1. Introduction
It is a common practice that the item parameters of the cognitive diagnosis models (CDMs) are calibrated only using the item response data. Such practice could result in challenges in item development. For example, when the item parameter estimate(s) suggest that an item is of low quality (e.g., the correct answer is easy to be guessed), it is hard to identify the cause of such low quality or to devise an effective item revision plan to improve the item quality.
Similar issues were encountered in the Item Response Theory (IRT) framework as well where the item parameters were traditionally estimated solely by the response data. Fortunately, the availability of the item features has provided viable solutions to both issues in the IRT framework. In particular, the item linguistic features were found to be associated with the item difficulty (e.g.,
Drum et al. 1981;
Embretson and Wetzel 1987;
Jerman and Mirman 1973;
Lepik 1990) and served as an additional piece of information to explain and inform the IRT model parameters (e.g.,
Embretson and Wetzel 1987;
Paap et al. 2015). In the item explanatory IRT models proposed by
De Boeck and Wilson (
2004), the observed item features were included in the traditional IRT models to explain the item parameters that had traditionally been descriptive. A well-known instance of the item explanatory IRT model is the linear logistic test model (LLTM;
Fischer 1973) where the item difficulty parameter of the Rasch model is explained by some item features.
The additional information provided by item features could be even more valuable in the CDM framework than in the IRT framework. The item parameters of the CDMs (e.g., guessing and slipping probabilities) could be less straightforward and harder to manipulate in the item writing process than those in the IRT models (e.g., item difficulty), which calls for more pressing needs of explaining these CDM item parameters with manifest item features. However, to date, no studies have been performed to link the item features to the item parameters of the CDMs, despite the fact that some emerging explanatory CDMs have linked some person covariates to the CDM person or the structural parameters (
Ayers et al. 2013;
Park et al. 2018;
Park and Lee 2014,
2019). Historically, a possible obstacle to incorporating the item features in the measurement models could be the fact that the item feature extraction tasks used to be costly in time and human resources. For example, the item features may need to be analyzed and be coded manually by multiple groups of readers (e.g.,
Drum et al. 1981).
To fill the gap in the research on the CDMs with item features, we propose the item explanatory CDMs that explain the CDM item parameters with item features. We also took advantage of natural language processing (NLP), which makes it feasible to extract the item features efficiently. The most direct implication of the proposed models is that they reveal the relationships between the descriptive CDM item parameters (particularly the guessing and slipping parameters in this study) and the manifest item linguistic features. Understanding such explanatory relationships could further shed light on the item revision to improve item quality. The rest of the paper is structured as follows: After establishing the theoretical framework and detailing the specifications of the proposed models, we demonstrate their application using the Trends in International Mathematics and Science Study (TIMSS) data. We particularly focus on explaining item parameters with item features. To assist future researchers, the process of item feature engineering is detailed. The robustness of our empirical data analysis is supported by a simulation study, which evaluates model parameter recovery under various feature configurations.
5. Results
Model fit. The posterior predictive model check (
Guttman 1967;
Rubin 1981,
1984) was conducted to evaluate the data-model fit. The posterior predictive
p-value (PPP) of the sum of squares of standardized residuals, which is a discrepancy measure between the data and the model, was calculated. Extremely small PPP value indicates a bad fit and this study regards PPP < 0.05 as a sign as bad model–data fit. Additionally, deviance information criterion (DIC;
Spiegelhalter et al. 2002) was used to evaluate relative model fit. According to the PPP values shown in
Table 1, all the five data-fitting models show an acceptable model–data fit. DIC results indicate that the IE-HO-DINA models (i.e., those without a residual term) are worse in model–data fit than the HO-DINA model or the IE-HO-DINA-R models, which is possibly due to the imperfect prediction of the item parameters from the item features. In contrast, the IE-HO-DINA-R models (i.e., those with a residual term) fit the data better than the HO-DINA model. The possible reason could be that, while the likelihood of the HO-DINA model and the IE-HO-DINA-R models were expected to be comparable, the IE-HO-DINA-R models contain fewer parameters than the HO-DINA model and, thus, could be less penalized for model complexity.
The relationship between item features and item parameters. and
coefficients (
Table 2 and
Table 3) quantify the relationships between the item features and item parameters. In this study, the item features explained around 26% and 30% of the variance in the logit of the guessing and slipping parameters, respectively. The Wald test was performed to examine the null hypothesis that the parameters,
or
, equals to 0. Only the “proportion of words with 6 or more letters” feature is statistically significant based on all the models. Specifically, this feature is negatively related to the guessing parameter but positively related to the slipping parameter.
The IE-HO-DINA-g or IE-HO-DINA-s model yields more statistically significant coefficients compared to the IE-HO-DINA-g-R model, the IE-HO-DINA-s-R model, or the two-step procedure. This could result from the fact that the standard errors of coefficients from the IE-HO-DINA-g or IE-HO-DINA-s model are only around 10% of those from the IE-HO-DINA-g-R model, the IE-HO-DINA-s-R model, or the two-step procedure.
Consistency of item parameter estimates and attribute profile classifications. The estimated guessing or slipping parameters from the HO-DINA model are highly correlated (correlation coefficient close to 1) with the predicted guessing or slipping parameters from the IE-HO-DINA-R models, but only moderately correlated (correlation coefficient ranging from 0.4 to 0.7) with those from the IE-HO-DINA models (i.e., those without residual terms). Accordingly, the attribute profile classifications from the HO-DINA model are highly consistent (consistency rate > 0.95) with those from the IE-HO-DINA-R models but relatively inconsistent (consistency rate at around 0.6) with the IE-HO-DINA models (i.e., those without residual terms). The item parameter correlation and attribute classification consistency among the models are listed in
Tables S5 and S6 in the Online Supplementary Materials.
A Simulation Study
In the empirical data analysis above, one of the major potential sources of misspecification of the proposed models is the misspecification of the explanatory part, i.e., the number of item features could be over-specified or under-specified. Therefore, this simulation study aims to examine the validity of the empirical data analysis results by investigating the impact of the misspecification of the explanatory component and, particularly, addressing two specific research questions (RQs): (1) How are the recoveries of feature coefficients, item parameters, and attribute profiles affected by the over-specification of the item features? (2) How are the recoveries of feature coefficients, item parameters, and attribute profiles affected by the under-specification of the item features?
The research questions were addressed under a scenario mimicking the empirical study: Twenty-five response datasets with 37 items measuring three attributes were generated. The Q-matrix remained the same as the one in the empirical data analysis. The response data were generated with an HO-DINA model. The true guessing and slipping parameters were both linear combinations of four simulated features along with some residual terms, i.e.,
and
. The simulated features can be either continuous or dichotomous, and be either strongly (
or
= 0.6) or weakly (
or
= 0.3) associated with the item parameters. The data-generating item features have explained approximately 60% of the variance in the true item parameters. The feature labels, true data generation model, item feature coefficients are listed in
Table 4. The resulting true guessing and slipping parameters range from 0 to 0.5 and, thus, the simulated items consist of both high-quality (1-
s-
g ≥ 0.65) and low-quality (1-
s-
g < 0.65) items.
Different sets of models were fit to the simulated datasets to address different research questions, as articulated in
Table 5. The impact of the over-specification of the explanatory component (RQ1) was examined by comparing the parameter recoveries from the correctly specified model against five over-specified models (each of the four proposed models and the two-step procedure had an over-specified version). Since item features were linked to both the slipping and guessing parameters in the data-generating model, the item feature coefficients in the correctly specified model had to be estimated with a two-step procedure since the IE-HO-DINA models cannot have item features linked to both guessing and slipping parameters simultaneously. In the over-specified models, four superfluous features in addition to the four data-generating features (i.e., a total of eight features) were linked to either guessing or slipping parameters. Details of the four superfluous item features are also listed in
Table 4.
The impact of the under-specification of the explanatory component (RQ2) was examined by comparing the parameter recoveries from the correctly specified model against four under-specified models. As the residual terms in the IE-HO-DINA-R models have absorbed the unexplained variance in the item parameters, the under-specification of the item feature was expected to have little impact on the recoveries on the IE-HO-DINA-R models. Therefore, the impact of under-specification was only examined for the IE-HO-DINA models that have no residual term. Two types of under-specified models were considered: the IE-HO-DINA-2-strong models only retained the “strong” features (i.e., features with or = v0.6) and ignored “weak” features (i.e., features with or = 0.3) in the data-generating model; the IE-HO-DINA-2-weak models only retained the “weak” features and ignored “strong” features in the data-generating model. Features in the IE-HO-DINA-2-strong and IE-HO-DINA-2-weak models have explained approximately 40% and 15% of the variance in the item parameters, respectively.
The recovery of the continuous model parameters (i.e., item feature coefficients and item parameters) was evaluated in terms of bias and root mean squared error (RMSE). Specifically, and , where y is the parameters to be evaluated and R is the number of replications. The recovery of the binary attribute parameters was evaluated in terms of the profile correct classification rate (PCCR) and the attribute correct classification rate (ACCR).
6. Results
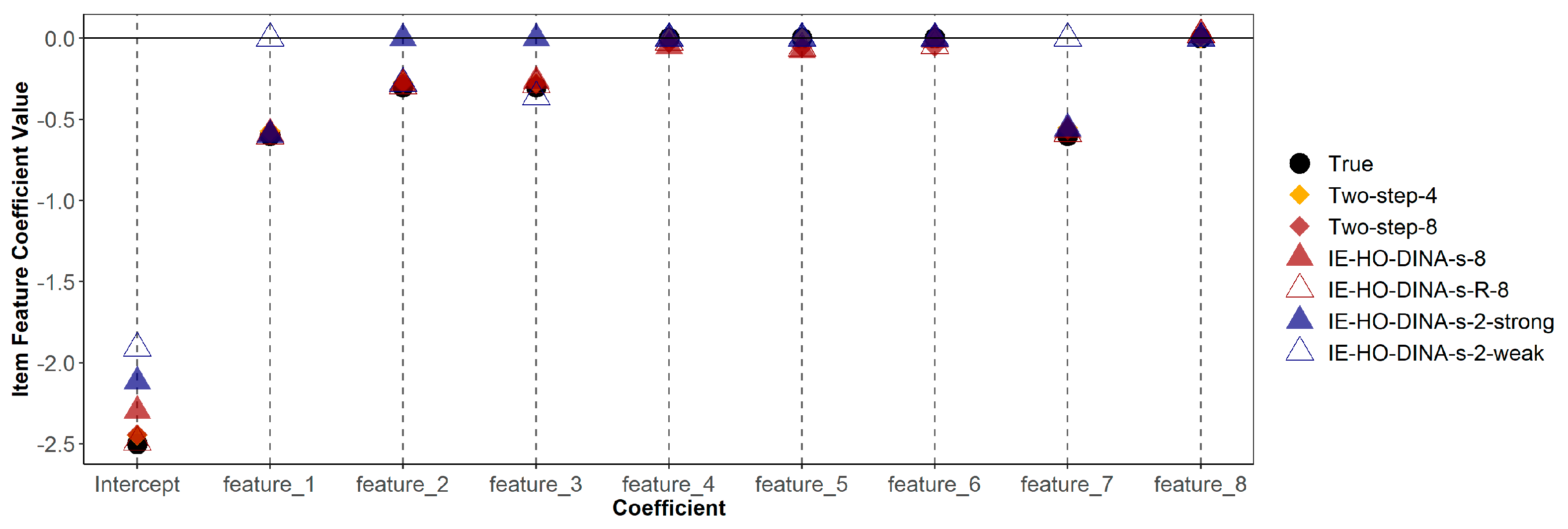
Table 6 demonstrates that misspecified models (both over-specified and under-specified) do not consistently show poorer recovery (in terms of bias or RMSE) of item feature coefficients compared to the correctly specified model. Additionally,
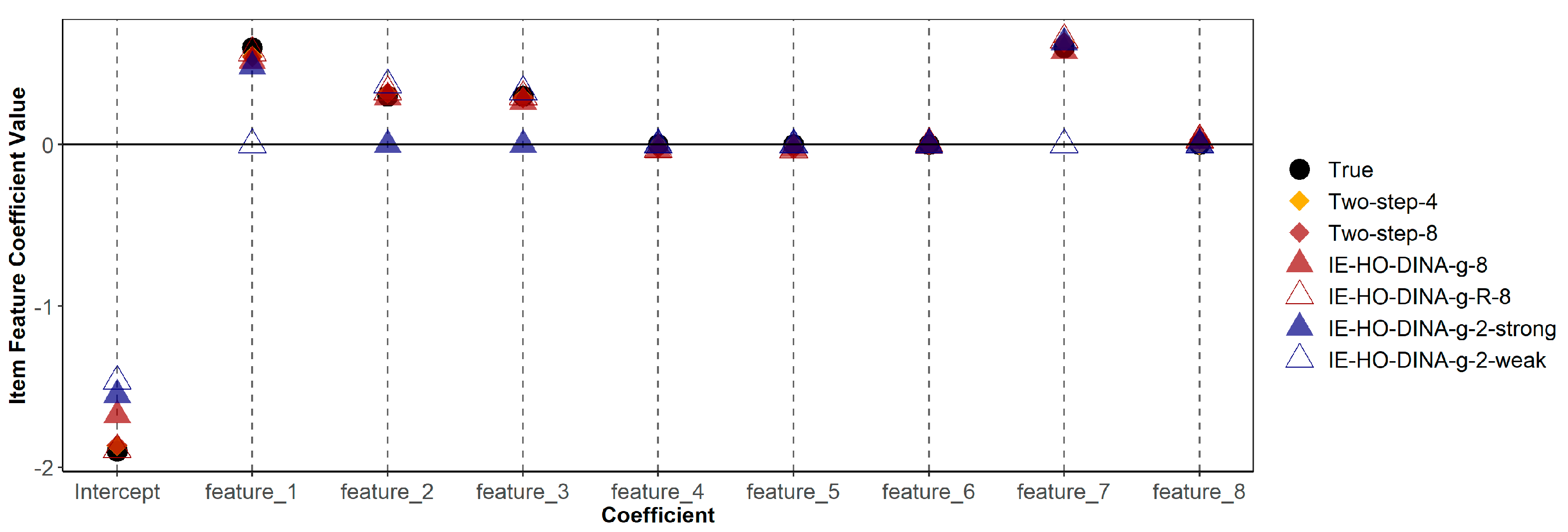
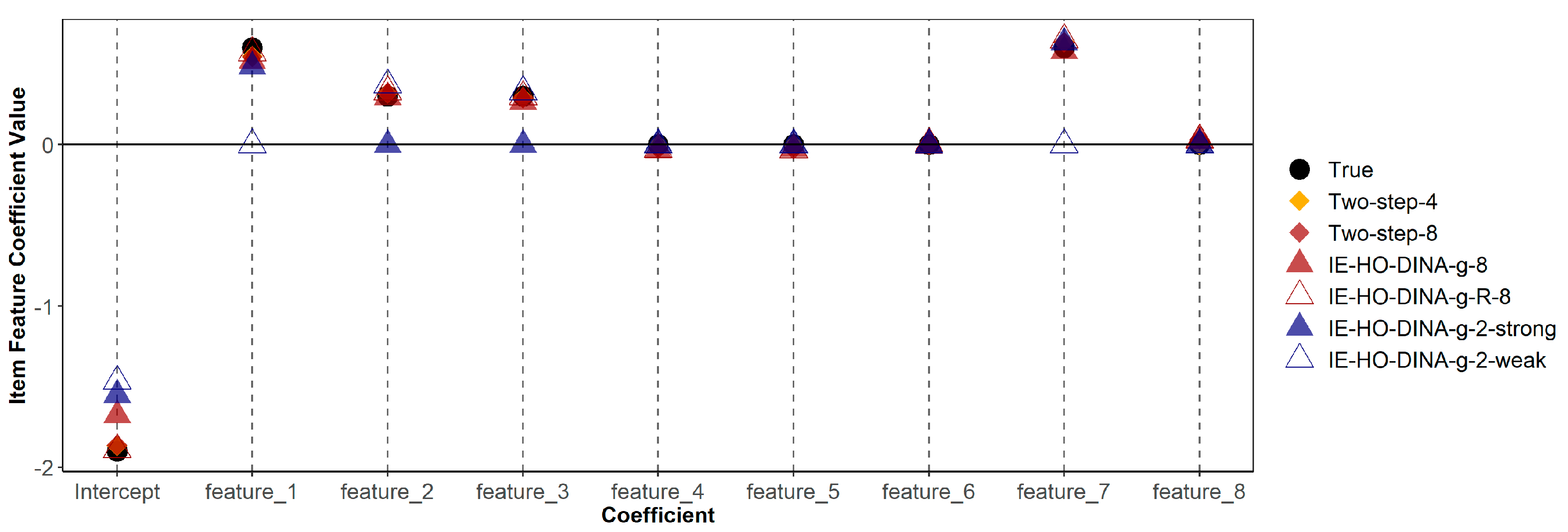
Figure 1 and
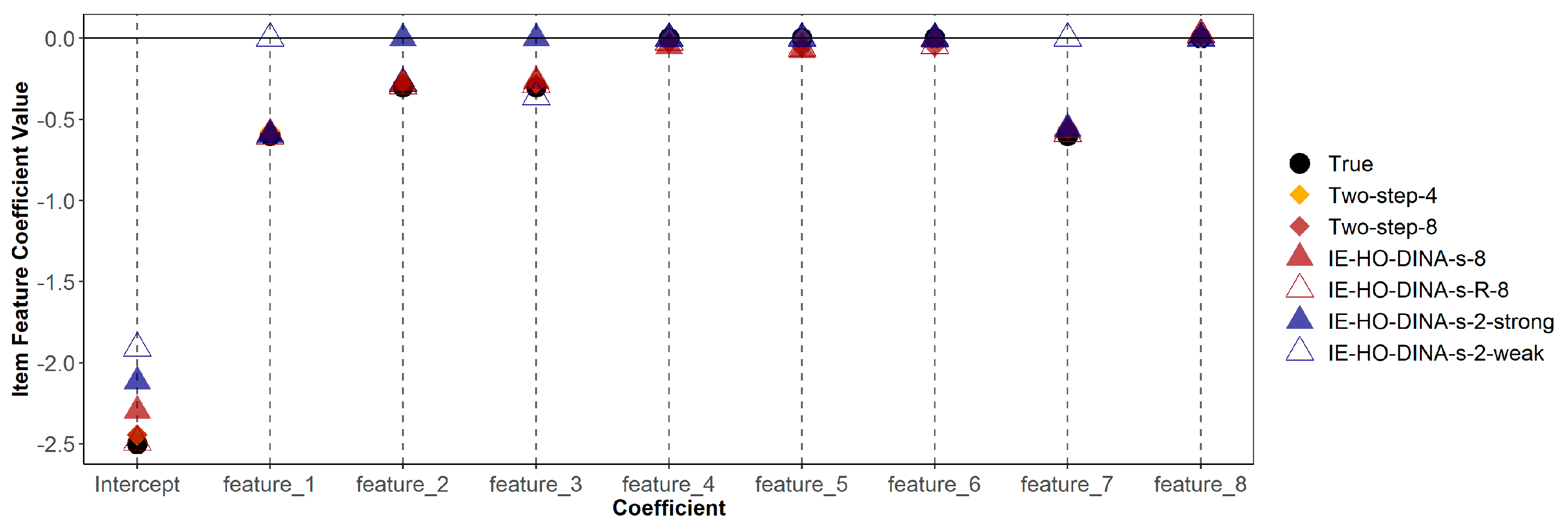
Figure 2 indicate that estimates of guessing/slipping feature coefficients are similar across the correctly specified and misspecified models. As shown in
Figure 1, in the over-specified models (IE-HO-DINA-g-8 and IE-HO-DINA-g-R-8), coefficients of superfluous features (features 4, 5, 6, and 8) are observed to be near zero. Conversely, in the under-specified models (IE-HO-DINA-g-2-strong and IE-HO-DINA-g-2-weak), despite the omission of certain data-generating features (i.e., omitting features 2 and 3 for IE-HO-DINA-g-2-strong and omitting features 1 and 7 for IE-HO-DINA-g-2-weak), the remaining feature coefficients closely approximate the true values. Nevertheless, the intercept estimates from the under-specified models show greater deviation from the true value than the other models. A similar pattern is observed for the slipping feature coefficients in
Figure 2.
The item parameter recoveries are summarized in
Table 7. Among the models without a residual term, the over-specified model (IE-HO-DINA-8) outperformed the under-specified models (IE-HO-DINA-2-strong and IE-HO-DINA-2-weak) in item parameter recovery. Although the magnitude of bias is comparable across these models, the RMSE is higher in the under-specified models. This suggests that an increase in unexplained variance in the item parameters may lead to greater random error in the item parameter estimates. However, compared to the model with a residual term (IE-HO-DINA-8-R) and the HO-DINA model, the model without a residual term (IE-HO-DINA-8) exhibits a larger RMSE. This increase in RMSE might be attributed to a significant portion of variance in item parameters remaining unexplained, even with the inclusion of 8 features. Incorporating a residual term could help absorb the unexplained variance in the item parameters, thereby potentially reducing the random error in item parameter estimates.
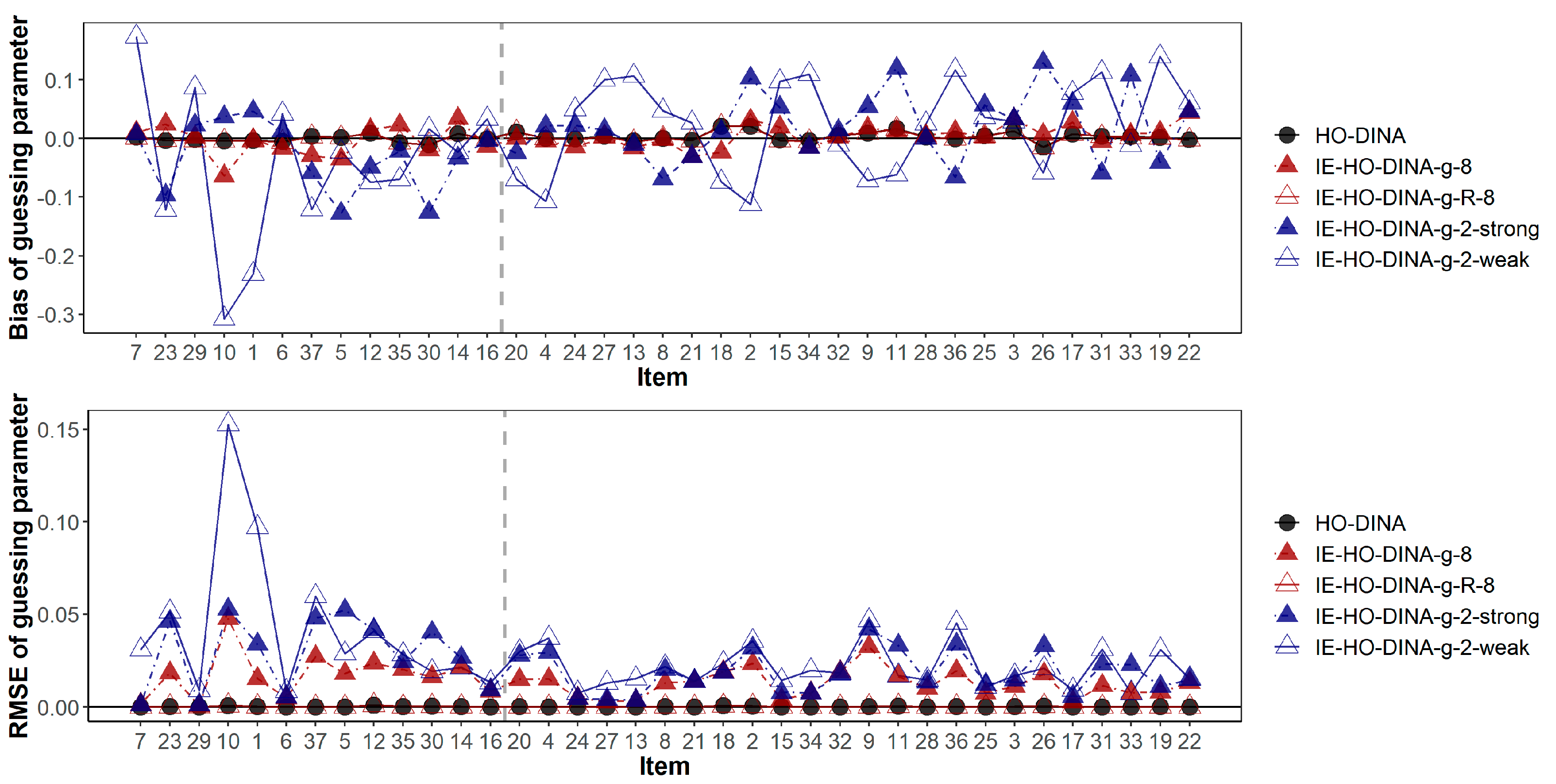
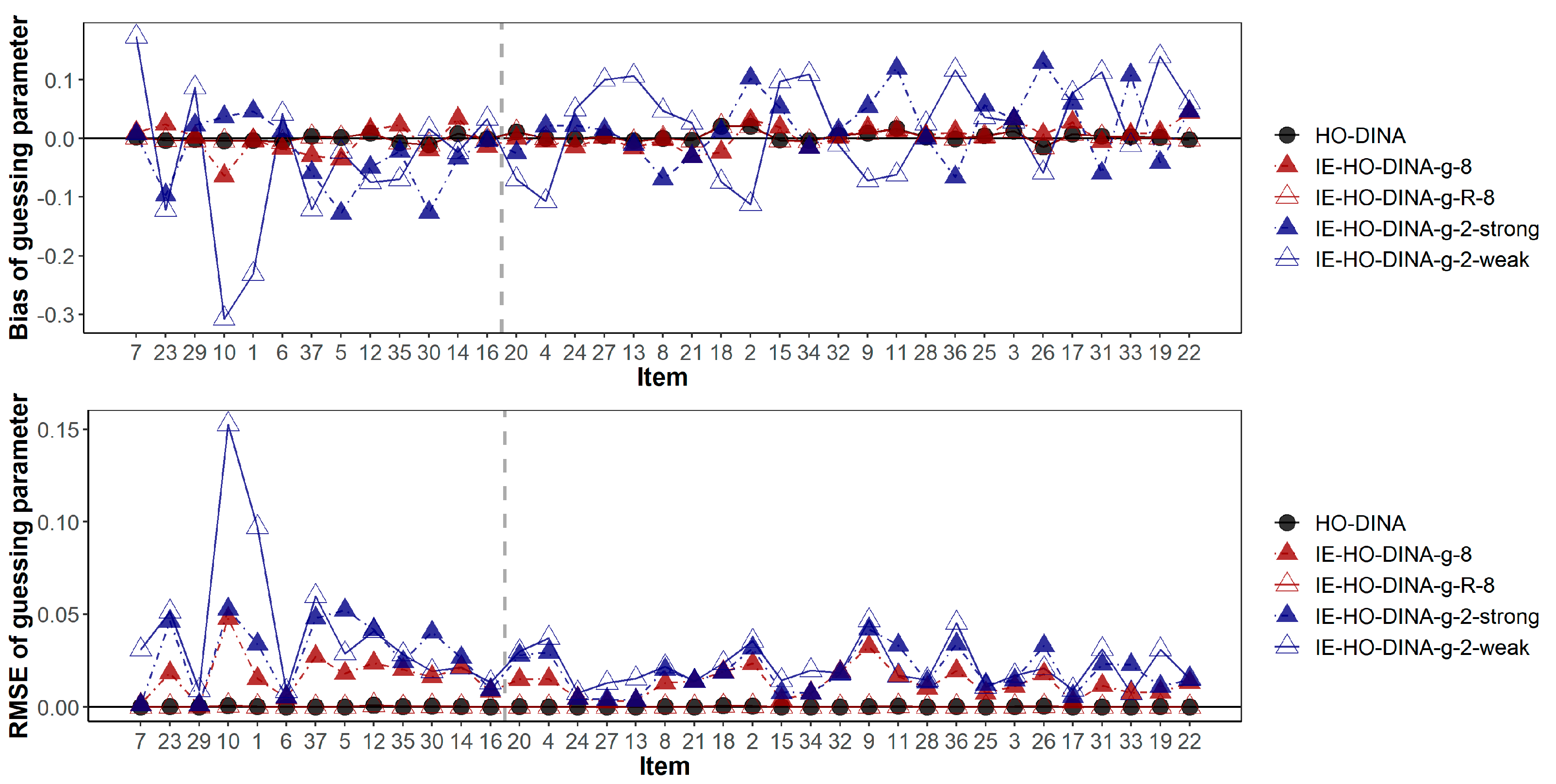
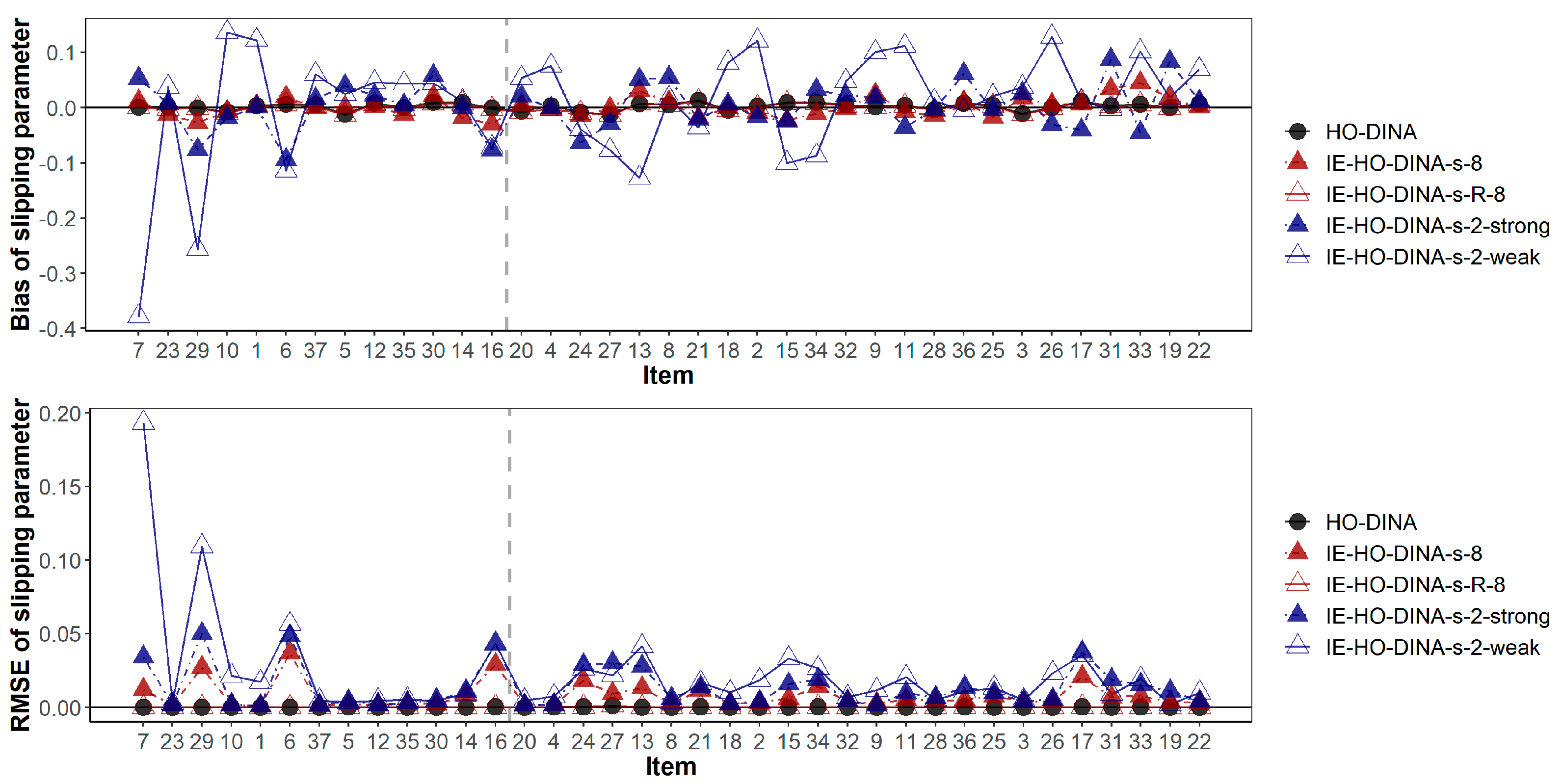
In addition,
Figure 3 and
Figure 4 have demonstrated the item-wise guessing/slipping parameter recoveries where the items are ascendingly ordered by their true item quality (quantified by 1-
s-
g) on the x-axis. On average, the guessing/slipping parameters of the low-quality items (items with true 1-
s-
g < 0.65) have higher absolute bias and RMSE than the high-quality items (items with true 1-
s-
g ≥ 0.65).
As for the attribute classification accuracy shown in
Table 8, the HO-DINA model, the over-specified models, and the IE-HO-DINA-2-strong models have achieved high attribute classification accuracy (PCCR and ACCRs > 0.9). Only the IE-HO-DINA-2-weak models have displayed lower attribute classification accuracy (PCCR and ACCRs ≤ 0.9) than the other models. These results have suggested that the imperfect prediction of the item parameters from the item features may not significantly diminish the attribute classification accuracy until a sufficiently large proportion of variance in the item parameters is left unexplained.
7. Summary and Discussion
Understanding the explanatory relationship between the item parameters and item features could help item developers discover the cause of the low-quality items (e.g., items with high guessing or slipping probabilities) and devise plans to revise them. The rapid advance of NLP and machine learning techniques has rendered it possible to extract more complex item features automatically and efficiently, thereby increasing the feasibility and usefulness of the proposed item explanatory CDMs.
The utility of the proposed models was demonstrated with the TIMSS released items and response data: around 20 item linguistic features were extracted with the NLP techniques; the proposed models were used to examine the relationships between the guessing/slipping parameters of the HO-DINA model and eight of the item features.
However, while the proposed models in this study aim to shed light on the relationship between item parameters and features, their inferences should not dictate item development practices deterministically. Instead, inferences from the models are intended to guide item developers by highlighting potential issues and areas for improvement. For instance, statistically significant features identified by the model can inform prioritization in item revision plans. In the case of reducing an item’s slipping probability, if the model indicates that “the proportion of words with 6 or more letters” significantly affects slipping, developers might first focus on modifying complex word proportions in the item stem. However, this focus on statistically significant features should not preclude consideration of other aspects such as item length. Additionally, from a score validity perspective, the proposed models can aid in uncovering sources of construct-irrelevant variance, such as the potential impact of complex wording on slipping effects. Ultimately, the model’s insights should complement, not replace, expert judgment in item development and revision processes.
The validity of the empirical data analysis results was further corroborated by a follow-up simulation study that mimicked the setting of the empirical data. The results from the simulation study have supported that, even with some slight misspecifications in the explanatory part of the proposed model, satisfactory recoveries in the item feature coefficients could be achieved. However, when a significant portion of variance in item parameters remains unexplained by the item features in item explanatory CDMs without a residual term, the recovery of the item parameters and attribute profiles may be compromised. Therefore, we recommend including a residual term in the item explanatory CDMs to enhance the accuracy of the model parameter estimates.
This study could be further extended in several directions. First, while this study has circumvented the multicollinearity issue by only including the weakly correlated features in the models, future studies could consider some modeling techniques which are robust to multicollinearity, such as the mean centering the variables (
Iacobucci et al. 2016) and ridge regression (
Hoerl and Kennard 1970), so that some potentially important features will not have to be eliminated. Moreover, key and distractor feature other than the item stem features could be included in the model as well.
Second, although this study has used the item features to explain only the guessing and slipping parameters of the HO-DINA model, it is straightforward to extend the proposed models to more generalized CDMs including the G-DINA model (
de la Torre 2011), the LCDM (
Henson et al. 2009) and the GDM (
von Davier 2005). In particular, once the appropriate item features are extracted, they can be incorporated in the CDMs to explain the item parameter(s) of interest through a regression-like component. Further, the item features could be useful to explain the differential item functioning (DIF). For instance, if an item is detected to function differently across different subpopulations, the cross-group item parameter difference could be linked to the item features to investigate whether the DIF is associated with any item features, thereby facilitating the understanding of the cause of DIF.
Third, enhancing the computational efficiency of the model estimation is crucial for broader research and application of the proposed models. Currently, running the IE-HO-DINA and IE-HO-DINA-R models, with two MCMC chains of 10,000 iterations each, requires approximately 6 h and 30 h, respectively.
1 This computational demand could limit more extensive explorations. Given that the ECDMs developed by
Park et al. (
2018), which include covariates on the person side, can be estimated using the expectation-maximization (EM) algorithm, future research could investigate the feasibility of adapting the EM algorithm for estimating parameters in the proposed models which have covariates on the item side.
Fourth, future research could consider varying sample sizes, test lengths, and Q-matrix specifications to enhance the generalizability of the simulation study. Additionally, investigating the impact of multicollinearity in item features on the inferences from item explanatory CDMs would be valuable. The scope of the current simulation study was limited by the substantial time required to run the models, constraining the feasibility to conduct broader simulations. Future studies, when feasible, could aim to determine the optimal number of items and persons necessary for accurate model parameter estimation.
Last but not least, the proposed models have the potential to be applied to address “cold start” problem in the future. Specifically, the newly developed assessments could suffer from the lack of empirical response data for item calibration, which was described as the “cold start” issue by
Settles et al. (
2020).
Settles et al. (
2020) have predicted the item difficulty parameters in the Rasch model with the item linguistic features, thus helping mitigate the “cold start” issue in a high-stakes language assessment. Analogously, the proposed models along with extracted item features may be used to predict the item parameters of the CDMs. Unfortunately, the limitations of the example empirical dataset restricted our ability to fully demonstrate the proposed model’s effectiveness in addressing the cold-start problem. The dataset’s small size, comprising only 37 items, limits its capacity for robustly training a model to learn the relationship between item features and parameters. Additionally, the item features extracted accounted for only about 30% of the variance in item parameters, reducing their predictive power for new items. Future research with larger item banks and more sophisticated NLP features, such as Bidirectional Encoder Representations from Transformers (BERT;
Devlin et al. 2019) features, could be more useful to evaluate the proposed models’ effectiveness in tackling the cold-start problem. For instance, training the explanatory models with a subset of items from a larger bank and then predicting parameters for the remaining items could be a viable approach. However, it is important to note that there is a potential trade-off between a model’s explanative power and its predictive accuracy. Advanced NLP features such as BERT embeddings may enhance prediction capabilities at the cost of reduced explainability, as these features are often complex and not easily interpretable. Therefore, we advise researchers to carefully balance the need for explanatory insight against predictive precision when selecting features for their models.




{kind=link}
{kind=link}
{kind=link}
{kind=link}