2.1. Current Research Status
Existing methods for the assessment of data quality typically focus on several key dimensions, including completeness, consistency, accuracy, timeliness, and reliability of data [
20,
21]. These dimensions are foundational in evaluating data quality across various fields, but there is a need for a more systematic approach to categorizing and assessing data quality frameworks. Schmidt et al. [
22] proposed a data quality assessment framework specifically for the health research field. This framework emphasizes completeness, consistency, and accuracy as the core dimensions for ensuring the reliability and validity of medical data. It adopts a multi-level, multi-dimensional analysis that enables thorough evaluation across different layers of data.
In the industrial domain, Song et al. [
23] introduced the Industrial Multivariate Time Series Data Quality Assessment (IMTSDQA) method, which builds upon traditional data quality evaluations by introducing fine-grained sub-dimensions within key categories such as completeness, normativeness, and accuracy. This fine-grained approach allows for a more detailed, objective, and comprehensive assessment of data quality, extending its applicability to complex industrial datasets.
Meanwhile, Vetro et al. [
24] focused on open government data and identified key dimensions such as completeness, traceability, timeliness, and accuracy. They argue that open data must go beyond meeting technical standards to include considerations for usability and transparency. These elements are essential for enhancing public trust and engagement, and they provide a useful framework for assessing data quality in the context of public governance.
While there has been substantial research on data quality assessment frameworks across various domains such as transportation [
25], healthcare [
26], and construction [
27], there remains a notable gap in the standardized scoring of government hotline data records. These data records represent a critical communication channel between the government and the public, and the quality of these data plays a pivotal role in the effectiveness of government services.
Government hotline data have specific characteristics and challenges that set them apart from other data types. For instance, they often contain large volumes of unstructured textual data, making their quality assessment particularly complex. Given these challenges, this study proposes a comprehensive data record standard evaluation system for government hotline data, focusing on dimensions such as reliability, correctness, and consistency. This system seeks to address the unique features of government hotline data and ensure that these records comply with standards, thereby enhancing government service efficiency and improving public satisfaction.
The process of evaluating government hotline data compliance involves several key steps, including topic identification, entity recognition, and text classification. Topic identification is crucial for extracting meaningful thematic information from large volumes of text. Traditional methods such as part-of-speech tagging (POS) and TF-IDF have been employed to identify topics within text [
28]. However, models like Latent Dirichlet Allocation (LDA), though useful for long texts, often struggle with short texts due to limited context awareness [
29,
30]. To address these limitations, more recent approaches, such as the Adaptive Online Biterm Topic Model (AOBTM) [
31], and the application of pre-trained models like BERT for topic classification [
32], have shown promise in improving topic identification accuracy, especially in dynamic environments. The BERTopic model further refines BERT’s capabilities for domain-specific topic recognition [
33].
Entity recognition, another essential component of this evaluation system, involves identifying and categorizing named entities within text. Early methods were based on rule-based and dictionary-based approaches [
34,
35,
36,
37,
38], but more recent advancements have leveraged machine learning [
39,
40] and deep learning models [
41] such as LSTM and BERT to enhance the accuracy of entity recognition, especially in large and complex datasets.
Finally, text classification is a critical step in categorizing government hotline data into predefined categories. Common classification techniques include k-nearest neighbors, naive Bayes, support vector machines (SVMs), and, more recently, graph neural networks [
42,
43,
44]. These methods contribute to the structured analysis of unstructured textual data, enabling more efficient processing and interpretation.
Quantitative methods for data quality assessment are essential for ensuring the reliability and validity of datasets across various domains. These methods use defined metrics to measure specific dimensions of data quality, enabling organizations to assess and enhance their data’s fitness for use. Typically, quantitative assessments focus on several key dimensions, such as accuracy, completeness, consistency, timeliness, and uniqueness, each evaluated using specific metrics [
45].
Accuracy involves comparing data to a known standard or ground truth. It ensures that data reflect the real-world phenomena they are supposed to represent. Completeness measures the proportion of available versus missing data entries, indicating whether data are sufficiently detailed and comprehensive. Consistency ensures uniformity and the absence of contradictions within or across datasets, ensuring that data align with established rules or standards. Timeliness evaluates whether data are current and available when needed, which is crucial for time-sensitive applications such as decision-making in government services. Uniqueness identifies and eliminates duplicate records, which is especially important in maintaining clean and reliable datasets.
The diversity of proposed dimensions—more than 50 distinct dimensions in total—demonstrates the complexity and multifaceted nature of data quality assessment [
45]. For example, Lewis et al. [
46] systematically reviewed the factors affecting electronic health record data and proposed five core dimensions—completeness, correctness, consistency, reasonableness, and timeliness—as a foundational framework for structured and semi-structured data.
Building upon this, Song et al. [
47] introduced a fine-grained data quality assessment framework, emphasizing sub-dimensions such as completeness, normativeness, consistency, uniqueness, and accuracy, offering more granular diagnostic capabilities for data quality analysis. However, these frameworks are often generalized, and they may not fully capture the unique challenges of textual and semi-structured data in government hotline work orders, which often contain free-text entries, inconsistent formats, and variable reporting standards.
Various frameworks have been developed to systematically assess data quality. Hierarchical data quality frameworks, for example, organize dimensions from general to specific, facilitating comprehensive evaluations. These are particularly suited for complex scenarios such as big data environments [
48]. Systematic literature reviews (SLRs) have summarized practices and challenges in data quality assessment, highlighting the need for standardized methodologies and the integration of quality management into data processes [
49]. Domain-specific frameworks, such as those used in public health, emphasize sector-specific data quality needs [
50]. Despite the progress, challenges remain, particularly in managing the vast volume, velocity, and variety inherent in big data, the lack of universally accepted standards for data quality dimensions, and the critical need for high-quality data in machine learning applications [
51].
However, while the literature has provided useful frameworks, government hotline data evaluation has mostly involved theoretical framework-based analyses, often lacking empirical studies to validate these models. These studies primarily focus on macro-level indicators like accuracy, completeness, consistency, and timeliness, but they seldom incorporate detailed or semantic indicators derived from text content. This is where our study innovates by focusing specifically on Chinese government hotline data, employing advanced methods such as BERT for precise text processing and text classification prediction, which significantly enhances the classification accuracy.
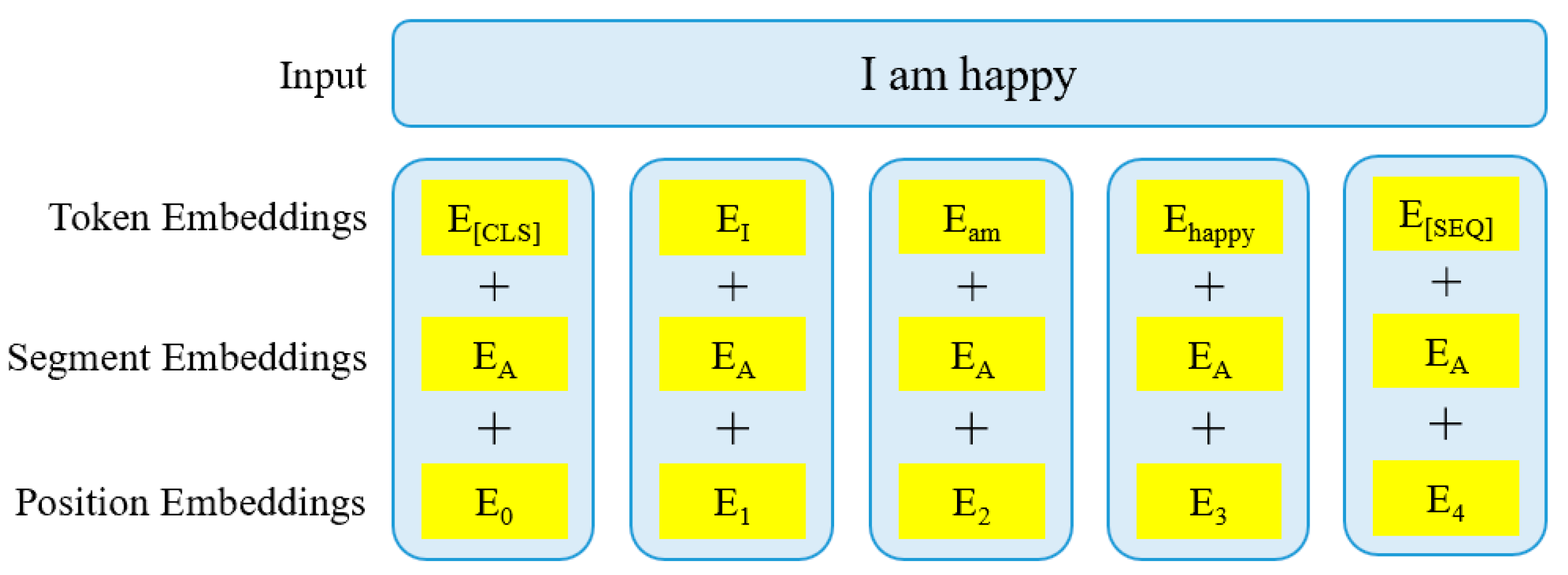
BERT (Bidirectional Encoder Representations from Transformers) has emerged as a leading method for natural language processing (NLP) tasks, particularly for handling unstructured text data. Its key advantage lies in its ability to capture the contextual relationships in text, allowing it to understand the nuances of language, which is crucial for processing government hotline work orders containing complex and varied textual data. Traditional NLP methods, such as rule-based or shallow machine learning models, often fail to grasp the deeper context or subtle patterns in the language, making BERT a more appropriate choice for this task.
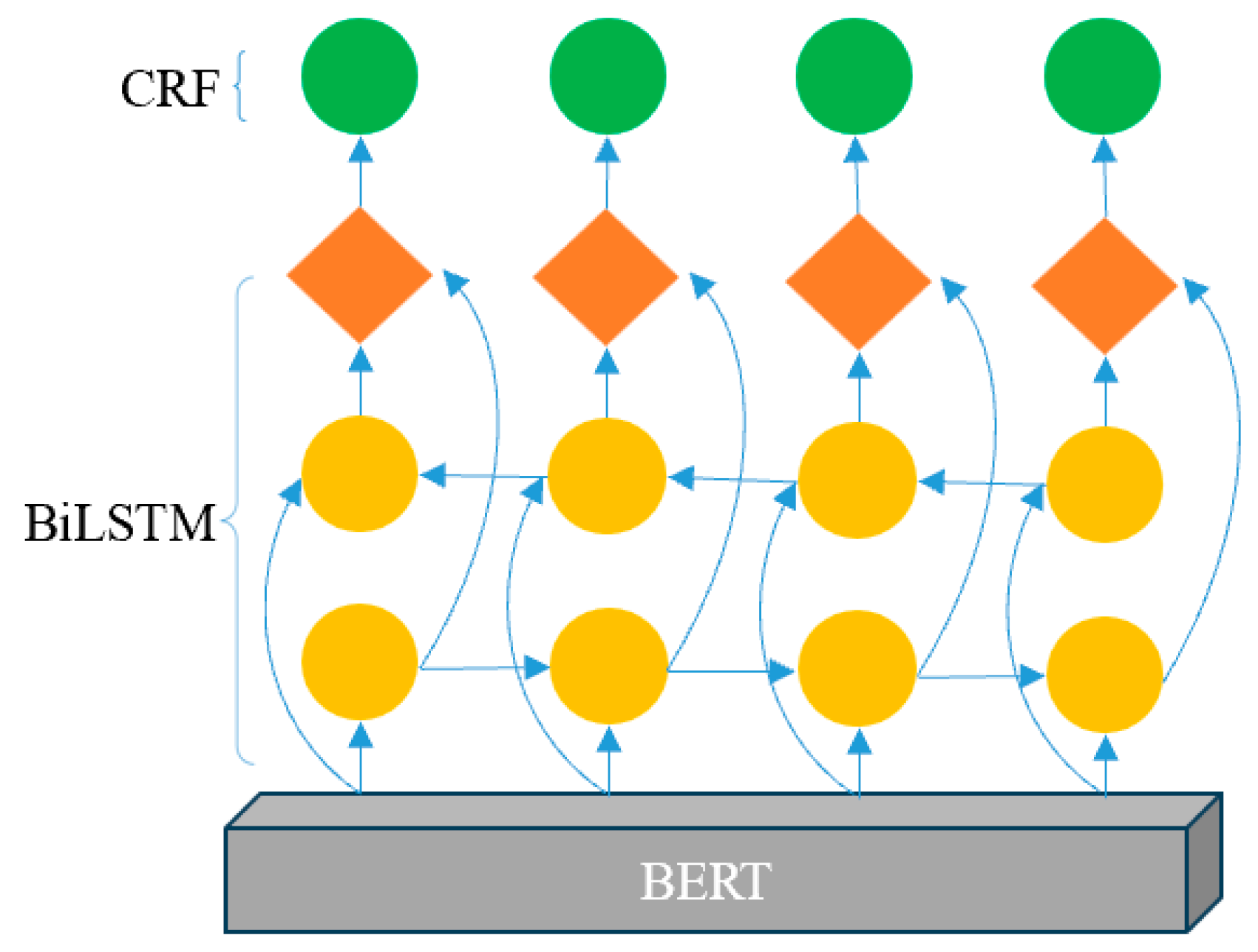
The hybrid model BERT-BiLSTM-CRF integrates the strengths of BERT’s contextualized embeddings with the BiLSTM (Bidirectional Long Short-Term Memory) network’s ability to model sequential dependencies and CRF’s (Conditional Random Field) capacity to enforce structured prediction constraints. This combination is particularly effective for named entity recognition (NER), which is essential for extracting critical semantic information such as addresses, names, dates, and contact details from government hotline work orders.
The advantages of BERT-BiLSTM-CRF over traditional methods are as follows:
Contextual Understanding: BERT’s pre-trained models enable deeper contextual understanding compared to traditional models like TF-IDF or Word2Vec, which treat words independently and fail to capture the context. For government hotline data, which often contain short, context-dependent phrases, BERT’s ability to understand words in relation to their surrounding context ensures a higher level of precision and recall in extracting meaning from text.
Improved Classification Accuracy: Traditional methods like SVM (support vector machine) or naive Bayes focus on vectorizing text and using shallow models for classification. However, BERT integrates language understanding directly into the model, improving the classification performance significantly. In our study, incorporating BERT’s language understanding improves the precision and recall for categorizing hotline data, leading to more accurate assessments of data compliance with predefined standards.
Enhanced Entity Recognition: Entity recognition is a critical task in government hotline work order texts, which often contain unstructured, free-text entries. Models like CRF or BiLSTM have been used for entity extraction but often struggle with semantic nuances in large datasets. By combining BiLSTM for sequential learning with CRF for structured prediction, our model is able to recognize locations, names, addresses, and other key entities with significantly higher accuracy compared to conventional methods, such as rule-based approaches or standalone machine learning techniques.
Adaptability and Fine-tuning: BERT offers a unique advantage in its adaptability. It can be fine-tuned for specific domains, such as government hotline data, using transfer learning. This approach allows for better performance on domain-specific tasks compared to traditional models, which would require extensive retraining for each new task or dataset. Our study demonstrates this advantage by fine-tuning BERT specifically on Chinese government hotline data, optimizing its performance for the task at hand.
While BERT has demonstrated clear advantages in this study, it is important to acknowledge the limitations of alternative methods. Traditional NLP methods like TF-IDF and naive Bayes focus on bag-of-words representations and often fail to capture the contextual meaning of words in short or ambiguous texts. SVM and Logistic Regression may perform well on structured datasets but struggle with unstructured text data like those found in government hotline work orders, which often contain inconsistent formats and varied vocabulary. Moreover, LSTM-based models, though capable of capturing sequential dependencies, do not have the sophisticated understanding of language that BERT provides, making them less effective in tasks involving complex textual content.
In contrast, BERT, by leveraging its transformer architecture, has revolutionized the processing of unstructured text by considering the entire context of a sentence rather than just individual words. This makes BERT particularly well suited for understanding the context-specific terminology and phrasing in government hotline work orders. The incorporation of BiLSTM-CRF further enhances the model by ensuring that the recognized entities maintain the correct sequential order, which is critical in the structured data extraction tasks required for evaluating government hotline data compliance.
2.2. Research Hypothesis
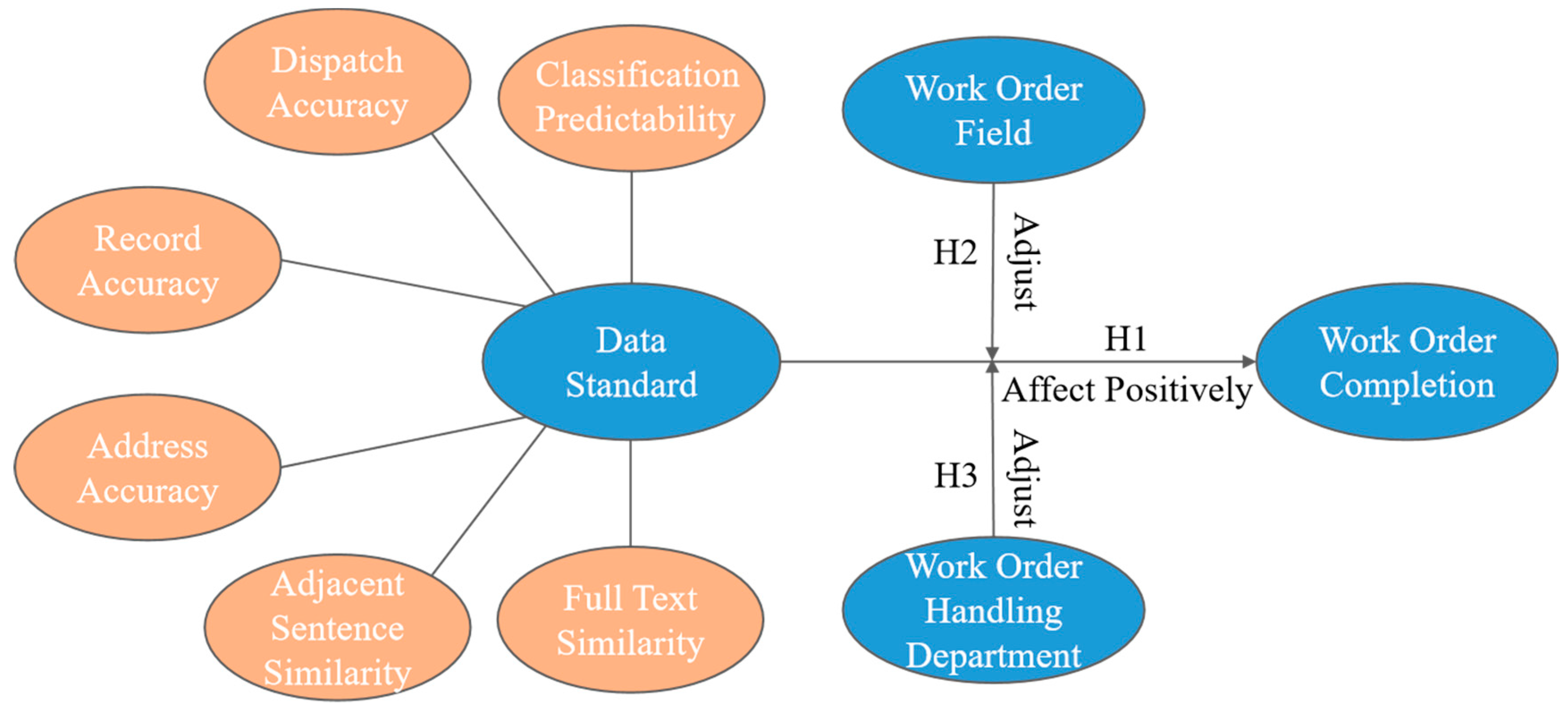
This study proposes a tailored data record standard evaluation system specifically designed for government hotline data. Drawing from the authoritative literature and the distinct characteristics of government work order systems, we define three core evaluation dimensions—reliability, correctness, and consistency—each supported by sub-indicators with robust theoretical and empirical foundations.
Reliability assesses whether the data effectively support accurate decision-making and task routing. According to Batini et al. [
52], data reliability is essential for ensuring that information can be effectively utilized for intended business operations. Similarly, Pipino et al. [
45] emphasize that reliable data should consistently meet user expectations for decision-making tasks, which validates our inclusion of classification predictability (the clarity and accuracy of assigning problem categories) and dispatch accuracy (the precise routing of problems to appropriate departments) as key sub-indicators.
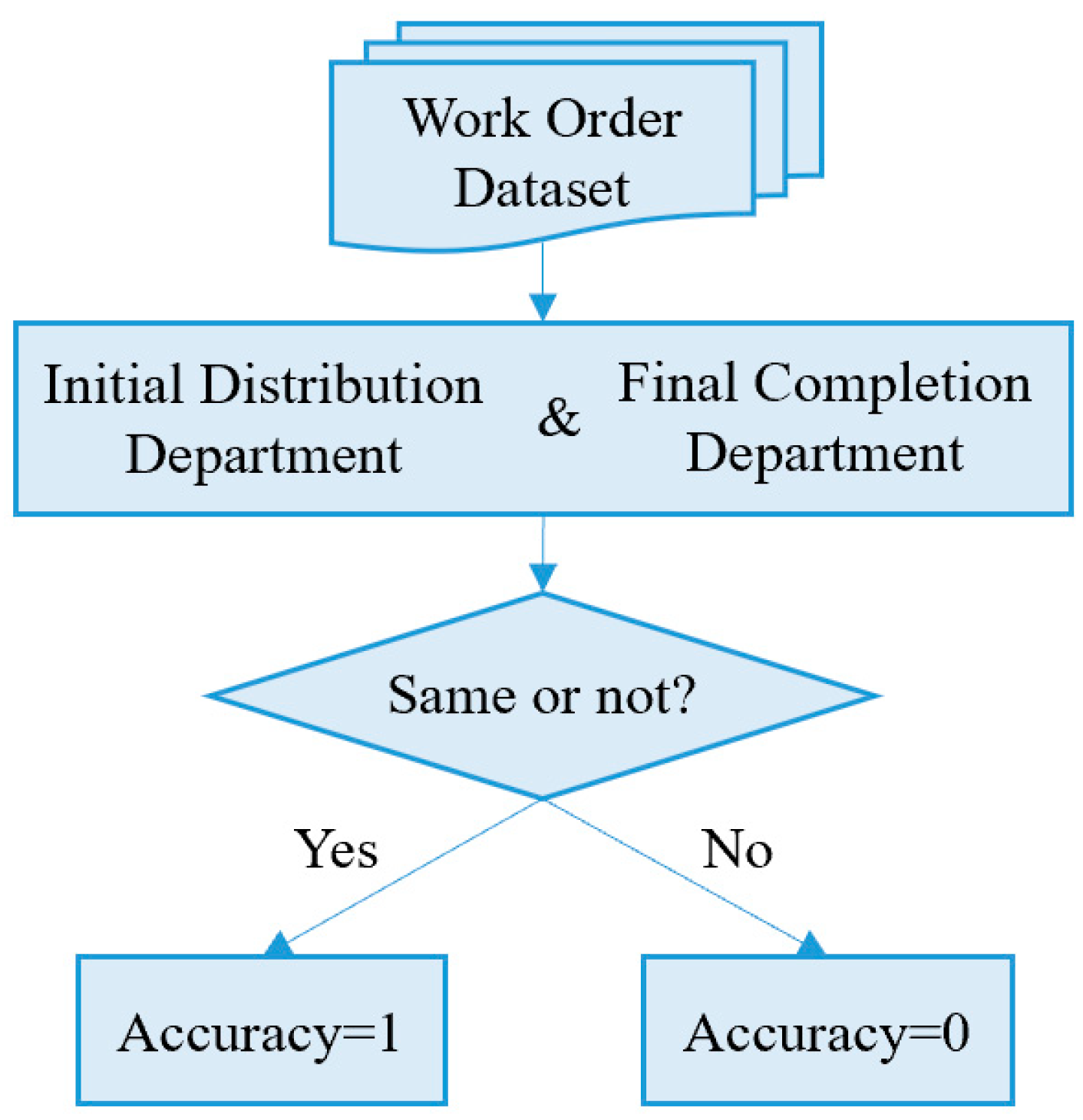
Correctness pertains to factual accuracy and compliance with data standards. Wang and Strong [
53] highlight accuracy as a fundamental dimension reflecting the degree to which data correctly represent real-world conditions. Hamdy et al. [
54] empirically confirm that record accuracy is directly correlated with overall data usability and quality, reinforcing our choice of record accuracy as a key sub-indicator. Additionally, Tian et al. [
55] demonstrated that address accuracy directly impacts downstream logistics operations, further validating our inclusion of address accuracy as critical for government service delivery.
Consistency ensures internal coherence and logical integrity within textual records. Redman [
56] established consistency as a critical dimension of data quality, referring to the uniformity and coherence of data within and across records. Building upon Gharehchopogh and Khalifelu’s [
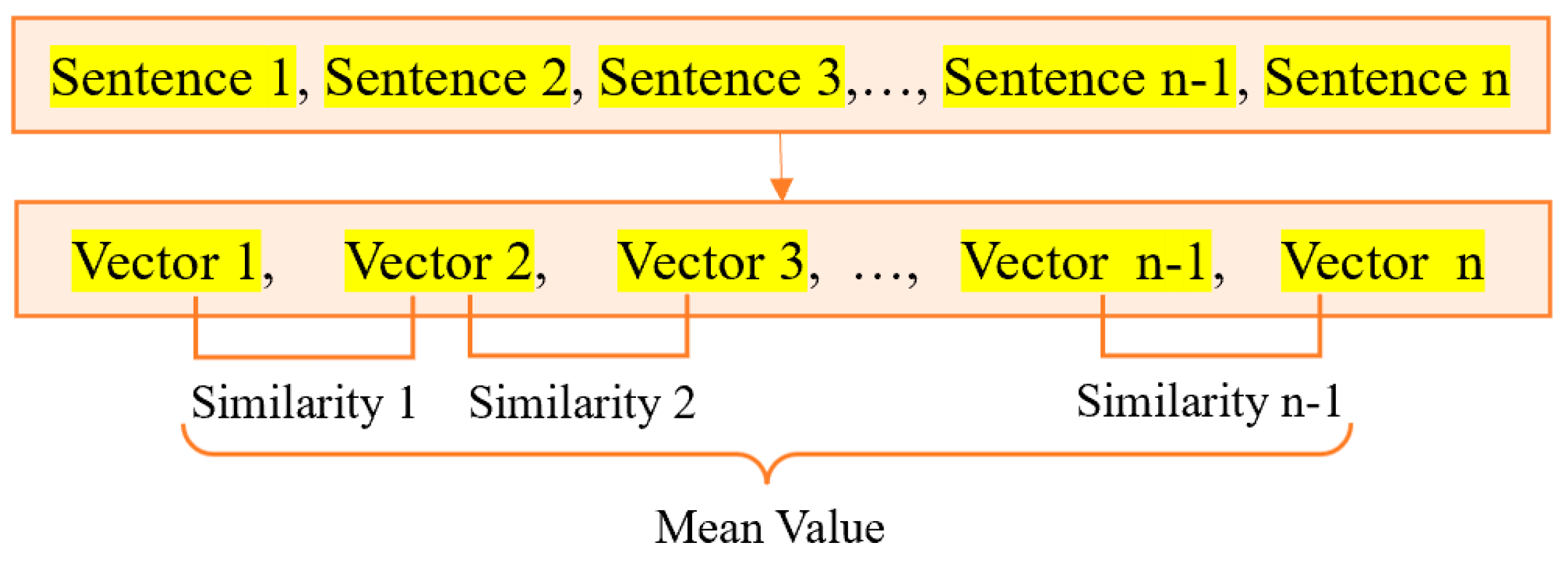
57] work on evaluating topic relevance in textual data, we include adjacent sentence similarity and full-text similarity as indicators of logical consistency and minimal redundancy within hotline work orders, improving semantic integrity and operational efficiency.
Compared to previous studies primarily focused on structured data or general metrics, our framework uniquely addresses the challenges posed by unstructured or semi-structured textual records, thus providing a nuanced and operationally relevant evaluation system for government hotline data.
Numerous studies affirm the critical role of rigorous data quality standards in improving governmental performance. Li and Shang [
58] showed that robust data standards significantly enhance administrative efficiency, while Cheng and Liu [
59] demonstrated that improved data governance substantially enhances policy effectiveness. Consequently, we propose the following hypotheses:
H1: Data record standards positively affect work order completion.
Furthermore, the impact of data quality standards may vary across different work order fields. Studies indicate that sectors with structured workflows, like transportation and healthcare, typically exhibit greater sensitivity to enhanced data accuracy and standardization [
60,
61]. Hence, we hypothesize the following:
H2: The work order field moderates the relationship between data record standards and work order completion.
Similarly, organizational capabilities also influence how effectively data standards are utilized. Strong organizational competencies in data management significantly enhance data quality implementation and operational outcomes [
62]. Departments with better training and clearer processes are more effective in utilizing standardized data, while those with limited capacities may struggle to realize these benefits. Thus, we propose the following:
H3: The work order handling department moderates the relationship between data record standards and work order completion.
These hypotheses form the basis of our proposed framework, as illustrated in
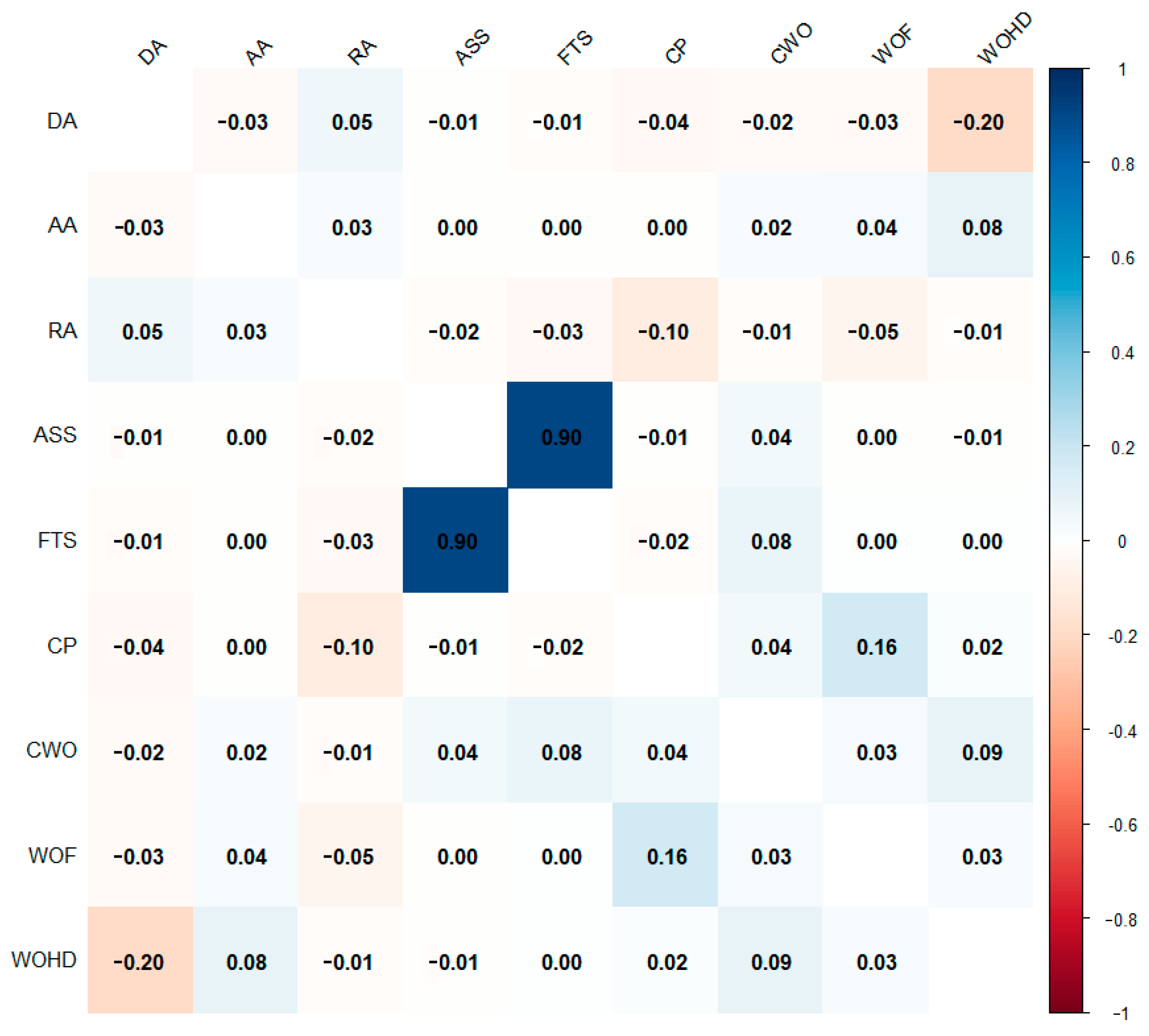
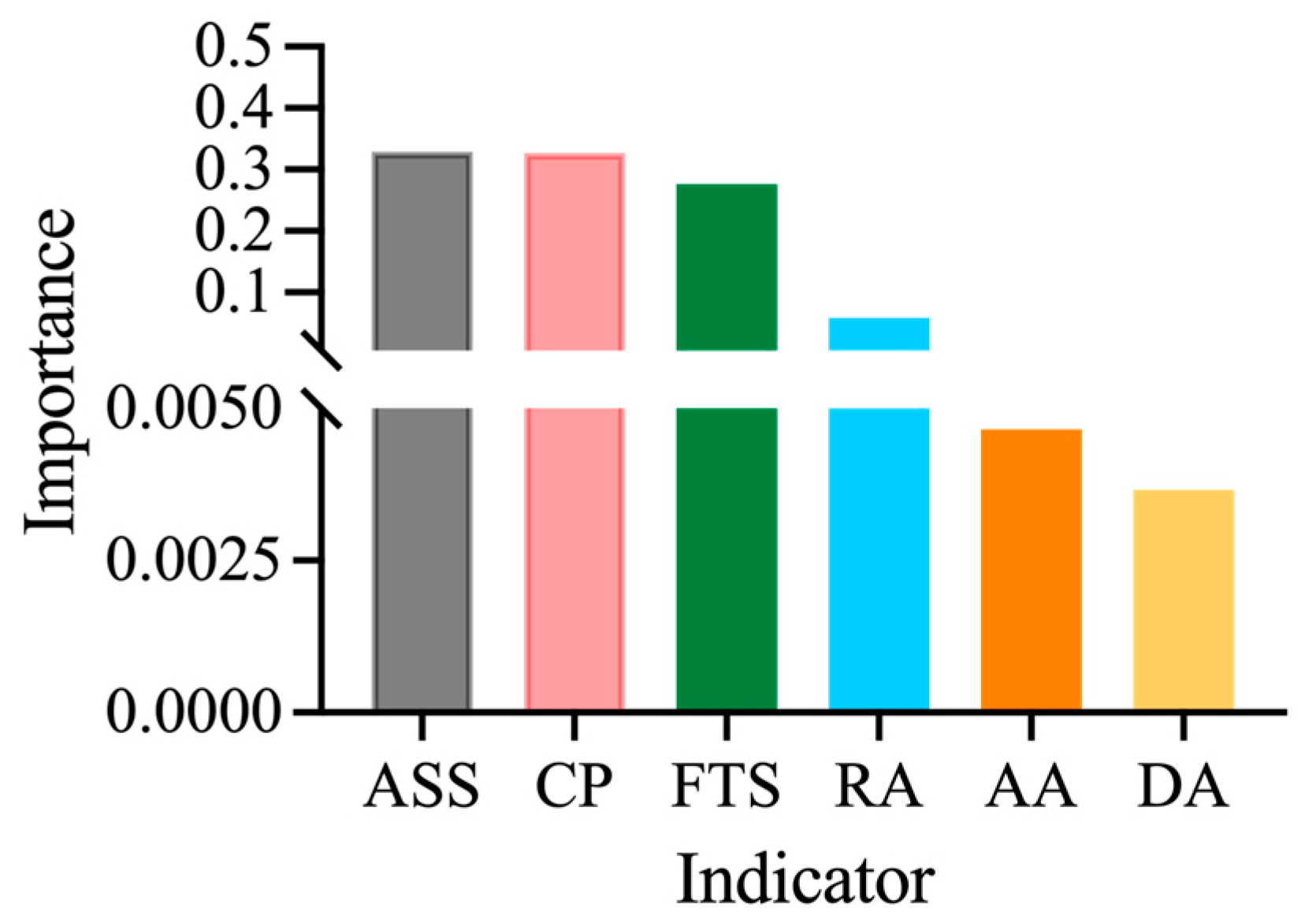
Figure 2. This figure illustrates the evaluation framework for government hotline data record standards. In particular, six secondary indicators—including dispatch accuracy, classification predictability, record accuracy, address accuracy, adjacent sentence similarity, and full-text similarity—are employed to assess data standards. The evaluation results are further linked to key work order attributes, such as the work order field and handling department, in order to analyze their influence on work order completion.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}