Development and Validation of the Open Matrices Item Bank


Abstract
:1. Introduction
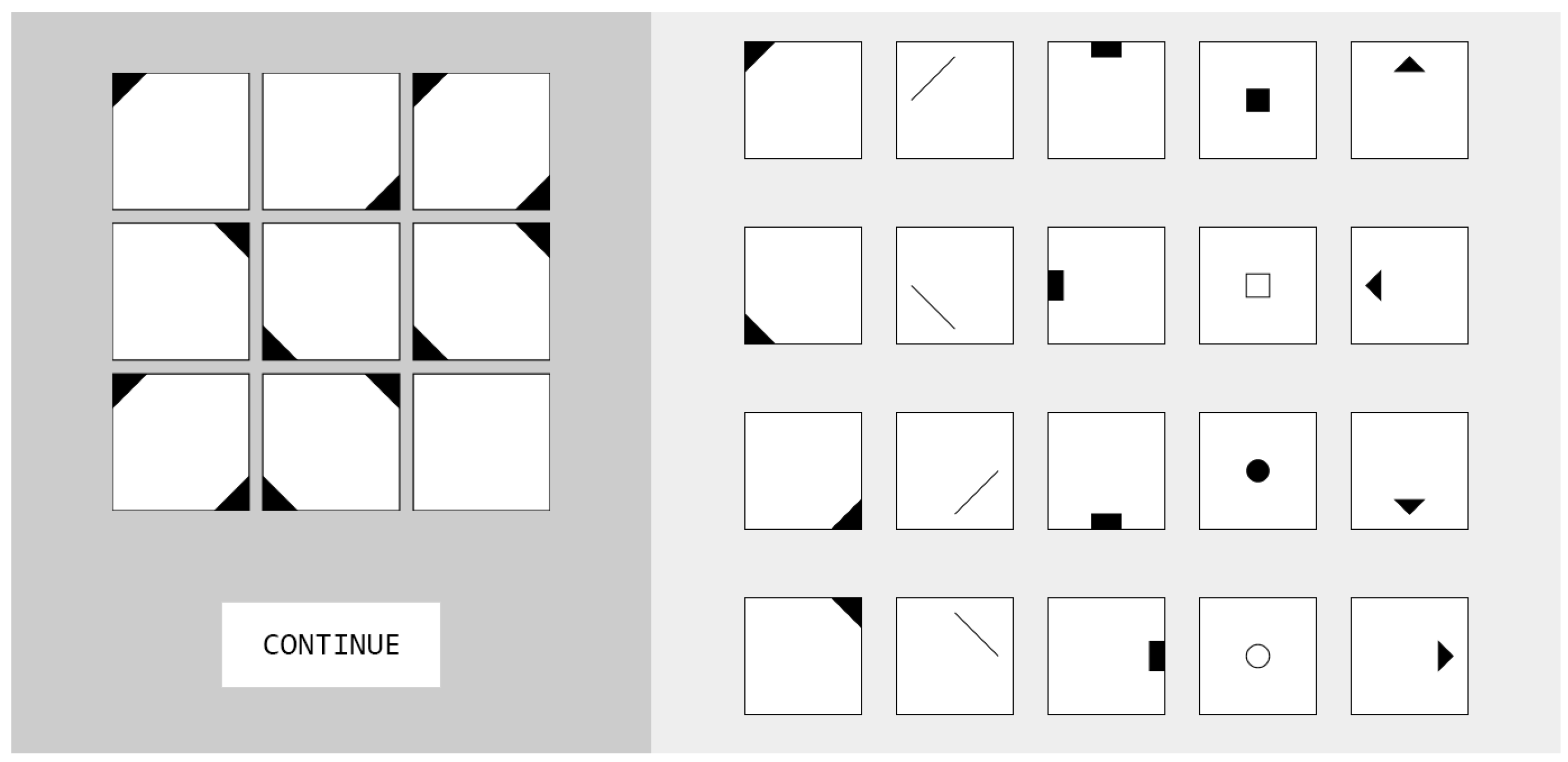
1.1. Figural Matrices
1.2. Item Banks
1.3. Aims of the Present Study
- develop 220 items that are based on the construction principles described by Becker and colleagues (Becker et al. 2016);
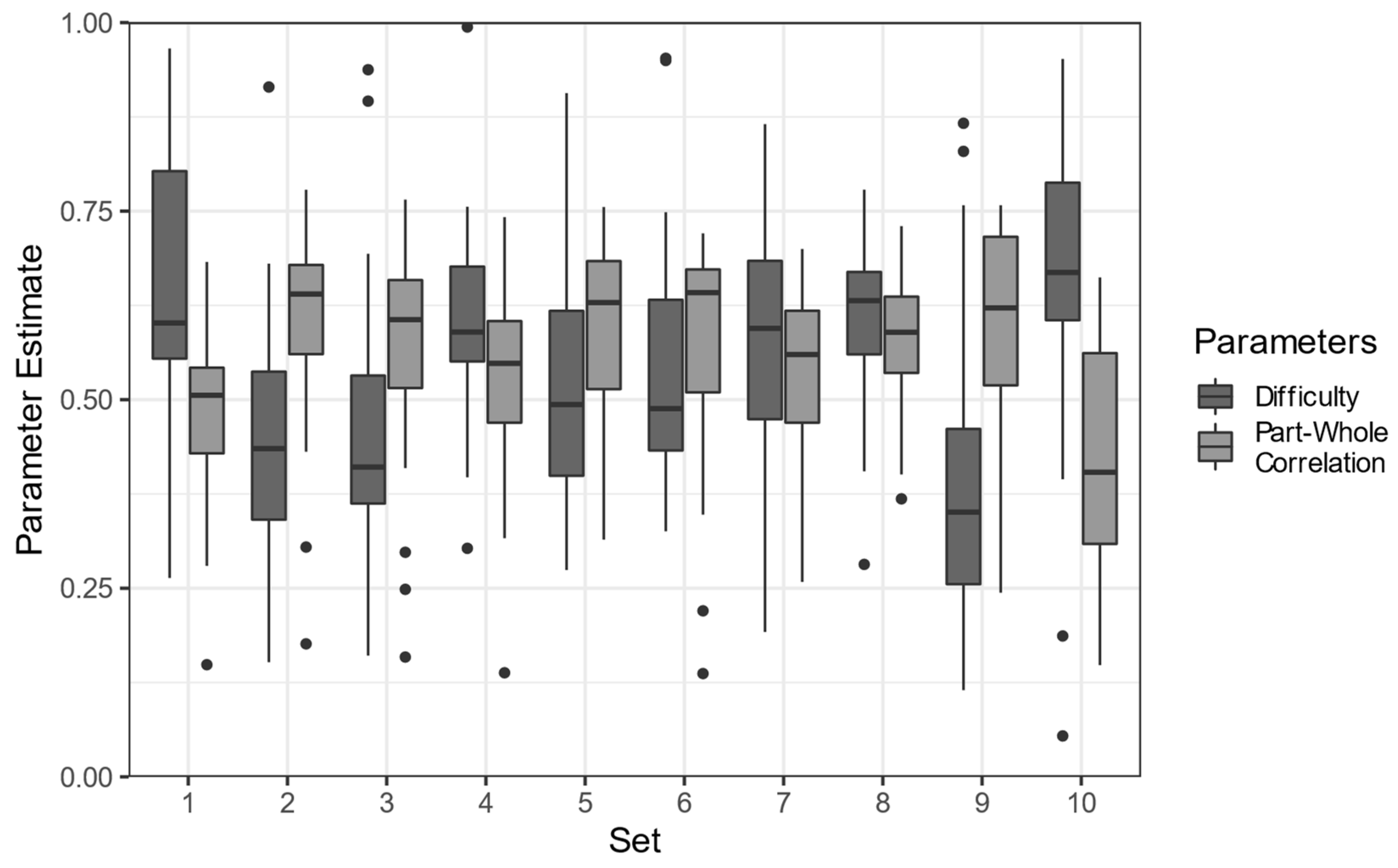
- evaluate the psychometric properties of all items (e.g., item difficulties and part–whole correlations from classical test theory);
- test the items under the assumption of IRT models and eliminate the nonfitting items;
- provide a dataset of the resulting item bank with detailed information on each item.
2. Materials and Methods
2.1. Sample
2.2. Procedure
2.3. Development of the Figural Matrices Items
2.4. Statistical Analyses
3. Results
4. Discussion
5. Access to the OMIB
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Arendasy, Martin E., and Markus Sommer. 2013. Reducing response elimination strategies enhances the construct validity of figural matrices. Intelligence 41: 234–43. [Google Scholar] [CrossRef]
- Battauz, Michela. 2017. Multiple Equating of Separate IRT Calibrations. Psychometrika 82: 610–36. [Google Scholar] [CrossRef] [PubMed]
- Battauz, Michela. 2021. equateMultiple: Equating of Multiple Forms. Available online: https://cran.r-project.org/web/packages/equateMultiple (accessed on 15 May 2022).
- Becker, Nicolas, and Frank M. Spinath. 2014. Design a Matrix Test. Ein Distraktorfreier Matrizentest zur Erfassung der Allgemeinen Intelligenz (DESIGMA). [Measurement instrument]. Göttingen: Hogrefe. [Google Scholar]
- Becker, Nicolas, Florian Schmitz, Anke M. Falk, Jasmin Feldbrügge, Daniel R. Recktenwald, Oliver Wilhelm, Franzis Preckel, and Frank M. Spinath. 2016. Preventing Response Elimination Strategies Improves the Convergent Validity of Figural Matrices. Journal of Intelligence 4: 2. [Google Scholar] [CrossRef] [Green Version]
- Bjorner, Jakob Bue, Chih-Hung Chang, David Thissen, and Bryce B. Reeve. 2007. Developing tailored instruments: Item banking and computerized adaptive assessment. Quality of Life Research 16: 95–108. [Google Scholar] [CrossRef] [PubMed]
- Carpenter, Patricia A., Marcel A. Just, and Peter Shell. 1990. What one intelligence test measures: A theoretical account of the processing in the Raven Progressive Matrices Test. Psychological Review 97: 404–31. [Google Scholar] [CrossRef]
- Carroll, John B. 1993. Human Cognitive Abilities: A Survey of Factor-Analytic Studies. Cambridge: Cambridge University Press. [Google Scholar]
- Chalmers, R. Philip. 2012. mirt: A Multidimensional Item Response Theory Package for the R Environment. Journal of Statistical Software 48: 1–29. [Google Scholar] [CrossRef] [Green Version]
- Chituc, Claudia-Melania, Marisa Herrmann, Daniel Schiffner, and Marc Rittberger. 2019. Towards the Design and Deployment of an Item Bank: An Analysis of the Requirements Elicited. In Advances in Web-Based Learning—ICWL 2019. Edited by Michael A. Herzog, Zuzana Kubincová, Peng Han and Marco Temperini. Basel: Springer International Publishing, vol. 11841, pp. 155–62. [Google Scholar] [CrossRef]
- Gignac, Gilles E. 2015. Raven’s is not a pure measure of general intelligence: Implications for g factor theory and the brief measurement of g. Intelligence 52: 71–79. [Google Scholar] [CrossRef]
- Gottfredson, Linda S., and Ian J. Deary. 2004. Intelligence Predicts Health and Longevity, but Why? Current Directions in Psychological Science 13: 1–4. [Google Scholar] [CrossRef]
- Hu, Li-tze, and Peter M. Bentler. 1999. Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Structural Equation Modeling: A Multidisciplinary Journal 6: 1–55. [Google Scholar] [CrossRef]
- Jensen, Arthur R. 1998. The g Factor: The Science of Mental Ability. Westport: Praeger. [Google Scholar]
- Krieger, Florian, Hubert D. Zimmer, Samuel Greiff, Frank M. Spinath, and Nicolas Becker. 2019. Why are difficult figural matrices hard to solve? The role of selective encoding and working memory capacity. Intelligence 72: 35–48. [Google Scholar] [CrossRef]
- Kyllonen, Patrick C., and Raymond E. Christal. 1990. Reasoning ability is (little more than) working-memory capacity?! Intelligence 14: 389–433. [Google Scholar] [CrossRef]
- Levacher, Julie, Marco Koch, Johanna Hissbach, Frank M. Spinath, and Nicolas Becker. 2021. You Can Play the Game Without Knowing the Rules—But You’re Better Off Knowing Them: The Influence of Rule Knowledge on Figural Matrices Tests. European Journal of Psychological Assessment 38: 15. [Google Scholar] [CrossRef]
- Marshalek, Brachia, David F. Lohman, and Richard E. Snow. 1983. The complexity continuum in the radex and hierarchical models of intelligence. Intelligence 7: 107–27. [Google Scholar] [CrossRef]
- McGrew, Kevin S. 2005. The Cattell-Horn-Carroll Theory of Cognitive Abilities: Past, Present, and Future. In Contemporary Intellectual Assessment: Theories, Tests, and Issues. New York City: The Guilford Press, pp. 136–81. [Google Scholar]
- McGrew, Kevin S. 2009. CHC theory and the human cognitive abilities project: Standing on the shoulders of the giants of psychometric intelligence research. Intelligence 37: 1–10. [Google Scholar] [CrossRef]
- Primi, Ricardo. 2014. Developing a fluid intelligence scale through a combination of Rasch modeling and cognitive psychology. Psychological Assessment 26: 774–88. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. 2021. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing, Available online: https://www.R-project.org/ (accessed on 15 May 2022).
- Revelle, William R. 2021. Psych: Procedures for Psychological, Psychometric, and Personality Research. Evanston: Northwestern University, Available online: https://CRAN.R-project.org/package=psych (accessed on 15 May 2022).
- Rosseel, Yves. 2012. lavaan: An R Package for Structural Equation Modeling. Journal of Statistical Software 48: 1–36. [Google Scholar] [CrossRef] [Green Version]
- Roth, Bettina, Nicolas Becker, Sara Romeyke, Sarah Schäfer, Florian Domnick, and Frank M. Spinath. 2015. Intelligence and school grades: A meta-analysis. Intelligence 53: 118–37. [Google Scholar] [CrossRef]
- Schmidt, Frank L., and John Hunter. 2016. General Mental Ability in the World of Work: Occupational Attainment and Job Performance. Thousand Oaks: Sage Publications, Inc. [Google Scholar]
- Schroeders, Ulrich, and Oliver Wilhelm. 2011. Equivalence of Reading and Listening Comprehension Across Test Media. Educational and Psychological Measurement 71: 849–69. [Google Scholar] [CrossRef]
- Steger, Diana, Ulrich Schroeders, and Timo Gnambs. 2018. A Meta-Analysis of Test Scores in Proctored and Unproctored Ability Assessments. European Journal of Psychological Assessment 36: 174–84. [Google Scholar] [CrossRef] [Green Version]
- Ward, Annie W., and Mildred Murray-Ward. 1994. An NCME Instructional Module: Guidelines for the Development of Item Banks. Educational Measurement: Issues and Practice 13: 34–39. [Google Scholar] [CrossRef]
- Waschl, Nicolette, and Nicholas R. Burns. 2020. Sex differences in inductive reasoning: A research synthesis using meta-analytic techniques. Personality and Individual Differences 164: 109959. [Google Scholar] [CrossRef]
- Weber, Dominik. 2021. Fest verankert—Eine Simulationsstudie zu den Voraussetzungen für robustes Test-Equating. Saarbrücken: Saarland University. [Google Scholar]
- Wechsler, David. 2008. Wechsler Adult Intelligence Scale, 4th ed. Measurement Instrument. London: Pearson Assessment. [Google Scholar]
- Weiss, David J. 2013. Item banking, test development, and test delivery. In APA Handbook of Testing and Assessment in Psychology, Vol. 1: Test Theory and Testing and Assessment in Industrial and Organizational Psychology. Edited by Kurt F. Geisinger, Bruce A. Bracken, Janet F. Carlson, Jo-Ida C. Hansen, Nathan R. Kuncel, Steven P. Reise and Michael C. Rodriguez. Washington, DC: American Psychological Association, pp. 185–200. [Google Scholar] [CrossRef] [Green Version]
- Wilhelm, Oliver, Andrea Hildebrandt, and Klaus Oberauer. 2013. What is working memory capacity, and how can we measure it? Frontiers in Psychology 4: 433. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wilson, Mark. 2005. Constructing Measures: An Item Response Modeling Approach. Mahwah: Lawrence Erlbaum Associates. [Google Scholar]
- Woelfle, Michael, Piero Olliaro, and Matthew H. Todd. 2011. Open science is a research accelerator. Nature Chemistry 3: 745–48. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
| Rules | Number of Items | Add | Sub | Dis | Int | Rot | Com |
|---|---|---|---|---|---|---|---|
| One | 20 | 4 | 4 | 3 | 3 | 3 | 3 |
| Two | 50 | 20 | 16 | 16 | 16 | 16 | 16 |
| Three | 80 | 44 | 44 | 37 | 41 | 37 | 37 |
| Four | 50 | 35 | 36 | 32 | 35 | 31 | 31 |
| Five | 20 | 17 | 17 | 17 | 17 | 16 | 16 |
| Sum | 220 | 120 | 117 | 105 | 112 | 103 | 103 |
| Rules | a | Mina | Maxa | b | Minb | Maxb |
|---|---|---|---|---|---|---|
| One | 1.45 | 0.11 | 3.16 | −1.87 | −8.98 | 1.43 |
| Two | 1.52 | 0.62 | 2.97 | −0.30 | −2.25 | 1.44 |
| Three | 2.01 | 1.05 | 3.63 | −0.16 | −1.12 | 1.65 |
| Four | 2.64 | 1.08 | 5.16 | 0.24 | −0.12 | 0.88 |
| Five | 3.10 | 1.63 | 4.48 | 0.67 | 0.27 | 2.41 |
| Average | 2.09 | 0.11 | 5.16 | −0.17 | −8.98 | 2.41 |
| Rules | B | β | t | p |
|---|---|---|---|---|
| Intercept | −1.56 | --- | --- | --- |
| Addition | 0.41 | 0.21 | 3.84 | <.001 |
| Subtraction | 0.51 | 0.26 | 4.84 | <.001 |
| Disjunctive union | 0.77 | 0.40 | 7.20 | <.001 |
| Intersection | 0.68 | 0.35 | 6.43 | <.001 |
| Rotation | 0.34 | 0.17 | 3.16 | .002 |
| Completeness | 0.12 | 0.06 | 1.11 | .267 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koch, M.; Spinath, F.M.; Greiff, S.; Becker, N. Development and Validation of the Open Matrices Item Bank. J. Intell. 2022, 10, 41. https://doi.org/10.3390/jintelligence10030041
Koch M, Spinath FM, Greiff S, Becker N. Development and Validation of the Open Matrices Item Bank. Journal of Intelligence. 2022; 10(3):41. https://doi.org/10.3390/jintelligence10030041
Chicago/Turabian StyleKoch, Marco, Frank M. Spinath, Samuel Greiff, and Nicolas Becker. 2022. "Development and Validation of the Open Matrices Item Bank" Journal of Intelligence 10, no. 3: 41. https://doi.org/10.3390/jintelligence10030041
APA StyleKoch, M., Spinath, F. M., Greiff, S., & Becker, N. (2022). Development and Validation of the Open Matrices Item Bank. Journal of Intelligence, 10(3), 41. https://doi.org/10.3390/jintelligence10030041