
A Slacks-Based Measure Model for Computing Game Cross-Efficiency


Abstract
1. Introduction
2. Literature Review
2.1. DEA Model for Cross-Efficiency
2.2. DEA Model for Game Cross-Efficiency
3. Model Development
3.1. SBM Cross-Efficiency Model
3.2. A Non-Oriented SBM Game Cross-Efficiency Model with Undesirable Outputs
- Calculate the frontier surface set Zd by using Equation (6).
- Substitute into Equations (8) and (9) to calculate ( and will be the solution of Equation (7)).
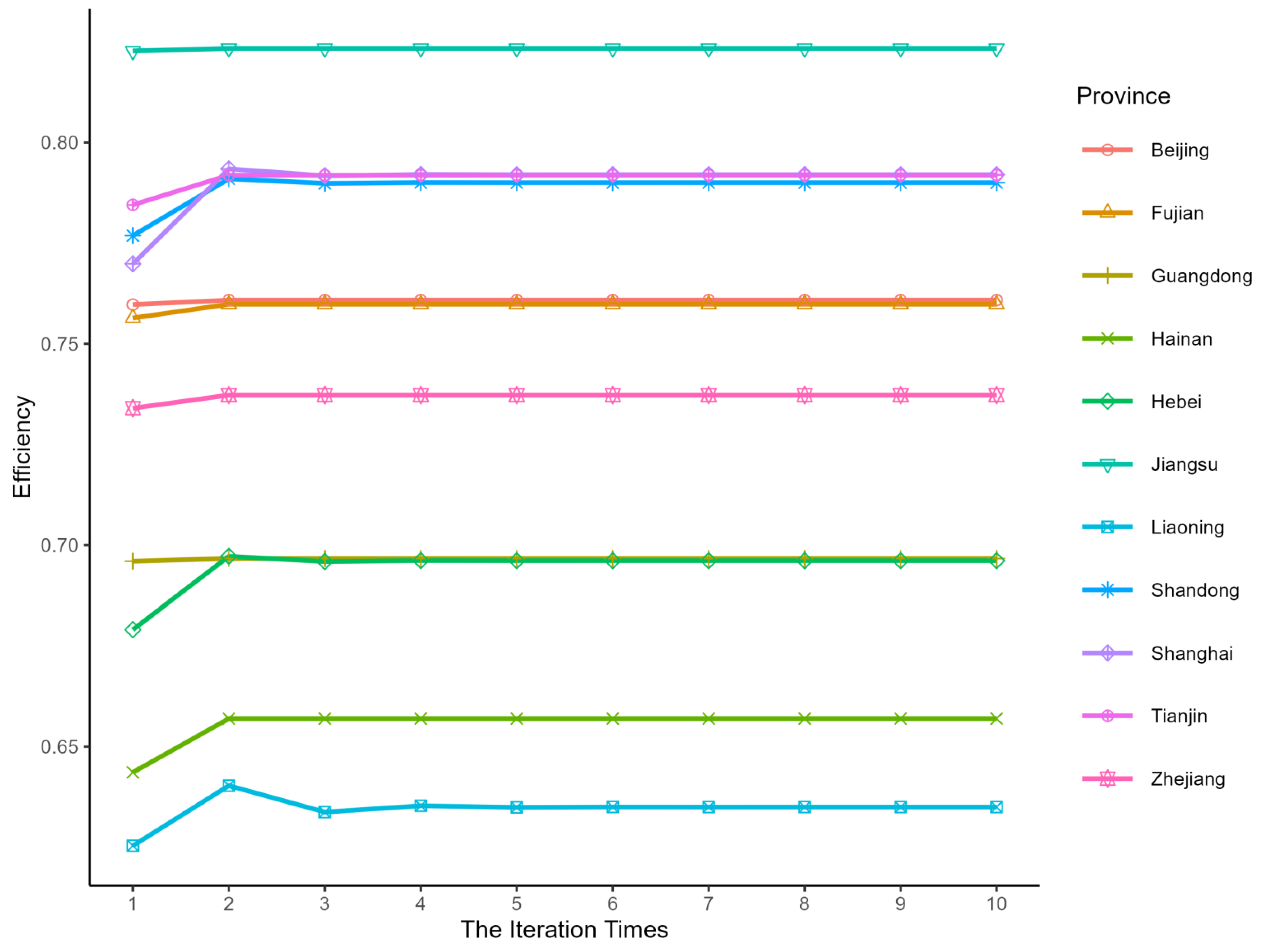
- Assume that is an exceptionally small specific positive value, if the existence of holds, then return to step 2 to continue the cyclic computation; if for all decision units the all hold, then stop the circular computation and convergence is achieved for the final average game cross-efficiency value. In general, takes the value of 0.001.
3.3. SBM Game Cross-Efficiency Models of Input-Oriented and Output-Oriented with Undesirable Outputs
3.3.1. Input-Oriented Model
3.3.2. Output-Oriented Model
3.4. Model Convergence Proof
- All data points of lie between and .
- All points with even t are non-increasing.
- All points with odd t are non-decreasing.
- (1)
- Equations (8) and (9) can be expressed as , meaning is a function of and the data of DMUj. For , it affects the feasible region and . When t and j remain constant, the larger is, the larger the feasible region becomes. A larger feasible region results in larger slack values obtained from the solution. Larger slack values lead to a smaller . Hence, we can conclude that the larger is, the smaller becomes, and vice versa; the smaller is, the larger becomes. Since , when , is at its minimum value. When , the solution of Equation (7) is a feasible solution for Equation (8), which is the cross-efficiency value . Therefore, for all t > 1, holds true.
- (2)
- First, let us observe the relationship between . Based on (1), we know that is the minimum value, and it follows that is the maximum value. Since , it can be deduced that . Further, as , we can infer that . Therefore, for all j, we have .
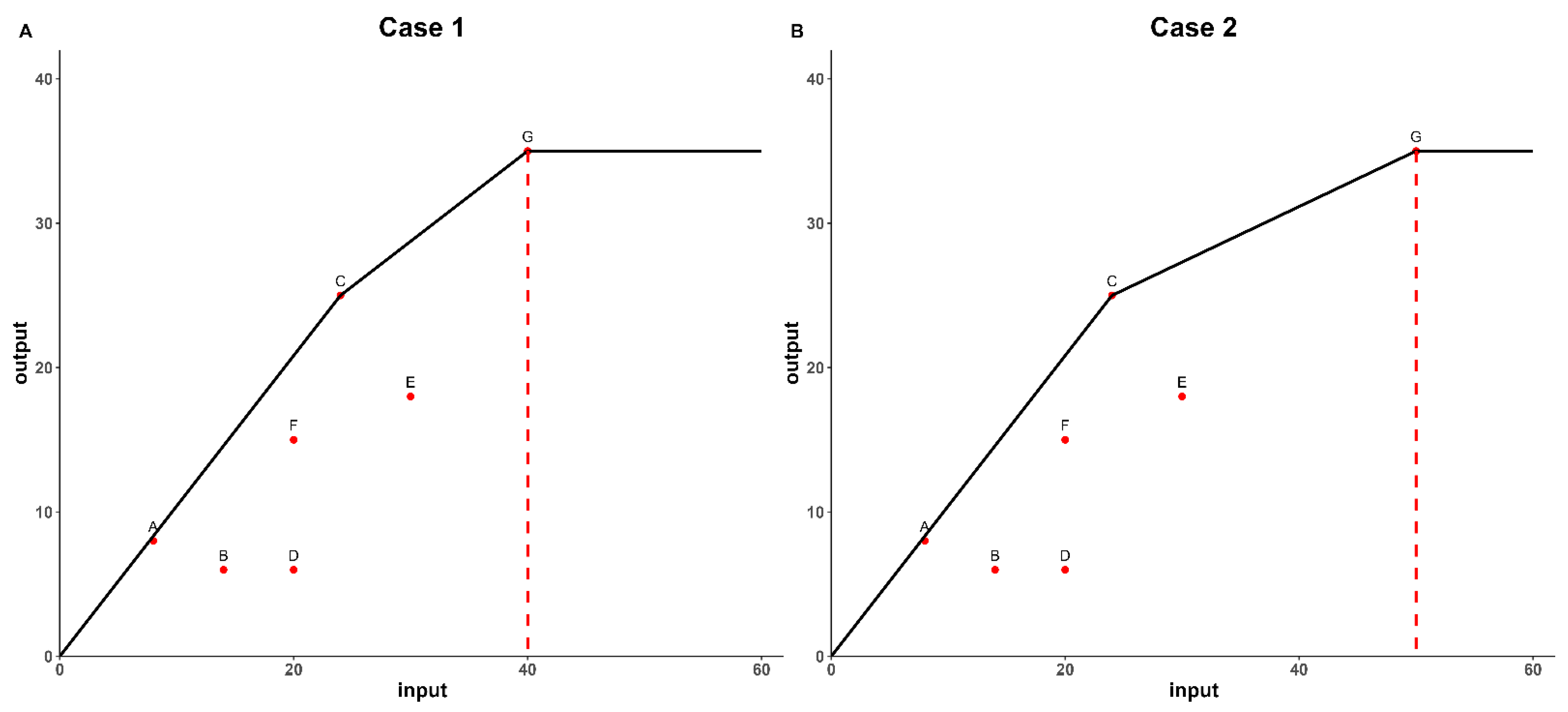
4. Numerical Example and Case Study
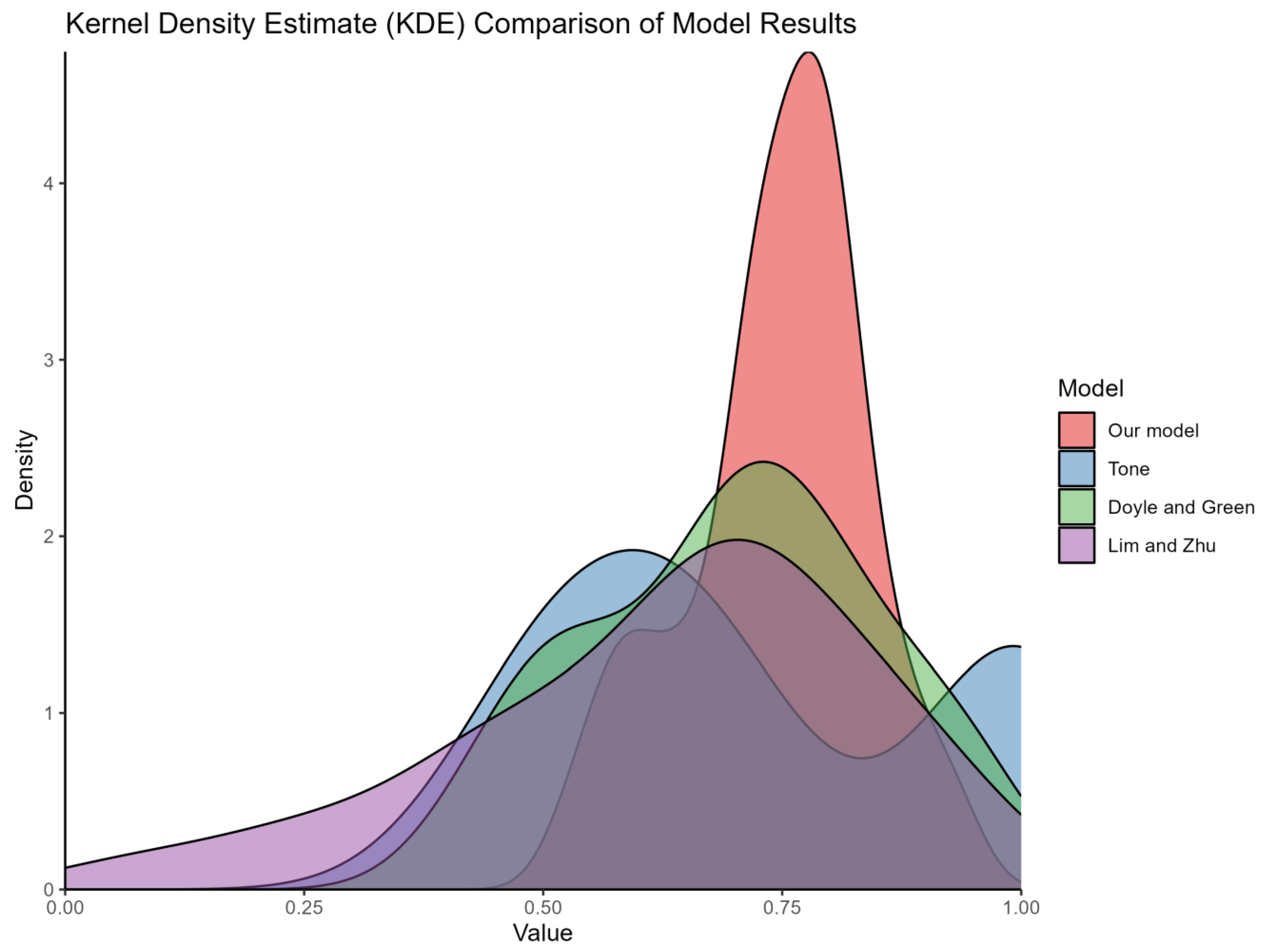
4.1. Model Comparison
4.2. Summary
5. Empirical Analysis and Discussion
5.1. Data
- Total industrial output value of industries above a designated size (TIOV). The industrial output data mainly come from the “China Industrial Statistical Yearbook” and the “China Urban Statistical Yearbook”. The data in the “China Industrial Statistical Yearbook” are only available up to 2011, so we supplement them with the aggregated data from various prefecture-level cities in the “China Urban Statistical Yearbook” and data from the statistical yearbooks of each province. The total output value data are deflated using the industrial product factory price index in the “China Price Statistical Yearbook” (with 2010 as the base year) to obtain constant-price data. The data are in units of 100 million yuan (CNY).
- CO2. Data on carbon dioxide (CO2) emissions have been obtained from CEADs’ provincial emissions inventory, which includes emissions by industry across 30 provinces and municipalities ranging from 2005 to 2019. These data have been calculated by scholars [30,31,32,33]. Therefore, they possess a high level of accuracy. The data for each province are determined by the summation of individual subsectors in million tons.
- Capital Stock (K). Capital stock data come from the net fixed capital value in the “China Industrial Statistical Yearbook”, which has already taken depreciation and current additions into account, so no further adjustment is needed. Capital stock data are deflated using the industrial product purchase price index from the “China Price Statistical Yearbook” (with 2010 as the base year) to obtain constant price data. The data are in units of 100 million yuan (CNY).
- Labor force (L). The labor force data are sourced from the average number of workers employed in the China Industrial Statistical Yearbook, with data missing for 2012. Missing data were added by interpolation. The unit of measurement is in ten thousand units.
- Energy (E). Energy consumption data have been obtained from CEADs’ provincial energy inventory scaling across 30 provinces and cities from 2010 to 2019. The data are categorized by industry and type of energy consumption (coal, gasoline, kerosene, diesel, natural gas, etc.). The standard coal consumption for each province is determined by converting the reference coefficients of various energy sources into standard coal by the National Bureau of Statistics. The total consumption is given in million tons.
5.2. Convergence Process
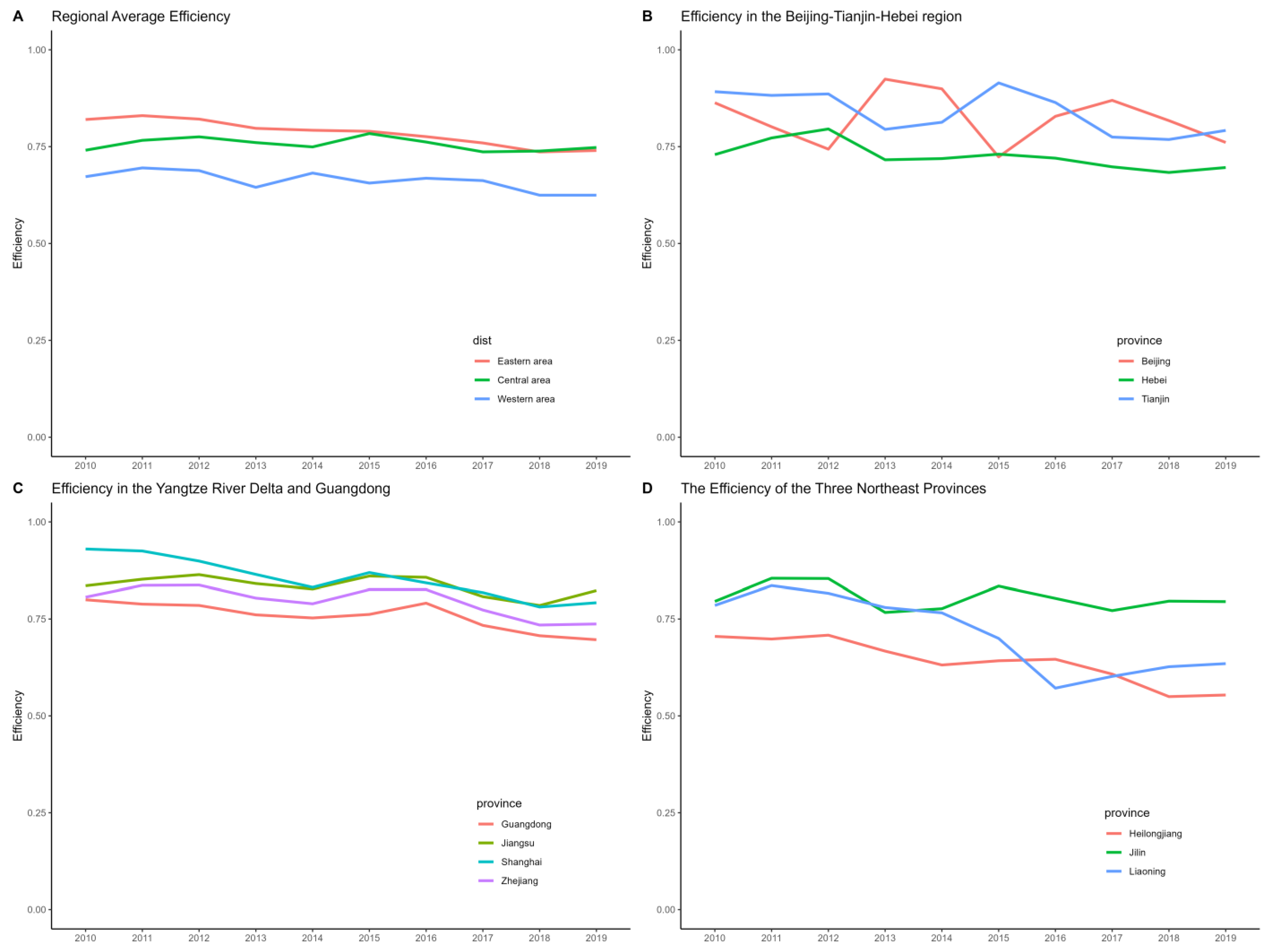
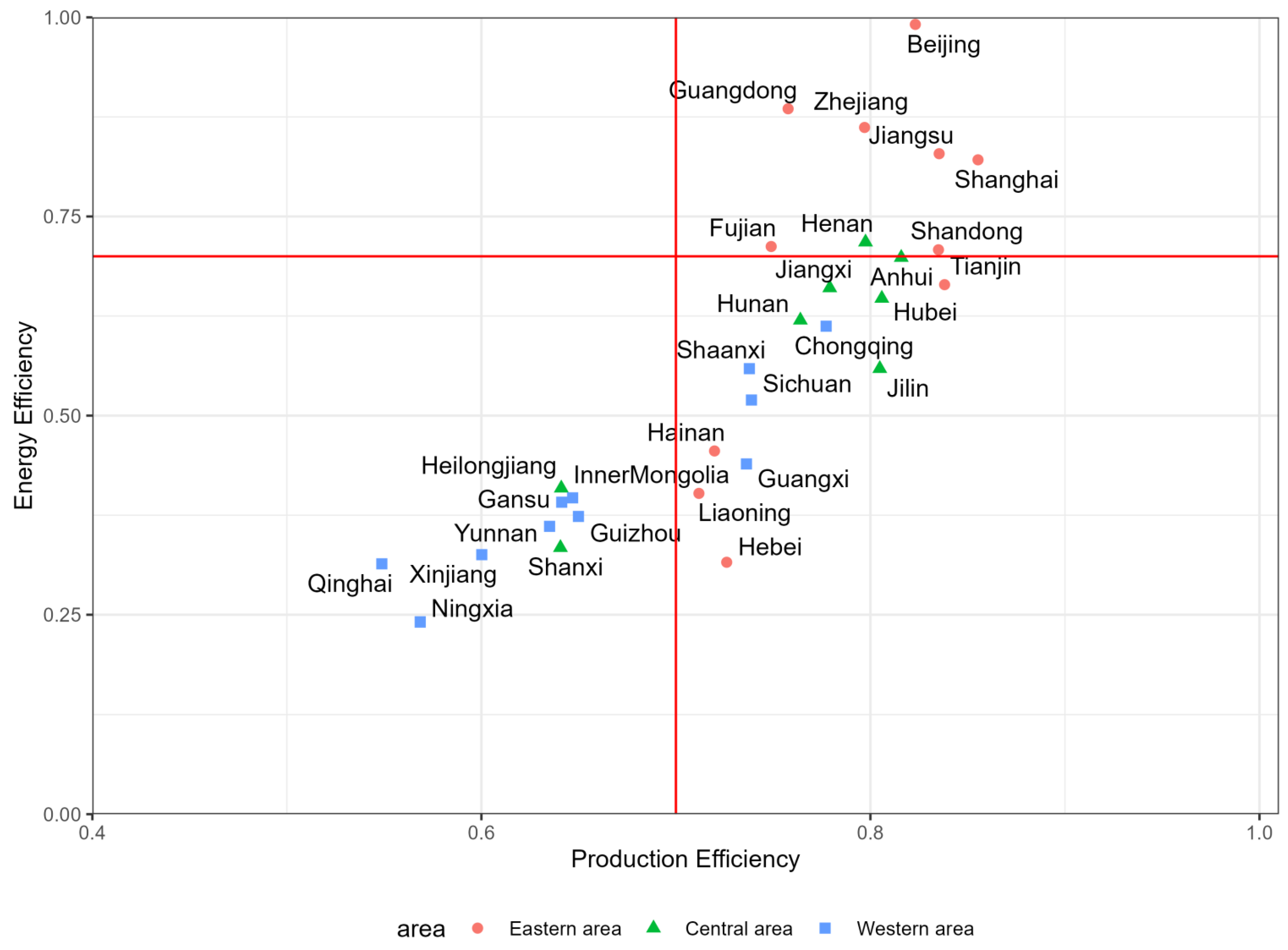
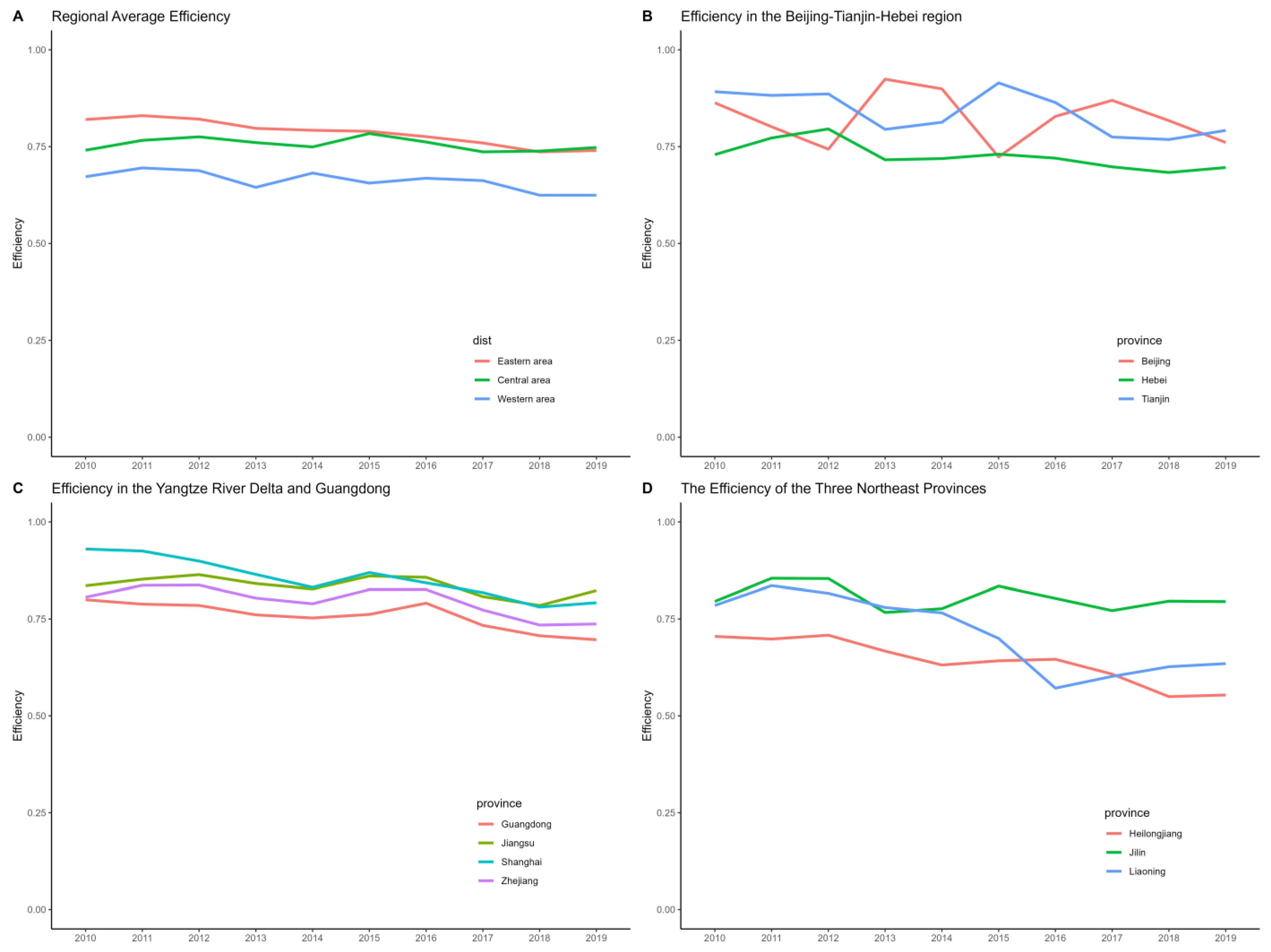
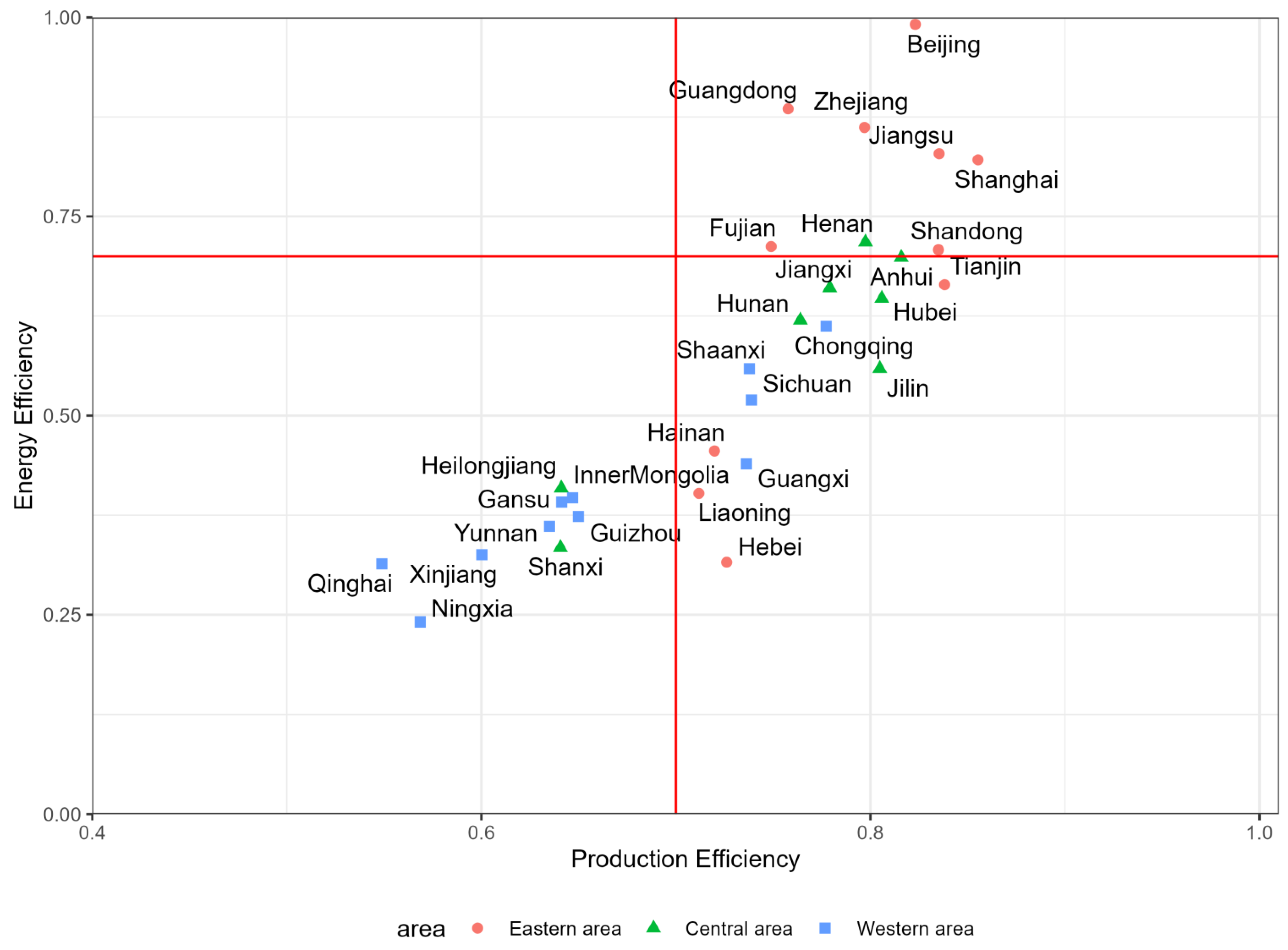
5.3. Analysis of Production Efficiency and Total Factor Energy Efficiency among Provinces in China
5.3.1. The Analysis of Production Efficiency
- Developed Infrastructure and Industrial Clusters: Cities in the eastern region, such as Beijing, Tianjin, and Shanghai, not only possess developed infrastructure but have also formed efficient industrial clusters. These clusters facilitate the effective flow of information, technology, and resources, further enhancing production efficiency.
- Policy Support: Some regions have benefited from national policy support and measures to improve the environment, contributing to efficiency gains.
- Differences in Economic Development Levels: Coastal provinces in the eastern region, especially Jiangsu, Shanghai, and Zhejiang, exhibit the highest production efficiency. Due to their open economic policies, advanced industrial bases, and convenient transportation and logistics conditions, these areas attract substantial domestic and foreign investment. This, in turn, promotes the development of high-tech industries and the improvement of production efficiency.
- Weak Industrial Base: Western regions, such as Gansu, Guizhou, and Ningxia, have a weaker industrial base, leading to generally lower production efficiency. The lower level of industrialization and technological base restricts the improvement of production efficiency.
- Geographical and Transportation Limitations: The complex terrain and inconvenient transportation in the western regions result in higher logistics costs, which also limit production efficiency.
- Shortage of Talent: The issues of low population density and a shortage of high-skilled industrial labor are particularly pronounced in the western regions, affecting the production efficiency and technological innovation capabilities of factories.
5.3.2. The Analysis on Total Factor Energy Efficiency
5.4. Robustness Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Doyle, J.; Green, R. Efficiency and Cross-Efficiency in DEA: Derivations, Meanings and Uses. J. Oper. Res. Soc. 1994, 45, 567–578. [Google Scholar] [CrossRef]
- Kao, C.; Liu, S.-T. A Slacks-Based Measure Model for Calculating Cross Efficiency in Data Envelopment Analysis. Omega 2020, 95, 102192. [Google Scholar] [CrossRef]
- Liang, L.; Wu, J.; Cook, W.D.; Zhu, J. The DEA Game Cross-Efficiency Model and Its Nash Equilibrium. Oper. Res. 2008, 56, 1278–1288. [Google Scholar] [CrossRef]
- Charnes, A.; Cooper, W.W.; Rhodes, E. Measuring the Efficiency of Decision Making Units. Eur. J. Oper. Res. 1978, 2, 429–444. [Google Scholar] [CrossRef]
- Sexton, T.R.; Silkman, R.H.; Hogan, A.J. Data Envelopment Analysis: Critique and Extensions. New Dir. Program Eval. 1986, 1986, 73–105. [Google Scholar] [CrossRef]
- Wu, J.; Sun, J.; Liang, L. Cross Efficiency Evaluation Method Based on Weight-Balanced Data Envelopment Analysis Model. Comput. Ind. Eng. 2012, 63, 513–519. [Google Scholar] [CrossRef]
- Wang, Y.-M.; Chin, K.-S.; Wang, S. DEA Models for Minimizing Weight Disparity in Cross-Efficiency Evaluation. J. Oper. Res. Soc. 2012, 63, 1079–1088. [Google Scholar] [CrossRef]
- Wang, Y.-M.; Chin, K.-S. The Use of OWA Operator Weights for Cross-Efficiency Aggregation. Omega 2011, 39, 493–503. [Google Scholar] [CrossRef]
- Wu, J.; Chu, J.; Sun, J.; Zhu, Q.; Liang, L. Extended Secondary Goal Models for Weights Selection in DEA Cross-Efficiency Evaluation. Comput. Ind. Eng. 2016, 93, 143–151. [Google Scholar] [CrossRef]
- Carrillo, M.; Jorge, J.M. An Alternative Neutral Approach for Cross-Efficiency Evaluation. Comput. Ind. Eng. 2018, 120, 137–145. [Google Scholar] [CrossRef]
- Kao, C.; Liu, S.-T. Cross Efficiency Measurement and Decomposition in Two Basic Network Systems. Omega 2019, 83, 70–79. [Google Scholar] [CrossRef]
- Liu, H.; Song, Y.; Yang, G. Cross-Efficiency Evaluation in Data Envelopment Analysis Based on Prospect Theory. Eur. J. Oper. Res. 2019, 273, 364–375. [Google Scholar] [CrossRef]
- Lim, S.; Zhu, J. DEA Cross-Efficiency Evaluation under Variable Returns to Scale. J. Oper. Res. Soc. 2015, 66, 476–487. [Google Scholar] [CrossRef]
- Lim, S. Minimax and Maximin Formulations of Cross-Efficiency in DEA. Comput. Ind. Eng. 2012, 62, 726–731. [Google Scholar] [CrossRef]
- Lin, R. Cross-Efficiency Evaluation Capable of Dealing with Negative Data: A Directional Distance Function Based Approach. J. Oper. Res. Soc. 2020, 71, 505–516. [Google Scholar] [CrossRef]
- Portela, M.C.A.S.; Thanassoulis, E.; Simpson, G. Negative Data in DEA: A Directional Distance Approach Applied to Bank Branches. J. Oper. Res. Soc. 2004, 55, 1111–1121. [Google Scholar] [CrossRef]
- Örkcü, H.H.; Özsoy, V.S.; Örkcü, M.; Bal, H. A Neutral Cross Efficiency Approach for Basic Two Stage Production Systems. Expert Syst. Appl. 2019, 125, 333–344. [Google Scholar] [CrossRef]
- Banker, R.D. A Game Theoretic Approach to Measuring Efficiency. Eur. J. Oper. Res. 1980, 5, 262–266. [Google Scholar] [CrossRef]
- Hao, G.; Wang, S.; Chen, H.; Zhang, W.; Jiang, S.; Li, L. Optimum Energy Efficiency in Lunar In-Situ Water Ice Utilization. Acta Astronaut. 2023, 207, 307–315. [Google Scholar] [CrossRef]
- Nakabayashi, K.; Tone, K. Egoist’s Dilemma: A DEA Game. Omega 2006, 34, 135–148. [Google Scholar] [CrossRef]
- Xie, B.-C.; Gao, J.; Zhang, S.; Pang, R.-Z.; Zhang, Z. The Environmental Efficiency Analysis of China’s Power Generation Sector Based on Game Cross-Efficiency Approach. Struct. Chang. Econ. Dyn. 2018, 46, 126–135. [Google Scholar] [CrossRef]
- Chen, W.; Wu, F.; Geng, W.; Yu, G. Carbon Emissions in China’s Industrial Sectors. Resour. Conserv. Recycl. 2017, 117, 264–273. [Google Scholar] [CrossRef]
- Yang, Z.; Wei, X. The Measurement and Influences of China’s Urban Total Factor Energy Efficiency under Environmental Pollution: Based on the Game Cross-Efficiency DEA. J. Clean. Prod. 2019, 209, 439–450. [Google Scholar] [CrossRef]
- Wu, J.; Liang, L.; Chen, Y. DEA Game Cross-Efficiency Approach to Olympic Rankings. Omega 2009, 37, 909–918. [Google Scholar] [CrossRef]
- Li, F.; Zhu, Q.; Liang, L. Allocating a Fixed Cost Based on a DEA-Game Cross Efficiency Approach. Expert Syst. Appl. 2018, 96, 196–207. [Google Scholar] [CrossRef]
- Li, Y.; Li, F.; Emrouznejad, A.; Liang, L.; Xie, Q. Allocating the Fixed Cost: An Approach Based on Data Envelopment Analysis and Cooperative Game. Ann. Oper. Res. 2019, 274, 373–394. [Google Scholar] [CrossRef]
- Wang, G.; Chao, Y.; Lin, J.; Chen, Z. Evolutionary Game Theoretic Study on the Coordinated Development of Solar Power and Coal-Fired Thermal Power under the Background of Carbon Neutral. Energy Rep. 2021, 7, 7716–7727. [Google Scholar] [CrossRef]
- Tone, K. A Slacks-Based Measure of Efficiency in Data Envelopment Analysis. Eur. J. Oper. Res. 2001, 130, 498–509. [Google Scholar] [CrossRef]
- Li, S.; Diao, H.; Wang, L.; Li, L. A Complete Total-Factor CO2 Emissions Efficiency Measure and “2030•60 CO2 Emissions Targets” for Shandong Province, China. J. Clean. Prod. 2022, 360, 132230. [Google Scholar] [CrossRef]
- Guan, Y.; Shan, Y.; Huang, Q.; Chen, H.; Wang, D.; Hubacek, K. Assessment to China’s Recent Emission Pattern Shifts. Earths Future 2021, 9, e2021EF002241. [Google Scholar] [CrossRef]
- Shan, Y.; Liu, J.; Liu, Z.; Xu, X.; Shao, S.; Wang, P.; Guan, D. New Provincial CO2 Emission Inventories in China Based on Apparent Energy Consumption Data and Updated Emission Factors. Appl. Energy 2016, 184, 742–750. [Google Scholar] [CrossRef]
- Shan, Y.; Guan, D.; Zheng, H.; Ou, J.; Li, Y.; Meng, J.; Mi, Z.; Liu, Z.; Zhang, Q. China CO2 Emission Accounts 1997–2015. Sci. Data 2018, 5, 170201. [Google Scholar] [CrossRef] [PubMed]
- Shan, Y.; Huang, Q.; Guan, D.; Hubacek, K. China CO2 Emission Accounts 2016–2017. Sci. Data 2020, 7, 54. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.-L.; Wang, S.-C. Total-Factor Energy Efficiency of Regions in China. Energy Policy 2006, 34, 3206–3217. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case 1 Data | Case 2 Data | ||||
|---|---|---|---|---|---|
| DMU | Input | Output | DMU | Input | Output |
| A | 8 | 8 | A | 8 | 8 |
| B | 14 | 6 | B | 14 | 6 |
| C | 24 | 25 | C | 24 | 25 |
| D | 20 | 6 | D | 20 | 6 |
| E | 30 | 18 | E | 30 | 18 |
| F | 20 | 15 | F | 20 | 15 |
| G | 40 | 35 | G | 50 * | 35 |
| DMU | Traditional SBM Non-Oriented Model | Game Cross-Efficiency SBM Non-Oriented Model | ||||||
|---|---|---|---|---|---|---|---|---|
| Case1 | Rank1 | Case2 | Rank2 | Case1 | Rank1 | Case2 | Rank2 | |
| A | 1.0000 | 1 | 1.0000 | 1 | 0.9943 | 2 | 0.9943 | 2 |
| B | 0.4174 | 6 | 0.4174 | 6 | 0.6978 | 6 | 0.6823 | 6 |
| C | 1.0000 | 1 | 1.0000 | 1 | 1.0000 | 1 | 1.0000 | 1 |
| D | 0.2892 | 7 | 0.2892 | 7 | 0.5742 | 7 | 0.5633 | 7 |
| E | 0.5760 | 5 | 0.5760 | 5 | 0.8420 | 5 | 0.8315 | 5 |
| F | 0.7229 | 4 | 0.7229 | 4 | 0.9096 | 4 | 0.9010 | 3 |
| G | 1.0000 | 1 | 1.0000 | 1 | 0.9600 | 3 | 0.8790 | 4 |
| DMU | SBM Non-Oriented Model | SBM Input-Oriented Model | ||||||
|---|---|---|---|---|---|---|---|---|
| Efficiency | Rank | Sx | Sy | Efficiency | Rank | Sx | Sy | |
| A | 0.9943 | 2 | 0.0457 | 0 | 0.9943 | 2 | 0.0457 | 0 |
| B | 0.6978 | 6 | 0 | 3.7057 | 0.5856 | 6 | 5.8014 | 0 |
| C | 1.0000 | 1 | 0 | 0.0000 | 1.0000 | 1 | 0.0000 | 0 |
| D | 0.5742 | 7 | 0 | 7.1306 | 0.4137 | 7 | 11.7262 | 0 |
| E | 0.8420 | 5 | 0 | 4.6112 | 0.7591 | 5 | 7.2261 | 0 |
| F | 0.9096 | 4 | 0 | 1.7884 | 0.8775 | 4 | 2.4503 | 0 |
| G | 0.9600 | 3 | 0 | 1.6340 | 0.9539 | 3 | 1.8424 | 0 |
| Vars | n | Mean | SD | Median | Min | Max | Skew | Kurtosis |
|---|---|---|---|---|---|---|---|---|
| TIOV | 300 | 34461.0472 | 35,150.7632 | 23,527.1382 | 1381.2500 | 169,739.0351 | 1.9390 | 3.3650 |
| CO2 | 300 | 27,846.2948 | 19,434.1233 | 21,566.4970 | 1891.5399 | 84,407.9331 | 1.0736 | 0.4206 |
| K | 300 | 10,549.0162 | 7914.5074 | 8517.8735 | 557.9705 | 43,839.6454 | 1.7075 | 3.2460 |
| L | 300 | 306.7343 | 327.3460 | 187.5600 | 10.0000 | 1568.0000 | 1.9664 | 3.5347 |
| E | 300 | 7461.0219 | 5254.2637 | 5787.4079 | 539.1105 | 27,451.7985 | 1.3925 | 1.7390 |
| Area | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | Average | Rank |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Eastern | 0.8252 | 0.8269 | 0.8126 | 0.8082 | 0.8023 | 0.7803 | 0.7761 | 0.7682 | 0.7439 | 0.7421 | 0.7886 | |
| Beijing | 0.8632 | 0.8013 | 0.7436 | 0.9242 | 0.8992 | 0.7236 | 0.8283 | 0.8695 | 0.8172 | 0.7609 | 0.8231 | 5 |
| Fujian | 0.7247 | 0.7365 | 0.7465 | 0.7709 | 0.7431 | 0.7622 | 0.7524 | 0.7515 | 0.7422 | 0.7598 | 0.7490 | 15 |
| Guangdong | 0.7997 | 0.7884 | 0.7851 | 0.7608 | 0.7528 | 0.7619 | 0.7910 | 0.7336 | 0.7069 | 0.6967 | 0.7577 | 14 |
| Hainan | 0.8384 | 0.8613 | 0.8109 | 0.6527 | 0.7391 | 0.6495 | 0.6373 | 0.7082 | 0.6441 | 0.6570 | 0.7198 | 20 |
| Hebei | 0.7295 | 0.7725 | 0.7956 | 0.7161 | 0.7192 | 0.7305 | 0.7203 | 0.6979 | 0.6834 | 0.6961 | 0.7261 | 19 |
| Jiangsu | 0.8353 | 0.8523 | 0.8640 | 0.8411 | 0.8273 | 0.8604 | 0.8571 | 0.8077 | 0.7849 | 0.8234 | 0.8353 | 3 |
| Liaoning | 0.7851 | 0.8358 | 0.8162 | 0.7797 | 0.7659 | 0.7000 | 0.5717 | 0.6020 | 0.6269 | 0.6349 | 0.7118 | 21 |
| Shandong | 0.8161 | 0.8390 | 0.8483 | 0.8611 | 0.8352 | 0.8880 | 0.8436 | 0.8180 | 0.8106 | 0.7900 | 0.8350 | 4 |
| Shanghai | 0.9300 | 0.9249 | 0.8989 | 0.8646 | 0.8314 | 0.8693 | 0.8429 | 0.8181 | 0.7810 | 0.7920 | 0.8553 | 1 |
| Tianjin | 0.8919 | 0.8823 | 0.8861 | 0.7946 | 0.8129 | 0.9145 | 0.8639 | 0.7747 | 0.7684 | 0.7919 | 0.8381 | 2 |
| Zhejiang | 0.8632 | 0.8013 | 0.7436 | 0.9242 | 0.8992 | 0.7236 | 0.8283 | 0.8695 | 0.8172 | 0.7609 | 0.8231 | 5 |
| Central | 0.7408 | 0.7663 | 0.7753 | 0.7605 | 0.7493 | 0.7838 | 0.7620 | 0.7365 | 0.7386 | 0.7478 | 0.7561 | |
| Anhui | 0.8017 | 0.8411 | 0.8543 | 0.8255 | 0.8147 | 0.8413 | 0.7944 | 0.7910 | 0.7947 | 0.7998 | 0.8158 | 6 |
| Henan | 0.7394 | 0.7795 | 0.8007 | 0.8133 | 0.8039 | 0.8416 | 0.8272 | 0.7850 | 0.7867 | 0.7975 | 0.7975 | 9 |
| Heilongjiang | 0.7052 | 0.6985 | 0.7083 | 0.6672 | 0.6314 | 0.6423 | 0.6462 | 0.6079 | 0.5498 | 0.5539 | 0.6411 | 25 |
| Hubei | 0.7735 | 0.8186 | 0.7974 | 0.8308 | 0.7972 | 0.8447 | 0.8024 | 0.7912 | 0.7984 | 0.8045 | 0.8059 | 7 |
| Hunan | 0.7462 | 0.7634 | 0.7693 | 0.7788 | 0.7597 | 0.7887 | 0.7437 | 0.7324 | 0.7669 | 0.7909 | 0.7640 | 13 |
| Jilin | 0.7955 | 0.8547 | 0.8540 | 0.7669 | 0.7766 | 0.8344 | 0.8032 | 0.7717 | 0.7962 | 0.7950 | 0.8048 | 8 |
| Jiangxi | 0.7607 | 0.7822 | 0.7847 | 0.7628 | 0.7408 | 0.7959 | 0.7850 | 0.7701 | 0.7871 | 0.8216 | 0.7791 | 11 |
| Shanxi | 0.6042 | 0.5924 | 0.6340 | 0.6387 | 0.6704 | 0.6816 | 0.6935 | 0.6430 | 0.6291 | 0.6195 | 0.6406 | 26 |
| Western | 0.6725 | 0.6951 | 0.6882 | 0.6450 | 0.6818 | 0.6560 | 0.6685 | 0.6624 | 0.6247 | 0.6247 | 0.6619 | |
| Gansu | 0.6417 | 0.7619 | 0.7546 | 0.6382 | 0.7073 | 0.6200 | 0.6311 | 0.5663 | 0.5717 | 0.5201 | 0.6413 | 24 |
| Guangxi | 0.7098 | 0.7320 | 0.7642 | 0.7555 | 0.7240 | 0.7390 | 0.7101 | 0.7037 | 0.7400 | 0.7844 | 0.7363 | 18 |
| Guizhou | 0.5340 | 0.6211 | 0.5835 | 0.6320 | 0.6378 | 0.7153 | 0.7306 | 0.7099 | 0.6610 | 0.6738 | 0.6499 | 22 |
| Inner Mongolia | 0.7712 | 0.7930 | 0.7338 | 0.6056 | 0.7009 | 0.6425 | 0.6440 | 0.5798 | 0.5024 | 0.4958 | 0.6469 | 23 |
| Ningxia | 0.5741 | 0.5316 | 0.5747 | 0.5763 | 0.6267 | 0.5469 | 0.5772 | 0.6153 | 0.5385 | 0.5242 | 0.5685 | 29 |
| Qinghai | 0.5819 | 0.6563 | 0.6158 | 0.5344 | 0.5939 | 0.5099 | 0.5510 | 0.5459 | 0.4479 | 0.4513 | 0.5488 | 30 |
| Shaanxi | 0.7910 | 0.7382 | 0.7759 | 0.7450 | 0.6901 | 0.7293 | 0.7341 | 0.7398 | 0.7205 | 0.7137 | 0.7378 | 17 |
| Sichuan | 0.7546 | 0.7356 | 0.7243 | 0.6679 | 0.7940 | 0.7341 | 0.7513 | 0.7411 | 0.7334 | 0.7522 | 0.7388 | 16 |
| Xinjiang | 0.6851 | 0.6940 | 0.6325 | 0.5308 | 0.5982 | 0.5724 | 0.5766 | 0.6347 | 0.5456 | 0.5321 | 0.6002 | 28 |
| Yunnan | 0.6440 | 0.6547 | 0.6800 | 0.6065 | 0.6384 | 0.5878 | 0.6175 | 0.6584 | 0.6356 | 0.6274 | 0.6350 | 27 |
| Chongqing | 0.7100 | 0.7280 | 0.7305 | 0.8032 | 0.7890 | 0.8186 | 0.8295 | 0.7914 | 0.7752 | 0.7970 | 0.7772 | 12 |
| Area | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | Average | Rank |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Eastern | 0.7538 | 0.7750 | 0.7876 | 0.6542 | 0.6428 | 0.7637 | 0.6744 | 0.6184 | 0.6197 | 0.6619 | 0.6952 | |
| Beijing | 0.9735 | 0.9881 | 0.9889 | 0.9933 | 0.9944 | 0.9931 | 0.9958 | 0.9957 | 0.9958 | 0.9926 | 0.9911 | 1 |
| Fujian | 0.6469 | 0.6646 | 0.7037 | 0.7511 | 0.6462 | 0.7502 | 0.6682 | 0.7036 | 0.7626 | 0.8259 | 0.7123 | 7 |
| Guangdong | 0.9763 | 0.9028 | 0.9235 | 0.8548 | 0.8152 | 0.9585 | 0.8878 | 0.8151 | 0.8358 | 0.8824 | 0.8852 | 2 |
| Hainan | 0.7219 | 0.7133 | 0.5902 | 0.2375 | 0.4735 | 0.4015 | 0.3703 | 0.4740 | 0.2689 | 0.3049 | 0.4556 | 18 |
| Hebei | 0.3041 | 0.4137 | 0.4931 | 0.2354 | 0.2387 | 0.3856 | 0.3075 | 0.2538 | 0.2318 | 0.2951 | 0.3159 | 28 |
| Jiangsu | 0.8314 | 0.8542 | 0.9250 | 0.8169 | 0.7675 | 0.9324 | 0.8641 | 0.7361 | 0.7604 | 0.8002 | 0.8288 | 4 |
| Liaoning | 0.4735 | 0.6195 | 0.5843 | 0.4695 | 0.4346 | 0.4455 | 0.2547 | 0.1856 | 0.2294 | 0.3269 | 0.4024 | 21 |
| Shandong | 0.6669 | 0.6835 | 0.7296 | 0.7494 | 0.6731 | 0.8651 | 0.7500 | 0.6869 | 0.6790 | 0.5985 | 0.7082 | 8 |
| Shanghai | 0.9517 | 0.9340 | 0.9493 | 0.7757 | 0.7093 | 0.8852 | 0.7631 | 0.6966 | 0.7447 | 0.8018 | 0.8211 | 5 |
| Tianjin | 0.8256 | 0.8386 | 0.8435 | 0.4812 | 0.5316 | 0.8458 | 0.6866 | 0.4826 | 0.5106 | 0.5978 | 0.6644 | 10 |
| Zhejiang | 0.9201 | 0.9123 | 0.9329 | 0.8311 | 0.7872 | 0.9374 | 0.8707 | 0.7727 | 0.7982 | 0.8552 | 0.8618 | 3 |
| Central | 0.5065 | 0.5774 | 0.6090 | 0.5317 | 0.5221 | 0.6928 | 0.5855 | 0.5204 | 0.6105 | 0.6514 | 0.5807 | |
| Anhui | 0.6270 | 0.6887 | 0.7576 | 0.6726 | 0.6607 | 0.8107 | 0.6665 | 0.6459 | 0.7244 | 0.7308 | 0.6985 | 9 |
| Henan | 0.4611 | 0.5847 | 0.6800 | 0.7262 | 0.7037 | 0.9119 | 0.8063 | 0.7282 | 0.7593 | 0.8168 | 0.7178 | 6 |
| Heilongjiang | 0.5249 | 0.5365 | 0.5495 | 0.3284 | 0.3098 | 0.5323 | 0.3580 | 0.2625 | 0.3421 | 0.3453 | 0.4089 | 20 |
| Hubei | 0.5106 | 0.6145 | 0.5365 | 0.6630 | 0.6163 | 0.7623 | 0.6613 | 0.6042 | 0.7141 | 0.7885 | 0.6471 | 12 |
| Hunan | 0.4834 | 0.5272 | 0.5832 | 0.6399 | 0.5864 | 0.7085 | 0.5774 | 0.5676 | 0.7272 | 0.7971 | 0.6198 | 13 |
| Jilin | 0.5109 | 0.6662 | 0.6800 | 0.3981 | 0.4153 | 0.6588 | 0.5788 | 0.4801 | 0.5949 | 0.6066 | 0.5590 | 15 |
| Jiangxi | 0.6092 | 0.6512 | 0.6837 | 0.5865 | 0.5364 | 0.7000 | 0.6618 | 0.6401 | 0.7316 | 0.8029 | 0.6603 | 11 |
| Shanxi | 0.3246 | 0.3500 | 0.4015 | 0.2392 | 0.3478 | 0.4581 | 0.3735 | 0.2349 | 0.2900 | 0.3229 | 0.3342 | 26 |
| Western | 0.4181 | 0.4923 | 0.4720 | 0.3071 | 0.4154 | 0.4667 | 0.4229 | 0.3876 | 0.3473 | 0.3915 | 0.4121 | |
| Gansu | 0.3892 | 0.6370 | 0.5804 | 0.2422 | 0.4274 | 0.4257 | 0.4082 | 0.2646 | 0.2628 | 0.2753 | 0.3913 | 23 |
| Guangxi | 0.4070 | 0.4170 | 0.4595 | 0.4447 | 0.3854 | 0.4768 | 0.4107 | 0.3904 | 0.4632 | 0.5384 | 0.4393 | 19 |
| Guizhou | 0.2836 | 0.2880 | 0.2923 | 0.2630 | 0.2963 | 0.5623 | 0.4811 | 0.4078 | 0.3983 | 0.4611 | 0.3734 | 24 |
| Inner Mongolia | 0.5829 | 0.7315 | 0.6195 | 0.2333 | 0.4947 | 0.3873 | 0.3233 | 0.2952 | 0.1429 | 0.1569 | 0.3968 | 22 |
| Ningxia | 0.2392 | 0.2590 | 0.3010 | 0.1745 | 0.3183 | 0.2682 | 0.2620 | 0.2740 | 0.1504 | 0.1647 | 0.2411 | 30 |
| Qinghai | 0.3869 | 0.5598 | 0.4317 | 0.1831 | 0.3672 | 0.2902 | 0.2860 | 0.2955 | 0.1615 | 0.1773 | 0.3139 | 29 |
| Shaanxi | 0.5790 | 0.6434 | 0.7193 | 0.4116 | 0.4598 | 0.6671 | 0.5566 | 0.5148 | 0.4863 | 0.5516 | 0.5589 | 16 |
| Sichuan | 0.5102 | 0.4876 | 0.5085 | 0.3605 | 0.5250 | 0.5948 | 0.5263 | 0.4708 | 0.5683 | 0.6437 | 0.5196 | 17 |
| Xinjiang | 0.4794 | 0.5386 | 0.3914 | 0.1614 | 0.3156 | 0.3097 | 0.2923 | 0.3635 | 0.1937 | 0.2084 | 0.3254 | 27 |
| Yunnan | 0.3316 | 0.4276 | 0.4227 | 0.2434 | 0.3966 | 0.4046 | 0.3604 | 0.3693 | 0.3064 | 0.3472 | 0.3610 | 25 |
| Chongqing | 0.4098 | 0.4260 | 0.4656 | 0.6601 | 0.5829 | 0.7468 | 0.7454 | 0.6173 | 0.6864 | 0.7823 | 0.6123 | 14 |
| Province | (1) | (2) | (3) | (4) | ||||
|---|---|---|---|---|---|---|---|---|
| Our Model | Rank | Tone | Rank | Doyle and Green | Rank | Lim and Zhu | Rank | |
| Beijing | 0.8632 | 3 | 1.0000 | 1 | 0.8792 | 5 | 0.8394 | 5 |
| Fujian | 0.7247 | 20 | 1.0000 | 1 | 0.6968 | 17 | 0.6721 | 16 |
| Guangdong | 0.7997 | 9 | 1.0000 | 1 | 0.7163 | 16 | 0.7034 | 12 |
| Hainan | 0.8384 | 4 | 1.0000 | 1 | 0.7803 | 10 | 0.2126 | 29 |
| Hebei | 0.7295 | 19 | 0.6577 | 16 | 0.8024 | 8 | 0.7695 | 7 |
| Jiangsu | 0.8353 | 5 | 1.0000 | 1 | 0.8860 | 4 | 0.8705 | 4 |
| Liaoning | 0.7851 | 12 | 0.7449 | 11 | 0.8342 | 6 | 0.8088 | 6 |
| Shandong | 0.8161 | 6 | 1.0000 | 1 | 0.9285 | 3 | 0.9103 | 2 |
| Shanghai | 0.9300 | 1 | 1.0000 | 1 | 0.9620 | 1 | 0.9420 | 1 |
| Tianjin | 0.8919 | 2 | 1.0000 | 1 | 0.9426 | 2 | 0.9026 | 3 |
| Zhejiang | 0.8064 | 7 | 0.9224 | 10 | 0.7413 | 12 | 0.7256 | 11 |
| Anhui | 0.8017 | 8 | 0.6981 | 13 | 0.7271 | 14 | 0.6953 | 14 |
| Henan | 0.7394 | 18 | 0.6949 | 14 | 0.7657 | 11 | 0.7381 | 10 |
| Heilongjiang | 0.7052 | 23 | 0.5376 | 23 | 0.5567 | 23 | 0.5113 | 22 |
| Hubei | 0.7735 | 13 | 0.6024 | 20 | 0.6706 | 18 | 0.6435 | 17 |
| Hunan | 0.7462 | 17 | 0.6725 | 15 | 0.7329 | 13 | 0.6983 | 13 |
| Jilin | 0.7955 | 10 | 0.7253 | 12 | 0.8121 | 7 | 0.7609 | 8 |
| Jiangxi | 0.7607 | 15 | 1.0000 | 1 | 0.7981 | 9 | 0.7576 | 9 |
| Shanxi | 0.6042 | 27 | 0.4444 | 29 | 0.5050 | 27 | 0.4709 | 24 |
| Gansu | 0.6419 | 26 | 0.4941 | 27 | 0.5163 | 26 | 0.4237 | 26 |
| Guangxi | 0.7098 | 22 | 0.5718 | 22 | 0.6222 | 22 | 0.5731 | 21 |
| Guizhou | 0.5340 | 30 | 0.4294 | 30 | 0.4406 | 29 | 0.3580 | 27 |
| Inner Mongolia | 0.7712 | 14 | 0.6433 | 17 | 0.7210 | 15 | 0.6809 | 15 |
| Ningxia | 0.5741 | 29 | 0.5099 | 26 | 0.4909 | 28 | 0.2671 | 28 |
| Qinghai | 0.5819 | 28 | 0.5349 | 24 | 0.4291 | 30 | 0.0677 | 30 |
| Shaanxi | 0.7910 | 11 | 0.6268 | 18 | 0.6613 | 19 | 0.6155 | 19 |
| Sichuan | 0.7546 | 16 | 0.5940 | 21 | 0.6526 | 21 | 0.6262 | 18 |
| Xinjiang | 0.6851 | 24 | 0.5114 | 25 | 0.5399 | 25 | 0.4392 | 25 |
| Yunnan | 0.6440 | 25 | 0.4889 | 28 | 0.5442 | 24 | 0.4727 | 23 |
| Chongqing | 0.7100 | 21 | 0.6200 | 19 | 0.6591 | 20 | 0.6085 | 20 |
| Mean | SD | Our Model | Tone | Doyle and Green | Lim and Zhu | |
|---|---|---|---|---|---|---|
| Our model | 0.7448 | 0.0945 | 1.0000 | |||
| Tone | 0.7242 | 0.2076 | 0.8001 *** | 1.0000 | ||
| Doyle and Green | 0.7005 | 0.1498 | 0.9137 *** | 0.8318 *** | 1.0000 | |
| Lim and Zhu | 0.6225 | 0.2133 | 0.7554 *** | 0.6096 *** | 0.8512 *** | 1.0000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, T.; Li, S.; Liu, F.; Diao, H. A Slacks-Based Measure Model for Computing Game Cross-Efficiency. Systems 2024, 12, 78. https://doi.org/10.3390/systems12030078
Huang T, Li S, Liu F, Diao H. A Slacks-Based Measure Model for Computing Game Cross-Efficiency. Systems. 2024; 12(3):78. https://doi.org/10.3390/systems12030078
Chicago/Turabian StyleHuang, Tingyang, Shuangjie Li, Fang Liu, and Hongyu Diao. 2024. "A Slacks-Based Measure Model for Computing Game Cross-Efficiency" Systems 12, no. 3: 78. https://doi.org/10.3390/systems12030078
APA StyleHuang, T., Li, S., Liu, F., & Diao, H. (2024). A Slacks-Based Measure Model for Computing Game Cross-Efficiency. Systems, 12(3), 78. https://doi.org/10.3390/systems12030078