Probabilistic Representation Differences between Decisions from Description and Decisions from Experience

Abstract
1. Introduction
1.1. Description–Experience Gap
1.2. Mechanisms of the Description–Experience Gap
1.3. Frequency Representation and Probability Representation
1.4. The Current Study
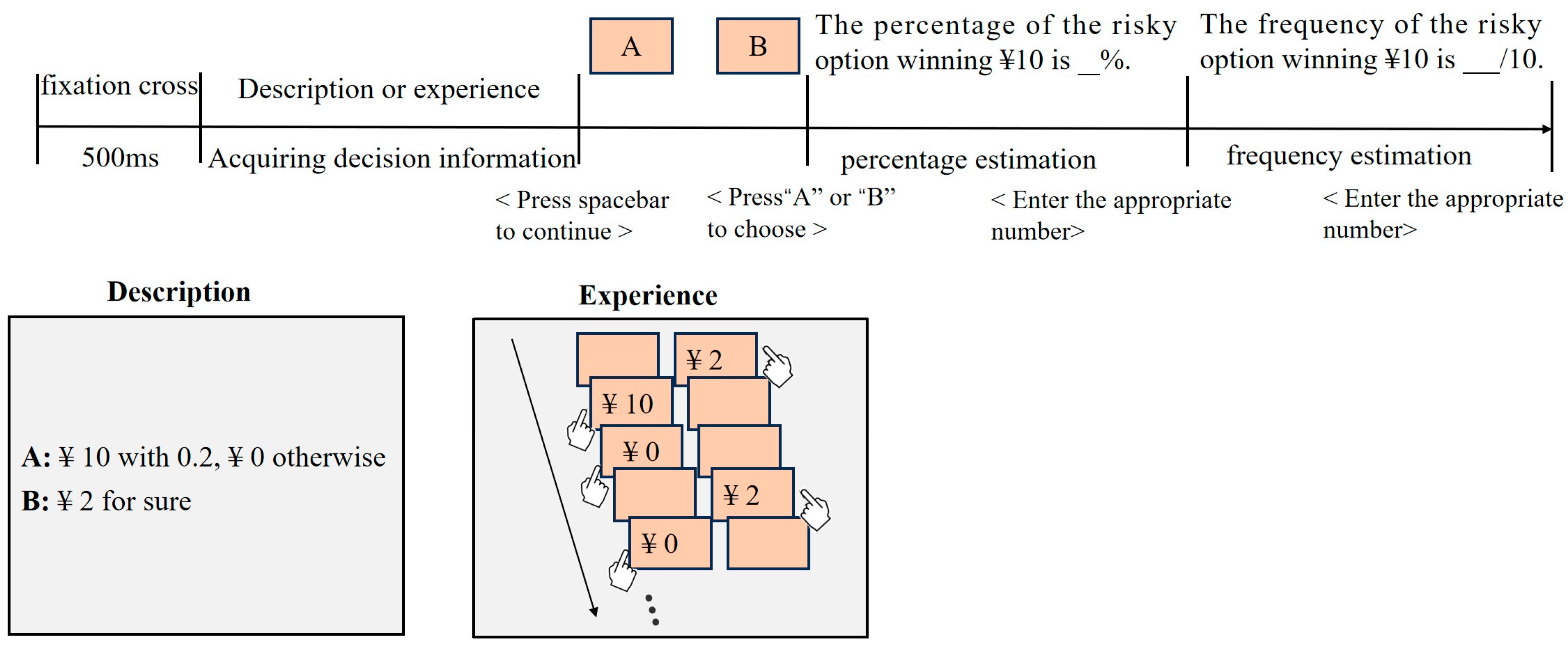
2. Experiment 1
2.1. Method
2.1.1. Participants and Design
2.1.2. Materials
2.1.3. Task and Procedure
2.2. Results
3. Experiment 2
3.1. Method
3.1.1. Participants and Design
3.1.2. Materials
3.1.3. Task and Procedure
3.2. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Decision Problem | Risky Option | Certain Option |
|---|---|---|
| 1 | 10, 0.1 | 2, 1 |
| 2 | 5, 0.1 | 0.5, 1 |
| 3 | 10, 0.2 | 2, 1 |
| 4 | 5, 0.2 | 1, 1 |
| 5 | 10, 0.25 | 2.5, 1 |
| 6 | 5, 0.25 | 0.75, 1 |
| Decision Problem | Risky Option | Certain Option |
|---|---|---|
| 1 | 10, 0.4 | 4, 1 |
| 2 | 5, 0.4 | 2, 1 |
| 3 | 10, 0.5 | 5, 1 |
| 4 | 5, 0.5 | 2.5, 1 |
| 5 | 10, 0.6 | 6, 1 |
| 6 | 5, 0.6 | 3, 1 |
| 7 | 10, 0.8 | 8, 1 |
| 8 | 5, 0.8 | 4, 1 |
| 9 | 10, 0.9 | 9, 1 |
| 10 | 5, 0.9 | 4.5, 1 |
| 11 | 10, 0.75 | 7.5, 1 |
| 12 | 5, 0.75 | 3.75, 1 |
References
- Aydogan, Ilke, and Yu Gao. 2020. Experience and rationality under risk: Re-examining the impact of sampling experience. Experimental Economics 23: 1100–28. [Google Scholar] [CrossRef] [PubMed]
- Barron, Greg, and Ido Erev. 2003. Small feedback-based decisions and their limited correspondence to description-based decisions. Journal of Behavioral Decision Making 16: 215–33. [Google Scholar] [CrossRef]
- Camilleri, Adrian R., and Ben R. Newell. 2009. The role of representation in experience-based choice. Judgment and Decision Making 4: 518–29. [Google Scholar] [CrossRef]
- Camilleri, Adrian R., and Ben R. Newell. 2011. Description- and experience-based choice: Does equivalent information equal equivalent choice? Acta Psychologica 136: 276–84. [Google Scholar] [CrossRef] [PubMed]
- Camilleri, Adrian R., and Ben R. Newell. 2013. Mind the gap? Description, experience, and the continuum of uncertainty in risky choice. Progress in Brain Research 202: 55–71. [Google Scholar] [CrossRef]
- Cubitt, Robin, Orestis Kopsacheilis, and Chris Starmer. 2022. An inquiry into the nature and causes of the Description-Experience gap. Journal of Risk and Uncertainty 65: 105–37. [Google Scholar] [CrossRef]
- Dai, Junyi, Thorsten Pachur, Timothy J. Pleskac, and Ralph Hertwig. 2019. What the Future Holds and When: A Description-Experience Gap in Intertemporal Choice. Psychological Science 30: 1218–33. [Google Scholar] [CrossRef]
- Evans, J. S. T. 2003. In two minds: Dual-process accounts of reasoning. Trends in Cognitive Sciences 7: 454–59. [Google Scholar] [CrossRef]
- Faul, Franz, Edgar Erdfelder, Axel Buchner, and Albert-Georg Lang. 2009. Statistical power analyses using G*Power 3.1: Tests for correlation and regression analyses. Behavior Research Methods 41: 1149–60. [Google Scholar] [CrossRef]
- FitzGerald, Thomas H. B., Ben Seymour, Dominik R. Bach, and Raymond J. Dolan. 2010. Differentiable Neural Substrates for Learned and Described Value and Risk. Current Biology 20: 1823–29. [Google Scholar] [CrossRef]
- Gigerenzer, Gerd, and U Hoffrage. 1995. How to improve Bayesian Reasoning without instruction: Frequency formats. Psychological Review of Economic Studies 102: 684–704. [Google Scholar] [CrossRef]
- Gloeckner, Andreas, Susann Fiedler, Guy Hochman, Shahar Ayal, and Benjamin E. Hilbig. 2012. Processing differences between descriptions and experience: A comparative analysis using eye-tracking and physiological measures. Frontiers in Psychology 3: 173. [Google Scholar] [CrossRef]
- Gonzalez, Cleotilde, Javier F Lerch, and Christian Lebiere. 2003. Instance-based learning in dynamic decision making. Cognitive Science 27: 591–635. [Google Scholar] [CrossRef]
- Gonzalez, Cleotilde, Varun Dutt, and Tomás Lejarraga. 2011. A loser can be a winner: Comparison of two instance-based learning models in a market entry competition. Games 2: 136–62. [Google Scholar] [CrossRef]
- Haines, Nathaniel, Jasmin Vassileva, and Woo-Young Ahn. 2018. The outcome-representation learning model: A novel reinforcement learning model of the Iowa Gambling Task. Cognitive Science 42: 2534–61. [Google Scholar] [CrossRef]
- Hau, Robin, Timothy J. Pleskac, and Ralph Hertwig. 2010. Decisions from Experience and Statistical Probabilities: Why They Trigger Different Choices Than a Priori Probabilities. Journal of Behavioral Decision Making 23: 48–68. [Google Scholar] [CrossRef]
- Hau, Robin, Timothy J. Pleskac, Jürgen Kiefer, and Ralph Hertwig. 2008. The description-experience gap in risky choice: The role of sample size and experienced probabilities. Journal of Behavioral Decision Making 21: 493–518. [Google Scholar] [CrossRef]
- Hertwig, Ralph, and Dirk U. Wulff. 2022. A Description-Experience Framework of the Psychology of Risk. Perspectives on Psychological Science 17: 631–51. [Google Scholar] [CrossRef]
- Hertwig, Ralph, and Ido Erev. 2009. The description-experience gap in risky choice. Trends in Cognitive Sciences 13: 517–23. [Google Scholar] [CrossRef]
- Hertwig, Ralph, Dirk U. Wulff, and Rui Mata. 2019. Three gaps and what they may mean for risk preference. Philosophical Transactions of the Royal Society B-Biological Sciences 374: 20180140. [Google Scholar] [CrossRef]
- Hertwig, Ralph, Greg Barron, Elke U. Weber, and Ido Erev. 2004. Decisions from experience and the effect of rare events in risky choice. Psychological Science 15: 534–39. [Google Scholar] [CrossRef] [PubMed]
- Hoffart, Janine Christin, Jana B. Jarecki, Gilles Dutilh, and Jörg Rieskamp. 2021. The influence of sample size on preferences from experience. Quarterly Journal of Experimental Psychology 75: 1–17. [Google Scholar] [CrossRef] [PubMed]
- Hoffart, Janine Christin, Jorg Rieskamp, and Gilles Dutilh. 2019. How Environmental Regularities Affect People’s Information Search in Probability Judgments from Experience. Journal of Experimental Psychology-Learning Memory and Cognition 45: 219–31. [Google Scholar] [CrossRef]
- Kahneman, Daniel, and Amos Tversky. 1973. On the psychology of prediction. Psychological Review 80: 237–51. [Google Scholar] [CrossRef]
- Kahneman, Daniel, and Amos Tversky. 1979. Prospect theory: An analysis of decision under risk. Econometrica 47: 263–91. [Google Scholar] [CrossRef]
- Kellen, David, Thorsten Pachur, and Ralph Hertwig. 2016. How (in)variant are subjective representations of described and experienced risk and rewards? Cognition 57: 126–38. [Google Scholar] [CrossRef]
- Klingebiel, Ronald, and Feibai Zhu. 2022. Sample decisions with description and experience. Judgment and Decision Making 17: 1146–75. [Google Scholar] [CrossRef]
- Kopsacheilis, Orestis. 2018. The role of information search and its influence on risk preferences. Theory and Decision 84: 311–39. [Google Scholar] [CrossRef]
- Lejarraga, Tomas. 2010. When Experience Is Better Than Description: Time Delays and Complexity. Journal of Behavioral Decision Making 23: 100–16. [Google Scholar] [CrossRef]
- Lejarraga, Tomas, and Cleotilde Gonzalez. 2011. Effects of feedback and complexity on repeated decisions from description. Organizational Behavior and Human Decision Processes 116: 286–95. [Google Scholar] [CrossRef]
- Liu, Hongzhi, Xingshan Li, Shu Li, and Lilin Rao. 2022. 基于期望值最大化的理论何时失效: 风险决策中为自己–为所有人决策差异的眼动研究 [When expectation-maximization-based theories work or do not work: An eye-tracking study of the discrepancy between everyone and every one]. Acta Psychologica Sinica 54: 1517–31. [Google Scholar] [CrossRef]
- Park, Inkyung, Paul D. Windschitl, Andrew R. Smith, Shanon Rule, Aaron M. Scherer, and Jillian O. Stuart. 2021. Context dependency in risky decision making: Is there a description-experience gap? PLoS ONE 16: e0245969. [Google Scholar] [CrossRef] [PubMed]
- Pindard-Lejarraga, Maud, and Jose Lejarraga. 2024. Information source and entrepreneurial performance expectations: Experience-based versus description-based opportunity evaluations. Journal of Business Research 172. [Google Scholar] [CrossRef]
- Plonsky, Ori, Kinneret Teodorescu, and Ido Erev. 2015. Reliance on small samples, the wavy recency effect, and similarity-based learning. Psychological Review 122: 621. [Google Scholar] [CrossRef] [PubMed]
- Rao, Li-Lin, Xiao-Nan Liu, Qi Li, Yuan Zhou, Zhu-Yuan Liang, Hong-Yue Sun, Ren-Lai Zhou, and Shu Li. 2013. Toward a mental arithmetic process in risky choices. Brain and Cognition 83: 307–14. [Google Scholar] [CrossRef] [PubMed]
- Rottenstreich, Yuval, and Ran Kivetz. 2006. On decision making without likelihood judgment. Organizational Behavior and Human Decision Processes 101: 74–88. [Google Scholar] [CrossRef]
- Su, Yin, Li-Lin Rao, Hong-Yue Sun, Xue-Lei Du, Xingshan Li, and Shu Li. 2013. Is Making a Risky Choice Based on a Weighting and Adding Process? An Eye-Tracking Investigation. Journal of Experimental Psychology-Learning Memory and Cognition 39: 1765–80. [Google Scholar] [CrossRef]
- Tversky, Amos, and Kahneman Daniel. 1992. Advances in prospect theory: Cumulative representation of uncertainty. Journal of Risk and Uncertainty 5: 297–323. [Google Scholar] [CrossRef]
- Ungemach, Christoph, Nick Chater, and Neil Stewart. 2009. Are Probabilities Overweighted or Underweighted When Rare Outcomes Are Experienced (Rarely)? Psychological Science 20: 473–79. [Google Scholar] [CrossRef]
- Weiss-Cohen, Leonardo, Emmanouil Konstantinidis, Maarten Speekenbrink, and Nigel Harvey. 2016. Incorporating conflicting descriptions into decisions from experience. Organizational Behavior and Human Decision Processes 135: 55–69. [Google Scholar] [CrossRef]
- Wulff, Dirk U., Max Mergenthaler-Canseco, and Ralph Hertwig. 2018. A Meta-Analytic Review of Two Modes of Learning and the Description-Experience Gap. Psychological Bulletin 144: 140–76. [Google Scholar] [CrossRef]
- Yang, Li, and Zhujing Hu. 2007. 概率的不同表征对贝叶斯推理的影响的研究 [Effects of Different Probability Representation on Bayesian Reasoning]. Psychological Exploration 27: 32–35. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nie, D.; Hu, Z.; Zhu, D.; Yang, J. Probabilistic Representation Differences between Decisions from Description and Decisions from Experience. J. Intell. 2024, 12, 89. https://doi.org/10.3390/jintelligence12090089
Nie D, Hu Z, Zhu D, Yang J. Probabilistic Representation Differences between Decisions from Description and Decisions from Experience. Journal of Intelligence. 2024; 12(9):89. https://doi.org/10.3390/jintelligence12090089
Chicago/Turabian StyleNie, Dandan, Zhujing Hu, Debiao Zhu, and Jianyong Yang. 2024. "Probabilistic Representation Differences between Decisions from Description and Decisions from Experience" Journal of Intelligence 12, no. 9: 89. https://doi.org/10.3390/jintelligence12090089
APA StyleNie, D., Hu, Z., Zhu, D., & Yang, J. (2024). Probabilistic Representation Differences between Decisions from Description and Decisions from Experience. Journal of Intelligence, 12(9), 89. https://doi.org/10.3390/jintelligence12090089