1. Introduction
The importance of digital forensics grows more significant as computers become more integrated into daily life and the work environment. Cybercrimes and security risks have intensified the need for proficient gathering and examination of digital evidence in criminal inquiries and security evaluations. Particularly in enterprise environments, where the Windows operating system predominates, forensic investigations often involve analyzing large volumes of files managed across multiple systems. File analysis is critical in Windows forensics as files constitute a primary carrier of digital evidence. Anomalies in file structures may manifest in various forms, such as files in unexpected locations, deviations from trusted system typical naming conventions, or unauthorized modifications to system-critical files. For example, if a system or application-related file goes in an unexpected path, it may indicate unauthorized activity or a security breach. Identifying such anomalies is essential for detecting cyber threats, unauthorized access, and potential malware infections. Building on our previous work with word-embedding methods (Word2Vec, FastText), we extend that expertise to sequence-aware modeling.
Forensic analysts often struggle to detect anomalies using conventional file analysis techniques in large-scale enterprise environments, where millions of files are distributed across complex directory structures. Examining each file individually is time-consuming and computationally inefficient, especially under incident-response deadlines. Existing approaches that rely on file content or static metadata face challenges in scalability and ignore the hierarchical nature of file paths. This research is motivated by the need for a scalable, structure-aware solution that can effectively detect anomalies in file paths—a common vector for malicious or unauthorized activity in Windows systems. We aim to preserve their semantic and positional characteristics by approaching file paths as sequential data for more accurate anomaly detection.
Traditional file analysis methods often concentrate on file content, metadata, or access patterns [
1,
2]. Although effective, these approaches can be time-consuming and resource-intensive when applied to the large datasets of modern systems. Previous research introduced an approach that leverages file paths rather than file content to detect anomalies, using static vector embeddings generated by word embedding techniques. This method reduced computational overhead by summarizing file path embeddings through operations such as summation and averaging. However, these aggregation-based methods discard hierarchical relationships and sequential dependencies within file paths. Thus, they may be confused when distinguishing structurally similar but semantically different file paths, leading to misclassification of normal and anomalous behaviors. In contrast, this study adopts Transformer-based sequence modeling to analyze file paths as structured data to preserve both their positional and contextual relationships [
3]. Since the attention mechanism of Transformers has the strength to capture long-range dependencies and intricate patterns within file structures, it is adequate for more precise anomaly detection.
We previously developed a word-embedding approach for path-based detection. Its failure to differentiate hierarchically similar yet semantically distinct paths motivates the present study. This study addresses two questions: (1) Does modeling file paths as structured sequences improve anomaly-detection accuracy? (2) How do Transformer-based models compare with aggregation-based baselines on enterprise forensic datasets?
By leveraging Transformer-based sequence modeling, this study enhances the precision and scalability while identifying scenarios in which traditional methods remain preferable. These findings indicate potential directions for future research, particularly in developing hybrid models that integrate both methodologies to create more robust frameworks for anomaly detection.
The structure of this paper is organized as follows:
Section 2 presents an in-depth review of prior studies on file system anomaly detection and embedding methods for sequence data, and the proposed method is introduced with details in
Section 3.
Section 4 offers an analysis of the experimental results. Additionally, several in-depth case studies are included.
Section 5 examines the benefits and drawbacks of the suggested approach. Finally,
Section 6 wraps up the paper by summarizing the key findings.
2. Related Work
Digital forensics research increasingly employs machine-learning and deep-learning methods for anomaly detection. Prior work can be grouped into three areas: (i) file-system anomaly detection, (ii) Transformer- and conventional model-based anomaly detection, and (iii) embedding techniques for sequential data.
2.1. File System Anomaly Detection
File systems are primary sources of forensic evidence, recording user activity, system operations, and security events. Detecting anomalies at this layer is therefore pivotal for both forensics and incident response. Early studies analyzed file metadata (timestamps, ownership, access counts), access patterns, and content features to flag suspicious behavior [
4]. However, rule-based approaches struggle with high-dimensional sparse data and distinguishing benign from malicious activity.
Machine-learning models partially overcome these limits by learning patterns from historical audit logs or file-operation sequences. However, their accuracy depends on domain-specific feature engineering, and they adapt poorly to novel threats. To improve triage, Xiaoyu et al. applied supervised learning to file-system metadata within a Digital-Forensics-as-a-Service (DFaaS) platform, accelerating artefact prioritization but not enabling real-time detection [
5]. Although file-path strings encode rich structural and contextual cues, few studies exploit them directly; most focus on metadata, content, or logs. We address this gap by modeling file paths as sequences to preserve hierarchical and semantic relations.
2.2. Transformer- and ML-Based Anomaly Detection
Transformers capture long-range dependencies in sequential data through self-attention and are widely used for log analysis, time-series monitoring, and network security. LSADNET combines convolutional layers with a Transformer encoder to model local and global patterns in log sequences, improving anomaly detection [
6]. Loader uses Transformer encoders to learn normal log behavior and flags deviations as anomalies [
7]. In network security, attention-based deep-packet-inspection (DPI) frameworks analyze raw payloads to detect malicious content without manual parsing [
8].
Although various models have been explored across domains, few studies have conducted systematic comparative evaluations of these models on the same anomaly detection task. We therefore compare Transformer, Random Forest (RF), Neural Network (NN), Support Vector Machine (SVM), and LightGBM classifiers on the same file-path task, assessing trade-offs in accuracy, interpretability, and generalization to unseen paths. By conducting this cross-model evaluation, this study aims to identify the most effective modeling strategies for file system anomaly detection. It contributes to a better understanding of how different algorithms perform when applied to structured sequence data while highlighting the strengths of attention-based architectures in capturing context-aware anomalies.
2.3. Embedding Techniques for Sequence Data
Recent advancements in artificial intelligence have significantly influenced security research, particularly in embedding-based anomaly detection in unstructured data. Techniques such as Word2Vec and FastText create dense vector representations of tokens, facilitating anomaly detection across various security domains, including network traffic analysis, system log modeling, and time-series anomaly detection. Notably, a Transformer framework that embeds raw network payloads has demonstrated superior performance compared to traditional intrusion detection baselines [
9].
Research in automotive security further illustrates this approach. Kim et al. [
10] introduced an intrusion detection system (IDS) for Controller Area Network (CAN) traffic, utilizing word embeddings to model sequential dependencies while addressing the resource constraints typical in vehicular environments. In a similar vein, Choi et al. [
11] developed a privacy-preserving IDS for In-Vehicle Networks (IVNs), implementing a fuzzy hashing-based embedding method alongside a Support Vector Machine (SVM) classifier. Other studies, including those considering HyDL-IDS [
12] and a prediction-based IDS framework [
13], have investigated the use of a combined model incorporating convolutional neural networks (CNNs) and long short-term memory (LSTM), achieving notable accuracy in identifying cyber-attacks within automotive systems.
Despite the demonstrated effectiveness of embedding-based approaches in network and automotive security, their application to file system data introduces distinct challenges. File paths have a hierarchical structure and complex contextual dependencies. Many prior studies have validated sequence embeddings for anomaly detection in relatively structured environments, but studies focusing on file path embeddings remain limited. Therefore, this study aims to address this gap by applying sequence modeling techniques to file system paths to preserve their hierarchical and contextual semantics for improved anomaly detection performance.
Although these studies provide valuable insights into file system analysis, they primarily focus on metadata, content features, or logs, neglecting the hierarchical structure of file paths. This points to a notable gap in research concerning the structural dependencies of file paths, particularly their ability to detect subtle anomalies. Consequently, this study proposes a method to preserve the semantic and positional relationships inherently present in file paths. A summary of existing approaches and their main contributions is provided in
Table 1.
2.4. Anomaly Detection Combined with Artificial Intelligence Algorithms
Recent advances in artificial intelligence have greatly improved the performance and applicability of anomaly detection across diverse domains. Trilles et al. [
14] conducted a systematic mapping study that explores anomaly detection methods in TinyML and edge computing environments. Their work highlights the unique constraints of deploying models on resource-limited devices and discusses trends and gaps in current research.
In the realm of multivariate time-series data, Deng and Hooi [
15] introduced a graph neural network (GNN)-based model that captures both temporal and inter-sensor dependencies for explainable anomaly detection. This method enhances interpretability while maintaining high detection accuracy.
Pang et al. [
16] proposed a weakly supervised anomaly detection framework using few-shot learning to address limited labeled data. Their PReNet architecture effectively generalizes to unseen anomalies using a few labeled samples, making it suited for real-world scenarios.
These studies collectively reflect the increasing maturity of AI-based anomaly detection techniques and motivate the need for comparative evaluations and adaptable architectures in practical applications.
In the domain of encrypted traffic analysis, Ji et al. [
17] conducted a systematic review on AI-based anomaly detection techniques applicable to TLS and other cryptographically protected channels. Given the limitations of Deep Packet Inspection (DPI) in such environments, the authors emphasized alternative approaches based on statistical traffic features and machine learning classifiers. Their review categorizes and assesses detection techniques across several stages, including feature extraction, preprocessing, and model selection.
Deep learning-based anomaly detection has also been comprehensively surveyed by Huang et al. [
18], who reviewed over 180 recent studies. They categorized deep learning-based methods into reconstruction-based and prediction-based models. They highlighted how hybrid architectures can balance the interpretability of traditional models with the representational power of deep learning techniques.
To improve the ability to generalize of semi-supervised AD models, Pang et al. [
19] proposed the Pairwise Relation Prediction Network (PReNet), a weakly supervised learning approach that detects both seen and unseen anomalies by learning relational patterns among training samples. This method addresses one of the key limitations of prior semi-supervised methods and achieves strong performance across 12 real-world datasets.
Despite the impressive capabilities of these AI-based methods, most are designed for general or network-oriented anomaly detection and do not consider the structural properties of file paths. Thus, these methods fail to readily capture the hierarchical and contextual relationships inherent in file paths, which are critical for detecting subtle anomalies in file system data. Our work fills this gap by focusing on applying Transformer-based sequence modeling to file path data, aiming to improve the accuracy and scalability of anomaly detection in real-world forensic environments.
Table 2 outlines recent AI-based anomaly detection studies that motivate our comparative evaluation and modeling approach.
Summary and Contributions. Most AI-based methods target generic or network data and overlook the hierarchical structure of file paths. We focus on Transformer-based sequence modeling of paths to improve anomaly detection in enterprise forensic settings.
We propose a context-aware embedding for file paths that preserves hierarchical semantics.
We apply Transformer sequence models to these embeddings and show gains over static and aggregated baselines in file-path anomaly detection.
We provide a comparative evaluation of classical and deep models on real forensic data and analyze case studies to illustrate the practical impact.
3. Methodology
This section describes the process of file path embedding and anomaly detection, which form the core of this research. The methodology involves extracting file paths from Windows systems, embedding them using a word embedding model, and using these embeddings to train models for anomalous file path detection. To enhance accuracy, a Transformer-based model is employed to capture sequential and contextual relationships within file paths, while traditional models are also evaluated for comparative analysis.
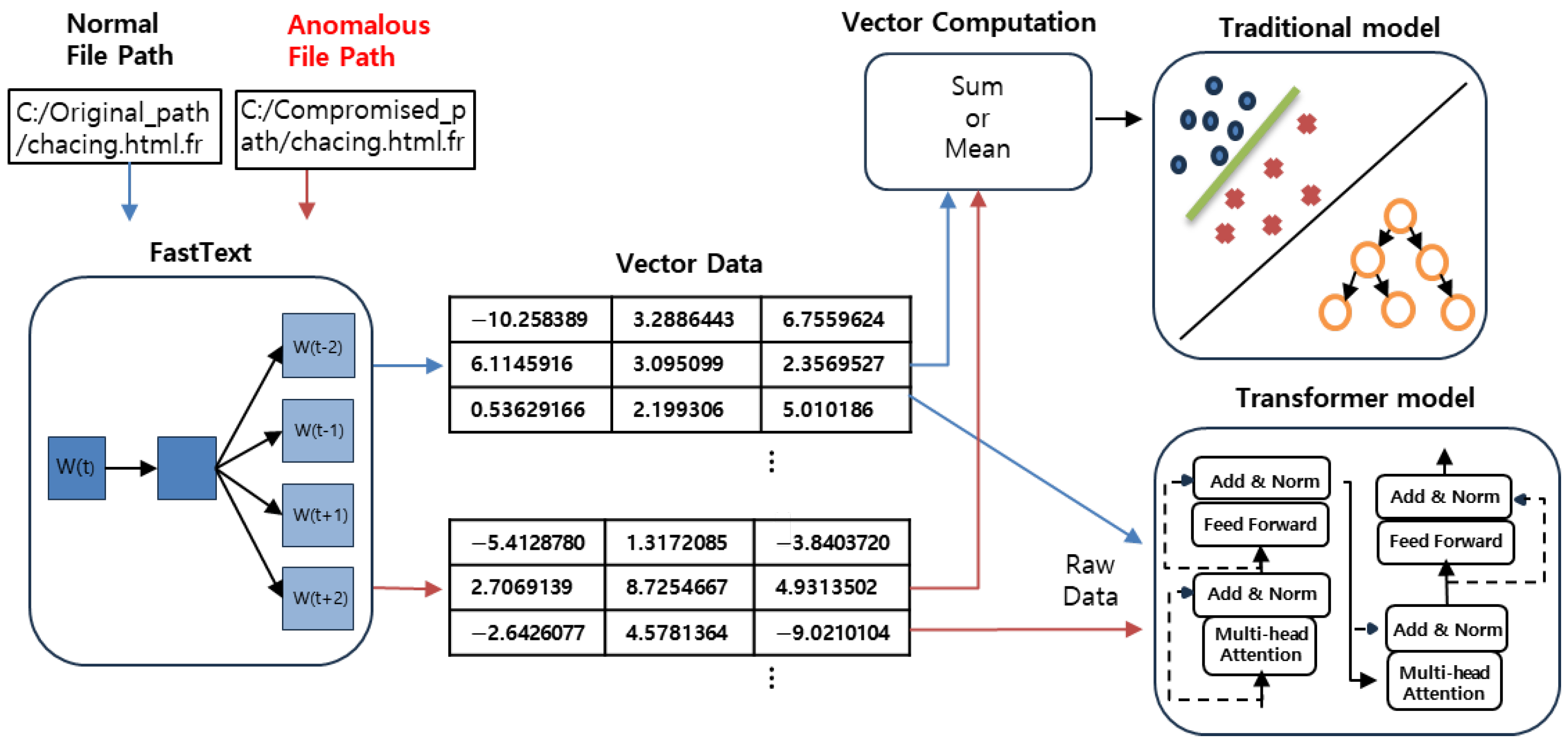
Figure 1 shows the framework for file path embedding and anomaly detection. In the process, normal and anomalous file paths are first input into the system. These file paths are embedded using the FastText model, generating vector representations. Afterward, these vector values are processed through two approaches: one involves aggregating the vectors using sum or mean operations, which are then passed to traditional machine learning models for anomaly detection. The other approach sends the raw embeddings directly to a Transformer model, which captures sequential and contextual relationships within the file paths to detect anomalies. This framework allows for the comparative evaluation of traditional and Transformer-based anomaly detection techniques.
3.1. File Path Data Collection and Preprocessing
This study extracted file path data from Windows systems using the NTFS Master File Table (MFT). The MFT contains metadata such as file paths, creation time, modification time, access time, and sequence numbers. For anomaly detection, only the file path data were utilized. To collect the file path data, FTK Imager [
20] was used to extract the MFT files from each system, and the AnalyzeMFT tool [
21] was employed to parse the extracted MFT files. The dataset was expanded to 35 different systems, increasing the diversity of file paths and improving the robustness of anomaly detection.
To ensure consistent processing, several preprocessing steps were applied. First, all user-specific directory names were replaced with the generic term “user” to maintain consistency across different systems and prevent machine learning models from learning system-specific biases. Additionally, since FastText treats spaces as word delimiters, all spaces in file paths were replaced with the “⌃” character to prevent unintended tokenization errors. Furthermore, file path delimiters “/” were converted into spaces so that each directory and filename could be treated as a separate token during the embedding process.
Figure 2 shows an example of these preprocessing steps. The original file paths contain user-specific directory names, spaces, and path delimiters, which are transformed into standardized representations for consistent processing.
At this stage, duplicate removal was not performed, ensuring that FastText could capture the full distribution of file paths without information loss.
3.2. File Path Embedding Using FastText
FastText was utilized to generate vector embeddings for file paths [
22,
23]. Unlike conventional word embedding techniques such as Word2Vec, FastText treats words as character n-grams, making it well suited for handling file paths that contain unseen or dynamically generated tokens. In this study, the tokenization process involved splitting file paths at the “/” delimiter, treating each directory and filename as an individual token. The Skip-gram method of FastText was employed, which predicts adjacent tokens, enabling the model to learn structural and contextual relationships within file paths [
24].
Formally, given a target token
w and a context token
c, FastText optimizes the objective function given below:
where
and
are the vector embeddings of the target and context tokens,
denotes the sigmoid function, and
is the set of negative samples. Unlike Word2Vec, FastText represents each token
w as a bag of character-level
n-grams
; the final embedding is computed as:
with
the embedding vector for subword
n-gram
g. This subword representation allows FastText to generate meaningful embeddings even for rare or unseen tokens by composing them from frequent subword units.
For model training, FastText was used with its default hyperparameters to maintain consistency with typical setups. The learning rate (lr) was set to 0.05, the window size (ws)) was fixed at 5, and the model was trained for 5 epochs. The minimum word count (minCount) was set to 5, filtering out infrequent tokens, and the subword n-gram range (minn to maxn) was set to span from 3 to 6 characters. These hyperparameters are standard defaults in FastText and were used to maintain a balanced configuration suited to file path data.
The embedding dimensions were set to three different values—16, 32, and 64—to analyze the impact of vector size on anomaly detection performance. Larger embedding dimensions are expected to capture more complex relationships between the file paths, but may come with increased computational cost. Multiple configurations were tested to find the optimal trade-off between representational capacity and computational efficiency.
3.3. Transformer-Based Model for File Path Anomaly Detection
To enhance anomaly detection performance and capture the sequential and contextual dependencies in file paths, a Transformer-based model was employed. Unlike traditional methods relying on aggregated embeddings, this model directly processes sequences of token embeddings derived from FastText, enabling it to learn dynamic, hierarchical relationships within file paths.
The Transformer encoder follows the standard architecture [
25,
26]. Each tokenised file path is represented as a matrix
, where
T is the token count and
d the embedding dimension. Positional encoding
is added to inject sequential information:
Multi-Head Self-Attention (MHSA) is computed as:
where
. The output then passes through a feed-forward network:
A final attention-pooling layer condenses the sequence into a single vector fed to a binary classifier producing the anomaly label .
In our implementation, the Transformer model used two encoder layers with four attention heads per layer and a key dimensin 64. The feedforward network had a hidden size of 128. The model was trained for 30 epochs using the Adam optimizer with a learning rate 0.001 and a batch size of 64.
This architecture allows the model to attend to relevant path components and capture nuanced structural patterns in file paths, thereby improving the detection of subtle anomalies.
3.4. Training and Testing Dataset Construction
A structured dataset was created from the extracted file paths to evaluate the anomaly detection models. Unlike the embedding stage, where all file paths were retained, duplicate removal was applied at this stage to prevent overfitting and to ensure that the dataset reflected meaningful variations rather than redundant patterns. For normal file paths, a filtering criterion was applied: a file path was considered normal if it appeared in at least 10% of all systems. This ensured that commonly shared directory structures were treated as normal, while system-specific anomalies were excluded.
Anomalous file paths were generated by modifying existing normal paths, primarily through relocation within different subdirectories while keeping filenames intact. This approach allowed the creation of anomaly cases that exhibited subtle deviations rather than entirely distinct paths, making anomaly detection more challenging and realistic.
Traditional machine learning models such as Support Vector Machine (SVM) [
27], Random Forest (RF) [
28], Neural Networks (NNs) [
29], and LightGBM [
30] were trained using precomputed FastText embeddings. Two embedding aggregation strategies were tested: summation-based embeddings, which emphasize structural depth and scale within a file path, and averaging-based embeddings, which provide a normalized representation independent of file path length.
In contrast, the Transformer-based model was trained directly on raw file path sequences without precomputed embeddings. This allowed the model to learn dependencies and hierarchical relationships dynamically without relying on static feature representations.
3.5. Procedural Overview of the Proposed Method
The methodology described above can be systematically summarized in Algorithm 1 as the following pseudocode. This procedural outline consolidates all key phases, data extraction, preprocessing, embedding, model training, and evaluation into a unified algorithmic flow for reproducibility and implementation clarity.
| Algorithm 1: File Path-Based Anomaly Detection Procedure |
![Systems 13 00403 i001]() |
This pseudocode, presented in Algorithm 1, offers a holistic representation of the proposed methodology. It clarifies how each phase connects with the previously described modules and highlights the data flow and decision points, thereby making the system architecture and experimental pipeline transparent and reproducible.
4. Experiment Results
This section presents the experimental setup, dataset, evaluation metrics, and results of the proposed anomaly detection method. The primary objective of this experiment is to assess the effectiveness of Transformer-based sequence modeling in detecting anomalous file paths. To ensure a comprehensive evaluation, we compare the proposed method with baseline approaches, including previously developed file path anomaly detection models.
4.1. Experimental Environment
The computational resources and environment used for the experiments are detailed below. All experiments were conducted on a local machine with the following system specifications:
Operating System: Windows 11 Pro (Version 24H2, Build 26100.3775)
CPU: Intel® Core™ i5–14500 @ 2.60 GHz
RAM: 64 GB
GPU: NVIDIA GeForce RTX 4070 (Driver Version 560.94, CUDA Version 12.6)
Deep Learning Framework: TensorFlow 2.16.1
4.2. Dataset
The dataset for training the embedding model was collected from 35 different computers in real-world environments. As summarized in
Table 3, the dataset was constructed by extracting file paths from NTFS Master File Table (MFT) files. In total, 18,674,072 file paths were obtained and subsequently converted into tokenized word lists. These tokenized lists were used to train the embedding model, which served as the basis for the anomaly detection task.
For training the anomaly detection models, the normal dataset was composed of file paths that appeared in at least 10% of the total computers. After filtering and removing duplicates, a total of 456,178 normal file paths were retained. The anomalous dataset was generated by modifying normal file paths, primarily by relocating files to different directory structures. This process resulted in 456,178 anomalous file paths.
After obtaining the normal and anomalous datasets, the entire dataset was split into 80% training and 20% test sets to ensure a balanced evaluation. Once the dataset was prepared, embeddings were generated using the trained FastText model. For the Transformer-based model, the raw embeddings were directly used as input sequences, while for traditional machine learning models, two types of embedding aggregation were applied: (1) the summation of embeddings, which captures structural depth and scale, and (2) the averaging of embeddings, which provides a normalized representation independent of file path length.
4.3. Evaluation Metrics
To evaluate the performance of the anomaly detection models, we utilized four standard classification metrics: Accuracy, Precision, Recall, and F1-score.
Accuracy: Measures the overall correctness of the model:
Precision: Indicates the proportion of correctly identified anomalies among all predicted anomalies:
Recall: Reflects the proportion of actual anomalies that were correctly identified:
F1-score: The harmonic mean of Precision and Recall:
Since anomaly detection often involves imbalanced datasets, the F1-score is particularly important as it considers false positives and false negatives. These metrics provide a comprehensive assessment of the model’s ability to distinguish normal and anomalous file paths.
4.4. Model Performance Comparison Across Different Embedding Dimensions
To evaluate the effectiveness of traditional anomaly detection models, we compared their performance using FastText embeddings with summation and averaging methods.
Table 4 presents the results.
The results indicate that Random Forest achieved the highest accuracy of 0.9729 using summed embeddings. The results suggest that higher embedding dimensions improve performance, with 64 dimensions generally outperforming 16 and 32 dimensions.
To further assess the impact of using a Transformer-based model that directly processes raw embedding sequences, we conducted additional experiments.
Table 5 presents the performance of the Transformer model.
Compared to traditional models, the Transformer model achieved its highest accuracy of 0.9782 at 32 dimensions, marginally outperforming the best-performing Random Forest model. However, increasing the embedding dimension beyond 32 did not provide significant improvements, suggesting a saturation point in the model’s capacity to capture meaningful file path structures. Interestingly, performance peaked at 32 dimensions, but declined at 64, suggesting that excessive embedding dimensions may introduce redundancy or overfitting.
While traditional models, particularly Random Forest, demonstrated competitive accuracy, the Transformer model achieved a higher F1-score of 0.9782 at 32 dimensions, highlighting its superior ability to distinguish anomalous file paths. The results also indicate that higher-dimensional embeddings do not always lead to improved performance, as observed in the decline at 64 dimensions.
These results demonstrate that the Transformer model achieves superior performance compared to traditional models when directly leveraging raw FastText embeddings. This improvement is attributed to its ability to capture contextual dependencies and hierarchical structures in file paths, which are often lost in aggregated embedding approaches. However, it is important to note that certain types of anomalies may exhibit simpler structural patterns that could be effectively captured by traditional models such as Random Forest. To further investigate this, we conducted case studies analyzing real-world scenarios, where the effectiveness of different approaches is examined in greater detail.
4.5. Case Study for Evaluating Hard-to-Detect Anomalies
To further assess the robustness of the proposed anomaly detection model, we conducted two case studies focusing on particularly challenging anomalies in forensic investigations. These studies evaluated the model’s ability to detect subtle deviations in file path structures that may indicate unauthorized activities.
4.5.1. Case Study Scenarios
Two case studies were conducted to validate the approach, focusing on hard-to-detect anomalies in forensic investigations.
Case 1: File Paths Found Only on a Single System
In the first case, anomalous file paths were defined as those found exclusively on a single system in the dataset. These paths did not exist in any other system, making them unique to that device. Such anomalies can arise from custom software installations, user-created directories, or unauthorized modifications. Detecting these anomalies is critical in forensic analysis, as they may indicate potential security breaches or malware artifacts.
Case 2: File Movements Within a Fixed Top-Level Directory
The second case examined file paths where the top-level directory remained unchanged, but files were relocated within different subdirectories. This scenario simulates an attacker attempting to obfuscate malicious activity by moving files without altering their names. The challenge is detecting these movements as anomalies, given their structural similarity to normal paths. The evaluation of this case provided insights into how well different models captured subtle structural deviations.
These case studies offered a deeper understanding of the model’s capabilities and limitations in real-world forensic scenarios. This study aims to determine the most effective methodology for file path anomaly detection by comparing traditional and Transformer-based approaches.
4.5.2. Dataset Construction
We curated datasets from real-world file path logs for both case studies, ensuring a diverse range of system configurations and usage patterns. The dataset was preprocessed using FastText embeddings, with each file path represented as an embedding vector.
For the anomaly detection models, we used a base set of normal file paths that were not included in the training phase of the detection models. This ensures that the models are evaluated on previously unseen normal data, making the anomaly detection task more realistic.
Case 1: File Paths Found Only on a Single System
In this scenario, we labeled file paths as anomalous if they appeared exclusively on a single system within the dataset. To simulate real-world conditions, we collected file paths from multiple systems and assigned labels accordingly:
Normal file paths: 91,153 file paths appearing on multiple systems that were not used in training.
Anomalous file paths: 91,153 file paths unique to a single system.
These anomalies often arise due to system-specific software installations, custom directories, or unauthorized modifications.
Visualization of Case 1
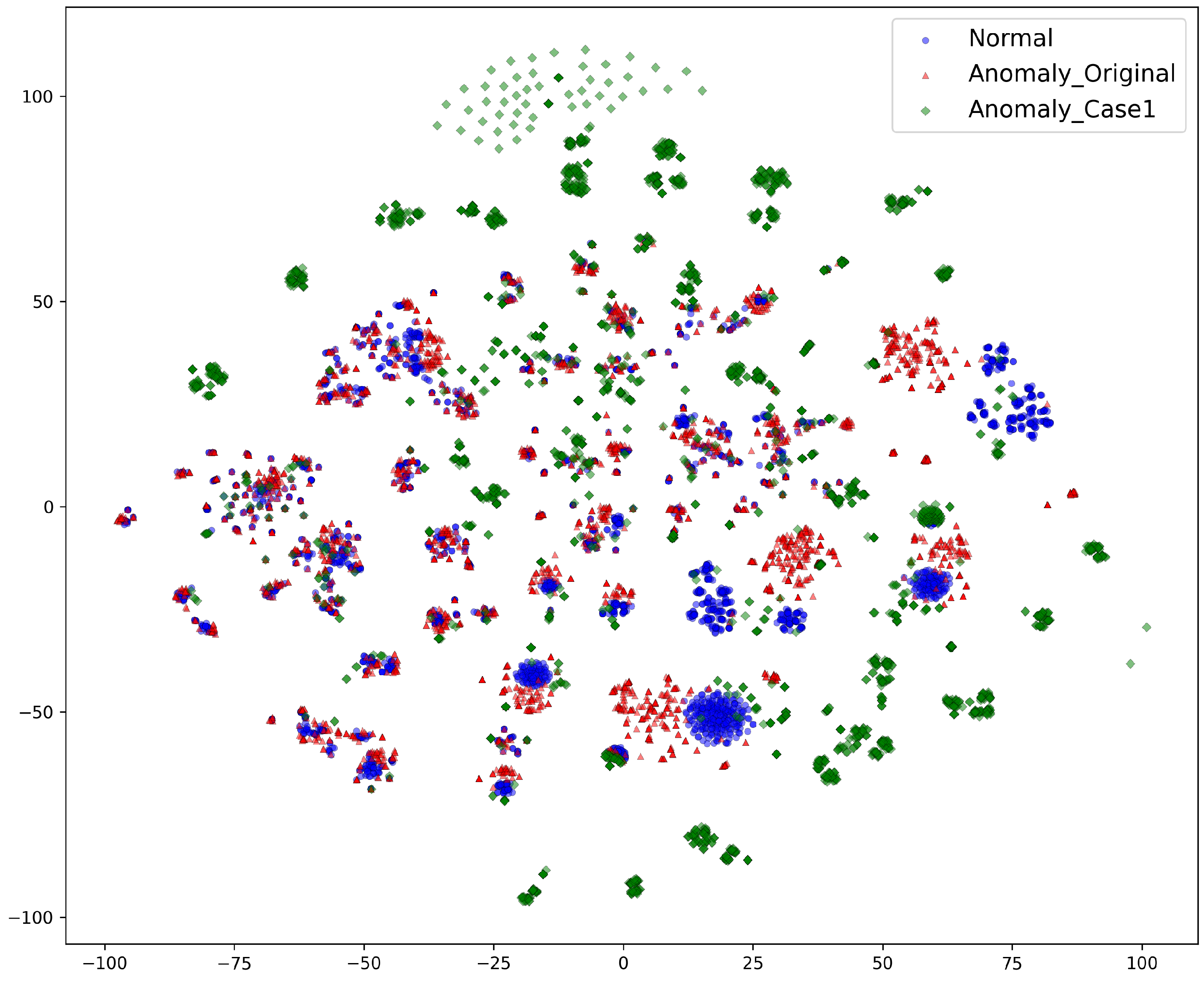
Figure 3 shows a visualization of the test dataset, mapping normal file paths, original anomalies, and anomalies introduced in Case 1 in the embedding space. As shown in
Figure 3, normal file paths (blue) and the original anomalies (red) tend to cluster in similar regions, indicating shared structural characteristics in their embeddings. However, the anomalies introduced in Case 1 (green) are more dispersed and located farther from the main clusters. This suggests that file paths found only on a single system form distinct, isolated patterns in the embedding space, making them more distinguishable using distance-based anomaly detection techniques.
This distribution pattern highlights how different anomaly detection models may perform when distinguishing these file paths from normal clusters. The separation observed in the visualization provides insight into how various models might leverage these differences to detect anomalies.
Case 2: File Movements Within a Fixed Top-Level Directory
For this case, we analyzed file paths where the top-level directory remained constant, but the file itself was relocated within subdirectories. The dataset was structured as follows:
Normal file paths: 91,153 file paths not used for training the detection models.
Anomalous file paths: 77,231 file paths generated by moving files within the same top-level directory, ensuring that their embedding vectors remain close to those of normal file paths.
This setup simulated attackers attempting to evade detection by shifting files without renaming them. By controlling the level of embedding deviation, we evaluate the model’s sensitivity to such subtle anomalies.
Visualization of Case 2
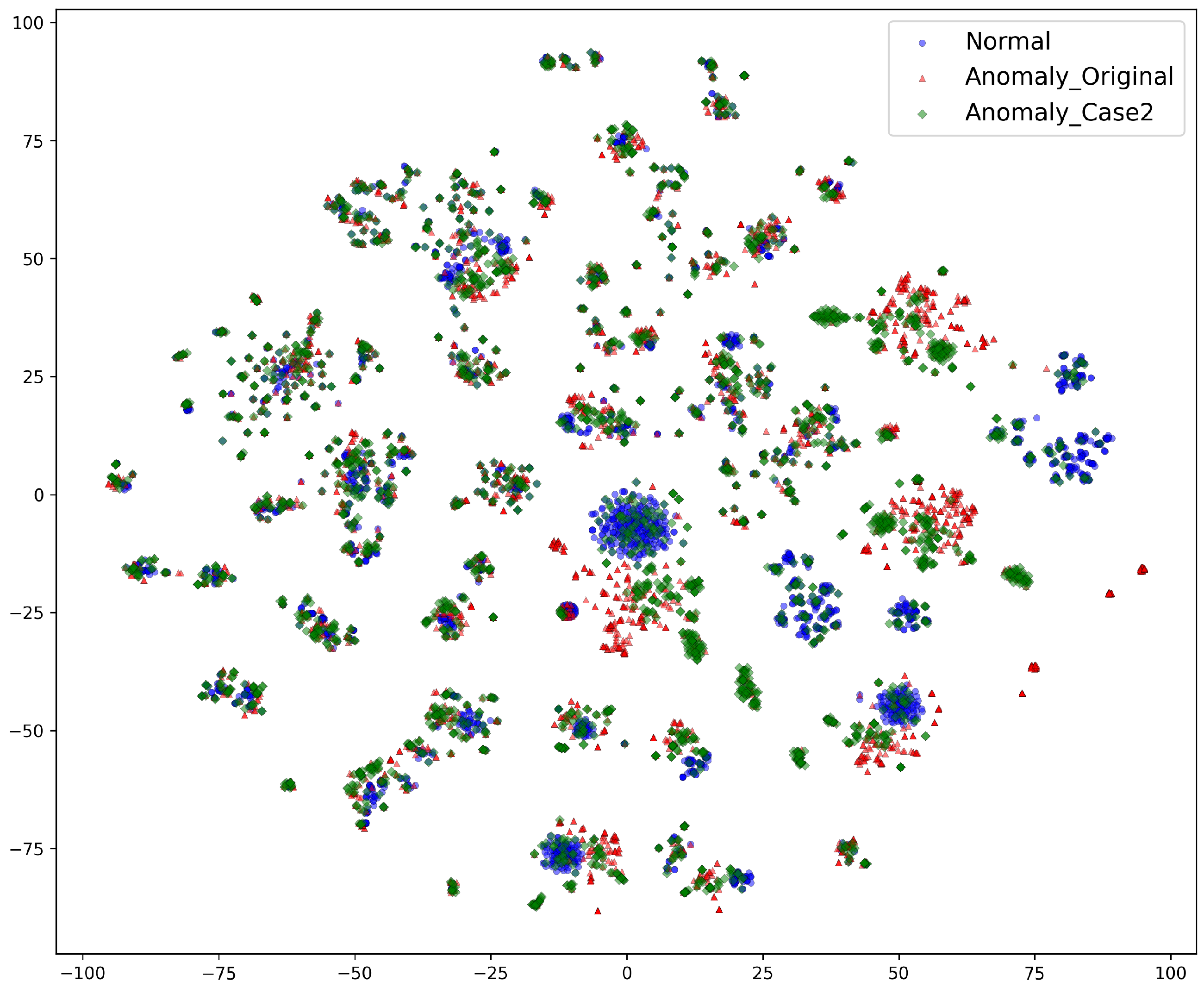
Figure 4 shows the distribution of anomalies in Case 2. As shown in
Figure 4, normal file paths (blue) and the anomalies from Case 2 (green) exhibit significant overlap in the embedding space. This is expected since file movements within the same top-level directory preserve much of the structural information, leading to only subtle embedding differences. While some Case 2 anomalies are positioned near original anomalies (red), many are interspersed among normal file paths, making them harder to distinguish.
This overlapping distribution suggests that models relying on clear cluster separations may struggle to detect these anomalies. Since file movements within the same top-level directory preserve much of their original structure, alternative methods such as sequence-based anomaly detection might be more effective. The visualization provides insight into the complexity of detecting such subtle file movements and highlights how different detection approaches might respond to this challenge.
4.5.3. Performance Evaluation
To evaluate the effectiveness of the proposed anomaly detection approach, we assessed the performance of both traditional models and the Transformer-based model under two conditions: (1) using their respective best-performing embedding dimensions and (2) using the same embedding dimension for direct comparison.
Unlike the previous general performance evaluation, where both sum- and mean-based embeddings were considered for traditional models, the case study results focus on the sum-based embeddings as they showed superior overall performance. Additionally, while traditional models were tested only with 64D embeddings, the Transformer model was evaluated under two conditions: using its best-performing setting (32D) and matching the 64D dimension for direct comparison with the traditional models. This design ensures a fair comparison while analyzing how embedding dimensionality affects anomaly detection under different conditions.
Case 1: File Paths Found Only on a Single System
In Case 1, anomalies were defined as file paths that appeared only once within a single system. This setting makes anomaly detection more challenging, as the models need to generalize from normal file paths while correctly identifying system-unique file paths as anomalous.
Traditional models using 64D embeddings were evaluated with their best aggregation method (sum-based embeddings), while Transformer models were evaluated with both their best-performing dimension (32D) and the same 64D setting for direct comparison.
Table 6 presents the model performance in Case Study 1.
The results indicate that the Random Forest model (64D) outperformed all other models, achieving the highest F1-score (0.9226). This suggests that RF is particularly effective at detecting rare, system-unique file paths.
The Transformer model’s performance improved with higher-dimensional embeddings (64D), achieving an F1-score of 0.8487 (64D) vs. 0.8245 (32D). This differs from the previous evaluation results, where Transformers performed best at 32D. One possible explanation is that, in this case study, rare and system-unique file paths require a more detailed representation to differentiate them from normal file paths. The increased embedding dimension (64D) may have provided additional feature space for capturing subtle differences in file path structures, enabling the Transformer to generalize better in this specific scenario.
A possible explanation is that detecting rare anomalies benefits from higher-dimensional feature representations, as they can encode more unique details.
Case 2: File Movements Within a Fixed Top-Level Directory
In Case 2, anomalies were defined as files moved within the same top-level directory. The key challenge here is distinguishing normal relocations from intentional obfuscation attempts by attackers. Since the embedding structure remains similar, detecting anomalies requires sensitivity to subtle spatial changes in the vector space.
As in Case 1, traditional models were tested with 64D sum-based embeddings, while Transformer models were evaluated with 32D and 64D embeddings.
Table 7 presents the model performance in Case Study 2.
While Transformer (32D) achieved the highest F1-score (0.9391), outperforming all traditional models, the difference from RF (64D) (F1-score = 0.9315) was relatively small. This suggests that Transformer embeddings are more effective in identifying subtle file movements within the same directory.
The Transformer (64D) model showed slightly lower performance then its 32D counterpart (F1-score: 0.9045 vs. 0.9391), suggesting that in some cases, higher-dimensional embeddings may introduce unnecessary complexity.
This result suggests that, in this specific setting, higher-dimensional embeddings might introduce unnecessary complexity for detecting small-scale variations, potentially leading to reduced generalization.
4.5.4. ROC Curves and Model Performance
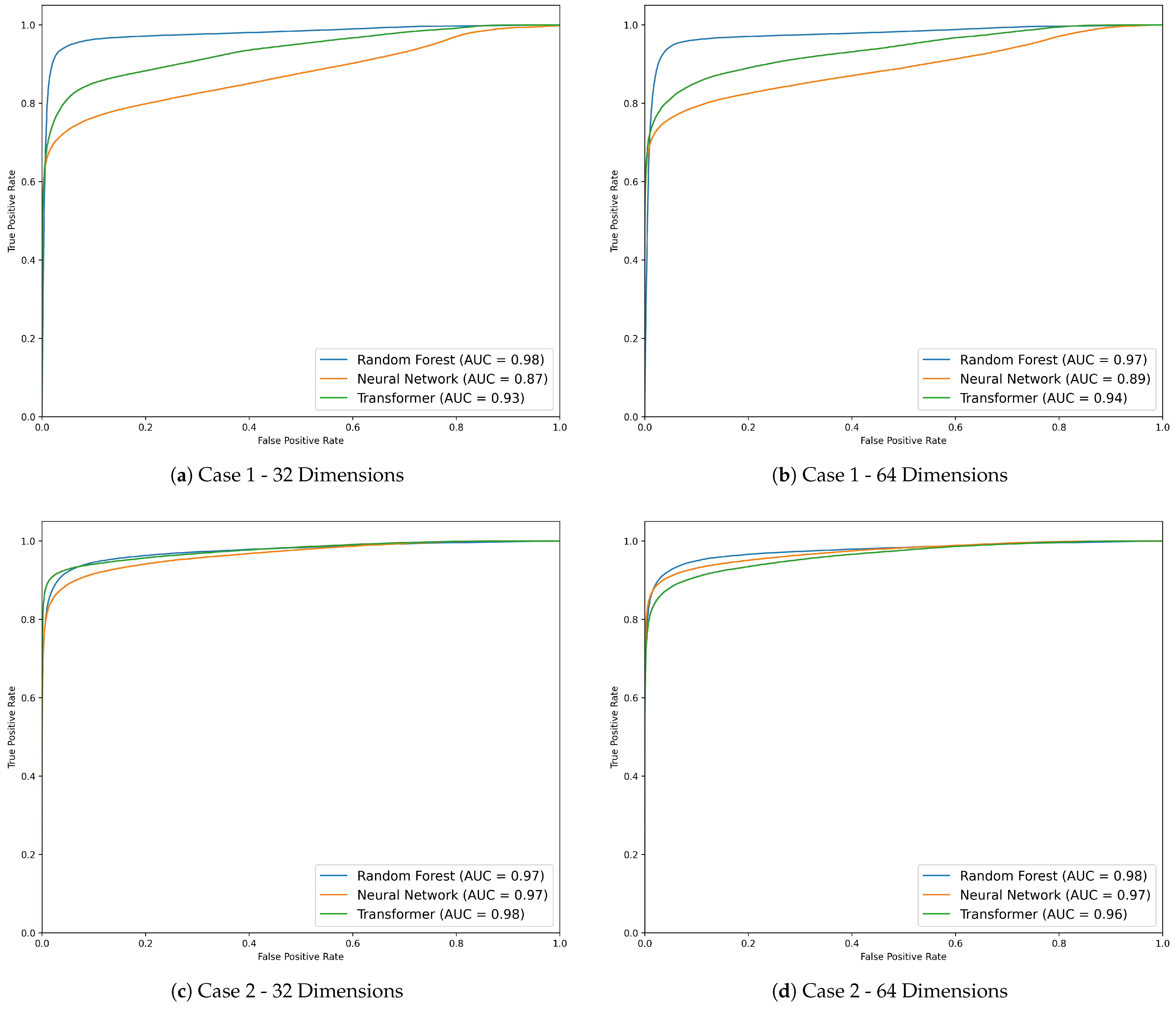
In addition to the performance metrics presented in the previous sections, we also analyzed the Receiver Operating Characteristic (ROC) curves for each model across the two case studies, as shown in
Figure 5. These curves illustrate the trade-offs between recall and false positive rate at different decision thresholds. The Area Under the Curve (AUC) scores provide a quantitative measure of a model’s overall classification performance, with higher AUC values indicating better model performance.
For Case 1, where anomalies were defined as file paths found only on a single system, the Random Forest (64D) model achieved the highest F1-score of 0.9226, and this is further corroborated by its AUC scores of 0.98 at 32 dimensions and 0.97 at 64 dimensions (
Figure 5a,b). The ROC curves highlight RF’s ability to correctly classify system-unique file paths, which are typically rare and distinctive, as anomalies. This demonstrates that Random Forest models can effectively handle cases where the feature space for anomalies significantly diverges from normal data.
In Case 2, where anomalies were defined by subtle movements within the same top-level directory, the Transformer (32D) model achieved the highest performance with an AUC of 0.98 (
Figure 5c). The self-attention mechanism of the Transformer allowed it to capture the fine-grained spatial changes necessary for detecting such subtle anomalies. However, the performance of the Transformer slightly degraded when using 64D embeddings, with the AUC dropping to 0.96 (
Figure 5d). This decline in performance supports the observation that, in some cases, higher-dimensional embeddings may introduce unnecessary complexity, which may not provide substantial benefits for detecting smaller variations.
Overall, the ROC curves reinforce the findings from
Figure 5, indicating that both traditional and Transformer models perform differently depending on the type of anomaly and the dimensionality of the embeddings. The curves further emphasize the importance of choosing appropriate embedding dimensions for different anomaly detection scenarios.
5. Discussion
The results of this study highlight the strengths of different modeling approaches depending on the nature of the anomaly. The Transformer model demonstrated strong performance in detecting structured anomalies (Case 2), where subtle variations in file paths signaled anomalous behavior. Its self-attention mechanism effectively captured contextual dependencies in sequential data. In contrast, the Random Forest model outperformed others in Case 1, where anomalies were defined by distinct file paths, utilizing feature divergence to classify anomalies effectively.
However, the proposed approach has several limitations. The dataset used primarily reflects one operating system environment, which may constrain its generalizability. Furthermore, this study only analyzed file paths and did not consider contextual signals like process activity, network behavior, or user interactions. These additional data sources could improve detection coverage and robustness.
Future research should investigate the application of this method in diverse file system environments, such as Linux or macOS. Given that file paths are structured consistently across operating systems, the proposed sequence-based modeling approach may generalize well. Additionally, integrating multi-modal signals and exploring hybrid models that combine Transformer and tree-based architectures could further enhance detection accuracy and adaptability across anomaly types.
6. Conclusions
This study proposed a file path-based anomaly detection approach utilizing Transformer and embedding-based models. Experimental results revealed that Transformer models are particularly effective for structured anomalies, while traditional models like Random Forest excel in detecting distinctive or rare path-based anomalies. These findings demonstrate the importance of model selection based on the specific characteristics of anomalous behaviors in file system data.
The proposed method shows promise for application in multi-platform environments due to the structural consistency of file paths across operating systems. This work contributes to developing flexible, scalable, and data-driven anomaly detection techniques for enhancing file system security.
Author Contributions
Methodology, R.-K.L. and T.-Y.Y.; Software, R.-K.L.; Validation, R.-K.L. and T.-Y.Y.; Investigation, R.-K.L.; Resources, H.-M.S. and T.-Y.Y.; Writing—original draft, R.-K.L.; Writing—review & editing, H.-M.S. and T.-Y.Y.; Visualization, R.-K.L.; Supervision, H.-M.S. and T.-Y.Y. Methodology, R.-K.L. and T.-Y.Y.; Software, R.-K.L.; Validation, R.-K.L. and T.-Y.Y.; Investigation, R.-K.L.; Resources, H.-M.S. and T.-Y.Y.; Writing—original draft, R.-K.L.; Writing—review & editing, H.-M.S. and T.-Y.Y.; Visualization, R.-K.L.; Supervision, H.-M.S. and T.-Y.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data used in this study can be obtained by making a reasonable request to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Carrier, B. File System Forensic Analysis; Addison-Wesley Professional: Boston, MA, USA, 2005. [Google Scholar]
- Buchholz, F.; Spafford, E. On the role of file system metadata in digital forensics. Digit. Investig. 2004, 1, 298–309. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. CSUR 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Mohammad, R.M.A.; Alqahtani, M. A comparison of machine learning techniques for file system forensics analysis. J. Inf. Secur. Appl. 2019, 46, 53–61. [Google Scholar] [CrossRef]
- Du, X.; Le, Q.; Scanlon, M. Automated Artefact Relevancy Determination from Artefact Metadata and Associated Timeline Events. In Proceedings of the 2020 International Conference on Cyber Security and Protection of Digital Services (Cyber Security), Dublin, Ireland, 15–19 June 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, X.; Zhang, H.; Zhang, H.; Han, P. Log Sequence Anomaly Detection Based on Local Information Extraction and Globally Sparse Transformer Model. IEEE Trans. Netw. Serv. Manag. 2021, 18, 4119–4133. [Google Scholar] [CrossRef]
- Xiao, T.; Quan, Z.; Wang, Z.J.; Le, Y.; Du, Y.; Liao, X.; Li, K.; Li, K. Loader: A Log Anomaly Detector Based on Transformer. IEEE Trans. Serv. Comput. 2023, 16, 3479–3492. [Google Scholar] [CrossRef]
- Stein, K.; Mahyari, A.; Francia, G.; El-Sheikh, E. A Transformer-Based Framework for Payload Malware Detection and Classification. In Proceedings of the 2024 IEEE World AI IoT Congress (AIIoT), Seattle, WA, USA, 29–31 May 2024; pp. 105–111. [Google Scholar] [CrossRef]
- Hassan, M.; Haque, M.E.; Tozal, M.E.; Raghavan, V.; Agrawal, R. Intrusion Detection Using Payload Embeddings. IEEE Access 2022, 10, 4015–4030. [Google Scholar] [CrossRef]
- Kim, H.; Song, H. Lightweight IDS Framework Using Word Embeddings for In-Vehicle Network Security. J. Wirel. Mob. Netw. Ubiquitous Comput. Dependable Appl. 2024, 15, 1–13. [Google Scholar] [CrossRef]
- Choi, M.; Jeong, I.; Song, H. Fast and Efficient Context-Aware Embedding Generation Using Fuzzy Hashing for In-Vehicle Network Intrusion Detection. Veh. Commun. 2024, 47, 100786. [Google Scholar] [CrossRef]
- Lo, W.; Alqahtani, H.; Thakur, K.; Almadhor, A.; Chander, S.; Kumar, G. A hybrid deep learning based intrusion detection system using spatial-temporal representation of in-vehicle network traffic. Veh. Commun. 2022, 35, 100471. [Google Scholar] [CrossRef]
- Mansourian, P.; Zhang, N.; Jaekel, A.; Kneppers, M. Deep Learning-Based Anomaly Detection for Connected Autonomous Vehicles Using Spatiotemporal Information. IEEE Trans. Intell. Transp. Syst. 2023, 24, 16006–16017. [Google Scholar] [CrossRef]
- Trilles, S.; Hammad, S.S.; Iskandaryan, D. Anomaly detection based on Artificial Intelligence of Things: A Systematic Literature Mapping. Internet Things 2024, 25, 101063. [Google Scholar] [CrossRef]
- Deng, A.; Hooi, B. Graph neural network-based anomaly detection in multivariate time series. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 4027–4035. [Google Scholar] [CrossRef]
- Pang, G.; Ding, C.; Shen, C.; Hengel, A.v.d. Explainable deep few-shot anomaly detection with deviation networks. arXiv 2021, arXiv:2108.00462. [Google Scholar] [CrossRef]
- Ji, I.H.; Lee, J.H.; Kang, M.J.; Park, W.J.; Jeon, S.H.; Seo, J.T. Artificial intelligence-based anomaly detection technology over encrypted traffic: A systematic literature review. Sensors 2024, 24, 898. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Wang, P.; Pei, J.; Wang, J.; Alexanian, S.; Niyato, D. Deep Learning Advancements in Anomaly Detection: A Comprehensive Survey. arXiv 2025, arXiv:2503.13195. [Google Scholar] [CrossRef]
- Pang, G.; Shen, C.; Jin, H.; van den Hengel, A. Deep weakly-supervised anomaly detection. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Long Beach, CA, USA, 6–10 August 2023; pp. 1795–1807. [Google Scholar] [CrossRef]
- Exterro. FTK Imager. Available online: https://www.exterro.com/digital-forensics-software/ftk-imager (accessed on 21 April 2024).
- rowingdude. analyzeMFT. Available online: https://github.com/rowingdude/analyzeMFT (accessed on 1 May 2024).
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Facebook. fastText. Available online: https://github.com/facebookresearch/fastText (accessed on 5 October 2024).
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; Burges, C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K., Eds.; Curran Associates, Inc.: Newry, UK, 2013; Volume 26. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; XU, C.; Wang, Y. Transformer in Transformer. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–14 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Newry, UK, 2021; Volume 34, pp. 15908–15919. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Suthaharan, S. Support vector machine. In Machine Learning Models and Algorithms for Big Data Classification: Thinking with Examples for Effective Learning; Springer: Berlin/Heidelberg, Germany, 2016; pp. 207–235. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Gurney, K. An Introduction to Neural Networks; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Newry, UK, 2017; Volume 30. [Google Scholar]
Figure 1.
Overview of the methodology framework for file path embedding and anomaly detection. Blue arrows represent the process for normal file paths, while red arrows indicate the process for anomalous paths.
Figure 1.
Overview of the methodology framework for file path embedding and anomaly detection. Blue arrows represent the process for normal file paths, while red arrows indicate the process for anomalous paths.
Figure 2.
Example of file path preprocessing, including user directory standardization, space character replacement, and path delimiter conversion.
Figure 2.
Example of file path preprocessing, including user directory standardization, space character replacement, and path delimiter conversion.
Figure 3.
Visualization of normal file paths, original anomalies, and anomalies specific to Case 1. The clear separation of file paths found only on a single system suggests that distance-based anomaly detection techniques may be effective in this scenario.
Figure 3.
Visualization of normal file paths, original anomalies, and anomalies specific to Case 1. The clear separation of file paths found only on a single system suggests that distance-based anomaly detection techniques may be effective in this scenario.
Figure 4.
Visualization of normal file paths, original anomalies, and anomalies specific to Case 2. The significant overlap between normal and anomalous file paths indicates that traditional distance-based anomaly detection methods may struggle, highlighting the need for alternative approaches.
Figure 4.
Visualization of normal file paths, original anomalies, and anomalies specific to Case 2. The significant overlap between normal and anomalous file paths indicates that traditional distance-based anomaly detection methods may struggle, highlighting the need for alternative approaches.
Figure 5.
ROC curves for Case 1 and Case 2 anomaly detection at 32 and 64 dimensions. (a,b) show Case 1 results with Random Forest achieving the highest AUC. (c,d) show Case 2 results, where the Transformer model performs best at 32D. These curves illustrate how model performance varies by anomaly type and embedding dimension.
Figure 5.
ROC curves for Case 1 and Case 2 anomaly detection at 32 and 64 dimensions. (a,b) show Case 1 results with Random Forest achieving the highest AUC. (c,d) show Case 2 results, where the Transformer model performs best at 32D. These curves illustrate how model performance varies by anomaly type and embedding dimension.
Table 1.
Summary of related works in anomaly detection.
Table 1.
Summary of related works in anomaly detection.
| Study | Data Type | Methodology | Key Findings |
|---|
| [4] | File metadata, timeline events | AI-based classification | Forensic evidence prioritization |
| [5] | File system metadata | Machine learning classification | Improved forensic analysis |
| [6] | Log sequences | LSADNET (CNN + Transformer) | Better log sequence modeling |
| [7] | Log sequences | Loader (Transformer encoder) | Effective normal pattern learning |
| [8] | Network payloads | Transformer-based DPI | Enhanced deep packet inspection |
| [9] | Network payloads | Transformer-based framework | Improved intrusion detection |
Table 2.
Studies on AI-based anomaly detection.
Table 2.
Studies on AI-based anomaly detection.
| Study | Data Type | Methodology | Key Findings |
|---|
| [14] | Sensor/IoT edge data | Mapping study (TinyML) | Identifies trends and challenges in on-device anomaly detection |
| [15] | Multivariate time-series | GNN-based explainable model | Models inter-sensor structure and improves interpretability |
| [16] | General anomaly benchmarks | Few-shot + weak supervision (PReNet) | Detects both seen and unseen anomalies effectively |
| [17] | Encrypted network traffic | Systematic review | Analyzes AI-based anomaly detection methods for TLS traffic |
| [18] | General high-dimensional data | Deep learning survey | Classifies AD into reconstruction/prediction-based and hybrid methods |
| [19] | 12 benchmark datasets | Pairwise relation learning (PReNet) | Weakly supervised model that generalizes to unseen anomalies |
Table 3.
Dataset composition for anomaly detection model training and evaluation.
Table 3.
Dataset composition for anomaly detection model training and evaluation.
| Data | Normal | Anomalous |
|---|
| Training | 365,025 | 364,860 |
| Test | 91,153 | 91,318 |
| Total | 456,178 | 456,178 |
Table 4.
Performance comparison of traditional anomaly detection models using FastText embeddings with Sum and Mean calculation.
Table 4.
Performance comparison of traditional anomaly detection models using FastText embeddings with Sum and Mean calculation.
| Model | Dim | Sum | Mean |
|---|
|
Accuracy
|
Precision
|
Recall
|
F1-Score
|
Accuracy
|
Precision
|
Recall
|
F1-Score
|
|---|
| RF | 16 | 0.9674 | 0.9739 | 0.9606 | 0.9672 | 0.9650 | 0.9732 | 0.9564 | 0.9647 |
| 32 | 0.9712 | 0.9758 | 0.9664 | 0.9711 | 0.9693 | 0.9746 | 0.9639 | 0.9691 |
| 64 | 0.9729 | 0.9764 | 0.9693 | 0.9729 | 0.9719 | 0.9769 | 0.9663 | 0.9717 |
| NN | 16 | 0.9519 | 0.9720 | 0.9306 | 0.9509 | 0.9490 | 0.9768 | 0.9199 | 0.9475 |
| 32 | 0.9630 | 0.9666 | 0.9593 | 0.9629 | 0.9618 | 0.9778 | 0.9452 | 0.9612 |
| 64 | 0.9712 | 0.9780 | 0.9641 | 0.9710 | 0.9694 | 0.9750 | 0.9635 | 0.9692 |
| SVM | 16 | 0.9113 | 0.9517 | 0.8668 | 0.9073 | 0.9199 | 0.9589 | 0.8775 | 0.9164 |
| 32 | 0.9349 | 0.9737 | 0.8941 | 0.9322 | 0.9403 | 0.9760 | 0.9029 | 0.9381 |
| 64 | 0.9497 | 0.9837 | 0.9146 | 0.9479 | 0.9529 | 0.9850 | 0.9199 | 0.9514 |
| LightGBM | 16 | 0.8769 | 0.8876 | 0.8633 | 0.8753 | 0.8883 | 0.9060 | 0.8668 | 0.8860 |
| 32 | 0.8846 | 0.8893 | 0.8787 | 0.8840 | 0.8972 | 0.9015 | 0.8820 | 0.8916 |
| 64 | 0.8881 | 0.8938 | 0.8870 | 0.8887 | 0.8977 | 0.9037 | 0.8902 | 0.8970 |
Table 5.
Performance of Transformer-based model using raw Fasttext embeddings.
Table 5.
Performance of Transformer-based model using raw Fasttext embeddings.
| Model | Dimension | Accuracy | Precision | Recall | F1-Score |
|---|
| Transformer | 16 | 0.9751 | 0.9751 | 0.9709 | 0.9750 |
| 32 | 0.9781 | 0.9809 | 0.9755 | 0.9782 |
| 64 | 0.9652 | 0.9724 | 0.9577 | 0.9650 |
Table 6.
Performance comparison of traditional models (64D) and Transformer model (32D, 64D) on Case Study 1.
Table 6.
Performance comparison of traditional models (64D) and Transformer model (32D, 64D) on Case Study 1.
| Model | Accuracy | Precision | Recall | F1-Score |
|---|
| RF (64D) | 0.9265 | 0.9740 | 0.8763 | 0.9226 |
| NN (64D) | 0.8436 | 0.9702 | 0.7090 | 0.8193 |
| SVM (64D) | 0.7612 | 0.9726 | 0.5375 | 0.6924 |
| LightGBM (64D) | 0.7178 | 0.8328 | 0.5449 | 0.6588 |
| Transformer (32D) | 0.8481 | 0.9741 | 0.7147 | 0.8245 |
| Transformer (64D) | 0.8652 | 0.9653 | 0.7573 | 0.8487 |
Table 7.
Performance comparison of traditional models (64D) and Transformer model (32D, 64D) on Case Study 2.
Table 7.
Performance comparison of traditional models (64D) and Transformer model (32D, 64D) on Case Study 2.
| Model | Accuracy | Precision | Recall | F1-Score |
|---|
| RF (64D) | 0.9385 | 0.9700 | 0.8935 | 0.9315 |
| NN (64D) | 0.9322 | 0.9716 | 0.8779 | 0.9224 |
| SVM (64D) | 0.8788 | 0.9769 | 0.7537 | 0.8509 |
| LightGBM (64D) | 0.8245 | 0.8527 | 0.7464 | 0.7959 |
| Transformer (32D) | 0.9461 | 0.9759 | 0.9050 | 0.9391 |
| Transformer (64D) | 0.9174 | 0.9637 | 0.8521 | 0.9045 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}