1. Introduction
Electric Vehicles (EVs) have become prominent these days as a result of their eco-friendliness and cost-saving characteristics [
1,
2]. Widespread adoption of electric vehicles (EVs) depends on the optimal placement of charging stations (CSs) [
3]. In recent years, the need to place CSs efficiently and plan CS needs for a region has turned into an important concern for urban planners and the public alike. Moreover, it has been found that service providers prefer clustering instead of separation in the EV charging market [
4]. Therefore, the electric vehicle charging station placement (EVCSP) problem, which tries to identify a CS for each EV such that the total distance traveled by EV owners for charging at the nearest CS is minimized, and tries to determine the CS need estimation for a region, have become two major research problems of EV charging station planning [
3,
5,
6,
7].
EVCSP solutions try to reduce the distance that the EV will travel to access the charging station and this impacts the state of the charge (SoC) of the electric vehicle [
8]. Moreover, the proper location of the CS reduces the total expected cost of the charging process and increases the EV owner’s convenience [
9]. A good CS need estimation for a region improves the customer satisfaction-involved operational cost, while considering the potential uncertainties [
10].
In previous studies, EVCSP solutions have been developed by focusing on any one system based on a clustering method [
11,
12] or Geographical Information System (GIS) [
13] or market survey, which often focus on spatial relationships to identify prime locations for CSs. Moreover, these methods have not been evaluated either quantitatively or qualitatively for a single planning area. In addition to this, the current CS needs estimators are based on weird adjustment factors and these estimations are also unexplainable [
14,
15]. Furthermore, these estimators have not considered future estimates of CS needs for the planning areas and they have not involved increasing EV penetration in these estimates.
In the majority of EVCSP solutions, the evaluation has been done predominantly using a single metric like the EV distance to the nearest CS, i.e., from an EV user’s perspective but not from a clustering efficiency perspective, i.e., urban planners or policy makers. Multiple metrics, i.e., (a) CS placement metrics and (b) clustering metrics, have been considered for EVCSP to evaluate if the clustering is good or not from a clustering perspective and an EV owners perspective, i.e., an acceptable distance to the nearest CS. These EVCSP metrics are explained in
Section 2.2.
In our work, quantitative and qualitative metrics have been involved to investigate optimal CS placements and aid in decision making. Different perspectives, such as the clustering efficiency from an urban planner perspective, and an EV owners perspective, i.e., an acceptable distance to the nearest CS, provide multiple results with trade-offs. These results can be used to guide urban planners in making better CS placement approval decisions when many CSs (in the order of hundreds or more) need to be placed for charging at different locations of a planning area in an efficient manner, i.e., considering the clustering efficiency, the EV owners convenience, and the visual analysis of the system. Using our CS need estimation methods urban planners can estimate the CS need range, i.e., minimalist need, actual need, and future need, to take an appropriate decision on the CSs required in a planning area. These methods also allow decision makers to prepare for the future by using estimates of CS needs with increasing EV penetration (EVP). Moreover, our work provides EV owners an explainable SoC recommendation to go for charging with a high success rate in finding a CS nearby.
CS need estimation [
14,
15] is another problem that has been solved traditionally using theoretical calculations using some assumptions like adjustment factors or constants. The average SoC of EVs in a planning area, EV penetration (EVP), and the average driving range of EVs are considered independently in existing works and not as a combined factor for CS size planning. How CS planning can be re-estimated for an area in a city with a changing EVP is also not available. Currently, there are no recommendations for EVs in a planning region indicating when to go for charging to have a better chance of finding a reachable CS.
Most research on CS need estimations is limited to traditional approaches described in
Section 2.3. Besides, previous studies have not dealt with key parameters such as SoC, the EV driving range, and the Average Travel Distance (ATD) of EVs simultaneously and an impact analysis considering these parameters has not been undertaken. Furthermore, most of the works have either used only a simulated system [
16] or a real system [
6,
17,
18,
19,
20,
21], but their investigations for CS need estimation are limited, as an analysis is not made for future requirements in these areas. This could be attributed to the reason, that these investigations require large-scale simulations, considering the planning area population or density, SoC, EV Driving Range, EV penetration (EVP), and the Average Travel Distance (ATD) of EVs, to estimate the needs for the future. We address some of these practical aspects in
Section 4.2 and
Section 4.3 of our work.
In most of the works, CS need estimation is undertaken for either a simulated distribution system [
16] or for some city planning areas in India [
17], China [
19], Singapore [
18], Australia [
21], Japan [
20], the UK [
6] and the US [
22]. However, limited investigations [
20,
23] have been done which consider the EVP in the planning areas and also the trend analysis on distances versus several installed CSs.
The present work is distinct in that we answer some of the practical questions of EV users and urban planners: (i) Given a city and a layout with several CSs, what is the standard recommendation of SoC for EV users to go for charging with a high success rate in finding a CS nearby? (ii) Given the EVP of an area and the quality of service, i.e., SoC, what is the CS requirement? (iii) How does the CS need planning change when the EVP changes in a planning area? In other work [
24], EV charge scheduling solutions have been proposed and evaluated considering the charging rates, traffic congestion, scalability, and waiting time at a charging station.
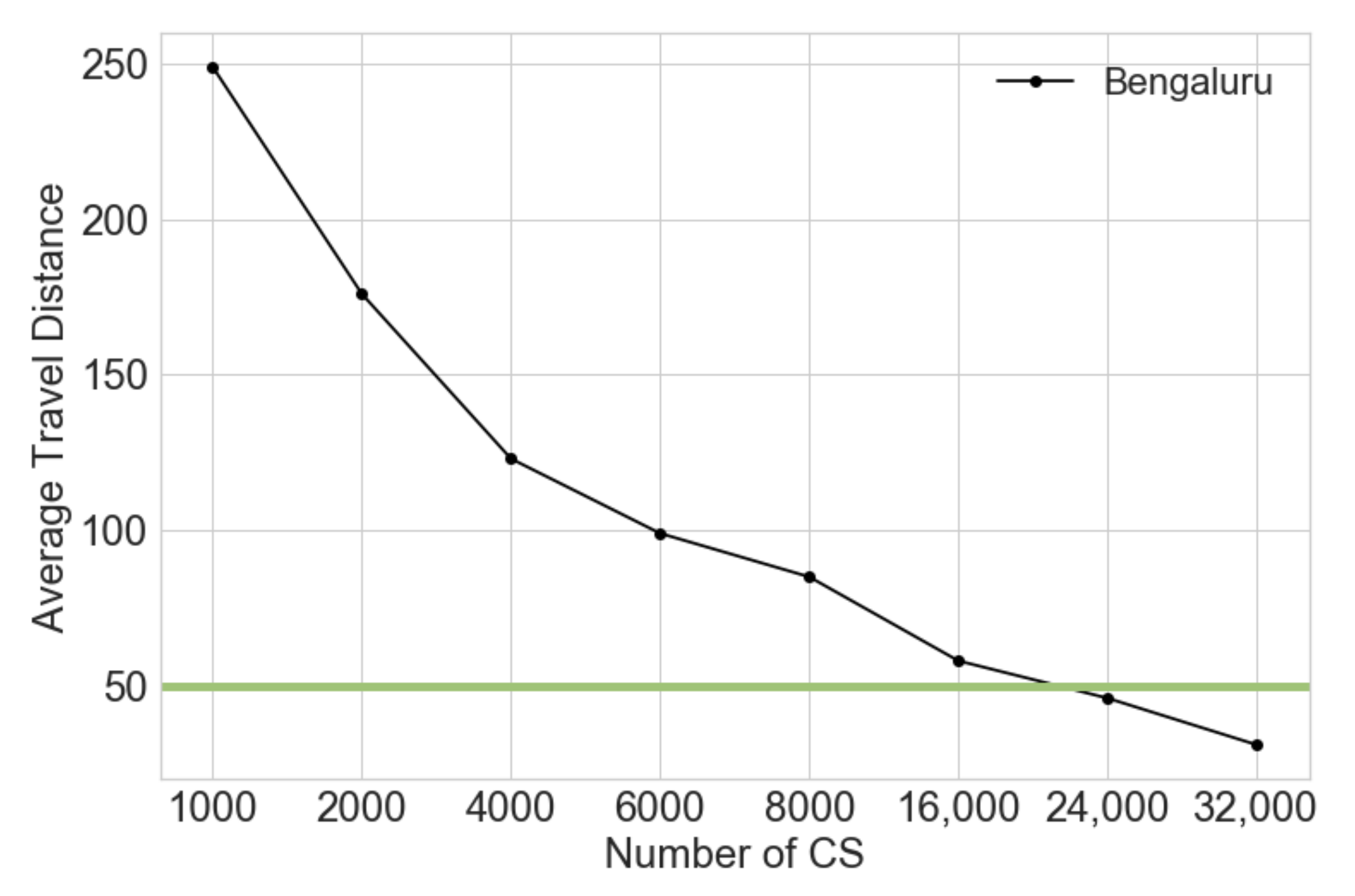
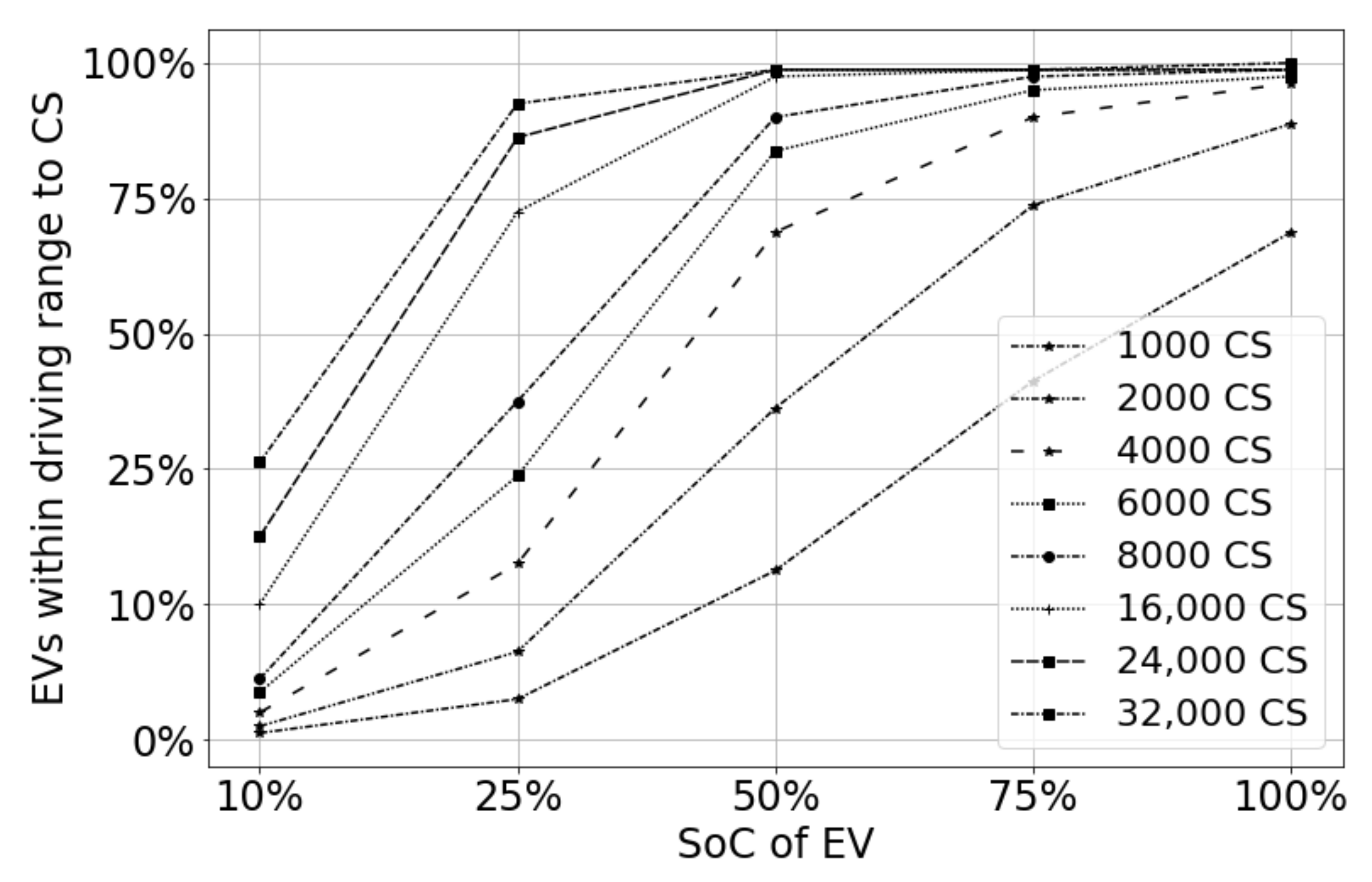
In our work, we have undertaken an impact analysis of key parameters, such as SoC, EV driving range, Average Travel Distance (ATD) of EV for a given SoC, and most importantly EVP, on the CS need estimation. We investigate some of the relationships between key CS need estimation parameters: (i) the CS size vs. EV allowable driving range relationship, (ii) the EV ATD and the number of installed CSs for different EVPs, and (iii) the CS need estimation variation with a varying EVPs for different SoCs. Another major contribution of this work is in identifying the CS size for a planning area without any adjustment factors, unlike traditional methods. Furthermore, the differences in CS estimation using (a) theoretical calculation, (b) machine learning, and (c) simulation were identified.
Overall, the key contributions of this paper are as follows:
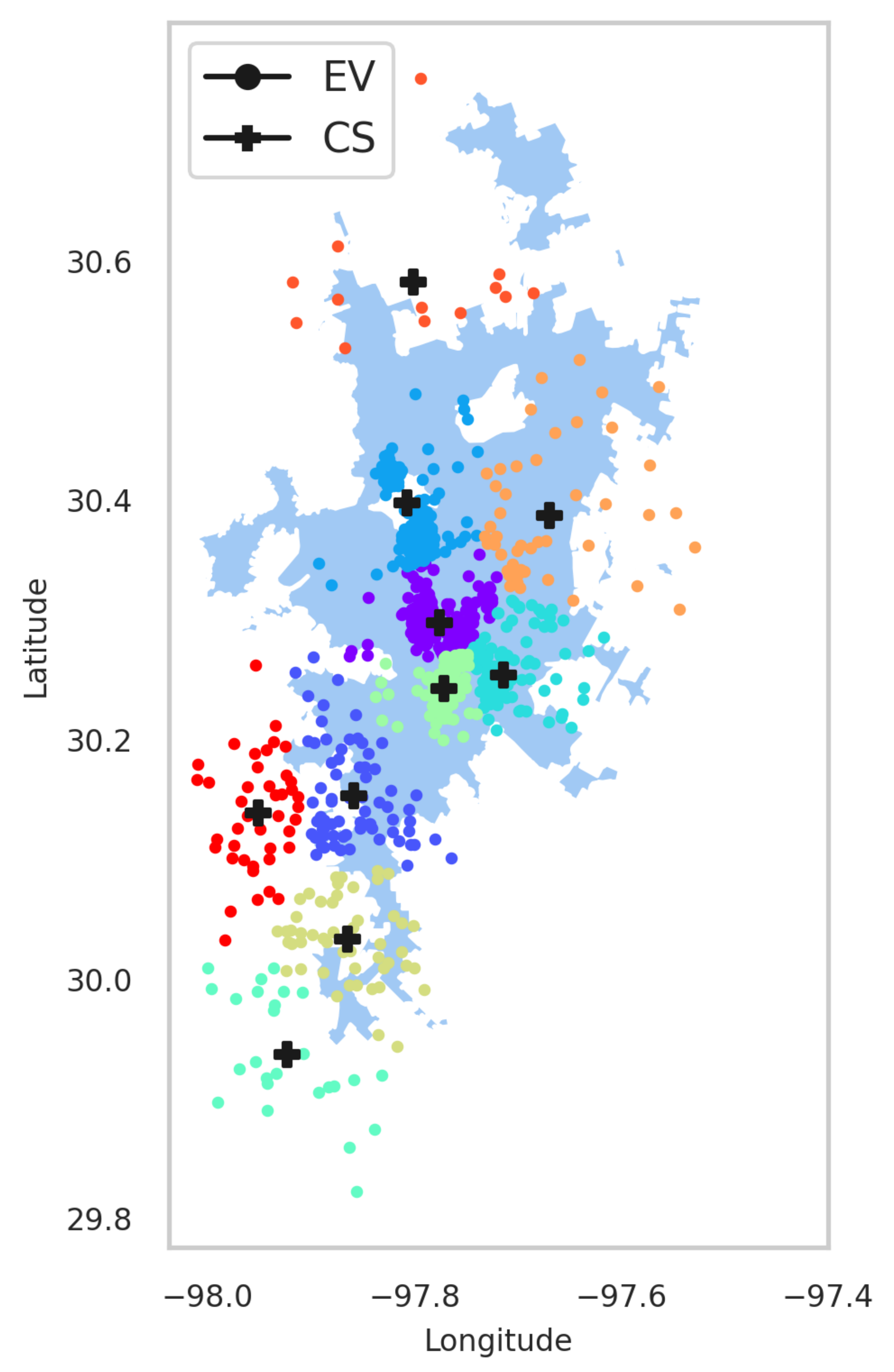
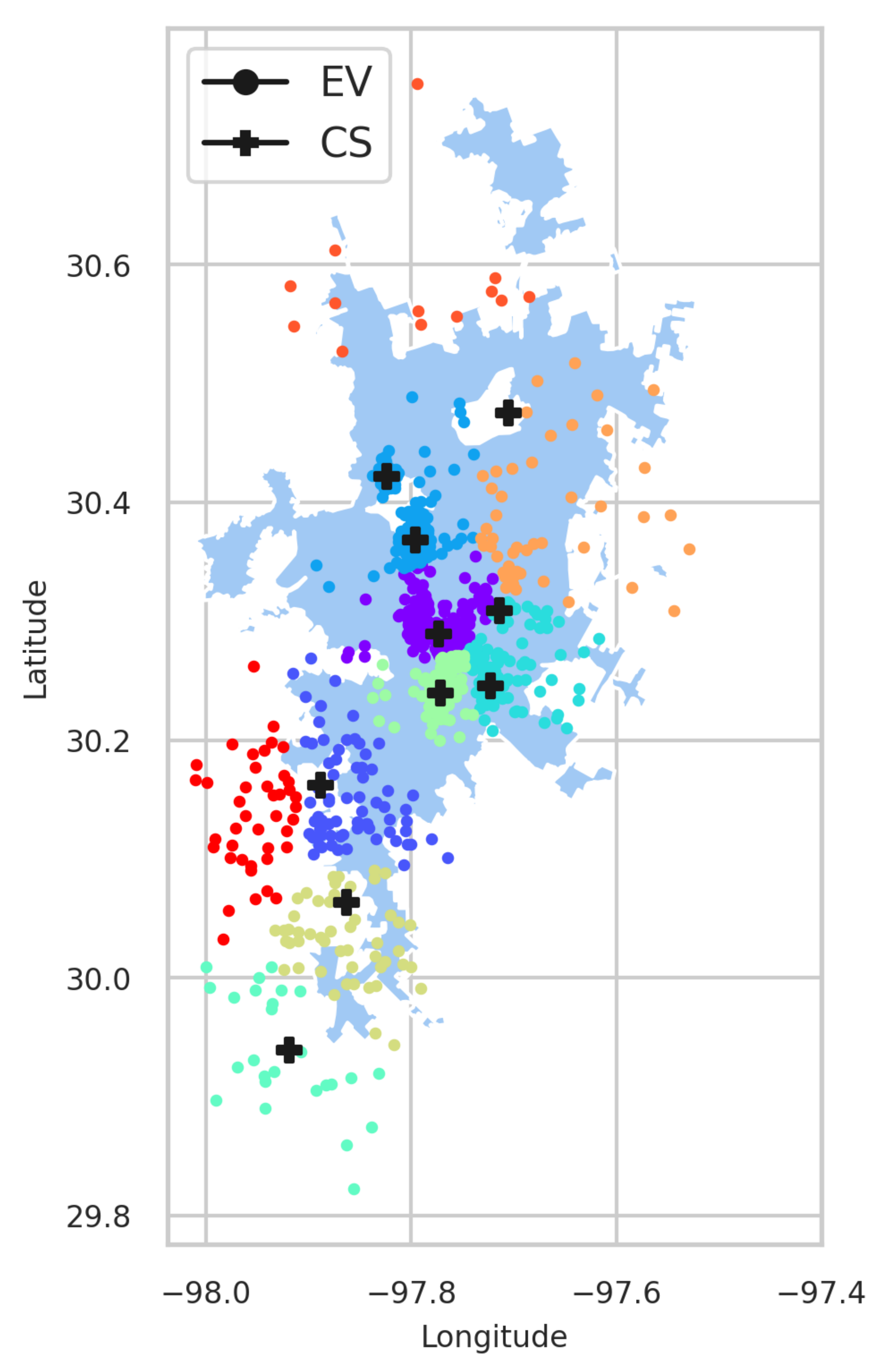
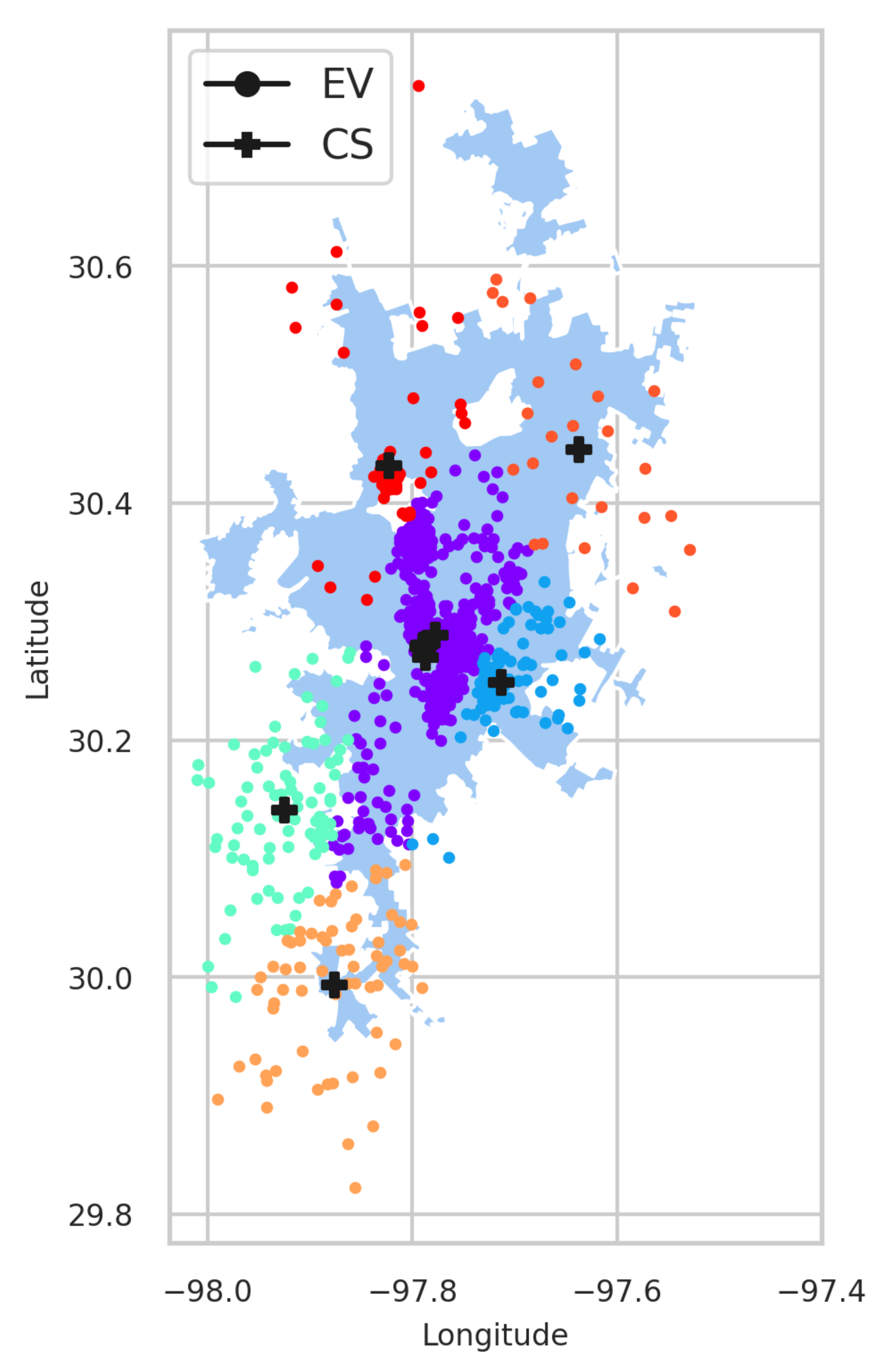
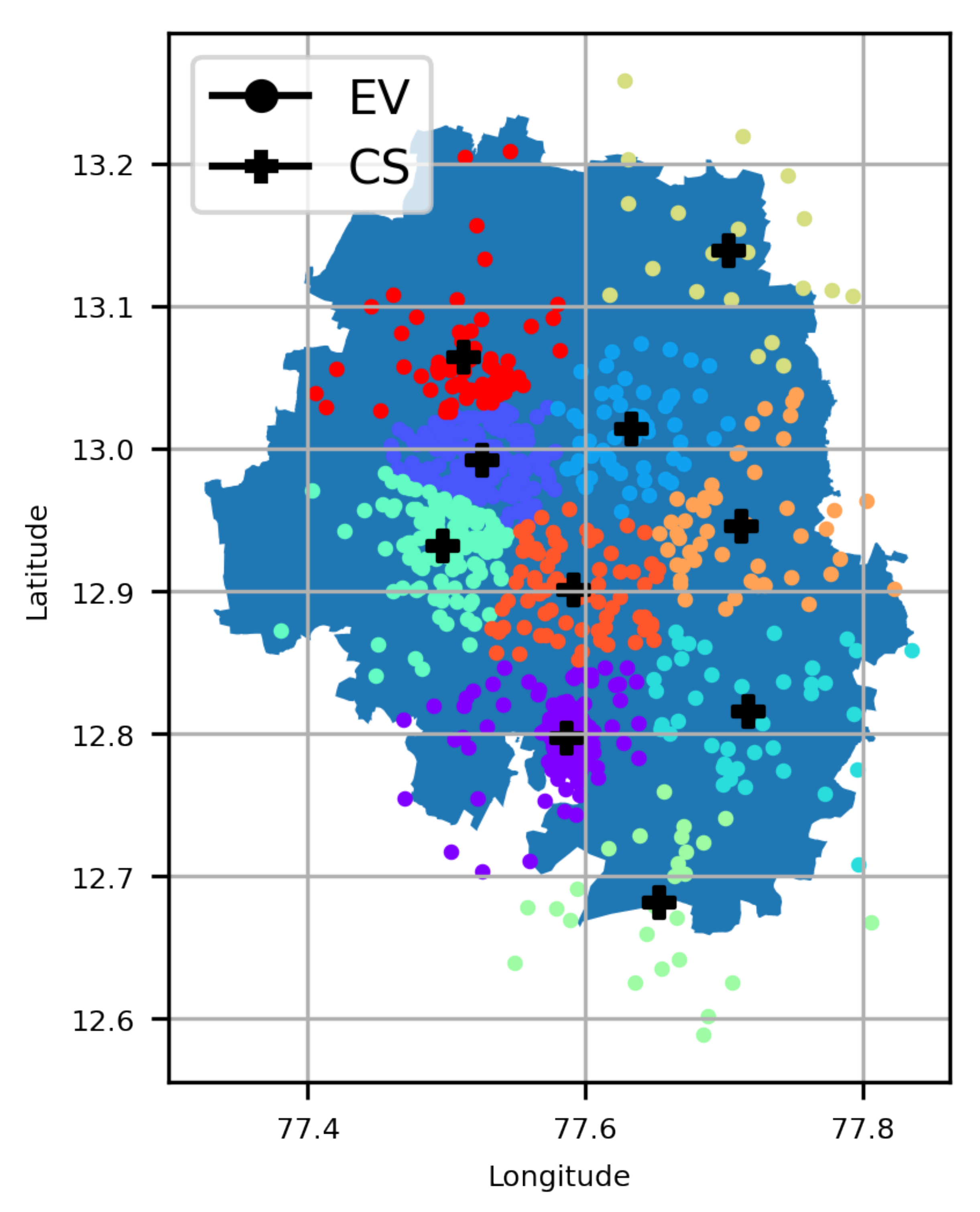
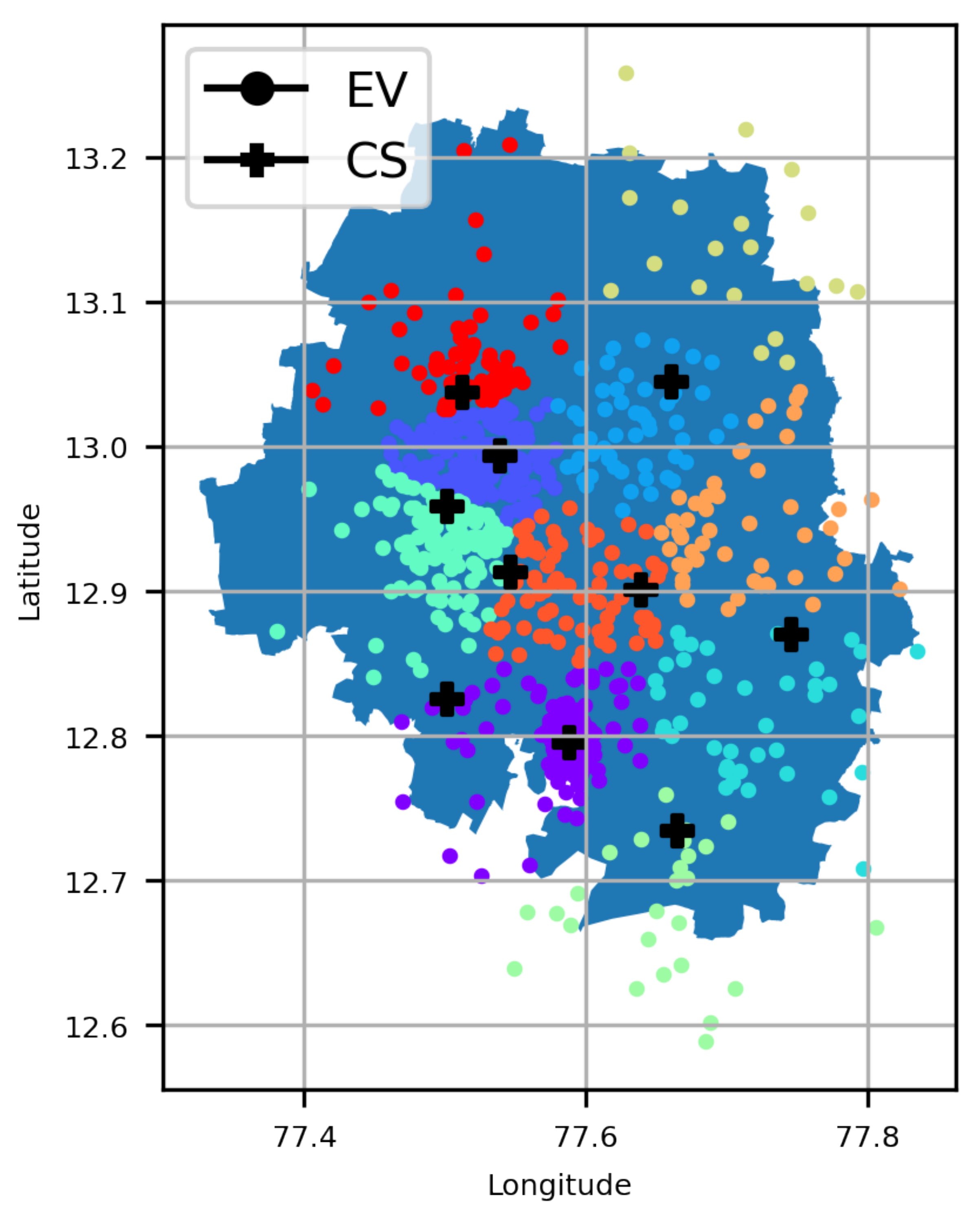
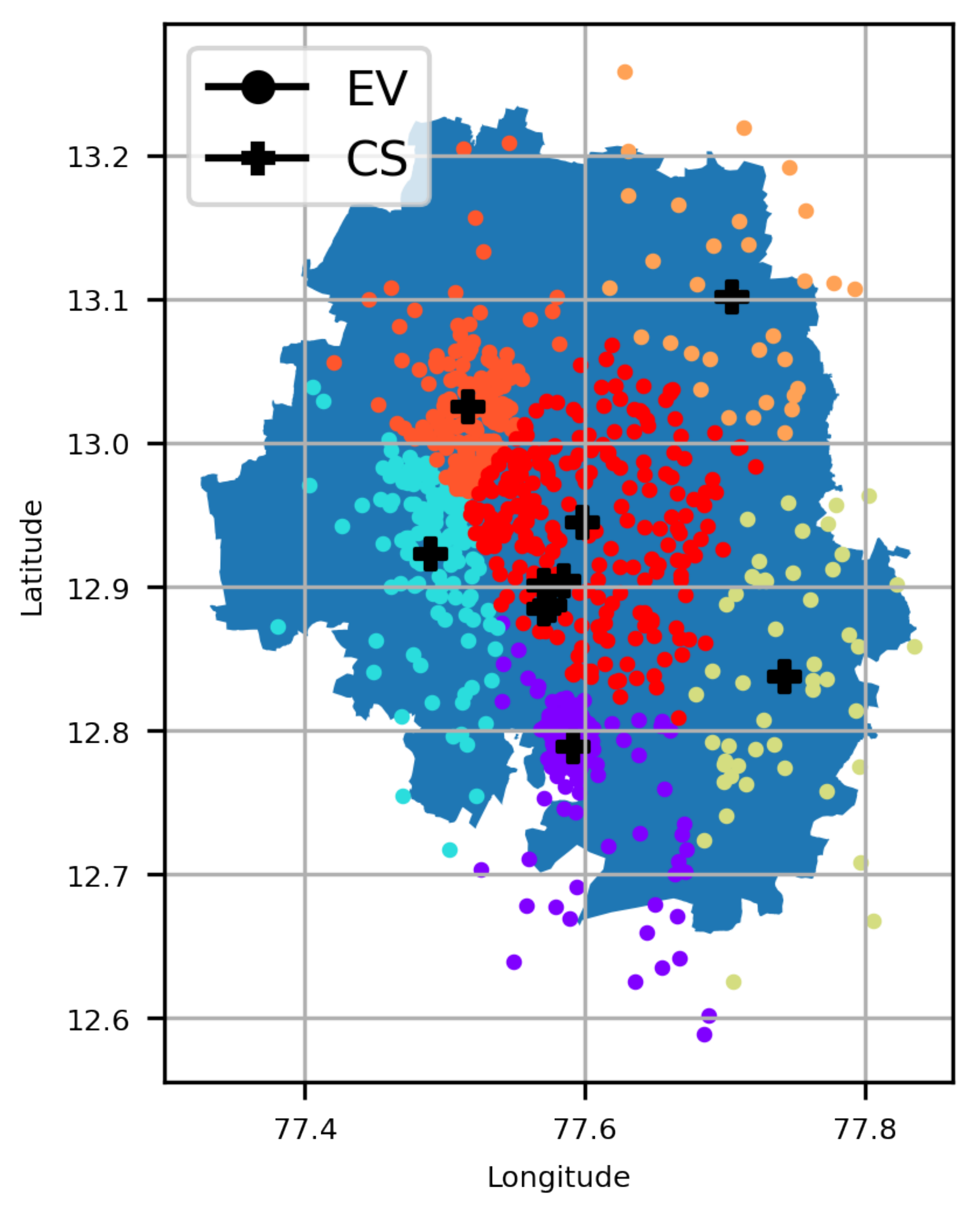
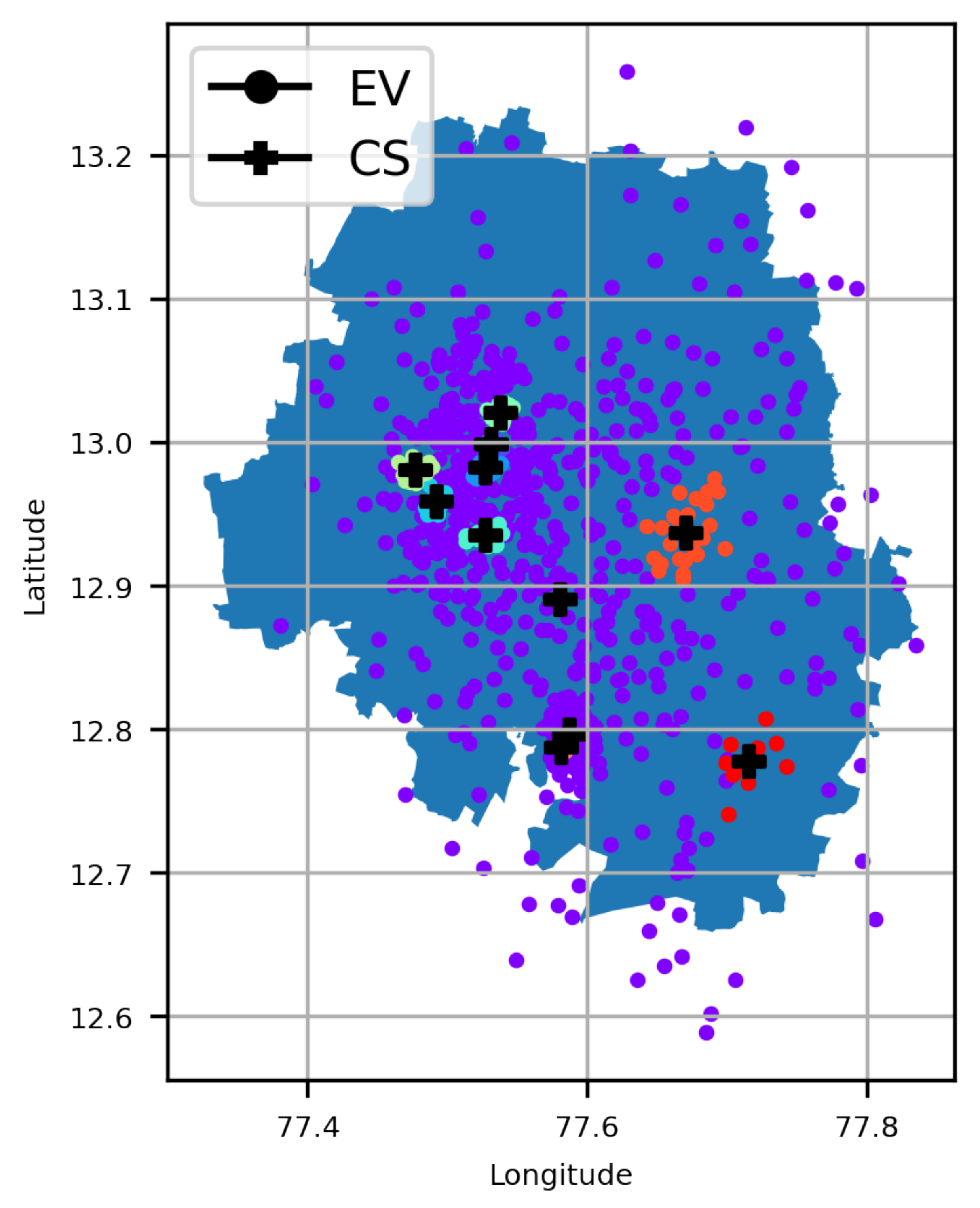
A major contribution of this work is the investigation of optimal CS placement, i.e., EVCSP solutions using (i) different classes of clustering solutions, i.e., mean-based, density-based, spectrum- or eigenvalues-based, and Gaussian distribution; (ii) multiple metrics, i.e., (a) CS placement metrics and (b) clustering metrics, to evaluate if the clustering is good or not from a clustering perspective and an EV owners perspective, i.e., an acceptable distance to the nearest CS; and (iii) a visual understanding of the pros and cons of actual CS placements.
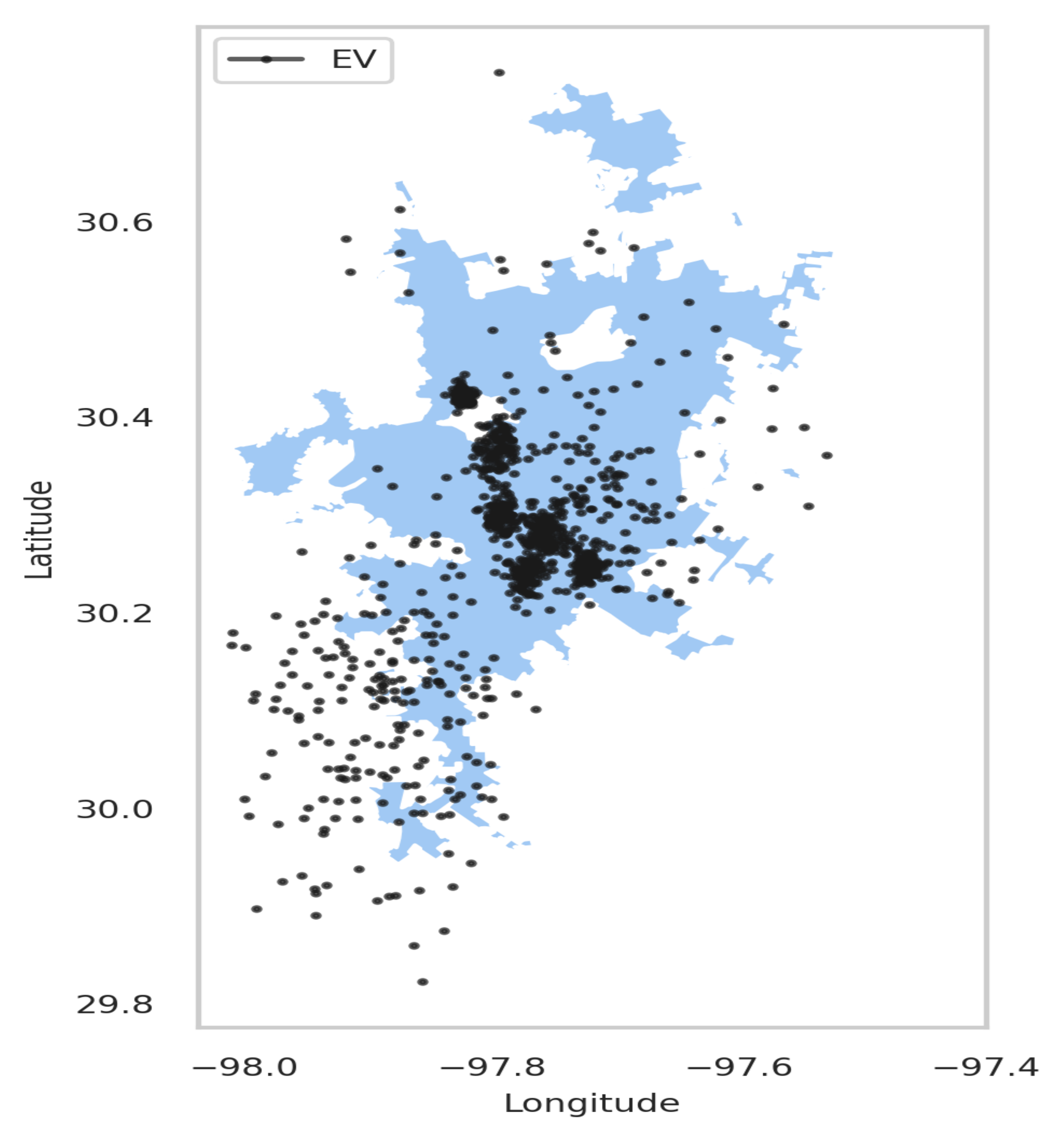
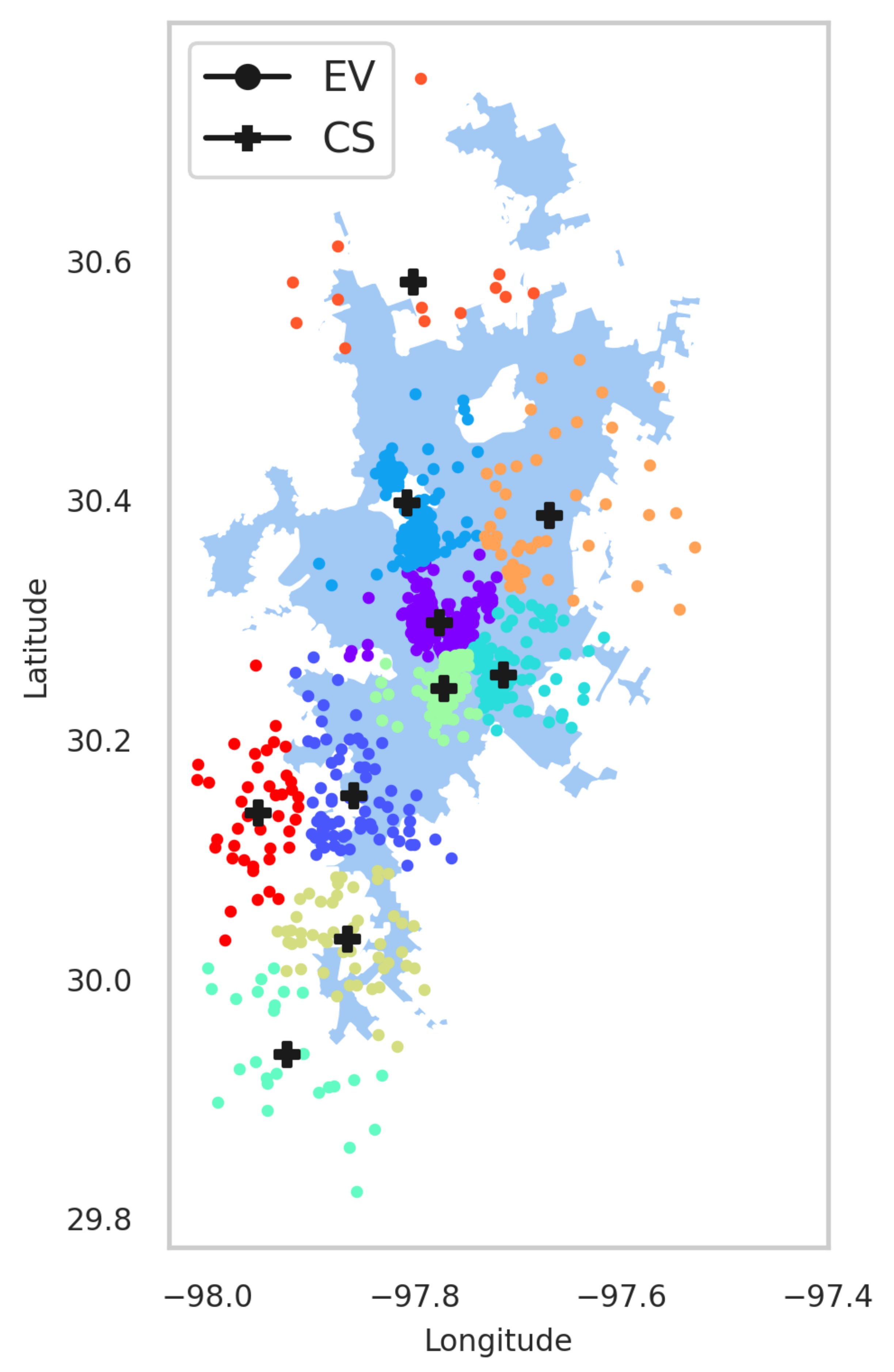
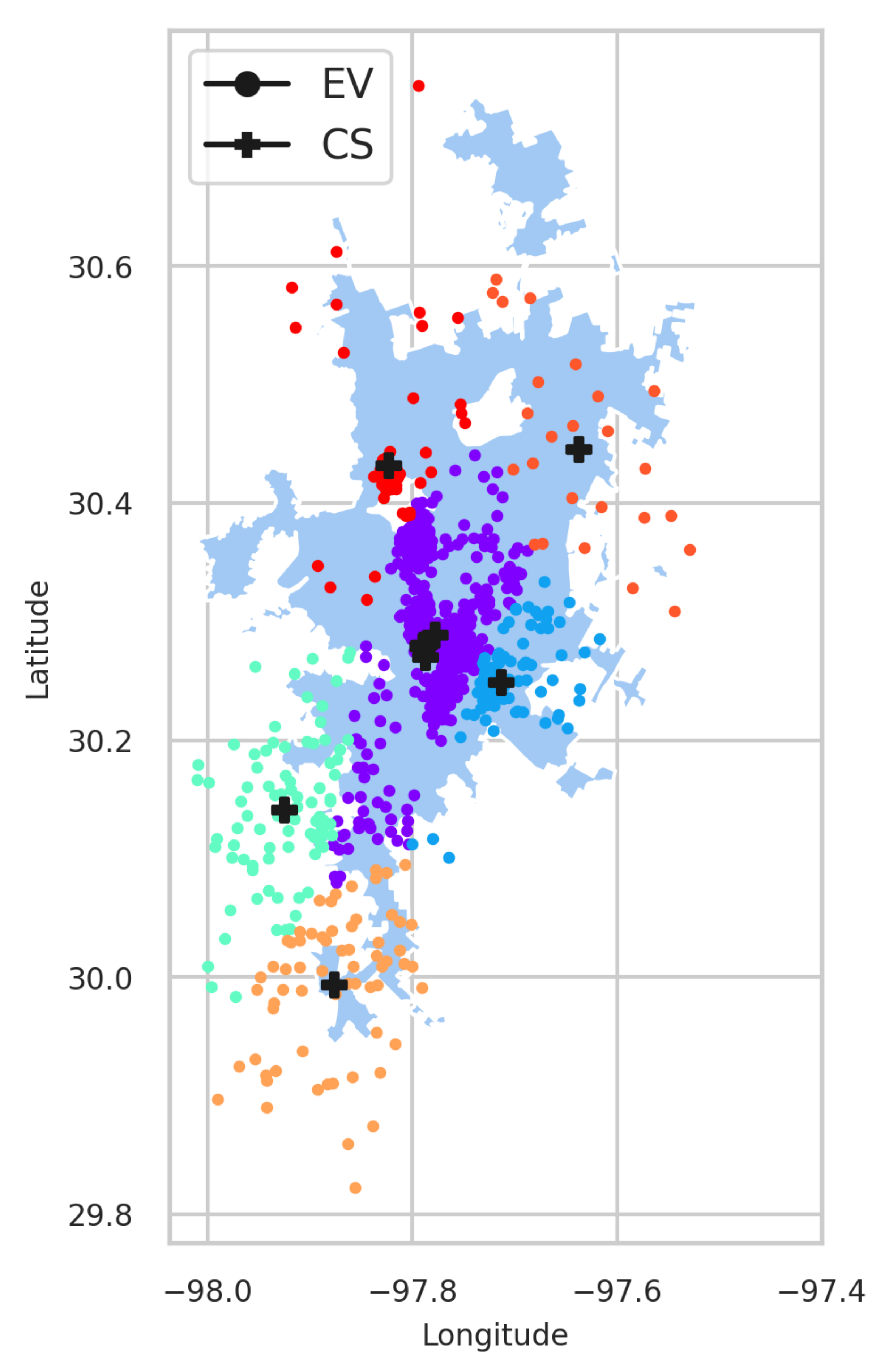
The EVCSP solutions were evaluated in two planning areas: the Austin area with real CS data to show the improvement over the existing setup, and a greenfield area like Bengaluru, where synthetic CS data is used.
A research gap in the CS need estimation was addressed, viz., the exclusion of SoC, EVP, and the EV driving range for CS need estimation.
Some of the practical questions of EV users and urban planners were answered both quantitatively and qualitatively: (i) Given a city and a layout of several CSs, what is the standard recommendation of SoC for EV users to go for charging with a high success rate in finding a CS nearby? (ii) Given the EVP of an area and the quality of service, i.e., SoC, what is the CS requirement? (iii) How does the CS need planning change when the EVP changes in a planning area?
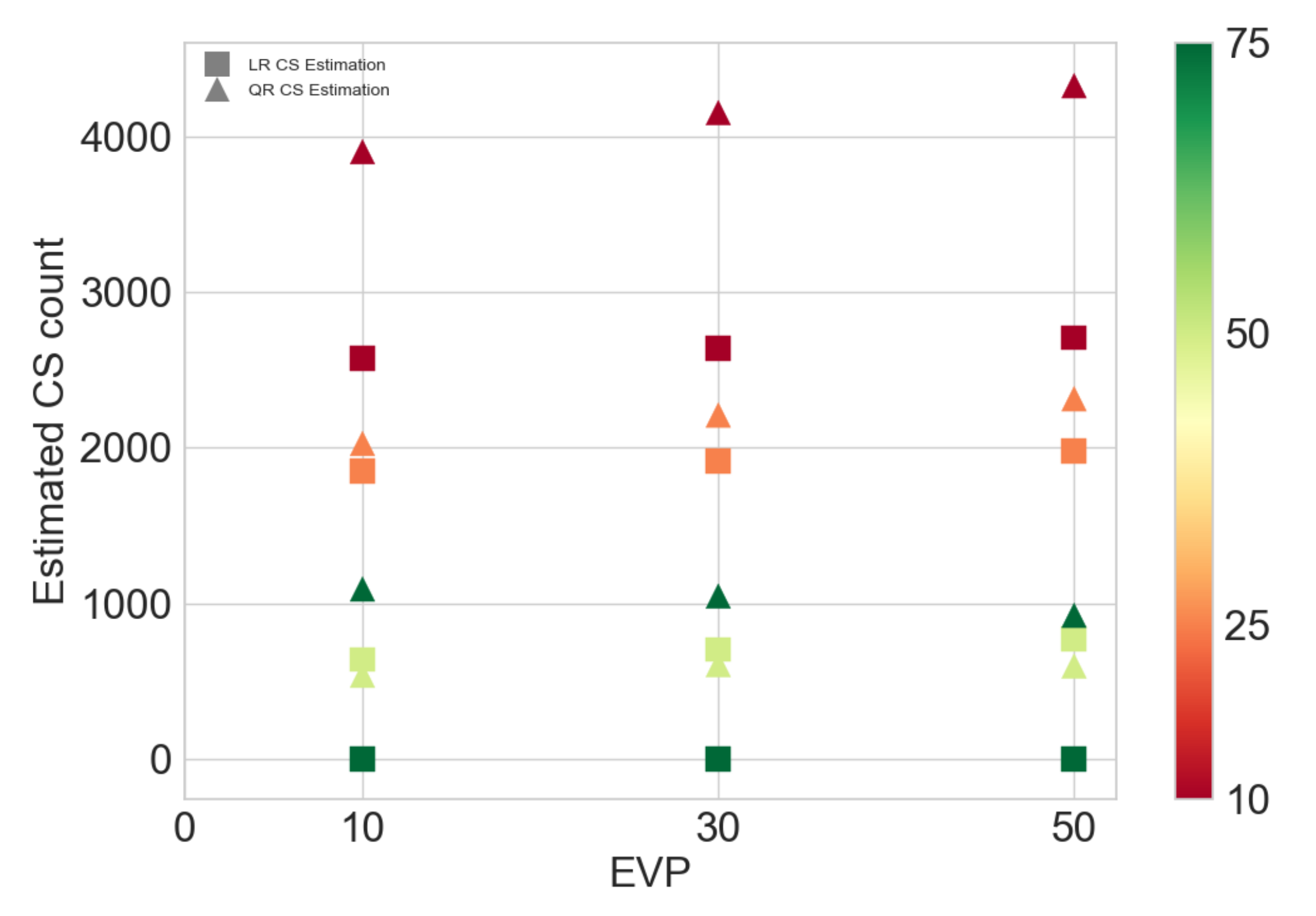
The relationships between CS need estimation parameters were identified: (i) the CS need estimation variation with varying EVPs for different SoCs; (ii) the EV ATD and the number of installed CSs for different EVP; and (iii) the CS size vs. the EV allowable driving range relationship and the EV driving feasibility were identified.
Another major contribution of this work is in identifying an explainable CS need for a planning area without any adjustment factors, unlike traditional methods. Moreover, the differences in CS estimation using (a) theoretical calculation, (b) machine learning, and (c) simulation-based approach were identified. Furthermore, this work provides urban planners and EV owners with an explainable CS need estimation for the present and the future.
2. Background
Numerous EVCSP solutions have been developed by researchers. Liu et al. [
25] determined CS locations using a Voronoi diagram [
26] by focusing on the service radius of EVs and environmental factors. Andy et al. [
27] utilized a hierarchical clustering analysis to solve EVCSP. Heuristic, numerical and analytical methods [
5,
28,
29,
30] have also been used for the CS placement of EVs, but the EVCSP is solved by assuming some fixed point equations to formulate a relationship between EV users and CSs. Clustering algorithms such as K-means [
11] and agglomerative clustering [
12] have been used for solving EVCSP. However, other classes of clustering methods have not been investigated in the EVCSP context.
Some later studies [
31,
32] have also used evolutionary algorithms for EVCSP, but they have been used when multiple objectives are involved along with EVCSP. Moreover, it has been shown [
33] that clustering methods are better compared to evolutionary algorithms due to their simplicity, operational efficiency, and reduced average distance for the CS. In our work, four classes of clustering method, i.e., mean-based, density-based, spectrum- or eigenvalues-based, and Gaussian distribution were employed for EVCSP. The EVCSP clustering methods are further explained in
Section 2.1.
The Mixed Integer Linear problem (MILP) [
6] has also been used, but the focus is to minimize the energy consumption of EVs to reach CSs. Game theory frameworks [
9] have been developed for EVCSP, but they concentrate on mileage anxiety from the EV user’s perspective only. Bae et al. [
34] has developed a game approach to solve EVCSP based on EV user preference and crowdedness. A graph-based approach [
7] has been developed to limit vehicle waiting times at all stations below a desirable threshold level, but a synchronization protocol is assumed for the network. The Monte Carlo simulation [
23] has been used for CS placement problems, but the focus is to avoid grid expansion and avoid power losses. Many of these solutions are complex and have been tested with at most, one dataset or planning area.
Evolutionary and nature-inspired algorithm-based solutions [
35,
36,
37,
38,
39,
40,
41] have been developed for CS placement problems, but they have advantages only when a multi-objective problem like power flow [
31] or a battery weight problem [
32] is explicitly defined. Dong et al. [
33] have shown that clustering algorithms have performed better than evolutionary algorithms like PSO in terms of their operational efficiency and reduced average distance for the CS.
2.1. EVCSP Clustering Methods
A data point in an EVCSP corresponds to an EV x location in a planning area, and K cluster centroids correspond to N charging stations, i.e., locations. The EVSCP clustering methods produce clusters where each cluster center represents a CS and the cluster points correspond to the EVS assigned to the same CS.
K-means [
42] clustering is an unsupervised learning algorithm to solve a clustering problem. It is a hard clustering algorithm to classify a given data set into the given K clusters so that the within-cluster sum of squares is minimized. Partitioning the data set into K mutually exclusive clusters is done in such a way that data points within each cluster remain as close as possible to each other, but as far as possible from a data point in other clusters.
The spectral clustering (SC) [
43] algorithm uses top eigenvectors of a matrix derived from the distance between data points. SC partitions a given data set into disjoint clusters with data points in the same cluster having high similarity and data points in different clusters having low similarity. This partitioning is then applied recursively to find K clusters.
OPTICS [
44] is a hierarchical density-based data clustering algorithm that discovers arbitrary shaped clusters. It will create a reachability plot that is then used to extract clusters using an input
. The minimum
denotes the core distance to make a distinct point a core point, given a finite
MinPts, i.e., minimum data points to consider.
The Gaussian mixture model [
45] is a probabilistic algorithm that assumes all the data points are generated from a mixture of a finite number of Gaussian distributions with unknown parameters. It is seen as a generalized K-means clustering to incorporate information about the covariance structure of the data as well as the centers of the latent Gaussians.
2.2. EVCSP Metrics
The performances of four clustering algorithms were compared in two aspects: (i) CS placement metrics and (ii) clustering metrics. The CS placement metrics comprise two parts: (i) the average distance of the EVs to the nearest CS (in km) and (ii) the maximum distance of the EVs to the nearest CS (in km). The cluster centers correspond to the CS placement location. The standard clustering metrics are defined by three scores [
46,
47] when the ground truth, i.e., the correct CS for an EV, is not available: (i) the Silhouette Coefficient [
48] to identify incorrect clustering and overlapping clusters using intra-cluster and inter-cluster distances of EVs; (ii) the Calinski-Harabasz index [
49] to identify how dense and well separated clusters are; and (iii) the Davies-Bouldin index [
50] to identify the average similarity between clusters.
The Silhouette Coefficient is defined for each EV
x and is composed of two scores: the average distance between an EV and all other EVs in the same cluster, i.e.,
, and the average distance between an EV and all other EVs in the next nearest cluster, i.e.,
. The Silhouette Coefficient for a set of EVs is given as the mean of the Silhouette Coefficient for each EV and is calculated [
46,
47] as
where
is the cluster
i,
is the number of EVs in
,
is the average distance between an EV
x and all other EVs in the same cluster,
is the average distance between an EV
x and all other EVs in the next nearest cluster, and
denotes the number of CSs or clusters in a planning region. The best value is 1 for a highly dense cluster and the worst value is −1 for incorrect clustering. This score is higher when clusters are dense and well separated. Negative values indicate incorrect clustering and scores near zero indicate overlapping clusters.
The Calinski-Harabasz index is also known as the Variance Ratio Criterion and is used when the ground truth is not known. It is calculated as a ratio between the within-cluster dispersion and the between-cluster dispersion where dispersion is defined as the sum of distances squared. The Calinski-Harabasz index is calculated [
46,
47] as
where
is the distance function,
c is the center of the planning area, and
denotes the total number of EVs in the planning area. The score is related to a model with better-defined clusters. It is higher when clusters are dense and well separated.
The Davies-Bouldin index denotes the average similarity between clusters, where the similarity is a measure that compares the distance between clusters with the size of the clusters themselves. The Davies-Bouldin index is computed [
46,
47] as
The index relates to a model with better separation between the clusters. Zero is the lowest possible score and values closer to zero indicate a better clustering.
2.3. CS Need Estimation: Traditional Approach
The number of EVs in a planning region will depend on the number of households, EVP, and the number of vehicles per household. The electricity demand of an EV per day will depend on
P, the power consumption of the EV, and the distance traveled by the EV per day [
14]. The average electricity demand of an EV per day is denoted by
.
is calculated as below:
where
is the power consumption of the EV in kWh/mile,
r is the battery range of the EV in miles,
denotes the charge cycles per day.
The total electricity demand denoted by
W in an area is calculated below:
where
is the number of EVs in a planning region
The number of charging stations
required in a planning region is calculated as below:
where
is an adjustment constant factor used in prior works [
14,
15] for the theoretical estimation of CS need,
is the capacity of CS, and
is the time needed to charge an EV to its full capacity.
6. Conclusions
Our results can be used to guide urban planners in making better CS placement approval decisions when many CSs (in the order of hundreds or more) need to be placed for charging at different locations of a planning area in an efficient manner, i.e., considering the clustering efficiency, the EV owners convenience, and the visual analysis of the system.
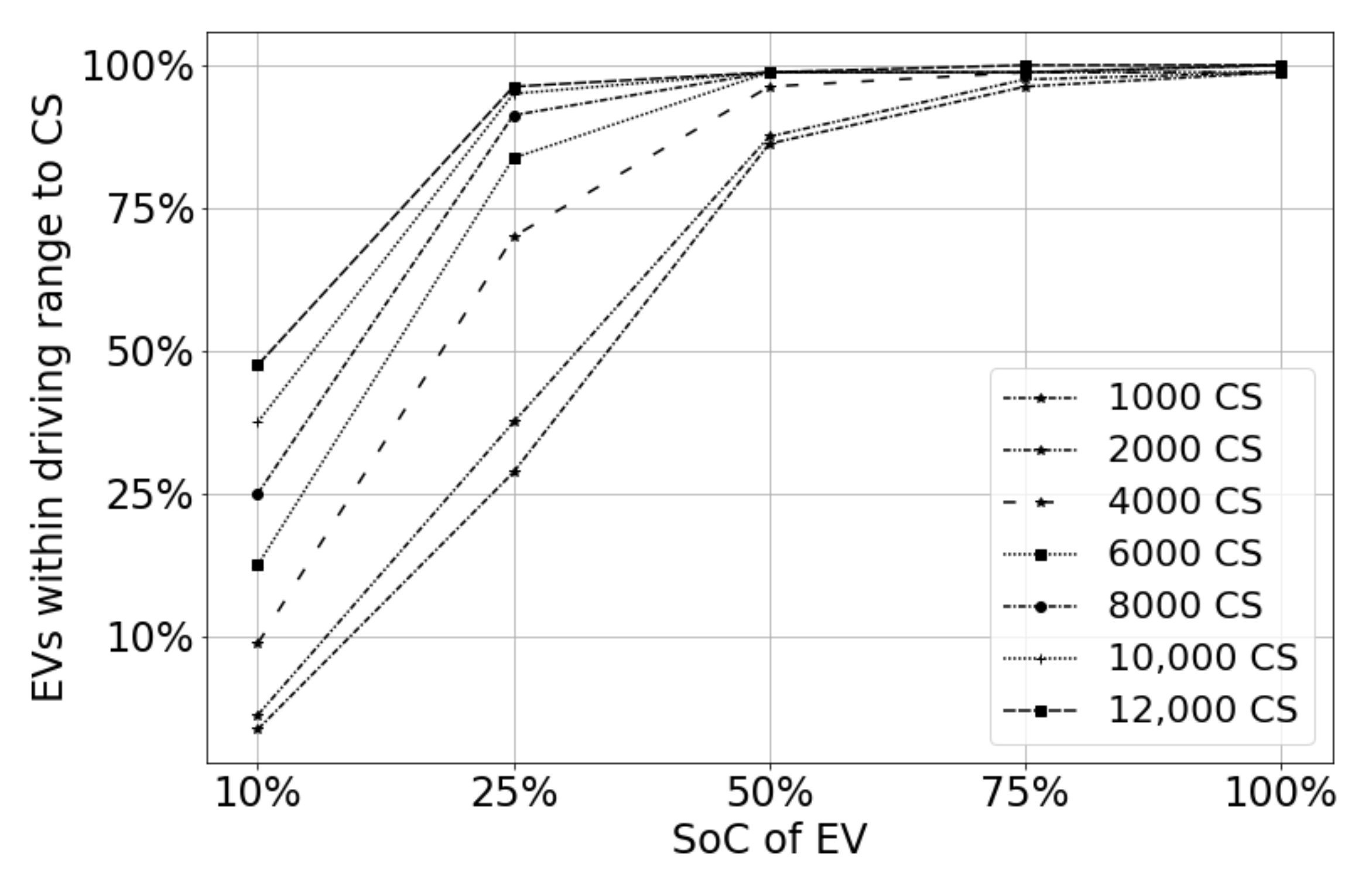
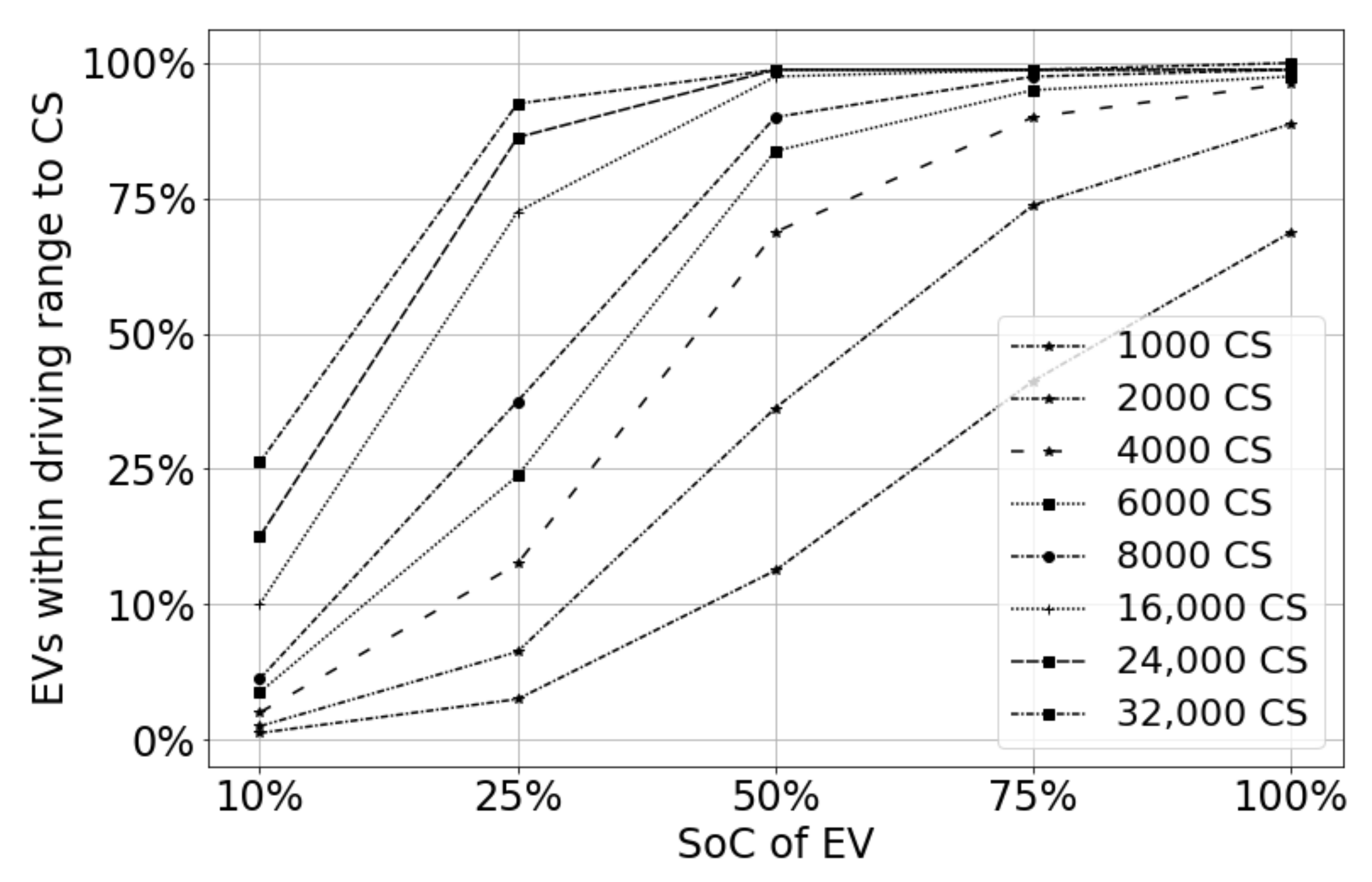
Using our CS need estimation methods, urban planners can estimate the CS need range, i.e., minimalist need, actual need, and future need, to take an appropriate decision on CSs required in a planning area. These methods also allow decision makers to prepare for the future by using estimates of CS needs with increasing EV penetration (EVP).
The present work is distinct in that we answer some of the practical questions of EV users and urban planners: (i) Given a city and a layout of several CSs, what is the standard recommendation of SoC for EV users to go for charging with a high success rate in finding a CS nearby? (ii) Given the EVP of an area and the quality of service, i.e., SoC, what is the CS requirement? (iii) How does the CS needs planning change when the EVP changes in a planning area?
A major contribution of this work is in identifying an explainable CS need for a planning area without any adjustment factors, unlike traditional methods. Moreover, this work compares the CS need estimates using different approaches, such as the machine learning methods built using the simulation data described in
Section 4.2 and the simulation methods described in
Section 4.3, to arrive at explainable lower and upper bound CS need estimates considering different factors. It confirms the advantages of using these solutions over the traditional methods. This work provides urban planners and EV owners with an explainable CS need estimation for the present and the future. Overall, this work gives explainable CS planning solutions both for urban planners and EV owners. It confirms the advantages of using these solutions over the traditional methods using real CS data of the Austin area and for a greenfield Bengaluru area.
In the future, these methods can be extended under a probabilistic environment for dealing with different traffic congestion scenarios in road networks. Another related problem is charging pile assignment, wherein the number of chargers at a CS needs to be identified based on recharging patterns that can be investigated in the future. The proposed CS planning can be used for some more planning areas in the future.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}