1. Introduction
Ship painting, as one of the three pillar processes of modern ship construction, runs through the entire shipbuilding process. Serving as a productive method for hull protection, it markedly mitigates the harmful impact of the ship’s demanding operational environment, curbing hull corrosion, cracking, and related issues. Beyond affording robust protection, painting operations also confer aesthetic enhancements, diminish resistance, and yield other ancillary benefits [
1,
2]. According to data from the China Shipbuilding Research Institute, the painting cost constitutes 8–10% of the total price for newly constructed ships in the domestic shipbuilding process. In advanced shipyards, such as those in Japan and South Korea, this proportion ranges from 5% to 6%, with specific shipyards even achieving percentages as low as 3% to 5%. In addition, as far as painting man-hours are concerned, some leading domestic shipbuilding companies consume three times as much as German shipyards did 15 years ago three times. Consequently, a considerable disparity exists between domestic painting costs and efficiency in comparison to developed countries, and addressing this gap is imperative to enhance painting efficiency and reducing costs. Man-hours, serving as a pivotal unit for cost measurement, constitute a crucial metric for the rational planning and scheduling of enterprise production. Rapid and precise estimation of painting man-hours stands as an effective strategy for elevating enterprises’ international competitiveness.
Within the realm of ship painting, numerous uncertainties arise from the interplay of personnel, processes, and environmental factors, rendering the prediction of man-hours a challenging endeavor. Typically, enterprises rely on process flow and historical experience to forecast man-hours; however, the accuracy of such predictions often needs to improve due to the multifaceted nature of the influencing factors. Consequently, the implementation of precise task assignments becomes a formidable challenge. Establishing a rational and efficient method for predicting painting man-hours holds the potential to intricately allocate a man-hour to each painting task. This, in turn, facilitates effective control over painting costs and production schedules, thereby enhancing the competitive edge of shipbuilding enterprises on the international stage.
The extensive application of machine learning and deep learning has proven effective not only in solving linear problems [
3] but also in exhibiting superior predictive capabilities in handling nonlinear issues [
4], coupled with a robust self-learning capacity [
5]. Scholars, both domestically and internationally, have conducted predictive studies on man-hours across various industries, including mechanical and electrical engineering [
6], as well as construction and building materials [
7]. Minhoe Hur et al. [
8] employed both the MLR (multiple linear regression) and CART (classification and regression trees) models, which balance model interpretability and accuracy for predicting shipbuilding man-hours. Their research demonstrated that the proposed models outperform traditional methods and expert predictions. Nur Najihah Abu Bakar et al. [
9] proposed a data-driven approach based on cold ironing forecasting of ship berthing, which includes various models such as artificial neural networks, decision trees, etc., and the results show that the artificial neural network model can handle the complex nonlinear port activity prediction problem. The authors of [
10] introduced a data-driven approach, combining multiple linear regression (MLR) with building information modeling (BIM) to establish a work-hour prediction model. The feasibility of this method was validated through its application in estimating labor man-hours in steel structure manufacturing. However, there are limitations to a single machine-learning model.
Ensemble learning, which combines a series of learners through certain rules to achieve a more significant generalization performance than individual learners [
11], is categorized into homogeneous and heterogeneous ensembles [
12]. Heterogeneous ensembles, in particular, have shown outstanding predictive effectiveness across various fields. Shuli Wen et al. [
13] proposed a heterogeneous integration method for optimal time interval forecasting of solar power generation based on a stochastic ship motion model and verified the feasibility of the method on the power system of a large oil tanker, which provides a reliable reference for ship power system operators to realize better energy management. Zhou Sun et al. predicted ship fuel consumption by constructing a heterogeneous integrated learning model, which was experimentally verified to produce excellent prediction results. Zeyu Wang et al. [
14] compared 57 heterogeneous ensemble learning models constructed from six base models using an exhaustive search method to identify the optimal model for predicting building energy consumption. Zhao Yuexu et al. [
15] built a heterogeneous ensemble learning model from the perspectives of model, sample, and parameter diversity, aiming to predict the duration of traffic accidents. These studies indicate that constructing heterogeneous ensemble models can effectively improve prediction accuracy. However, these models often lack optimization of the hyperparameters of the base learners, potentially leading to suboptimal solutions and significant influence from the choice of base learner hyperparameters. To address this, Park Uyeo et al. [
16] optimized the hyperparameters of base learners when constructing heterogeneous ensemble models, thereby enhancing the persuasiveness of their predictions. Chen Cheng et al. [
17] proposed an integrated learning (EL) based unmanned surface vehicle dynamics model for accuracy prediction and used particle swarm optimization and genetic algorithm to optimize the hyperparameters of the base learner.
While ensemble learning has demonstrated outstanding predictive performance across various fields, the use of a large number of learners may lead to redundancy and longer computational times, potentially giving rise to issues such as overfitting and underfitting in prediction outcomes [
18]. To address this challenge, selective ensemble learning has emerged [
19]. The core idea behind selective ensemble learning is to select superior learners from a group of individual learners based on a specific strategy and then integrate them to form a more generalized classifier. Shuai Liu et al. [
20] proposed a homogeneous selective ensemble forecasting framework based on an improved differential evolution algorithm to enhance the accuracy of hydrological forecasting. Huaiping Jin et al. [
21] employed a soft measurement method based on data augmentation and selective ensemble for predicting measurement results, validating the effectiveness and excellence of this approach. Zhang Fan et al. [
22] introduced a selective ensemble learning method based on the local model prediction accuracy and an adaptive weight calculation method for submodels. Simulations using accurate spatial dynamic wind power prediction data demonstrated the effectiveness of the proposed method in handling nonlinear, emotional, and multi-rate data regression problems in wind power generation. Additionally, Huaiping Jin et al. [
23] proposed a selective ensemble model based on finite mixture Gaussian process regression for wind power prediction. The results outperformed traditional global and ensemble wind power prediction methods, effectively addressing the temporal changes in wind power data while maintaining high predictive accuracy. However, it is worth noting that the scholars mentioned above did not perform selection on the individual learners when constructing selective ensemble learning models. This oversight could directly impact the final predictive results.
The studies of the scholars mentioned above show that there are limitations of a single learner; in contrast, the generalization performance of integrated learning is higher, which is more suitable for research in complex contexts, and selective integrated learning optimizes the individual-based learners on the basis of integrated learning, which further optimizes the structure of the model and improves the performance of the model. However, in the above study, the selected individual-based learners were not analyzed for their compatibility with the research context, and the direct selection may lead to non-optimal results.
Despite the positive applications of machine learning and deep learning across various fields, ranging from single models to ensemble learning formed by combining multiple models, experts and scholars have consistently affirmed their outstanding performance in prediction. However, in the context of predicting ship painting man-hours, there is a relatively limited amount of reported research. Due to the multitude of uncertainties affecting ships during the painting process, leading to the instability of painting man-hours, reliance on a single predictive model is restrictive and results in a significant decline in accuracy. Therefore, employing multiple algorithmic models with distinct characteristics as base learners to construct a selective ensemble learning model for prediction holds the potential to enhance accuracy and robustness significantly.
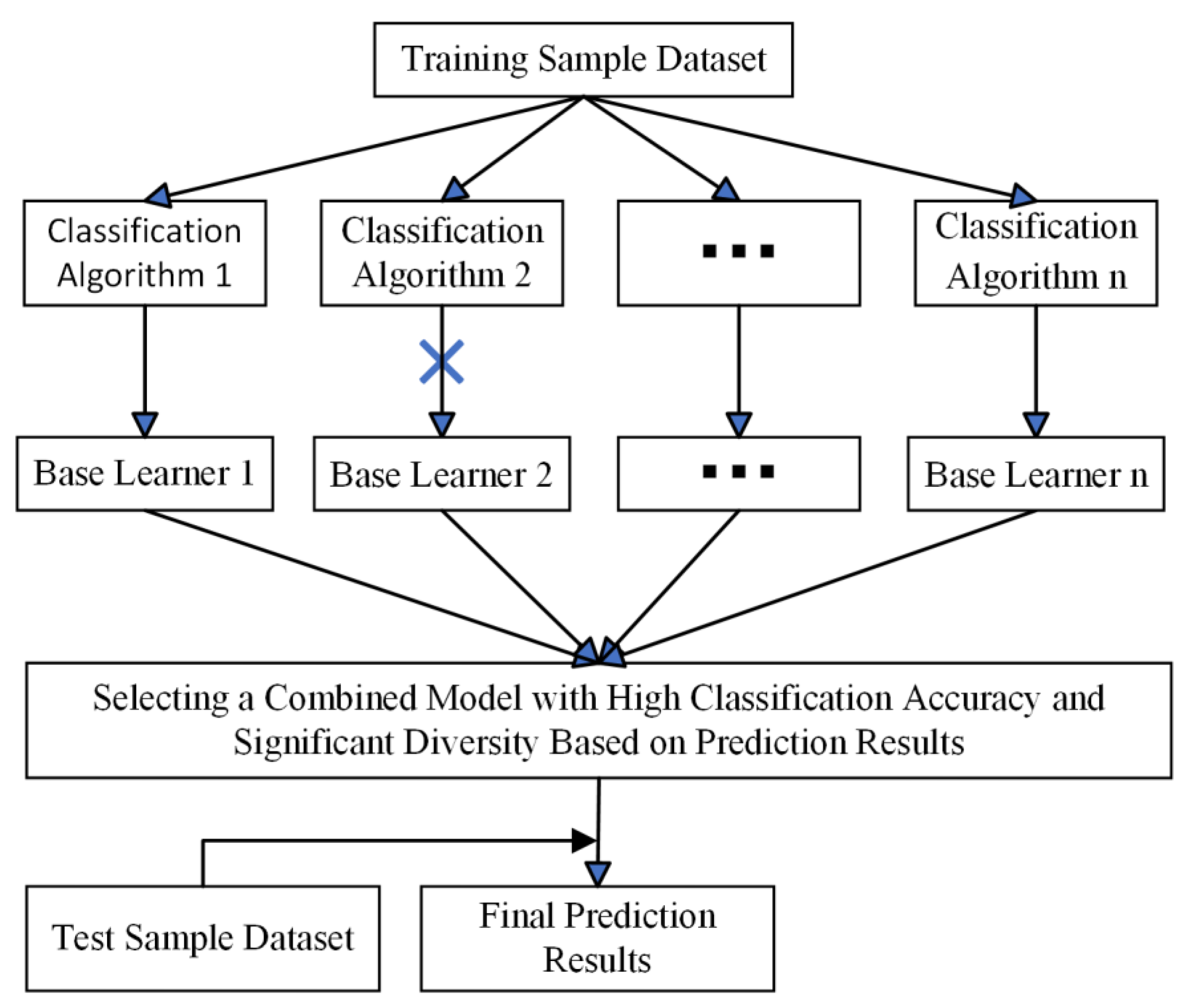
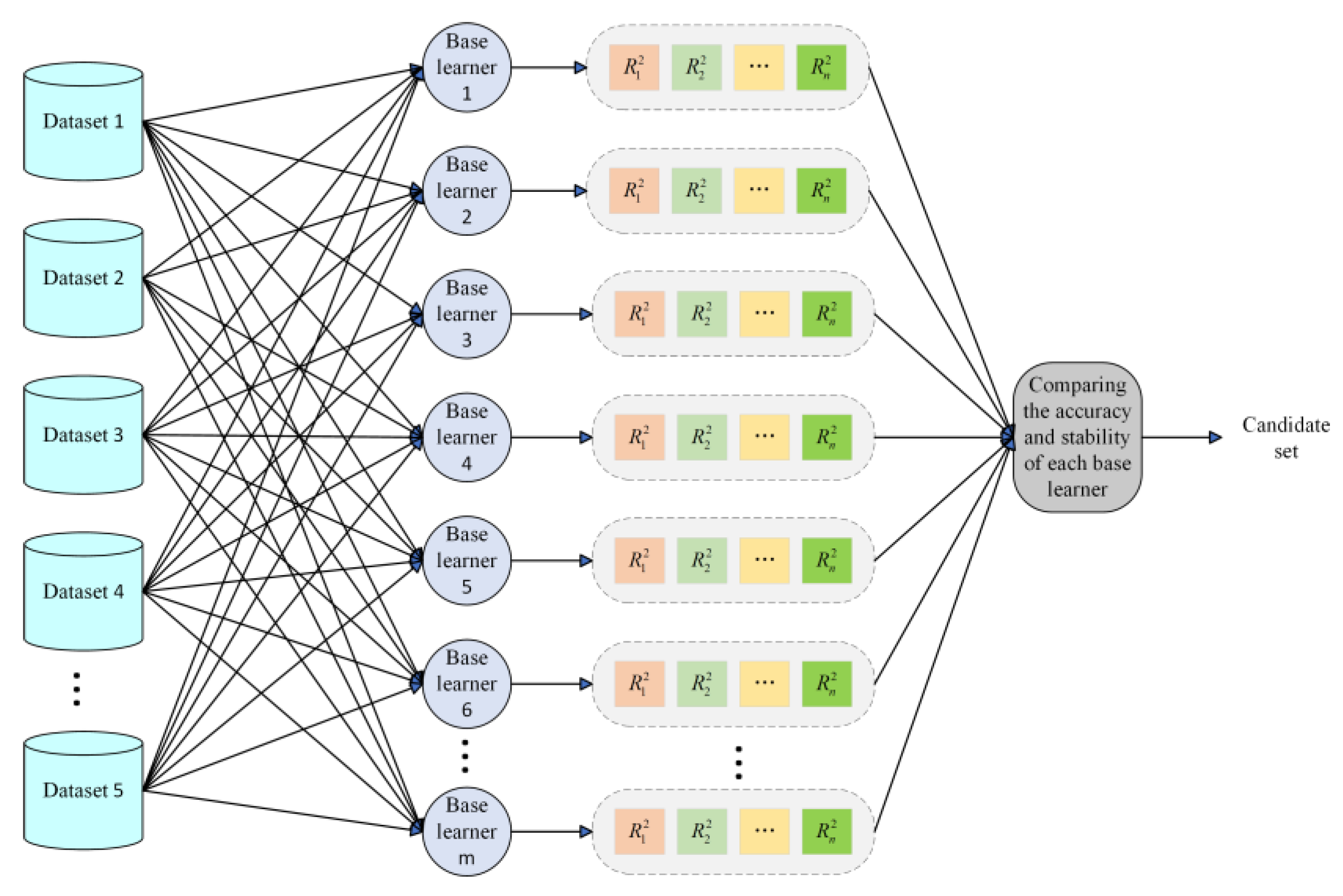
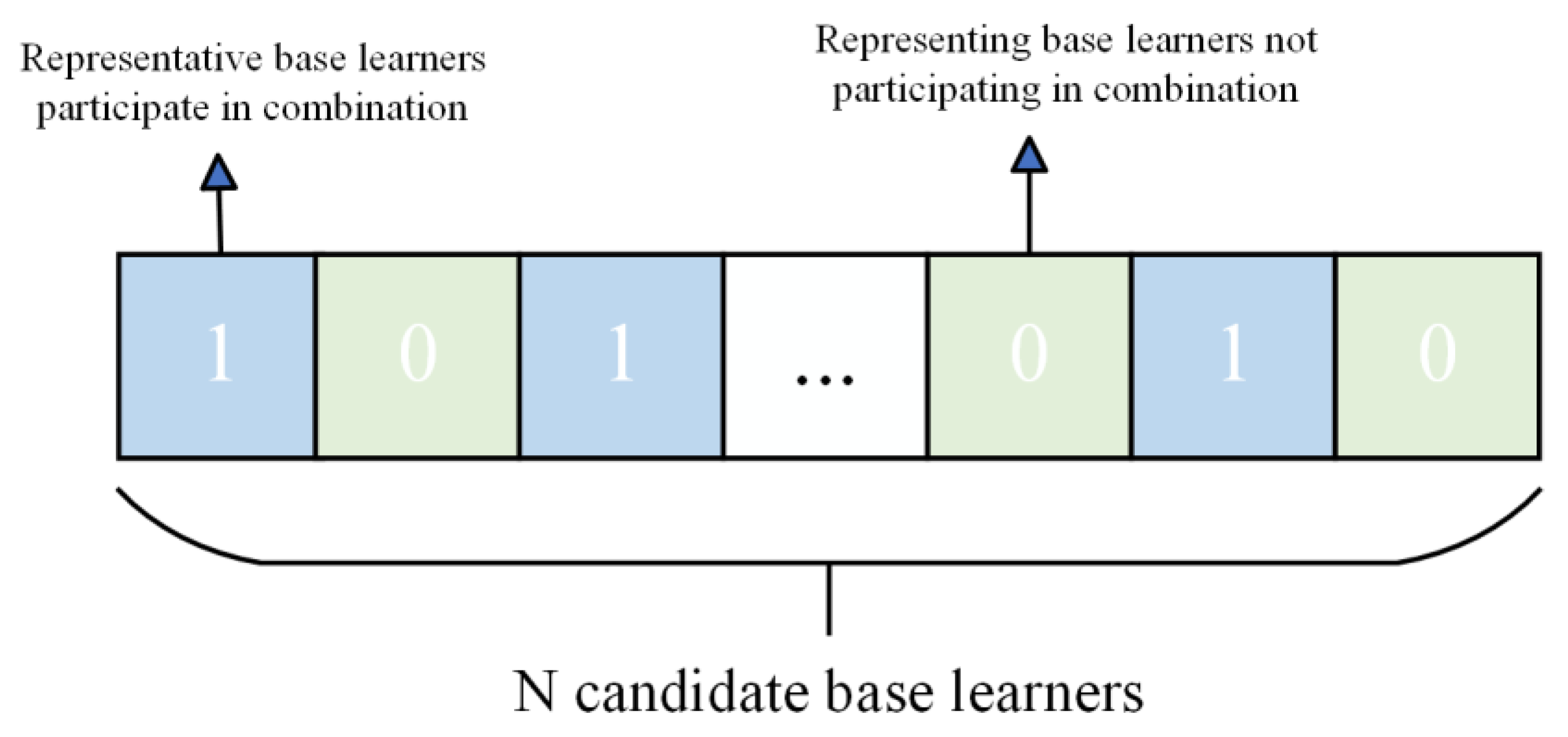
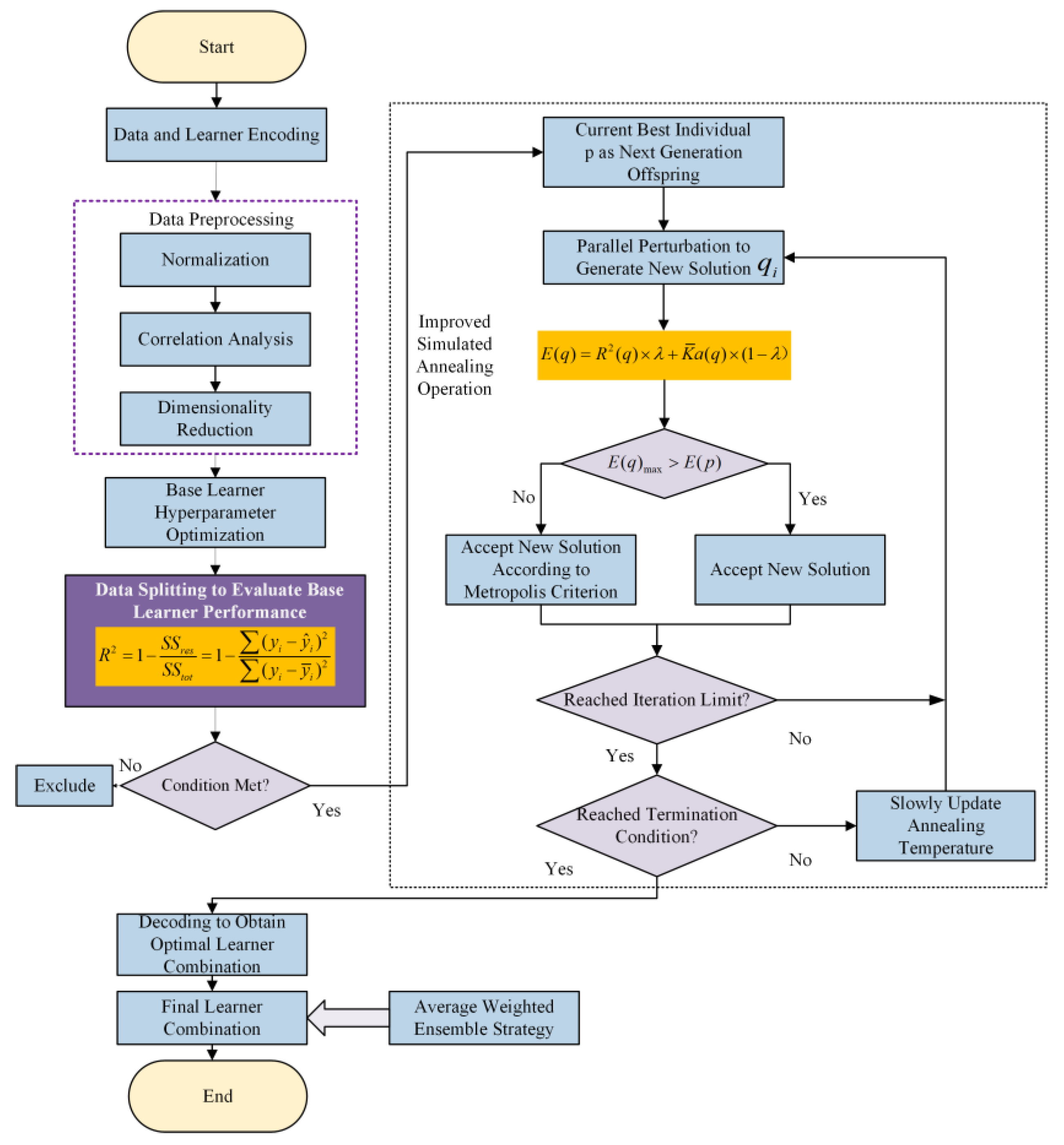
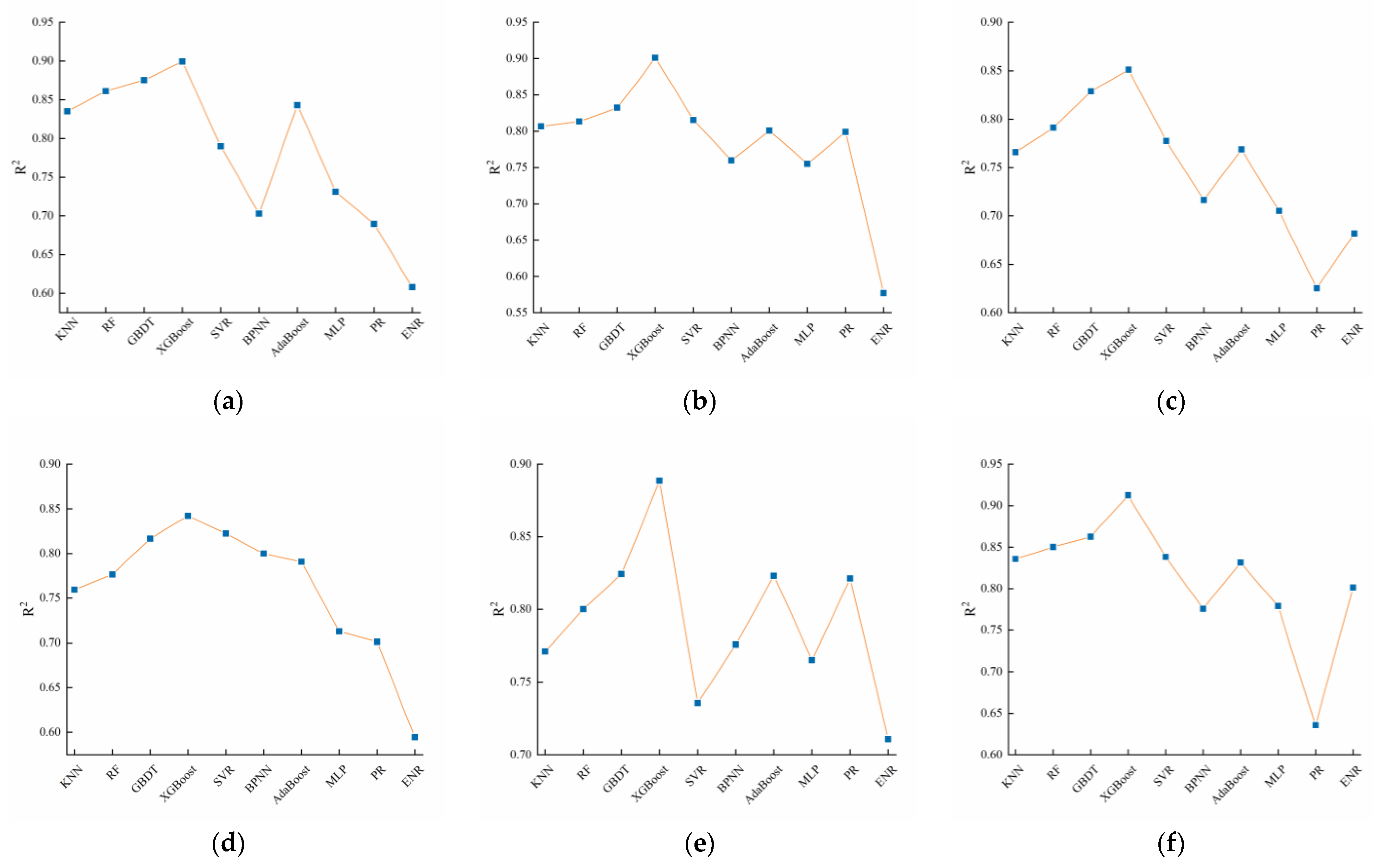
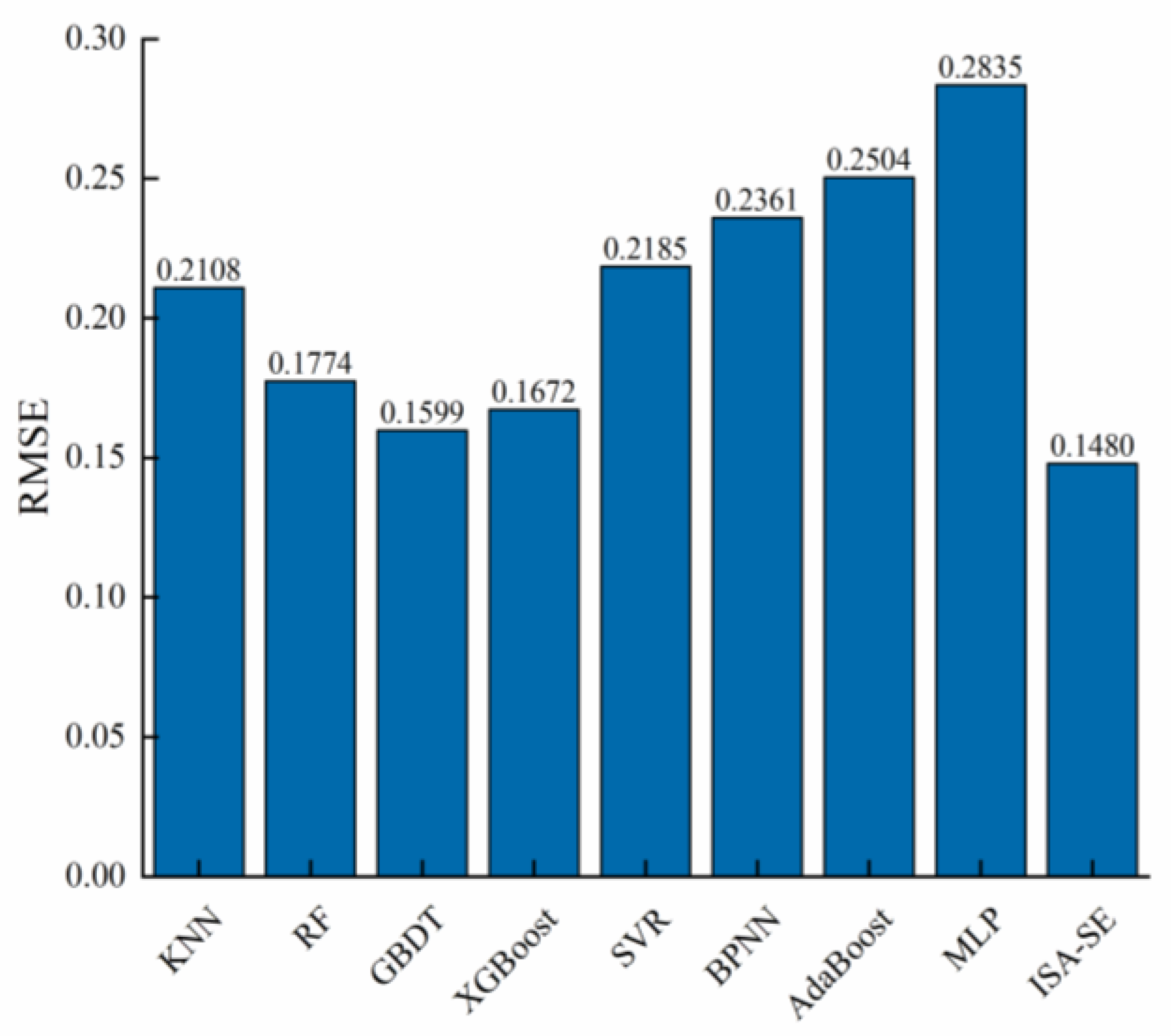
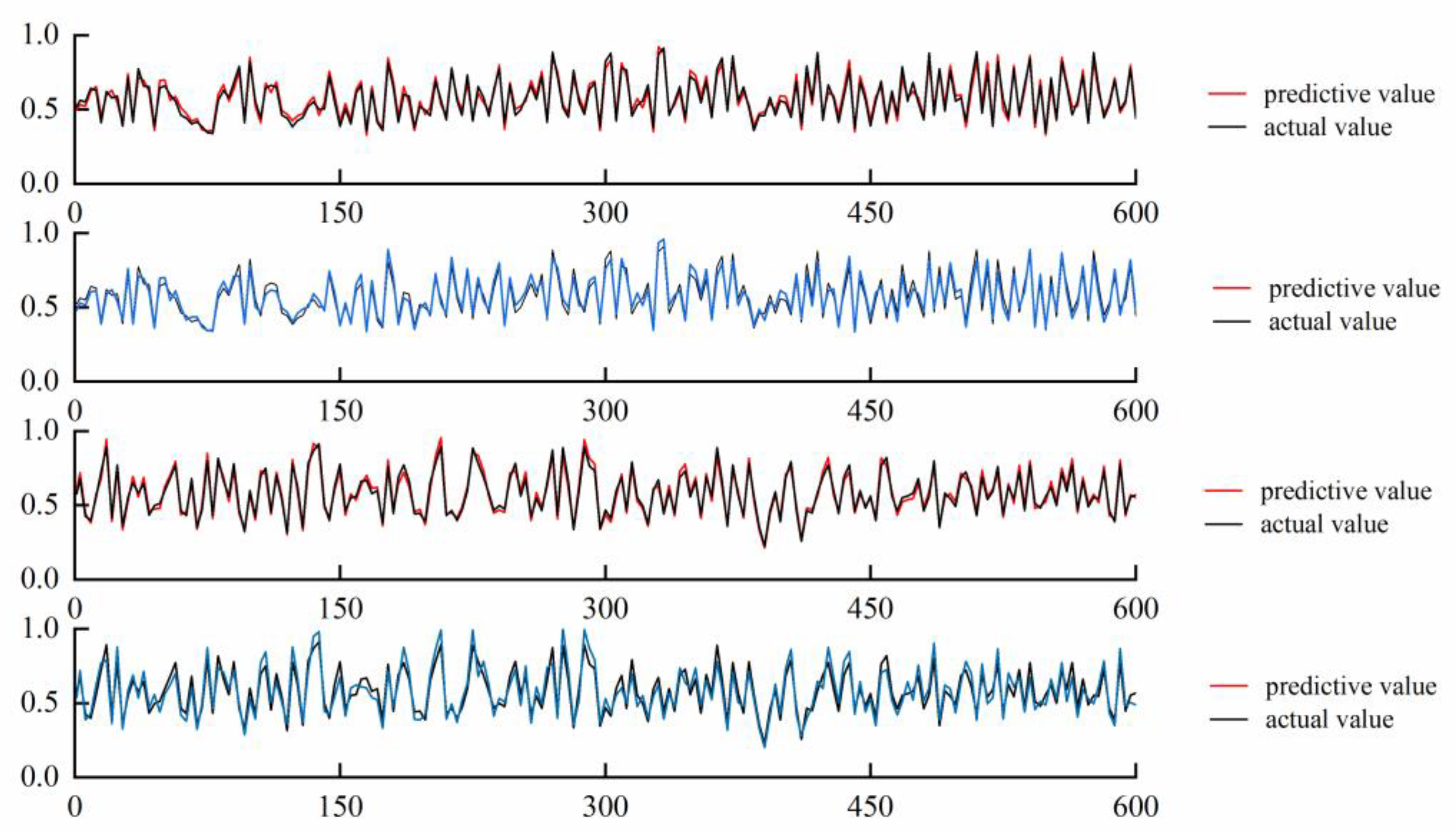
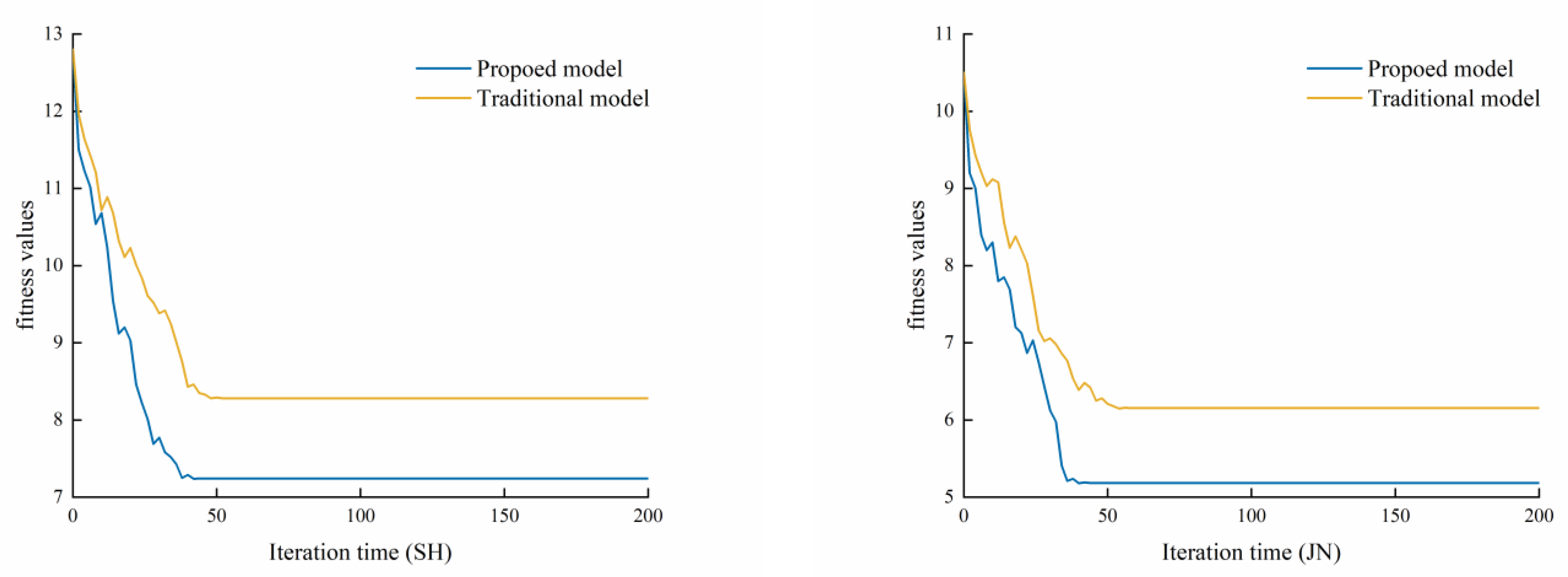
In view of the above shortcomings, this paper proposes a selective integrated learning model (ISA-SE) based on an improved simulated annealing algorithm to predict the man-hours of ship painting. This model employs ten different algorithms, including random forest (RF), support vector regression (SVR), and extreme gradient boosting (XGBoost), as base learners. Initially, the hyperparameters of these ten base learners are optimized through cross-validation and the MPSO algorithm. Subsequently, the dataset is randomly divided into six subsets using data grouping techniques. The optimal hyperparameters of the base learners are utilized as initial data, and predictions are made using each base learner separately. Base learners that meet the criteria are selected as candidate learners based on a comparison of the prediction results. To address the potential issue of local optima in the simulated annealing algorithm, a selection approach incorporating increased random perturbations is adopted, and a parallel perturbation search is conducted on this selection path to expand the search range. Finally, the improved simulated annealing algorithm is applied to further filter the candidate learners, selecting the optimal combination of diverse base learners to predict ship painting duration accurately.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}