
Data Quality Assessment in Smart Manufacturing: A Review





Abstract
1. Introduction
2. Related Work
2.1. Data Quality
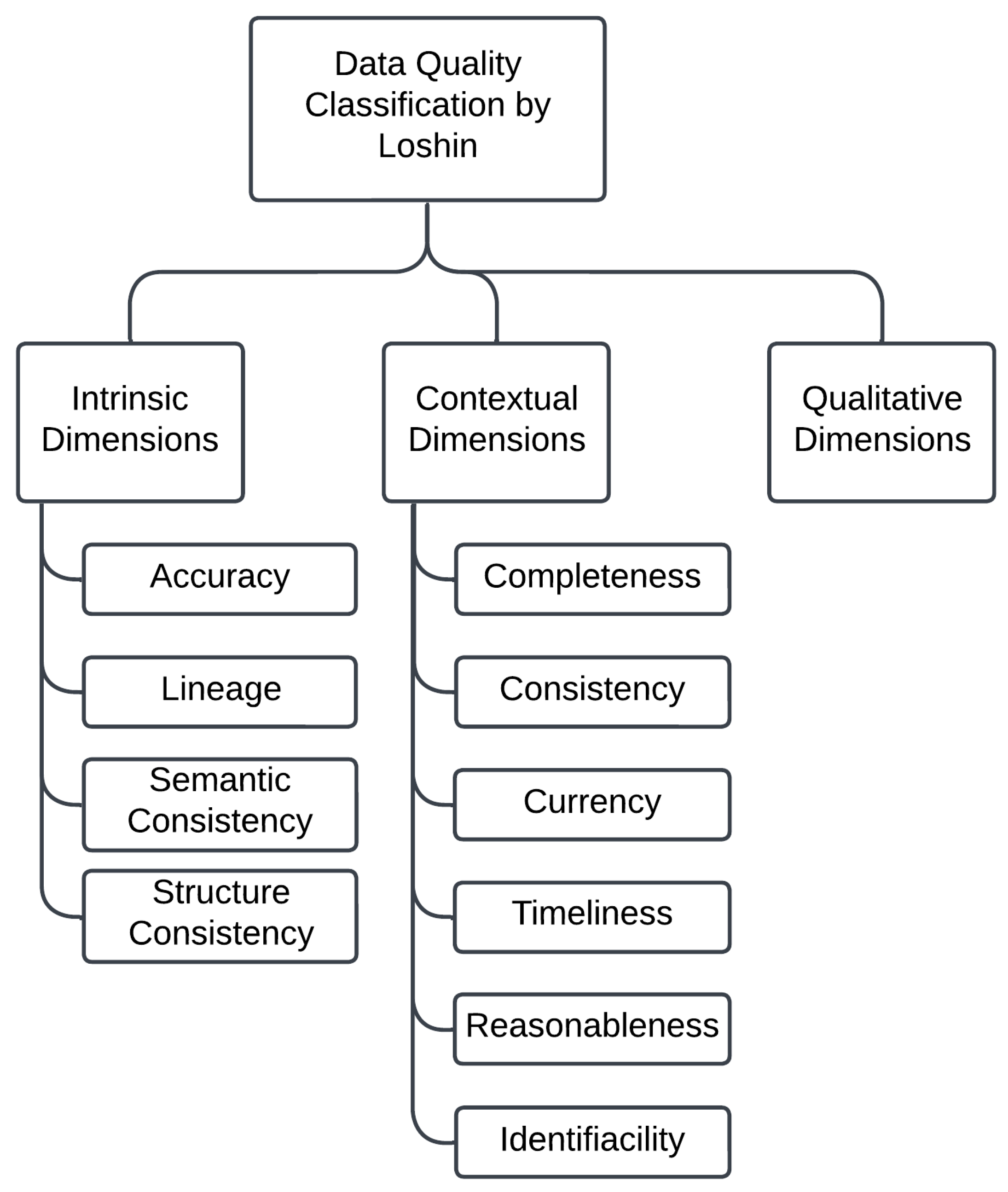
2.2. Data Quality Classification
3. Measuring Data Quality Dimensions
3.1. Structural Accuracy
3.1.1. Measuring Accuracy at the Data Record Level
3.1.2. Measuring Accuracy at the Data Element Level
3.1.3. Measuring Accuracy at the Data Value Level
3.2. Temporal Accuracy
3.2.1. Measuring Timeliness Based on Time Interval
3.2.2. Measuring Timeliness Considering Currency and Volatility
3.3. Completeness
3.3.1. Measuring the Completeness Metric at the Data Element Level
3.3.2. Measuring Completeness at the Data Record
3.3.3. Measuring Completeness in Event Occurrences over Time
3.4. Consistency
3.4.1. Measuring Data Element Consistency
3.4.2. Measuring Cross-Record Consistency
3.4.3. Measuring Dataset Consistency
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rangineni, S.; Bhanushali, A.; Suryadevara, M.; Venkata, S.; Peddireddy, K. A Review on Enhancing Data Quality for Optimal Data Analytics Performance. Int. J. Comput. Sci. Eng. 2023, 11, 51–58. [Google Scholar] [CrossRef]
- Goknil, A.; Nguyen, P.; Sen, S.; Politaki, D.; Niavis, H.; Pedersen, K.J.; Suyuthi, A.; Anand, A.; Ziegenbein, A. A Systematic Review of Data Quality in CPS and IoT for Industry 4.0. ACM Comput. Surv. 2023, 55, 1–38. [Google Scholar] [CrossRef]
- Hu, C.; Sun, Z.; Li, C.; Zhang, Y.; Xing, C. Survey of Time Series Data Generation in IoT. Sensors 2023, 23, 6976. [Google Scholar] [CrossRef] [PubMed]
- Teh, H.Y.; Kempa-Liehr, A.W.; Wang, K.I.K. Sensor data quality: A systematic review. J. Big Data 2020, 7, 11. [Google Scholar] [CrossRef]
- Tverdal, S.; Goknil, A.; Nguyen, P.; Husom, E.J.; Sen, S.; Ruh, J.; Flamigni, F. Edge-Based Data Profiling and Repair as a Service for IoT; Association for Computing Machinery: New York, NY, USA, 2024; pp. 17–24. [Google Scholar] [CrossRef]
- Kuemper, D.; Iggena, T.; Toenjes, R.; Pulvermueller, E. Valid.IoT: A framework for sensor data quality analysis and interpolation. In Proceedings of the 9th ACM Multimedia Systems Conference, Amsterdam, The Netherlands, 12–15 June 2018; pp. 294–303. [Google Scholar] [CrossRef]
- Krishnamurthi, R.; Kumar, A.; Gopinathan, D.; Nayyar, A.; Qureshi, B. An overview of IoT sensor data processing, fusion, and analysis techniques. Sensors 2020, 20, 6076. [Google Scholar] [CrossRef]
- Li, F.; Nastic, S.; Dustdar, S. Data quality observation in pervasive environments. In Proceedings of the 2012 IEEE 15th International Conference on Computational Science and Engineering, Paphos, Cyprus, 5–7 December 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 602–609. [Google Scholar] [CrossRef]
- Corallo, A.; Crespino, A.M.; Vecchio, V.D.; Lazoi, M.; Marra, M. Understanding and Defining Dark Data for the Manufacturing Industry. IEEE Trans. Eng. Manag. 2023, 70, 700–712. [Google Scholar] [CrossRef]
- Zhang, L.; Jeong, D.; Lee, S. Data Quality Management in the Internet of Things. Sensors 2021, 21, 5834. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Peng, G.; Kong, Y.; Li, S.; Chen, S. Data Quality Affecting Big Data Analytics in Smart Factories: Research Themes, Issues and Methods. Symmetry 2021, 13, 1440. [Google Scholar] [CrossRef]
- Qasim Jebur Al-Zaidawi, M.; Çevik, M. Advanced Deep Learning Models for Improved IoT Network Monitoring Using Hybrid Optimization and MCDM Techniques. Symmetry 2025, 17, 388. [Google Scholar] [CrossRef]
- Loshin, D. The Practitioner’s Guide to Data Quality Improvement; Elsevier: Amsterdam, The Netherlands, 2010. [Google Scholar] [CrossRef]
- Batini, C.; Scannapieco, M. Data and Information Quality; Springer: Berlin/Heidelberg, Germany, 2016; Volume 63. [Google Scholar] [CrossRef]
- Mahanti, R. Data Quality: Dimensions, Measurement, Strategy, Management, and Governance; ASQ Quality Press: Milwaukee, WI, USA, 2019; Available online: https://asq.org/quality-press/display-item?item=H1552 (accessed on 15 September 2024).
- Gimpel, G.; Alter, A. Benefit From the Internet of Things Right Now by Accessing Dark Data. IT Prof. 2021, 23, 45–49. [Google Scholar] [CrossRef]
- Wang, R.Y.; Strong, D.M. Beyond Accuracy: What Data Quality Means to Data Consumers. J. Manag. Inf. Syst. 1996, 12, 5–33. [Google Scholar] [CrossRef]
- Karkouch, A.; Mousannif, H.; Al Moatassime, H.; Noel, T. Data quality in internet of things: A state-of-the-art survey. J. Netw. Comput. Appl. 2016, 73, 57–81. [Google Scholar] [CrossRef]
- Cichy, C.; Rass, S. An Overview of Data Quality Frameworks. IEEE Access 2019, 7, 24634–24648. [Google Scholar] [CrossRef]
- Cheng, H.; Feng, D.; Shi, X.; Chen, C. Data quality analysis and cleaning strategy for wireless sensor networks. EURASIP J. Wirel. Commun. Netw. 2018, 2018, 61. [Google Scholar] [CrossRef]
- Byabazaire, J.; O’Hare, G.; Delaney, D. Using trust as a measure to derive data quality in data shared IoT deployments. In Proceedings of the 2020 29th International Conference on Computer Communications and Networks (ICCCN), Honolulu, HI, USA, 3–6 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Sicari, S.; Cappiello, C.; Pellegrini, F.D.; Miorandi, D.; Coen-Porisini, A. A security-and quality-aware system architecture for Internet of Things. Inf. Syst. Front. 2016, 18, 665–677. [Google Scholar] [CrossRef]
- Ballou, D.; Wang, R.; Pazer, H.; Tayi, G. Modeling Information Manufacturing Systems to Determine Information Product Quality. Manag. Sci. 1998, 44, 462–484. [Google Scholar] [CrossRef]
- Naumann, F. Data profiling revisited. ACM Sigmod Rec. 2014, 42, 40–49. [Google Scholar] [CrossRef]
- Abedjan, Z.; Golab, L.; Naumann, F.; Papenbrock, T. Data Profiling. Synth. Lect. Data Manag. 2018, 10, 1–154. [Google Scholar] [CrossRef]
- Zhong, K.; Jackson, T.; West, A.; Cosma, G. Building a Sustainable Knowledge Management System from Dark Data in Industrial Maintenance. In Proceedings of the International Conference on Knowledge Management in Organizations, Kaohsiung, Taiwan, 29 July–4 August 2024; Uden, L., Ting, I.H., Eds.; Springer: Cham, Switzerland, 2024; pp. 263–274. [Google Scholar] [CrossRef]
- Trajanov, D.; Zdraveski, V.; Stojanov, R.; Kocarev, L. Dark Data in Internet of Things (IoT): Challenges and Opportunities. In Proceedings of the 7th Small Systems Simulation Symposium, Cavan, Ireland, 16–18 April 2018; pp. 1–9. Available online: https://www.researchgate.net/publication/323337110_Dark_Data_in_Internet_of_Things_IoT_Challenges_and_Opportunities (accessed on 22 October 2024).
- Khram, I.; Shamseddine, M.; Itani, W. STCCS: Segmented Time Controlled Count-Min Sketch. In Proceedings of the 2020 ITU Kaleidoscope: Industry-Driven Digital Transformation (ITU K), Online, 7–11 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Gribonval, R.; Chatalic, A.; Keriven, N.; Schellekens, V.; Jacques, L.; Schniter, P. Sketching data sets for large-scale learning: Keeping only what you need. IEEE Signal Process. Mag. 2021, 38, 12–36. [Google Scholar] [CrossRef]
- Rusu, F.; Dobra, A. Sketching Sampled Data Streams. In Proceedings of the 2009 IEEE 25th International Conference on Data Engineering, Shanghai, China, 29 March–2 April 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 381–392. [Google Scholar] [CrossRef]
- Cormode, G. Data sketching. Commun. ACM 2017, 60, 48–55. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Criterion | Description |
|---|---|
| Clarity of definition | The metric must be clearly defined, specifying what is being measured, acceptable value ranges, and providing a qualitative segmentation of the range that relates the score to performance. |
| Measurability | The metric must be quantifiable and measurable within a discrete range. |
| Business relevance | The metric must relate to a relevant aspect of the company’s operations or performance, showing how its score impacts performance evaluation. |
| Controllability | The metric should prompt corrective action if its value falls outside the desirable range. |
| Representation | The metric should be visually represented in a concise and meaningful manner. |
| Reportability | The metric must be clearly summarized in reports, demonstrating how it contributes to overall assessments. |
| Trackability | The metric should enable the measurement of performance improvements over time and support statistical control. |
| Drill-down capability | The metric should facilitate identifying patterns and root causes of low scores to eliminate flaws in the process. |
| Associated Dimension | Data Quality Issues | Description | Importance |
|---|---|---|---|
| Accuracy | Anomalies, outliers, noise, and invalid data. | Data are deviated from the patterns of normal data and are out of all potential values. | Accurate data are critical for analysis, as inaccuracies can lead to poor decisions. |
| Timeliness | Old data, antiquated data, or time-alignment issues. | Data are out of date. | Timeliness is critical to keeping data relevant in dynamic production environments, as old or outdated data can lead to misleading analysis and reduce operational efficiency. |
| Completeness | Missing data/values. | Data values are null. | Completeness is essential since missing data can lead to incomplete analyses and potentially erroneous conclusions. |
| Consistency | Data inconsistencies, data redundancies, and duplicates. | Data elements from different sources are contradictory, or data from the same observation appear to be inconsistent. | Data consistency is important since data inconsistencies can cause confusion and lead to conflicting insights. |
| Criterion | Description |
|---|---|
| Clarity of definition | The metric is clearly defined and calculated by direct comparison to reference data. The result of the metric is in the range [0, 1], where the desired result is 1. |
| Measurability | The metric is quantifiable and measurable within a discrete range. |
| Business relevance | In an IoT environment, data accuracy is critical, as numerous automated processes are dependent on precise readings to optimize operations and make informed decisions. However, applying this metric can be challenging in environments where the variability of some elements is inherent, such as in IoT systems, where sensors may occasionally generate minor discrepancies that do not impact overall operation. |
| Controllability | The metric allows for the identification of records that are not fully accurate, which can help take corrective actions. |
| Representation | The metric can be represented visually and clearly. This facilitates communication of results, but more granularity may be needed to identify where errors are concentrated within a dataset, especially in complex contexts such as IoT where multiple data types are integrated. |
| Reportability | The metric is easy to report since the value of accurate records can be succinctly summarized. |
| Trackability | The metric allows for tracking the accuracy of records over time, which is useful for evaluating the effectiveness of data quality improvement efforts. However, the requirement for total accuracy across all elements can make it difficult to perceive incremental progress since a small error in any element of a record can disqualify the entire record. |
| Drill-down capability | The metric has limitations in terms of detail. While it identifies which records are not accurate, it does not provide insights into which elements within a specific record are causing problems. This makes it harder to diagnose and correct the underlying causes of inaccuracy, especially in complex records involving many elements. |
| Criterion | Description |
|---|---|
| Clarity of definition | The metric is clearly defined, measuring the number of data elements that are accurate, meaning they belong to the allowed value domain, and it is easy to define a range of values representing valid limits. The result of the metric lies between the range of values [0, 1] with the desirable result being 1. |
| Measurability | The metric is directly measurable as it simply requires comparing elements with reference values. In an IoT environment, where many devices generate data, this metric can be scalable but depends on the constant updating of reference values. |
| Business relevance | This metric can be directly related to system performance in smart manufacturing environments. |
| Controllability | While the metric allows for the identification of exactly which data elements have low accuracy, it does not provide details about the causes, such as sensor issues or external interferences. For example, if the accuracy of a temperature sensor’s data drops, it is possible to know that the problem lies in those data, but not the exact reason, which could lead to ineffective or insufficient corrective actions to address the root cause of the issue. |
| Representation | The metric can be represented simply and visually, such as a number of accurate elements by sensor. |
| Reportability | The metric is easy to report as a number, but in complex IoT environments, where data come from multiple sources, more detailed reporting may be needed. |
| Trackability | The metric allows for tracking over time, enabling the monitoring of whether the accuracy of specific elements is improving or declining. |
| Drill-down capability | The metric allows for identifying problem areas, such as specific sensors that may be compromising accuracy. |
| Criterion | Description |
|---|---|
| Clarity of definition | The metric is clearly defined, using a formula that normalizes the values concerning the minimum and maximum of the dataset. This makes it easy to understand how the value positions itself relative to the total data range. Values close to 0 indicate proximity to the lower limit, while values close to 1 are close to the upper limit. Case is outside the interval [0, 1] this suggests that the analyzed value may be an outlier or an error, while values within this range are considered valid. |
| Measurability | The metric is measurable and quantifiable, using specific values from the dataset for the calculation. |
| Business relevance | The metric is relevant because understanding how data are distributed around the extremes can help identify trends, outliers, and anomalies that can aid in predictive maintenance. |
| Controllability | The metric allows for the identification of values outside the expected range, suggesting the presence of outliers or errors. Since the analysis is done at the data value level, it is possible to identify which sensor is generating incorrect data and determine whether the values are significantly above or below expectations. This enables specific corrective actions, such as adjustments or repairs, to improve data quality. |
| Representation | The metric can be presented visually, making it easier to identify values outside the desired range. Scatter plots or histograms can be used to visualize how the values are distributed in relation to the interval. |
| Reportability | The metric is clearly reportable, with results expressed as normalized values for easy and understandable presentation in reports. |
| Trackability | The metric allows for tracking over time, helping to monitor how values move within the data range. It is important to note that minimum and maximum values can and should be adjusted over time as new data are collected. This ensures that the metric remains relevant and reflective of the current conditions in the environment, enabling the identification of trends in data quality and the impact of interventions over time. |
| Drill-down capability | The metric offers a level of detail by indicating when a value is close to 0 or 1. This information can be useful for identifying which values need attention, helping to direct corrective actions or further investigation. However, the metric still does not provide information about the underlying causes of outliers, limiting the ability to understand why these values fall outside the desired range. |
| Criterion | Description |
|---|---|
| Clarity of definition | The metric is clear in its definition, specifying that it measures the time interval between the moment the event occurred in real life and the moment the user accesses the data. The desired value for this metric would be as small as possible, given the threshold defined earlier. |
| Measurability | The metric is quantifiable, as it calculates a time difference, and requires a clear discrete threshold to define an acceptable or unacceptable time interval. |
| Business relevance | The metric is highly relevant to business operations since the ability to make informed decisions depends on the timeliness of the data. |
| Controllability | The metric should allow stakeholders to determine if the data being analyzed is timely enough to support decisions. If the score indicates that the data are not timely, this should lead to corrective actions, such as updating the data or adjusting the analyses. |
| Representation | The metric can be visually represented clearly, using graphs or indicators that quickly show data timeliness relative to the moment of analysis. |
| Reportability | The metric is easily summarized in reports, showing how data timeliness affects the quality of analysis and decision-making. Examples of how the score impacts practical results can strengthen this presentation. |
| Trackability | The timeliness metric allows for continuous monitoring of data timeliness, helping identify trends and assess whether the data remain relevant over time. |
| Drill-down capability | Through the analysis of this metric, it is not possible to investigate the causes of outdated data. Still, it is possible to identify where the delay is occurring, making it easier to identify the problem and implement improvements in future data collection and delivery processes. |
| Criterion | Description |
|---|---|
| Clarity of definition | The timeliness metric is clearly defined, using the formulas for currency and volatility. The concepts of currency and volatility are well explained, making it easier to understand what is being measured. The ideal value for this metric would be 1 or as close to 1 as possible. |
| Measurability | The metric is measurable, as it uses quantitative values and results in a score between 0 and 1, allowing for an accurate assessment of how timely the data are for use. |
| Business relevance | The metric is highly relevant to smart manufacturing scenarios, where real-time decision-making is crucial since it allows the temporal quality of data to be monitored, ensuring that critical decisions are made with up-to-date and reliable information. |
| Controllability | The timeliness metric can trigger corrective actions. For instance, if the timeliness score is low, the frequency of data updates or the way they are delivered can be adjusted, promoting improvements in data collection and management. |
| Representation | The visual representation of the timeliness metric is particularly useful in smart manufacturing dashboards, where operators can monitor data readiness in real-time and quickly respond to any discrepancies. |
| Reportability | The metric can be easily included in reports, allowing for a clear synthesis of the state of timeliness of the data. |
| Trackability | The metric allows for continuous monitoring of improvements over time. With ongoing data collection, trends in timeliness can be observed, and it can be assessed whether implemented interventions are yielding positive results. |
| Drill-down capability | The timeliness metric can be used to identify patterns of low data readiness, allowing teams to analyze root causes, such as delays in data updates or information delivery issues. |
| Criterion | Description |
|---|---|
| Clarity of definition | The metric is clearly defined at the data element level, measuring the value of present data for each attribute. For each data element, missing values are accounted for, and the formula clearly specifies how to calculate this proportion relative to the total expected elements. The result of this metric is in the interval [0, 1], with the desired result being 1. |
| Measurability | The metric is fully measurable and quantifiable, as it is based on direct counts of present or missing data elements. |
| Business relevance | This metric is highly relevant in smart manufacturing environments, where incomplete data can compromise decision-making and operational efficiency. For example, the absence of critical data during maintenance or machine monitoring operations can lead to unexpected failures or interruptions, making this metric essential for evaluating data integrity. |
| Controllability | The metric provides good control capabilities, allowing actions to be taken when the level of completeness does not meet the expected value. |
| Representation | The metric can be easily represented visually through bar charts, or other diagrams showing the percentage of completeness for data elements. |
| Reportability | The metric is simple and straightforward to report. |
| Trackability | The metric can be monitored over time to see if data completeness is improving or deteriorating. |
| Drill-down capability | While the metric identifies which data elements are incomplete, it does not directly provide a detailed analysis of why the data are missing. |
| Criterion | Description |
|---|---|
| Clarity of definition | The metric is clearly defined and measures the value of completeness in records. The result of this metric is in the interval [0, 1], with the desired result being 1. |
| Measurability | The metric is objectively measurable. By verifying that all critical fields in a record are completed. |
| Business relevance | This metric is highly relevant, particularly in contexts where complete records of critical data are essential for effective operations. |
| Controllability | The metric allows for the identification of incomplete records, facilitating corrective action. |
| Representation | The metric can be easily represented visually through bar charts, or other diagrams showing the value of completeness. |
| Reportability | The metric can be easily reported and provides a clear view of data quality in terms of record completeness. |
| Trackability | The metric supports monitoring over time, showing trends of improvement or degradation in record completeness. This is especially useful for tracking data quality in continuous processes. |
| Drill-down capability | If the completeness value in a dataset is consistently low over multiple records, this may be an indicator of existing or impending problems in the machine sending data through the sensors, making the metric extremely useful for diagnostics. However, while the metric identifies incomplete records, it does not specify which items are missing. This limitation reduces its capacity for direct investigation, but it still provides a valuable starting point for more detailed analysis, allowing problematic records to be highlighted. |
| Criterion | Description |
|---|---|
| Clarity of definition | The definition of the metric is clear and well-specified. It assesses the completeness of the data based on the regularity of events occurring in defined time intervals. The result of this metric is in the interval [0, 1], with the desired result being 1. |
| Measurability | The metric is objectively measurable. The number of observed events and the expected number of events can be easily counted within specific time intervals, allowing for a clear quantitative assessment of event completeness over time. |
| Business relevance | The metric is particularly relevant for scenarios where the regularity of events is critical. The absence of events may indicate data collection failures or performance issues, and this metric helps monitor data completeness over time, which is vital for maintenance and quality control in continuous production environments. |
| Controllability | The metric allows for direct corrective action. If the number of observed events is lower than expected, it may indicate gaps in data collection, which can be investigated and addressed to prevent future failures. |
| Representation | The metric can be easily represented visually in line or bar charts that show the relationship between the number of occurrences and the expected number over various time intervals. |
| Reportability | The metric can be summarized in reports, highlighting periods with low event completeness and providing an overview of data completeness over time. |
| Trackability | It allows for monitoring over time, providing an effective means of tracking the evolution of event regularity and identifying trends of improvement or deterioration in data collection. |
| Drill-down capability | The metric can easily detail when gaps or irregularities occurred, as it directly measures event occurrences in specific time intervals. |
| Criterion | Description |
|---|---|
| Clarity of definition | The metric is clearly defined, detailed, and measures the relationship between specific elements in a dataset, placing it in a range between 0 and 1, with 1 being the desirable value. |
| Measurability | The metric is quantifiable and measurable. |
| Business relevance | In the context of smart manufacturing, consistency of data elements is important to ensure that data from different sensors and devices can be accurately correlated. |
| Controllability | The metric provides a high level of control, allowing specific corrective actions to be taken in problematic combinations, which is critical when multiple devices or sensors are involved. |
| Representation | The metrics can be visually displayed in detail, highlighting which rules are not being followed. |
| Reportability | The ability to report specific details about consistency rules is essential. Data element consistency offers this granularity, allowing reports to pinpoint exactly where failures occur. |
| Trackability | The metric allows for tracking over time, making it easier to monitor the evolution of relationships between specific elements. |
| Drill-down capability | The metric is very useful in this context as it provides details of failures in specific data rules, which is essential in complex systems. |
| Criterion | Description |
|---|---|
| Clarity of definition | The metric is clearly defined, specifying the data elements to be evaluated and the rules that will guide the consistency verification. The result of the metric lies between the range of values [0, 1] with the desirable result being 1. |
| Measurability | The metric is quantifiable, allowing consistency to be measured and compared over time. |
| Business relevance | The cross-record consistency metric is highly relevant for business operations, especially in Industry 4.0 environments where the integration of data from multiple sources is critical. The absence of consistency can lead to incorrect decisions, impacting operational efficiency. |
| Controllability | The metric allows for the application of specific corrective actions by identifying which relationships are compromising the quality of the data, allowing for specific actions to be taken, without having to review the entire dataset. |
| Representation | The metric can be visually represented through graphs and reports. However, visual representation can become complex if the number of records is very high, making it necessary to summarize the information. |
| Reportability | The metric provides a good ability to report details about which records are inconsistent, allowing you to quickly identify where problems are occurring. |
| Trackability | The metric is useful for monitoring, as it allows consistent tracking over time. This is essential for detecting trends and changes in data quality, enabling organizations to respond proactively to any degradation. |
| Drill-down capability | The metric allows for in-depth analysis, as identifying inconsistent records allows for examination of the root causes of inconsistencies. |
| Criterion | Description |
|---|---|
| Clarity of definition | The consistency metric at the dataset level is well-defined. It measures the difference between the records from the source and the target. The range of acceptable values is between 0 and 1 and the desirable value is 0 since the result of the metric is inconsistency. |
| Measurability | The metric is measurable and quantifiable. |
| Business relevance | The relevance of this metric is crucial in scenarios where data transfer between systems is frequent. In Industry 4.0 environments, where real-time synchronization between different data sources is essential, this metric can ensure that there are no significant data losses during transfers or integrations. |
| Controllability | The metric indicates that an inconsistency has occurred, but does not provide granular details. |
| Representation | The metric can be easily represented by graphs that show the discrepancies between the source and the target. |
| Reportability | The metric provides a basic level of reportability, indicating that there were inconsistencies but without providing specific details about where the errors are. It allows for the generation of reports with a high level of abstraction but may not be sufficient in cases where it is necessary to identify specific records that failed in the loading process. |
| Trackability | The metric can be calculated regularly to ensure that consistency between the source and the target is maintained. |
| Drill-down capability | The drill-down capability of the metric is limited. It only detects inconsistency as a whole, without providing a detailed view of how records or values were lost. |
| Metric | Advantages | Disadvantages | Application Scenario |
|---|---|---|---|
| Metric (2) | Identifies the relative position of a value within the data range, helping to detect anomalies and outliers. Tracks data quality trends over time, allowing early detection of sensor faults. | Requires constant updates to minimum and maximum values to reflect new system conditions. Limited insight into the root cause of anomalies. May not identify context-specific issues without further analysis. | Used in industrial environments for continuous monitoring of sensor data (e.g., temperature, pressure). Anomalies such as values outside the expected range could indicate impending sensor or machine failures, prompting preventive maintenance actions. |
| Metric | Advantages | Disadvantages | Application Scenario |
|---|---|---|---|
| Metric (5) | Provides a comprehensive assessment by combining data currency with volatility. Normalized output (0 to 1) offers clear and intuitive insights, useful for comparisons and monitoring. Useful for dynamic environments with varying data update frequencies. | Requires the definition and maintenance of an appropriate volatility threshold, which may vary by system. | In smart manufacturing systems, especially where sensors or equipment may update at varying intervals, such as automated production lines. Helps ensure that decisions are based on the most up-to-date and valid data, supporting real-time adjustments to machine parameters. |
| Metric | Advantages | Disadvantages | Application Scenario |
|---|---|---|---|
| Metric (6) (Element Level) | Identifies missing values at the element level, ensuring all required attributes are available for decision-making. Key for maintaining operational integrity. | May not be effective if missing values are sporadic or not critical for immediate decisions. | In scenarios where every attribute of a record is essential, such as ensuring that all required sensor readings (e.g., temperature, pressure) are present for each production cycle. Missing values could indicate sensor failure or data collection issues that need to be addressed immediately. |
| Metric (6)(Record Level) | Provides insight into missing values at the record level. Helps detect incomplete records that may signal operational problems. | May overlook patterns of missing data in periodic or critical events. | Ensuring completeness in data records for equipment status logs or machine maintenance reports, where missing data might delay key decisions. |
| Metric (7)(Occurrences Over Time) | Monitors the regularity and coverage of events over time, revealing data collection failures or interruptions. Useful for detecting duplicated or missing records. | Does not identify the specific cause of missing data and may require additional metrics for detailed analysis. | In environments requiring high data frequency, such as monitoring automated assembly lines, where missing or duplicated data can affect the overall process performance. |
| Metric | Advantages | Disadvantages | Application Scenario |
|---|---|---|---|
| Metric (8) (Data Element Consistency) | Ensures logical relationships between data elements, helping identify violations of established rules. | May not detect inconsistencies where elements interact in more complex ways or in a non-linear fashion. | In environments where data elements must consistently align, such as monitoring a plastic extrusion process where the temperature increase should correspond with pressure levels. |
| Metric (8) (Record Consistency) | Assures consistency across records, especially when data are collected from different sources. | Can be computationally intensive for large datasets. May miss inconsistencies that only appear over time or in certain conditions. | In scenarios where data are sourced from multiple sensors or machines, ensuring that records from different machines are consistent and reliable. |
| Metric (9) (Dataset Consistency) | Ensures that the data in the target system are consistent with the source system, avoiding issues from errors in data loading or synchronization. Vital for ensuring reliable reporting and decision-making. | May not detect inconsistencies in real-time if data updates are delayed or not synchronized properly. | In environments where data synchronization between multiple systems is critical, such as in the integration of real-time data from IoT devices to centralized data platforms for accurate operational analysis and decision-making. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peixoto, T.; Oliveira, B.; Oliveira, Ó.; Ribeiro, F. Data Quality Assessment in Smart Manufacturing: A Review. Systems 2025, 13, 243. https://doi.org/10.3390/systems13040243
Peixoto T, Oliveira B, Oliveira Ó, Ribeiro F. Data Quality Assessment in Smart Manufacturing: A Review. Systems. 2025; 13(4):243. https://doi.org/10.3390/systems13040243
Chicago/Turabian StylePeixoto, Teresa, Bruno Oliveira, Óscar Oliveira, and Fillipe Ribeiro. 2025. "Data Quality Assessment in Smart Manufacturing: A Review" Systems 13, no. 4: 243. https://doi.org/10.3390/systems13040243
APA StylePeixoto, T., Oliveira, B., Oliveira, Ó., & Ribeiro, F. (2025). Data Quality Assessment in Smart Manufacturing: A Review. Systems, 13(4), 243. https://doi.org/10.3390/systems13040243