1. Introduction
A structural equation model (SEM) is a statistical approach for analyzing multivariate data (
Bartholomew et al. 2011;
Bollen 1989;
Browne and Arminger 1995;
Jöreskog et al. 2016;
Shapiro 2012;
Yuan and Bentler 2007). These models relate a multivariate vector
of observed
I variables (also referred to as items or indicators) to a vector of latent variables (i.e., factors)
of a dimension smaller than
I. SEMs constrain the mean vector
and the covariance matrix
of the random variable
as a function of an unknown parameter vector
. By doing so, the mean vector is constrained as
, and the covariance matrix is constrained as
.
The LSEM method is particularly suited for studying differentiation or dedifferentiation hypotheses (see
Hildebrandt et al. 2009 or
Molenaar et al. 2010b). Differentiation hypotheses of intelligence and general scholastic abilities describe changes in the relationship between different cognitive abilities (i.e., their structural organization) depending on the level of general ability (ability differentiation), age (differentiation in children and adolescents; dedifferentiation in older adults), and their interaction.
Breit et al. (
2022) presented a systematic review of 33 reports with data from 51 studies with over 260,000 participants that examined differentiation effects. The findings indicated practically significant ability differentiation in children and adults, and significant age dedifferentiation in older adults, with effect sizes that implicate a practical significance of the effects. However,
Breit et al. (
2022) also showed that age differentiation in children and adolescents was not supported. Instead, small but negligible effect sizes were found for age dedifferentiation in adolescents.
The LSEM method has been extended to two moderator variables by
Hartung et al. (
2018).
Molenaar (
2021) proposed a semiparametric moderated factor modeling approach in which no assumption concerning the functional form between the moderator and the model parameters are imposed. In contrast to the original definition of LSEM (
Hildebrandt et al. 2009), some model parameters are allowed to be invariant across the continuous moderator variable.
This article reviews and extends LSEM estimation methods and discusses the implementation in the R package sirt. In previous literature, LSEM was fitted as a sequence of models that are separately evaluated as each value of the moderator variables. In this article, a joint estimation approach is proposed that is a simultaneous estimation method across all moderator values and also allows some model parameters to be invariant with respect to the moderator. Sufficient detail on the core estimation functions in the sirt package is provided. The article also evaluates two significance testing approaches to assess whether the moderator values are related to a model parameter in two simulation studies. Finally, an empirical example demonstrates the usefulness of the LSEM methodology.
The remainder of this article is structured as follows.
Section 2 overviews the most important LSEM applications in the literature. In
Section 3, different LSEM estimation and significance testing approaches are presented. Details about LSEM implementation in the sirt package can be found in
Section 4.
Section 5 discusses R input code and R output of an LSEM analysis involving illustrative datasets.
Section 6 includes a simulation study investigating parameter recovery in LSEM regarding bias and root mean square error.
Section 7 includes a simulation study that investigates different estimators of variability in parameter curves and the statistical properties of significance tests of parameter variation. In
Section 8, an empirical example is presented that reanalyzes SON-R intelligence data for children aged between 2
and 7 years. Finally,
Section 9 closes with a discussion.
2. Review of LSEM Applications
We now review important LSEM applications to demonstrate that this method is widely applied in substantive research. The original LSEM publication of
Hildebrandt et al. (
2009) (“Complementary and competing factor analytic approaches for the investigation of measurement invariance”) has been cited 93 times and 80 times, according to Google Scholar and ResearchGate (accessed on 18 July 2023), respectively. The second methodological LSEM publication by
Hildebrandt et al. (
2016) (“Exploring factor model parameters across continuous variables with local structural equation models”) has been cited 111 times, 89 times, and 77 times, according to Google Scholar, ResearchGate, and Web of Science (accessed on 18 July 2023), respectively. Hence, one could say that LSEM fills some niche in the researcher’s methodological toolbox.
In the following, some LSEM applications are briefly described. The studies are loosely organized according to the fields of application.
Olaru and Allemand (
2022) examined differential and correlated change in personality across the adult lifespan using LSEM.
Brandt et al. (
2022) applied LSEM to four waves of data obtained with the full NEO Personality Inventory collected over 11 years from 1667 adults in a US sample using age as a continuous moderator.
Hartung et al. (
2021) investigated the age-moderated covariance structure of the satisfaction with life scale (SWLS) and the domains of health satisfaction and financial satisfaction using LSEM.
Olaru et al. (
2019) analyzed NEO personality indicators across ages between 16 and 66 years by means of LSEM. They selected items for short scales that had the greatest extent of measurement invariance across age.
Seifert et al. (
2022) studied whether the rank-order stability of personality increases until midlife and declines later in old age and found that this inverted U-shaped pattern was not consistently observed in two reanalyzes utilizing LSEM. Loneliness across different age levels was investigated by LSEM in
Entringer and Gosling (
2022) and
Panayiotou et al. (
2022).
Van den Akker et al. (
2021) applied LSEM for students aged between 8 and 18 years to investigate whether levels of conscientiousness and agreeableness decrease when levels of neuroticism increase, indicating a dip in personality maturation.
Gnambs (
2013) applied LSEM in a multitrait multi-informant meta-analysis for the big five factors.
Hartung et al. (
2022) investigated the structure of the “dark personality factor” across age and gender using LSEM.
Krasko and Kaiser (
2023) investigated measurement invariance across age for the dark triad by means of LSEM.
Bratt et al. (
2018) investigated levels of perceived age discrimination across early to late adulthood by employing LSEM, using data from the European social survey (ESS) collected in 29 countries.
Dutton and Kirkegaard (
2022) applied LSEM to investigate a particular question about the association between religiousness and intelligence.
Allemand et al. (
2022) used LSEM to investigate the effects of continuous age and COVID-19 virus worry on mean levels and correlations between gratitude and remaining opportunities and time.
Allemand et al. (
2021) examined age-related psychometrics and differences in the measurement, mean-levels, variances, and correlations of gratitude and future time perspective across adulthood using data in a representative Swiss sample for participants aged between 19 and 98 years.
Schroeders et al. (
2015) studied the differentiation fluid and crystallized intelligence in German students of grades 5 to 12.
Watrin et al. (
2022) studied the age differentiation hypothesis of declarative knowledge, as proposed in Cattell’s investment theory.
Hülür et al. (
2011) studied with LSEM whether cognitive abilities become more differentiated with increasing age during childhood for children from age 2.5 to 7.
Hartung et al. (
2020) tested whether associations among executive functions strengthened from middle childhood to adolescence using cross-sectional data from a sample of children aged between 7 and 15 years.
Gnambs and Schroeders (
2020) examined the effects of cognitive abilities on the factor structure of the Rosenberg self-esteem scale across age by means of LSEM.
Whitley et al. (
2016) explored cross-sectional associations of age with five cognitive tests (word recall, verbal fluency, subtraction, number sequence, and numerical problem solving) in a large representative sample aged between 16 and 100 living in the UK.
Breit et al. (
2020) investigated ability differentiation, developmental differentiation, and their interaction with LSEM in two studies.
Breit et al. (
2021) provided a review of the literature on ability and developmental differentiation effects in children and youths.
Breit et al. (
2023) studied ability differentiation, including creativity measures, through LSEM for German students aged between 12 and 16 years.
Hildebrandt et al. (
2010) employed LSEM to investigate structural invariance and age-related performance differences in face cognition.
Hildebrandt et al. (
2013) studied the specificity of face cognition compared with object cognition from individual differences and aging perspective by determining the amount of overlap between these abilities at the level of latent constructs across age. By utilizing LSEM,
Liu et al. (
2022) found that individual differences in white matter microstructure of the face processing brain network were more differentiated from global fibers with increasing ability.
LSEM was also applied in behavioral neurosciences
Kaltwasser et al. (
2017).
Jokić-Begić et al. (
2019) used LSEM for assessing measurement invariance across age for cyperchondria, a process of increased anxiety over one’s health as a result of excessive online searching.
Lodi-Smith et al. (
2021) found that autism characteristics measured by the autism-spectrum quotient scale were not strongly associated with age by utilizing LSEM.
Cox et al. (
2016) used LSEM to quantify microstructural properties of the human brain’s connections for understanding normal ageing and disease (see also
Briley et al. (
2015b)). Researchers
de Mooij et al. (
2018) used LSEM to study differences within and between brain and cognition across the adult life span.
Zheng et al. (
2019) investigated whether genetic and environmental influences on achievement goal orientations shift were moderated with age.
Madole et al. (
2019) applied LSEM in network analysis as a method for investigating symptom-level associations that underlie comorbidity connecting diagnostic syndromes.
Olaru et al. (
2019) utilized LSEM in combination with ant colony optimization (see also
Olaru and Jankowsky 2022) to resample and weight subjects to study differences in the measurement model across age as a continuous moderator variable.
An overview of different modeling strategies of LSEM for longitudinal data is presented in
Olaru et al. (
2020).
Wagner et al. (
2019) investigated through LSEM whether personality becomes more stable with age. They disentangled state and trait effects for the big five across the life span by applying LSEM to trait-state-occasion models.
Gana et al. (
2023) applied trait-state-occasion models in tandem with LSEM to investigate whether the characteristics of the depression EURO-D scale were associated with age.
LSEM was also applied to moderator variables different from age.
Klieme and Schmidt-Borcherding (
2023) employed LSEM to explore whether there is noninvariance for indicators of research self-efficacy regarding different training levels of students operationalized as the number of studied semesters.
Weiss et al. (
2020) investigated the threshold hypothesis of creativity by handling intelligence as a continuous moderator in LSEM.
Schroeders and Jansen (
2022) studied by means of LSEM whether the multidimensional structure of the science self-concept is moderated by levels of the cognitive ability in science.
Basarkod et al. (
2023) investigated whether reading self-concept dimensions vary across reading achievement levels in the PISA study.
Olaru et al. (
2022) examined the effects of family background on children’s receptive vocabulary using LSEM with latent growth curve models.
Bolsinova and Molenaar (
2019) (see also
Bolsinova and Molenaar 2018) used LSEM for indicator-specific covariates and extended LSEM to the study of cognitive tests involving reaction times.
4. Implementation of Local Structural Equation Models in the Sirt Package
In this section, we discuss the implementation of LSEM in the R (
R Core Team 2023) package sirt (
Robitzsch 2023b). The CRAN version can be installed within R using
utils::install.packages(’sirt’), while the most recent GitHub version can be installed employing
devtools::install_github(’alexanderrobitzsch/sirt’). The four primary LSEM functions are
sirt::lsem.estimate(),
sirt::lsem.bootstrap(),
sirt::lsem.test() and
sirt::lsem.permutationTest(), which will be discussed below. The new CRAN release of sirt from August 2023 (sirt 3.13-228;
https://cran.r-project.org/web/packages/sirt/ accessed on 11 August 2023) includes the functionality described in this article.
LSEM estimation in sirt provides a wrapper to the SEM package lavaan (
Rosseel 2012). The model specification follows the lavaan syntax, which eases the familiarity with R code for LSEM estimation because lavaan seems to be the most popular open-source SEM software.
In Listing 1, the main function sirt::lsem.estimate() is displayed. This function is the main LSEM estimation function. We now discuss the most important arguments in detail.
| Listing 1. LSEM function sirt::lsem.estimate(). |
![Jintelligence 11 00175 i001]() |
In
data, a data frame must be provided by the user. The data frame should also include the moderator variable, whose variable name must be specified in
moderator. The set of focal points can be defined as a vector
moderator.grid. In
lavmodel, lavaan syntax must be provided for estimating the LSEM. The default of the argument
type is
“LSEM”; that is, an LSEM is estimated. By choosing
type=”MGM”, a multiple-group model with a discretized moderator variable is estimated. The bandwidth in
sirt::lsem.estimate() can be specified by
h or
bw. The arguments are related through the formula:
where
denotes the estimated standard deviation of the moderator variable
A (i.e., the argument
moderator). The logical argument
residualize indicates whether local regression smoothing of the mean structure should be applied before estimating conditional covariances. The argument
fit_measures defines fit statistics available in lavaan that should be included in the LSEM output. The logical argument
standardized defines whether standardized parameters should appear in the LSEM output. The type of standardization is specified in
standardized_type whose conventions follow the lavaan package. In
lavaan_fct, the lavaan function is specified that is used for LSEM estimation. The default
lavaan_fct="sem" refers to
lavaan::sem(). Other options are
"cfa" (for
lavaan::cfa()) and
"lavaan" (for
lavaan::lavaan()). The logical argument
sufficient_statistics indicates whether sufficient statistics (i.e., conditional mean and conditional covariances) should be used in estimation. Without missing data, ML can always rely on sufficient statistics. However, in the presence of missing data, conditional covariance matrices are estimated based on pairwise deletion. However, if full information maximum likelihood was utilized, the mean structure cannot be properly residualized. Hence, researchers are advised either to believe in missing data mechanisms close to missing completely at random that justify the usage of pairwise deletion or to apply an appropriate multiple imputation procedure prior to LSEM analysis if there are missing values in the dataset.
Users can also input a vector of sampling weights in
sampling_weights. The logical argument
loc_linear_smooth defines whether local quadratic regression (see (
17)) should be applied in the estimation of conditional covariances. If the default
loc_linear_smooth=TRUE is changed into
loc_linear_smooth=FALSE, the weighting formula (
16) is utilized. The logical argument
est_joint indicates whether joint LSEM estimation (i.e., the default; see
Section 3.6 or
Section 3.8) or pairwise LSEM estimation (see
Section 3.5) is applied. Invariant model parameters can be specified in the vector argument
par_invariant. If there are some invariant parameters, joint LSEM estimation is automatically chosen (i.e.,
est_joint=TRUE). Linear or quadratic parameter constraints on model parameters (see
Section 3.8) can be specified with
par_linear and
par_quadratic, respectively. The number of segments in piecewise linear or piecewise quadratic parameter constrained estimation can be specified with
pw_linear or
pw_quadratic. The default is that the constrains should be applied across all moderator values (i.e., there is only one segment of a piecewise linear or quadratic function). The argument
partable_joint allows the input of a lavaan parameter table in joint estimation. This argument has the advantage that arbitrary parameter constraints can be specified by the user (e.g., additional equality constraints in piecewise quadratic functions). The logical argument
pd indicates whether non-positive definite conditional covariance matrices should be smoothed to ensure positive definiteness. The logical argument
est_DIF defines whether DIF effects should be estimated (see
Section 3.7). Note that DIF effects can only be estimated if the LSEM model contains some invariant model parameters. The argument
kernel allows the choice of the kernel function. Possible options are
“gaussian”,
“epanechnikov”, and
“uniform”. Finally, the logical argument
verbose indicates whether some output should be displayed in the R console when estimating the LSEM model.
Listing 2 displays the LSEM bootstrapping function in the sirt package. An object
object must be provided that is the output of the
sirt::lsem.estimate() function. The number of bootstrap samples can be specified by the argument
R. Bootstrap can also be applied at the level of higher-order units. For example, school classes, schools, or organizations can be bootstrapped instead of bootstrapping subjects. Such a kind of cluster bootstrap is required if there is an additional dependency structure in the data. In this case, users can define a vector of cluster units in
cluster. The
sirt::lsem.bootstrap() also allows more general replication designs such as jackknife, balanced repeated replication, or half sampling (
Kolenikov 2010) by providing an
matrix of resampling weights in the argument
repl_design. In the case of more complex designs, a scale factor
repl_factor must be defined by the user for a correct standard error computation. In the case of jackknife, it is 1 (or
), while it is
in the case of bootstrap resampling. The bootstrap function
sirt::lsem.bootstrap() is needed for computing the standard deviation statistic of parameter curves and its statistical inference (see
Section 3.9). The
sirt::lsem.bootstrap() function also allows an option for parallel computing. The number of employed cores can be specified by the argument
n.core. The default is the use of one core which means that no parallel computing is applied in LSEM bootstrap estimation.
| Listing 2. LSEM function sirt::lsem.bootstrap(). |
![Jintelligence 11 00175 i002]() |
Listing 3 displays the LSEM function
sirt::lsem.test() that performs the Wald tests for parameter variation (see
Section 3.9). Instead of applying a test of the equality of a parameter curve on
T focal points
, the specification in
models allows the test of significant regression parameters for a particular function. For example, a specification
"FX=∼X1"=y∼m+I(m^2) tests whether the vector of the linear and the quadratic regression coefficient of the factor loading
FX=∼X1 differs from
. Note that
sirt::lsem.test() requires the output of
sirt::lsem.estimate() in
mod and the output of the application of the bootstrap (or general resampling) of
sirt::lsem.bootstrap() in
bmod.
| Listing 3. LSEM function sirt::lsem.test(). |
![Jintelligence 11 00175 i003]() |
Listing 4 displays the LSEM function
sirt::lsem.permutationTest() that carries out the permutation test for a statistical significance test for variation in parameter curves of the LSEM model
Hildebrandt et al. (
2009,
2016). In the permutation test, the values of the moderator variables are randomly resampled in the dataset to create a null distribution of parameter curves under the assumption of no relation to the moderator. The number of permutation samples can be specified in the argument
B. As in
sirt::lsem.bootstrap(), parallel computing can be requested by the number of cores in the argument
n.core.
| Listing 4. LSEM function sirt::lsem.permutationTest(). |
![Jintelligence 11 00175 i004]() |
5. Illustrative Datasets
In this section, we illustrate LSEM estimation with the R package sirt. Three simulated datasets involving six variables X1, X2, X3, Y1, Y2, and Y3 are used for illustration. The analysis model is a two-dimensional factor model with a simple loading structure, where the first factor FX is measured by X1, X2, and X3, and the second factor FY is measured by Y1, Y2, and Y3. The moderator variable age was assessed at 13 time points, referring to ages . An anonymous reviewer pointed out that using 13 time points would look like longitudinal data. However, we only used the 13 time points for illustratory purposes. For example, there could be 13 cross-sectional age groups that are assessed.
The population parameters of the factor model for each age
and each of the three datasets
DATA1,
DATA2, and
DATA3 can be found in the directory “
POPPARS” at
https://osf.io/puaz9/?view_only=63ffb2fd30f5400e89c59d03366bf793 (accessed on 3 June 2023). From these population parameters, 10,000 subjects were simulated at each of the 13 age points. The distribution at each age point exactly coincides with the specified conditional mean vector and the conditional covariance matrix (see, e.g., the
lavaan::simulateData() function with the argument
empirical=FALSE for a similar functionality). Data were simulated from a multivariate normal distribution. This simulation ensures that the population data involving 130,000 subjects (i.e.,
subjects) exactly follows the specified covariance structure. In
DATA1, all model parameters except for residual variances were assumed noninvariant. In
DATA2, only the structural parameters (i.e., factor correlation and factor variances) were noninvariant, while factor loadings and residual variances were assumed invariant. In
DATA3, all measurement and structural model parameters were assumed invariant. The population datasets and the data-generating model parameters can be found in the directory “
POPDATA” at
https://osf.io/puaz9/?view_only=63ffb2fd30f5400e89c59d03366bf793 (accessed on 3 June 2023). The illustrative datasets used in this section were subsamples of 2000 subjects from datasets
DATA1,
DATA2, and
DATA3. The main motivation for using a subsample of the data is to show that LSEM produces some variability in model parameter estimates even if the model parameter is invariant across the moderator values in the data-generating model. The subsamples were created by random sampling without replacement from the population datasets. These datasets can be found in the directory “
ILLUSDATA” at
https://osf.io/puaz9/?view_only=63ffb2fd30f5400e89c59d03366bf793 (accessed on 3 June 2023).
Listing 5 contains the specification of the LSEM model involving two factors FX and FY. In lines 5–10 in Listing 5, the lavaan syntax for the factor model is specified in the string lavmodel. Line 13 in Listing 5 defines the parameter names (i.e., the factor loadings of X2, X3, Y2, and Y3) that are assumed invariant across the values of the moderator variable age. Line 16 in Listing 5 specifies the vector of focal points at which the LSEM model should be estimated. Lines 19–21 in Listing 5 contain the R command for applying sirt::lsem.estimate(). Note that the invariant model parameters are provided with the argument par_invariant, DIF effects were estimated due to est_DIF=TRUE, and the bandwidth factor h was chosen as 1.1. Joint LSEM estimation was applied because invariance constraints among parameters were imposed. In line 25 in Listing 5, the random seed is fixed, which ensures that bootstrap resampling will not change when applying code at a different time. Line 26 in Listing 5 specifies bootstrapping using sirt::lsem.bootstrap(). In total, bootstrap samples were utilized. Note that the specified factor model in Listing 5 is misspecified for the dataset DATA1, but correctly specified for the datasets DATA2 and DATA3.
| Listing 5. Illustrative datasets: Specification of LSEM with invariant factor loadings in sirt::lsem.estimate() and subsequent bootstrap in sirt::lsem.bootstrap(). |
![Jintelligence 11 00175 i005]() |
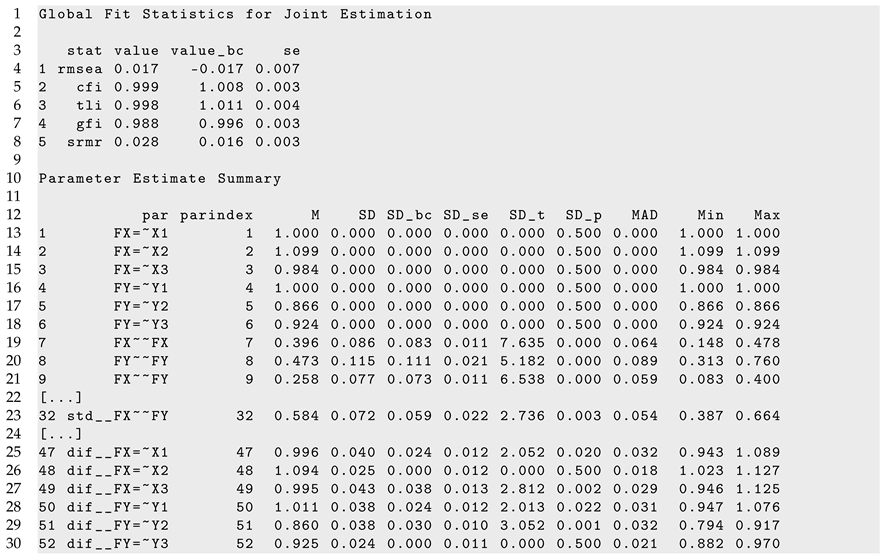
A part of R output of the sirt::lsem.bootstrap() function can be found in Listing 5. A slight misfit is detected in fit statistics RMSEA and SRMR. The CFI and TLI fit statistics are not indicative of the incorrect invariance assumption of factor loadings.
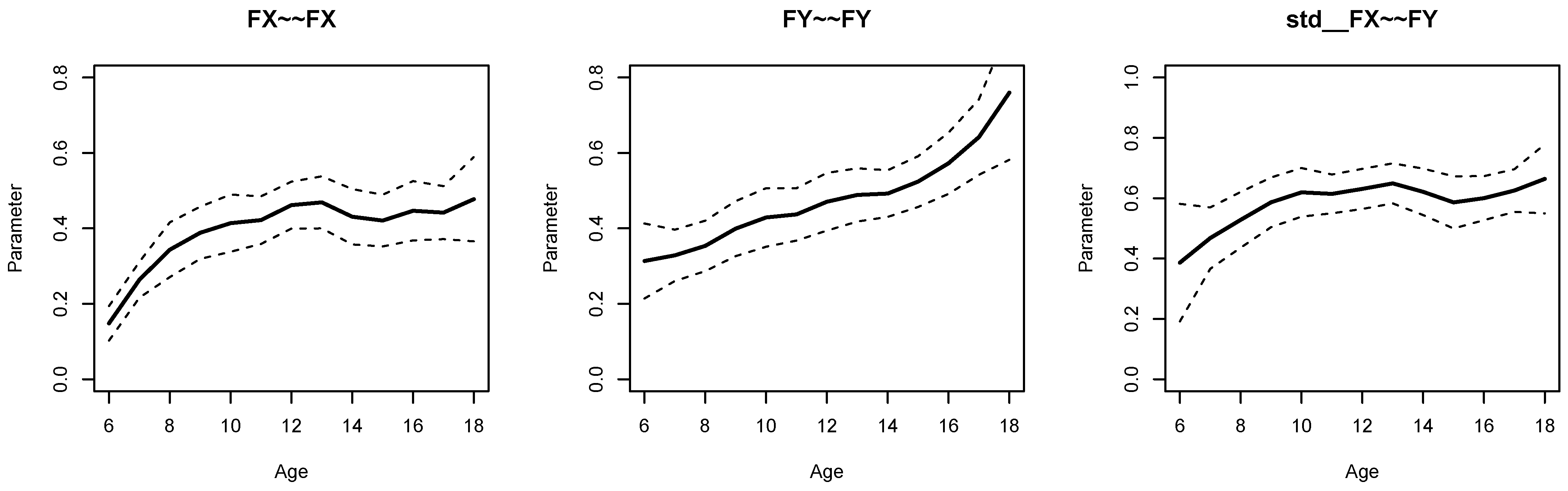
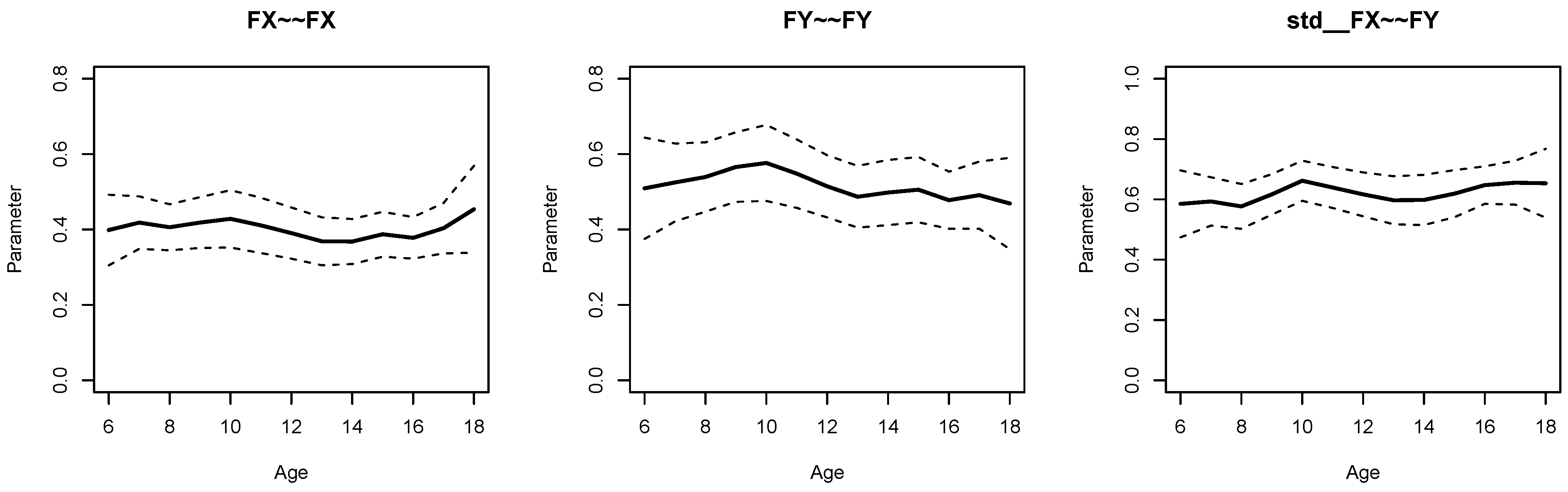
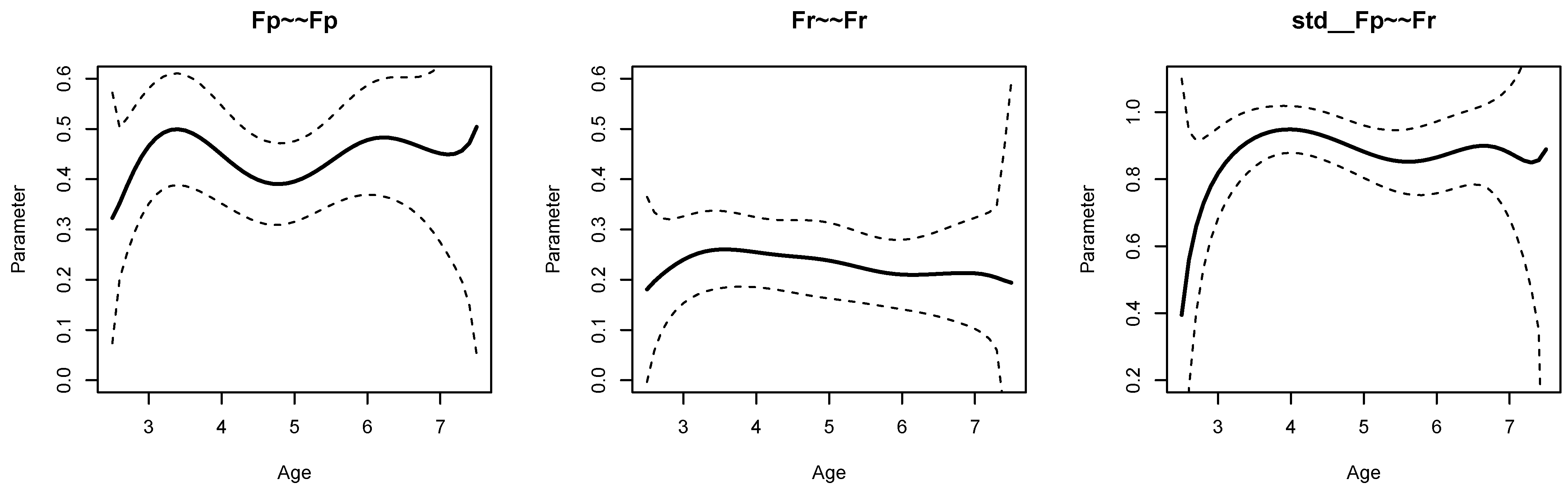
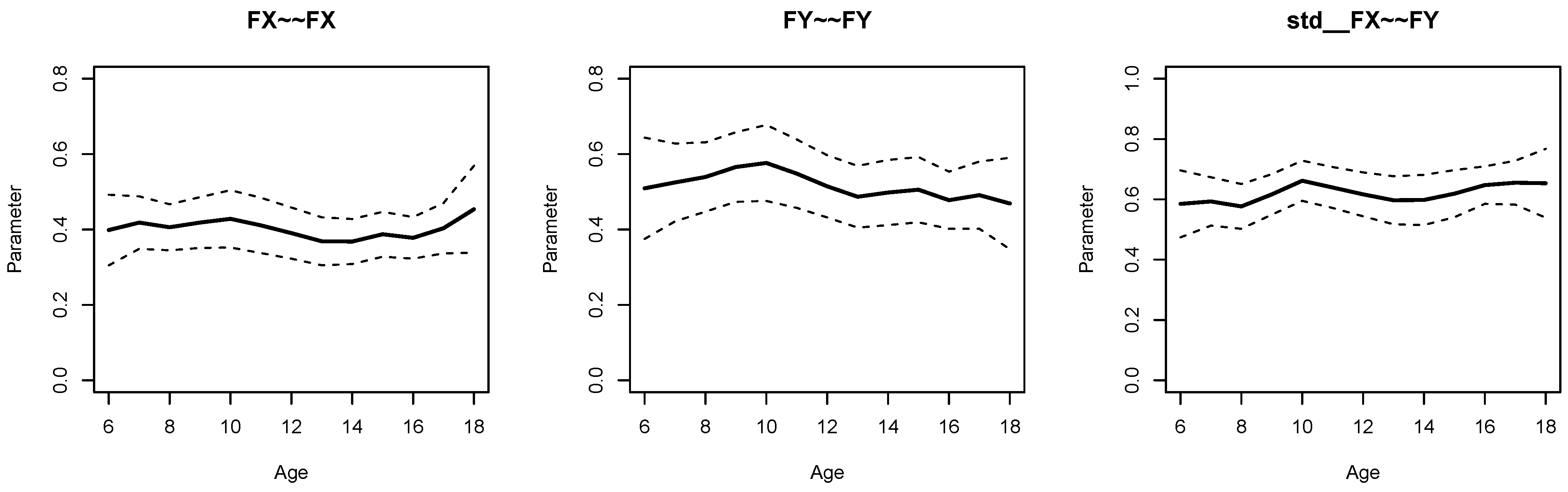
Figure 1 displays parameter curves for the two factor variances (i.e.,
FX∼∼FX and
FY∼∼FY) and the factor correlation (i.e.,
std FX∼∼FY) for the illustrative dataset
DATA1. From Listing 5, we see that the variance of
FX had an average of 0.396 with significant parameter variation (
,
), and
FY had an average of 0.473 with significant parameter variation (
,
). Moreover, the factor correlation had an average of 0.584 and also showed a significant parameter variation (
,
).
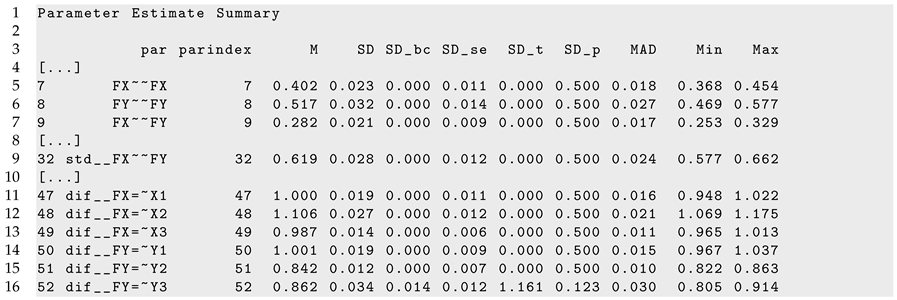
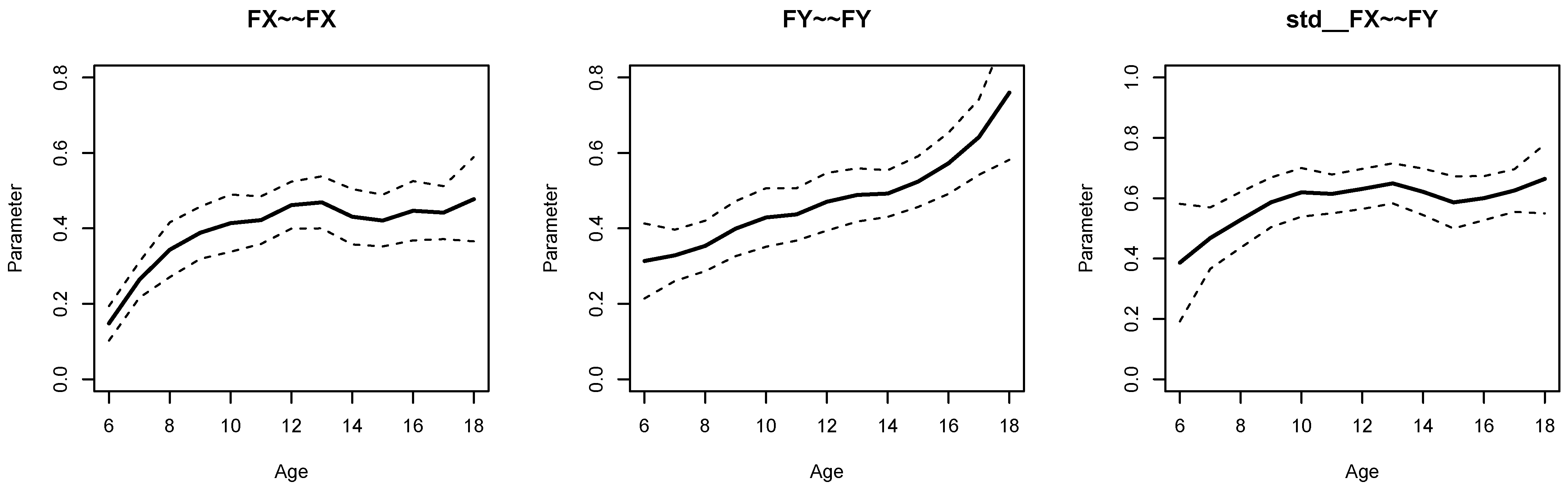
Figure 2 displays parameter curves for the two factor variances and the factor correlation for the illustrative dataset
DATA3, which had no simulated parameter variation in these parameters. By comparing
Figure 1 and
Figure 2, it is evident that there is negligible parameter variation for the dataset
DATA3 compared to the dataset
DATA1.
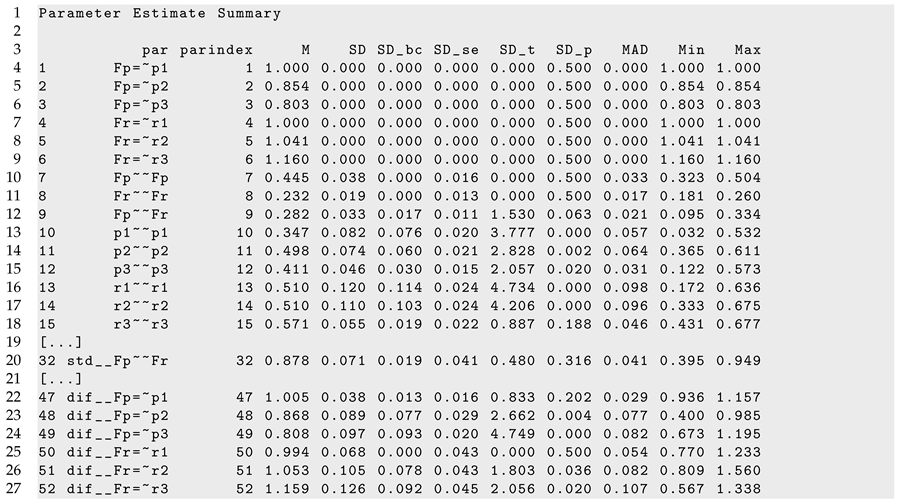
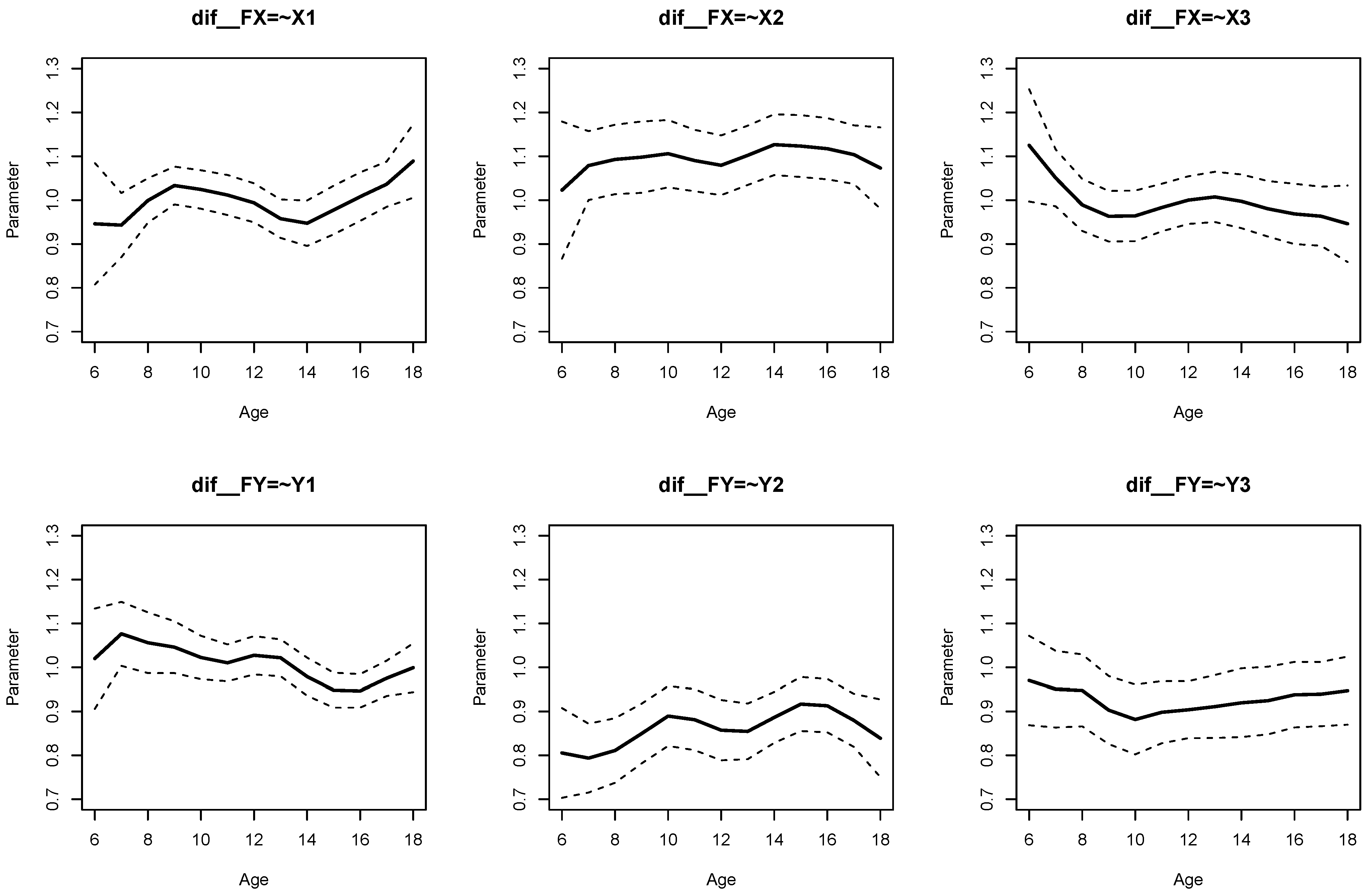
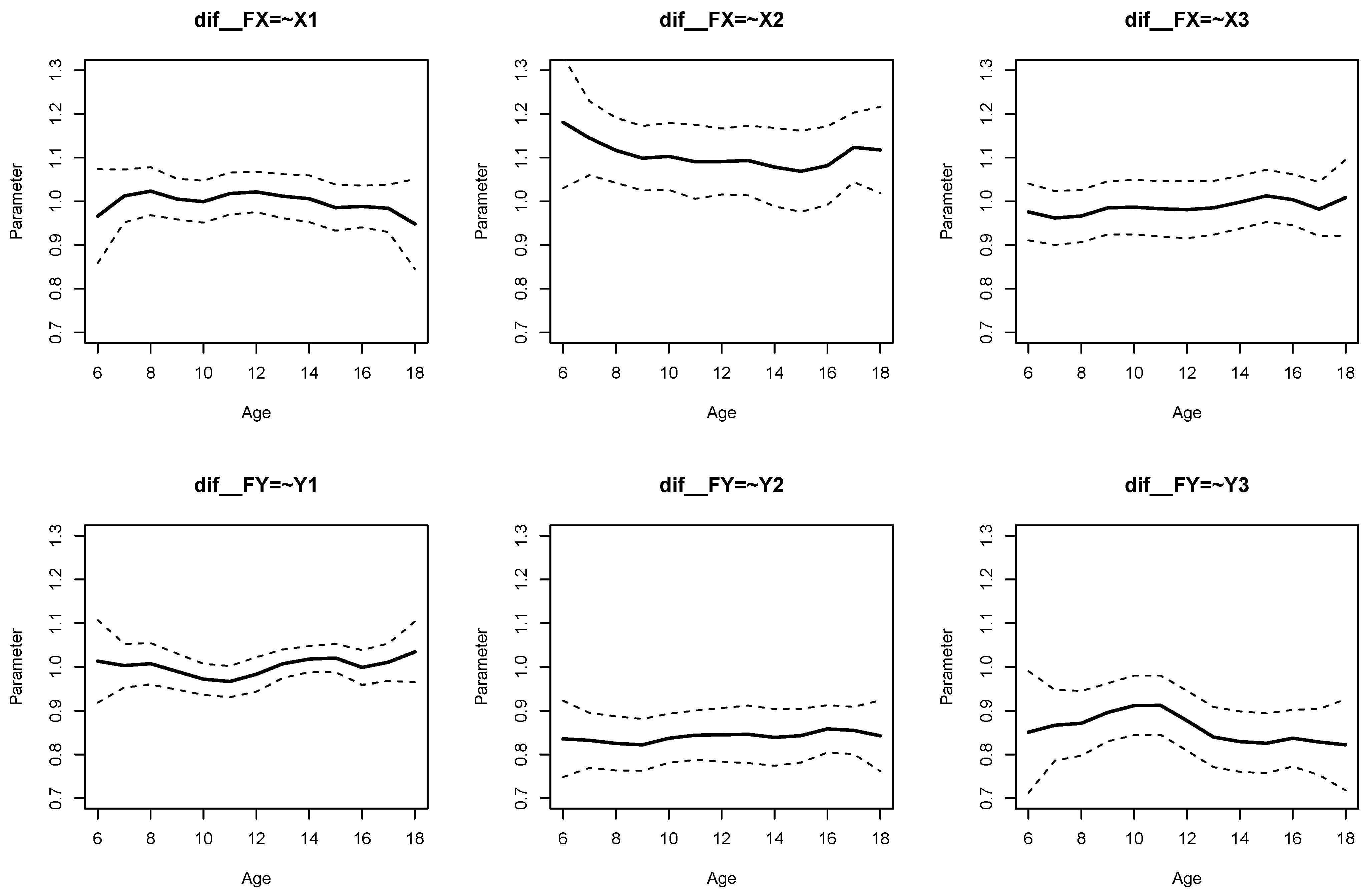
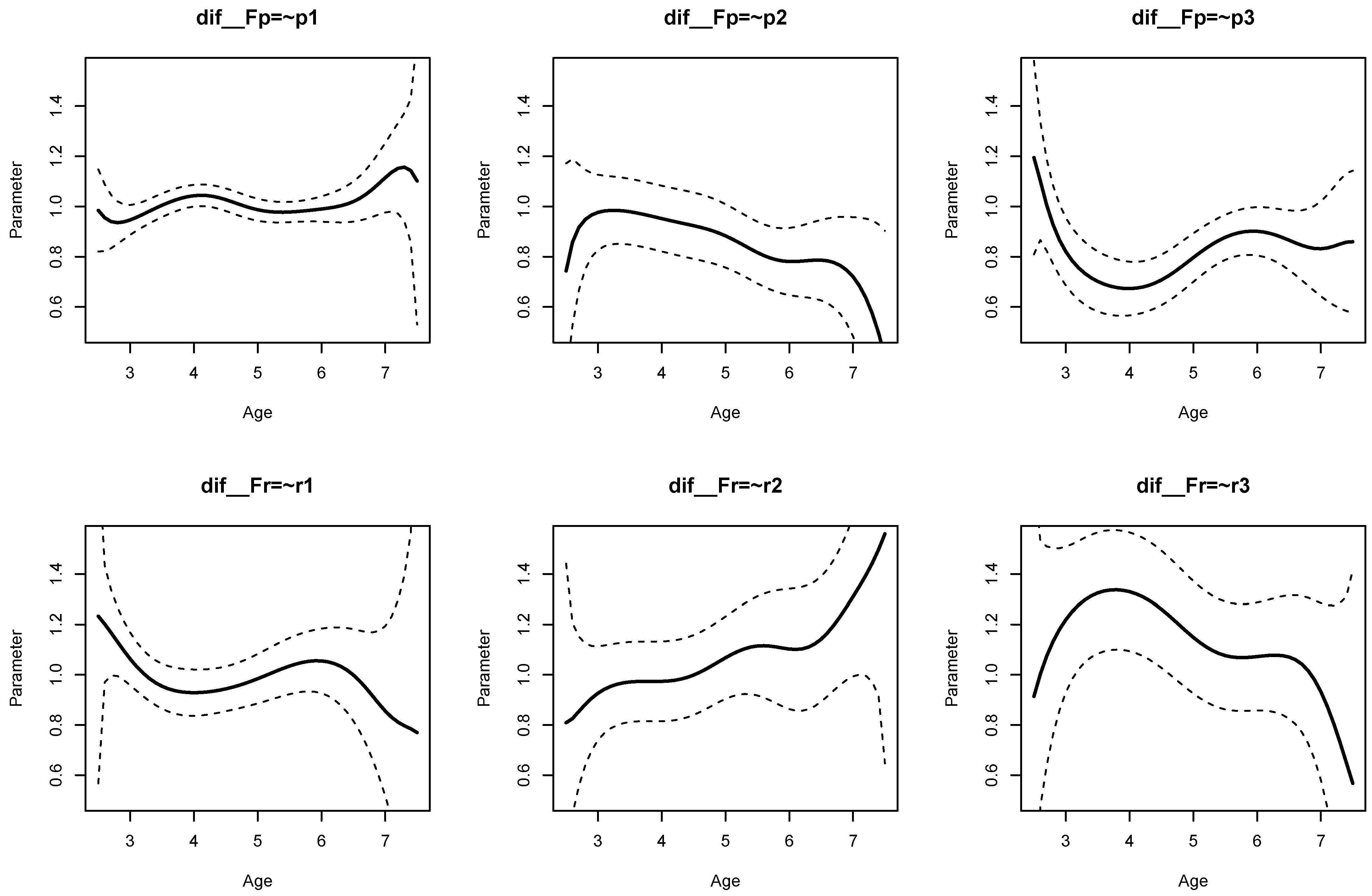
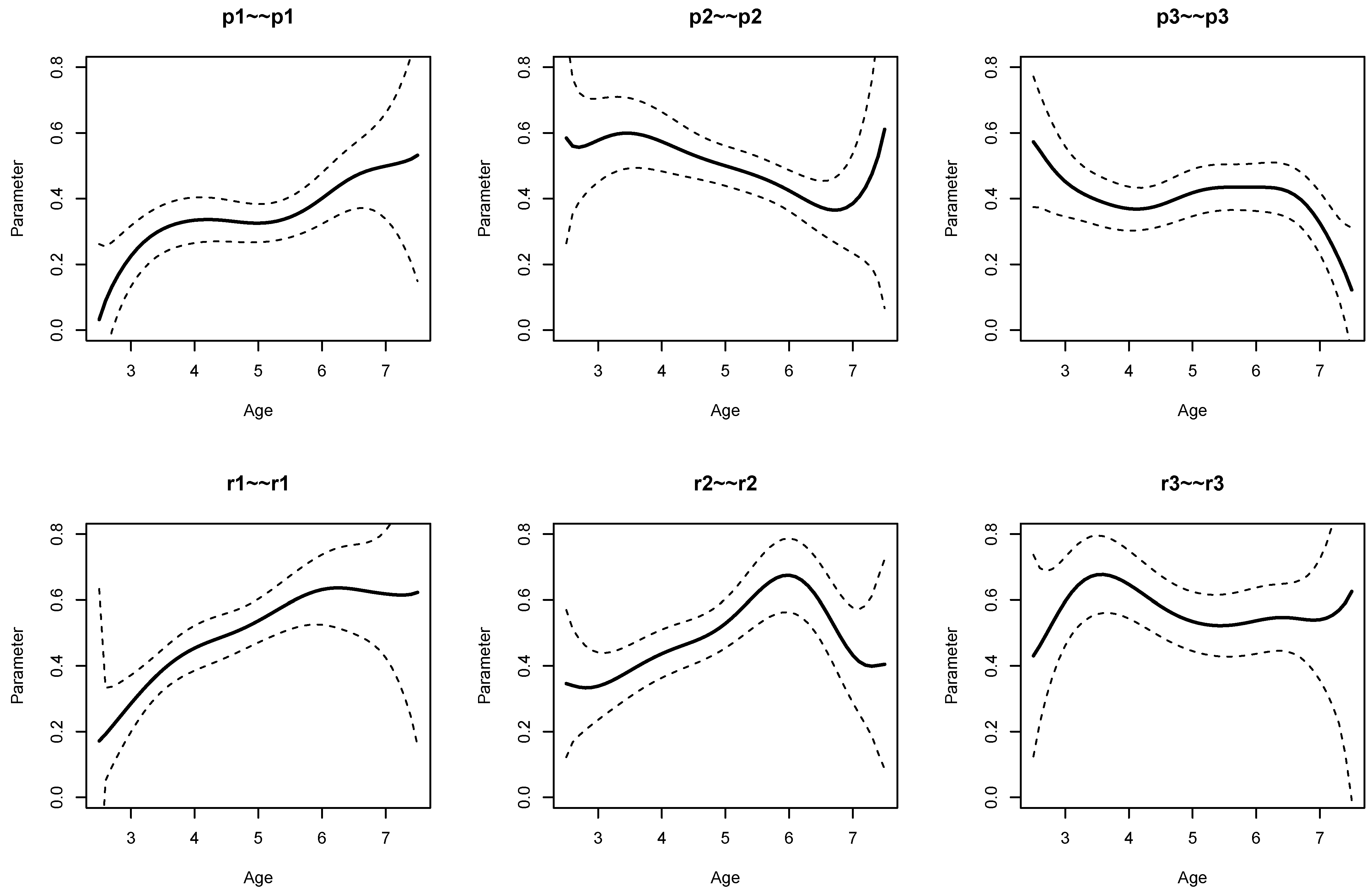
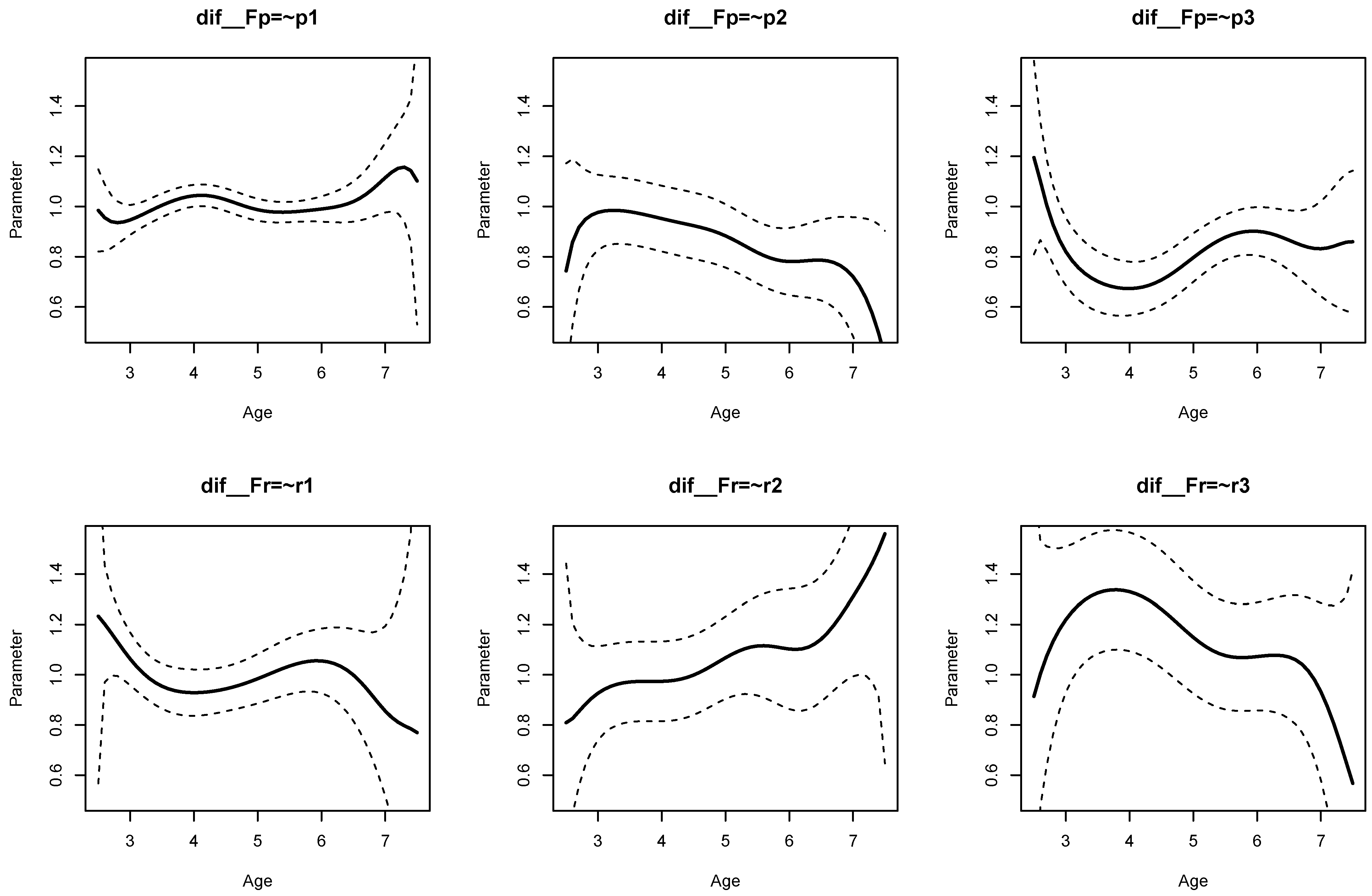
The parameter curves for DIF effects for factor loadings for datasets
DATA1 and
DATA2 are displayed in
Figure 3 and
Figure 4, respectively. For
DATA1, factor loadings were simulated as noninvariant, while they were assumed invariant across age for
DATA2. This fact is visible when comparing
Figure 3 and
Figure 4.
It can be seen from Listing 6 that DIF effects for factor loadings X1 (, ), X3 (, ), Y1 (, ), and Y2 (, ) had significant parameter variation for dataset DATA1, while they were not significant for loadings of X2 and Y3.
| Listing 6. Illustrative datasets: Part of the output of sirt::lsem.bootstrap() for the illustrative dataset DATA1. |
![Jintelligence 11 00175 i006]() |
Finally, part of the R output of sirt::lsem.bootstrap() for dataset DATA3 is displayed in Listing 7. In accordance with the data-generating model, both factor variances, the factor correlation, and the DIF effects for factor loadings did not show significant parameter variation across age.
| Listing 7. Illustrative datasets: Part of the output of sirt::lsem.bootstrap() for the illustrative dataset DATA3. |
![Jintelligence 11 00175 i007]() |
Note that a researcher will only have one dataset available for analysis. This section shows that LSEM model parameter output and figures are able to distinguish between situations of noninvariant and invariant model parameters. The standard deviation of a model parameter quantifies the variability of a model parameter across the values of the moderator.
For identification and interpretation reasons, it is useful to specify LSEM models with (some) invariant factor loadings. DIF effects reported in the LSEM output provide a post hoc assessment of the variability of parameter curves across the moderator values if parameter invariance was specified in the LSEM.
9. Discussion
In this article, we discussed the implementation of LSEM in the R package sirt. Joint LSEM estimation and two different significance tests for a test of parameter variation were introduced and evaluated through two simulation studies.
Simulation Study 1 demonstrated that the joint LSEM estimation method can be successfully applied to structural equation models whose parameters vary across different values of the moderator variable. It turned out that the bandwidth factor can generally be recommended as a default choice. Notably, LSEM model parameters can be quite variable for small () or moderate sample sizes (). In Simulation Study 2, two significance testing approaches for constant parameter curves were investigated: a test statistic based on the standard deviation of a parameter curve and a Wald-type test statistic. Both testing approaches rely on bootstrap samples for statistical inference. The standard-deviation-based test statistics had a higher power than the Wald test-type test statistic, but also came with an inflated type-I error rate. It is recommended to use the significance test based on the standard deviation with a significance level of if a nominal significance level of is required.
The application of LSEM in applied research can be regarded more as an exploratory than a confirmatory statistical method (
Jacobucci 2022). Functional forms of parameter curves obtained with LSEM can be validated in other samples or future studies with more confirmatory approaches, such as moderated nonlinear factor analysis. We would like to emphasize that sufficiently large sample sizes are required in LSEM in order to allow a reliable interpretation of the obtained nonlinear parameter curves. Moreover, the true variability in parameter curves must be sufficiently large to have enough power to statistically detect the significant parameter variability. A statistical significance test on parameter curve regression coefficients in a moderated nonlinear factor analysis might have more power than a test based on the nonparametric LSEM method. Finally, moderated nonlinear factor analysis, if estimated by maximum likelihood, allows likelihood ratio tests for testing among nested models or using information criteria for model comparisons.
In this article, the moderator variable was exclusively age and a bounded variable. There might be applications in which the moderator differs from age, such as unbounded self-concept factor variables or ability values obtained from item response models (
Basarkod et al. 2023). Because the metric of such variables is often arbitrary, it is advised to transform such moderators into a bounded metric. For example, the percentage ranks of an unbounded moderator variable could be utilized to obtain a bounded moderator variable.
If the moderator variable is an error-prone variable such as a factor variable or a scale score, an expected a posteriori (EAP) factor score estimate can be used as a moderator to obtain unbiased estimates of LSEM model parameters (
Bartholomew et al. 2011).
As explained in
Section 4, datasets with missing values should either be handled with pairwise deletion methods for computing sufficient statistics (i.e., the conditional covariance matrices) in LSEM or should be multiply imputed. The imputation model should be flexibly specified to represent the complex associations modeled with LSEM. For example, the moderator variable could be discretized into 5 or 10 distinct groups, and the resulting datasets should be separately imputed in the separate subdatasets. Statistical inference should be carried out that involves the multiply imputed datasets (
Little and Rubin 2002).
Finally, we only discussed LSEM in the case of one moderator variable. With more than one moderator variable (
Hartung et al. 2018), moderated nonlinear factor analysis might be easier to estimate because multivariate kernel functions for LSEM are difficult to estimate with sparse data.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}