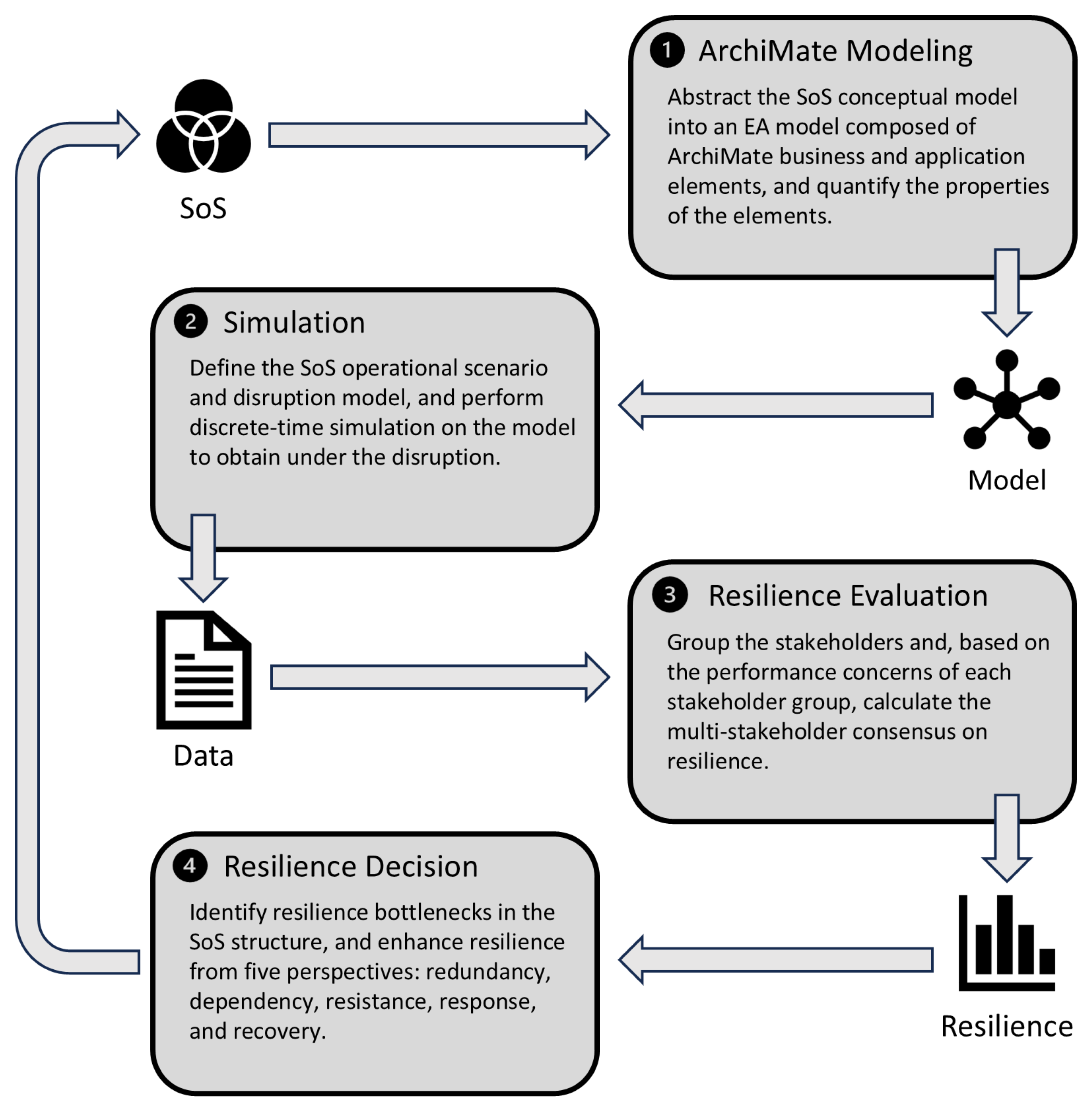
The proposed framework, as illustrated in
Figure 1, consists of ArchiMate modeling, simulation, resilience evaluation, and resilience-informed decision making. This method has three key objectives: (1) to provide quantitative metrics for evaluating the resilience of the SoS, (2) to identify critical CS services, and (3) to offer recommendations for resilience-oriented design. In the SoS life cycle defined in ISO 21839 [
62], the proposed framework facilitates resilience evaluation to support SoS design in the development phase. During the utilization phase, the proposed indicators remain applicable for resilience monitoring. When changes occur in the SoS environment or internal structure (e.g., legal amendments or the addition or removal of CSs), the SoS undergoes an iterative phase for resilience reevaluation and redesign.
Table 3 summarizes the variables and parameters introduced in this section along with their definitions.
3.1. ArchiMate Modeling
The EA tool ArchiMate offers a standardized modeling language for describing the operation of business processes, organizational structures, information flows, IT systems, and technical infrastructure. Built upon the TOGAF framework, it facilitates the end-to-end process from requirements analysis to organizational design and iterative improvements [
63]. The process of modeling the SoS using the TOGAF framework includes the development of the SoS conceptual model, the business architecture model, the application architecture model, and the technology architecture model. This research employs its business architecture and application architecture to establish a description of the static structure of the SoS and the relationships among its CSs.
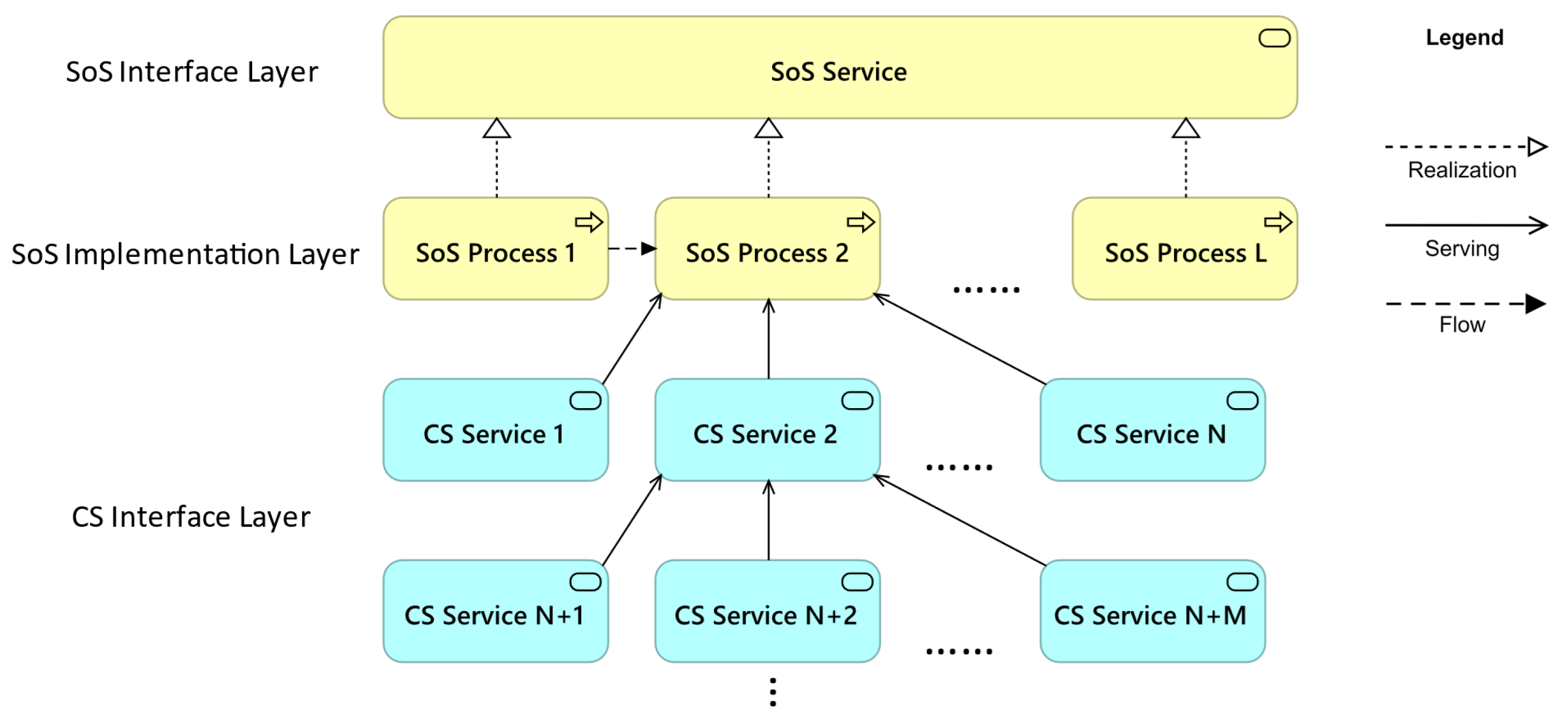
As illustrated in
Figure 2, the real-world SoS is abstracted to the conceptual SoS architectures and matched with the concepts in the ArchiMate architecture. Three layers of ArchiMate’s core architecture: the business layer, application layer, and technology layer correspond to the SoS layer, the CS layer, and the system elements layer in the SoS architecture. Each layer consists of an interface layer that provides external services and an implementation layer that handles internal functionalities. This research focuses on modeling the relationship between CSs and SoS and therefore the internal composition of the CS function and their lower-level elements are omitted in the illustration, despite ArchiMate providing corresponding concepts to match them.
Table 4 provides definitions for key ArchiMate elements used in this study. The application layer defines the composition and interoperability of CSs, while the business layer expands the model to include additional stakeholders such as users, society, and SoS organizers. Unlike conventional models that focus solely on the flat, structural design of SoS, this model adopts a multidimensional perspective, capturing both its internal configuration and its broader socio-technical interactions.
As illustrated in
Figure 2, an SoS can be represented as an ArchiMate model, depicted in
Figure 3. The model comprises four key elements: two nodes—the SoS process and CS service—and two directed edges representing the flow and serving relationships. The implementation of an SoS service follows a sequential execution of SoS processes, each requiring a certain amount of time to complete. When a specific SoS process is triggered, it utilizes the corresponding CS service, which may include information technology services (e.g., data provisioning), socio-technical services (e.g., transportation), or production and market services (e.g., inventory management). This operational logic serves as the foundation for the simulation detailed below. To enable quantitative simulation, key properties have been defined for these elements.
The flow relationship depicts the movement of users between the business processes and does not possess any inherent properties.
The serving relationship denotes that an element delivers its functionality to another element. It has a property, serving dependency (
), which quantifies the degree of dependency of the target on the source in a serving relationship. This property is the answer to the following question: “How much source service is required when a target service is requested?”. This is defined as the product of request probability and absence tolerance, ranging from 0 to 1. Request probability quantifies the frequency at which the source service is requested when the target service is needed. Absence tolerance quantifies the degree to which the target service can tolerate the unavailability of the source service. They are quantified through a structured evaluation conducted among service-related stakeholders, using a quantitative rating table (see
Table 5). For instance, if Service A frequently requires Service B, then the request probability of this serving relationship is 0.8. If Service A can tolerate a moderate absence from Service B, then the absence tolerance of this serving relationship is 0.6. Ultimately, the serving dependency (
) value is the product of the two, resulting in 0.48. In other words, when there are 100 requests for Service A, 80 requests are made for Service B.
CS service represents an explicitly defined externally accessible application behavior provided by the CS. CS service has two properties: CS Service Self Capacity () and CS Service Real Capacity ().
quantifies the maximum number of user requests processed per unit time, assuming unlimited external resources and constrained solely by the system’s inherent capacity.
is formally defined in Equation (
1).
represents the steady-state demand (in the absence of disruptions) for a CS service. This parameter ensures supply–demand equilibrium for services before disruptions occur.
is determined by stakeholder-defined dependability requirements in the presence of potential CS risks and is expressed as a percentage.
represents the impact of unexpected events on the performance of the CS service, quantified in percentage. Here, 0% signifies a complete loss of CS service performance, while 100% indicates no impact on CS service performance. The specific disruption model is detailed in
Section 3.2.
quantifies the number of requests that can be fulfilled per unit time, determined by both its inherent capacity and the
of its dependent services.
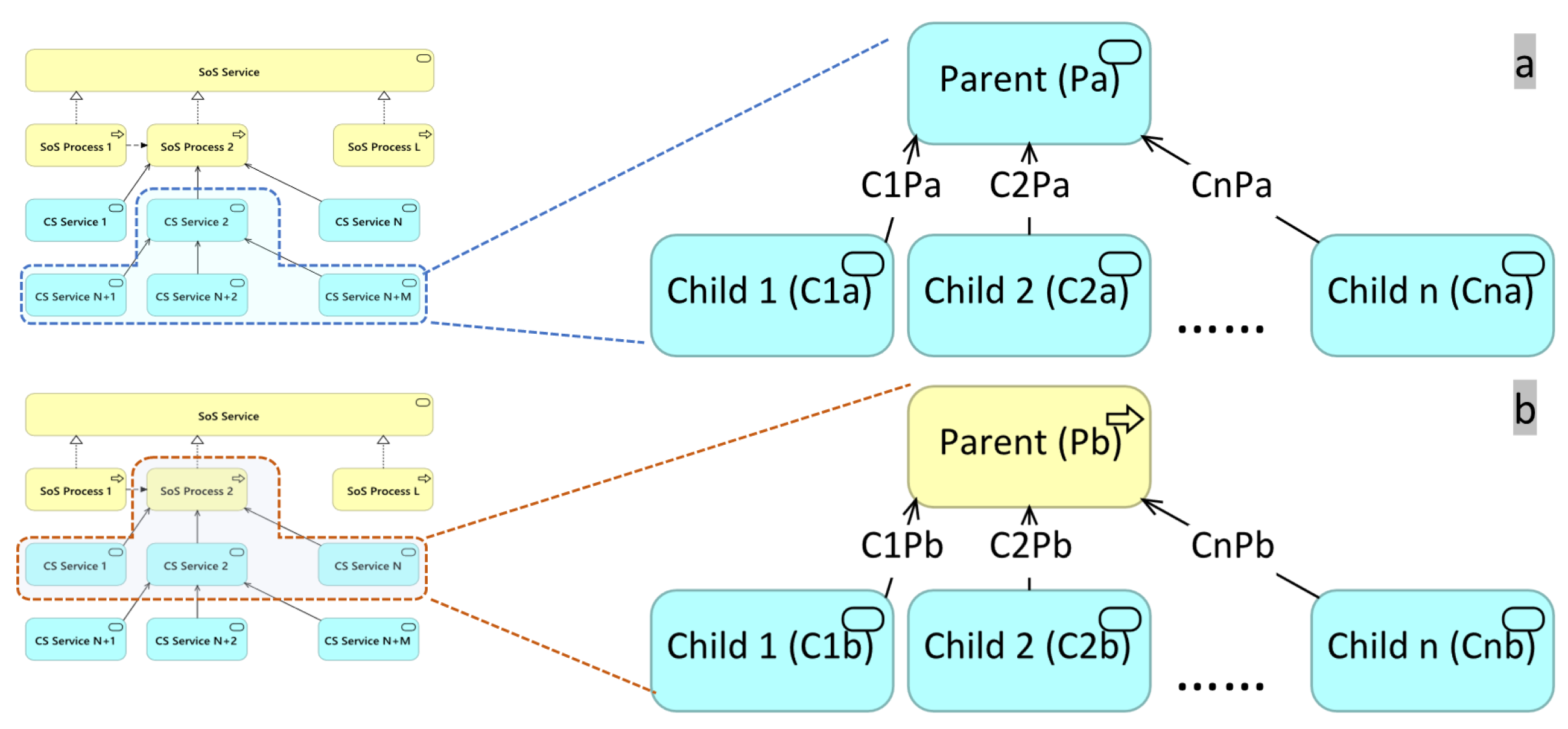
Figure 4a illustrates the scenario where a CS service relies on multiple CS services. The parent element
depends on the child elements
,
,...,
, with the
of the serving relationships between them denoted as
,
,...,
.
is formally defined in Equation (
2). It indicates that
depends on the weakest point, which could be its own capacity,
, or the service capacity of other dependencies,
.
The SoS process represents a sequence of business behaviors that achieves a specific result, such as a defined set of products or business services. It has two properties, SoS process regular time () and SoS process capacity ().
quantifies the time required to complete the target SoS process in the absence of disruptions. The property is derived from the average time taken to complete the SoS process.
quantifies the number of requests that can be fulfilled for the current process, determined by the
of its dependent CS service.
Figure 4b shows the scenario where a parent SoS process relies on multiple CS services.
is determined by Equation (
3). Similar to the computation of
, Equation (
3) signifies that
depends on the weakest service capability among the CS services it relies on.
3.2. Simulation
Resilience is highly context-dependent, influenced not only by the objective structure but also by the operational scenario and the nature of disruptive events [
5]. Therefore, defining the operational scenario and disruption model is essential for resilience simulation.
Assumption of operational scenario: The user agent represents the source of service requests as well as the entity being served. Based on requirement analysis, the number of users generated per unit time (
) can be determined. The generated agents simulate request behavior within the SoS, beginning with the initial SoS process and sequentially executing each subsequent process until completion. Agents are assumed to exist in three fixed states. If the SoS process is available, meaning that there is remaining capacity (defined as Equation (
3)), then the agent will enter the running state and occupy the capacity at the current time step. Otherwise, the agent will enter the blocking state. Upon completion of an SoS process, the agent transitions to the ready state in preparation for the next SoS process. Given the configuration of
, the variable
(from Equation (
1)) can be determined through steady-state simulation. In the steady-state simulation, disruptions are absent, ensuring a perfectly balanced supply and demand for services.
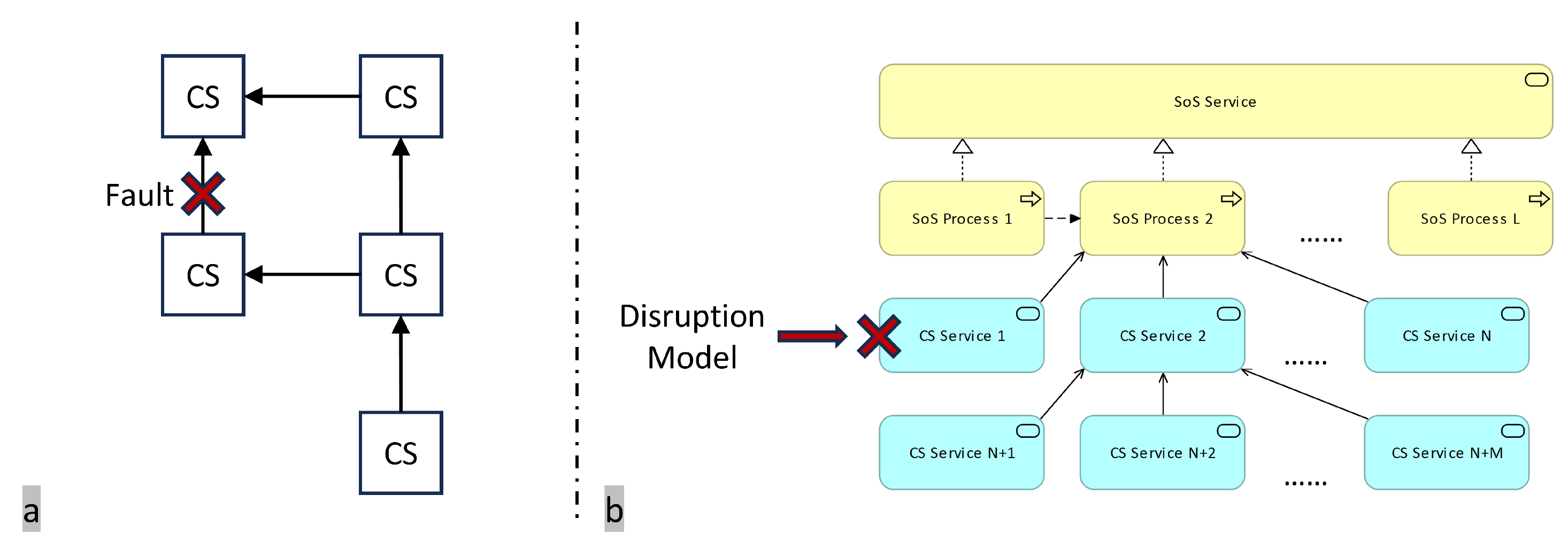
Assumption of disruption model: The disruption model captures the impact of disruptive events on CS services, as illustrated in
Figure 5. Disruptive events can originate from any CS function or external environment. This study does not examine the causes of these events but rather focuses on their impact on CS services, as resilience primarily concerns how the failure of a CS function affects the integrity of the SoS.
represents the time when the disruption occurs, and the CS service affected by the disruption immediately experiences a decrease in its capacity to a low level (
), indicating the CS service’s resistance capability to disruption.
denotes the start of the affected CS service’s recovery. The time interval between
and
reflects the CS service’s response capability to disruption, denoted as
.
represents the time when the CS service fully recovers to its original capacity. The time interval between
and
quantifies the CS service’s recovery capability following a disruption, denoted as
. The specific values for
,
, and
need to be set in the simulation.
Generally, the parameters of the three aforementioned disruption models can be determined by the following three methods.
Risk-informed method: If sufficient risk knowledge is available, then it can be acquired using various mature techniques, such as fault tree analysis. The parameters of the disruption model at the CS service level can then be determined through calculations or simulations at the system or component level. However, this approach may result in a reactive design paradigm, which is not conducive to macro-level resilient design [
5].
History-informed method: If ample historical data on CS service disruptions are available, then the parameters of the disruption model can be directly inferred from representative cases. However, this approach is often inadequate for predicting unknown scenarios.
Requirement-informed method: Resilience engineering emphasizes the macro-level capacity to withstand disruptions. From this perspective, defining the parameters of the disruption model based on top–down requirements is a reasonable approach. This approach entails determining the extent of disruption that stakeholders expect the SoS to withstand while maintaining sufficient resilience and ensuring acceptable stakeholder losses. In this case, the disruption model serves as a benchmark similar to those used in software performance testing.
ArchiMate does not provide a dedicated simulation tool, but it does offer a scripting language called JArchi for model computation and batch processing. Based on JArchi, the author developed a discrete-time simulation program suitable for the model established in
Section 3.1 (ArchiMate Version: 4.10.0, JArchi Version: 1.9.0) [
64]. In the simulation, the state of the user agent and the properties of the CS change over time steps according to the equations in
Section 3.1 and the settings in
Section 3.2. The simulation progress is illustrated in Algorithm 1. Specifically, the disruption model is iteratively applied to each CS service to evaluate the resilience of the SoS, as represented by the loop in lines 3–15. During the simulation of a CS service disruption, user agents are instantiated at each time step (line 6), the SoS’s current performance is computed (line 7), the next state of each user agent is determined (lines 8–10), and the capacity utilization of each CS service is assessed (line 11).
The simulation output for each CS service disruption comprises the following elements: planned execution time (
) for each user; actual execution time (
) for each user; available service capacity (
); service utilization (
) for each CS service; SoS process at each simulation time; the number of active users (
) within the entire SoS; the number of queued users (
) within the entire SoS.
| Algorithm 1 Simulation for SoS MODEL. |
| Require: SoS Model (Topology and Properties) |
| Ensure: performance-related Data. |
| 1: | Disruption Setting: , , |
| 2: | User Setting: , , |
| 3: | for in SoS Model do |
| 4: | Load Disruption to |
| 5: | for i = 1,2,3... do |
| 6: | Put number of agents in AgentActiveArray. |
| 7: | Traversal calculation of and . |
| 8: | for in ActiveAgentArray do |
| 9: | Function: StateMachine() |
| 10: | end for |
| 11: | Traversal calculation of and |
| 12: | Store the data of time i |
| 13: | end for |
| 14: | Save the data of in file format. |
| 15: | end for |
3.3. Resilience Evaluation
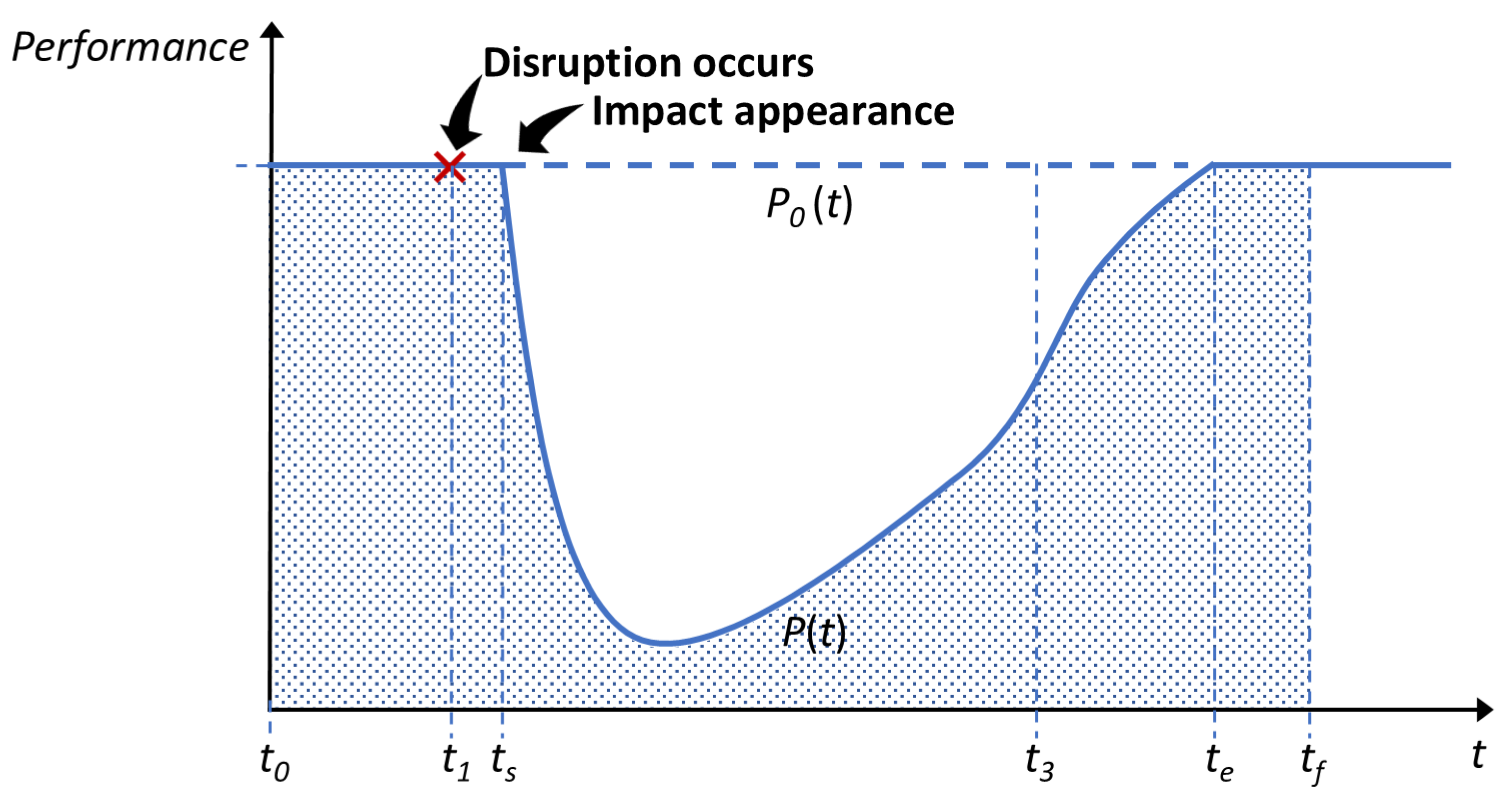
The performance method, which is currently the mainstream approach for resilience evaluation, employs a characteristic indicator as defined in Equation (
4). Resilience is quantified based on the disrupted performance curve,
, and the regular performance curve,
[
61].
In this equation,
denotes the time at which the disruption impact becomes evident, while
represents the duration required for the SoS to restore its regular performance following the disruption.
Figure 6 illustrates the two performance curves defined in Equation (
4).
Building on Equation (
4), Watson proposed a method for evaluating the resilience of SoS, as formulated in Equation (
5) [
27]. He developed a physical flow graph model for the SoS, depicted in
Figure 7a, where nodes represent CS and edges represent flow (e.g., energy flow within an ecological chain). By sequentially disrupting each individual edge (totaling
k edges) and analyzing the corresponding performance curves, he derived the overall resilience of the SoS. Here,
denotes the time required for full recovery.
The study further explores this resilience definition from the perspective of the established ArchiMate model and a multistakeholder approach.
First, we introduce the disruption model as mentioned in
Section 3.2. The term “fault” in Equation (
5) denotes the disruption of an edge in the graphical structure, which implies the complete failure of the source CS. However, as a system, the CS is neither atomic nor strictly binary in terms of functionality—i.e., it is not either working or not working. Instead, it operates through three phases: disruption, response, and recovery. Therefore, we introduced the disruption model with parameters showing survival and recovery capability to simulate more detailed scenarios, as shown in
Figure 7b. Resilience
is defined in Equation (
6), which quantifies the resilience of the SoS when CS service
i experiences a disruption. In
Figure 6, because
and
vary across different disruptions, we set
as the starting time, assuming a uniform disruption occurrence time in the simulation, and define the maximum of all
values as the end time
to maintain consistent time intervals for all resilience computations.
Second, we introduce multiple stakeholders. In Equation (
5), performance is defined in a singular manner. This is more characteristic of general systems, where stakeholders typically have closer relationships and more aligned objectives. In contrast, stakeholders in a SoS are often diverse, decentralized, and concerned with broader societal impacts and interests, resulting in a more heterogeneous definition of performance. However, considering the performance objectives of all individual stakeholders is infeasible. A feasible approach is to group stakeholders with similar interests [
65]. Based on stakeholder theory, the SoS should consider internal stakeholders who focus on profit, such as CS service providers and the SoS organizer, and external stakeholders who prioritize Quality of Service (QoS), namely users and society, since these four stakeholder groups play a crucial role in SoS decision making [
66]. At the end of
Section 3.2, some outputs of the simulation that can be used to calculate the performance indicators of each stakeholder group are mentioned, and we summarize them in
Table 6.
Using Equation (
6), the resilience indicators corresponding to the above performance indicators are derived, denoted as
,
,
, and
. The overall resilience indicator
reflects the consensus among the four stakeholder groups. Equations (
7) and (
8) define a basic consensus process, where
denotes the set of the four stakeholder groups, and
represents the cost incurred by the corresponding stakeholder group when adjusting their resilience evaluation to reach consensus. This parameter is determined based on loss estimation in accordance with real-world conditions. This optimization determines the overall resilience indicator
by minimizing the total adjustment cost incurred by all stakeholder groups when aligning their individual resilience evaluations
to a consensus value.
The solution of this consensus process is not unique. To ensure fairness in consensus formation, we introduce the Shapley value from cooperative game theory. we construct a cooperative game model
. The player set is the set
.
T means any coalition composed of members of
. The characteristic function
equals the optimal value
for Equations (
9)–(
11) below. Equation (
9) identifies the most favorable solution to coalition
T among the solutions of Equation (
7), i.e., the one with the minimal total cost caused by adjustment for
T. Therefore, an additional constraint (
10) is introduced, ensuring that the sum of all stakeholders’ resilience evaluation adjustments equals the optimal value of Equation (
7), noted as
.
The Shapley value distributes benefits and costs according to marginal contributions and satisfies several desirable axiomatic properties, such as efficiency, symmetry, linearity, and the null player condition, which guarantees fairness in the allocation process [
67,
68]. As defined in Equation (
12), the Shapley value
assigned to stakeholder
i is computed based on the characteristic function
. It quantifies the resilience adjustment cost allocated to each stakeholder.
By incorporating the Shapley value
into the consensus process, the optimization problem formulated in Equations (
13)–(
15) determines the resilience evaluation
by minimizing the total weighted adjustment cost across all stakeholder groups while ensuring that each stakeholder’s individual adjustment cost equals their allocated Shapley value
, thereby maintaining a fair distribution of resilience adjustments.
Third, we introduce the importance coefficient. In Equation (
5), the resilience of the SoS under each fault scenario is evaluated, and the overall resilience is computed as the average of these evaluations. This implies that disruptions with significant losses are given the same weight as those with minor losses. However, resilience refers to the capacity to withstand low-frequency, high-impact disruptions [
5]. Therefore, the overall resilience indicator should account for the significance of critical CS services. Here, we introduce the coefficients
, as shown in Equation (
16), to quantify the relative importance of each CS service. This implies that CS services with lower resilience
are assigned higher importance weights, where
m denotes the total number of CS services.
The overall resilience of the SoS is defined as
and shown in Equation (
17).
3.4. Resilience Decision
The purpose of this section is to demonstrate the significance of the proposed resilience evaluation method, namely providing a basis for decision making in the SoS resilience designing phase. Three key questions arise in this phase:
Q1: Among multiple SoS design options, which design option is preferable?
Q2: Which CSs are the bottlenecks that need improvement when a design option lacks resilience?
Q3: What measures should be taken based on identified bottlenecks?
For Q1, serves as an indicator for assessing the resilience of multiple design options, providing a quantitative basis for decision making.
For Q2, quantifies the criticality of CS service i. A larger value suggests that a disruption in CS service i would result in more significant losses for the SoS. This helps prioritize resilience measures by identifying critical CS services.
For Q3, first, it is important to distinguish reliability from resilience. Reliability focuses on the system by predicting and mitigating risk-related factors (e.g., probability of failure and impact). However, resilience is not about avoiding failure but ensuring system quality by monitoring and improving the system’s leading indicators (e.g., survival and recovery capability) [
69]. Specifically, these indicators related to robustness, self-healing capability, redundancy, and decentralization [
70].
Table 7 shows the corresponding properties of these indicators in the SoS EA model established in this paper. Resilience engineers should consider the potential disruptions and prepare the corresponding properties of critical CS services during the SoS design phase and design monitoring mechanism to ensure the resilience of SoS during runtime.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}