
Exploiting the Outcome of Outlier Detection for Novel Attack Pattern Recognition on Streaming Data



Abstract
1. Introduction
- SOAAPR is the first framework that exploits the output of online OD algorithms to mine attack pattern information in a streaming fashion.
- Online OD algorithms are equipped with an alert generation functionality that can be used for alert processing, including timestamp, feature scoring causing the outlierness (root cause) and equally normalized outlier score results utilizing a common format—IDEA.
- Two more novel types of fingerprint-like signatures, apart from , are introduced, and , which can be used to characterize and compare attack patterns.
- Attack scenario information in the form of a signature-tuple can be shared in a privacy-preserved way generated from a novel attack pattern utilizing the STIX language.
2. Related Work
2.1. Aspects on Unsupervised Online Outlier Detection
2.2. Aspects on Alert Correlation
2.3. Alert Correlation for Outlier Detection
2.4. Streaming Alert Correlation
2.5. Delimitation from SOAAPR
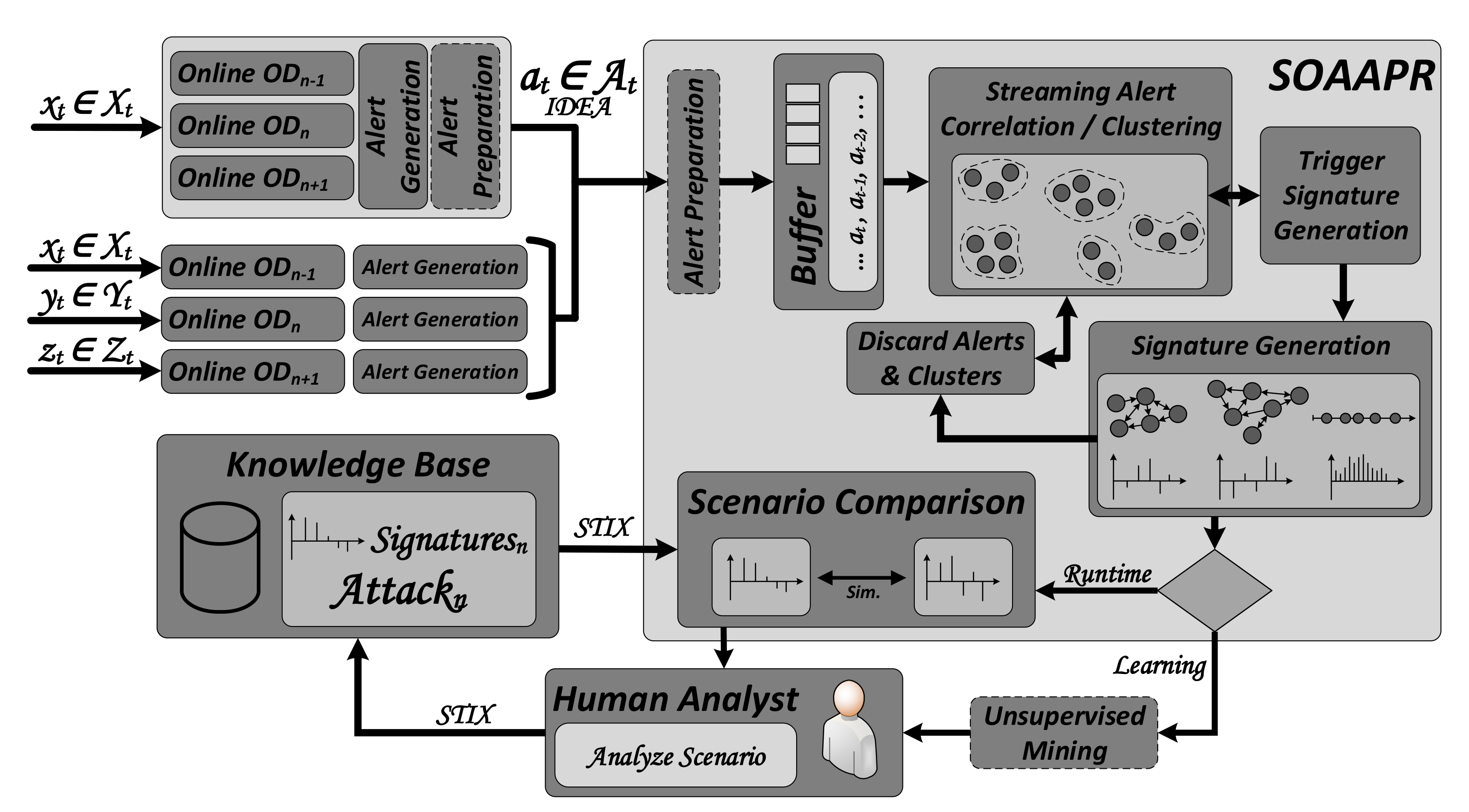
3. Streaming Outlier Analysis and Attack Pattern Recognition
3.1. Operation Principle
3.2. Alert Generation and Preparation
3.3. Streaming Alert Correlation and Clustering
| Algorithm 1: The Operation Principle of Streaming Alert Correlation/Clustering. |
 |
| Algorithm 2: Monitoring of Trigger Signature Generation and Discard Alerts and Clusters. |
 |
3.4. Signature Generation and Sharing
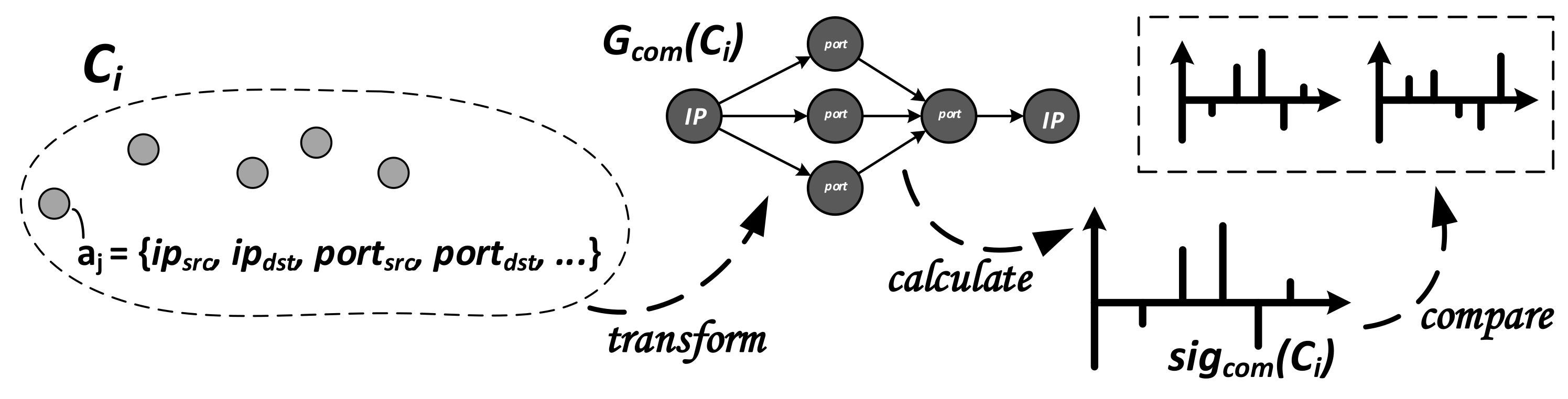
3.4.1. Generation and Comparison of
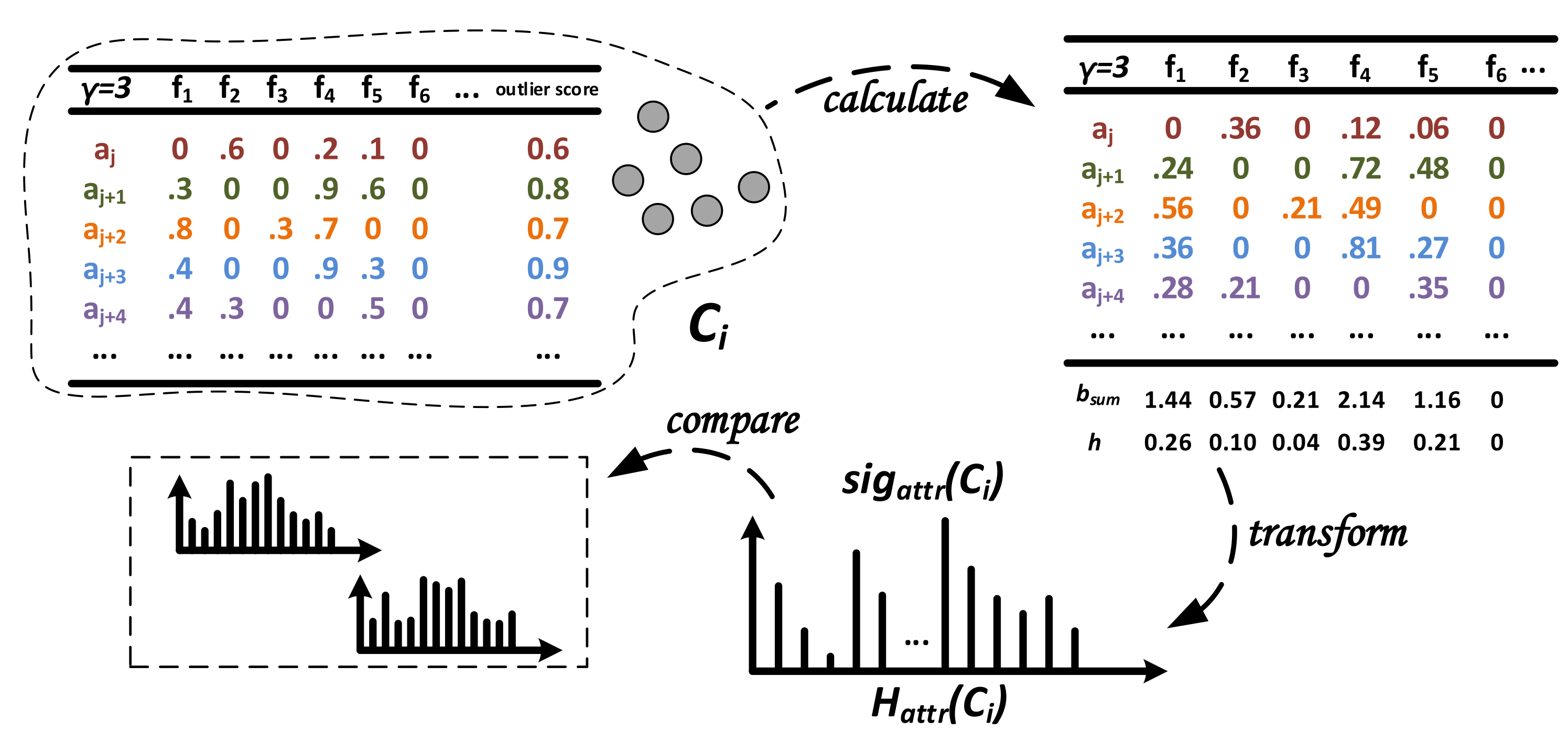
3.4.2. Generation and Comparison of
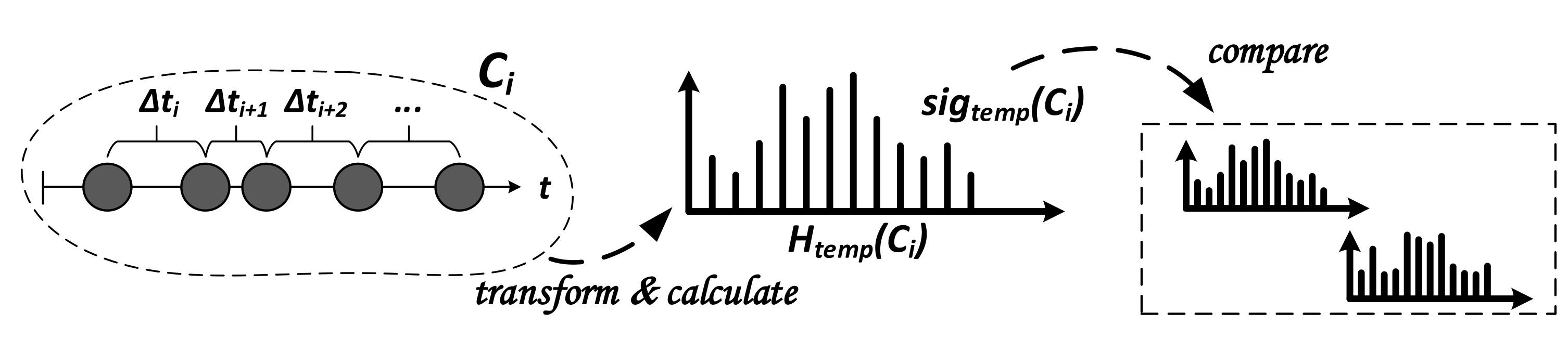
3.4.3. Generation and Comparison of
3.4.4. Handling of the Signatures
4. Experimental Evaluation
4.1. Methodology and Settings
4.2. Data Source
4.3. Evaluation Criteria
5. Discussion of Results
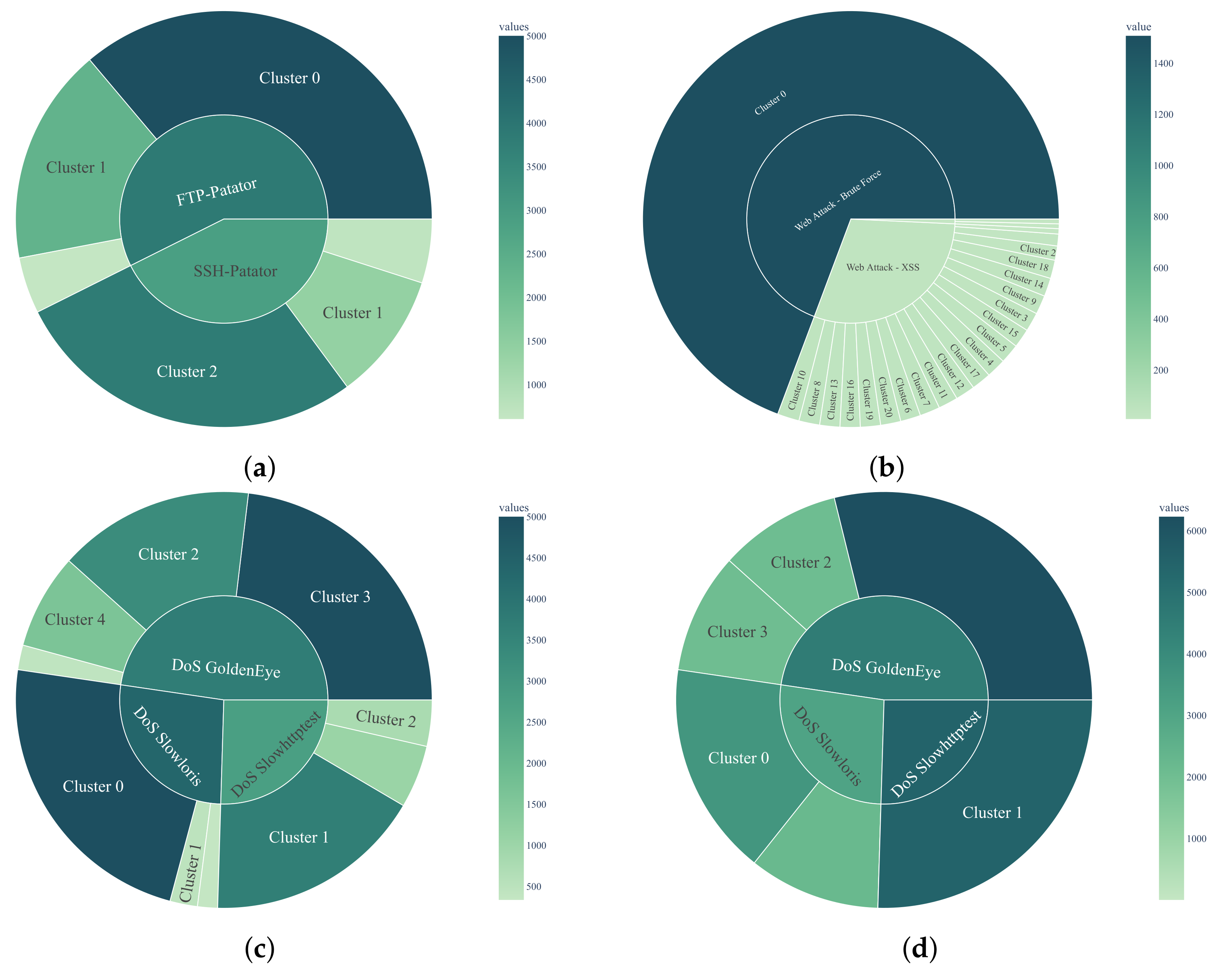
5.1. SOAAPR Clustering
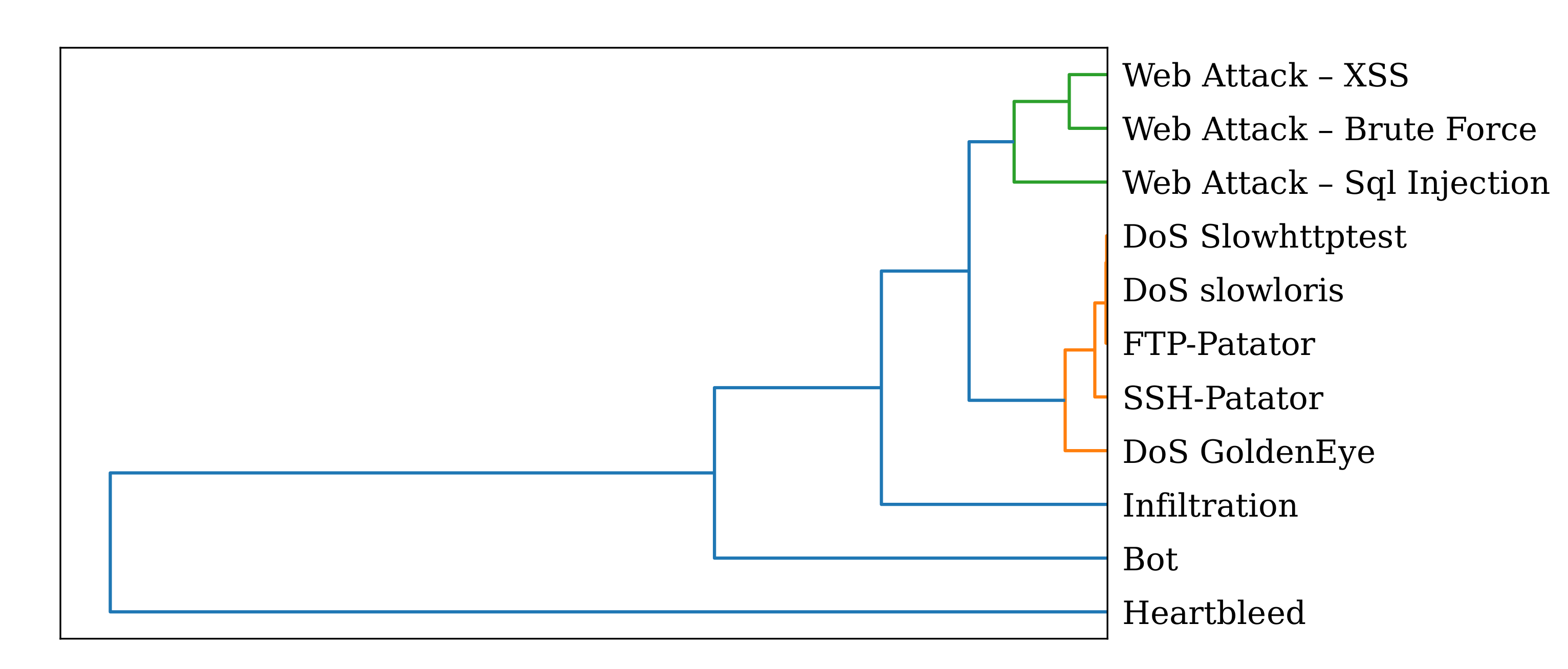
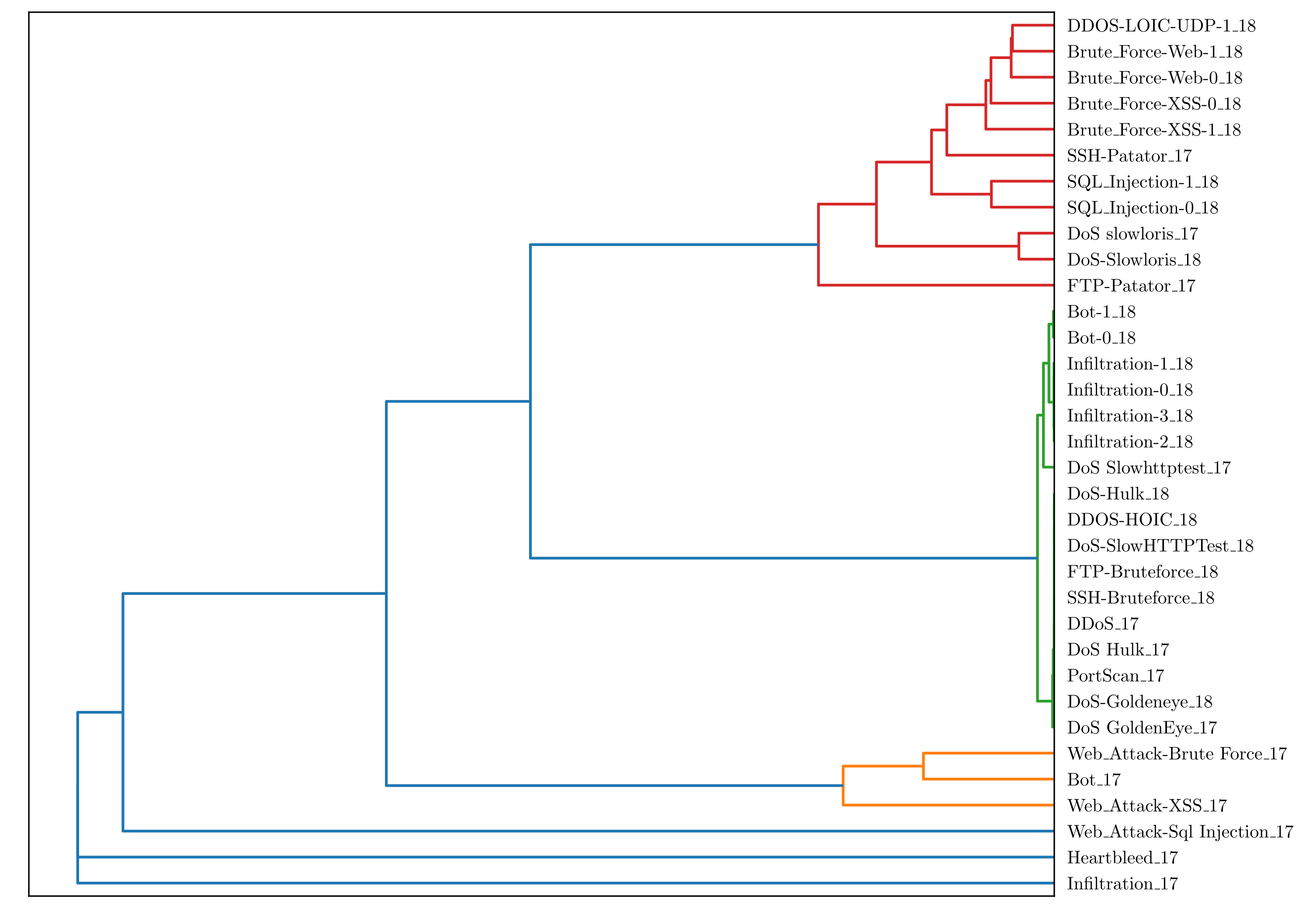
5.2. SOAAPR Signaturing
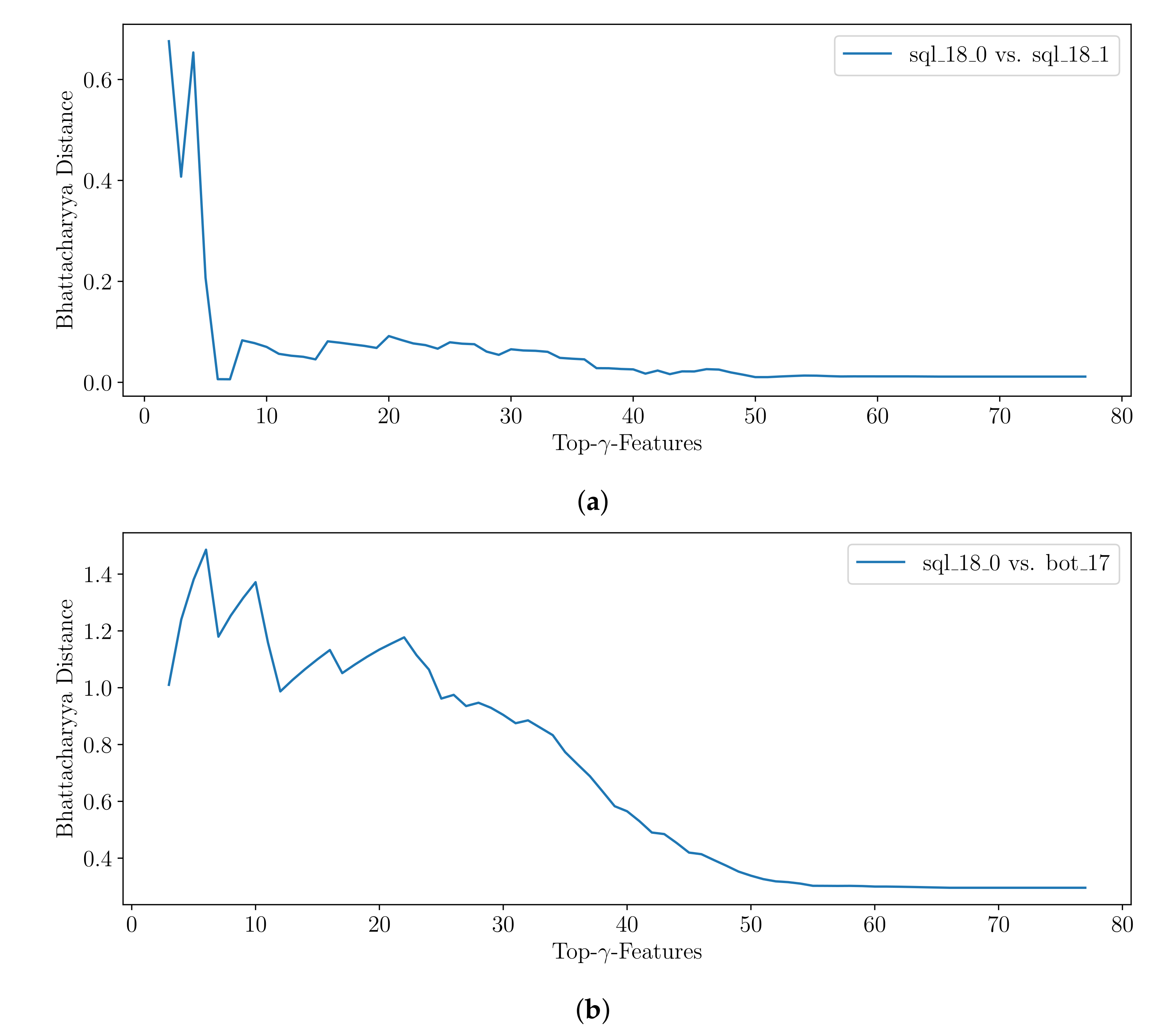
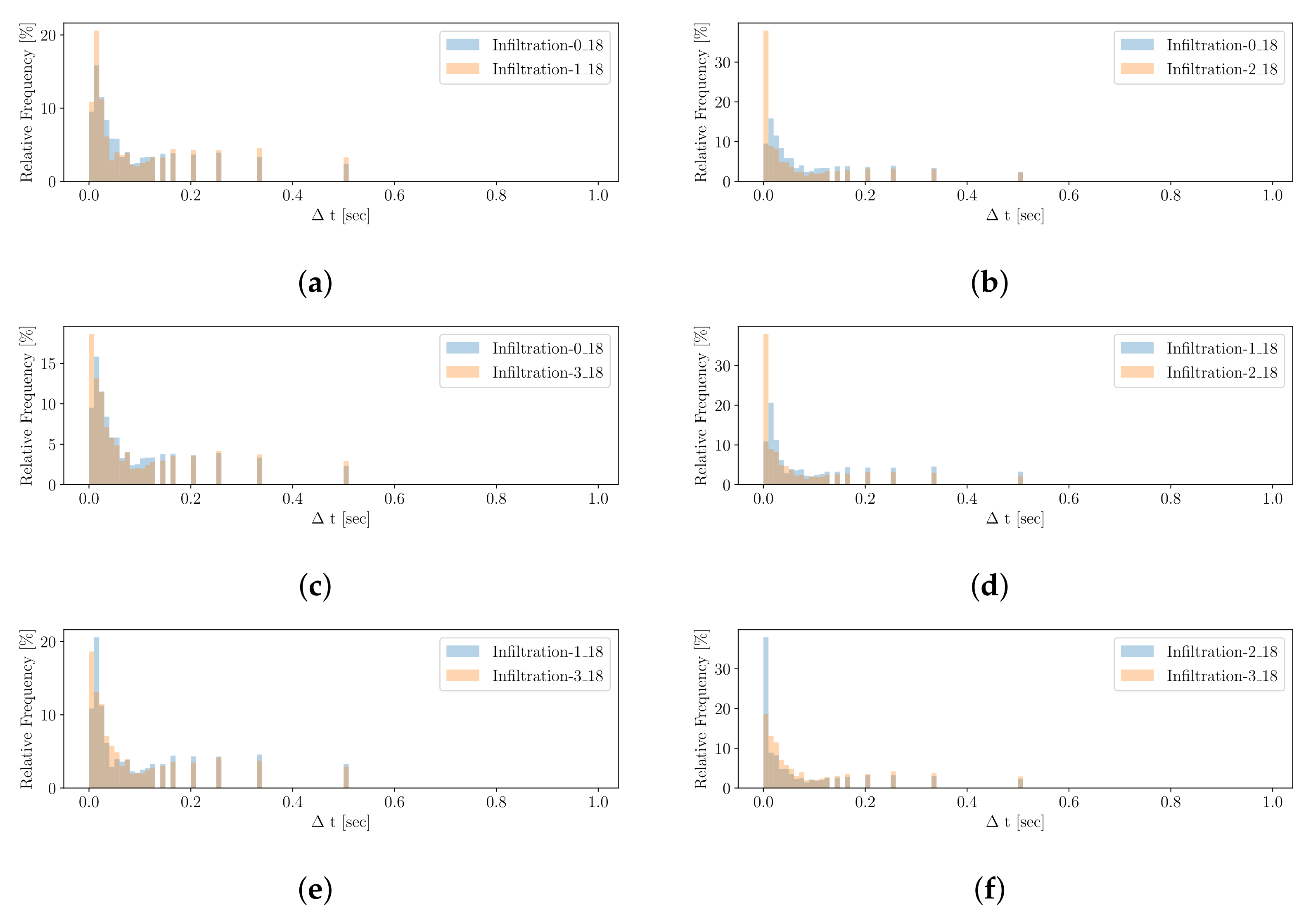
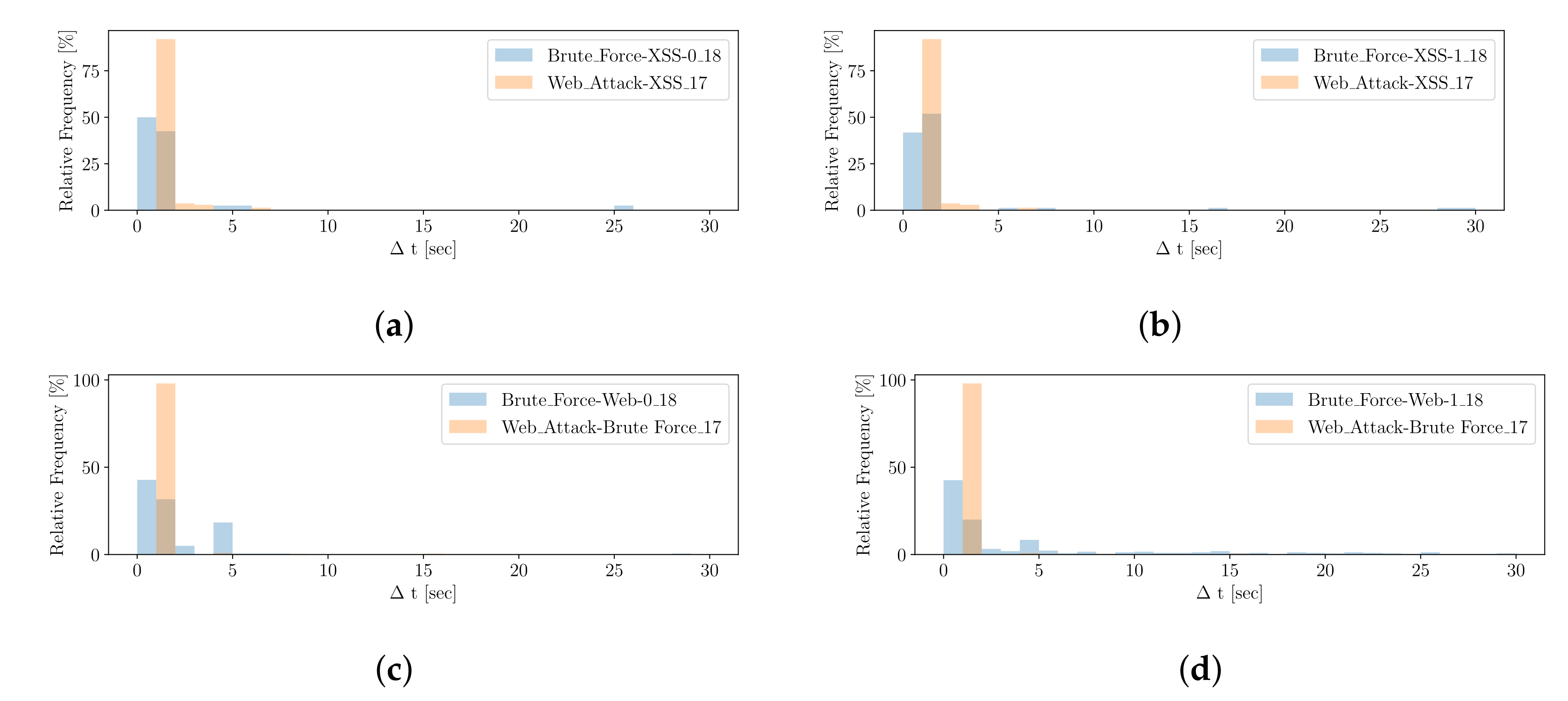
5.2.1.
5.2.2.
5.2.3.
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mironeanu, C.; Archip, A.; Amarandei, C.-M.; Craus, M. Experimental Cyber Attack Detection Framework. Electronics 2021, 10, 1682. [Google Scholar] [CrossRef]
- Liu, H.; Lang, B. Machine learning and deep learning methods for intrusion detection systems: A survey. Appl. Sci. 2019, 9, 4396. [Google Scholar] [CrossRef]
- Ramaki, A.A.; Rasoolzadegan, A.; Bafghi, A.G. A systematic mapping study on intrusion alert analysis in intrusion detection systems. ACM Comput. Surv. 2018, 51, 1–41. [Google Scholar] [CrossRef]
- Nespoli, P.; Papamartzivanos, D.; Gomez Marmol, F.; Kambourakis, G. Optimal countermeasures selection against cyber attacks: A comprehensive survey on reaction frameworks. IEEE Commun. Surv. Tutor. 2018, 20, 1361–1396. [Google Scholar] [CrossRef]
- Zhang, K.; Zhao, F.; Luo, S.; Xin, Y.; Zhu, H.; Chen, Y. Online intrusion scenario discovery and prediction based on Hierarchical Temporal Memory (HTM). Appl. Sci. 2020, 10, 2596. [Google Scholar] [CrossRef]
- Ma, J.; Li, Z.-T.; Li, W.-M. Real-time alert stream clustering and correlation for discovering attack strategies. In Proceedings of the 2008 Fifth International Conference on Fuzzy Systems and Knowledge Discovery, Jinan, China, 18–20 October 2008; 4, pp. 379–384. [Google Scholar] [CrossRef]
- Togbe, M.U.; Barry, M.; Boly, A.; Chabchoub, Y.; Chiky, R.; Montiel, J.; Tran, V.-T. Anomaly detection for data streams based on isolation forest using scikit-multiflow. In Computational Science and Its Applications—ICCSA 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 15–30. [Google Scholar] [CrossRef]
- Kovačević, I.; Groš, S.; Slovenec, K. Systematic review and quantitative comparison of cyberattack scenario detection and projection. Electronics 2020, 9, 1722. [Google Scholar] [CrossRef]
- Haas, S.; Wilkens, F.; Fischer, M. Efficient attack correlation and identification of attack scenarios based on network-motifs. In Proceedings of the 2019 IEEE 38th International Performance Computing and Communications Conference (IPCCC), London, UK, 29–31 October 2019; pp. 1–11. [Google Scholar] [CrossRef]
- Sundaramurthy, S.C.; Zomlot, L.; Ou, X. Practical IDS Alert Correlation in the Face of Dynamic Threats. In Proceedings of the 11th International Conference on Security and Management (SAM), Las Vegas, NV, USA, 20 July 2011. [Google Scholar]
- Pang, G.; Cao, L.; Chen, L.; Liu, H. Unsupervised feature selection for outlier detection by modelling hierarchical value-feature couplings. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 410–419. [Google Scholar] [CrossRef]
- Wang, H.; Bah, M.J.; Hammad, M. Progress in outlier detection techniques: A survey. IEEE Access 2019, 7, 107964–108000. [Google Scholar] [CrossRef]
- Heigl, M.; Anand, K.A.; Urmann, A.; Fiala, D.; Schramm, M.; Hable, R. On the improvement of the isolation forest algorithm for outlier detection with streaming data. Electronics 2021, 10, 1534. [Google Scholar] [CrossRef]
- Muallem, A.; Shetty, S.; Pan, J.W.; Zhao, J.; Biswal, B. Hoeffding tree algorithms for anomaly detection in streaming datasets: A survey. J. Inf. Secur. 2017, 8, 339–361. [Google Scholar] [CrossRef]
- Saffari, A.; Leistner, C.; Santner, J.; Godec, M.; Bischof, H. On-line random forests. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 1393–1400. [Google Scholar] [CrossRef]
- Liu, L.; Hu, M.; Kang, C.; Li, X. Unsupervised anomaly detection for network data streams in industrial control systems. Information 2020, 11, 105. [Google Scholar] [CrossRef]
- Yao, H.; Fu, X.; Yang, Y.; Postolache, O. An incremental local outlier detection method in the data stream. Appl. Sci. 2018, 8, 1248. [Google Scholar] [CrossRef]
- Mirsky, Y.; Doitshman, T.; Elovici, Y.; Shabtai, A. Kitsune: An ensemble of autoencoders for online network intrusion detection. In Proceedings of the Network and Distributed System Security Symposium 2018 (NDSS’18), San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Yu, K.; Shi, W.; Santoro, N. Designing a streaming algorithm for outlier detection in data mining—An incremental approach. Sensors 2020, 20, 1261. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.-H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar] [CrossRef]
- Tan, S.C.; Ting, K.M.; Liu, T.F. Fast anomaly detection for streaming data. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence—Volume Two; AAAI Press: New York, NY, USA, 2011; pp. 1511–1516. [Google Scholar] [CrossRef]
- Sathe, S.; Aggarwal, C.C. Subspace outlier detection in linear time with randomized hashing. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 459–468. [Google Scholar] [CrossRef]
- Pevný, T. Loda: Lightweight on-line detector of anomalies. Mach. Learn. 2016, 102, 275–304. [Google Scholar] [CrossRef]
- Manzoor, E.; Lamba, H.; Akoglu, L. xStream: Outlier detection in feature-evolving data streams. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; ACM: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Sathe, S. Theoretical foundations and algorithms for outlier ensembles. SIGKDD Explor. 2015, 17, 24–47. [Google Scholar] [CrossRef]
- Ding, Z.; Fei, M. An anomaly detection approach based on isolation forest algorithm for streaming data using sliding window. IFAC Proc. 2013, 46, 12–17. [Google Scholar] [CrossRef]
- Togbe, M.U.; Chabchoub, Y.; Boly, A.; Barry, M.; Chiky, R.; Bahri, M. Anomalies detection using isolation in concept-drifting data streams. Computers 2021, 10, 13. [Google Scholar] [CrossRef]
- Sun, H.; He, Q.; Liao, K.; Sellis, T.; Guo, L.; Zhang, X.; Shen, J.; Chen, F. Fast anomaly detection in multiple multi-dimensional data streams. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 1218–1223. [Google Scholar] [CrossRef]
- Ma, H.; Ghojogh, B.; Samad, M.N.; Zheng, D.; Crowley, M. Isolation Mondrian forest for batch and online anomaly detection. In Proceedings of the 2020 IEEE International Conference on Systems, Man, Toronto, ON, Canada, 11–14 October 2020, and Cybernetics (SMC); pp. 3051–3058. [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 4768–4777. [Google Scholar] [CrossRef]
- Salah, S.; Maciá-Fernández, G.; Díaz-Verdejo, J.E. A model-based survey of alert correlation techniques. Comput. Netw. 2013, 57, 1289–1317. [Google Scholar] [CrossRef]
- Hubballi, N.; Suryanarayanan, V. False alarm minimization techniques in signature-based intrusion detection systems: A survey. Comput. Commun. 2014, 49, 1–17. [Google Scholar] [CrossRef]
- Bhuyan, M.H.; Bhattacharyya, D.K.; Kalita, J.K. Network Traffic Anomaly Detection and Prevention: Concepts, Techniques, and Tools, 1st ed.; Springer International Publishing: Cham, Switzerland, 2017; ISBN 9783319651866. [Google Scholar]
- Mirheidari, S.A.; Arshad, S.; Jalili, R. Alert correlation algorithms: A survey and taxonomy. In Cyberspace Safety and Security; Springer International Publishing: Cham, Switzerland, 2013; pp. 183–197. [Google Scholar] [CrossRef]
- Bolzoni, D.; Etalle, S.; Hartel, P.H. Panacea: Automating attack classification for anomaly-based network intrusion detection systems. In Recent Advances in Intrusion Detection; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–20. [Google Scholar] [CrossRef]
- Qassim, Q.S.; Zin, A.M.; Aziz, M.J.A. Anomaly-based network IDS false alarm filter using cluster-based alarm classification approach. Int. J. Secur. Netw. 2017, 12, 13. [Google Scholar] [CrossRef]
- Shin, J.; Choi, S.-H.; Liu, P.; Choi, Y.-H. Unsupervised multi-stage attack detection framework without details on single-stage attacks. Future Gener. Comput. Syst. 2019, 100, 811–825. [Google Scholar] [CrossRef]
- Sudheera, K.L.K.; Divakaran, D.M.; Singh, R.P.; Gurusamy, M. ADEPT: Detection and identification of correlated attack stages in IoT networks. IEEE Internet Things J. 2021, 8, 6591–6607. [Google Scholar] [CrossRef]
- Haas, S.; Fischer, M. On the alert correlation process for the detection of multi-step attacks and a graph-based realization. ACM SIGAPP Appl. Comput. Rev. 2019, 19, 5–19. [Google Scholar] [CrossRef]
- Milo, R.; Shen-Orr, S.; Itzkovitz, S.; Kashtan, N.; Chklovskii, D.; Alon, U. Network motifs: Simple building blocks of complex networks. Science 2002, 298, 824–827. [Google Scholar] [CrossRef]
- Wang, L.; Liu, A.; Jajodia, S. Using attack graphs for correlating, hypothesizing, and predicting intrusion alerts. Comput. Commun. 2006, 29, 2917–2933. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Yu, P.S.; Han, J.; Wang, J. A framework for clustering evolving data streams. In Proceedings of the VLDB ’03: Proceedings of the 29th international conference on Very large data bases; Berlin, Germany, 9–12 September 2003, Volume 29, pp. 81–92. [CrossRef]
- Sadoddin, R.; Ghorbani, A.A. Real-time alert correlation using stream data mining techniques. In Proceedings of the 20th National Conference on Innovative Applications of Artificial Intelligence, Chicago, IL, USA, 13–17 July 2008; Volume 3, pp. 1731–1737. [Google Scholar] [CrossRef]
- Ren, H.; Stakhanova, N.; Ghorbani, A.A. An online adaptive approach to alert correlation. In Detection of Intrusions and Malware, and Vulnerability Assessment; Springer: Berlin/Heidelberg, Germany, 2010; pp. 153–172. [Google Scholar] [CrossRef]
- Ramaki, A.A.; Amini, M.; Ebrahimi Atani, R. RTECA: Real time episode correlation algorithm for multi-step attack scenarios detection. Comput. Secur. 2015, 49, 206–219. [Google Scholar] [CrossRef]
- Faraji Daneshgar, F.; Abbaspour, M. Extracting fuzzy attack patterns using an online fuzzy adaptive alert correlation framework: Fuzzy adaptive alert correlation. Secur. Commun. Netw. 2016, 9, 2245–2260. [Google Scholar] [CrossRef]
- Zhang, K.; Zhao, F.; Luo, S.; Xin, Y.; Zhu, H. An intrusion action-based IDS alert correlation analysis and prediction framework. IEEE Access 2019, 7, 150540–150551. [Google Scholar] [CrossRef]
- Ossenbuhl, S.; Steinberger, J.; Baier, H. Towards automated incident handling: How to select an appropriate response against a network-based attack? In Proceedings of the 2015 Ninth International Conference on IT Security Incident Management & IT , IT Forensics, Magdeburg, Germany, 18–20 May 2015; pp. 51–67. [Google Scholar] [CrossRef]
- Zohrevand, Z.; Glässer, U. Should I Raise The Red Flag? A comprehensive survey of anomaly scoring methods toward mitigating false alarms. arXiv 2019, arXiv:1904.06646. [Google Scholar]
- Ourston, D.; Matzner, S.; Stump, W.; Hopkins, B. Applications of hidden Markov models to detecting multi-stage network attacks. In Proceedings of the 36th Annual Hawaii International Conference on System Sciences, Big Island, HI, USA, 6–9 January 2003; 10. [Google Scholar] [CrossRef]
- Kriegel, H.-P.; Kroger, P.; Schubert, E.; Zimek, A. Interpreting and Unifying Outlier Scores. In Proceedings of the 2011 SIAM International Conference on Data Mining, Mesa, AZ, USA, 28–30 April 2011; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2011. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, H.; Jin, X.; Li, Y.; Jiang, Z.; Liang, Y.; Jin, Z.; Wen, Q. A multi-step attack detection model based on alerts of smart grid monitoring system. IEEE Access 2020, 8, 1031–1047. [Google Scholar] [CrossRef]
- Xylogiannopoulos, K.; Karampelas, P.; Alhajj, R. Early DDoS detection based on data mining techniques. In Information Security Theory and Practice—Securing the Internet of Things; Springer: Berlin/Heidelberg, Germany, 2014; pp. 190–199. [Google Scholar] [CrossRef]
- Prakash, A.; Satish, M.; Bhargav, T.S.S.; Bhalaji, N. Detection and mitigation of denial of service attacks using stratified architecture. Procedia Comput. Sci. 2016, 87, 275–280. [Google Scholar] [CrossRef]
- Galeano-Brajones, J.; Carmona-Murillo, J.; Valenzuela-Valdés, J.F.; Luna-Valero, F. Detection and mitigation of DoS and DDoS attacks in IoT-based stateful SDN: An experimental approach. Sensors 2020, 20, 816. [Google Scholar] [CrossRef]
- Welford, B.P. Note on a method for calculating corrected sums of squares and products. Technometrics 1962, 4, 419–420. [Google Scholar] [CrossRef]
- Heigl, M.; Doerr, L.; Tiefnig, N.; Fiala, D.; Schramm, M. A resource-preserving self-regulating Uncoupled MAC algorithm to be applied in incident detection. Comput. Secur. 2019, 85, 270–287. [Google Scholar] [CrossRef]
- Zubaroğlu, A.; Atalay, V. Data stream clustering: A review. Artif. Intell. Rev. 2021, 54, 1201–1236. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy, Austin, TX, USA, 12–15 December 2021; pp. 108–116. [Google Scholar] [CrossRef]
- Kurniabudi; Stiawan, D.; Darmawijoyo; Bin Idris, M.Y.; Bamhdi, A.M.; Budiarto, R. CICIDS-2017 dataset feature analysis with information gain for anomaly detection. IEEE Access 2020, 8, 132911–132921. [Google Scholar] [CrossRef]
- Jeng, M. Error in statistical tests of error in statistical tests. BMC Med. Res. Methodol. 2006, 6, 45. [Google Scholar] [CrossRef] [PubMed]
- Bhattacharyya, A. On a measure of divergence between two statistical populations defined by their probability distributions. Bull. Calcutta Math. Soc. 1943, 35, 99–109. [Google Scholar]
- Gunter Ollmann. Why STIX/TAXII/CybOX Sharing Is Incompatible with AI Threat Detection Systems. Available online: https://www.linkedin.com/pulse/why-stixtaxiicybox-sharing-incompatible-ai-threat-systems-ollmann (accessed on 19 July 2021).
- Sadique, F.; Cheung, S.; Vakilinia, I.; Badsha, S.; Sengupta, S. Automated structured threat information expression (STIX) document generation with privacy preservation. In Proceedings of the 2018 9th IEEE Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 8–10 November 2018; pp. 847–853. [Google Scholar] [CrossRef]
- Wang, Q.; Jiang, J.; Shi, Z.; Wang, W.; Lv, B.; Qi, B.; Yin, Q. A novel multi-source fusion model for known and unknown attack scenarios. In Proceedings of the 2018 17th IEEE International Conference On Trust, Security And Privacy in Computing and Communications/12th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018; pp. 727–736. [Google Scholar] [CrossRef]
- Wang, X.; Yu, L.; He, H.; Gong, X. MAAC: Novel alert correlation method to detect multi-step attack. arXiv 2020, arXiv:2011.07793. [Google Scholar]
- Kenyon, A.; Deka, L.; Elizondo, D. Are public intrusion datasets fit for purpose characterising the state of the art in intrusion event datasets. Comput. Secur. 2020, 99, 102022. [Google Scholar] [CrossRef]
- Ahmad, Z.; Shahid Khan, A.; Wai Shiang, C.; Abdullah, J.; Ahmad, F. Network intrusion detection system: A systematic study of machine learning and deep learning approaches. Trans. Emerg. Telecommun. Technol. 2021, 32. [Google Scholar] [CrossRef]
- Ning, P.; Cui, Y.; Reeves, D.S.; Xu, D. Techniques and tools for analyzing intrusion alerts. ACM Trans. Inf. Syst. Secur. (TISSEC) 2004, 7, 274–318. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Normal | Normal | Abnormal | Normal | Abnormal |
|---|---|---|---|---|---|
| #1 | TN (0.2) | TN (0.3) | TN(0.9) | FP(0.6) | FN(0.5) |
| #2 | TN (0.1) | FP (0.7) | FN(0.5) | TN (0.3) | TP (0.9) |
| #3 | FP (0.6) | FP (0.6) | TP (0.9) | TN (0.3) | FN (0.4) |
| #4 | TN (0.1) | TN (0.2) | FN (0.5) | TN (0.2) | TP (1.0) |
| #5 | TN (0.2) | TN (0.2) | TP (0.8) | TN (0.1) | FN (0.5) |
| 0.20 | 0.20 | 0.20 | 0.20 | 0.20 | |
| 0.24 | 0.40 | 0.72 | 0.30 | 0.66 | |
| 1.00 | 0.50 | 0.33 | 1.00 | 0.50 | |
| 0.60 | 0.65 | 0.87 | 0.60 | 0.95 | |
| 1/5 | 2/5 | 3/5 | 1/5 | 2/5 | |
| 0.12 | 0.26 | 0.52 | 0.12 | 0.38 | |
| Meta-Alert | ✗ | ✗ | ✓ | ✗ | ✓ |
| Dataset | Attack Type | # Instances | Outliers (%) | Duration (min) |
|---|---|---|---|---|
| Tuesday-WorkingHours | SSH-Patator | 5897 | 1.32 | 62 |
| FTP-Patator | 7938 | 1.78 | 73 | |
| Wednesday-WorkingHours | DoS Hulk | 231,073 | 33.35 | 24 |
| DoS GoldenEye | 10,293 | 1.49 | 9 | |
| DoS Slowloris | 5796 | 0.84 | 467 | |
| DoS Slowhttptest | 5499 | 0.79 | 22 | |
| Heartbleed | 11 | 0.002 | 20 | |
| Thursday-WorkingHours-Morning | Web Attack—Brute Force | 1507 | 0.88 | 45 |
| Web Attack—XSS | 652 | 0.38 | 20 | |
| Web Attack—Sql Injection | 21 | 0.01 | 2 | |
| Thursday-WorkingHours-Afternoon | Infiltration * | 36 | 0.01 | 86 |
| Friday-WorkingHours-Morning | Bot | 1966 | 1.03 | 205 |
| Friday-WorkingHours-Afternoon | Portscan | 158,930 | 55.48 | 138 |
| Friday-WorkingHours-Afternoon (2) | DDoS | 128,027 | 56.71 | 20 |
| Computation | |
|---|---|
| Attack Scenario | SOAAPR | GAC | ||||||
|---|---|---|---|---|---|---|---|---|
| No. Clusters | No. Alerts | Metrics | Time (s) | No. Clusters | No. Alerts | Metrics | Time (s) | |
| FTP-Patator | 1/2 | 7938/7938 | 1.0/1.0/1.0 | 105.11 | 2/3 1 | 10,000/7938 | 1.0/1.0/0.92 | 1424.17 |
| SSH-Patator | 1/2 | 5897/5897 | 1.0/1.0/1.0 | 2/3 1 | 8835/5897 | 1.0/1.0/0.88 | ||
| WA—Brute Force | 1/24 | 1507/1507 | 1.0/1.0/1.0 | 2.32 | 1/1 | 2180/2180 | 1.0/0.69/0.69 | 266.56 |
| WA—XSS | 21/24 | 652/652 | 1.0/1.0/1.0 | 1/1 | 2180/2180 | 1.0/0.30/0.30 | ||
| WA—Sql Injection | 2/24 | 16/21 | 0.76/1.0/0.76 | 1/1 | 2180/2180 | 1.0/0.01/0.01 | ||
| DoS GoldenEye | 2/4 2 | 4065/10,293 | 0.39/1.0/0.39 | 63.62 | 3/5 1 | 11,588/10,293 | 1.0/1.0/0.96 | 12,107.17 |
| DoS Slowloris | 1/4 2 | 3588/5796 | 0.62/1.0/0.62 | 2/5 1 | 10,000/5796 | 1.0/1.0/0.94 | ||
| DoS Slowhttptest | 1/4 2 | 5501/5499 | 1.0/1.0/1.0 3 | 2/5 1 | 10,000/5499 | 1.0/1.0/0.81 | ||
| Heartbleed | 0/4 2 | 0/11 | 0.0/0.0/0.0 | 0/5 1 | 0/11 | 0.0/0.0/0.0 | ||
| Infiltration | 1/1 | 36/36 | 1.0/1.0/1.0 | ∼0.0 | 1/1 | 36/36 | 1.0/1.0/1.0 | ∼0.0 |
| Bot | 2/2 | 1926/1966 | 0.98/1.0/0.98 | 2.51 | 2/2 | 1962/1966 | 1.0/1.0/1.0 3 | 75.09 |
| Bot | Infiltration | WA— Brute Force | WA— XSS | WA— Sql Injection | FTP-Patator | SSH-Patator | DoS Slowloris | DoS Slow- httptest | DoS Golden- Eye | Heartbleed | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Bot | - | 0.7903 | 0.7477 | 0.7742 | 0.8068 | 0.6861 | 0.6955 | 0.6874 | 0.6868 | 0.6595 | 0.3085 |
| Infiltration | - | 0.8610 | 0.8731 | 0.9120 | 0.8210 | 0.8279 | 0.8220 | 0.8216 | 0.8006 | 0.3517 | |
| WA—Brute Force | - | 0.9734 | 0.9251 | 0.9382 | 0.9477 | 0.9395 | 0.9389 | 0.9115 | 0.2908 | ||
| WA—XSS | - | 0.9448 | 0.9115 | 0.9210 | 0.9128 | 0.9123 | 0.8849 | 0.2870 | |||
| WA—Sql Injection | - | 0.8698 | 0.8787 | 0.8711 | 0.8705 | 0.8446 | 0.2807 | ||||
| FTP-Patator | - | 0.9905 | 0.9987 | 0.9993 | 0.9734 | 0.3049 | |||||
| SSH-Patator | - | 0.9918 | 0.9912 | 0.9639 | 0.3021 | ||||||
| DoS slowloris | - | 0.9994 | 0.9721 | 0.3045 | |||||||
| DoS Slowhttptest | - | 0.9727 | 0.3047 | ||||||||
| DoS GoldenEye | - | 0.3134 | |||||||||
| Heartbleed | - | ||||||||||
| Dataset | Attack Type | # Instances | Outliers (%) | Duration (min) |
|---|---|---|---|---|
| Thursday-22-02 | Brute-Force-Web-0 | 250 | 0.023 | 56.01 |
| Brute-Force-XSS-0 | 81 | 0.008 | 0.90 | |
| SQL-Injection-0 | 31 | 0.003 | 13.35 | |
| Friday-23-02 | Brute-Force-Web-1 | 363 | 0.035 | 48.85 |
| Brute-Force-XSS-1 | 151 | 0.014 | 69.02 | |
| SQL-Injection-1 | 50 | 0.005 | 0.97 | |
| Wednesday-28-02 | Infiltration-1 | 42,760 | 6.974 | 22.25 |
| Infiltration-0 | 26,111 | 4.259 | 6.00 | |
| Thursday-01-03 | Infiltration-3 | 54,311 | 16.403 | 96.98 |
| Infiltration-2 | 38,752 | 11.704 | 57.98 | |
| Friday-02-03 | Bot-0 | 190,240 | 18.143 | 473.27 |
| Bot-1 | 95,951 | 9.151 | 89.82 |
| brute_force_18_0 | brute_force_18_1 | brute_force_17 | sql_18_0 | sql_18_1 | sql_17 | xss_18_0 | xss_18_1 | xss_17 | bot_18_0 | bot_18_1 | bot_17 | infiltration_18_0 | infiltration_18_1 | infiltration_18_2 | infiltration_18_3 | infiltration_17 | heartbleed_17 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| No. Alerts | 250 | 363 | 1507 | 31 | 50 | 21 | 81 | 151 | 652 | 190,240 | 95,951 | 1966 | 42,760 | 26,111 | 38,752 | 54,311 | 36 | 308 |
| Time (ms) | 1.23 | 3.08 | 6.99 | 0.34 | 0.62 | 0.21 | 0.62 | 1.03 | 3.08 | 988.69 | 492.8 | 9.05 | 220.39 | 135.9 | 199.42 | 282.69 | 0.41 | 3.08 |
| brute_force_17 | xss_17 | sql_17 | infiltration_17 | ddos_17 | dos_hulk_17 | dos_slowloris_17 | dos_slowhttptest_17 | dos_goldeneye_17 | port_scan_17 | ftp-patator_17 | ssh-patator_17 | bot_17 | heartbleed_17 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| No. Alerts | 1507 | 652 | 21 | 36 | 128,027 | 231,073 | 5796 | 5499 | 10,293 | 158,930 | 7938 | 5897 | 1966 | 11 |
| Generating Δts (s) | 0.1873 | 0.0810 | 0.0030 | 0.0053 | 15.6347 | 28.8301 | 0.7102 | 0.6742 | 1.2875 | 19.6687 | 0.9818 | 0.7314 | 2.4444 | 0.0018 |
| Generating Histograms (ms) | 0.69 | 0.58 | 0.51 | 0.54 | 13.78 | 24.49 | 1.14 | 1.10 | 1.57 | 17.06 | 1.38 | 1.18 | 0.76 | 0.57 |
| brute_force_18_0 | brute_force_18_1 | sql_18_0 | sql_18_1 | xss_18_0 | xss_18_1 | bot_18_0 | bot_18_1 | infiltration_18_0 | infiltration_18_1 | infiltration_18_2 | infiltration_18_3 | ddos-hoic_18 | dos-hulk_18 | dos-slowhttptest_18 | dos-slowloris_18 | ddos-loic-udp_18 | dos-goldeneye_18 | ftp-bruteforce_18 | ssh-bruteforce_18 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| No. Alerts | 363 | 250 | 50 | 31 | 81 | 151 | 190,240 | 95,951 | 42,760 | 26,111 | 38,752 | 54,311 | 686,012 | 461,912 | 139,890 | 10,990 | 1730 | 41,508 | 193,360 | 187,589 |
| Generating Δts (s) | 0.0484 | 0.0701 | 0.0088 | 0.0142 | 0.0214 | 0.0400 | 49.1716 | 24.7964 | 10.4209 | 6.3606 | 9.4362 | 13.2450 | 170.4973 | 104.9426 | 23.1637 | 1.8217 | 0.3151 | 6.5640 | 29.9785 | 38.7183 |
| Generating Histograms (ms) | 0.58 | 0.61 | 0.56 | 0.56 | 0.57 | 0.59 | 21.56 | 11.06 | 5.52 | 3.54 | 4.91 | 6.77 | 75.33 | 51.48 | 15.60 | 1.14 | 0.76 | 5.27 | 21.35 | 20.94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Heigl, M.; Weigelt, E.; Urmann, A.; Fiala, D.; Schramm, M. Exploiting the Outcome of Outlier Detection for Novel Attack Pattern Recognition on Streaming Data. Electronics 2021, 10, 2160. https://doi.org/10.3390/electronics10172160
Heigl M, Weigelt E, Urmann A, Fiala D, Schramm M. Exploiting the Outcome of Outlier Detection for Novel Attack Pattern Recognition on Streaming Data. Electronics. 2021; 10(17):2160. https://doi.org/10.3390/electronics10172160
Chicago/Turabian StyleHeigl, Michael, Enrico Weigelt, Andreas Urmann, Dalibor Fiala, and Martin Schramm. 2021. "Exploiting the Outcome of Outlier Detection for Novel Attack Pattern Recognition on Streaming Data" Electronics 10, no. 17: 2160. https://doi.org/10.3390/electronics10172160
APA StyleHeigl, M., Weigelt, E., Urmann, A., Fiala, D., & Schramm, M. (2021). Exploiting the Outcome of Outlier Detection for Novel Attack Pattern Recognition on Streaming Data. Electronics, 10(17), 2160. https://doi.org/10.3390/electronics10172160