
Blockchain-Enabled Transaction Scanning Method for Money Laundering Detection

 ,
,  ,
, 
 and
and
Abstract
:1. Introduction
- Novel rules have been formulated for anomalous transaction detection that support the fight against money laundering.
- A blockchain transaction scanning method is employed that involves the rich features of data mining and the blockchain for deciding between confirmed malicious and legitimate transactions.
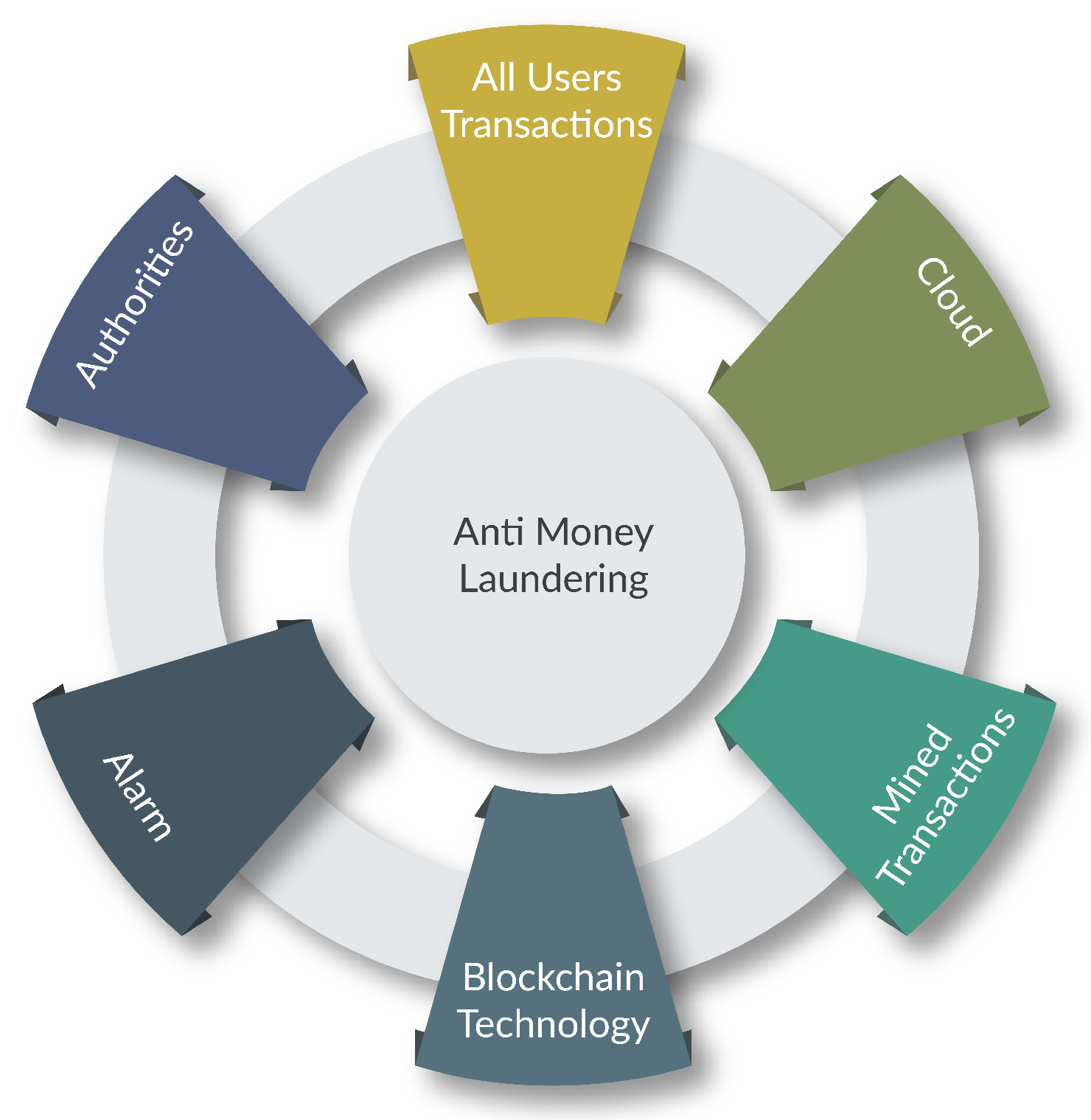
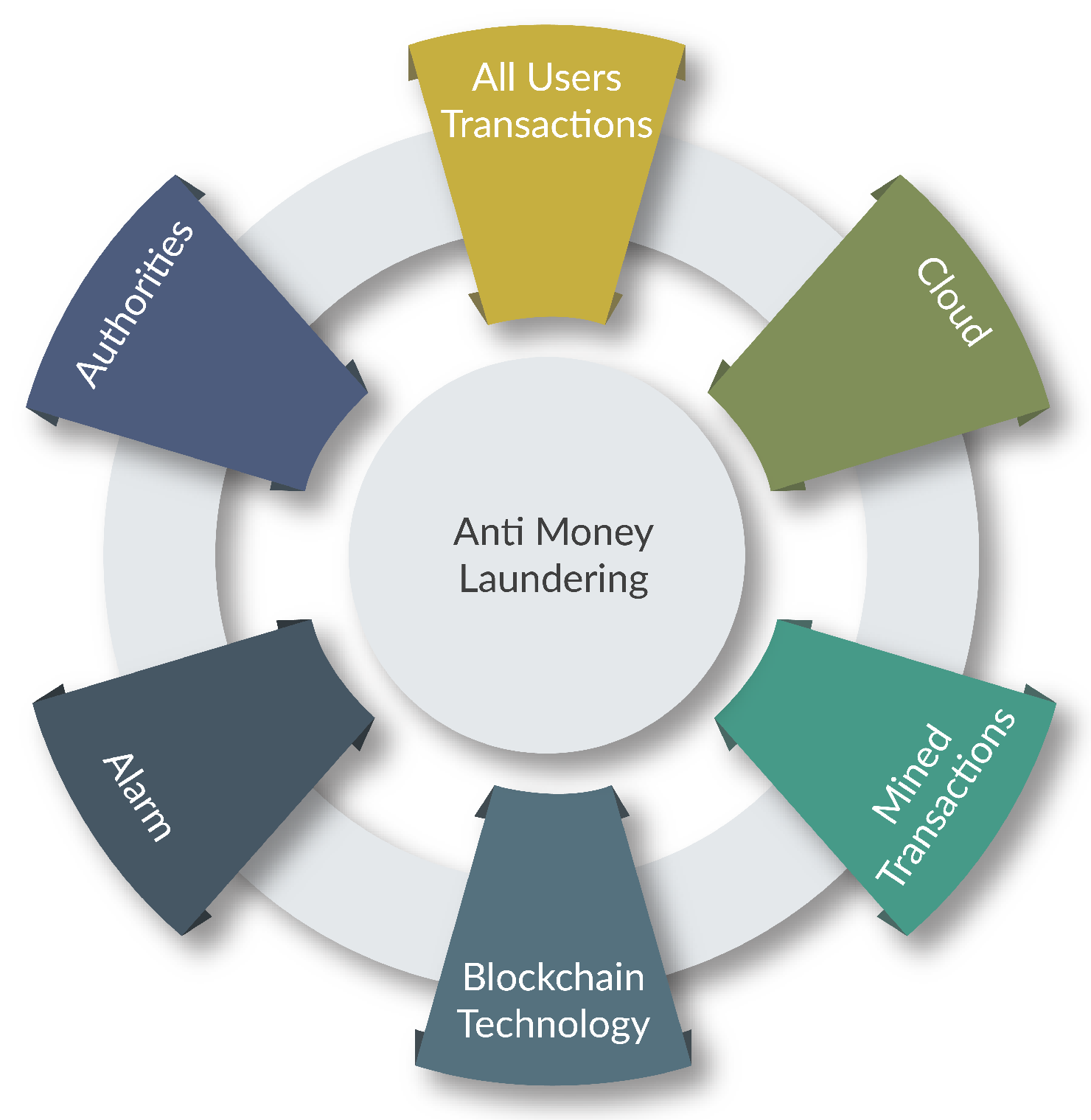
2. Problem Identification
3. Related Works
4. System Model
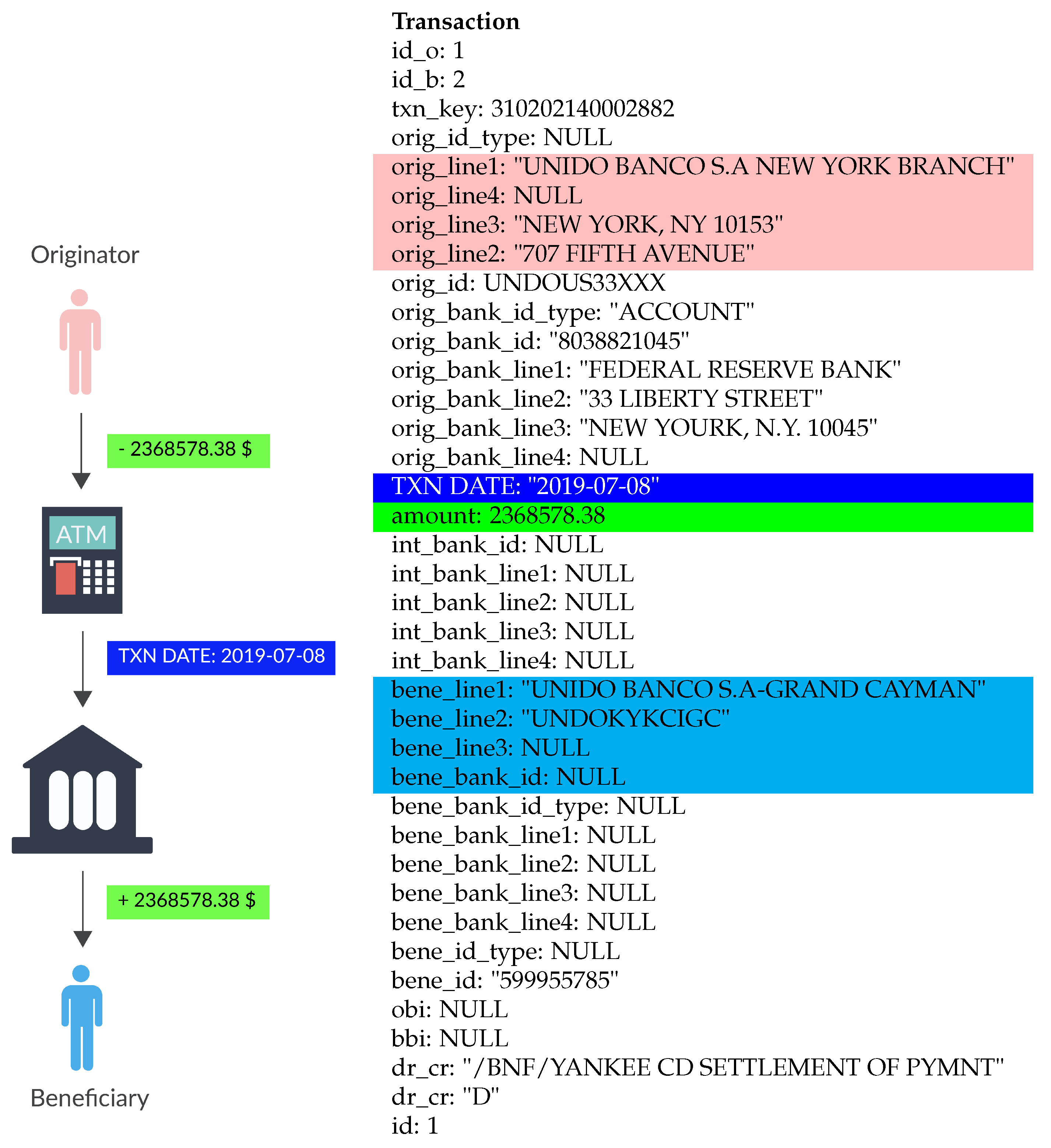
- Originator;
- Beneficiary;
- Transaction committed date;
- Amount of money.
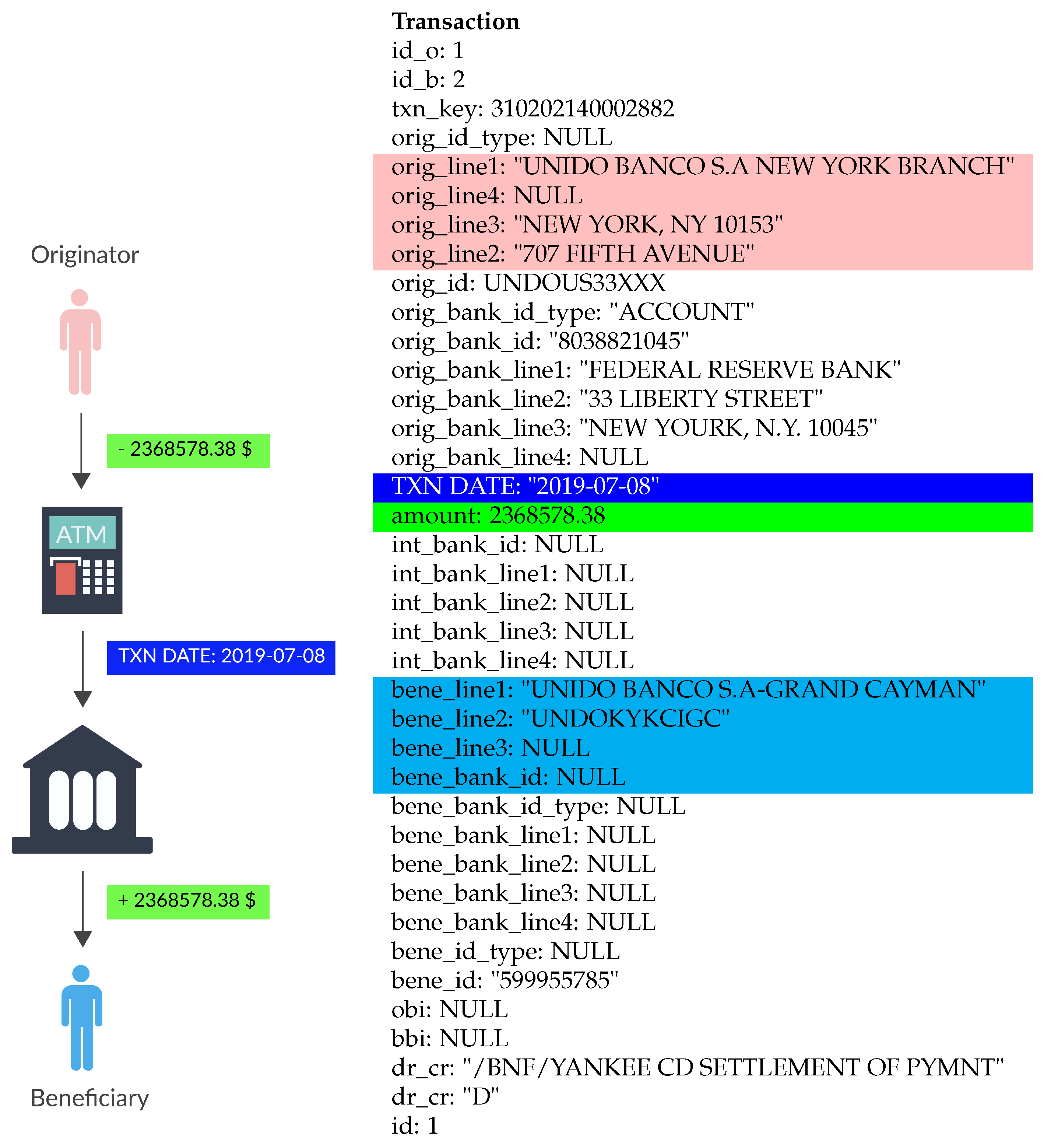
4.1. Originator
4.2. Beneficiary
4.3. Transaction Committed Date
4.4. Amount of Money
5. Problem Formulation Rules for Transaction Anomaly Detection
- Outlier detection;
- Rapid mvmt funds.
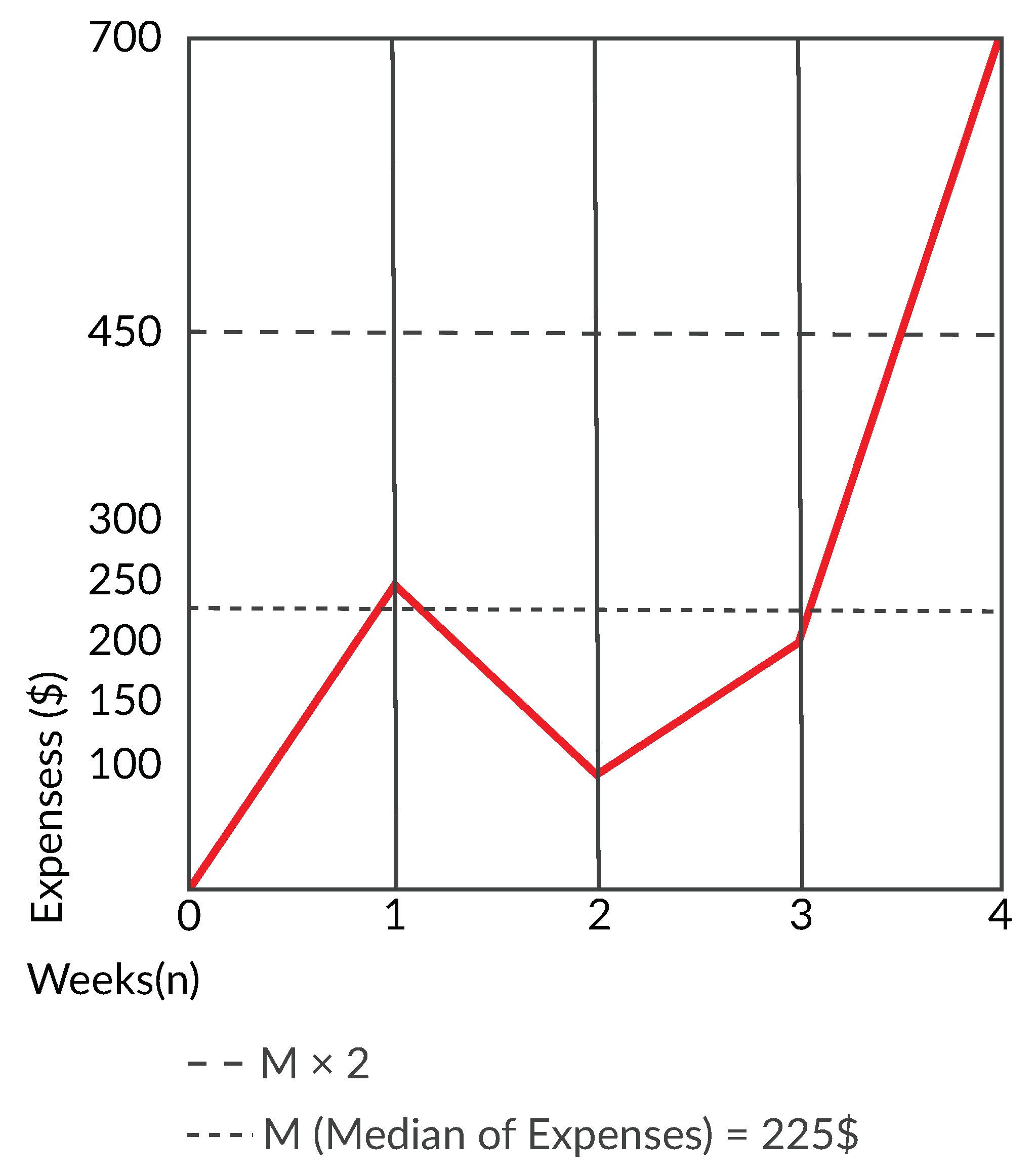
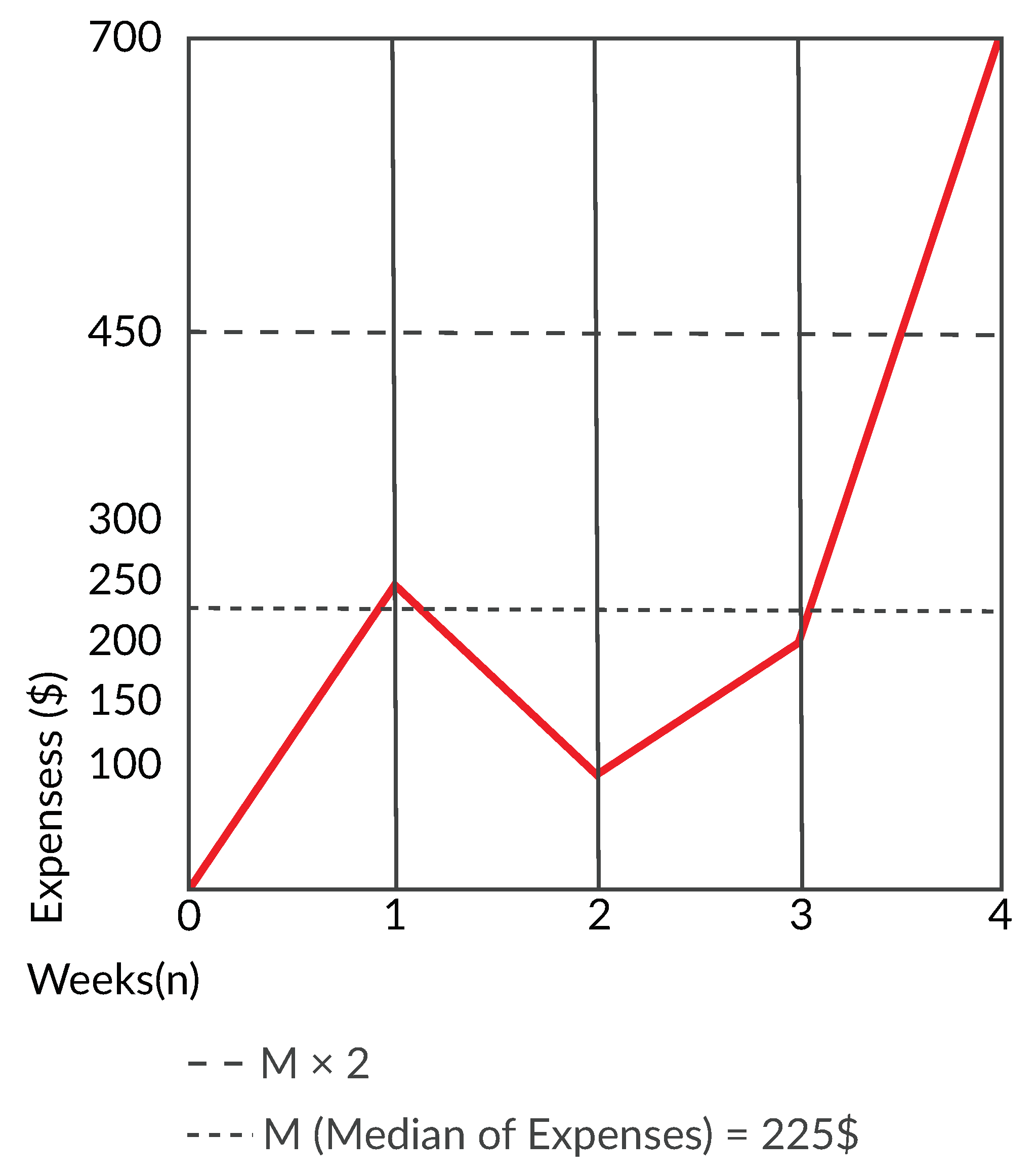
5.1. Outlier Detection
- Investment or savings;
- Mandatory payments;
- Variable costs.
5.1.1. Investment or Savings
5.1.2. Mandatory Payments
5.1.3. Variable Costs
| Algorithm 1: Outlier Detection |
|
5.2. Rapid Mvmt Funds
- Digital services: Internet money transfer services are not only more difficult for authorities to control but also allow criminals to bypass identity verification processes.
- Prepaid cards: Every bank consumer can use prepaid cards to send and withdraw money through ATMs.
- Third party engaging: Money launderers can hire third parties on their behalf to perform transactions. Such third parties are called money mules.
- Ownership: Given the spread of money transfer services, to avoid the rules, money launderers can obtain ownership of a money transfer company.
- Structuring: Different accounts may be used by money launderers to participate in multiple money transfer transactions.
| Algorithm 2: Rapid Movements of Funds. |
|
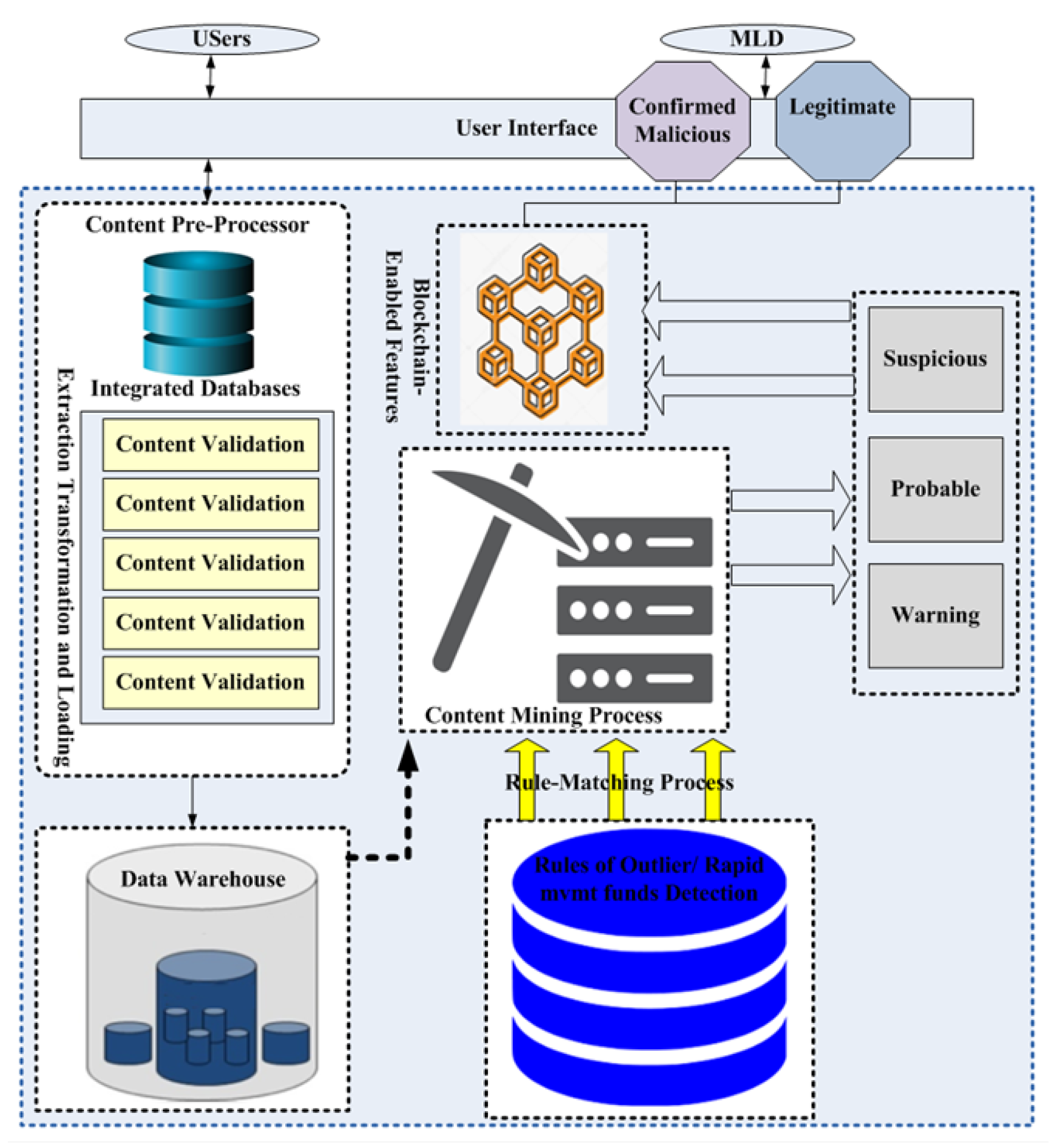
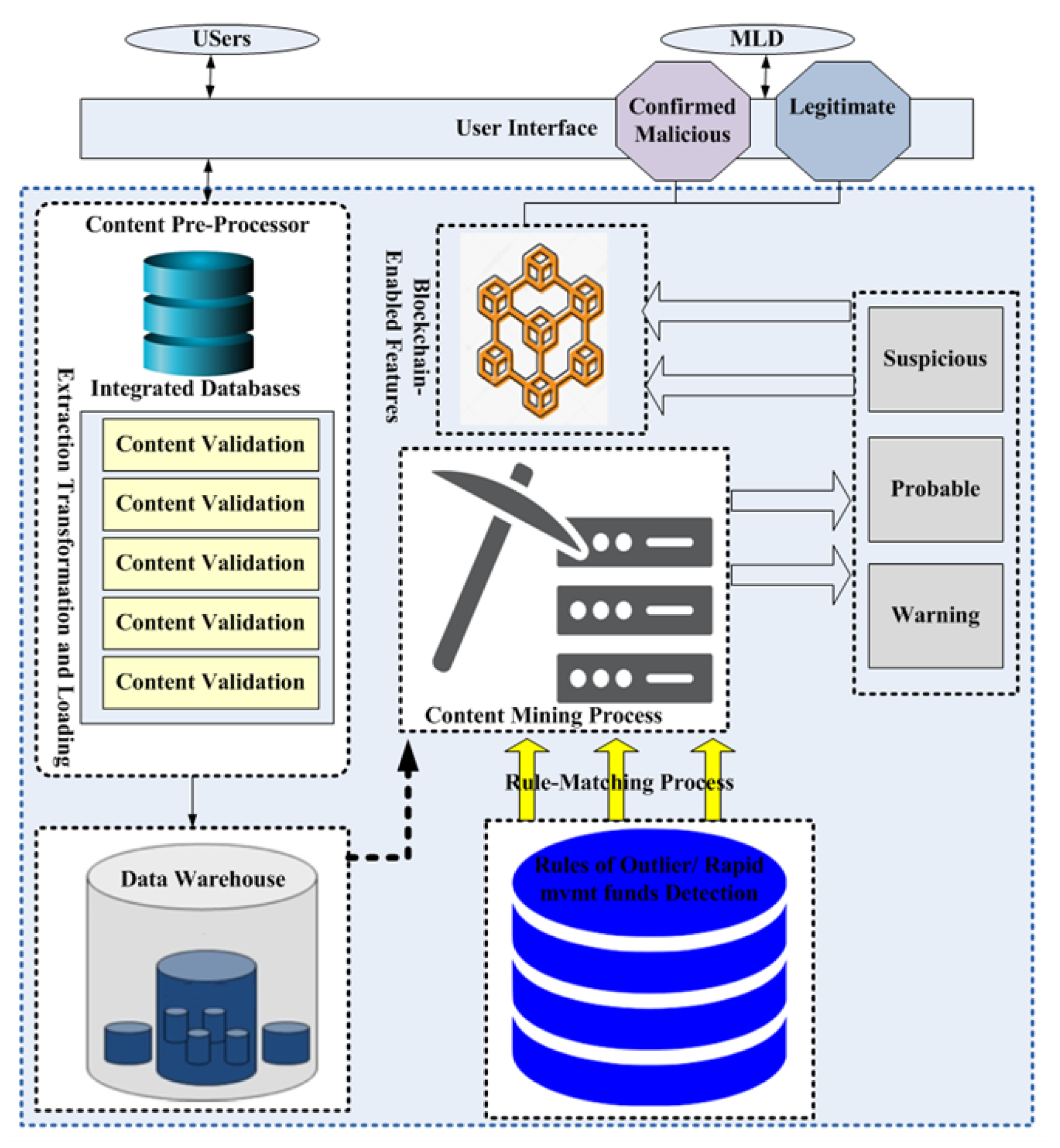
6. Proposed BTS Method for Money Laundering Detection
- Content pre-processing;
- Content mining and blockchain-enabled features.
6.1. Content Pre-Processing
- Null or dummy values: This happens in most of the data fields of the databases except the identity of the user, the user type (individual, joint, or company), and fund name.
- Misspelling: Usually phonetic and typo errors. Additionally, banking datasets are mostly organized in a distributed fashion to maintain security and flexibility. The heterogeneity of the contents can pose a threat to the content quality, particularly when an integrating process is required. Therefore, the basic content quality issues can be addressed using pre-processing.
6.2. Content Mining and Blockchain-Enabled Features
| Algorithm 3: Rule-Matching Process Using Content Mining |
|
7. Experimental Results
- Outlier detection;
- Rapid mvmt funds.
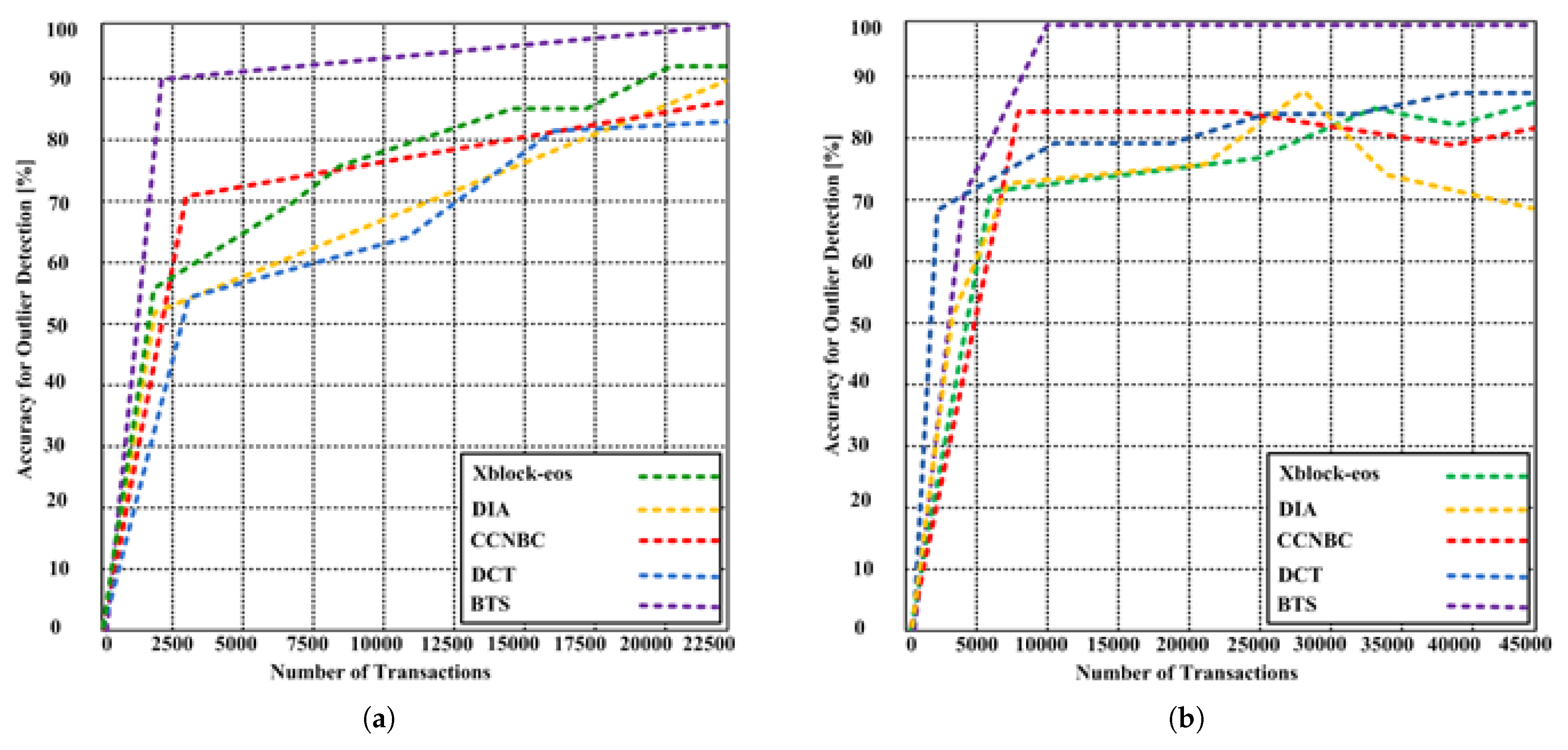
7.1. Outlier Detection
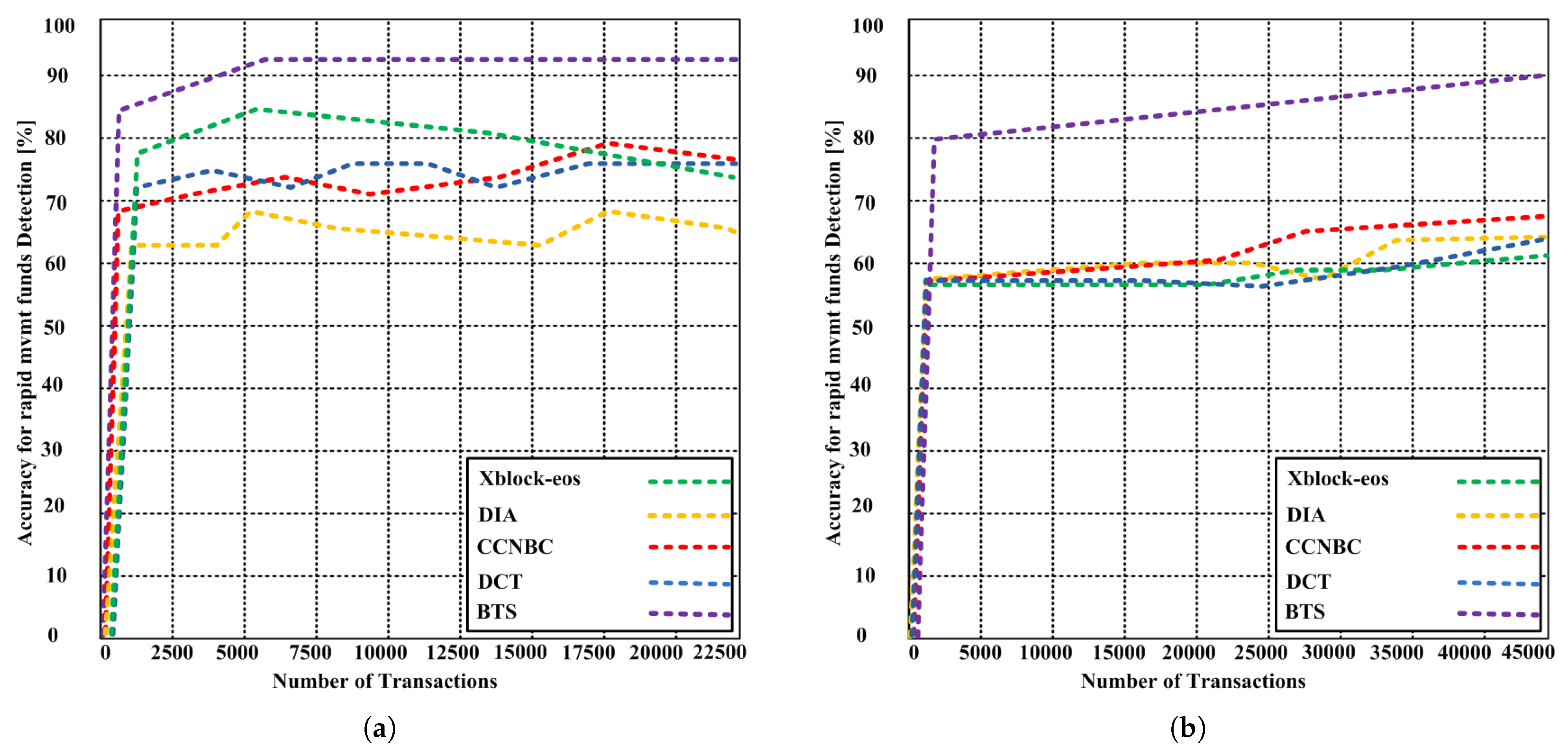
7.2. Rapid Mvmt Funds
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Haller, D.R.; Nguyen, T.; Rowney, K.T.; Berger, D.A.; Kramer, G.A. System, Method and Article of Manufacture for Managing Transactions in a High Availability System. U.S. Patent 6,363,363, 26 March 2002. [Google Scholar]
- Dodgson, M.; Gann, D.; Wladawsky-Berger, I.; Sultan, N.; George, G. Managing digital money. Acad. Manag. J. 2015, 58, 325–333. [Google Scholar] [CrossRef] [Green Version]
- Adrian, T.; Mancini-Griffoli, T. The rise of digital money. Annu. Rev. Financ. Econ. 2019. Available online: file:///C:/Users/MDPI/AppData/Local/Temp/FTNEA2019001.pdf (accessed on 5 June 2021). [CrossRef] [Green Version]
- Kruisbergen, E.W.; Leukfeldt, E.R.; Kleemans, E.R.; Roks, R.A. Money talks money laundering choices of organized crime offenders in a digital age. J. Crime Justice 2019, 42, 569–581. [Google Scholar] [CrossRef]
- Chong, A.; Lopez-De-Silanes, F. Money laundering and its regulation. Econ. Politics 2015, 27, 78–123. [Google Scholar] [CrossRef]
- Weber, J.; Kruisbergen, E.W. Criminal markets: The dark web, money laundering and counterstrategies-an overview of the 10th research conference on organized crime. Trends Organ. Crime 2019, 22, 346–356. [Google Scholar] [CrossRef]
- Levi, M. Money for crime and money from crime: Financing crime and laundering crime proceeds. Eur. J. Crim. Policy Res. 2015, 21, 275–297. [Google Scholar] [CrossRef] [Green Version]
- Chaikin, D. Money laundering and tax evasion—The assisting of the banking sector. In The Handbook of Business and Corruption; Emerald Publishing Limited: Bingley, UK, 2017. [Google Scholar]
- Alldridge, P. Tax avoidance, tax evasion, money laundering and the problem of ‘offshore’. In Greed, Corruption, and the Modern State; Edward Elgar Publishing: Cheltenham, UK, 2015. [Google Scholar]
- Kurnia, D.A. Study on money laundering practices from the criminal action results of political parties. Translitera: J. Kaji. Komun. Dan Studi Media 2018, 6, 24–36. [Google Scholar] [CrossRef]
- Ams, J.; Kyriakos-Saad, N.; El Khoury, C.; Almeida, Y.; Robert, E.; Hagan, S. Anti-Money Laundering/Combating the Financing of Terrorism (AML/CFT). In Anti-Money Laundering/Combating the Financing of Terrorism (AML/CFT); International Monetary Fund, 2018. [Google Scholar] [CrossRef]
- Sullivan, K. Anti-Money Laundering in a Nutshell: Awareness and Compliance for Financial Personnel and Business Managers; Apress: New York, NY, USA, 2015. [Google Scholar]
- Maximillian, F.; Teichmann, J. Twelve methods of money laundering. J. Money Laund. Control. 2017, 20, 130–137. [Google Scholar]
- Salehi, A.; Ghazanfari, M.; Fathian, M. Data mining techniques for anti money laundering. Int. J. Appl. Eng. Res. 2017, 12, 10084–10094. [Google Scholar]
- Sobh, T.S. An Intelligent and Secure Framework for Anti-Money Laundering. J. Appl. Secur. Res. 2020, 15, 517–546. [Google Scholar] [CrossRef]
- Pol, R.F. Anti-money laundering: The world’s least effective policy experiment? together, we can fix it. Policy Des. Pract. 2020, 3, 73–94. [Google Scholar] [CrossRef] [Green Version]
- Alldridge, P. What Went Wrong with Money Laundering Law? Springer: Berlin, Germany, 2016. [Google Scholar]
- Bergþórsdóttir, K. Local Explanation Methods for Isolation Forest: Explainable Outlier Detection in Anti-Money Laundering. Master’s Thesis, Delft University of Technology, Delft, The Netherlands, 28 August 2020. [Google Scholar]
- Singh, K.; Best, P. Anti-money laundering: Using data visualization to identify suspicious activity. Int. J. Account. Inf. Syst. 2019, 34, 100418. [Google Scholar] [CrossRef]
- Kolhatkar, J.S.; Fatnani, S.S.; Yao, Y.; Matsumoto, K. Multi-Channel Data Driven, Real-Time Anti-Money Laundering System for Electronic Payment Cards. U.S. Patent 8,751,399, 10 June 2014. [Google Scholar]
- Raza, S.; Haider, S. Suspicious activity reporting using dynamic bayesian networks. Procedia Comput. Sci. 2011, 3, 987–991. [Google Scholar] [CrossRef] [Green Version]
- Weber, M.; Chen, J.; Suzumura, T.; Pareja, A.; Ma, T.; Kanezashi, H.; Kaler, T.; Leiserson, C.E.; Schardl, T.B. Scalable graph learning for anti-money laundering: A first look. arXiv 2018, arXiv:1812.00076. [Google Scholar]
- Luo, X. Suspicious transaction detection for anti-money laundering. Int. J. Secur. Appl. 2014, 8, 157–166. [Google Scholar] [CrossRef]
- Colladon, A.F.; Remondi, E. Using social network analysis to prevent money laundering. Expert Syst. Appl. 2017, 67, 49–58. [Google Scholar] [CrossRef]
- Warren, E.; Tyagi, A.W. All Your Worth: The Ultimate Lifetime Money Plan; Simon and Schuster: New York, NY, USA, 2005. [Google Scholar]
- FATF; MENAFATF. Money Laundering through Money Remittance and Currency Exchange Providers. The Financial Action Task Force Website. Available online: https://www.fatf-gafi.org/publications/methodsandtrends/documents/ml-through-physical-transportation-of-cash.html (accessed on 27 June 2015).
- Theodorou, V.; Jovanovic, P.; Abellò, A.; Nakuçi, E. Data generator for evaluating etl process quality. Inf. Syst. 2017, 63, 80–100. [Google Scholar] [CrossRef] [Green Version]
- Jullum, M.; Løland, A.; Huseby, R.B.; Ånonsen, G.; Lorentzen, J. Detecting money laundering transactions with machine learning. J. Money Laund. Control 2020, 23, 173–186. [Google Scholar] [CrossRef]
- Zheng, W.; Zheng, Z.; Dai, H.-N.; Chen, X.; Zheng, P. Xblock-eos: Extracting and exploring blockchain data from eosio. Inf. Process. Manag. 2021, 58, 102477. [Google Scholar] [CrossRef]
- Albakri, A.; Mokbel, C. Convolutional neural network biometric cryptosystem for the protection of the blockchain’s private key. Procedia Comput. Sci. 2019, 160, 235–240. [Google Scholar] [CrossRef]
- Baek, H.; Oh, J.; Kim, C.Y.; Lee, K. A model for detecting cryptocurrency transactions with discernible purpose. In Proceedings of the 2019 Eleventh International Conference on Ubiquitous and Future Networks (ICUFN), Split, Croatia, 2–5 July 2019; pp. 713–717. [Google Scholar]
- Farrugia, S.; Ellul, J.; Azzopardi, G. Detection of illicit accounts over the ethereum blockchain. Expert Syst. Appl. 2020, 150, 113318. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| OS | Ubuntu 20.04.1 LTS |
| Processor | Intel® Core™ i7-8550U CPU @ 1.80 GHz |
| Processor architecture | x64 |
| Graphic card | GeForce MX150/PCIe/SSE2 |
| Hard drive | 256 GB SSD |
| RAM | 15.5 GB |
| Outlier Detection | Rapid Mvmt | |
|---|---|---|
| Execution time | 138,606 ms | 139,701 ms |
| Number of rows generated | 581 | 143 |
| CPU usage | 1.40 GHz | 1.50 GHz |
| RAM usage | 2 GB | 2 GB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oad, A.; Razaque, A.; Tolemyssov, A.; Alotaibi, M.; Alotaibi, B.; Zhao, C. Blockchain-Enabled Transaction Scanning Method for Money Laundering Detection. Electronics 2021, 10, 1766. https://doi.org/10.3390/electronics10151766
Oad A, Razaque A, Tolemyssov A, Alotaibi M, Alotaibi B, Zhao C. Blockchain-Enabled Transaction Scanning Method for Money Laundering Detection. Electronics. 2021; 10(15):1766. https://doi.org/10.3390/electronics10151766
Chicago/Turabian StyleOad, Ammar, Abdul Razaque, Askar Tolemyssov, Munif Alotaibi, Bandar Alotaibi, and Chenglin Zhao. 2021. "Blockchain-Enabled Transaction Scanning Method for Money Laundering Detection" Electronics 10, no. 15: 1766. https://doi.org/10.3390/electronics10151766
APA StyleOad, A., Razaque, A., Tolemyssov, A., Alotaibi, M., Alotaibi, B., & Zhao, C. (2021). Blockchain-Enabled Transaction Scanning Method for Money Laundering Detection. Electronics, 10(15), 1766. https://doi.org/10.3390/electronics10151766