The Effects of (Dis)similarities Between the Creator and the Assessor on Assessing Creativity: A Comparison of Humans and LLMs


Abstract
1. Introduction
1.1. Current Research on Assessing GenAI’s Creativity
1.2. Vice Versa: Using (Gen)AI to Assess Humans’ Creativity
1.3. Cultural (Dis)similarity Affects People’s Assessment of Creativity
1.4. LLMs vs. Humans: Two Prominent Sources of Dissimilarities
1.5. The Present Study
2. Method
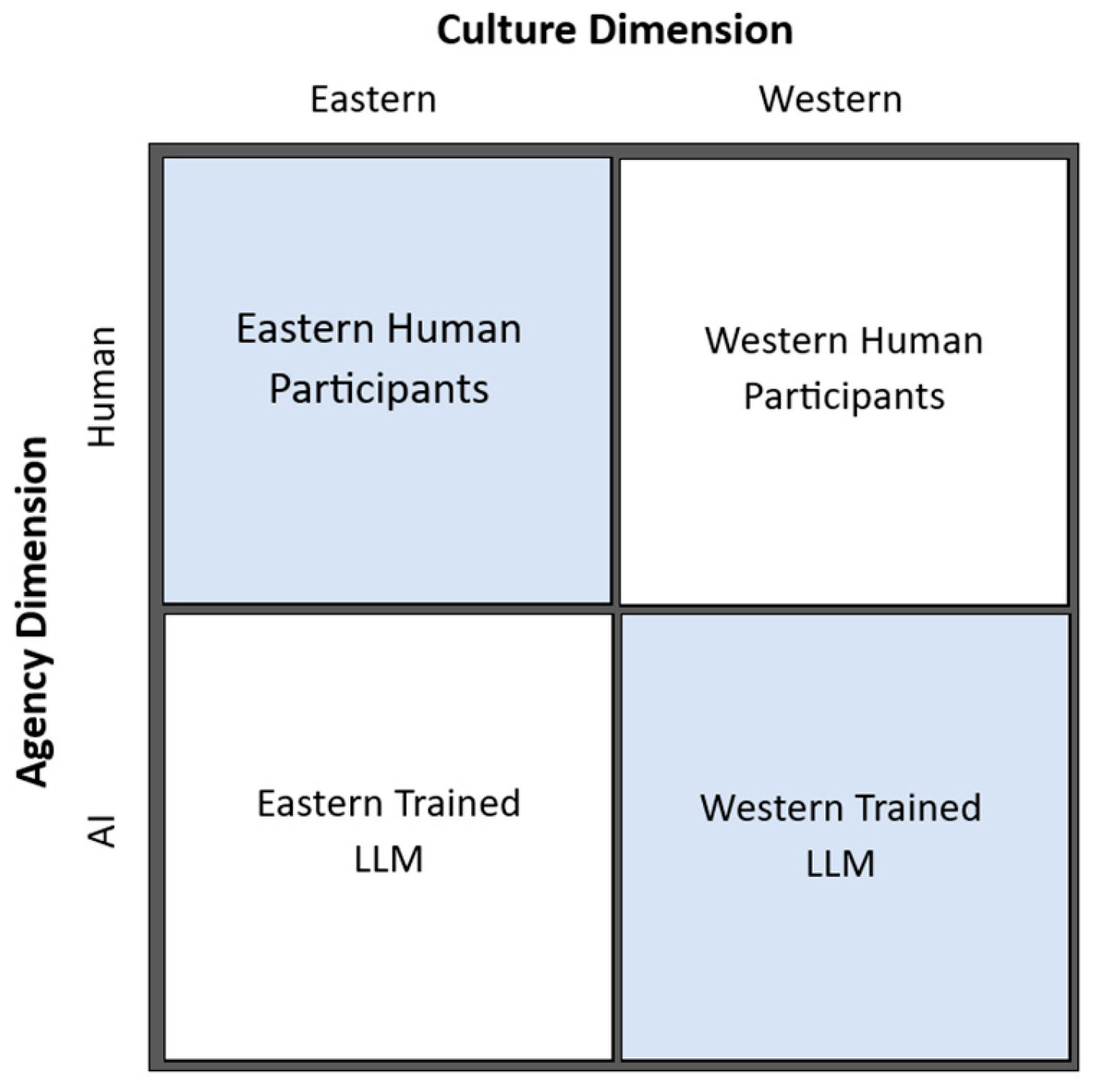
2.1. Research Design, Subjects, and Overall Procedures
2.2. Stage 1: Story Creation—Subjects as Creators
2.2.1. Testing Paradigm
2.2.2. Specific Procedures per Subject Group
2.2.3. Story Selection & Modification
2.3. Stage 2: Story Assessment–Subjects as Assessors
2.3.1. Dimensions of Story Assessment
- Originality refers to an idea or product being unique from other ideas or products, typically with a lower probability of occurring among the general population, and most people would not think of it.
- Appropriateness refers to an idea or product being appropriate and valuable in the specific context wherein it is generated, typically (with some imagination) reasonable or realizable.
2.3.2. Specific Procedures per Subject Group
2.4. Analysis Plan
3. Results
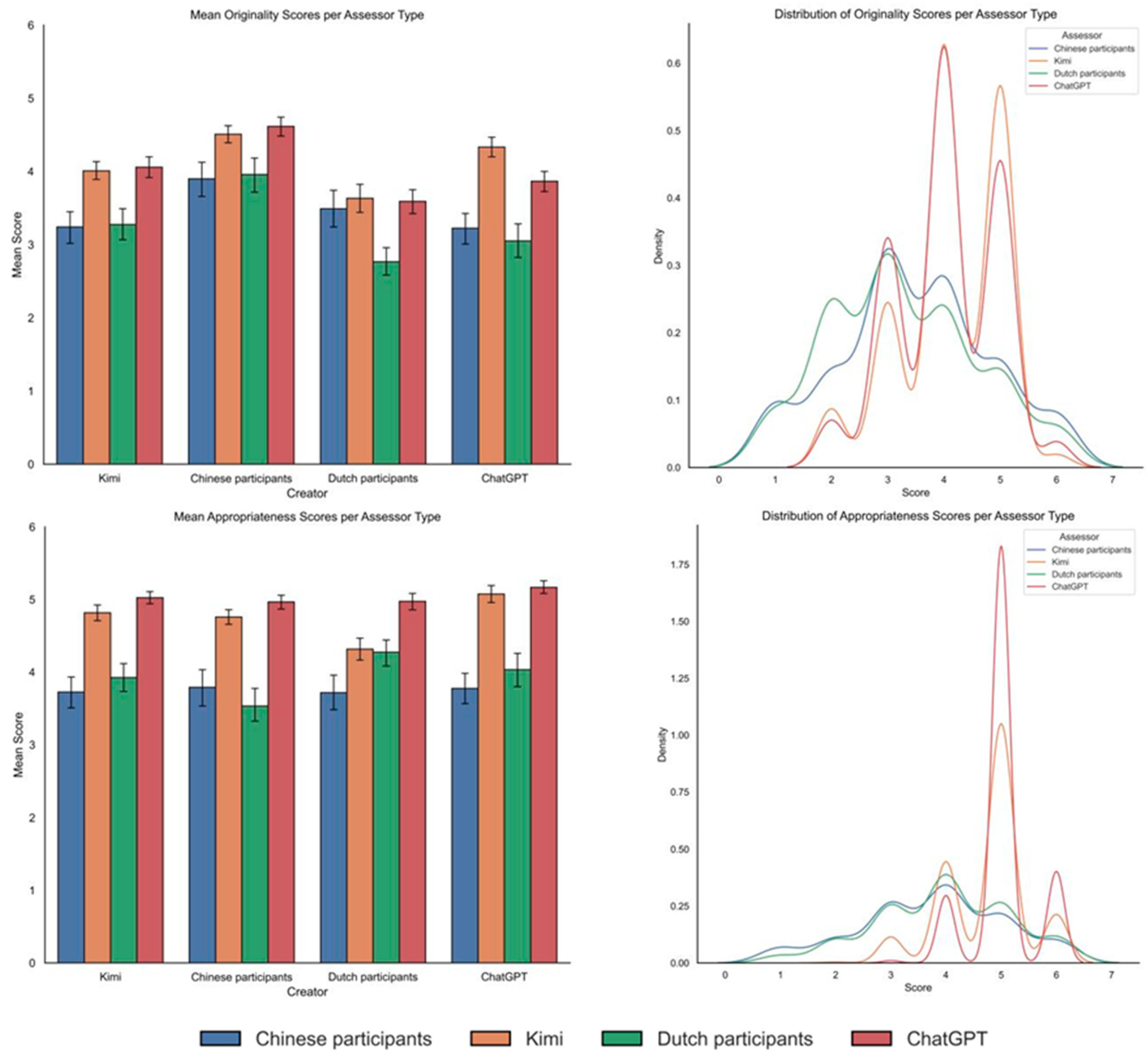
3.1. Descriptive Statistics
3.2. ICCs and Correlations
3.3. Multilevel Linear Regression
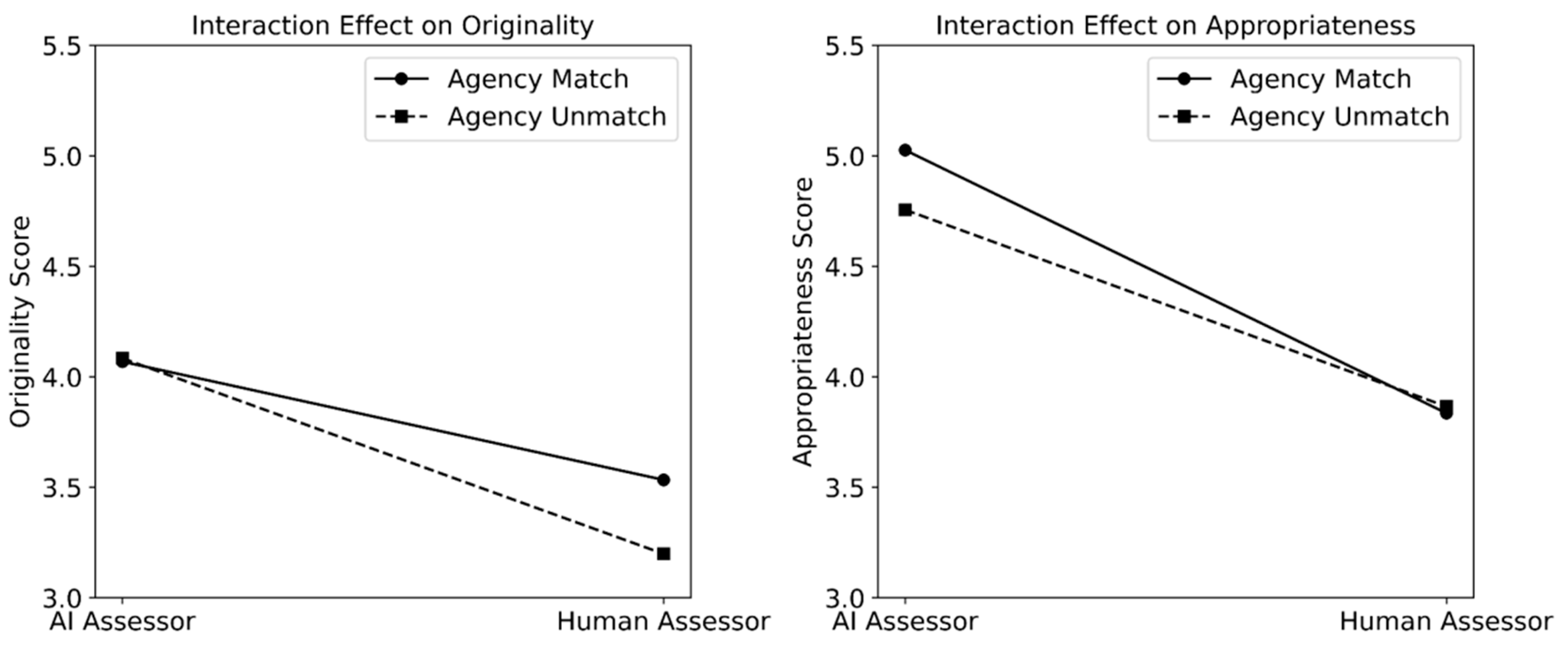
3.3.1. Main and Interaction Effects of Agentic Similarity
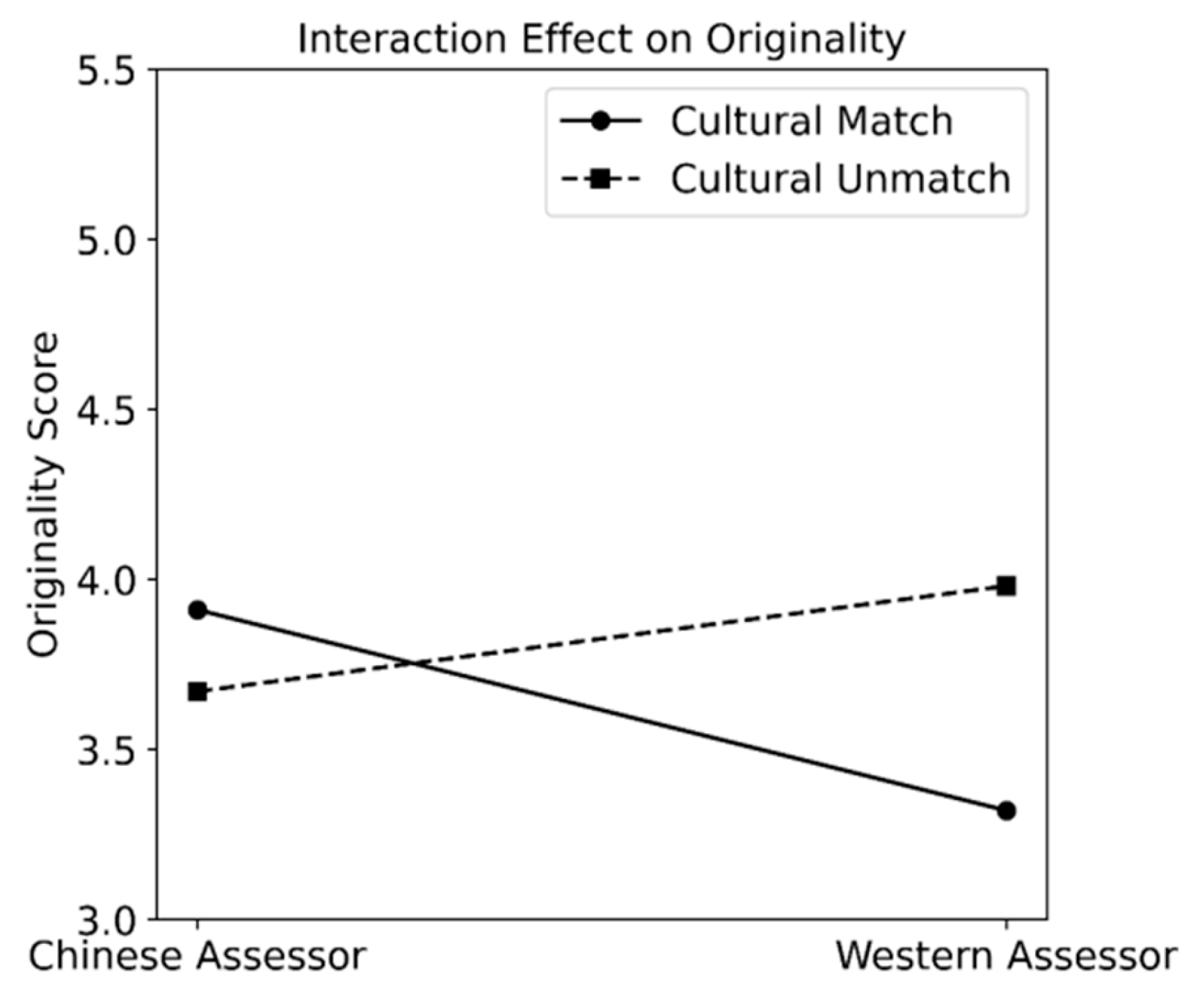
3.3.2. Main and Interaction Effects of Cultural Similarity
4. Discussion
4.1. Effects of Agentic Similarity on Assessing Creativity
4.2. Effects of Cultural Similarity on Assessing Creativity
4.3. Limitations, Implications, and Future Research
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1 | In Chinese, the basic meaningful linguistic unit is character, and a word can consist of a single character (e.g., the single character of “我” equals to “I” in English) or two or more characters (e.g., “人工智能” equals to “artificial intelligence” in English). |
References
- Agarwal, Dhruv, Mor Naaman, and Aditya Vashistha. 2025. AI suggestions homogenize writing toward Western styles and diminish cultural nuances. Paper presented at 2025 CHI Conference on Human Factors in Computing Systems. Yokohama, Japan, April 26–May 1. [Google Scholar]
- Arendt, Hannah. 2013. The Human Condition. Chicago: University of Chicago Press. [Google Scholar]
- Bai, Honghong, Lukshu Chan, Aoxin Luo, Evelyn Kroesbergen, and Stella Christie. 2024. Creativity in dialogues: How do children interact with parents vs. with strangers for generating creative ideas? PsyArXiv. [Google Scholar] [CrossRef]
- Beaty, Roger E., and Dan R. Johnson. 2021. Automating creativity assessment with semdis: An open platform for computing semantic distance. Behavior Research Methods 53: 757–80. [Google Scholar] [CrossRef] [PubMed]
- Bommasani, Rishi, Kathleen A. Creel, Ananya Kumar, Dan Jurafsky, and Percy Liang. 2022. Picking on the same person: Does algorithmic monoculture lead to outcome homogenization? In Advances in Neural Information Processing Systems. Red Hook: Curran Associates Inc, pp. 3663–78. [Google Scholar]
- Chamberlain, Rebecca, Caitlin Mullin, Bram Scheerlinck, and Johan Wagemans. 2018. Putting the art in artificial: Aesthetic responses to computer-generated art. Psychology of Aesthetics, Creativity, and the Arts 12: 177–92. [Google Scholar] [CrossRef]
- Corazza, Giovanni Emanuele. 2021. Creative Inconclusiveness. In The Palgrave Encyclopedia of the Possible. Cham: Palgrave Macmillan, pp. 1–8. [Google Scholar] [CrossRef]
- Cropley, David. 2023. Is artificial intelligence more creative than humans? Chatgpt and the divergent association task. Learning Letters 2: 13. [Google Scholar] [CrossRef]
- Cropley, David, and Rebecca L. Marrone. 2022. Automated scoring of figural creativity using a convolutional neural network. Psychology of Aesthetics, Creativity, and the Arts 19: 77–86. [Google Scholar] [CrossRef]
- Dai, Wang-Zhou, Qiuling Xu, Yang Yu, and Zhi-Hua Zhou. 2019. Bridging machine learning and logical reasoning by abductive learning. In Advances in Neural Information Processing Systems 32. Red Hook: Curran Associates Inc. [Google Scholar]
- DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, and et al. 2024. DeepSeek-V3 Technical Report. arXiv arXiv:2412.19437. [Google Scholar]
- Elgammal, Ahmed, Bingchen Liu, Mohamed Elhoseiny, and Marian Mazzone. 2017. CAN: Creative adversarial networks: Generating” art” by learning about styles and deviating from style norms. Paper presented at 8th International Conference on Computational Creativity (ICCC 2017), Atlanta, GA, USA, June 19–June 23. [Google Scholar]
- Evans, Jonathan St BT. 2002. Logic and human reasoning: An assessment of the deduction paradigm. Psychological Bulletin 128: 978–96. [Google Scholar] [CrossRef]
- Forthmann, Boris, Andrea Wilken, Philipp Doebler, and Heinz Holling. 2016. Strategy Induction Enhances Creativity in Figural Divergent Thinking. Journal of Creative Behavior 53: 18–29. [Google Scholar] [CrossRef]
- Gangadharbatla, Harsha. 2022. The role of AI attribution knowledge in the evaluation of artwork. Empirical Studies of the Arts 40: 125–42. [Google Scholar] [CrossRef]
- Glăveanu, Vlad Petre. 2013. Rewriting the language of creativity: The five A’s framework. Review of General Psychology 17: 69–81. [Google Scholar] [CrossRef]
- Grassini, Simone, and Mika Koivisto. 2024. Understanding how personality traits, experiences, and attitudes shape negative bias toward AI-generated artworks. Scientific Reports 14: 4113. [Google Scholar] [CrossRef] [PubMed]
- Guzik, Erik E., Christian Byrge, and Christian Gilde. 2023. The originality of machines: AI takes the Torrance Test. Journal of Creativity 33: 100065. [Google Scholar] [CrossRef]
- Hattori, Eline Aya, Mayu Yamakawa, and Kazuhisa Miwa. 2024. Human bias in evaluating AI product creativity. Journal of Creativity 34: 100087. [Google Scholar] [CrossRef]
- Hempel, Paul S., and Christina Sue-Chan. 2010. Culture and the assessment of creativity. Management and Organization Review 6: 415–35. [Google Scholar] [CrossRef]
- Hong, Joo-Wha. 2018. Bias in perception of art produced by artificial intelligence. In International conference on human-computer interaction. Cham: Springer International Publishing, pp. 290–303. [Google Scholar]
- Horton, C. Blaine, Jr., Michael White, and Sheena S. Iyengar. 2023. Bias against AI art can enhance perceptions of human creativity. Scientific Reports 13: 19001. [Google Scholar] [CrossRef]
- Huntsinger, Carol S., Paul E. Jose, Dana Balsink Krieg, and Zupei Luo. 2011. Cultural differences in Chinese American and European American children’s drawing skills over time. Early Childhood Research Quarterly 26: 134–45. [Google Scholar] [CrossRef]
- Ivancovsky, Tal, Oded Kleinmintz, Joo Lee, Jenny Kurman, and Simone G. Shamay-Tsoory. 2018. The neural underpinnings of cross-cultural differences in creativity. Human Brain Mapping 39: 4493–508. [Google Scholar] [CrossRef]
- Koivisto, Mika, and Simone Grassini. 2023. Best humans still outperform artificial intelligence in a creative divergent thinking task. Scientific Reports 13: 13601. [Google Scholar] [CrossRef]
- Liou, Shyhnan, and Xuezhao Lan. 2018. Situational salience of norms moderates cultural differences in the originality and usefulness of creative ideas generated or selected by teams. Journal of Cross-Cultural Psychology 49: 290–302. [Google Scholar] [CrossRef]
- Magni, Federico, Jiyoung Park, and Melody Manchi Chao. 2024. Humans as creativity gatekeepers: Are we biased against AI creativity? Journal of Business and Psychology 39: 643–56. [Google Scholar] [CrossRef]
- Maltese, Anne-Gaëlle, Pierre Pelletier, and Rémy Guichardaz. 2024. Can AI enhance its creativity to beat humans? arXiv arXiv:2409.18776. [Google Scholar]
- Marrone, Rebecca, David H. Cropley, and Zhengzheng Wang. 2023. Automatic assessment of mathematical creativity using natural language processing. Creativity Research Journal 35: 661–76. [Google Scholar] [CrossRef]
- Mukherjee, Anirban, and Hannah Hanwen Chang. 2024. Heuristic reasoning in AI: Instrumental use and mimetic absorption. arXiv arXiv:2403.09404. [Google Scholar]
- Niu, Weihua, and James C. Kaufman. 2013. Creativity of Chinese and American cultures: A synthetic analysis. Journal of Creative Behavior 47: 77–87. [Google Scholar] [CrossRef]
- Niu, Weihua, and Robert J. Sternberg. 2001. Cultural influences on artistic creativity and its evaluation. International Journal of Psychology 36: 225–41. [Google Scholar] [CrossRef]
- Niu, Weihua, and Robert Sternberg. 2002. Contemporary studies on the concept of creativity: The east and the west. Journal of Creative Behavior 36: 269–88. [Google Scholar] [CrossRef]
- Niu, Weihua, John X. Zhang, and Yingrui Yang. 2007. Deductive reasoning and creativity: A cross-cultural study. Psychological Reports 100: 509–19. [Google Scholar] [CrossRef]
- Olson, Jay A., Johnny Nahas, Denis Chmoulevitch, Simon J. Cropper, and Margaret E. Webb. 2021. Naming unrelated words predicts creativity. Proceedings of the National Academy of Sciences 118: e2022340118. [Google Scholar] [CrossRef]
- Organisciak, Peter, Selcuk Acar, Denis Dumas, and Kelly Berthiaume. 2023. Beyond semantic distance: Automated scoring of divergent thinking greatly improves with large language models. Thinking Skills and Creativity 49: 101356. [Google Scholar] [CrossRef]
- Rathje, Steve, Dan-Mircea Mirea, Ilia Sucholutsky, Raja Marjieh, Claire E. Robertson, and Jay VanBavel. 2024. GPT is an effective tool for multilingual psychological text analysis. Proceedings of the National Academy of Sciences 121: e2308950121. [Google Scholar] [CrossRef]
- Romberg, Alexa R., and Jenny R. Saffran. 2010. Statistical learning and language acquisition. Wiley Interdisciplinary Reviews: Cognitive Science 1: 906–14. [Google Scholar] [CrossRef]
- Runco, Mark A. 2023. AI can only produce artificial creativity. Journal of Creativity 33: 100063. [Google Scholar] [CrossRef]
- Runco, Mark A., and Garrett J. Jaeger. 2012. The standard definition of creativity. Creativity Research Journal 24: 92–96. [Google Scholar] [CrossRef]
- Samo, Andrew, and Scott Highhouse. 2023. Artificial intelligence and art: Identifying the aesthetic judgment factors that distinguish human- and machine-generated artwork. Psychology of Aesthetics, Creativity, and the Arts. Advance online publication. [Google Scholar] [CrossRef]
- Sawyer, R. Keith. 2021. The iterative and improvisational nature of the creative process. Journal of Creativity 31: 100002. [Google Scholar] [CrossRef]
- Snijders, Tom A. B., and Roel Bosker. 2011. London: Sage. In Multilevel Analysis: An Introduction to Basic and Advanced Multilevel Modeling, 2nd ed. London: Sage. [Google Scholar]
- Storme, Martin, Todd Lubart, Nils Myszkowski, Ping Chung Cheung, Toby Tong, and Sing Lau. 2017. A cross-cultural study of task specificity in creativity. Journal of Creative Behavior 51: 263–74. [Google Scholar] [CrossRef]
- Tao, Yan, Olga Viberg, Ryan S. Baker, and René F. Kizilcec. 2024. Cultural bias and cultural alignment of large language models. PNAS Nexus 3: 346. [Google Scholar] [CrossRef]
- Taylor, Christa L., James C. Kaufman, and Baptiste Barbot. 2021. Measuring creative writing with the storyboard task: The role of effort and story length. Journal of Creative Behavior 55: 476–88. [Google Scholar] [CrossRef]
- Tömmel, Tatjana, and Maurizio Passerin d’Entreves. 2024. Hannah Arendt. In The Stanford Encyclopedia of Philosophy. Summer 2024 ed. Edited by Edward N. Zalta and Uri Nodelman. Stanford: Metaphysics Research Lab, Stanford University. [Google Scholar]
- Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems. Red Hook: Curran Associates Inc. [Google Scholar]
- Wang, Haonan, James Zou, Michael Mozer, Anirudh Goyal, Alex Lamb, Linjun Zhang, Weijie J. Su, Zhun Deng, Michael Qizhe Xie, Hannah Brown, and et al. 2024. Can AI be as creative as humans? arXiv arXiv:2401.01623. [Google Scholar]
- Webb, Taylor, Keith J. Holyoak, and Hongjing Lu. 2023. Emergent analogical reasoning in large language models. Nature Human Behaviour 7: 1526–41. [Google Scholar] [CrossRef]
- Wong, Regine, and Weihua Niu. 2013. Cultural difference in stereotype perceptions and performances in nonverbal deductive reasoning and creativity. Journal of Creative Behavior 47: 41–59. [Google Scholar] [CrossRef]
- Yi, Xinfa, Weiping Hu, Herbert Scheithauer, and Weihua Niu. 2013. Cultural and bilingual influences on artistic creativity performances: Comparison of German and Chinese students. Creativity Research Journal 25: 108–97. [Google Scholar] [CrossRef]
- Yiu, Eunice, Eliza Kosoy, and Alison Gopnik. 2023. Transmission versus truth, imitation versus innovation: What children can do that large language and language-and-vision models cannot (yet). Perspectives on Psychological Science 19: 874–83. [Google Scholar] [CrossRef]
- Zhou, Yizhen, and Hideaki Kawabata. 2023. Eyes can tell: Assessment of implicit attitudes toward AI art. i-Perception 14: 20416695231209846. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Creativity | Originality | Appropriateness | |||||
|---|---|---|---|---|---|---|---|
| Assessor | Creator | M | SD | M | SD | M | SD |
| Chinese participants | All creator types | 3.50 | 1.34 | 3.46 | 1.34 | 3.75 | 1.30 |
| Chinese participants | 3.94 | 1.34 | 3.90 | 1.39 | 3.79 | 1.38 | |
| Kimi | 3.38 | 1.32 | 3.24 | 1.24 | 3.73 | 1.24 | |
| Dutch participants | 3.38 | 1.43 | 3.49 | 1.44 | 3.72 | 1.40 | |
| ChatGPT | 3.29 | 1.18 | 3.23 | 1.16 | 3.78 | 1.18 | |
| Kimi | All creator types | 4.09 | 0.87 | 4.12 | 0.89 | 4.74 | 0.75 |
| Chinese participants | 4.51 | 0.65 | 4.51 | 0.68 | 4.76 | 0.59 | |
| Kimi | 3.96 | 0.69 | 4.01 | 0.72 | 4.82 | 0.59 | |
| Dutch participants | 3.59 | 1.07 | 3.63 | 1.09 | 4.32 | 0.90 | |
| ChatGPT | 4.31 | 0.74 | 4.33 | 0.75 | 5.08 | 0.68 | |
| Dutch participants | All creator types | 3.49 | 1.27 | 3.26 | 1.31 | 3.94 | 1.21 |
| Chinese participants | 4.08 | 1.18 | 3.96 | 1.28 | 3.53 | 1.31 | |
| Kimi | 3.43 | 1.14 | 3.28 | 1.25 | 3.93 | 1.07 | |
| Dutch participants | 3.17 | 1.13 | 2.77 | 1.07 | 4.28 | 1.00 | |
| ChatGPT | 3.30 | 1.42 | 3.05 | 1.35 | 4.03 | 1.32 | |
| ChatGPT | All creator types | 3.94 | 0.96 | 4.03 | 0.90 | 5.03 | 0.54 |
| Chinese participants | 4.81 | 0.84 | 4.62 | 0.72 | 4.97 | 0.56 | |
| Kimi | 3.98 | 0.73 | 4.06 | 0.81 | 5.03 | 0.46 | |
| Dutch participants | 3.37 | 0.89 | 3.59 | 0.94 | 4.98 | 0.61 | |
| ChatGPT | 3.62 | 0.68 | 3.87 | 0.78 | 5.17 | 0.49 | |
| Assessor | ICC Type | ICC [95% CI] | |||
|---|---|---|---|---|---|
| Creativity | Originality | Appropriateness | |||
| Chinese participants | Absolute agreement | Single measures | 0.14 [0.07, 0.30] | 0.15 [0.08, 0.31] | 0.02 [0.00, 0.06] |
| Average measures | 0.83 [0.69, 0.93] | 0.84 [0.71, 0.93] | 0.33 [0.01, 0.66] | ||
| Consistency | Single measures | 0.24 [0.13, 0.45] | 0.23 [0.12, 0.43] | 0.03 [0.00, 0.11] | |
| Average measures | 0.91 [0.82, 0.96] | 0.90 [0.81, 0.96] | 0.48 [0.03, 0.79] | ||
| Kimi | Absolute agreement | Single measures | 0.82 [0.71, 0.92] | 0.78 [0.65, 0.90] | 0.58 [0.42, 0.77] |
| Average measures | 0.99 [0.99, 1.0] | 0.99 [0.98, 1.0] | 0.98 [0.96, 0.99] | ||
| Consistency | Single measures | 0.82 [0.71, 0.92] | 0.81 [0.70, 0.91] | 0.65 [0.49, 0.82] | |
| Average measures | 0.99 [0.99, 1.0] | 0.99 [0.99, 1.0] | 0.98 [0.97, 0.99] | ||
| Dutch participants | Absolute agreement | Single measures | 0.24 [0.13, 0.44] | 0.31 [0.18, 0.52] | 0.11 [0.05, 0.25] |
| Average measures | 0.90 [0.82, 0.96] | 0.93 [0.87, 0.97] | 0.78 [0.61, 0.91] | ||
| Consistency | Single measures | 0.29 [0.17, 0.51] | 0.38 [0.24, 0.61] | 0.14 [0.07, 0.31] | |
| Average measures | 0.93 [0.87, 0.97] | 0.95 [0.91, 0.98] | 0.83 [0.68, 0.93] | ||
| ChatGPT | Absolute agreement | Single measures | 0.13 [0.06, 0.28] | 0.09 [0.04, 0.21] | 0.09 [0.04, 0.22] |
| Average measures | 0.81 [0.65, 0.92] | 0.74 [0.52, 0.89] | 0.75 [0.54, 0.89] | ||
| Consistency | Single measures | 0.12 [0.06, 0.28] | 0.09 [0.04, 0.22] | 0.10 [0.04, 0.24]. | |
| Average measures | 0.81 [0.64, 0.92] | 0.75 [0.53, 0.90] | 0.77 [0.56, 0.90] | ||
| (a) | Creativity | Originality | Appropriateness | Creativity | Originality | Appropriateness | |
|---|---|---|---|---|---|---|---|
| Chinese participants (above diagonal)/ Kimi (below diagonal) | Dutch participants (above diagonal)/ ChatGPT (below diagonal) | ||||||
| Creativity | 0.97 ** | 0.20 | 0.98 ** | −0.86 ** | |||
| Originality | 1.00 ** | 0.18 | 0.85 ** | −0.92 ** | |||
| Appropriateness | 0.87 *** | 0.87 ** | 0.83 ** | 0.89 ** | |||
| (b) | Chinese participants | Kimi | Dutch participants | ChatGPT | Kimi | Dutch participants | ChatGPT |
| Creativity (above diagonal)/Originality (below diagonal) | Appropriateness | ||||||
| Chinese participants | 0.81 ** | 0.74 ** | −0.06 | 0.09 | 0.03 | −0.15 | |
| Kimi | 0.75 ** | 0.68 ** | −0.02 | −0.26 | 0.21 | ||
| Dutch participants | 0.65 ** | 0.66 ** | −0.02 | −0.08 | |||
| ChatGPT | −0.07 | 0.25 | 0.19 | ||||
| Originality | Appropriateness | |||||||
|---|---|---|---|---|---|---|---|---|
| Models | M0 | Mcontrol | M1 | M2 | M0 | Mcontrol | M1 | M2 |
| Predictors | Coefficient (s.e.) | |||||||
| Intercept | 0.01 (0.05) | −0.37 (0.05) *** | 0.01 (0.05) | 1.08 (0.18) *** | 0.02 (0.06) | −0.12 (0.06) + | 0.02 (0.06) | 1.05 (0.19) *** |
| Story type | 0.77 (0.03) *** | 0.27 (0.03) *** | ||||||
| Agentic match | 0.09 (0.04) * | 0.13 (0.04) *** | 0.14 (0.03) *** | 0.09 (0.03) * | ||||
| Cultural match | −0.17 (0.04) *** | −0.17 (0.04) *** | 0.10 (0.03) *** | 0.09 (0.03) ** | ||||
| Assessor agency | −0.60 (0.08) *** | −0.92 (0.09) *** | ||||||
| Assessor culture | −0.12 (0.08) | 0.22 (0.09) * | ||||||
| Agentic match × assessor agency | 0.31 (0.08) *** | −0.23 (0.07) *** | ||||||
| Cultural match × assessor culture | −0.75 (0.07) *** | 0.07 (0.06) | ||||||
| Random part | Variance (s.e.) | |||||||
| σ2subject | 0.75 | 0.57 | 0.77 | 0.74 | 0.64 | 0.58 | 0.62 | 0.61 |
| σ2error | 0.50 | 0.50 | 0.50 | 0.39 | 0.66 | 0.66 | 0.66 | 0.45 |
| Deviance (df) | 5037.02 (6) | 4587.50 (7) | 5011.86 (8) | 4846.33 (12) | 4371.72 (6) | 4286.81 (7) | 4337.26 (8) | 4245.93 (12) |
| AIC | 5049.02 | 4601.50 | 5027.86 | 4870.33 | 4383.72 | 4300.81 | 4353.26 | 4269.93 |
| BIC | 5082.38 | 4640.42 | 5072.34 | 4937.05 | 4417.08 | 4339.73 | 4397.74 | 4336.65 |
| Change in deviance (Δdf) | 449.52 (1) *** | 9.16 (2) * | 165.53 (4) *** | 84.91 (1) *** | 34.46 (2) *** | 125.79 (4) *** | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
op ‘t Hof, M.; Hu, K.; Tong, S.; Bai, H. The Effects of (Dis)similarities Between the Creator and the Assessor on Assessing Creativity: A Comparison of Humans and LLMs. J. Intell. 2025, 13, 80. https://doi.org/10.3390/jintelligence13070080
op ‘t Hof M, Hu K, Tong S, Bai H. The Effects of (Dis)similarities Between the Creator and the Assessor on Assessing Creativity: A Comparison of Humans and LLMs. Journal of Intelligence. 2025; 13(7):80. https://doi.org/10.3390/jintelligence13070080
Chicago/Turabian Styleop ‘t Hof, Martin, Ke Hu, Song Tong, and Honghong Bai. 2025. "The Effects of (Dis)similarities Between the Creator and the Assessor on Assessing Creativity: A Comparison of Humans and LLMs" Journal of Intelligence 13, no. 7: 80. https://doi.org/10.3390/jintelligence13070080
APA Styleop ‘t Hof, M., Hu, K., Tong, S., & Bai, H. (2025). The Effects of (Dis)similarities Between the Creator and the Assessor on Assessing Creativity: A Comparison of Humans and LLMs. Journal of Intelligence, 13(7), 80. https://doi.org/10.3390/jintelligence13070080