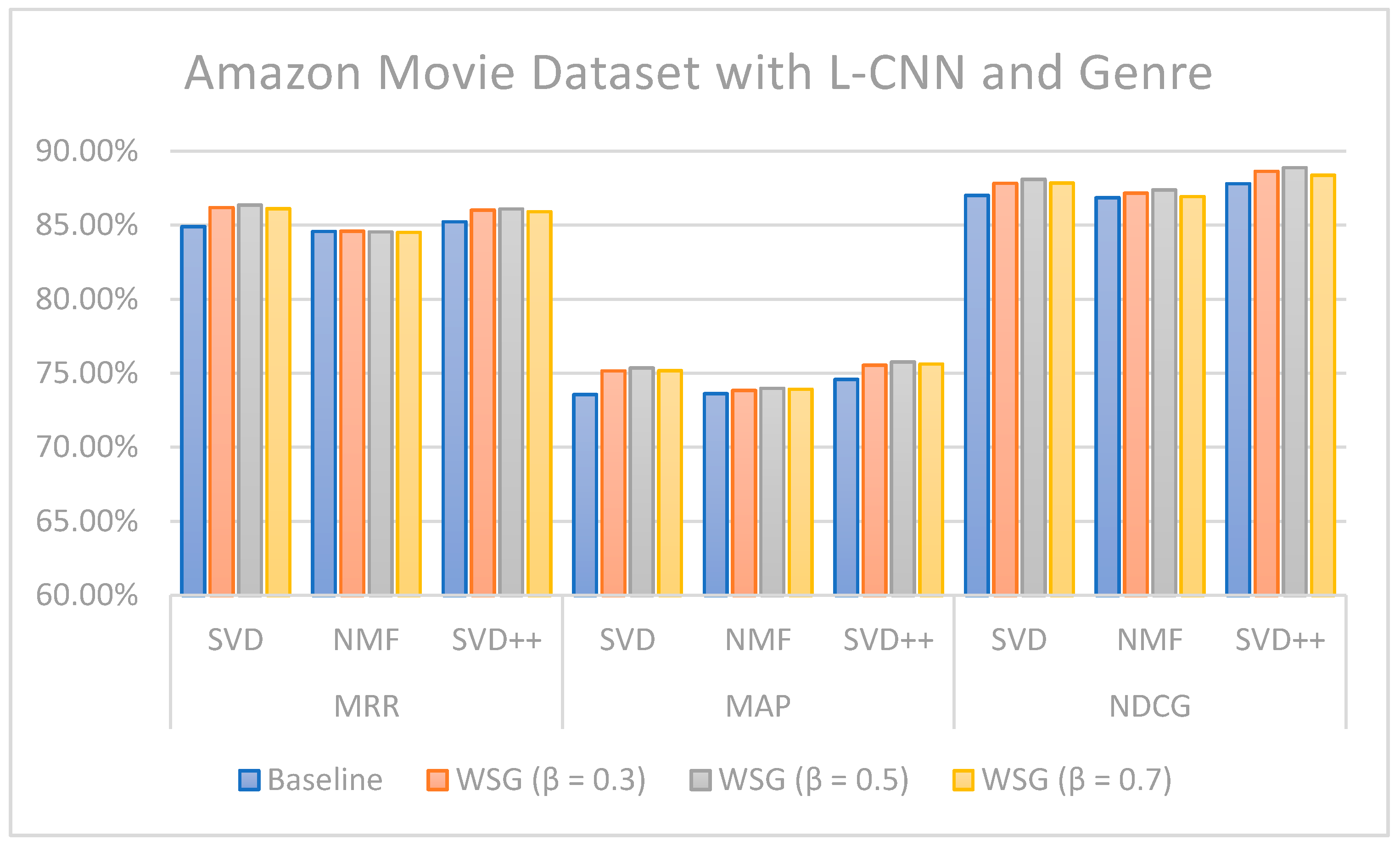
The values of MRR, MAP, and NDCG show that the proposed methods can improve topN recommendations. In the case of the Amazon Movie dataset for the SVD algorithm combined with L-CNN sentiment and genres-based model with different values, the increase was 1.46 (MMR), 1.81 (MAP), and 1.08 (NDCG) percentage points over the models without sentiment analysis and genres. Regarding the MARD dataset with = 0.7 and L-CNN sentiment and genres-based model with SVD++ algorithms, the increase was 1.64 (MMR), 1.35 (MAP), and 0.31 (NDCG) percentage points over the approaches without sentiment and genre. If we consider all the results as a whole, we can conclude that, in general, the combination of the SVD++ method with the proposed model based on sentiment and genre is the one that provides the highest values of the three metrics: MMR, MAP and NDCG.
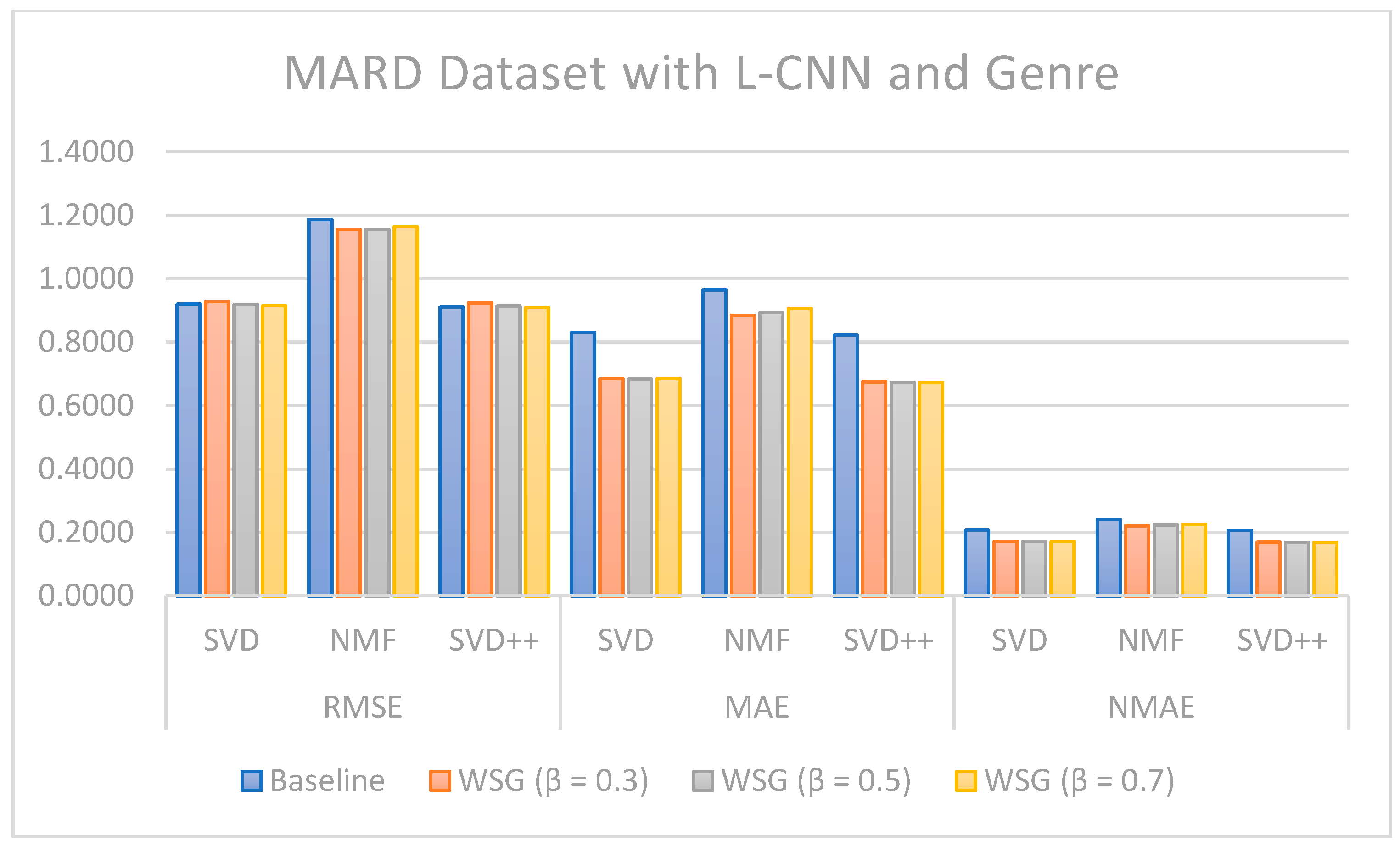
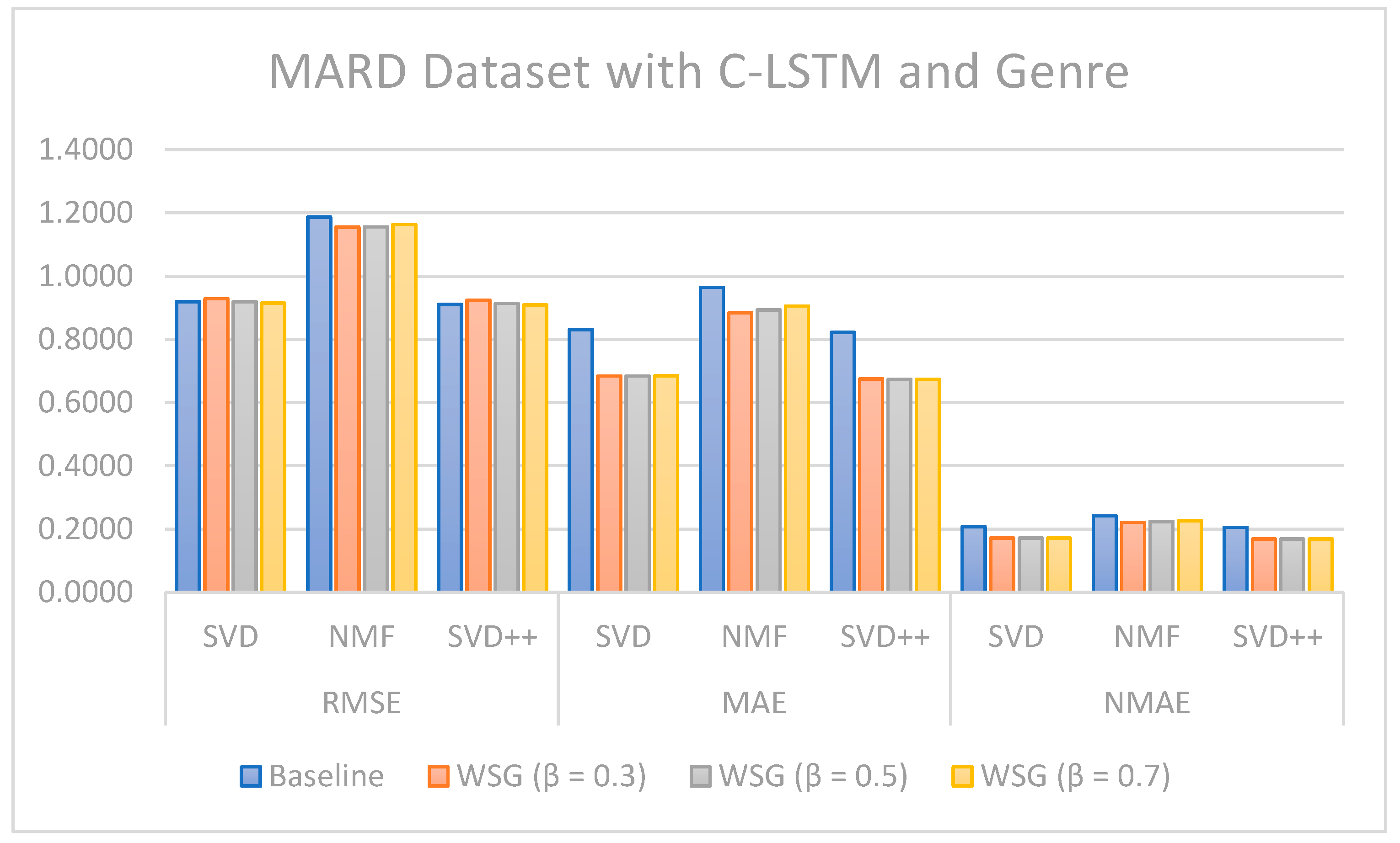
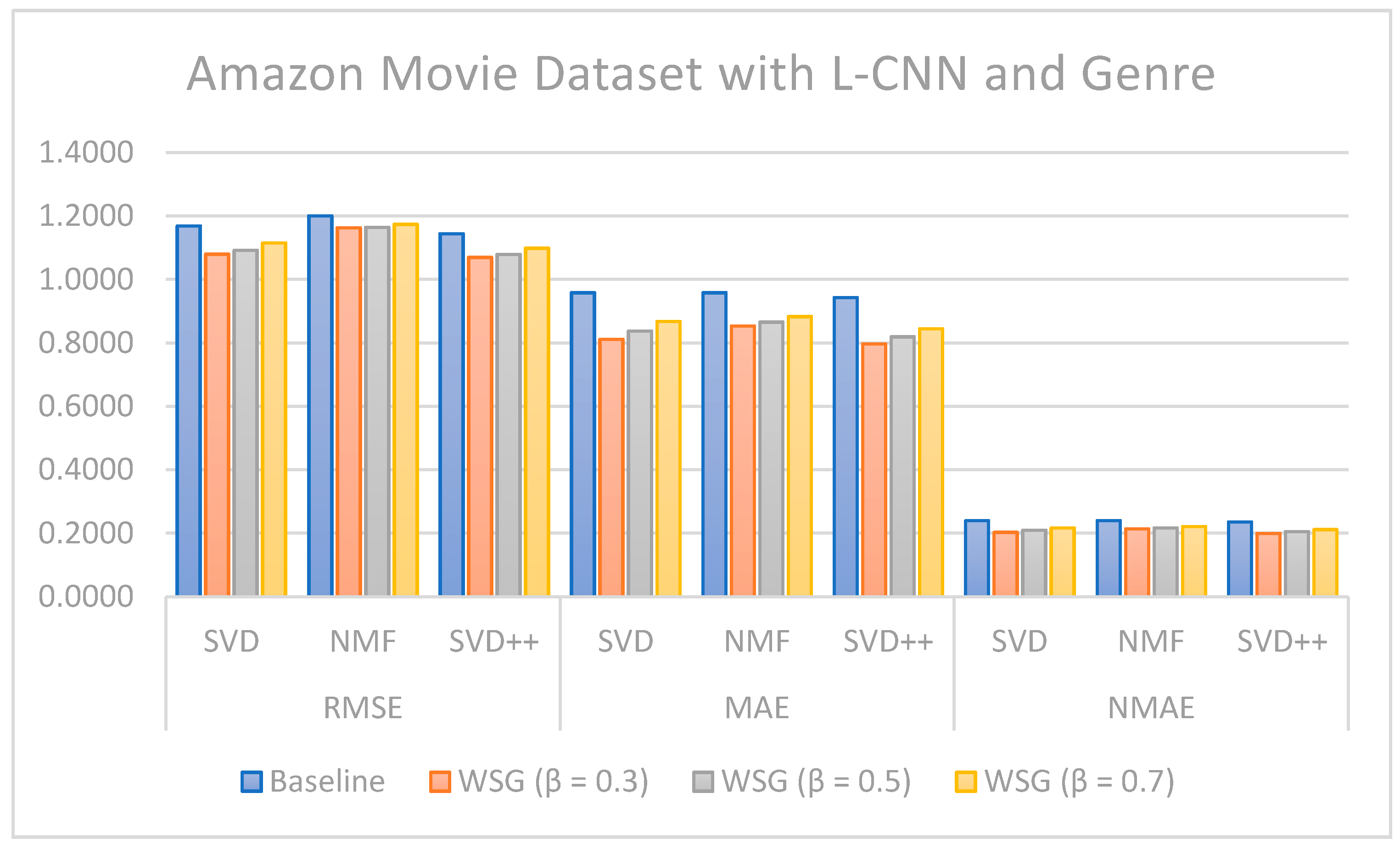
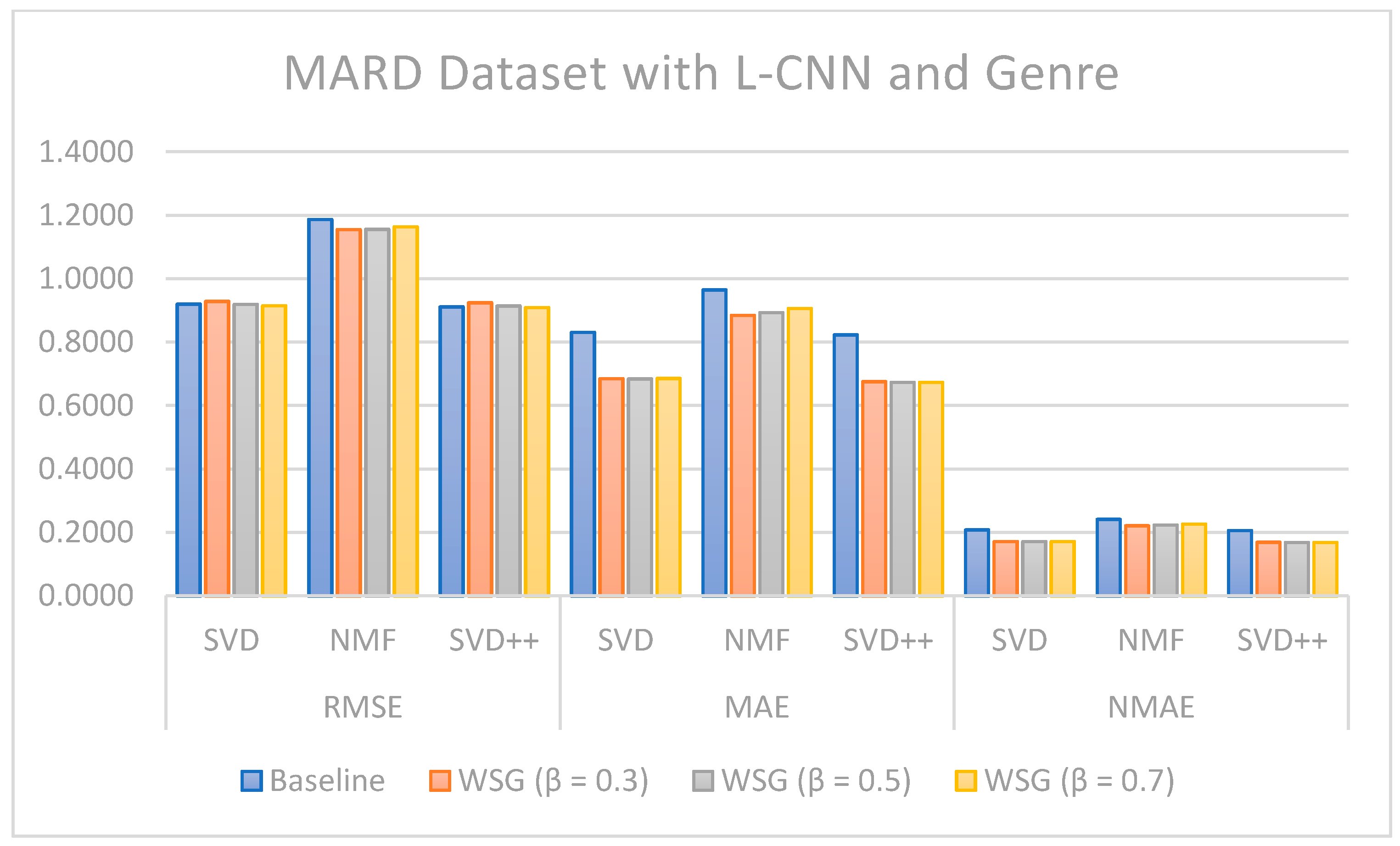
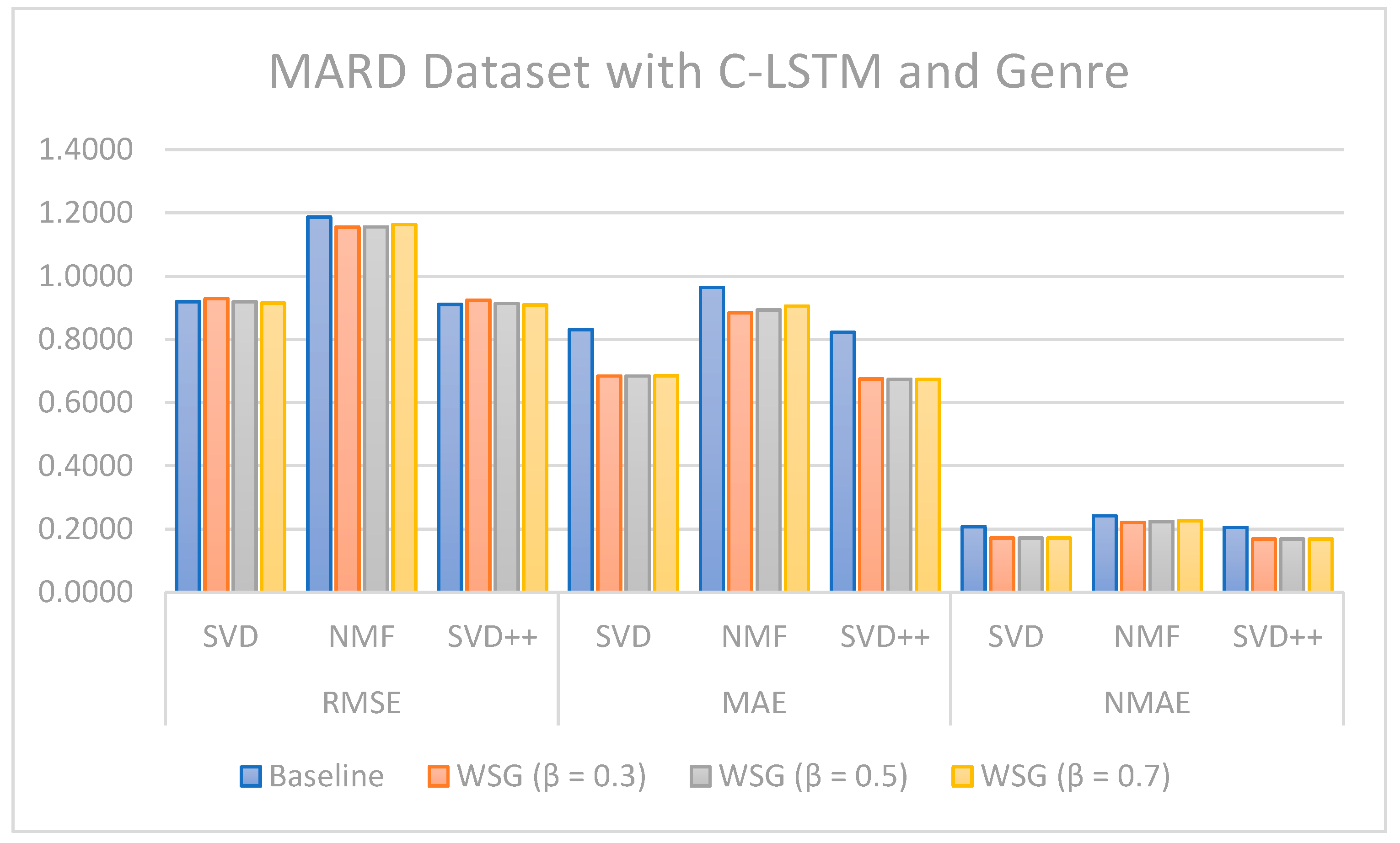
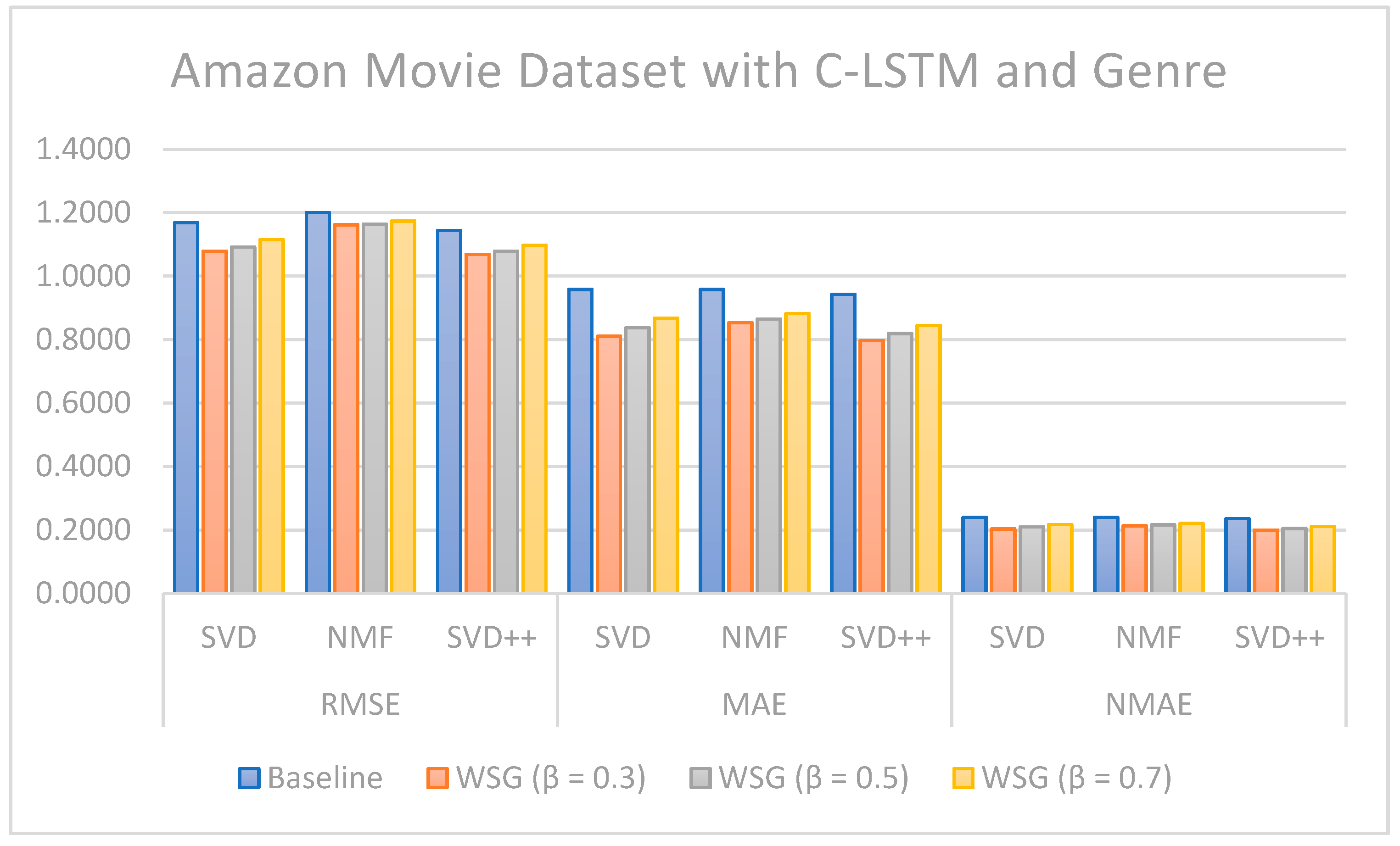
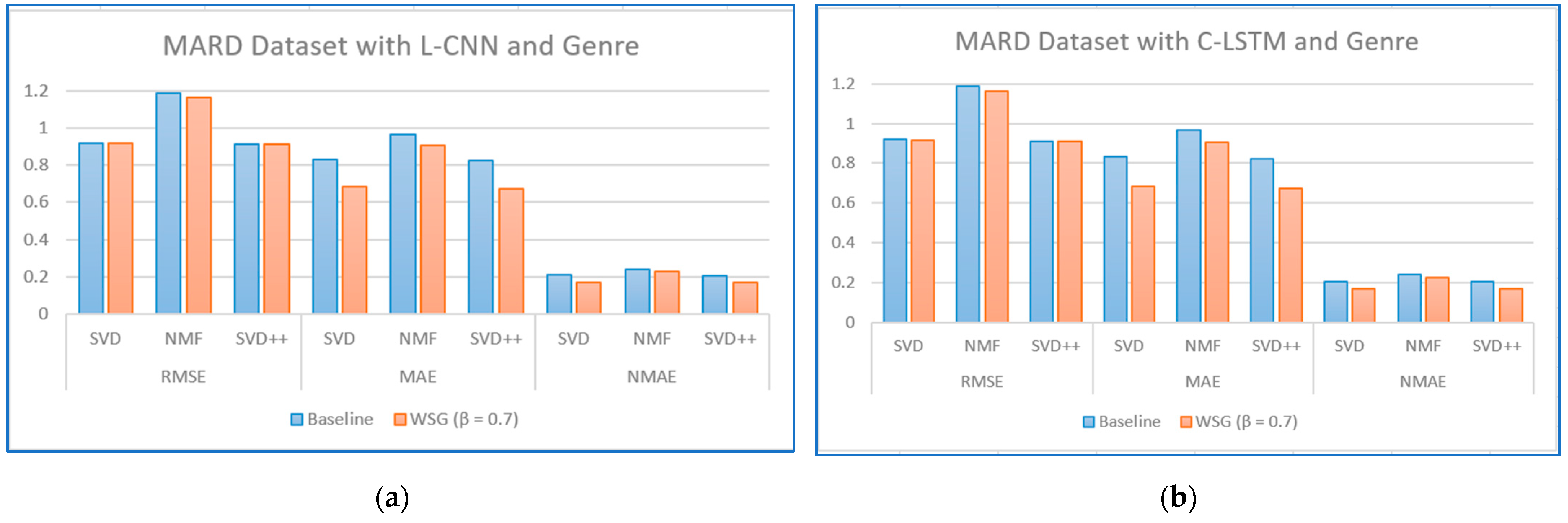
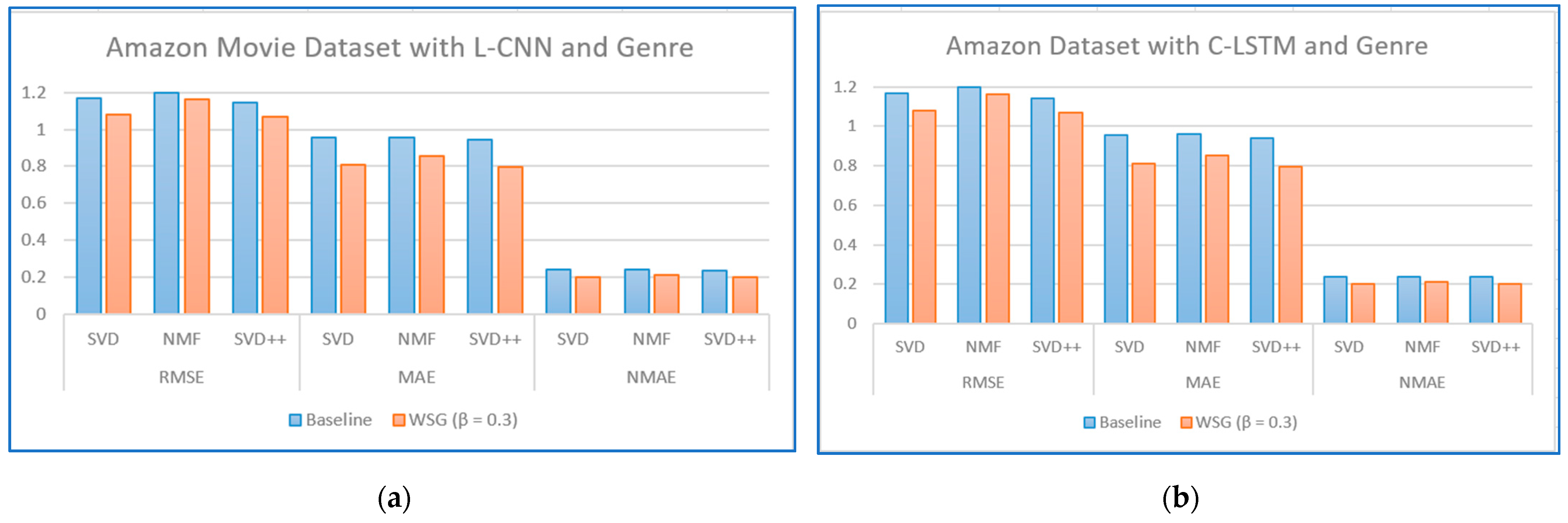
Regarding the evaluation of rating prediction, the results in
Table 5,
Table 6,
Table 7 and
Table 8 show that RSME, MAE, and NMAE given by the approach that combines CF with sentiment analysis and genres are better than the error rates given by traditional CF methods without sentiment and genre on all algorithms. We found that the best results of the proposal are obtained with
= 0.7 on the MARD dataset and with
= 0.3 on the Amazon Movie database.
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12 and
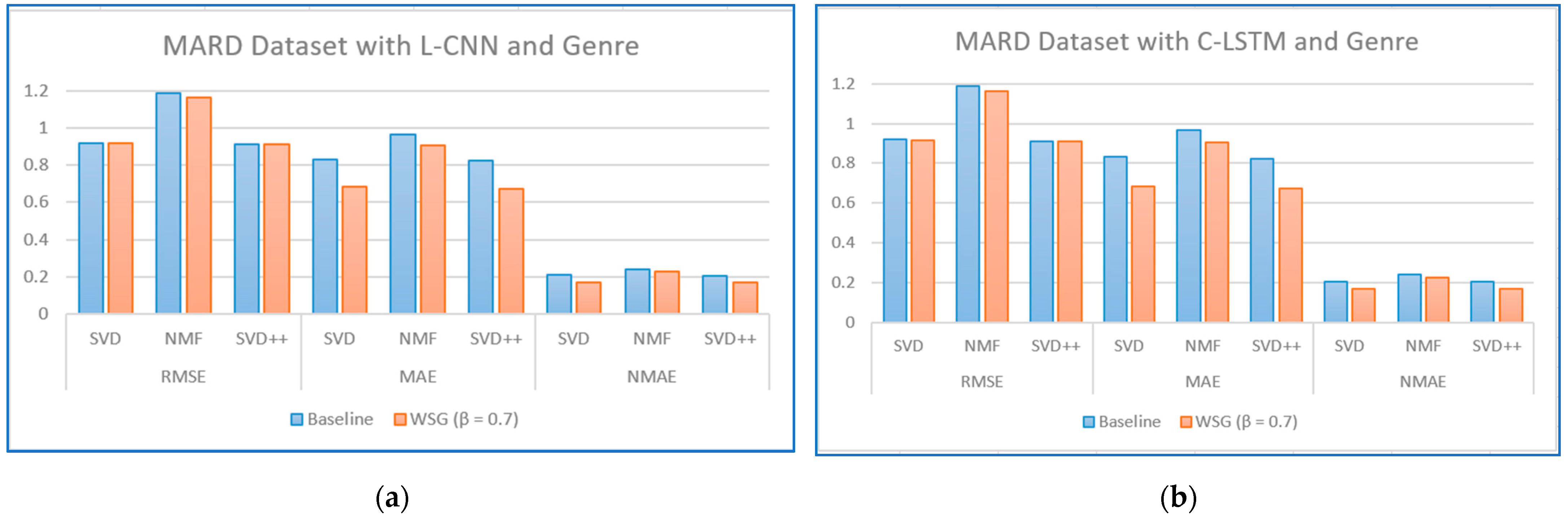
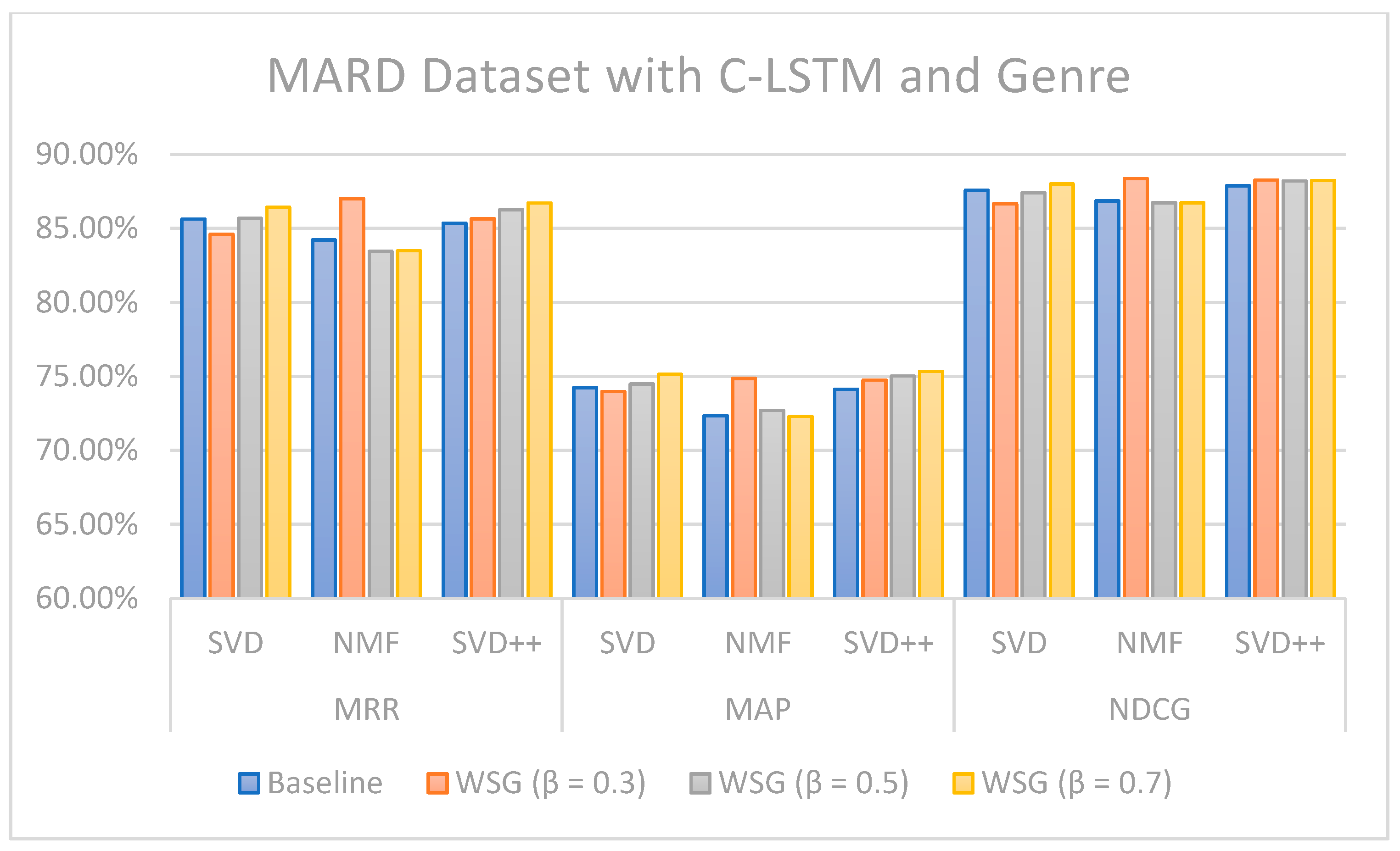
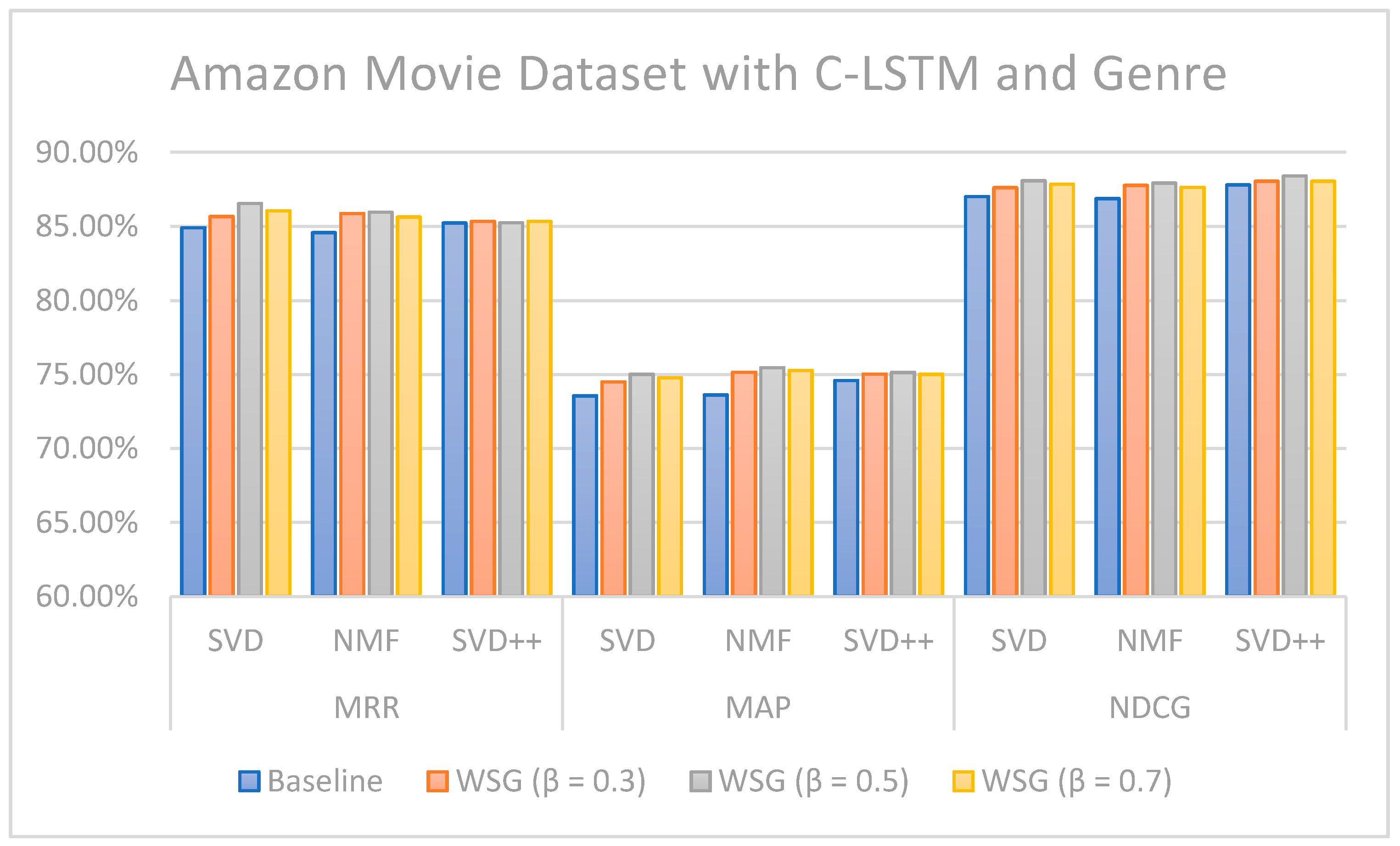
Figure 13 illustrate the comparison of the sentiment-based methods and genres with the L-CNN and C-LCTM with non-sentiment-based and genre methods with MARD and Amazon Movie datasets. We found that C-LSTM and L-CNN provide similar results. In addition, the sentiment-based and genre approach provides better results on Amazon Movie dataset.
Three algorithms (SVD, NMF, and SVD++) were tested in two ways, with explicit ratings only, and combining explicit ratings with sentiment extracted from reviews and genre embedding. As we mentioned, the genres attribute is preprocessed with advanced natural language processing techniques. Thus, our method is generalized to future data, such as other attributes of items, especially social tags, or other data generated by users. In most cases, the combined approach where two sentiment classification models (C-LSTM and L-CNN) are applied on music and movie review datasets gave better results than baselines tested. However, the improvement for top n recommendation is not as significant as that achieved for the rating prediction.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}