Applying Machine Learning and SHAP Method to Identify Key Influences on Middle-School Students’ Mathematics Literacy Performance


Abstract
1. Introduction
- (1)
- Which machine learning model is best for predicting middle-school students’ math literacy?
- (2)
- What are the important factors that affect mathematical literacy performance?
1.1. Student Factors
1.2. Family Factors
1.3. School Factors
2. Materials and Methods
2.1. The Data Sources and Processing
2.1.1. Data Sources
2.1.2. Data Processing
2.2. Methods
2.2.1. Machine Learning Methods
- (1)
- Multiple linear regression (MLR)
- (2)
- Support vector machine regression (SVR)
- (3)
- Decision tree (DT)
- (4)
- Random forest (RF)
- (5)
- XGBoost
2.2.2. SHAP Method
3. Results
3.1. Model Training and Prediction Ability
3.2. Model Explanation
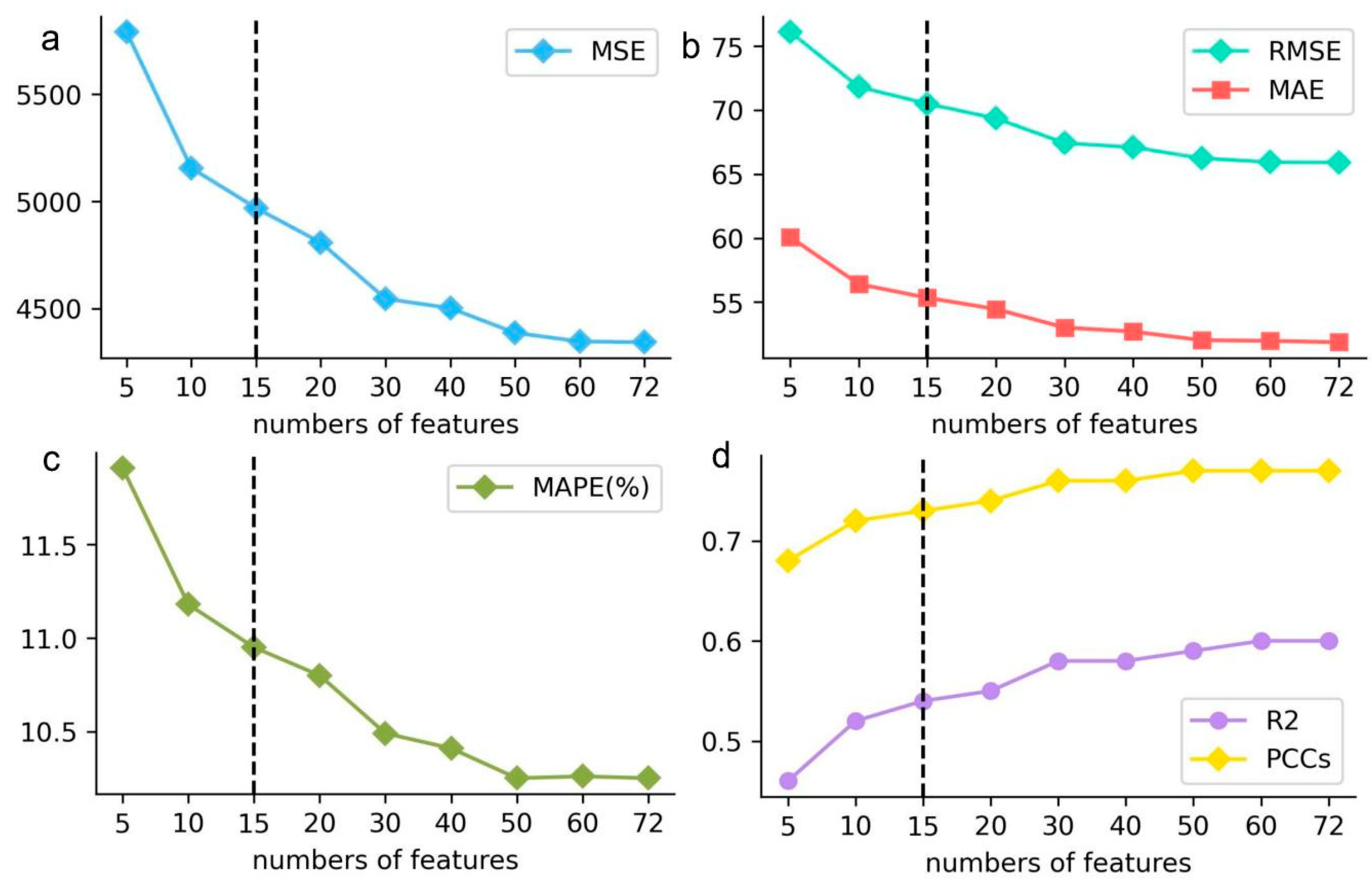
3.2.1. The Number of Key Influencing Factors
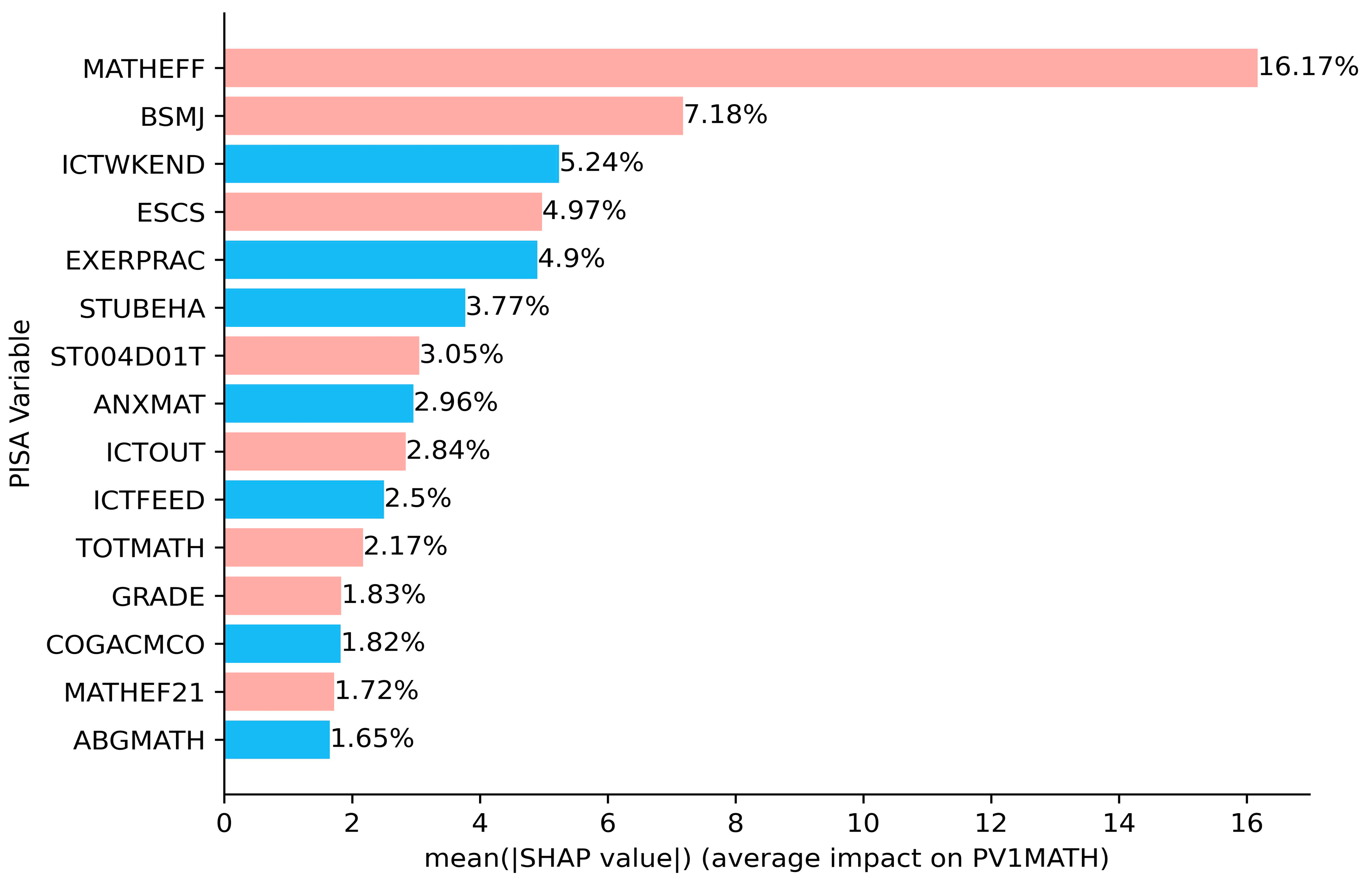
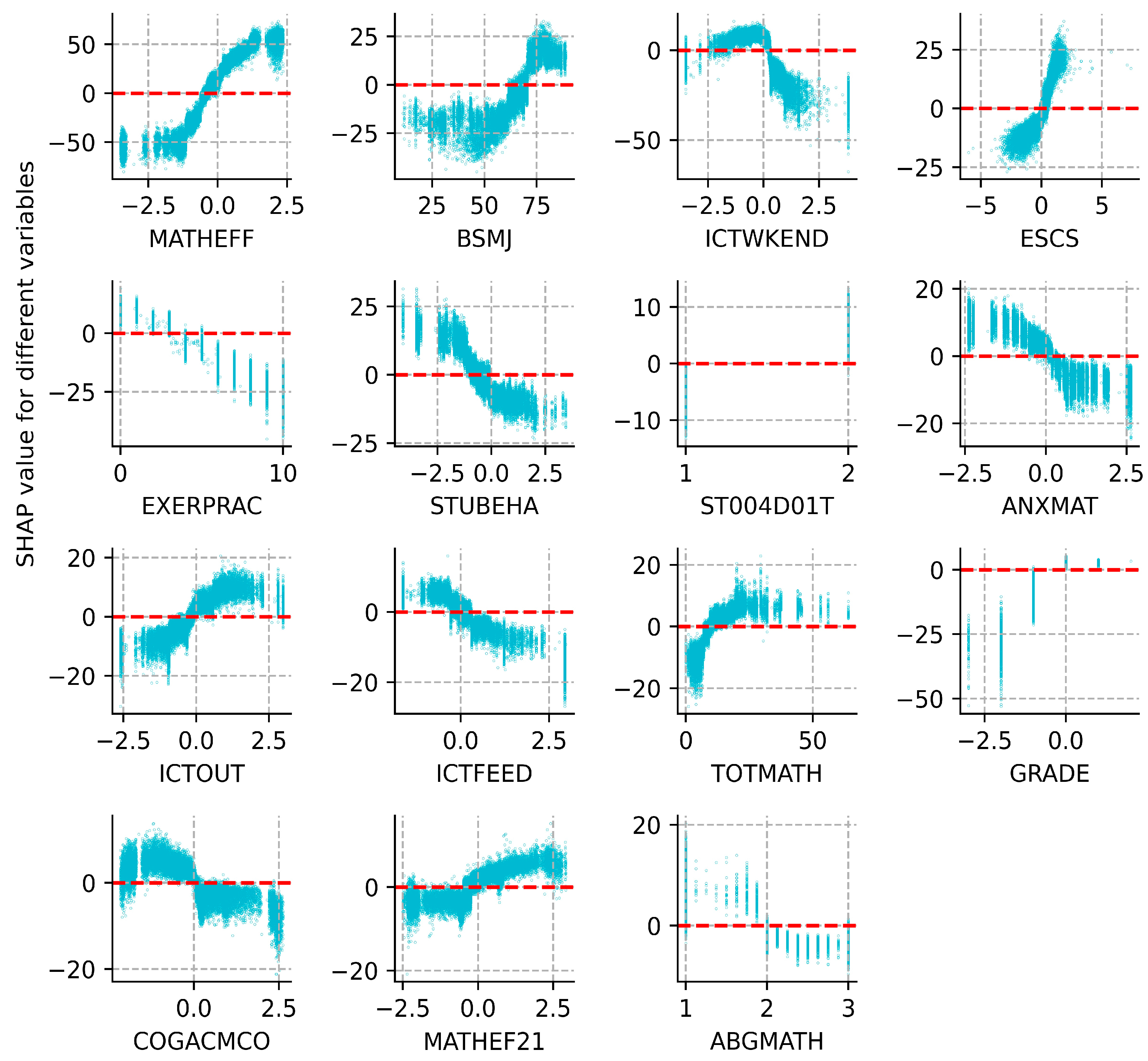
3.2.2. All Samples Analysis
- Key influencing factors
- (1)
- Student factors
- (2)
- Family factors
- (3)
- School factors
- 2.
- Contribution of key influencing factors
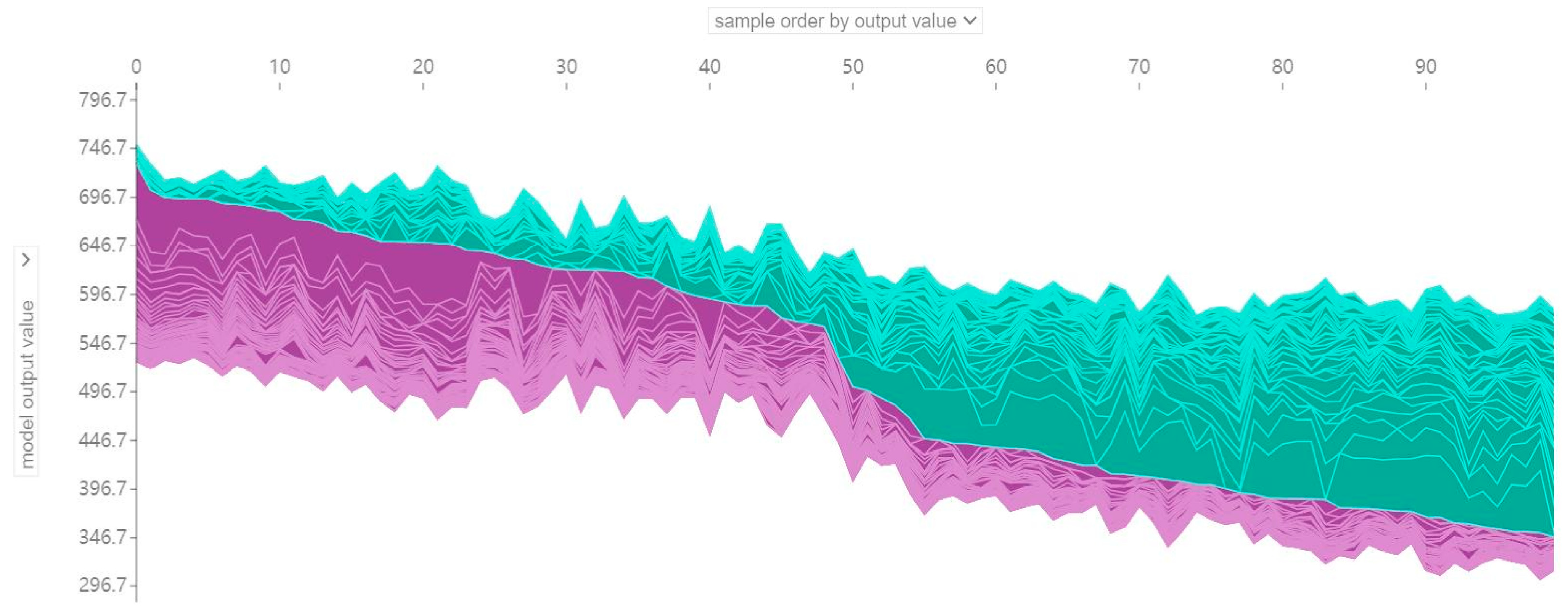
3.2.3. Specific and Multiple Sample Analysis
4. Discussion
- (1)
- XGBoost is the best model for predicting the mathematical literacy of middle-school students.
- (2)
- A total of 15 variables, including math self-efficacy, are key influences on math literacy.
- (3)
- Math self-efficacy is the most significant influence on math literacy.
- (4)
- Differences in key influences affecting math literacy and the extent of their contribution across individuals.
5. Conclusions and Limitations
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Acıslı-Celik, Sibel, and Cafer Mert Yesilkanat. 2023. Predicting science achievement scores with machine learning algorithms: A case study of OECD PISA 2015–2018 data. Neural Computing and Applications 35: 21201–28. [Google Scholar] [CrossRef]
- Aguayo-Téllez, Ernesto, and Flor E. Martínez-Rodríguez. 2020. Early school entrance and middle-run academic performance in Mexico: Evidence for 15-year-old students from the PISA test. Large-Scale Assessments in Education 8: 11. [Google Scholar] [CrossRef]
- Aksoy, Tevfik, and Charles R Link. 2000. A panel analysis of student mathematics achievement in the US in the 1990s: Does increasing the amount of time in learning activities affect math achievement? Economics of Education Review 19: 261–77. [Google Scholar] [CrossRef]
- Barnard-Brak, Lucy, William Y. Lan, and Zhanxia Yang. 2018. Differences in mathematics achievement according to opportunity to learn: A 4pL item response theory examination. Studies in Educational Evaluation 56: 1–7. [Google Scholar] [CrossRef]
- Barroso, Connie, Colleen M. Ganley, Amanda L. McGraw, Elyssa A. Geer, Sara A. Hart, and Mia C. Daucourt. 2021. A Meta-Analysis of the Relation Between Math Anxiety and Math Achievement. Psychological Bulletin 147: 134–68. [Google Scholar] [CrossRef]
- Bernardo, Allan B. I. 2021. Socioeconomic status moderates the relationship between growth mindset and learning in mathematics and science: Evidence from PISA 2018 Philippine data. International Journal of School and Educational Psychology 9: 208–22. [Google Scholar] [CrossRef]
- Bernardo, Allan B. I., Macario O. Cordel, Marissa Ortiz Calleja, Jude Michael M. Teves, Sashmir A. Yap, and Unisse C. Chua. 2023. Profiling low-proficiency science students in the Philippines using machine learning. Humanities and Social Sciences Communications 10: 192. [Google Scholar] [CrossRef]
- Bernardo, Allan B. I., Macario O. Cordel, Minie Rose C. Lapinid, Jude Michael M. Teves, Sashmir A. Yap, and Unisse C. Chua. 2022. Contrasting Profiles of Low-Performing Mathematics Students in Public and Private Schools in the Philippines: Insights from Machine Learning. Journal of Intelligence 10: 61. [Google Scholar] [CrossRef]
- Betts, Julian R., and Jamie L. Shkolnik. 2000. The effects of ability grouping on student achievement and resource allocation in secondary schools. Economics of Education Review 19: 1–15. Available online: www.elsevier.com/locate/econedurev (accessed on 17 December 2023). [CrossRef]
- Bhutoria, Aditi, and Nayyaf Aljabri. 2022. Patterns of cognitive returns to Information and Communication Technology (ICT) use of 15-year-olds: Global evidence from a Hierarchical Linear Modeling approach using PISA 2018. Computers & Education 181: 104447. [Google Scholar] [CrossRef]
- Bokhove, Christian, and Gillian Hampden-Thompson. 2022. Country and school family composition’s effects on mathematics achievement. School Effectiveness and School Improvement 33: 280–302. [Google Scholar] [CrossRef]
- Brow, Mark V. 2019. Significant predictors of mathematical literacy for top-tiered countries/economies, Canada, and the United States on PISA 2012: Case for the sparse regression model. British Journal of Educational Psychology 89: 726–49. [Google Scholar] [CrossRef] [PubMed]
- Bücker, Susanne, Sevim Nuraydin, Bianca A. Simonsmeier, Michael Schneider, and Maike Luhmann. 2018. Subjective well-being and academic achievement: A. meta-analysis. Journal of Research in Personality 74: 83–94. [Google Scholar] [CrossRef]
- Cao, Canxi, Tongxin Zhang, and Tao Xin. 2024. The effect of reading engagement on scientific literacy—An analysis based on the XGBoost method. Frontiers in Psychology 15: 1329724. [Google Scholar] [CrossRef] [PubMed]
- Caro, Daniel H., Jenny Lenkeit, and Leonidas Kyriakides. 2016. Teaching strategies and differential effectiveness across learning contexts: Evidence from PISA 2012. Studies in Educational Evaluation 49: 30–41. [Google Scholar] [CrossRef]
- Cheema, Jehanzeb R., and Bo Zhang. 2013. Quantity and quality of computer use and academic achievement: Evidence from a large-scale international test program. International Journal of Education and Development using Information and Communication Technology (IJEDICT) 9: 95–106. [Google Scholar]
- Chen, Jiangping, Yang Zhang, Yueer Wei, and Jie Hu. 2021. Discrimination of the Contextual Features of Top Performers in Scientific Literacy Using a Machine Learning Approach. Research in Science Education 51: 129–58. [Google Scholar] [CrossRef]
- Chen, Tianqi, and Carlos Guestrin. 2016. XGBoost: A Scalable Tree Boosting System. Paper presented at the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, August 13–17; pp. 785–94. [Google Scholar] [CrossRef]
- Cheung, Kwok Cheung. 2017. The effects of resilience in learning variables on mathematical literacy performance: A study of learning characteristics of the academic resilient and advantaged low achievers in Shanghai, Singapore, Hong Kong, Taiwan and Korea. Educational Psychology 37: 965–82. [Google Scholar] [CrossRef]
- Courtney, Matthew, Mehmet Karakus, Zara Ersozlu, and Kaidar Nurumov. 2022. The influence of ICT use and related attitudes on students’ math and science performance: Multilevel analyses of the last decade’s PISA surveys. Large-Scale Assessments in Education 10: 8. [Google Scholar] [CrossRef]
- Daucourt, Mia C., Amy R. Napoli, Jamie M. Quinn, Sarah G. Wood, and Sara A. Hart. 2021. The Home Math Environment and Math Achievement: A Meta-Analysis. Psychological Bulletin 147: 565–96. [Google Scholar] [CrossRef] [PubMed]
- Denny, Kevin, and Veruska Oppedisano. 2013. The surprising effect of larger class sizes: Evidence using two identification strategies. Labour Economics 23: 57–65. [Google Scholar] [CrossRef]
- de Vink, Isabelle C., Lisette Hornstra, and Evelyn H. Kroesbergen. 2023. Latent Profile Analysis of Working Memory: Relations with Creativity and Academic Achievement. Creativity Research Journal 35: 1–17. [Google Scholar] [CrossRef]
- Dockery, Alfred Michael, Paul Koshy, and Ian W. Li. 2020. Culture, migration and educational performance: A focus on gender outcomes using Australian PISA tests. The Australian Educational Researcher 47: 39–59. [Google Scholar] [CrossRef]
- Eickelmann, Birgit, Kerstin Drossel, Heike Wendt, and Wilfried Bos. 2012. ICT-use in primary schools and children’s mathematics achievement-a multi-level approach to compare educational systems through an international lens with TIMSS data. Paper presented at Joint AARE APERA International Conference, WERA Focal Meeting, Sydney, Australia, December 2–6, vol. 2012. [Google Scholar]
- Erdogdu, Funda. 2022. Potential predictors of student attainment: A longitudinal study at global level. Education and Information Technologies 27: 9689–711. [Google Scholar] [CrossRef]
- Evans, Danielle, and Andy P. Field. 2020. Maths attitudes, school affect and teacher characteristics as predictors of maths attainment trajectories in primary and secondary education. Royal Society Open Science 7: 200975. [Google Scholar] [CrossRef]
- Fan, Xizhen, Ronald K. Hambleton, and Minqiang Zhang. 2019. Profiles of mathematics anxiety among 15-year-old students: A cross-cultural study using multi-group latent profile analysis. Frontiers in Psychology 10: 1217. [Google Scholar] [CrossRef]
- Fernández-Gutiérrez, Marcos, Gregorio Gimenez, and Jorge Calero. 2020. Is the use of ICT in education leading to higher student outcomes? Analysis from the Spanish Autonomous Communities. Computers & Education 157: 103969. [Google Scholar] [CrossRef]
- Forsythe, Alex, and Sophie Johnson. 2017. Thanks, but no-thanks for the feedback. Assessment & Evaluation in Higher Education 42: 850–59. [Google Scholar]
- Fung, Francis, Cheng Yong Tan, and Gaowei Chen. 2018. Student engagement and mathematics achievement: Unraveling main and interactive effects. Psychology in the Schools 55: 815–31. [Google Scholar] [CrossRef]
- Gamazo, Adriana, and Fernando Martínez-Abad. 2020. An Exploration of Factors Linked to Academic Performance in PISA 2018 Through Data Mining Techniques. Frontiers in Psychology 11: 575167. [Google Scholar] [CrossRef] [PubMed]
- Gevrek, Z. Eylem, Deniz Gevrek, and Christian Neumeier. 2020. Explaining the gender gaps in mathematics achievement and attitudes: The role of societal gender equality. Economics of Education Review 76: 101978. [Google Scholar] [CrossRef]
- Giannelli, Gianna Claudia, and Chiara Rapallini. 2016. Immigrant student performance in Math: Does it matter where you come from? Economics of Education Review 52: 291–304. [Google Scholar] [CrossRef]
- Gjicali, Kalina, and Anastasiya A. Lipnevich. 2021. Got math attitude? (In)direct effects of student mathematics attitudes on intentions, behavioral engagement, and mathematics performance in the U.S. PISA. Contemporary Educational Psychology 67: 102019. [Google Scholar] [CrossRef]
- Gorostiaga, Arantza, and José Luis Rojo-Álvarez. 2016. On the use of conventional and statistical-learning techniques for the analysis of PISA results in Spain. Neurocomputing 171: 625–37. [Google Scholar] [CrossRef]
- Gómez-Talal, Ismael, Luis Bote-Curiel, and José Luis Rojo-Álvarez. 2024. Understanding the disparities in Mathematics performance: An interpretability-based examination. Engineering Applications of Artificial Intelligence 133: 108109. [Google Scholar] [CrossRef]
- Gümüş, Sedat, Mehmet Şükrü Bellibaş, and Marcus Pietsch. 2022. School leadership and achievement gaps based on socioeconomic status: A search for socially just instructional leadership. Journal of Educational Administration 60: 419–38. [Google Scholar] [CrossRef]
- Hajovsky, Daniel B., Kari A. Oyen, Steven R. Chesnut, and Susan J. Curtin. 2020. Teacher–student relationship quality and math achievement: The mediating role of teacher self-efficacy. Psychology in the Schools 57: 111–34. [Google Scholar] [CrossRef]
- Hilbert, Sven, Stefan Coors, Elisabeth Kraus, Bernd Bischl, Alfred Lindl, Mario Frei, Johannes Wild, Stefan Krauss, David Goretzko, and Clemens Stachl. 2021. Machine learning for the educational sciences. Review of Education 9: e3310. [Google Scholar] [CrossRef]
- Hu, Jie, and Rushi Yu. 2021. Influence of students’ perceptions of instruction quality on their digital reading performance in 29 OECD countries: A multilevel analysis. Computers & Education 189: 104591. [Google Scholar] [CrossRef]
- Hu, Jie, and Yanyu Wang. 2022. The effects of ICT-based social media on adolescents’ digital reading performance: A longitudinal study of PISA 2009, PISA 2012, PISA 2015 and PISA 2018. Computers & Education 175: 104342. [Google Scholar] [CrossRef]
- Hu, Xiang, Yang Gong, Chun Lai, and Frederick K. S. Leung. 2018. The relationship between ICT and student literacy in mathematics, reading, and science across 44 countries: A multilevel analysis. Computers & Education 125: 1–13. [Google Scholar] [CrossRef]
- Juhaňák, Libor, Jiří Zounek, Klára Záleská, Ondřej Bárta, and Kristýna Vlčková. 2018. The Relationship between Students’ ICT Use and Their School Performance: Evidence from PISA 2015 in the Czech Republic. Orbis Scholae 12: 37–64. [Google Scholar] [CrossRef]
- Karakus, Mehmet, Matthew Courtney, and Hasan Aydin. 2023. Understanding the academic achievement of the first- and second-generation immigrant students: A multi-level analysis of PISA 2018 data. Educational Assessment, Evaluation and Accountability 35: 233–78. [Google Scholar] [CrossRef]
- Kim, Sunha. 2018. ICT and the UN’s sustainable development goal for education: Using ICT to boost the math performance of immigrant youths in the US. Sustainability 10: 4584. [Google Scholar] [CrossRef]
- Konishi, Chiaki, Shelley Hymel, Bruno D. Zumbo, and Zhen Li. 2010. Do School Bullying and Student—Teacher Relationships Matter for Academic Achievement? A Multilevel Analysis. Canadian Journal of School Psychology 25: 19–39. [Google Scholar] [CrossRef]
- Kriegbaum, Katharina, and Birgit Spinath. 2016. Explaining Social Disparities in Mathematical Achievement: The Role of Motivation. European Journal of Personality 30: 45–63. [Google Scholar] [CrossRef]
- Laaninen, Markus, Nevena Kulic, and Jani Erola. 2024. Age of entry into early childhood education and care, literacy and reduction of educational inequality in Nordic countries. European Societies 26: 1–30. [Google Scholar] [CrossRef]
- Lee, Hanol. 2022. What drives the performance of Chinese urban and rural secondary schools: A machine learning approach using PISA 2018. Cities 123: 103609. [Google Scholar] [CrossRef]
- Lee, Jihyun. 2021. Teacher–student relationships and academic achievement in Confucian educational countries/systems from PISA 2012 perspectives. Educational Psychology 41: 764–85. [Google Scholar] [CrossRef]
- Lerner, Rachel E., Wendy S. Grolnick, Alessandra J. Caruso, and Madeline R. Levitt. 2022. Parental involvement and children’s academics: The roles of autonomy support and parents’ motivation for involvement. Contemporary Educational Psychology 68: 102039. [Google Scholar] [CrossRef]
- Levpušček, Melita Puklek, and Maja Zupančič. 2009. Math achievement in early adolescence: The role of parental involvement, teachers’ behavior, and students’ motivational beliefs about math. The Journal of Early Adolescence 29: 541–70. [Google Scholar] [CrossRef]
- Lezhnina, Olga, and Gábor Kismihók. 2022. Combining statistical and machine learning methods to explore German students’ attitudes towards ICT in PISA. International Journal of Research & Method in Education 45: 180–99. [Google Scholar] [CrossRef]
- Li, Hang. 2023. Machine Learning Methods. Berlin: Springer Nature. [Google Scholar]
- Linchevski, Liora, and Bilha Kutscher. 1998. Tell Me with Whom You’re Learning, and I’ll Tell You How Much You’ve Learned: Mixed-Ability versus Same-Ability Grouping in Mathematics. Journal for Research in Mathematics Education 29: 533–54. [Google Scholar] [CrossRef]
- Lindberg, Sara M., Janet Shibley Hyde, Marcia C. Linn, and Jennifer L. Petersen. 2010. New Trends in Gender and Mathematics Performance: A Meta-Analysis. Psychological Bulletin 136: 1123. [Google Scholar] [CrossRef]
- Liu, Ou Lydia, and Mark Wilson. 2009. Gender differences in large-scale math assessments: PISA trend 2000 and 2003. Applied Measurement in Education 22: 164–84. [Google Scholar] [CrossRef]
- Lundberg, Scott M., and Su-In Lee. 2017. A unified approach to interpreting model predictions. Advances in Neural Information Processing Systems 30: 4765–4774. [Google Scholar]
- Luschei, Thomas F., and Dong Wook Jeong. 2021. School Governance and Student Achievement: Cross-National Evidence From the 2015 PISA. Educational Administration Quarterly 57: 331–71. [Google Scholar] [CrossRef]
- Ma, Lihong, Haifeng Luo, and Leifeng Xiao. 2021. Perceived teacher support, self-concept, enjoyment and achievement in reading: A multilevel mediation model based on PISA 2018. Learning and Individual Differences 85: 101947. [Google Scholar] [CrossRef]
- Mammadov, Sakhavat, and Kayla Schroeder. 2023. A meta-analytic review of the relationships between autonomy support and positive learning outcomes. Contemporary Educational Psychology 75: 102235. [Google Scholar] [CrossRef]
- Melkonian, Michael, Shaljan Areepattamannil, Luisa Menano, and Patricia Fildago. 2019. Examining acculturation orientations and perceived cultural distance among immigrant adolescents in Portugal: Links to performance in reading, mathematics, and science. Social Psychology of Education 22: 969–89. [Google Scholar] [CrossRef]
- Michael, Demos, and Leonidas Kyriakides. 2023. Mediating effects of motivation and socioeconomic status on reading achievement: A secondary analysis of PISA 2018. Large-Scale Assessments in Education 11: 31. [Google Scholar] [CrossRef]
- Munir, Hussan, Bahtijar Vogel, and Andreas Jacobsson. 2022. Artificial Intelligence and Machine Learning Approaches in Digital Education: A Systematic Revision. Information 13: 203. [Google Scholar] [CrossRef]
- OECD. 2003. Literacy Skills for the World of Tomorrow-Further Results from Pisa 2000 Executive Summary Organisation for Economic co-Operation and Development Unesco Institute for Statistics. Available online: www.copyright.com (accessed on 24 March 2024).
- OECD. 2009. PISA Data Analysis Manual: SPSS. Paris: OECD Publishing. [Google Scholar] [CrossRef]
- OECD. 2023a. PISA 2022 Results. Paris: OECD Publishing, vol. I. [Google Scholar] [CrossRef]
- OECD. 2023b. PISA 2022 Results (Volume II): Learning During–and From–Disruption. Paris: OECD Publishing. [Google Scholar] [CrossRef]
- OECD. 2023c. PISA 2022 Technical Report. Paris: OECD Publishing. [Google Scholar] [CrossRef]
- OECD, and UNESCO Institute for Statistics. 2003. Literacy Skills for the World of Tomorrow. Available online: https://www.oecd-ilibrary.org/content/publication/9789264102873-en (accessed on 12 March 2024).
- Pinquart, Martin, and Markus Ebeling. 2020. Parental Educational Expectations and Academic Achievement in Children and Adolescents—A Meta-analysis. Educational Psychology Review 32: 463–80. [Google Scholar] [CrossRef]
- Pitsia, Vasiliki, Andy Biggart, and Anastasios Karakolidis. 2017. The role of students’ self-beliefs, motivation and attitudes in predicting mathematics achievement: A multilevel analysis of the Programme for International Student Assessment data. Learning and Individual Differences 55: 163–73. [Google Scholar] [CrossRef]
- Pivovarova, Margarita, and Jeanne M. Powers. 2019. Generational status, immigrant concentration and academic achievement: Comparing first and second-generation immigrants with third-plus generation students. Large-Scale Assessments in Education 7: 7. [Google Scholar] [CrossRef]
- Posso, Alberto. 2016. Internet Usage and Educational Outcomes Among 15-Year-Old Australian Students. International Journal of Communication 10. Available online: http://ijoc.org (accessed on 15 June 2024).
- Rodríguez, Susana, Isabel Piñeiro, Ma Luisa Gómez-Taibo, Bibiana Regueiro, Iris Estévez, and Antonio Valle. 2017. Un modelo explicativo del rendimiento en matemáticas: Percepción de la implicación parental y motivación académica. Psicothema 29: 184–90. [Google Scholar] [CrossRef]
- Rudolf, Robert, and Jieun Lee. 2023. School climate, academic performance, and adolescent well-being in Korea: The roles of competition and cooperation. Child Indicators Research 16: 917–40. [Google Scholar] [CrossRef]
- Salas-Velasco, Manuel, Dolores Moreno-Herrero, and José Sánchez-Campillo. 2021. Positive Geographical Spillovers of Human Capital on Student Learning Outcomes. Applied Spatial Analysis and Policy 14: 415–43. [Google Scholar] [CrossRef]
- Sälzer, Christine, and Jörg-Henrik Heine. 2016. Students’ skipping behavior on truancy items and (school) subjects and its relation to test performance in PISA 2012. International Journal of Educational Development 46: 103–13. [Google Scholar] [CrossRef]
- Sebastian, James, and Haigen Huang. 2016. Examining the relationship of a survey based measure of math creativity with math achievement: Cross-national evidence from PISA 2012. International Journal of Educational Research 80: 74–92. [Google Scholar] [CrossRef]
- Segal, Mark R. 2004. Machine Learning Benchmarks and Random Forest Regression. San Francisco: UCSF Center for Bioinformatics and Molecular Biostatistics. Available online: https://escholarship.org/uc/item/35x3v9t4 (accessed on 23 September 2024).
- Selvaraj, Anne Malar, Hazita Azman, and Wahiza Wahi. 2021. Teachers’ feedback practice and students’ academic achievement: A systematic literature review. International Journal of Learning, Teaching and Educational Research 20: 308–322. [Google Scholar] [CrossRef]
- Skaalvik, Einar M., Roger A. Federici, and Robert M. Klassen. 2015. Mathematics achievement and self-efficacy: Relations with motivation for mathematics. International Journal of Educational Research 72: 129–36. [Google Scholar] [CrossRef]
- Skryabin, Maxim, JingJing Zhang, Luman Liu, and Danhui Zhang. 2015. How the ICT development level and usage influence student achievement in reading, mathematics, and science. Computers & Education 85: 49–58. [Google Scholar] [CrossRef]
- Slavin, Robert E. 1987. Ability Grouping and Student Achievement in Elementary Schools: A Best-Evidence Synthesis. Review of Educational Research 57: 293–336. [Google Scholar] [CrossRef]
- Smith, Frances M., and Cheryl O. Hausafus. 1998. Relationship of family support and ethnic minority students’ achievement in science and mathematics. Science Education 82: 111–25. [Google Scholar] [CrossRef]
- Spörlein, Christoph, and Elmar Schlueter. 2018. How education systems shape cross-national ethnic inequality in math competence scores: Moving beyond mean differences. PLoS ONE 13: e0193738. [Google Scholar] [CrossRef] [PubMed]
- Stankov, Lazar, Jihyun Lee, Wenshu Luo, and David J. Hogan. 2012. Confidence: A better predictor of academic achievement than self-efficacy, self-concept and anxiety? Learning and Individual Differences 22: 747–58. [Google Scholar] [CrossRef]
- Sulis, Isabella, Francesca Giambona, and Mariano Porcu. 2020. Adjusted indicators of quality and equity for monitoring the education systems over time. Insights on EU15 countries from PISA surveys. Socio-Economic Planning Sciences 69: 100714. [Google Scholar] [CrossRef]
- Tan, Cheng Yong. 2017. Do parental attitudes toward and expectations for their children’s education and future jobs matter for their children’s school achievement? British Educational Research Journal 43: 1111–30. [Google Scholar] [CrossRef]
- Tan, Cheng Yong, and Khe Foon Hew. 2019. The Impact of Digital Divides on Student Mathematics Achievement in Confucian Heritage Cultures: A Critical Examination Using PISA 2012 Data. International Journal of Science and Mathematics Education 17: 1213–32. [Google Scholar] [CrossRef]
- Tanskanen, Antti O., Jani Erola, and Johanna Kallio. 2016. Parental Resources, Sibship Size, and Educational Performance in 20 Countries: Evidence for the Compensation Model. Cross-Cultural Research 50: 452–77. [Google Scholar] [CrossRef] [PubMed]
- Tourón, Javier, Emelina López González, Luis Lizasoain, M. J. Pedro, and Enrique Navarro Asencio. 2018. Spanish High and Low achievers in Science in PISA 2015: Impact analysis of some contextual variables. Revista de Educacion 148: 156–84. [Google Scholar] [CrossRef]
- Tourón, Javier, Enrique Navarro-Asencio, Luis Lizasoain, Emelina López-González, and María José García-San Pedro. 2019. How teachers’ practices and students’ attitudes towards technology affect mathematics achievement: Results and insights from PISA 2012. Research Papers in Education 34: 263–75. [Google Scholar] [CrossRef]
- Useem, Elizabeth L. 1992. Middle Schools and Math Groups: Parents’ Involvement in Children’s Placement. Sociology of Education 65: 263–79. [Google Scholar] [CrossRef]
- Wang, Faming, Ronnel B. King, and Shing On Leung. 2023a. Why do East Asian students do so well in mathematics? A machine learning study. International Journal of Science and Mathematics Education 21: 691–711. [Google Scholar] [CrossRef]
- Wang, Faming, Yaping Liu, and Shing On Leung. 2022. Disciplinary Climate, Opportunity to Learn, and Mathe-matics Achievement: An Analysis Using Doubly Latent Multilevel Structural Equation Modeling. School Effectiveness and School Improvement 33: 479–96. [Google Scholar] [CrossRef]
- Wang, Xiaofang Sarah, Laura B. Perry, Anabela Malpique, and Tobias Ide. 2023b. Factors predicting mathematics achievement in PISA: A systematic review. Large-Scale Assessments in Education 11: 24. [Google Scholar] [CrossRef]
- Wang, Xuran, Richard T. Houang, William H. Schmidt, and Kimberly S. Kelly. 2024. Relationship between Opportunity to Learn, Mathematics Self-Efficacy, and Math Performance: Evidence from PISA 2012 in 63 Countries and Economies. International Journal of Science and Mathematics Education 22: 1–26. [Google Scholar] [CrossRef]
- Wang, Yajing, and Yashuang Wang. 2023. Exploring the relationship between educational ICT resources, student engagement, and academic performance: A multilevel structural equation analysis based on PISA 2018 data. Studies in Educational Evaluation 79: 101308. [Google Scholar] [CrossRef]
- Wijaya, Tommy Tanu, Imam Fitri Rahmadi, Siti Chotimah, Jailani Jailani, and Dhoriva Urwatul Wutsqa. 2022a. A Case Study of Factors That Affect Secondary School Mathematics Achievement: Teacher-Parent Support, Stress Levels, and Students’ Well-Being. International Journal of Environmental Research and Public Health 19: 16247. [Google Scholar] [CrossRef]
- Wijaya, Tommy Tanu, Yiming Cao, Robert Weinhandl, and Maximus Tamur. 2022b. A Meta-Analysis of the Effects of E-Books on students’ mathematics achievement. Heliyon 8: e09432. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Feiya, and Li Sun. 2021. Students’ Motivation and Affection Profiles and Their Relation to Mathematics Achievement, Persistence, and Behaviors. Frontiers in Psychology 11: 533593. [Google Scholar] [CrossRef]
- Xiao, Feiya, and Li Sun. 2022. Profiles of student ICT use and their relations to background, motivational factors, and academic achievement. Journal of Research on Technology in Education 54: 456–72. [Google Scholar] [CrossRef]
- Yamamura, Eiji. 2019. Gender wage gap and its effect on test scores of immigrant students. Journal of Economic Studies 46: 872–87. [Google Scholar] [CrossRef]
- Yao, Yiling, Qiping Kong, and Jinfa Cai. 2018. Investigating Elementary and Middle School Students’ Subjective Well-Being and Mathematical Performance in Shanghai. International Journal of Science and Mathematics Education 16: 107–27. [Google Scholar] [CrossRef]
- You, Sukkyung, Eui Kyung Kim, Sun Ah Lim, and Myley Dang. 2021. Student and Teacher Characteristics on Student Math Achievement. Journal of Pacific Rim Psychology 15: 1834490921991428. [Google Scholar] [CrossRef]
- Zhang, Yuan, Shannon Russell, and Sean Kelly. 2022. Engagement, achievement, and teacher classroom practices in mathematics: Insights from TIMSS 2011 and PISA 2012. Studies in Educational Evaluation 73: 101146. [Google Scholar] [CrossRef]
- Zhao, Yuyang, and Cody Ding. 2019. The association between students mathematic knowledge and factors related to students, parents, and school: A cross-cultural comparison study. International Journal of Educational Research 93: 210–17. [Google Scholar] [CrossRef]
- Zhou, Zhi-Hua. 2021. Machine Learning. Berlin: Springer Nature. [Google Scholar]
- Zhu, Yan, Gabriele Kaiser, and Jinfa Cai. 2018. Gender equity in mathematical achievement: The case of China. Educational Studies in Mathematics 99: 245–60. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Hyperparameter Combinations | Optimal Hyperparameter Combination |
|---|---|---|
| MLR | default | default |
| SVR | ‘C’: [0.01, 0.1, 1, 10, 100], ‘gamma’: [1, 0.1, 0.01, 0.001, 0.0001], ‘kernel’: [‘rbf’] | C = 100, gamma = 0.01, kernel = ‘rbf’ |
| DT | ‘max_features’: [‘sqrt’, ‘log2’, ‘None’], ‘max_depth’: [5, 6, 7, 8, 9, 10, 11, 12, 15, 20, 30], ‘criterion’: [‘squared_error’] | criterion = ‘squared_error’, max_depth = 8, max_features = ‘sqrt’ |
| RF | ‘n_estimators’: [100, 200, 300, 500], ‘criterion’: [‘squared_error’], ‘max_features’: [‘sqrt’, ‘log2’, ‘None’], ‘max_depth’: [6, 7, 8, 9, 10, 11, 12, 15, 20, 30, 40, 50] | max_features = ‘sqrt’, n_estimators = 500, max_depth = 30 |
| XGBoost | ‘learning_rate’: [0.01, 0.015, 0.025, 0.05, 0.1, 0.01, 0.015, 0.025, 0.05, 0.1], ‘gamma’: [0.05, 0.1, 0.3, 0.5, 0.7, 0.9, 1], ‘reg_alpha’: [0, 0.01, 0.1, 1], ‘reg_lambda’: [0, 0.1, 0.5, 1], ‘max_depth’: [3, 5, 6, 7, 9, 12, 15, 17, 25], ‘min_child_weight’: [1, 3, 5, 7], ‘subsample’: [0.6, 0.7, 0.8, 0.9, 1], ‘colsample_bytree’: [0.6, 0.7, 0.8, 0.9,1], ‘objective’: [“reg: squarederror”] | learning_rate = 0.1, gamma = 0.05, reg_alpha = 0.01, reg_lambda = 0.5, max_depth = 7, min_child_weight = 3, subsample = 1, colsample_bytree = 0.6, objective = “reg: squarederror” |
| Models | MSE | RMSE | MAE | MAPE | PCCs | |
|---|---|---|---|---|---|---|
| MLR | 5457.59 | 73.88 | 58.2 | 11.57% | 0.49 | 0.70 |
| SVR | 4560.49 | 67.53 | 52.93 | 10.51% | 0.58 | 0.76 |
| DT | 7279.3 | 85.32 | 67.85 | 13.50% | 0.32 | 0.57 |
| RF | 4926.58 | 70.19 | 55.42 | 11.08% | 0.54 | 0.75 |
| XGBoost | 4344.98 | 65.92 | 51.72 | 10.21% | 0.60 | 0.77 |
| Numbers of Features | MSE | RMSE | MAE | MAPE | PCCs | |
|---|---|---|---|---|---|---|
| 5 | 5791.34 | 76.10 | 60.08 | 0.46 | 11.91% | 0.68 |
| 10 | 5155.85 | 71.80 | 56.41 | 0.52 | 11.18% | 0.72 |
| 15 | 4969.04 | 70.49 | 55.34 | 0.54 | 10.95% | 0.73 |
| 20 | 4807.67 | 69.34 | 54.46 | 0.55 | 10.80% | 0.74 |
| 30 | 4545.81 | 67.42 | 53.02 | 0.58 | 10.49% | 0.76 |
| 40 | 4501.69 | 67.09 | 52.70 | 0.58 | 10.41% | 0.76 |
| 50 | 4386.68 | 66.23 | 52.03 | 0.59 | 10.25% | 0.77 |
| 60 | 4346.37 | 65.93 | 51.98 | 0.60 | 10.26% | 0.77 |
| 72 | 4342.73 | 65.90 | 51.87 | 0.60 | 10.25% | 0.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Zhou, Y.; Chen, J.; Wu, D. Applying Machine Learning and SHAP Method to Identify Key Influences on Middle-School Students’ Mathematics Literacy Performance. J. Intell. 2024, 12, 93. https://doi.org/10.3390/jintelligence12100093
Huang Y, Zhou Y, Chen J, Wu D. Applying Machine Learning and SHAP Method to Identify Key Influences on Middle-School Students’ Mathematics Literacy Performance. Journal of Intelligence. 2024; 12(10):93. https://doi.org/10.3390/jintelligence12100093
Chicago/Turabian StyleHuang, Ying, Ying Zhou, Jihe Chen, and Danyan Wu. 2024. "Applying Machine Learning and SHAP Method to Identify Key Influences on Middle-School Students’ Mathematics Literacy Performance" Journal of Intelligence 12, no. 10: 93. https://doi.org/10.3390/jintelligence12100093
APA StyleHuang, Y., Zhou, Y., Chen, J., & Wu, D. (2024). Applying Machine Learning and SHAP Method to Identify Key Influences on Middle-School Students’ Mathematics Literacy Performance. Journal of Intelligence, 12(10), 93. https://doi.org/10.3390/jintelligence12100093