
A Summary of F-Transform Techniques in Data Analysis




Abstract
:1. Introduction
2. Preliminaries
2.1. Basic Functions
- 1.
- (locality)
- 2.
- (positivity)
- 3.
- Ak is continuous in (continuity)
- 4.
- Ak is strictly decreasing in (xk−1, xk) and strictly increasing in (xk, xk+1)
- 5.
- (Ruspini condition).
- 1.
- 2.
2.2. One-Dimensional Direct and Inverse F-Transform
2.3. Multi-Dimensional Direct and Inverse F-Transform
3. Multi-Dimensional F-Transform Methods to Explore Dependency and Rules in the Data
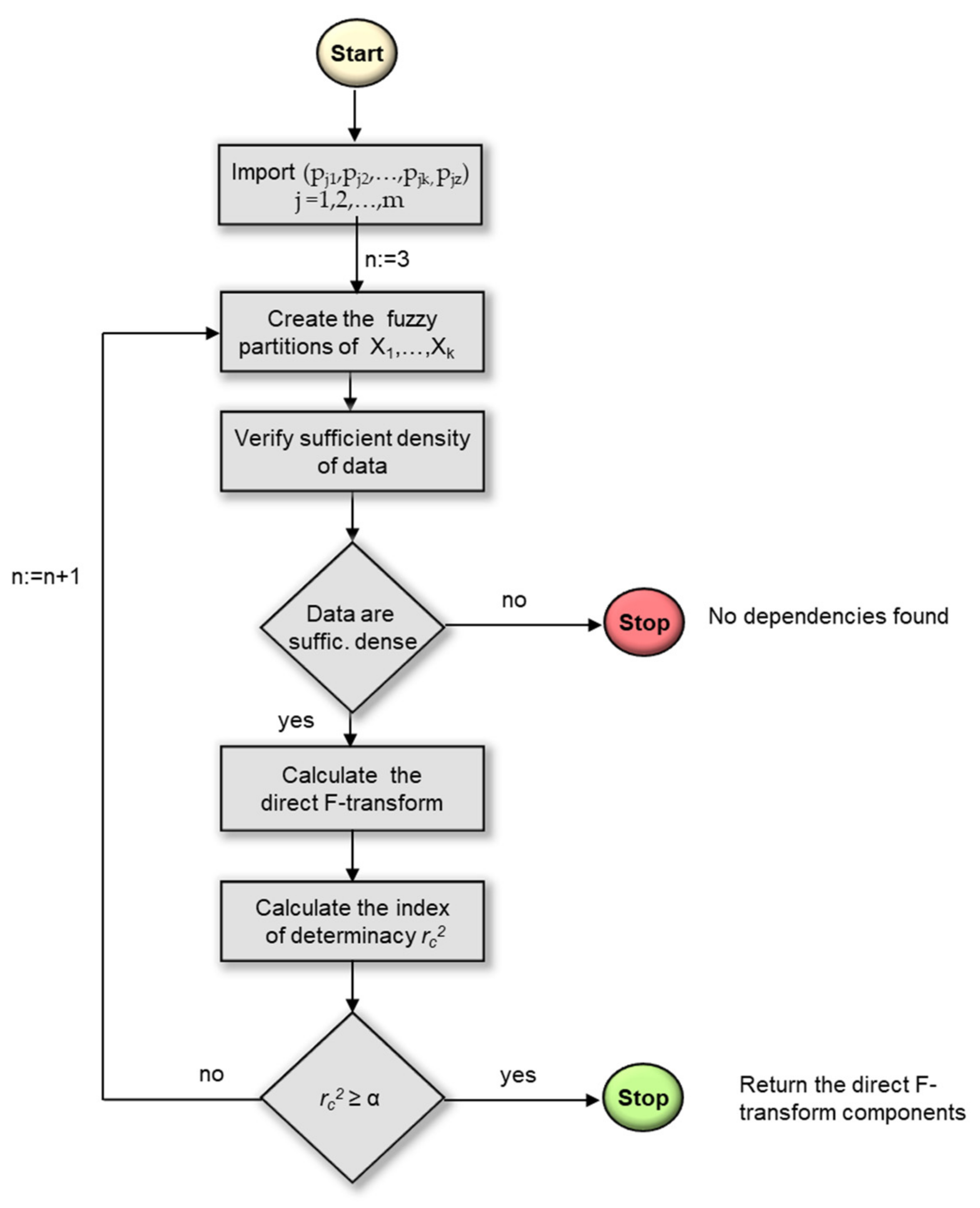
3.1. Multi-Dimensional F-Transform Techniques to Detect Dependency between Attributes in Datasets
3.2. Multi-Dimensional F-Transform Techniques for Mining Association Rules
4. F-Transform Techniques for Time Series Analysis
4.1. One-Dimensional F-Transform Time Series Models
4.2. Multi-Dimensional F-Transform Time Series Model
4.3. F-Transform Seeasonal Time Series Model
5. F-Transform in Data Classification
- -
- is the percentage of all the misclassified data points in the kth training set;
- -
- is the percentage of all the misclassified data points in the kth validation set.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Table of Acronyms and Abbreviations

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronym/Abbreviation | Explanation |
|---|---|
| F-transform | Fuzzy transform |
| Multidimensional F-transform | Multi-dimensional Fuzzy transform |
| MFAD | Massive F-transform Attribute Dependency method |
| SVM | Support Vector regression Method |
| MLP | MultiLayer Perceptron method |
| avgSV | AVeraGe Seasonal Variation model |
| SARIMA | Seasonal AutoRegressive Integrated Moving Average model |
| MF-tr | Multi-dimensional Fuzzy TRansform forecasting model |
| TFSS | Time Series Seasonal time series F-transform model |
| ADANN | Automatic Design of Artificial Neural Networks model |
| MFC | Multidimensional F-transform Classification method |
| UCI | University of California, Irvine |
| K-fold | Cross-validation K-fold resampling method applied in classification. |
| Naïve Bayes | Naïve Bayesian classification method |
| J48 | Decision tree J48 classification algorithm in the Weka data mining tool. |
| Lazy IBK | Lazy K-Nearest Neighbor Instance-Bases learning with parameter K classification method. |
| PCA | Principal Component Analysis. |
References
- Perfilieva, I.; Haldeeva, E. Fuzzy transformation. In Proceedings of the IFSA World Congress and 20th NAFIPS International Conference, Joint 9th, Vancouver, Canada, 25–28 July 2001; IEEE: Piscataway, NJ, USA, 2001; Volume 4, pp. 1946–1948. [Google Scholar]
- Perfilieva, I. Fuzzy transforms: Theory and applications. Fuzzy Sets Syst. 2006, 157, 993–1023. [Google Scholar] [CrossRef]
- Di Martino, F.; Sessa, S. Fuzzy Transforms for Image Processing and Data Analysis. Core Concepts, Processes and Applications; Springer: Cham, Switzerland, 2020; p. 217. [Google Scholar] [CrossRef]
- Bede, B.; Rudas, I.J. Approximation properties of fuzzy transforms. Fuzzy Sets Syst. 2011, 180, 20–40. [Google Scholar] [CrossRef]
- Khastan, A. A new representation for inverse fuzzy transform and its application. Soft Comput. 2017, 21, 3503–3512. [Google Scholar] [CrossRef]
- Perfilieva, I.; Dankova, M.; Bede, B. Towards a higher degree f-transform. Fuzzy Sets Syst. 2020, 180, 3–19. [Google Scholar] [CrossRef]
- Alikhani, R.; Zeinali, M.; Bahrami, F.; Shahmorad, S.; Perfilieva, I. Trigonometric fm-transform and its approximative properties. Soft Comput. 2017, 21, 3567–3577. [Google Scholar] [CrossRef]
- Zeinali, M.; Alikhani, R.; Bahrami, F.; Shahmorad, S.; Perfilieva, I. On the structural properties of fm-transform with application. Fuzzy Sets Syst. 2018, 342, 31–52. [Google Scholar] [CrossRef]
- Di Martino, F.; Sessa, S. Seasonal Time Series Forecasting by F1-Fuzzy Transform, Special Issue Intelligent Systems in Sensor Networks and Internet of Things. Axioms 2019, 19, 3611. [Google Scholar]
- Perfilieva, I.; Novàk, V.; Dvoràk, A. Fuzzy transforms in the analysis of data. Int. J. Approx. Reason. 2008, 48, 36–46. [Google Scholar] [CrossRef] [Green Version]
- Di Martino, F.; Loia, V.; Sessa, S. Fuzzy transforms method and attribute dependency in data analysis. Inf. Sci. 2010, 180, 493–505. [Google Scholar] [CrossRef]
- Di Martino, F.; Sessa, S. Attribute dependency data analysis for massive datasets by fuzzy transforms. Soft Comput. 2021. [Google Scholar] [CrossRef]
- Wold, H. A Study in Analysis of Stationary Time Series. R. Stat. Soc. 1939, 102, 295–298. [Google Scholar]
- Wei, W.W.S. Time Series Analysis Univariate and Multivariate Methods, 2nd ed.; Pearson Addison Wesley: Boston, MA, USA, 2006; p. 605. ISBN 0-321-32216-9. [Google Scholar]
- Perfilieva, I.G.; Yarushkina, N.G.; Afanasieva, T.V. In Proceedings of International Conference on Fuzzy Systems, Barcelona, Spain, 18–23 July 2010.
- Perfilieva, I.; Yarushkina, N.; Afanasieva, T.; Romanov, A. Time series analysis using soft computing methods. Int. J. Gen. Syst. 2013, 42, 687–705. [Google Scholar] [CrossRef]
- Novàk, V.; Perfilieva, I.; Kreinovich, V. Filtering out high frequencies in time series using F-transform. Inf. Sci. 2014, 274, 192–209. [Google Scholar] [CrossRef] [Green Version]
- Di Martino, F.; Loia, V.; Sessa, S. Fuzzy transforms method in prediction data analysis. Fuzzy Sets Syst. 2011, 180, 146–163. [Google Scholar] [CrossRef]
- Di Martino, F.; Sessa, S. Fuzzy transform prediction in spatial analysis and its application to demographic balance data. Soft Comput. 2017, 21, 3537–3550. [Google Scholar] [CrossRef] [Green Version]
- Ziegel, E.R.; Box, G.E.P.; Reinsel, G.C.; Jenkins, S. Time Series Analysis, Forecasting, and Control. Technometrics Taylor Fr. Milton Park 1995, 37, 238–239. [Google Scholar] [CrossRef]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C. Time Series Analysis: Forecasting and Control, 5th ed.; Prentice Hall: Englewood Cliffs, NJ, USA, 2015; p. 712. ISBN 978-1-118-67502-1. [Google Scholar]
- Di Martino, F.; Sessa, S. Time series seasonal analysis based on fuzzy transforms. Symmetry 2017, 9, 281. [Google Scholar] [CrossRef] [Green Version]
- Pai, P.F.; Lin, K.P.; Lin, C.S.; Chang, P.T. Time series forecasting by a seasonal support vector regression model. Exp. Syst. Appl. 2010, 37, 4261–4265. [Google Scholar] [CrossRef]
- Štepnicka, M.; Cortez, P.; Peralta Donate, J.; Štepnickova, L. Forecasting seasonal time series with computational intelligence: On recent methods and the potential of their combinations. Exp. Syst. Appl. 2013, 40, 1981–1992. [Google Scholar] [CrossRef] [Green Version]
- Di Martino, F.; Sessa, S. A classification algorithm based on multi-dimensional fuzzy transforms. Ambient Intell. Humaniz. Comput. 2021. [Google Scholar] [CrossRef]
- Bhargawa, N.; Sharma, G.; Bhargava, R.; Mathuria, M. Decision Tree Analysis on J48 Algorithm for Data Mining. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2013, 3, 1114–1119. [Google Scholar]
- Pal, S.K.; Mitra, S. Multilayer perceptron, fuzzy sets, and classification. IEEE Trans. Neural Netw. 1992, 3, 683–697. [Google Scholar] [CrossRef] [PubMed]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective (Adaptive Computation and Machine Learning Series), 1st ed.; The MIT Press: London, UK, 2012; p. 1070. ISBN 978-0262018029. [Google Scholar]
- Aha, D.W. (Ed.) Lazy Learning; Kluwer Academic Publishers: Norwell, MA, USA, 1997; p. 436. ISBN 978-0792345848. [Google Scholar]
- Hurtik, P.; Molek, V.; Perfilieva, I. Novel dimensionality reduction approach for unsupervised learning on small datasets. Pattern Recognit. 2020, 103, 107291. [Google Scholar] [CrossRef]
- Harirchian, E.; Ehsan, S.; Hosseini, A.; Jadhav, K.; Kumari, V.; Rasulzade, S.; Işık, E.; Wasif, M.; Lahmer, T. A review on application of soft computing techniques for the rapid visual safety evaluation and damage classification of existing buildings. J. Build. Eng. 2021, 43, 102536. [Google Scholar] [CrossRef]
- Harirchian, E.; Lhamer, T. Developing a hierarchical type-2 fuzzy logic model to improve rapid evaluation of earthquake hazard safety of existing buildings. Structures 2020, 28, 1384–1399. [Google Scholar] [CrossRef]
- Georgieva, A. Application of Double Fuzzy Natural Transform for Solving Fuzzy Partial Equations, AIP Conference Proceedings; AIP Publishing: Melville, NY, USA, 2021; Volume 2333, p. 080006. [Google Scholar] [CrossRef]
- Mazandarani, M.; Xiu, L. A Review on Fuzzy Differential Equations. IEEE Access 2021, 9, 62195–62211. [Google Scholar] [CrossRef]






| X1 | ... | Xi | ... | Xr | |
|---|---|---|---|---|---|
| O1 | p11 | . | p1i | . | p1r |
| . | . | . | . | . | . |
| . | . | . | . | . | . |
| . | . | . | . | . | . |
| Oj | pj1 | . | pji | . | pjr |
| . | . | . | . | . | . |
| . | . | . | . | . | . |
| . | . | . | . | . | . |
| Om | pm1 | . | pmi | . | pmr |
| s | Index of Determinacy |
|---|---|
| 1 | 0.881 |
| 8 | 0.872 |
| 9 | 0.872 |
| 10 | 0.874 |
| 11 | 0.875 |
| 13 | 0.877 |
| 16 | 0.878 |
| 20 | 0.878 |
| 26 | 0.875 |
| 40 | 0.872 |
| Station | RMSE | |||||
|---|---|---|---|---|---|---|
| avgSV | SARIMA | MF-tr. | TSSF | SVM | ADANN | |
| Alpe Gorreto | 2.98 | 1.20 | 1.49 | 0.84 | 0.81 | 0.83 |
| Campo Ligure | 2.74 | 1.09 | 1.34 | 0.76 | 0.71 | 0.76 |
| Barbagelata | 3.25 | 1.30 | 1.57 | 0.89 | 0.84 | 0.90 |
| Camogli | 3.39 | 1.38 | 1.68 | 0.95 | 0.88 | 0.86 |
| Campo ligure | 3.02 | 1.20 | 1.49 | 0.83 | 0.77 | 0.79 |
| Carlasco | 2.91 | 1.15 | 1.42 | 0.80 | 0.77 | 0.76 |
| Chiavari | 2.78 | 1.12 | 1.39 | 0.78 | 0.73 | 0.77 |
| Genova Bolzaneto | 2.95 | 1.16 | 1.41 | 0.81 | 0.77 | 0.75 |
| Genova Pegli | 3.34 | 1.29 | 1.64 | 0.94 | 0.89 | 0.88 |
| Panesi | 3.20 | 1.29 | 1.56 | 0.87 | 0.84 | 0.83 |
| Rapallo | 2.71 | 1.08 | 1.33 | 0.75 | 0.78 | 0.84 |
| Rovegno | 2.94 | 1.18 | 1.45 | 0.82 | 0.82 | 0.80 |
| Tigliolo | 3.06 | 1.24 | 1.52 | 0.85 | 0.80 | 0.85 |
| Viganego | 3.17 | 1.28 | 1.57 | 0.88 | 0.82 | 0.83 |
| Algorithm | Accuracy | Precision | Recall |
|---|---|---|---|
| MFC Classifier | 98.15% | 98.09% | 97.36% |
| Decision tree J48 | 98.38% | 98.17% | 97.51% |
| Multilayer Perceptron | 98.22% | 98.23% | 97.48% |
| Naive Bayes | 96.55% | 91.89% | 90.65% |
| Lazy IBK | 97.17% | 93.30% | 91.44% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martino, F.D.; Perfilieva, I.; Sessa, S. A Summary of F-Transform Techniques in Data Analysis. Electronics 2021, 10, 1771. https://doi.org/10.3390/electronics10151771
Martino FD, Perfilieva I, Sessa S. A Summary of F-Transform Techniques in Data Analysis. Electronics. 2021; 10(15):1771. https://doi.org/10.3390/electronics10151771
Chicago/Turabian StyleMartino, Ferdinando Di, Irina Perfilieva, and Salvatore Sessa. 2021. "A Summary of F-Transform Techniques in Data Analysis" Electronics 10, no. 15: 1771. https://doi.org/10.3390/electronics10151771
APA StyleMartino, F. D., Perfilieva, I., & Sessa, S. (2021). A Summary of F-Transform Techniques in Data Analysis. Electronics, 10(15), 1771. https://doi.org/10.3390/electronics10151771