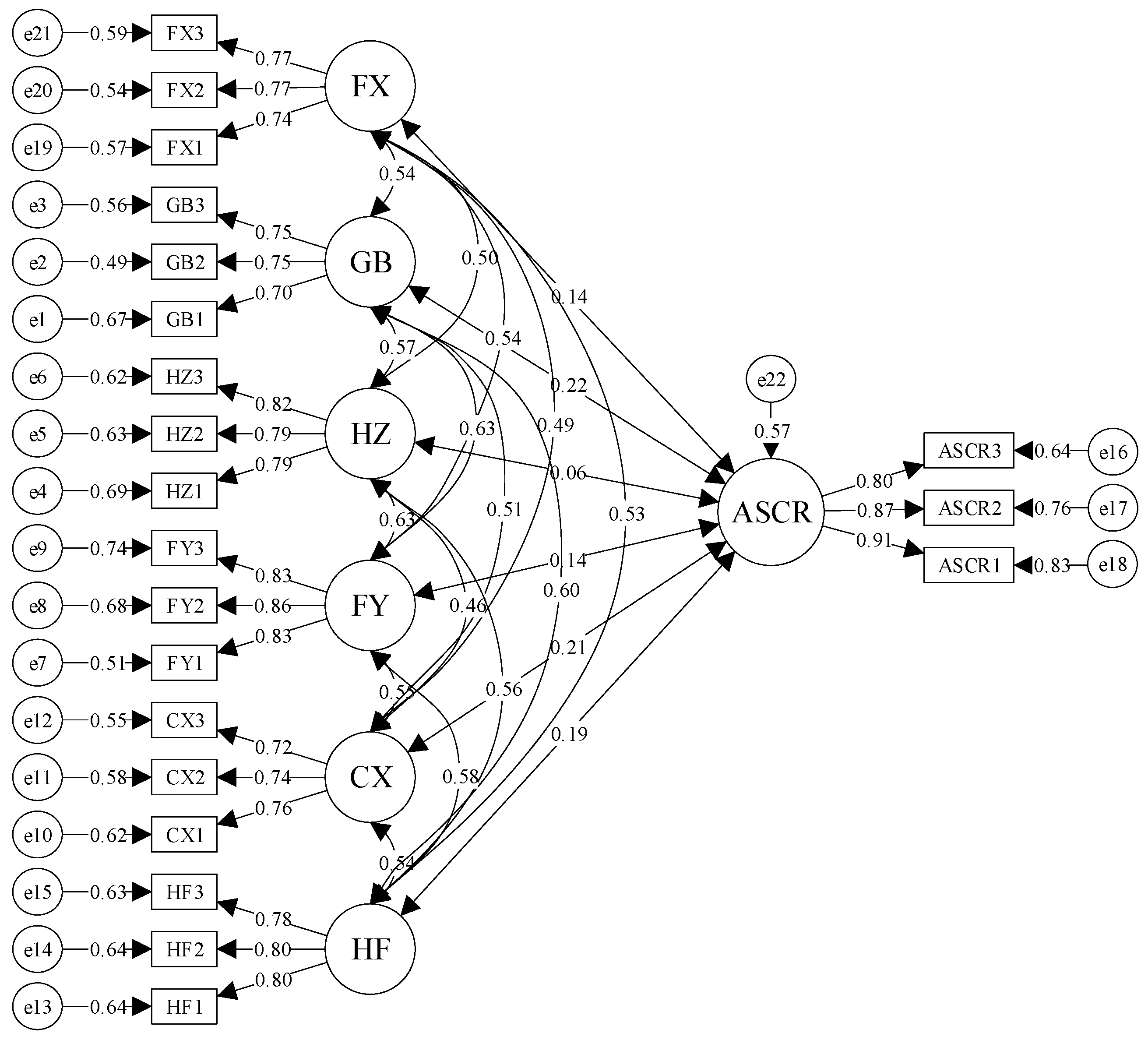
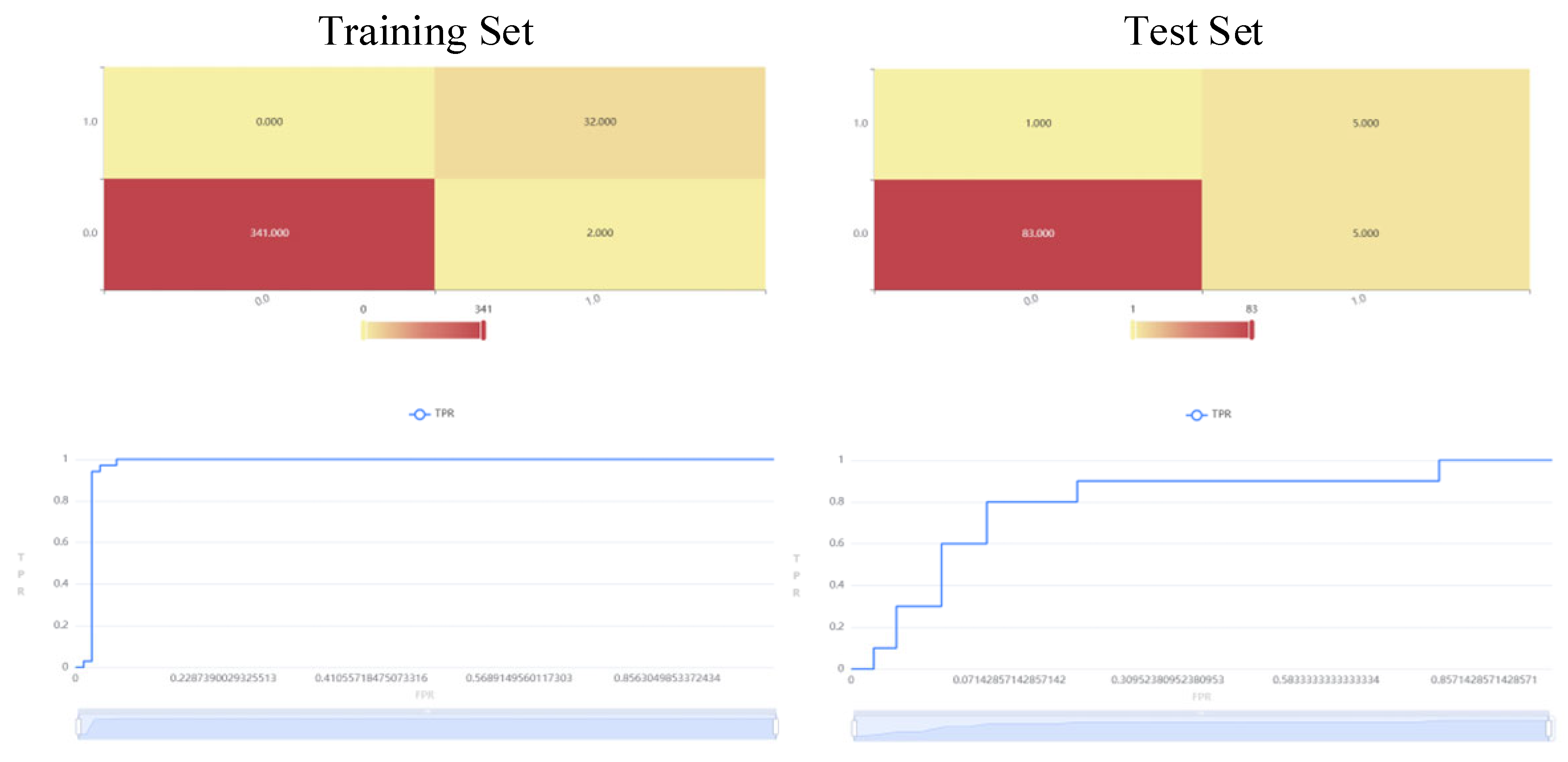
Based on the intrinsic properties of the research questions and the characteristics of the data structure, this study selected five algorithmic models—Random Forest, Decision Tree, AdaBoost, ExtraBoost, and SGBoost—as benchmark algorithms. This algorithmic spectrum spans basic single models and current mainstream ensemble learning paradigms, all of which are mainstream, efficient, and fully validated predictive tools oriented toward structured (tabular) data. More importantly, the aforementioned models exhibit significant heterogeneity in dimensions such as interpretability, noise resistance, handling of class imbalance, regularization capability, and performance benchmarks, enabling them to accurately match the high noise, imbalance, and interpretive needs of questionnaire survey data. Through a systematic comparison of these algorithms’ performance in predicting the resilience level of agricultural product green supply chains, rigorous and comprehensive empirical references can be provided for the relative advantages of fsQCA-XGBoost.
In contrast, methods such as Support Vector Machines (SVM) and Artificial Neural Networks (ANN) are more advantageous in scenarios involving high-dimensional small samples or in processing unstructured data. However, they are inconsistent with the data characteristics and prediction objectives of this study and thus were not included in the analytical framework.
5.1. Method Selection and Model Construction
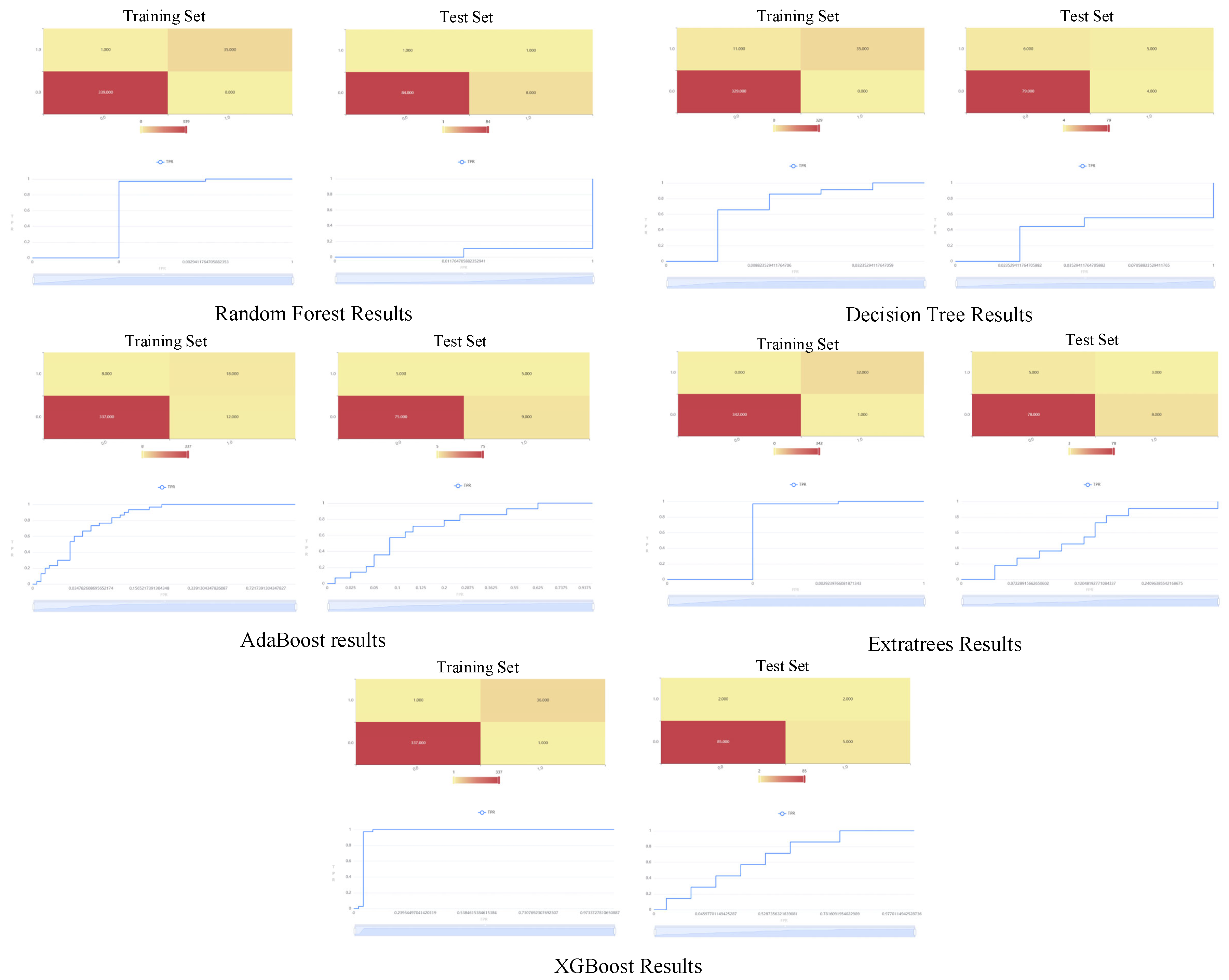
Based on questionnaire data preprocessing and Structural Equation Modeling (SEM), this study selects five popular machine learning algorithms for comparison with the previously constructed fsQCA-XGBoost model, in order to identify the optimal prediction model. The selected algorithms include Random Forest, Decision Tree, AdaBoost (Adaptive Boosting), ExtraTrees (Extra Randomized Trees), and XGBoost (Extreme Gradient Boosting).
(1) Random Forest Algorithm. The Random Forest algorithm is an ensemble learning method that improves model performance and stability by constructing multiple decision trees and integrating their predictions through voting or averaging. During the construction of the Random Forest, each tree is generated through key steps including row sampling (bootstrap sampling) and column sampling (feature randomness). The algorithm is known for its high accuracy and robustness, demonstrating low sensitivity to noisy data and datasets with redundant features, making it particularly suitable for handling survey-based data. Moreover, the Random Forest algorithm provides the functionality of ranking feature importance and can automatically capture complex interactions between features. The process of selecting splitting features in individual subtrees is illustrated in
Figure 3.
In this study, a Random Forest classification model was first built using the training dataset to obtain the model structure. Subsequently, feature importance scores were calculated based on the trained Random Forest. Finally, the established model was applied to both the training and test datasets to evaluate its classification performance.
The study sets 100 basic decision trees (n_estimators = 100), and adopts the sampling with replacement (Bootstrap) and the feature random subspace strategy (each tree randomly selects “sqrt(total number of features)” features). The optimization ranges of key hyperparameters include the following: the evaluation criterion for node splitting is “gini”, the selection standard for feature split points is “best”, the maximum depth of a single tree “max_depth” is {5, 10, 15}, the minimum number of samples for node splitting “min_samples_split” is {2, 5}, the minimum number of samples for leaf nodes “min_samples_leaf” is {2, 5}, the ratio of the training set to the test set is 8:2, and parameter tuning is performed through five-fold cross-validation to determine the optimal parameter combination, with the goal of maximizing the AUC value. In this study, the bootstrap sampling process is:
The random subspace projection is:
where
, and
is the randomly selected matrix.
The decision tree ensemble is constructed as:
where
is the 0–1 loss function.
The ensemble prediction mechanism is:
where
is the uniform weight.
The configuration feature importance measure is:
where
is the out-of-bag sample set,
is the out-of-bag sample after feature k is permuted, and A is the accuracy function.
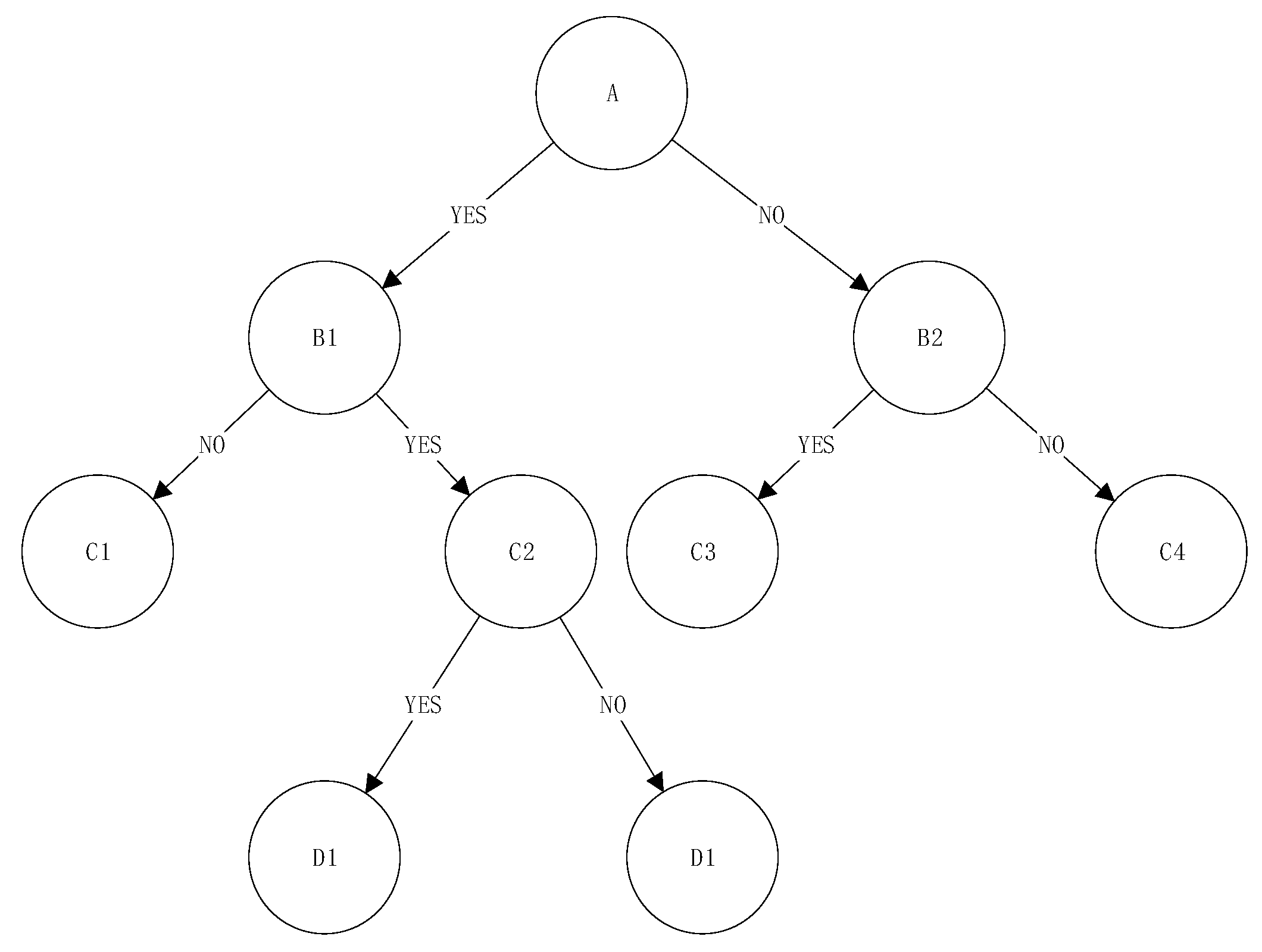
(2) Decision Tree Algorithm. The Decision Tree is a commonly used tree-based algorithm in machine learning for handling both regression and classification tasks. It constructs a tree-like structure through recursive data partitioning, where each node splits the data based on the threshold of a selected feature. This process continues until a predefined stopping condition is met, and the final class label (e.g., high risk/low risk) is output at the leaf nodes. The core mechanism of the Decision Tree involves evaluating potential features for splitting by computing metrics such as information gain (used in the ID3 algorithm) or Gini impurity (used in the CART algorithm). These metrics assess the effectiveness of different features in separating the dataset, thereby enabling the selection of the optimal feature and threshold for node splitting. The Decision Tree algorithm offers strong interpretability due to its transparent decision-making process, and its tree structure can be intuitively visualized. Therefore, it was selected as one of the predictive models in this study. The underlying principle is illustrated in
Figure 4.
This paper selects the classic CART algorithm to construct a binary decision tree. During the model construction process, “gini” is selected as the impurity algorithm, the random seed is set to {42}, the feature split point is “best”, the maximum depth of the tree “max_depth” is {3, 5, 7, 10}, the minimum number of samples for leaf nodes “min_samples_leaf” is {3, 5, 10}, and the minimum number of samples for splitting nodes “min_samples_split” is {2, 5, 10}. The ratio of the training set to the test set is 8:2, and parameter optimization is performed through the Grid Search method combined with five-fold cross-validation. The parameter combination with the highest F1-score on the validation set is selected to construct the optimal model. In this study, the feature space is defined as:
The standardized transformation is:
where
is the feature mean vector,
is the variance diagonal matrix, and
.
For the node splitting criterion (CART algorithm), the Gini impurity of node
is defined as:
where
.
The optimal split is solved by:
where
.
The resilience level prediction function is:
where
is the leaf node region,
.
(3) AdaBoost (Adaptive Boosting) Algorithm. AdaBoost constructs a strong predictive model by iteratively training weak classifiers—such as decision stumps (decision trees of depth 1). In each iteration, the algorithm adjusts the weights of the training samples: misclassified samples receive higher weights, causing subsequent weak learners to focus more on these difficult cases. Finally, the predictions from all weak classifiers are combined through weighted voting to produce the final output. In this study, which focuses on predicting resilience levels in green agricultural supply chains, high-risk samples are typically in the minority class, only accounting for about 9% of the dataset. The AdaBoost algorithm leverages its weight adjustment mechanism to significantly enhance the detection of high-risk instances, thereby improving the recall performance on imbalanced datasets. This makes it particularly suitable for the present research. The underlying principle is illustrated in
Figure 5.
In this study, the AdaBoost algorithm employs decision trees of depth 1 (decision stumps) as weak classifiers, iteratively training through adaptive adjustment of sample weights. Key parameter settings include the following: the number of weak classifiers “n_estimators” set to {50, 100, 200}, the learning rate “learning_rate” set to {0.8, 1.0, 1.2} (controlling the magnitude of weight updates), and the maximum depth of the base classifier “base_estimator__max_depth” fixed at {1} (decision stumps). Grid search combined with five-fold cross-validation is used to optimize parameters, with a focus on recall to enhance the identification of high-risk samples. The feature space is defined as:
The weak classifier is defined as:
where
is the feature mapping function, and m = 1,2,…,M is the number of iterations.
The iterative optimization process is:
where (18) is the weighted error rate, (19) is the classifier weight, (20) is the sample weight update, and
is the normalization numerator.
The ensemble prediction function is:
The action mechanism of configuration features is:
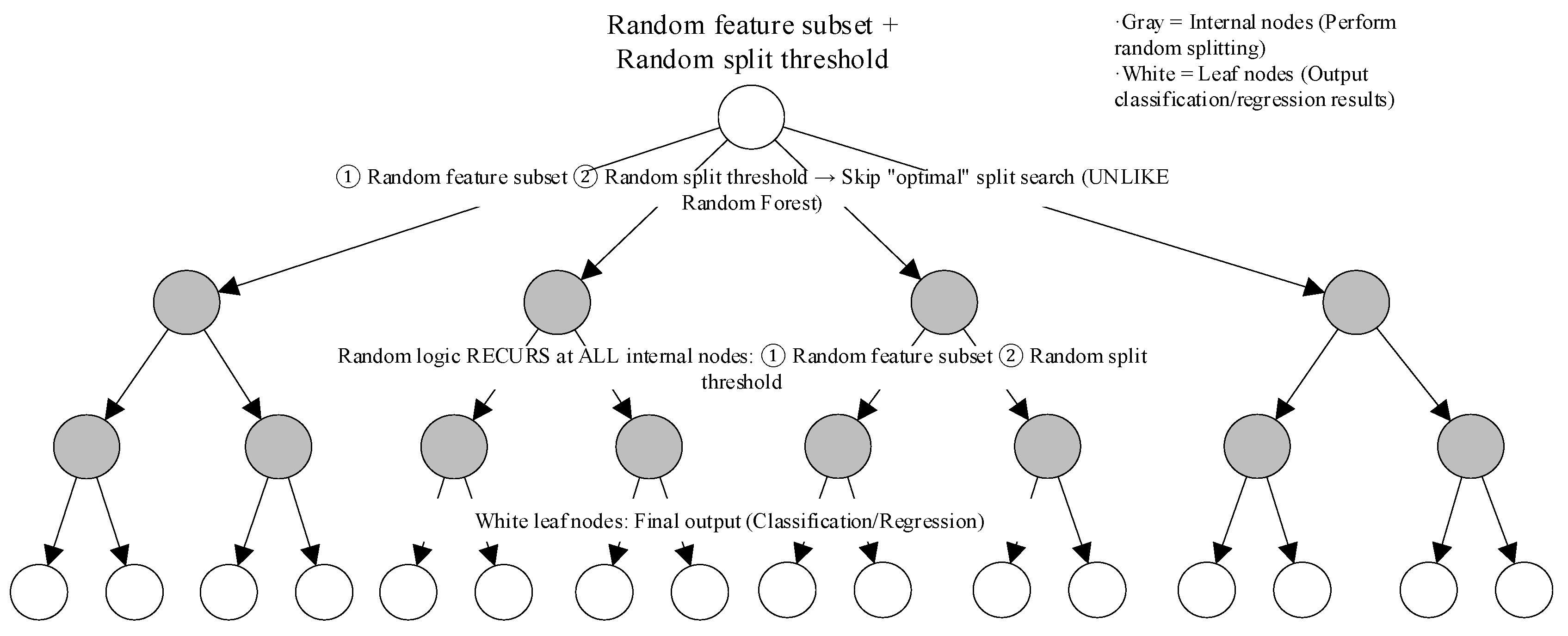
(4) ExtraTrees Algorithm. The ExtraTrees (Extremely Randomized Trees) algorithm is an ensemble learning method based on Random Forests, but it introduces additional randomness during the construction of decision trees. Compared to Random Forests, the key differences lie in its more random splitting and use of the full sample for each tree. During node splitting, ExtraTrees not only randomly selects features but also chooses split thresholds in a random manner. This enhances the model’s generalization ability. Using the full sample for training reduces the variance introduced by bootstrap sampling, thereby further improving the stability of the model. ExtraTrees exhibits high computational efficiency, making it particularly suitable for medium-sized survey datasets (e.g., datasets containing several hundred samples). Additionally, it demonstrates greater robustness when dealing with noisy features (such as redundant items in surveys), effectively reducing the risk of overfitting and ensuring the model’s stability and reliability in practical applications. Therefore, this method was chosen for resilience level prediction in this study. The underlying principle is illustrated in
Figure 6.
The model in this paper adopts a gradient boosting framework, using the “binary:logistic” objective function for binary classification tasks. The optimization ranges for key parameters are as follows: learning rate “learning_rate”: {0.01, 0.1, 0.2}; maximum tree depth “max_depth”: {3, 5, 7}; minimum sum of sample weights for leaf nodes “min_child_weight”: {1, 3, 5}; L2 regularization coefficient “reg_lambda”: {0.1, 1, 10}; subsampling ratio “subsample”: {0.8, 1.0}; with the random seed fixed at seed=42. Parameter optimization is performed through 50 rounds of iterative search using Bayesian Optimization, with the F1-score from five-fold cross-validation as the optimization objective. In this study, the extended form of the random forest is:
where
is the random parameter set.
The extreme random splitting mechanism is:
where (24) is the random feature selection, (25) is the random threshold generation, (26) is the splitting criterion, and
is the set of random candidate split points.
The ensemble prediction function is:
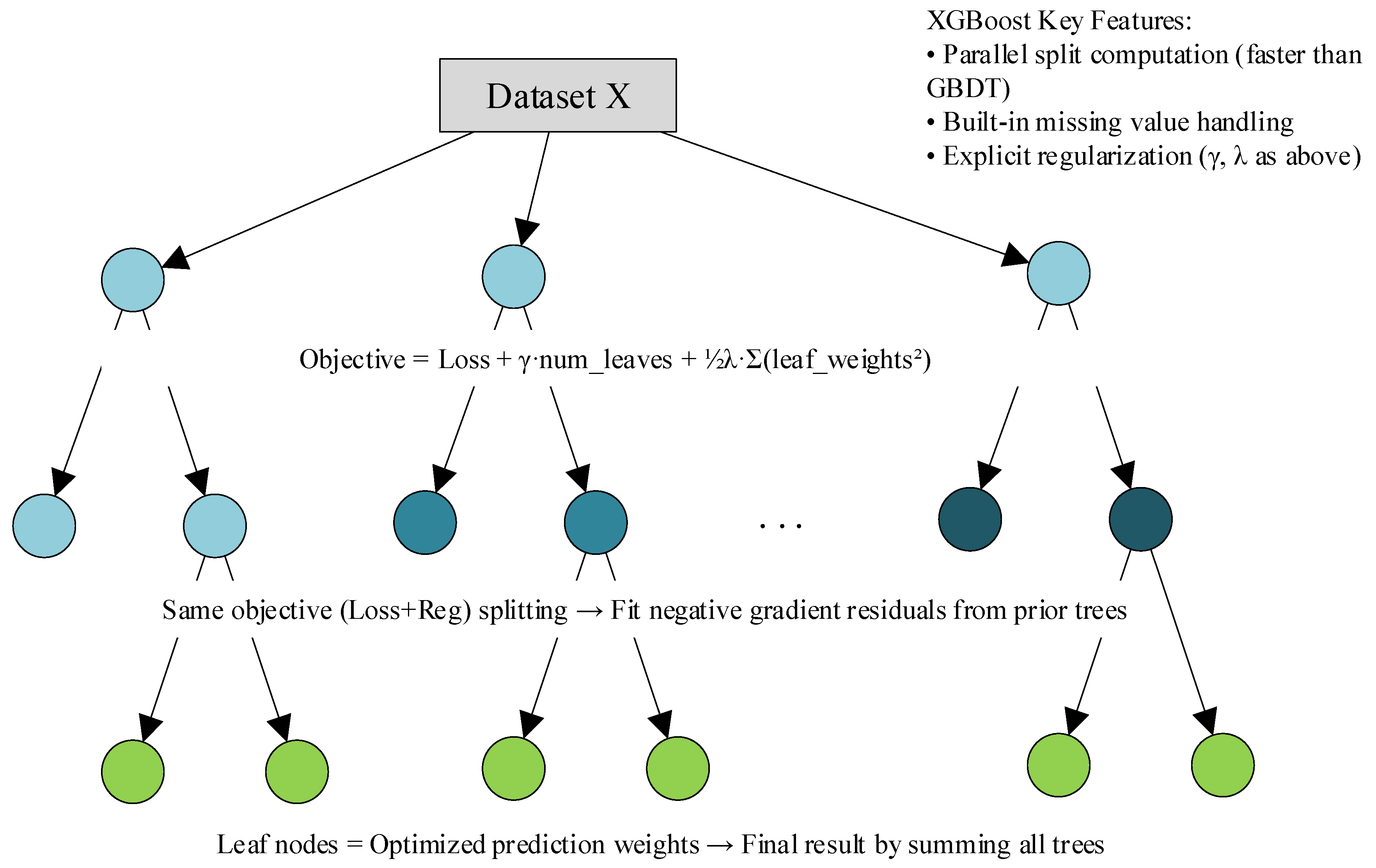
(5) The eXtreme Gradient Boosting (XGBoost) model is an efficient gradient boosting framework. It comprises multiple decision trees, each functioning as a weak classifier, which combine to form a strong classifier. Core advantages of XGBoost include second-order derivative optimization, regularization (L1/L2), and parallel computing. It typically delivers optimal predictive performance in benchmark tests and practical applications across fields. Moreover, by adjusting the “scale_pos_weight” parameter to increase the weight of high-risk samples, XGBoost enhances its performance on imbalanced datasets. The principle behind this is illustrated in
Figure 7.
In this study, the XGBoost model employs a gradient boosting framework and uses the “binary:logistic” objective function for binary classification tasks. The optimization ranges for key hyperparameters are as follows: learning rate “learning_rate”: {0.01, 0.1, 0.2}; maximum tree depth “max_depth”: {3, 5, 7}; minimum sum of sample weights for leaf nodes “min_child_weight”: {1, 3, 5}; L2 regularization coefficient “reg_lambda”: {0.1, 1, 10}; and subsampling ratio “subsample”: {0.8, 1.0}. Bayesian Optimization is used for 50 rounds of iterative search, with the F1-score from five-fold cross-validation as the optimization objective. In this research, the core XGBoost model is:
Objective Function:
where
is the logistic loss function:
.
Gradient Boosting Framework:
where (30) is the Taylor approximation expansion, (31) is the leaf node weight optimization, and (32) is the structural score.
.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}