Development of Decision Support Software for Deep Learning-Based Automated Retinal Disease Screening Using Relatively Limited Fundus Photograph Data

 , ,
, ,
Abstract
1. Introduction
2. Methods
- (1)
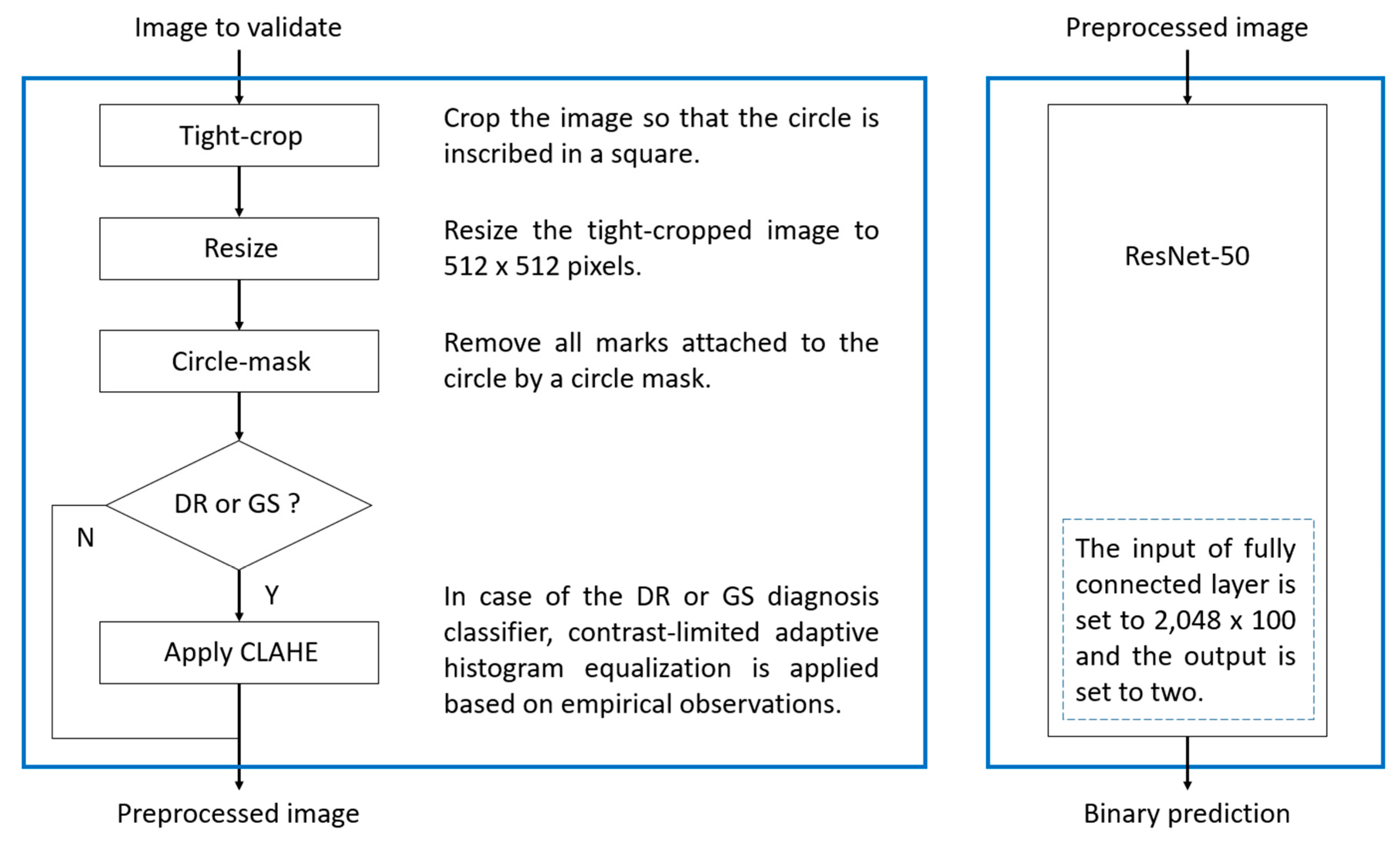
- Considering the relatively limited size of the training dataset, we intended to train each diagnosis detector in a way fully specific to each diagnosis without limitation by constructing individual pipelines, which includes a preprocessing unit, the low-level to high-level feature extractor, and the classification head. For instance, it is empirically observed that diabetic retinopathy and glaucoma suspect are better detected after applying preprocessing such as contrast-limited adaptive histogram equalization (CLAHE) [10]. The parallelism can be the best architecture that reflects this diversified situation with ease and flexibility.
- (2)
- In a real clinical environment, the fundus photo that our model reviews can have multiple diagnoses and not necessarily a single diagnosis. In our second validation dataset, for example, the portion of multiples is up to 8.66%. In this condition that the number of diagnoses varies, it is very hard to make an appropriate prediction using a single multi-class detector because the commonly used softmax score is best fit for top-1 prediction and can cause ambiguity for top-k prediction. We might manage to design a multi-class cutoff threshold system without knowing the number of diagnosis in the photo, but the resulting threshold system must be very complex or confusing. Therefore, this can lead to even less accuracy, as well as ambiguity; thus, it may not be a good architecture. When we conducted training of a single multi-class detector to test feasibility, the average sensitivity was only 79.0% for top-1 prediction and 86.3% for top-2 predictions even though one false positive was allowed. This result supports our idea that multiple one-versus-rest classifiers work properly and can achieve better accuracy for prediction.
2.1. Disease Definition
2.1.1. Age-Related Macular Degeneration
2.1.2. Diabetic Retinopathy
2.1.3. Epiretinal Membrane
2.1.4. Retinal Vein Occlusion
2.1.5. Suspected Glaucoma
2.1.6. Multiple Diagnoses
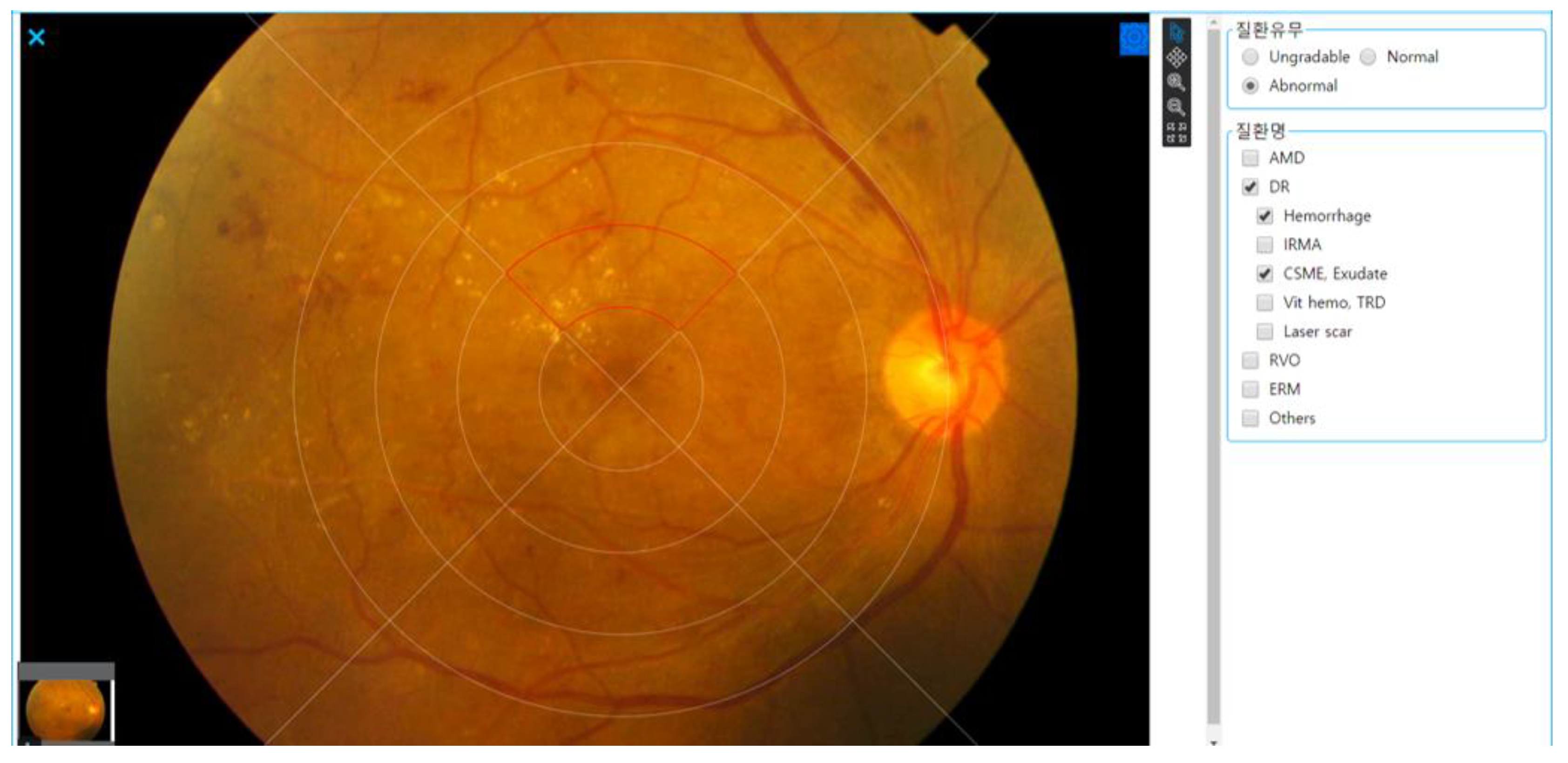
2.2. Grading and Annotation Process
2.3. Algorithm Development
2.4. Evaluation Metric and Statistical Analysis
3. Results
3.1. Overall Outcome: The Macro-Average Performance of the Five OVR Classifiers
3.2. Individual Outcome: The Performance of the OVR Classifier for Each Specific Disease
3.3. Additional Analysis: Algorithm Performance for Multiple Diagnosis Photographs or Diseases that Were Not Included in the Training Dataset
3.4. External Evaluation: Fundus Photographs from Youngnam University Hospital
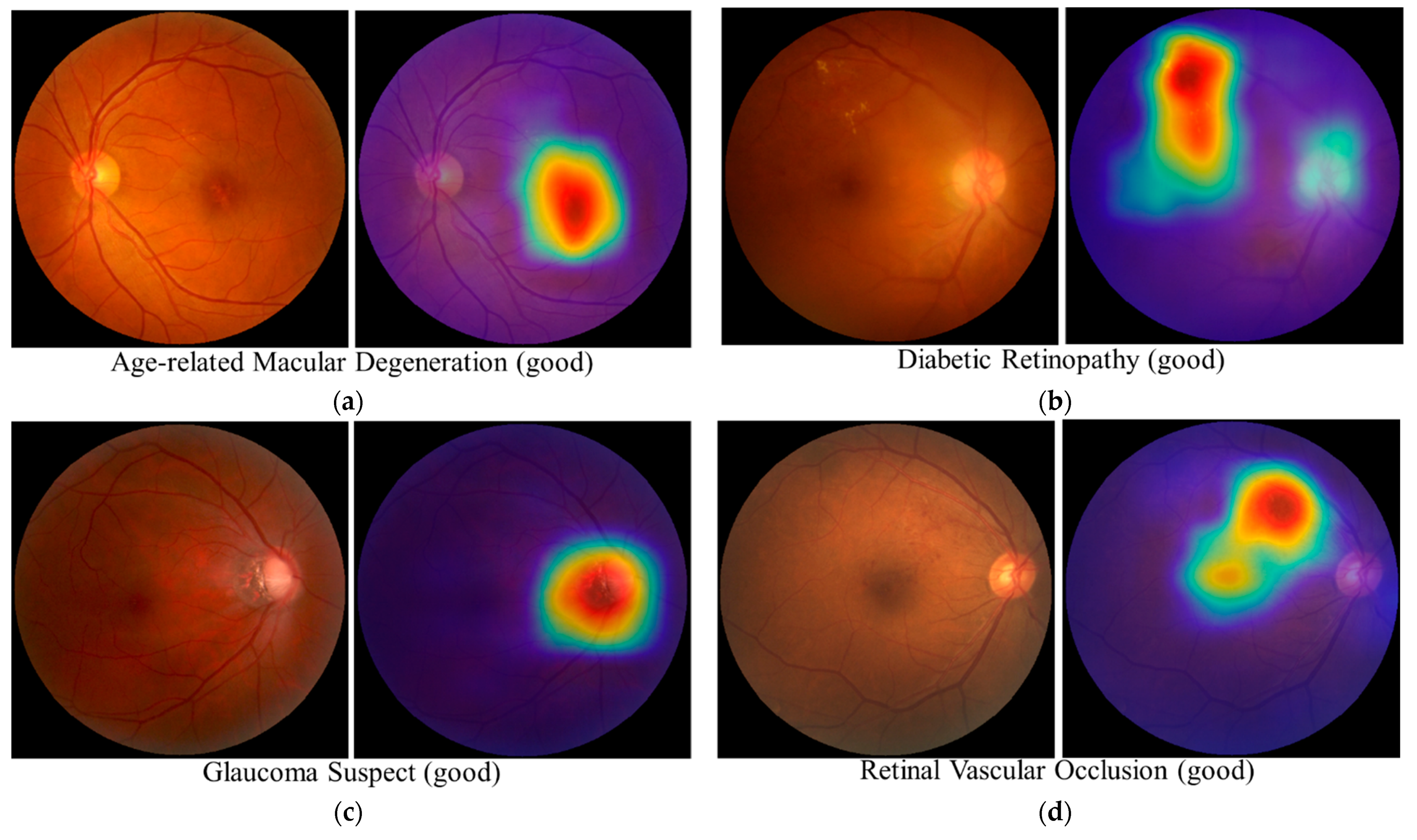
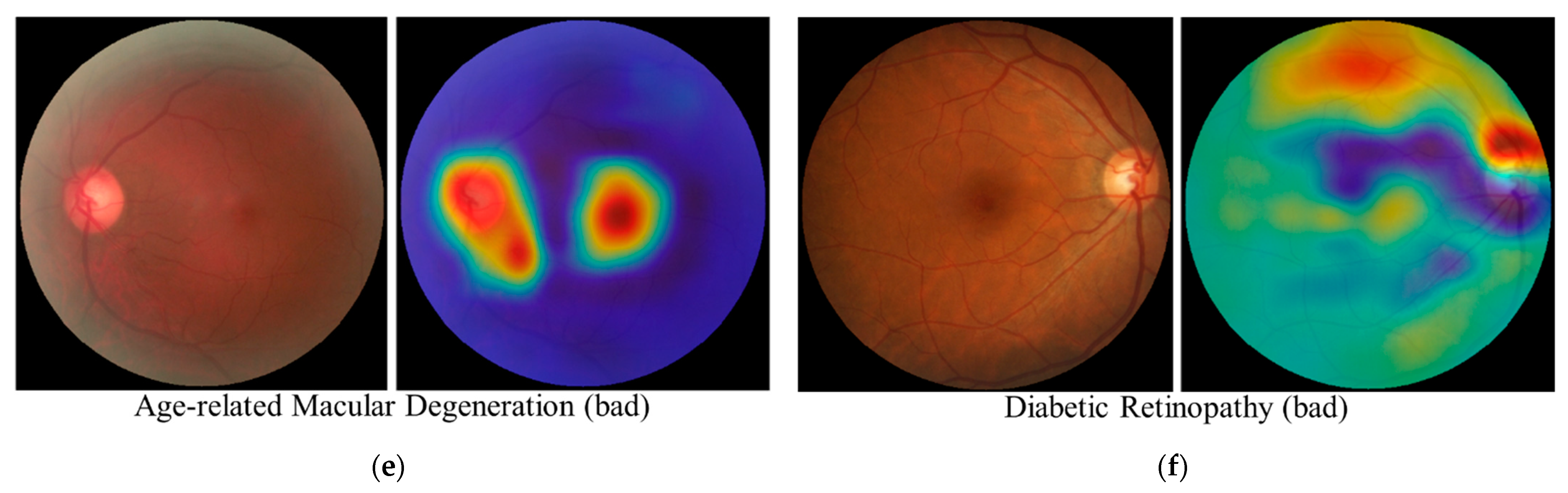
3.5. Interpretability Considerations
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abramoff, M.D.; Lou, Y.; Erginay, A.; Clarida, W.; Amelon, R.; Folk, J.C.; Niemeijer, M. Improved Automated Detection of Diabetic Retinopathy on a Publicly Available Dataset through Integration of Deep Learning. Investig. Opthalmology Vis. Sci. 2016, 57, 5200–5206. [Google Scholar] [CrossRef] [PubMed]
- Gargeya, R.; Leng, T. Automated Identification of Diabetic Retinopathy Using Deep Learning. Ophthalmology 2017, 124, 962–969. [Google Scholar] [CrossRef] [PubMed]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Ting, D.S.W.; Cheung, C.Y.-L.; Lim, G.; Tan, G.S.W.; Quang, N.D.; Gan, A.; Hamzah, H.; Garcia-Franco, R.; Yeo, I.Y.S.; Lee, S.Y.; et al. Development and Validation of a Deep Learning System for Diabetic Retinopathy and Related Eye Diseases Using Retinal Images from Multiethnic Populations with Diabetes. JAMA 2017, 318, 2211–2223. [Google Scholar] [CrossRef] [PubMed]
- Choi, J.Y.; Yoo, T.K.; Seo, J.G.; Kwak, J.; Um, T.T.; Rim, T.H. Multi-categorical deep learning neural network to classify retinal images: A pilot study employing small database. PLoS ONE 2017, 12, e0187336. [Google Scholar] [CrossRef] [PubMed]
- Park, S.J.; Shin, J.Y.; Kim, S.; Son, J.; Jung, K.-H.; Park, K.H. A Novel Fundus Image Reading Tool for Efficient Generation of a Multi-dimensional Categorical Image Database for Machine Learning Algorithm Training. J. Korean Med. Sci. 2018, 33, 239. [Google Scholar] [CrossRef] [PubMed]
- Burlina, P.M.; Joshi, N.; Pacheco, K.D.; Freund, D.E.; Kong, J.; Bressler, N.M. Use of Deep Learning for Detailed Severity Characterization and Estimation of 5-Year Risk among Patients with Age-Related Macular Degeneration. JAMA Ophthalmol. 2018, 136, 1359–1366. [Google Scholar] [CrossRef] [PubMed]
- Poplin, R.; Varadarajan, A.V.; Blumer, K.; Liu, Y.; McConnell, M.V.; Corrado, G.S.; Peng, L.; Webster, D.R. Prediction of cardiovascular risk factors from retinal fundus photographs via deep learning. Nat. Biomed. Eng. 2018, 2, 158–164. [Google Scholar] [CrossRef] [PubMed]
- Seong, S.C.; Kim, Y.-Y.; Park, S.K.; Khang, Y.H.; Kim, H.C.; Park, J.H.; Kang, H.-J.; Do, C.-H.; Song, J.-S.; Lee, E.-J.; et al. Cohort profile: The National Health Insurance Service-National Health Screening Cohort (NHIS-HEALS) in Korea. BMJ Open 2017, 7. [Google Scholar] [CrossRef] [PubMed]
- Setiawan, A.W.; Mengko, T.R.; Santoso, O.S.; Suksmono, A.B. Color retinal image enhancement using CLAHE. In Proceedings of the International Conference on ICT for Smart Society (ICISS), Jakarta, Indonesia, 13–14 June 2013. [Google Scholar] [CrossRef]
- Youm, D.J.; Oh, H.-S.; Yu, H.G.; Song, S.J. The Prevalence of Vitreoretinal Diseases in a Screened Korean Population 50 Years and Older. J. Korean Ophthalmol. Soc. 2009, 50, 1645–1651. [Google Scholar] [CrossRef]
- Bird, A.C.; Bressler, N.M.; Bressler, S.B.; Chisholm, I.H.; Coscas, G.; Davis, M.D.; de Jong, P.T.; Klaver, C.C.W.; Klein, B.; Klein, R.; et al. An international classification and grading system for age-related maculopathy and age-related macular degeneration: The International ARM Epidemiological Study Group. Surv. Ophthalmol. 1995, 39, 367–374. [Google Scholar] [CrossRef]
- Early Treatment Diabetic Retinopathy Study Research Group. Grading Diabetic Retinopathy from Stereoscopic Color Fundus Photographs—An Extension of the Modified Airlie House Classification. Ophthalmology 1991, 98 (Suppl. 5), 786–806. [Google Scholar] [CrossRef]
- Kim, K.E.; Kim, M.J.; Park, K.H.; Jeoung, J.W.; Kim, S.H.; Kim, C.Y.; Kang, S.W. Prevalence, awareness, and risk factors of primary open-angle glaucoma: Korea National Health and Nutrition Examination Survey 2008–2011. Ophthalmology 2016, 123, 532–541. [Google Scholar] [CrossRef] [PubMed]
- Kim, C.S.; Seong, G.J.; Lee, N.H.; Song, K.C.; Society, K.G.; Namil Study Group. Prevalence of primary open-angle glaucoma in central South Korea the Namil study. Ophthalmology 2011, 118, 1024–1030. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition Recognition (CVPR 2016), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2014, arXiv:1312.6229. [Google Scholar]
- Vapnik, V.N. Statistical Learning Theory; Wiley: New York, NY, USA, 1998; pp. 416–417. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual network. In Proceedings of the 27th British Machine Vision Conference, York, UK, 19–22 September 2016. [Google Scholar] [CrossRef]
- Ro, Y.; Choi, J.; Jo, D.U.; Heo, B.; Lim, J.; Choi, J.Y. Backbone can not be trained at once: Rolling back to pre-trained network for person re-identification. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence (AAAI-19), Honolulu, HW, USA, 27 January–1 February 2019. [Google Scholar] [CrossRef]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum classifier discrepancy for unsupervised domain adaptation. In Proceedings of the 2018 Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep Networks via gradient-based localization. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Quellec, G.; Lee, K.; Dolejsi, M.; Garvin, M.K.; Abramoff, M.D.; Sonka, M. Three-dimensional analysis of retinal layer texture: Identification of fluid-filled regions in SD-OCT of the macula. IEEE Trans. Med. Imaging. 2010, 29, 1321–1330. [Google Scholar] [CrossRef] [PubMed]
- Rhee, E.J.; Chung, P.W.; Wong, T.Y.; Song, S.J. Relationship of retinal vascular caliber variation with intracranial arterial stenosis. Microvasc. Res. 2016, 108, 64–68. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Overall | Training Data | Tuning Data | |
|---|---|---|---|
| Numbers | 43,227 | 33,895 | 9332 |
| Participants | 25,905 | 20,498 | 5407 |
| Age (mean ± SD, years) | 53.38 ± 10.97 | 52.13 ± 10.75 | 56.71 ± 10.79 |
| Sex (female, %) | 16,365 | 12,702 (38.57%) | 3663 (40.27%) |
| Location (right eye, %) | 22,348 | 17,543 (51.76%) | 4805 (51.49%) |
| Abnormal grading (instances, %) | 23,613 | 18,209 (53.7%) | 5404 (57.9%) |
| Label (%) | |||
| AMD (instances, %) | 13,471 | 10,485 (30.92%) | 2986 (31.99%) |
| ERM (instances, %) | 2599 | 1998 (5.89%) | 601 (6.44%) |
| DR (instances, %) | 5441 | 4045 (11.93%) | 1396 (14.96%) |
| RVO (instances, %) | 1166 | 930 (2.74%) | 236 (2.53%) |
| Suspected glaucoma (instances, %) | 949 | 763 (2.25%) | 186 (1.99%) |
| Testing Data | |
|---|---|
| Numbers | 11,707 |
| Abnormal grading (instances, %) | 1327 (11.34%) |
| Label (%) | |
| AMD (instances, %) | 857 (7.32%) |
| ERM (instances, %) | 176 (1.50%) |
| DR (instances, %) | 103 (0.88%) |
| RVO (instances, %) | 69 (0.59%) |
| Suspected glaucoma (instances, %) | 122 (1.04%) |
| AMD | DR | ERM | GS | RVO | |
|---|---|---|---|---|---|
| Mean | 0.9432 | 0.9621 | 0.9816 | 0.9727 | 0.9612 |
| Min, 95% CI | 0.9323 | 0.9402 | 0.9713 | 0.9535 | 0.9354 |
| Max, 95% CI | 0.9541 | 0.9839 | 0.9919 | 0.9920 | 0.9870 |
| AMD | DR | ERM | GS | RVO | |
|---|---|---|---|---|---|
| Mean | 0.8917 | 0.9117 | 0.9430 | 0.9423 | 0.8605 |
| Min, 95% CI | 0.8706 | 0.8598 | 0.9127 | 0.8905 | 0.7963 |
| max, 95% CI | 0.9127 | 0.9635 | 0.9733 | 0.9941 | 0.9246 |
| AMD | DR | ERM | GS | RVO | |
|---|---|---|---|---|---|
| Mean | 0.8624 | 0.8945 | 0.9283 | 0.8933 | 0.9610 |
| Min, 95% CI | 0.8404 | 0.8338 | 0.8881 | 0.8147 | 0.9109 |
| Max, 95% CI | 0.8844 | 0.9552 | 0.9685 | 0.9719 | 1.0000 |
| Gulshan et al. [3] | Burlina et al. [7] | Ting et al. [4] | This Work | |
|---|---|---|---|---|
| Diseases of interest | DR | AMD | DR, AMD, GS | DR, AMD, GS, ERM, RVO |
| Referable DR or DME | 0.974 (0.971–0.978) | 0.936 (0.925–0.943) | 0.962 (0.940–0.984) | |
| Referable AMD | 0.95 (0.94–0.96) | 0.942 (0.929–0.954) | 0.943 (0.932–0.954) | |
| Glaucoma Suspected | 0.942 (0.929–0.954) | 0.973 (0.954–0.992) | ||
| ERM | 0.982 (0.971–0.992) | |||
| RVO | 0.961 (0.935-0.987) |
| Testing Data | |
|---|---|
| Numbers | 1698 |
| Participants | 1080 |
| Age (mean ± SD, years) | 59.59 ± 14.58 |
| Sex (female, %) | 455 (42.13%) |
| Location (OD, %) | 858 (50.53%) |
| Abnormal grading (instances, %) | 1501 (88.40%) |
| Label (%) | |
| AMD (instances, %) | 545 (32.10%) |
| ERM (instances, %) | 152 (8.95%) |
| DR (instances, %) | 581 (34.22%) |
| RVO (instances, %) | 154 (9.07%) |
| Suspected glaucoma (instances, %) | 46 (2.71%) |
| Others (instances, %) | 176 (10.37%) |
| Multiple diagnosis (instances, %) | 147 (8.66%) |
| AMD | DR | ERM | GS | RVO | |
|---|---|---|---|---|---|
| Mean | 0.9497 | 0.9070 | 0.8438 | 0.9451 | 0.8667 |
| Min, 95% CI | 0.9366 | 0.8858 | 0.7960 | 0.8937 | 0.8232 |
| Max, 95% CI | 0.9628 | 0.9282 | 0.8917 | 0.9965 | 0.9102 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Lee, J.; Cho, S.; Song, J.; Lee, M.; Kim, S.H.; Lee, J.Y.; Shin, D.H.; Kim, J.M.; Bae, J.H.; et al. Development of Decision Support Software for Deep Learning-Based Automated Retinal Disease Screening Using Relatively Limited Fundus Photograph Data. Electronics 2021, 10, 163. https://doi.org/10.3390/electronics10020163
Lee J, Lee J, Cho S, Song J, Lee M, Kim SH, Lee JY, Shin DH, Kim JM, Bae JH, et al. Development of Decision Support Software for Deep Learning-Based Automated Retinal Disease Screening Using Relatively Limited Fundus Photograph Data. Electronics. 2021; 10(2):163. https://doi.org/10.3390/electronics10020163
Chicago/Turabian StyleLee, JoonHo, Joonseok Lee, Sooah Cho, JiEun Song, Minyoung Lee, Sung Ho Kim, Jin Young Lee, Dae Hwan Shin, Joon Mo Kim, Jung Hun Bae, and et al. 2021. "Development of Decision Support Software for Deep Learning-Based Automated Retinal Disease Screening Using Relatively Limited Fundus Photograph Data" Electronics 10, no. 2: 163. https://doi.org/10.3390/electronics10020163
APA StyleLee, J., Lee, J., Cho, S., Song, J., Lee, M., Kim, S. H., Lee, J. Y., Shin, D. H., Kim, J. M., Bae, J. H., Song, S. J., Sagong, M., & Park, D. (2021). Development of Decision Support Software for Deep Learning-Based Automated Retinal Disease Screening Using Relatively Limited Fundus Photograph Data. Electronics, 10(2), 163. https://doi.org/10.3390/electronics10020163