4.1. Data Analysis
Empirical Data Analysis—In this section, data analysis is executed with the statistical package for the social sciences (SPSS) and SmartPLS software. Data manipulation is the process before the final analysis required for data screening, cleaning, and checking data errors [
39]. However, certain phenomena are also checked in further analysis, such as descriptive statistics, measurement scales of internal consistency, and validation of the items through exploratory factor analysis. As a result, EFA identified the items that were reliable and valid for further analysis, such as structural equation modeling. Particularly, this is important for the reflective model of variance-based structural equation modeling (VB-SEM) [
39,
40].
Data Screening Earlier to Analysis—Data screening was the first point after the data collection survey was completed. It identified if there were any missing values and checked the data errors [
41]. It is vital to be undertaken before the final execution of any statistical analysis. However, there were a few missing items on the answer sheet where respondents put their opinion. Therefore, the collected data were checked, and it was confirmed that the data were error-free and there was no missing value for the subsequent analysis such as descriptive and inferential statistics.
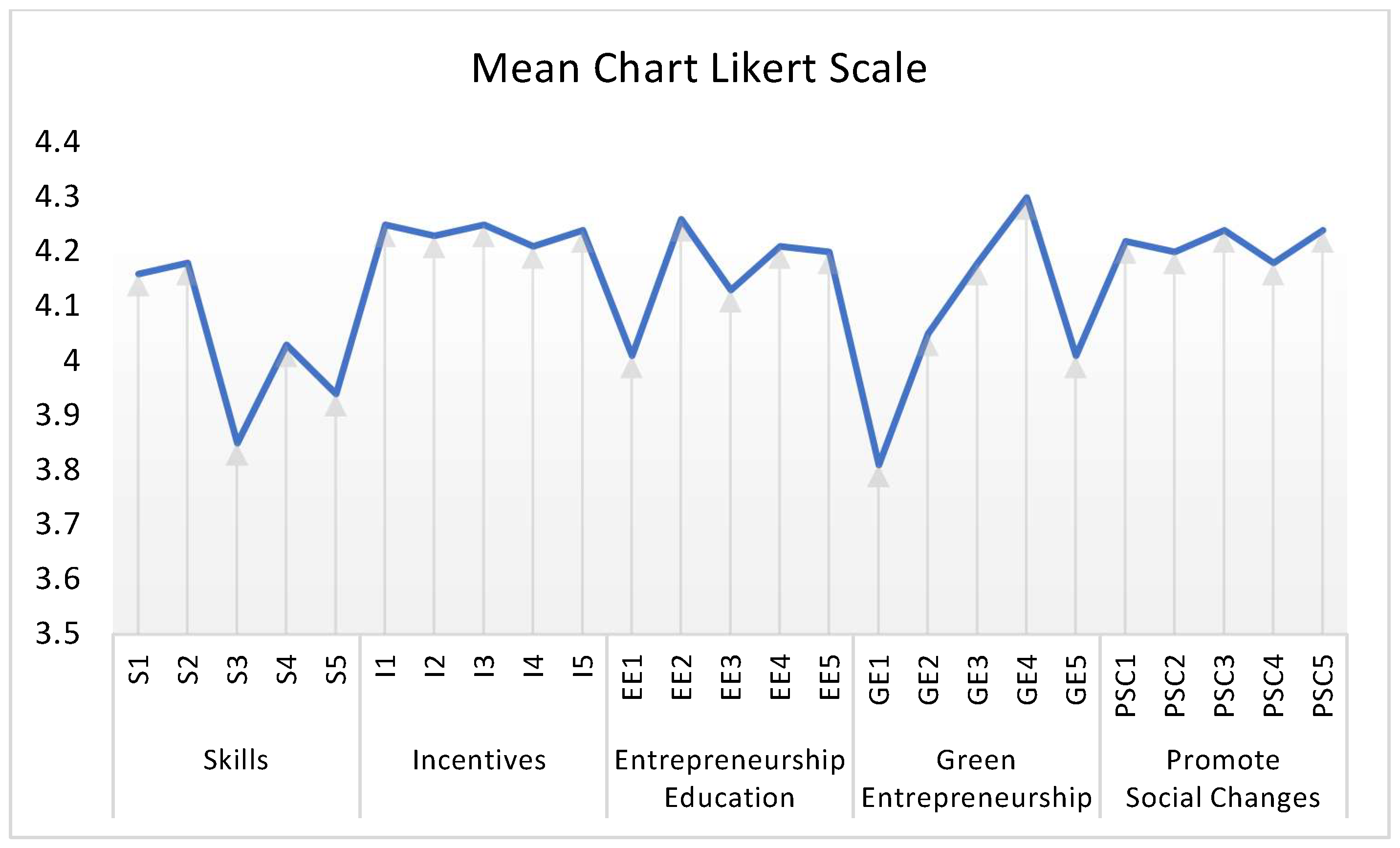
Data Analyzing Using Descriptive Statistics—Descriptive statistics is the division of statistics that provides recommendations on how to summarize research data in tables, figures, charts, and graphs. Before the execution of a descriptive breakdown, it is of paramount importance to review the objective or objectives [
42]. The
Table 1 represents the respondent’s demographic profile summaries, with age and gender profiles displayed with cross-tabulation.
The
Table 1 displays the respondent’s details with regard to gender and age; the highest demographic of respondents was males of the age (18–20). However, the most common female demographic, with 47 respondents, was the age (21–23). Therefore, the age of (18–20) had the highest number of respondents out of N 302.
Validate Measurement Scales with EFA—Exploratory factor analysis (EFA) is a statistical tool executed for numerous derivatives. It was initially developed in the early 1900s to regulate unitary or multidimensional paradigms [
44]. There are several tests in EFA to perform, which are confirmed by measurement scales to discern whether the items have enough factor loading indications, such as KMO with a Sig level, factor loadings, and cumulative percentage. The
Table 2 display the EFA execution outputs.
In EFA, the output of KMO and Bartlett’s Test of Sphericity is an essential statistical method for the decisive factor structure that establishes the measured variable that statistically shows the significance level of the α parameter [
45]. However, if the value of KMO is 0.70 to 0.80, then it is desirable; once the value is >0.80, then it is excellent. The value is significant at the level of ≤0.05 [
46]. The achieved test results of KMO were more than desirable: KMO was 0.87, which is greater than 0.80, indicating an excellent score with Bartlett’s test of Sphericity. The Sig. level value was 0.000, which is <0.001. Therefore, the computed test of the survey data was statistically significant, and allowed us to undertake further analysis such as the reliability and validity tests. Nevertheless, the
Table 3 displays the factor loadings of each questionnaire analyzed through the varimax rotated component matrix.
The
Table 3 displays the factor loadings of each item according to the rotated component matrix of the extraction method and the rotation method of computed varimax with Kaiser normalization. Each variable identified a rotation converged in five iterations. EFA normally explores the probable underlying factor loading, which is a set of the empirical data with the structure defined [
46]. However, once the factor outcome is ≥0.50, then it is desirable for the questionnaire to be measured by the empirical data and without cross-loading the factor [
45]. The
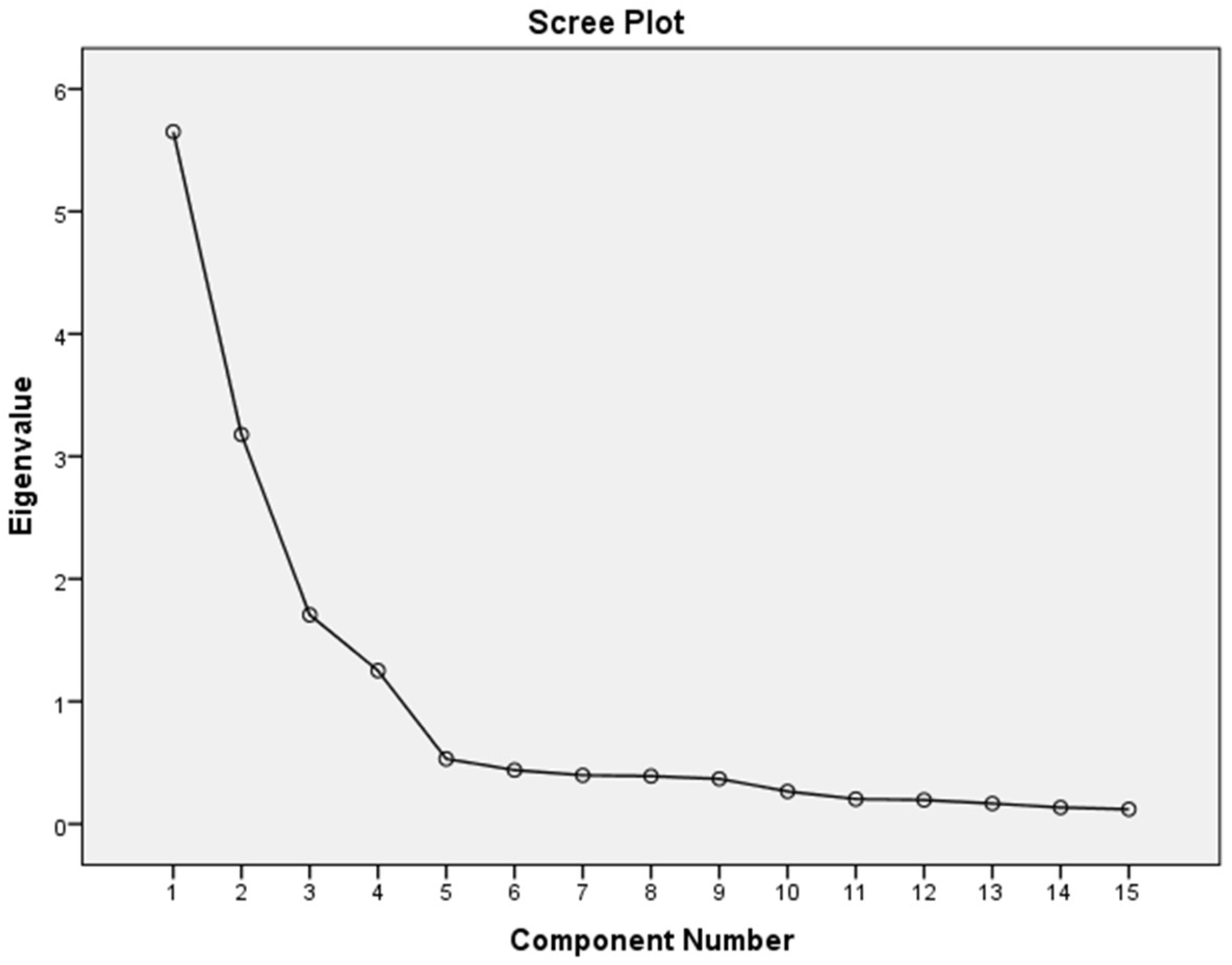
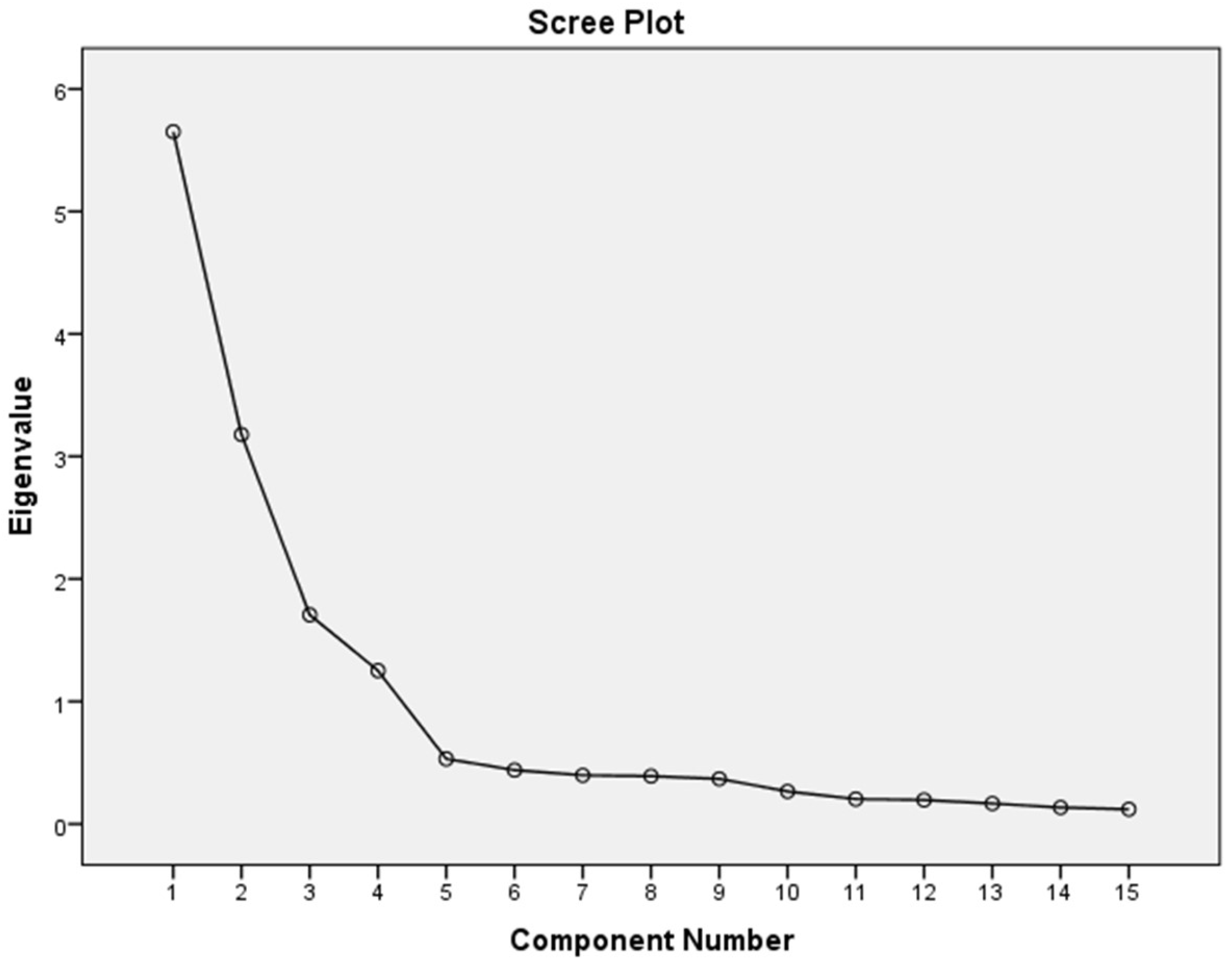
Table 3 shows that the outputs of the pragmatic data were strongly desirable, i.e., >0.70 each of the factor loadings. However, the cumulative extraction sums of squared loadings received 65.17%, accumulated with five components. However, the EFA identified that the items were valid, and are usable in further tests for the different demographic regions for intention to promote social change for green business sustainability. Moreover, the
Figure 2 of the scree plot also shows that the component number is reliable in further statistical analysis, such as to test the internal consistency of measurement scales.
Measurement Scales of Internal Consistency—Reliability and validity are very important to obtain information on survey questionnaires for individual items respondents have voiced their opinion on [
36,
47]. However, reliability measures consistency, and validity measures the accuracy of the data [
47]. The
Table 4 shows the reliability and validity tests executed on the empirical data to obtain their parameters, such as Cronbach’s alpha (α). A value of Cronbach’s alpha (α) ≥0.70 is desirable, while >0.80 is high in social science research [
36]. One of the well-known tests for reliability statistics in the procedure method is called Cronbach’s alpha [
36,
48]. Cronbach’s alpha is a common method to measure reliability when calculating the reliability score to recap the information of numerous items in questionnaires [
49].
The
Table 4 confirms that the internal consistency of the measurement items achieve more than the desired value of >0.70 [
36,
48]. The reliability of skills alpha (α) is 0.88, and the validity level is above 0.30, which is good, as the cut-off line of validity is 0.30 [
46,
50]. However, the alpha value for incentives is 0.84, entrepreneurship education is 0.86, green entrepreneurship is 0.82, and entrepreneurial intention to promote social changes is 0.86, which all demonstrate that the constructs are reliable with the validity scores of the corrected item–total correlation. Indeed, each item of Cronbach’s alpha is reliable and valid. Thus, the variable of each α is >0.70, and the validity of each item is confirmed as >0.30, and thus their parameters are indicated to have strong internal consistency [
50]. Therefore, skills, incentives, entrepreneurship education, green entrepreneurship, and entrepreneurial intention to promote social change parameters are confirmed as items that can be demonstrated in empirical survey data for further statistical analysis. Nevertheless, the following section elaborates on the SEM analysis using SmartPLS to validate the structural model to test the hypotheses.
4.2. Structural Equation Model
In the structural equation model, there are two types of analysis. The first analysis is called the partial least square (pls) SEM algorithm, and the second is called the bootstrapping analysis [
26,
27,
28,
39,
51]. Therefore, the following point is first illustrated by the PLS-SEM algorithm and secondly by the bootstrapping model [
39,
40,
51,
52].
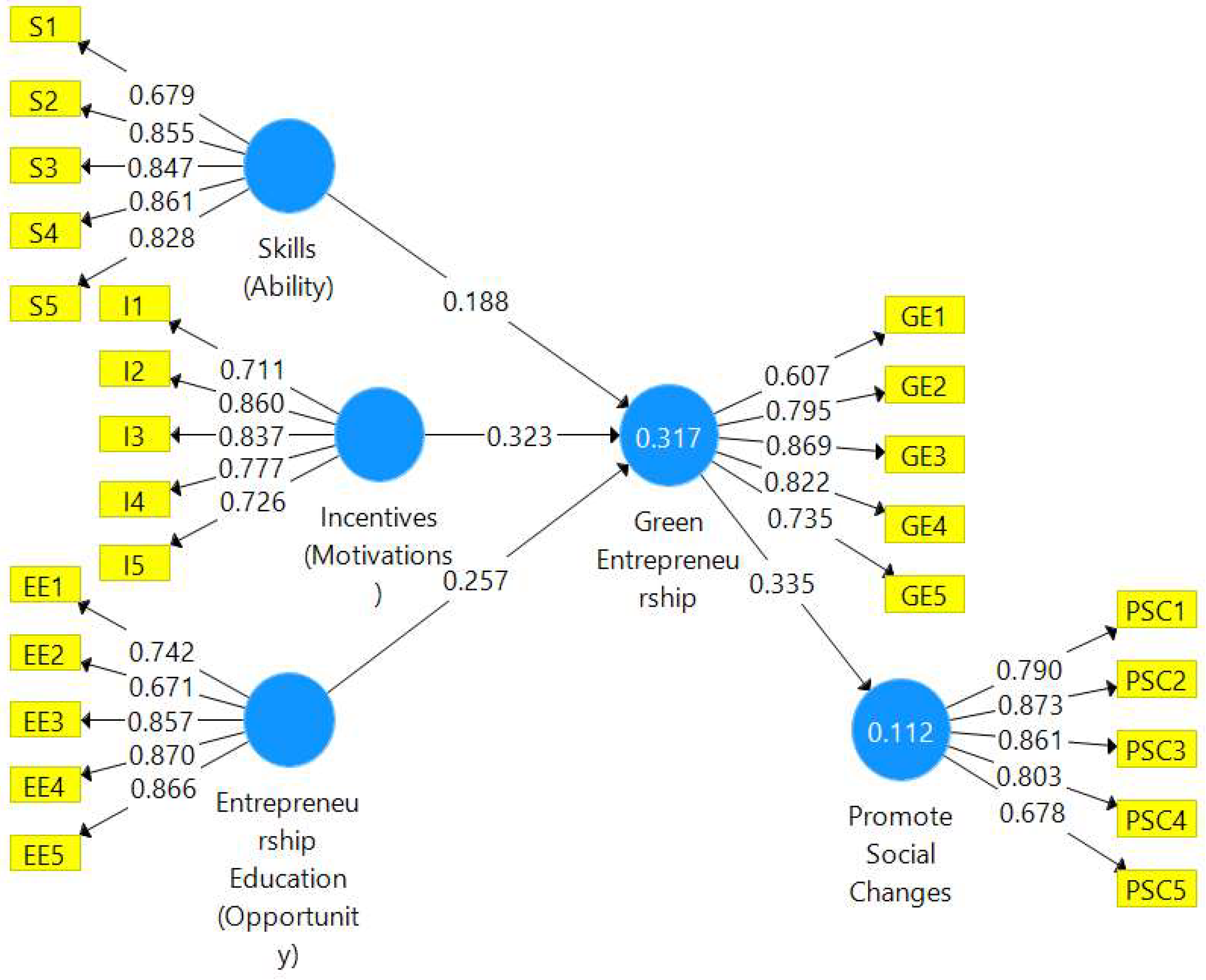
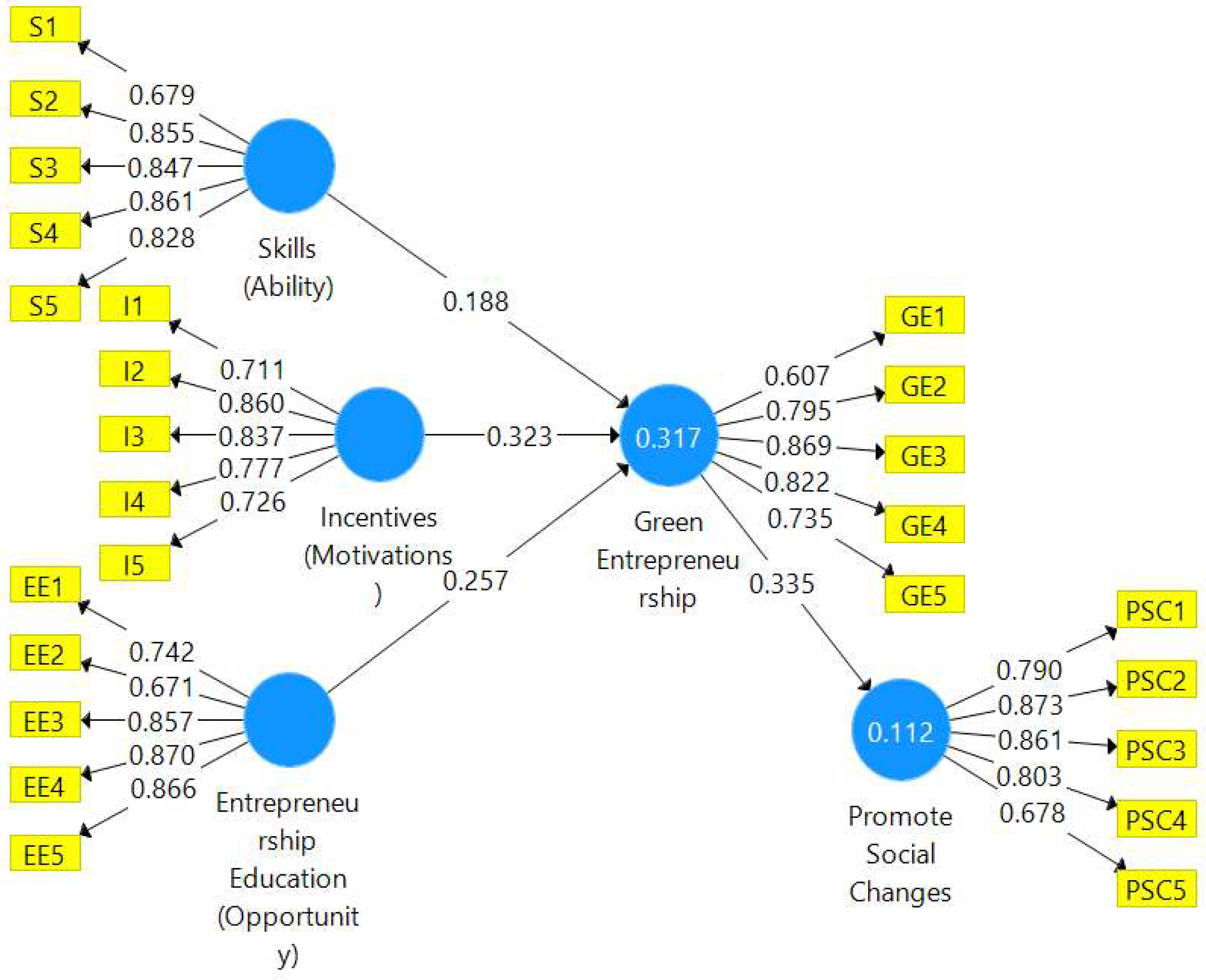
PLS-SEM Algorithm—The
Figure 3 of the measuring model is executed by SmartPLS which provides the inter-consistency of survey items for the value of path coefficients (β), outer loadings, construct reliability and validity, discriminant validity, and collinearity statistics. Therefore, the consequent parameters are explained below.
PLS-SEM Algorithm—A number between −1 and +1 is the correlation coefficient [
53]. A correlation coefficient greater than 0.6 is sufficient for a student of natural, social, or economic science, whereas correlation coefficients less than 0.3 are regarded as weak, between 0.3 and 0.7 as moderate, and greater than 0.7 as high [
53]. From the
Figure 3, the path correlations between skills and entrepreneurship education toward green entrepreneurship can be seen to be less than 0.30, i.e., 0.188 and 0.257 with positive but weak relations. Likewise, the correlation between incentives and green entrepreneurship is r = 0.323, which has a moderate and positive relationship. However, the mediating variable of green entrepreneurship and the dependent variable of entrepreneurial intention to promote social change is r = 0.335, which is also a positive and moderate association. Therefore, the path correlation coefficients illustrate that the correlation coefficients are positive between all of them.
Outer Loadings—The outer loadings, for instance, arrows from the latent variable to its indicators, are estimated connections in reflective measurement models [
40]. The absolute contribution of an item to its assigned construct is determined by its outside loadings once the loading is ≥0.70 [
45]. Though, the range between 0.50 and 0.70 is also acceptable if the HTMT and AVE criterion is reached at the desired value, which is better to assess the discriminant validity [
54]. The PLS algorithm demonstrates more than 0.70 for the outer loadings, except for 4 items out of 25. However, the following discriminant validity is checked and no issues are found for Fornell–Larcker or HTMT, despite the cross-loadings of each item. Therefore, the outer loading is estimated as the connection with the latent variables that are demonstrated without any issues and assessed with discriminant validity.
Construct Reliability and Validity—The construct’s reliability and validity is an assessment of the internal consistency for the constructs such as Cronbach’s alpha, rho_A, composite reliability (C.R.), and AVE (average variance extracted) [
39,
40,
45,
51,
55].
The
Table 5 displays that the phenomenon of Cronbach’s alpha, which measures the internal consistency of the construct, was attained at more than 0.70 with all of the variables [
52]. Therefore, each scale item measured the construct closely. On the other hand, the value of rho_A demonstrates whether the value between Cronbach’s alpha and composite reliability is achieved or not [
55]. Nevertheless, the rho_A demonstrated in the
Table 5 shows that every construct is in between Cronbach’s alpha and composite reliability. Therefore, the value of rho_A perfectly aligns with one of the assessments of internal consistency. Thirdly, the value of composite reliability generated above 0.70 for each construct is similar to Cronbach’s alpha, which is measured by the item for internal consistency. However, C.R. offers a smaller amount of biased calculation than Cronbach’s alpha, provided the construct is reliable and valid. However, the AVE is the mean of the squared loadings of each indicator connected to a build used to compute the AVE [
45,
52]. Once the average variance extracted (AVE) value is more than 0.50, convergent validity is demonstrated statistically [
45,
55,
56]. However, the
Table 5 shows that the AVE is achieved as greater than 0.50. Thus, convergent validity is statistically demonstrated, and there is no issue convergently. Indeed, the assessment for construct reliability and validity is established by every phenomenon.
Discriminant Validity—The level of differentiation and asymmetry between the components is referred to as discriminant validity. According to the rule, variables should have stronger relationships with their factor than with another factor [
54]. The
Table 6 displays the first discriminant validity illustrated [
52]. It can be seen that entrepreneurship education is more significant than in the column, and green entrepreneurship, incentives, promoting social change, and skills are higher than every column of their engaged row and column.
Fornell–Larcker, cross-loadings, and the outcomes of the HTMT criteria are used to evaluate discriminant validity [
54]; however, it is widely recommended to establish discriminant validity using Fornell–Larcker and the HTMT criteria [
54]. Likewise, discriminant validity between two reflective conceptions is proven, and if the Fornell–Larcker has a higher value in the same row and column, and the HTMT value is less than 0.90, then discriminant validity is established [
39,
54]. Therefore, the
Table 7 shows that discriminant validity is established, as every construct is less than 0.90. Therefore, the discriminant validity is established through Fornell–Larcker and HTMT [
52].
Collinearity statistics—The variance inflation factor (VIF) is examined to determine the degree of collinearity statistics in PLS-SEM [
57,
58]. There are two often used guidelines: if the VIF value is 5 or greater, there may be a collinearity problem [
54]. Indeed, in the measurement items, there are no values which are less than 4. However, the VIF values are mostly less than 3. Therefore, no collinearity issues in the measured items are found, and all of the PLS algorithms have provided outputs that are desirable. Thus, we can continue to the path analysis for the hypotheses test predicted by the literature with the deductive approach.
4.3. Bootstrapping of the Path Model
With the path model, it is possible to assess the statistical significance of different PLS-SEM outcomes, such as path coefficients and r-square (R
2) values, using the nonparametric approach of bootstrapping [
51,
54]. Consequently, the following bootstrapping model and results are clarified.
Path Coefficients—Path coefficients are normalized versions of linear regression weights that may be employed in the structural equation modeling technique to investigate potential causal relationships between statistical data [
51].
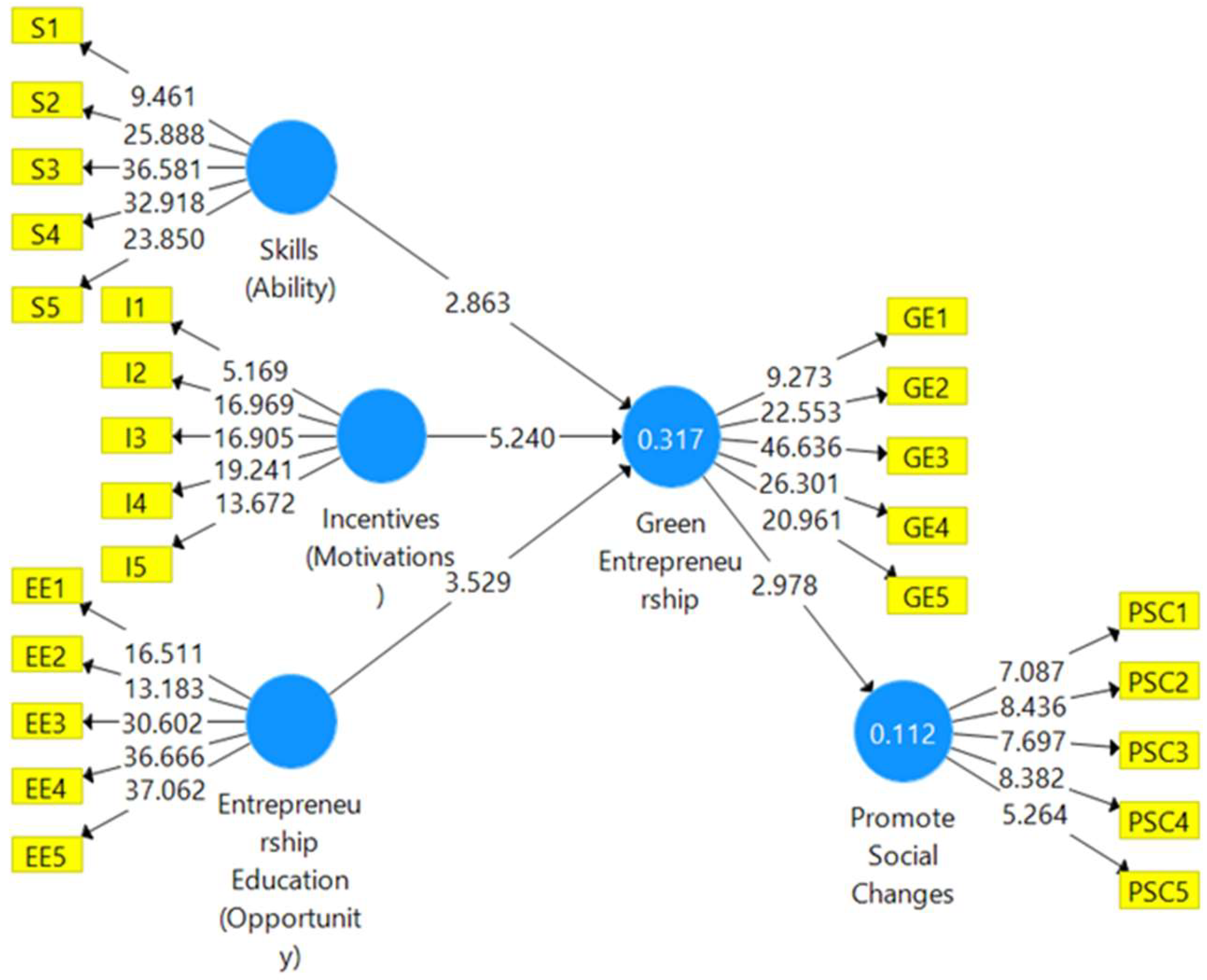
The
Table 8 confirms the two most common components, t-statistics and the
p-values, are achieved by the cut-off value [
52]. However, if the t-statistic is 1.96, then it becomes significant when the
p-value is ≤0.05 [
40,
45,
50,
55,
59]. The path direction of hypothesis, H1, is accepted for skills → green entrepreneurship: the t-statistic is 2.863 and the
p-value is 0.004, which is ≥1.96 for the t-statistic, and ≤0.05 for the
p-value. Therefore, hypothesis H1 is established by the literature and is confirmed as statistically significant. The factor of skills is strongly associated with green entrepreneurship. Thus, if students have the opportunity to develop their skills at university level then the business will be aligned with the green concept that is demonstrated in emerging nations such as Bangladesh [
3,
9,
10,
18]. The second hypothesis, H2, of incentive → green entrepreneurship is illustrated at the desired level: the t-statistic is 5.24 and the
p-value is 0.000, which is greater than 1.96 and less than 0.05, respectively. Therefore, in this scenario, the student is motivated to start the business and also has a positive significant association with green entrepreneurship. Thus, incentive has more power to motivate university students to think green [
3,
18,
20]. Likewise, if we look at the third hypothesis, H3, the relationship of entrepreneurship education → green entrepreneurship is also strongly related: the t-statistic is 3.529 and the probability level is 0.000. Therefore, hypothesis H3 achieved more than 1.96 and a
p-value smaller than 0.05, which means that proper guidance and practical learning have a strong relationship. Moreover, opportunity allows students with a positive mindset embrace a green approach [
18,
32]. Nevertheless, the final hypothesis is also confirmed by the empirical data: the t-statistic is 2.978 and the
p-value is 0.003. Therefore, hypothesis H4 is accepted, confirming the significant relationship (
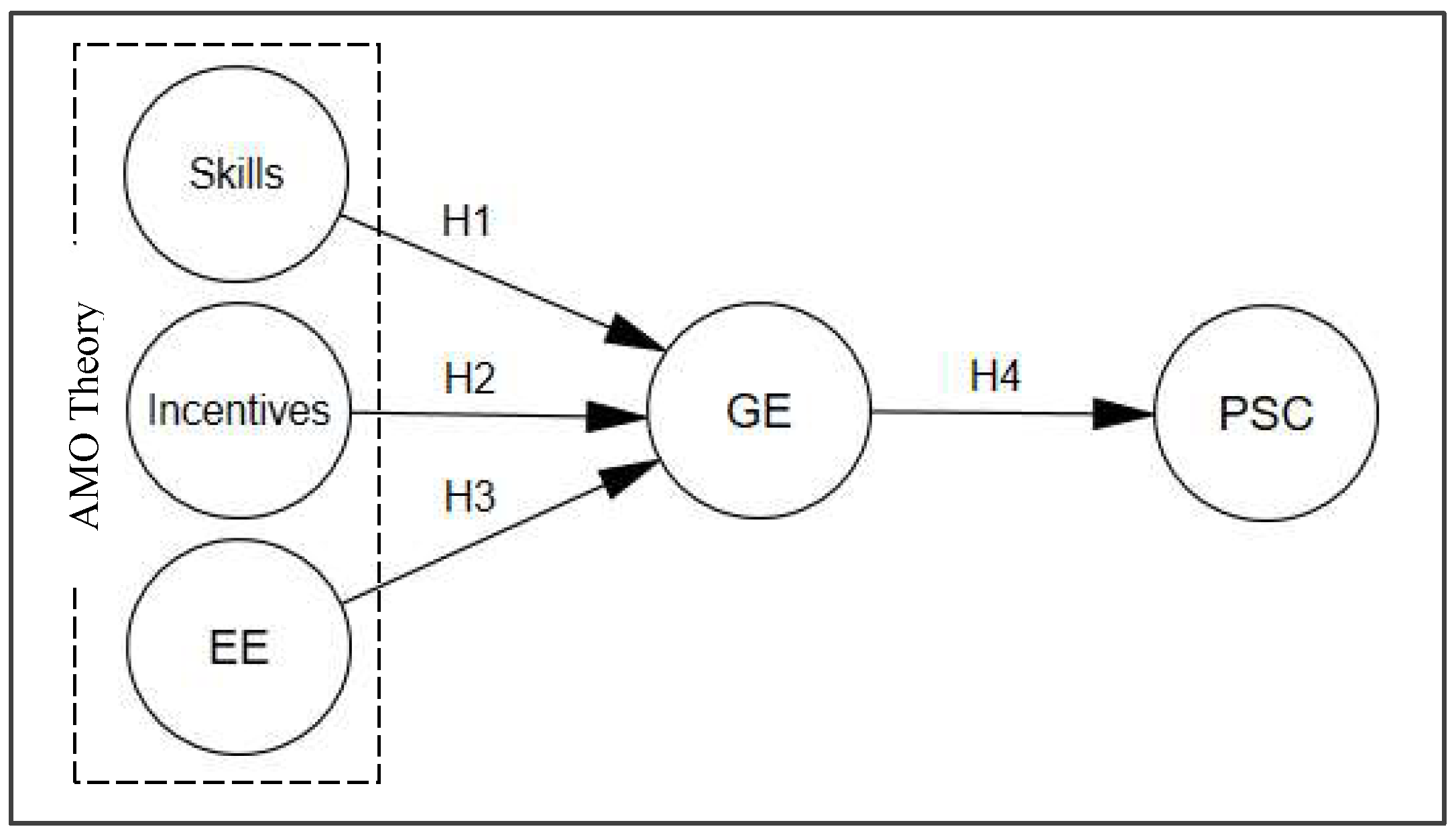
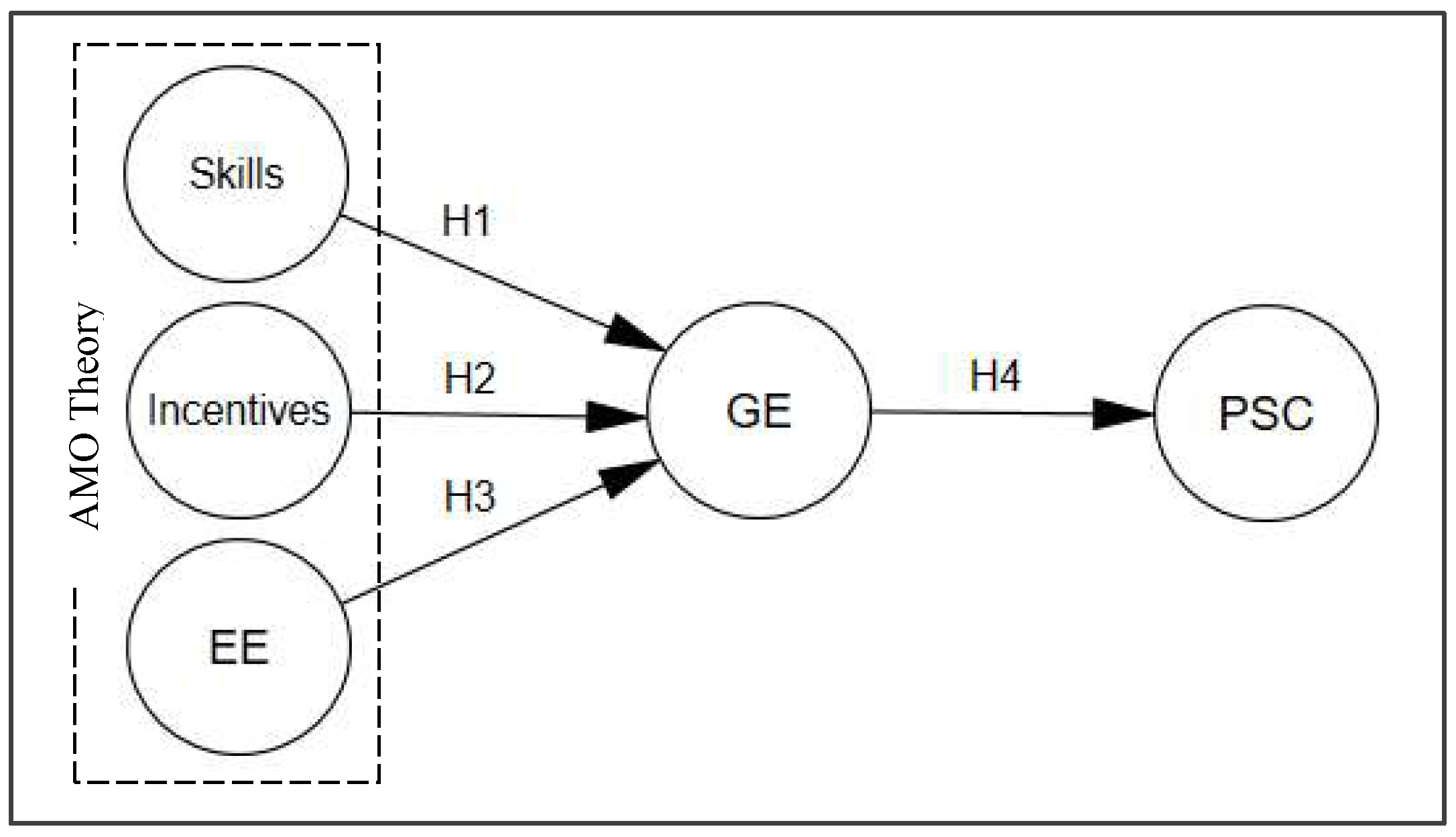
Figure 1). An entrepreneurship education encourages businesses to think green by installing solar panels, employing eco-friendly businesses, and undertaking recycling operations. Many prospective businesses can be considered green enterprises by embracing creative opportunists and ethical views [
6,
18,
20]. Indeed, the four hypotheses are demonstrated to be statistically significant by the survey data, in which respondents offered their opinion on a Likert scale of 1 to 5 points.
The
Table 9 displays the specific indirect effects of mediation between skills and promoting social change with green entrepreneurship, which are closely related. However, the t-statistic is 1.90 and the
p-value is 0.058; thus, the cut-off line of the t-value should be 1.96, and the
p-value becomes 0.05 [
40,
45,
50,
55,
59]. Therefore, the mediation of skills and promoting social change through green entrepreneurship have a poorly fit indirect relationship. On the second mediation between incentives and promoting social change, a statistically significant relationship is demonstrated through green entrepreneurship. The value of the t-statistic is 2.22 and the
p-value is 0.27, which is more than 1.96, and the
p-value is achieved at less than 0.05. Eventually, the mediation between entrepreneurship education and promoting social change through green entrepreneurship achieved a significant and positive association. The t-statistic is 2.14 and the
p-value is 0.033, which is greater than the cut-off line of the t-value with a statistically identified
p-value as well. Therefore, the conceptual model demonstrates hypothetical and statistical significance with direct and partial mediation as well, and the four hypotheses are positively significant with mediation.
R2 (r-square)—The values of R
2 vary from 0 to 1, and they are frequently expressed as percentages from 0% to 100% [
39,
55]. Therefore, the R
2 of 100% indicates that changes in the independent variable fully explain all changes in another dependent variable. However, from the
Figure 4 displays that the value of R
2 is 0.317 for green entrepreneurship, which is around 32% of that predicted by the variables of skills, incentives, and entrepreneurship education [
60,
61,
62]. Entrepreneurial intention to promote social change is 0.112, which is 11% influenced by green entrepreneurship. Therefore, the rest of the influence might be other predictable variables. However, the dependent variable was influenced poorly at only 11% by green entrepreneurship, whereas 89% (100–11) might be other predicted variables. Therefore, the research hypotheses demonstrate that the research model is valid and it will be helpful for students to adopt a green mindset instead of traditional propensity.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}