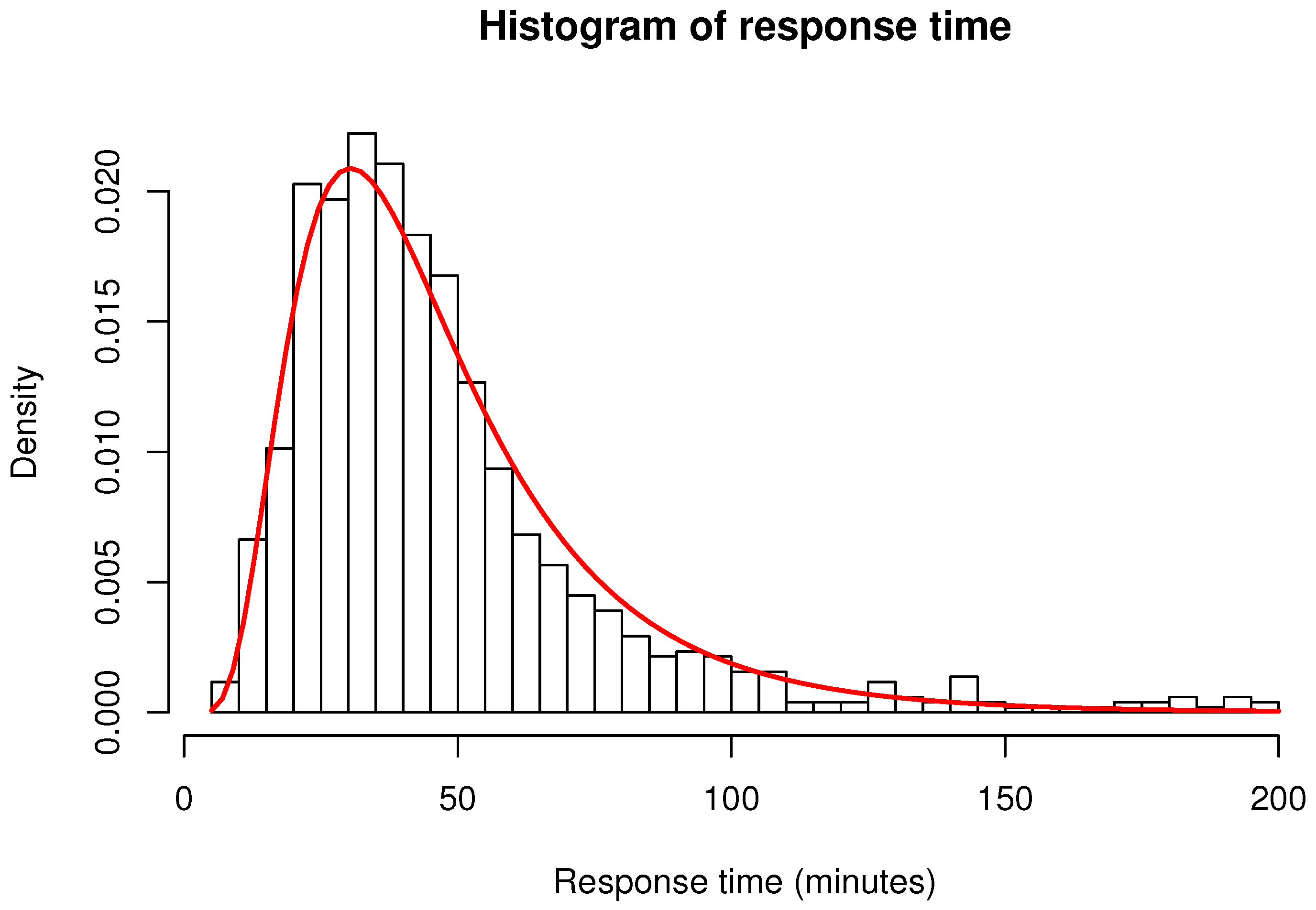
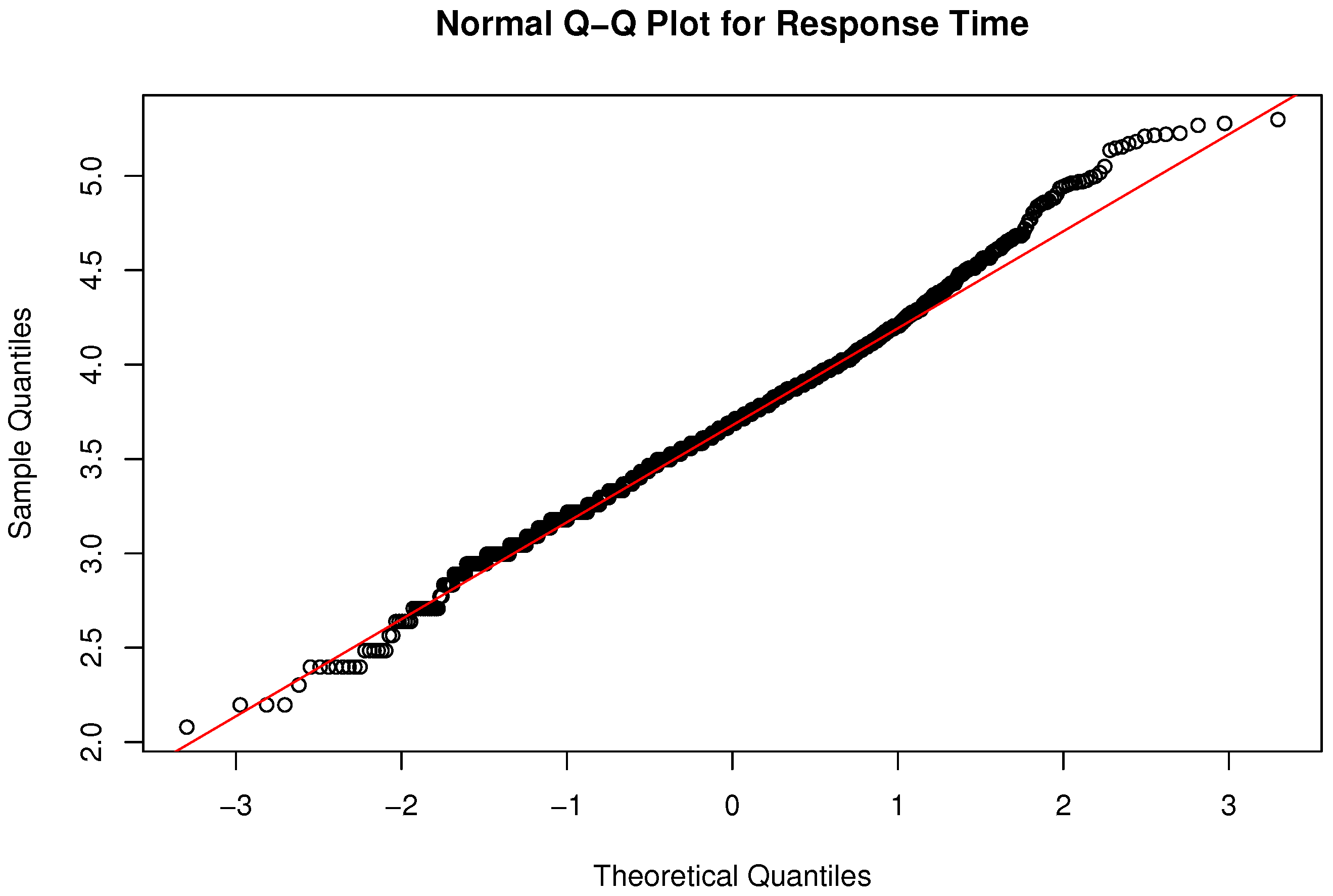
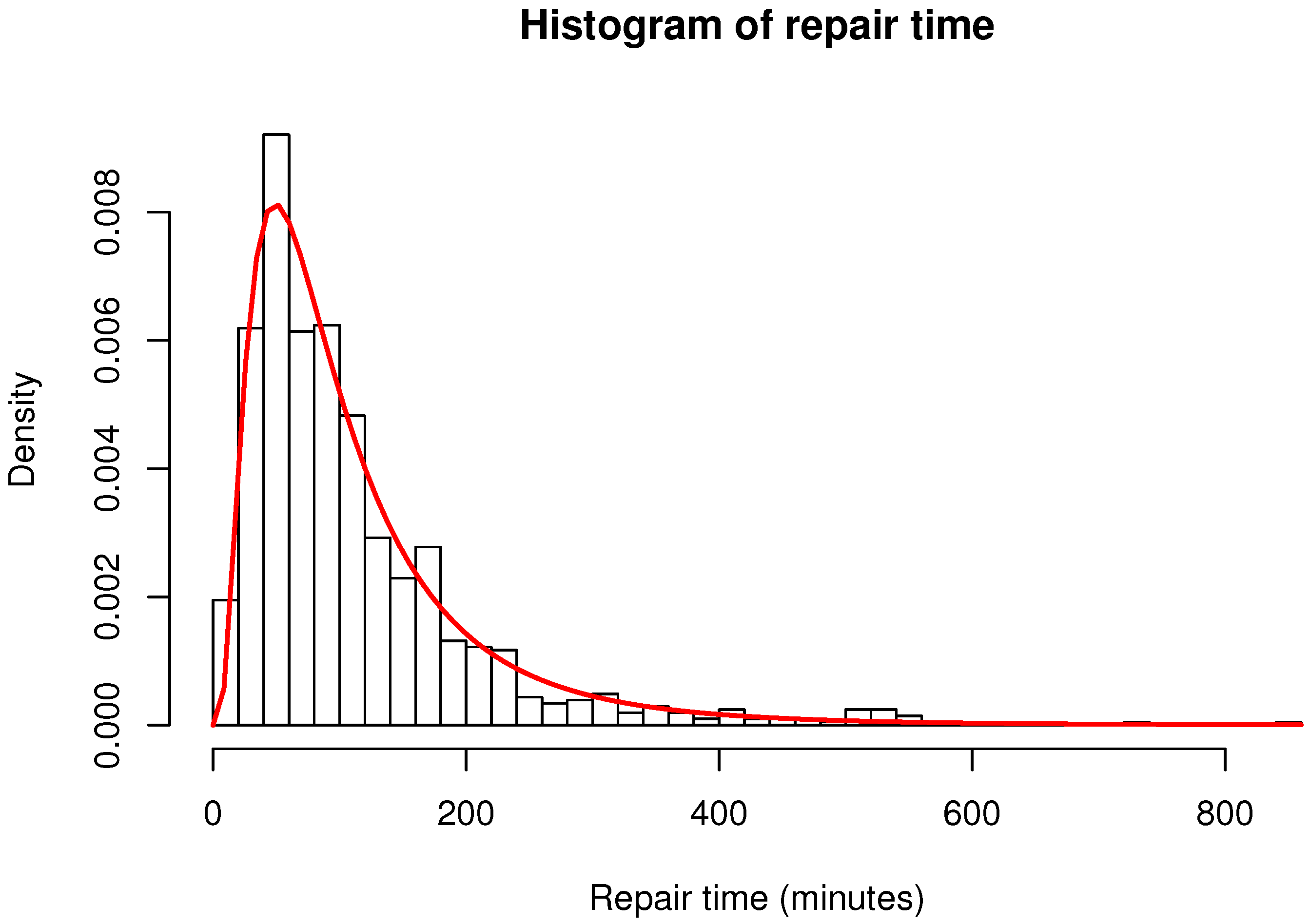
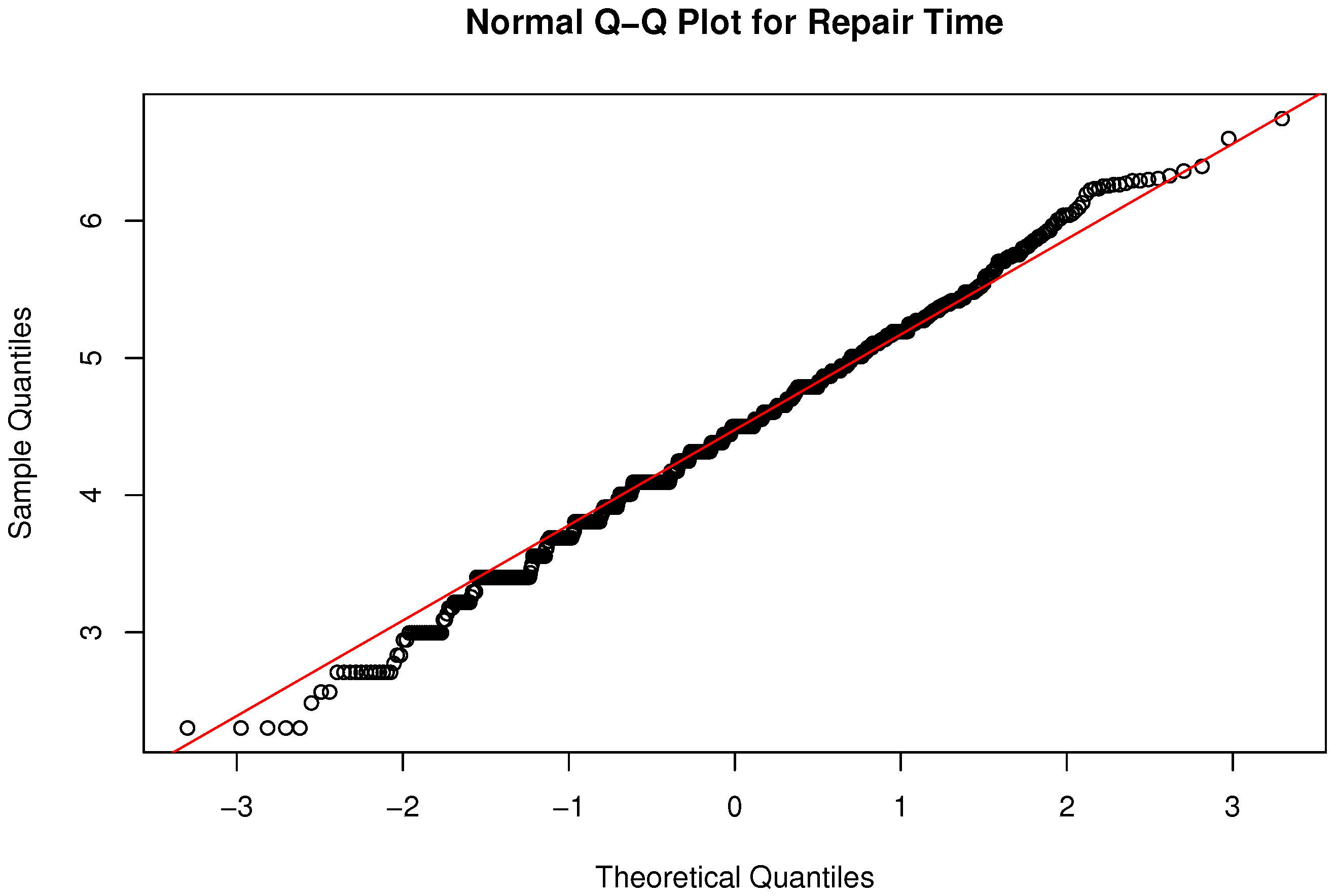
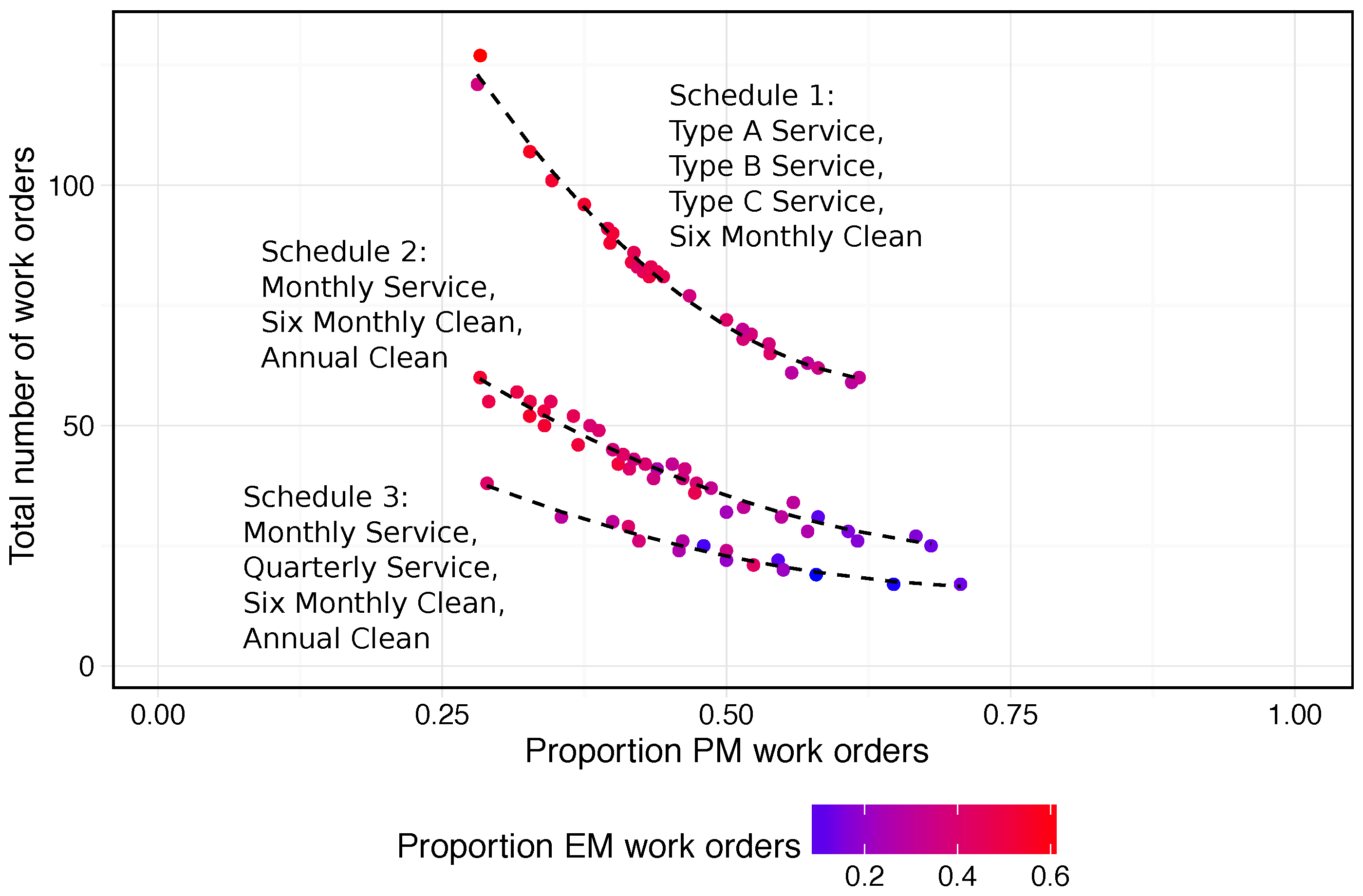
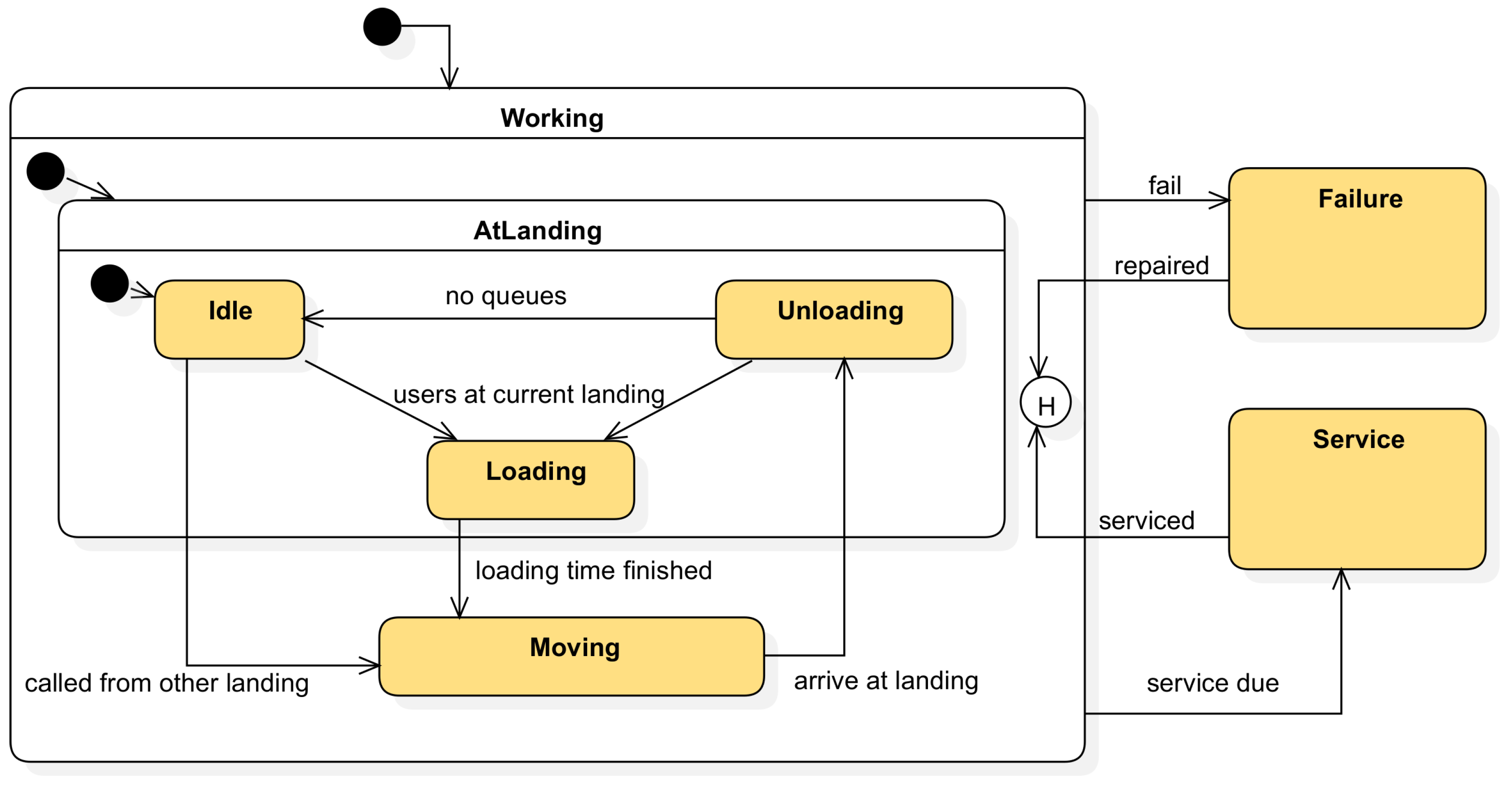
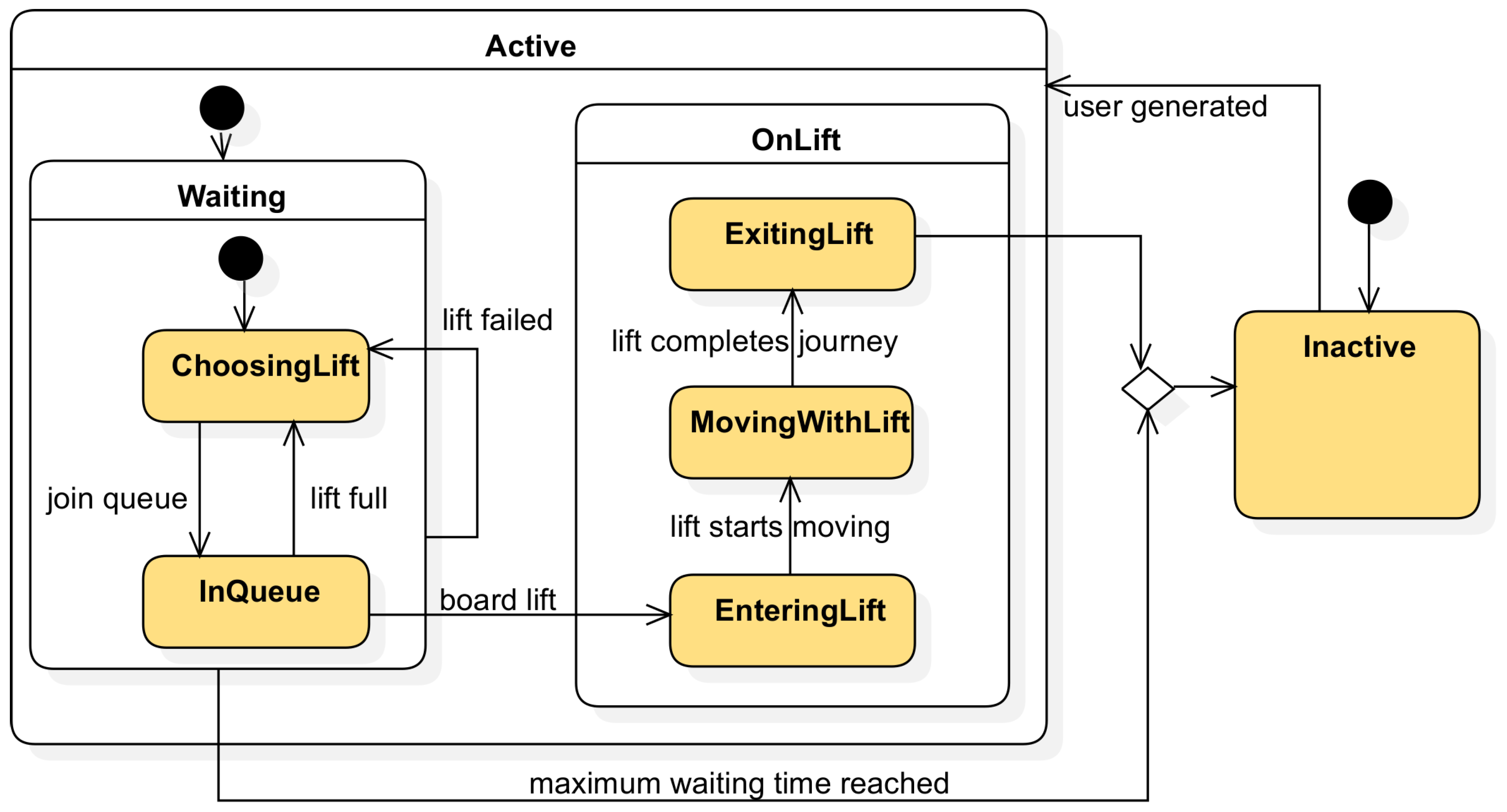
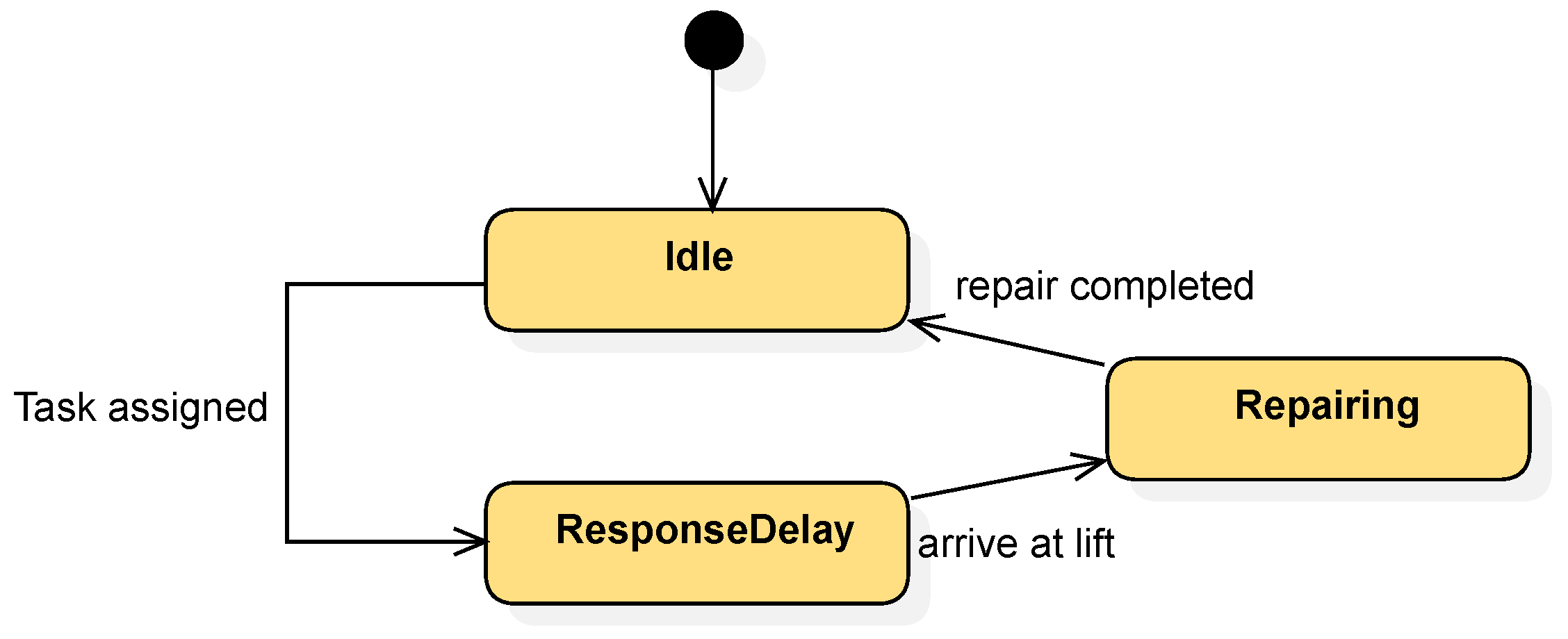
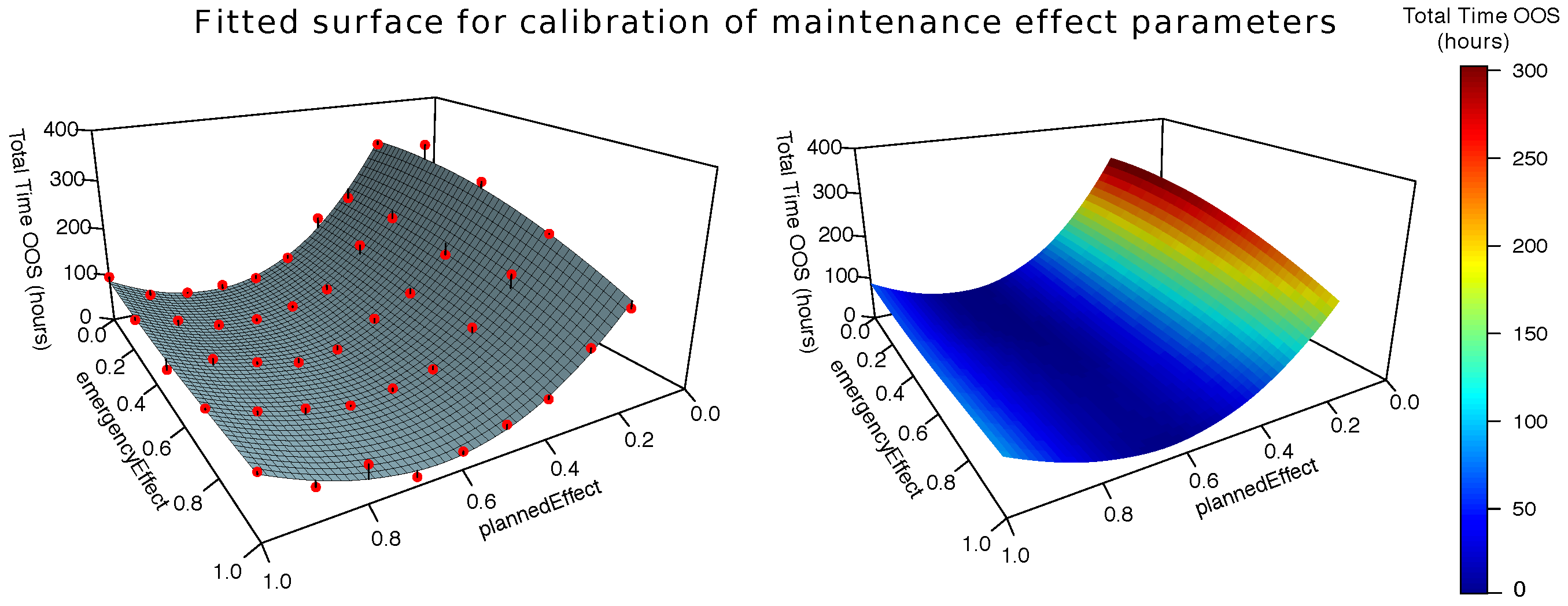
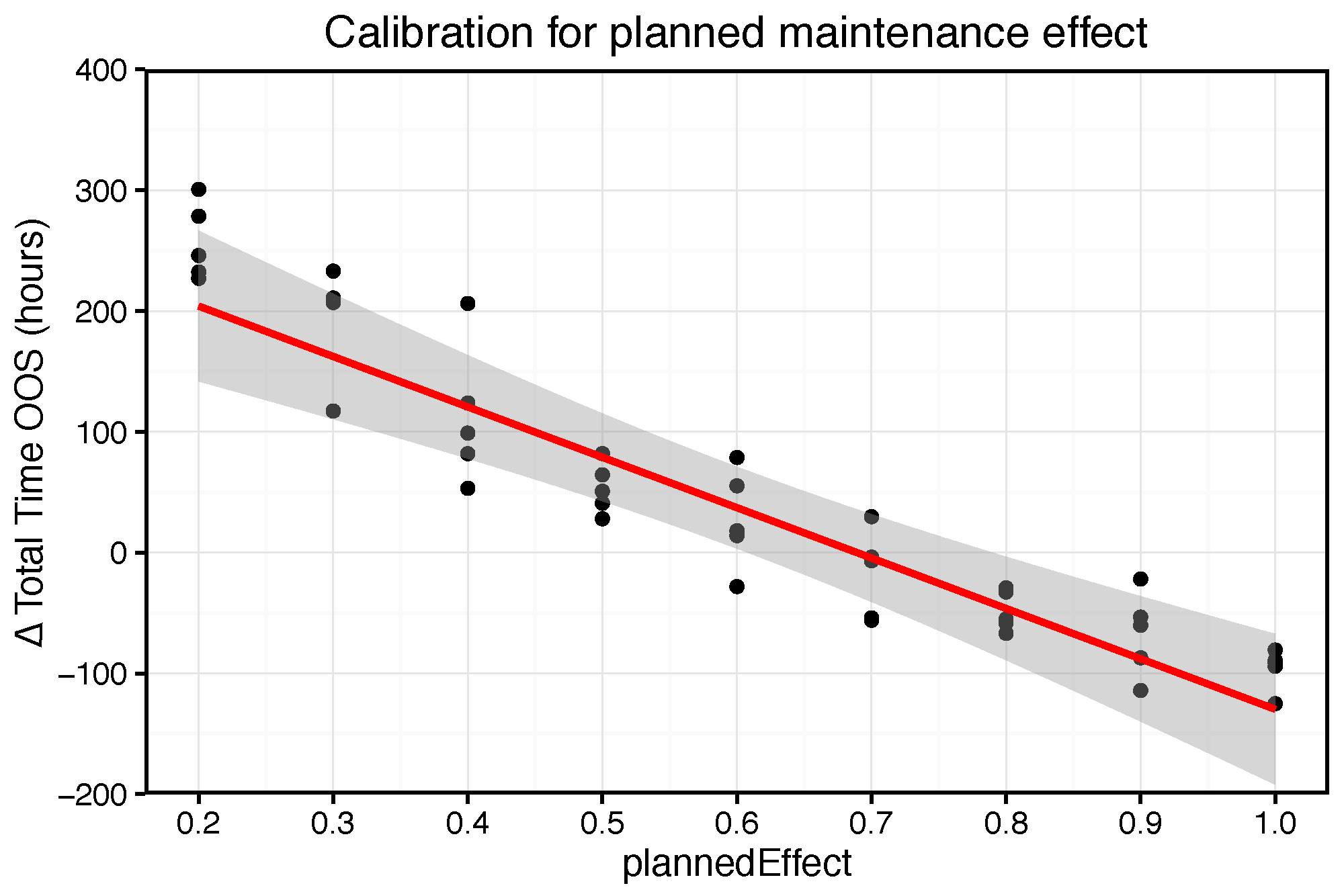
6.1. Simulation Output
Repeated runs of the ABM were executed for the time period from 7 January 2012 to 16 March 2016 (1530 days). Base cases were run where no sensors were attached to the Lift agents and only emergency and planned maintenance work was completed. What-if cases with predictive maintenance were then performed for each entry in a range of AssetManager thresholds. The values tested were , , , and as well as the no sensors instance. In each case, 100 simulation runs over this time period were carried out to investigate the full spectrum of results that could be achieved.
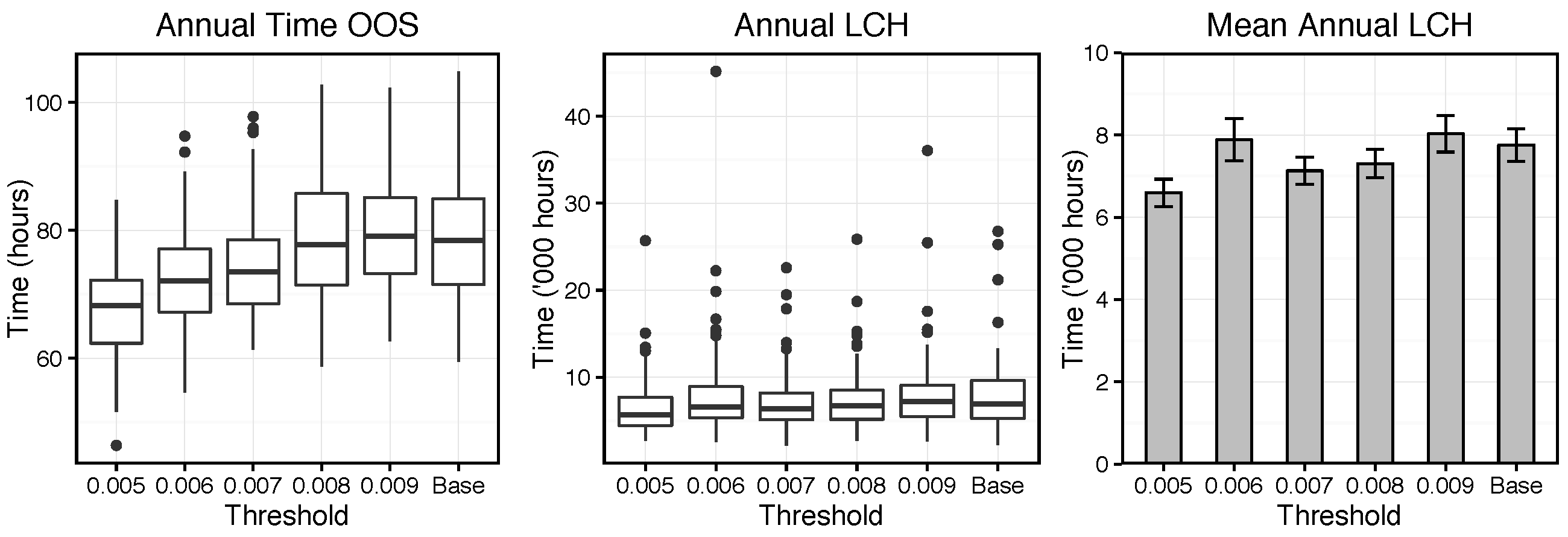
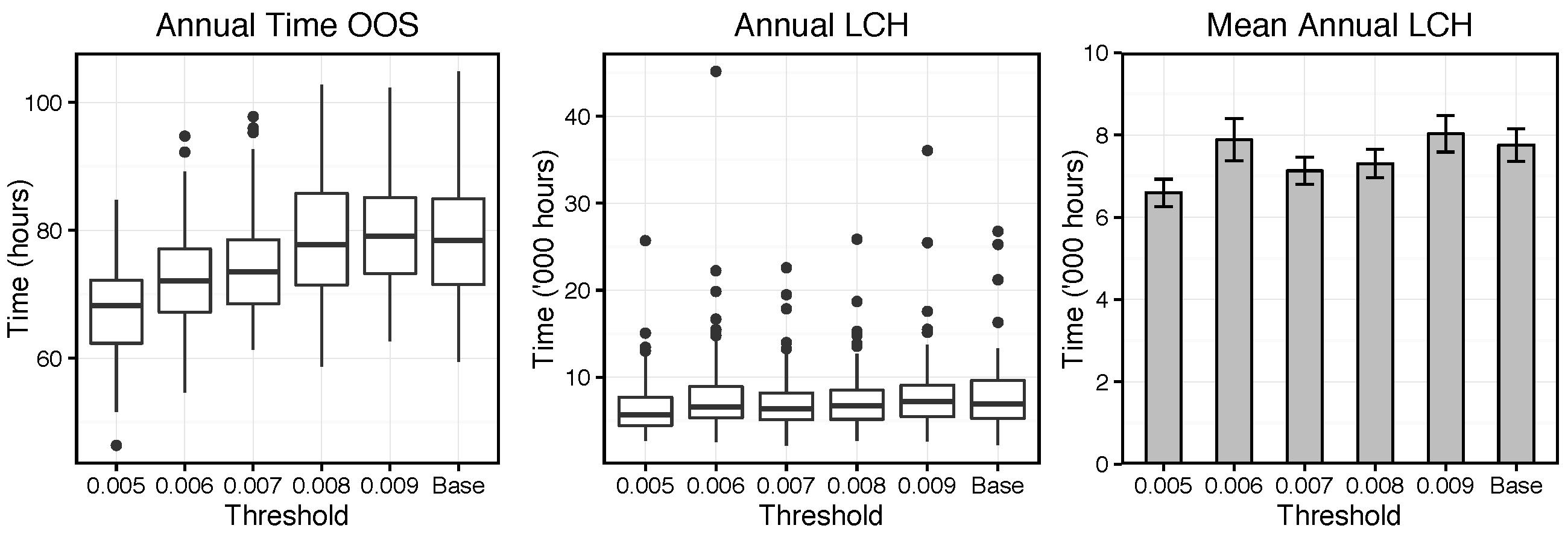
Figure 9 presents the output at each simulation setting. The left graph shows box plots of the annual time Lift agents have spent out of service (OOS). The centre box plot displays the annual Lost Customer Hours (LCH) value accrued by the User agents as a consequence of disruptions. The right bar chart presents the same LCH values summarised as means, to avoid scaling to outliers.
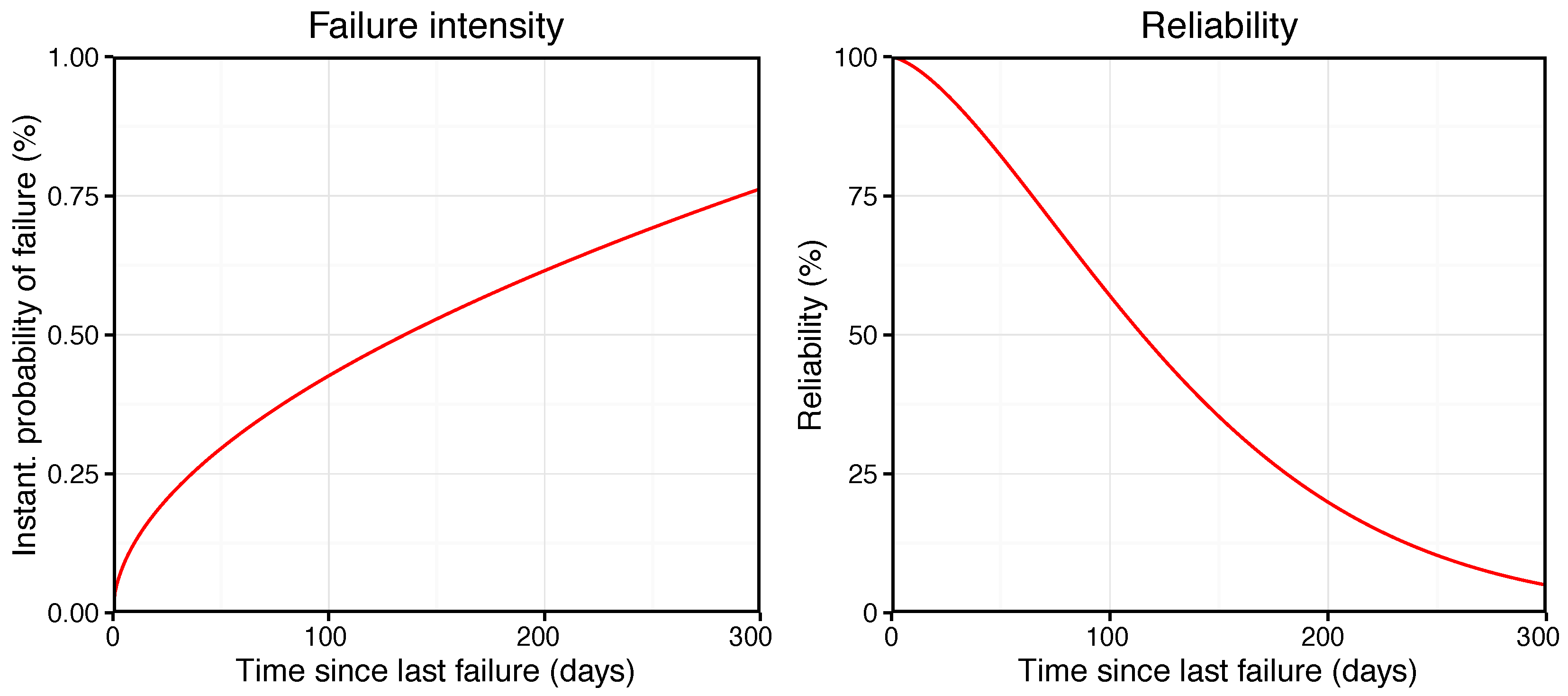
A number of observations can be made from the left plot. Firstly, there is significant variation in the time OOS between simulations at the same threshold setting. This is a consequence of the stochastic nature of the ABM; each simulation run is distinct as different values are drawn from probability distributions embedded in the model. Secondly, a general trend is observed of reducing time OOS as the threshold parameter is lowered. At the threshold values of and the plot shows little impact from the addition of predictive maintenance into the model. However, once the threshold is reduced below this level the response becomes more apparent. This is an intuitive concept, as a lower threshold value would imply more predictive maintenance tasks were scheduled and the installation of condition monitoring sensors has a greater effect.
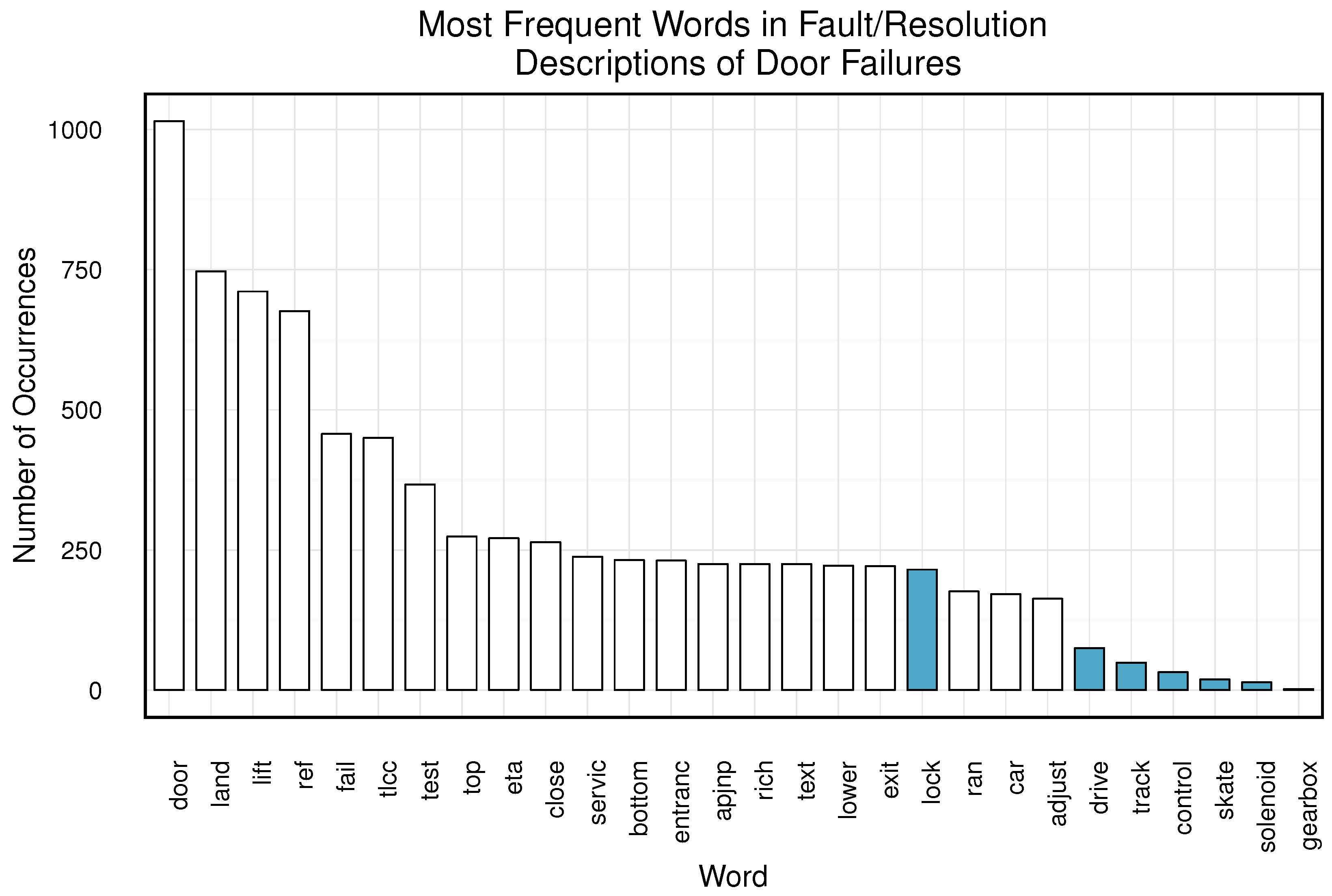
The magnitude of the reduction from the base case is perhaps not as significant as might be expected from the introduction of predictive maintenance capabilities. A potential cause for this rests in an assumption made in development of individual Component failure weightings: that they correspond to the
Occurrence value from the FMEA document. This is not an unreasonable assumption as the FMEA analysis was completed by skilled engineers. However, exploratory frequency text mining of manually-typed
Problem Description fields in the Failures Dataset provides opposing evidence to those values (see
Appendix E). As the sensors are only assumed to monitor a subset of Components in a Lift, their impact is limited by these weightings.
The remaining plots in
Figure 9 show the annual LCH for each threshold setting. The variation in these values is greater than for the previous output discussed and the box plot indicates a much larger number of outliers. The bar graph shows that the mean of the
threshold level is particularly affected by these anomalies. The reason for this large variation is believed to be a combination of the LCH calculation method, processes in the real system which the current model does not account for and the relatively short time period over which simulations were run.
As mentioned in the description of the User agent process, the LCH values calculated from these simulations use a literal interpretation of the term in absence of the method applied in the real system (see Equation (
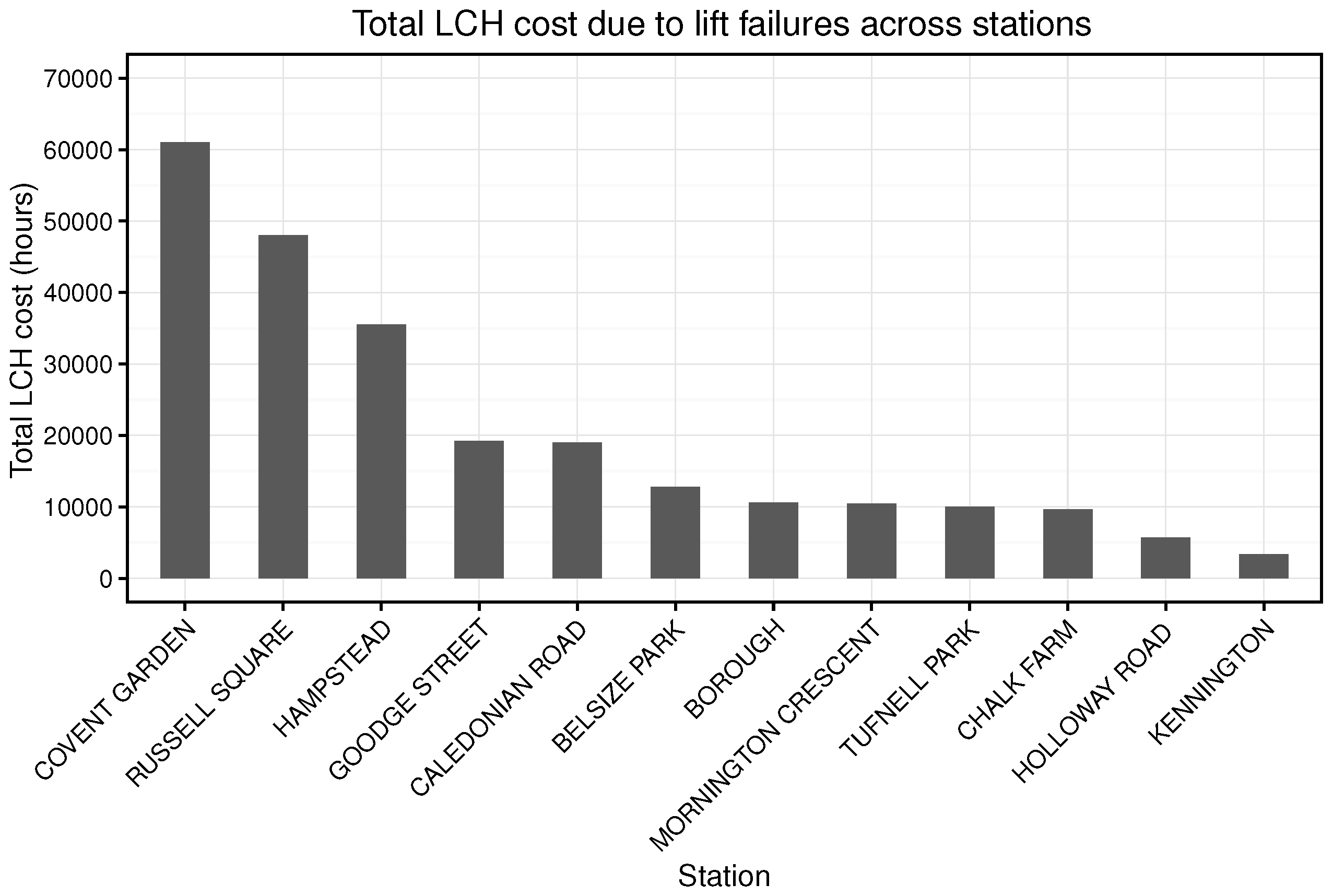
5)). Moreover, the model in its current form does not account for situations where a station can be closed as a result of asset failure. In the case of Covent Garden station, a single lift failing at a peak time of day (when over 1000 customers could be expected to travel through the station in either direction within a 15 min period) can force the station to shut. In these situations, the LCH value attributed to the event in the real system effectively has an upper bound.
In contrast, if one of these
rare events occurs within the simulation, it can have a significant impact on an individual run due to the lack of this upper bound.
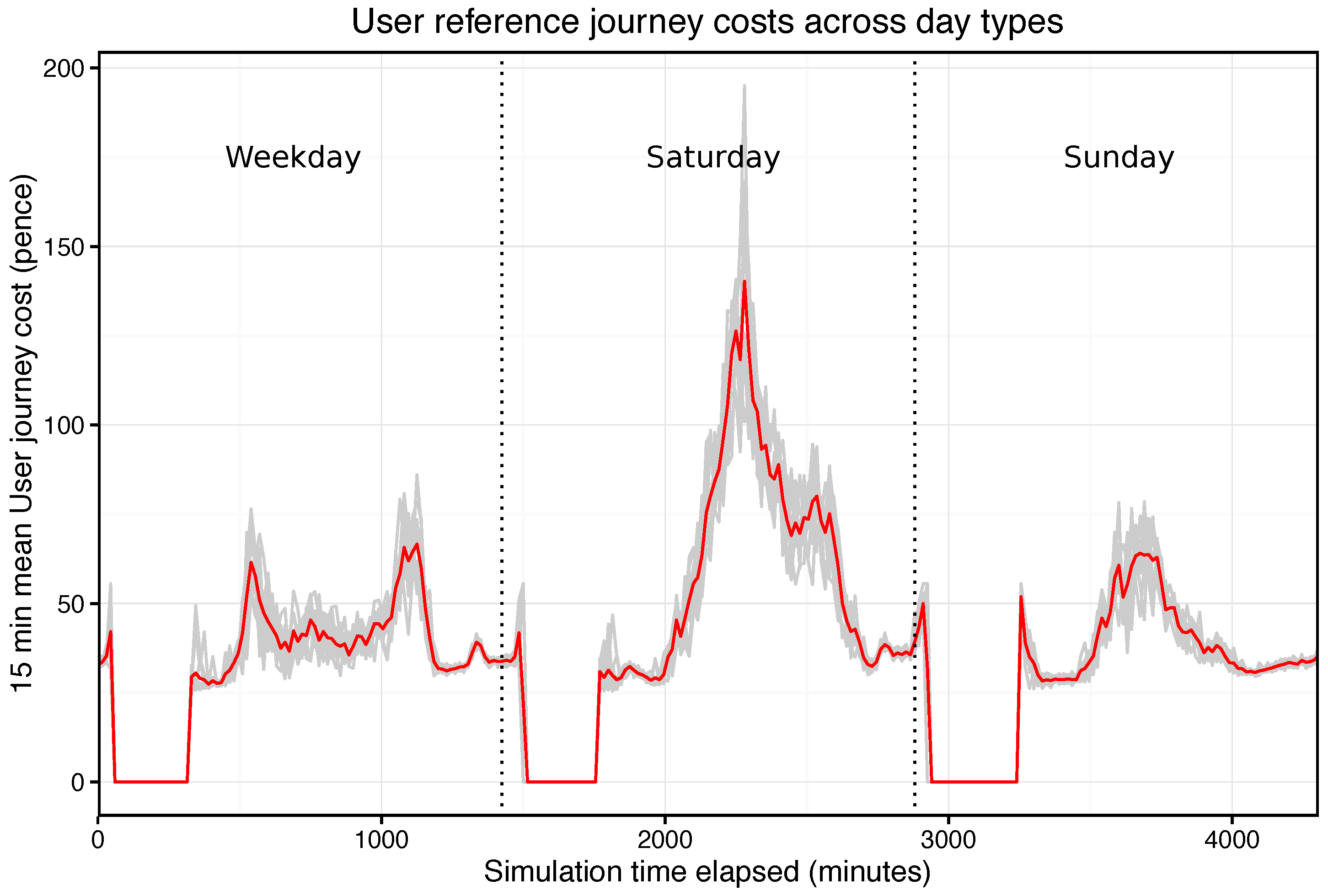
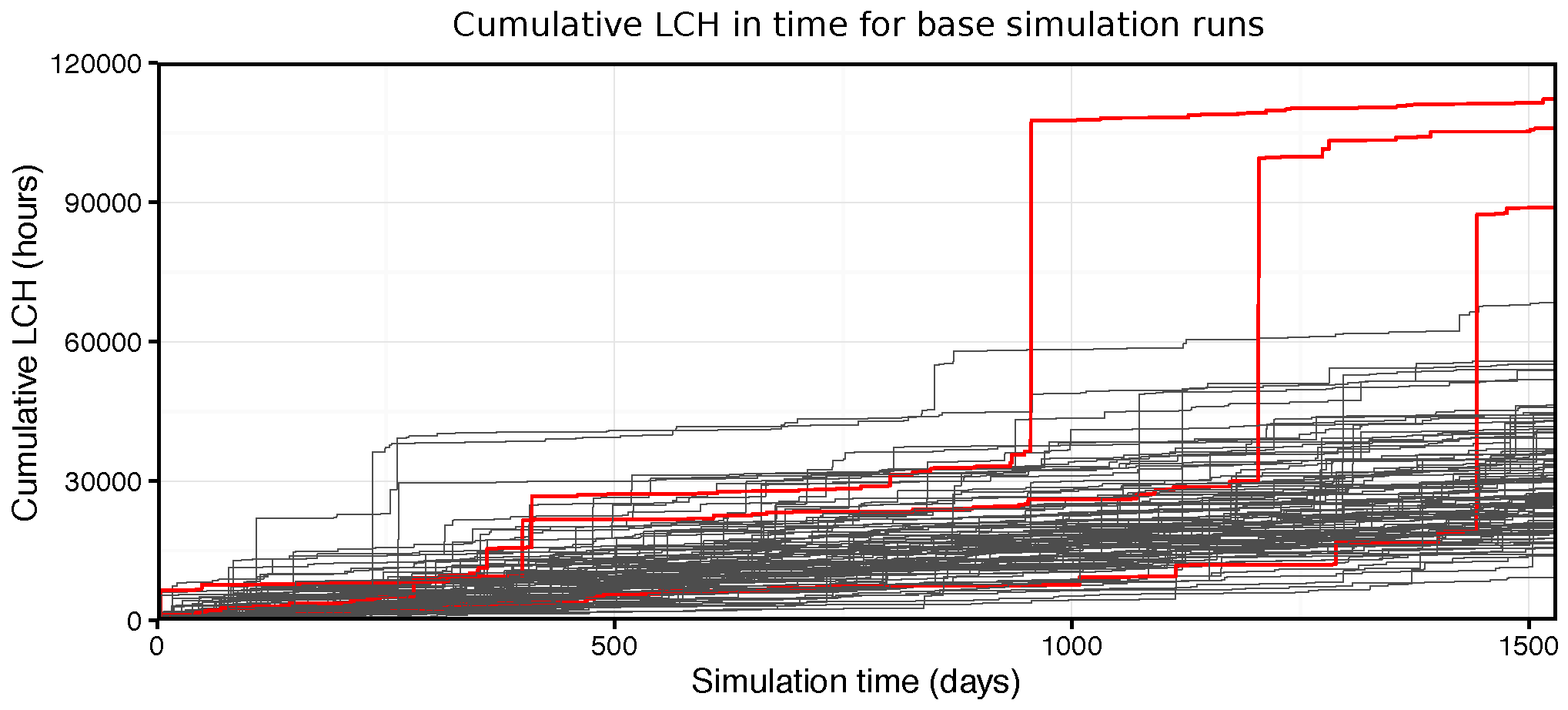
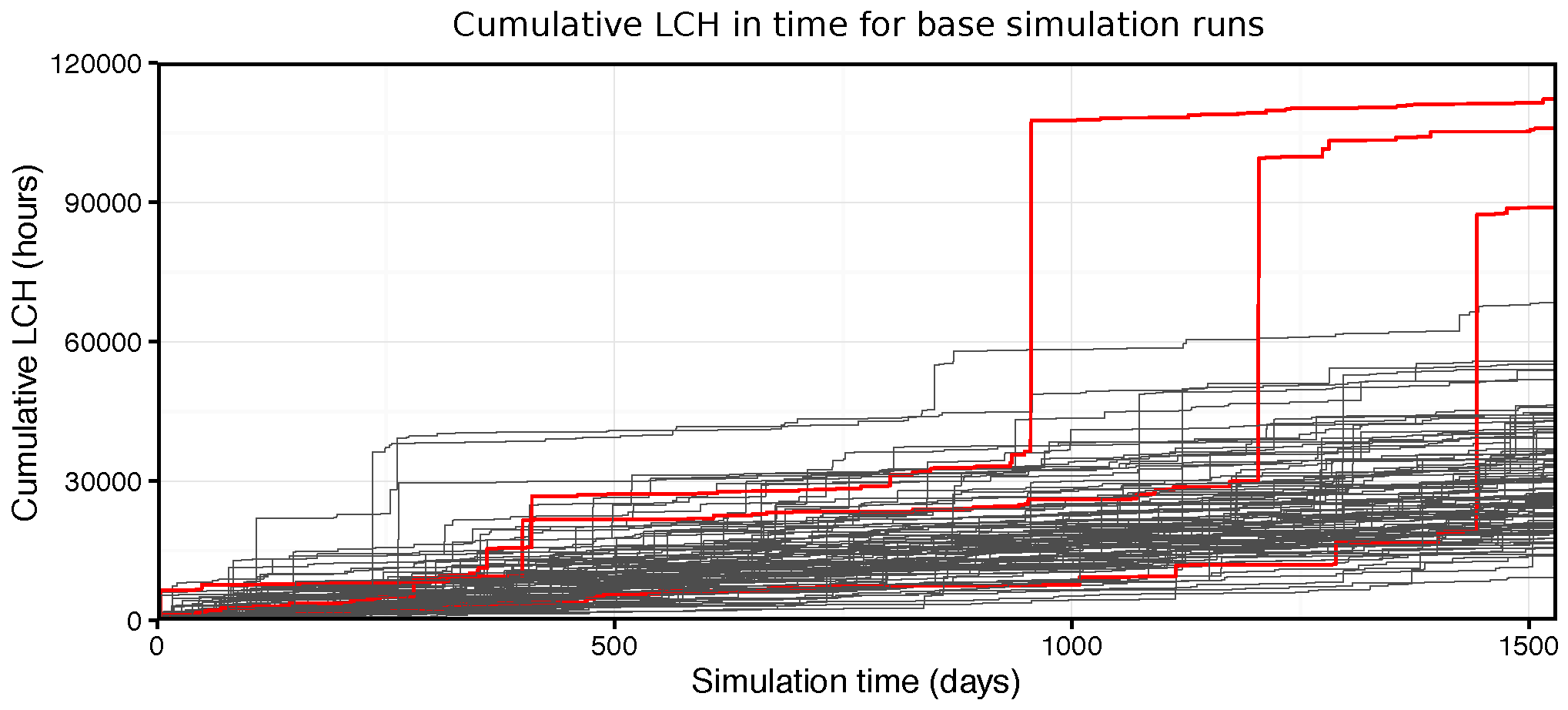
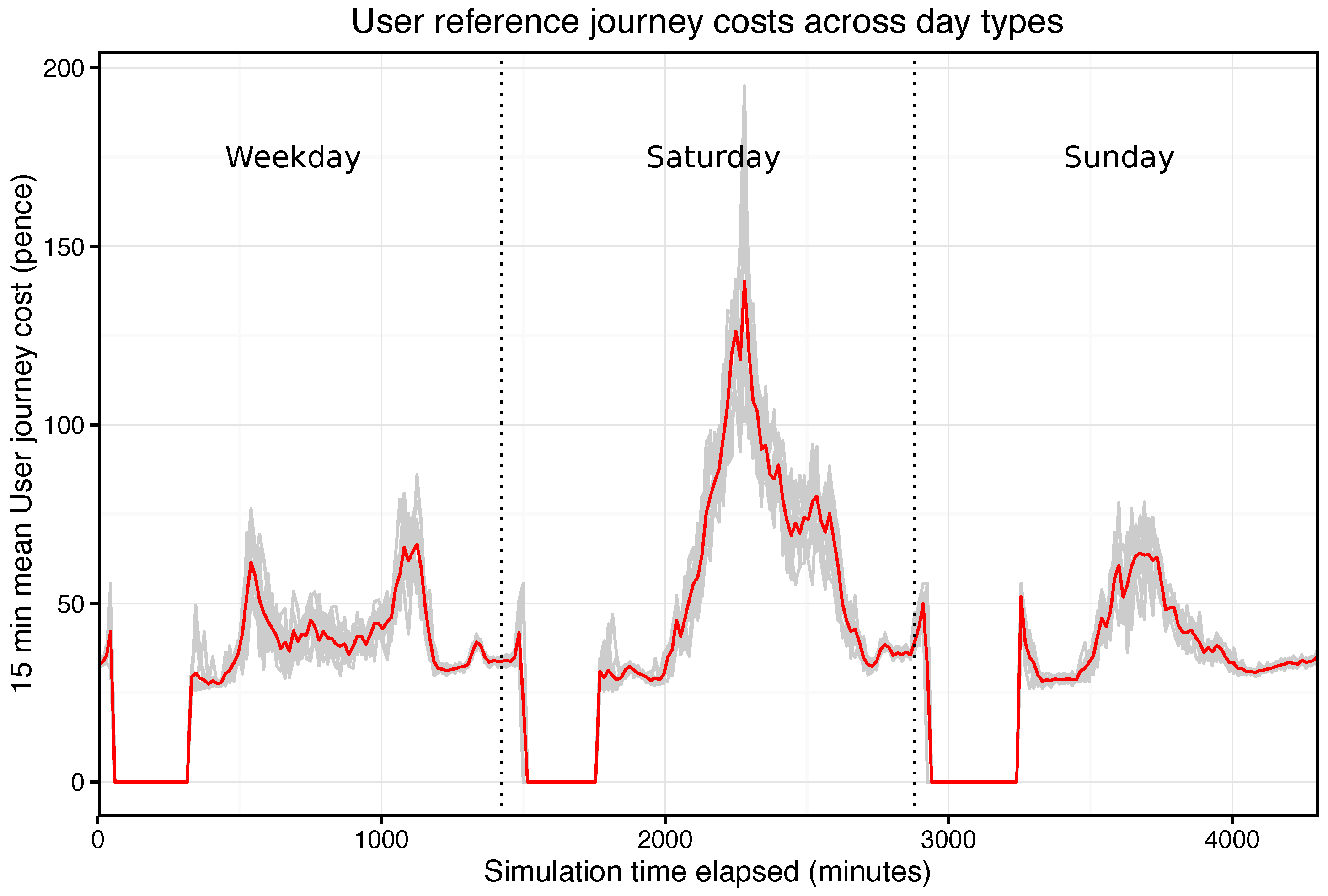
Figure 10 illustrates this effect. The plot shows the LCH accumulated over the course of multiple simulations (in this example the base case with no sensors) and three specific runs are highlighted in which these
rare events arose. While the maximum waiting time of individual User agents was implemented to provide some stability in these circumstances, additional measures may be required to further take them into account.
Although a minor downward trend is observed in annual LCH with the introduction of sensors, it is difficult to assign a confident value in the face of this large variation. Nonetheless, this aspect of the results identifies a potentially useful, if unintended, application for the model in risk analysis (for example in estimating the likelihood of specific undesirable events occurring).
6.2. Return on Investment
It was possible to quantify the direct costs in the ABM results using the values discussed in
Section 5.3. However, for the indirect costs, the LCH output obtained from the model was highly variable. Therefore, to characterise these indirect costs as a result of asset downtime in a more consistent way between simulations, a reference rate was inferred from the base model runs. The median of the LCH values from the base simulations was calculated and converted to an
indirect cost per hour asset downtime (the median was used here as it is less affected by extreme outliers in the dataset and therefore an improved descriptor of the typical case in this situation). This reference value was subsequently applied in establishing indirect costs throughout the other simulations.
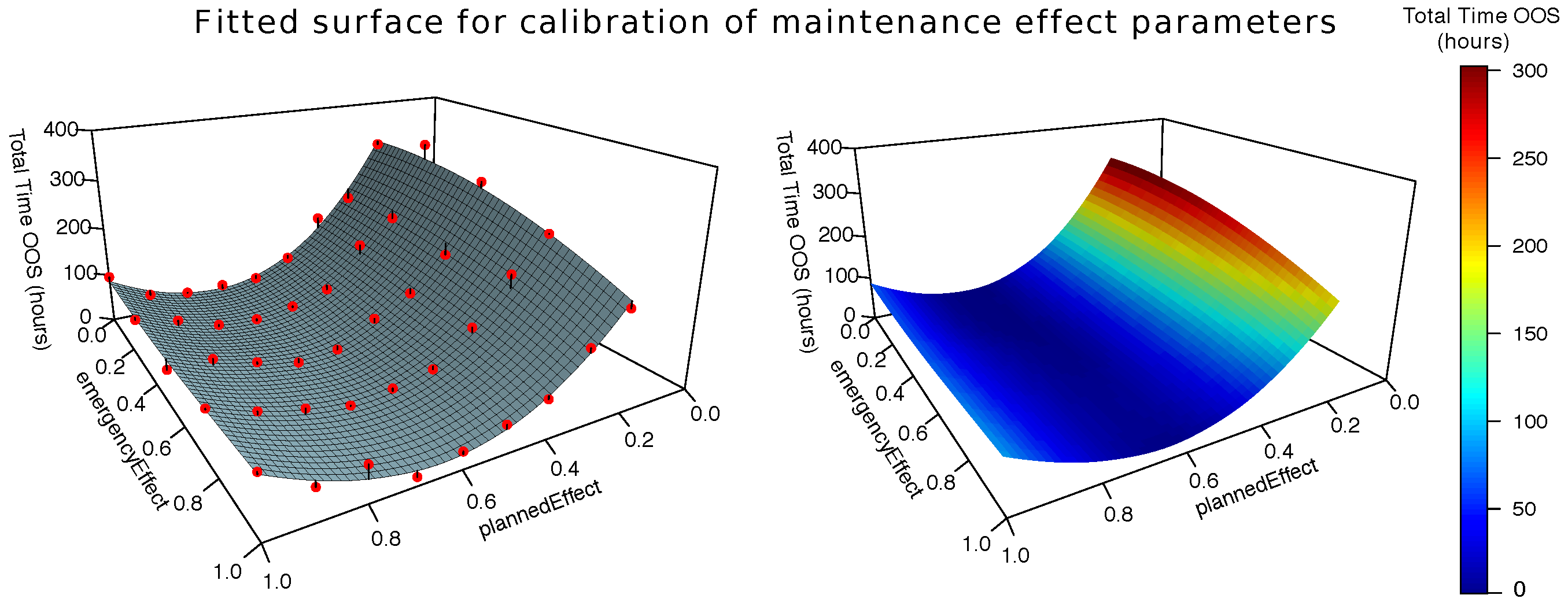
The average annual costs accrued during simulations were determined for each threshold setting. Initially, a very small set of values were observed to be having a significant impact on the mean costs. These were removed by setting limits at
absolute deviations around the median [
122]. The annual saving rates were subsequently calculated by taking the difference between the annual costs for the base and predictive cases.
Table 5 presents these results alongside mean multi-year RoI values. It is important to note there are large uncertainties introduced into these figures from the stochastic nature of the ABM, making it more challenging to draw conclusive insights.
As the threshold parameter is reduced, the results show that savings from predictive maintenance increase. These values also highlight a possible tipping point between thresholds of and . Above this value, there is no beneficial effect of predictive maintenance. This implies that monitored Components would generally fail before reaching the required threshold for the AssetManager to schedule predictive maintenance. Once this threshold is reduced, savings are achieved as additional predictive maintenance is performed in response to condition monitoring.
It may be expected an optimum should exist where the extra cost of predictive maintenance outweighs the realised benefits. However, the simulation results show no optimum value within the range of threshold levels investigated. A possible explanation for this could be additional complexities in the real system which the current model does not take into account.
These initial results were presented to experienced consultants within Amey Strategic Consulting and APJNP asset managers. Their feedback highlighted that at low values of the threshold level, the risk of false positive sensor readings could increase dramatically. In the real system, these type I errors can be introduced if minor deviations from an asset’s normal operating conditions breach a low failure threshold level despite there being no underlying problem. In these cases, if a decision is made based solely on whether asset conditions exceed this threshold, predictive maintenance could be carried out needlessly. This would incur extra cost without a corresponding benefit. Furthermore, this cost is not solely monetary. If a maintenance engineer is assigned to repair a part that is already in good condition, they may become sceptical of the true value of condition monitoring. These issues have the potential to undermine the effectiveness of the entire venture within an organisation.
Given the amount of predictive maintenance that occurs in the simulation at the lowest threshold in comparison to other levels, it was suggested that extra costs incurred as a result of the above considerations could significantly reduce or eliminate any benefit realised. The threshold settings at and were recommended to represent a more appropriate estimation of the RoI in this predictive maintenance strategy.
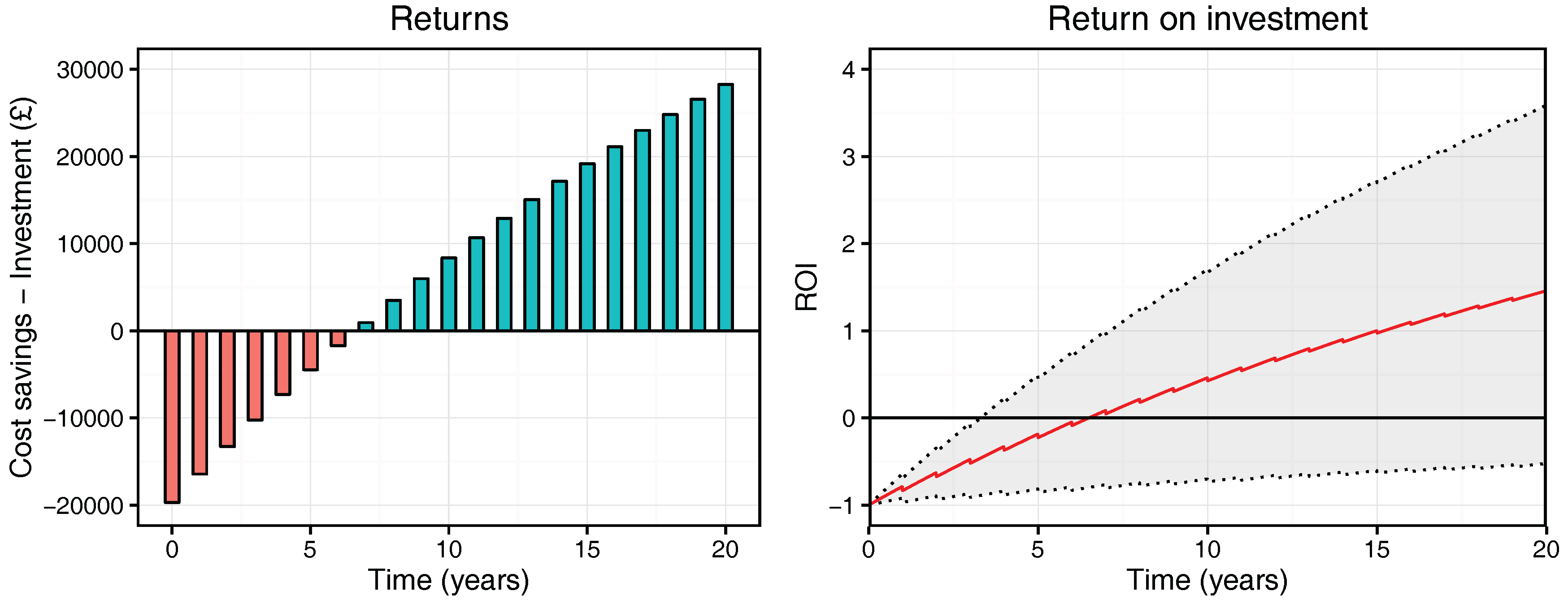
Figure 11 shows further detail of the estimated mean returns (
Cost savings minus
Investment) and discounted RoI for the threshold level of
. The grey shaded area in the RoI plot represents the range of outcomes as indicated from the variation in simulation results. A key aspect in both of these plots is the time taken to achieve a positive RoI. After this stage, the initial investment has been reclaimed and true returns start to be realised. The mean savings in both plots suggest this time would occur between 6 and 7 years after the initial installation (albeit with significant uncertainty).
The stochastic nature of the ABM also offers an insight into best- and worst-case scenarios. It is important to take these potential possibilities and risks into account when interpreting the results from the model. The right plot in
Figure 11 shows that, in the worst-case, it could take a far greater period of time for a positive RoI to be realised. This is a consequence of lower savings and discounting applied to future values. Conversely, in the best-case scenario, the results suggest a positive RoI could be achieved approximately 3 years after sensor installation.
The question that this case study was initially developed to address was what is the RoI of installing remote condition monitoring sensors on lift doors in Covent Garden station? The current results suggest that a positive RoI can be realised in approximately 6 to 7 years, after which returns would continue to accrue and increase the RoI value. However, it is important to note the wide range of outcomes observed in the ABM output.
The results also imply that a positive RoI will only occur if an effective predictive maintenance strategy is implemented alongside the sensor installation. If readings from the sensors are disregarded and not acted upon (i.e., the threshold parameter is above the tipping point), the benefits of such a system may not be achieved. Similarly, if the data is not analysed appropriately and the derived information interpreted incorrectly by the asset manager (i.e., the threshold parameter is too low), extra costs can be incurred by unnecessary maintenance which could offset any potential benefit.
6.3. Suggestions for Future Work
The results produced by this ABM present an interesting view of the business case for installing condition monitoring sensors on lift assets. It would be desirable to use the insights gained up to this point to progress development of the model further, in keeping with the previously suggested data mining revision process [
74,
87]. Unfortunately, this was not possible within the scope of the current work. This section proposes questions which could be addressed in future research to realise a more complete approximation of the real system.
6.3.1. How Does the Failure Model Affect the Results?
The failure behaviour developed in this model only represents one of a number of ways to describe this aspect of the system. A more complex behaviour could be developed using one of the techniques discussed in
Section 2.1.4, such as hidden Markov models or a form of Bayesian updating. A major limitation to the development of the former would be the lack of sufficient data regarding door lift failures, but this could be somewhat alleviated through a combination with the latter.
An advantage of redesigning the failure behaviour using the Bayesian updating approach would be that the sensors themselves could be more rigorously simulated. It was noted in the previous section that at lower threshold levels we could expect more false positive alerts, but the current ABM does not account for this. As Bayesian updating allows one to assign probability values to the sensor correctly identifying the asset’s condition state, the method would enable the ABM to capture this additional level of complexity.
A further factor to consider in the failure probability could be to build an interaction between the Behaviour object and the User agents. The theory behind this consideration is that the lifts may be more likely to undergo treatment that leads to failure when a large number of customers are passing through them, for example by trapped objects in doors. This heightened likelihood of failure could be characterised by temporarily increasing the failure probability of specific Components during busy periods throughout a day.
In addition, insight gathered from APJNP asset managers suggested that heterogeneity could be an important consideration in the nature of asset failures. Each lift in this ABM is assumed to follow the same general failure behaviour but a future extension could incorporate a variation of behaviours between separate assets.
6.3.2. How Is the RoI Affected If the Extra Predictive Maintenance Is Offset by Removal of Planned Maintenance?
This case study has focused on applying predictive maintenance in addition to an existing planned maintenance schedule. The results highlight the need for a changed approach to maintenance within the asset management organisation if a condition monitoring strategy is to be effective. The introduction of predictive maintenance led to savings in emergency maintenance costs. However, these were partly offset by the existing planned maintenance schedules which remain constant between scenarios.
It only became apparent after these results were analysed that it would be valuable to study how a reduction in the frequency of maintenance tasks within predefined schedules would affect the overall RoI of the venture. For example, this could potentially be implemented by skipping planned maintenance in the simulation if condition data observed by the AssetManager agent suggests failure is unlikely. A difficulty here would be that the sensors are assumed to only provide information relating to certain Component objects. Therefore, reducing the planned maintenance would be removing work on some Components without supplying an alternative. A further consideration is that some of the planned maintenance work is required to satisfy industry standards in the real system. Further investigation would need to be conducted into which specific tasks could potentially be excluded.
6.3.3. Will Agent Intelligence Improve the RoI Outcome?
The complexity of the current model could be further increased through the introduction of more advanced agent decision-making processes. For the AssetManager agent, it would be interesting to incorporate forecasting ability into the predictive maintenance scheduling. Rather than the basic case of a constant threshold level to initiate predictive maintenance, the AssetManager could be extended with the ability to observe trends in condition. Further interviews with asset managers could also be conducted to design a more realistic behaviour for this agent.
The queueing system for the User agents could also be enhanced. The current model only takes into account two choice preferences. Application of more advanced queueing theory may create interesting interactions between Users in different queues waiting for Lifts, which could have a consequential effect on their efficiency in passing through the station. For example, jockeying could be added where Users dynamically move between queues if they believe they may be able to board an earlier Lift.
6.3.4. How Does the ABM Scale in Time?
A number of assumptions had to be made when considering how the results evolved over long periods of time. The current failure behaviour is based on relatively recent historical data and so it may not continue to apply far into the future. Additionally, the complete refurbishment or replacement of lift assets is not accounted for in the ABM. Finally, the possibility of the sensor hardware itself failing and requiring replacement is not considered in the calculations. In extending the model, it would be valuable to assess how incorporating these longer-term aspects affects the value added by condition monitoring.
6.3.5. How Does the ABM Scale in Space?
This work only addresses the installation of sensors at a single, but critical, station on the London Underground. In future work, it would be valuable to investigate whether similar returns can be realised at other locations with different agent parameters. It could perhaps be expected that the sensor network would not offer a good investment at quieter stations, where the same indirect cost savings could not be achieved from reducing asset downtime. From a more ambitious perspective, the scope of the ABM could be increased dramatically by combining multiple station models to represent an entire network of lift assets.
6.3.6. Could We Set Threshold Values in Order to Optimise KPIs?
A key aspect that could be explored when running large scale simulations (i.e., covering all lift assets) of the presented work is regarding the effect of different threshold values for different lifts. The reasoning behind this is that not all assets are equally important to an organisation, even when the assets could be exactly the same. As pointed out in this report, lifts at Covent Garden have a much greater influence on KPIs such as LCH than any other lift in the network. This implies that it is possible to tolerate lift failure at stations with low number of passenger (high threshold values could be used) while it is unacceptable to have lift failures at key stations such as Covent Garden (requiring low threshold values). In fact, threshold values could become a function of not just space/location but also time among other variables (lift failures at Covent Garden are more damaging on Saturday afternoon than on weekdays).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}