Abstract
In a recent publication in the Journal of Intelligence, Dennis McFarland mischaracterized previous research using latent variable and psychometric network modeling to investigate the structure of intelligence. Misconceptions presented by McFarland are identified and discussed. We reiterate and clarify the goal of our previous research on network models, which is to improve compatibility between psychological theories and statistical models of intelligence. WAIS-IV data provided by McFarland were reanalyzed using latent variable and psychometric network modeling. The results are consistent with our previous study and show that a latent variable model and a network model both provide an adequate fit to the WAIS-IV. We therefore argue that model preference should be determined by theory compatibility. Theories of intelligence that posit a general mental ability (general intelligence) are compatible with latent variable models. More recent approaches, such as mutualism and process overlap theory, reject the notion of general mental ability and are therefore more compatible with network models, which depict the structure of intelligence as an interconnected network of cognitive processes sampled by a battery of tests. We emphasize the importance of compatibility between theories and models in scientific research on intelligence.
1. Introduction
In a recent issue of the Journal of Intelligence, McFarland (2020) compares traditional latent variable models of intelligence to more recent psychometric network models. In contrast to Kan et al. (2019) and Schmank et al. (2019), McFarland finds that latent variable models generally outperform network models. McFarland suggests that previous support for network models reported by Kan et al. (2019) and Schmank et al. (2019) is limited to analyses based on partial, rather than uncorrected, correlation matrices. If correct, this finding calls into question recent claims that psychometric network models provide unique support for theories of intelligence like mutualism and process overlap theory.
We are grateful to McFarland for providing such a detailed comparison of latent variable and network models of intelligence. In many ways, it is representative of his program of research on intelligence, which managed to combine statistical rigor and theoretical impact. Indeed, it has forced us to reconsider both methodological and theoretical aspects of our recent work on psychometric network models of intelligence. It has also provided us with plenty of food for thought and ideas for future research.
At the same time, unfortunately, we get the impression that McFarland misunderstood some methodological details, as well as the overall purpose of Kan et al. (2019) and Schmank et al. (2019). Kan et al. (2020) have already addressed McFarland’s misconceptions of Kan et al. (2019) and so we focus here on issues that pertain to Schmank et al. (2019). We also report an analysis of Wechsler Adult Intelligence Scale–Fourth Edition (WAIS-IV) data generously provided by McFarland. We conducted the same exact statistical procedures reported in Schmank et al. (2019). To preview, the results are consistent with Schmank et al. (2019) and Kan et al. (2019) and illustrate that network models can account for the psychometric structure of intelligence and should therefore be considered as a viable alternative to latent variable models. For many investigators, network models are an attractive alternative because they are more compatible with recent theories of intelligence like mutualism (Van Der Maas et al. 2006) and process overlap theory (Kovacs and Conway 2016). We argue that compatibility between theories and models of intelligence can, and should, guide model selection.
We review here two general concerns with the discussion of our previous research by McFarland (2020). First, McFarland states, “[t]he rationale for the use of partial correlations is that one can rule out the relationship between any pair of variables as being due to the other variables in the analysis and thus more readily infer causation” (p. 1). We agree that partial correlations can be used for this purpose; however, this was not the rationale behind the Schmank et al. (2019) study. Psychometric network modeling offers an alternative approach to investigations of the underlying structure of individual differences in cognitive abilities (i.e., intelligence), without the assumptions that come with reflective latent variable models (Conway et al. 2021; see also Goring et al. 2019). According to the view of intelligence endorsed by Schmank et al. (2019), process overlap theory (Kovacs and Conway 2016), there is no need to assume that (all or some of) the factors in higher-order factor models represent common causes of individual differences in test performance. It is in this sense that process overlap theory fits with the network approach, which also does not assume the presence of reflective latent variables.
Second, McFarland (2020) states “[b]oth Kan et al. (2019) and Schmank et al. (2019) compared model fit indices for network models with those for traditional latent variable models” (p. 1). He then goes on to state “[o]ne problem in attempting to compare network models with traditional latent variable models […] is that the two deal with different aspects of test correlations” (p. 2). The first statement is inconsistent with Schmank et al. (2019): “[d]irect model comparisons were not conducted […] we caution readers from making direct comparisons based on the presented model fit indices” (p. 7). To be clear, these two kinds of models can be compared in principle, namely when they are both confirmatory, but this was not the case here. The second statement is also inaccurate. The data for all latent variable and psychometric network modeling analyses were uncorrected correlation matrices.
To be sure, we reviewed our R scripts (https://osf.io/3wpcm/) but we found no direct comparisons of network models and latent variable models or partial correlations matrices. However, in our original pre-print of the Schmank et al. (2019) publication (https://osf.io/f9d2v/), we did report a direct comparison of the models. We therefore assume that the pre-print was the source of the confusion. To be clear, that pre-print was an unpublished draft and was later revised. The direct comparison between the model fit of latent variable and psychometric network models was not included in Schmank et al. (2019).
Commentary Reanalysis
The remainder of this commentary provides a statistical reanalysis of the uncorrected WAIS-IV correlation matrices used by McFarland (2020). McFarland provided these correlation matrices to our research group and we then conducted the same set of analyses reported by Schmank et al. (2019). Thus, these correlation matrices were used as input for reflective latent variable modeling and psychometric network modeling, respectively. First, confirmatory factor analyses were conducted to determine the underlying measurement model of the WAIS-IV data assuming a correlated latent variable model. Next, we assessed the Cattell–Horn–Carrol model (Carroll 1993; Cattell 1943; Horn and Cattell 1966)—a reflective, higher-order model of intelligence—using an additional confirmatory factor analysis. Finally, psychometric network modeling was employed as an alternative method to traditional latent variable modeling techniques. For all psychometric models considered we provide model fit indices.
2. Materials and Methods
2.1. Participants and Measures
The WAIS-IV correlation matrices provided by McFarland (2020) were based on three groups of participants (which we refer to here as younger, middle, and older). The age range of the younger group was 16–19 (n = 400); the age range of the middle group was 20–54 (n = 1000); the age range of the older group was 55–69 (n = 400). The three uncorrected correlation matrices were used as input for all confirmatory latent variable and exploratory psychometric network models. The analyses were conducted by following the Statistical Procedure outlined in Schmank et al. (2019).
The WAIS-IV consists of 15 subtests described as Information, Vocabulary, Comparisons, Similarities, Picture Completion, Block Design, Figure Weights, Matrix Reasoning, Visual Puzzles, Arithmetic, Digit Span, Letter–Number Sequencing, Cancellation, Coding, and Symbol Search. Information about these measures can be found in the Technical and Interpretative Manual (Wechsler 2008).
Two latent variable models were tested: a correlated four-factor model (Model 1), and a higher-order reflective g four-factor model (Model 2). Model 2 is based on the Cattell–Horn–Carroll model (Carroll 1993; Cattell 1943; Horn and Cattell 1966). Model fit indices were examined to compare Models 1 and 2 and to determine whether the same model fits equally well across groups when using the same modeling technique (i.e., psychometric network modeling or latent variable modeling).
2.2. Statistical Procedure and Analysis
2.2.1. Confirmatory Factor Analyses
As an initial step, factor analyses were conducted to assess whether the provided correlation matrices demonstrated the same underlying structure (i.e., measurement model). The current project employed a measurement model with four latent variables representing crystallized intelligence, fluid reasoning, working memory, and processing speed. Additionally, a higher-order model was assessed by specifying a latent variable model with one superordinate second-order latent variable (representing g), and four subordinate first-order latent variables (crystallized intelligence, fluid reasoning, working memory, and processing speed). Latent variable models were conducted using lavaan (Rosseel 2012) and openMx (Neale et al. 2016) packages freely available in R (R Core Team 2013). The most parsimonious latent variable model is displayed in figures using visualization software freely available using Ωnyx (von Oertzen et al. 2015). For access to the R-scripts used in this project, see the following OSF project page: https://osf.io/kfujs/.
2.2.2. Psychometric Network Analyses
Psychometric network analyses were conducted using the default estimation strategy provided by the qgraph package. For each psychometric network model conducted, 100 network models were generated with varying tuning parameter lambda values. Additionally, the ratio of minimum to maximum lambda values was set to 0.01 as specified by Epskamp et al. (2018). The final network was selected by the qgraph package by minimizing the Extended Bayesian Information Criteria utilizing the specified hyperparameter gamma that was set to 0.50. Psychometric network analyses were conducted using qgraph (Epskamp et al. 2012) and openMx (Neale et al. 2016) packages freely available in R. These network models were visualized using qgraph. Additionally, the average Layout () function within the qgraph package was used to make an average layout that can be beneficial for comparing the interconnectivity of each network model. It is important to reiterate that these packages were previously used in publications concerning the use of psychometric network analysis on cognitive ability measures (Kan et al. 2019; Schmank et al. 2019; Van Der Maas et al. 2017). Finally, the EGAnet (Golino and Epskamp 2017) package and EGA () function were used to assess the number of clusters (i.e., latent dimensions) and which observed variables belong to which cluster.
2.2.3. Approach to Model Fit
The same approach to model fit evaluation was used in the current project as described in Schmank et al. (2019). Model fit will be deemed appropriate when (a) the ratio of model chi-square (χ2) to degrees of freedom is less than or equal to 3.00, (b) comparative fit indices (e.g., Comparative Fit Index (CFI) and Tucker–Lewis Index (TLI)) greater than or equal to 0.95, and (c) Root Mean Square Error of Approximation (RMSEA)1 values less than or equal to 0.06. Additionally, Akaike Information Criteria (AIC) and Bayesian Information Criteria (BIC) values can be used to compare models: smaller values indicate better fit. Furthermore, fit indices were extracted using functions within the lavaan, openMx, and qgraph packages which compare original covariance matrices to the implied covariance matrices generated by each latent variable and psychometric network model.
3. Results
The correlation matrices used in the current project are presented in Table 1, Table 2 and Table 3. Model fit indices are presented in Table 4, Table 5 and Table 6. Two sets of fit indices are reported because we estimated model fit using two R packages: lavaan and openMx. The packages differ with respect to model specification and estimation but the results here are identical. This was established and reported here to check the accuracy of our results and to facilitate reproducibility.

Table 1.
Uncorrected correlation matrix provided by McFarland (2020): youngest group.
Table 2.
Uncorrected correlation matrix provided by McFarland (2020): middle group.
Table 3.
Uncorrected correlation matrix provided by McFarland (2020): older group.
Table 4.
Model fit for latent variable and network models of WAIS-IV correlations (young group).
Table 5.
Model fit for latent variable and network models of WAIS-IV correlations (middle group).
Table 6.
Model fit for latent variable and network models of WAIS-IV correlations (older group).
With respect to the latent variable modeling analysis, the correlated four-factor model (Model 1) was preferred over the higher-order model (Model 2), based on model comparisons: Younger Group: Δχ2(2) = 5.56, p = 0.06; Middle Group: Δχ2(2) = 15.36, p < 0.001; Older Group: Δχ2(2) = 21.01, p < 0.001. For a visualization of these three models, see Figure 1, Figure 2 and Figure 3. In our original publication (Schmank et al. 2019), we presented data representative of the higher-order (g theory) model of intelligence, as this model tends to be the most well-known specification of latent variable models of intelligence. However, our findings after conducting these analyses on the McFarland data are inconsistent with a preference for the higher-order model of intelligence. Thus, when considering latent variable modeling, the three standardized WAIS-IV correlation matrices used by McFarland fit best when specifying a correlated, four-factor latent variable model.
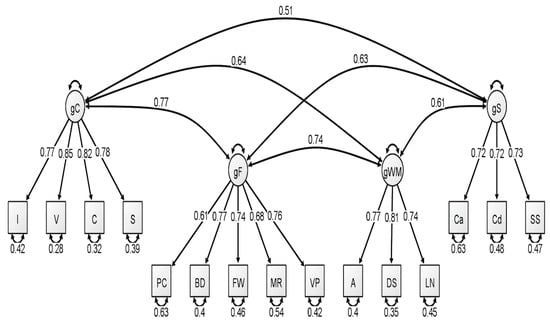
Figure 1.
Correlated four-factor measurement model of the young group WAIS-IV correlation matrix. All values are standardized from the confirmatory factor analysis conducted using lavaan. Figure generated using Ωnyx. gC = crystallized intelligence; gF = fluid reasoning; gWM = working memory; gS = processing speed; BD = block design; S = similarities; DS = digit span; MR = matrix reasoning; V = vocabulary; A = arithmetic; SS = symbol search; VP = visual puzzles; I = information; Cd = coding; LN = letter–number sequencing; FW = figure weights; C = comparisons; Ca = cancellation; PC = picture completion.
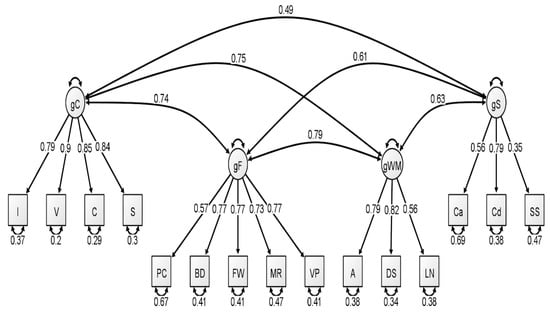
Figure 2.
Correlated four-factor measurement model of the middle group WAIS-IV correlation matrix. All values are standardized from the confirmatory factor analysis conducted using lavaan. Figure generated using Ωnyx. gC = crystallized intelligence; gF = fluid reasoning; gWM = working memory; gS = processing speed; BD = block design; S = similarities; DS = digit span; MR = matrix reasoning; V = vocabulary; A = arithmetic; SS = symbol search; VP = visual puzzles; I = information; Cd = coding; LN = letter–number sequencing; FW = figure weights; C = comparisons; Ca = cancellation; PC = picture completion.
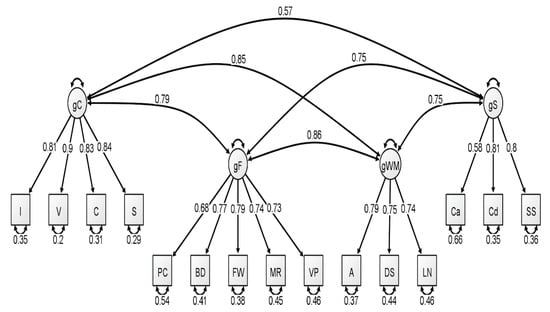
Figure 3.
Correlated four-factor measurement model of the older group WAIS-IV correlation matrix. All values are standardized from the confirmatory factor analysis conducted using lavaan. Figure generated using Ωnyx. gC = crystallized intelligence; gF = fluid reasoning; gWM = working memory; gS = processing speed; BD = block design; S = similarities; DS = digit span; MR = matrix reasoning; V = vocabulary; A = arithmetic; SS = symbol search; VP = visual puzzles; I = information; Cd = coding; LN = letter–number sequencing; FW = figure weights; C = comparisons; Ca = cancellation; PC = picture completion.
Consistent with the results of Schmank et al. (2019), most fit indices indicated that the latent variable models provided an acceptable fit to the WAIS-IV data, with the exception of the chi-square test, which was nonsignificant for all latent variable models. However, the ratio of χ2 to degrees of freedom was less than 3.00 for three latent variable models: each model attributed to the younger group and for the higher-order model attributed to the older group. The reported RMSEA values for all latent variable models exceeded the conservative value used by the current authors to demonstrate appropriate model fit (all latent variable RMSEA values were 0.07). However, these RMSEA values would be adequate based on more liberal standards (see Browne and Cudeck 1993; Schermelleh-Engel et al. 2003). Additionally, comparative fit indices (i.e., CFI and TLI) demonstrated values in the acceptable range for all latent variable analyses. We also considered the quality of each measure by evaluating the standardized factor loadings in each model. The squared value of the standardized factor loading indicates the amount of variance in the measure that can be explained by the overarching latent construct. For the younger group, only two standardized loadings, specific to the fluid reasoning latent variable, failed to surpass the cutoff value of 0.70 that is typically used to indicate a quality measure (see Schmank et al. 2019). For the middle group, four standardized loadings failed to surpass the 0.70 cutoff value, specific to fluid reasoning, working memory, and processing speed. Finally, the oldest group demonstrated two standardized loadings that failed to reach 0.70, specific to the fluid reasoning and processing speed latent variables.
With respect to the exploratory psychometric network modeling analysis, consistent with Schmank et al. (2019), the network models indicated excellent model fit across the majority of reported fit indices. First, only the psychometric network model for the middle group demonstrated a statistically significant χ2 value (p < 0.05); however, the value of the ratio between χ2 and degrees of freedom for each of these models was well below the 3.00 cutoff value determined prior to analyses. Finally, the comparative fit indices (i.e., CFI and TLI) demonstrated near perfect fit, while RMSEA values were well below the cutoff value specified.
For the visualization of the psychometric network models, see Figure 4, Figure 5 and Figure 6. First, nodes in the models have been colored to reflect the latent structure of the finalized measurement model. Second, the connections between nodes have been colored so that blue and red indicate positive and negative partial correlations, respectively. Third, the width of each connection between nodes represents the magnitude or size of the association or partial correlation estimated between each pair of cognitive task nodes. Additionally, the psychometric network models and their respective exploratory graph analyses revealed four clusters or latent dimensions. For the young (Figure 4), middle (Figure 5), and older groups (Figure 6) these four dimensions reflect crystallized intelligence, fluid reasoning, working memory, and processing speed. Interestingly, the Arithmetic (A) node in the older group network was explained by the crystallized intelligence dimension and not the working memory or fluid reasoning dimensions. Finally, three additional network models were generated that shared an averaged network layout (Figure 7).
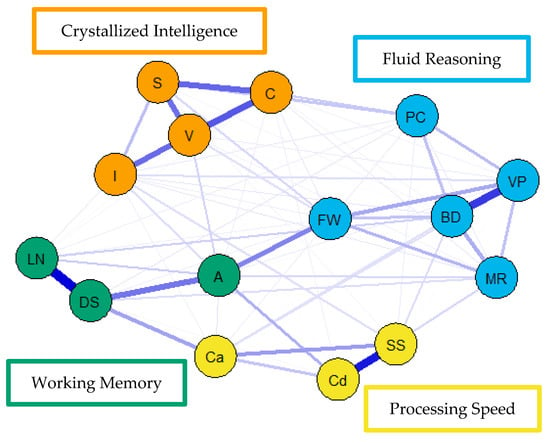
Figure 4.
Weighted, undirected psychometric network model of the young group WAIS-IV correlation matrix. BD = block design; S = similarities; DS = digit span; MR = matrix reasoning; V = vocabulary; A = arithmetic; SS = symbol search; VP = visual puzzles; I = information; Cd = coding; LN = letter–number sequencing; FW = figure weights; C = comparisons; Ca = cancellation; PC = picture completion.
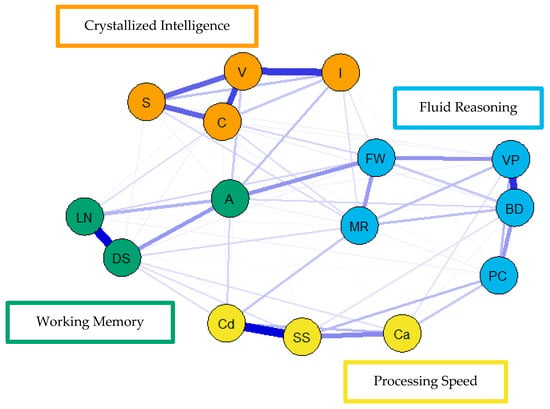
Figure 5.
Weighted, undirected psychometric network model of the middle group WAIS-IV correlation matrix. BD = block design; S = similarities; DS = digit span; MR = matrix reasoning; V = vocabulary; A = arithmetic; SS = symbol search; VP = visual puzzles; I = information; Cd = coding; LN = letter–number sequencing; FW = figure weights; C = comparisons; Ca = cancellation; PC = picture completion.
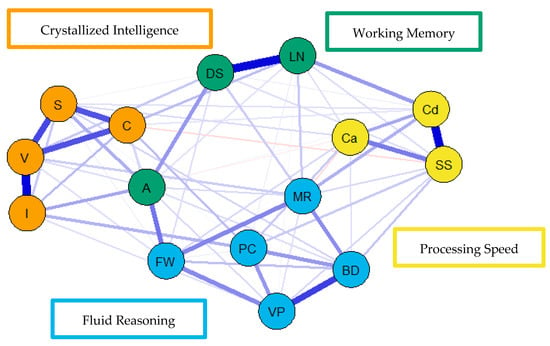
Figure 6.
Weighted, undirected psychometric network model of the older group WAIS-IV correlation matrix. BD = block design; S = similarities; DS = digit span; MR = matrix reasoning; V = vocabulary; A = arithmetic; SS = symbol search; VP = visual puzzles; I = information; Cd = coding; LN = letter–number sequencing; FW = figure weights; C = comparisons; Ca = cancellation; PC = picture completion.
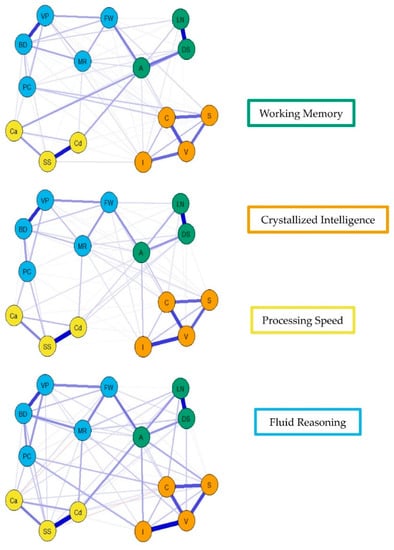
Figure 7.
Youngest (top), middle (middle), and older (bottom) group WAIS-IV weighted, undirected psychometric network models with averaged layout.
4. Discussion
The current commentary addressed several inaccurate statements made by McFarland (2020). The commentary also provided an opportunity to further examine confirmatory latent variable models and exploratory psychometric network models of intelligence. Our general goal was to establish that psychometric network modeling can provide an alternative approach of the psychometric structure of test scores from the WAIS-IV like latent variable modeling. Furthermore, uncorrected correlation matrices of standardized WAIS-IV data provided by McFarland (2020) were submitted to the statistical procedures used by Schmank et al. (2019).
The results are consistent with the findings presented in Kan et al. (2019) and Schmank et al. (2019). Based on the criteria provided by Schreiber et al. (2006), when confirmatory latent variable modeling and psychometric network modeling techniques were applied to the WAIS-IV correlation matrices provided by McFarland (2020), the resulting model fit indices were generally within what best practices and standards deem acceptable. From the perspective of model fit indices, we have corroborated the major findings presented by Kan et al. (2019); however, due to the exploratory nature of the psychometric network models and the confirmatory nature of the latent variable models, a direct comparison was not tenable as these types of analyses represent two separate stages of the psychometric research process, exploration, and confirmation.
It is worth restating the main point presented in Schmank et al. (2019): that theories of intelligence like mutualism and process overlap theory (Kovacs and Conway 2016) are incompatible with reflective, higher-order latent variable models. By assuming process overlap theory, g is viewed as an emergent property or index and not some higher-order reflective factor. Process overlap theory is, however, compatible with psychometric network analysis. Furthermore, the psychometric network models presented in the current project are visual representations of the positive manifold as interconnected networks of the interaction between pairs of cognitive tests, similar to how process overlap theory proposes formative g using the explanation of the positive manifold via overlapping general and specific processes. Ultimately, this demonstrates that psychometric network models are viable alternatives to latent variable models. In future, projects focused on theory building or theory assessment must first determine the underlying data-generating mechanisms assumed by the theories to establish whether a latent variable or psychometric network approach is most appropriate.
5. Limitations and Future Directions
The aim of this paper was to address specific comments by McFarland (2020) regarding the network models reported in Schmank et al. (2019). Therefore, many remaining important theoretical issues, as well as further analyses of the current data, are beyond the scope of the current paper. In particular, the conditions of comparability of the model fit of network and latent variable models will probably invoke important exchanges in the future.
A shortcoming of the current study is that it did not address the developmental question introduced by McFarland, that is, we did not repeat the analysis for different age categories. This clearly is a possible line of future research. In particular, such an analysis would make cross-validation possible, just like in the case of McFarland’s analysis.
Additionally, some of the models fitted by McFarland, such as a bifactor model and a penta-factor model, were not investigated in the current paper. Since these were important aspects of McFarland’s paper, further investigation on the matters discussed in this paper should address them. Our purpose with the current paper was to focus on what we perceived as central issues of McFarland’s paper as well as possible misconceptions of our previous results. There are excellent ideas and analyses in McFarland (2020) that have not been addressed here and which are worthy of exploration by future research.
Author Contributions
Conceptualization, K.K. and A.R.A.C.; Methodology, C.J.S. and S.A.G.; Formal Analysis, C.J.S.; Writing—Original Draft Preparation, C.J.S. and S.A.G.; Writing—Review & Editing, K.K. and A.R.A.C. All authors have read and agreed to the published version of the manuscript.
Funding
Kristof Kovacs received funding by the National Research, Development and Innovation Office of Hungary: Grant PD-17-125360 and Grant KH-18-130424.
Institutional Review Board Statement
Not Applicable.
Informed Consent Statement
Not Applicable.
Data Availability Statement
The data and statistical analyses presented in this study are openly available via the Open Science Framework at https://doi.org/10.17605/OSF.IO/KFUJS.
Acknowledgments
The authors of this commentary want to take a moment to acknowledge the passing of Dennis McFarland in April 2020. McFarland was a noteworthy researcher and we are honored that his input on our paper was among the many works published during his industrious career. As we acknowledge this great loss to the scientific community, our thoughts go out to his family and friends for their loss of a loved one.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Browne, Michael. W., and Robert Cudeck. 1993. Alternative ways of assessing model fit. In Testing Structural Equation Models. Edited by Kenneth A. Bollen and J. Scott Long. Newbury Park: Sage, pp. 136–62. [Google Scholar]
- Carroll, John B. 1993. Human Cognitive Abilities: A Survey of Factor-Analytic Studies. New York: Cambridge University Press. [Google Scholar] [CrossRef]
- Cattell, Raymond B. 1943. The measurement of adult intelligence. Psychological Bulletin 40: 153–93. [Google Scholar] [CrossRef]
- Conway, Andrew R. A., Kristof Kovacs, Han Hao, Sare Anne Goring, and Christopher J. Schmank. 2021. The Struggle is Real: Challenges and Solutions in Theory Building. Psychological Inquiry 31: 302–9. [Google Scholar] [CrossRef]
- Epskamp, Sacha, Angelique O. J. Cramer, Lourens J. Waldorp, Verena D. Schmittmann, and Denny Borsboom. 2012. Qgraph: Network visualizations of relationships in psychometric data. Journal of Statistical Software 48. [Google Scholar] [CrossRef]
- Epskamp, Sacha, Gaby Lunansky, Pia Tio, and Denny Borsboom. 2018. Recent Developments on the Performance of Graphical LASSO Networks. April. Available online: http://psychosystems.org/author/sachaepskamp/ (accessed on 24 May 2018).
- Golino, Hudson F., and Sacha Epskamp. 2017. Exploratory graph analysis: A new approach for estimating the number of dimensions in psychological research. PLoS ONE 12: e0174035. [Google Scholar] [CrossRef]
- Goring, Sare Anne, Christopher J. Schmank, Michael J. Kane, and Andrew R. A. Conway. 2019. Psychometric Models of Individual Differences in Reading Comprehension: A Reanalysis of Freed, Hamilton, and Long (2017). Journal of Memory and Language. in press. [Google Scholar] [CrossRef]
- Horn, John L., and Raymond B. Cattell. 1966. Refinement and test of the theory of fluid and crystallized general intelligences. Journal of Educational Psychology 57: 253–70. [Google Scholar] [CrossRef] [PubMed]
- Kan, Kees-Jan, Hannelies de Jonge, Han L. J. van der Maas, Stephen Z. Levine, and Sacha Epskamp. 2020. How to compare psychometric factor and network models. Journal of Intelligence 8: 35. [Google Scholar] [CrossRef]
- Kan, Kees-Jan, Han L. J. van der Maas, and Stephen Z. Levine. 2019. Extending psychometric network analysis: Empirical evidence against g in favor of mutualism? Intelligence 73: 52–62. [Google Scholar] [CrossRef]
- Kovacs, Kristof, and Andrew R. A. Conway. 2016. Process Overlap Theory: A unified account of the general factor of intelligence. Psychological Inquiry 27: 151–77. [Google Scholar] [CrossRef]
- McFarland, Dennis. 2020. The effects of using partial or uncorrected correlation matrices when comparing network and latent variable models. Journal of Intelligence 8: 7. [Google Scholar] [CrossRef]
- Neale, Michael C., Michael D. Hunter, Joshua N. Pritikin, Mahsa Zahery, Timothy R. Brick, Robert M. Kirkpatrick, Ryne Estabrook, Timothy C. Bates, Hermine H. Maes, and Steven M. Boker. 2016. OpenMx 2.0: Extended structural equation and statistical modeling. Psychometrika 81: 535–49. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. 2013. R: A Language and Environment for Statistical Computing. Vienna and Austria: R Foundation for Statistical Computing. Available online: http://www.R-project.org/ (accessed on 13 August 2015).
- Rosseel, Yves. 2012. Lavaan: An R Package for Structural Equation Modeling. Journal of Statistical Software 48: 1–36. Available online: http://www.jstatsoft:v48/i02/ (accessed on 10 August 2017). [CrossRef]
- Schermelleh-Engel, Karin, Helfried Moosbrugger, and Hans Müller. 2003. Evaluating the fit of structural equation models: Tests of significance and descriptive goodness-of-fit measures. Methods of Psychological Research Online 8: 23–74. [Google Scholar]
- Schmank, Christopher J., Sara Anne Goring, Kristof Kovacs, and Andrew R. A. Conway. 2019. Psychometric network analysis of the Hungarian WAIS. Journal of Intelligence 7: 21. [Google Scholar] [CrossRef] [PubMed]
- Schreiber, James B., Frances K. Stage, Jamie King, Amaury Nora, and Elizabeth A. Barlow. 2006. Reporting structural equation modeling and confirmatory factor analysis results: A review. Journal of Educational Research 99: 323–38. [Google Scholar] [CrossRef]
- Van Der Maas, Han L. J., Conor V. Dolan, Raoul P. Grasman, Jelte M. Wicherts, Hilde M. Huizenga, and Maartje E. Raijmakers. 2006. A dynamical model of general intelligence: The positive manifold of intelligence by mutualism. Psychological Review 113: 842–61. [Google Scholar] [CrossRef] [PubMed]
- Van Der Maas, Han L. J., Kees-Jan Kan, Maarten Marsman, and Claire E. Stevenson. 2017. Network models for cognitive development and intelligence. Journal of Intelligence 5: 16. [Google Scholar] [CrossRef] [PubMed]
- von Oertzen, Timo, Andreas M. Brandmaier, and Siny Tsang. 2015. Structural equation modeling with Ωnyx. Structural Equation Modeling: A Multidisciplinary Journal 22: 148–61. [Google Scholar] [CrossRef]
- Wechsler, David. 2008. Wechsler Adult Intelligence Scale, 4th ed. WAIS-IV. San Antonio: NCS Pearson. [Google Scholar]
| 1. | The present paper and Schmank et al. (2019) employ RMSEA cutoff values representing the strictest value deemed acceptable by Schreiber et al. (2006); it should be noted that values less than 0.08 can also indicate adequate model fit (Browne and Cudeck 1993; Schermelleh-Engel et al. 2003). |







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).