
Enhancing Chinese Dialogue Generation with Word–Phrase Fusion Embedding and Sparse SoftMax Optimization


 ,
,  , ,
, ,  and
and 
Abstract
1. Introduction
2. Methods
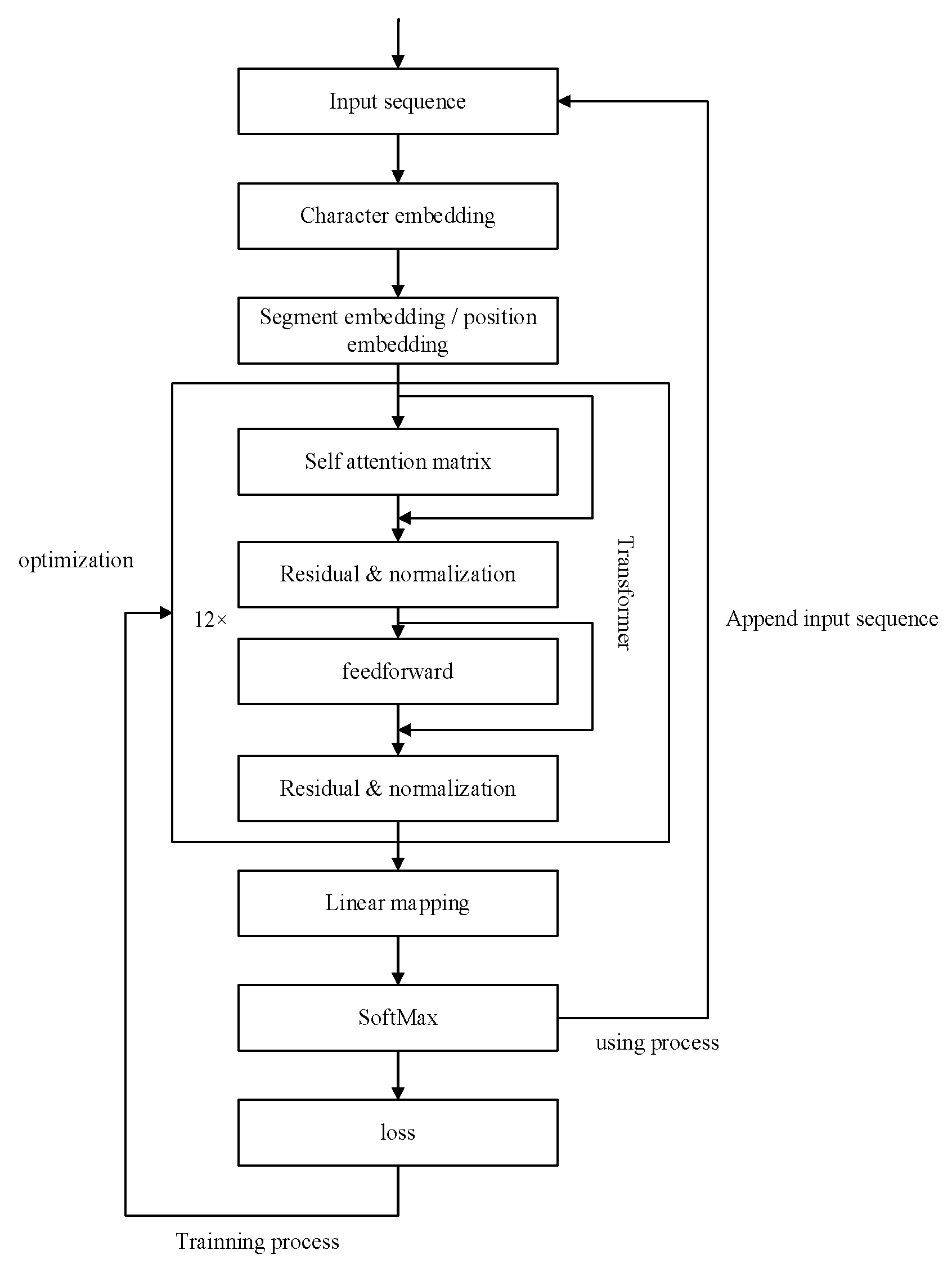
2.1. Transformer-Based Dialogue System
2.2. Embedding of Word-Phrase Fusion
- The input sequence is transformed from a one-hot encoding into a character vector compatible with the transformer model by initializing it with a random character-embedding matrix, . After feeding the one-hot encoding into the character-embedding network, we obtain character embeddings , as shown in Equation (1):where represents the embedding dimension of the character vectors. Meanwhile, is the character-embedding matrix with dimensions ×, with being the size of the character vocabulary;
- We obtain the pre-trained word-embedding matrix based on a pre-trained language model. The size of this matrix is where is the size of the vocabulary in the pre-trained model and is the embedding dimension of the word vectors. The word embeddings are obtained through the word-embedding matrix, as shown in Equation (2).
2.3. Sparse Softmax
3. Experiments
3.1. Dataset
3.2. Experimental Setting
3.3. Evaluation Standards
4. Result
4.1. Evaluation Index Results
4.2. Self-Attention Visualization Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Song, T.; Chen, N.; Jiang, J.; Zhu, Z.; Zou, Y. Improving Retrieval-Based Dialogue System Via Syntax-Informed Attention. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023. [Google Scholar]
- Jung, W.; Shim, K. Dual Supervision Framework for Relation Extraction with Distant Supervision and Human Annotation. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020. [Google Scholar]
- Tao, C.; Feng, J.; Yan, R.; Wu, W.; Jiang, D. A Survey on Response Selection for Retrieval-based Dialogues. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, WI, USA, 19–27 August 2021. [Google Scholar]
- Hua, K.; Feng, Z.; Tao, C.; Yan, R.; Zhang, L. Learning to Detect Relevant Contexts and Knowledge for Response Selection in Retrieval-Based Dialogue Systems. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Online, 19–23 October 2020. [Google Scholar]
- Lan, T.; Mao, X.-L.; Wei, W.; Gao, X.; Huang, H. PONE: A Novel Automatic Evaluation Metric for Open-domain Generative Dialogue Systems. ACM Trans. Inf. Syst. TOIS 2020, 39, 1–37. [Google Scholar] [CrossRef]
- Firdaus, M.; Thangavelu, N.; Ekbal, A.; Bhattacharyya, P. I Enjoy Writing and Playing, Do You?: A Personalized and Emotion Grounded Dialogue Agent Using Generative Adversarial Network. IEEE Trans. Affect. Comput. 2022, 14, 2127–2138. [Google Scholar] [CrossRef]
- Yao, L.; Zhang, Y.; Feng, Y.; Zhao, D.; Yan, R. Towards Implicit Content-Introducing for Generative Short-Text Conversation Systems. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017. [Google Scholar]
- Pai, K.-C.; Kuo, B.-C.; Liao, C.-H.; Liu, Y.-M. An application of Chinese dialogue-based intelligent tutoring system in remedial instruction for mathematics learning. Educ. Psychol. 2021, 41, 137–152. [Google Scholar] [CrossRef]
- Zhang, Z.; Takanobu, R.; Zhu, Q.; Huang, M.; Zhu, X. Recent advances and challenges in task-oriented dialog systems. Sci. China Technol. Sci. 2020, 63, 2011–2027. [Google Scholar] [CrossRef]
- Liu, X.; Wang, S.; Lu, S.; Yin, Z.; Li, X.; Yin, L.; Tian, J.; Zheng, W. Adapting Feature Selection Algorithms for the Classification of Chinese Texts. Systems 2023, 11, 483. [Google Scholar] [CrossRef]
- Jung, W.; Shim, K. T-REX: A Topic-Aware Relation Extraction Model. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Online, 19–23 October 2020. [Google Scholar]
- Ni, J.; Young, T.; Pandelea, V.; Xue, F.; Cambria, E. Recent advances in deep learning based dialogue systems: A systematic survey. Artif. Intell. Rev. 2023, 56, 3055–3155. [Google Scholar] [CrossRef]
- Liao, K.; Zhong, C.; Chen, W.; Liu, Q.; Peng, B.; Huang, X. Task-oriented dialogue system for automatic disease diagnosis via hierarchical reinforcement learning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Han, Z.; Zhang, Z. Multi-turn Dialogue System Based on Improved Seq2Seq Model. In Proceedings of the 2020 International Conference on Communications, Information System and Computer Engineering (CISCE), Kuala Lumpur, Malaysia, 3–5 July 2020. [Google Scholar]
- Ma, Z.; Du, B.; Shen, J.; Yang, R.; Wan, J. An encoding mechanism for seq2seq based multi-turn sentimental dialogue generation model. Procedia Comput. Sci. 2020, 174, 412–418. [Google Scholar] [CrossRef]
- He, Q.; Liu, W.; Cai, Z. B&Anet: Combining bidirectional LSTM and self-attention for end-to-end learning of task-oriented dialogue system. Speech Commun. 2020, 125, 15–23. [Google Scholar]
- Yan, M.; Lou, X.; Chan, C.A.; Wang, Y.; Jiang, W. A semantic and emotion-based dual latent variable generation model for a dialogue system. CAAI Trans. Intell. Technol. 2023, 8, 319–330. [Google Scholar] [CrossRef]
- Shang, W.; Zhu, S.; Xiao, D. Research on human-computer dialogue based on improved Seq2seq model. In Proceedings of the 2021 IEEE/ACIS 20th International Fall Conference on Computer and Information Science (ICIS Fall), Xi’an, China, 13–15 October 2021. [Google Scholar]
- He, W.; Yang, M.; Yan, R.; Li, C.; Shen, Y.; Xu, R. Amalgamating knowledge from two teachers for task-oriented dialogue system with adversarial training. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP): System Demonstrations, Online, 16–20 November 2020. [Google Scholar]
- Zandie, R.; Mahoor, M.H. Emptransfo: A multi-head transformer architecture for creating empathetic dialog systems. In Proceedings of the Thirty-Third International FLAIRS Conference (FLAIRS-33), North Miami Beach, FL, USA, 17–20 May 2020. [Google Scholar]
- Zhao, Y.; Zhang, J.; Zong, C. Transformer: A general framework from machine translation to others. Mach. Intell. Res. 2023, 20, 514–538. [Google Scholar] [CrossRef]
- Zhao, X.; Wang, L.; He, R.; Yang, T.; Chang, J.; Wang, R. Multiple knowledge syncretic transformer for natural dialogue generation. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020. [Google Scholar]
- Varshney, D.; Ekbal, A.; Nagaraja, G.P.; Tiwari, M.; Gopinath, A.A.M.; Bhattacharyya, P. Natural language generation using transformer network in an open-domain setting. In Proceedings of the Natural Language Processing and Information Systems: 25th International Conference on Applications of Natural Language to Information Systems, NLDB 2020, Saarbrücken, Germany, 24–26 June 2020. [Google Scholar]
- Kenton, J.D.M.-W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL-HLT, Minneapolis, Minnesota, 2–7 June 2019. [Google Scholar]
- Yenduri, G.; Ramalingam, M.; Selvi, G.C.; Supriya, Y.; Srivastava, G.; Maddikunta, P.K.R.; Raj, G.D.; Jhaveri, R.H.; Prabadevi, B.; Wang, W. GPT (generative pre-trained transformer)—A comprehensive review on enabling technologies, potential applications, emerging challenges, and future directions. IEEE Access 2024, 12, 54608–54649. [Google Scholar] [CrossRef]
- Yang, Y.; Li, Y.; Quan, X. Ubar: Towards fully end-to-end task-oriented dialog system with gpt-2. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021. [Google Scholar]
- Zhao, H.; Lu, J.; Cao, J. A short text conversation generation model combining BERT and context attention mechanism. Int. J. Comput. Sci. Eng. 2020, 23, 136–144. [Google Scholar] [CrossRef]
- Zhou, H.; Ke, P.; Zhang, Z.; Gu, Y.; Zheng, Y.; Zheng, C.; Tang, J. Eva: An open-domain chinese dialogue system with large-scale generative pre-training. arXiv 2021, arXiv:2108.01547. [Google Scholar]
- Li, M.; Xiang, L.; Kang, X.; Zhao, Y.; Zhou, Y.; Zong, C. Medical term and status generation from chinese clinical dialogue with multi-granularity transformer. IEEE ACM Trans. Audio Speech Lang. Process. 2021, 29, 3362–3374. [Google Scholar] [CrossRef]
- Lin, T.; Chonghui, G.; Jingfeng, C. Review of Chinese word segmentation studies. Data Anal. Knowl. Discov. 2020, 4, 1–17. [Google Scholar]
- Du, G. Research advanced in Chinese word segmentation methods and challenges. Appl. Comput. Eng. 2024, 37, 16–22. [Google Scholar] [CrossRef]
- Novak, J.R.; Minematsu, N.; Hirose, K. Phonetisaurus: Exploring grapheme-tophoneme conversion with joint n-gram models in the WFST framework. Nat. Lang. Eng. 2016, 22, 907–938. [Google Scholar] [CrossRef]
- Mor, B.; Garhwal, S.; Kumar, A. A systematic review of hidden Markov models and their applications. Arch. Comput. Methods Eng. 2021, 28, 1429–1448. [Google Scholar] [CrossRef]
- Yuan, H.; Ji, S. Structpool: Structured graph pooling via conditional random fields. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Li, P.; Luo, A.; Liu, J.; Wang, Y.; Zhu, J.; Deng, Y.; Zhang, J. Bidirectional gated recurrent unit neural network for Chinese address element segmentation. ISPRS Int. J. Geo-Inf. 2020, 9, 635. [Google Scholar] [CrossRef]
- Cheng, J.; Liu, J.; Xu, X.; Xia, D.; Liu, L.; Sheng, V.S. A review of Chinese named entity recognition. KSII Trans. Internet Inf. Syst. 2021, 15, 2012–2029. [Google Scholar]
- Choe, J.; Noh, K.; Kim, N.; Ahn, S.; Jung, W. Exploring the Impact of Corpus Diversity on Financial Pretrained Language Models. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023. [Google Scholar]
- The Segmentation Guidelines for the Penn Chinese Treebank (3.0). Available online: https://hanlp.hankcs.com/docs/annotations/tok/ctb.html (accessed on 6 April 2024).
- Wei, J.; Ren, X.; Li, X.; Huang, W.; Liao, Y.; Wang, Y.; Lin, J.; Jiang, X.; Chen, X.; Liu, Q. Nezha: Neural contextualized representation for chinese language understanding. arXiv 2019, arXiv:1909.00204. [Google Scholar]
- Wang, H.; Lu, Z.; Li, H.; Chen, E. A dataset for research on short-text conversations. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013. [Google Scholar]
- Zheng, W.; Gong, G.; Tian, J.; Lu, S.; Wang, R.; Yin, Z.; Li, X.; Yin, L. Design of a modified transformer architecture based on relative position coding. Int. J. Comput. Intell. Syst. 2023, 16, 168. [Google Scholar] [CrossRef]
- Laha, A.; Chemmengath, S.A.; Agrawal, P.; Khapra, M.; Sankaranarayanan, K.; Ramaswamy, H.G. On controllable sparse alternatives to softmax. In Proceedings of the Thirty-Second Annual Conference on Neural Information Processing Systems (NIPS), Montréal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Batra, P.; Chaudhary, S.; Bhatt, K.; Varshney, S.; Verma, S. A review: Abstractive text summarization techniques using NLP. In Proceedings of the 2020 International Conference on Advances in Computing, Communication & Materials (ICACCM), Dehradun, India, 21–22 August 2020. [Google Scholar]
- Jangabylova, A.; Krassovitskiy, A.; Mussabayev, R.; Ualiyeva, I. Greedy Texts Similarity Mapping. Computation 2022, 10, 200. [Google Scholar] [CrossRef]
- Bayot, R.; Gonçalves, T. Multilingual author profiling using word embedding averages and SVMs. In Proceedings of the 2016 10th International Conference on Software, Knowledge, Information Management & Applications (SKIMA), Chengdu, China, 15–17 December 2016. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dialogue Dataset Type | Dialogue Unit | Data Volume |
|---|---|---|
| Train | posts | 219,905 |
| responses | 4,308,211 | |
| pairs | 4,435,959 | |
| Test | test posts | 110 |
| Label | post | 225 |
| responses | 6017 | |
| labeled pairs | 6017 | |
| Fine-tuning (SMT-based) | posts | 2925 |
| responses | 3000 | |
| pairs | 3000 |
| Item | Model |
|---|---|
| Processor | Intel(R) Core(TM) i7-9800X CPU @ 3.80 GHz |
| Memory | 64 GB |
| Graphics card | NVIDIA GeForce GTX2080 Ti |
| Operating system | Ubuntu 18.04.3 LTS |
| Development environment | Pycharm + Anaconda |
| Open-source framework | TensorFlow2.1.0, Keras2.3.1, and BERT4Keras0.9.8 |
| Configuration | Baseline | Char-Word |
|---|---|---|
| Pre-training Model | BERT | NEZHA |
| Vocabulary Size | 13,088 | 13,088 |
| Embedding Dimension | 384 | 384 |
| Maximum Text Length | 256 | 256 |
| Transformer layers | 12 | 12 |
| Softmax and Cross Entropy | Default | Sparsity |
| Optimization Algorithm | Adam | Adam |
| Learning Rate | ||
| Weight Decay Rate | 0.01 | 0.01 |
| Batch Size | 16 | 16 |
| k | Rouge-L | Rouge-1 | Rouge-2 | Greedy Matching | Embedding Average | |
|---|---|---|---|---|---|---|
| Baseline | 64.51 | 66.75 | 56.73 | 65.89 | 78.94 | |
| Char-word | 65.38 | 67.52 | 57.83 | 66.06 | 83.38 | |
| Char-word | 10 | 66.85 | 68.83 | 58.51 | 66.34 | 84.12 |
| Char-word | 50 | 66.65 | 68.81 | 58.67 | 66.24 | 83.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, S.; Lu, S.; Wang, R.; Yin, L.; Yin, Z.; A. AlQahtani, S.; Tian, J.; Zheng, W. Enhancing Chinese Dialogue Generation with Word–Phrase Fusion Embedding and Sparse SoftMax Optimization. Systems 2024, 12, 516. https://doi.org/10.3390/systems12120516
Lv S, Lu S, Wang R, Yin L, Yin Z, A. AlQahtani S, Tian J, Zheng W. Enhancing Chinese Dialogue Generation with Word–Phrase Fusion Embedding and Sparse SoftMax Optimization. Systems. 2024; 12(12):516. https://doi.org/10.3390/systems12120516
Chicago/Turabian StyleLv, Shenrong, Siyu Lu, Ruiyang Wang, Lirong Yin, Zhengtong Yin, Salman A. AlQahtani, Jiawei Tian, and Wenfeng Zheng. 2024. "Enhancing Chinese Dialogue Generation with Word–Phrase Fusion Embedding and Sparse SoftMax Optimization" Systems 12, no. 12: 516. https://doi.org/10.3390/systems12120516
APA StyleLv, S., Lu, S., Wang, R., Yin, L., Yin, Z., A. AlQahtani, S., Tian, J., & Zheng, W. (2024). Enhancing Chinese Dialogue Generation with Word–Phrase Fusion Embedding and Sparse SoftMax Optimization. Systems, 12(12), 516. https://doi.org/10.3390/systems12120516