
Data and Model Harmonization Research Challenges in a Nation Wide Digital Twin


{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Data and Model Harmonization in a Nation Wide Digital Twin
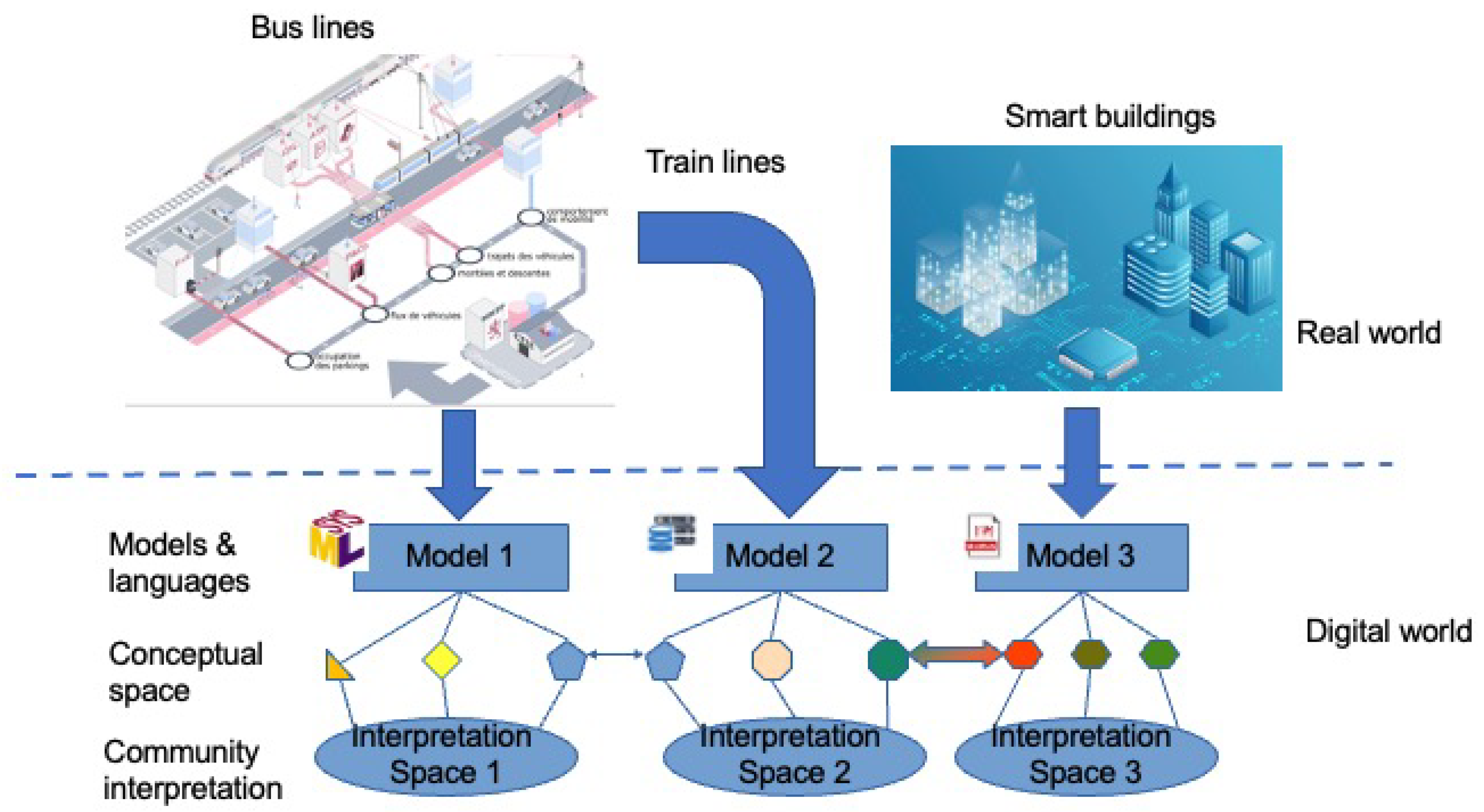
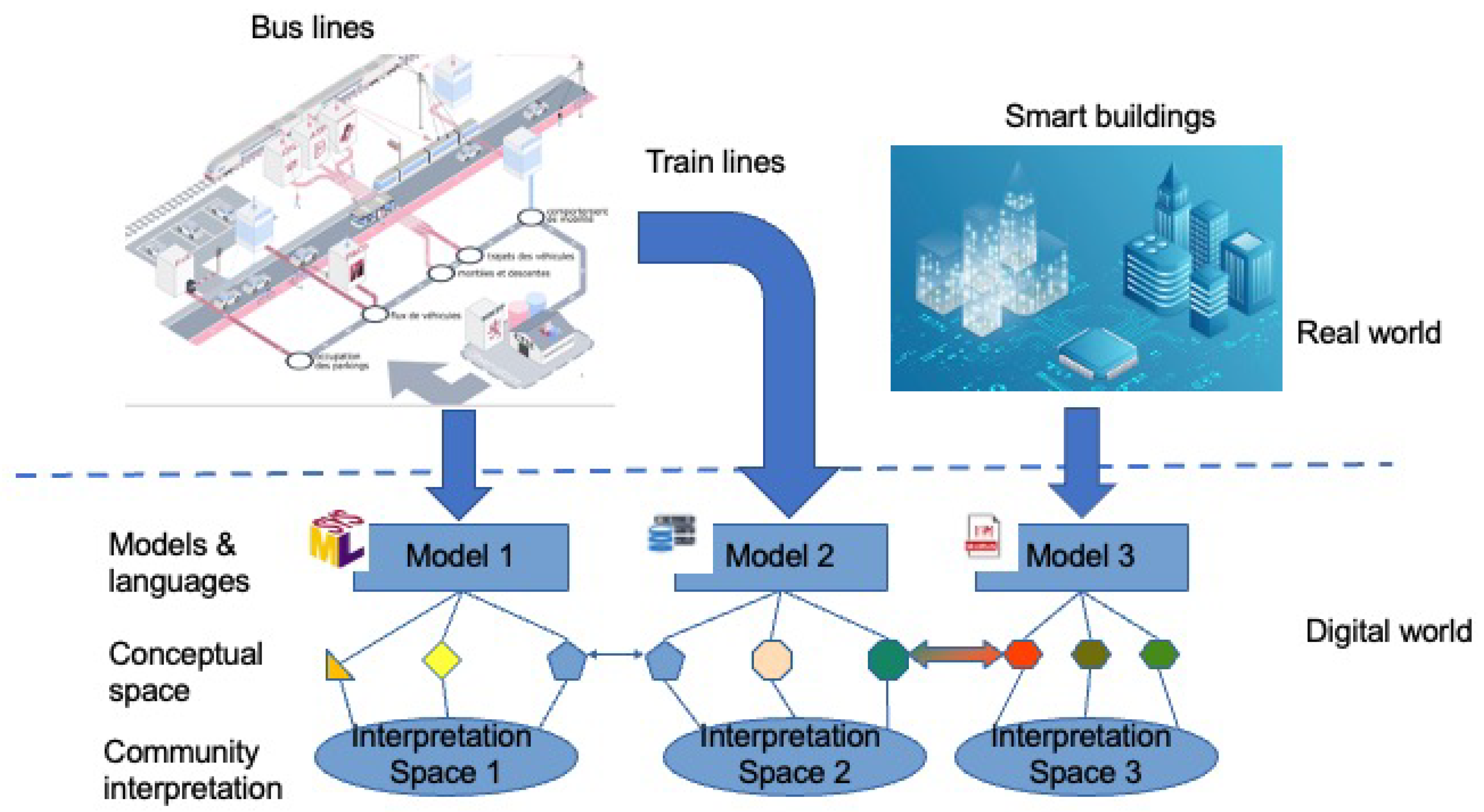
2.1. Standards vs. Proprietary Reference Models
2.2. Open World vs. Close World Assumption
2.3. Static vs. Dynamic Models
3. Model Life-Cycle Management and Consistency Checking
- By virtue of real world evolution, we consider that the physical system is constantly evolving—even if some parts of it remain very stable over time. As the perception, political orientation, citizen concerns and, event impacting the world change over time.
- It is hardly possible to have a clear and complete view of a country and therefore, the construction of a complete NWDT at once is hardly reachable. As a result, a NWDT will progressively be refined through time.
- In practice, we will not consider a whole encompassing NWDT but rather the connection of existing local or domain DTs to form a federation of DTs. This requires the consideration of a distributed model approach, with restricted access to the model elements (as they will remains the property of third party entities).
3.1. Supporting the Evolution of the Physical System
- The physical part of the NWDT changed. This result in changing a part of the models of the digital part that correspond to the identified changes in the real world.
- The model is not aligned to reality due to bad modelling work. This is usually detected at consistency checking or at run time when analysing the behavior of the NWDT.
- The perception of the reality coming from the sensors or given by the humans has changed. This can result in a drastic change of the NWDT models because they are no longer aligned with the perceived reality. This can also reveal a drift in the semantics of the element of the models (see Section 4.2), which lead to precising some part of the model or on the contrary to add uncertainty.
3.2. Continuous Building of Nwdt
3.3. Connecting External Models from Other DT
4. Research Challenges
4.1. Model Reconciliation/Semantic Mismatch
- Models have to be properly documented and the semantics of the different elements composing them must be explicit to have a clear, deep and unambiguous understanding of the models. In classical DT approaches, software developers have the global overview on the various models involved which reduces drastically the bad interpretation of the content of the models. However, in a NWDT context, specific problems raise. On the one hand, as evoked in Section 2.1, elements from different models can have the same labels but have different semantics because of the different views one can have when building the model or simply because the models have totally different context or even because of semantic drift issues (see Section 4.2). On the other hand, elements of different models can have different labels but the same semantics and therefore must be properly aligned to be used. Current works approach this problem via knowledge graphs. This is the case of [40] where the ability of knowledge graphs for knowledge representation and the dynamic of agents to update the graphs in near real-time are considered for a NWDT focusing on energy saving. In [41], the authors addresses the design of a complex DT design where classical DT are augmented with much more elements, the variable scale of working environments and changeable process among others. In their approach, they use ontologies to establish the complete information library of the entities on different digital twins and knowledge graphs to bridges the structure relationship between the different scales of digital twins.
- Models evolution needs to be properly managed to ensure a continuous exploitation of the DT. In a NWDT context this is even more difficult since different models, evolving at different speed, are implemented. As evoked in Section 3, the evolution of models have first to be captured and characterised this means that we need to know what has changed in the model and what kind of changes occurred (e.g., atomic changes like addition or deletion or a combination of atomic changes like split or merge). The complexity of computing this diff is highly depending on the nature of the model (e.g., graph based [42]) and on the formalism used to express these models. This phase is crucial for another important aspect that consists in propagating the changes to depending artefacts (i.e., other models composing the DT) [43,44] which requires a proper governance of the NWDT (see Section 4.4).
4.2. Semantic Drift
4.3. Model Flexibility
4.4. Security and Governance Aspects
- Ensuring the privacy (Transparency, Unlinkability and Controllability) of the processing of data.
- Ensuring the sovereignty of the data controller to decide on the terms of use of data by the involved third parties
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
| 1 | A physical system is referred to as the actual system under study and may also cover its digital aspects. |
| 2 | We can call it a XWDT where is X can be replaced by the scope of the DT, e.g., RWDT for region-wide DT; our the ultimate goal is to consider holistic problems at a nation level. |
| 3 | https://eur-lex.europa.eu/eli/reg/2016/679/oj (accessed on 12 December 2022). |
References
- Grieves, M.; Vickers, J. Digital twin: Mitigating unpredictable, undesirable emergent behavior in complex systems. In Transdisciplinary Perspectives on Complex Systems; Springer: Berlin/Heidelberg, Germany, 2017; pp. 85–113. [Google Scholar]
- Boschert, S.; Rosen, R. Digital twin—The simulation aspect. In Mechatronic Futures; Springer: Berlin/Heidelberg, Germany, 2016; pp. 59–74. [Google Scholar]
- Zhang, Y.; Feng, K.; Ji, J.; Yu, K.; Ren, Z.; Liu, Z. Dynamic Model-Assisted Bearing Remaining Useful Life Prediction Using the Cross-Domain Transformer Network. IEEE/ASME Trans. Mechatron. 2022, 1–11. [Google Scholar] [CrossRef]
- Liu, Z.; Meyendorf, N.; Mrad, N. The role of data fusion in predictive maintenance using digital twin. In AIP Conference Proceedings; AIP Publishing LLC: Melville, NY, USA, 2018; Volume 1949, p. 020023. [Google Scholar]
- Feng, K.; Ji, J.; Zhang, Y.; Ni, Q.; Liu, Z.; Beer, M. Digital twin-driven intelligent assessment of gear surface degradation. Mech. Syst. Signal Process. 2023, 186, 109896. [Google Scholar] [CrossRef]
- Becker, F.; Bibow, P.; Dalibor, M.; Gannouni, A.; Hahn, V.; Hopmann, C.; Jarke, M.; Koren, I.; Kröger, M.; Lipp, J.; et al. A Conceptual Model for Digital Shadows in Industry and its Application. In Proceedings of the International Conference on Conceptual Modeling, Virtual Event, 18–21 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 271–281. [Google Scholar]
- Cirillo, F.; Solmaz, G.; Berz, E.L.; Bauer, M.; Cheng, B.; Kovacs, E. A standard-based open source IoT platform: FIWARE. IEEE Internet Things Mag. 2019, 2, 12–18. [Google Scholar] [CrossRef]
- Microsoft. Azur Digital Twin. Available online: https://azure.microsoft.com/en-gb/products/digital-twins/ (accessed on 2 October 2022).
- Kirchhof, J.C.; Michael, J.; Rumpe, B.; Varga, S.; Wortmann, A. Model-driven digital twin construction: Synthesizing the integration of cyber-physical systems with their information systems. In Proceedings of the 23rd ACM/IEEE International Conference on Model Driven Engineering Languages and Systems, Virtual Event, Canada, 18–23 October 2020; pp. 90–101. [Google Scholar]
- Bibow, P.; Dalibor, M.; Hopmann, C.; Mainz, B.; Rumpe, B.; Schmalzing, D.; Schmitz, M.; Wortmann, A. Model-driven development of a digital twin for injection molding. In Proceedings of the International Conference on Advanced Information Systems Engineering, Grenoble, France, 8–12 June 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 85–100. [Google Scholar]
- Ruohomäki, T.; Airaksinen, E.; Huuska, P.; Kesäniemi, O.; Martikka, M.; Suomisto, J. Smart city platform enabling digital twin. In Proceedings of the IEEE 2018 International Conference on Intelligent Systems (IS), Madeira, Portugal, 25–27 September 2018; pp. 155–161. [Google Scholar]
- Deren, L.; Wenbo, Y.; Zhenfeng, S. Smart city based on digital twins. Comput. Urban Sci. 2021, 1, 1–11. [Google Scholar] [CrossRef]
- Tao, F.; Qi, Q. Singapore Country-Scale Digital Twin. 2022. Available online: https://www.youtube.com/watch?v=557k_5CeZ9U (accessed on 29 December 2022).
- Villalonga, A.; Negri, E.; Fumagalli, L.; Macchi, M.; Castaño, F.; Haber, R. Local decision making based on distributed digital twin framework. IFAC-PapersOnLine 2020, 53, 10568–10573. [Google Scholar] [CrossRef]
- Combemale, B.; Kienzle, J.; Mussbacher, G.; Ali, H.; Amyot, D.; Bagherzadeh, M.; Batot, E.; Bencomo, N.; Benni, B.; Bruel, J.M.; et al. A Hitchhiker’s Guide to Model-Driven Engineering for Data-Centric Systems. IEEE Softw. 2020, 38, 71–84. [Google Scholar] [CrossRef]
- Rubin, J. Federated Systems; MIT report; MIT: Cambridge, MA, USA, 2015; Available online: https://rubin.io/public/pdfs/federation.pdf (accessed on 12 December 2022).
- Zhang, Q.; Wang, X.; Palacharla, P.; Ikeuchi, T. Distributed service orchestration: Interweaving switch and service functions across domains. In Proceedings of the 2016 IEEE Conference on Network Function Virtualization and Software Defined Networks (NFV-SDN), Palo Alto, CA, USA, 7–10 November 2016; pp. 13–18. [Google Scholar]
- Union, E. Data Governance Act. 2022. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=celex%3A52020PC0767 (accessed on 12 December 2022).
- Lu, Y.; Liu, C.; Kevin, I.; Wang, K.; Huang, H.; Xu, X. Digital Twin-driven smart manufacturing: Connotation, reference model, applications and research issues. Robot. Comput.-Integr. Manuf. 2020, 61, 101837. [Google Scholar] [CrossRef]
- Hu, L.; Nguyen, N.T.; Tao, W.; Leu, M.C.; Liu, X.F.; Shahriar, M.R.; Al Sunny, S.N. Modeling of cloud-based digital twins for smart manufacturing with MT connect. Procedia Manuf. 2018, 26, 1193–1203. [Google Scholar] [CrossRef]
- Shahriar, M.R.; Al Sunny, S.N.; Liu, X.; Leu, M.C.; Hu, L.; Nguyen, N.T. MTComm based virtualization and integration of physical machine operations with digital-twins in cyber-physical manufacturing cloud. In Proceedings of the 2018 5th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/2018 4th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), Shanghai, China, 22–24 June 2018; pp. 46–51. [Google Scholar]
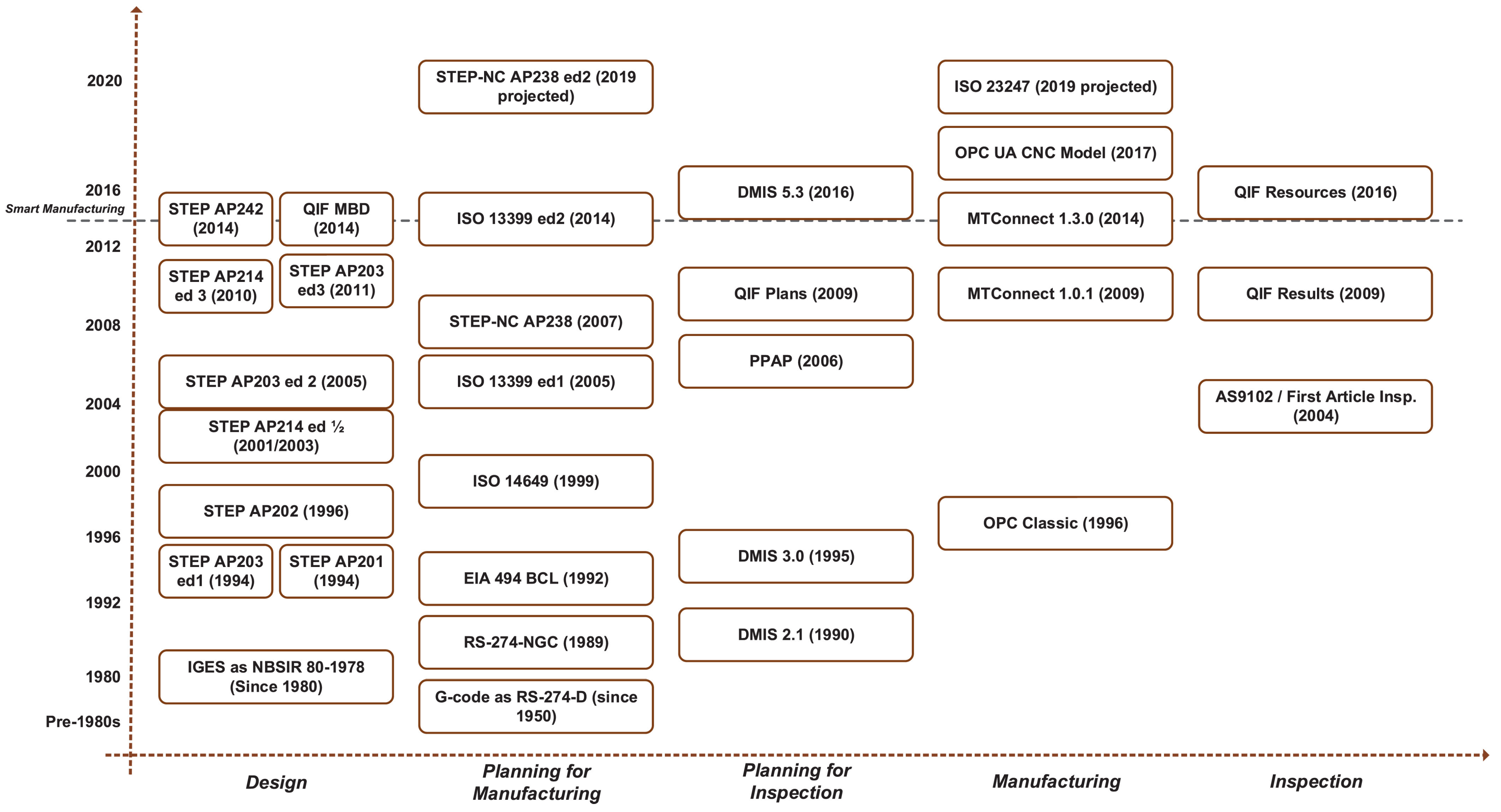
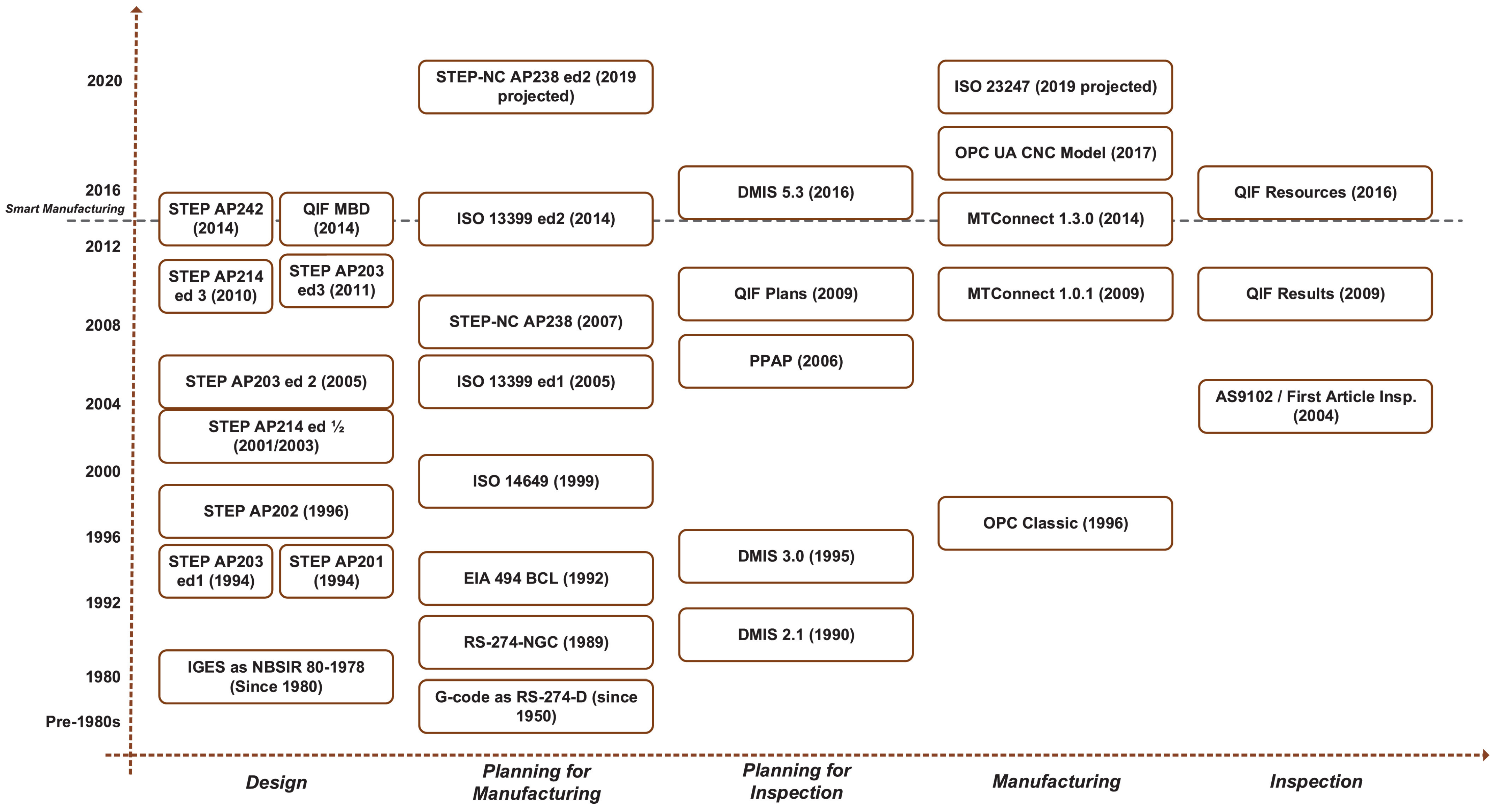
- Jacoby, M.; Usländer, T. Digital Twin and Internet of Things—Current Standards Landscape. Appl. Sci. 2020, 10, 6519. [Google Scholar] [CrossRef]
- Paige, R.F.; Zolotas, A.; Kolovos, D. The changing face of model-driven engineering. In Present and Ulterior Software Engineering; Springer: Berlin/Heidelberg, Germany, 2017; pp. 103–118. [Google Scholar]
- Bertoa, M.F.; Moreno, N.; Barquero, G.; Burgueño, L.; Troya, J.; Vallecillo, A. Expressing measurement uncertainty in OCL/UML datatypes. In Proceedings of the European Conference on Modelling Foundations and Applications, Toulouse, France, 26–28 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 46–62. [Google Scholar]
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Halpin, T. Object-Role Modeling: An Overview. White Paper. 1998. Available online: www.orm.net (accessed on 5 October 2022).
- Singh, S.; Shehab, E.; Higgins, N.; Fowler, K.; Reynolds, D.; Erkoyuncu, J.A.; Gadd, P. Data management for developing digital twin ontology model. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2021, 235, 2323–2337. [Google Scholar] [CrossRef]
- Lu, Y.; Wang, H.; Xu, X. ManuService ontology: A product data model for service-oriented business interactions in a cloud manufacturing environment. J. Intell. Manuf. 2019, 30, 317–334. [Google Scholar] [CrossRef]
- Sottet, J.S.; Brimont, P.; Feltus, C.; Gâteau, B.; Merche, J.F. Towards a Lightweight Model-driven Smart-city Digital Twin. In Proceedings of the 10th Conference on Model-Driven Engineering and Software Development, Vienna, Austria, 6–8 February 2022. [Google Scholar]
- Mengerink, J.G.; Serebrenik, A.; Schiffelers, R.R.; van den Brand, M.G. Automated analyses of model-driven artifacts: Obtaining insights into industrial application of MDE. In Proceedings of the 27th International Workshop on Software Measurement and 12th International Conference on Software Process and Product Measurement, Gothenburg, Sweden, 25–27 October 2017; pp. 116–121. [Google Scholar]
- Bryce, D.; Benton, J.; Boldt, M.W. Maintaining Evolving Domain Models. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, IJCAI’16, New York, NY, USA, 9–15 July 2016; AAAI Press: Palo Alto, CA, USA, 2016; pp. 3053–3059. [Google Scholar]
- Troya, J.; Moreno, N.; Bertoa, M.F.; Vallecillo, A. Uncertainty representation in software models: A survey. Softw. Syst. Model. 2021, 20, 1183–1213. [Google Scholar] [CrossRef]
- Eramo, R.; Pierantonio, A.; Rosa, G. Approaching Collaborative Modeling as an Uncertainty Reduction Process. In Proceedings of the COMMitMDE@ MoDELS, Saint Malo, France, 2–7 October 2016; pp. 27–34. [Google Scholar]
- Lovett, R.; Lee, V.; Kukutai, T.; Cormack, D.; Rainie, S.C.; Walker, J. Good data practices for Indigenous data sovereignty and governance. In Good Data; Institute of Network Cultures: Amsterdam, The Netherlands, 2019; pp. 26–36. [Google Scholar]
- Braud, A.; Fromentoux, G.; Radier, B.; Le Grand, O. The road to European digital sovereignty with Gaia-X and IDSA. IEEE Netw. 2021, 35, 4–5. [Google Scholar] [CrossRef]
- Lepri, B.; Oliver, N.; Letouzé, E.; Pentland, A.; Vinck, P. Fair, transparent, and accountable algorithmic decision-making processes. Philos. Technol. 2018, 31, 611–627. [Google Scholar] [CrossRef]
- Meier, J.; Werner, C.; Klare, H.; Tunjic, C.; Aßmann, U.; Atkinson, C.; Burger, E.; Reussner, R.; Winter, A. Classifying approaches for constructing single underlying models. In Proceedings of the International Conference on Model-Driven Engineering and Software Development, Valletta, Malta, 25–27 February 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 350–375. [Google Scholar]
- Abhervé, A.; Almeida, M. Modelio Project Management Server Constellation. In Model-Driven Development and Operation of Multi-Cloud Applications; Springer: Cham, Switzerland, 2017; pp. 113–122. [Google Scholar]
- Costantini, A.; Di Modica, G.; Ahouangonou, J.C.; Duma, D.C.; Martelli, B.; Galletti, M.; Antonacci, M.; Nehls, D.; Bellavista, P.; Delamarre, C.; et al. IoTwins: Toward Implementation of Distributed Digital Twins in Industry 4.0 Settings. Computers 2022, 11, 67. [Google Scholar] [CrossRef]
- Akroyd, J.; Mosbach, S.; Bhave, A.; Kraft, M. Universal digital twin-a dynamic knowledge graph. Data-Centric Eng. 2021, 2, e14. [Google Scholar] [CrossRef]
- Jia, W.; Wang, W.; Zhang, Z. From simple digital twin to complex digital twin Part I: A novel modeling method for multi-scale and multi-scenario digital twin. Adv. Eng. Inform. 2022, 53, 101706. [Google Scholar] [CrossRef]
- Benavides, S.D.; Cardoso, S.D.; Da Silveira, M.; Pruski, C. DynDiff: A Tool for Comparing Versions of Large Ontologies. In Proceedings of the 5th Workshop on Semantic Web Solutions for Large-Scale Biomedical Data Analytics, Crete, Greece, 29–30 May 2022. [Google Scholar]
- Dos Reis, J.C.; Pruski, C.; Da Silveira, M.; Reynaud-Delaître, C. DyKOSMap: A framework for mapping adaptation between biomedical knowledge organization systems. J. Biomed. Inform. 2015, 55, 153–173. [Google Scholar] [CrossRef]
- Cardoso, S.D.; Chantal, R.D.; Da Silveira, M.; Pruski, C. Combining rules, background knowledge and change patterns to maintain semantic annotations. In Proceedings of the AMIA Annual Symposium Proceedings, American Medical Informatics Association, Washington, DC, USA, 4–8 November 2017; Volume 2017, p. 505. [Google Scholar]
- Gulla, J.A.; Solskinnsbakk, G.; Myrseth, P.; Haderlein, V.; Cerrato, O. Semantic Drift in Ontologies. In Proceedings of the WEBIST (2), Valencia, Spain, 7–10 April 2010; pp. 13–20. [Google Scholar]
- Wang, S.; Schlobach, S.; Klein, M. Concept drift and how to identify it. J. Web Semant. 2011, 9, 247–265. [Google Scholar] [CrossRef]
- Stavropoulos, T.G.; Andreadis, S.; Kontopoulos, E.; Kompatsiaris, I. SemaDrift: A hybrid method and visual tools to measure semantic drift in ontologies. J. Web Semant. 2019, 54, 87–106. [Google Scholar] [CrossRef]
- Demšar, J.; Bosnić, Z. Detecting concept drift in data streams using model explanation. Expert Syst. Appl. 2018, 92, 546–559. [Google Scholar] [CrossRef]
- Lifna, C.; Vijayalakshmi, M. Identifying concept-drift in twitter streams. Procedia Comput. Sci. 2015, 45, 86–94. [Google Scholar] [CrossRef]
- Kalaboukas, K.; Rožanec, J.; Košmerlj, A.; Kiritsis, D.; Arampatzis, G. Implementation of cognitive digital twins in connected and agile supply networks—An operational model. Appl. Sci. 2021, 11, 4103. [Google Scholar] [CrossRef]
- Gama, J.; Žliobaitė, I.; Bifet, A.; Pechenizkiy, M.; Bouchachia, A. A survey on concept drift adaptation. ACM Comput. Surv. (CSUR) 2014, 46, 1–37. [Google Scholar] [CrossRef]
- Armel, K.C.; Gupta, A.; Shrimali, G.; Albert, A. Is disaggregation the holy grail of energy efficiency? The case of electricity. Energy Policy 2013, 52, 213–234. [Google Scholar] [CrossRef]
- Michael, J.; Pfeiffer, J.; Rumpe, B.; Wortmann, A. Integration challenges for digital twin systems-of-systems. In Proceedings of the 10th IEEE/ACM International Workshop on Software Engineering for Systems-of-Systems and Software Ecosystems, Pittsburg, PA, USA, 16 May 2022; pp. 9–12. [Google Scholar]
- Dinh, D.; Dos Reis, J.C.; Pruski, C.; Da Silveira, M.; Reynaud-Delaître, C. Identifying relevant concept attributes to support mapping maintenance under ontology evolution. J. Web Semant. 2014, 29, 53–66. [Google Scholar] [CrossRef]
- Sottet, J.S.; Biri, N. JSMF: A flexible JavaScript modelling framework. In Proceedings of the Workshop on Flexible Model Driven Eng, (FlexMDE @ Models), Saint Malo, France, 2–7 October 2016. [Google Scholar]
- Wang, J.; Fei, Z.; Chang, Q.; Fu, Y.; Li, S. Energy-saving operation of multistage stochastic manufacturing systems based on fuzzy logic. Int. J. Simul. Model. 2019, 18, 138–149. [Google Scholar] [CrossRef]
- He, R.; Chen, G.; Dong, C.; Sun, S.; Shen, X. Data-driven digital twin technology for optimized control in process systems. ISA Trans. 2019, 95, 221–234. [Google Scholar] [CrossRef]
- Fuller, A.; Fan, Z.; Day, C.; Barlow, C. Digital twin: Enabling technologies, challenges and open research. IEEE Access 2020, 8, 108952–108971. [Google Scholar] [CrossRef]
- Damjanovic-Behrendt, V. A digital twin-based privacy enhancement mechanism for the automotive industry. In Proceedings of the 2018 International Conference on Intelligent Systems (IS), Funchal Madeira, Portugal, 25–27 September 2018; pp. 272–279. [Google Scholar]
- Solman, H.; Kirkegaard, J.K.; Smits, M.; Van Vliet, B.; Bush, S. Digital twinning as an act of governance in the wind energy sector. Environ. Sci. Policy 2022, 127, 272–279. [Google Scholar] [CrossRef]
- Alcaraz, C.; Lopez, J. Digital Twin: A Comprehensive Survey of Security Threats. IEEE Commun. Surv. Tutorials 2022, 24, 1475–1503. [Google Scholar] [CrossRef]
- Gehrmann, C.; Gunnarsson, M. A digital twin based industrial automation and control system security architecture. IEEE Trans. Ind. Inform. 2019, 16, 669–680. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sottet, J.-S.; Pruski, C. Data and Model Harmonization Research Challenges in a Nation Wide Digital Twin. Systems 2023, 11, 99. https://doi.org/10.3390/systems11020099
Sottet J-S, Pruski C. Data and Model Harmonization Research Challenges in a Nation Wide Digital Twin. Systems. 2023; 11(2):99. https://doi.org/10.3390/systems11020099
Chicago/Turabian StyleSottet, Jean-Sébastien, and Cédric Pruski. 2023. "Data and Model Harmonization Research Challenges in a Nation Wide Digital Twin" Systems 11, no. 2: 99. https://doi.org/10.3390/systems11020099
APA StyleSottet, J.-S., & Pruski, C. (2023). Data and Model Harmonization Research Challenges in a Nation Wide Digital Twin. Systems, 11(2), 99. https://doi.org/10.3390/systems11020099