1. Introduction
Inventory management research is a significant branch of operations research that addresses the challenges businesses face in meeting customer demand while minimizing costs associated with excess and insufficient inventory. The traditional newsvendor model has long been a cornerstone of inventory management theory, providing a framework for single-location inventory decisions under uncertainty. However, in today’s globalized and interconnected business environment, companies often operate across multiple locations, each with its own unique demand dynamics and inventory [
1]. For instance, a clothing store chain may operate multiple outlets in a city [
2]. In this way, the store chain can carry out transshipment if one store has excess inventory and another is experiencing a stockout [
3]. In such a system, efficient management of inventory across multiple locations is vital to maintaining customer satisfaction and operational efficiency.
The current literature on inventory management and transshipment primarily presupposes a known demand distribution, hence the inventory managers can derive optimal inventory levels and transshipment strategies [
3,
4]. Yet in practice, the specific form of the demand distribution is generally unknown, and inventory decisions must be made based on limited demand samples. This serves the starting point for research on data-driven inventory management strategies that can adapt to unknown demand patterns. When demand distribution is unknown a priori, inventory managers must learn the demand on the fly and make inventory decisions by past demand data [
5,
6]. Despite the prevalence of data-driven inventory management studies, current studies mainly focus on single-location inventory decisions.
Given the aforementioned challenges, this paper considers a multiperiod, two-location inventory system with perishable products. The firm can incur a cost to transship excess inventory in one location to the other experiencing stockout. The model with full demand information has been explored in [
3,
4]. Our work differs from previous research by assuming the demand distributions are unknown and by proposing data-drive algorithms tailored for the two-location inventory system. In this paper, the demand distributions in the two locations are assumed to follow a parametric family of distributions and are unknown a priori. Inventory decisions can only be made by past demand data. The objective of our paper is to design an adaptive algorithm for two-location inventory systems and to establish the theoretical performance of the algorithm.
Next, we summarize the main results of our work. First, we propose a parametric data-driven algorithm called DD2LI, specifically designed for the two-location inventory system with transshipment. This algorithm utilizes past demand data, employs maximum likelihood estimation to approximate the unknown demand parameters, and determines the order quantity based on the estimations. Second, we characterize the regret bound of our proposed algorithm based on asymptotics of the maximum likelihood estimator. The regret bound of our algorithm is and can be strengthened to with an additional assumption that the optimal order quantity is Lipschitz continuous with respect to parameters. Finally, the proved regret bound is validated through numerical experiments.
There are two main contributions in this paper. First, we design adaptive inventory control algorithms for two-location inventory systems with unknown demand distributions. This algorithm holds significant practical value, given the common scenario of unknown demand in real-world applications. We also hope that our study will offer valuable insights to store managers tasked with inventory management across multiple locations. Second, our paper is among the first to explore data-driven inventory management strategies for problems with more than one location. The novelty of our work lies in the performance analysis of DD2LI, where we bound the difference between expected cost functions using demand parameters. We provide proof that our proposed algorithm achieves an optimal convergence rate.
The remainder of this paper is organized as follows. The literature is reviewed in
Section 2. In
Section 3, we outline the classic standard newsvendor model and the two-location inventory system with transshipment. In
Section 4, we present the formulation of a multiperiod, two-location inventory system. In
Section 5, we propose a data-driven algorithm called DD2LI, and we present its performance analysis in the section Performance Analysis. In
Section 6, we present results of numerical experiments under two scenarios. We conclude our paper in
Section 7.
2. Literature Review
We review the relevant literature from two aspects: two-location inventory systems with transshipment and data-driven inventory management.
2.1. Two-Location Inventory Systems with Transshipment
First, our paper relates to the literature on two-location inventory systems with transshipment. Ref. [
7] first introduced the concept of inventory sharing across multiple locations. It is demonstrated that, when the demand at each location follows an independent normal distribution, inventory sharing can reduce the system’s total cost to
, where
n is the number of locations, without considering transportation costs. Ref. [
7] serves as a foundation for expanding the standard newsvendor model to incorporate multilocation extensions. An important research stream is the study of inventory transshipment. For a comprehensive review, please refer to [
8]. When multiple locations can adjust inventory through transshipment, Ref. [
9] studied a centralized transshipment network of
n newsvendors, establishing the optimality of a base-stock policy. Refs. [
10,
11,
12,
13] conducted research on optimal strategies for two-location production and sales systems, considering various settings and using different demand and supply models. Ref. [
14] examined single-warehouse multilocation inventory systems and proved that there are five possible optimal strategies. Ref. [
4] considered the impact of the manufacturer’s pricing on multi-retailer systems, finding that the manufacturer’s profit is significantly influenced by whether the manufacturer is the price setter or price taker in the presence of retailer inventory sharing. Recent literature has examined general multilocation systems. Ref. [
15] investigated multi-warehouse, multi-store systems with no external replenishment, designing asymptotically optimal policy via Lagrangian relaxation. Ref. [
16] applied distributionally robust optimization to analyze a multilocation newsvendor network with demand ambiguity. The authors applied a moment-based uncertainty set and derived inventory levels that minimize the worst-case expected cost. Ref. [
17] studied a multilocation inventory system with an additive or multiplicative random yield. They found the comparison between centralization and decentralization hinges significantly on demand uncertainty.
Another important stream explores the strategic behavior of decentralized newsvendors. Ref. [
3] investigated the behavior of two newsvendors maximizing profits through mutual transshipment, deriving equilibrium order quantities and transshipment prices. Ref. [
18] explored the impact of demand information asymmetry and designed an optimal information coordination mechanism. Ref. [
19] developed a two-stage game model to examine the inventory and end-of-season transshipment decisions between competing retailers. Ref. [
20] examined the impact of inventory transshipment network structures on transshipment equilibria. Additionally, from a behavioral perspective, Ref. [
21] studied the transshipment equilibrium between bounded rational newsvendors. Ref. [
22] found that overconfidence could undermine the benefits brought by transshipment. Ref. [
23] discovered from the practices of procurement managers that they tend to order less when inventory sharing is involved. Based on this observation, the authors in [
23] constructed a behavioral model to explain this phenomenon.
The existing literature on inventory transshipment primarily assumes that the underlying demand distribution is known. We complement this line of research by developing data-driven inventory control strategies for a two-location inventory system with transshipment when the demand distribution is unknown a priori.
2.2. Data-Driven Inventory Management
Our work is also related to data-driven inventory management, particularly focusing on the parametric stream. The data-driven research on inventory management can primarily be categorized into two parts: one assumes that the demand distribution falls within a specific parametric family, while the other approach does not make such an assumption. Our work belongs to the former category. Early studies in this category are mainly based on Bayesian dynamic programming. Ref. [
24] assumed that the demand distribution was generated from a certain parametric family with unknown parameters, but the posterior distribution of the parameters could be obtained from demand samples, thereby modeling inventory decisions as a Bayesian Markov decision process. Refs. [
25,
26] examined cases where the demand distribution follows a specific parametric family. Ref. [
26] provides explicit solutions for inventory control strategies when the demand distribution follows the Weibull distribution. Ref. [
27] studied nonstationary demand process. Nevertheless, methods based on Bayesian Markov decision processes only guarantee the convergence of the algorithm, providing no performance analysis compared to full information benchmarks. The methods’ performances are solely described through limited numerical experiments, offering only a partial understanding of their effectiveness.
Recent research on parametric methods utilizes maximum likelihood estimation (MLE) and concentration inequalities to obtain the regret bound. Ref. [
5] studied a joint pricing and inventory management problem for perishable products with changing demand distributions. The authors in [
5] considered that the random error in the demand distribution follows an exponential family distribution and then used the maximum likelihood estimation to estimate the parameters of the exponential family distribution. Refs. [
28,
29] investigated joint pricing and inventory management with limited price adjustments and parametric demand. Ref. [
29] provided the concentration properties of the maximum likelihood estimator for censored demand. In addition, there are other research studies that employ different underlying methods. Ref. [
30] studied the network revenue management problem, assuming a parameterized prior distribution for the demand. They designed an algorithm based on Thompson sampling by calculating the Bayesian posterior distribution from demand samples. Ref. [
31] introduced operational statistics, which integrate demand estimation and inventory optimization.
Contrary to existing studies that mainly investigate single-location inventory problems, our work contributes to the literature by proposing a parametric learning algorithm tailored for two-location inventory systems. Moreover, we have successfully established the performance of our algorithm and validated its effectiveness through numerical experiments.
3. Preliminaries
3.1. The Standard Newsvendor Model
This section provides a review of the setup and solution to the standard newsvendor model. For a more comprehensive review of the newsvendor model, readers may refer to [
32,
33].
The newsvendor model assumes that the demand distribution for a product is stochastic, represented by the random variable D. At the beginning of the period, the risk-neutral newsvendor must decide on the order quantity y. The product has a fixed unit retail price of p, a unit purchase cost of , and, for simplicity, the salvage cost is normalized to zero.
For a real number
x, let
represent
. The expected profit of the newsvendor, denoted as
, is a function of the order quantity
y. It is defined as follows:
When
D is a continuous random variable,
is differentiable. Setting the derivative of
to zero, it can be found that the optimal order quantity
satisfies the equation
which shows that the optimal order quantity is the
quantile of the demand distribution.
3.2. Two-Location Inventory System with Transshipment
To fulfill demand efficiently and maximize profits, a firm operating two outlets can carry out transshipments whenever a stockout occurs in one location, while excess stock is available at the other location.
We follow the framework established by [
4]. Consider two retailers designated as
i and
j (where
). The two retailers are operated by a single firm. In the event of a stockout at one location, excess demand can be met through transshipment if another location has surplus inventory. We represent the random demand in the two locations as
and
. It is assumed that the demands are continuous random variables, each characterized by differentiable cumulative distribution functions
and
, as well as continuous probability density functions
and
.
A central planner decides the order quantity and for the two locations. The product has a unit price p and a unit purchase , and transshipment can be carried out at a cost of .
The transshipment quantity between the two retailers is the minimum of excess demand and demand shortage. It can be expressed as .
The central planner aims to maximize the per-period expected profit:
The expected profit comprises three components: the expected revenue generated from direct sales at both locations, minus the associated costs, and the additional revenue obtained through transshipment.
The equality (
1) follows from the observation that
and the fact that
and
.
Taking partial derivatives of
Q with respect to
, we obtain
and
where and
represent the distribution function and probability density function of
, respectively.
Following the analysis in [
4,
9], we claim that
is jointly concave in
, and the profit-maximizing central planner chooses optimal order quantity
satisfying the first order condition if the distributions of
and
are known:
4. Problem Formulation
In this section, we consider a T-period two-location inventory system with parametric demand distributions.
For each period , we denote as the demand distributions for the two locations and as their realizations. For ease of exposition, we introduce the random vector and its realization . Specifically, we assume is parameterized by , where is a compact subset of and represents the domain of . We denote this parameterized demand distribution as and its corresponding probability density function as .
We make the following assumptions about the demand distributions.
Assumption 1. The random vector is independently and identically distributed (i.i.d.) across time period t.
Assumption 2. The family of distributions is identifiable: the probability function for .
Assumption 3. The Fisher information matrix is bounded and positive definite. is defined bywhere is the likelihood function. Assumption 1 assumes the demand process is stationary. This assumption is common in inventory literature [
6,
34,
35]. Assumption 2 assumes the family of parametric demand distributions under consideration is identifiable, ensuring that each parameter vector uniquely determines the corresponding probability distribution. Identifiability is an important concept in mathematical statistics, and it has been extensively employed in the literature [
36]. Assumption 3 ensures the convergence of the maximum likelihood estimator (MLE). Notably, exponential family distributions inherently satisfy both Assumptions 2 and 3. Consequently, the analysis presented in our paper applies to a wide range of common parametric distribution families.
At the beginning of each period t, the central planner decides the order quantities for both outlets. The central planner has no knowledge of the true underlying demand distribution a priori but can rely on historical demand data and make adaptive inventory decisions based on the available information.
In this work, we consider only perishable products, implying there are no inventory carryovers across periods. Therefore, in each period
t, the central planner collects the profit
. We define
as the per-period expected profit function when the order quantity is
and when the demand parameter is
:
Let represent the sequence of filtrations generated by demand data and decisions accumulated up to time t. Precisely, is defined as the sigma algebra with . A feasible policy is a sequence of functions , which maps the historical information to current inventory decisions.
According to the analysis in
Section 3.2, if the underlying demand distribution is known, then there exists an order quantity
that maximizes the per-period profit, i.e.,
. In the system with perishable products, the optimal policy is a myopic policy
that sets the order quantity as
. We refer to
as the clairvoyant optimal solution and
as the clairvoyant optimal policy.
To measure the performance of data-driven policy
, we use regret as the criterion, which is defined as the expected total profit loss incurred by
when compared to the clairvoyant optimal policy
:
Regret is a widely adopted metric in the literature on data-driven inventory management [
6,
29,
37]. The metric quantifies the reduced profit caused by a lack of demand information. A lower regret value indicates a more effective policy. Thus, the central planner’s goal is to devise an algorithm that minimizes regret.
Finally, we make the following assumptions about the problem.
Assumption 4. The clairvoyant optimal order quantity is upper-bounded by : , .
Assumption 5. The profit function is Lipschitz continuous with respect to θ: there exists a constant such that for .
Assumption 6. is Lipschitz continuous with respect to θ: there exists a constant such that for , where is the optimal order quantity given the demand parameter θ.
Assumption 4 is mild. It claims the clairvoyant optimal order quantity is upper-bounded, which can be met with common demand distributions. This assumption facilitates our theoretical analysis. Assumption 5 assumes that the per-period profit function exhibits Lipschitz continuity with respect to demand parameters. This assumption suggests that an accurate estimation of the unknown demand parameter can lead to a close approximation of the actual per-period profit function. Assumption 6 assumes the optimal order quantity is Lipschitz continuous with respect to demand parameters. This assumption implies that minor changes in the parameter will not result in significant variations in the optimal order quantity. Similar assumptions can be found in [
5,
29].
While Assumption 6 is not an absolute necessity for our algorithm, it plays a pivotal rule in improving the regret bound. We remark that, although Assumption 6 is generally satisfied in most situations, there exist degenerate cases where it may not hold true by the following example.
Example 1. Consider a two-location system where one location’s demand is equal to zero and where the demand distribution in the other location is a Bernoulli distribution with a cumulative distribution function (CDF)where θ is the parameter under consideration. For a small enough , the slight change in θ from to will lead to a shift in its optimal order quantity, from 1 to 0. 5. Data-Driven Inventory Control Algorithms
Without any knowledge of the true underlying distribution of a priori, we aim to find a provably good, adaptive, data-driven inventory control policy that makes the total expected system profits close to the optimal strategy. In this section, we introduce the data-driven algorithm DD2LI (Data-Driven Two-Location Inventory Management Algorithm) and prove its theoretical performance.
Detailed steps of DD2LI are presented below.
DD2LI: Data-Driven Two-Location Inventory Management Algorithm
- Step 0.
(Initialization.) In period , order an initial quantity or select any other permissible value. Collect demand and initialize the demand dataset to be the available demand data up to decision time.
For each period , repeat the following steps:
- Step 1.
(Maximum Likelihood Estimation.) Given the past demand dataset
S, compute the maximum likelihood estimation of parameter
:
- Step 2.
(Order Quantity Optimization.) Using the estimated parameter from Step 1, compute , and order for the current period t.
- Step 3.
(Demand Data Update.) Observe the realized demand , and update the demand dataset S by adding the new data point: .
Throughout the algorithm, we maintain a set containing past demand data that can be used to make adaptive inventory decisions. In Step 1, given the available demand data, we compute the MLE of the unknown demand parameter constrained on the compact parameter set . In Step 2, we use the MLE estimator to obtain an empirically optimal order quantity and implement it. Lastly, in Step 3, we update the demand dataset.
Performance Analysis
In this subsection, we analyze the performance of our proposed algorithm. To facilitate our analysis, we initially introduce several lemmas that serve as useful tools in our investigation.
Lemma 1 is the direct result of Theorem 36.3 in [
36].
Lemma 1. Defining as the unconstrained maximum likelihood estimator given demand data :then there exists the positive constant , such that, for , It is well-known in mathematical statistics that maximum likelihood estimators are asymptotically normal under proper conditions. Additionally, Lemma 1 provides a further concentration inequality pertaining to MLE, which plays a vital role in performance analysis.
Corollary 1. For , the projection onto Θ
of the maximum likelihood estimator defined in (
4)
satisfies Proof. Note
. Replacing
with
in (
5) yields the result. □
Below, we introduce a lemma that is widely used in probability. Lemma 2 states the expectation of X can be obtained by the integral of its survival function.
Lemma 2. Suppose a continuous random variable is nonnegative; if , then Proof. We relegate the detailed proof of Lemma 2 to
Appendix A.1. □
Theorem 1 below presents one of the main results in our paper.
Theorem 1. With Assumption 6, there exists some positive constant such that, for ,where is the order quantity generated by algorithm DD2LI. Proof. First, we apply Taylor’s expansion to
at the maximizer
,
Since is maximized at , we have .
In addition, given Assumption 4, we claim that
is continuous and hence upper-bounded in a compact set. Therefore, we get the inequality that there exists a constant
such that
The second inequality follows from Assumption 6.
Next, we define an event
by
According to Corollary 1, we have
Now, we decompose
by event
:
The inequality (
8) follows from
and
. Here,
is the diameter of the set
. The inequality (9) is due to Lemma 2 and Corollary 1. By inequality (10), we claim the result is bounded by
.
Combining (
6) and (10) yields
Recall a well-known result in mathematical analysis that the sequence
converges to Euler’s constant as
, which indicates
. Hence, we claim the theorem holds. □
Theorem 1 states the regret bound is
if Assumption 6 holds. According to [
37], it will never be possible to find a policy with a regret smaller than
. Hence, our proposed algorithm can achieve the best possible regret bound.
In contrast, for cases where Assumption 6 does not hold, we have the following theorem:
Theorem 2. Without Assumption 6, there exists some positive constant such that, for ,where is the order quantity generated by algorithm DD2LI. Proof. First, we decompose the per-period regret
into three parts:
Since
is maximized at
, the second part in (
11) is
For the first and third parts, by Assumption 5 we have
Recall the definition of
in (
7). Now, we decompose
by event
:
Since
, the integral in (
14) can be bounded by
. By (15), we claim the result is bounded by
.
Combining (
11), (
12), (
13), and (15) yields
where the last inequality follows from the fact
. □
By comparing the proofs of Theorems 1 and 2, it is shown that Assumption 6 serves to strengthen the continuity between per-period profit function and the parameter (see the difference between (
6) and (
13)). Specifically, the inclusion of Assumption 6 allows for a more precise estimation of the per-period profit function compared to scenarios where this assumption is not applicable.
In addition, we remark on the analogy between Assumption 6 in our paper and Assumption (iii) in [
37]. As discussed in [
38], the absence of a key assumption about the optimal quantity and the parameter will lead the cumulative regret to change from
to
.
Overall, in this section, we have proposed the algorithm DD2LI and proved its regret bound. The algorithm’s regret bound is at least under proper conditions. Furthermore, with a stronger assumption about the optimal quantity’s continuity with respect to the parameter, we are able to further enhance the regret bound to . These regret bounds demonstrate that our algorithm is close to the optimal strategy on average when the time periods are large enough.
6. Numerical Experiments
In this section, we conduct numerical experiments for two scenarios. Following [
39], we measure the performance of a learning algorithm by the percentage of relative regret defined as
In both scenarios, we set unit price , unit cost , and unit transshipment cost .
In the first scenario, we consider that the demand distributions in the two locations follow exponential distributions and . Hence, the demand parameter .
Given the demand data up to period
t, the parameters
can be estimated by
For two parameter sets, we conduct
runs and compute the average. The results are shown in
Figure 1 and
Figure 2.
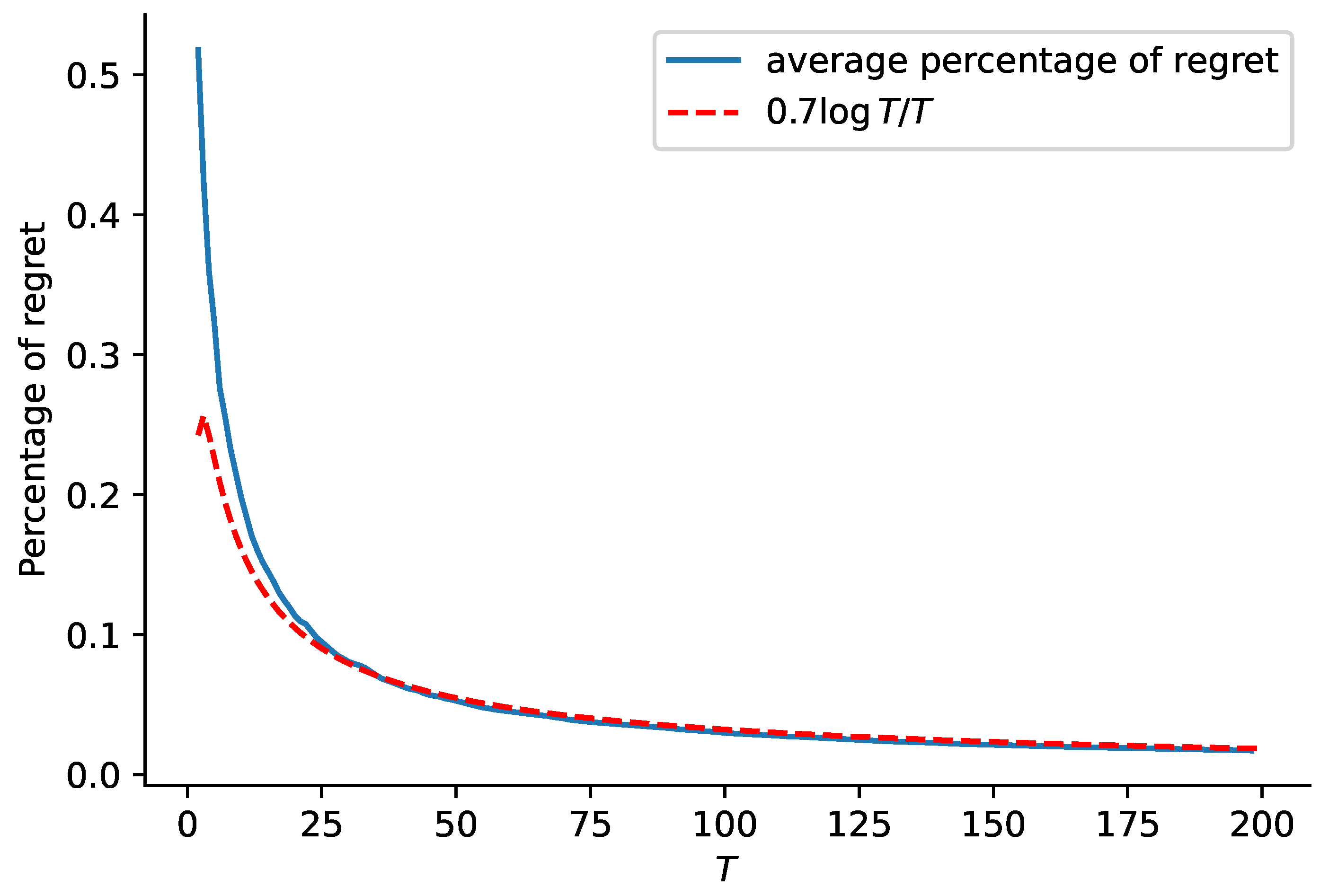
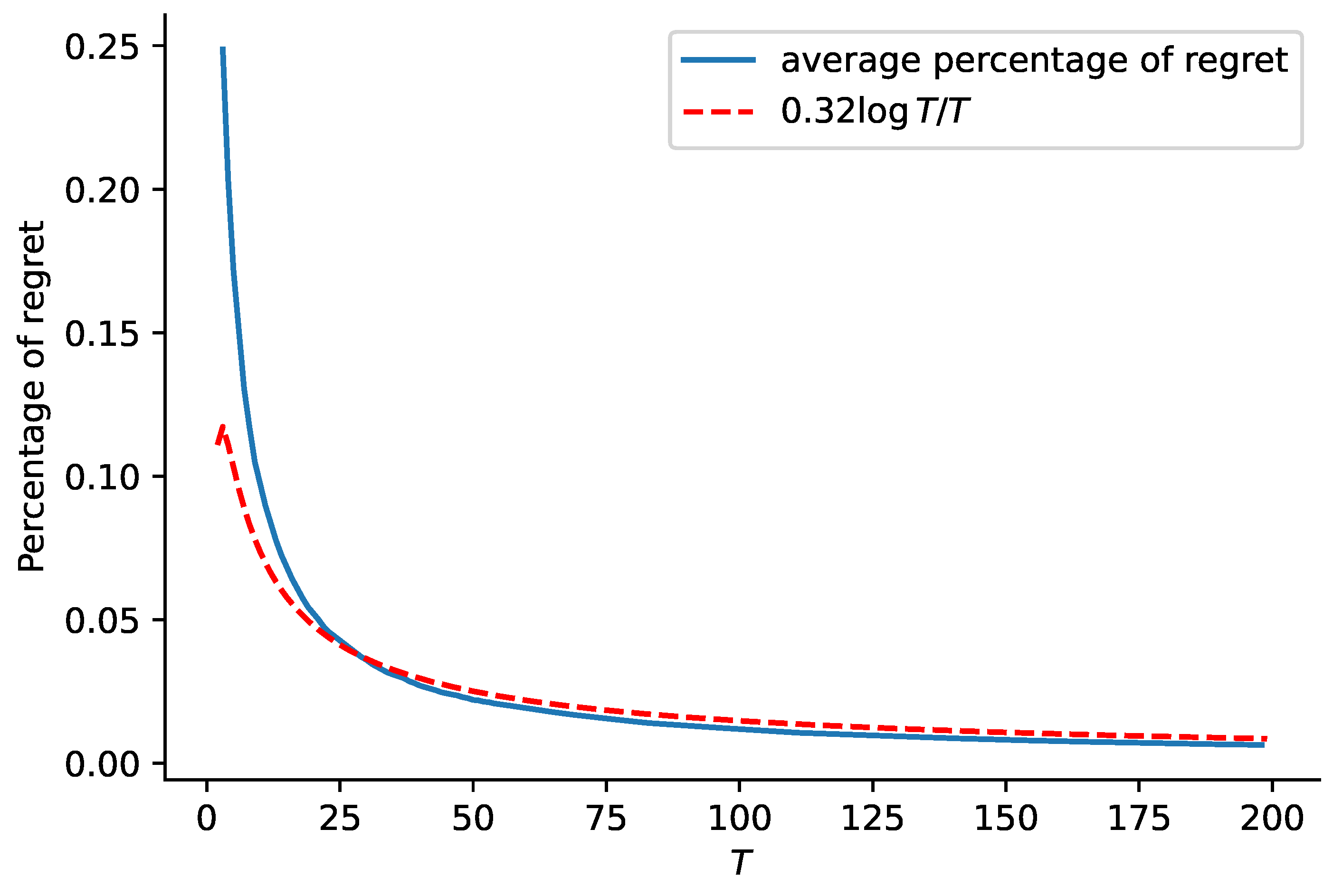
The blue curves in
Figure 1 and
Figure 2 show the average percentage of regret for
and
, respectively, while the red dashed curves in the two figures represent function
and
, respectively. This comparison shows that the regret of our proposed algorithm is close to the rate of
.
In the second scenario, we consider that the demand distributions in the two locations follow a multivariate normal distribution with mean vector and covariance matrix . Hence, the parameter . Note that, in this scenario, the demand distributions in the two locations may be correlated.
Given the demand data up to period
, the parameters can be estimated by
For two parameter sets, we conduct
runs and compute the average. The results are shown in
Figure 3 and
Figure 4.
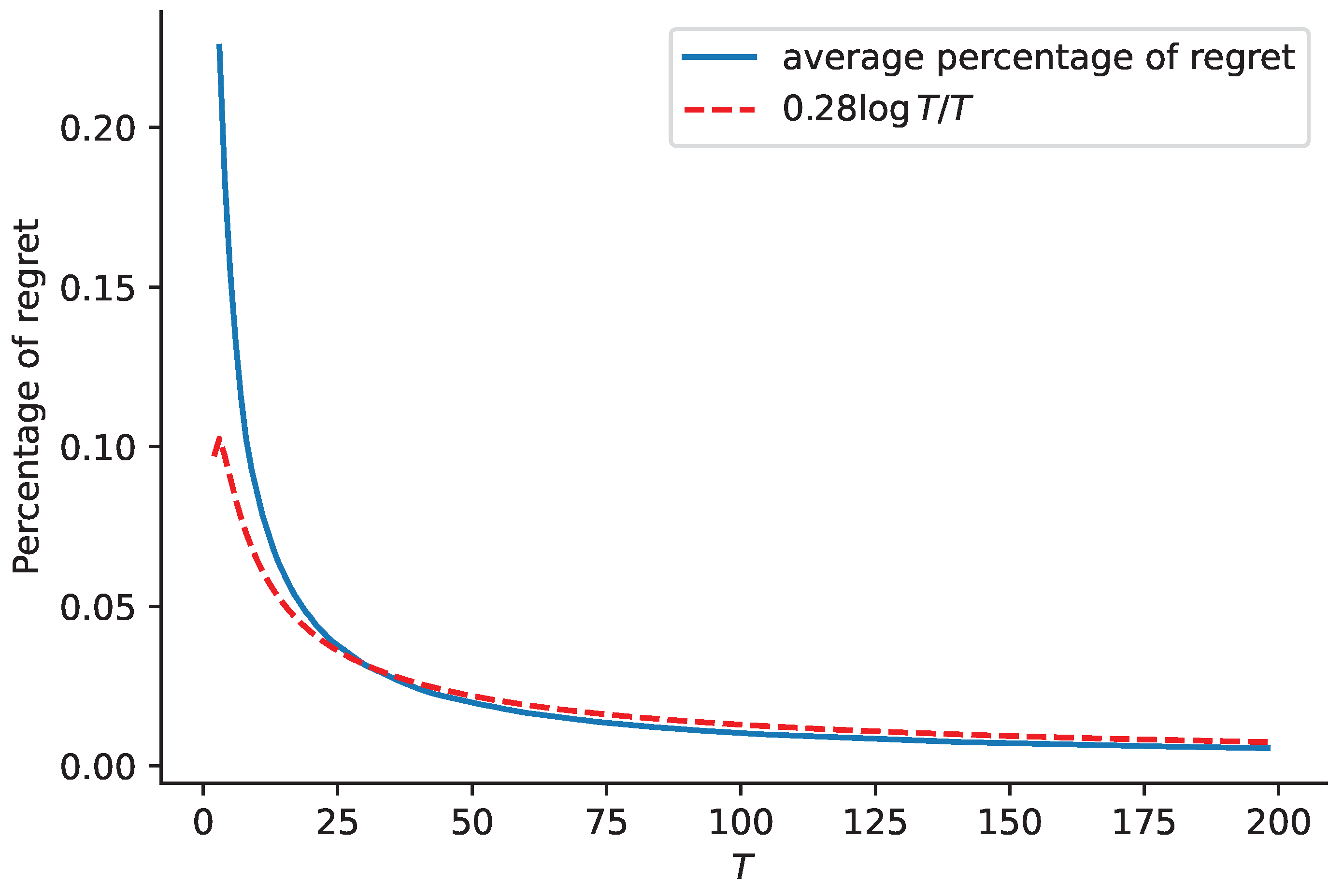
The blue curves in
Figure 1 and
Figure 2 show average percentage of regret for
and
, respectively, while the red dashed curves in the two figures represent functions
and
, respectively. This comparison shows that the regret of our proposed algorithm is close to the rate of
, and it is also applicable to correlated demands.
Based on the outcomes of four experiments, we can also conclude that Assumption 6 holds when demand follows exponential distributions or Gaussian distributions.
7. Conclusions
When a firm operates multiple stores, to better fulfill customer demand and make more profit, transshipment can be carried out if one location has excess inventory while another is experiencing a stockout. Despite the extensive research on transshipment between newsvendors, most assume the demand distribution is known a priori.
In this work, we introduce a data-driven inventory management algorithm for a multiperiod, two-location inventory system with perishable products and unknown demand distributions, which are assumed to follow a family of parametric distributions. The proposed algorithm, called DD2LI, uses past demand data to make adaptive inventory decisions. By using maximum likelihood estimation to estimate the unknown parameters, the algorithm determines the order quantity based on these estimations. We successfully derive the regret bound of the proposed algorithm under proper assumptions, which shows the algorithm is close to the optimal strategy on average. Additionally, we emphasize the assumption that the continuity of optimal order quantity with respect to parameters plays a key role in a tighter regret bound. Finally, to validate the effectiveness of our proposed algorithm, we conduct numerical experiments in two distinct scenarios.
There are several future research directions. First, future studies can design algorithms for two-location inventory systems when demand data are censored. Note that the demand censoring may be more intricate in two-location inventory systems with transshipment than in the single-location newsvendor problem. Second, while our work considers the stationary demand process, it is worth exploring algorithms that handle shifting demand. Third, our work only considers two locations, which restrict its use in practice. Future research can try to design algorithms for more complex inventory networks.




{kind=link}
{kind=link}
{kind=link}
{kind=link}