Scoring German Alternate Uses Items Applying Large Language Models

 , , , , , and
, , , , , and
Abstract
1. Introduction
1.1. Assessment of Divergent Thinking
1.2. Automated Scoring of Divergent Thinking Tasks
1.3. The Present Research
2. Materials and Methods
2.1. Transparency and Openness
2.2. Data Sources
2.3. Human Creativity Ratings
2.4. Large Language Model Creativity Ratings
Evaluate how creative the following use for the object %s is: %s.
An idea should be considered creative if it meets the following criteria: On the one hand, a creative idea should be novel (in the sense of being unusual, original, unique, or surprising), and on the other hand, it should also be effective (in the sense of being appropriate, useful, clever, interesting, exciting, or humorous).
Rate each idea on a scale from 10 (not creative at all) to 50 (very creative).
2.5. Alternate Uses Task Data Preparation
2.6. Analysis Strategy
3. Results
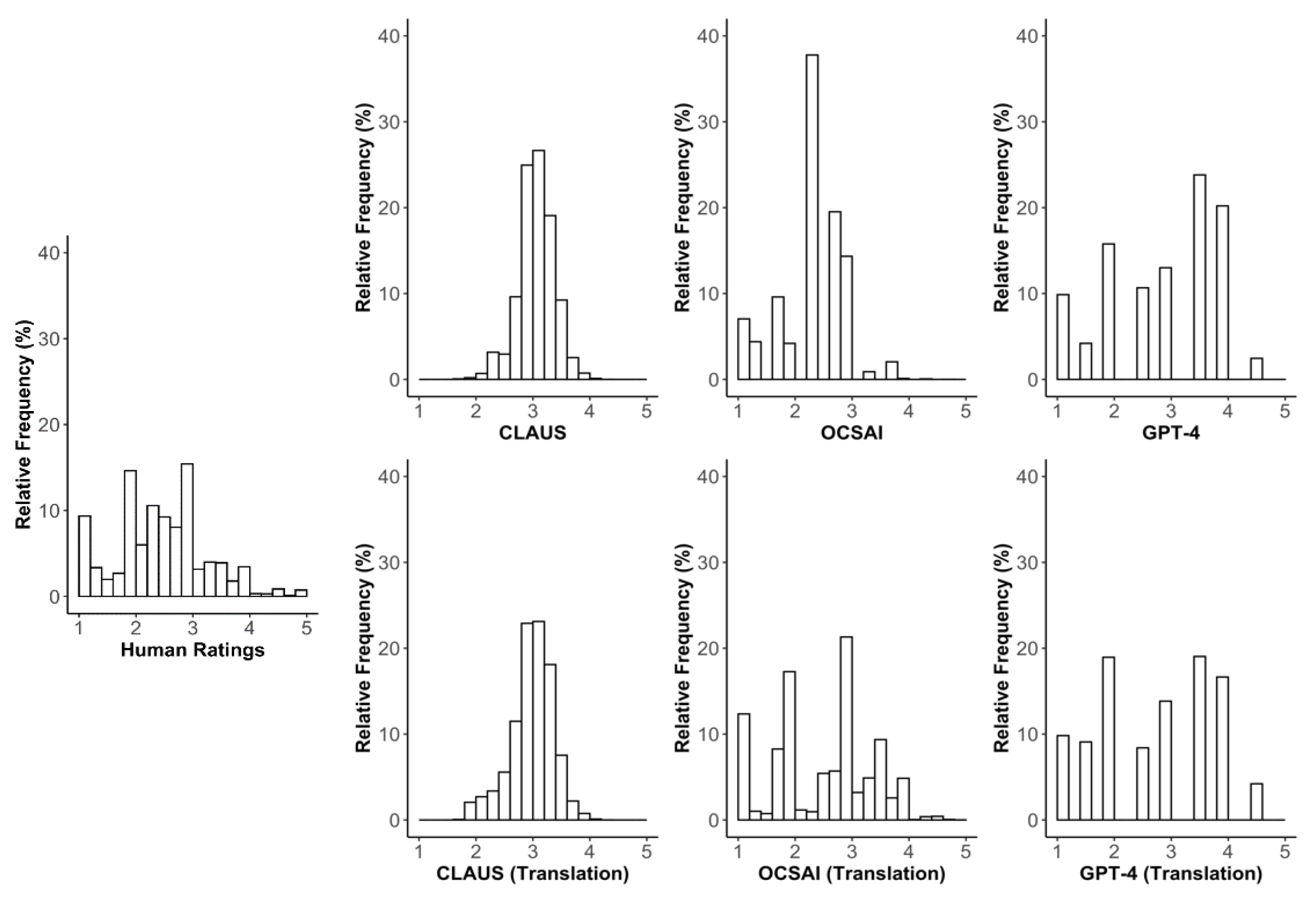
3.1. Distribution of Creativity Ratings Across Studies
3.2. Correlations Between Human and Large Language Model-Based Creativity Ratings
3.2.1. Correlations Across All Responses
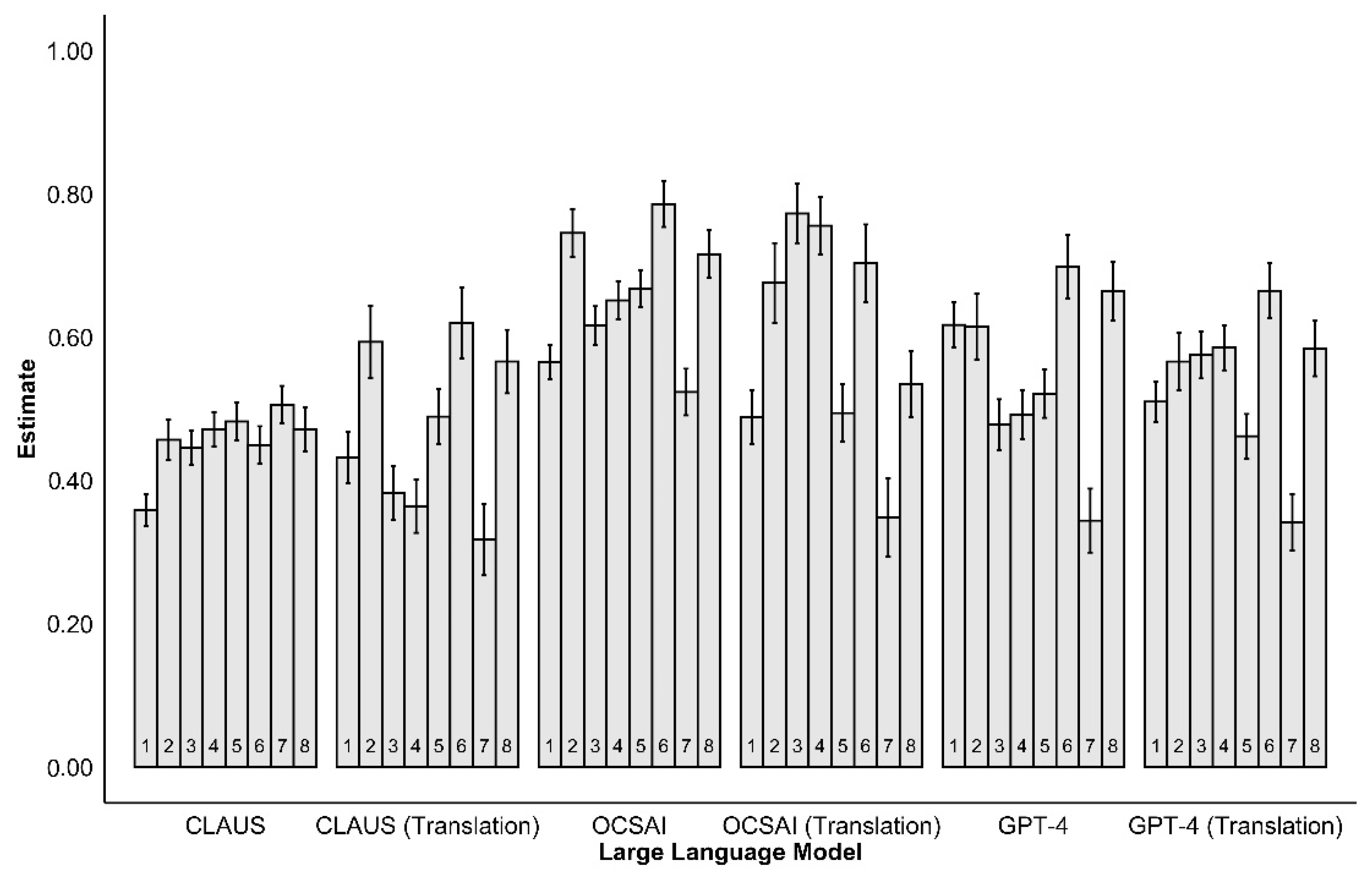
3.2.2. Correlations per Study
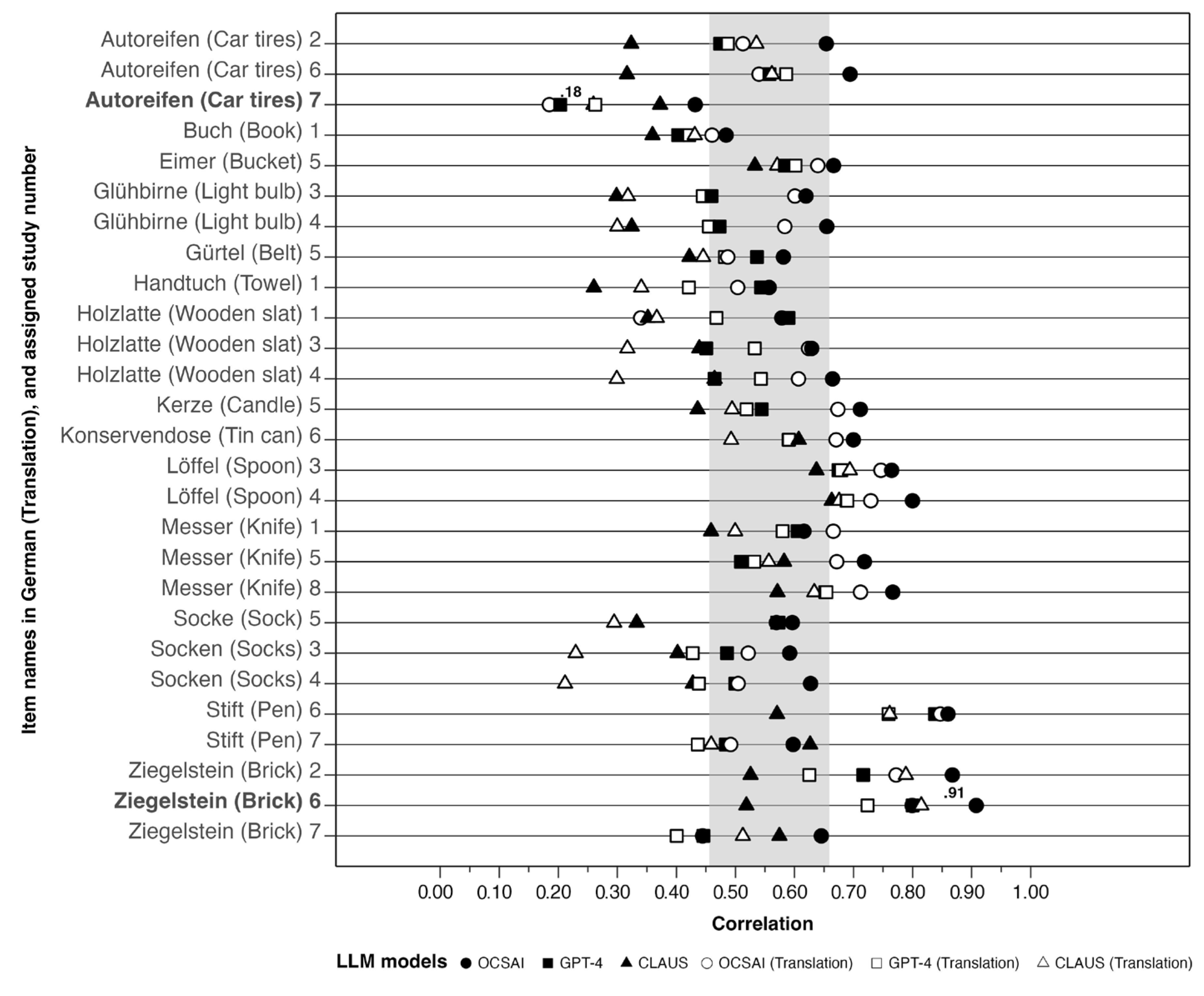
3.2.3. Correlations per Item
3.3. Exploring the Effectiveness of Large Language Model Scorings by Means of Rater Statistics
4. Discussion
4.1. Comparison of Large Language Models
4.2. Effects of Response Translation
4.3. Variation Across Items and Studies
4.4. Can Large Language Models Replace Human Raters?
4.5. Limitations and Future Directions
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Study | Responses | CLAUS | OCSAI | GPT-4 | |||
|---|---|---|---|---|---|---|---|
| German | Translation | German | Translation | German | Translation | ||
| Across Studies | 48,507 | 0.46 | 0.47 | 0.66 | 0.60 | 0.55 | 0.54 |
| 1 | 11,151 | 0.36 | 0.43 | 0.57 | 0.49 | 0.62 | 0.51 |
| 2 | 2319 | 0.46 | 0.59 | 0.75 | 0.68 | 0.62 | 0.57 |
| 3 | 2733 | 0.45 | 0.38 | 0.62 | 0.77 | 0.48 | 0.58 |
| 4 | 4917 | 0.47 | 0.36 | 0.65 | 0.76 | 0.49 | 0.59 |
| 5 | 7608 | 0.48 | 0.49 | 0.67 | 0.49 | 0.52 | 0.46 |
| 6 | 13,244 | 0.45 | 0.62 | 0.79 | 0.70 | 0.70 | 0.66 |
| 7 | 5675 | 0.51 | 0.32 | 0.52 | 0.35 | 0.34 | 0.34 |
| 8 | 860 | 0.47 | 0.67 | 0.72 | 0.53 | 0.66 | 0.58 |
| ID | Item | CLAUS | OCSAI | GPT-4 | ||||
|---|---|---|---|---|---|---|---|---|
| N | German | Translation | German | Translation | German | Translation | ||
| 1 | Buch (Book) | 1825 | 0.36 | 0.43 | 0.48 | 0.46 | 0.40 | 0.42 |
| 1 | Handtuch (Towel) | 4493 | 0.26 | 0.34 | 0.56 | 0.50 | 0.54 | 0.42 |
| 1 | Holzlatte (Wooden slat) | 1803 | 0.35 | 0.37 | 0.58 | 0.34 | 0.59 | 0.47 |
| 1 | Messer (Knife) | 3030 | 0.46 | 0.50 | 0.62 | 0.67 | 0.61 | 0.58 |
| 2 | Autoreifen (Car tires) | 1078 | 0.32 | 0.54 | 0.65 | 0.51 | 0.47 | 0.49 |
| 2 | Ziegelstein (Brick) | 1241 | 0.53 | 0.79 | 0.87 | 0.77 | 0.72 | 0.63 |
| 3 | Glühbirne (Light bulb) | 517 | 0.30 | 0.32 | 0.62 | 0.60 | 0.46 | 0.44 |
| 3 | Holzlatte (Wooden slat) | 921 | 0.44 | 0.32 | 0.63 | 0.62 | 0.45 | 0.53 |
| 3 | Löffel (Spoon) | 636 | 0.64 | 0.69 | 0.76 | 0.75 | 0.67 | 0.68 |
| 3 | Socken (Socks) | 659 | 0.40 | 0.23 | 0.59 | 0.52 | 0.49 | 0.43 |
| 4 | Glühbirne (Light bulb) | 1009 | 0.32 | 0.30 | 0.65 | 0.58 | 0.47 | 0.46 |
| 4 | Holzlatte (Wooden slat) | 1467 | 0.46 | 0.30 | 0.66 | 0.61 | 0.46 | 0.54 |
| 4 | Löffel (Spoon) | 1166 | 0.66 | 0.68 | 0.80 | 0.73 | 0.69 | 0.69 |
| 4 | Socken (Socks) | 1275 | 0.43 | 0.21 | 0.63 | 0.50 | 0.50 | 0.44 |
| 5 | Eimer (Bucket) | 1751 | 0.53 | 0.57 | 0.67 | 0.64 | 0.58 | 0.60 |
| 5 | Gürtel (Belt) | 1476 | 0.42 | 0.45 | 0.58 | 0.49 | 0.54 | 0.48 |
| 5 | Kerze (Candle) | 1294 | 0.44 | 0.49 | 0.71 | 0.67 | 0.54 | 0.52 |
| 5 | Messer (Knife) | 1316 | 0.58 | 0.56 | 0.72 | 0.67 | 0.51 | 0.53 |
| 5 | Socke (Sock) | 1771 | 0.33 | 0.29 | 0.60 | 0.57 | 0.57 | 0.57 |
| 6 | Autoreifen (Car tires) | 3182 | 0.32 | 0.56 | 0.69 | 0.54 | 0.56 | 0.59 |
| 6 | Konservendose (Tin can) | 3529 | 0.61 | 0.49 | 0.70 | 0.67 | 0.59 | 0.59 |
| 6 | Stift (Pen) | 3154 | 0.57 | 0.76 | 0.86 | 0.85 | 0.84 | 0.76 |
| 6 | Ziegelstein (Brick) | 3379 | 0.52 | 0.81 | 0.91 | 0.80 | 0.80 | 0.72 |
| 7 | Autoreifen (Car tires) | 1969 | 0.37 | 0.26 | 0.43 | 0.18 | 0.20 | 0.26 |
| 7 | Stift (Pen) | 1742 | 0.63 | 0.46 | 0.60 | 0.49 | 0.48 | 0.44 |
| 7 | Ziegelstein (Brick) | 1964 | 0.57 | 0.51 | 0.65 | 0.44 | 0.45 | 0.40 |
| 8 | Messer (Knife) | 860 | 0.57 | 0.63 | 0.77 | 0.71 | 0.65 | 0.66 |
| 1 | Three additional datasets were initially considered in the pre-registration but not included in the analyses. Weiss et al. (2023) was excluded because its ratings focused solely on assessing the appropriateness of responses. Kleinkorres et al. (2021) and Forthmann and Doebler (2022) were excluded because they were part of the German training dataset for the fine-tuned LLMs (see Patterson et al. 2023), which undermines the independence of the test data. |
| 2 | We used the GPT-4 model instead of the pre-registered GPT-4o, as GPT-4o was not available for the data volume at the time of data collection. |
| 3 | Note: GPT is available both through OpenAI’s chat interface and via a paid Application Programming Interface (API). While the chat interface allows for manual interactions, the API is recommended for processing larger datasets. The R code provided in the OSF Supplemental Material documents the procedure used in this study. |
References
- Amabile, Teresa M. 1982. Social Psychology of Creativity: A Consensual Assessment Technique. Journal of Personality and Social Psychology 43: 997–1013. [Google Scholar] [CrossRef]
- Amabile, Teresa M. 1996. Creativity in Context: Update to the Social Psychology of Creativity. London: Routledge. [Google Scholar]
- Baer, John, James C. Kaufman, and Claudia A. Gentile. 2004. Extension of the Consensual Assessment Technique to Nonparallel Creative Products. Creativity Research Journal 16: 113–17. [Google Scholar] [CrossRef]
- Bates, Douglas, Martin Mächler, Ben Bolker, and Steve Walker. 2015. Fitting Linear Mixed-Effects Models Using Lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Beaty, Roger E., and Dan R. Johnson. 2021. Automating creativity assessment with SemDis: An open platform for computing semantic distance. Behavior Research Methods 53: 757–80. [Google Scholar] [CrossRef] [PubMed]
- Beaty, Roger E., Dan R. Johnson, Daniel C. Zeitlen, and Boris Forthmann. 2022. Semantic Distance and the Alternate Uses Task: Recommendations for Reliable Automated Assessment of Originality. Creativity Research Journal 34: 245–60. [Google Scholar] [CrossRef]
- Benedek, Mathias, and Izabela Lebuda. 2024. Managing Your Muse: Exploring Three Levels of Metacognitive Control in Creative Ideation. Creativity Research Journal 13: 1–12. [Google Scholar] [CrossRef]
- Benedek, Mathias, Caterina Mühlmann, Emanuel Jauk, and Aljoscha C. Neubauer. 2013. Assessment of Divergent Thinking by Means of the Subjective Top-Scoring Method: Effects of the Number of Top-Ideas and Time-on-Task on Reliability and Validity. Psychology of Aesthetics, Creativity, and the Arts 7: 341–49. [Google Scholar] [CrossRef]
- Campbell, Donald T., and Donald W. Fiske. 1959. Convergent and Discriminant Validation by the Multitrait-Multimethod Matrix. Psychological Bulletin 56: 81–105. [Google Scholar] [CrossRef]
- Ceh, Simon Majed, Carina Edelmann, Gabriela Hofer, and Mathias Benedek. 2022. Assessing Raters: What Factors predict Discernment in Novice Creativity Raters? The Journal of Creative Behavior 56: 41–54. [Google Scholar] [CrossRef]
- Cropley, David H., and Rebecca L. Marrone. 2022. Automated scoring of figural creativity using a convolutional neural network. Psychology of Aesthetics, Creativity, and the Arts 19: 77–86. [Google Scholar] [CrossRef]
- Curran, Patrick J., and Andrea M. Hussong. 2009. Integrative Data Analysis: The Simultaneous Analysis of Multiple Data Sets. Psychological Methods 14: 81–100. [Google Scholar] [CrossRef] [PubMed]
- Diedrich, Jennifer, Mathias Benedek, Emanuel Jauk, and Aljoscha C. Neubauer. 2015. Are Creative Ideas Novel and Useful? Psychology of Aesthetics, Creativity, and the Arts 9: 35–40. [Google Scholar] [CrossRef]
- DiStefano, Paul V., John D. Patterson, and Roger E. Beaty. 2024. Automatic Scoring of Metaphor Creativity with Large Language Models. Creativity Research Journal, 1–15. [Google Scholar] [CrossRef]
- Dumas, Denis, Peter Organisciak, Shannon Maio, and Michael Doherty. 2021. Four Text-Mining Methods for Measuring Elaboration. The Journal of Creative Behavior 55: 517–31. [Google Scholar] [CrossRef]
- Forthmann, Boris, and Philipp Doebler. 2022. Fifty Years Later and Still Working: Rediscovering Paulus et al.’s (1970) Automated Scoring of Divergent Thinking Tests. Psychology of Aesthetics, Creativity, and the Arts 19: 63–76. [Google Scholar] [CrossRef]
- Forthmann, Boris, Benjamin Goecke, and Roger E. Beaty. 2023. Planning Missing Data Designs for Human Ratings in Creativity Research: A Practical Guide. Creativity Research Journal 37: 167–78. [Google Scholar] [CrossRef]
- Forthmann, Boris, David Jendrycko, J. Meinecke, and Heinz Holling. 2017a. Tackling Creative Quality in Divergent Thinking: Dissection of Ingredients. [Unpublished manuscript]. Münster: University of Münster. [Google Scholar]
- Forthmann, Boris, Heinz Holling, Pinar Çelik, Martin Storme, and Todd Lubart. 2017b. Typing Speed as a Confounding Variable and the Measurement of Quality in Divergent Thinking. Creativity Research Journal 29: 257–69. [Google Scholar] [CrossRef]
- Goecke, Benjmain, Paul V. DiStefano, Wolfgang Aschauer, Kurt Haim, Roger Beaty, and Boris Forthmann. 2024. Automated Scoring of Scientific Creativity in German. The Journal of Creative Behavior 58: 321–27. [Google Scholar] [CrossRef]
- Grattafiori, Aaron, Abhimanyu Dubey, Abhinav Jauhri, Abhhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and et al. 2024. The llama 3 herd of models. arXiv arXiv:2407.21783. [Google Scholar]
- Guilford, Joy Paul. 1950. Creativity. American Psychologist 5: 444–54. [Google Scholar] [CrossRef]
- Guilford, Joy Paul. 1967. The Nature of Human Intelligence. New York: MacGraw Hill. [Google Scholar]
- Huang, Yudong, Hongyang Du, Xinyuan Zhang, Dusit Niyato, Jiawen Kang, Zehui Xiong, Shuo Wang, and Tao Huang. 2024. Large Language Models for Networking: Applications, enabling Techniques, and Challenges. IEEE Network 39: 235–42. [Google Scholar] [CrossRef]
- Jaggy, Ann-Kathrin, Dan John, Noel Wytopil, Amelie Schönle, Jessika Golle, Benjamin Nagengast, and Ulrich Trautwein. 2025. Talent-Study. Available online: https://osf.io/kbwz7 (accessed on 3 February 2025).
- Kamaluddin, Mohamad Ihsan, Moch Wildan Khoeurul Rasyid, Fourus Haznutal Abqoriyyah, and Andang Saehu. 2024. Accuracy analysis of DeepL: Breakthroughs in machine translation technology. Journal of English Education Forum 4: 122–26. [Google Scholar] [CrossRef]
- Kaufmann, Esther, Ulf-Dietrich Reips, and Katharina Maag Merki. 2016. Avoiding Methodological Biases in Meta-Analysis. Zeitschrift für Psychologie 224: 157–167. [Google Scholar] [CrossRef]
- Kleinkorres, Ruben, Boris Forthmann, and Heinz Holling. 2021. An Experimental Approach to Investigate the Involvement of Cognitive Load in Divergent Thinking. Journal of Intelligence 9: 3. [Google Scholar] [CrossRef] [PubMed]
- Knopf, Thomas, and Clemens M. Lechner. 2025. Measuring Innovation Skills with the Behavioral, Emotional and Social Skills Inventory (BESSI): Validating Self-Reports Against Eight Performance Tests of Cognitive Abilities. [Manuscript in Preparation]. Mannheim: GESIS–Leibniz Institute for the Social Sciences. [Google Scholar]
- Kuznetsova, Alexandra, Per B. Brockhoff, and Rune H. B. Christensen. 2017. lmerTest Package: Tests in Linear Mixed Effects Models. Journal of Statistical Software 82: 1–26. [Google Scholar] [CrossRef]
- Landauer, Thomas K., Peter W. Foltz, and Darrell Laham. 1998. An Introduction to Latent Semantic Analysis. Discourse Processes 25: 259–84. [Google Scholar] [CrossRef]
- Lebuda, Izabela, and Mathias Benedek. 2024. Contributions of Metacognition to Creative Performance and Behavior. The Journal of Creative Behavior 59: e652. [Google Scholar] [CrossRef]
- Linlin, Li. 2024. Artificial Intelligence Translator DeepL Translation Quality Control. Procedia Computer Science 247: 710–17. [Google Scholar] [CrossRef]
- Luchini, Simone A., Ibraheem Muhammad Moosa, John D. Patterson, Dan R. Johnson, Matthijs Baas, Baptiste Barbot, Iana P. Bashmakova, Mathias Benedek, Qunlin Chen, Giovanni E. Corazza, and et al. 2025a. Automated Assessment of Creativity in Multilingual Narratives. Psychology of Aesthetics, Creativity, and the Arts. advance online publication. [Google Scholar] [CrossRef]
- Luchini, Simone A., Nadine T. Maliakkal, Paul V. DiStefano, Antonio Laverghetta, John D. Patterson, Roger E. Beaty, and Roni Reiter-Palmon. 2025b. Automatic Scoring of Creative Problem-Solving with Large Language Models: A Comparison of Originality and Quality Ratings. Psychology of Aesthetics, Creativity, and the Arts. advance online publication. [Google Scholar] [CrossRef]
- Mouchiroud, Christophe, and Todd Lubart. 2001. Children’s Original Thinking: An Empirical Examination of Alternative Measures derived from Divergent Thinking Tasks. The Journal of Genetic Psychology 162: 382–401. [Google Scholar] [CrossRef]
- Myszkowski, Nils, and Martin Storme. 2019. Judge response theory? A call to upgrade our psychometrical account of creativity judgments. Psychology of Aesthetics, Creativity, and the Arts 13: 167–75. [Google Scholar] [CrossRef]
- Organisciak, Peter, Selcuk Acar, Denis Dumas, and Kelly Berthiaume. 2023. Beyond Semantic Distance: Automated Scoring of Divergent Thinking Greatly Improves with Large Language Models. Thinking Skills and Creativity 49: 101356. [Google Scholar] [CrossRef]
- Patterson, John D., Baptiste Barbot, James Lloyd-Cox, and Roger E. Beaty. 2024a. AuDrA: An Automated Drawing Assessment Platform for Evaluating Creativity. Behavior Research Methods 56: 3619–36. [Google Scholar] [CrossRef] [PubMed]
- Patterson, John D., Hannah M. Merseal, Dan R. Johnson, Sergio Agnoli, Matthisj Baas, Brendan S. Baker, Baptiste Barbot, Mathias Benedek, Khatereh Borhani, Qunlin Chen, and et al. 2023. Multilingual Semantic Distance: Automatic Verbal Creativity Assessment in many Languages. Psychology of Aesthetics, Creativity, and the Arts 17: 495. [Google Scholar] [CrossRef]
- Patterson, John, Jimmy Pronchick, Ruchi Panchanadikar, Mark Fuge, Janet van Hell, Scarlett Miller, Dan Johnson, and Roger Beaty. 2024b. CAP: The Creativity Assessment Platform for Online Testing and Automated Scoring. [Manuscript submitted for publication]. State College: Department of Psychology, Pennsylvania State University. [Google Scholar]
- Paulus, Dieter H., and Joseph S. Renzuli. 1968. Scoring Creativity Tests by Computer. Gifted Child Quarterly 12: 79–83. [Google Scholar] [CrossRef]
- Rogozińska, Ewelina, Nadine Marlin, Shakila Thangaratinam, Khalid S. Khan, and Javier Zamora. 2017. Meta-Analysis using Individual Participant Data from Randomised Trials: Opportunities and Limitations created by Access to Raw Data. BMJ Evidence-Based Medicine 22: 157–62. [Google Scholar] [CrossRef] [PubMed]
- Saretzki, Janika, Boris Forthmann, and Mathias Benedek. 2024a. A systematic quantitative review of divergent thinking assessments. Psychology of Aesthetics, Creativity and the Arts. advance online publication. [Google Scholar] [CrossRef]
- Saretzki, Janika, Rosalie Andrae, Boris Forthmann, and Mathias Benedek. 2024b. Investigation of Response Aggregation Methods in Divergent Thinking Assessments. The Journal of Creative Behavior. [Google Scholar] [CrossRef]
- Silvia, Paul J. 2008. Discernment and creativity: How well can people identify their most creative ideas? Psychology of Aesthetics, Creativity, and the Arts 2: 139–46. [Google Scholar] [CrossRef]
- Silvia, Paul J., Beate P. Winterstein, John T. Willse, Christopher M. Barona, Joshua T. Cram, Karl I. Hess, Jenna L. Martinez, and Crystal A. Richard. 2008. Assessing Creativity with Divergent Thinking Tasks: Exploring the Reliability and Validity of new Subjective Scoring Methods. Psychology of Aesthetics, Creativity, and the Arts 2: 68–85. [Google Scholar] [CrossRef]
- Stevenson, Claire, Iris Smal, Matthijs Baas, Raoul Grasman, and Han van der Maas. 2022. Putting GPT-3’s Creativity to the (Alternative Uses) Test. arXiv arXiv:2206.08932. [Google Scholar]
- Thomas, Doneal, Sanyath Radji, and Andrea Benedetti. 2014. Systematic Review of Methods for Individual Patient Data Meta-Analysis with Binary Outcomes. BMC Medical Research Methodology 14: 79. [Google Scholar] [CrossRef] [PubMed]
- Torrance, E. Paul. 1972. Predictive Validity of the Torrance Tests of Creative Thinking. The Journal of Creative Behavior 6: 236–52. [Google Scholar] [CrossRef]
- Touvron, Hugo, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bhargava, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, and et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv arXiv:2307.09288. [Google Scholar]
- van Aert, Robbie C. 2022. Analyzing Data of a Multilab Replication Project With Individual Participant Data Meta-Analysis. Zeitschrift für Psychologie 230: 60–72. [Google Scholar] [CrossRef]
- Vinchon, Florent, Todd Lubart, Sabrina Bartolotta, Valentin Gironnay, Marion Botella, Samira Bourgeois-Bougrine, Jean-Marie Burkhardt, Nathalie Bonnardel, Giovanni Emanuele Corazza, Vlad Glăveanu, and et al. 2023. Artificial Intelligence & Creativity: A manifesto for Collaboration. The Journal of Creative Behavior 57: 472–84. [Google Scholar] [CrossRef]
- Wahbeh, Helané, Cedric Cannard, Garret Yount, Arnaud Delorme, and Dean Radin. 2024. Creative Self-Belief Responses Versus Manual and Automated Guilford Alternate Use Task Scoring: A Cross-Sectional Study [Preprint]. PsyArXiv. Available online: https://osf.io/preprints/psyarxiv/vjqnu_v1 (accessed on 27 January 2025).
- Wallach, Michael A., and Nathan Kogan. 1965. A New Look at the Creativity-Intelligence Distinction. Journal of Personality 33: 348–69. [Google Scholar] [CrossRef]
- Weiss, Selina, Benjamin Goecke, and Oliver Wilhelm. 2024. How Much Retrieval Ability Is in Originality? The Journal of Creative Behavior 58: 370–87. [Google Scholar] [CrossRef]
- Weiss, Selina, Sally Olderbak, and Oliver Wilhelm. 2023. Conceptualizing and Measuring Ability Emotional Creativity. Psychology of Aesthetics, Creativity, and the Arts 19: 450–65. [Google Scholar] [CrossRef]
- Wilson, Robert C., Joy Paul Guilford, Paul R. Christensen, and Donald J. Lewis. 1954. A Factor-Analytic Study of Creative-Thinking Abilities. Psychometrika 19: 297–311. [Google Scholar] [CrossRef]
- Yang, Tianchen, Qifan Zhang, Zhaoyang Sun, and Yubo Hou. 2024. Automatic Assessment of Divergent Thinking in Chinese Language with TransDis: A Transformer-Based Language Model Approach. Behavior Research Methods 56: 5798–819. [Google Scholar] [CrossRef] [PubMed]
- Yu, Yuhua, Roger E. Beaty, Boris Forthmann, Mark Beeman, John Henry Cruz, and Dan Johnson. 2023. A MAD method to assess idea novelty: Improving validity of automatic scoring using maximum associative distance (MAD). Psychology of Aesthetics, Creativity, and the Arts. advance online publication. [Google Scholar] [CrossRef]
- Zielińska, Aleksandra, Peter Organisciak, Denis Dumas, and Maciej Karwowski. 2023. Lost in Translation? Not for Large Language Models: Automated Divergent Thinking Scoring Performance Translates to Non-English Contexts. Thinking Skills and Creativity 50: 101414. [Google Scholar] [CrossRef]
| ID | Reference | N | Items | Responses | Raters | ICC [95% CI] |
|---|---|---|---|---|---|---|
| 1 | Weiss et al. 2024 | 328 | 4 | 11,599 | 3 | 0.786 [0.779, 0.793] |
| 2 | Knopf and Lechner 2025 | 443 | 2 | 2445 | 2 | 0.810 [0.795, 0.825] |
| 3 | Jaggy et al. 2025 | 129 | 4 | 2835 | 2 1 | 0.804 [0.744, 0.857] |
| 4 | Jaggy et al. 2025 | 218 | 4 | 5042 | 2 1 | 0.814 [0.785, 0.909] |
| 5 | Saretzki et al. 2024b | 300 | 5 | 7691 | 6 | 0.855 [0.850, 0.860] |
| 6 | Lebuda and Benedek 2024 | 425 | 4 | 13,244 | 6 | 0.813 [0.808, 0.818] |
| 7 | Benedek and Lebuda 2024 | 317 | 3 | 5675 | 6 | 0.808 [0.800, 0.815] |
| 8 | Forthmann et al. 2017a | 160 | 1 | 860 | 3 | 0.902 [0.890, 0.913] |
| Total | - | 2320 | 27 2 | 49,391 | 30 | - |
| 1. 1 | 2. | 3. | 4. | 5. | 6. | |
|---|---|---|---|---|---|---|
| 1. Human Ratings | - | |||||
| 2. CLAUS | 0.46 | - | ||||
| 3. CLAUS (Translation) | 0.47 | 0.54 | - | |||
| 4. OCSAI | 0.66 | 0.57 | 0.63 | - | ||
| 5. OCSAI (Translation) | 0.60 | 0.45 | 0.55 | 0.72 | - | |
| 6. GPT-4 | 0.55 | 0.48 | 0.54 | 0.73 | 0.59 | - |
| 7. GPT-4 (Translation) | 0.54 | 0.45 | 0.56 | 0.69 | 0.65 | 0.81 |
| LLM | Estimate | SE | Prediction Interval | Interval Range | |
|---|---|---|---|---|---|
| LL | UL | ||||
| CLAUS | 0.46 | 0.04 | 0.36 | 0.55 | 0.10 |
| CLAUS (Translation) | 0.47 | 0.06 | 0.24 | 0.71 | 0.23 |
| OCSAI | 0.66 | 0.04 | 0.48 | 0.84 | 0.18 |
| OCSAI (Translation) | 0.60 | 0.07 | 0.29 | 0.90 | 0.31 |
| GPT-4 | 0.55 | 0.05 | 0.32 | 0.79 | 0.24 |
| GPT-4 (Translation) | 0.54 | 0.05 | 0.34 | 0.74 | 0.20 |
| LLM(s) as Weakest Rater | LLM(s) Neither Weakest nor Best | LLM(s) as Best Rater | Mean LLM-Total Correlation | |
|---|---|---|---|---|
| CLAUS | 80.0% | 20.0% | - | 0.66 |
| CLAUS (Translation) | 80.0% | 20.0% | - | 0.69 |
| OCSAI | 20.0% | 40.0% | 40.0% | 0.80 |
| OCSAI (Translation) | 40.0% | 60.0% | - | 0.71 |
| GPT-4 | 20.0% | 80.0% | - | 0.74 |
| GPT-4 (Translation) | 60.0% | 40.0% | - | 0.72 |
| Average | 50.0% | 43.3% | 6.7% | 0.71 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saretzki, J.; Knopf, T.; Forthmann, B.; Goecke, B.; Jaggy, A.-K.; Benedek, M.; Weiss, S. Scoring German Alternate Uses Items Applying Large Language Models. J. Intell. 2025, 13, 64. https://doi.org/10.3390/jintelligence13060064
Saretzki J, Knopf T, Forthmann B, Goecke B, Jaggy A-K, Benedek M, Weiss S. Scoring German Alternate Uses Items Applying Large Language Models. Journal of Intelligence. 2025; 13(6):64. https://doi.org/10.3390/jintelligence13060064
Chicago/Turabian StyleSaretzki, Janika, Thomas Knopf, Boris Forthmann, Benjamin Goecke, Ann-Kathrin Jaggy, Mathias Benedek, and Selina Weiss. 2025. "Scoring German Alternate Uses Items Applying Large Language Models" Journal of Intelligence 13, no. 6: 64. https://doi.org/10.3390/jintelligence13060064
APA StyleSaretzki, J., Knopf, T., Forthmann, B., Goecke, B., Jaggy, A.-K., Benedek, M., & Weiss, S. (2025). Scoring German Alternate Uses Items Applying Large Language Models. Journal of Intelligence, 13(6), 64. https://doi.org/10.3390/jintelligence13060064