
Design of Efficient Human Head Statistics System in the Large-Angle Overlooking Scene




Abstract
:1. Introduction
- We propose the YOLOv5-H network as the detection benchmark of the statistics system, where CIoU is taken as the loss function of the network to make the predicted boxes more in line with the real boxes;
- We propose a fusion hash algorithm and include it in the DeepSORT [15] algorithm for feature extraction to track human heads;
- The cross-boundary counting algorithm based on scene segmentation is proposed to count human heads;
- We evaluate the detection performance of the improved YOLOv5-H on the SCUT_HEAD dataset and the statistics performance of the system on the TownCentreXVID dataset.
2. Related Work and Background
2.1. Related Work
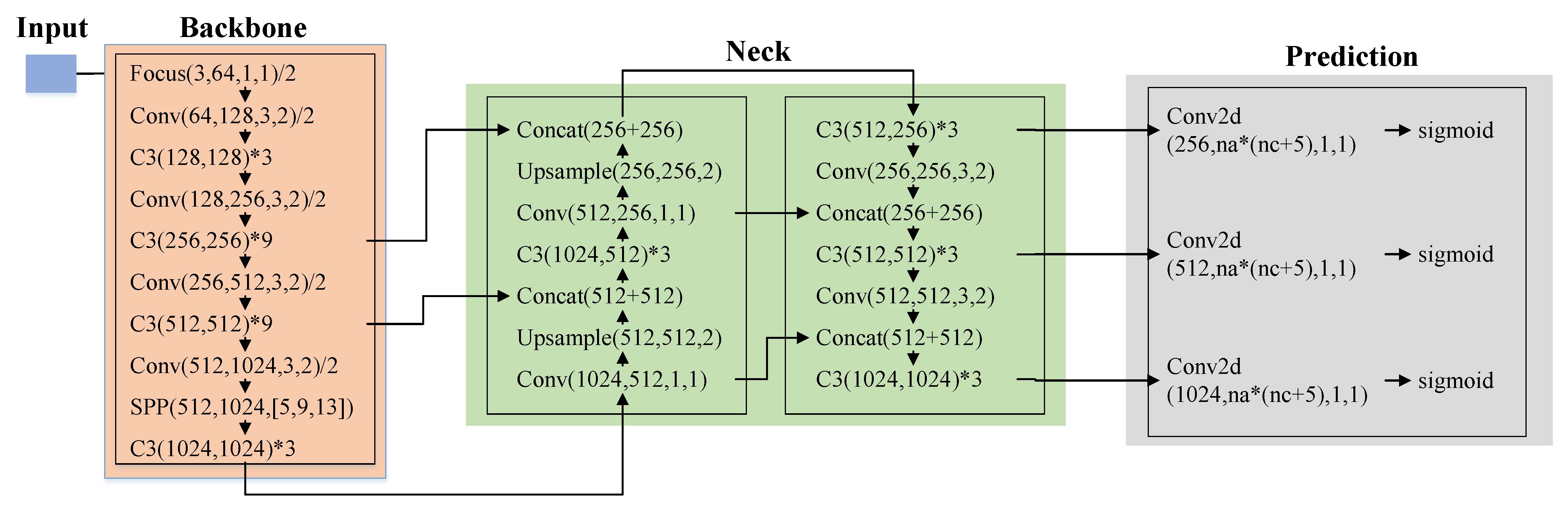
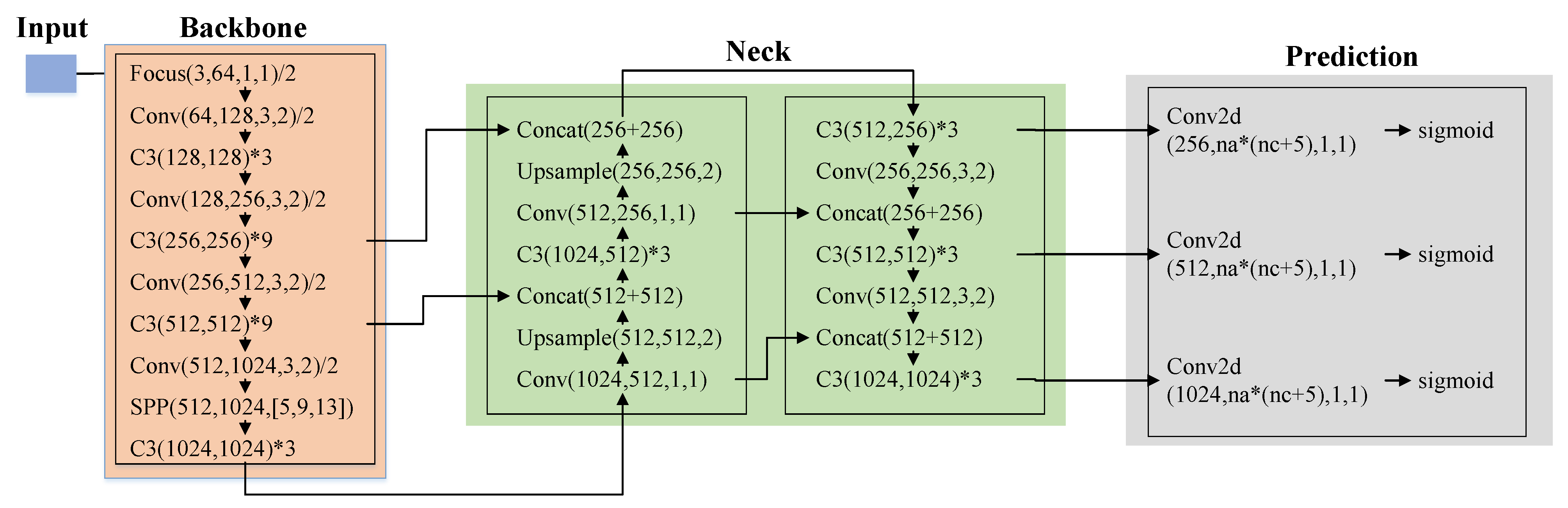
2.2. YOLOv5
2.2.1. Input
2.2.2. Backbone
2.2.3. Neck
2.2.4. Prediction
2.3. DeepSORT
3. The Algorithm Architecture of Human Head Statistics System
3.1. Detection: YOLOv5-H
- The prediction box is inside the real box;
- The prediction box is the same size as the real box.
3.2. Tracking: DeepSORT-FH
| Algorithm 1 Fusion hash feature extraction algorithm. |
 |
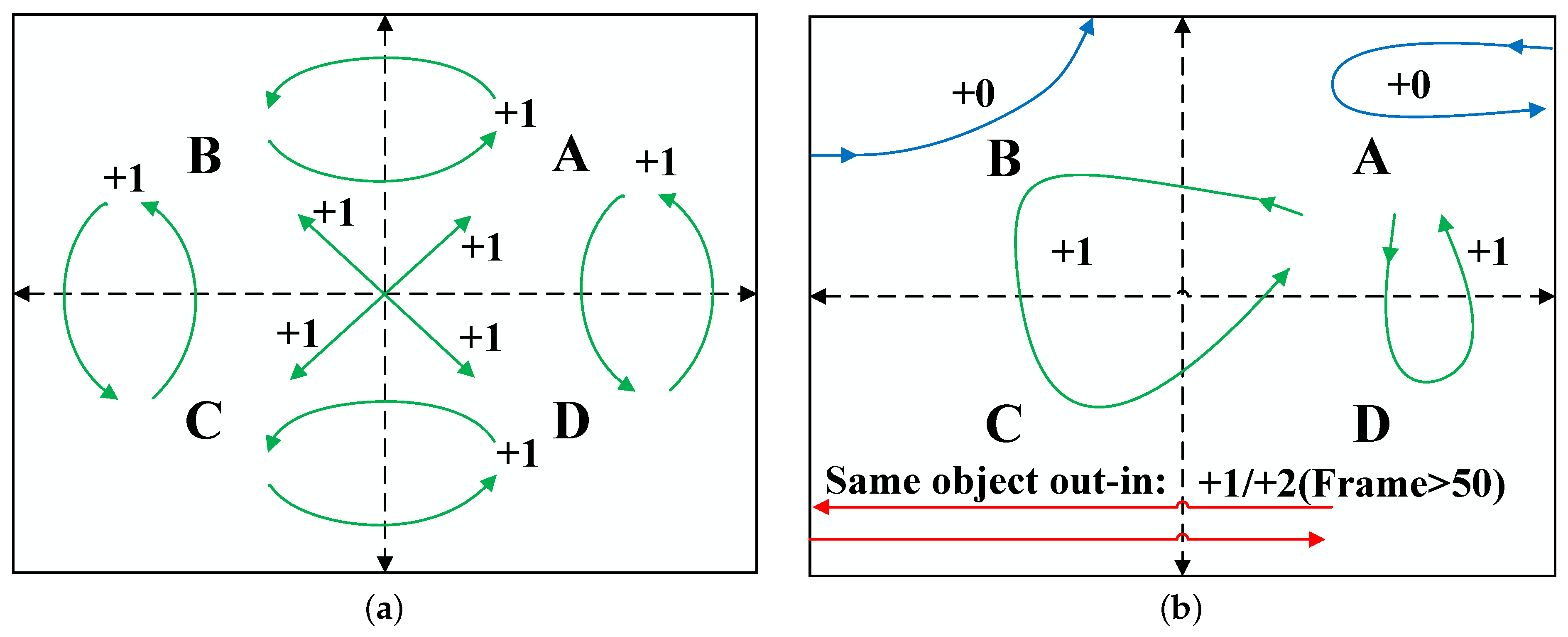
3.3. Statistics: Cross-Boundary Counting Algorithm Based on Scene Segmentation
4. Experimental Results and Discussion
4.1. Dataset
4.1.1. Image: SCUT_HEAD
4.1.2. Video: TownCentreXVID
4.2. Detection Accuracy of YOLOv5-H
4.3. The Accuracy of Human Head Statistics System
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. Acm Trans. Intell. Syst. Technol. (TIST) 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Li, X.; Wang, L.; Sung, E. AdaBoost with SVM-based component classifiers. Eng. Appl. Artif. Intell. 2008, 21, 785–795. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 23–28 June 2014. [Google Scholar]
- Peng, D.; Sun, Z.; Chen, Z.; Cai, Z.; Xie, L.; Jin, L. Detecting Heads using Feature Refine Net and Cascaded Multi-scale Architecture. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2528–2533. [Google Scholar] [CrossRef] [Green Version]
- Stewart, R.; Andriluka, M.; Ng, A.Y. End-To-End People Detection in Crowded Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:cs.CV/1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:cs.CV/1612.08242. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:cs.CV/1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:cs.CV/2004.10934. [Google Scholar]
- Wei, L.; Dragomir, A.; Dumitru, E.; Christian, S.; Scott, R.; Cheng-Yang, F.; Alexander, B. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Springer: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Veeramani, B.; Raymond, J.W.; Chanda, P. DeepSort: Deep convolutional networks for sorting haploid maize seeds. BMC Bioinform. 2018, 19, 289. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vu, T.H.; Osokin, A.; Laptev, I. Context-Aware CNNs for Person Head Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Li, W.; Li, H.; Wu, Q.; Meng, F.; Xu, L.; Ngan, K.N. HeadNet: An End-to-End Adaptive Relational Network for Head Detection. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 482–494. [Google Scholar] [CrossRef]
- Gao, C.; Li, P.; Zhang, Y.; Liu, J.; Wang, L. People counting based on head detection combining Adaboost and CNN in crowded surveillance environment. Neurocomputing 2016, 208, 108–116. [Google Scholar] [CrossRef]
- Jie, Z.; Li, C.; Zheng, L.; Sen, W.; Ze, C. Pedestrian head detection algorithm based on clustering and Faster RCNN. J. Northwest Univ. (Natural Sci. Ed.) 2020, 50, 971–978. (In Chinese) [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy Rate | Recall Rate | mAP@.5 | mAP@.5:.95 | Average Time |
|---|---|---|---|---|---|
| YOLOv5s-H@640 | 0.880 | 0.904 | 0.891 | 0.450 | 3.0 ms |
| YOLOv5m-H@640 | 0.884 | 0.919 | 0.901 | 0.459 | 5.7 ms |
| YOLOv5s-H@1024 | 0.885 | 0.940 | 0.930 | 0.479 | 7.0 ms |
| YOLOv5m-H@1024 | 0.888 | 0.943 | 0.931 | 0.486 | 15.0 ms |
| Model | Accuracy Rate | Recall Rate | mAP@.5 |
|---|---|---|---|
| ReInspect [7] | 0.80 | 0.86 | 0.78 |
| DSCA-Net [6] | 0.88 | 0.86 | 0.87 |
| DSCA-Net + DSM | 0.91 | 0.88 | 0.89 |
| CFR-PHD [19] | 0.89 | 0.91 | 0.877 |
| YOLOv5s@1024 | 0.87 | 0.882 | 0.878 |
| YOLOv5m@1024 | 0.884 | 0.902 | 0.886 |
| YOLOv5s-H@1024 | 0.885 | 0.94 | 0.930 |
| YOLOv5m-H@1024 | 0.888 | 0.943 | 0.931 |
| Method | Actual Heads | Counted Heads | Error Counted Heads | Error Rate | Frames |
|---|---|---|---|---|---|
| YOLOv5s-H + DeepSORT-FH | 230 | 521 | 291 more | 165.2% | 21FPS |
| YOLOv5s-H + DeepSORT-FH + Cross-boundary | 230 | 273 | 43 more | 18.7% | 21FPS |
| YOLOv5m-H + DeepSORT-FH | 230 | 455 | 225 more | 97.8% | 18FPS |
| YOLOv5m-H + DeepSORT-FH + Cross-boundary | 230 | 238 | 8 more | 3.5% | 18FPS |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, A.; Cao, X.; Lu, L.; Zhou, X.; Sun, X. Design of Efficient Human Head Statistics System in the Large-Angle Overlooking Scene. Electronics 2021, 10, 1851. https://doi.org/10.3390/electronics10151851
Wang A, Cao X, Lu L, Zhou X, Sun X. Design of Efficient Human Head Statistics System in the Large-Angle Overlooking Scene. Electronics. 2021; 10(15):1851. https://doi.org/10.3390/electronics10151851
Chicago/Turabian StyleWang, An, Xiaohong Cao, Lei Lu, Xinjing Zhou, and Xuecheng Sun. 2021. "Design of Efficient Human Head Statistics System in the Large-Angle Overlooking Scene" Electronics 10, no. 15: 1851. https://doi.org/10.3390/electronics10151851
APA StyleWang, A., Cao, X., Lu, L., Zhou, X., & Sun, X. (2021). Design of Efficient Human Head Statistics System in the Large-Angle Overlooking Scene. Electronics, 10(15), 1851. https://doi.org/10.3390/electronics10151851